

YOLO-LSM: A Lightweight UAV Target Detection Algorithm Based on Shallow and Multiscale Information Learning

Abstract
1. Introduction
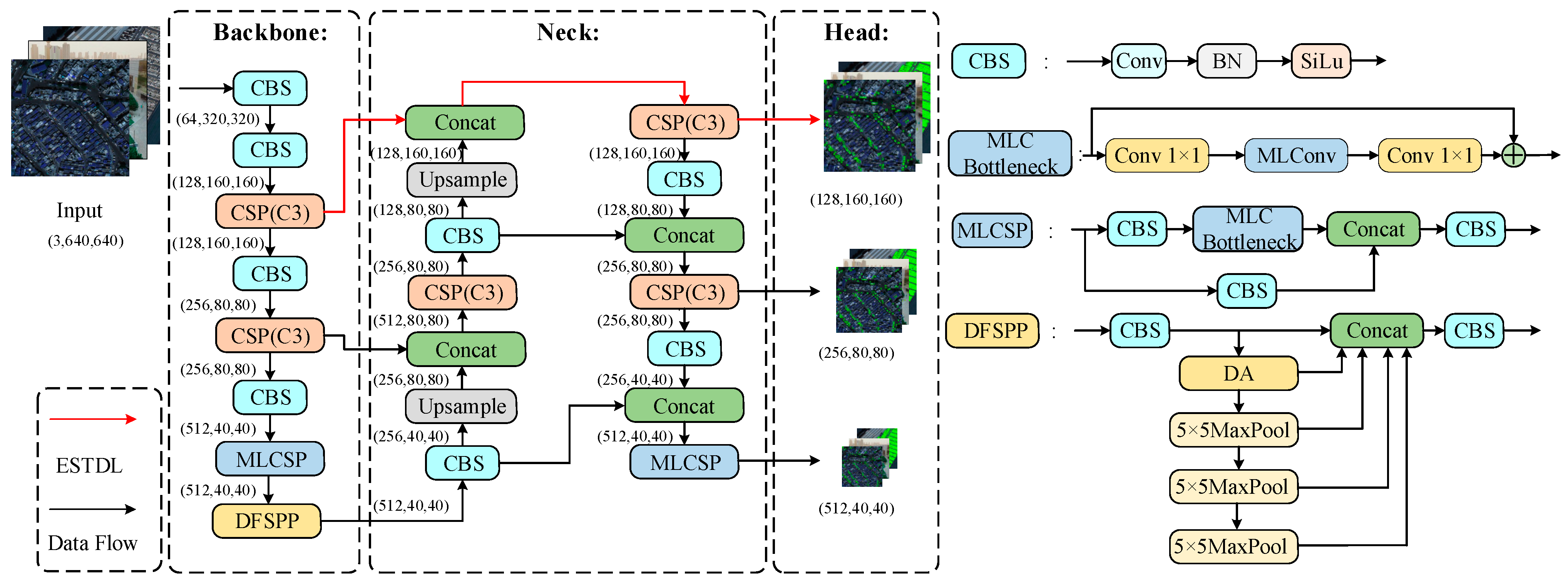
2. Proposed Method
- To enhance the extraction of small target features, a new Efficient Small Target Detection Layer (ESTDL) is added to the neck network. When the input is 640 × 640, the detection layer can predict on the 160 × 160 feature map to enhance the perception ability of the model to small targets.
