In this subsection, we discuss specific aspects of using different versions of Microsoft Kinect cameras in connection with movement and gesture analysis. We also point out the observed research gap.
In their work, Albert et al. (2020) [
9] used the 2019 Azure Kinect device launched by Microsoft to investigate the accuracy of gait assessment on a treadmill. For the experiments, five young and healthy subjects walked on a treadmill at three different velocities while recording the data simultaneously. Spatiotemporal gait features were described in this study, which included step length, step time, and step width. The results were compared against the gold standard Vicon 3D camera system, which relies on markers attached to significant body parts. The results showed that the Azure Kinect device achieved higher accuracy than its predecessor. However, there was no recommendation regarding which ML approach could enhance results. Interestingly, the results demonstrated that the predecessor of Kinect v2 performed better when tracking the upper body region. Nevertheless, for spatiotemporal accuracy, the tracking error of Azure Kinect was only 11.5 mm. However, no significant accuracy differences were found between the two cameras for temporal gait parameters (Albert et al. 2020) [
9]. Another study considering the range of motion of patients was presented by Gao et al. (2021) [
1]. In their paper, the authors particularly emphasized the time-consuming and inefficient way of measuring the range of motion in the manual and traditional way using a goniometer. Hence, working with an Azure Kinect depth camera automates not only the ROM evaluation but also the collection and processing of data. Accordingly, applying a virtual ROM estimation approach reduces the time spent on office work; however, it may also increase accuracy. The other advantages mentioned were the increase in patient comfort, reduced need for medical staff, and time saved by rehabilitation physicians (Gao et al. 2021) [
