

Enhancing Rare Class Performance in HOI Detection with Re-Splitting and a Fair Test Dataset
Abstract
1. Introduction
2. Related Work
2.1. Overview of HOI Detection and the HICO-DET Dataset
2.2. HOI Detection Models: One-Stage vs. Two-Stage Approaches
2.3. Existing Approaches to Address Class Imbalance
2.4. Dataset Splitting Strategies and DreamSim-Based Balancing
2.5. The Role of External Test Datasets in HOI Generalization
3. Materials and Methods
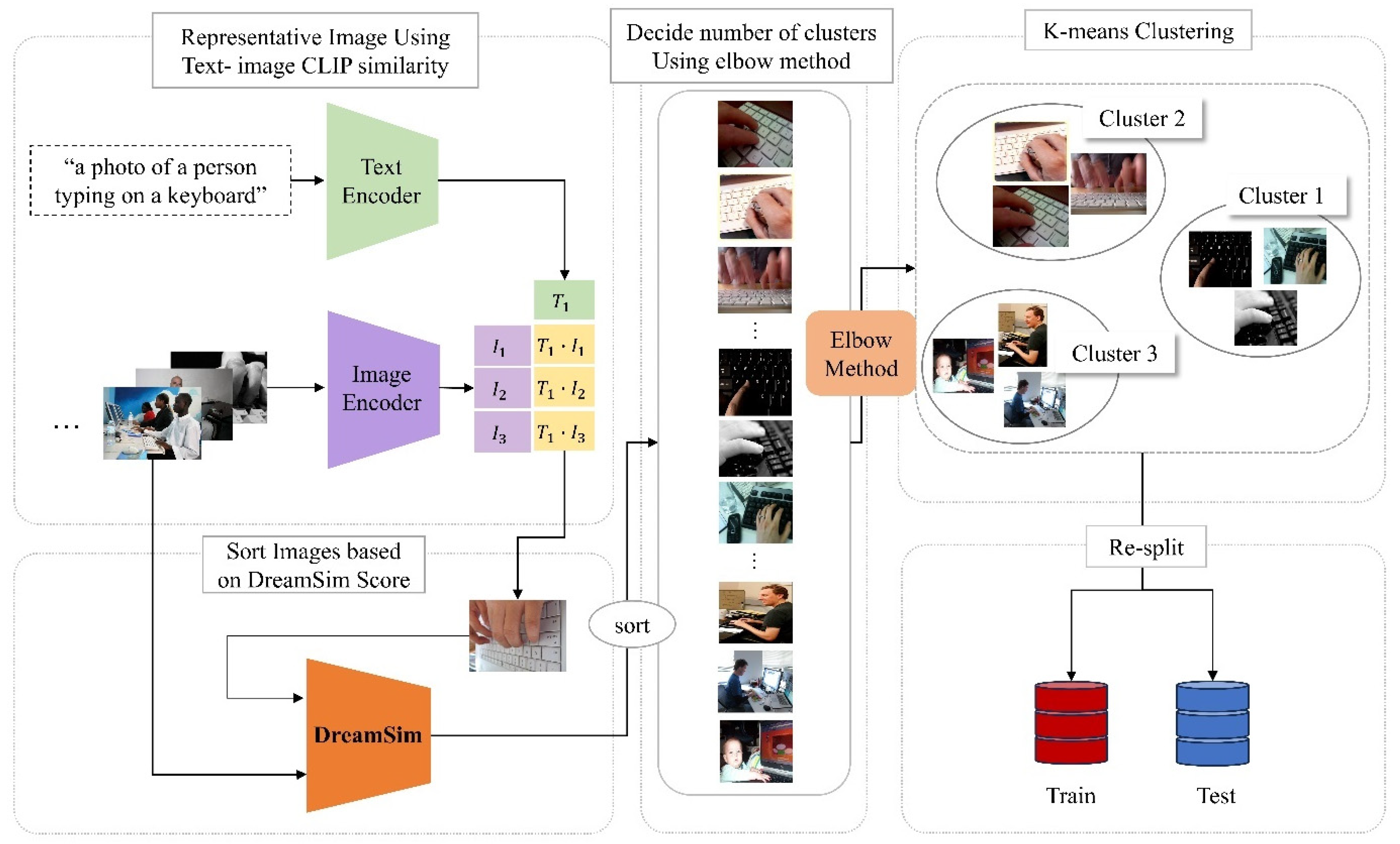
3.1. DreamSim-Based Re-Splitting Strategy for Mitigating Dataset Bias
- i.
- ii.
- DreamSim Score Computation: Each image in the dataset is assigned a DreamSim score, which quantifies its semantic similarity to the representative image. This ensures that images with similar contextual meanings are grouped together.
- iii.
- Clustering Optimization with the Elbow Method: To determine the optimal number of clusters for dataset partitioning, we apply the Elbow Method. This helps in minimizing intra-cluster variance and maximizing inter-cluster separation.
- iv.
- Train–Test Dataset Re-Splitting: Using the determined cluster structure, the dataset is restructured by distributing images into training and test sets in a way that balances the diversity by leveraging the feature-level representation within all interaction classes.
