
A Review of Computer Vision Technology for Football Videos





Abstract
1. Introduction
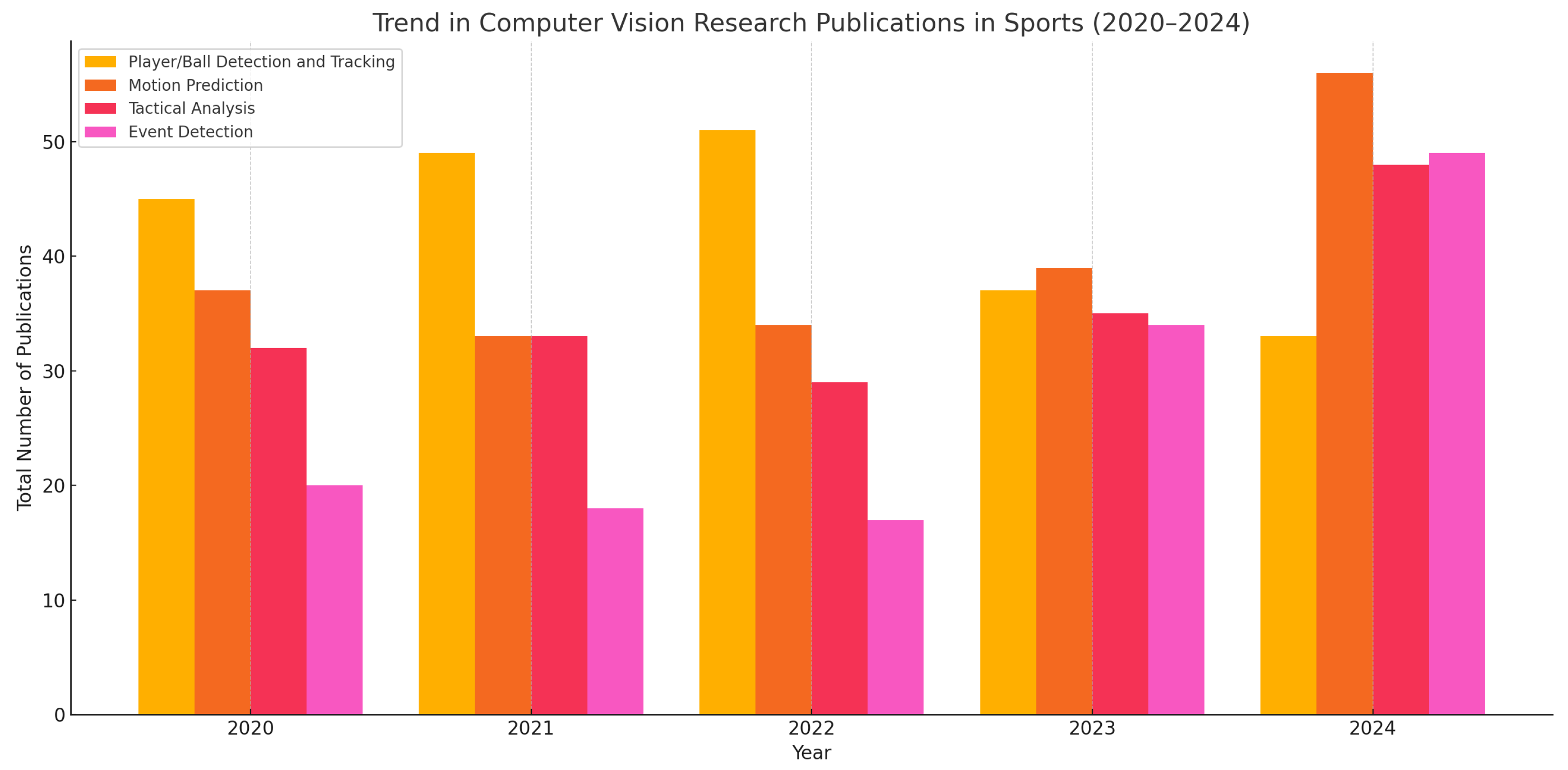
2. Four Ultimate Purposes for CV Research in Sports
2.1. Player/Ball Detection and Tracking
2.2. Motion Prediction
2.3. Tactical Analysis
2.4. Event Detection
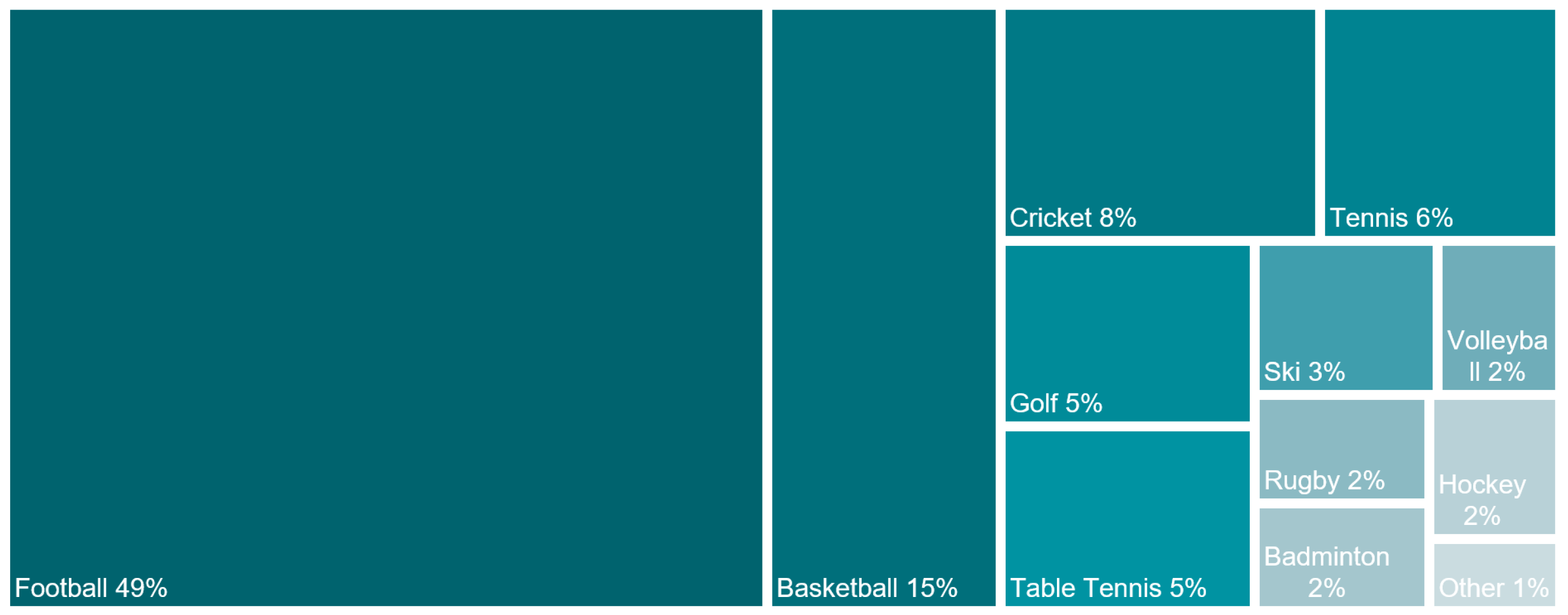
3. CV for Football Games
