As machine learning (ML) and artificial intelligence (AI) are rapidly proliferating in many aspects of decision-making in society, there is growing concern regarding their ethical use and their potential to perpetuate existing racial biases, as highlighted in predictive policing [
1,
2], in mortgage lending practices [
3], in financial services [
4] and in healthcare [
5,
6,
7,
8,
9]. At the intersection of health, machine learning and fairness, a comprehensive review [
10] of the ethical considerations that arise during the model development of machine learning in health has been laid out in five stages, namely problem selection, data collection, outcome definition, algorithm development and post-deployment considerations, the latter two of which are the main focus of this present research. For each of these five stages, there are considerations for machine learning to not only mitigate and/or prevent the exacerbation of existing social injustices, but also to attempt to prevent the creation of new ones. First, interest and available funding influence the selection of a research problem and this, together with the lack of diversity in the scientific workforce, leads to the exacerbation of existing global, racial and gender injustices [
11,
12,
13]. Second, biases in data collection arise from two processes that result in a loss of data. On one hand, the type of collected data has been shown to suffer, at varying degrees, from challenges and limitations, as illustrated for randomized controlled trials [
14,
15,
16], electronic health records [
17,
18,
19] and administrative health records [
20,
21]. On the other hand, historically underserved groups, which include low- and middle-income nationals [
22,
23], transgender and gender-nonconforming individuals [
24], undocumented immigrants [
25] and pregnant women [
26,
27], are often underrepresented, misrepresented or missing from the health data that inform consequential health policy decisions. The third stage in the model pipeline is outcome definition, which may appear to be a straightforward healthcare task—for example, defining whether a patient has a disease—but, surprisingly, can be skewed by the prevalence of such disease and the way that it manifests in some patient populations. One such instance may occur during clinical diagnosis. For example, the outcome label for the development of cardiovascular disease could be defined through the occurrence of specific phrases in the clinical notes. However, women can manifest symptoms of acute coronary syndrome differently [
28] and receive delayed care as a result [
29]. In addition, ambiguities occur as a result of diagnosis codes being leveraged for billing purposes, rather than for clinical research [
30]. Another instance in which outcome definition can lead to biases and the exacerbation of inequities is the use of non-reliable proxies to account for and predict a health outcome given that socioeconomic factors affect access to both healthcare and financial resources. The fourth stage in the model pipeline is algorithm development per se. Even when all considerations and precautions have been taken into account in the previous three stages to minimize the infiltration of biases, noise and errors in the data, the choice of the algorithm is not neutral and often is a source of obstruction to the ethical deployment of the algorithm. The crucial factors in model development are understanding confounding, feature selection, parameter tuning, performance metric selection and group fairness definition. Indeed, confounding features are those features that influence both the independent and dependent variables, and, as the vast majority of models learn patterns based on observed correlations within the training dataset, even when such correlations do not occur in the testing dataset, it is critical to account for confounding features, as illustrated in classification models designed to detect hair color [
31] and in predicting the risk of pneumonia and hospital 30-day readmission [
32]. Moreover, blindly incorporating factors like race and ethnicity, which are increasingly available due to the large-scale digitization of electronic health records, may exacerbate inequities for a wide range of diagnoses and treatments [
33]. Therefore, it is crucial to carefully select the model’s features and to consider the human-in-the-loop framework, where the incorporation of automated procedures is blended with investigator knowledge and expertise [
34]. Another crucial component of algorithm development is the tuning of the parameters, which can be set a priori, selected via cross-validation or extracted from a default setting from software. These methods that can lead to the overfitting of the model to the training dataset and a loss of generalizability to the target population, the latter of which is a central concern for ethical machine learning. To assess and evaluate a model, many performance metrics are commonly used, such as the area under the receiver operating characteristic curve (AUC) and area under the precision–recall curve (AUPRC) for regression models, on one hand, and the accuracy, true positive rate and precision for classification models, on the other hand. It is important to use a performance metric that reflects the intended use case and to be aware of potential misleading conclusions when using so-called objective metrics and scores [
33]. Finally, the fifth stage of the model pipeline is the post-deployment of the model in a clinical, epidemiological or policy service. Robust deployment requires careful performance reporting and the auditing of generalizability, documentation and regulation. Indeed, it is important to measure and address the downstream impacts of models through auditing for bias and the examination of clinical impacts [
35]. It is also crucial to evaluate and audit the deployment of its generalization, as any shift in the data distribution can significantly impact model performance when the settings for development and deployment differ, as illustrated in chest X-ray models [
36,
37,
38]. While some algorithms have been proposed to account for distribution shifts post-deployment [
39], their implementation suffers from significant limitations due to the requirement for the specification of the nature or amount of distributional shift, thus requiring tedious periodic monitoring and auditing. The last two components for the ethical post-deployment of machine learning are the establishment of clear and insightful model and data documentation and adherence to best practices and compliance with regulations. In addition, the introduction of complex machine learning models can sometimes lead to “black box” solutions, where the decision-making process is not transparent. Enhancing the clinical interpretability of the algorithms, possibly through the integration of explainable AI (XAI) techniques, could increase their acceptance among healthcare professionals. Providing insights into how and why predictions are made can aid in clinical decision-making, fostering trust and facilitating the adoption of these models in medical practice.