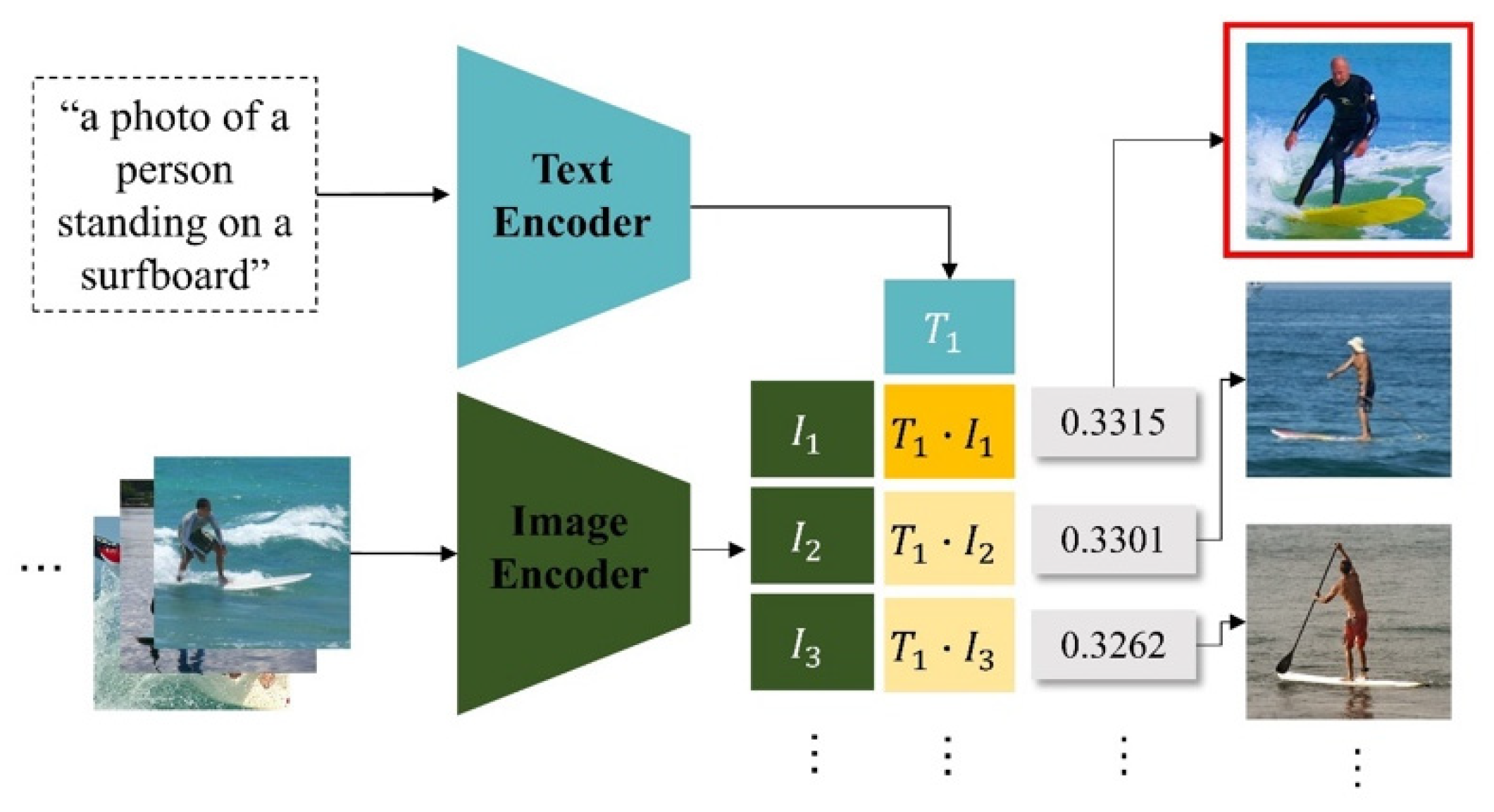
3.2. Representative Image Selection Using CLIP
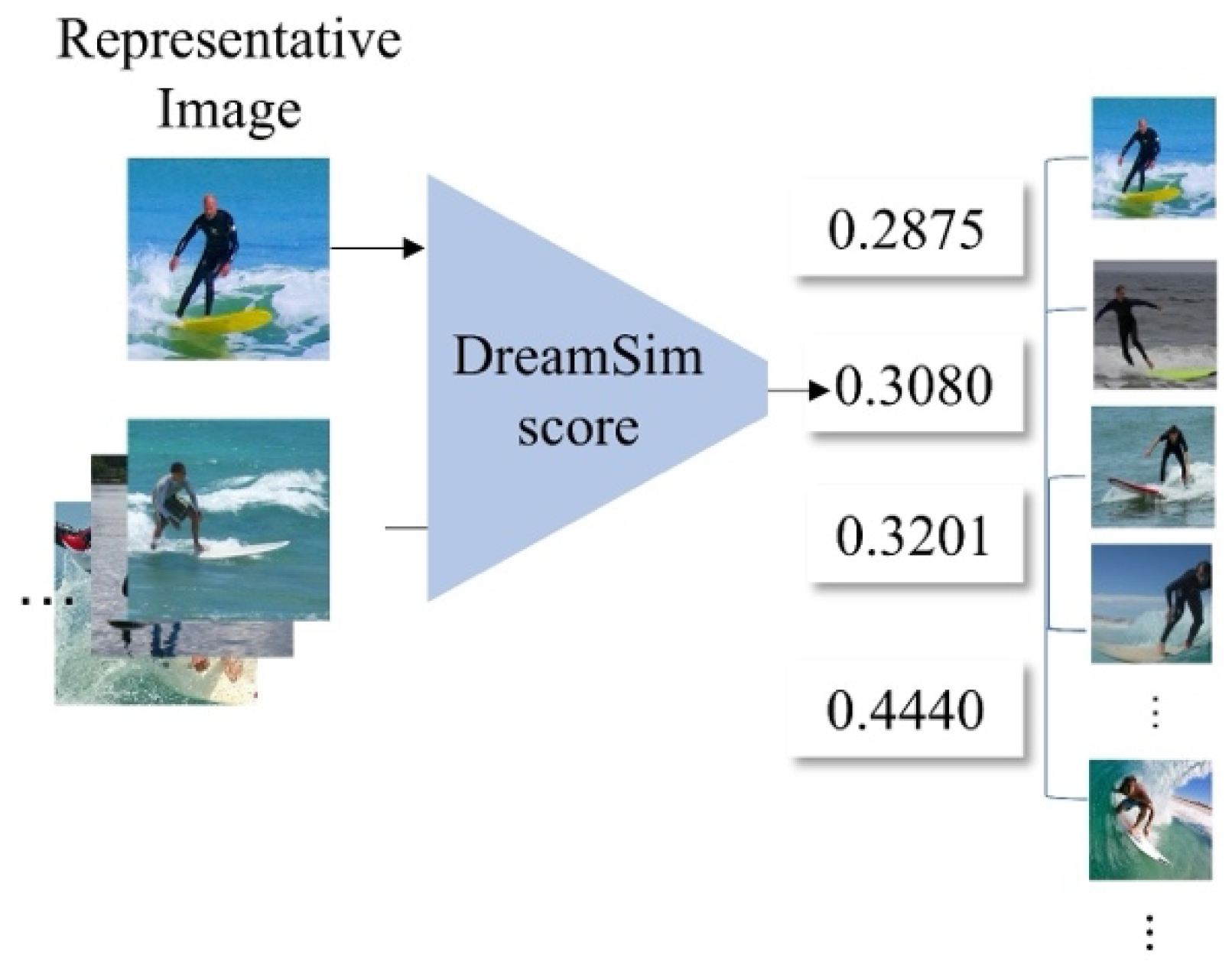
3.3. Dreamsim-Based Similarity Scoring and Image Sorting
- , ;
- is the textual description of the interaction class ;
- CLIP (, ) computes the similarity between the text and image embeddings;
- represents the DreamSim score, indicating how distant is to the representative image .
