
Adaptive Intervention Architecture for Psychological Manipulation Detection: A Culture-Specific Approach for Adolescent Digital Communications


Abstract
1. Introduction
2. Related Work
2.1. Gaslighting: Definition and Characteristics
2.2. NLP Approaches to Harmful Dialogue Detection
2.3. Emotion Analysis and Multimodal Approaches
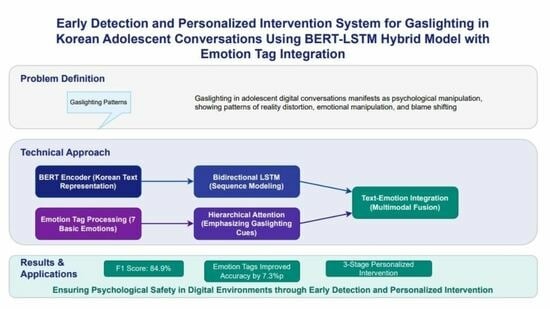
3. Methodology
3.1. Research Design Overview
3.2. Gaslighting Pattern Detection Techniques
3.2.1. Classification of Major Gaslighting Types
3.2.2. Linguistic Feature Analysis
3.2.3. Emotional Transition Analysis
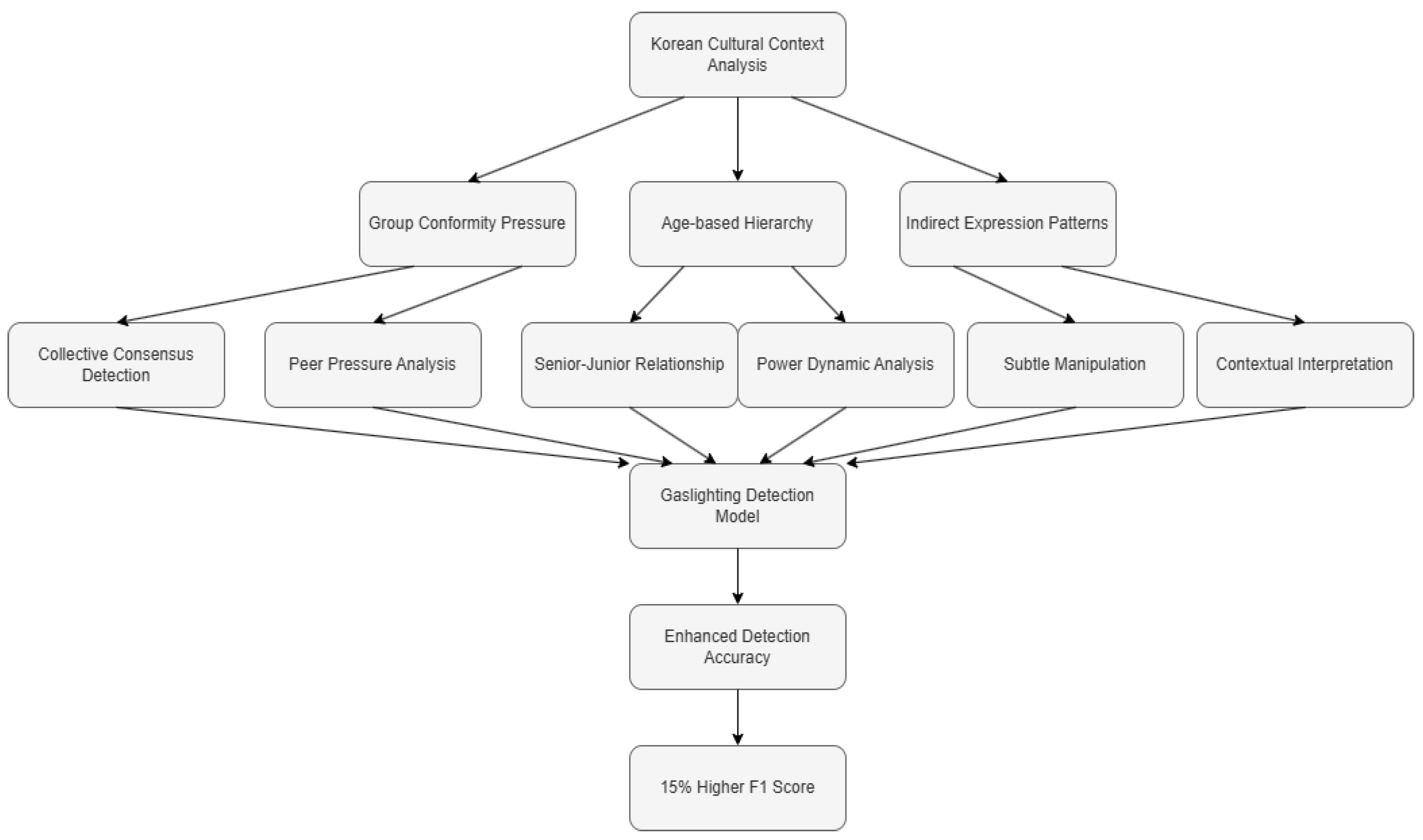
3.2.4. Cultural Context Consideration
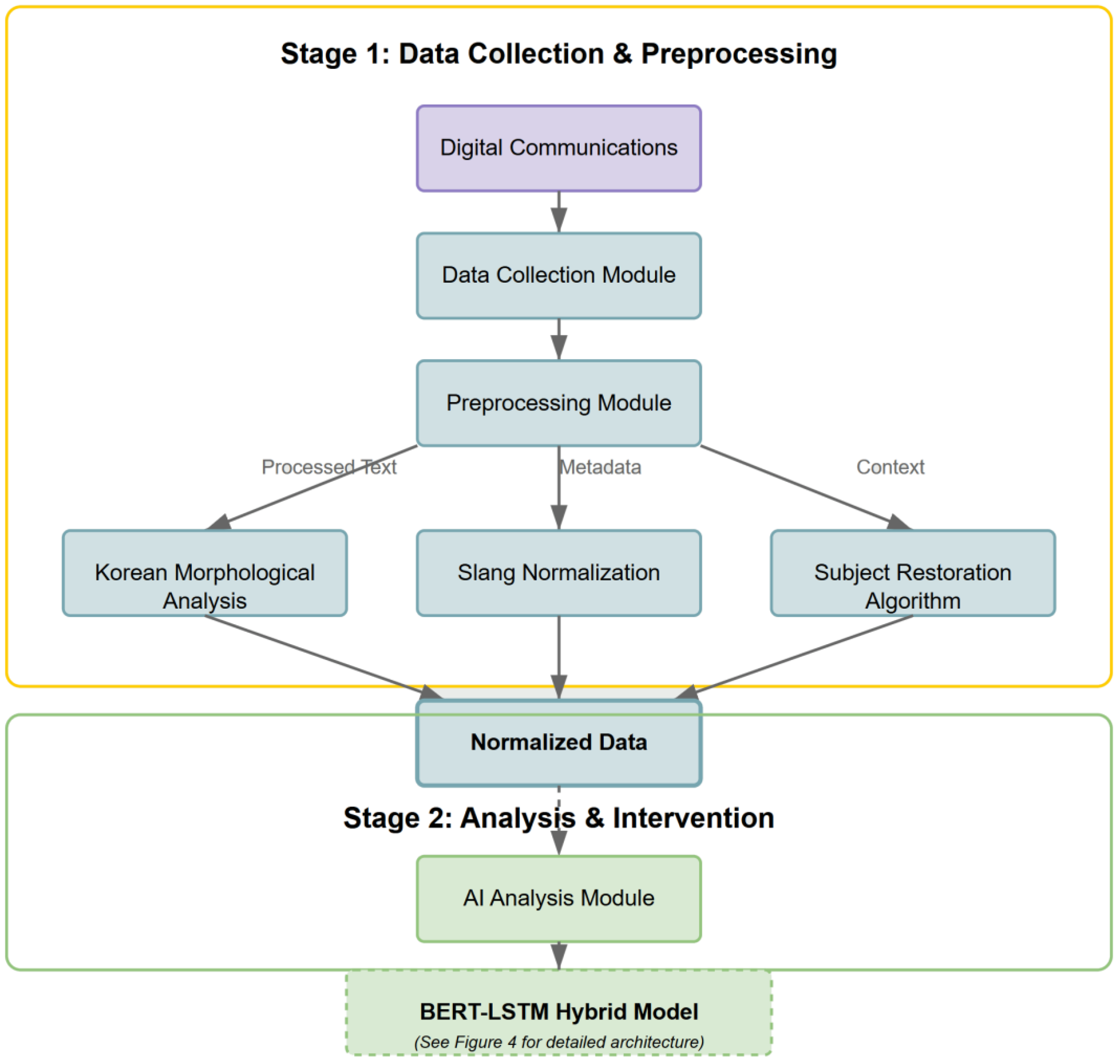
3.3. Dataset Construction and Preprocessing
- (1)
- Korean SNS Multi-Turn Conversation Dataset
- (2)
- Emotion-Tagged Adolescent Free Conversation Dataset
- High confidence (>0.85): These predictions (5124 conversations, 58.6% of total) were automatically incorporated as new labels.