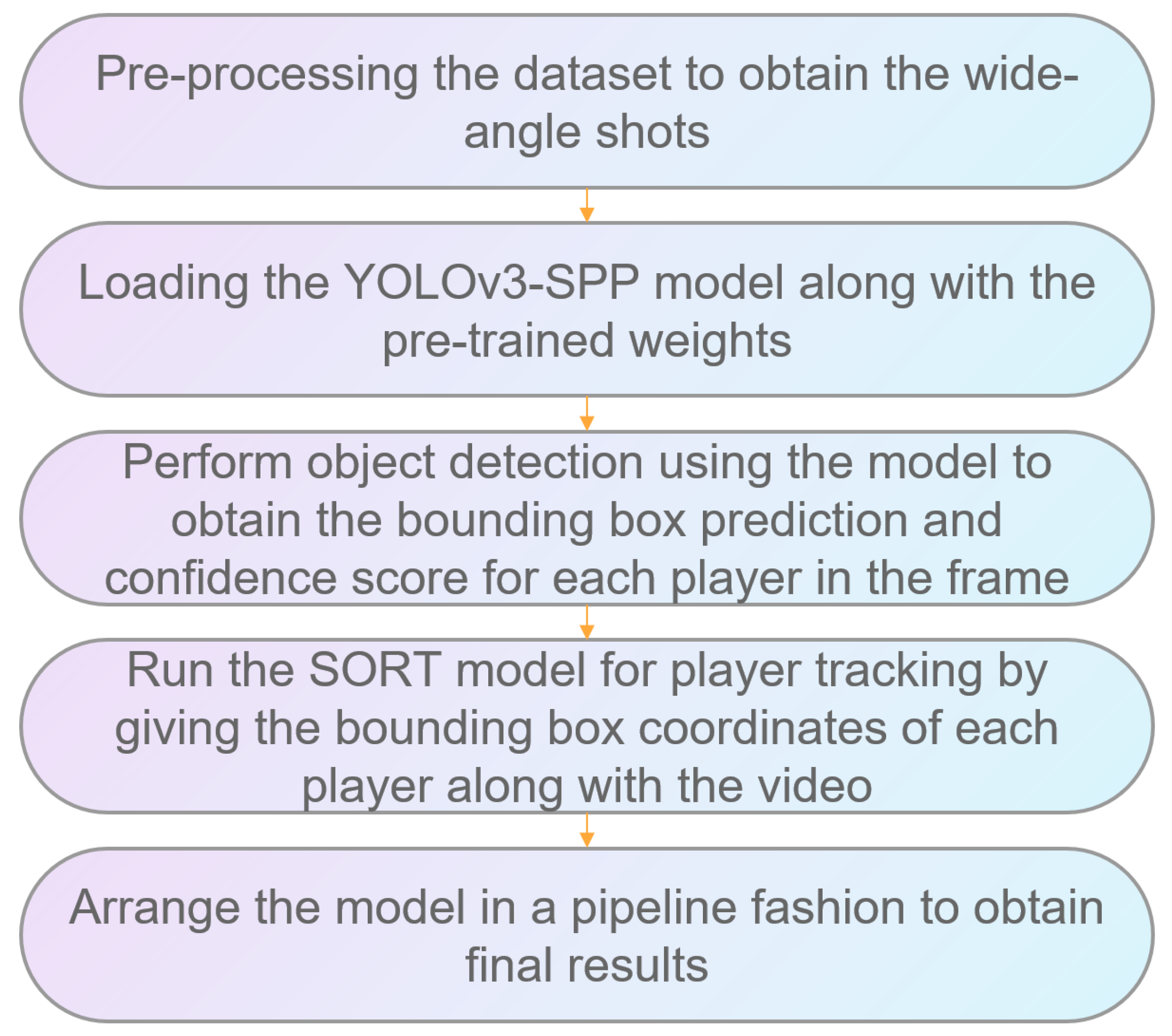
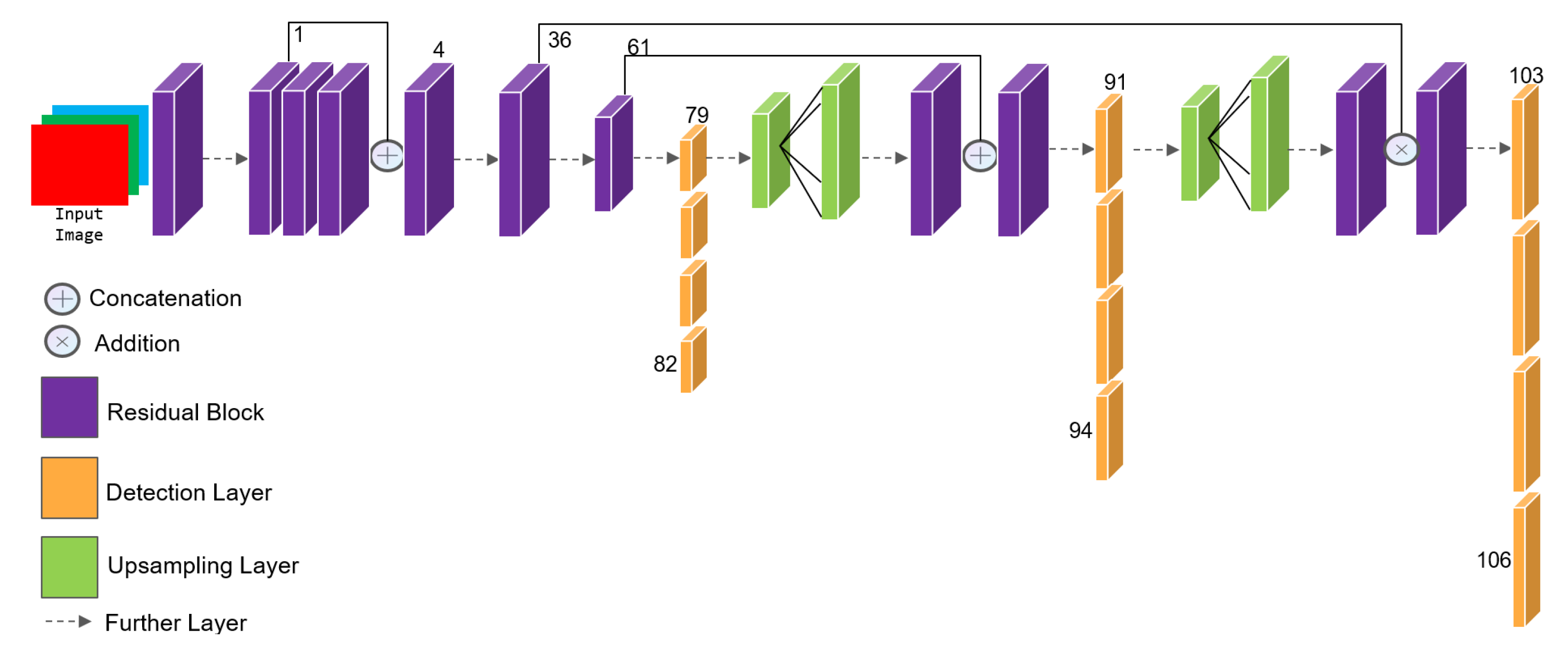
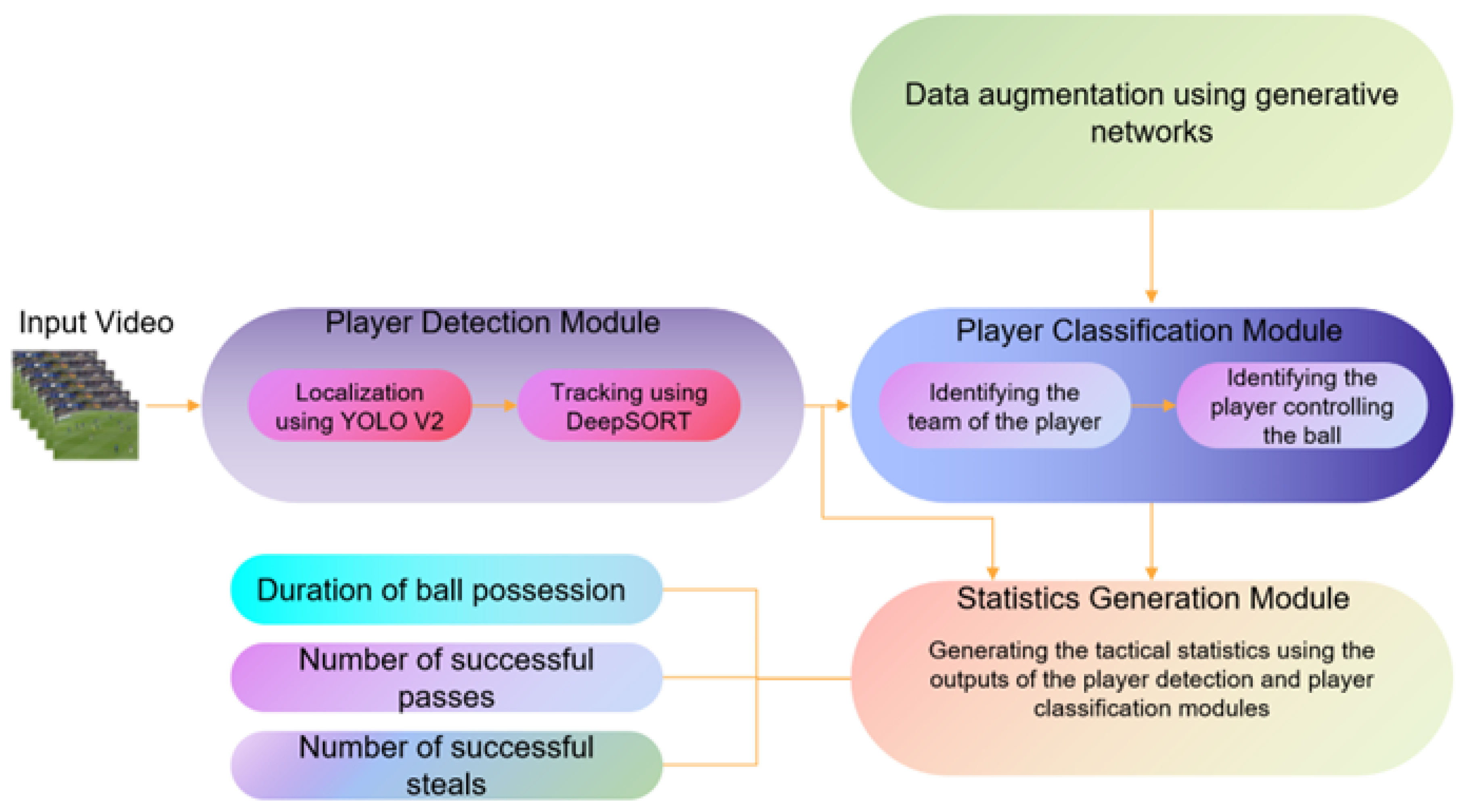
3.1. Player/Ball Detection and Tracking in Football
3.2. Motion Prediction in Football
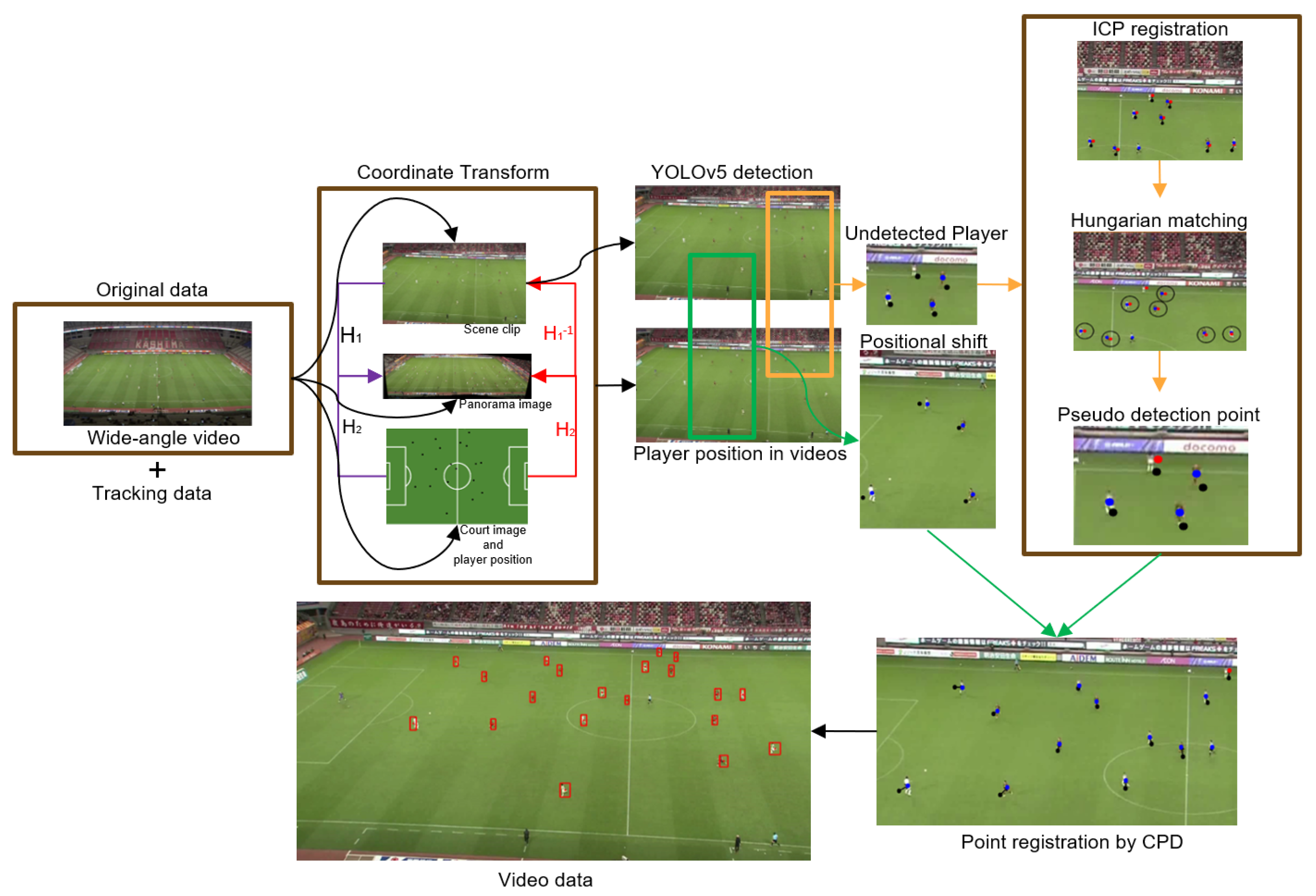
- Alignment of Video and Trajectory Data: The study uses wide-angle videos and 2D trajectories of players to align the visual and positional data. This alignment involves transforming the players’ 2D positions from the field coordinate system to video frames using homography matrices H1 and H2. YOLOv5 [43] is employed for detecting players in video frames, and iterative closest point (ICP) [44] and coherent point drift (CPD) [45] algorithms refine these positions, as shown in Figure 7.
