


SYNCode: Synergistic Human–LLM Collaboration for Enhanced Data Annotation in Stack Overflow †

Abstract

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
- We present a structured annotation pipeline combining lexical filtering, semantic analysis using advanced transformer models, and iterative human validation.
- Our approach supports multi-platform collaboration, providing user-friendly interfaces across desktop, mobile, and web applications. This infrastructure includes robust synchronization mechanisms, ensuring real-time, seamless collaborative annotation while effectively handling potential conflicts and concurrent edits.
- Our framework strategically applies both lexical and semantic relevance checks, significantly reducing irrelevant or minimally relevant data entries. The detailed case study clearly demonstrates how SynCode effectively isolates high-quality, contextually relevant Stack Overflow post-code pairs, improving both the annotation efficiency and the overall dataset quality for subsequent machine learning applications.
2. Related Work
2.1. Reliability and Limitations of LLMs
2.2. Human–LLM Collaboration
2.3. Human–LLM Collaboration for Data Annotation
2.4. Factors Influencing Human–AI Collaborative Performance
3. Approach
3.1. Data Annotation via NLP Transformer
3.2. Data Annotation via UniXcoder
4. Case Study
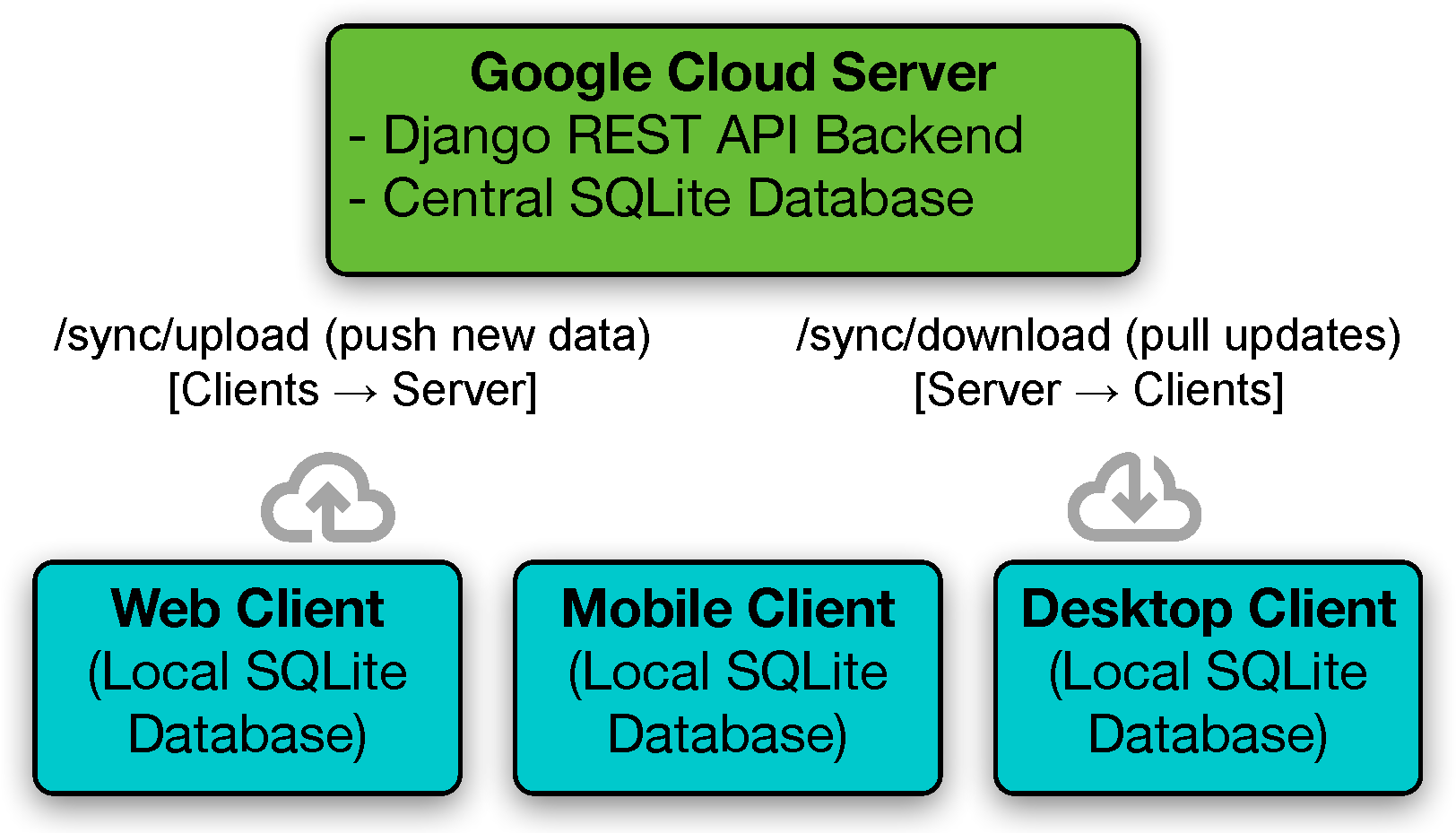
4.1. System Architecture and Configuration
4.2. Multi-Platform Collaborative Annotation Workflow
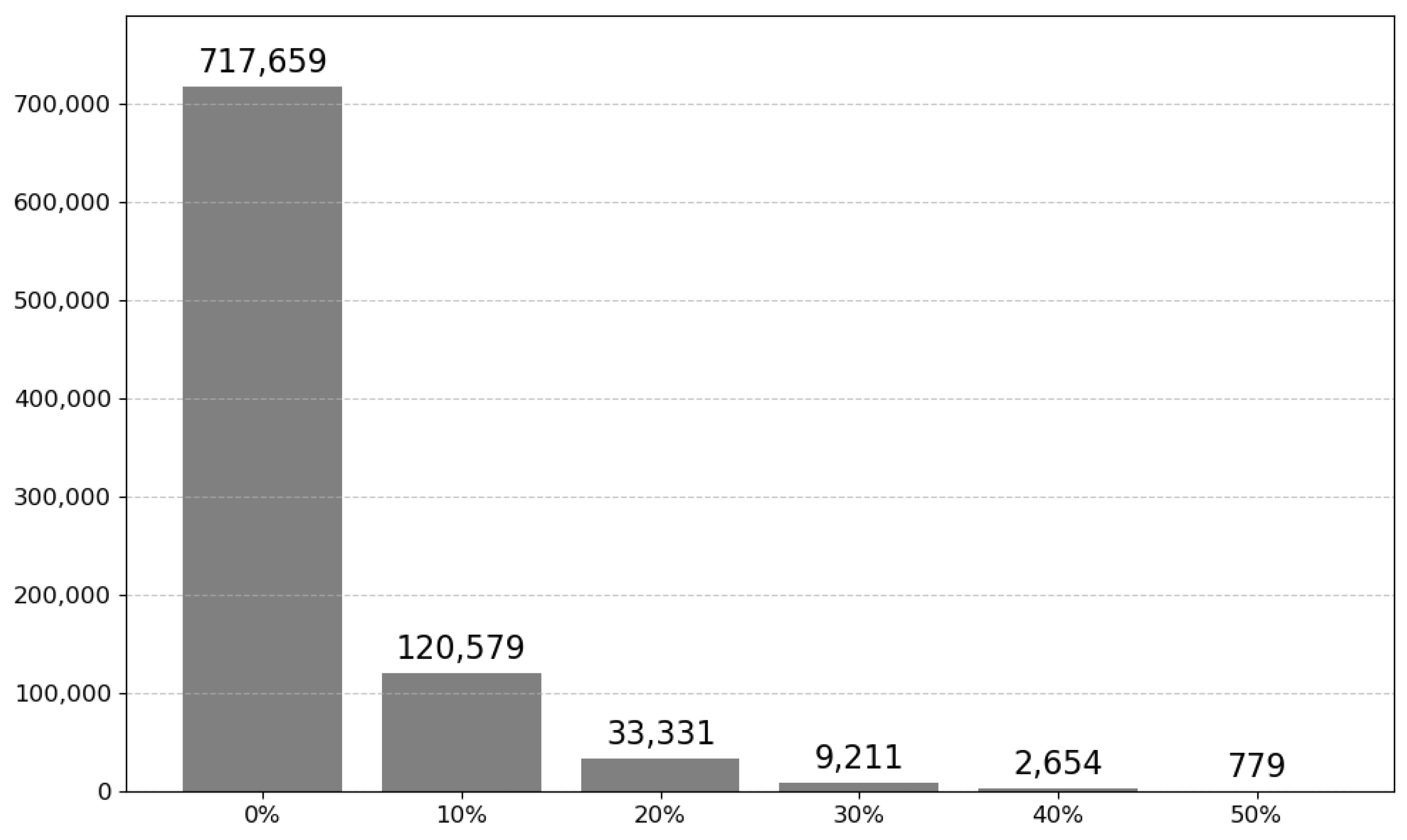
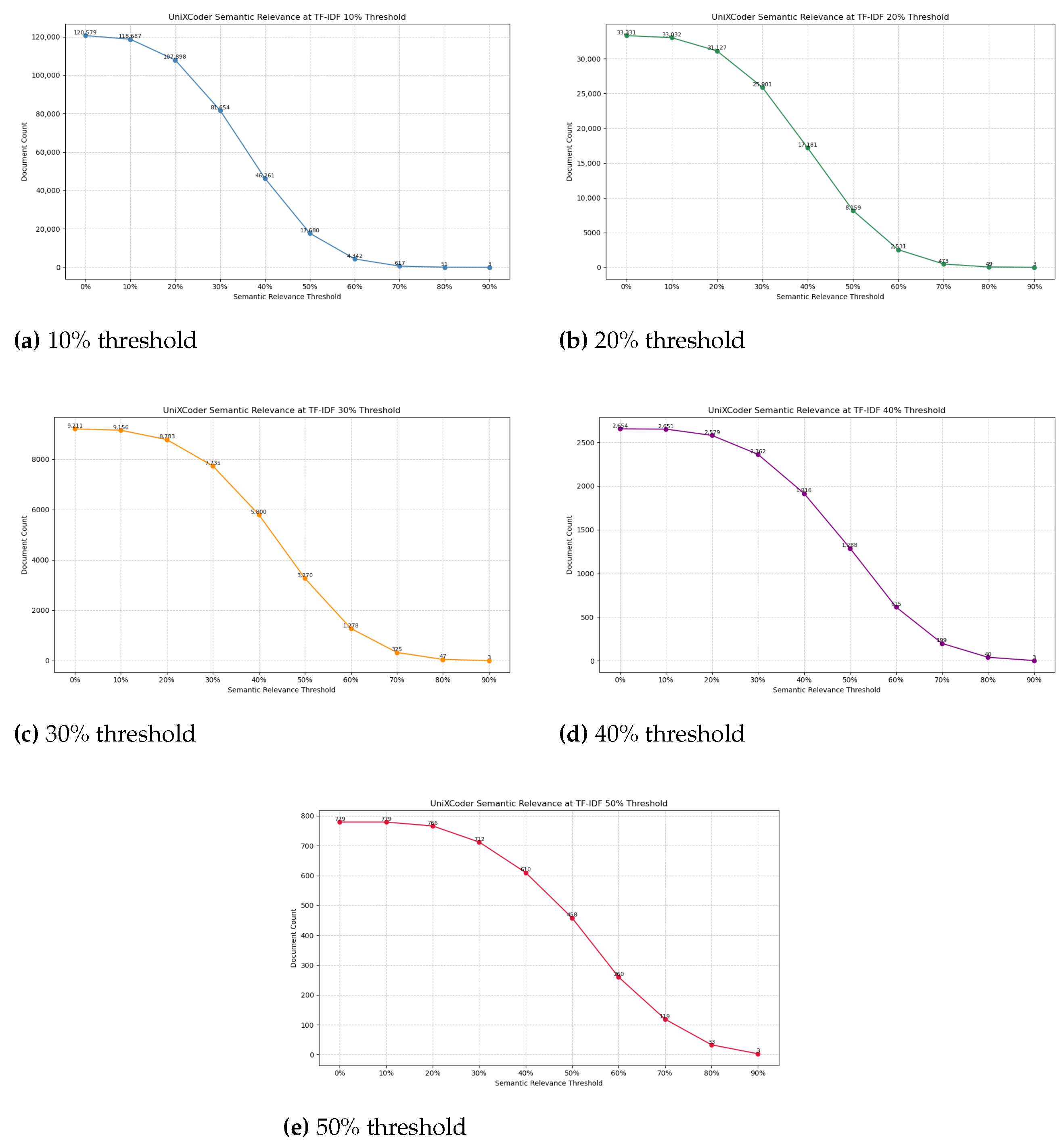
4.3. Lexical and Semantic Relevance in SynCode’s Annotation Pipeline
5. Threats to Validity
6. Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Devlin, J. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Fan, A.; Gokkaya, B.; Harman, M.; Lyubarskiy, M.; Sengupta, S.; Yoo, S.; Zhang, J.M. Large language models for software engineering: Survey and open problems. arXiv 2023, arXiv:2310.03533. [Google Scholar]
- Zheng, Z.; Ning, K.; Wang, Y.; Zhang, J.; Zheng, D.; Ye, M.; Chen, J. A survey of large language models for code: Evolution, benchmarking, and future trends. arXiv 2023, arXiv:2311.10372. [Google Scholar]
