
E-Exam Cheating Detection System for Moodle LMS

 , ,
, ,  ,
,
Abstract
1. Introduction
2. Background
2.1. E-Learning and Learning Management Systems
2.2. E-Learning Integrity Systems and Cheating Deterrence
2.3. Behavior and Data Analysis of Online Assessment Attempts
3. Related Work
4. Design and Analysis
4.1. Design Requirements
- Affordability: The system will be licensed under the GNU General Public License [44], which ensures free use, modification, and sharing of the software.
- Scalability: The system must also be able to run on any number of examinees and present credible results and conclusions, regardless of the sample size. To obtain that, we employed statistical analysis methods to determine suitable anomaly detection margins for the algorithm based on the sample size.
- Usability: The system must be user-friendly and provide clear, easy-to-understand results and outcomes. We implemented data visualization techniques, including charts, graphs, and histograms, using the D3.js graphing library. Additionally, we created individual profiles for each examinee and provided a breakdown of the suspicious anomalies that triggered the algorithm.
- Run on the Moodle framework: The system requires a web server installed with the Moodle LMS framework.
- Detecting anomalies and suspicious activities during an examinee’s assessment.
- To detect the occurrence of foul play in an examinee’s attempt, the system must employ data analysis methods on the assessment and student data provided by the Moodle database.
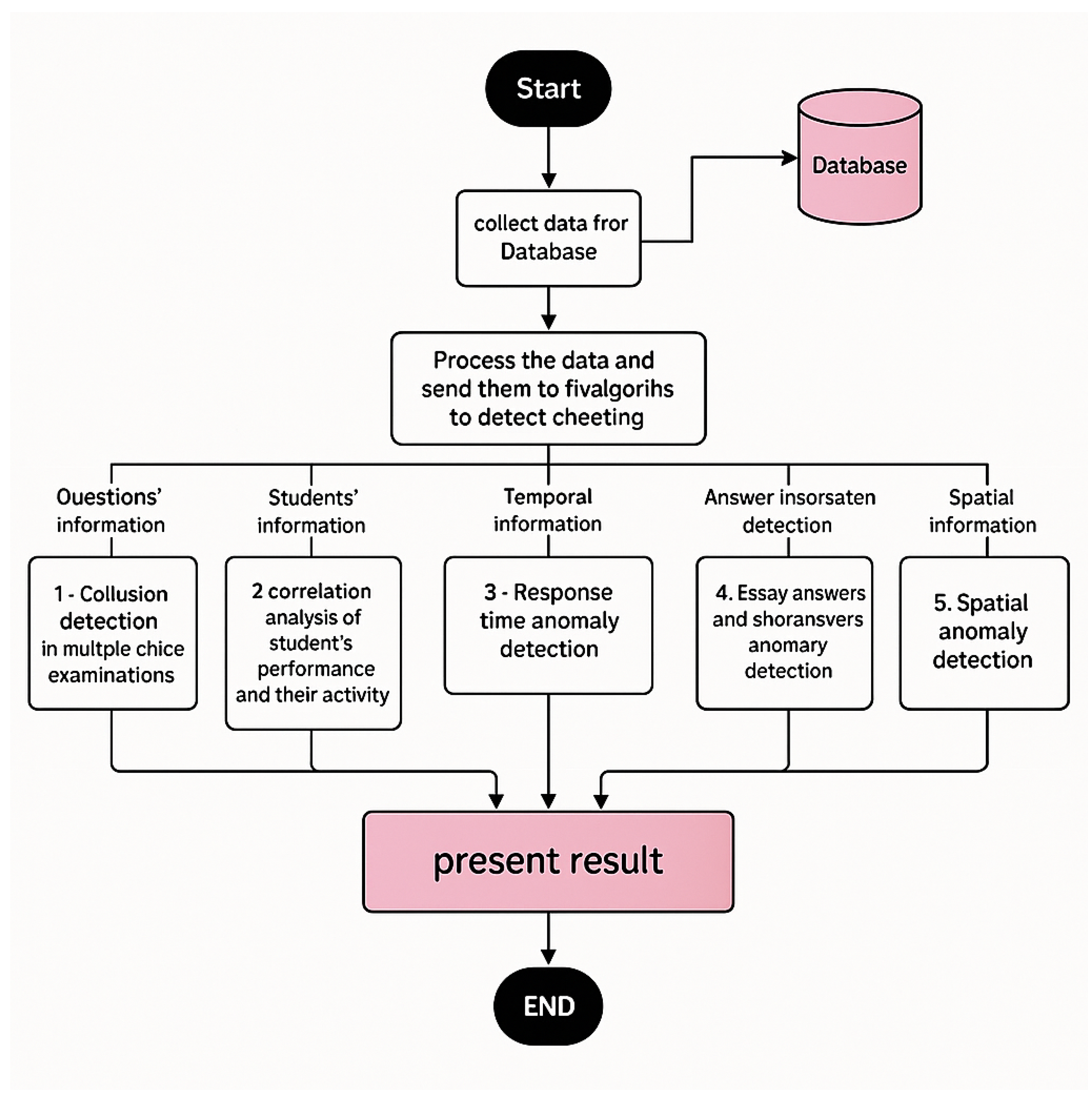
4.2. System Design
4.2.1. Data Collection
- General quiz information and course information:These data pertain to the quiz itself, most notably its properties, including the start and finish times of the quiz, the nature of question display ordering (shuffled or ordered), and whether the quiz is in a one-way format. Most importantly, the assigned ID for the quiz is also included.
- Students’ information:This includes data on students who registered for the course associated with the quiz and attempted it. It contains students’ names, IDs, grades, the number of activities each student has participated in during the course, and the IP address from which they attempted the quiz.
- Spatial information:These data are extracted from each student’s IP address and used to determine their location when taking the quiz using the geolocation API.
- Questions’ information:These data pertain to the questions included in the quiz. Each question has distinct properties, including its type (e.g., multiple-choice, short-answer, essay), ID, question text, grade, answer, and options.
- Temporal information:These data pertain to each student’s response time to each question. The quiz’s response times, as well as the start and finish times, are formatted in Unix time.
- Response information:These data pertain to each student’s answer to each question in the attempt, indicating whether the answer was correct, partially correct, or incorrect.
4.2.2. Data Processing: Applying Cheating Detection Algorithms
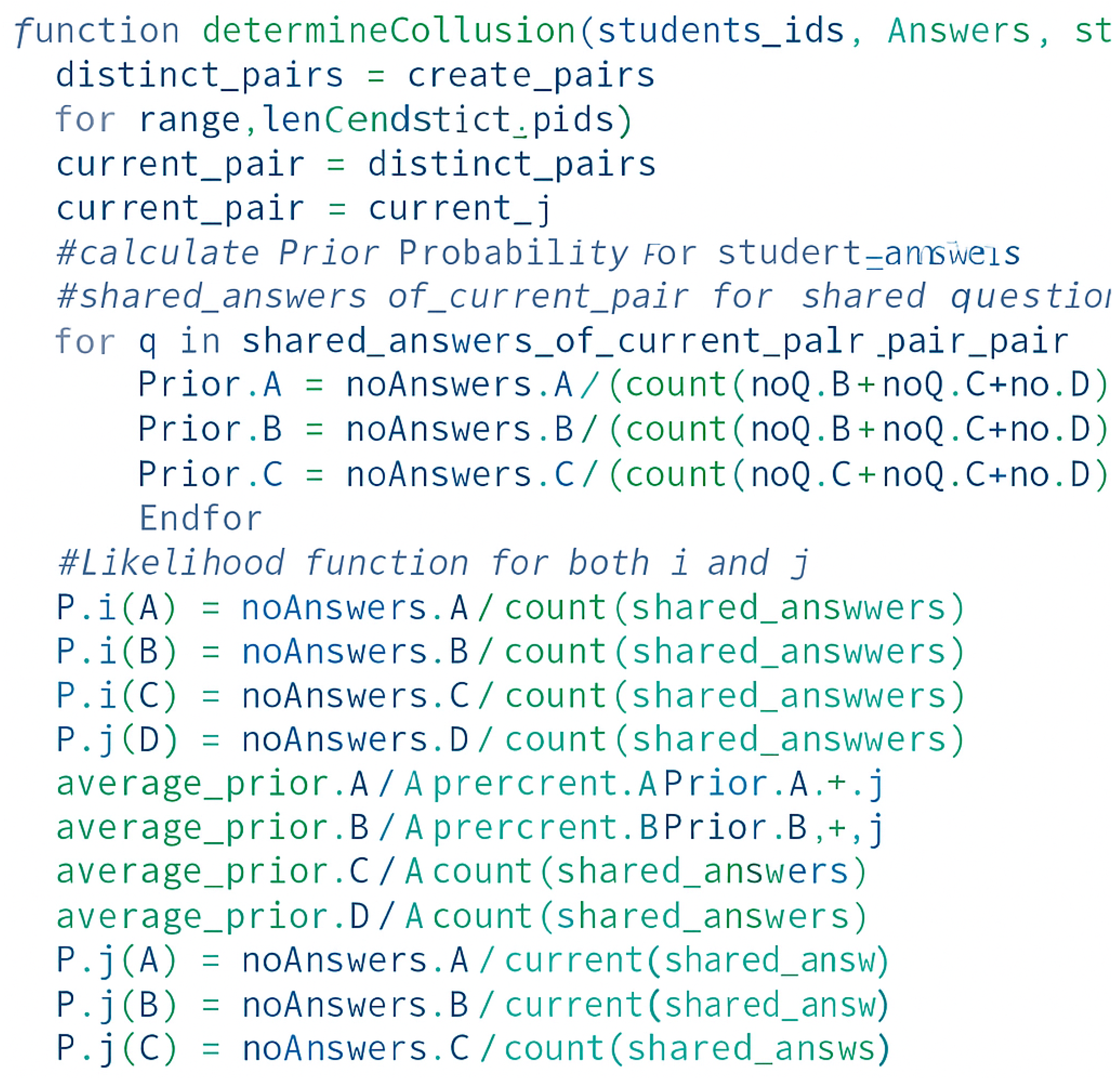
- Collusion detection in multiple-choice examinations:The first algorithm employed in the system involves a Bayesian probability-based analysis of excessive similarity in students’ answers to multiple-choice questions. Each question has four choices: A, B, C, and D. This algorithm was implemented and tested by A. Ercole in 2002 [23] to determine the existence of collusion between pairs of students on an exam. The algorithm is divided into nine steps as follows:
- Step 1: Generate a list of all possible pairs of students that attempted the quiz. The list size is .
- Step 2: For each pair of students (i, j) in the list, repeat the following steps 3–8:
- Step 3: Estimate the prior probabilities for each question across all other students responses, excluding the questions that were not answered by both students (i, j). The prior probabilities are expressed as follows:where
- *
- , , , are the number of students who answered the question ‘A’, ‘B’, ‘C’, and ‘D’, respectively (always excluding the selected pair).
- *
- , , , are the prior probabilities for the question being answered ‘A’, ‘B’, ‘C’, and ‘D’, respectively. These probabilities add up to one.
- Step 4: Calculate the likelihood functions , , and Pi(D). For each student pair (i, j), we first reorder the question options so that all students have the same order of options, where option ‘A’ is the correct answer and the rest are incorrect. If a multiple-choice question contains a negatively marked option, it is ordered as option ‘D’. This is important for determining the student’s performance on the test. For example, if the candidate is observed () to have answered all questions as ‘A’, then the .
- Step 5: Calculate the posterior probabilities for the pair (i, j), and their averages over all questions using Bayes’ theorem. Posterior probabilities are expressed as follows:where , , and The posterior probabilities of a student answering on this examination are ‘A’, ‘B’, ‘C’, and ‘D’, respectively. Based on Bayes’ theorem, this probability calculates the probability of an event occurring given new information (i.e., the student’s likelihood function calculated previously).