- Body Motion Embedding: The authors address player motion embedding by using TV video frames of 20 football players, excluding goalkeepers, captured before a pass. They employ a feature extraction method that relies on individually cropped frames of each player, ensuring no crucial player information is lost. They incorporate temporal context using a 3D CNN, specifically leveraging part of the 3D ResNet [46] architecture. The shared weights of this model enable efficient and consistent feature extraction across all players.
- Trajectory Embedding: The authors analyze the 2D positions of 20 players and the ball within a field coordinate system for a set duration before a pass. They employ a one-layer LSTM network to extract trajectory features, emphasizing movements immediately preceding the pass. Features are extracted separately for each player and the ball, with shared LSTM weights ensuring consistency across all entities.
- Combining Trajectory and Body Movement Features: These features, along with the ball’s positional features, are used to model player interactions as a complete graph, leveraging the influence of every player on each other. A Transformer encoder with multi-head attention is employed to learn multiple interaction perspectives, such as offensive and defensive dynamics. The 21 input features (20 players and the ball) are ordered by the passer, potential receivers, opponents, and the ball, with position encoding indicating input order. A residual connection enhances interaction learning, and fully connected layers followed by a SoftMax operation predict the pass receiver’s probability, as shown in Figure 8.
3.3. Tactical Analysis in Football
- Stadium Modeling: The authors converted the player’s position from the video perspective to a top view to reduce redundant video information and enable accurate physical fitness and spatial positioning analysis. Perspective transformation adjusted the pixel positions in the video to reflect accurate Euclidean distances in the top view. The transformation matrix used for perspective transformation is defined aswhere are the pixel coordinates in the original image and are the coordinates in the transformed image.
- RNN: The RNN used in this study includes input, hidden, and output layers. It established connections between neurons in the same layer, allowing the network to learn from sequential data.
- LSTM: The authors used LSTM networks to handle the sequential nature of football match data. LSTM networks are designed to capture long-term dependencies and avoid the shortcomings of the general RNN.
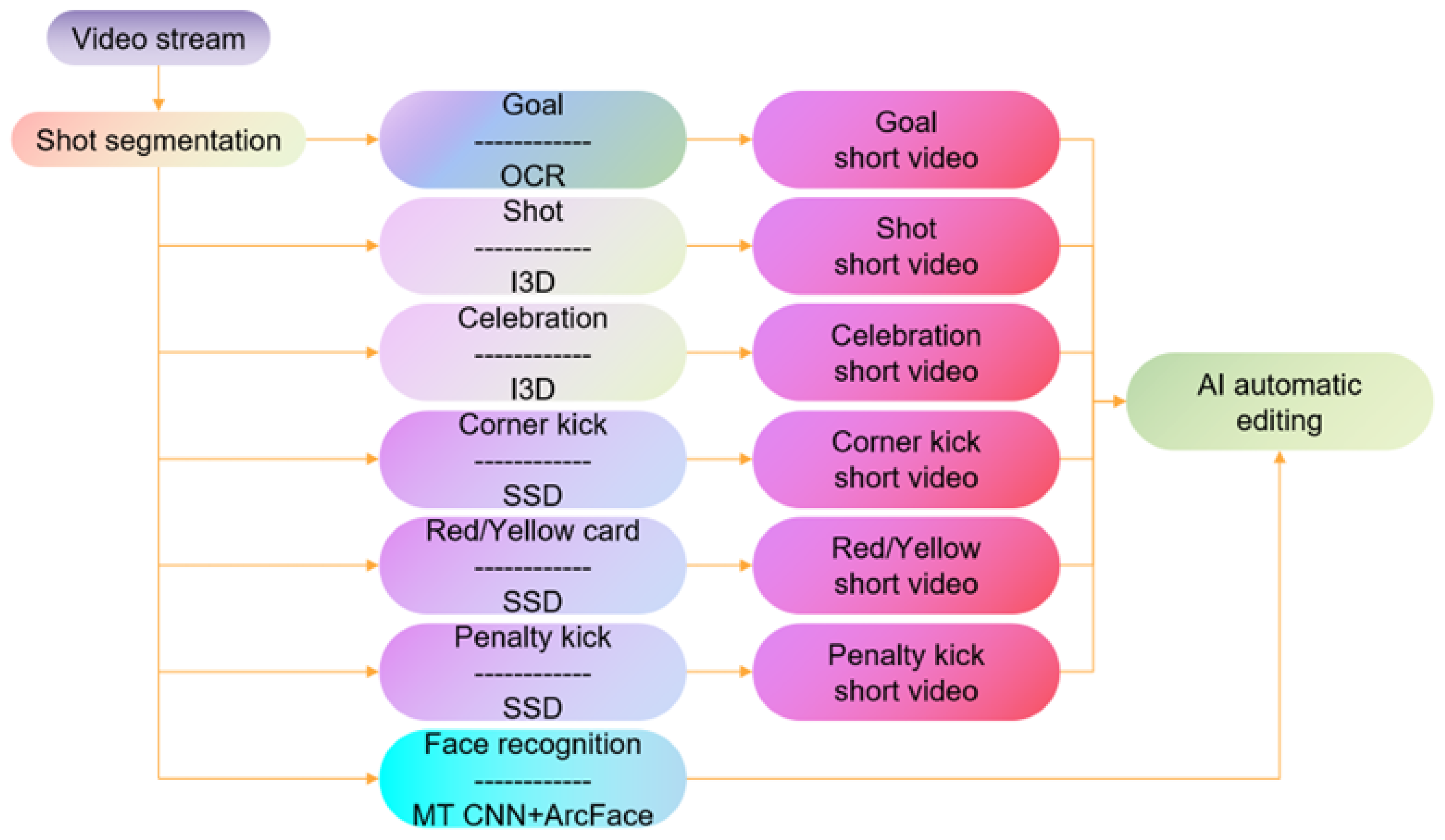
3.4. Event Detection in Football
4. Summary of Research Related to Football Games
Comparison Measurement
- TP (True Positive): The number of positive examples that are correctly predicted, that is, the actual value of the data is a positive example, and the predicted value is also a positive example.
