
YOLOv8n-Al-Dehazing: A Robust Multi-Functional Operation Terminals Detection for Large Crane in Metallurgical Complex Dust Environment


Abstract
1. Introduction
- In response to the real-time monitoring requirements for multi-functional operation terminals in aluminum electrolysis environments, we establish a high-resolution surveillance system capable of capturing and identifying dynamic multi-functional operation terminals in real-time.
- We devise a real-time monitoring scheme for operation terminals that integrates the efficient dehazing capabilities of 4KDehazing with the precise detection prowess of YOLOv8n. This integration effectively addresses the challenge of object detection in high-resolution images obscured by non-uniform smoke, achieving superior accuracy compared to using YOLOv8n alone for detection. To mitigate the computational performance degradation caused by network stacking, we optimize the YOLOv8n network architecture. This enhancement ensures that, while maintaining detection accuracy, the parameter count is significantly reduced, thus preserving the real-time efficiency of the combined network.
2. Related Works
2.1. Analysis of Object Detection Algorithm
2.2. Analysis of Dehazing Algorithm
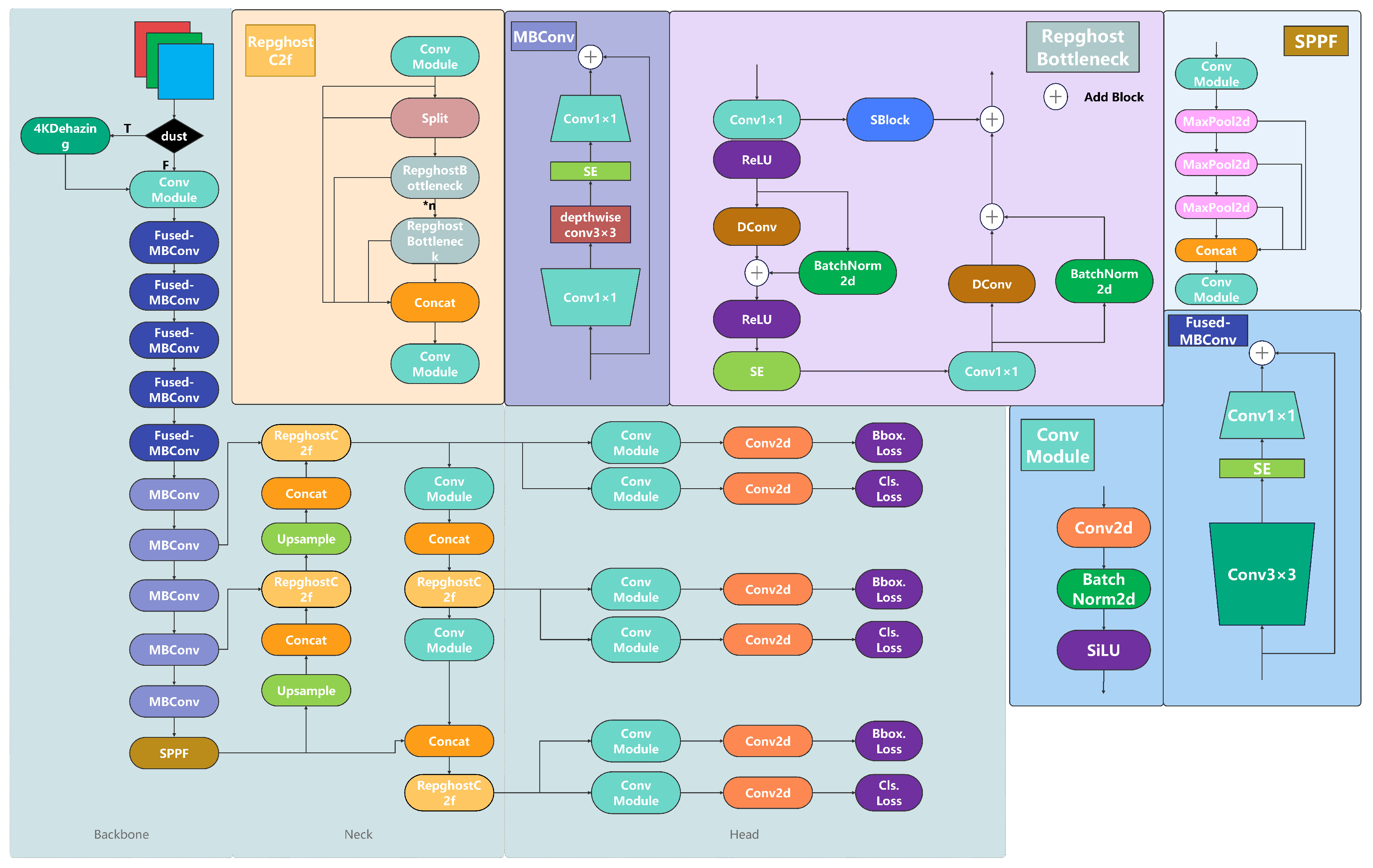
3. Proposed Method
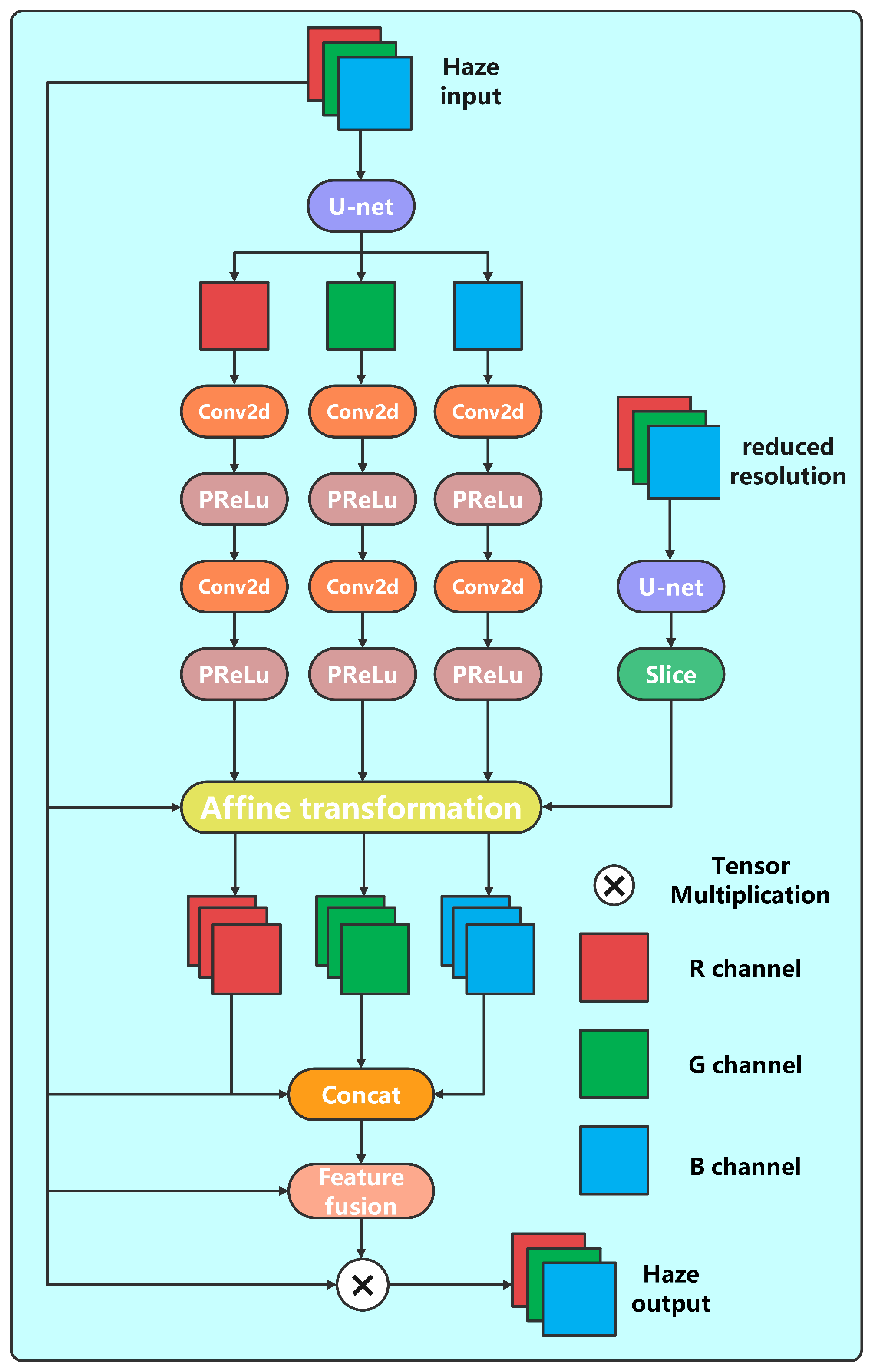
3.1. 4KDehazing
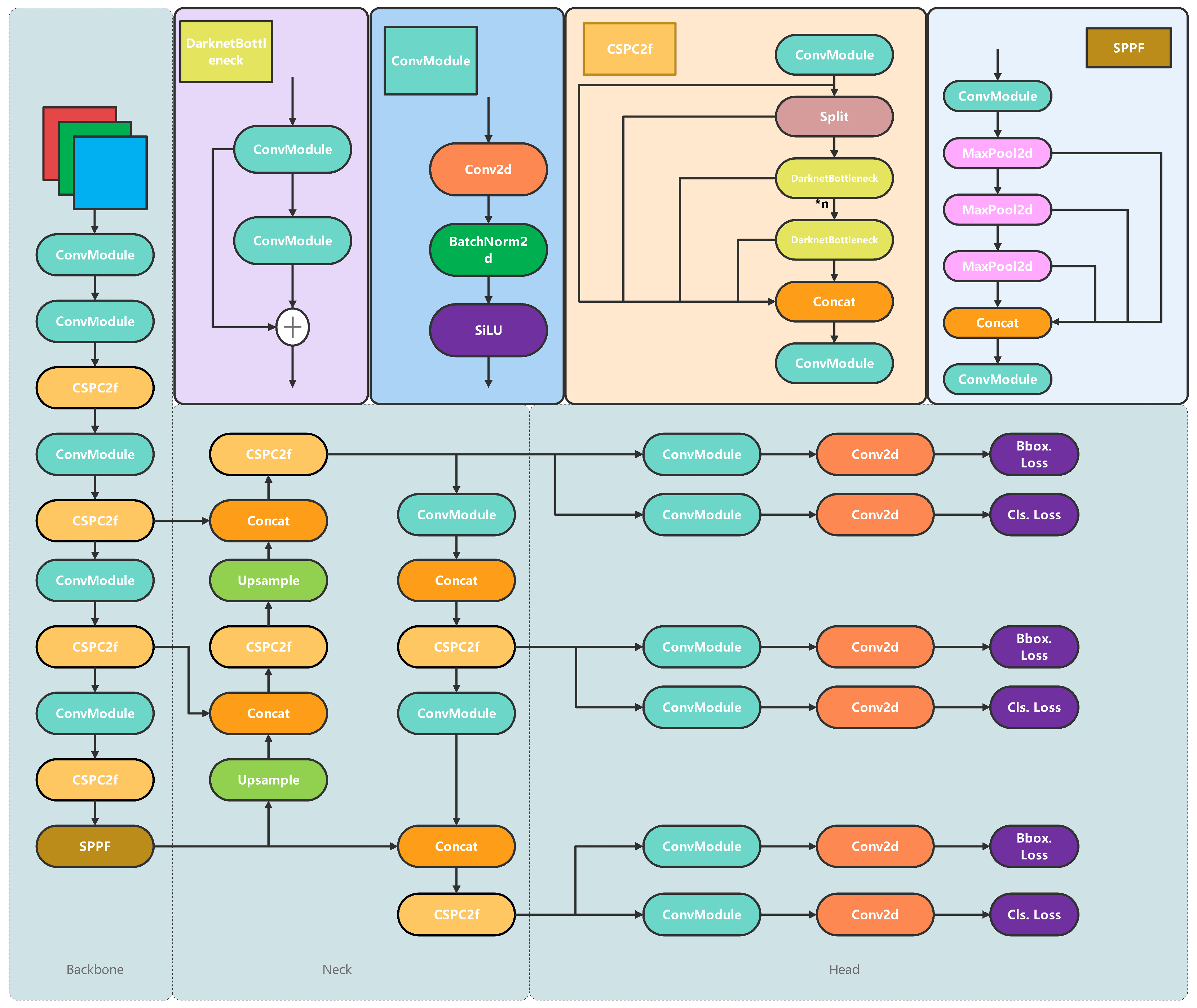
3.2. YOLOv8n
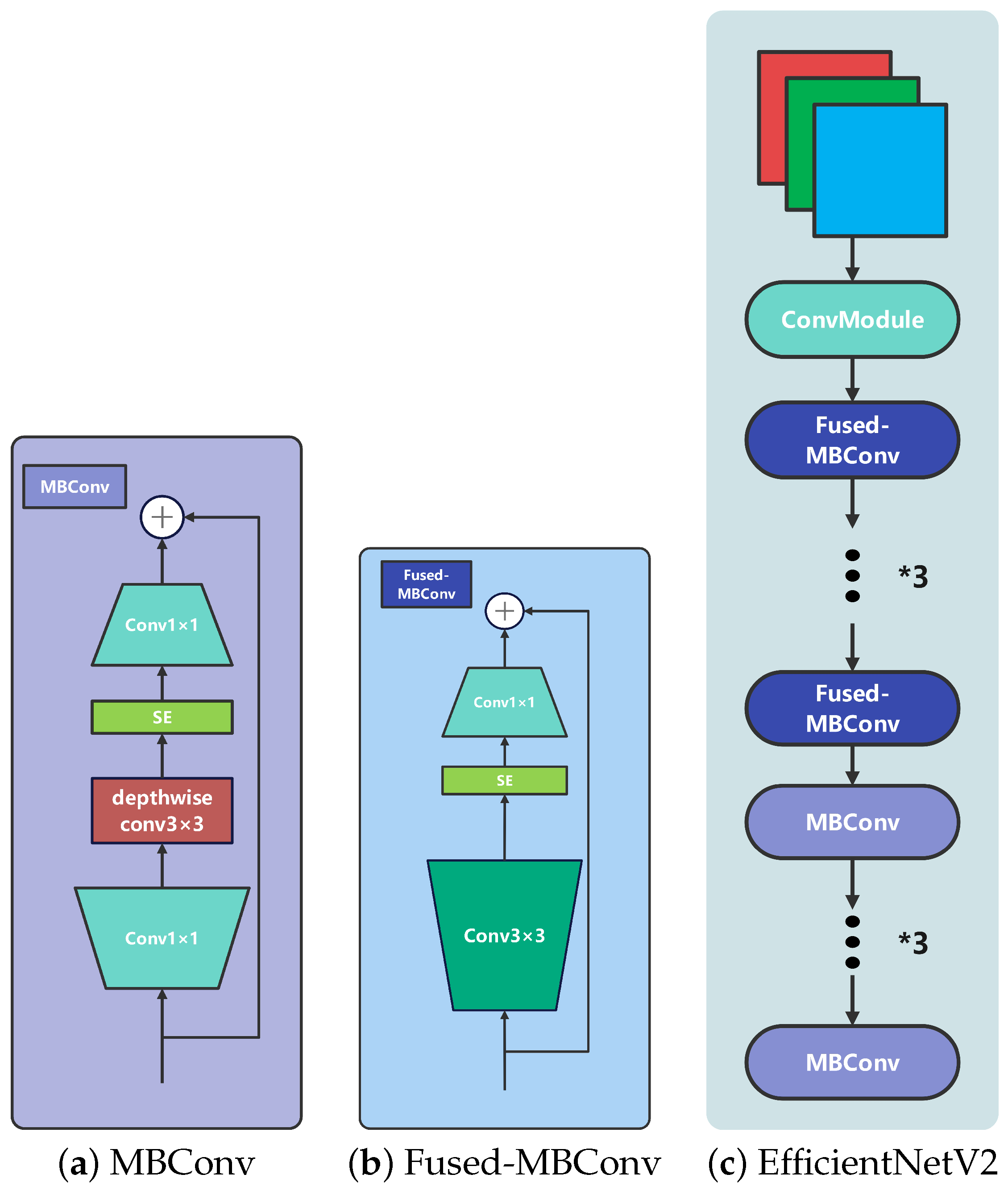
3.3. EfficientNetV2
3.4. C2fRepghost
4. Experiments
4.1. Experimental Setup
