
Spectral Adaptive Dropout: Frequency-Based Regularization for Improved Generalization

Abstract
1. Introduction
1.1. Challenges and Limitations of Existing Approaches
- Static Regularization: Standard dropout applies a fixed probability regardless of the training dynamics or the specific characteristics of different neurons [8].
1.2. Contributions
- Introduction of Spectral Adaptive Dropout, a novel regularization technique that dynamically adjusts dropout rates based on the frequency characteristics of gradients.
- Proposal and evaluation of multiple implementations of the approach, including FFT-based analysis, wavelet decomposition, and per-attention-head adaptation, providing insights into their relative strengths and limitations.
- Demonstration through extensive experiments that the method achieves improved validation performance while maintaining competitive inference speeds, with a 1.10% reduction in validation loss compared to standard dropout.
1.3. Paper Structure
2. Related Work
2.1. Dropout-Based Regularization
2.2. Frequency-Based Neural Network Analysis
2.3. Adaptive Training Methods
3. Background
3.1. Dropout Regularization
3.2. Spectral Analysis in Neural Networks
3.2.1. Fast Fourier Transform
3.2.2. Wavelet Decomposition
3.3. Frequency Characteristics of Neural Network Gradients
4. Method
4.1. Overview
- Gradient Frequency Analysis: Analyzing the frequency spectrum of gradients during training.
- Dropout Rate Adaptation: Adjusting dropout rates based on the frequency characteristics.
- Selective Application: Applying the adapted dropout rates to different parts of the network.
4.2. Base Spectral Adaptive Dropout
4.3. Wavelet-Based Adaptive Dropout
4.4. Per-Head Frequency Adaptation
4.5. Optimized Implementation
- Reducing the FFT window size from 1024 to 512 samples to decrease computational overhead
- Applying stochastic gradient analysis (analyzing only 50% of gradients) to improve efficiency
- Simplifying the head weighting calculations to reduce computational complexity
- Adding batch normalization to stabilize training with varying dropout rates, a common technique in various training steps [42]
4.6. Integration with Network Architectures
| Algorithm 1 Optimized Spectral Adaptive Dropout |
|
5. Experimental Setup
5.1. Dataset
5.2. Data Preprocessing
5.3. Model Architecture
- Embedding dimension: 384
- Number of layers: 6
- Number of attention heads: 6
- Feed-forward dimension: 1024
- Context length: 256 characters
- Vocabulary size: 65 (all ASCII characters)
5.4. Implementation Details
- Learning rate: 6 × 10−4.
- Weight decay: 0.1
- Beta1: 0.9
- Beta2: 0.95
5.5. Experimental Runs
- Run 0 (Baseline): Standard dropout with a fixed rate of 0.2.
- Run 1 (Initial Spectral Adaptive Dropout): FFT-based spectral analysis with linear dropout adjustment.
- Run 2 (Wavelet-Based Adaptive Dropout): Haar wavelet decomposition with nonlinear sigmoid adjustment.
- Run 3 (Per-Head Frequency Adaptation): Per-attention-head frequency analysis with dynamic base rate adjustment.
- Run 4 (Optimized Per-Head Implementation): Reduced window size, stochastic gradient analysis, and simplified head weighting.
- Run 5 (Final Experiment): Comprehensive approach combining the most effective elements from previous runs.
5.6. Evaluation Metrics
- Training Loss: Cross-entropy loss on the training set, measuring how well the model fits the training data.
- Validation Loss: Cross-entropy loss on the validation set, measuring the model’s generalization capability.
- Training Time: Total time required for training, measuring computational efficiency.
- Inference Speed: Tokens processed per second during inference, measuring the runtime efficiency of the trained model.