With the algorithm development and post-deployment considerations of the five-stage model pipeline [
10] on one hand, and with the improvement of the generalizability recommended in [
40] on the other hand, this research uses the well-known Framingham coronary heart disease data as a case study and focuses on the comparison of several classification algorithms, in a paired design setting, using electronic health records, with the goal of identifying a methodology that is not only ethical, robust and understandable by practitioners or community members but also generalizable. While regression models for dichotomous observations are widely used by modelers, the probability outcome for patient-level data may not be insightful or helpful to determine whether a given patient should undergo further intervention, i.e., whenever the response of a practitioner to a patient (or family member) is expected to be a binary response rather than a vague probability statement. Despite the fact that this research was conducted before the publication of [
40], the relevance of our comparative analysis is its response to one of the limiting factors highlighted in [
40], which is the lack of performance benchmarking against conventional predictive models, with the majority of the atrial fibrillation studies (10/16) utilizing only one model architecture, without comparing the performance of machine learning models against baseline models such as logistic regression. Our study compares several machine learning algorithms in a paired design framework with a high number of cross-validation steps across several stratified training/testing scenarios, using the same data and set of variables. In
Section 2, we recall the historical context of the Framingham Heart Study, and we then describe the seven predictors and the four training/testing scenarios used in this comparative analysis. We also recall the definitions of commonly used performance metrics for classification algorithms, i.e., the accuracy, true positive rate (sensitivity) and true negative rate (specificity). We then make the distinction between positive precision (resp., observed prevalence), which is simply called precision (resp., prevalence) in the literature, and negative precision (resp., predicted prevalence), which we introduce and define. Finally, we introduce the classification performance matrix as an extension of the confusion matrix with these seven performance metrics (accuracy, true positive/negative rates, positive/negative precision and observed/predicted prevalence) as a comprehensive and transparent means of assessing and comparing the machine learning algorithms. In
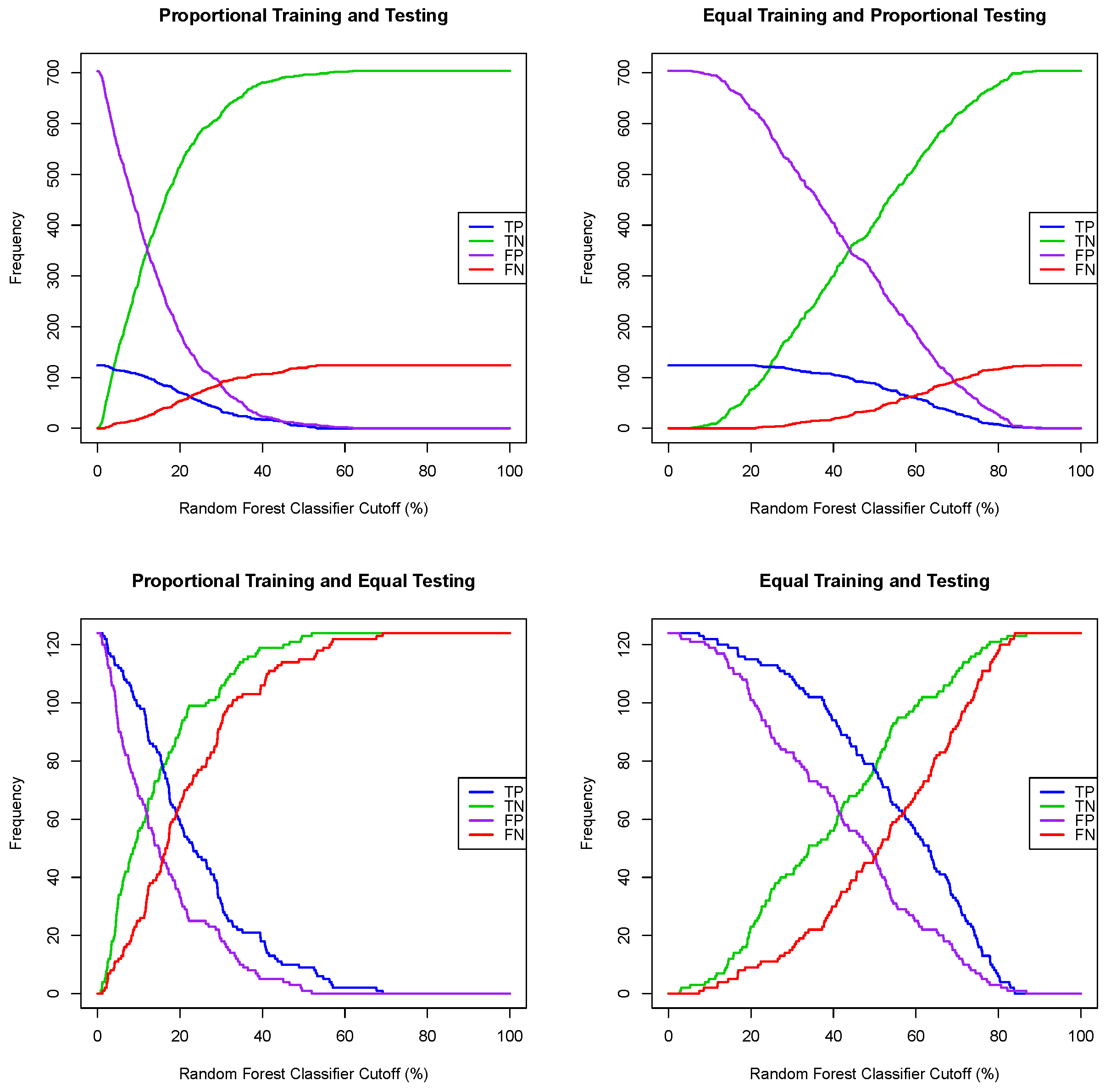
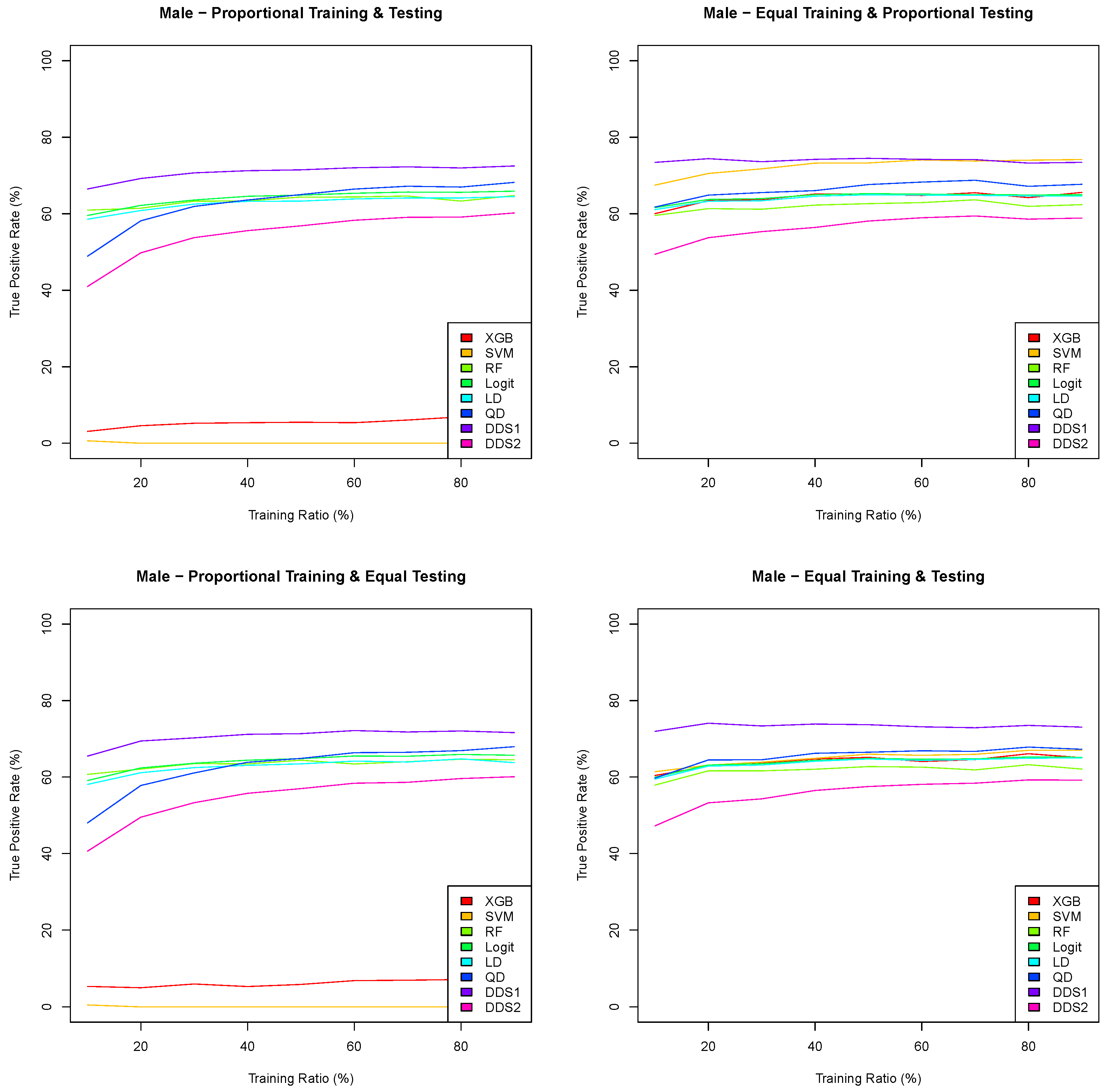
Section 3, we not only show that the naive choice of a 50% probability cutoff to convert a regression algorithm for dichotomous observation into a classification algorithm leads to misclassification, but we show also how a balanced and optimal probability cutoff can be determined to effectively convert logistic [
41] and random forest [
42] regression models into classifiers. We investigate also the effect of using the significant variables of a logistic regression model on the classification performance. We then compare the performance of eight classification algorithms, two of which are widely used supervised machine learning algorithms, namely extreme gradient boosting (XGB) [
43] and support vector machine (SVM) [
44], together with the logistic and random forest classifiers and two uncommonly used supervised machine functions, i.e., linear and quadratic discriminant functions [
