
A Spoofing Speech Detection Method Combining Multi-Scale Features and Cross-Layer Information


_Zheng.png)
Abstract

1. Introduction
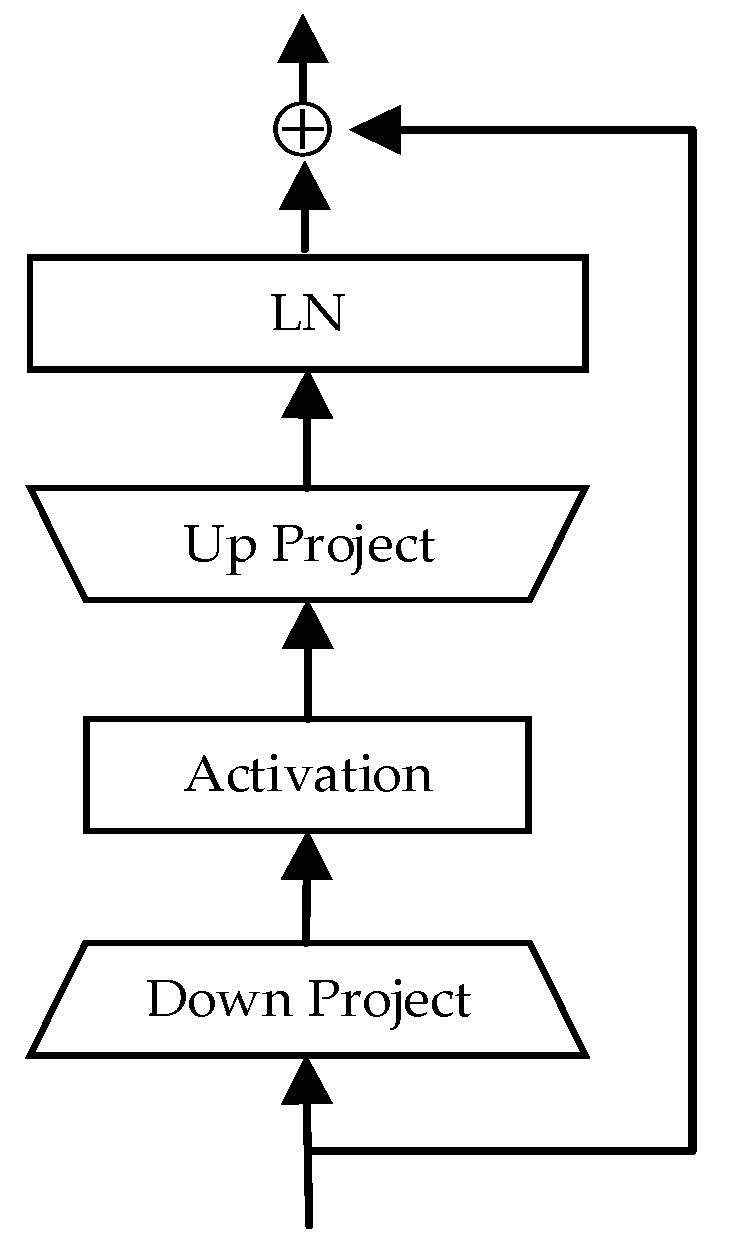
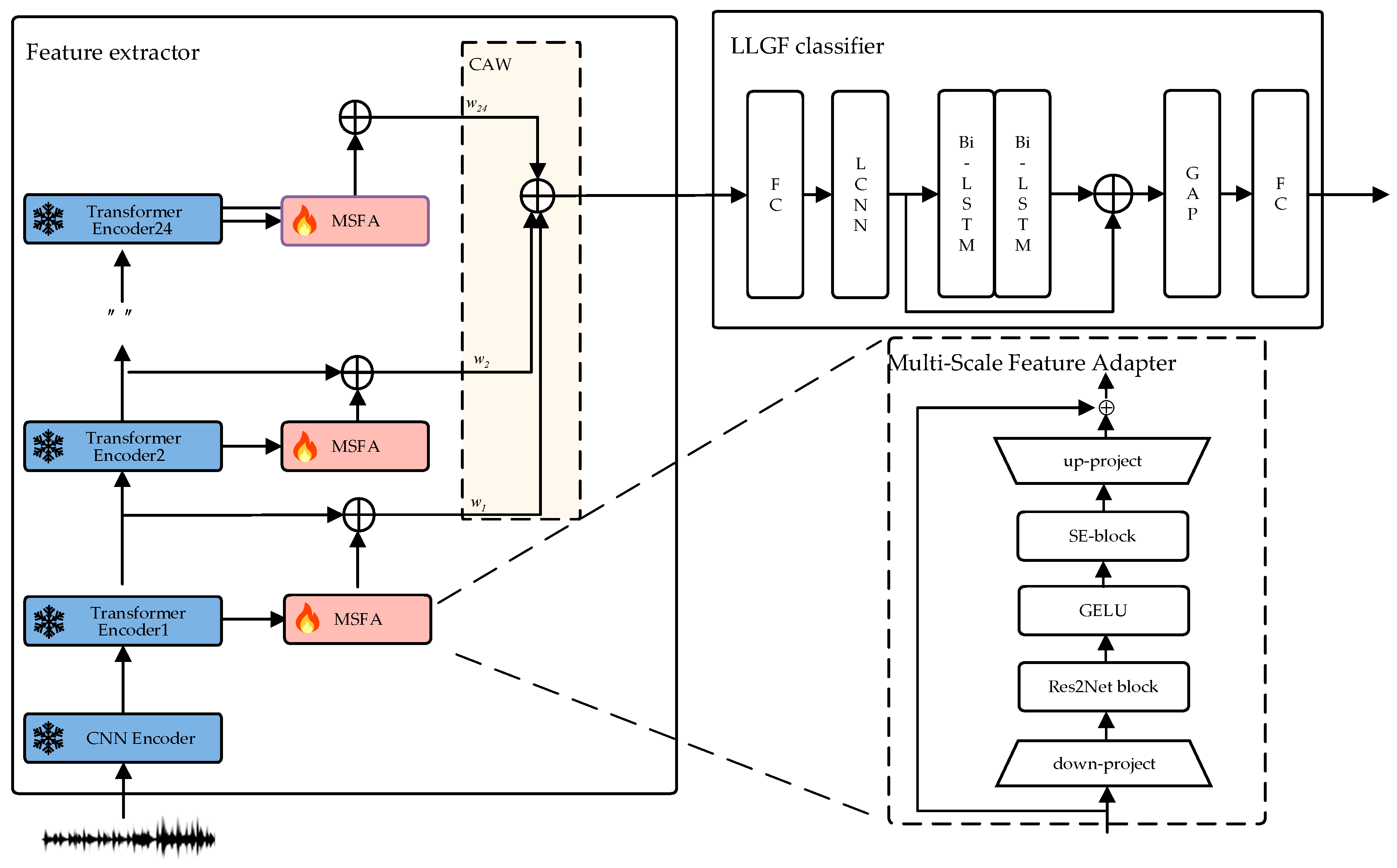
- We propose MSFA, a new adapter design tailored for the spoofing speech detection task. MSFA effectively utilizes the local detail features overlooked by pre-trained models, making it more suitable for spoofing detection.
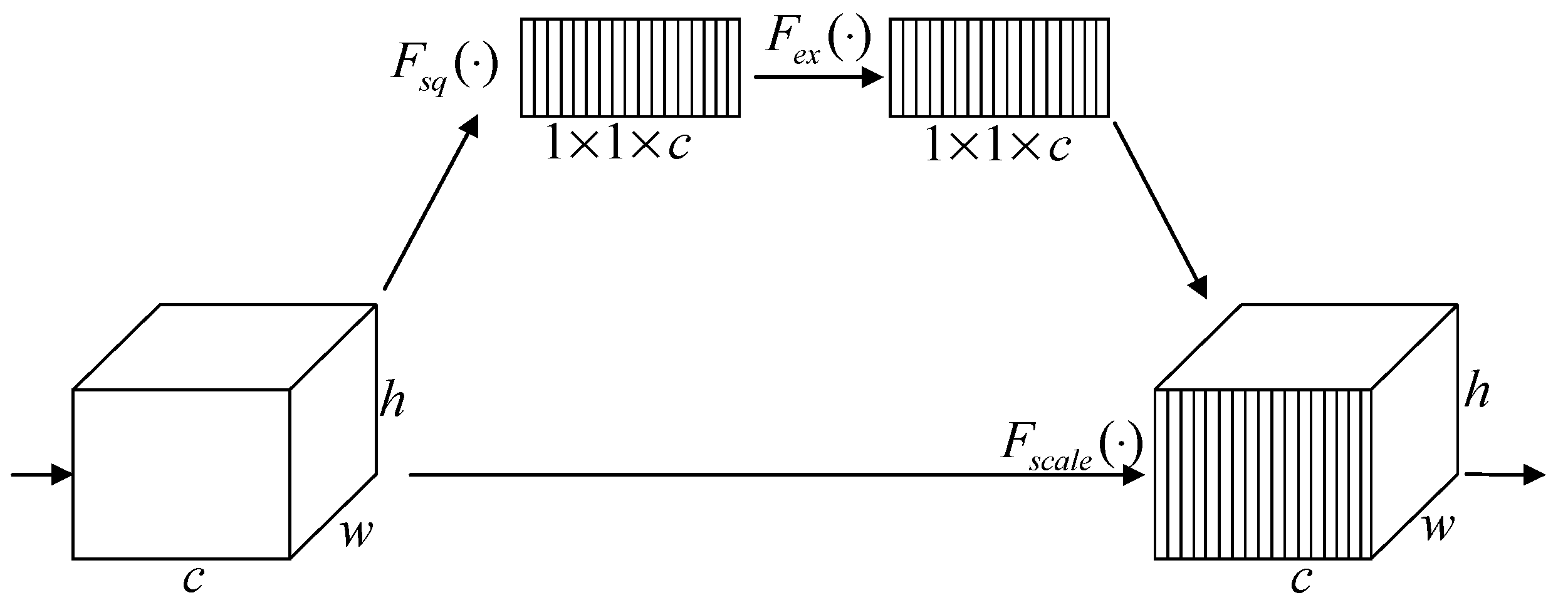
- To better leverage the information embedded in different layers of the pre-trained model, CAWs were introduced to assign different weights to each layer. This mechanism enables the model to focus on task-relevant layers, improving the ability of the speech representation to distinguish between bona fide and spoofed speech.
- We conducted experiments on ASVspoof2019 logical access (LA) and ASVspoof2021 LA datasets. The results demonstrated that our method achieved an equal error rate (EER) of 0.36% on ASVspoof2019 LA and exhibited good generalization capabilities on ASVspoof2021 LA.
2. Related Work
2.1. Handcrafted Feature-Based Spoofing Speech Detection
2.2. Deep Feature-Based Spoofing Speech Detection
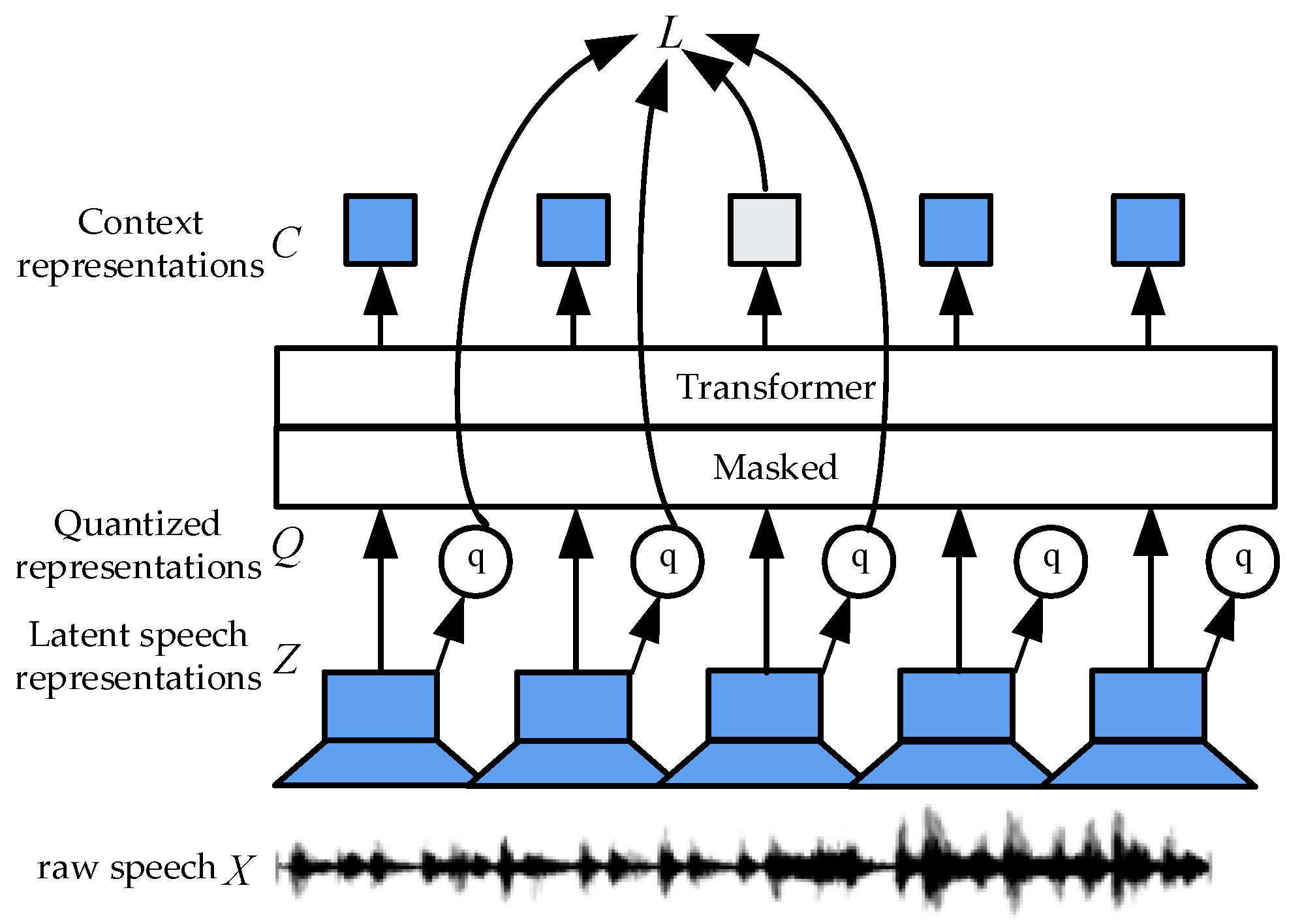
2.3. Spoofing Speech Detection Based on Pre-Trained Speech Models
3. Methods
3.1. XLSR-LLGF
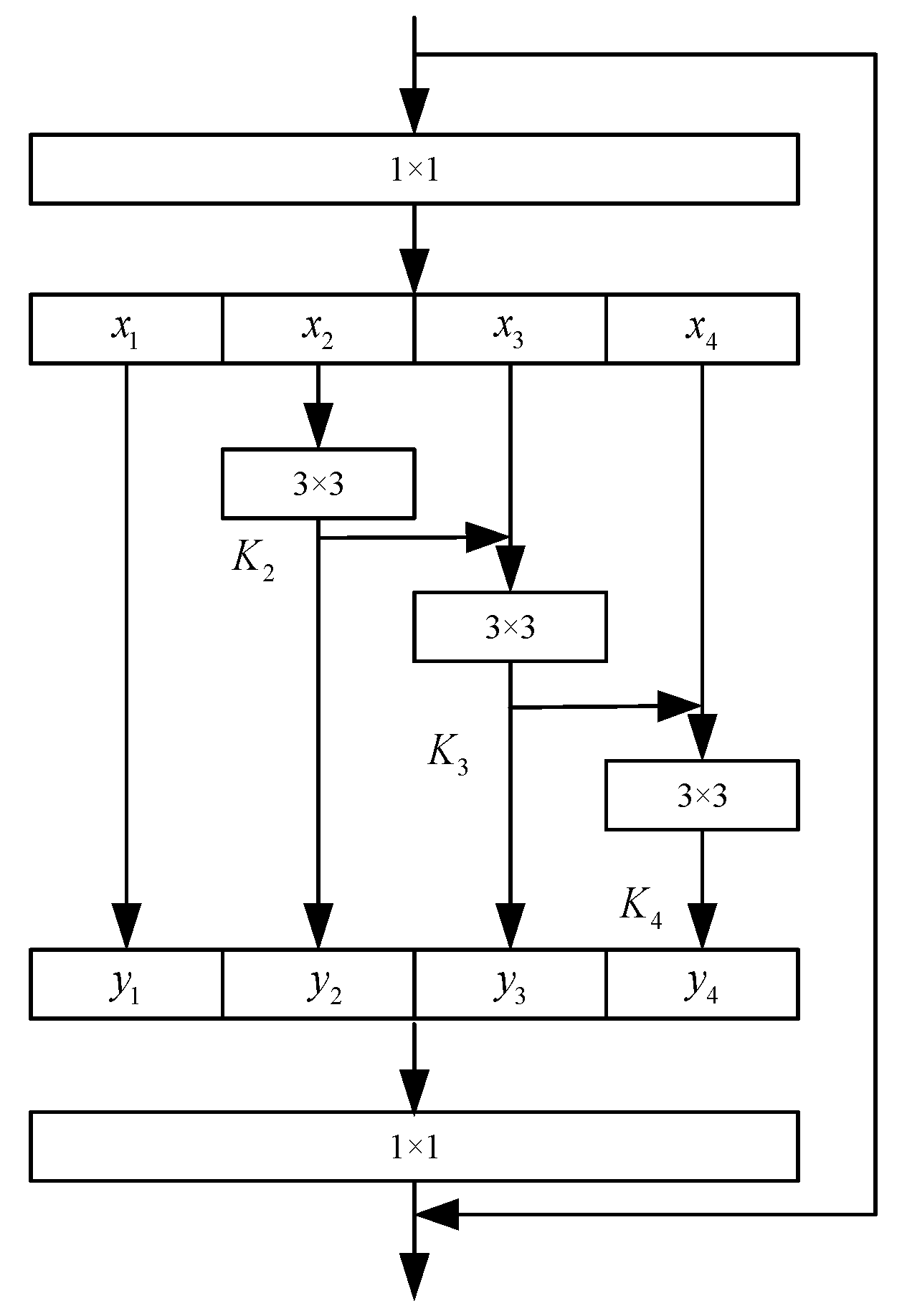
3.2. MSFA
3.3. CAWs
4. Experiments
4.1. Dataset
4.2. Experiment Environment and Performance Metrics
4.3. Experimental Setup
4.4. Experimental Result and Analysis