- Chowdhary, K.; Chowdhary, K. Natural language processing. In Fundamentals of Artificial Intelligence; Springer: New Delhi, India, 2020; pp. 603–649. [Google Scholar]
- Guo, D.; Ren, S.; Lu, S.; Feng, Z.; Tang, D.; Liu, S.; Zhou, L.; Duan, N.; Svyatkovskiy, A.; Fu, S.; et al. Graphcodebert: Pre-training code representations with data flow. arXiv 2020, arXiv:2009.08366. [Google Scholar]
- Kanade, A.; Maniatis, P.; Balakrishnan, G.; Shi, K. Learning and evaluating contextual embedding of source code. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 3–18 July 2020; pp. 5110–5121. [Google Scholar]
- Feng, Z.; Guo, D.; Tang, D.; Duan, N.; Feng, X.; Gong, M.; Shou, L.; Qin, B.; Liu, T.; Jiang, D.; et al. Codebert: A pre-trained model for programming and natural languages. arXiv 2020, arXiv:2002.08155. [Google Scholar]
- Xia, C.S.; Wei, Y.; Zhang, L. Practical program repair in the era of large pre-trained language models. arXiv 2022, arXiv:2210.14179. [Google Scholar]
- Niu, C.; Li, C.; Ng, V.; Ge, J.; Huang, L.; Luo, B. Spt-code: Sequence-to-sequence pre-training for learning source code representations. In Proceedings of the 44th International Conference on Software Engineering, Pittsburgh, PA, USA, 21–29 May 2022; pp. 2006–2018. [Google Scholar]
- He, X.; Lin, Z.; Gong, Y.; Jin, A.; Zhang, H.; Lin, C.; Jiao, J.; Yiu, S.M.; Duan, N.; Chen, W.; et al. Annollm: Making large language models to be better crowdsourced annotators. arXiv 2023, arXiv:2303.16854. [Google Scholar]
- Zhu, Y.; Zhang, P.; Haq, E.U.; Hui, P.; Tyson, G. Can chatgpt reproduce human-generated labels? a study of social computing tasks. arXiv 2023, arXiv:2304.10145. [Google Scholar]
- Le, T.; Taylor, W.; Maharjan, S.; Xia, M.; Song, M. SYNC: Synergistic Annotation Collaboration between Humans and LLMs for Enhanced Model Training. In Proceedings of the 23rd IEEE/ACIS International Conference on Software Engineering Research, Management and Applications (SERA), Las Vegas, NV, USA, 29–31 May 2025. [Google Scholar]