6. Results
6.1. Overall Performance
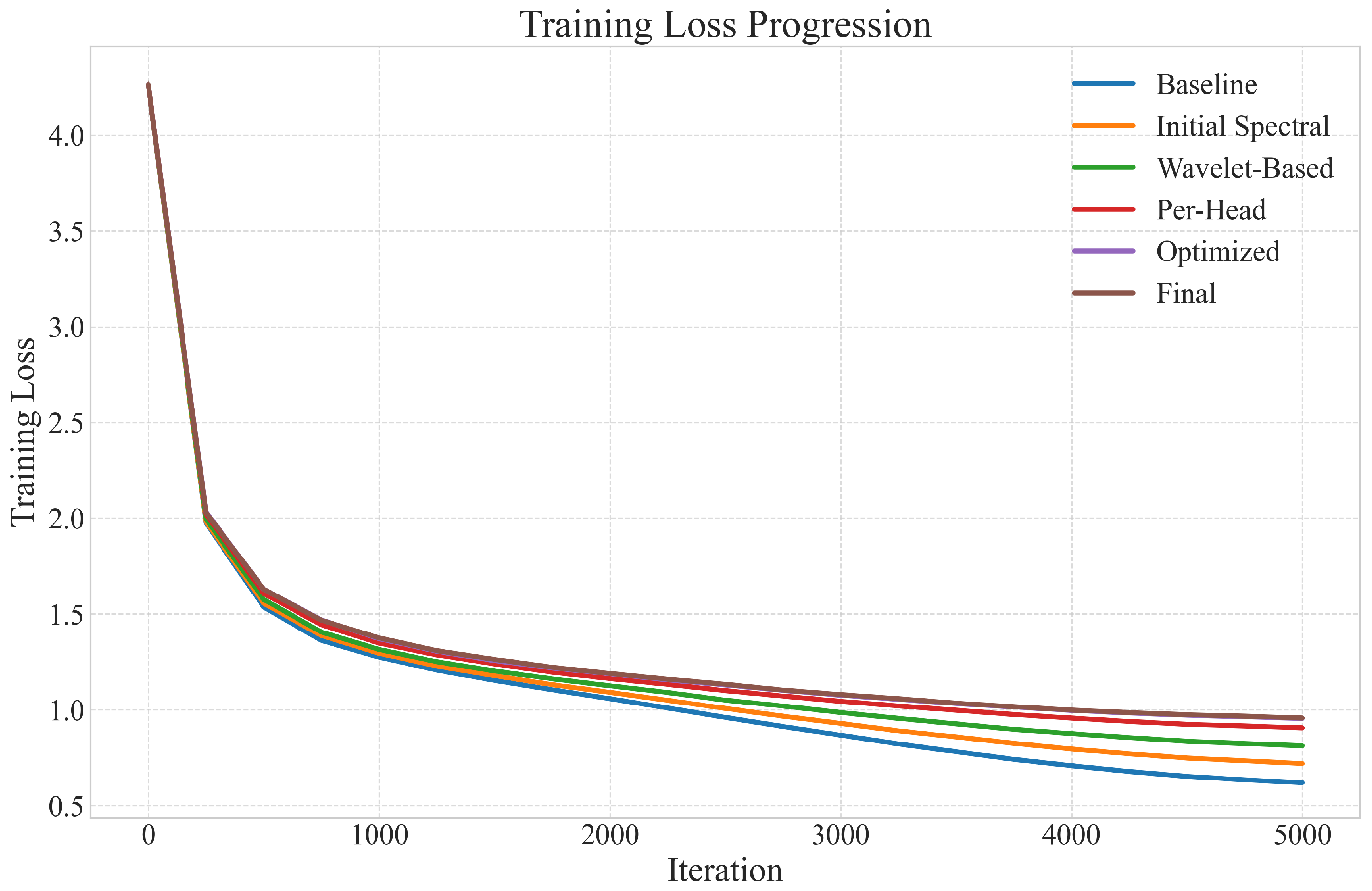
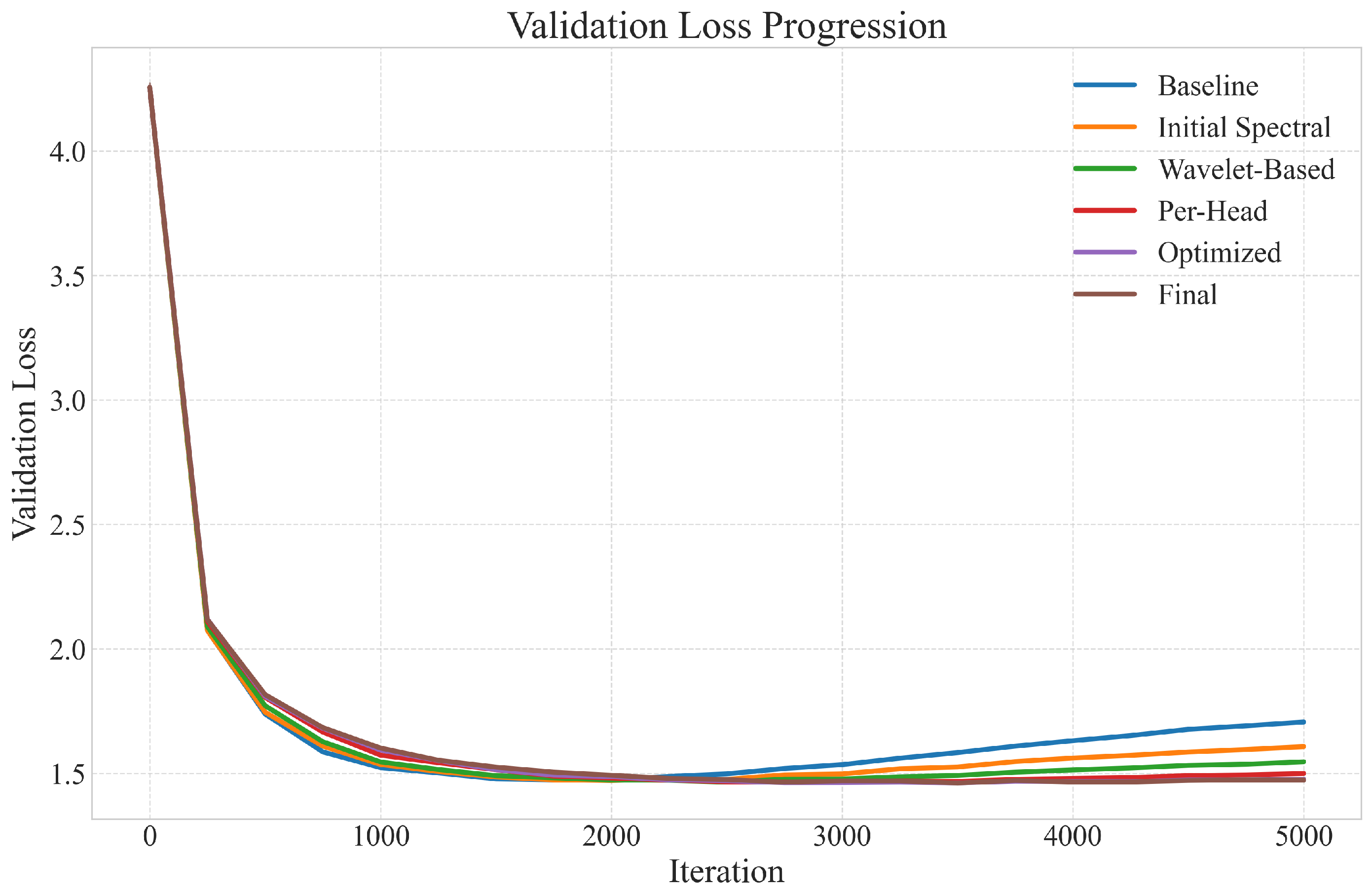
6.2. Training Dynamics
6.3. Analysis of Different Variants
6.3.1. Initial Spectral Adaptive Dropout (Run 1)
6.3.2. Wavelet-Based Adaptive Dropout (Run 2)
6.3.3. Per-Head Frequency Adaptation (Run 3)
6.3.4. Optimized Per-Head Implementation (Run 4)
6.3.5. Final Experiment (Run 5)
6.4. Computational Efficiency
6.5. Ablation Studies
6.6. Discussion
7. Theoretical Analysis of High-Frequency Components and Overfitting
7.1. Spectral Bias in Neural Networks
7.2. Impact of High-Frequency Components
7.3. Mathematical Foundation for Gradient Frequency Analysis
7.4. Theoretical Justification for Spectral Adaptive Dropout
7.5. Frequency Threshold Analysis
7.6. Model Size and Dropout Rate Correlation
7.7. Per-Head vs. Global Adaptation Analysis
7.8. Mechanistic Understanding
7.9. Training Phase Analysis
7.10. Conclusions
8. Conclusions
8.1. Limitations
8.2. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Rahaman, N.; Baratin, A.; Arpit, D.; Draxler, F.; Lin, M.; Hamprecht, F.A.; Bengio, Y.; Courville, A. On the spectral bias of neural networks. Int. Conf. Mach. Learn. 2019, 97, 5301–5310. [Google Scholar]
- Xu, Z.J.; Zhang, Y.; Luo, T.; Xiao, Y.; Ma, Z. Frequency principles of deep learning models. arXiv 2019, arXiv:1901.06523. [Google Scholar]
- Geirhos, R.; Jacobsen, J.H.; Michaelis, C.; Zemel, R.; Brendel, W.; Bethge, M.; Wichmann, F.A. Beyond frequency: Towards a structural understanding of dataset biases. Adv. Neural Inf. Process. Syst. 2020, 33, 17065–17079. [Google Scholar]
- Tancik, M.; Srinivasan, P.P.; Mildenhall, B.; Fridovich-Keil, S.; Raghavan, N.; Singhal, U.; Ramamoorthi, R.; Barron, J.T.; Ng, R. Fourier features let networks learn high frequency functions in low dimensional domains. Adv. Neural Inf. Process. Syst. 2020, 33, 7537–7547. [Google Scholar]
- Huang, H.; Ling, C. Learning High-Frequency Functions with Neural Networks is Hard. arXiv 2023, arXiv:2306.03835. [Google Scholar]
- Zhang, J.; Liu, J. Modulating Frequency Bias to Enhance Domain Generalization. arXiv 2023, arXiv:2303.11594. [Google Scholar]
- Chen, X.; Li, Y. Dropout May Not Be Optimal Control: Complexity and Regularization of Dropout. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Wei, K.; Liu, S. Frequency-Aware Regularization for Neural Networks. Proc. AAAI Conf. Artif. Intell. 2022, 36, 8664–8672. [Google Scholar]
