

A Cloud-Based Deep Learning Framework for Downy Mildew Detection in Viticulture Using Real-Time Image Acquisition from Embedded Devices and Drones

 ,
,  ,
,  and
and 
Abstract
1. Introduction
2. Materials and Methods
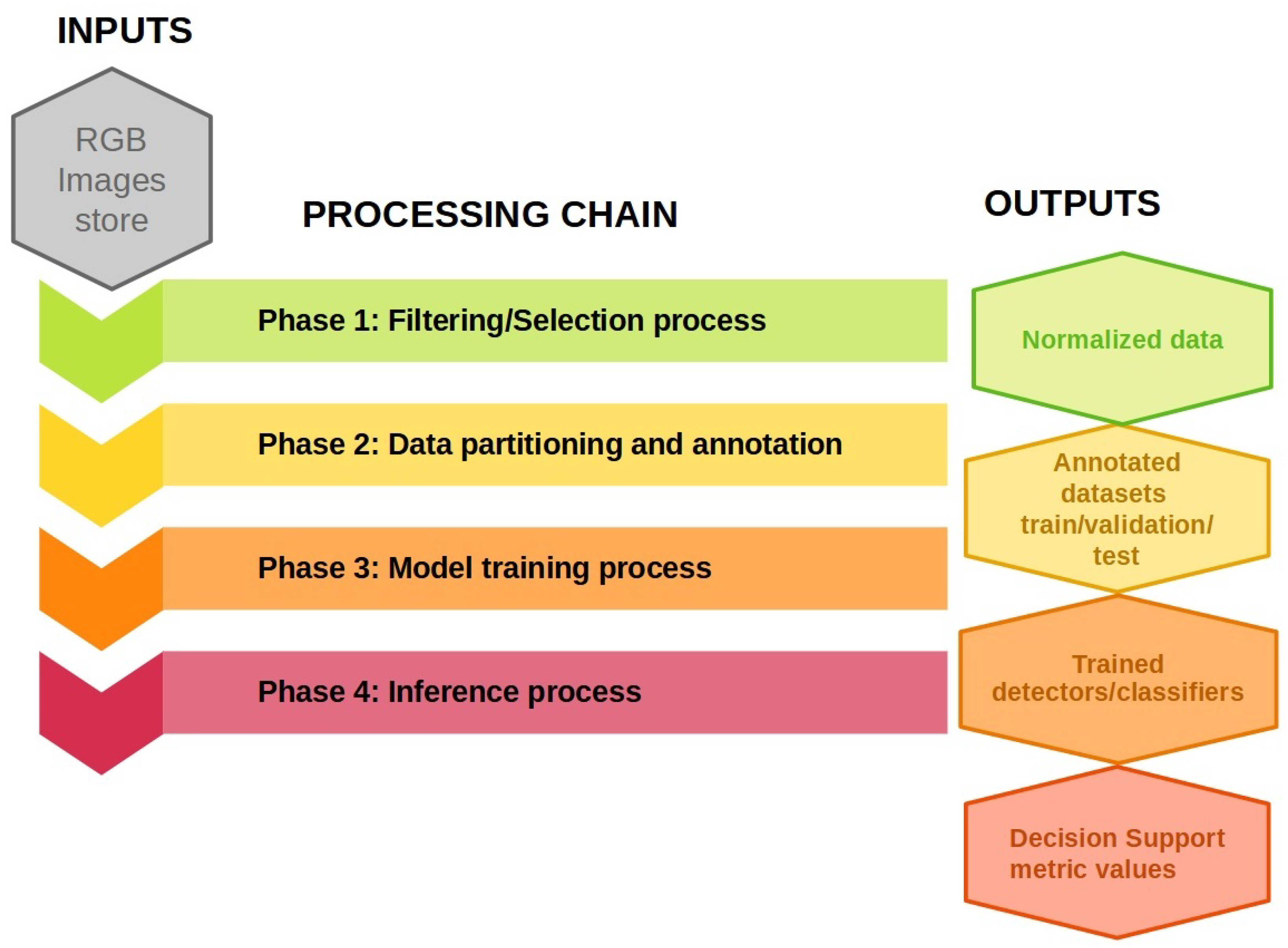
2.1. Proposed Object Detection Framework
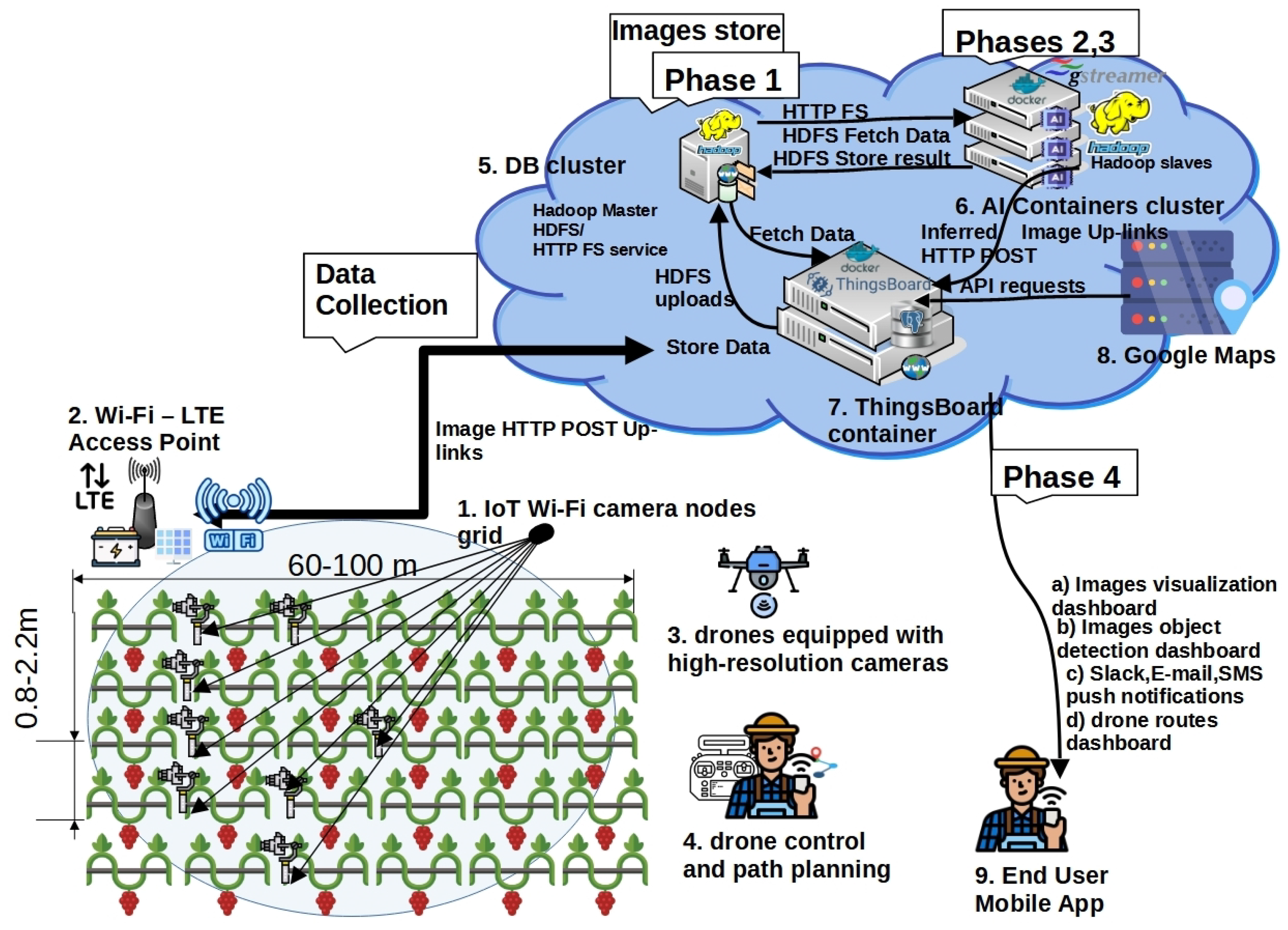
2.2. Proposed High-Level System Architecture Incorporating the Framework
- Aerial LiDaR mapping needs to be performed in the surveyed field area using UAVs as a preprocessing step to create a 3D survey representation. LiDaR instruments can measure the Earth’s surface at sampling pulse rates greater than 200 KHz, offering a point cloud of highly accurate georeferenced elevation points.