4.2. Training Parameters
4.3. Evaluation Metrics
4.4. Dataset Design
4.5. Selection of Baseline Network Models
4.5.1. High-Resolution Image Real-Time Dehazing Algorithm 4KDehazing
4.5.2. Experiments Related to YOLOv8n
4.6. Experiments on Object Detection Algorithms in Aluminum Electrolysis Smoke Scenarios
4.6.1. Backbone Comparison Experiment
4.6.2. Neck Comparison Experiment
4.6.3. Comparison with Lightweight Object Detection Models and Ablation Study
4.7. Comparison with State-of-the-Arts
4.8. Comparative Experiment on the Detection Effect of Different Categories of Aluminum Electrolytic Operation Tool
4.9. Visualization Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the Computer Vision & Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1956–1963. [Google Scholar] [CrossRef]
- Zhu, Q.; Mai, J.; Shao, L. A Fast Single Image Haze Removal Algorithm Using Color Attenuation Prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar] [CrossRef]
- Dong, H.; Pan, J.; Xiang, L.; Hu, Z.; Zhang, X.; Wang, F.; Yang, M.-H. Multi-Scale Boosted Dehazing Network with Dense Feature Fusion. arXiv 2020, arXiv:2004.13388. [Google Scholar]
- Shao, Y.; Li, L.; Ren, W.; Gao, C.; Sang, N. Domain Adaptation for Image Dehazing. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision & Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2805–2814. [Google Scholar] [CrossRef]
