


Generating Human-Interpretable Rules from Convolutional Neural Networks



Abstract

1. Introduction
2. Materials and Methods
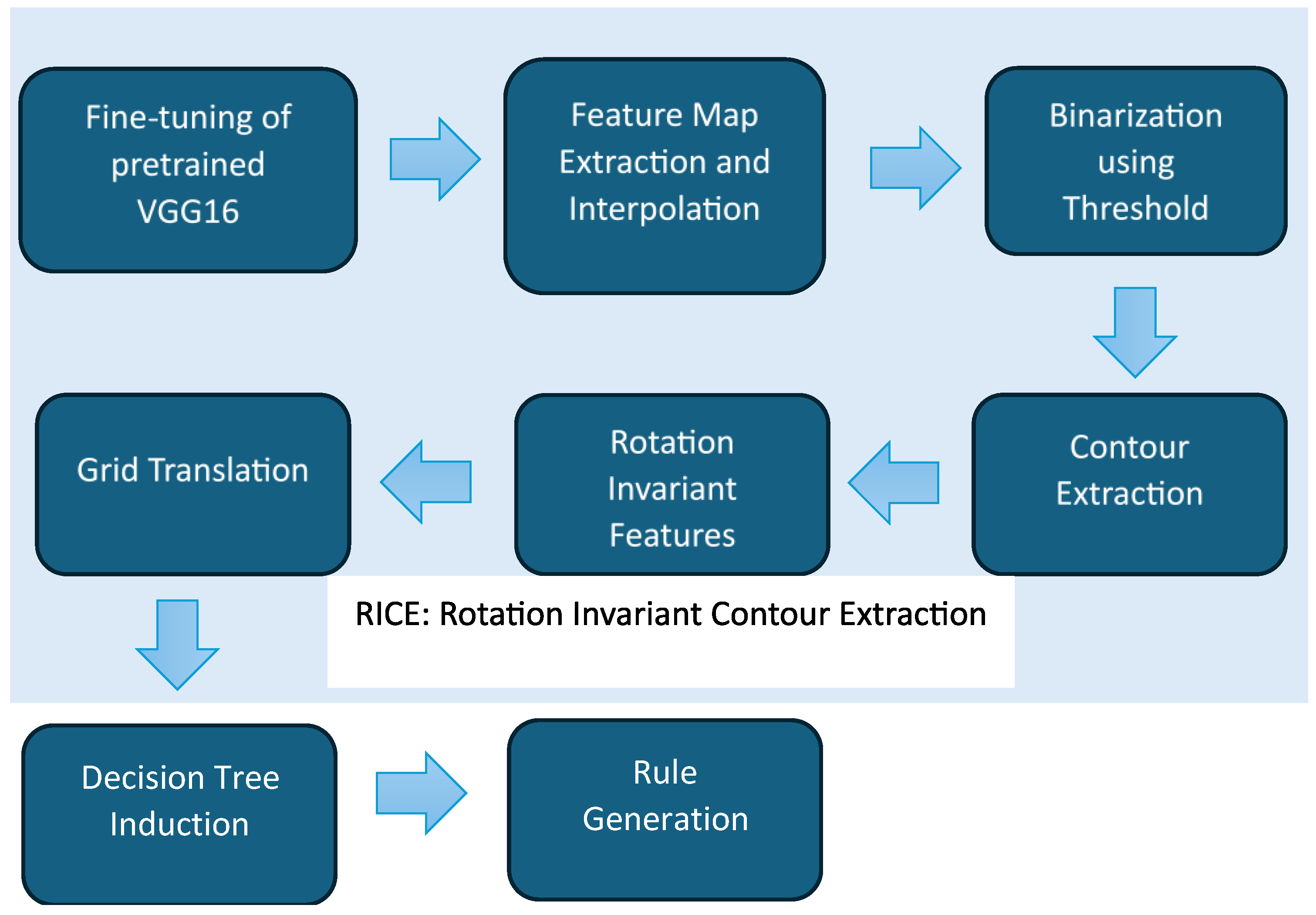
2.1. Overview of Methodology
2.2. Feature Extraction and Rule Generation
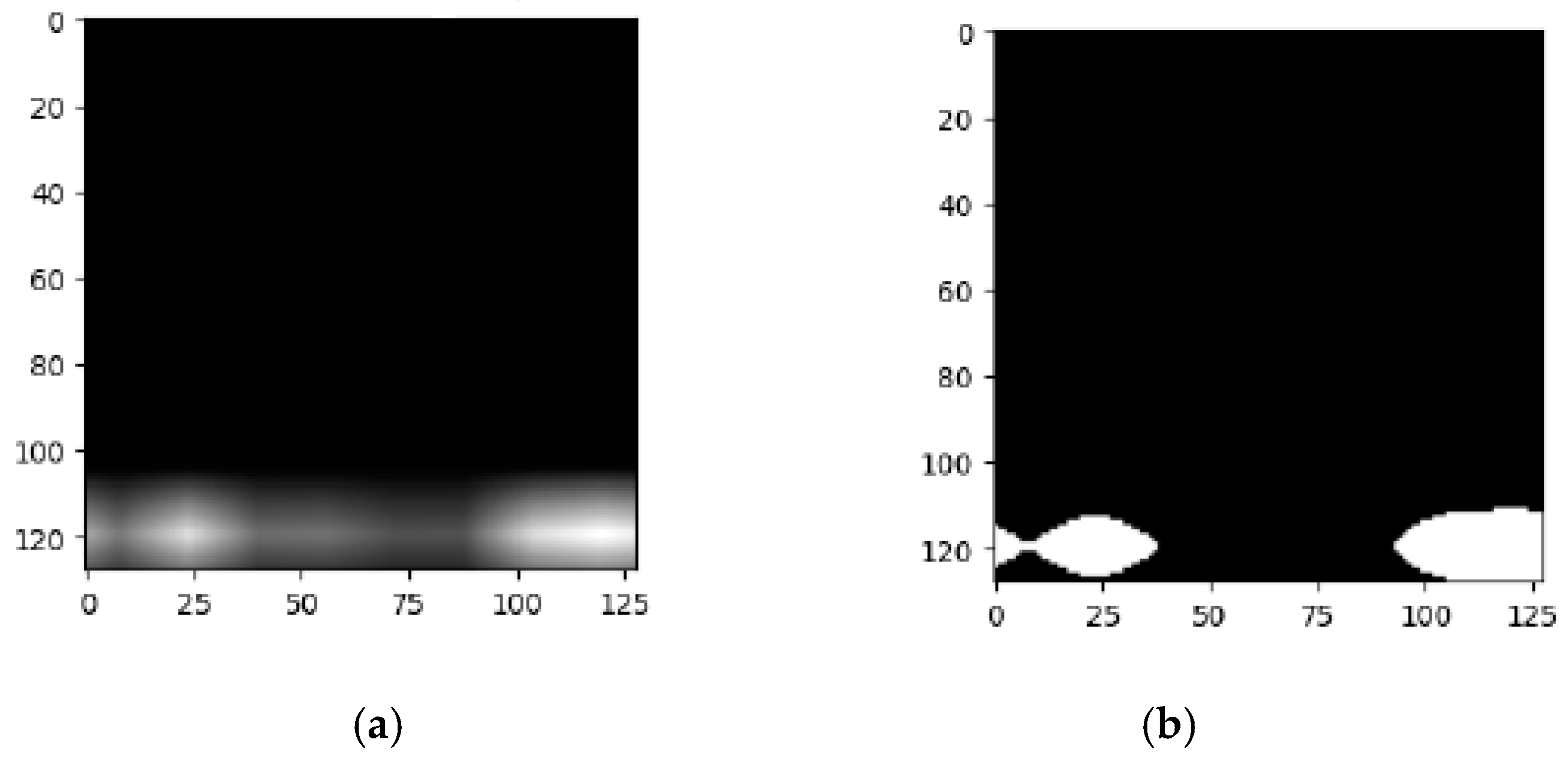