1]. The range of motion measurement results of the Microsoft Kinect version 2 (v2) camera did not differ significantly from marker-based approaches. In their publication about musculoskeletal models driven by Microsoft Kinect v2 Sensor data, Skals et al. (2017) [
19] found comparable results for the markerless approach compared to a marker-based approach for the vertical ground reaction force—the force exerted on pressure plates during exercises. Additionally, the ROM results did not differ significantly. However, for lower limbs, the markerless approach resulted in larger standard deviations. The experiments were performed in a standardized way and captured by two Kinect v2 cameras. Skals et al. (2017) [
19] emphasized the limitation of their results for upper limb assessment since the model for lower limbs and more complex exercises with higher velocity showed inferior performance. According to Tölgyessy et al. (2021) [
20], the most recent version of Microsoft Azure Kinect performed well compared to prior versions. The authors focused on the comparison of the predecessors of Azure Kinect cameras, namely, Kinect v1 and Kinect v2. Their paper aimed to judge the precision (repeatability), accuracy, and depth noise of the reflectivity of 18 different materials, as well as the performance in both indoor and outdoor environments. While performing extensive experiments under different conditions in the outdoor setting, the authors concluded that the Azure Kinect camera performed well in indoor settings but could not always produce reliable results in outdoor settings due to the time-of-flight (ToF) technology used to measure distances. Tölgyessy et al. (2021) [