- Zheng, Z.; Ren, W.; Cao, X.; Hu, X.; Wang, T.; Song, F.; Jia, X. Ultra-High-Definition Image Dehazing via Multi-Guided Bilateral Learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE/CVF Conference on Computer Vision & Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Wang, Y.; Liu, X.; Zhao, Q.; He, H.; Yao, Z. Target Detection for Construction Machinery Based on Deep Learning and Multisource Data Fusion. IEEE Sens. J. 2023, 23, 11070–11081. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, Z.; Hammad, A. Automated excavators activity recognition and productivity analysis from construction site surveillance videos. Autom. Constr. 2020, 110, 103045. [Google Scholar] [CrossRef]
- Golcarenarenji, G.; Martinez-Alpiste, I.; Wang, Q.; Alcaraz-Calero, J.M. Machine-learning-based top-view safety monitoring of ground workforce on complex industrial sites. Neural Comput. Appl. 2022, 34, 4207–4220. [Google Scholar] [CrossRef]
- Hao, F.; Zhang, T.; He, G.; Dou, R.; Meng, C. CaSnLi-YOLO: Construction site multi-target detection method based on improved YOLOv5s. Meas. Sci. Technol. 2024, 35, 085202. [Google Scholar] [CrossRef]
- Kim, H.; Kim, H.; Hong, Y.W.; Byun, H. Detecting Construction Equipment Using a Region-Based Fully Convolutional Network and Transfer Learning. J. Comput. Civ. Eng. 2018, 32, 04017082. [Google Scholar] [CrossRef]
- Jiang, T.; Liu, G.; Zhang, Q.; Zeng, Z.; Cheng, S.; Zhang, J.; Zhang, Y. Obstacle Detection and Path Planning for Intelligent Overhead Cranes Using Dual 3D LiDARs in a Brewing Environment. In Proceedings of the 2022 12th International Conference on CYBER Technology in Automation, Control, and Intelligent Systems (CYBER), Baishan, China, 27–31 July 2022; pp. 289–294. [Google Scholar]