4.5. Visual Analytics
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ASV | Automatic Speaker Verification |
| CAWs | Cross Adaptable Weights |
| CQCCs | Constant Q Cepstral Coefficients |
| CNNs | Convolutional Neural Networks |
| DNNs | Deep Neural Networks |
| EER | Equal Error Rate |
| FFN | Feed-Forward Network |
| FAR | False Acceptance Rate |
| FRR | False Rejection Rate |
| FC | Fully Connected Layer |
| GAP | Global Average Pooling Layer |
| GELU | Gaussian Error Linear Unit |
| LA | Logical Access |
| LCNN | Lightweight Convolutional Neural Network |
| LFCCs | Linear Frequency Cepstral Coefficients |
| LSTMs | Long Short-Term Memory Networks |
| MFCCs | Mel-Frequency Cepstral Coefficients |
| min t-DCF | minimum tandem Detection Cost Function |
| MSFA | Multi-Scale Feature Adapter |
| PF | Partially Fake Audio Detection |
| ReLU | Rectified Linear Unit |
| SE | Squeeze and Excitation Mechanism |
| t-SNE | t-Distributed Stochastic Neighbor Embedding |
References
- Evans, N.; Kinnunen, T.; Yamagishi, J. Spoofing and countermeasures for automatic speaker verification. In Proceedings of the 2013 14th Conference of the International Speech Communication Association, Lyon, France, 25–29 August 2013; pp. 925–929. [Google Scholar]
- Sathya, P.; Ramakrishnan, S. Non-redundant frame identification and keyframe selection in DWT-PCA domain for authentication of video. IET Image Process. 2020, 14, 366–375. [Google Scholar] [CrossRef]