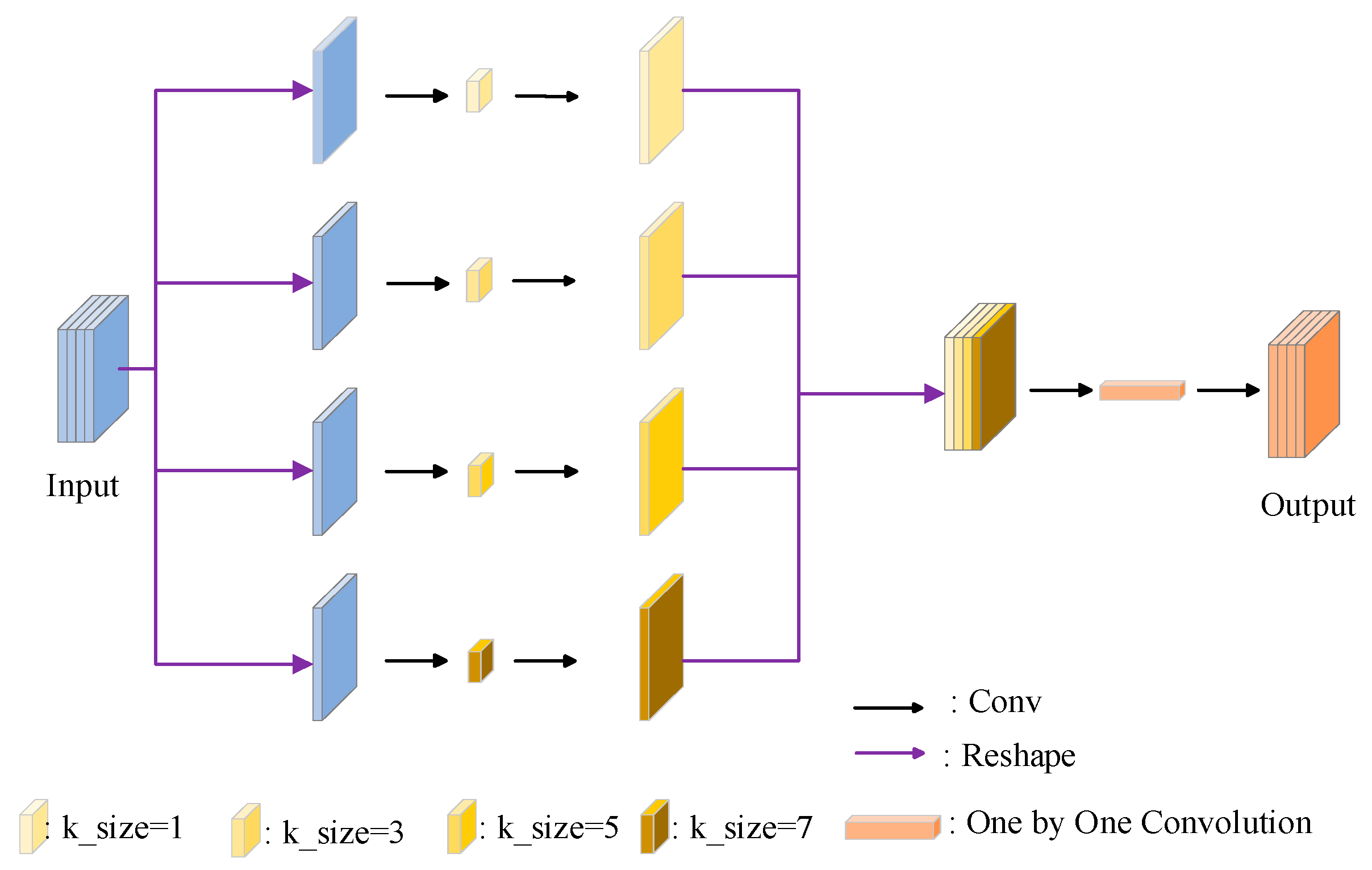
- A Multiscale Lightweight Convolution (MLConv) is designed and applied to the feature extraction module. A new feature extraction module, MLCSP, is designed to improve the situation of insufficient extraction of original feature information, improve the accuracy of small target detection, and reduce the number of parameters and the computational burden of the model.
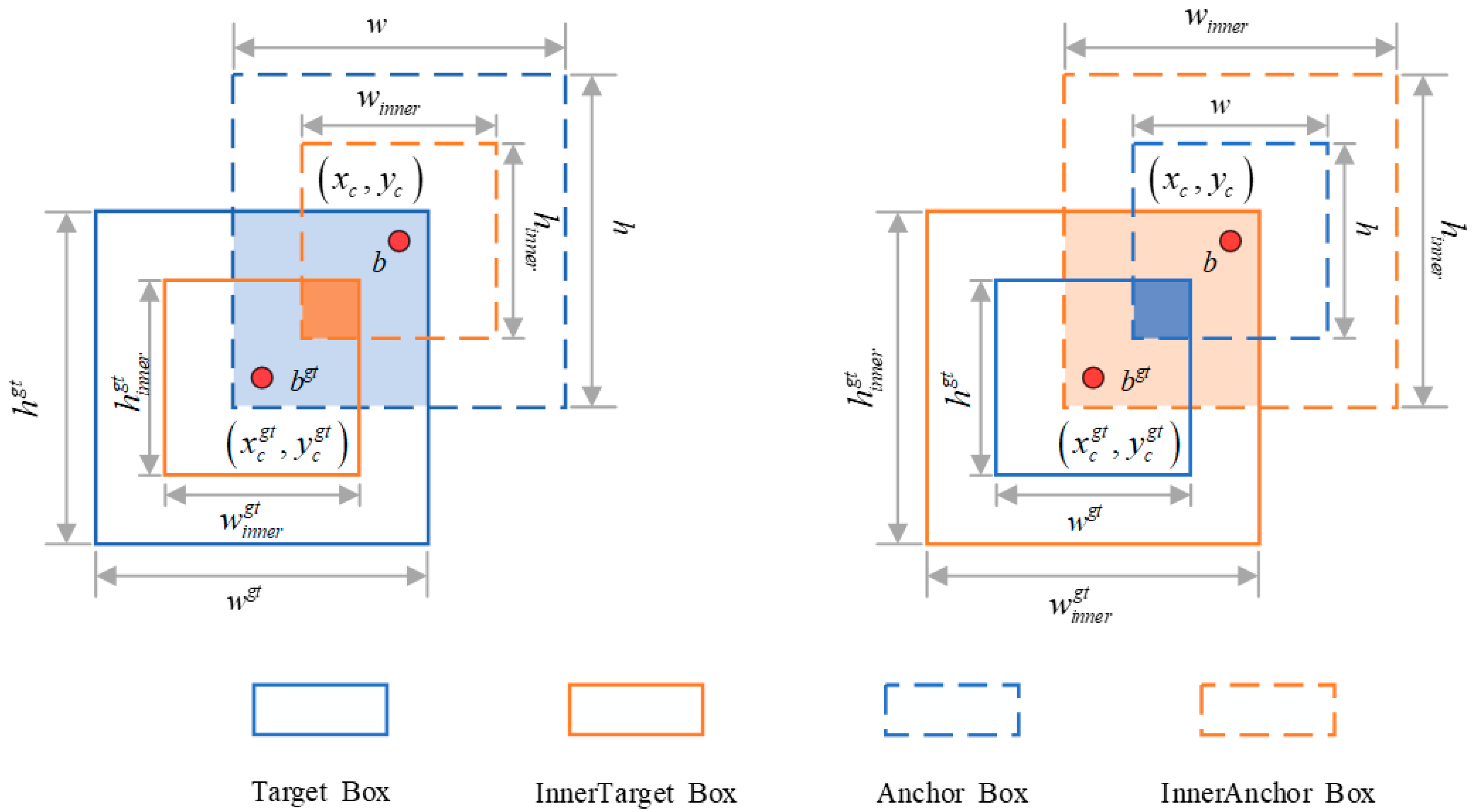
- The adopted Focaler inner IoU (Intersection over Union) loss function uses the scaling factor of the inner IoU to control the size of the auxiliary frame to accelerate the convergence of the calculated loss. At the same time, by combining with the Focaler IoU to focus on different regression samples, it can improve the detection performance of the model.
- To enhance the model’s perception of features at different scales, we introduced the Deformable Attention (DA) mechanism to improve the model’s ability to understand details, and designed the Deformable Attention Fast-Spatial Pyramid Pooling (DFSPP) module combined with the Spatial Pyramid Pooling-Fast (SPPF) module to reduce the rates of false detection and missed detection and enhance the robustness of the model.
2.1. Efficient Small Target Detection Layer