20] confirmed the officially stated values of the standard deviation of ≤17 mm and a distance error of <11 mm in up to 3.5 m distance from the sensor. In addition, they recommended a warmup time for Azure Kinect to provide reliable tracking results. Since the Kinect v2 and Azure Kinect cameras both work on the same ToF measurement principle, both cameras have the highest noise rates in terms of depth accuracy on the sides of the gathered images. They describe the four different field modes of the Azure Kinect camera, each providing different results in the experiments. NFOV (narrow field of view depth mode) unbinned/binned is ideally used for scenes with smaller extents in the x and y dimensions, but larger extents in the z dimension, and WFOV (wide field-of-view depth mode) unbinned/binned is used for large x and y extents but smaller z ranges. In addition, the standard deviations of each camera version were compared. The results showed improvements for all tested distances, ranging from 1.907 mm for Kinect v1 to 0.6132 mm for Azure Kinect at the closest distance, as well as 10.9928 mm for Kinect v1 to 0.9776 mm for Azure Kinect at the farthest distance tested (Tölgyessy et al. 2021) [
20]. Another finding by Tölgyessy et al. (2021) [
20] is the influence of different material textures on the distance error: fuzzy, porous, or partially transparent textures increase the measuring error. Breedon et al. (2016) [
21] reviewed the capabilities of Microsoft Kinect v2 and Kinect v1 cameras as low-cost approaches for objectively assessing clinical outcomes and their utility in clinical trials. They addressed the problem of subjective investigator ratings, which could not sensitively detect small improvements. In addition, inter- and intra-investigator variability was addressed. In this study, different Microsoft Kinect camera approaches were explored as objective measurements and sensitive methods for movement and mobility detection. The primary measures of gait and balance, upper extremity