1. Introduction
With the increasing reliance on written communication in both professional and everyday contexts, the ability to clearly and accurately express ideas is increasingly valued, making error correction essential for improving overall language competence. As such, grammatical error correction (GEC) is an essential task that can help people who may not be familiar with rules specific to a language or have learning language difficulties that require improving their communication skills. As such, it is an important educational resource for the general population to assist individuals in improving their writing skills.
In addition to the obvious correction support, GEC has many usage scenarios. Jesús-Ortiz and Calvo-Ferrer [
1] presented how native language (L1) patterns can make second-language (L2) acquisition more cumbersome, especially in areas where the two languages differ structurally. For instance, when considering L1 (Spanish) and L2 (English) learners, errors arise since Spanish speakers are used to a system where grammatical gender is tied to the noun (possessum) rather than the possessor; in contrast, possessive determiners depend on the possessor’s gender in English when the possessor is a singular third person.
GEC tasks cannot be solved efficiently using transfer learning due to specific language rules. It is challenging to design a set of applicable rules that covers common language aspects from multiple languages. Rei and Yannakoudakis [
2] explored improving error detection within a sentence by incorporating various features such as frequency, error type (e.g., incorrect verb form), the first language of the learner, part-of-speech (POS), and grammatical relations. Their experiments on CoNLL-14 [
3] and FCE [
4] showed that word frequency and first language identification do not significantly improve error detection performance. In contrast, including error types, POS tags, and grammatical relations leads to consistent improvements.
We now focus on the language targeted by this study, namely Romanian, which presents challenges in terms of agreement issues and diacritics. However, Romanian is a limited-resource language compared to widely spoken languages such as English. There is no advanced GEC solution for Romanian, except for limited grammatical corrections in Microsoft Word or LanguageTools [
5], a popular open-source grammar and style checker with Romanian support. As such, developing an autonomous tool capable of correcting user inputs in Romanian is highly beneficial.
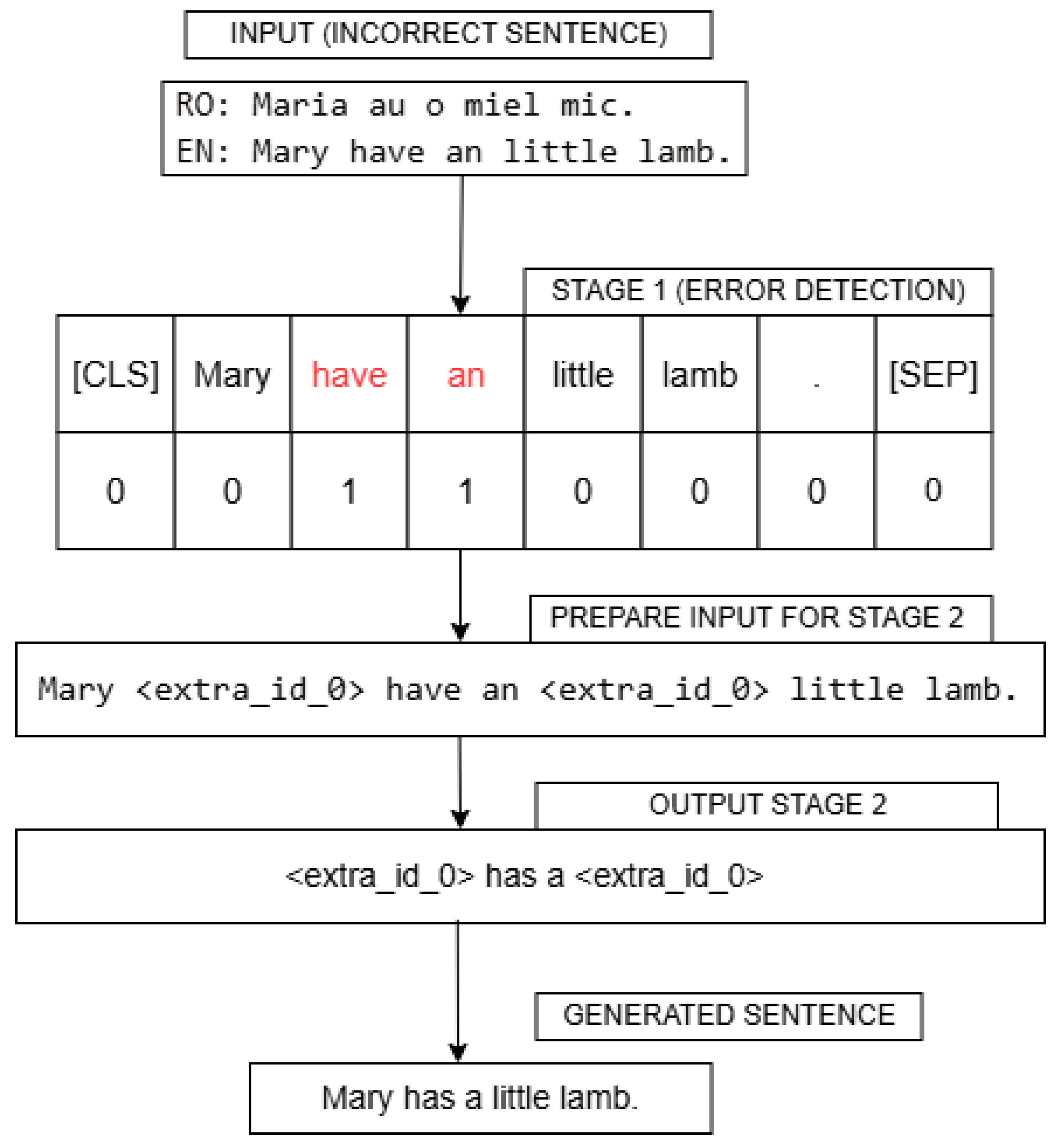
Our strategy for GEC is divided into two phases. In the first phase of grammatical error detection (GED), we focus on identifying incorrect tokens within a sentence. In the second phase centered on GEC, we rely on an encoder–decoder model to correct the highlighted errors by replacing the erroneous tokens with appropriate suggestions. Compared to traditional end-to-end neural models, our approach provides advantages mainly in terms of explainability because it isolates the mistaken words and corrects them using the surrounding context. In addition, we ensure modularity by separating the two phases mimicking human behavior; as such, each component can be improved separately over time.