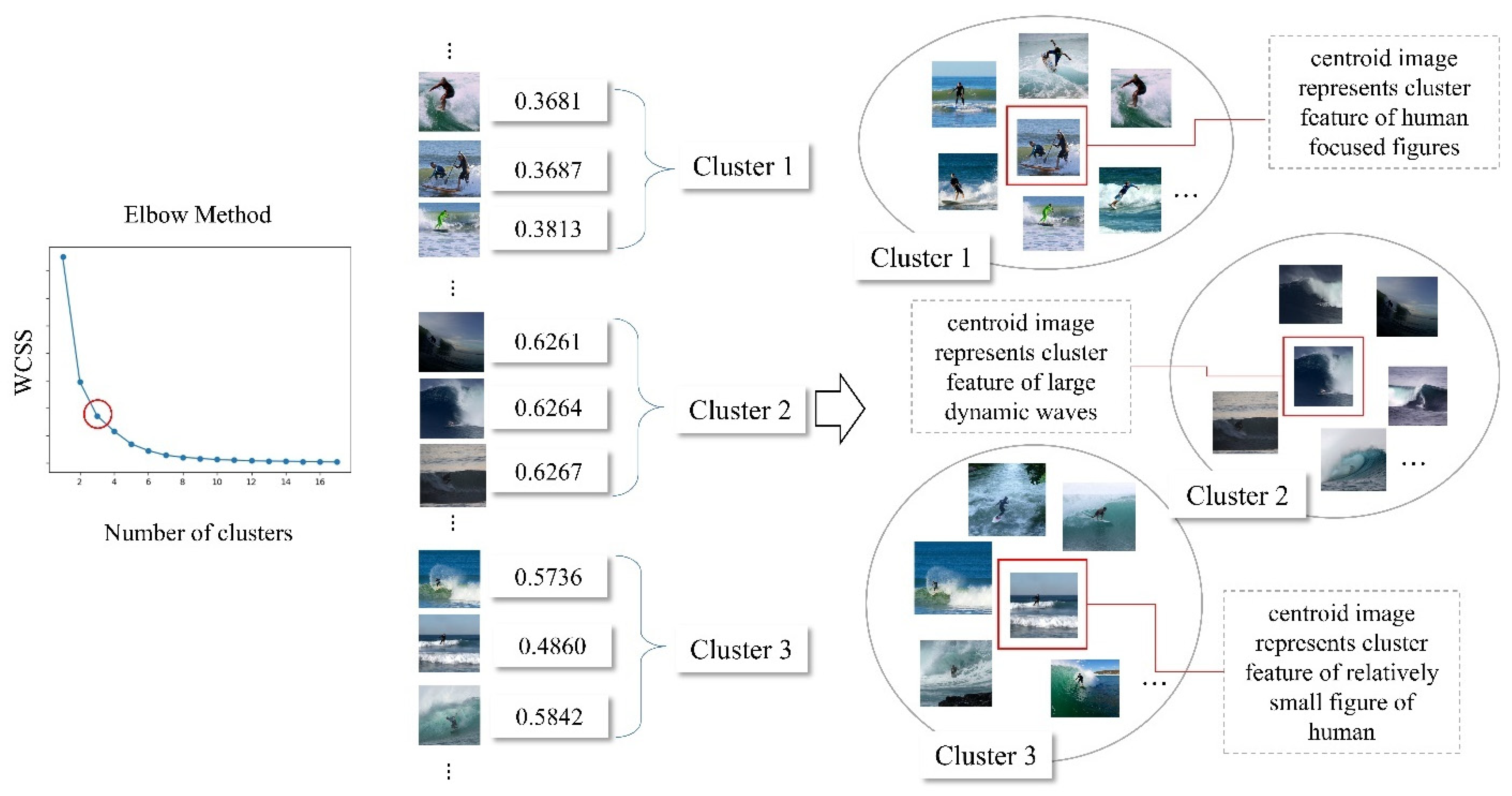
3.4. Determining the Optimal Number of Clusters Using the Elbow Method
- is the number of clusters;
- represents the set of data points belonging to cluster ;
- is the centroid of cluster ;
- is a data point in cluster ;
- is the squared Euclidean distance between the data point and the cluster centroid.