Feature Extraction from Feature Maps
3. Results
3.1. System Configuration
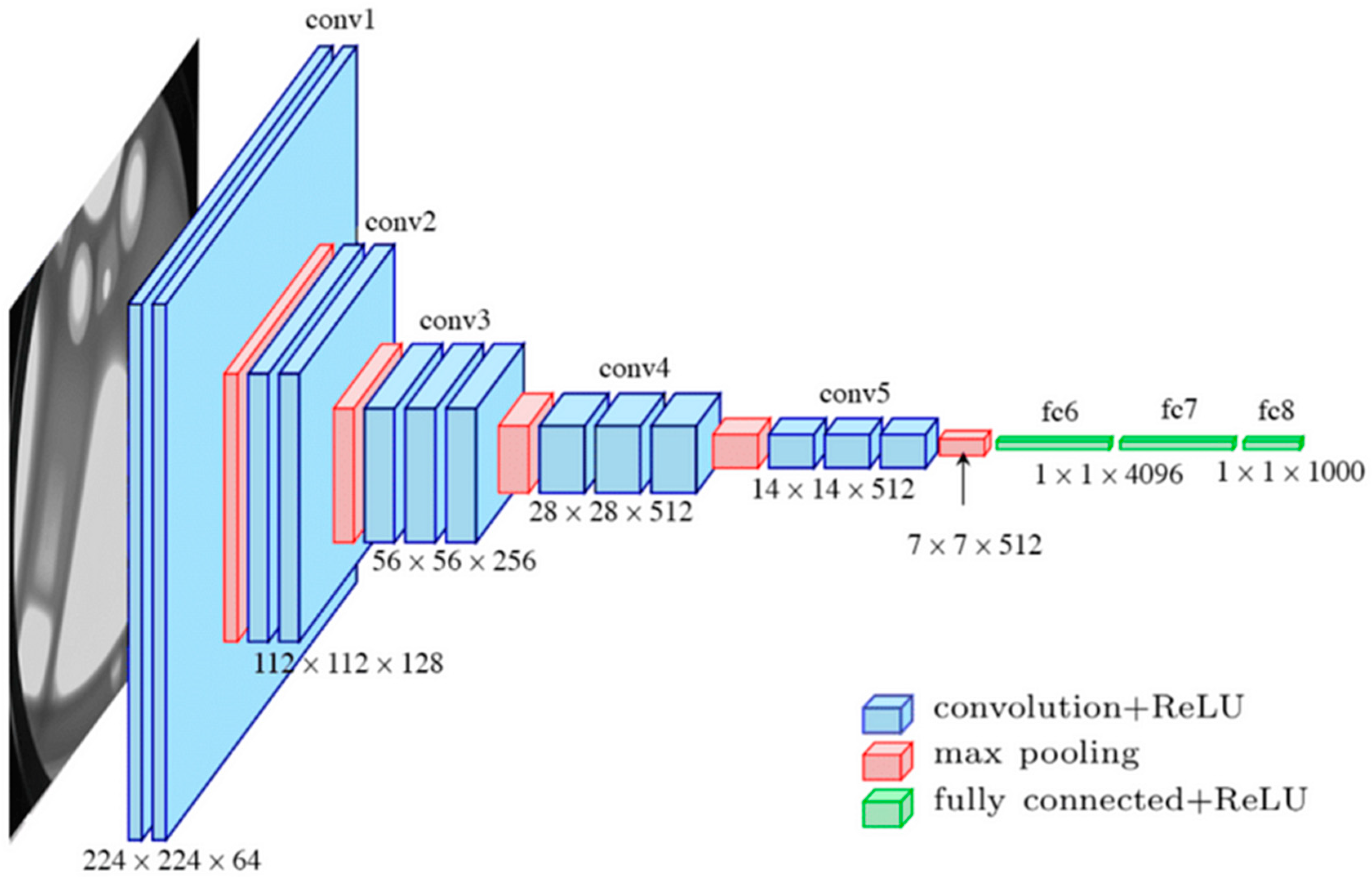