- Saha, S.; Hase, P.; Rajani, N.; Bansal, M. Are hard examples also harder to explain? A study with human and model-generated explanations. arXiv 2022, arXiv:2211.07517. [Google Scholar]
- Wang, P.; Chan, A.; Ilievski, F.; Chen, M.; Ren, X. Pinto: Faithful language reasoning using prompt-generated rationales. arXiv 2022, arXiv:2211.01562. [Google Scholar]
- Wiegreffe, S.; Hessel, J.; Swayamdipta, S.; Riedl, M.; Choi, Y. Reframing human-AI collaboration for generating free-text explanations. arXiv 2021, arXiv:2112.08674. [Google Scholar]
- Bhat, M.M.; Sordoni, A.; Mukherjee, S. Self-training with few-shot rationalization. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Virtual, 7–11 November 2021; pp. 10702–10712. [Google Scholar]
- Marasović, A.; Beltagy, I.; Downey, D.; Peters, M.E. Few-shot self-rationalization with natural language prompts. arXiv 2021, arXiv:2111.08284. [Google Scholar]
- Wang, P.; Wang, Z.; Li, Z.; Gao, Y.; Yin, B.; Ren, X. Scott: Self-consistent chain-of-thought distillation. arXiv 2023, arXiv:2305.01879. [Google Scholar]
- Wiegreffe, S.; Marasović, A.; Smith, N.A. Measuring association between labels and free-text rationales. arXiv 2020, arXiv:2010.12762. [Google Scholar]
- Turpin, M.; Michael, J.; Perez, E.; Bowman, S. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting. Adv. Neural Inf. Process. Syst. 2023, 36, 74952–74965. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Anil, R.; Dai, A.M.; Firat, O.; Johnson, M.; Lepikhin, D.; Passos, A.; Shakeri, S.; Taropa, E.; Bailey, P.; Chen, Z.; et al. Palm 2 technical report. arXiv 2023, arXiv:2305.10403. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Wang, S.; Liu, Y.; Xu, Y.; Zhu, C.; Zeng, M. Want to reduce labeling cost? GPT-3 can help. arXiv 2021, arXiv:2108.13487. [Google Scholar]
- Gilardi, F.; Alizadeh, M.; Kubli, M. ChatGPT outperforms crowd workers for text-annotation tasks. Proc. Natl. Acad. Sci. USA 2023, 120, e2305016120. [Google Scholar] [CrossRef] [PubMed]
- Ziems, C.; Held, W.; Shaikh, O.; Chen, J.; Zhang, Z.; Yang, D. Can large language models transform computational social science? Comput. Linguist. 2024, 50, 237–291. [Google Scholar] [CrossRef]