- UAVs’ aerial RTK GPS receivers that receive the RTCM correction stream must be utilized. Then, point locations with 1–3 cm accuracy in real time (nominal) must be provided to georeferenced maps or APIs.
- The fundamental vertical accuracy (FVA) of the open data areas measured must be at a high confidence level above 92%.
- The absolute point altitude accuracies of the acquired LiDaR system elevation points must be in the range of 10–20 cm to offer drone flights close to the vines.
- UAV mappings of vegetation areas need to be performed with the concurrent utilization of multispectral cameras in the near-infrared band of 750–830 nm so as to detect and exclude non viticulture areas of low or high refractivity by performing post processing NDVI metric calculations [49] on map layers.
- Using EU-DEM [11] as a base altitude reference, appropriate altitude corrections must be made to the GIS path-planning map grid. Then, the surveying drones need to perform periodic HTTP requests to acquire sampling altitude corrections. If viticulture fields’ surface altitude variances are no more than 0.5–1 m in grid surface areas of at least 1–5 km, then with the exception of dense plantation areas (such as forests, provided by NDVI measurements), the altitude values can be set as a fixed vertical parameter value of drone altitude offset for the specific survey areas.
3. Experimental Scenario
Evaluation Metrics
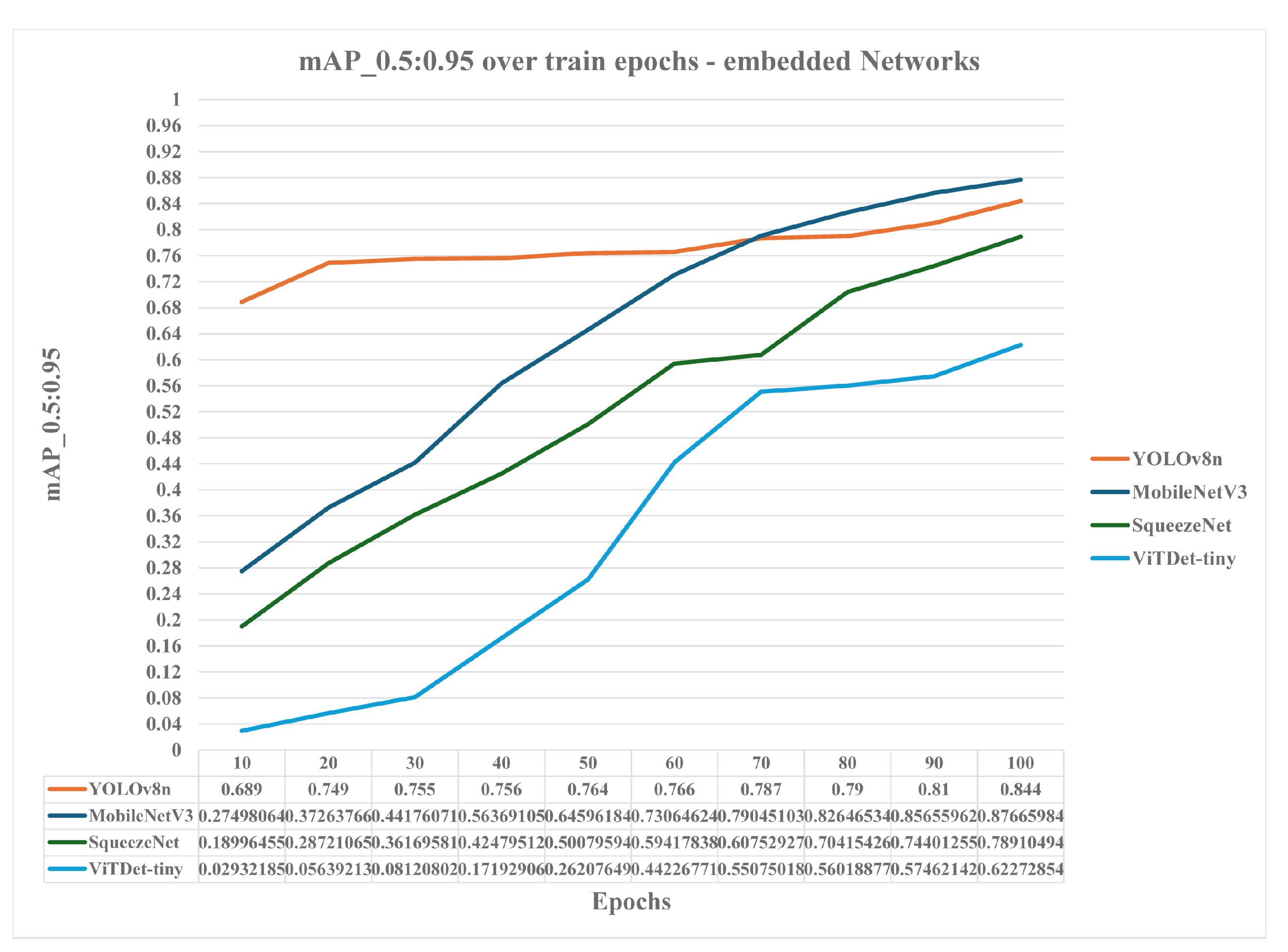
4. Experimental Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AS | application server |
| CNN | convolutional neural network |
| CPU | central processing unit |
| DSS | decision support system |
| EIRP | equivalent isotropic radiated power |
| EXIF | exchangeable image file format |
| GPS | Global Positioning System |
| FVA | fundamental vertical accuracy |
| HDFS | Hadoop Distributed File System |
| HTML | hypertext markup language |
| IoU | intersection over union |
| LTE | telecommunication systems’ long-term evolution (4G) |
| NTP | network time protocol |
| PSRAM | pseudostatic memory - RAM |
| R-CNN | Regions with CNN features |
| RPN | Region Proposal Network |
| RAM | random access memory |
| RTC | real-time clock |
| RTCM | Radio Technical Commission for Maritime |