movements, and facial analysis were explored. The authors concluded that exergaming approaches, including low-cost sensor solutions, offer significant value for rehabilitation and drug development. On the one hand, they emphasized the advantage of gross spatial movement data collection with cameras. On the other hand, they pointed out regulatory acceptance, which would require a comprehensive assessment of the validity and clinical relevance of such approaches. Finally, Breedon et al. (2016) [
21] provided an outlook for the future use of exergaming technology in pharmaceutical development to better understand treatment effects. In a more recent study by Bertram et al. (2023) [
22], the Microsoft Azure Kinect technology was used for clinical measurements of motor functions, such as the quiet stance test to measure static postural control or a stand-up and sit-down test. The obtained results showed good-to-excellent accuracy (0.84 to 0.99) and were compared with those from a clinical reference standard multicamera motion capture system. However, the limitations of the suggested approach were similar to those observed with the predecessor technology. Another recent study (Abdelnour et al. 2024) [
23] compared Azure Kinect and Kinect v2 for one specific movement (drop vertical jump) and found the new model not to be a reliable successor of the older camera version. However, another study (Ripic et al. 2022) [
24] found that Azure Kinect provided higher accuracy compared to previous studies using Kinect v2 considering data from walking trials.





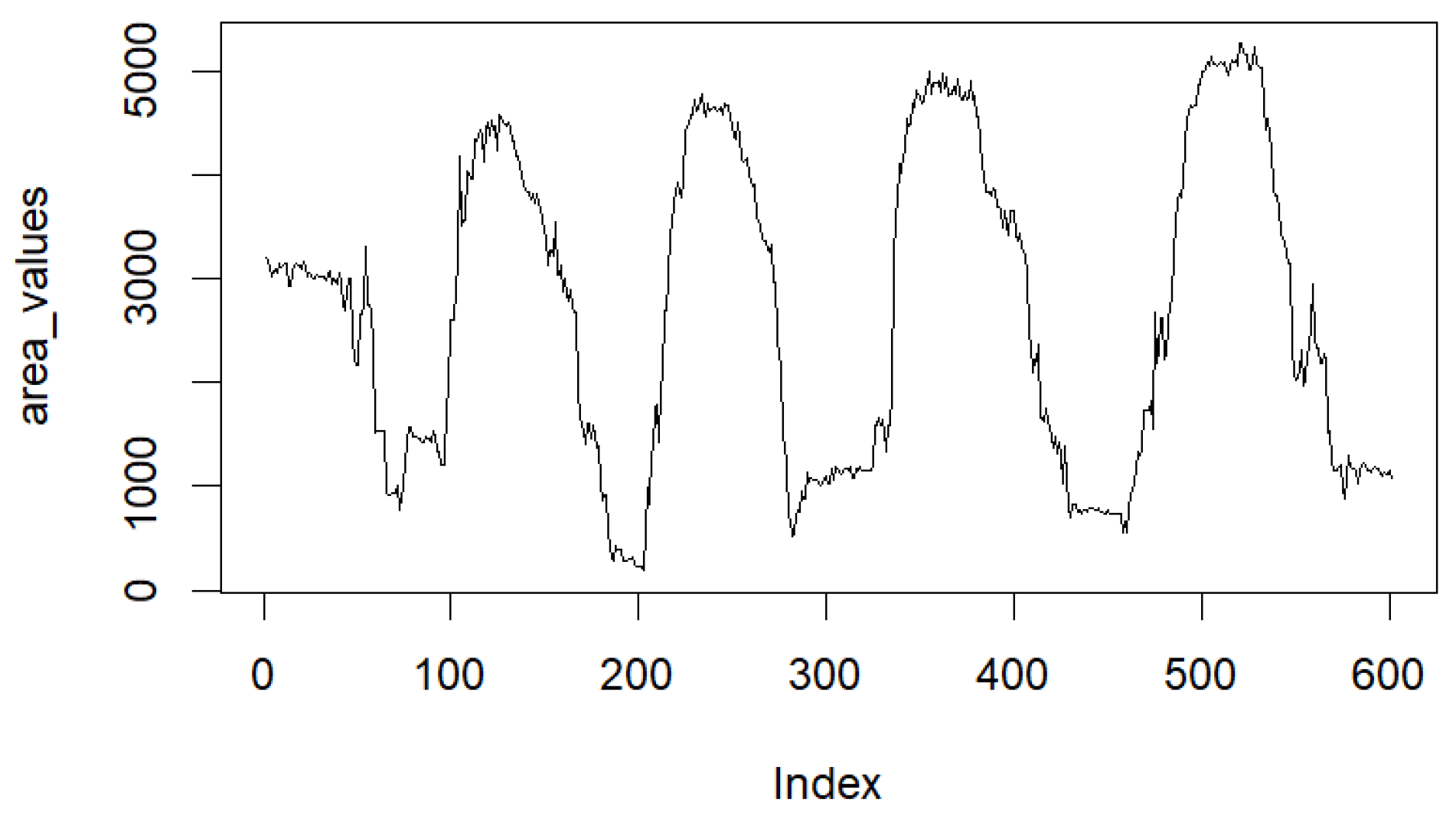
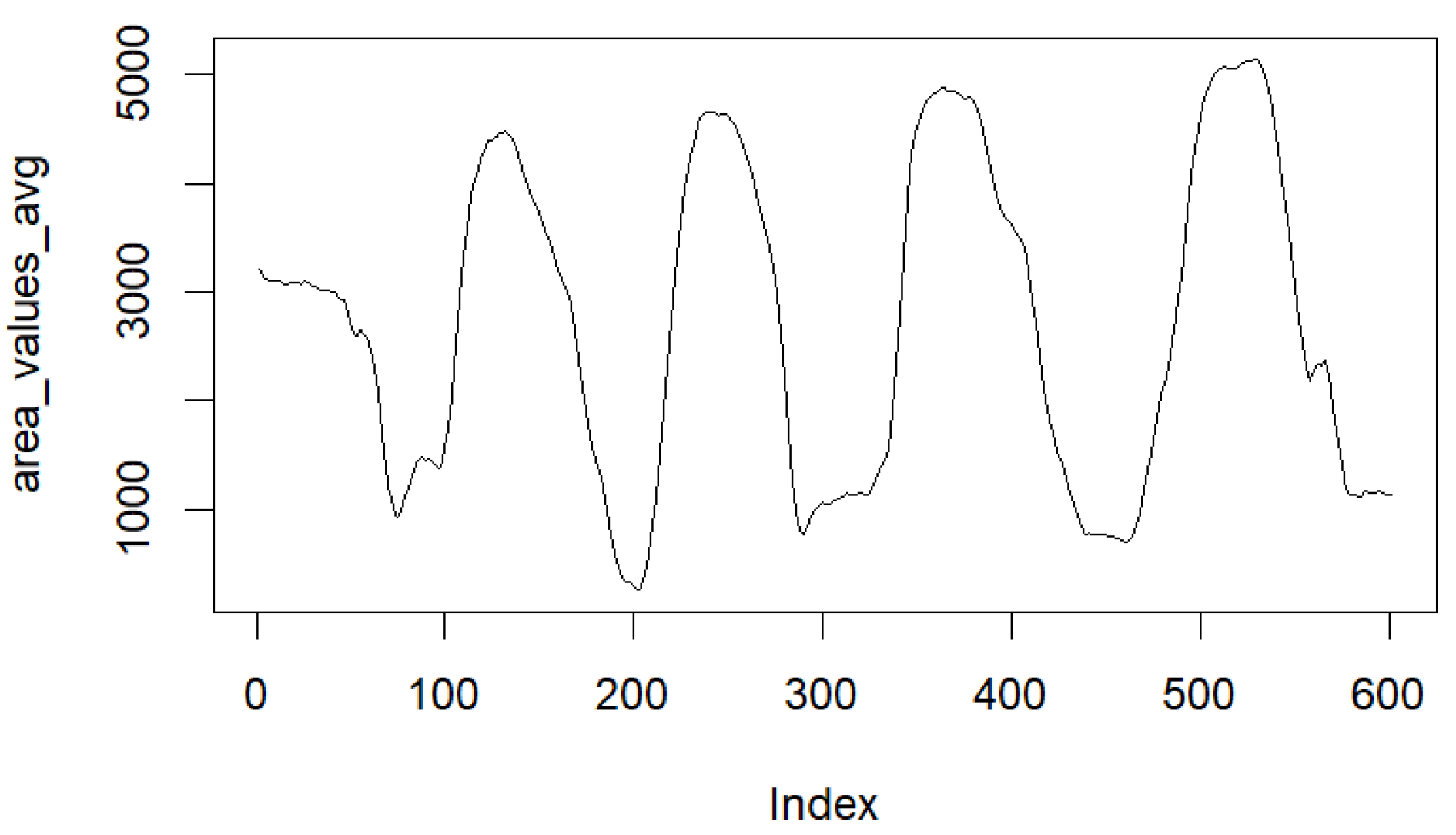
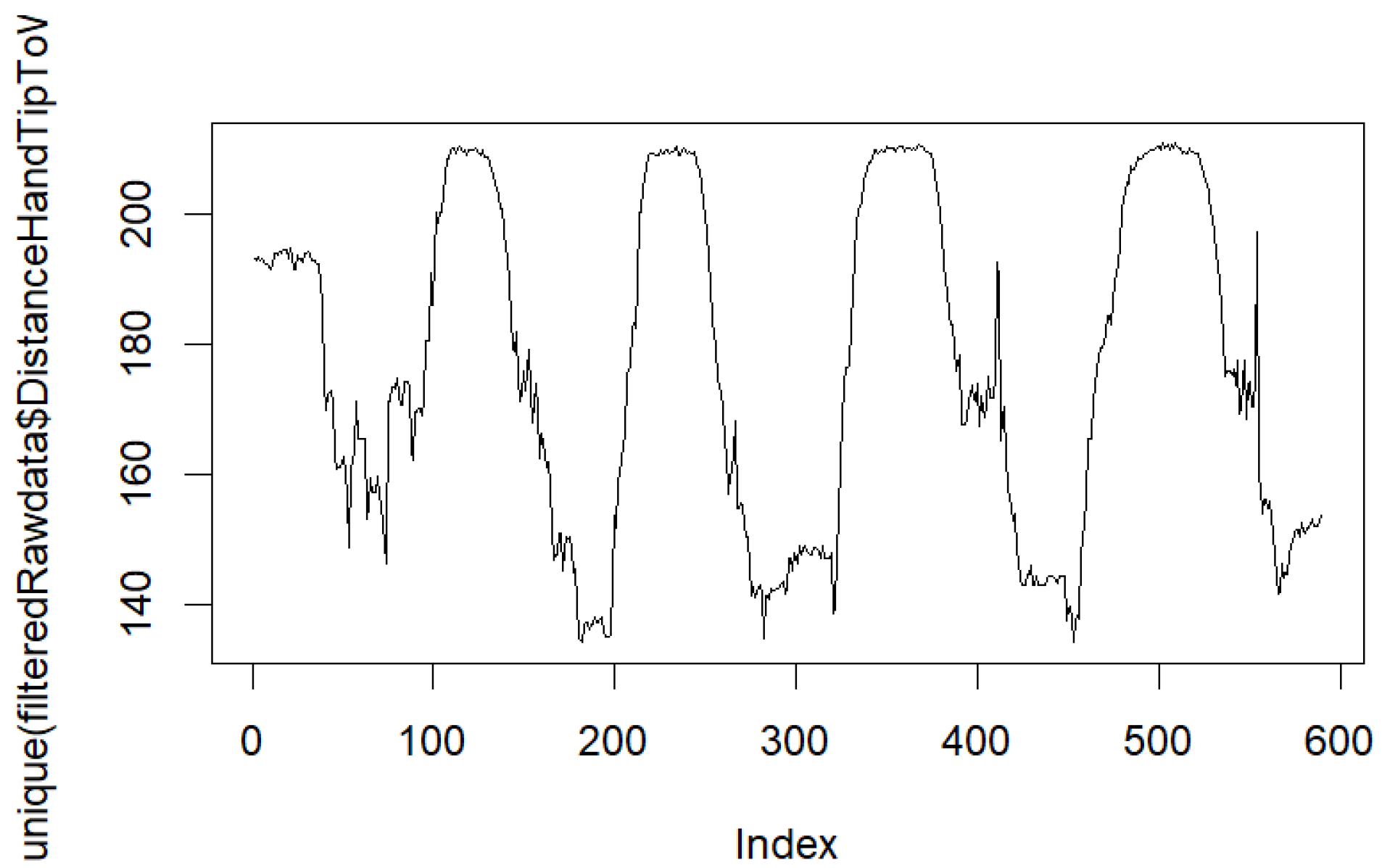
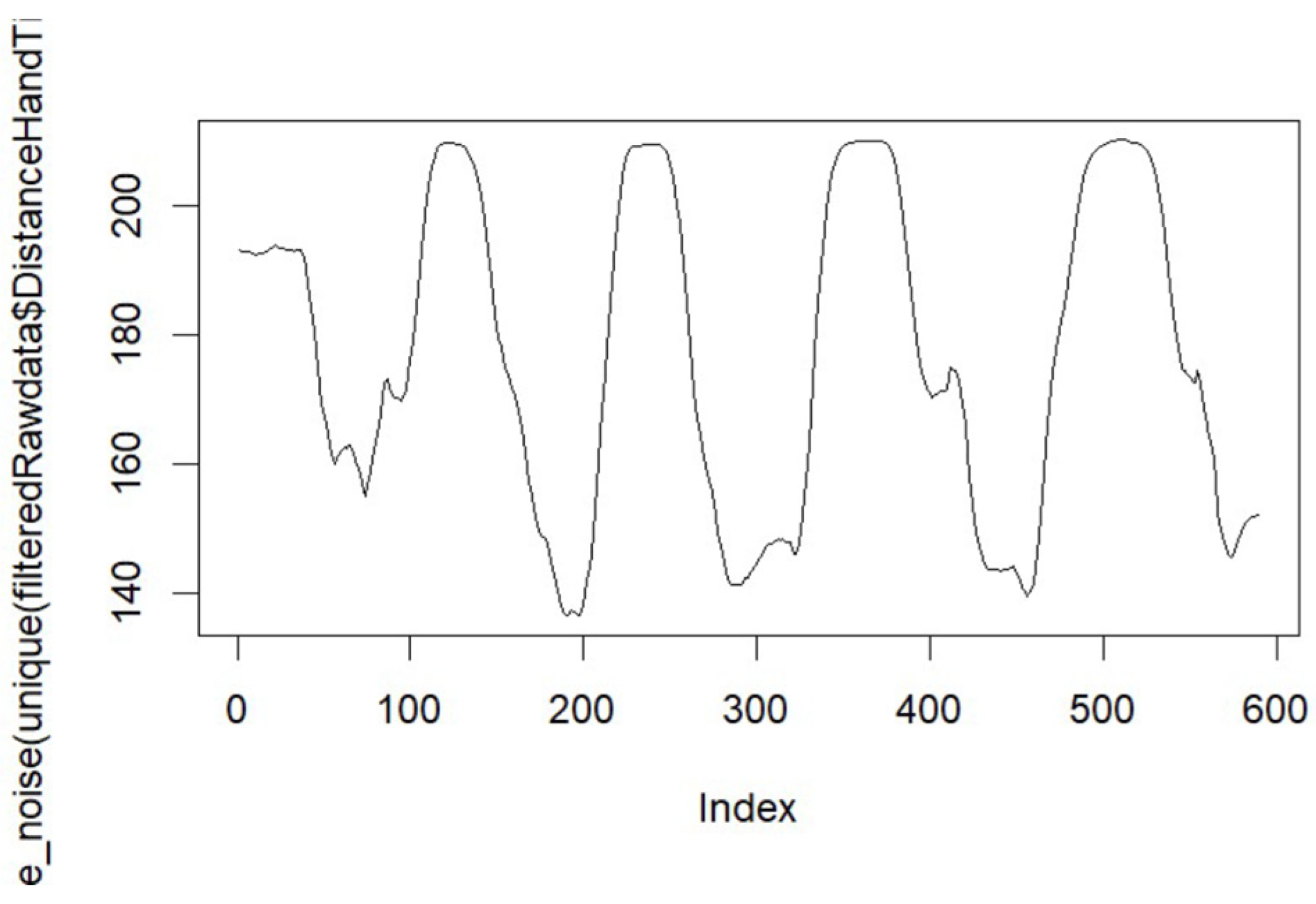
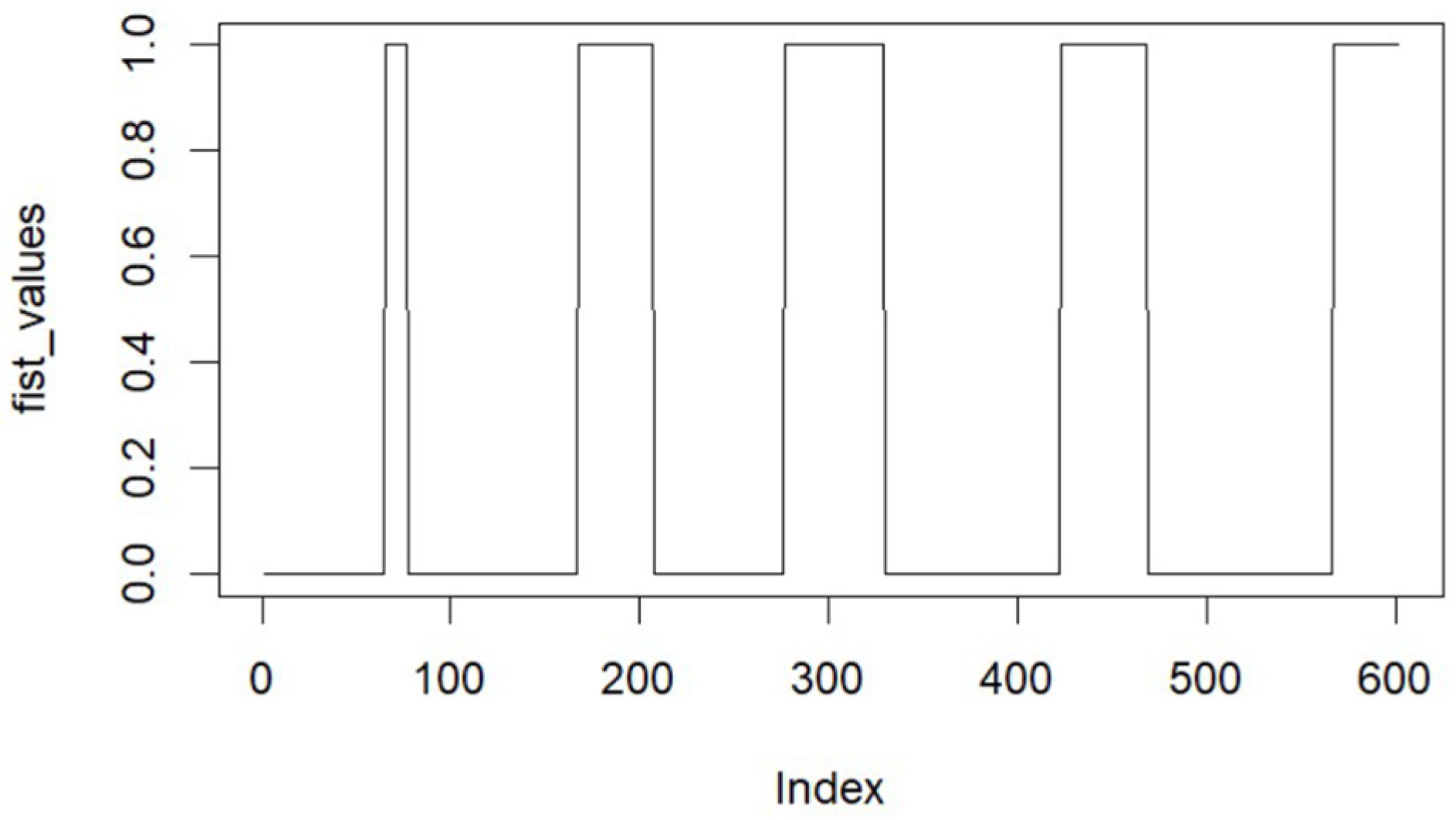

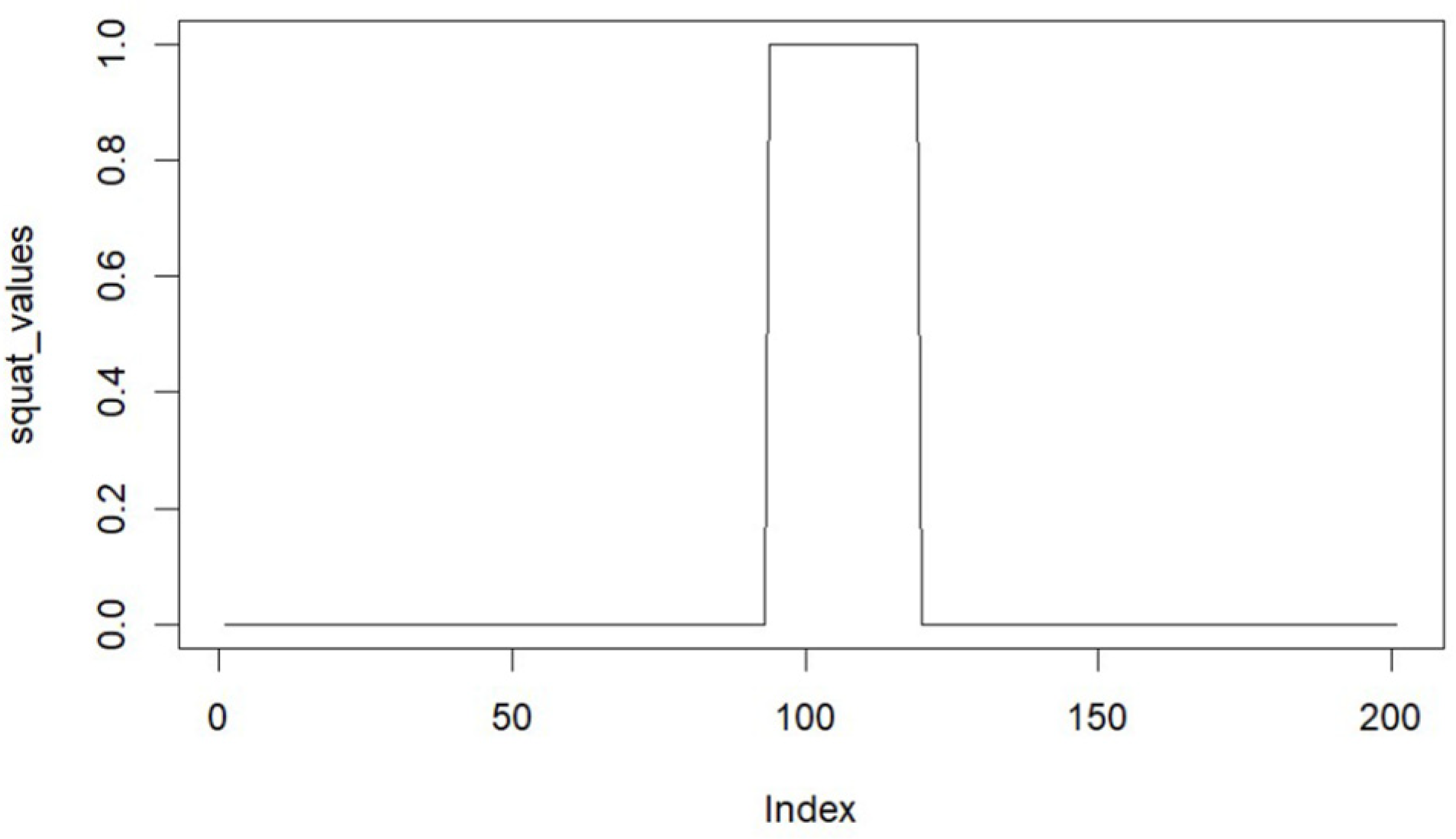
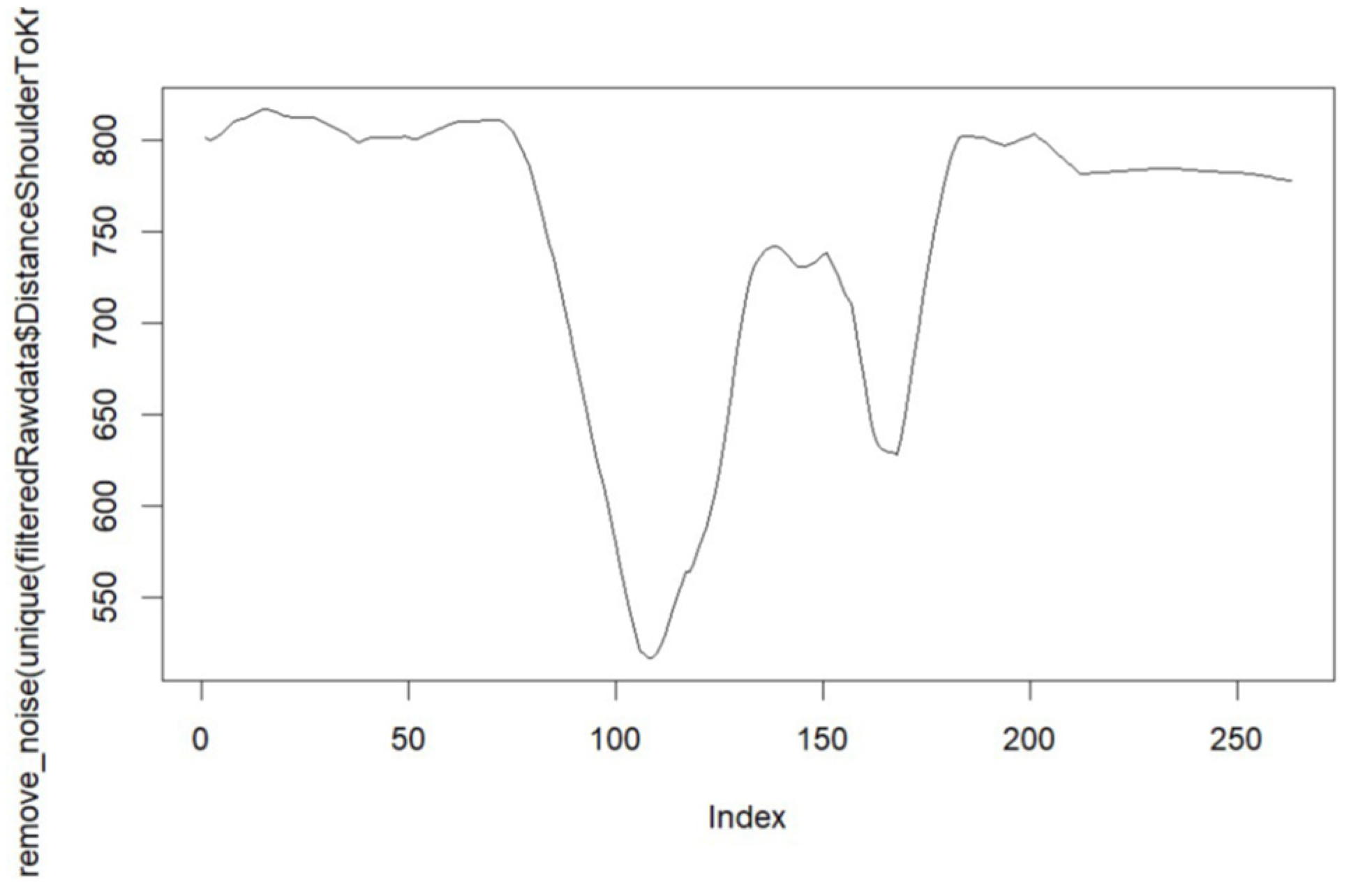

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}