
Fusion of Aerial and Satellite Images for Automatic Extraction of Building Footprint Information Using Deep Neural Networks

 , and
, and 
Abstract
1. Introduction
- Most existing models rely solely on either high-resolution aerial imagery or high-radiometric-resolution satellite images, limiting their adaptability across different datasets;
- While deep learning models have demonstrated strong feature extraction capabilities, they still struggle with occlusions, shadows, and complex urban landscapes, leading to errors in footprint delineation;
- Previous studies have primarily focused on single-source data (e.g., aerial or satellite imagery), with limited exploration of how integrating multiple data sources might enhance model performance;
- Many state-of-the-art models achieve high accuracy at the cost of significant computational overhead, limiting their real-world applicability.
- Proposes a novel approach that combines aerial and satellite imagery to improve building footprint extraction, leveraging complementary spatial and spectral information;
- Develops an optimized deep learning framework that integrates multi-source data without significantly increasing computational complexity;
- Evaluates the impact of data fusion on model accuracy across different urban environments, offering insights into the scalability and robustness of the approach and finally;
- Introduces an enhanced U-Net-based architecture with specific modifications tailored to multi-source data integration, improving segmentation performance.
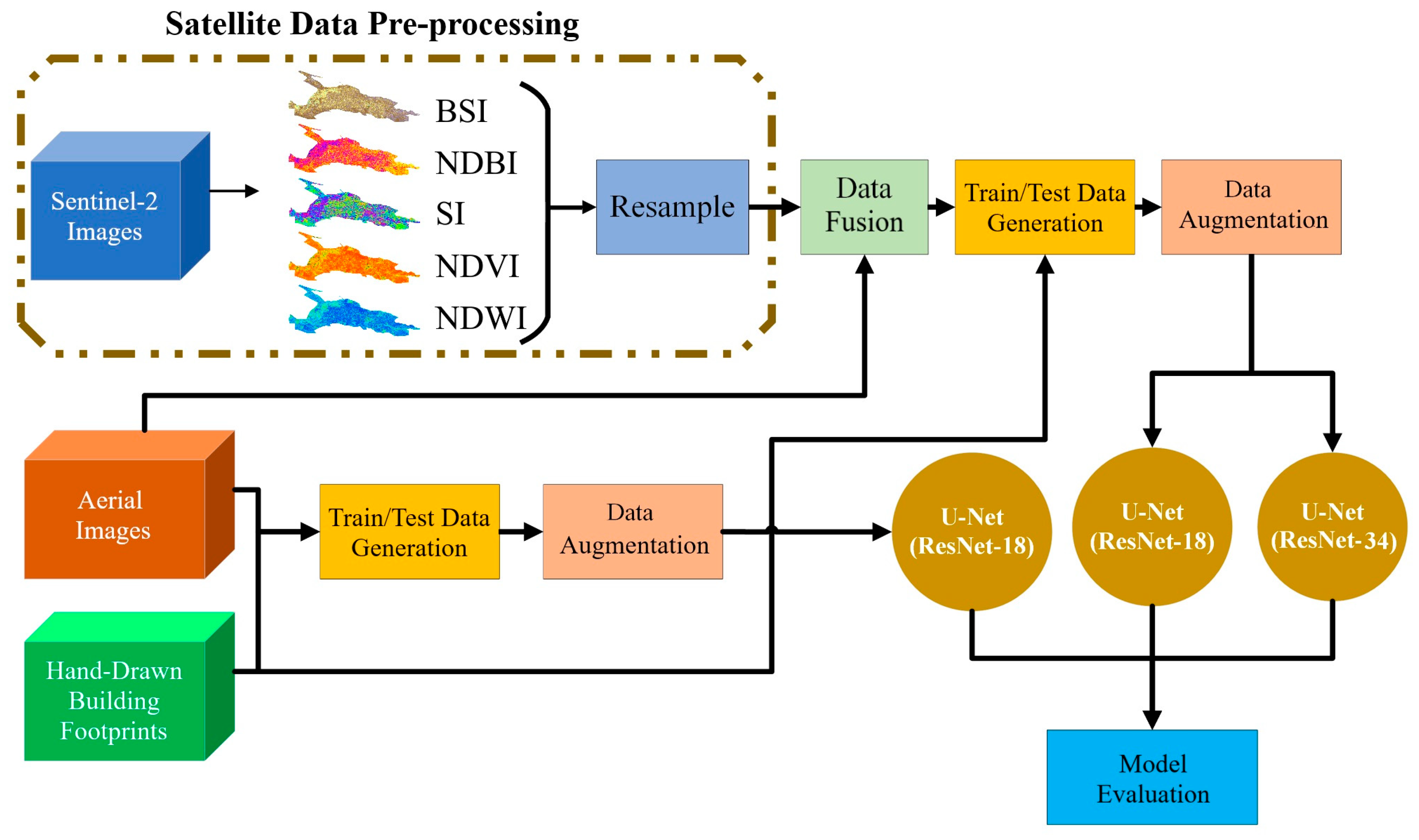
2. Materials and Methods
2.1. Study Area and Datasets
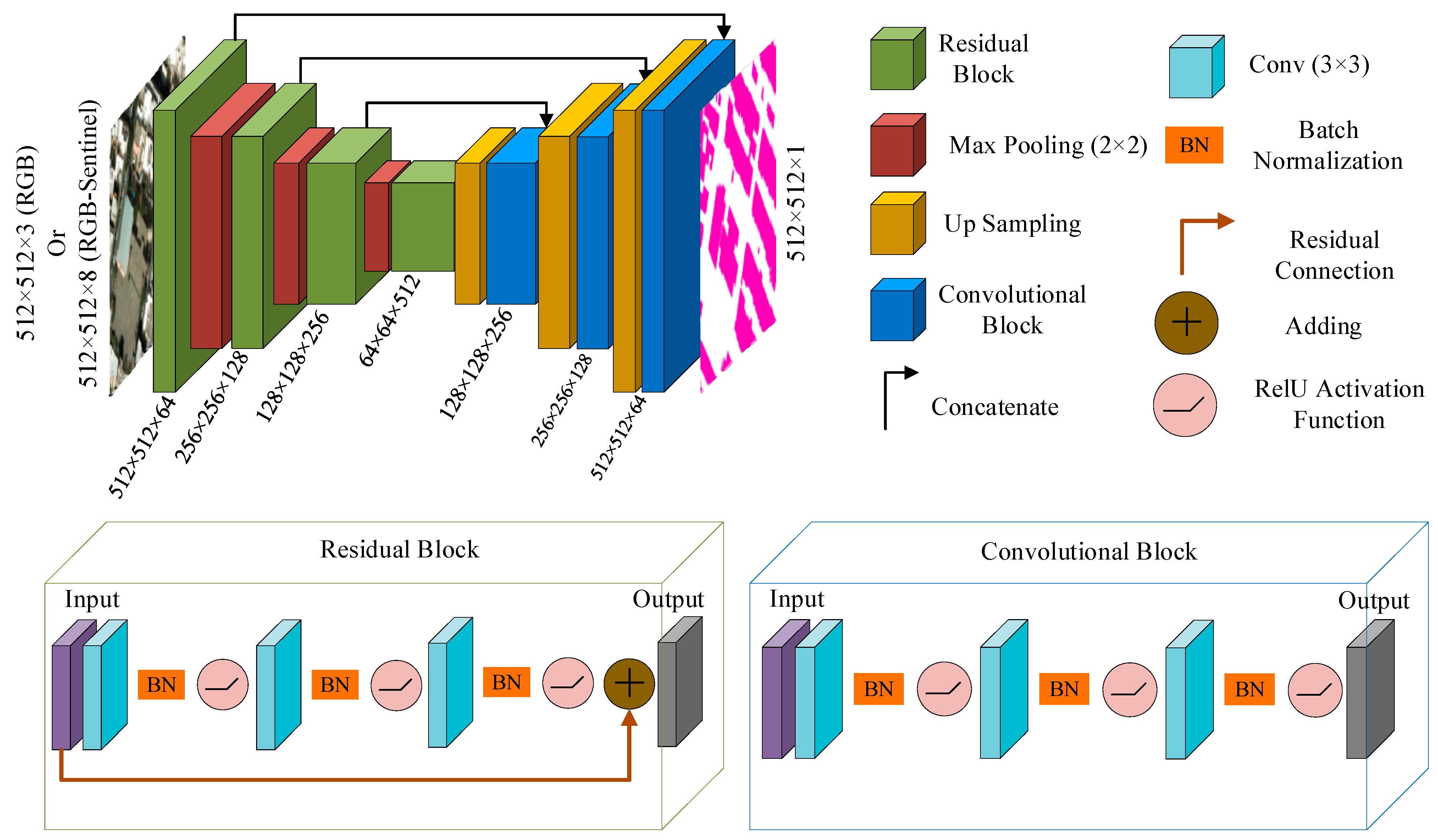
2.2. U-Net Model
2.3. ResNet Model
2.4. Combination of U-Net and ResNet
2.5. Model Training Parameters
2.6. Model Evaluation Metrics
3. Results and Discussion