| PV | photovoltaic cell |
| SSD | Single Shot Detector, object detection algorithm |
| SPI | synchronous peripheral interface |
| UID | unique identification |
| Vitis Vinifera | common grape vine varieties in EU |
| Plasmopara Viticola (P. Viticola) | downy mildew |
| UAV | unoccupied aerial vehicle |
| YOLO | You Only Look Once object detection algorithm |
References
- Sapaev, J.; Fayziev, J.; Sapaev, I.; Abdullaev, D.; Nazaraliev, D.; Sapaev, B. Viticulture and wine production: Challenges, opportunities and possible implications. E3S Web Conf. 2023, 452, 01037. [Google Scholar] [CrossRef]
- Peladarinos, N.; Piromalis, D.; Cheimaras, V.; Tserepas, E.; Munteanu, R.A.; Papageorgas, P. Enhancing Smart Agriculture by Implementing Digital Twins: A Comprehensive Review. Sensors 2023, 23, 7128. [Google Scholar] [CrossRef] [PubMed]
- Bove, F.; Savary, S.; Willocquet, L.; Rossi, V. Designing a modelling structure for the grapevine downy mildew pathosystem. Eur. J. Plant Pathol. 2020, 157, 251–268. [Google Scholar] [CrossRef]
- Velasquez-Camacho, L.; Otero, M.; Basile, B.; Pijuan, J.; Corrado, G. Current Trends and Perspectives on Predictive Models for Mildew Diseases in Vineyards. Microorganisms 2022, 11, 73. [Google Scholar] [CrossRef]
- Rossi, V.; Caffi, T.; Gobbin, D. Contribution of molecular studies to botanical epidemiology and disease modelling: Grapevine downy mildew as a case-study. Eur. J. Plant Pathol. 2013, 135, 641–654. [Google Scholar] [CrossRef]
- Caffi, T.; Gilardi, G.; Monchiero, M.; Rossi, V. Production and release of asexual sporangia in Plasmopara viticola. Phytopathology 2013, 103, 64–73. [Google Scholar] [CrossRef]
- Vanegas, F.; Bratanov, D.; Powell, K.; Weiss, J.; Gonzalez, F. A Novel Methodology for Improving Plant Pest Surveillance in Vineyards and Crops Using UAV-Based Hyperspectral and Spatial Data. Sensors 2018, 18, 260. [Google Scholar] [CrossRef]
- Li, Y.; Shen, F.; Hu, L.; Lang, Z.; Liu, Q.; Cai, F.; Fu, L. A Stare-Down Video-Rate High-Throughput Hyperspectral Imaging System and Its Applications in Biological Sample Sensing. IEEE Sens. J. 2023, 23, 23629–23637. [Google Scholar] [CrossRef]