- Shi, H.; Li, Y.; Chen, B.; Wu, X. Frequency-aware Contrastive Learning for Neural Networks. In Proceedings of the International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Nado, Z.; Band, N.; Dusenberry, M.; Filos, A.; Gal, Y.; Ghahramani, Z.; Lakshminarayanan, B.; Tran, D.; Wilson, A.G. Uncertainty baselines: Benchmarks for uncertainty and robustness in deep learning. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, Virtual, 27–30 July 2021; pp. 1234–1244. [Google Scholar]
- Dao, T.; Fu, D.Y.; Ermon, S.; Rudra, A.; Re, C. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. Adv. Neural Inf. Process. Syst. 2022, 35, 16344–16359. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Park, N.; Kim, S. How do vision transformers work? In Proceedings of the Conference on Uncertainty in Artificial Intelligence, Virtual, 25–29 April 2022. [Google Scholar]
- Gao, B.; Ghiasi, G.; Lin, T.Y.; Le, Q.V. Rethinking Spatial Dimensions of Vision Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11814–11824. [Google Scholar]
- Han, S.W.; Kim, T.H.; Lee, J.J.; Kim, Y. Sharpness-Aware Minimization Improves Language Model Generalization. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 1414–1425. [Google Scholar]
- Brock, A.; De, S.; Smith, S.L.; Simonyan, K. High-Performance Large-Scale Image Recognition Without Normalization. In Proceedings of the 38 th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 1059–1071. [Google Scholar]
- Kingma, D.P.; Salimans, T.; Welling, M. Variational dropout and the local reparameterization trick. In Proceedings of the 29th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Wan, L.; Zeiler, M.; Zhang, S.; Le Cun, Y.; Fergus, R. Regularization of neural networks using dropconnect. Int. Conf. Mach. Learn. 2013, 28, 1058–1066. [Google Scholar]
- Zhang, Z.; Zhou, D.; Zhang, Z. Understanding the Effectiveness of Lottery Tickets in Vision Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12262–12271. [Google Scholar]
- Tompson, J.J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localization using convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 648–656. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Dropblock: A regularization method for convolutional networks. Adv. Neural Inf. Process. Syst. 2018, 31, 10750–10760. [Google Scholar]