2.2. Multiscale Lightweight Feature Extraction Module
2.3. Deformable Attention Fast-Spatial Pyramid Pooling
2.4. Focaler Inner Intersection over Union
| Algorithm 1 The pseudo code of Focaler inner IoU. |
| Input: Map, Anchor box1 (1,4) and box2 (n,4), format is (x, y, w, h), and optional parameters: ratio, u, d Output: Focaler inner IoU, processed Boxes |
| 1: Compute intersection(inter) |
| 2: Compute Union (with ratio adjustment, default ratio = 0.7) 3: Compute 4: The linear interval mapping method is used to reconstruct the IoU (d = 0, u = 0.95) 5: Return Focaler inner IoU and processed boxes |
3. Simulation and Validation
3.1. Datasets and Evaluation Environment Setup
3.2. Evaluation Metrics
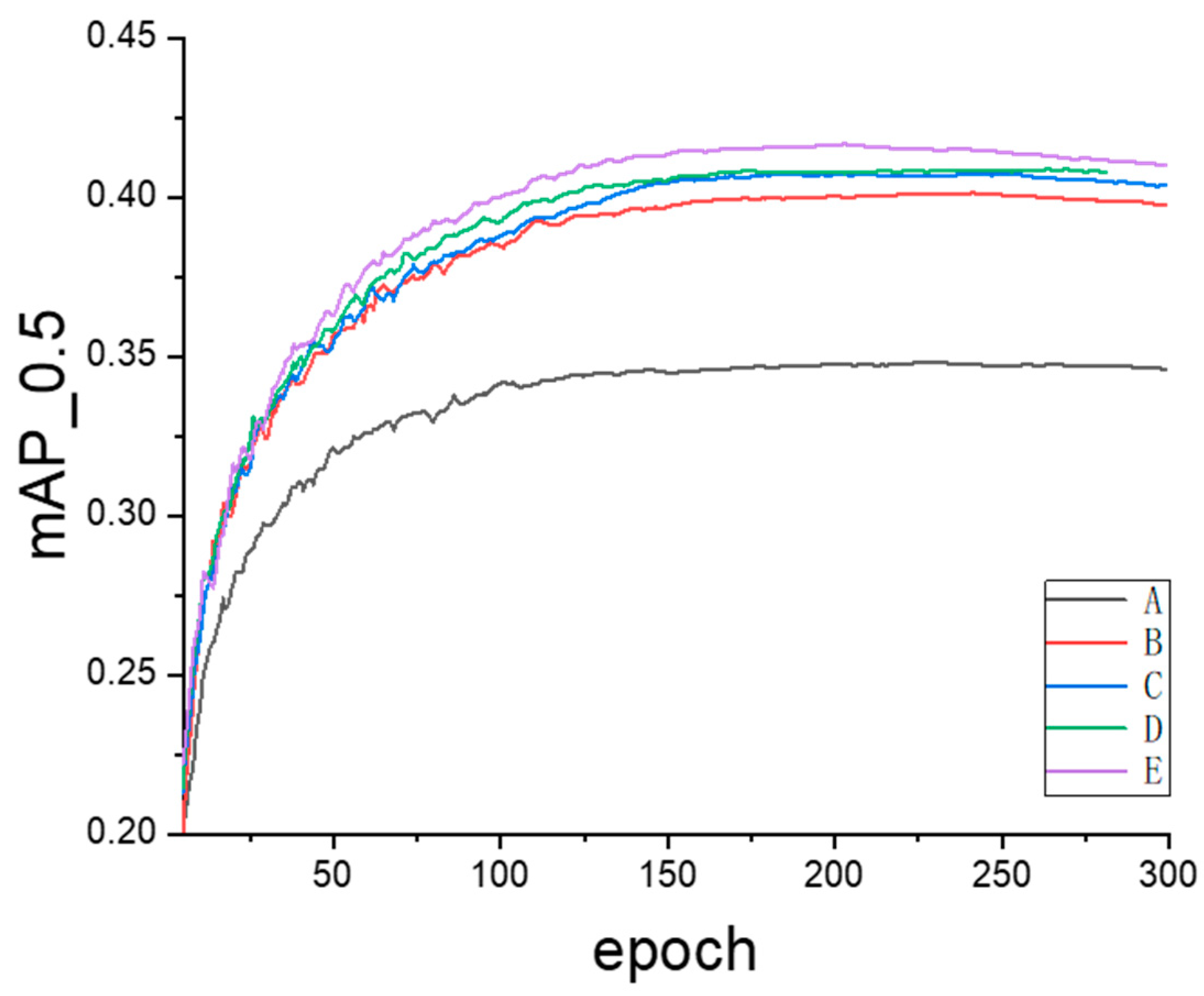
3.3. Comparison Analysis
3.4. Performance Comparison of Each Module
- 1.
- Efficient Small Target Detection Layer
- 2.
- Multiscale Lightweight Feature Extraction Module
- 3.
- Deformable Attention Fast-Spatial Pyramid Pooling
- 4.
- Focaler inner Intersection over Union
3.5. Ablation Study
- Baseline Setup: The test results of YOLOv5s are selected as the benchmark. Since the proposed YOLO-LSM is built upon YOLOv5s by incorporating ESTDL, MLCSP, Focaler inner IoU, and DFSPP, it becomes more convenient to quantitatively assess the impact of the improved modules. According to Table 9, the Mean Average Precision (mAP0.5) is 34.7%, Precision is 47.4%, Recall is 34.9%, and the number of parameters is 7.04 million.
- Effect of Adding ESTDL: By enhancing the YOLOv5 architecture and designing the Efficient Small Target Detection Layer ESTDL, the model parameters are reduced to 2.04 million, with a Precision increase of 1.3%, a Recall increase of 5.0%, and a mAP0.5 increase of 5.4%. This indicates that the ESTDL module can fully capture the details of the tiny targets, improving the model’s detection accuracy and facilitating deployment on UAV devices.
- Effect of Adding ESTDL and MLCSP: With the parameters reduced to 1.86 million, Map0.5 increases by 0.6%. The MLCSP module utilizes convolutional kernels of various sizes, enabling the capture of feature information at different scales, thereby enhancing the extraction of multiscale information while reducing the model’s parameters.
- Effect of Adding ESTDL, MLCSP, and the Focaler Inner IoU: The proposed Focaler inner IoU improves mAP0.5 to 40.9% without altering the number of parameters. It also accounts for the impact of internal overlap areas between targets and the distribution of targets in bounding box regression, accelerating the model’s convergence speed.