- Medium confidence (0.7–0.85): These predictions (2118 conversations, 24.2% of total) underwent expert review before inclusion.
- Low confidence (<0.7): These predictions were excluded from the training data.
3.4. System Architecture
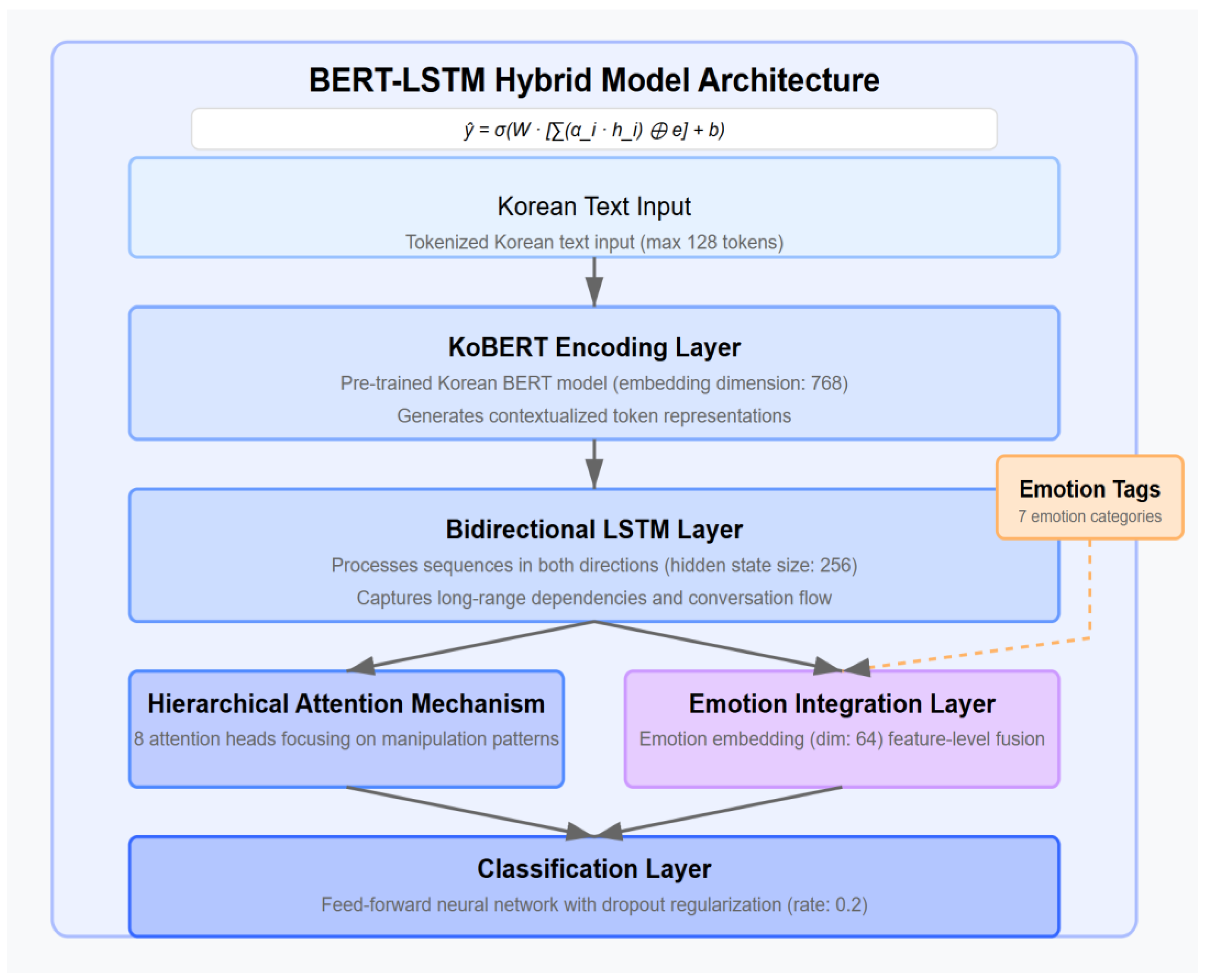
3.5. BERT-LSTM Hybrid Model
3.6. Emotion Tag Integration
3.7. Intervention System Design
| Algorithm 1. Intervention System Logic |
| function DETERMINEINTERVENTION(gaslightingProbability, conversationContext, userProfile) if gaslightingProbability ≥ 0.9 then riskLevel ← HIGH else if gaslightingProbability ≥ 0.7 then riskLevel ← MEDIUM else if gaslightingProbability ≥ 0.5 then riskLevel ← LOW else return null // No intervention needed end if intervention ← SELECTINTERVENTIONSTRATEGY(riskLevel) personalizedIntervention ← PERSONALIZEINTERVENTION(intervention, userProfile) if ISRECENTLYSIMILARINTERVENTION(personalizedIntervention, userProfile) then personalizedIntervention ← ADJUSTFORREPETITION(personalizedIntervention) end if alertMessage ← GENERATEALERTMESSAGE(personalizedIntervention, conversationContext) actionOptions ← GENERATEACTIONOPTIONS(riskLevel) return { "alertMessage": alertMessage, "actionOptions": actionOptions, "riskLevel": riskLevel, "deliveryMethod": DETERMINEDELIVERYMETHOD(riskLevel) } end function |
4. Experimental Setup
4.1. Evaluation Metrics
4.2. Baseline Models
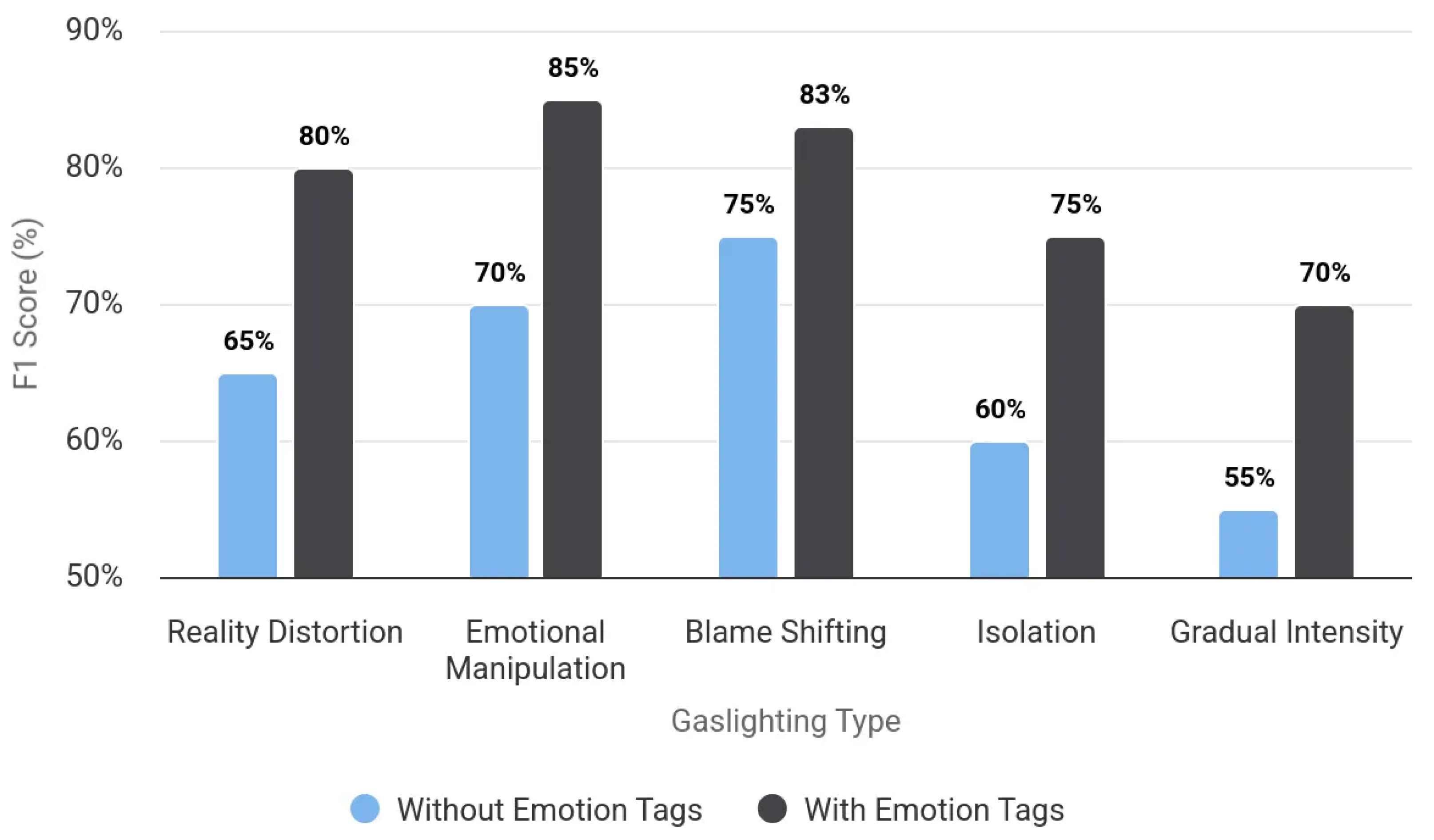
4.3. Ablation Studies
4.4. Expert Evaluation Protocol
5. Results
5.1. Detection Performance
5.2. Intervention System Evaluation
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ministry of Science and ICT; National Information Society Agency. Investigation on the Over-Dependence on Smartphones; NIA VIII-RSE-C-23065; National Information Society Agency: Daegu, Republic of Korea, 2023. [Google Scholar]
- Jobst, N. Cyberbullying in South Korea—Statistics & Facts. Statista. Available online: https://www.statista.com/topics/10240/cyberbullying-in-south-korea/ (accessed on 15 March 2025).