- TN (True Negative): A negative example that is correctly predicted, that is, the actual value of the data is a negative example, and the predicted value is also a negative example.
- FP (False Positive): A positive example that is incorrectly predicted. This is when the actual value of the data is a negative example, but it is mispredicted as a positive example.
- FN (False Negative): A negative example that is incorrectly predicted. This is when the actual value of the data is a positive example, but it is mispredicted as a negative example.
- Recall: The recall represents the ratio between the number of positive samples predicted correctly classified as true positive and the total number of positive examples. Recall measures the ability of a model to predict positive samples. The recall reflects the recognition ability of the model on positive examples, and the higher the recall, the stronger the recognition ability of the model on positive examples.
- Precision: The precision represents the ratio between the number of positive samples predicted correctly classified as true positive and the total number of samples classified as positive (either correctly or incorrectly). The precision measures the model’s accuracy in organizing an example as positive. The precision reflects the discrimination ability of the model to negative samples. The higher the precision, the stronger the discrimination ability of the model to negative samples.
- F1-Score: Precision and recall are a pair of contradictory measures. The recall value is often low when precision is high. When the precision value is low, the recall value is often high. The F1-Score is the harmonic mean of precision and recall, considering these two indexes comprehensively. The higher the F1-Score, the more robust the model. The maximum is 1; the minimum is 0. The core idea of F1-Score is that while improving the precision and recall as much as possible, the difference between them should be as slight as possible.
5. Conclusions
5.1. Challenges and Limitations
5.2. Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BSV | Broadcast Soccer Video |
| CV | Computer Vision |
| CPD | Coherent Point Drift |
| CTPN | Connectionist Text Proposal Network |
| DCNN | Deep Convolutional Neural Network |
| DeepSORT | Deep Association Metric |
| DCGAN | Deep Convolutional Generative Adversarial Network |
| FFT | Fourier Transform Feature |
| HOG | Histogram of Oriented Gradients |
| HPT | Homographic Perspective Transform |
| ICP | Iterative Closest Point |
| I3D | Inflated 3D ConvNet |
| IMUs | Inertial Measurement Units |
| KF | Kalman Filter |
| LSTM | Long Short-Term Memory |
| LDA | Linear Discriminant Analysis |
| LBP | Local Binary Pattern |
| MDN | Mixture Density Network |
| mAP | Mean Average Precision |
| PNN | Probabilistic Neural Network |
| R-CNN | Region-based Convolutional Neural Network |
| RNN | Recurrent Neural Network |
| SOTA | State Of The Art |
| SVM | Support Vector Machine |
| SSD | Single-Shot Multi-Box Detector |
| TSM | Temporal Shift Module |
| VAE | Variational Autoencoder |
| WIF | Weighted Intersect Fusion |
| YOLO | You Only Look Once |
References
- Rodriguez, M.D.; Ahmed, J.; Shah, M. Action mach a spatio-temporal maximum average correlation height filter for action recognition. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Feiszli, M. Video classification with channel-separated convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5552–5561. [Google Scholar]
- Ibrahim, M.S.; Muralidharan, S.; Deng, Z.; Vahdat, A.; Mori, G. A hierarchical deep temporal model for group activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1971–1980. [Google Scholar]
- Bagautdinov, T.; Alahi, A.; Fleuret, F.; Fua, P.; Savarese, S. Social scene understanding: End-to-end multi-person action localization and collective activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4315–4324. [Google Scholar]
- Tang, Y.; Wang, Z.; Li, P.; Lu, J.; Yang, M.; Zhou, J. Mining semantics-preserving attention for group activity recognition. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1283–1291. [Google Scholar]
- Ramanathan, V.; Huang, J.; Abu-El-Haija, S.; Gorban, A.; Murphy, K.; Li, F.-F. Detecting events and key actors in multi-person videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3043–3053. [Google Scholar]
- Li, X.; Chuah, M.C. Rehar: Robust and efficient human activity recognition. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 362–371. [Google Scholar]
- Yu, H.; Cheng, S.; Ni, B.; Wang, M.; Zhang, J.; Yang, X. Fine-grained video captioning for sports narrative. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6006–6015. [Google Scholar]
- Alhejaily, R.; Alhejaily, R.; Almdahrsh, M.; Alessa, S.; Albelwi, S. Automatic Team Assignment and Jersey Number Recognition in Football Videos. Intell. Autom. Soft Comput. 2023, 36, 2669–2684. [Google Scholar] [CrossRef]
- Singh, A.; Bevilacqua, A.; Aderinola, T.B.; Nguyen, T.L.; Whelan, D.; O’Reilly, M.; Caulfield, B.; Ifrim, G. An examination of wearable sensors and video data capture for human exercise classification. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Turin, Italy, 18–22 September 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 312–329. [Google Scholar]
- Barris, S.; Button, C. A review of vision-based motion analysis in sport. Sport. Med. 2008, 38, 1025–1043. [Google Scholar] [CrossRef] [PubMed]
- Shih, H.C. A survey of content-aware video analysis for sports. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 1212–1231. [Google Scholar] [CrossRef]