- Sjöberg, I. Modelling and Fault Detection of an Overhead Travelling Crane System. Master’s Thesis, Linköping University, Automatic Control, Linköping, Sweden, 2018. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In European Conference on Computer Vision—ECCV 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Wang, T.; Yuan, L.; Chen, Y.; Feng, J.; Yan, S. Pnp-detr: Towards efficient visual analysis with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 4661–4670. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1904–1916. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6154–6162. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2020, 128, 642–656. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Meimetis, D.; Daramouskas, I.; Perikos, I.; Hatzilygeroudis, I. Real-time multiple object tracking using deep learning methods. Neural Comput. Appl. 2023, 35, 89–118. [Google Scholar] [CrossRef]
- Gai, R.; Chen, N.; Yuan, H. A detection algorithm for cherry fruits based on the improved YOLO-v4 model. Neural Comput. Appl. 2023, 35, 13895–13906. [Google Scholar] [CrossRef]
- Alaftekin, M.; Pacal, I.; Cicek, K. Real-time sign language recognition based on YOLO algorithm. Neural Comput. Appl. 2024, 36, 7609–7624. [Google Scholar] [CrossRef]
- Zuiderveld, K. Contrast Limited Adaptive Histogram Equalization. In Graphics Gems IV; Academic Press: San Diego, CA, USA, 1994; pp. 474–485. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1397–1409. [Google Scholar] [CrossRef]