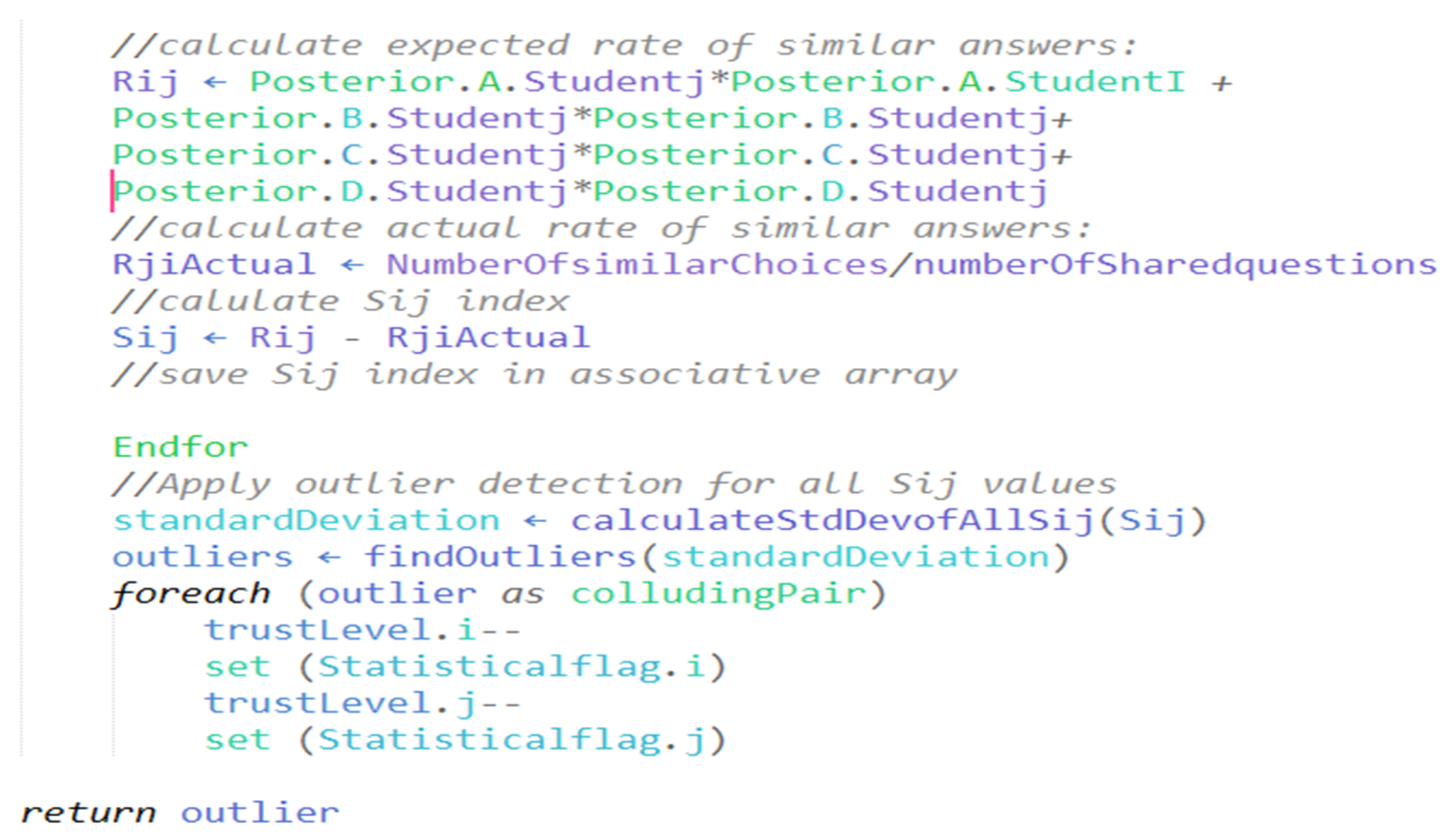
- Step 6: For the pair of candidates (i, j), compute the expected rate of similar answers, as follows:
- Step 7: Calculate , as expressed in the following equation:where n stands for the number of questions answered by both students (i, j), and is the number of identical question answers for both students (i, j).
- Step 8: Calculate , the suspicion index for the pair. is expressed in the following equation:
- Step 9: High values of demonstrate the possibly suspicious similarity between answers for a pair of students. Finding the high values in all distinct pairs of students in the exam is achieved using a Gaussian distribution of all the N(N − 1) values. Outlier values are determined using the standard deviation. Values that are four standard deviations or more away from the mean of the data are considered outliers, indicating a high suspicion index.
- Step 10: The collusion flag is raised for each pair with a high suspicion index value and saved in an array. Flagged students receive a trust-level penalty relative to their suspicion index.
- Correlation Analysis of Students’ Performance and Their Online ActivityThe Moodle built-in logging system logs all students’ activities on the platform. This includes the activity type, grading status, and submission status. Algorithm 2 utilizes these logs, which have been shown to positively correlate with the student’s performance in an online learning course [25]. Furthermore, logs adequately gauge the expected student’s performance in the semester [6]. The algorithm performs a correlation analysis on students’ quiz grades and their logs and activities. Such correlation is calculated using Pearson’s correlation index r, as expressed in the following equation:where r is the Pearson coefficient, is the x-variable in the sample representing the number of students’ logs and activities, is the mean of the values of the x-variable in the sample, is the y-variable representing the students’ grades in the quiz, and is the mean of the values of the y-variable in the sample.The Pearson correlation coefficient, r, expresses the strength of the relationship between the two variables and their direction, which is either positive or negative. The r-value range is [−1, 1]. For example, if r = −0.9, a strong inverse relationship exists between the x- and y-variables. Conversely, if r = +0.9, a strong positive relationship exists between the x- and y-variables. r is sensitive to the course content. Therefore, it is necessary to calculate the r-value for the course that contains quizzes, as each course has different methods and E-learning processes. Some courses’ activities may not impact a student’s