- Effects of YOLO-LSM: mAP0.5 was increased from 34.7% to 41.6%, the accuracy was increased from 47.4% to 50.6%, the recall rate was increased from 34.9% to 41.0%, and the number of model parameters was decreased from 7.04 M to 1.97 M. The reason is that the Deformable Attention mechanism can help the model better integrate the features of different scales and improve the model’s ability to understand details. Ablation studies show the effectiveness of the improved method.
3.6. Deployment Experiment
3.7. Visual Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, Z.; Yang, S.; Qin, H.; Liu, Y.; Ding, J. CCW-YOLO: A Modified YOLOv5s Network for Pedestrian Detection in Complex Traffic Scenes. Information 2024, 15, 762. [Google Scholar] [CrossRef]
- Žigulić, N.; Glučina, M.; Lorencin, I.; Matika, D. Military Decision-Making Process Enhanced by Image Detection. Information 2024, 15, 11. [Google Scholar] [CrossRef]
- Vu, V.Q.; Tran, M.-Q.; Amer, M.; Khatiwada, M.; Ghoneim, S.S.M.; Elsisi, M. A Practical Hybrid IoT Architecture with Deep Learning Technique for Healthcare and Security Applications. Information 2023, 14, 379. [Google Scholar] [CrossRef]
- Saradopoulos, I.; Potamitis, I.; Rigakis, I.; Konstantaras, A.; Barbounakis, I.S. Image Augmentation Using Both Background Extraction and the SAHI Approach in the Context of Vision-Based Insect Localization and Counting. Information 2025, 16, 10. [Google Scholar] [CrossRef]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J.; Berkeley, U. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R.B. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.P. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A.; Recognition, P. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 779–788. [Google Scholar]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision–European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar]
- Yan, P.; Liu, Y.; Lyu, L.; Xu, X.; Song, B.; Wang, F. AIOD-YOLO: An algorithm for object detection in low-altitude aerial images. J. Electron. Imaging 2024, 33, 013023. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, C.; Guo, W.; Zhang, T.; Li, W. CFANet: Efficient Detection of UAV Image Based on Cross-Layer Feature Aggregation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–11. [Google Scholar] [CrossRef]
- Min, L.; Fan, Z.; Lv, Q.; Reda, M.; Shen, L.; Wang, B. YOLO-DCTI: Small Object Detection in Remote Sensing Base on Contextual Transformer Enhancement. Remote Sens. 2023, 15, 3970. [Google Scholar] [CrossRef]
- Li, J.; Zhang, Y.; Liu, H.; Guo, J.; Liu, L.; Gu, J.; Deng, L.; Li, S. A novel small object detection algorithm for UAVs based on YOLOv5. Phys. Scr. 2024, 99, 036001. [Google Scholar] [CrossRef]
- Li, J.; Liang, X.; Wei, Y.; Xu, T.; Feng, J.; Yan, S.; Recognition, P. Perceptual Generative Adversarial Networks for Small Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1951–1959. [Google Scholar]
- Ma, M.; Pang, H. SP-YOLOv8s: An Improved YOLOv8s Model for Remote Sensing Image Tiny Object Detection. Appl. Sci. 2023, 13, 8161. [Google Scholar] [CrossRef]
- Xie, S.; Zhou, M.; Wang, C.; Huang, S. CSPPartial-YOLO: A Lightweight YOLO-Based Method for Typical Objects Detection in Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 388–399. [Google Scholar] [CrossRef]