- Balamurali, B.T.; Lin, K.E.; Lui, S.; Chen, J.-M.; Herremans, D. Toward robust audio spoofing detection: A detailed comparison of traditional and learned features. IEEE Access 2019, 7, 84229–84241. [Google Scholar] [CrossRef]
- Tak, H.; Patino, J.; Todisco, M.; Nautsch, A.; Evans, N.; Larcher, A. End-to-end anti-spoofing with rawnet2. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6369–6373. [Google Scholar]
- Liu, X.; Liu, M.; Wang, L.; Lee, K.A.; Zhang, H.; Dang, J. Leveraging positional-related local-global dependency for synthetic speech detection. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 6–10 June 2023; pp. 1–5. [Google Scholar]
- Yoon, S.H.; Yu, H.J. Multiple points input for convolutional neural networks in replay attack detection. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual Conference, 4–9 May 2020; pp. 6444–6448. [Google Scholar]
- Chen, S.; Wang, C.; Chen, Z.; Wu, Y.; Liu, S.; Chen, Z.; Li, J.; Kanda, N.; Yoshioka, T.; Xiao, X.; et al. WavLM: Large-scale self-supervised pre-training for full stack speech processing. IEEE J. Sel. Top. Signal Process. 2022, 16, 1505–1518. [Google Scholar] [CrossRef]
- Hsu, W.N.; Bolte, B.; Tsai, Y.H.H.; Lakhotia, K.; Salakhutdinov, R.; Mohamed, A. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3451–3460. [Google Scholar] [CrossRef]
- Chen, S.; Wu, Y.; Wang, C.; Chen, Z.; Chen, Z.; Liu, S.; Wu, J.; Qian, Y.; Wei, F.; Li, J.; et al. UniSpeech-SAT: Universal speech representation learning with speaker aware pre-training. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 6152–6156. [Google Scholar]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. Wav2vec 2.0: A framework for self-supervised learning of speech representations. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; pp. 12449–12460. [Google Scholar]