performance, while in other courses, the same activities may have a significant impact on a student’s performance.A regression analysis is carried out on the results of each quiz’s grades and the students’ logs if the determined correlation value is solid and positive. The student’s grades become the dependent variable in a regression model, while the logs of the grades become the independent variable. Then, using student scatter plots and the regression line equation, this regression model is utilized to identify outliers. The distance of the student from the regression line is then determined.Outliers in this analysis are the students whose points are three standard deviations or more from the mean distance to the regression line. Those outliers are flagged as statistical anomalies and have their level of trust demoted accordingly. This method will not be applied to students in the quiz if the r-value is less than 0.3.Figure 3 shows the flowchart for the correlation analysis algorithm:
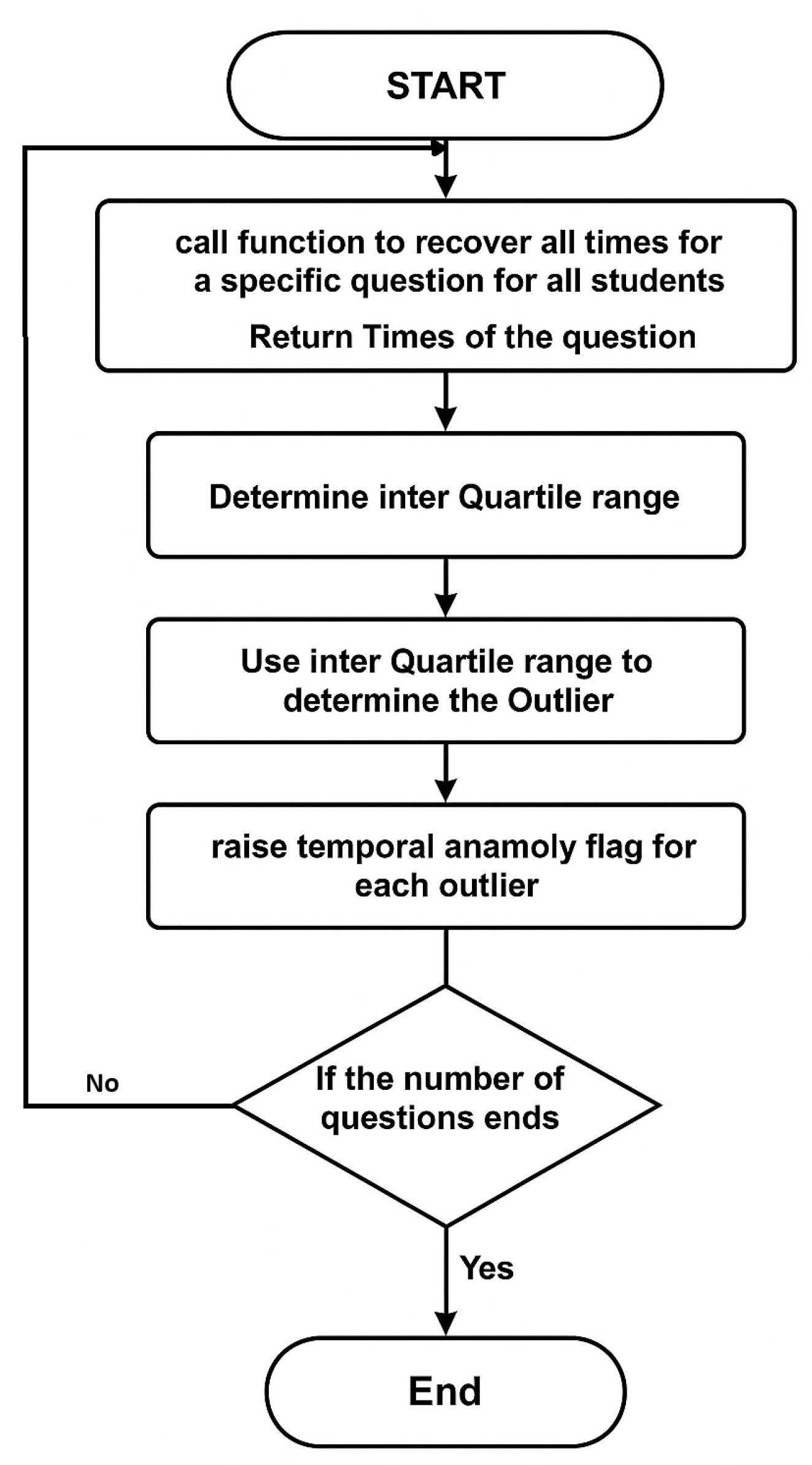
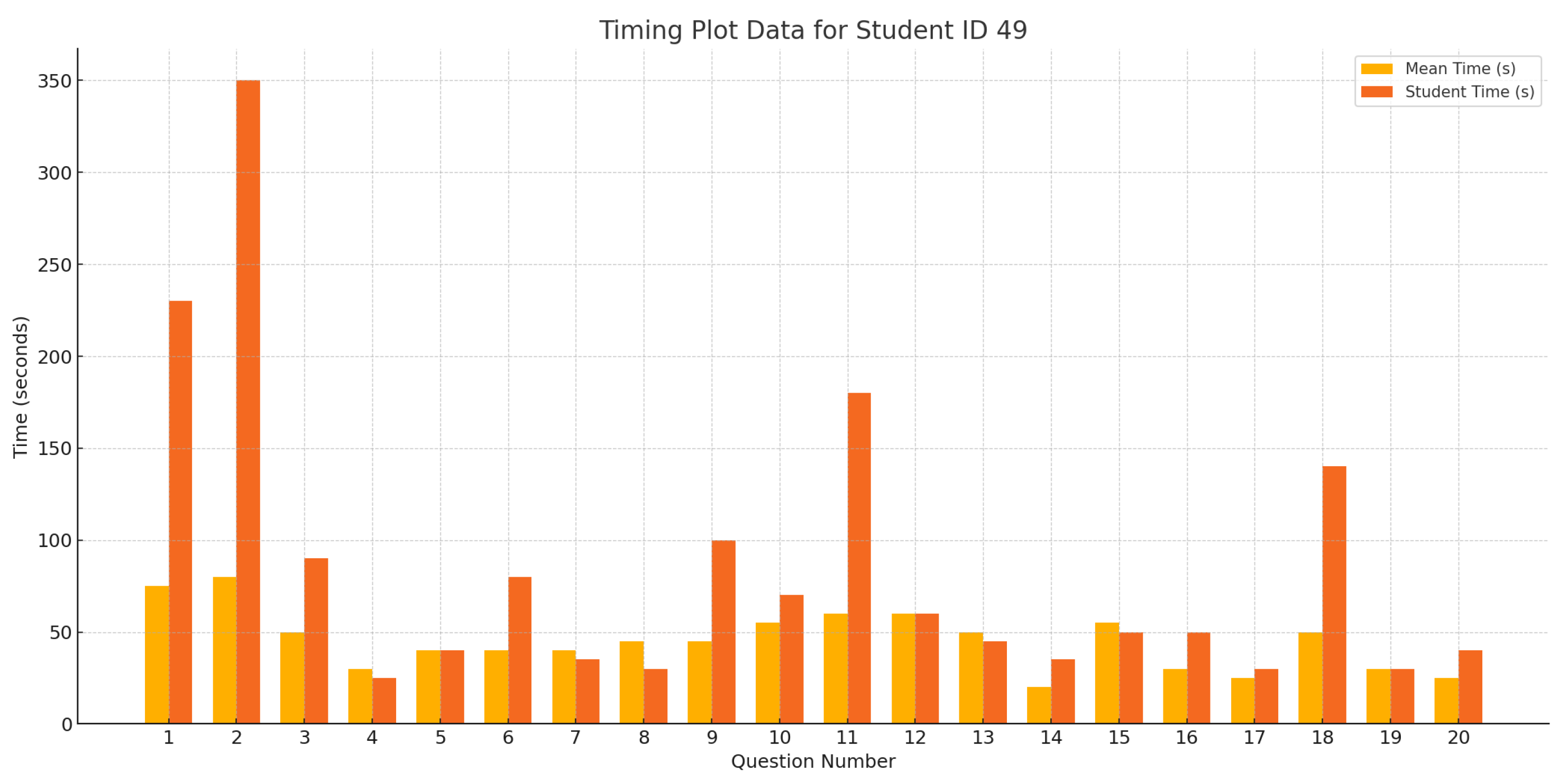
- Response Time Anomaly Detection: Student response time measures the time it takes to answer a question and confirm the answer. Algorithm 3 is designed to detect suspicious students’ activities based on their response times. According to recent research [45], using online studying assistance websites, such as Chegg, among others, to breach academic integrity has been proven to be a real problem. Students who use those websites typically upload all their examination questions to the website and wait for solutions to be provided by an expert hired by the website. Detecting this case is relatively easy because a student would spend a long time waiting before answering the questions in a relatively short time. Additionally, some students have opted to wait, in one-way ordered exams, for their colleagues to solve their questions and share the answers with them. This would compromise the purpose of one-way examinations if it were supported by response time analysis. The response time anomaly algorithm is designed to detect students’ suspicious response times on each exam question. The students’ response times for each question are sorted to enable the use of the interquartile range (IQR) method. IQR stands for interquartile range, a measure of data dispersion in a sample. The following equation measures IQR:where Q3 is the middle value in the third quarter of the data, and Q1 is the middle value in the first half of the data. IQR is calculated for every question’s response time. Outlier students’ times are computed using the following equation:where T is the time in seconds, j is the student, and q is the question