3.2. Architecture Exploration
3.3. Experimental Study
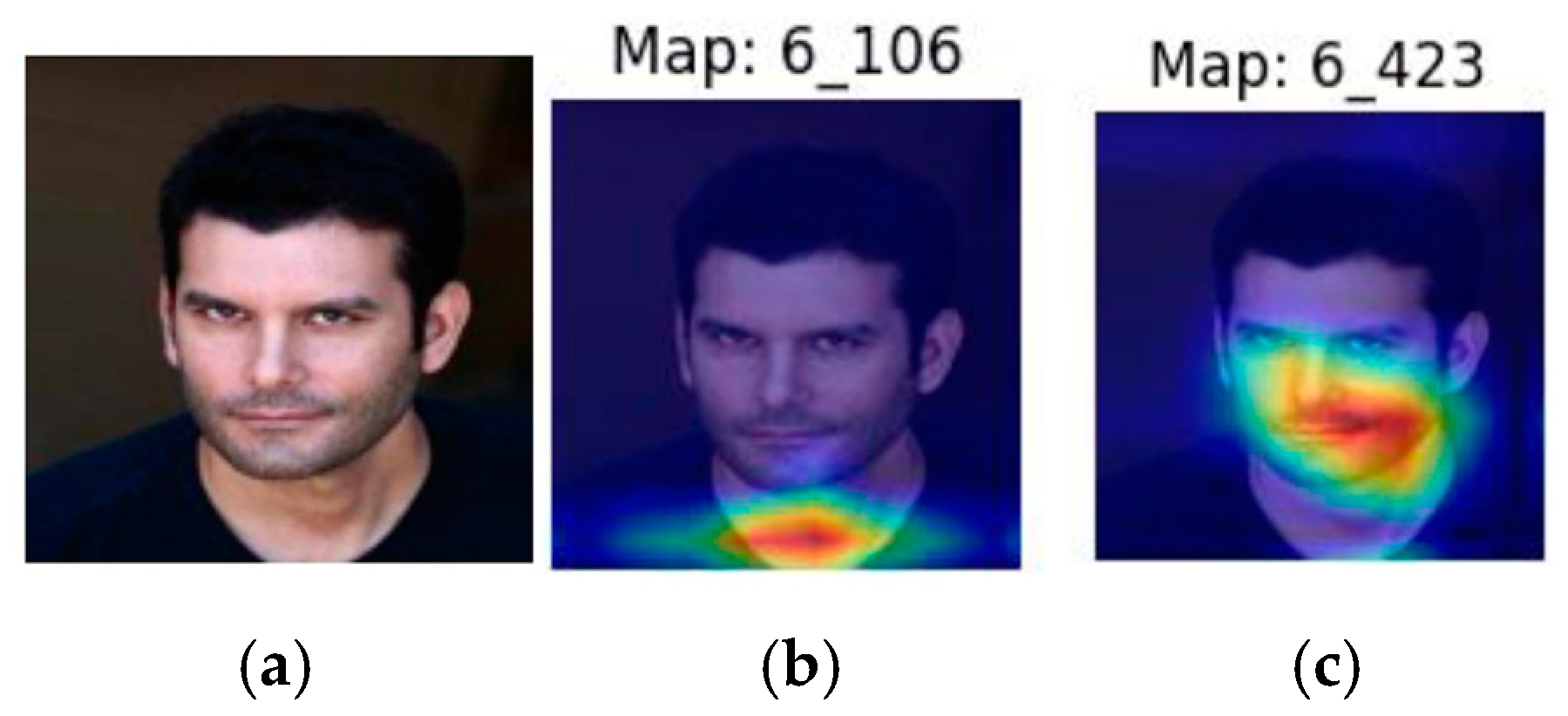
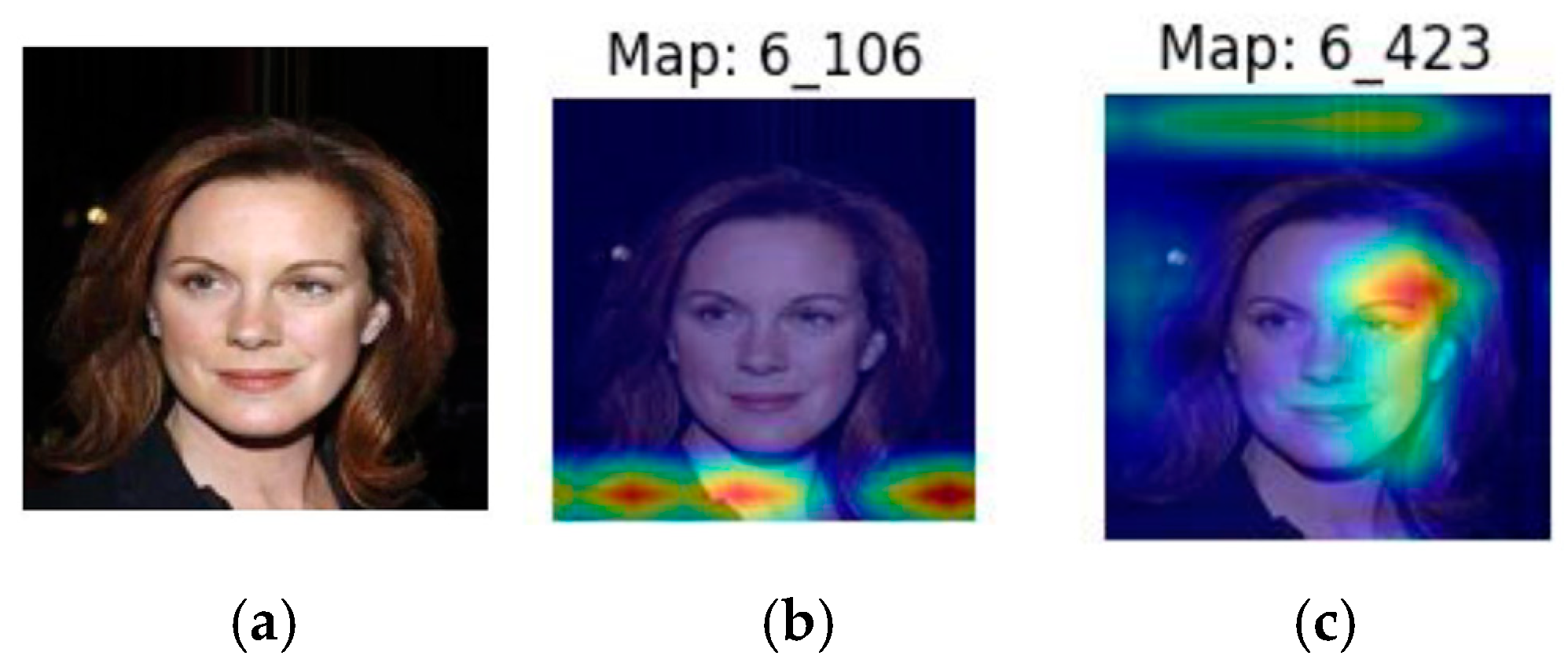