- Thomas, G.; Gade, R.; Moeslund, T.B.; Carr, P.; Hilton, A. Computer vision for sports: Current applications and research topics. Comput. Vis. Image Underst. 2017, 159, 3–18. [Google Scholar] [CrossRef]
- Rahmad, N.A.; As’Ari, M.A.; Ghazali, N.F.; Shahar, N.; Sufri, N.A.J. A survey of video based action recognition in sports. Indones. J. Electr. Eng. Comput. Sci. 2018, 11, 987–993. [Google Scholar] [CrossRef]
- Naik, B.T.; Hashmi, M.F.; Bokde, N.D. A comprehensive review of computer vision in sports: Open issues, future trends and research directions. Appl. Sci. 2022, 12, 4429. [Google Scholar] [CrossRef]
- Host, K.; Ivašić-Kos, M. An overview of Human Action Recognition in sports based on Computer Vision. Heliyon 2022, 8, e09633. [Google Scholar] [CrossRef]
- Jin, G. Player target tracking and detection in football game video using edge computing and deep learning. J. Supercomput. 2022, 78, 9475–9491. [Google Scholar] [CrossRef]
- Maglo, A.; Orcesi, A.; Pham, Q.C. Efficient tracking of team sport players with few game-specific annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3461–3471. [Google Scholar]
- Saseendran, S.; Thanalakshmi, S.P.V.; Prabakaran, S.; Ravisankar, P. Analysis of player tracking data extracted from football match feed. Rom. J. Inf. Technol. Autom. Control 2023, 33, 89–102. [Google Scholar] [CrossRef]
- Patel, S.H.; Kamdar, D. Object detection in hockey sport video via pretrained yolov3 based deep learning model. Ictact J. Image Video Process. 2023, 13, 2893–2898. [Google Scholar] [CrossRef]
- Suda, S.; Makino, Y.; Shinoda, H. Prediction of volleyball trajectory using skeletal motions of setter player. In Proceedings of the 10th Augmented Human International Conference 2019, Reims, France, 11–12 March 2019; pp. 1–8. [Google Scholar]
- Wu, E.; Koike, H. Futurepong: Real-time table tennis trajectory forecasting using pose prediction network. In Proceedings of the Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–8. [Google Scholar]
- Li, H.; Ali, S.G.; Zhang, J.; Sheng, B.; Li, P.; Jung, Y.; Wang, J.; Yang, P.; Lu, P.; Muhammad, K.; et al. Video-based table tennis tracking and trajectory prediction using convolutional neural networks. Fractals 2022, 30, 2240156. [Google Scholar] [CrossRef]
- Gowda, M.S.; Shindhe, S.D.; Omkar, S. Free-Throw Prediction in Basketball Sport Using Object Detection and Computer Vision. In Proceedings of the International Conference on Computer Vision and Image Processing, Nagpur, India, 4–6 November 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 515–528. [Google Scholar]
- Chen, L.; Wang, W. Analysis of technical features in basketball video based on deep learning algorithm. Signal Process. Image Commun. 2020, 83, 115786. [Google Scholar] [CrossRef]
- Li, W. Tactical analysis of table tennis video skills based on image fuzzy edge recognition algorithm. IEEE Access 2024, 12, 40425–40438. [Google Scholar] [CrossRef]
- Jin, B. Original Research Article Video analysis and data-driven tactical optimization of sports football matches: Visual recognition and strategy analysis algorithm. J. Auton. Intell. 2024, 7, 1–15. [Google Scholar]
- He, Y.; Yuan, Z.; Wu, Y.; Cheng, L.; Deng, D.; Wu, Y. ViSTec: Video Modeling for Sports Technique Recognition and Tactical Analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26–27 February 2024; Volume 38, pp. 8490–8498. [Google Scholar]
- Yan, C.; Li, X.; Li, G. A new action recognition framework for video highlights summarization in sporting events. In Proceedings of the 2021 16th International Conference on Computer Science & Education (ICCSE), Lancaster, UK, 17–19 August 2021; pp. 653–666. [Google Scholar]
- Abbas, Q.; Li, Y. Cricket video events recognition using HOG, LBP and multi-class SVM. J. Phys. Conf. Ser. 2021, 1732, 012036. [Google Scholar] [CrossRef]
- Darapaneni, N.; Kumar, P.; Malhotra, N.; Sundaramurthy, V.; Thakur, A.; Chauhan, S.; Thangeda, K.C.; Paduri, A.R. Detecting key Soccer match events to create highlights using Computer Vision. arXiv 2022, arXiv:2204.02573. [Google Scholar]
- Khan, A.A.; Shao, J. SPNet: A deep network for broadcast sports video highlight generation. Comput. Electr. Eng. 2022, 99, 107779. [Google Scholar] [CrossRef]
- Naik, B.T.; Hashmi, M.F. Ball and player detection & tracking in soccer videos using improved yolov3 model. Res. Sq. 2021. [Google Scholar] [CrossRef]
- Moutselos, K.; Maglogiannis, I. Setting a Baseline for long-shot real-time Player and Ball detection in Soccer Videos. In Proceedings of the 2023 14th International Conference on Information, Intelligence, Systems & Applications (IISA), Volos, Greece, 10–12 July 2023; pp. 1–7. [Google Scholar]
- Redmon, J. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Komorowski, J.; Kurzejamski, G.; Sarwas, G. Footandball: Integrated player and ball detector. arXiv 2019, arXiv:1912.05445. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLOv8 by Ultralytics, January 2023; pp. 10–31. Available online: https://github.com/ultralytics/ultralytics (accessed on 15 January 2025).
- Cioppa, A.; Deliege, A.; Giancola, S.; Ghanem, B.; Van Droogenbroeck, M. Scaling up SoccerNet with multi-view spatial localization and re-identification. Sci. Data 2022, 9, 355. [Google Scholar] [CrossRef] [PubMed]
- Honda, Y.; Kawakami, R.; Yoshihashi, R.; Kato, K.; Naemura, T. Pass receiver prediction in soccer using video and players’ trajectories. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3503–3512. [Google Scholar]