ID. All students’ response times that satisfy Equation (8) are tagged and saved in the outlier array. The outlier’s trust level is then demoted relative to each question it was tagged on, based on the following equation:where is the mean of all students’ times on q; this algorithm considers the relative timing of all class members’ times in finding the suspicious response times. Thus, a relatively difficult question in the examination would have a higher average response time than easier questions. Figure 4 demonstrates the flowchart for the response time anomaly detection algorithm:
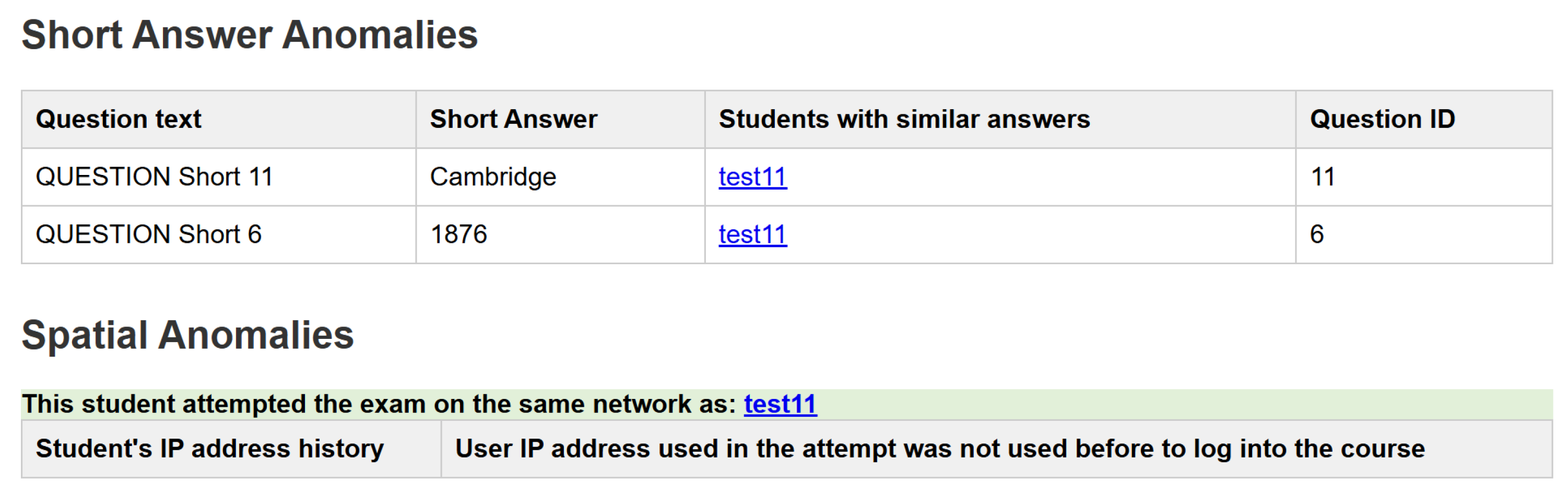
- Spatial Anomaly Detection:Internet Protocol (IP) provides sufficient information regarding students’ spatial information, such as country, city, Internet Service Provider (ISP), and more. Moodle logs each student’s IP address once they start the quiz attempt. Using the Geo plug-in, a Moodle-integrated IP look-up AIP, we accurately determine the students’ spatial information by using their IP addresses. The geo plug-in takes IP as a parameter. It returns spatial information about it, such as students’ locations during exam attempts and whether they are on the same local network as other students. If two or more students are found to be on the same local network during an examination, they are all flagged, and their trust level is demoted. Moodle maintains logs of every student’s login event, including their IP address, to collect historical spatial data for each student. Inspecting these historical data helps us determine if a student has never used their examination IP address to log in before, which is also flagged as an anomaly in the system. Figure 5 demonstrates the flowchart for Algorithm 4:
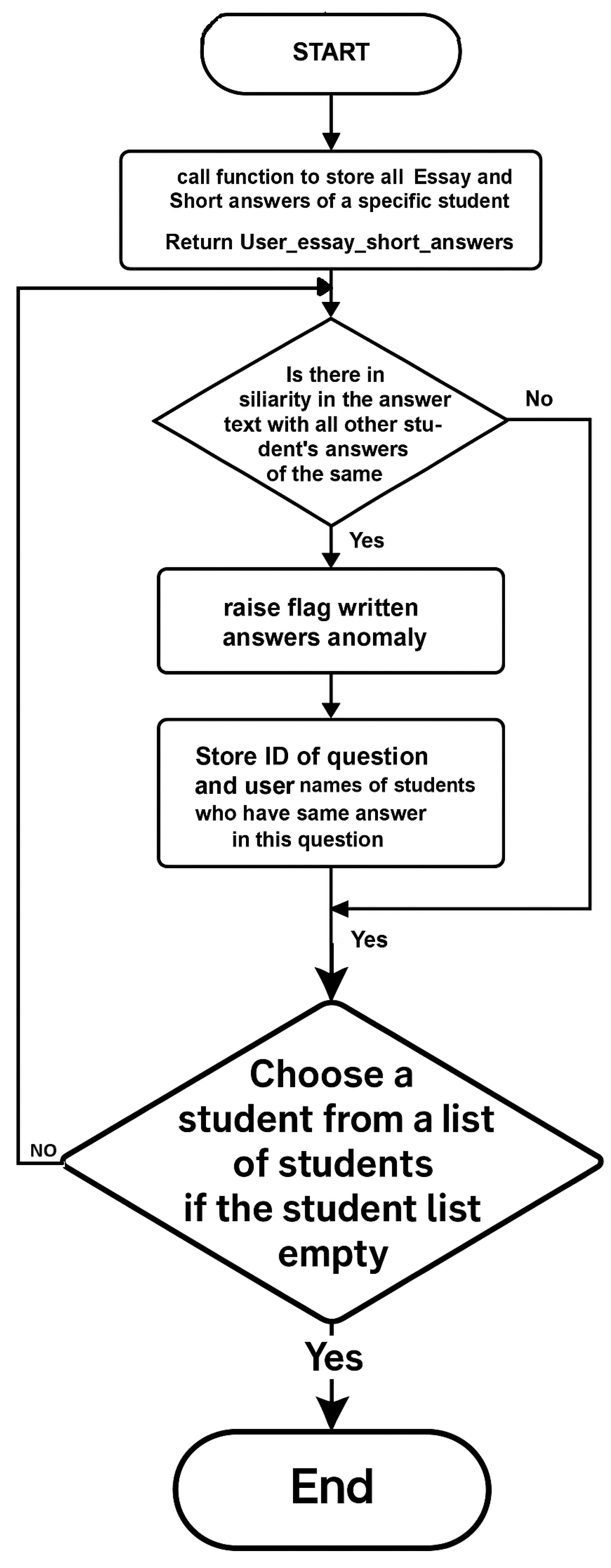
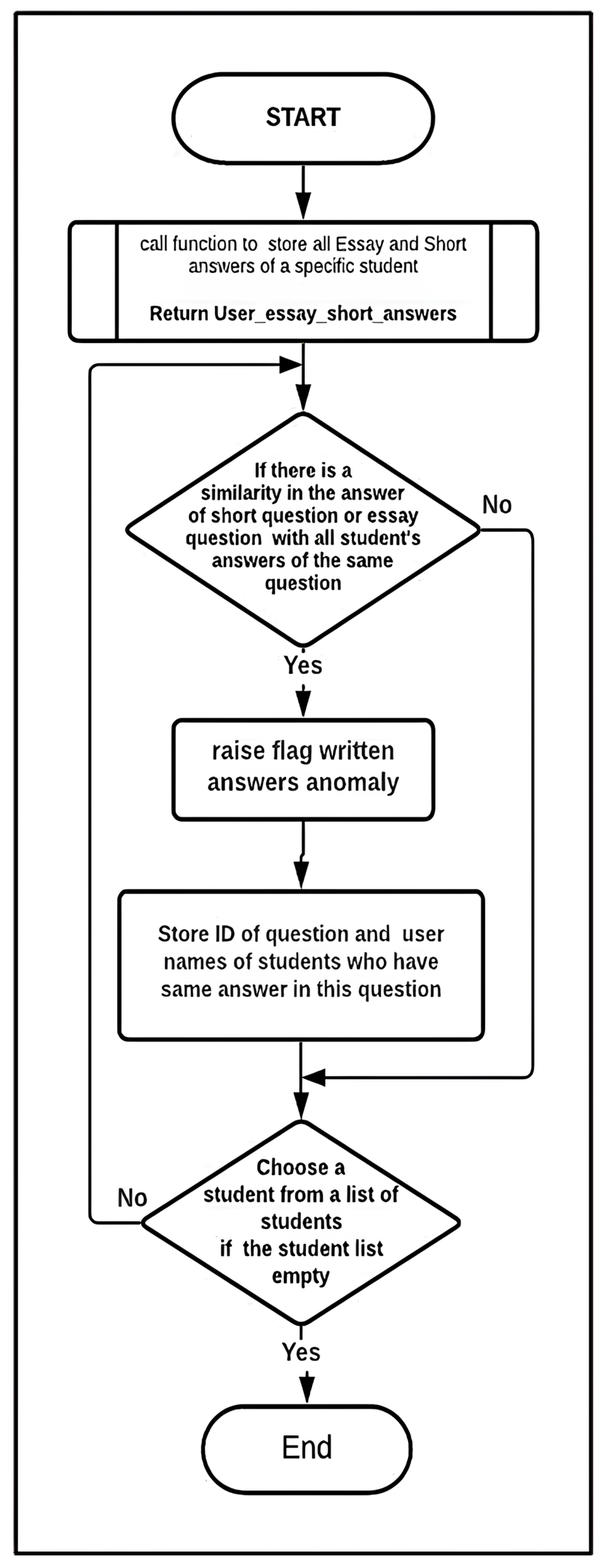
- Written Answer Submissions: This algorithm is proposed for written answer submissions. It detects extreme similarity in students’ answers. The algorithm examines the answers to each written question and checks for a high similarity score. Each answer is given a similarity score compared to all other answers in the exam. After that, the IQR outlier detection method, previously discussed, is used to identify the highest similarity scores, which are flagged as outliers. These outliers then receive a trust-level penalty. Figure 6 demonstrates Algorithm 5:
4.2.3. Result Visualization
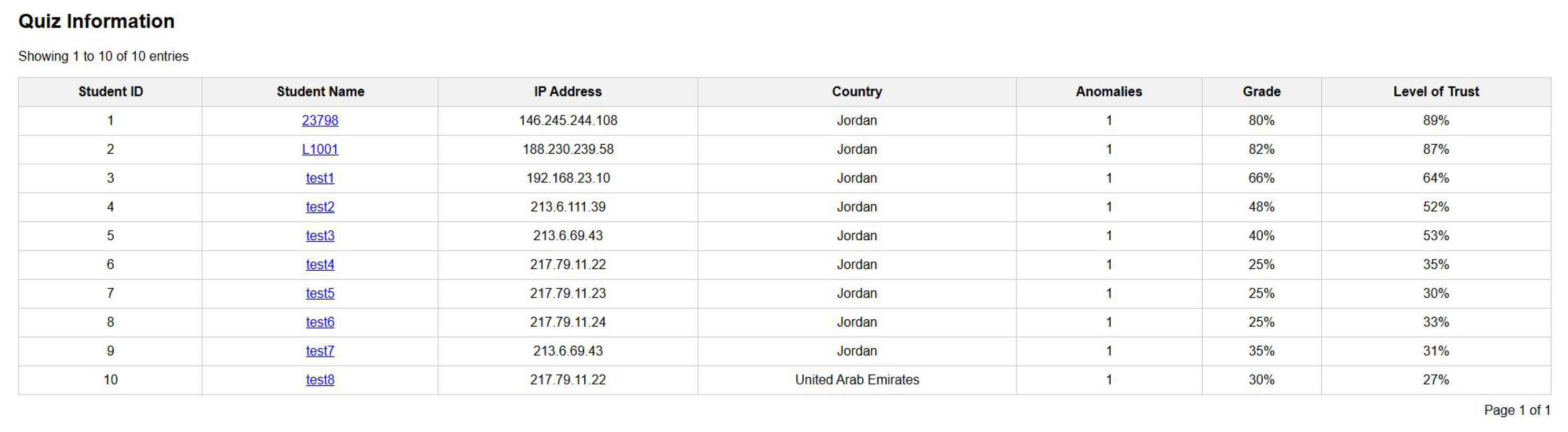
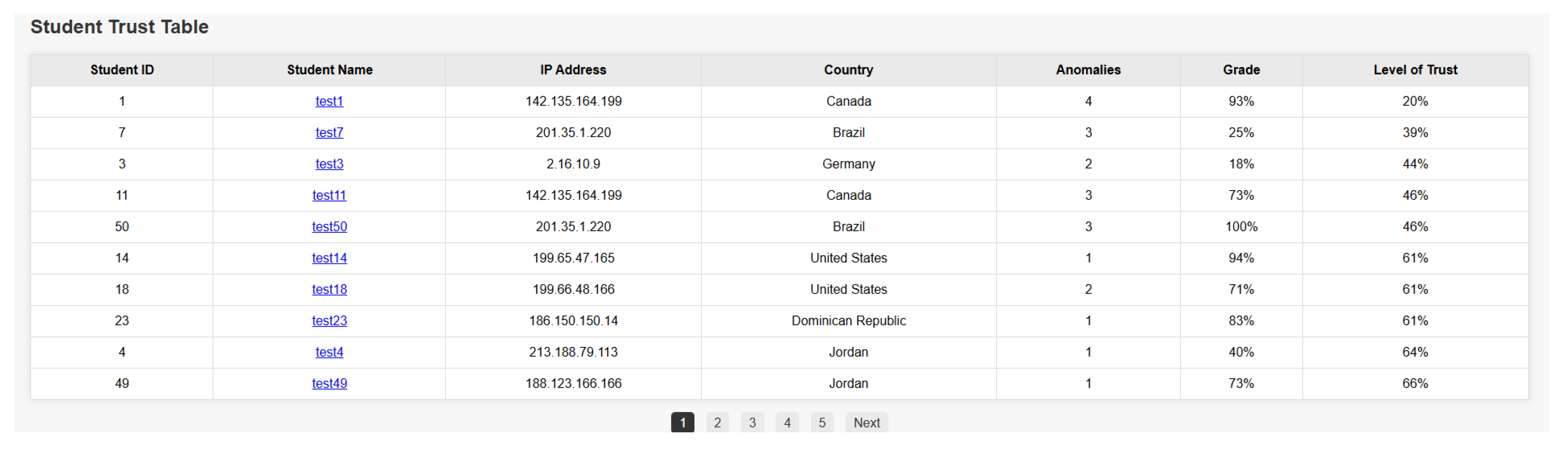
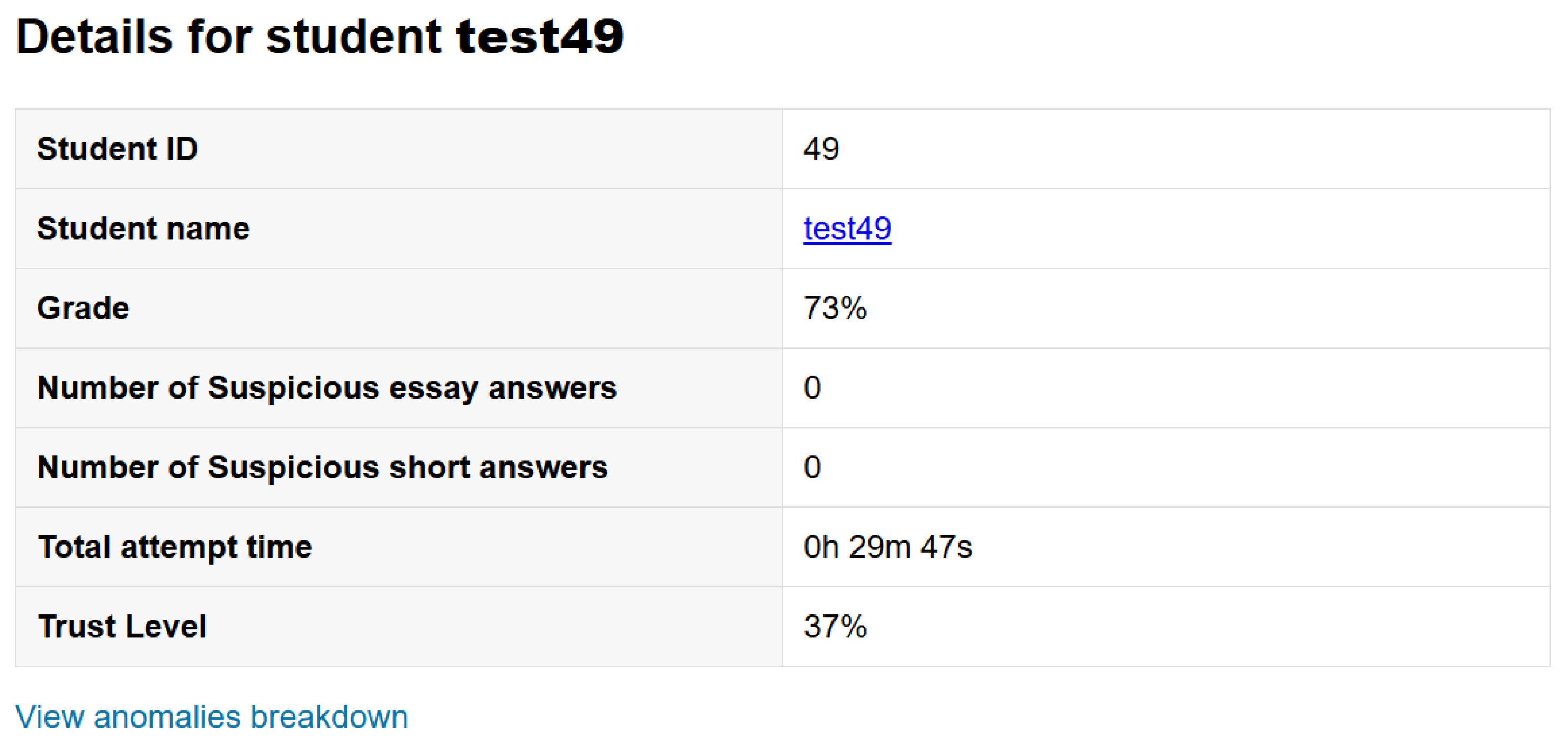
- Data table, which displays all students who had attempted the quiz, their achieved grade in the quiz, their trust level, and the number of anomaly flags that had been triggered.