- Lacotte, V.; Peignier, S.; Raynal, M.; Demeaux, I.; Delmotte, F.; Da Silva, P. Spatial–Spectral Analysis of Hyperspectral Images Reveals Early Detection of Downy Mildew on Grapevine Leaves. Int. J. Mol. Sci. 2022, 23, 10012. [Google Scholar] [CrossRef]
- Pithan, P.A.; Ducati, J.R.; Garrido, L.R.; Arruda, D.C.; Thum, A.B.; Hoff, R. Spectral characterization of fungal diseases downy mildew, powdery mildew, black-foot and Petri disease on Vitis vinifera leaves. Int. J. Remote Sens. 2021, 42, 5680–5697. [Google Scholar] [CrossRef]
- EU-DEM. EU-DEM-GISCO-Eurostat. 2023. Available online: https://ec.europa.eu/eurostat/web/gisco/geodata/reference-data/elevation/eu-dem (accessed on 10 December 2023).
- Abdelghafour, F.; Keresztes, B.; Germain, C.; Da Costa, J.P. In Field Detection of Downy Mildew Symptoms with Proximal Colour Imaging. Sensors 2020, 20, 4380. [Google Scholar] [CrossRef]
- Kontogiannis, S.; Asiminidis, C. A Proposed Low-Cost Viticulture Stress Framework for Table Grape Varieties. IoT 2020, 1, 337–359. [Google Scholar] [CrossRef]
- Zhang, Z.; Qiao, Y.; Guo, Y.; He, D. Deep Learning Based Automatic Grape Downy Mildew Detection. Front. Plant Sci. 2022, 13, 872107. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2014. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks. arXiv 2014. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. arXiv 2015. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2012; Volume 25, pp. 1097–1107. ISBN 978-1-62748-003-1. [Google Scholar]
- Muhammad, U.; Wang, W.; Chattha, S.P.; Ali, S. Pre-trained VGGNet Architecture for Remote-Sensing Image Scene Classification. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; Volume 1, pp. 1622–1627. [Google Scholar] [CrossRef]
- Bagaskara, A.; Suryanegara, M. Evaluation of VGG-16 and VGG-19 Deep Learning Architecture for Classifying Dementia People. In Proceedings of the 2021 4th International Conference of Computer and Informatics Engineering (IC2IE), Depok, Indonesia, 14 September 2021; Volume 1, pp. 1–4. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016. [Google Scholar] [CrossRef]
- Anwar, A. Difference between alexnet, vggnet, resnet and inception. Medium-Towards Data Sci. 2019. Available online: https://towardsdatascience.com/the-w3h-of-alexnet-vggnet-resnet-and-inception-7baaaecccc96 (accessed on 15 March 2021).