- Qin, D.; Leichner, C.; Delakis, M.; Fornoni, M.; Luo, S.; Yang, F.; Wang, W.; Banbury, C.R.; Ye, C.; Akin, B.; et al. MobileNetV4: Universal Models for the Mobile Ecosystem. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 78–96. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C.; Recognition, P. GhostNet: More Features From Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar]
- Cai, Z.; Shen, Q.J.A. FalconNet: Factorization for the Light-weight ConvNets. arXiv 2023, arXiv:2306.06365. [Google Scholar]
- Hu, M.; Li, Z.; Yu, J.; Wan, X.; Tan, H.; Lin, Z. Efficient-Lightweight YOLO: Improving Small Object Detection in YOLO for Aerial Images. Sensors 2023, 23, 6423. [Google Scholar] [CrossRef]
- Yu, Z.; Guan, Q.; Yang, J.; Yang, Z.; Zhou, Q.; Chen, Y.; Chen, F. LSM-YOLO: A Compact and Effective ROI Detector for Medical Detection. arXiv 2024, arXiv:2408.14087. [Google Scholar]
- Zhu, P.; Du, D.; Wen, L.; Bian, X.; Ling, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The Vision Meets Drone Object Detection in Image Challenge Results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 213–226. [Google Scholar]
- Yu, X.; Gong, Y.; Jiang, N.; Ye, Q.; Han, Z. Scale Match for Tiny Person Detection. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 1246–1254. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Zhang, R.; Shao, Z.; Huang, X.; Wang, J.; Li, D. Object Detection in UAV Images via Global Density Fused Convolutional Network. Remote. Sens. 2020, 12, 3140. [Google Scholar] [CrossRef]
- Dang, C.; Wang, Z.; He, Y.; Wang, L.; Cai, Y.; Shi, H.; Jiang, J. The Accelerated Inference of a Novel Optimized YOLOv5-LITE on Low-Power Devices for Railway Track Damage Detection. IEEE Access 2023, 11, 134846–134865. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M.; Recognition, P. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Varghese, R.; M, S. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; pp. 1–6. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 318–327. [Google Scholar] [CrossRef]
- Bi, L.; Deng, L.; Lou, H.; Zhang, H.; Lin, S.; Liu, X.; Wan, D.; Dong, J.; Liu, H. URS-YOLOv5s: Object detection algorithm for UAV remote sensing images. Phys. Scr. 2024, 99, 086005. [Google Scholar] [CrossRef]
- Xue, C.; Xia, Y.; Wu, M.; Chen, Z.; Cheng, F.; Yun, L. EL-YOLO: An efficient and lightweight low-altitude aerial objects detector for onboard applications. Expert Syst. Appl. 2024, 256, 124848. [Google Scholar] [CrossRef]
- Gao, S.; Gao, M.; Wei, Z. MCF-YOLOv5: A Small Target Detection Algorithm Based on Multi-Scale Feature Fusion Improved YOLOv5. Information 2024, 15, 285. [Google Scholar] [CrossRef]
- Lou, H.; Liu, X.; Bi, L.; Liu, H.; Guo, J. BD-YOLO: Detection algorithm for high-resolution remote sensing images. Phys. Scr. 2024, 99, 066003. [Google Scholar] [CrossRef]
- Chen, Y.; Jin, Y.; Wei, Y.; Hu, W.; Zhang, Z.; Wang, C.; Jiao, X. LIS-DETR: Small target detection transformer for autonomous driving based on learned inverted residual cascaded group. J. Electron. Imaging 2025, 34, 013003. [Google Scholar] [CrossRef]
- Han, Z.; Jia, D.; Zhang, L.; Li, J.; Cheng, P. FNI-DETR: Real-time DETR with far and near feature interaction for small object detection. Eng. Res. Express 2025, 7, 015204. [Google Scholar] [CrossRef]