3.1. Extraction and Processing of Spectral Indices
- The RGB dataset, containing only aerial imagery with three channels (red, green, and blue);
- The RGB–Sentinel dataset, containing the aerial image (three channels) plus five additional channels representing the NDVI, NDWI, NDBI, SI, and BSI indices, for a total of eight channels per image.
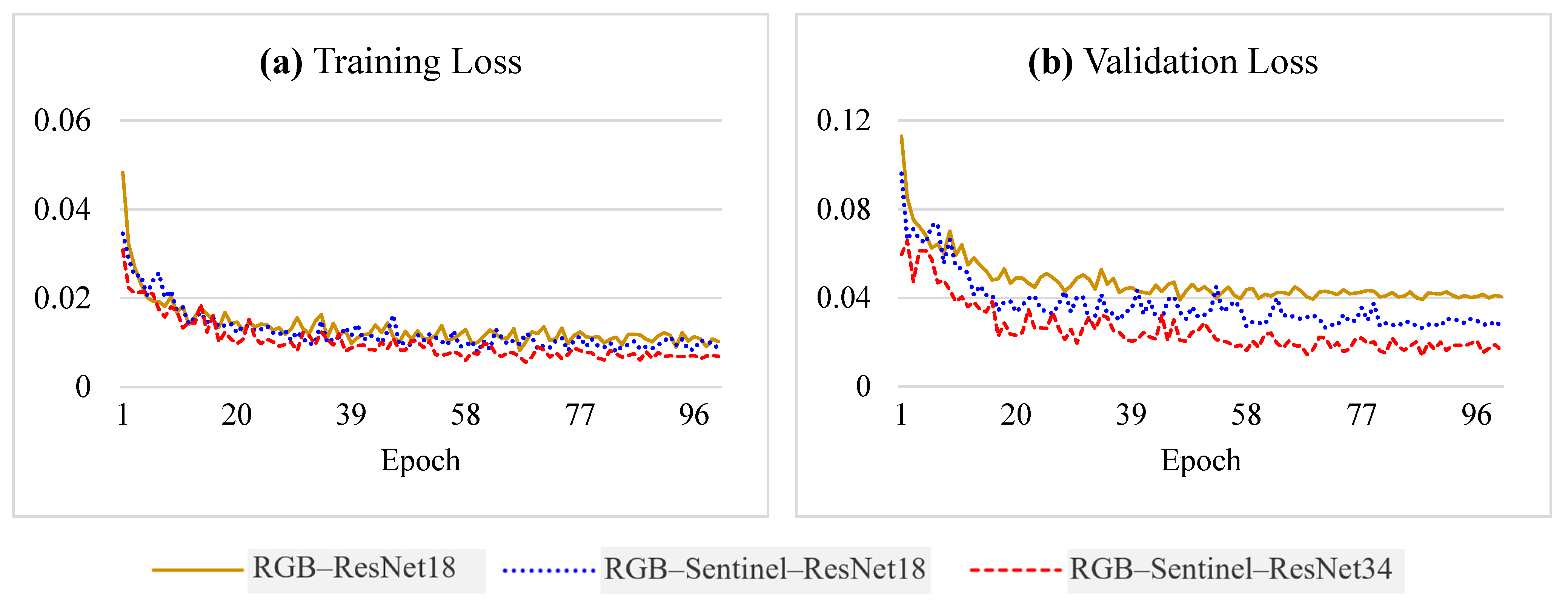
3.2. Model Training and Performance Evaluation
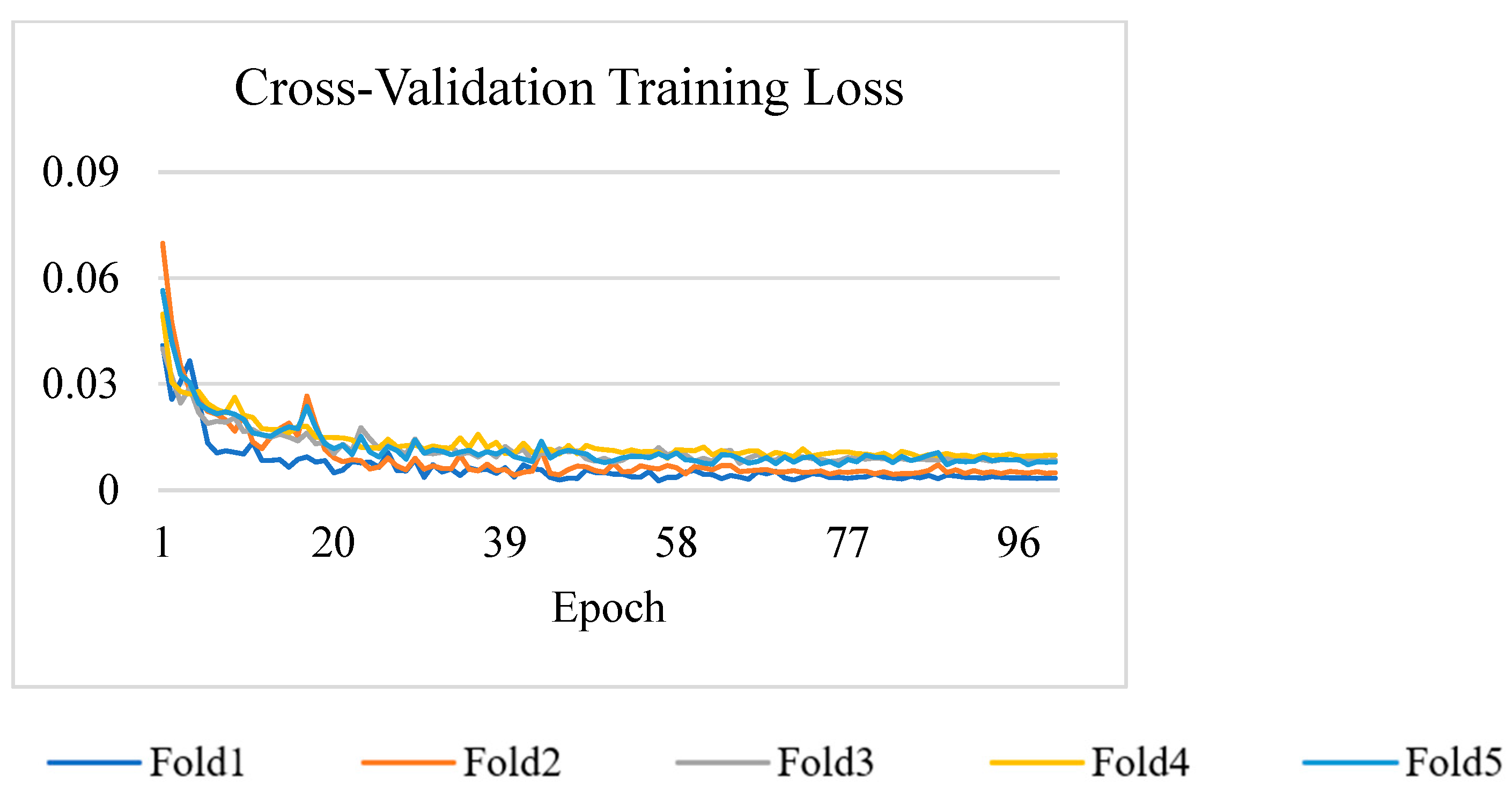
3.3. Cross-Validation of the Best Model
3.4. Limitations and Future Directions
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nurkarim, W.; Wijayanto, A.W. Building footprint extraction and counting on very high-resolution satellite imagery using object detection deep learning framework. Earth Sci. Inform. 2023, 16, 515–532. [Google Scholar] [CrossRef]
- Soleimani, R.; Soleimani-Babakamali, M.H.; Meng, S.; Avci, O.; Taciroglu, E. Computer vision tools for early post-disaster assessment: Enhancing generalizability. Eng. Appl. Artif. Intell. 2024, 136, 108855. [Google Scholar] [CrossRef]
- Bittner, K.; Adam, F.; Cui, S.; Körner, M.; Reinartz, P. Building footprint extraction from VHR remote sensing images combined with normalized DSMs using fused fully convolutional networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2615–2629. [Google Scholar] [CrossRef]
- Guo, H.; Shi, Q.; Marinoni, A.; Du, B.; Zhang, L. Deep building footprint update network: A semi-supervised method for updating existing building footprint from bi-temporal remote sensing images. Remote Sens. Environ. 2021, 264, 112589. [Google Scholar] [CrossRef]
- Chen, H.; Li, W.; Shi, Z. Adversarial instance augmentation for building change detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Liu, P.; Liu, X.; Liu, M.; Shi, Q.; Yang, J.; Xu, X.; Zhang, Y. Building footprint extraction from high-resolution images via spatial residual inception convolutional neural network. Remote Sens. 2019, 11, 830. [Google Scholar] [CrossRef]