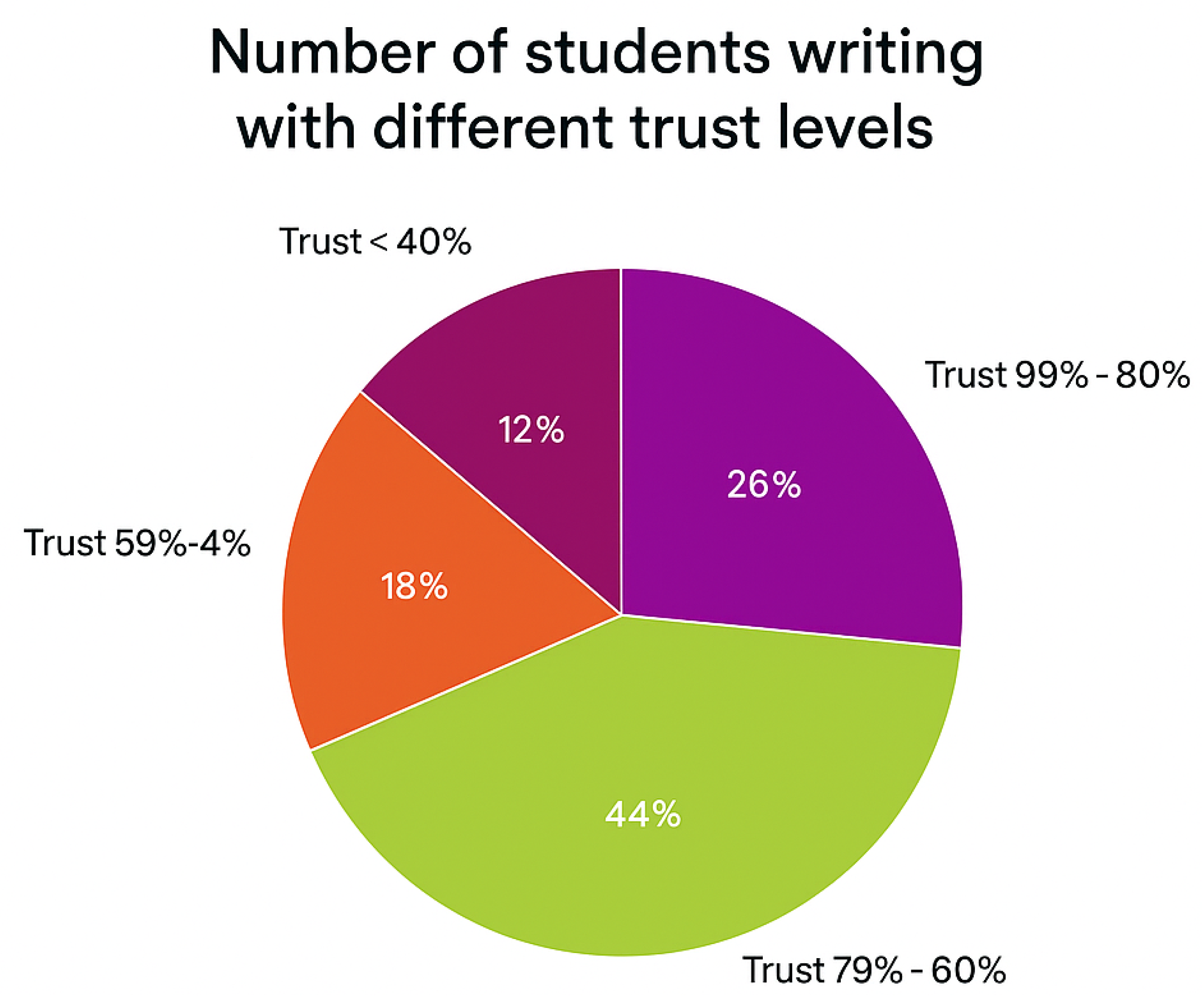
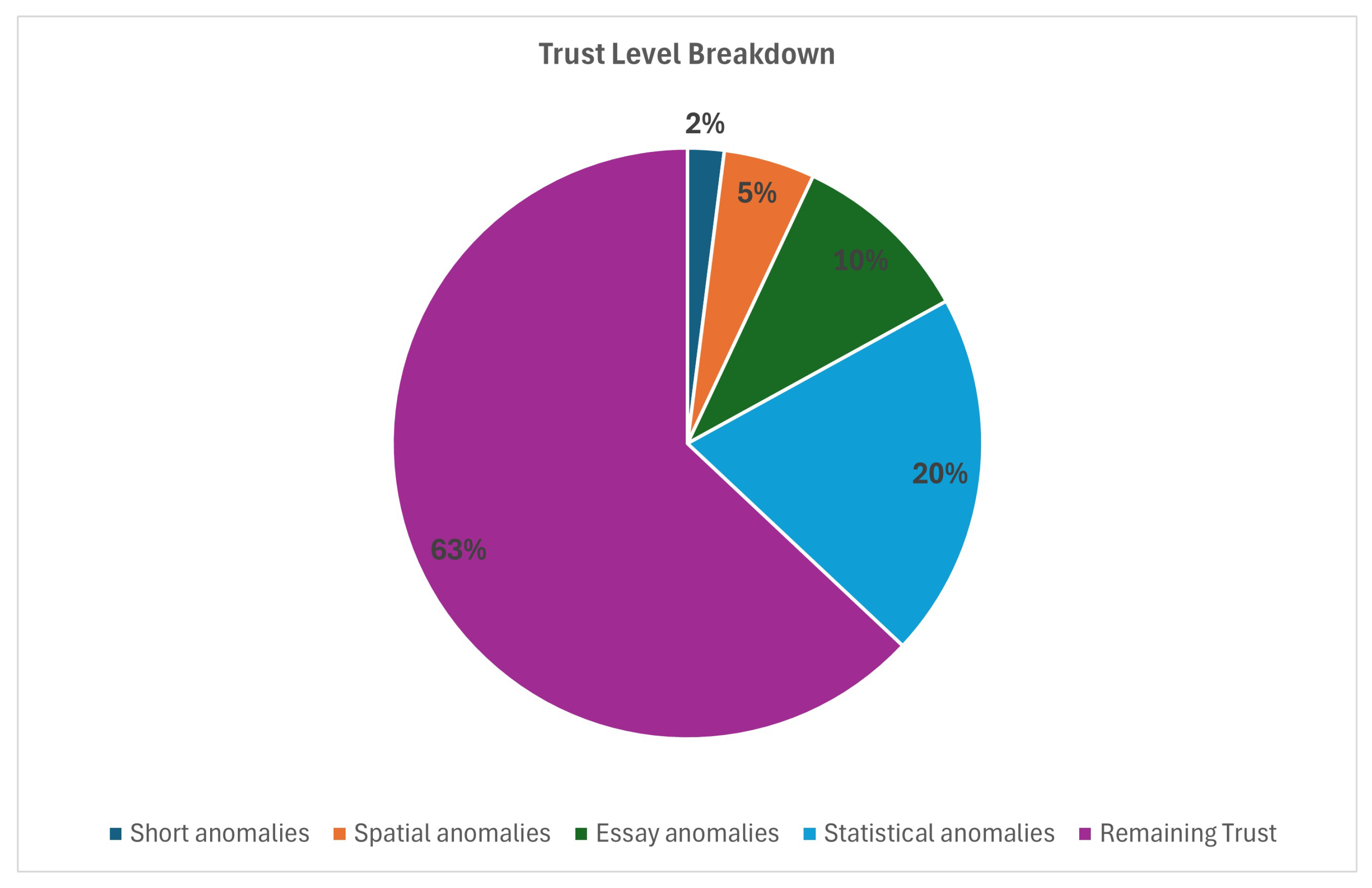
- An interactive pie chart divides trust levels into ranges and presents the percentage of students for each range. Trust ranges start from [0%, 20%] to [80–100%]. Ranges are color-coded.
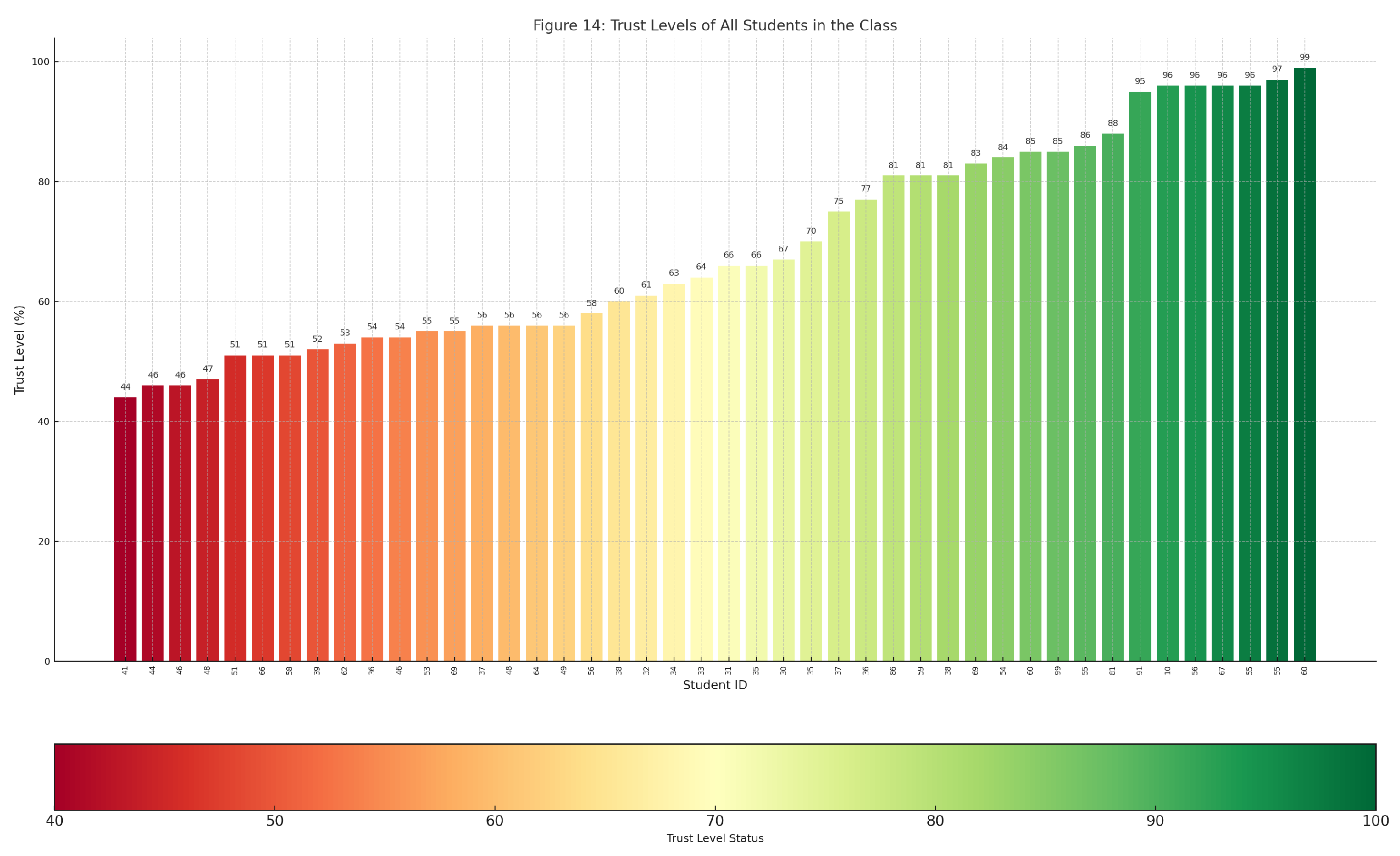
- Interactive bar chart, with each bar resembling a student’s level of trust. The bar chart is color-coded using a red-to-green gradient, where the red color represents the lowest level of trust. Hovering over a student’s bar shows more details regarding that student and their anomalies.