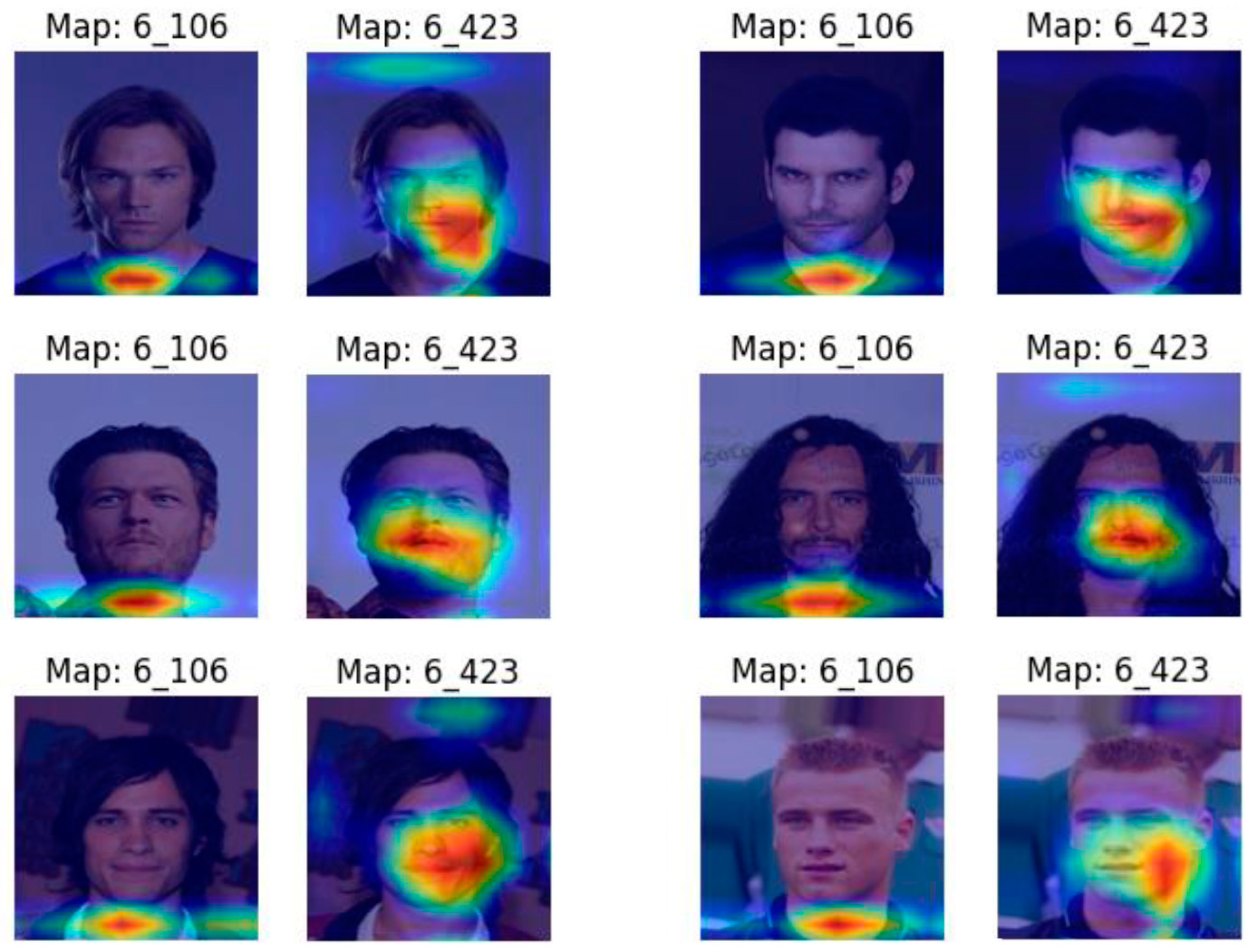
3.3.1. CelebA Case Study: Fine-Tuning, Feature Selection, and Image Superposition