- Chen, D.; Shang, S.; Wu, C. Shadow-based Building Detection and Segmentation in High-resolution Remote Sensing Image. J. Multim. 2014, 9, 181–188. [Google Scholar] [CrossRef]
- Ziaei, Z.; Pradhan, B.; Mansor, S.B. A rule-based parameter aided with object-based classification approach for extraction of building and roads from WorldView-2 images. Geocarto Int. 2014, 29, 554–569. [Google Scholar] [CrossRef]
- Norman, M.; Shahar, H.M.; Mohamad, Z.; Rahim, A.; Mohd, F.A.; Shafri, H.Z.M. Urban building detection using object-based image analysis (OBIA) and machine learning (ML) algorithms. IOP Conf. Ser. Earth Environ. Sci. 2021, 620, 012010. [Google Scholar] [CrossRef]
- Dai, Y.; Gong, J.; Li, Y.; Feng, Q. Building segmentation and outline extraction from UAV image-derived point clouds by a line growing algorithm. Int. J. Digit. Earth 2017, 10, 1077–1097. [Google Scholar] [CrossRef]
- Femiani, J.; Li, E.; Razdan, A.; Wonka, P. Shadow-based rooftop segmentation in visible band images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 8, 2063–2077. [Google Scholar] [CrossRef]
- Turker, M.; Koc-San, D. Building extraction from high-resolution optical spaceborne images using the integration of support vector machine (SVM) classification, Hough transformation and perceptual grouping. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 58–69. [Google Scholar] [CrossRef]
- Shi, Y.; Li, Q.; Zhu, X.X. Building footprint generation using improved generative adversarial networks. IEEE Geosci. Remote Sens. Lett. 2018, 16, 603–607. [Google Scholar] [CrossRef]