- Makkar, D.; Malhotra, M. Single Image Haze Removal Using Dark Channel Prior. Int. J. Adv. Trends Comput. Sci. Eng. 2016, 33, 2341–2353. [Google Scholar] [CrossRef]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. DehazeNet: An End-to-End System for Single Image Haze Removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. AOD-Net: All-in-One Dehazing Network. In Proceedings of the 2017 IEEE/CVF International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4770–4778. [Google Scholar]
- Chen, W.T.; Ding, J.J.; Kuo, S.Y. PMS-Net: Robust Haze Removal Based on Patch Map for Single Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11681–11689. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Chen, C.; Guo, Z.; Zeng, H.; Xiong, P.; Dong, J. RepGhost: A Hardware-Efficient Ghost Module via Re-parameterization. arXiv 2022, arXiv:2211.06088. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision & Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. GridDehazeNet: Attention-Based Multi-Scale Network for Image Dehazing. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7314–7323. [Google Scholar] [CrossRef]
- Dong, H.; Pan, J.; Xiang, L.; Hu, Z.; Zhang, X.; Wang, F.; Yang, M.-H. Multi-scale boosted dehazing network with dense feature fusion. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2157–2167. [Google Scholar]
- Liu, X.; Peng, H.; Zheng, N.; Yang, Y.; Hu, H.; Yuan, Y. Efficientvit: Memory efficient vision transformer with cascaded group attention. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 14420–14430. [Google Scholar]
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 10096–10106. [Google Scholar]




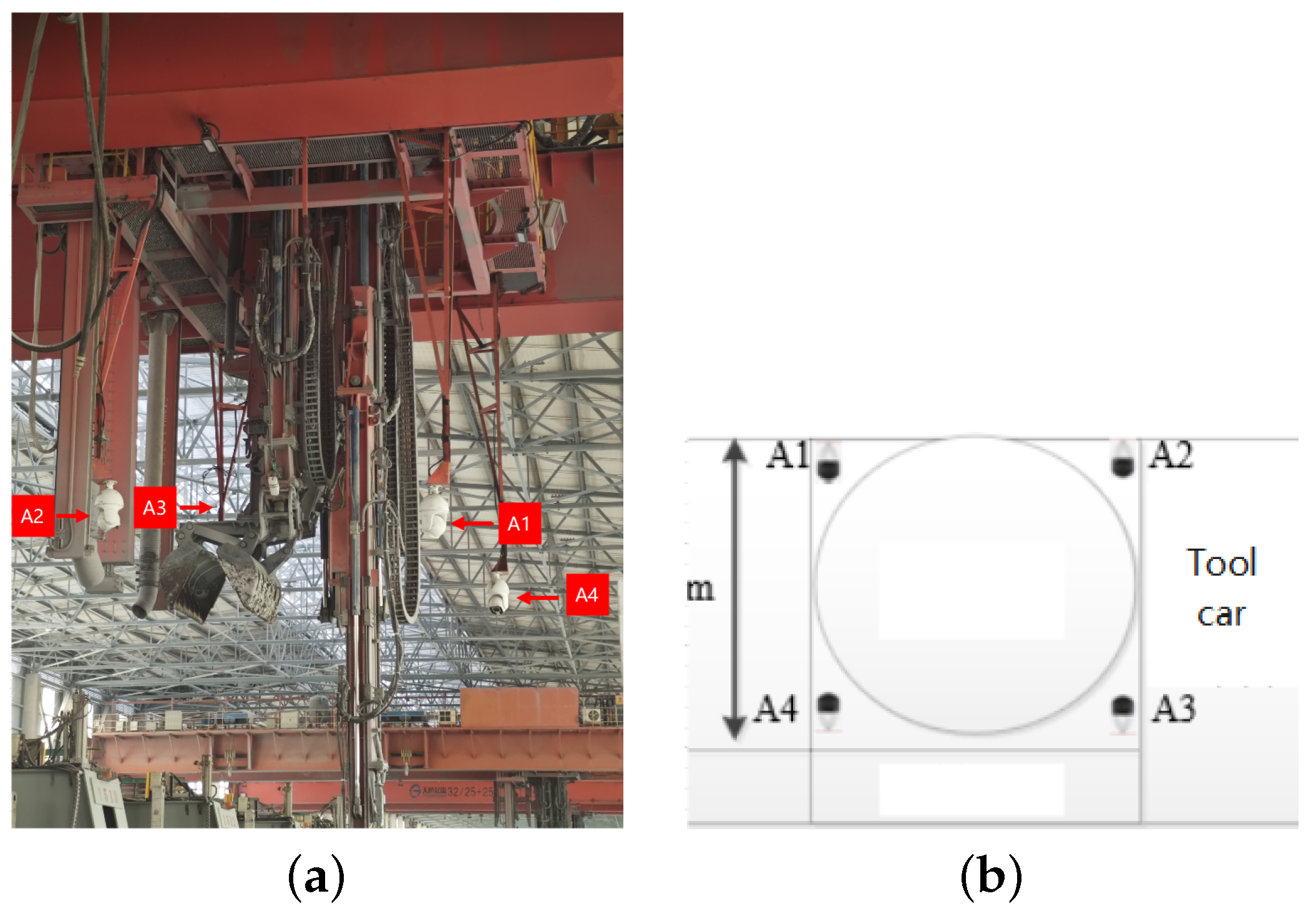



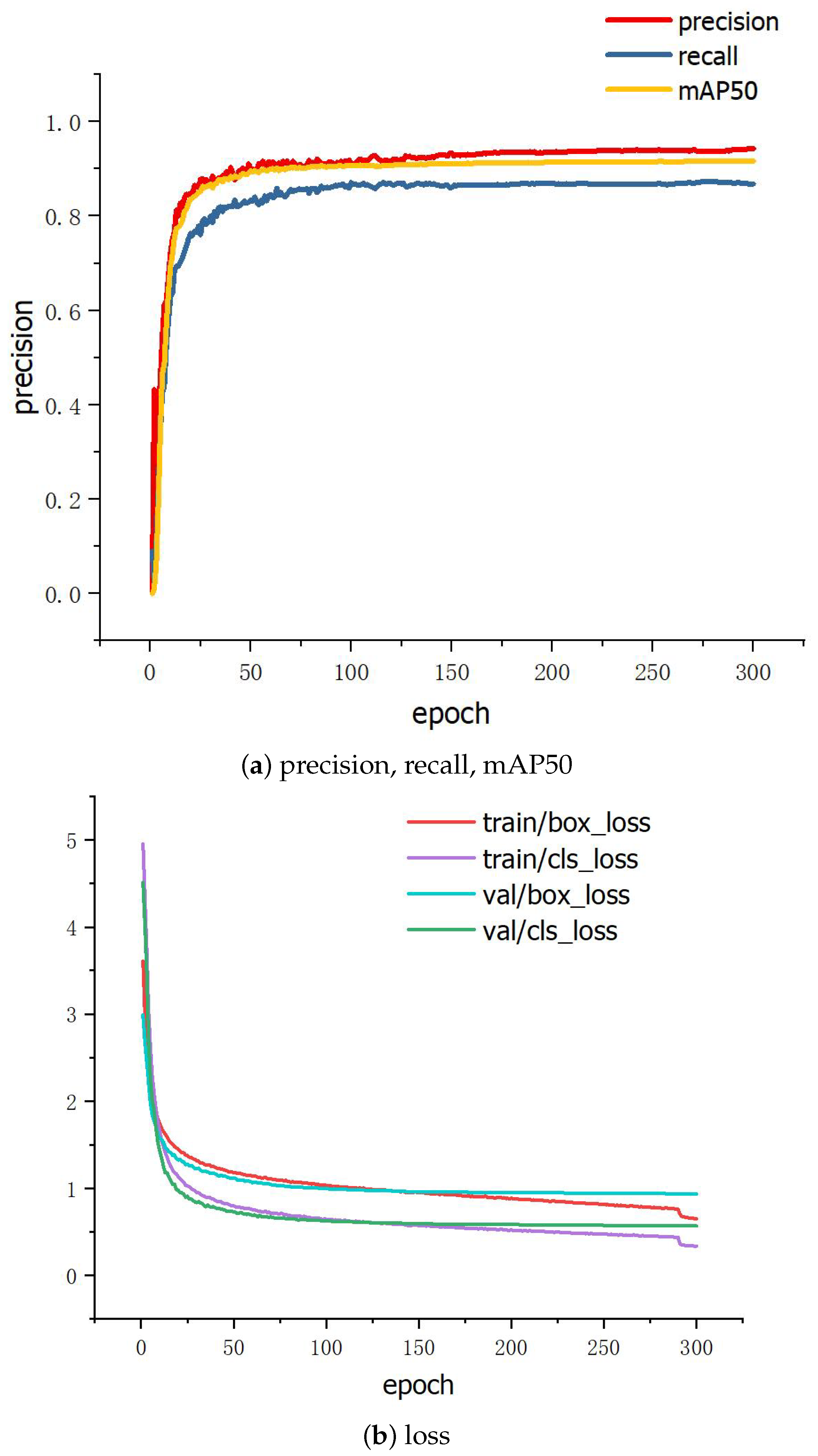


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Laboratory Setting | Configuration Information |
|---|---|---|
| 1 | CPU | AMD Ryzen 9 7950X 16-Core Processor 4.50 GHz |
| 2 | GPU | NVIDIA RTX4080 16 G |
| 3 | Operating System | Windows 11 |
| 4 | RAM | 32 GB |
| 5 | Programming Language | Python 3.11.5 |
| 6 | Deep Learning Framework | PyTorch 2.11 Torchvision 0.16.1 |
| 7 | CUDA | CU11.8 |
| Models | PSNR | Time |
|---|---|---|
| DA | 16.86 | - |
| PMS | 17.78 | - |
| GridDehazeNet | 16.66 | - |
| MSBDN | 17.76 | - |
| AOD | 15.10 | 34 ms |
| DehazeNet | 17.57 | 105 ms |
| 4KDehazing | 18.43 | 16 ms |
| Models | FLOPs/G | Parameters/M |
|---|---|---|
| YOLOv8n(baseline) | 8.1 | 3.01 |
| +EfficientVit | +2.0 | +1.00 |
| +EfficientNetV2 | −5.4 | −0.51 |
| +C2frepghost | −1.1 | −0.40 |
| +Ghostnet | −3.1 | −1.30 |
| +Ghostnet & C2frepghost | −2.3 | −1.06 |
| ours | −5.6 | −0.92 |
| Models | FLOPs/G | Parameters/M |
|---|---|---|
| YOLOv8n(baseline) | 8.1 | 3.01 |
| +Ghostnet(C3ghost) | −1.3 | −0.69 |
| +C2fFaster | −1.7 | −0.71 |
| +C2frepghost | −1.1 | −0.40 |
| ours | −5.6 | −0.92 |
| Models | mAP (%) | FLOPs/G | Parameters/M | Precision (%) | Recall (%) |