- Xu, S.; Zhang, M.; Chen, J.; Zhong, Y. YOLO-HyperVision: A vision transformer backbone-based enhancement of YOLOv5 for detection of dynamic traffic information. Egypt. Inform. J. 2024, 27, 100523. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.-h.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Li, J.; Wen, Y.; He, L. SCConv: Spatial and Channel Reconstruction Convolution for Feature Redundancy. In Proceedings of the IEEE/CVF Conference on Computer Vision Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6153–6162. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environment | Hyperparameters | Data Augmentation |
|---|---|---|
| PyTorch 2.2.1 CUDA 11.8 Python 3.8 RTX 4060Ti | momentum: 0.937 weight_decay: 0.0005 warmup_momentum: 0.8 warmup_bias_lr: 0.1 warmup_epochs: 3.0 epochs: 300 | Scale: 0.5 fliplr: 0.5 mosaic: 1.0 mixup: 0.1 hsv_h: 0.015 hsv_s: 0.7 hsv_v: 0.4 |
| Model | F1-Score/% | mAP0.5/% | Parameters/M | FLOPs/G |
|---|---|---|---|---|
| YOLOv5s | 39.5 | 34.7 | 7.04 | 16.0 |
| YOLOX-s | 41.2 | 40.2 | 9.0 | 26.8 |
| YOLOv5m | 44 | 39.6 | 21.17 | 48.9 |
| YOLOLite-G | 32.8 | 27.4 | 5.57 | 16.3 |
| YOLOX-Tiny | 38.5 | 38.1 | 5.06 | 6.45 |
| YOLOv7-Tiny | 42.9 | 37.2 | 6.23 | 13.2 |
| YOLOv8s | 44.4 | 40.7 | 11.13 | 28.5 |
| YOLOv9t | 39.0 | 34.4 | 2.6 | 10.7 |
| YOLOv10s | 44.6 | 39.7 | 8.1 | 24.8 |
| YOLOv11s | 44.8 | 40.6 | 9.4 | 21.6 |
| SSD | — | 10.6 | — | — |
| RetinaNet | — | 25.5 | — | — |
| CenterNet | — | 29.0 | — | — |
| Faster-RCNN | — | 35.8 | — | — |
| EL-YOLO | 42 | 40.6 | 4.29 | 24.7 |
| MCF-YOLOv5s | 40.7 | 38.3 | 10.31 | 25.52 |
| URS-YOLOv5s | 45.3 | 41.1 | 10.9 | 30.4 |
| UA-YOLOv5s | 43.3 | 39.1 | — | 33.3 |
| LIS-DETR | — | 40.1 | 15.22 | 75.5 |
| FNI-DETR | 45.2 | 37.4 | 42 | 111.4 |
| YOLO-HV | 42.9 | 38.10 | 38 | 111.9 |
| YOLO-LSM | 45.5 | 41.6 | 1.97 | 13.8 |
| Model | p-Value (Paired t-Test) | Statistical Significance (p < 0.05) |
|---|---|---|
| YOLOv5s | — | — |
| YOLOv7-Tiny | 3 × 10−16 | Significant |
| YOLOv8s | 8 × 10−34 | Significant |
| YOLOv11s | 4 × 10−28 | Significant |
| YOLO-LSM | 3 × 10−47 | Significant |
| Model | F1-Score/% | mAP0.5/% | Parameters/M | FLOPs/G |
|---|---|---|---|---|
| YOLOv5s | 33.0 | 25.7 | 7.04 | 16.0 |
| YOLOX-Tiny | 24.5 | 20.7 | 5.06 | 6.45 |
| YOLOX-s | 25.6 | 21.2 | 9.0 | 26.8 |
| YOLOLite-G | 33.6 | 22.9 | 5.6 | 16.3 |
| YOLOv7-Tiny | 34.6 | 24.4 | 6.0 | 13.2 |
| YOLOv8s | 31.1 | 26.4 | 11.2 | 28.6 |
| YOLOv9t | 28.1 | 21.5 | 2.6 | 10.7 |
| YOLOv10s | 33.6 | 25.0 | 8.1 | 24.8 |
| YOLOv11s | 31.5 | 27.4 | 9.4 | 21.6 |
| UA-YOLOv5s | 30.3 | 21.6 | — | 33.2 |
| BD-YOLOv8s | — | 18.7 | — | 28.5 |
| SP-YOLOv8s | — | 34.5 | 11.2 | 86.4 |
| AIOD-YOLO | — | 27.3 | 3.9 | 45.7 |
| YOLO-LSM | 36.7 | 29.2 | 1.96 | 13.8 |
| Methods | F1-Score/% | mAP0.5/% | Parameters/M | FLOPs/G |
|---|---|---|---|---|
| P345 (80 × 80, 40 × 40, 20 × 20) | 40.2 | 34.7 | 7.04 | 16.0 |
| P234 (160 × 160, 80 × 80, 40 × 40) | 44.7 | 40.8 | 5.39 | 17.2 |
| P2345 (160 × 160, 80 × 80, 40 × 40, 20 × 20) | 44.8 | 40.7 | 7.18 | 18.7 |
| ESTDL (160 × 160, 80 × 80, 40 × 40) | 43.9 | 40.1 | 2.04 | 14.1 |
| Methods | F1-Score/% | mAP0.5/% | Parameters/M | FLOPs/G |
|---|---|---|---|---|
| C3 | 39.5 | 34.7 | 7.04 | 16.0 |
| +MoblieNetV4 | 32.2 | 26.1 | 5.45 | 8.4 |
| +C3_Pconv | 39.5 | 34.3 | 6.35 | 13.8 |
| +C3_GhostConv | 39.4 | 34.0 | 6.36 | 13.8 |