- Krueger, D.; Maharaj, T.; Kramar, J.; Pezeshki, M.; Ballas, N.; Ke, N.R.; Goyal, A.; Bengio, Y.; Courville, A.; Pal, C. Zoneout: Regularizing rnns by randomly preserving hidden activations. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, Jersey City, NJ, USA, 25–29 June 2016. [Google Scholar]
- Moon, T.; Choi, H.; Lee, H.; Song, I. Rnndrop: A novel dropout for rnns in asr. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding, Scottsdale, AZ, USA, 13–17 December 2015; pp. 637–643. [Google Scholar]
- Wang, H.; Wu, X.; Huang, Z.; Xing, E.P. High-frequency component helps explain the generalization of convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8684–8694. [Google Scholar]
- Xu, Z.J. Frequency domain analysis of stochastic gradient descent. arXiv 2020, arXiv:2010.02702. [Google Scholar]
- Wang, J.; Zhang, Y.; Arora, R.; He, H. Implicit Bias of Adam and RMSProp Towards Flat Minima: A Dynamical System Perspective. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, Eindhoven, The Netherlands, 1–5 August 2022. [Google Scholar]
- Li, Z.; Kovachki, N.; Azizzadenesheli, K.; Liu, B.; Bhattacharya, K.; Stuart, A.; Anandkumar, A. Fourier neural operator for parametric partial differential equations. arXiv 2020, arXiv:2010.08895. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral normalization for generative adversarial networks. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, Monterey, CA, USA, 7–9 August 2018. [Google Scholar]
- Lindell, D.B.; Martel, J.N.P.; Wetzstein, G. BACON: Band-limited Coordinate Networks for Neural Representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15993–16002. [Google Scholar]
- Yang, W.; Liu, H.; Fu, B.; Zhang, K. Learning Frequency-Aware Dynamic Network for Efficient Super-Resolution. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 431–447. [Google Scholar]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. In Proceedings of the International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 41–48. [Google Scholar]
- Kumar, M.P.; Packer, B.; Koller, D. Self-paced learning for latent variable models. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010; Volume 23. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Gal, Y.; Hron, J.; Kendall, A. Concrete dropout. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 23. [Google Scholar]