|---|---|---|---|---|---|
| YOLOv8n(baseline) | 78.6 | 8.1 | 3.01 | 83.3 | 84.1 |
| YOLOv8n-ghost | 75.9 | 5.0 | 1.71 | 83.0 | 69.8 |
| YOLOv8n-c2fRepghost | 80.2 | 7.3 | 2.61 | 82.9 | 75.3 |
| YOLOv8n-EfficientVit | 76.9 | 10.1 | 4.01 | 83.5 | 70.2 |
| YOLOv8n-EfficientNetV2 | 72.7 | 2.7 | 2.50 | 79.8 | 66.8 |
| YOLOv8n-ghost-c2freghost(neck) | 79.4 | 6.8 | 2.30 | 82.7 | 75.1 |
| YOLOv8n-ghost-c2freghost(backbone) | 79.9 | 5.8 | 1.95 | 83.6 | 74.3 |
| YOLOv8n-EfficientNetV2-c2fRepghost | 71.7 | 2.5 | 2.09 | 81.5 | 65.1 |
| YOLOv8n-Al-Dehazing(ours) | 89.7 | 2.5 | 2.09 | 91.0 | 83.4 |
| EfficientNetV2 | C2freghost | FLOPs/G | Parameters/M | Precision (%) |
|---|---|---|---|---|
| 8.1 | 3.01 | 83.3 | ||
| ✓ | 2.7 | 2.50 | 79.8 | |
| ✓ | 6.8 | 2.30 | 82.7 | |
| ✓ | ✓ | 2.5 | 2.09 | 81.5 |
| Models | mAP % | FLOPs/G | Parameters/M | Precision (%) | Recall (%) | FPS |
|---|---|---|---|---|---|---|
| YOLOv3 | 84.3 | 193.9 | 120.50 | 86.9 | 78.8 | 55.0 |
| YOLOv5n | 78.3 | 7.1 | 2.50 | 82.6 | 72.9 | 100.0 |
| YOLOv6n | 83.1 | 11.8 | 4.23 | 86.5 | 77.0 | 84.6 |
| YOLOv8n | 78.6 | 8.1 | 3.01 | 83.3 | 84.1 | 104.2 |
| YOLOv8s | 82.4 | 28.5 | 11.12 | 85.2 | 78.1 | 78.5 |
| YOLOv8m | 83.4 | 78.7 | 25.85 | 85.1 | 77.6 | 55.0 |
| YOLOv8l | 84.3 | 164.9 | 43.61 | 84.5 | 79.8 | 32.1 |
| YOLOv8x | 83.4 | 257.4 | 68.13 | 85.6 | 77.5 | 16.7 |
| RT-DETR | 80.9 | 103.5 | 32.00 | 82.4 | 79.0 | 27.8 |
| DINO-4scale | 71.9 | 279.0 | 47.00 | 74.0 | 70.2 | - |
| Deformable-DETR | 0.10 | 173.0 | 40.00 | 0.0 | 3.2 | - |