- Yoon, S. AI-Based Digital Therapeutics for Adolescent Mental Health Management and Disaster Response. Information 2024, 15, 620. [Google Scholar] [CrossRef]
- Shekhar, S.; Tripathi, K.M. Impact of Gaslighting on Mental Health among Young Adults. Int. J. Indian Psychol. 2024, 12, 3941–3950. [Google Scholar]
- Abell, L.; Brewer, G.; Qualter, P.; Austin, E. Machiavellianism, Emotional Manipulation, and Friendship Functions in Women’s Friendships. Pers. Individ. Differ. 2016, 88, 108–113. [Google Scholar] [CrossRef]
- Kim, D.-H.; Son, W.-H.; Kwak, S.-S.; Yun, T.-H.; Park, J.-H.; Lee, J.-D. A Hybrid Deep Learning Emotion Classification System Using Multimodal Data. Sensors 2023, 23, 9333. [Google Scholar] [CrossRef] [PubMed]
- Farhadipour, A.; Ranjbar, H.; Chapariniya, M.; Vukovic, T.; Ebling, S.; Dellwo, V. Multimodal Emotion Recognition and Sentiment Analysis in Multi-Party Conversation Contexts. arXiv 2025, arXiv:2503.06805. [Google Scholar]
- Yoo, S.; Lee, H.; Song, J.; Kim, J.; Lee, J.; Yoon, S. A Korean Emotion-Factor Dataset for Extracting Emotion and Factors in Korean Conversations. Sci. Rep. 2023, 13, 18547. [Google Scholar] [CrossRef] [PubMed]
- Stark, C.A. Gaslighting, Misogyny, and Psychological Oppression. Monist 2019, 102, 221–235. [Google Scholar] [CrossRef]
- Sweet, P.L. The Sociology of Gaslighting. Am. Sociol. Rev. 2019, 84, 851–875. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, Y.-I.; Kim, K. Differences of Linguistic and Psychological Dimensions between Internet Malicious and Normal Comments. J. Korean Data Anal. Soc. 2013, 15, 3191–3201. [Google Scholar]
- Philipo, A.; Sarwatt, D.; Ding, J.; Daneshmand, M.; Ning, H. Assessing Text Classification Methods for Cyberbullying Detection on Social Media Platforms. arXiv 2024, arXiv:2412.19928. [Google Scholar]
- Abdali, S. Multi-modal Misinformation Detection: Approaches, Challenges and Opportunities. arXiv 2022, arXiv:2203.13883. [Google Scholar] [CrossRef]