- Suresh, V.; Ait-Mokhtar, S.; Brun, C.; Calapodescu, I. An adapter-based unified model for multiple spoken language processing tasks. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 10676–10680. [Google Scholar]
- Lv, Z.; Zhang, S.; Tang, K.; Hu, P. Fake audio detection based on unsupervised pretraining models. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 9231–9235. [Google Scholar]
- Wang, X.; Yamagishi, J. Investigating self-supervised front ends for speech spoofing countermeasures. arXiv 2021, arXiv:2111.07725. [Google Scholar]
- Wu, H.; Zhang, J.; Zhang, Z.; Zhao, W.; Gu, B.; Guo, W. Robust Spoof Speech Detection Based on Multi-Scale Feature Aggregation and Dynamic Convolution. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 10156–10160. [Google Scholar]
- Thomas, B.; Kessler, S.; Karout, S. Efficient adapter transfer of self-supervised speech models for automatic speech recognition. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 7102–7106. [Google Scholar]
- Peng, J.; Stafylakis, T.; Gu, R.; Plchot, O.; Mošner, L.; Burget, L.; Černocký, J. Parameter efficient transfer learning of pre-trained transformer models for speaker verification using adapters. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 6–10 June 2023; pp. 1–5. [Google Scholar]
- Li, Y.; Huang, H.; Chen, Z.; Guan, W.; Lin, J.; Li, L.; Hong, Q. SR-HuBERT: An efficient pre-trained model for speaker verification. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 11591–11595. [Google Scholar]
- Babu, A.; Wang, C.; Tjandra, A.; Lakhotia, K.; Xu, Q.; Goyal, N.; Singh, K.; von Platen, P.; Saraf, Y.; Pino, J.; et al. XLS-R: Self-supervised cross-lingual speech representation learning at scale. arXiv 2021, arXiv:2111.09296. [Google Scholar]
- Chen, Z.; Chen, S.; Wu, Y.; Qian, Y.; Wang, C.; Liu, S.; Qian, Y.; Zeng, M. Large-scale self-supervised speech representation learning for automatic speaker verification. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 6147–6151. [Google Scholar]
- Nautsch, A.; Wang, X.; Evans, N.; Kinnunen, T.H.; Vestman, V.; Todisco, M.; Delgado, H.; Sahidullah, M.; Yamagishi, J.; Lee, K.A. ASVspoof 2019: Spoofing countermeasures for the detection of synthesized, converted and replayed speech. IEEE Trans. Biom. Behav. Identity Sci. 2021, 3, 252–265. [Google Scholar] [CrossRef]
- Yamagishi, J.; Wang, X.; Todisco, M.; Sahidullah, M.; Patino, J.; Nautsch, A.; Liu, X.; Lee, K.A.; Kinnunen, T.; Evans, N.; et al. ASVspoof 2021: Accelerating progress in spoofed and deepfake speech detection. arXiv 2021, arXiv:2109.00537. [Google Scholar]
- Guo, Y.; Huang, H.; Chen, X.; Zhao, H.; Wang, Y. Audio deepfake detection with self-supervised wavlm and multi-fusion attentive classifier. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 12702–12706. [Google Scholar]