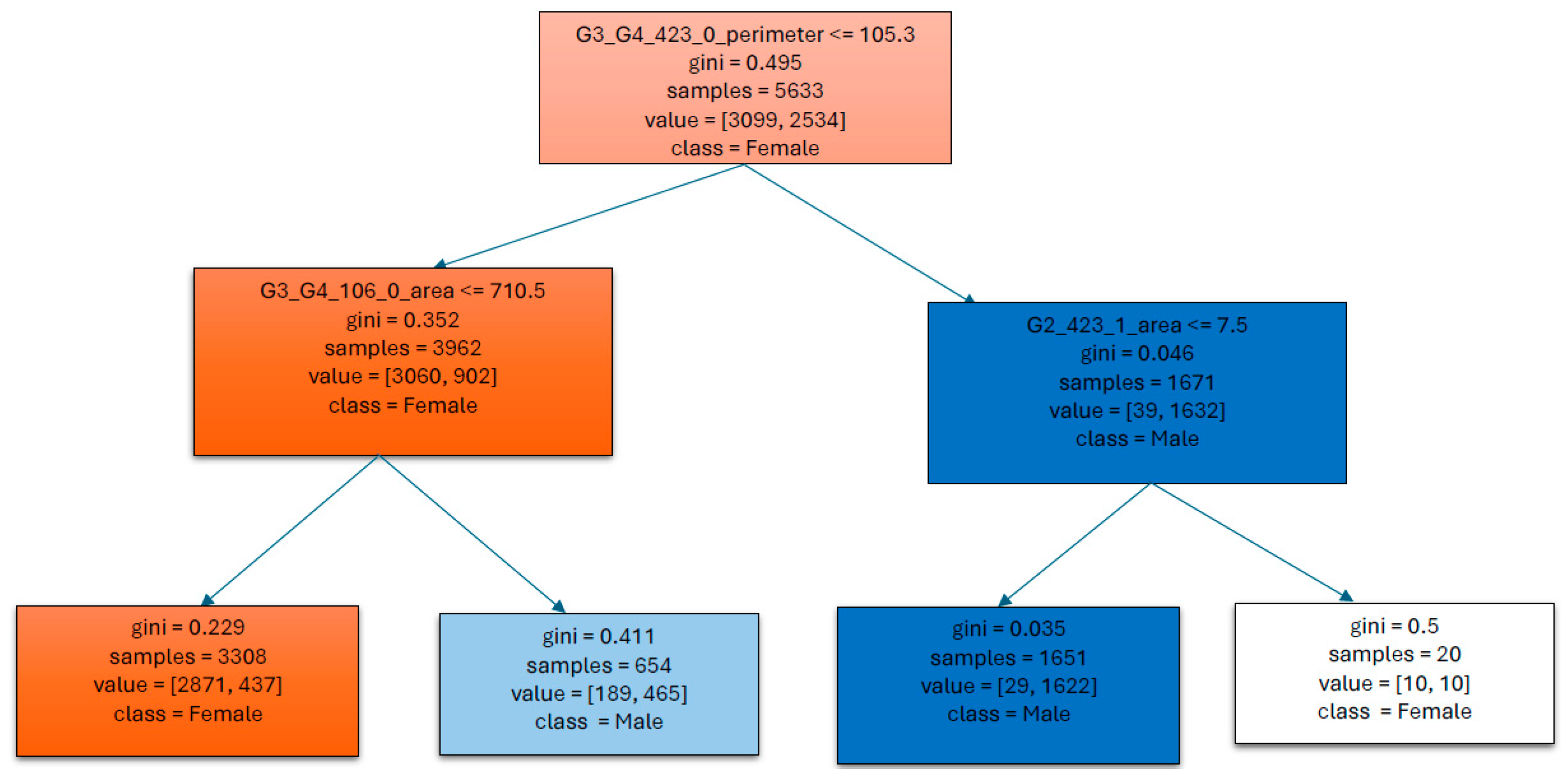
- Rule-1: If lip and left cheek perimeter is >105.305 and left eyebrow area is ≤7.5 then male, else female.