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2020. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv 2019. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. arXiv 2019. [Google Scholar] [CrossRef]
- Li, Y.; Mao, H.; Girshick, R.; He, K. Exploring Plain Vision Transformer Backbones for Object Detection. arXiv 2022. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision–ECCV, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science. Springer International Publishing: Berlin/Heidelberg, Germany, 2016. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, F.; Wang, L. Fruit Classification Model Based on Improved Darknet53 Convolutional Neural Network. In Proceedings of the 2020 International Conference on Intelligent Transportation, Big Data and Smart City (ICITBS), Vientiane, Laos, 11–12 January 2020; Volume 1, pp. 881–884. [Google Scholar] [CrossRef]
- Liu, H.; Sun, F.; Gu, J.; Deng, L. SF-YOLOv5: A Lightweight Small Object Detection Algorithm Based on Improved Feature Fusion Mode. Sensors 2022, 22, 5817. [Google Scholar] [CrossRef]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. RTMDet: An Empirical Study of Designing Real-Time Object Detectors. arXiv 2022. [Google Scholar] [CrossRef]
- e Hani, U.; Munir, S.; Younis, S.; Saeed, T.; Younis, H. Automatic Tree Counting from Satellite Imagery Using YOLO V5, SSD and UNET Models: A case study of a campus in Islamabad, Pakistan. In Proceedings of the 2023 3rd International Conference on Artificial Intelligence (ICAI), Wuhan, China, 17–19 November 2023; pp. 88–94. [Google Scholar] [CrossRef]
- Casado-García, A.; Heras, J.; Milella, A.; Marani, R. Semi-supervised deep learning and low-cost cameras for the semantic segmentation of natural images in viticulture. Precis. Agric. 2022, 23, 2001–2026. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the Computer Vision–ECCV, Online, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Cham, Swizerland, Lecture Notes in Computer Science. Springer: Singapore, 2018; pp. 833–851. [Google Scholar] [CrossRef]
- Hernández, I.; Gutiérrez, S.; Ceballos, S.; Iñíguez, R.; Barrio, I.; Tardaguila, J. Artificial Intelligence and Novel Sensing Technologies for Assessing Downy Mildew in Grapevine. Horticulturae 2021, 7, 103. [Google Scholar] [CrossRef]
- Boulent, J.; Beaulieu, M.; St-Charles, P.L.; Théau, J.; Foucher, S. Deep learning for in-field image-based grapevine downy mildew identification. In Precision Agriculture’19; Wageningen Academic Publishers: Wageningen, The Netherlands, 2019; p. 8689. [Google Scholar]
- Zendler, D.; Malagol, N.; Schwandner, A.; Töpfer, R.; Hausmann, L.; Zyprian, E. High-Throughput Phenotyping of Leaf Discs Infected with Grapevine Downy Mildew Using Shallow Convolutional Neural Networks. Agronomy 2021, 11, 1768. [Google Scholar] [CrossRef]
- Singh, V.K.; Taram, M.; Agrawal, V.; Baghel, B.S. A Literature Review on Hadoop Ecosystem and Various Techniques of Big Data Optimization. In Advances in Data and Information Sciences; Kolhe, M.L., Trivedi, M.C., Tiwari, S., Singh, V.K., Eds.; Lecture Notes in Networks and Systems; Springer: Singapore, 2018; pp. 231–240. [Google Scholar] [CrossRef]
- Mostafaeipour, A.; Jahangard Rafsanjani, A.; Ahmadi, M.; Arockia Dhanraj, J. Investigating the performance of Hadoop and Spark platforms on machine learning algorithms. J. Supercomput. 2021, 77, 1273–1300. [Google Scholar] [CrossRef]
- ThingsBoard. ThingsBoard Open-Source IoT Platform, 2019. Available online: https://thingsboard.io/ (accessed on 18 October 2020).