- Cluster 1: Focuses on human-centered figures with clearly visible people standing on surfboards.
- Cluster 2: Contains images with large, dynamic waves and minimal human presence.
- Cluster 3: Includes images where humans appear smaller in the frame, often surrounded by extensive background elements.
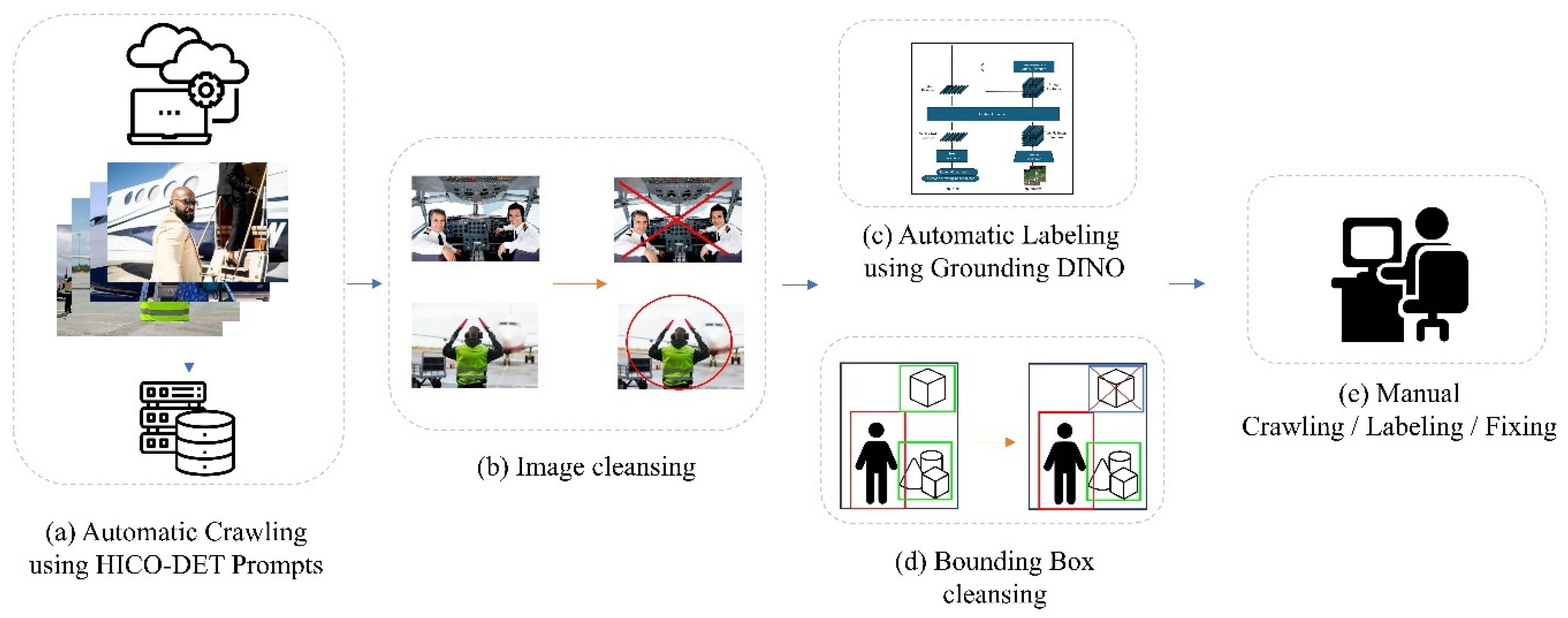
3.5. Development of a Balanced Real-World External Dataset for HOI Detection
3.5.1. Balanced Dataset Development: Objectives and Scope
3.5.2. Methodology for Developing a Real-World Test Dataset
3.5.3. Challenges in Collecting a Balanced Dataset
3.5.4. Statistical Improvements in the Balanced Dataset
- A reduction in the disparity between maximum and minimum annotation counts from 449× in HICO-DET to 15×, representing a 30-fold decrease in imbalance.
- A substantial decrease in annotation variability, with the standard deviation dropping from 100.68 to 12.22 from HICO-DET to ours, an 8-fold improvement in annotation consistency.
- A more even distribution of interaction instances, with the number of annotations per class ranging from 6 to 90, averaging 18.16 annotations per class.