- Rule-2: If lip and left cheek perimeter is ≤105.305 and neck area is ≤710.5 then female, else male.
- Rule-1: If lip and left cheek perimeter is large and eyebrow area is small then male, else female.
- Rule-2: If lip and left cheek perimeter is small and neck area is also small then female, else male.
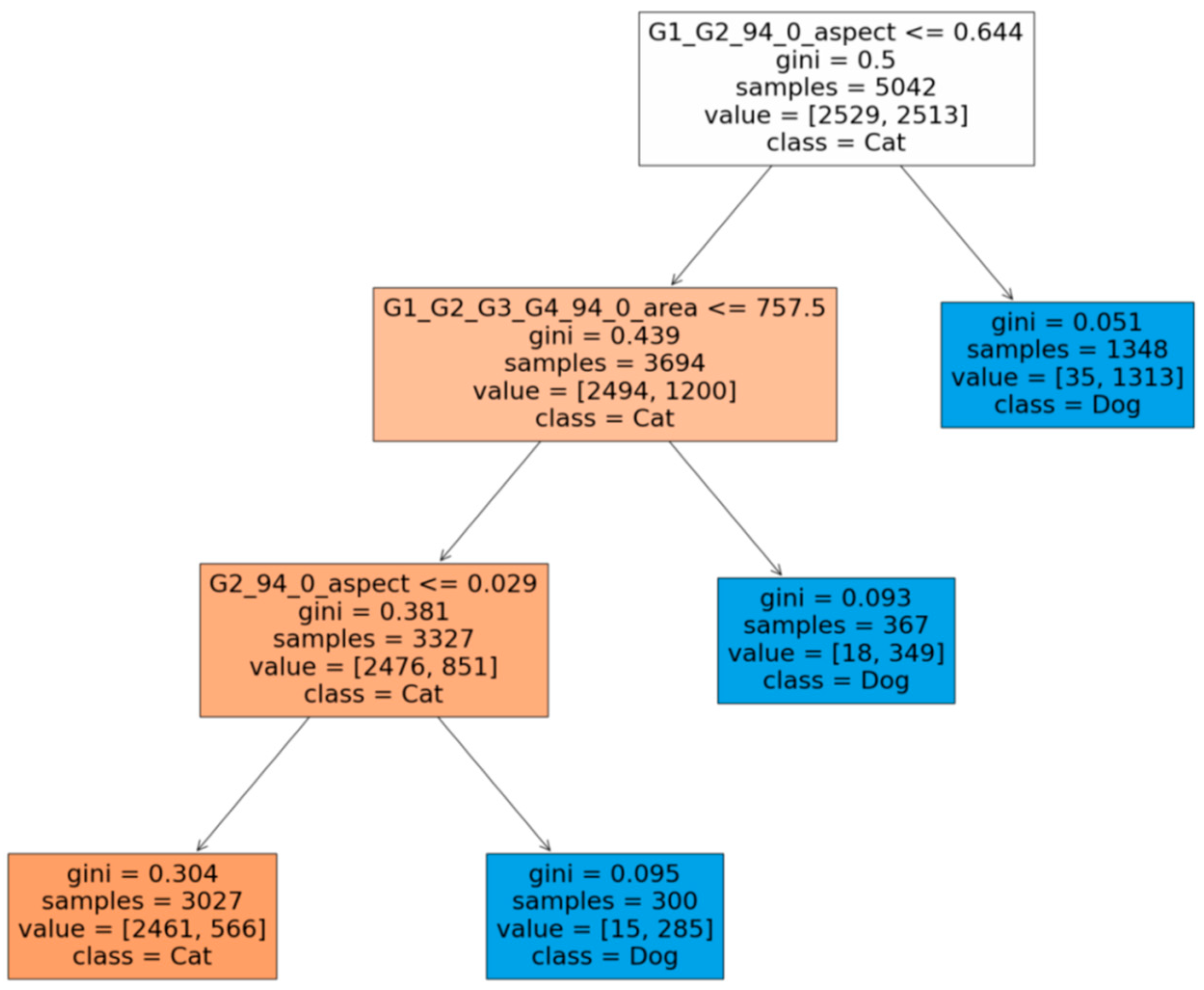
3.3.2. Cats vs. Dogs Case Study: Fine-Tuning, Feature Selection, and Image Superposition
- Rule-1: If face aspect ratio is >0.644 then dog, else cat.