45]. We introduce two different combinations of the linear and quadratic discriminant functions into two scoring functions, which we call the double discriminant scoring of types 1 and 2. Using a paired design setup, we perform a sampling distribution analysis for these eight classification algorithms under four different training/testing scenarios and for varying training/testing ratios. We determine, from the comparison of the performance sampling distributions, the algorithm that consistently outperforms the others and is the least sensitive to distributional shifts. We then lay out and illustrate a methodology to extract an optimal variable hierarchy, i.e., a sequence of variables that provides the most robust and most generalizable variable selection for the classification algorithm for a given performance metric. For instance, if the optimal variable hierarchy for a classification algorithm and a performance metric is a sequence of two variables, then the first variable is the optimal single variable among the set of all features, the first and second variables constitute the optimal pair of variables among all pairs of features and the inclusion of any extra feature in this two-variable hierarchy would diminish the performance metric. We show in particular that the optimal variable hierarchy of the double discriminant scoring of type 1, with respect to the true positive rate and applied to the Framingham coronary heart data, satisfies the Bellman principle of optimality, leading then to the reduction of the sampling distribution tests from
iterations to at most
, where
p is the number of variables (features). This methodology is applied to the entire Framingham CHD data and to both the male and female Framingham CHD data. Finally, in
Section 4, we discuss the findings of the comparative analyses and summarize the strengths and limitations of our study.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}