- Mikeš, S.; Haindl, M.; Scarpa, G.; Gaetano, R. Benchmarking of remote sensing segmentation methods. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2240–2248. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Marmanis, D.; Datcu, M.; Esch, T.; Stilla, U. Deep learning earth observation classification using ImageNet pretrained networks. IEEE Geosci. Remote Sens. Lett. 2015, 13, 105–109. [Google Scholar] [CrossRef]
- Li, Z.; Xin, Q.; Sun, Y.; Cao, M. A deep learning-based framework for automated extraction of building footprint polygons from very high-resolution aerial imagery. Remote Sens. 2021, 13, 3630. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; Proceedings, Part III 18; pp. 234–241. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef]
- Pasquali, G.; Iannelli, G.C.; Dell’Acqua, F. Building footprint extraction from multispectral, spaceborne earth observation datasets using a structurally optimized U-Net convolutional neural network. Remote Sens. 2019, 11, 2803. [Google Scholar] [CrossRef]
- Zhu, Q.; Liao, C.; Hu, H.; Mei, X.; Li, H. MAP-Net: Multiple attending path neural network for building footprint extraction from remote sensed imagery. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6169–6181. [Google Scholar] [CrossRef]
- Haghighi Gashti, E.; Delavar, M.R.; Guan, H.; Li, J. Semantic Segmentation Uncertainty Assessment of Different U-net Architectures for Extracting Building Footprints. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2024, 10, 141–148. [Google Scholar] [CrossRef]
- Ayala, C.; Sesma, R.; Aranda, C.; Galar, M. A deep learning approach to an enhanced building footprint and road detection in high-resolution satellite imagery. Remote Sens. 2021, 13, 3135. [Google Scholar] [CrossRef]
- Tao, C.; Meng, Y.; Li, J.; Yang, B.; Hu, F.; Li, Y.; Cui, C.; Zhang, W. MSNet: Multispectral semantic segmentation network for remote sensing images. GIScience Remote Sens. 2022, 59, 1177–1198. [Google Scholar] [CrossRef]