- Chakraborty, D.; Kaushik, M.M.; Akash, S.K.; Zishan, M.S.R.; Mahmud, M.S. Deep Learning-Based Prediction of Football Players’ Performance During Penalty Shootout. In Proceedings of the 2023 26th International Conference on Computer and Information Technology (ICCIT), Cox’s Bazar, Bangladesh, 13–15 December 2023; pp. 1–6. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; Chaurasia, A.; Changyu, L.; Hogan, A.; Hajek, J.; Diaconu, L.; Kwon, Y.; Defretin, Y.; et al. ultralytics/yolov5: V5. 0-YOLOv5-P6 1280 Models, AWS, Supervise.ly and YouTube Integrations; Zenodo: Geneva, Switzerland, 2021. [Google Scholar]
- Zhang, Z. Iterative point matching for registration of free-form curves and surfaces. Int. J. Comput. Vis. 1994, 13, 119–152. [Google Scholar] [CrossRef]
- Myronenko, A.; Song, X. Point set registration: Coherent point drift. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 2262–2275. [Google Scholar] [CrossRef]
- Hara, K.; Kataoka, H.; Satoh, Y. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6546–6555. [Google Scholar]
- Fang, L.; Wei, Q.; Xu, C.J. Technical and tactical command decision algorithm of football matches based on big data and neural network. Sci. Program. 2021, 2021, 5544071. [Google Scholar] [CrossRef]
- Theagarajan, R.; Bhanu, B. An automated system for generating tactical performance statistics for individual soccer players from videos. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 632–646. [Google Scholar] [CrossRef]
- Wang, B.; Shen, W.; Chen, F.; Zeng, D. Football match intelligent editing system based on deep learning. KSII Trans. Internet Inf. Syst. (TIIS) 2019, 13, 5130–5143. [Google Scholar]
- Gao, X.; Liu, X.; Yang, T.; Deng, G.; Peng, H.; Zhang, Q.; Li, H.; Liu, J. Automatic key moment extraction and highlights generation based on comprehensive soccer video understanding. In Proceedings of the 2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Naik, B.T.; Hashmi, M.F.; Geem, Z.W.; Bokde, N.D. DeepPlayer-track: Player and referee tracking with jersey color recognition in soccer. IEEE Access 2022, 10, 32494–32509. [Google Scholar] [CrossRef]
- Naik, B.T.; Hashmi, M.F.; Keskar, A.G. Modified Scaled-YOLOv4: Soccer Player and Ball Detection for Real Time Implementation. In Proceedings of the International Conference on Computer Vision and Image Processing, Nagpur, India, 4–6 November 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 154–165. [Google Scholar]
- Diwan, K.; Bandi, R.; Dicholkar, S.; Khadse, M. Football player and ball tracking system using deep learning. In Proceedings of the International Conference on Data Science and Applications: ICDSA 2022; Springer: Berlin/Heidelberg, Germany, 2023; Volume 1, pp. 757–769. [Google Scholar]
- Rezaei, A.; Wu, L.C. Automated soccer head impact exposure tracking using video and deep learning. Sci. Rep. 2022, 12, 9282. [Google Scholar] [CrossRef]
- Malamatinos, M.C.; Vrochidou, E.; Papakostas, G.A. On predicting soccer outcomes in the greek league using machine learning. Computers 2022, 11, 133. [Google Scholar] [CrossRef]
- Jo, H.; Matsuoka, H.; Ando, K.; Nishijima, T. Construction of offensive play measurement items and shot prediction model applying machine learning in Japan professional football league. Footb. Sci. 2022, 19, 1–21. [Google Scholar]
- Fang, J.; Yeung, C.; Fujii, K. Foul prediction with estimated poses from soccer broadcast video. arXiv 2024, arXiv:2402.09650. [Google Scholar]
- Athanesious, J.J.; Kiruthika, S. Perspective Transform based YOLO with Weighted Intersect Fusion for forecasting the Possession Sequence of the Live Football Game. IEEE Access 2024, 12, 75542–75558. [Google Scholar] [CrossRef]
- Goes, F.; Kempe, M.; Van Norel, J.; Lemmink, K. Modelling team performance in soccer using tactical features derived from position tracking data. IMA J. Manag. Math. 2021, 32, 519–533. [Google Scholar] [CrossRef]
- Forcher, L.; Beckmann, T.; Wohak, O.; Romeike, C.; Graf, F.; Altmann, S. Prediction of defensive success in elite soccer using machine learning-Tactical analysis of defensive play using tracking data and explainable AI. Sci. Med. Footb. 2024, 8, 317–332. [Google Scholar] [CrossRef]
- Madake, J.; Thokal, D.; Ullah, M.A.; Bhatlawande, S. Offside Detection for Better Decision-Making and Gameplay in Football. In Proceedings of the 2023 IEEE International Conference on Blockchain and Distributed Systems Security (ICBDS), New Raipur, India, 6–8 October 2023; pp. 1–7. [Google Scholar]
- Uchida, I.; Scott, A.; Shishido, H.; Kameda, Y. Automated offside detection by spatio-temporal analysis of football videos. In Proceedings of the 4th International Workshop on Multimedia Content Analysis in Sports, Chengdu, China, 20–24 October 2021; pp. 17–24. [Google Scholar]
- Karimi, A.; Toosi, R.; Akhaee, M.A. Soccer event detection using deep learning. arXiv 2021, arXiv:2102.04331. [Google Scholar]
- Nergård Rongved, O.A.; Stige, M.; Hicks, S.A.; Thambawita, V.L.; Midoglu, C.; Zouganeli, E.; Johansen, D.; Riegler, M.A.; Halvorsen, P. Automated event detection and classification in soccer: The potential of using multiple modalities. Mach. Learn. Knowl. Extr. 2021, 3, 1030–1054. [Google Scholar] [CrossRef]
- Sanford, R.; Gorji, S.; Hafemann, L.G.; Pourbabaee, B.; Javan, M. Group activity detection from trajectory and video data in soccer. In Proceedings of the CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 3932–3940. [Google Scholar]