- Rule-2: If face aspect ratio is ≤0.644 and face area is ≤757.5 then cat else dog.
- Rule-1: If face aspect ratio is large then dog, else cat → capturing the vast majority of dogs.
- Rule-2: If face aspect ratio is small and face area is also small then cat, else dog → capturing the vast majority of cats but also a small fraction of dogs that happen to be small.
4. Discussion and Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach, 4th ed.; Prentice Hall: Englewood Cliffs, NJ, USA, 2020. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Jia, D.; Wei, D.; Richard, S.; Li, J.L.; Kai, L.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: http://www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf (accessed on 2 February 2024).
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Castelvecchi, D. Can we open the black box of AI? Nat. News 2016, 538, 20. [Google Scholar] [CrossRef] [PubMed]
- Das, A.; Rad, P. Opportunities and challenges in explainable artificial intelligence (xai): A survey. arXiv 2020, arXiv:2006.11371. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you? ” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Goodman, B.; Flaxman, S. European Union regulations on algorithmic decision-making and a “right to explanation”. AI Mag. 2017, 38, 50–57. [Google Scholar] [CrossRef]
- Craven, M.; Shavlik, J. Extracting tree-structured representations of trained networks. Adv. Neural Inf. Process. Syst. 1995, 8, 24–30. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings of the Part I 13. Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Oh, S.J.; Schiele, B.; Fritz, M. Towards reverse-engineering black-box neural networks. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning; Springer: Cham, Switzerland, 2019; pp. 121–144. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [PubMed]
- Achtibat, R.; Dreyer, M.; Eisenbraun, I.; Bosse, S.; Wiegand, T.; Samek, W.; Lapuschkin, S. From “where” to “what”: Towards human-understandable explanations through concept relevance propagation. arXiv 2022, arXiv:2206.03208. [Google Scholar]
- Imagenet Dataset. Available online: https://image-net.org/ (accessed on 2 February 2024).
- Sharma, A.K. Human Interpretable Rule Generation from Convolutional Neural Networks Using RICE: Rotation Invariant Contour Extraction. Master’s Thesis, University of North Texas, Denton Texas, TX, USA, July 2024. [Google Scholar]
- Press, W.H.; Teukolsky, S.A.; Vetterling, W.T.; Flannery, B.P. Numerical Recipes in C: The Art of Scientific Computing, 2nd ed.; Cambridge University Press: New York, NY, USA, 1992; pp. 123–128. [Google Scholar]
- Large-Scale CelebFaces Attributes (CelebA) Dataset. Available online: https://mmlab.ie.cuhk.edu.hk/projects/CelebA.html (accessed on 15 January 2024).
- Kaggle Cats and Dogs Dataset. Available online: https://www.microsoft.com/en-us/download/details.aspx?id=54765&msockid=3d36009b0d73606d12a7146f0c7b6140 (accessed on 2 February 2024).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description and Value |
|---|---|
| VGG-16 trainable layers | Last 2 convolutional layers from Block 5 |
| Number of dense layers used | 2 dense layers, 1024 units in layer 1 and 512 in layer 2 |
| Learning rate | 0.0017 |
| Epochs | 50 |
| Batch size | 512 |
| Early stopping | Yes, with patience value of 6 |
| Optimizer | Adam |
| Input image shape | (128,128,3) |
| Train test validation split | For CelebA, there were 202,599 images in total, out of which 80% was used in training, 10% was used for validation, and 10% was used for testing. For the Cats vs. Dogs dataset, there were 25,000 images in total; the same ratios were used for training/validation/testing as for the CelebA dataset. Both datasets were balance with respect their classes. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pears, R.; Sharma, A.K. Generating Human-Interpretable Rules from Convolutional Neural Networks. Information 2025, 16, 230. https://doi.org/10.3390/info16030230
Pears R, Sharma AK. Generating Human-Interpretable Rules from Convolutional Neural Networks. Information. 2025; 16(3):230. https://doi.org/10.3390/info16030230
Chicago/Turabian StylePears, Russel, and Ashwini Kumar Sharma. 2025. "Generating Human-Interpretable Rules from Convolutional Neural Networks" Information 16, no. 3: 230. https://doi.org/10.3390/info16030230
APA StylePears, R., & Sharma, A. K. (2025). Generating Human-Interpretable Rules from Convolutional Neural Networks. Information, 16(3), 230. https://doi.org/10.3390/info16030230