- Borawar, L.; Kaur, R. ResNet: Solving vanishing gradient in deep networks. In Proceedings of International Conference on Recent Trends in Computing; Lecture Notes in Networks and Systems; Springer: Singapore, 2023; Volume 600, pp. 235–247. [Google Scholar]
- Gupta, A.; Arora, S.; Jain, M.; Jain, K. Comparative Analysis of ResNet-18 and ResNet-50 Architectures for Pneumonia Detection in Medical Imaging. In Proceedings of Fifth Doctoral Symposium on Computational Intelligence: DoSCI 2023; Lecture Notes in Networks and Systems; Springer: Singapore, 2025; Volume 1096, pp. 355–365. [Google Scholar]
- Sarwinda, D.; Paradisa, R.H.; Bustamam, A.; Anggia, P. Deep learning in image classification using residual network (ResNet) variants for detection of colorectal cancer. Procedia Comput. Sci. 2021, 179, 423–431. [Google Scholar] [CrossRef]
- Ruby, U.; Theerthagiri, P.; Jacob, I.J.; Vamsidhar, Y. Binary cross entropy with deep learning technique for image classification. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 5393–5397. [Google Scholar]
- Gordon-Rodriguez, E.; Loaiza-Ganem, G.; Pleiss, G.; Cunningham, J.P. Uses and abuses of the cross-entropy loss: Case studies in modern deep learning. arXiv 2020, arXiv:2011.05231. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhang, J.; Karimireddy, S.P.; Veit, A.; Kim, S.; Reddi, S.J.; Kumar, S.; Sra, S. Why ADAM beats SGD for attention models. arXiv 2019, arXiv:1912.03194. [Google Scholar]
- Zhou, D.; Fang, J.; Song, X.; Guan, C.; Yin, J.; Dai, Y.; Yang, R. Iou loss for 2d/3d object detection. In Proceedings of the 2019 International Conference on 3D Vision (3DV), Québec City, QC, Canada, 16–19 September 2019; pp. 85–94. [Google Scholar]
- Blagec, K.; Dorffner, G.; Moradi, M.; Samwald, M. A critical analysis of metrics used for measuring progress in artificial intelligence. arXiv 2020, arXiv:2008.02577. [Google Scholar]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring vegetation systems in the Great Plains with ERTS. NASA Spec. Publ. 1974, 351, 309. [Google Scholar]