- Sultan, D.; Mendes, M.; Kassenkhan, A.; Akylbekov, O. Hybrid CNN-LSTM Network for Cyberbullying Detection on Social Networks using Textual Contents. Int. J. Adv. Comput. Sci. Appl. 2023, 14. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Kim, Y.; Kim, J.H.; Lee, J.M.; Jang, M.J.; Yum, Y.J.; Kim, S.; Shin, U.; Kim, Y.M.; Joo, H.J.; Song, S. A Pre-trained BERT for Korean Medical Natural Language Processing. Sci. Rep. 2022, 12, 13847. [Google Scholar] [CrossRef] [PubMed]
- Song, J.; Kim, B.; Kim, M.; Iverson, P. The Korean Speech Recognition Sentences: A Large Corpus for Evaluating Semantic Context and Language Experience in Speech Perception. J. Speech Lang. Hear. Res. 2023, 66, 3399–3412. [Google Scholar] [CrossRef] [PubMed]
- Ravindran, V.; Shreejith, G.; Jetti, A.; Sivanaiah, R.; Deborah, A.; Thankanadar, M.; Milton, S. TECHSSN at SemEval-2024 Task 10: LSTM-based Approach for Emotion Detection in Multilingual Code-Mixed Conversations. In Proceedings of the 18th International Workshop on Semantic Evaluation (SemEval-2024), Mexico City, Mexico, 9–14 June 2024; pp. 763–769. [Google Scholar] [CrossRef]
- Park, S. KR-BERT: A Small-Scale Korean-Specific Language Model. arXiv 2020, arXiv:2008.03979. [Google Scholar]
- Lee, S.K.; Kim, S.-D. A Spoken Dialogue Analysis Platform for Effective Counselling. Teh. Vjesn. 2022, 29, 1592–1601. [Google Scholar] [CrossRef]
- Zadeh, A.; Liang, P.; Mazumder, N.; Poria, S.; Cambria, E.; Morency, L.-P. Memory Fusion Network for Multi-view Sequential Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Kim, T.-Y.; Yang, J.; Park, E. MSDLF-K: A Multimodal Feature Learning Approach for Sentiment Analysis in Korean Incorporating Text and Speech. IEEE Trans. Multimed. 2024, 27, 1266–1276. [Google Scholar] [CrossRef]
- Jung, M.; Lim, Y.; Kim, S.; Jang, J.Y.; Shin, S.; Lee, K.-H. An Emotion-based Korean Multimodal Empathetic Dialogue System. In Proceedings of the Second Workshop on When Creative AI Meets Conversational AI, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 16–22. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gaslighting Type | Characteristics | Linguistic Markers | Key Parameters |