- Reis, D.; Piedade, B.; Correia, F.F.; Dias, J.P.; Aguiar, A. Developing Docker and Docker-Compose Specifications: A Developers’ Survey. IEEE Access 2022, 10, 2318–2329. [Google Scholar] [CrossRef]
- Kontogiannis, S.; Koundouras, S.; Pikridas, C. Proposed Fuzzy-Stranded-Neural Network Model That Utilizes IoT Plant-Level Sensory Monitoring and Distributed Services for the Early Detection of Downy Mildew in Viticulture. Computers 2024, 13, 63. [Google Scholar] [CrossRef]
- Bitharis, S.; Fotiou, A.; Pikridas, C.; Rossikopoulos, D. A New Velocity Field of Greece Based on Seven Years (2008–2014) Continuously Operating GPS Station Data. In International Symposium on Earth and Environmental Sciences for Future Generations; Freymueller, J.T., Sánchez, L., Eds.; International Association of Geodesy Symposia; Springer: Cham, Swizerland, 2018; pp. 321–329. [Google Scholar] [CrossRef]
- Rose, M.B.; Mills, M.; Franklin, J.; Larios, L. Mapping Fractional Vegetation Cover Using Unoccupied Aerial Vehicle Imagery to Guide Conservation of a Rare Riparian Shrub Ecosystem in Southern California. Remote Sens. 2023, 15, 5113. [Google Scholar] [CrossRef]
- labelImg Tool. 2018. Available online: https://github.com/HumanSignal/labelImg (accessed on 12 December 2021).
- Kumar, N. Big Data Using Hadoop and Hive; Mercury Learning and Information Inc.: Herndon, VA, USA, 2021; ISBN 978-1-68392-643-6. [Google Scholar]
- Newmarch, J. GStreamer. In Linux Sound Programming; Newmarch, J., Ed.; Apress: Berkeley, CA, USA, 2017; pp. 211–221. [Google Scholar] [CrossRef]
- Prasetiyo, B.; Alamsyah; Muslim, M.A.; Subhan; Baroroh, N. Automatic geotagging using GPS EXIF metadata of smartphone digital photos in tree planting location mapping. J. Phys. Conf. Ser. 2021, 1918, 042001. [Google Scholar] [CrossRef]
- Kaiming, H.; Xiangyu, Z.; Shaoqing, R.; Jian, S. Deep Residual Networks Repository. 2016. Available online: https://github.com/KaimingHe/deep-residual-networks (accessed on 23 September 2023).
- Roboflow (Version 1.0). 2022. Available online: https://roboflow.com (accessed on 15 March 2023).
- Torchvision Models-Torchvision 0.11.0 Documentation. 2023. Available online: https://pytorch.org/vision/0.11/models.html (accessed on 12 January 2023).
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLO. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 15 June 2023).
- Oracle Cloud Infrastructure ARM Compute. 2019. Available online: https://www.oracle.com/cloud/compute/arm/ (accessed on 10 September 2021).
- Padilla, R.; Passos, W.L.; Dias, T.L.B.; Netto, S.L.; da Silva, E.A.B. A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit. Electronics 2021, 10, 279. [Google Scholar] [CrossRef]
- Jiang, S.; Qin, H.; Zhang, B.; Zheng, J. Optimized Loss Functions for Object detection: A Case Study on Nighttime Vehicle Detection. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2022, 236, 1568–1578. [Google Scholar] [CrossRef]
- Sotirios, K. Debina Vineyard IoT Nodes Annotated Dataset v3. 2023. Available online: https://sensors.math.uoi.gr:3002/MCSL_Team/vitymildew (accessed on 13 March 2024).
- Iandola, F.N. SqueezeNet V.1.1. 2020. Available online: https://github.com/forresti/SqueezeNet/tree/master/SqueezeNet_v1.1 (accessed on 15 September 2023).
- Luke, M.K. EfficientNet PyTorch Implementation. 2019. Available online: https://github.com/lukemelas/EfficientNet-PyTorch (accessed on 15 September 2023).
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. MobileNetV3 Python Implementation. Available online: https://github.com/d-li14/mobilenetv3.pytorch (accessed on 15 September 2023).