- Gao, B.-C. NDWI—A normalized difference water index for remote sensing of vegetation liquid water from space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Karanam, H.K.; Neela, V. Study of normalized difference built-up (NDBI) index in automatically mapping urban areas from Landsat TN imagery. Int. J. Eng. Sci. Math. 2017, 8, 239–248. [Google Scholar]
- Sun, G.; Huang, H.; Weng, Q.; Zhang, A.; Jia, X.; Ren, J.; Sun, L.; Chen, X. Combinational shadow index for building shadow extraction in urban areas from Sentinel-2A MSI imagery. Int. J. Appl. Earth Obs. Geoinf. 2019, 78, 53–65. [Google Scholar] [CrossRef]
- Chen, W.; Liu, L.; Zhang, C.; Wang, J.; Wang, J.; Pan, Y. Monitoring the seasonal bare soil areas in Beijing using multitemporal TM images. In Proceedings of the IGARSS 2004—2004 IEEE International Geoscience and Remote Sensing Symposium, Anchorage, AK, USA, 20–24 September 2004; pp. 3379–3382. [Google Scholar]
- Berrar, D. Cross-validation. In Encyclopedia of Bioinformatics and Computational Biology; Academic Press: Cambridge, MA, USA, 2019; Volume 1, pp. 542–545. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Band | Band Name | Spatial Resolution (m) | Central Wavelength |
|---|---|---|---|
| 1 | Aerosol | 60 | 443 |
| 2 | Blue | 10 | 490 |
| 3 | Green | 10 | 560 |
| 4 | Red | 10 | 665 |
| 5 | Red edge | 20 | 705 |
| 6 | - | 20 | 740 |
| 7 | - | 20 | 783 |
| 8 | NIR | 10 | 842 |
| 8A | - | 20 | 865 |
| 9 | - | 60 | 945 |
| 10 | - | 60 | 1375 |
| 11 | SWIR1 | 20 | 1610 |
| 12 | SWIR2 | 20 | 2190 |
| Class | Metric | RGB–ResNet18 (%) | RGB–Sentinel–ResNet18 (%) | RGB–Sentinel–ResNet34 (%) |
|---|---|---|---|---|
| Background Class | Precision | 92.85 | 95.17 | 96.59 |