In addition to the previous method, we developed a synthetic dataset specifically for training purposes. For testing purposes, we consider two smaller datasets, namely CNA [
6], an updated and curated version, and RoComments, a newly introduced dataset with erroneous human comments from social media, both containing real-life mistakes.
The main contributions of this paper imply the following:
Author Contributions
Conceptualization, M.-C.T., S.R. and M.D.; methodology, M.-C.T., S.R. and M.D.; software, M.-C.T.; validation, S.R. and M.D.; formal analysis, M.-C.T., S.R. and M.D.; investigation, S.R.; resources, M.-C.T.; data curation, M.-C.T.; writing—original draft preparation, M.-C.T.; writing—review and editing, S.R. and M.D.; visualization, M.-C.T.; supervision, S.R. and M.D.; project administration, M.D.; funding acquisition, M.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the project “Romanian Hub for Artificial Intelligence—HRIA”, Smart Growth, Digitization and Financial Instruments Program, 2021–2027, MySMIS no. 334906.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| BERT | Bidirectional Encoder Representations from Transformers |
| CGEC | Chinese Grammatical Error Correction |
| CNA | The National Audiovisual Council (Romanian abbreviation) |
| ERRANT | ERRor ANnotation Toolkit |
| ESD | Erroneous Span Detection |
| ESC | Erroneous Span Correction |
| FCE | First Certificate in English |
| GEC | Grammatical Error Correction |
| GED | Grammatical Error Detection |
| LLM | Large Language Models |
| NLPCC | Natural Language Processing and Chinese Computing |
| NUCLE | NUS Corpus of Learner English |
| T5 | Text-to-Text Transfer Transformer |
References
- Jesús-Ortiz, E.; Calvo-Ferrer, J.R. His or Her? Errors in Possessive Determiners Made by L2-English Native Spanish Speakers. Languages 2023, 8, 278. [Google Scholar] [CrossRef]
- Rei, M.; Yannakoudakis, H. Auxiliary Objectives for Neural Error Detection Models. In Proceedings of the 12th Workshop on Innovative Use of NLP for Building Educational Applications, Association for Computational Linguistics, Copenhagen, Denmark, 8 September 2017; pp. 33–43. [Google Scholar]
- Ng, H.T.; Wu, S.M.; Briscoe, T.; Hadiwinoto, C.; Susanto, R.H.; Bryant, C. The CoNLL-2014 Shared Task on Grammatical Error Correction. In Proceedings of the 18th Conference on Computational Natural Language Learning: Shared Task, Baltimore, MD, USA, 26–27 June 2014; Ng, H.T., Wu, S.M., Briscoe, T., Hadiwinoto, C., Susanto, R.H., Bryant, C., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 1–14. [Google Scholar] [CrossRef]
- Yannakoudakis, H.; Briscoe, T.; Medlock, B. A New Dataset and Method for Automatically Grading ESOL Texts. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011. [Google Scholar]
- Naber, D. A Rule-Based Style and Grammar Checker. 2003. Available online: https://www.researchgate.net/publication/239556866_A_Rule-Based_Style_and_Grammar_Checker (accessed on 24 January 2025).