4. Experiment and Evaluation
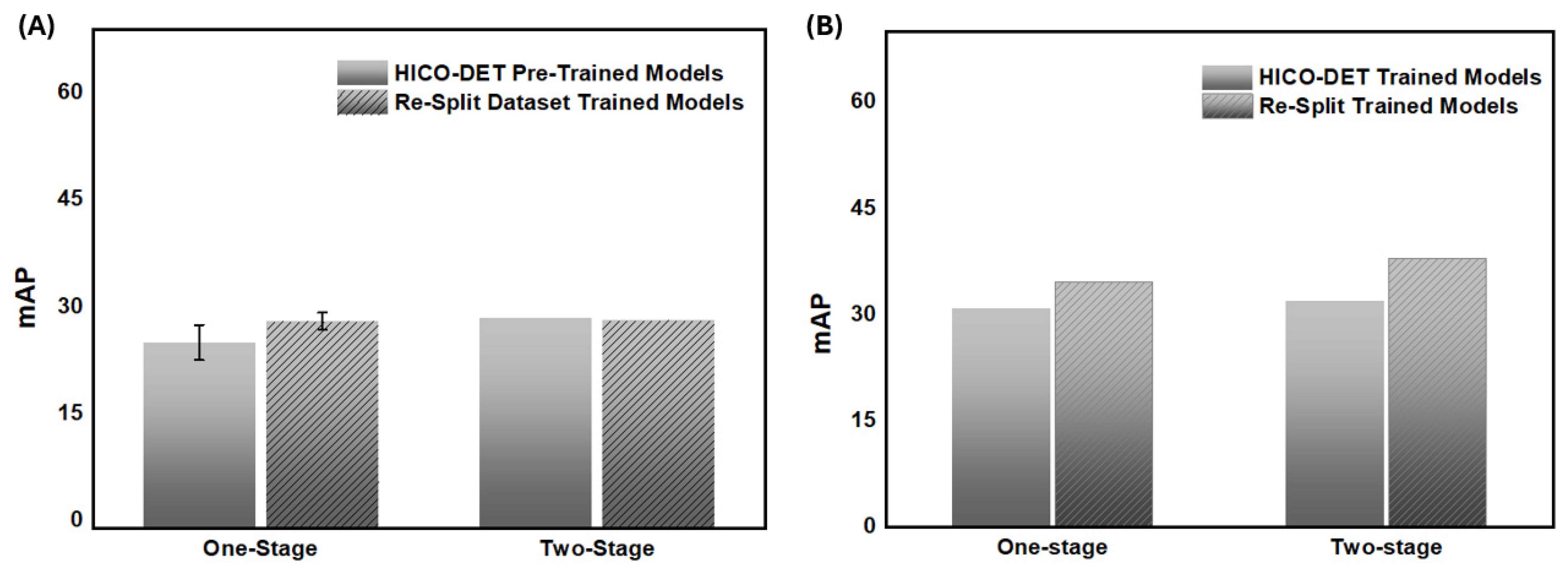
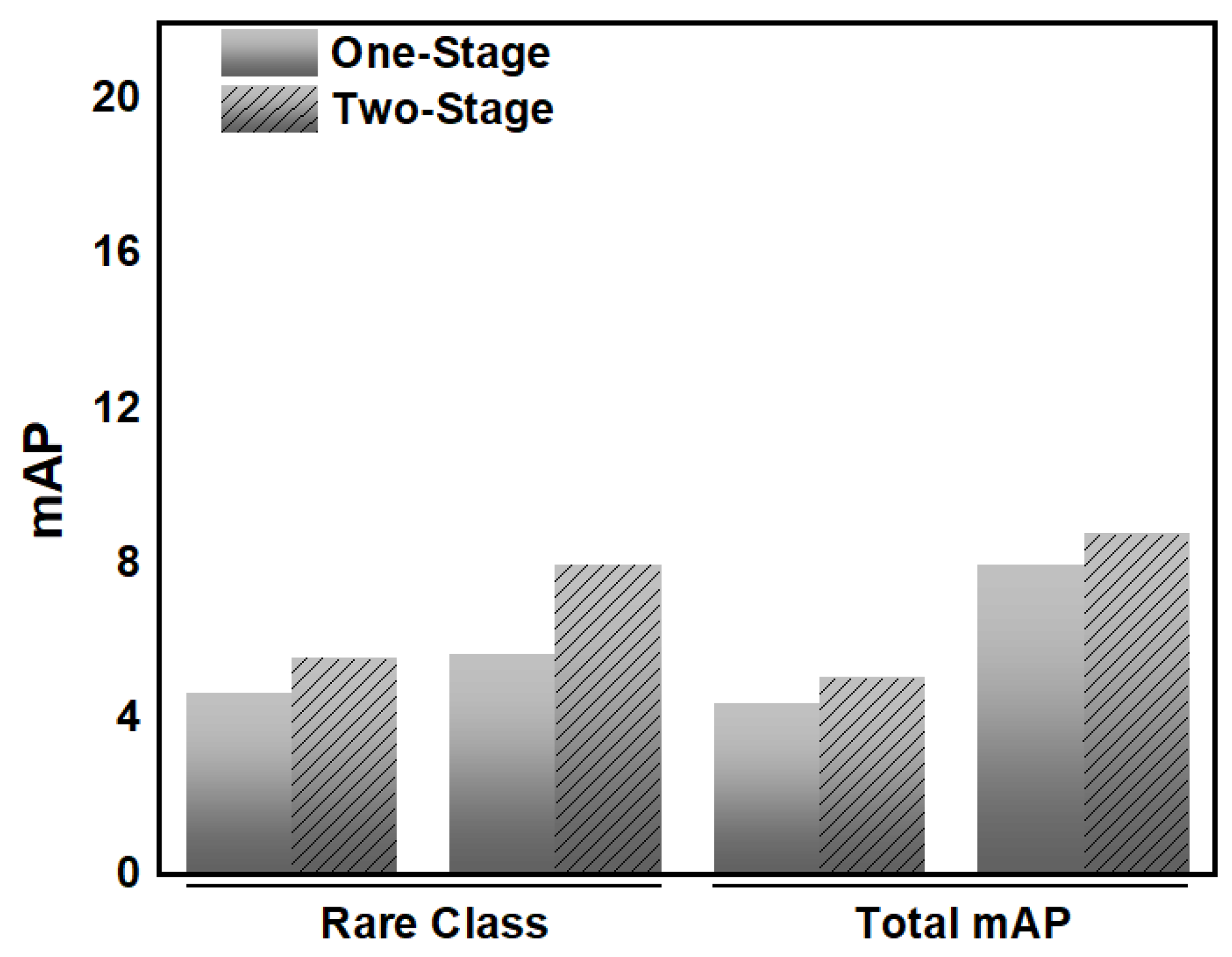
4.1. Experimental Setup and Training Protocols for Re-Splitting and Real-World Test Dataset Evaluation
4.2. Performance Evaluation of HOI Detection Models on Re-Splitting and Real-World Test Datasets
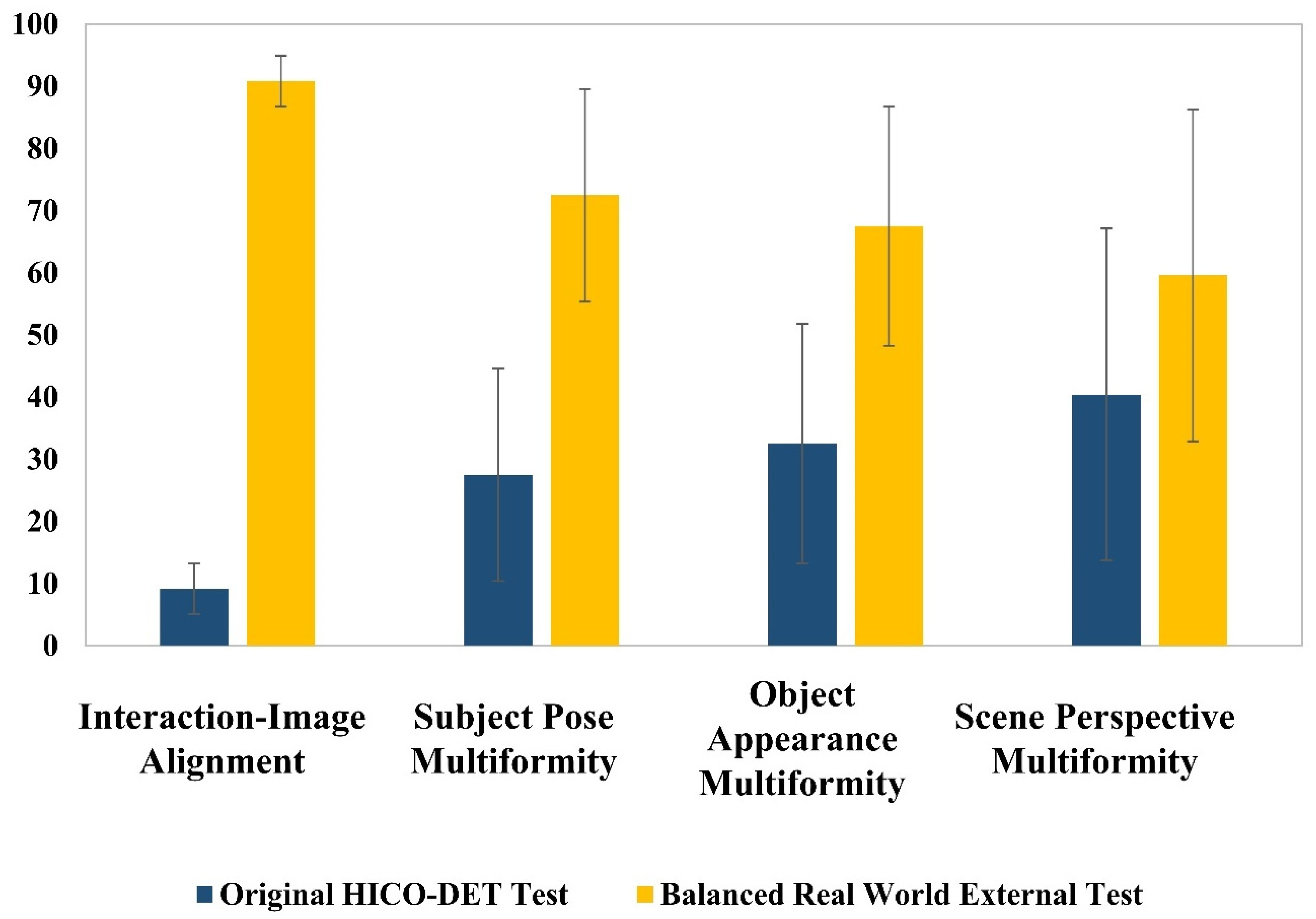
4.3. User Study on Dataset Diversity and Annotation Quality
- Object Appearance Multiformity: Participants assessed whether the dataset contained a wider variety of visual representations for objects (e.g., different appearances of an orange).
- Camera Perspective Multiformity: Participants determined which dataset exhibited a broader range of camera angles when capturing an interaction.
- Interaction–Image Alignment: Participants evaluated whether the images in a dataset accurately represented the given interaction prompt.
- Subject Pose Multiformity: Participants compared the variation in human poses performing the same interaction across datasets.
- Interaction–Image Alignment showed the most significant improvement, with the Real-World Test Dataset achieving 90.83% accuracy in aligning with the intended interaction descriptions, compared to 9.17% for HICO-DET.
- Subject Pose Multiformity was notably higher in the Real-World Test Dataset (72.5%) than in HICO-DET (27.5%), indicating a wider range of human postures for each interaction.
- Object Appearance Multiformity improved substantially, increasing from 32.5% in HICO-DET to 67.5% in the Real-World Test Dataset, ensuring more varied object representations.
- Camera Perspective Multiformity was also enhanced, with the Real-World Test Dataset scoring 59.58%, compared to 40.42% in HICO-DET, allowing models to generalize better across different viewpoints.