- Wang, H.; Hee, M.S.; Awal, M.; Choo, K.; Lee, R.K.W. Evaluating GPT-3 Generated Explanations for Hateful Content Moderation. arXiv 2023, arXiv:2305.17680. [Google Scholar] [CrossRef]
- Skeppstedt, M. Annotating named entities in clinical text by combining pre-annotation and active learning. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics Proceedings of the Student Research Workshop, Sofia, Bulgaria, 4–9 August 2013; pp. 74–80. [Google Scholar]
- Fort, K.; Sagot, B. Influence of pre-annotation on POS-tagged corpus development. In Proceedings of the fourth ACL Linguistic Annotation Workshop, Uppsala, Sweden, 15–16 July 2010; pp. 56–63. [Google Scholar]
- Lingren, T.; Deleger, L.; Molnar, K.; Zhai, H.; Meinzen-Derr, J.; Kaiser, M.; Stoutenborough, L.; Li, Q.; Solti, I. Evaluating the impact of pre-annotation on annotation speed and potential bias: Natural language processing gold standard development for clinical named entity recognition in clinical trial announcements. J. Am. Med. Inform. Assoc. 2014, 21, 406–413. [Google Scholar] [CrossRef]
- Mikulová, M.; Straka, M.; Štěpánek, J.; Štěpánková, B.; Hajič, J. Quality and efficiency of manual annotation: Pre-annotation bias. arXiv 2023, arXiv:2306.09307. [Google Scholar]
- Ogren, P.V.; Savova, G.K.; Chute, C.G. Constructing Evaluation Corpora for Automated Clinical Named Entity Recognition. In Proceedings of the LREC, Marrakech, Morocco, 26 May–1 June 2008; Volume 8, pp. 3143–3150. [Google Scholar]
- South, B.R.; Mowery, D.; Suo, Y.; Leng, J.; Ferrández, O.; Meystre, S.M.; Chapman, W.W. Evaluating the effects of machine pre-annotation and an interactive annotation interface on manual de-identification of clinical text. J. Biomed. Inform. 2014, 50, 162–172. [Google Scholar] [CrossRef]
- Skeppstedt, M.; Paradis, C.; Kerren, A. PAL, a tool for pre-annotation and active learning. J. Lang. Technol. Comput. Linguist. 2017, 31, 91–110. [Google Scholar] [CrossRef]
- Sujoy, S.; Krishna, A.; Goyal, P. Pre-annotation based approach for development of a Sanskrit named entity recognition dataset. In Proceedings of the Computational Sanskrit & Digital Humanities: Selected Papers Presented at the 18th World Sanskrit Conference, Canberra, Australia, 9–13 January 2023; pp. 59–70. [Google Scholar]