- Jung, J.; Heo, H.S.; Tak, H.; Shim, H.J.; Chung, J.S.; Lee, B.J.; Yu, H.J.; Evans, N. AASIST: Audio anti-spoofing using integrated spectro-temporal graph attention networks. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6367–6371. [Google Scholar]
- Tak, H.; Jung, J.W.; Patino, J.; Kamble, M.; Todisco, M.; Evans, N. End-to-end spectro-temporal graph attention networks for speaker verification anti-spoofing and speech deepfake detection. arXiv 2021, arXiv:2107.12710. [Google Scholar]
- Wang, X.; Yamagishi, J. A comparative study on recent neural spoofing countermeasures for synthetic speech detection. arXiv 2021, arXiv:2103.11326. [Google Scholar]
- Li, X.; Li, N.; Weng, C.; Liu, X.; Su, D.; Yu, D.; Meng, H. Replay and synthetic speech detection with res2net architecture. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6354–6358. [Google Scholar]
- Ma, Y.; Ren, Z.; Xu, S. RW-Resnet: A novel speech anti-spoofing model using raw waveform. arXiv 2021, arXiv:2108.05684. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Speeches | ||
|---|---|---|---|
| Bona Fide | Spoof | ||
| 2019LA | Train | 2580 | 22,800 |
| Dev | 2548 | 22,296 | |
| Test | 7355 | 63,882 | |
| 2021LA | Test | 14,816 | 133,360 |
| ID | System | 2019 LA | 2021 LA | ||||||
|---|---|---|---|---|---|---|---|---|---|
| I | II | III | Average | I | II | III | Average | ||
| 1 | Baseline | 3.43 | 3.35 | 3.10 | 3.29 | 16.04 | 16.63 | 13.13 | 15.27 |
| 2 | Average weight | 1.48 | 1.42 | 1.53 | 1.48 | 10.57 | 11.35 | 10.50 | 10.81 |