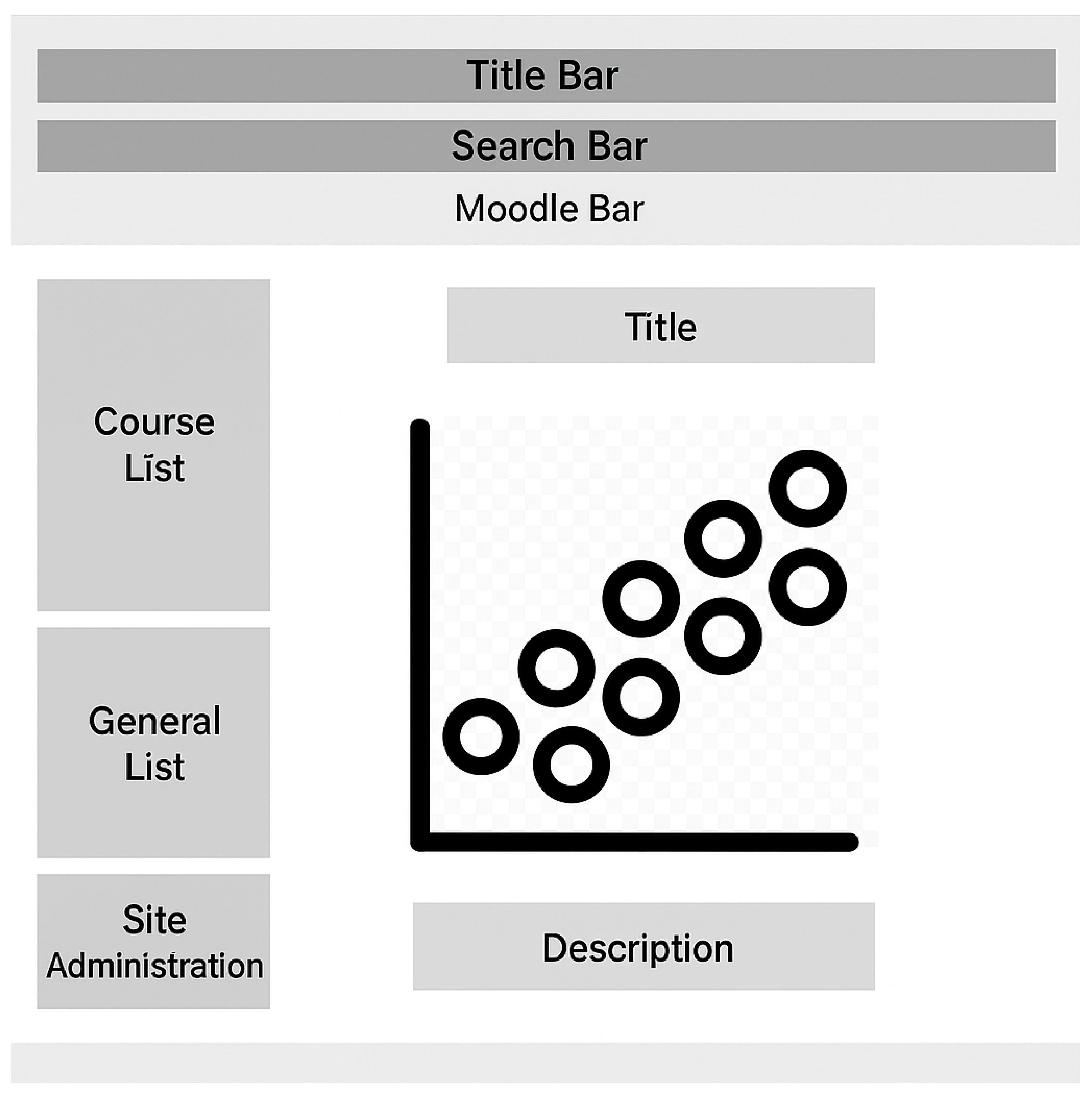
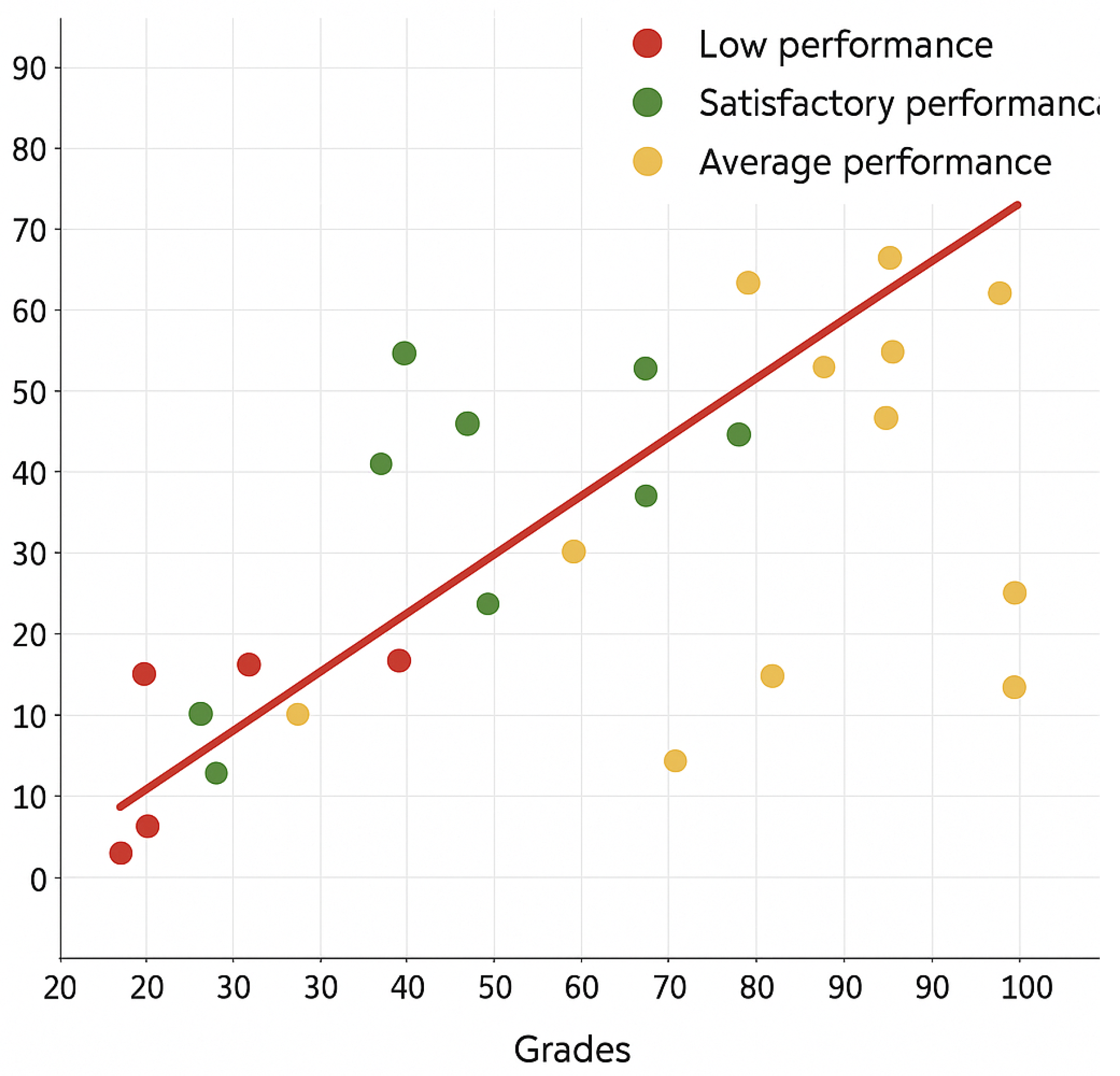
- Scatter plot that demonstrates the regression analysis results of the grades and logs of all students in the quiz. Each dot in the scatter plot represents a student. The x-axis is the number of activities and logs, and the y-axis is the grade from 0 to 100%. Figure 7 demonstrates the wireframe of the scatter plot.
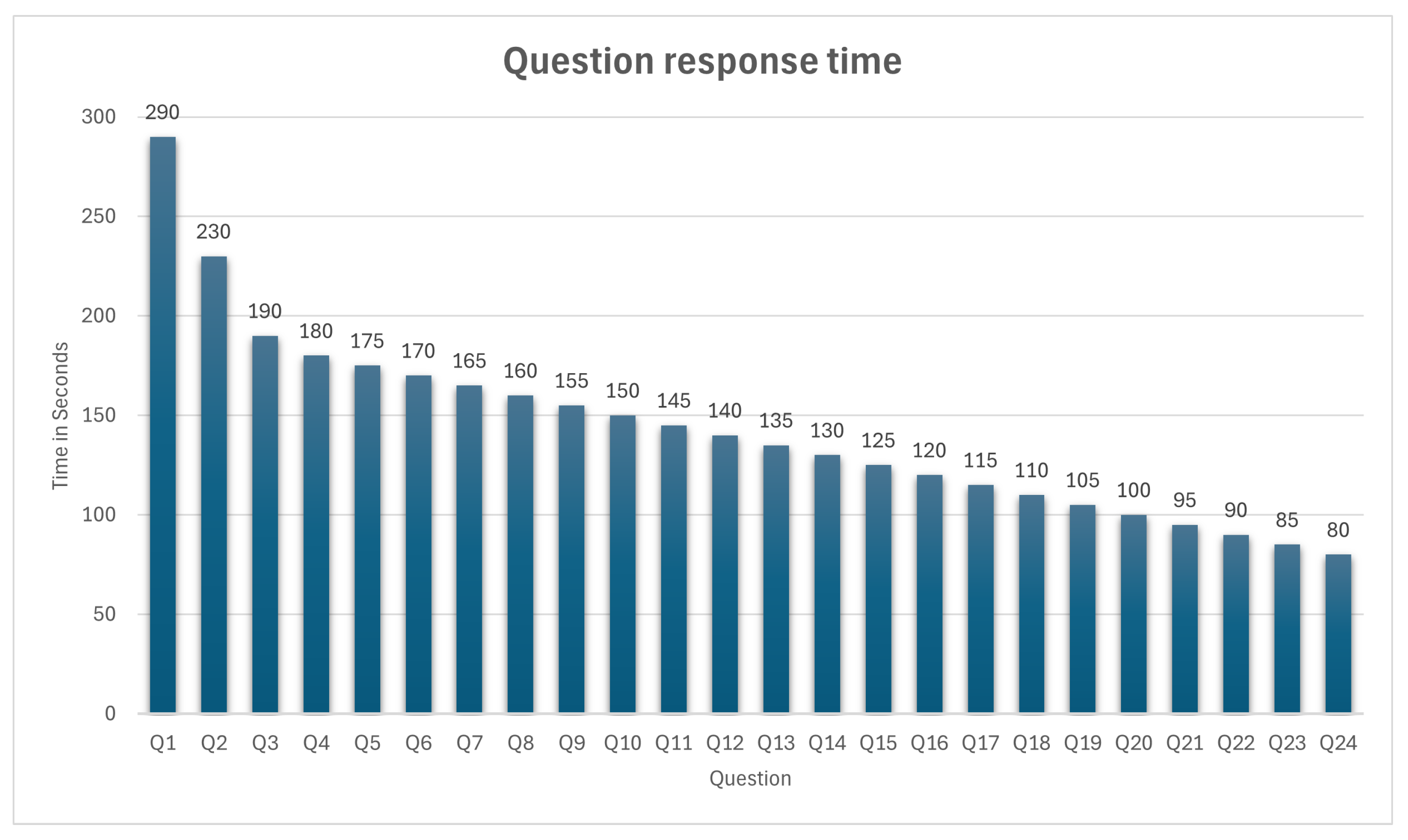
- An interactive plot chart that demonstrates the average student’s response time for each question in the quiz.
5. Implementation
5.1. Setup
- db/access.php script: contains the necessary report access control settings for each Moodle user role. After the plug-in installation, the Moodle core access API retrieves the capability database and verifies access permissions for any user attempting to view the report.Our plug-in is a quiz report designed for instructors. Hence, it has access capabilities for the roles of ‘editing teacher’, ‘course teacher’, and ‘admin’. It denies access to the ‘student role’. This is achieved using the following code snippet in Figure 8.
- cheatdet/locallib: contains utility functions that are frequently used. This includes functions to set up database queries and retrieve their results as associative arrays or lists. Other functions are used to convert the output of an algorithm into data tables and charts using a dedicated JavaScript module.
- cheatdet/report.php script: The main script is in the plug-in. It displays the report page and sets up the quiz and course data. It includes the implementation of the class quiz_default_class, which is responsible for setting up the user session and the Moodle page footer. The script also retrieves the necessary data for analysis and passes them to the respective methods and classes. The analysis results are then passed to the JavaScript modules to render them properly.