- Ajayi, O.G.; Ashi, J.; Guda, B. Performance evaluation of YOLO v5 model for automatic crop and weed classification on UAV images. Smart Agric. Technol. 2023, 5, 100231. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. ViTDet model v.3. 2023. Available online: https://github.com/hyuse202/mmdet-vitdet (accessed on 15 September 2023).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Trained Model | JPEG Compressed Image Input Sizes (W × H, MB) | No Trainable Parameters | Estimated Model Sizes (MB) |
|---|---|---|---|
| ResNet-152 | (640 × 640, 0.49) | 199,874,714 | 980 |
| ResNet-101 | (640 × 640, 0.49) | 184,231,066 | 704 |
| YOLOv3-Darknet | (640 × 640, 0.49) | 84,364,442 | 338.5 |
| EfficientNet-b0 | (640 × 640, 0.49) | 84,141,782 | 337 |
| FRCNN-VGG16 | (640 × 640, 0.49) | 43,877,530 | 168 |
| ResNet-50 | (640 × 640, 0.49) | 41,304,286 | 159 |
| YOLOv5-small (YOLOv5s) | (640 × 640, 0.49) | 7,468,160 | 101.5 |
| SqueezeNet | (4128 × 4128, 3.6) | 29,876,890 | 98 |
| ViTDet-tiny | (4128 × 4128, 3.6) | 22,786,382 | 87 |
| MobileNetV3 | (4128 × 4128, 3.6) | 18,935,354 | 73 |
| YOLOv8-nano (YOLOv8n) | (4128 × 4128, 3.6) | 3,151,904 | 29.8 |
| Model | -20 Epochs | -50 Epochs | -100 Epochs |
|---|---|---|---|
| ResNet-152 | 0.9934 | 0.995 | 0.9951 |
| ResNet-101 | 0.989 | 0.995 | 0.995 |
| ResNet-50 | 0.65 | 0.92 | 0.9949 |
| EfficientNet-b0 | 0.29 | 0.68 | 0.868 |
| FRCNN-VGG16 | 0.9944 | 0.9949 | 0.995 |
| YOLOv3-Darknet | 0.26 | 0.78 | 0.94 |
| YOLOv5-small (YOLOv5s) | 0.92 | 0.92 | 0.96 |
| SqueezeNet | 0.558 | 0.783 | 0.981 |
| ViTDet-tiny | 0.16 | 0.55 | 0.901 |
| MobileNetV3 | 0.37 | 0.64 | 0.99 |
| YOLOv8-nano (YOLOv8n) | 0.86 | 0.91 | 0.94 |
| Model | Achieved Mean FPS | |
|---|---|---|
| ResNet-152 | 0.262 | 0.9476 |
| ResNet-101 | 0.321 | 0.9411 |
| ResNet-50 | 0.511 | 0.940 |
| FRCNN-VGG16 | 0.404 | 0.9106 |
| YOLOv3-Darknet | 0.591 | 0.633 |
| YOLOv5-small (YOLOv5s) | 1.28 | 0.812 |
| SqueezeNet | 1.645 | 0.789 |
| ViTDet-tiny | 0.517 | 0.622 |
| MobileNetV3 | 3.24 | 0.876 |
| YOLOv8-nano (YOLOv8n) | 2.08 | 0.84 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kontogiannis, S.; Konstantinidou, M.; Tsioukas, V.; Pikridas, C. A Cloud-Based Deep Learning Framework for Downy Mildew Detection in Viticulture Using Real-Time Image Acquisition from Embedded Devices and Drones. Information 2024, 15, 178. https://doi.org/10.3390/info15040178
Kontogiannis S, Konstantinidou M, Tsioukas V, Pikridas C. A Cloud-Based Deep Learning Framework for Downy Mildew Detection in Viticulture Using Real-Time Image Acquisition from Embedded Devices and Drones. Information. 2024; 15(4):178. https://doi.org/10.3390/info15040178
Chicago/Turabian StyleKontogiannis, Sotirios, Myrto Konstantinidou, Vasileios Tsioukas, and Christos Pikridas. 2024. "A Cloud-Based Deep Learning Framework for Downy Mildew Detection in Viticulture Using Real-Time Image Acquisition from Embedded Devices and Drones" Information 15, no. 4: 178. https://doi.org/10.3390/info15040178
APA StyleKontogiannis, S., Konstantinidou, M., Tsioukas, V., & Pikridas, C. (2024). A Cloud-Based Deep Learning Framework for Downy Mildew Detection in Viticulture Using Real-Time Image Acquisition from Embedded Devices and Drones. Information, 15(4), 178. https://doi.org/10.3390/info15040178