- Andriluka, M.; Uijlings, J.R.; Ferrari, V. Fluid annotation: A human-machine collaboration interface for full image annotation. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1957–1966. [Google Scholar]
- Hernandez, A.; Hochheiser, H.; Horn, J.; Crowley, R.; Boyce, R. Testing pre-annotation to help non-experts identify drug-drug interactions mentioned in drug product labeling. In Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, Pittsburgh, PA, USA, 2–4 November 2014; Volume 2, pp. 14–15. [Google Scholar]
- Kuo, T.T.; Huh, J.; Kim, J.; El-Kareh, R.; Singh, S.; Feupe, S.F.; Kuri, V.; Lin, G.; Day, M.E.; Ohno-Machado, L.; et al. The impact of automatic pre-annotation in Clinical Note Data Element Extraction-the CLEAN Tool. arXiv 2018, arXiv:1808.03806. [Google Scholar]
- Ghosh, T.; Saha, R.K.; Jenamani, M.; Routray, A.; Singh, S.K.; Mondal, A. SeisLabel: An AI-Assisted Annotation Tool for Seismic Data Labeling. In Proceedings of the IGARSS 2023–2023 IEEE International Geoscience and Remote Sensing Symposium, Pasadena, CA, USA, 16–21 July 2023; pp. 5081–5084. [Google Scholar]
- Green, B.; Chen, Y. Disparate interactions: An algorithm-in-the-loop analysis of fairness in risk assessments. In Proceedings of the Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 29–31 January 2019; pp. 90–99. [Google Scholar]
- Kneusel, R.T.; Mozer, M.C. Improving human-machine cooperative visual search with soft highlighting. ACM Trans. Appl. Percept. 2017, 15, 1–21. [Google Scholar] [CrossRef]
- Lai, V.; Tan, C. On human predictions with explanations and predictions of machine learning models: A case study on deception detection. In Proceedings of the Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 29–31 January 2019; pp. 29–38. [Google Scholar]
- Ma, S.; Lei, Y.; Wang, X.; Zheng, C.; Shi, C.; Yin, M.; Ma, X. Who should i trust: Ai or myself? Leveraging human and ai correctness likelihood to promote appropriate trust in ai-assisted decision-making. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023; pp. 1–19. [Google Scholar]