| YOLOv8n-Al-Dehazing | 89.7 | 2.5 | 2.09 | 91.0 | 83.4 | 120.4 |
| Tools Type | YOLOv8n (AP%) | YOLOv8n-Al-Dehazing (AP%) |
|---|---|---|
| Anode grabbing rod | 91.2 | 97.3 |
| Feeding Pipe | 84.3 | 86.3 |
| Excavator Bucket | 95.1 | 98.4 |
| Head of Crust Breaker | 85.8 | 95.4 |
| End of Crust Breaker | 80.4 | 96.3 |
| Crust Breaker | 75.5 | 96.2 |
| Anode Stem | 61.6 | 92.3 |
| Spent Anode | 69.0 | 73.9 |
| New Anode | 59.7 | 83.1 |
| Person | 83.3 | 77.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, Y.; Long, Y.; Li, X.; Cai, Y. YOLOv8n-Al-Dehazing: A Robust Multi-Functional Operation Terminals Detection for Large Crane in Metallurgical Complex Dust Environment. Information 2025, 16, 229. https://doi.org/10.3390/info16030229
Pan Y, Long Y, Li X, Cai Y. YOLOv8n-Al-Dehazing: A Robust Multi-Functional Operation Terminals Detection for Large Crane in Metallurgical Complex Dust Environment. Information. 2025; 16(3):229. https://doi.org/10.3390/info16030229
Chicago/Turabian StylePan, Yifeng, Yonghong Long, Xin Li, and Yejing Cai. 2025. "YOLOv8n-Al-Dehazing: A Robust Multi-Functional Operation Terminals Detection for Large Crane in Metallurgical Complex Dust Environment" Information 16, no. 3: 229. https://doi.org/10.3390/info16030229
APA StylePan, Y., Long, Y., Li, X., & Cai, Y. (2025). YOLOv8n-Al-Dehazing: A Robust Multi-Functional Operation Terminals Detection for Large Crane in Metallurgical Complex Dust Environment. Information, 16(3), 229. https://doi.org/10.3390/info16030229