| 3 | CAW | 1.17 | 1.27 | 1.29 | 1.24 | 9.49 | 9.48 | 9.51 | 9.49 |
| 4 | Adapter-CAW | 1.09 | 0.85 | 0.94 | 0.96 | 8.58 | 8.79 | 7.75 | 8.37 |
| 5 | MFSA-CAW | 0.35 | 0.39 | 0.34 | 0.36 | 4.23 | 3.99 | 4.66 | 4.29 |
| System | 2019 LA | |
|---|---|---|
| EER (%) | min t-DCF | |
| MFSA-CAW | 0.36 | 0.0269 |
| WavLM + MFA [22] | 0.42 | 0.0126 |
| Rawformer [5] | 0.59 | 0.0184 |
| AASIST [23] | 0.83 | 0.0275 |
| RawGAT-ST [24] | 1.06 | 0.0355 |
| LCNN-LSTM-sum [25] | 1.92 | 0.0524 |
| W2V2-XLSR, fine-tuned [13] | 1.35 | 0.1003 |
| SE-Res2Net50 [26] | 2.50 | 0.0743 |
| RW-Resnet [27] | 2.98 | 0.0820 |
| W2V2-XLSR, fixed [13] | 3.11 | 0.1320 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, H.; Zhang, L.; Niu, B.; Zheng, X. A Spoofing Speech Detection Method Combining Multi-Scale Features and Cross-Layer Information. Information 2025, 16, 194. https://doi.org/10.3390/info16030194
Yuan H, Zhang L, Niu B, Zheng X. A Spoofing Speech Detection Method Combining Multi-Scale Features and Cross-Layer Information. Information. 2025; 16(3):194. https://doi.org/10.3390/info16030194
Chicago/Turabian StyleYuan, Hongyan, Linjuan Zhang, Baoning Niu, and Xianrong Zheng. 2025. "A Spoofing Speech Detection Method Combining Multi-Scale Features and Cross-Layer Information" Information 16, no. 3: 194. https://doi.org/10.3390/info16030194
APA StyleYuan, H., Zhang, L., Niu, B., & Zheng, X. (2025). A Spoofing Speech Detection Method Combining Multi-Scale Features and Cross-Layer Information. Information, 16(3), 194. https://doi.org/10.3390/info16030194