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chao, Y.-W.; Liu, Y.; Liu, X.; Zeng, H.; Deng, J. Learning to Detect Human-Object Interactions. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 381–389. [Google Scholar]
- Fang, H.S.; Xie, Y.; Shao, D.; Li, Y.L.; Lu, C. Decaug: Augmenting hoi detection via decomposition. Proc. AAAI Conf. Artif. Intell. 2021, 35, 1300–1308. [Google Scholar] [CrossRef]
- Zhang, A.; Liao, Y.; Liu, S.; Lu, M.; Wang, Y.; Gao, C.; Li, X. Mining the Benefits of Two-stage and One-stage HOI Detection. Adv. Neural Inf. Process. Syst. 2021, 21, 17209–17220. [Google Scholar]
- Ikotun, A.M.; Ezugwu, A.E.; Abualigah, L.; Abuhaija, B.; Heming, J. K-means clustering algorithms: A comprehensive review, variants analysis, and advances in the era of big data. Inf. Sci. 2023, 622, 178–210. [Google Scholar] [CrossRef]
- Schubert, E. Stop using the elbow criterion for k-means and how to choose the number of clusters instead. ACM SIGKDD Explor. Newsl. 2023, 25, 36–42. [Google Scholar] [CrossRef]
- Takemoto, K.; Yamada, M.; Sasaki, T.; Akima, H. HICO-DET-SG and V-COCO-SG: New Data Splits to Evaluate Systematic Generalization in Human-Object Interaction Detection. In Proceedings of the NeurIPS 2022 Workshop on Distribution Shifts: Connecting Methods and Applications, New Orleans, LA, USA, 3 December 2022; pp. 1–19. [Google Scholar]
- Liu, X.; Li, Y.L.; Lu, C. Highlighting object category immunity for the generalization of human-object interaction detection. Proc. AAAI Conf. Artif. Intell. 2022, 36, 1819–1827. [Google Scholar] [CrossRef]
- Tavakoli, H.; Suh, S.; Walunj, S.; Pahlevannejad, P.; Plociennik, C.; Ruskowski, M. Object Detection for Human–Robot Interaction and Worker Assistance Systems. In Artificial Intelligence in Manufacturing: Enabling Intelligent, Flexible and Cost-Effective Production Through AI; Springer Nature: Cham, Switzerland, 2023; pp. 319–332. [Google Scholar]
- Achirei, S.D.; Heghea, M.C.; Lupu, R.G.; Manta, V.I. Human activity recognition for assisted living based on scene understanding. Appl. Sci. 2022, 12, 10743. [Google Scholar] [CrossRef]
- Tang, S.; Roberts, D.; Golparvar-Fard, M. Human-object interaction recognition for automatic construction site safety inspection. Autom. Constr. 2020, 120, 103356. [Google Scholar] [CrossRef]
- Wang, Y.; Xiong, Q.; Lei, Y.; Xue, W.; Liu, Q.; Wei, Z. A Review of Human-Object Interaction Detection. In Proceedings of the 2024 2nd International Conference on Computer, Vision and Intelligent Technology (ICCVIT), Huaibei, China, 24–27 November 2024. [Google Scholar]
- Crasto, N. Class Imbalance in Object Detection: An Experimental Diagnosis and Study of Mitigation Strategies. arXiv 2024, arXiv:2403.07113. [Google Scholar]
- Tamura, M.; Ohashi, H.; Yoshinaga, T. QPIC: Query-Based Pairwise Human-Object Interaction Detection with Image-Wide Contextual Information. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10405–10414. [Google Scholar] [CrossRef]
- Zhang, Y.; Pan, Y.; Yao, T.; Huang, R.; Mei, T.; Chen, C.W. Exploring Structure-aware Transformer over Interaction Proposals for Human-Object Interaction Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 19526–19535. [Google Scholar] [CrossRef]
- Liao, Y.; Zhang, A.; Lu, M.; Wang, Y.; Li, X.; Liu, S. GEN-VLKT: Simplify Association and Enhance Interaction Understanding for HOI Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20091–20100. [Google Scholar] [CrossRef]
- Xie, C.; Zeng, F.; Hu, Y.; Liang, S.; Wei, Y. Category Query Learning for Human-Object Interaction Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 15275–15284. [Google Scholar] [CrossRef]
- Zhang, F.Z.; Yuan, Y.; Campbell, D.; Zhong, Z.; Gould, S. Exploring Predicate Visual Context in Detecting of Human-Object Interactions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 10377–10387. [Google Scholar] [CrossRef]
- Zhang, F.; Sheng, L.; Guo, B.; Chen, R.; Chen, J. SQA: Strong Guidance Query with Self-Selected Attention for Human-Object Interaction Detection. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rodos, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Paullada, A.; Raji, I.D.; Bender, E.M.; Denton, E.; Hanna, A. Data and its (dis) contents: A survey of dataset development and use in machine learning research. Patterns 2021, 2, 100336. [Google Scholar] [CrossRef]
- Mumuni, A.; Mumuni, F. Data augmentation: A comprehensive survey of modern approaches. Array 2022, 16, 100258. [Google Scholar] [CrossRef]
- Patil, P.; Boardley, B.; Gardner, J.; Loiselle, E.; Parthipan, D. Reimplementation of Learning to Reweight Examples for Robust Deep Learning. arXiv 2024, arXiv:2405.06859. [Google Scholar]
- Ratnasari, A.P. Performance of Random Oversampling, Random Undersampling, and SMOTE-NC Methods in Handling Imbalanced Class in Classification Models. Int. J. Sci. Res. Manag. 2024, 12, 494–501. [Google Scholar] [CrossRef]
- Wang, C.; Dong, Q.; Wang, X.; Wang, H.; Sui, Z. Statistical dataset evaluation: Reliability, difficulty, and validity. arXiv 2022, arXiv:2212.09272. [Google Scholar]