|---|---|---|---|
| Reality Distortion | Denial or distortion of the target’s experiences or memories | “That never happened”, “Your memory is wrong”, “I never said that” | contradiction_threshold: 0.75 history_window_size: 10 min_contradiction_confidence: 0.65 |
| Emotional Manipulation | Invalidation or manipulation of the target’s emotional responses | “Don’t be so sensitive”, “There’s no reason to be angry”, “Calm down” | emotion_invalidation_threshold: 0.7 emotion_discrepancy_weight: 0.65 confidence_to_confusion_weight: 0.8 |
| Blame Shifting | Redirection of responsibility from manipulator to target | “I did that because you acted that way”, “It’s your fault”, “I had no choice” | responsibility_inversion_threshold: 0.68<br>blame_pattern_weight: 0.75<br>causal_language_markers: [“because”, “since”] |
| Isolation | Social isolation of the target | “Your friends don’t understand you”, “Let’s keep this between us”, “Don’t tell others” | relationship_undermining_threshold: 0.7 isolation_pattern_confidence: 0.72 secrecy_phrases: [“between us”, “don’t tell”] |
| Gradual Intensity | Incremental increase in manipulation intensity over time | Initial: subtle contradictions Later: direct reality distortion Advanced: complete invalidation of the target’s perceptions | baseline_window_size: 5 intensity_monitoring_period: 20 min_escalation_delta: 0.15 |
| Category | Count | Percentage |
|---|---|---|
| Total conversations | 8742 | 100% |
| Gaslighting-containing conversations | 1283 | 14.7% |
| Gaslighting type distribution: | ||
| Reality distortion | 498 | 38.8% |
| Emotional manipulation | 412 | 32.1% |
| Blame shifting | 276 | 21.5% |
| Isolation | 67 | 5.2% |
| Gradual intensity | 30 | 2.3% |
| Labeling method: | ||
| Direct expert labeling | 1500 | 17.2% |