- Wagh, A.K.; Ranjan, N.M.; Jainak, S.S.; Pande, S.D.; Pawar, M.D. Self Generated Soccer Highlights Using Inflated 3D Convolutional Neural Network. In Proceedings of the 2023 7th International Conference On Computing, Communication, Control and Automation (ICCUBEA), Pune, India, 18–19 August 2023; pp. 1–6. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Person | Ball | I | ||||||
|---|---|---|---|---|---|---|---|---|
| COCO mAP | COCO mAP | Avg. Prec. | Avg. Rec. | % | ms | |||
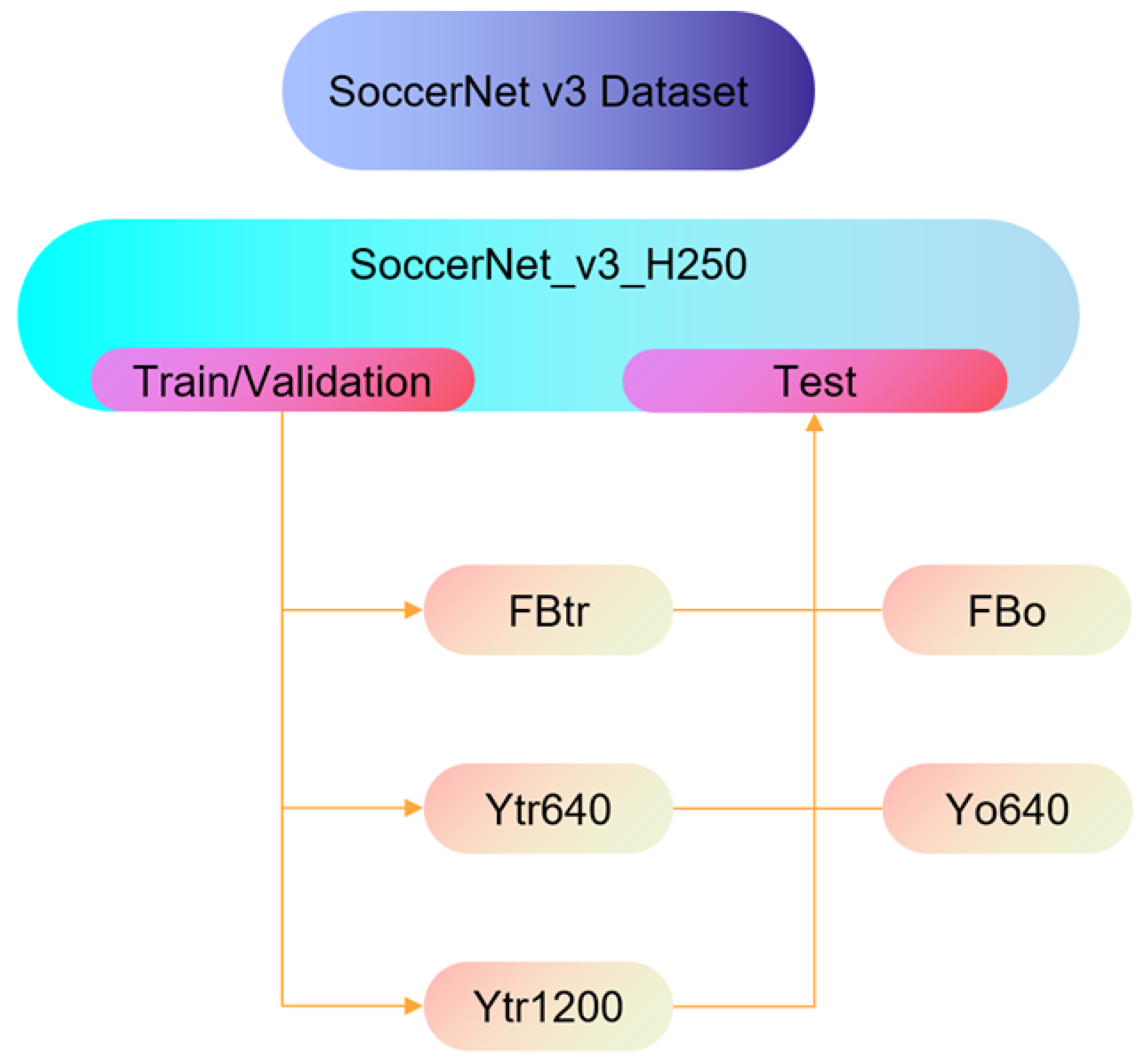
| FBo | 0.3254 | 0.0771 | 0.0096 | 0.0003 | 0.783 | 0.022 | 0.234 | 9.5 |
| FBtr | 0.3905 | 0.1045 | 0.0165 | 0.0029 | 0.843 | 0.678 | 0.703 | 9.4 |
| Yo640 | 0.7127 | 0.5195 | 0.1333 | 0.0370 | 0.524 | 0.118 | 0.284 | 7.2/9.0 |
| Ytr640 | 0.9052 | 0.6824 | 0.3093 | 0.1207 | 0.856 | 0.410 | 0.518 | 7.3/9.2 |
| Ytr1200 | 0.9058 | 0.7025 | 0.5361 | 0.2362 | 0.877 | 0.707 | 0.724 | 7.4/10.2 |
| Ground-Truth | Predicted | |
|---|---|---|
| Positive | Negative | |
| Positive | True Positive | False Negative |
| Negative | False Positive | True Negative |
| Ref | Ultimate Purpose | Technical Approach | Recall (%) | Precision (%) | F1-Score (%) | Limitation |
|---|---|---|---|---|---|---|
| [51] | Player/Ball Detection and Tracking | YOLOv4, SORT | 93 | 95 | 94 | Identity switching occurs when players with similar jerseys occlude each other. |
| [52] | Player/Ball Detection and Tracking | Modified Scaled-YOLOv4 | 92.3 | 93.8 | 93 | Small white spots, like shoes or distant flags, are sometimes detected as soccer balls. |
| [53] | Player/Ball Detection and Tracking | YOLOv5, DeepSORT | 79 | 94 | 85.8 | Struggles with low-resolution frames when objects are far from the camera or clustered players. |
| [54] | Player/Ball Detection and Tracking | YOLOv5, CNN, temporal shift module (TSM) | 92.9 | 21.1 | 34.4 | Significant precision drop on independent data, indicating sensitivity to datasets. |
| Ref | Ultimate Purpose | Technical Approach | Recall (%) | Precision (%) | F1-Score (%) | Limitation |
|---|---|---|---|---|---|---|
| [55] | Motion Prediction | CatBoost | 67.7 | 68 | 67.9 | Reliance on historical data, which may not account for unforeseen factors affecting match outcomes. |
| [56] | Motion Prediction | Gradient Boosting Decision Tree | 90.5 | 85 | 87.6 | Dependency on ball touch data, which may need to capture the full tactical context of the game. |
| [57] | Motion Prediction | CNN + RNN | 75 | 79 | 76.9 | Difficulty in detecting poses and bounding boxes due to player overlap and smaller players in video frames. |
| [58] | Motion Prediction | Homographic Perspective Transform (HPT), YOLO with Weighted Intersect Fusion (WIF) | 97.5 | 96 | 96.7 | Dependency on initial object detection accuracy; reduced performance in occlusions or when the ball is not clearly visible in the frames. |
| Ref | Ultimate Purpose | Technical Approach | Recall (%) | Precision (%) | F1-Score (%) | Limitation |
|---|---|---|---|---|---|---|
| [59] | Tactical Analysis | Linear Discriminant Analysis (LDA) | 71 | 71 | 71 | Focuses on match outcomes without accounting for draws; limited generalizability due to reliance on a single league dataset. |
| [60] | Tactical Analysis | Random Forest | 70 | 47 | 57 | Focuses solely on predicting ball gains as a defensive measure, neglecting the specific defensive tactics of individual teams and potentially limiting the generalizability of the findings. |
| [61] | Tactical Analysis | HOG, Random Forest | 98.5 | 98.5 | 98.5 | Dependency on camera angles and frame rates can introduce errors in player detection and classification. |
| [62] | Tactical Analysis | YOLOv4, Kalman Filter (KF) | 60 | 66.7 | 63.2 | Dependency on camera calibration and annotation quality introduces noise and errors in the offside detection process. |
| Ref | Ultimate Purpose | Technical Approach | Recall (%) | Precision (%) | F1-Score (%) | Limitation |
|---|---|---|---|---|---|---|
| [63] | Event Detection | Variational Autoencoder (VAE), EfficientNetB0 | 92.4 | 91.2 | 91.8 | Difficulty distinguishing visually similar events like red and yellow cards. |
| [64] | Event Detection | 3D ResNet, 2D ResNet, Log-Mel, SoftMax | 90.1 | 92.2 | 91.2 | Multimodal integration benefits are inconsistent; goal detection improves, but card and substitution events lag. |
| [65] | Event Detection | I3D, Transformer | 76.7 | 59.3 | 65.7 | Short temporal context used for training and testing, which affects the model’s ability to accurately distinguish actions requiring longer temporal understanding, such as a player controlling the ball before making a pass or shot. |
| [66] | Event Detection | I3D CNN, 2D ConvNet, 3D ConvNet, SoftMax | 96.4 | 97 | 96.8 | Use of predefined 45 s timestamps may miss the full context of events. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, F.; Al-Hamid, D.Z.; Chong, P.H.J.; Yang, C.; Li, X.J. A Review of Computer Vision Technology for Football Videos. Information 2025, 16, 355. https://doi.org/10.3390/info16050355
Zheng F, Al-Hamid DZ, Chong PHJ, Yang C, Li XJ. A Review of Computer Vision Technology for Football Videos. Information. 2025; 16(5):355. https://doi.org/10.3390/info16050355
Chicago/Turabian StyleZheng, Fucheng, Duaa Zuhair Al-Hamid, Peter Han Joo Chong, Cheng Yang, and Xue Jun Li. 2025. "A Review of Computer Vision Technology for Football Videos" Information 16, no. 5: 355. https://doi.org/10.3390/info16050355
APA StyleZheng, F., Al-Hamid, D. Z., Chong, P. H. J., Yang, C., & Li, X. J. (2025). A Review of Computer Vision Technology for Football Videos. Information, 16(5), 355. https://doi.org/10.3390/info16050355