- Fu, S.; Tamir, N.; Sundaram, S.; Chai, L.; Zhang, R.; Dekel, T.; Isola, P. DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data. arXiv 2023, arXiv:2306.09344. [Google Scholar]
- Kambhatla, G.; Nguyen, T.; Choi, E. Quantifying Train-Evaluation overlap with nearest neighbors. In Findings of the Association for Computational Linguistics: ACL 2023; Association for Computational Linguistics: Toronto, ON, Canada, 2023; pp. 2905–2920. [Google Scholar]
- Goyal, M.; Mahmoud, Q.H. A Systematic Review of Synthetic Data Generation Techniques Using Generative AI. Electronics 2024, 13, 3509. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Lüddecke, T.; Ecker, A. Image segmentation using text and image prompts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7086–7096. [Google Scholar]
- Gong, Y.; Liu, G.; Xue, Y.; Li, R.; Meng, L. A survey on dataset quality in machine learning. Inf. Softw. Technol. 2023, 162, 107268. [Google Scholar] [CrossRef]
- Stolte, M.; Kappenberg, F.; Rahnenführer, J.; Bommert, A. Methods for quantifying dataset similarity: A review, taxonomy and comparison. Stat. Surv. 2024, 18, 163–298. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Volume 8693, pp. 740–755. [Google Scholar] [CrossRef]
- Salman, S.; Liu, X. Overfitting mechanism and avoidance in deep neural networks. arXiv 2019, arXiv:1901.06566. [Google Scholar]
- Li, H.; Rajbahadur, G.K.; Lin, D.; Bezemer, C.P.; Jiang, Z.M. Keeping deep learning models in check: A history-based approach to mitigate overfitting. IEEE Access 2024, 12, 70676–70689. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Rice, L.; Wong, E.; Kolter, Z. Overfitting in adversarially robust deep learning. In Proceedings of the 37th International Conference on Machine Learning, Online, 13–18 July 2020; pp. 8093–8104. [Google Scholar]
- Hou, Z.; Yu, B.; Qiao, Y.; Peng, X.; Tao, D. Detecting human-object interaction via fabricated compositional learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14646–14655. [Google Scholar]
- Wang, G.; Guo, Y.; Wong, Y.; Kankanhalli, M. Chairs can be stood on: Overcoming object bias in human-object interaction detection. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 654–672. [Google Scholar]
- Jin, Y.; Chen, Y.; Wang, L.; Wang, J.; Yu, P.; Liang, L.; Hwang, J.N.; Liu, Z. The overlooked classifier in human-object interaction recognition. arXiv 2022, arXiv:2203.05676. [Google Scholar]
- Souza, V.M.; dos Reis, D.M.; Maletzke, A.G.; Batista, G.E. Challenges in benchmarking stream learning algorithms with real-world data. Data Min. Knowl. Discov. 2020, 34, 1805–1858. [Google Scholar] [CrossRef]
- Zhu, F.; Xie, Y.; Xie, W.; Jiang, H. Diagnosing human-object interaction detectors. Int. J. Comput. Vis. 2025, 133, 2227–2244. [Google Scholar] [CrossRef]
- Zhong, X.; Ding, C.; Hu, Y.; Tao, D. Disentangled Interaction Representation for One-Stage Human-Object Interaction Detection. arXiv 2023, arXiv:2312.01713. [Google Scholar]
- Antoun, M.; Asmar, D. Human object interaction detection: Design and survey. Image Vis. Comput. 2023, 130, 104617. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Pre-Trained (Original Test) | Re-Split (Re-Split Test) | Pre-Trained (External) | Re-Split (External) | |
|---|---|---|---|---|---|
| QPIC | total | 29.14 | 29.24 | 33.14 | 33.14 |
| rare | 21.74 | 26.85 | 27.27 | 29.06 | |
| non-rare | 31.35 | 29.78 | 34.95 | 34.54 | |
| CDN | total | 31.44 | 32.63 | 35.04 | 37.69 |
| rare | 27.24 | 29.50 | 29.24 | 36.10 | |
| non-rare | 32.69 | 33.35 | 37.31 | 38.59 | |
| STIP | total | 29.15 | 29.65 | 35.81 | 36.14 |
| rare | 27.07 | 29.86 | 33.70 | 37.74 | |
| non-rare | 29.77 | 29.60 | 36.99 | 36.30 | |
| GEN-VLKT | total | - | 34.27 | - | 39.62 |
| rare | 29.11 | 29.28 | 33.28 | 37.98 | |
| non-rare | 35.00 | 35.40 | 38.94 | 39.82 | |
| QPIC+CQL | total | 30.96 | 30.73 | 34.76 | 35.37 |
| rare | 25.48 | 30.04 | 30.76 | 32.40 | |
| non-rare | 32.60 | 30.89 | 36.48 | 36.82 | |
| SQA | total | 27.65 | 28.85 | 34.67 | 35.82 |
| rare | 26.34 | 26.23 | 32.96 | 36.44 | |
| non-rare | 28.04 | 29.45 | 35.80 | 36.20 | |
| PViC | total | 34.70 | 36.15 | 39.44 | 39.91 |
| rare | 32.83 | 32.02 | 37.55 | 39.55 | |
| non-rare | 35.26 | 37.38 | 40.01 | 40.01 |
| Original HICO-DET Test | Balanced Real World External Test | |
|---|---|---|
| 1 | 9.17 | 90.83 |
| 2 | 27.50 | 72.50 |
| 3 | 32.50 | 67.50 |
| 4 | 40.42 | 59.58 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, G.; Soomro, A.M. Enhancing Rare Class Performance in HOI Detection with Re-Splitting and a Fair Test Dataset. Information 2025, 16, 474. https://doi.org/10.3390/info16060474
Park G, Soomro AM. Enhancing Rare Class Performance in HOI Detection with Re-Splitting and a Fair Test Dataset. Information. 2025; 16(6):474. https://doi.org/10.3390/info16060474
Chicago/Turabian StylePark, Gyubin, and Afaque Manzoor Soomro. 2025. "Enhancing Rare Class Performance in HOI Detection with Re-Splitting and a Fair Test Dataset" Information 16, no. 6: 474. https://doi.org/10.3390/info16060474
APA StylePark, G., & Soomro, A. M. (2025). Enhancing Rare Class Performance in HOI Detection with Re-Splitting and a Fair Test Dataset. Information, 16(6), 474. https://doi.org/10.3390/info16060474