| High-confidence automatic labeling | 5124 | 58.6% |
| Human-AI collaborative labeling | 2118 | 24.2% |
| Model | Accuracy | Precision | Recall | F1 Score | ROC-AUC |
|---|---|---|---|---|---|
| Keyword-Based | 68.5% | 72.3% | 54.1% | 61.9% | 0.671 |
| SVM (TF-IDF) | 76.2% | 77.8% | 68.5% | 72.9% | 0.762 |
| Random Forest | 74.7% | 80.2% | 61.3% | 69.5% | 0.748 |
| BERT-only | 84.6% | 83.3% | 79.8% | 81.5% | 0.881 |
| LSTM-only | 79.5% | 78.1% | 74.2% | 76.1% | 0.821 |
| CNN-based | 80.3% | 79.4% | 75.5% | 77.4% | 0.834 |
| Emotion-Only | 71.8% | 70.4% | 67.3% | 68.8% | 0.728 |
| BERT-LSTM (no emotion) | 86.5% | 84.7% | 82.1% | 83.4% | 0.902 |
| BERT-LSTM (with emotion) | 89.4% | 86.2% | 83.7% | 84.9% | 0.921 |
| Age Group | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Adolescents (13–19) | 90.1% | 87.3% | 84.2% | 85.7% |
| Children (8–12) | 86.5% | 84.0% | 81.9% | 82.9% |
| Young Adults (20–25) | 88.7% | 85.4% | 82.8% | 84.1% |
| Adults (26+) | 87.2% | 83.9% | 81.5% | 82.7% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoon, S.; Kim, B. Adaptive Intervention Architecture for Psychological Manipulation Detection: A Culture-Specific Approach for Adolescent Digital Communications. Information 2025, 16, 379. https://doi.org/10.3390/info16050379
Yoon S, Kim B. Adaptive Intervention Architecture for Psychological Manipulation Detection: A Culture-Specific Approach for Adolescent Digital Communications. Information. 2025; 16(5):379. https://doi.org/10.3390/info16050379
Chicago/Turabian StyleYoon, Sungwook, and Byungmun Kim. 2025. "Adaptive Intervention Architecture for Psychological Manipulation Detection: A Culture-Specific Approach for Adolescent Digital Communications" Information 16, no. 5: 379. https://doi.org/10.3390/info16050379
APA StyleYoon, S., & Kim, B. (2025). Adaptive Intervention Architecture for Psychological Manipulation Detection: A Culture-Specific Approach for Adolescent Digital Communications. Information, 16(5), 379. https://doi.org/10.3390/info16050379