| +C3_SCConv | 37.9 | 33.1 | 6.46 | 14.1 |
| +MLCSP | 40.3 | 35.2 | 6.45 | 14.9 |
| Methods | F1-Score/% | mAP0.5/% | Parameters/M | FLOPs/G |
|---|---|---|---|---|
| SPPF | 39.5 | 34.7 | 7.04 | 16.0 |
| +SPPF_CA | 39.9 | 34.8 | 7.14 | 15.9 |
| +SPPF_SE | 39.9 | 34.8 | 7.17 | 15.9 |
| +SPPF_CBAM | 40.0 | 34.8 | 7.17 | 16.0 |
| +SPPF_MLCA | 40.1 | 35.0 | 7.04 | 16.0 |
| +SPPF_ECA | 40.5 | 35.1 | 7.04 | 15.8 |
| +SPPF_EMA | 40.6 | 35.2 | 7.08 | 16.4 |
| +DFSPP | 40.6 | 35.3 | 7.45 | 16.2 |
| Methods | Precision | Recall | mAP0.5/% |
|---|---|---|---|
| CIoU | 47.4 | 34.9 | 34.7 |
| +SIoU | 45.9 | 35.9 | 35.2 |
| +GIoU | 46.4 | 34.5 | 34.4 |
| +DIoU | 46.0 | 34.8 | 34.8 |
| +inner IoU | 46.5 | 35.6 | 35.7 |
| +Focaler IoU | 46.8 | 35.9 | 35.4 |
| +Focaler inner IoU | 46.7 | 36.2 | 36.0 |
| Baseline | ESTDL | MLCSP | Focaler Inner IoU | DFSPP | P | R | FPS | mAP0.5 | Parameters/M | Size/MB |
|---|---|---|---|---|---|---|---|---|---|---|
| √ | 47.4 | 34.9 | 116 | 34.7 | 7.04 | 13.7 | ||||
| √ | √ | 48.7 | 39.9 | 86 | 40.1 | 2.04 | 4.43 | |||
| √ | √ | 47.4 | 35.0 | 78 | 35.2 | 6.45 | 12.6 | |||
| √ | √ | 46.7 | 36.2 | 129 | 36.0 | 7.04 | 14.4 | |||
| √ | √ | 46.5 | 36.1 | 66 | 35.4 | 7.45 | 14.5 | |||
| √ | √ | √ | 49.5 | 39.9 | 74 | 40.7 | 1.86 | 4.22 | ||
| √ | √ | √ | 49.5 | 40.0 | 95 | 40.8 | 2.04 | 4.52 | ||
| √ | √ | √ | 50.9 | 39.3 | 62 | 40.2 | 2.15 | 4.74 | ||
| √ | √ | √ | √ | 49.3 | 40.1 | 77 | 41.2 | 1.98 | 4.43 | |
| √ | √ | √ | √ | 50.2 | 39.9 | 75 | 40.9 | 1.86 | 4.22 | |
| √ | √ | √ | √ | √ | 50.6 | 41.0 | 73 | 41.6 | 1.97 | 4.43 |
| Methods | p-Value (Paired t-Test) | Statistical Significance (p < 0.05) |
|---|---|---|
| Baseline | — | — |
| ESTDL | 9 × 10−25 | Significant |
| MLCSP | 7 × 10−13 | Significant |
| Focaler inner IoU | 2 × 10−17 | Significant |
| DFSPP | 3 × 10−15 | Significant |
| Methods | Pre-Process/ms | Inference/ms | NMS/ms | FPS | mAP0.5/% | Inference Power/W | Energy per Frame (J/Frame) |
|---|---|---|---|---|---|---|---|
| YOLOv5s | 1.8 | 23.5 | 3.0 | 35.33 | 34.7 | 1.8 | 0.051 |
| YOLOv8s | 5.6 | 31.5 | 3.3 | 24.75 | 40.7 | 2.7 | 0.109 |
| YOLOv10s | 5.5 | 34.9 | 2.8 | 23.14 | 39.7 | 2.3 | 0.099 |
| YOLOv11s | 5.5 | 31.7 | 3.0 | 24.88 | 40.6 | 2.2 | 0.088 |
| YOLO-LSM | 1.8 | 35.9 | 2.8 | 24.69 | 41.6 | 2.2 | 0.089 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, C.; Cai, C.; Xiao, F.; Wang, J.; Guo, Y.; Ma, L. YOLO-LSM: A Lightweight UAV Target Detection Algorithm Based on Shallow and Multiscale Information Learning. Information 2025, 16, 393. https://doi.org/10.3390/info16050393
Wu C, Cai C, Xiao F, Wang J, Guo Y, Ma L. YOLO-LSM: A Lightweight UAV Target Detection Algorithm Based on Shallow and Multiscale Information Learning. Information. 2025; 16(5):393. https://doi.org/10.3390/info16050393
Chicago/Turabian StyleWu, Chenxing, Changlong Cai, Feng Xiao, Jiahao Wang, Yulin Guo, and Longhui Ma. 2025. "YOLO-LSM: A Lightweight UAV Target Detection Algorithm Based on Shallow and Multiscale Information Learning" Information 16, no. 5: 393. https://doi.org/10.3390/info16050393
APA StyleWu, C., Cai, C., Xiao, F., Wang, J., Guo, Y., & Ma, L. (2025). YOLO-LSM: A Lightweight UAV Target Detection Algorithm Based on Shallow and Multiscale Information Learning. Information, 16(5), 393. https://doi.org/10.3390/info16050393