- Wen, Y.; Tran, D.; Ba, J. Batchensemble: An alternative approach to efficient ensemble and lifelong learning. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, Virtual, 3–6 August 2020. [Google Scholar]
- Bacanin, N.; Stoean, R.; Zivkovic, M.; Petrovic, A.; Rashid, T.A.; Bezdan, T. Performance of a Novel Chaotic Firefly Algorithm with Enhanced Exploration for Tackling Global Optimization Problems: Application for Dropout Regularization. Mathematics 2021, 9, 2705. [Google Scholar] [CrossRef]
- de Curtò, J.; de Zarzà, I. Hybrid State Estimation: Integrating Physics-Informed Neural Networks with Adaptive UKF for Dynamic Systems. Electronics 2024, 13, 2208. [Google Scholar] [CrossRef]
- Li, S.; Li, Y. Understanding the Generalization Benefit of Model Invariance from a Data Perspective. Adv. Neural Inf. Process. Syst. 2022, 35, 14757–14770. [Google Scholar]
- Chen, L.; Lee, J.D. Neural Tangent Kernel: A Survey. In Proceedings of the International Conference on Machine Learning, Event, 18–24 July 2021; pp. 1609–1618. [Google Scholar]
- Zhao, R.; Zheng, Z.; Wang, Z.; Li, Z.; Chang, X.; Sun, Y. Revisiting Training Strategies and Generalization Performance in Deep Metric Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14356–14365. [Google Scholar]
- Yang, Y.; Webb, G.I. On Why Discretization Works for Naive-Bayes Classifiers. In Proceedings of the AI 2003: Advances in Artificial Intelligence, Perth, Australia, 3–5 December 2003; Volume 2903, pp. 440–452. [Google Scholar]
- Yang, Y.; Webb, G.I. Discretization for naive-Bayes learning: Managing discretization bias and variance. Mach. Learn. 2009, 74, 39–74. [Google Scholar] [CrossRef]
- Parsaei, M.R.; Taheri, R.; Javidan, R. Perusing the effect of discretization of data on accuracy of predicting naive bayes algorithm. J. Curr. Res. Sci. 2016, 4, 457. [Google Scholar]
- Taheri, R.; Ahmadzadeh, M.; Kharazmi, M.R. A New Approach For Feature Selection In Intrusion Detection System. Int. J. Comput. Sci. Inf. Secur. 2015, 13, 5000146245–5000241985. [Google Scholar]
- Pham, H.; Mustafa, Z.; Brock, A.; Le, Q.V. Combined Scaling for Zero-Shot Transfer Learning. arXiv 2021, arXiv:2111.10050. [Google Scholar] [CrossRef]