5.2. Algorithms’ Implementation
5.2.1. Collusion Detection Algorithm
5.2.2. Regression Analysis of Activities and Logs
5.2.3. Spatial Information Analysis
5.2.4. Temporal Information Analysis
5.3. Integration with Moodle
- Quiz attempts and question-level responses.
- Timestamped logs of student interactions (e.g., clicks, submissions).
- Network metadata, such as IP addresses and session origins.
- Course-level engagement metrics (login frequency, assignment submissions, etc.).
6. Report Generation
6.1. Data Table
6.2. Trust-Level Distribution Using Pie Chart
6.3. Trust Levels Using Interactive Bar Chart
6.4. Regression Analysis Results Using Scatter Plot
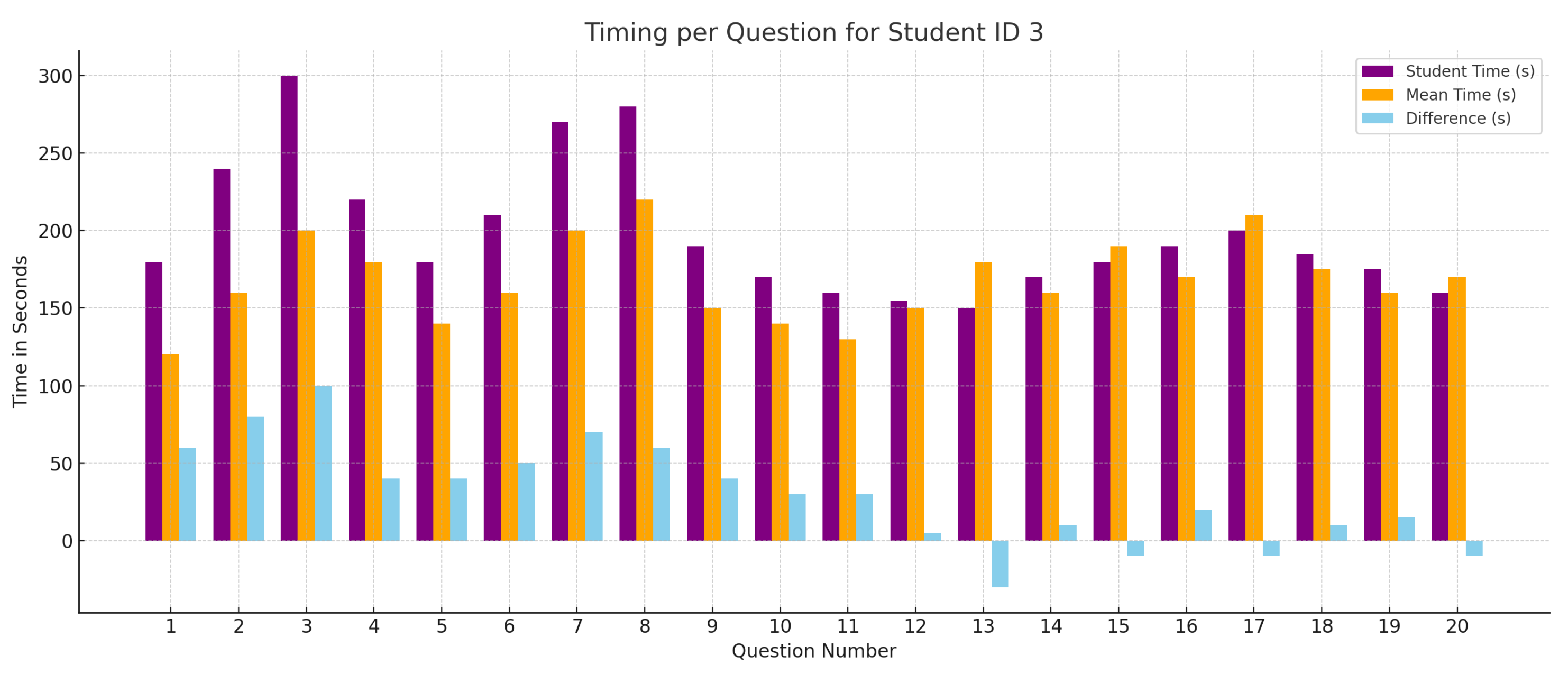
6.5. Timing Bar Chart
6.6. Student Personal Report Page
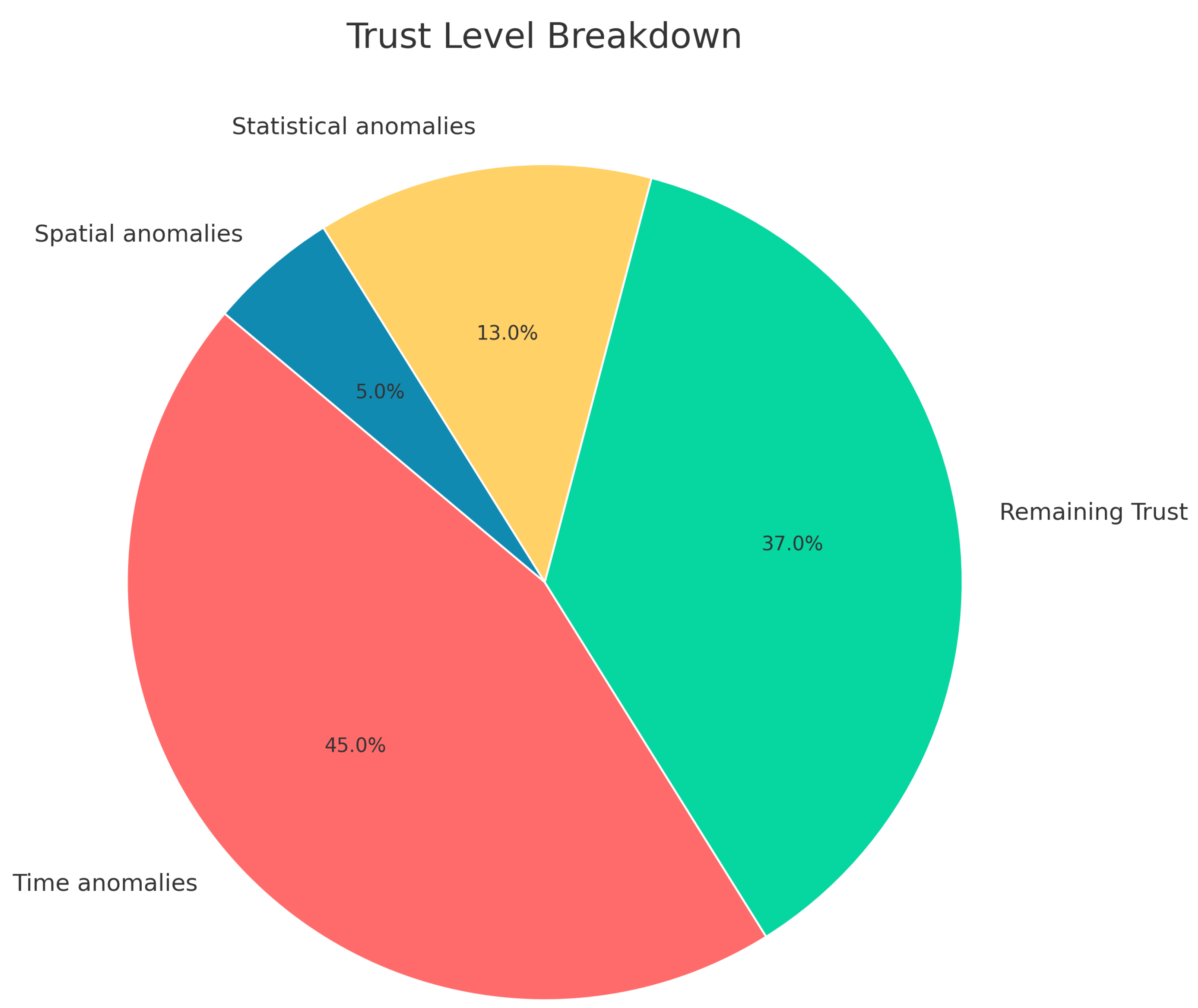
6.7. Trust Doughnut Chart
6.8. Response Time Analysis Chart
6.9. Anomalies Breakdown Page
6.10. Multiple-Choice Analysis Results
7. Results and Discussion
7.1. Performance Evaluation of Collusion Detection
7.2. Evaluation of Individual Students’ Cheating Detection
7.3. Detailed Results and Evaluation
7.4. Ethical Considerations and Data Privacy
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Andersen, K.; Thorsteinsson, S.E.; Thorbergsson, H.; Gudmundsson, K.S. Adapting engineering examinations from paper to online. In Proceedings of the 2020 IEEE Global Engineering Education Conference (EDUCON), Porto, Portugal, 27–30 April 2020; pp. 1891–1895. [Google Scholar]
- Bilen, E.; Matros, A. Online Cheating amid COVID-19. J. Econ. Behav. Organ. 2021, 182, 196–211. [Google Scholar] [CrossRef]
- Lowenthal, P.R.; Leech, N.L. Mixed research and online learning: Strategies for improvement. In Online Education and Adult Learning: New Frontiers for Teaching Practices; IGI Global: Hershey, PA, USA, 2010; pp. 202–211. [Google Scholar] [CrossRef]
- Dendir, S.; Maxwell, R.S. Cheating in online courses: Evidence from online proctoring. Comput. Hum. Behav. Rep. 2020, 2, 100033. [Google Scholar] [CrossRef]
- Raza, S.A.; Qazi, W.; Khan, K.A.; Salam, J. Social isolation and acceptance of the learning management system (LMS) in the time of COVID-19 pandemic: An expansion of the UTAUT model. J. Educ. Comput. Res. 2021, 59, 183–208. [Google Scholar] [CrossRef]
- Liu, D.; Richards, D.; Froissard, C.; Atif, A. Validating the Effectiveness of the Moodle Engagement Analytics Plugin to Predict Student Academic Performance. In Proceedings of the 21st Americas Conference on Information Systems (AMCIS 2015), Fajardo, Puerto Rico, 13–15 August 2015; pp. 1–10. [Google Scholar]
- Prewitt, T. The development of distance learning delivery systems. High. Educ. Eur. 1998, 23, 187–194. [Google Scholar] [CrossRef]
- Beldarrain, Y. Distance education trends: Integrating new technologies to foster student interaction and collaboration. Distance Educ. 2006, 27, 139–153. [Google Scholar] [CrossRef]
- The Rise of Online Learning During the COVID-19 Pandemic | World Economic Forum. 2021. Available online: https://www.weforum.org/agenda/2020/04/coronavirus-education-global-covid19-online-digital-learning/ (accessed on 22 September 2021).
- Education During COVID-19; Moving Towards e-Learning | data.europa.eu. 2021. Available online: https://data.europa.eu/en/impact-studies/covid-19/education-during-covid-19-moving-towards-e-learning (accessed on 22 September 2021).
- Alias, N.A.; Zainuddin, A.M. Innovation for better teaching and learning: Adopting the learning management system. Malays. Online J. Instr. Technol. 2005, 2, 27–40. [Google Scholar]
- Ain, N.; Kaur, K.; Waheed, M. The influence of learning value on learning management system use: An extension of UTAUT2. Inf. Dev. 2016, 32, 1306–1321. [Google Scholar] [CrossRef]
- Awad Ahmed, F.R.; Ahmed, T.E.; Saeed, R.A.; Alhumyani, H.; Abdel-Khalek, S.; Abu-Zinadah, H. Analysis and challenges of robust E-exams performance under COVID-19. Results Phys. 2021, 23, 103987. [Google Scholar] [CrossRef]
- Michael, T.B.; Williams, M.A. Student equity: Discouraging cheating in online courses. Adm. Issues J. 2013, 3, 6. [Google Scholar] [CrossRef]
- Bawarith, R.; Basuhail, A.; Fattouh, A.; Gamalel-Din, S. E-exam cheating detection system. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 176–181. [Google Scholar] [CrossRef]
- Li, M.; Luo, L.; Sikdar, S.; Nizam, N.I.; Gao, S.; Shan, H.; Kruger, M.; Kruger, U.; Mohamed, H.; Xia, L.; et al. Optimized collusion prevention for online exams during social distancing. NPJ Sci. Learn. 2021, 6, 1–9. [Google Scholar] [CrossRef]
- Mohammed, H.M.; Ali, Q.I. E-Proctoring Systems: A review on designing techniques, features and abilities against threats and attacks. Quantum J. Eng. Sci. Technol. 2022, 3, 14–30. [Google Scholar]
- Online Exam Proctoring Catches Cheaters, Raises Concerns. 2017. Available online: https://www.insidehighered.com/digital-learning/article/2017/05/10/online-exam-proctoring-catches-cheaters-raises-concerns (accessed on 22 September 2021).