| Recall | 95.21 | 97.49 | 98.30 | |
| F1-score | 94.02 | 96.32 | 97.44 | |
| Building Footprint Class | Precision | 89.50 | 92.37 | 92.96 |
| Recall | 83.04 | 86 | 88.29 | |
| F1-score | 86.15 | 89.06 | 90.56 |
| Class | Metric | Fold 1 (%) | Fold 2 (%) | Fold 3 (%) | Fold 4 (%) | Fold 5 (%) |
|---|---|---|---|---|---|---|
| Background Class | Precision | 96.47 | 95.56 | 97.05 | 96.31 | 96.66 |
| Recall | 99.22 | 98.62 | 99.39 | 99.41 | 97.88 | |
| F1-score | 97.83 | 97.07 | 98.21 | 97.84 | 96.91 | |
| Building Footprint Class | Precision | 94.16 | 92.35 | 94.14 | 94.01 | 93.42 |
| Recall | 87.14 | 84.63 | 87.78 | 85.52 | 86.34 | |
| F1-score | 90.51 | 88.32 | 90.85 | 89.56 | 89.81 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haghighi Gashti, E.; Bahiraei, H.; Valadan Zoej, M.J.; Ghaderpour, E. Fusion of Aerial and Satellite Images for Automatic Extraction of Building Footprint Information Using Deep Neural Networks. Information 2025, 16, 380. https://doi.org/10.3390/info16050380
Haghighi Gashti E, Bahiraei H, Valadan Zoej MJ, Ghaderpour E. Fusion of Aerial and Satellite Images for Automatic Extraction of Building Footprint Information Using Deep Neural Networks. Information. 2025; 16(5):380. https://doi.org/10.3390/info16050380
Chicago/Turabian StyleHaghighi Gashti, Ehsan, Hanieh Bahiraei, Mohammad Javad Valadan Zoej, and Ebrahim Ghaderpour. 2025. "Fusion of Aerial and Satellite Images for Automatic Extraction of Building Footprint Information Using Deep Neural Networks" Information 16, no. 5: 380. https://doi.org/10.3390/info16050380
APA StyleHaghighi Gashti, E., Bahiraei, H., Valadan Zoej, M. J., & Ghaderpour, E. (2025). Fusion of Aerial and Satellite Images for Automatic Extraction of Building Footprint Information Using Deep Neural Networks. Information, 16(5), 380. https://doi.org/10.3390/info16050380