- Wang, X.; Lu, Z.; Yin, M. Will you accept the ai recommendation? Predicting human behavior in ai-assisted decision making. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 1697–1708. [Google Scholar]
- Stites, M.C.; Nyre-Yu, M.; Moss, B.; Smutz, C.; Smith, M.R. Sage advice? The impacts of explanations for machine learning models on human decision-making in spam detection. In Proceedings of the International Conference on Human-Computer Interaction, Virtual Event, 24–29 July 2021; pp. 269–284. [Google Scholar]
- Yin, M.; Wortman Vaughan, J.; Wallach, H. Understanding the effect of accuracy on trust in machine learning models. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–12. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Guo, D.; Lu, S.; Duan, N.; Wang, Y.; Zhou, M.; Yin, J. Unixcoder: Unified cross-modal pre-training for code representation. arXiv 2022, arXiv:2203.03850. [Google Scholar]
- Husain, H.; Wu, H.H.; Gazit, T.; Allamanis, M.; Brockschmidt, M. Codesearchnet challenge: Evaluating the state of semantic code search. arXiv 2019, arXiv:1909.09436. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, M.; Maharjan, S.; Le, T.; Taylor, W.; Song, M. SYNCode: Synergistic Human–LLM Collaboration for Enhanced Data Annotation in Stack Overflow. Information 2025, 16, 392. https://doi.org/10.3390/info16050392
Xia M, Maharjan S, Le T, Taylor W, Song M. SYNCode: Synergistic Human–LLM Collaboration for Enhanced Data Annotation in Stack Overflow. Information. 2025; 16(5):392. https://doi.org/10.3390/info16050392
Chicago/Turabian StyleXia, Meng, Shradha Maharjan, Tammy Le, Will Taylor, and Myoungkyu Song. 2025. "SYNCode: Synergistic Human–LLM Collaboration for Enhanced Data Annotation in Stack Overflow" Information 16, no. 5: 392. https://doi.org/10.3390/info16050392
APA StyleXia, M., Maharjan, S., Le, T., Taylor, W., & Song, M. (2025). SYNCode: Synergistic Human–LLM Collaboration for Enhanced Data Annotation in Stack Overflow. Information, 16(5), 392. https://doi.org/10.3390/info16050392