- Kolski, T.; Weible, J. Examining the relationship between student test anxiety and webcam-based exam proctoring. Online J. Distance Learn. Adm. 2018, 21, 1–15. Available online: https://eric.ed.gov/?id=EJ1191463 (accessed on 15 January 2025).
- Alessio, H.M.; Malay, N.; Maurer, K.; Bailer, A.J.; Rubin, B. Examining the effect of proctoring on online test scores. Online Learn. 2017, 21, 146–161. [Google Scholar] [CrossRef]
- Cluskey, G., Jr.; Ehlen, C.R.; Raiborn, M.H. Thwarting online exam cheating without proctor supervision. J. Acad. Bus. Ethics 2011, 4, 1–7. [Google Scholar]
- Conijn, R.; Desmet, P.; van der Vleuten, C.; van Merriënboer, J. The fear of big brother: The potential negative side-effects of online proctored exams on student well-being. J. Comput. Assist. Learn. 2022, 38, 1–12. [Google Scholar] [CrossRef]
- Ercole, A.; Whittlestone, K.; Melvin, D.; Rashbass, J. Collusion detection in multiple choice examinations. Med. Educ. 2002, 36, 166–172. [Google Scholar] [CrossRef]
- Maynes, D.D. Detecting potential collusion among individual examinees using similarity analysis. In Handbook of Quantitative Methods for Detecting Cheating on Tests; Cizek, G.J., Wollack, J.A., Eds.; Routledge: New York, NY, USA, 2016; pp. 47–69. Available online: https://www.taylorfrancis.com/chapters/edit/10.4324/9781315743097-3/detecting-potential-collusion-among-individual-examinees-using-similarity-analysis-dennis-maynes (accessed on 29 April 2025).
- Rapposelli, J.A. The Correlation Between Attendance and Participation with Respect to Student Achievement in an Online Learning Environment; Liberty University: Lynchburg, VA, USA, 2014; Available online: https://core.ac.uk/download/pdf/58825526.pdf (accessed on 5 April 2024).
- Liu, D.Y.T.; Atif, A.; Froissard, J.C.; Richards, D. An enhanced learning analytics plugin for Moodle: Student engagement and personalised intervention. In Proceedings of the 32nd Annual Conference of the Australasian Society for Computers in Learning in Tertiary Education (ASCILITE 2015), Perth, Australia, 29 November–2 December 2015; Reiners, T., von Konsky, B.R., Gibson, D., Chang, V., Irving, D., Eds.; ASCILITE: Perth, Australia, 2015; pp. 339–349. Available online: https://www.researchgate.net/publication/286264716_An_enhanced_learning_analytics_plugin_for_Moodle_student_engagement_and_personalised_intervention (accessed on 12 November 2024).
- Wesolowsky, G.O. Detecting excessive similarity in answers on multiple choice exams. J. Appl. Stat. 2000, 27, 909–921. [Google Scholar] [CrossRef]
- Cheating Detection in Online Exams Using Deep Learning and Machine Learning Models. Appl. Sci. 2023, 15, 400.
- Ramachandra, C.K.; Joseph, A. IEyeGASE: An Intelligent Eye Gaze-Based Assessment System for Deeper Insights into Learner Performance. Sensors 2021, 21, 6783. [Google Scholar] [CrossRef]
- Kundu, D.; Mehta, A.; Kumar, R.; Lal, N.; Anand, A.; Singh, A.; Shah, R.R. Keystroke Dynamics Against Academic Dishonesty in the Age of LLMs. arXiv 2024, arXiv:2406.15335. [Google Scholar]
- Najjar, A.A.; Ashqar, H.I.; Darwish, O.A.; Hammad, E. Detecting AI-Generated Text in Educational Content: Leveraging Machine Learning and Explainable AI for Academic Integrity. arXiv 2025, arXiv:2501.03203. [Google Scholar]
- Yan, G.; Li, J.J.; Biggin, M.D. Question-Score Identity Detection (Q-SID): A Statistical Algorithm to Detect Collusion Groups with Error Quantification from Exam Question Scores. arXiv 2024, arXiv:2407.07420. [Google Scholar] [CrossRef]
- Shih, Y.S.; Liao, M.; Liu, R.; Baig, M.B. Human-in-the-Loop AI for Cheating Ring Detection. arXiv 2024, arXiv:2403.14711. [Google Scholar] [CrossRef]
- Proctorio Inc. Proctorio and Similar Online Proctoring Tools. Available online: https://proctorio.com/products/online-proctoring (accessed on 30 April 2025).
- Smith, J.; Doe, J. Detecting Plagiarism in Free-Text Exams Using Similarity Analysis Techniques. J. Educ. Technol. 2024, 22, 345–360. [Google Scholar]
- Learning Map Plugin. Available online: https://moodle.org/plugins/mod_learningmap (accessed on 30 April 2025).
- Ercole, L.; Whittlestone, K. A Bayesian Approach to Detecting Cheating in Multiple Choice Examinations. 2002; Unpublished Manuscript. [Google Scholar]
- Berrios Moya, J.A. Blockchain for Academic Integrity: Developing the Blockchain Academic Credential Interoperability Protocol (BACIP). arXiv 2024, arXiv:2406.15482. [Google Scholar]
- Team, C.E. A Systematic Review of Blockchain-Based Initiatives in Comparison to Traditional Systems in Education. Computers 2024, 14, 141. [Google Scholar]
- Nurpeisova, A.; Shaushenova, A.; Mutalova, Z.; Ongarbayeva, M.; Niyazbekova, S.; Bekenova, A.; Zhumaliyeva, L.; Zhumasseitova, S. Research on the Development of a Proctoring System for Conducting Online Exams in Kazakhstan. Computation 2023, 11, 120. [Google Scholar] [CrossRef]
- Dilini, N.; Senaratne, A.; Yasarathna, T.L.; Warnajith, N. Cheating Detection in Browser-Based Online Exams through Eye Gaze Tracking. In Proceedings of the 2021 6th International Conference on Information Technology Research (ICITR), Moratuwa, Sri Lanka, 1–3 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Bergmans, L.; Bouali, N.; Luttikhuis, M.; Rensink, A. On the Efficacy of Online Proctoring Using Proctorio. In Proceedings of the 13th International Conference on Computer Supported Education (CSEDU 2021), Online, 23–25 April 2021; pp. 279–290. [Google Scholar] [CrossRef]
- Moodle Community. MEAP Plugin for Moodle. 2023. Available online: https://moodle.org/plugins/ (accessed on 30 April 2025).
- The GNU General Public License v3.0—GNU Project—Free Software Foundation. Available online: https://www.gnu.org/licenses/gpl-3.0.en.html (accessed on 25 September 2021).
- Lancaster, T.; Cotarlan, C. Contract cheating by STEM students through a file sharing website: A Covid-19 pandemic perspective. Int. J. Educ. Integr. 2021, 17, 3. [Google Scholar] [CrossRef]
- Step-by-Step Installation Guide for Ubuntu—MoodleDocs. 2021. Available online: https://docs.moodle.org/311/en/Step-by-step_Installation_Guide_for_Ubuntu#Before_you_begin (accessed on 25 September 2021).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method / Tool | Approach | Limitation(s) | Year |
|---|---|---|---|
| Deep Learning and ML Models [28] | Utilize DNN, SVM, and XGBoost to detect unethical patterns | Require large datasets; risk of overfitting | 2025 |
| Gaze Analysis [41] | Eye tracking to detect off-screen behavior during tests | Requires specialized hardware; limits scalability | 2024 |
| AI Text Detection [31] | Uses explainable ML models to flag LLM-generated answers | Domain-specific tuning required; generalization issues | 2025 |
| Keystroke Dynamics [30] | Typing behavior used to distinguish user identity or detect AI assistance | Intrusive; affected by user variability | 2024 |
| Q-SID Algorithm [32] | Collusion detection based on question-score identity distributions | Works only with MCQs; not generalizable to other formats | 2024 |
| Human-in-the-Loop AI [33] | Combines ML predictions with human judgment in review loops | Not scalable for large-scale exams | 2024 |
| Proctoring Tools (e.g., Proctorio) [42] | Use webcam, mic, and screen monitoring for live supervision | Privacy concerns; hardware- and bandwidth-intensive | 2023–2025 |
| Essay Similarity Analysis [35] | NLP-based comparison of open-ended student responses | Effective but computationally demanding | 2024 |
| MEAP Plug-in [43] | Predicts student risk using Moodle activity logs | Predictive only; not specific to cheating | 2023 |
| Bayesian Collusion Detection [37] | Flags unlikely response similarities in MCQs using probabilistic inference | Requires timing/location data for reliability | 2002 |
| Blockchain Academic Records [38] | Tamper-resistant tracking of academic credentials via blockchain | Scalability and integration challenges | 2024 |
| Blockchain Review [39] | Compares blockchain with traditional education record systems | Transition cost and technical barriers | 2024 |
| Kazakhstan Proctoring System [40] | Regionally developed online proctoring tailored to local conditions | Limited global applicability | 2023 |
| Pair | Student A | Student B | Description |
|---|---|---|---|
| 1 | Test1 | Test11 | same local area network |
| 2 | Test7 | Test50 | similar spatial information |
| 3 | Test140 | Test180 | distinct spatial information |
| 4 | Test30 | Test230 | distinct spatial information |
| Anomaly Type | Detected Cases | Confirmed Cases | Precision (%) |
|---|---|---|---|
| Multiple-Choice Collusion | 14 | 14 | 100% |
| Short-Answer Similarity | 9 | 9 | 100% |
| Response Time Outliers | 15 | 15 | 100% |
| Spatial/IP Anomalies | 7 | 7 | 100% |
| Activity vs. Grade Mismatch | 10 | 10 | 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shatnawi, A.S.; Awad, F.; Mustafa, D.; Al-Falaky, A.-W.; Shatarah, M.; Mohaidat, M. E-Exam Cheating Detection System for Moodle LMS. Information 2025, 16, 388. https://doi.org/10.3390/info16050388
Shatnawi AS, Awad F, Mustafa D, Al-Falaky A-W, Shatarah M, Mohaidat M. E-Exam Cheating Detection System for Moodle LMS. Information. 2025; 16(5):388. https://doi.org/10.3390/info16050388
Chicago/Turabian StyleShatnawi, Ahmed S., Fahed Awad, Dheya Mustafa, Abdel-Wahab Al-Falaky, Mohammed Shatarah, and Mustafa Mohaidat. 2025. "E-Exam Cheating Detection System for Moodle LMS" Information 16, no. 5: 388. https://doi.org/10.3390/info16050388
APA StyleShatnawi, A. S., Awad, F., Mustafa, D., Al-Falaky, A.-W., Shatarah, M., & Mohaidat, M. (2025). E-Exam Cheating Detection System for Moodle LMS. Information, 16(5), 388. https://doi.org/10.3390/info16050388