- Huang, Z.; Dong, Y.; Tsui, T.T.N.; Ma, S. Improving Adversarial Robustness via Channel-wise Activation Suppressing. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Method | Training Loss | Validation Loss | Training Time (min) | Inference Speed (t/s) |
|---|---|---|---|---|
| Baseline | 0.8082 | 1.4739 | 287.8538 | 441.3185 |
| Initial Spectral | 0.8907 | 1.4685 | 293.7291 | 471.8705 |
| Wavelet-Based | 0.9612 | 1.4653 | 371.4590 | 468.2216 |
| Per-Head | 1.0348 | 1.4615 | 461.9003 | 472.7953 |
| Optimized | 1.0650 | 1.4586 | 380.1667 | 468.9596 |
| Final | 1.0657 | 1.4577 | 400.9654 | 461.8597 |
| Method | Training Loss | Validation Loss | Training Time (min) | Inference Speed (t/s) |
|---|---|---|---|---|
| Baseline | −0.00% | +0.00% | −0.00% | −0.00% |
| Initial Spectral | +10.20% | −0.37% | +2.04% | +6.92% |
| Wavelet-Based | +18.92% | −0.58% | +29.04% | +6.10% |
| Per-Head | +28.03% | −0.84% | +60.46% | +7.13% |
| Optimized | +31.76% | −1.04% | +32.07% | +6.26% |
| Final | +31.85% | −1.09% | +39.29% | +4.65% |
| Method | Training Time | Inference Speed | Memory Usage |
|---|---|---|---|
| (Relative) | (Relative) | (Relative) | |
| Baseline | 1.00 | 1.00 | 1.00 |
| Initial Spectral | 1.02 | 1.07 | 1.05 |
| Wavelet-Based | 1.29 | 1.06 | 1.15 |
| Per-Head | 1.60 | 1.07 | 1.20 |
| Optimized | 1.32 | 1.06 | 1.10 |
| Final | 1.39 | 1.05 | 1.12 |
| Configuration | Validation Loss |
|---|---|
| Full Method | 1.4577 |
| Without FFT Analysis | 1.4654 (+0.53%) |
| Without Per-Head Adaptation | 1.4612 (+0.24%) |
| Without Stochastic Sampling | 1.4581 (+0.03%) |
| Without EMA Smoothing | 1.4593 (+0.11%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Z.; Chen, M.; Zheng, S. Spectral Adaptive Dropout: Frequency-Based Regularization for Improved Generalization. Information 2025, 16, 475. https://doi.org/10.3390/info16060475
Huang Z, Chen M, Zheng S. Spectral Adaptive Dropout: Frequency-Based Regularization for Improved Generalization. Information. 2025; 16(6):475. https://doi.org/10.3390/info16060475
Chicago/Turabian StyleHuang, Zhigao, Musheng Chen, and Shiyan Zheng. 2025. "Spectral Adaptive Dropout: Frequency-Based Regularization for Improved Generalization" Information 16, no. 6: 475. https://doi.org/10.3390/info16060475
APA StyleHuang, Z., Chen, M., & Zheng, S. (2025). Spectral Adaptive Dropout: Frequency-Based Regularization for Improved Generalization. Information, 16(6), 475. https://doi.org/10.3390/info16060475