- Cotet, T.M.; Ruseti, S.; Dascalu, M. Neural grammatical error correction for romanian. In Proceedings of the 2020 IEEE 32nd International Conference on Tools with Artificial Intelligence (ICTAI), Baltimore, MD, USA, 9–11 November 2020; pp. 625–631. [Google Scholar]
- Dahlmeier, D.; Ng, H.T.; Wu, S.M. Building a large annotated corpus of learner English: The NUS corpus of learner English. In Proceedings of the 8th Workshop on Innovative Use of NLP for Building Educational Applications, Atlanta, GA, USA, 13 June 2013; pp. 22–31. [Google Scholar]
- Mizumoto, T.; Matsumoto, Y. Discriminative reranking for grammatical error correction with statistical machine translation. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1133–1138. [Google Scholar]
- Zhang, B. Features and functions of the HSK dynamic composition corpus. Int. Chin. Lang. Educ. 2009, 4, 71–79. [Google Scholar]
- Omelianchuk, K.; Liubonko, A.; Skurzhanskyi, O.; Chernodub, A.; Korniienko, O.; Samokhin, I. Pillars of Grammatical Error Correction: Comprehensive Inspection Of Contemporary Approaches In The Era of Large Language Models. In Proceedings of the 19th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2024), Mexico City, Mexico, 20 June 2024; pp. 17–33. [Google Scholar]
- Yuan, Z.; Briscoe, T. Grammatical error correction using neural machine translation. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; Knight, K., Nenkova, A., Rambow, O., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 380–386. [Google Scholar] [CrossRef]
- Rothe, S.; Mallinson, J.; Malmi, E.; Krause, S.; Severyn, A. A Simple Recipe for Multilingual Grammatical Error Correction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Online, 1–6 August 2021; Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 702–707. [Google Scholar] [CrossRef]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 483–498. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Lin, N.; Fu, Y.; Lin, X. A New Evaluation Method: Evaluation Data and Metrics for Chinese Grammar Error Correction. arxiv 2023, arXiv:2205.00217. [Google Scholar] [CrossRef]
- Chen, M.; Ge, T.; Zhang, X.; Wei, F.; Zhou, M. Improving the Efficiency of Grammatical Error Correction with Erroneous Span Detection and Correction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Webber, B., Cohn, T., He, Y., Liu, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 7162–7169. [Google Scholar] [CrossRef]
- Qiu, Z.; Qu, Y. A two-stage model for Chinese grammatical error correction. IEEE Access 2019, 7, 146772–146777. [Google Scholar] [CrossRef]
- Keita, M.K.; Homan, C.; Hamani, S.A.; Bremang, A.; Zampieri, M.; Alfari, H.A.; Ibrahim, E.A.; Owusu, D. Grammatical Error Correction for Low-Resource Languages: The Case of Zarma. arXiv 2024, arXiv:2410.15539. [Google Scholar]
- Maity, S.; Deroy, A.; Sarkar, S. How Ready Are Generative Pre-trained Large Language Models for Explaining Bengali Grammatical Errors? arXiv 2024, arXiv:2406.00039. [Google Scholar]
- Lytvyn, V.; Pukach, P.; Vysotska, V.; Vovk, M.; Kholodna, N. Identification and Correction of Grammatical Errors in Ukrainian Texts Based on Machine Learning Technology. Mathematics 2023, 11, 904. [Google Scholar] [CrossRef]
- Musyafa, A.; Gao, Y.; Solyman, A.; Wu, C.; Khan, S. Automatic correction of indonesian grammatical errors based on transformer. Appl. Sci. 2022, 12, 10380. [Google Scholar] [CrossRef]
- Bryant, C.; Felice, M.; Briscoe, T. Automatic Annotation and Evaluation of Error Types for Grammatical Error Correction. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Barzilay, R., Kan, M.Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 793–805. [Google Scholar] [CrossRef]
- RoTex. RoTex Corpus Builder. 2019. Available online: https://github.com/aleris/ReadME-RoTex-Corpus-Builder (accessed on 16 May 2024).
- Bucur, C. Cele mai Frecvente Greșeli de Gramatică din Limba Română. 2018. Available online: https://life.ro/cele-mai-frecvente-greseli-de-gramatica-din-limba-romana/ (accessed on 16 May 2024).
- SpotMedia. Cum Scriem Corect: Nu Face Sau nu fă? Cum Folosim Negația la Imperativ. 2021. Available online: https://spotmedia.ro/stiri/educatie/cum-scriem-corect-nu-face-sau-nu-fa-cum-folosim-negatia-la-imperativ (accessed on 16 May 2024).
- Mititelu, V.B.; Irimia, E.; Perez, C.A.; Ion, R.; Simionescu, R.; Popel, M. UD Romanian RRT. Available online: https://universaldependencies.org/treebanks/ro_rrt/index.html (accessed on 21 May 2024).
- Destepti.ro. Cum Este Corect–Alţii Sau Alţi? 2014. Available online: https://destepti.ro/cum-este-corect-altii-sau-alti/ (accessed on 16 May 2024).
- Muennighoff, N.; Wang, T.; Sutawika, L.; Roberts, A.; Biderman, S.; Le Scao, T.; Bari, M.S.; Shen, S.; Yong, Z.X.; Schoelkopf, H.; et al. Crosslingual Generalization through Multitask Finetuning. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023. [Google Scholar]
- Chung, H.W.; Hou, L.; Longpre, S.; Zoph, B.; Tay, Y.; Fedus, W.; Li, E.; Wang, X.; Dehghani, M.; Brahma, S.; et al. Scaling Instruction-Finetuned Language Models. arXiv 2022, arXiv:2210.11416. [Google Scholar] [CrossRef]
- Dumitrescu, S.; Avram, A.M.; Pyysalo, S. The birth of Romanian BERT. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 4324–4328. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




{kind=link}