
STAR-3D: A Holistic Approach for Human Activity Recognition in the Classroom Environment



Abstract
1. Introduction
- STAR-3D is capable of automatically analysing the various actions as per the action categories in the EduNet dataset;
- It functions as an intelligent classroom monitoring system. These analysed activities can be presented to the school management dashboard in a score based or any other preferred format;
- To our knowledge, STAR-3D is the first deep-learning-based method to classify students’ and teachers’ activities in a classroom environment;
- This model can also be integrated with the humanoid robot to assist in the classroom to monitor students’ and teachers’ engagement, such as monitoring active participation, interactive classroom behaviour analysis, collaboration assessment during group activity, etc.
2. Related Study
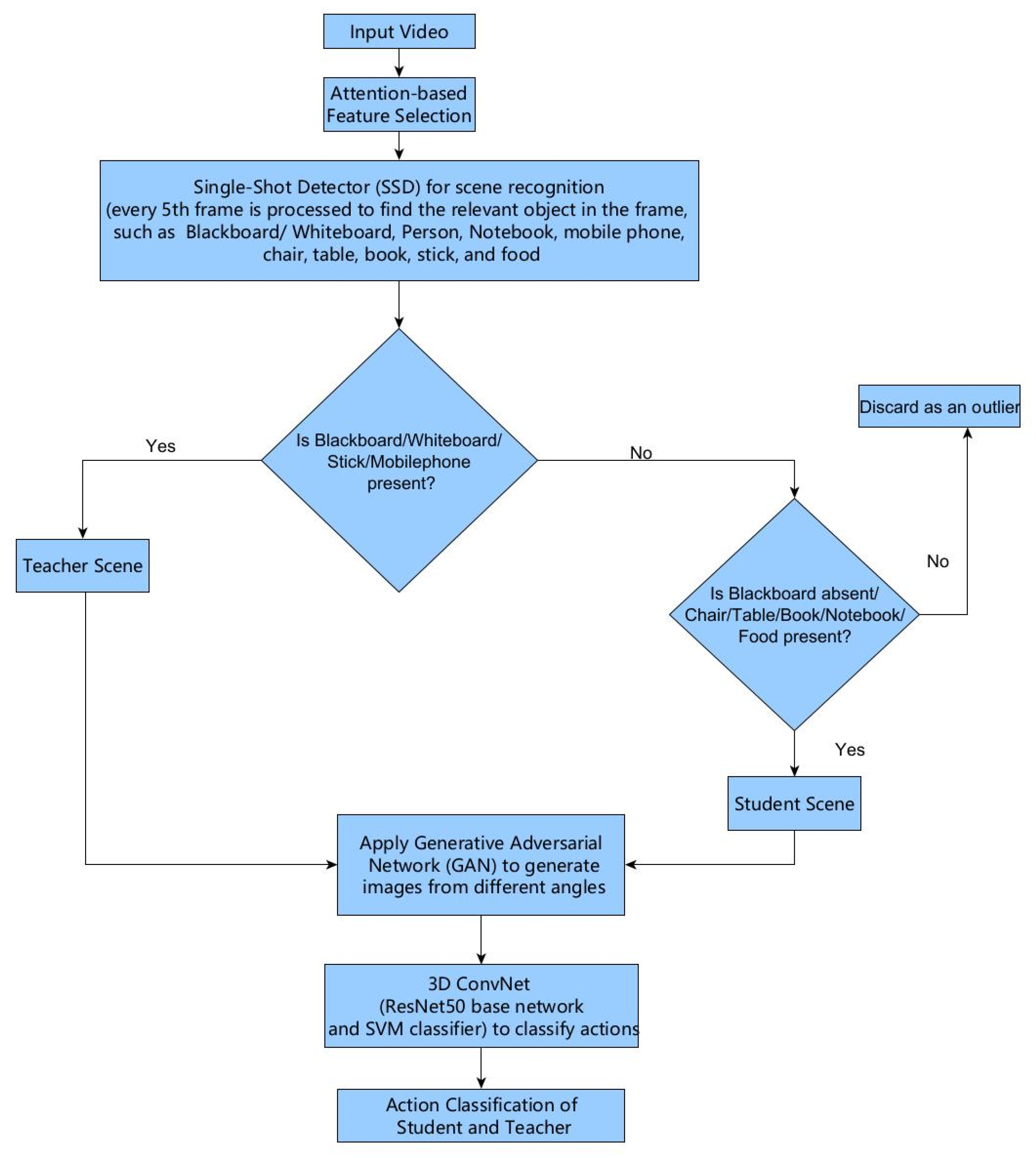
3. Proposed Methodology
3.1. Attention-Based Student and Teacher Scene Recognition
3.2. Data Generator
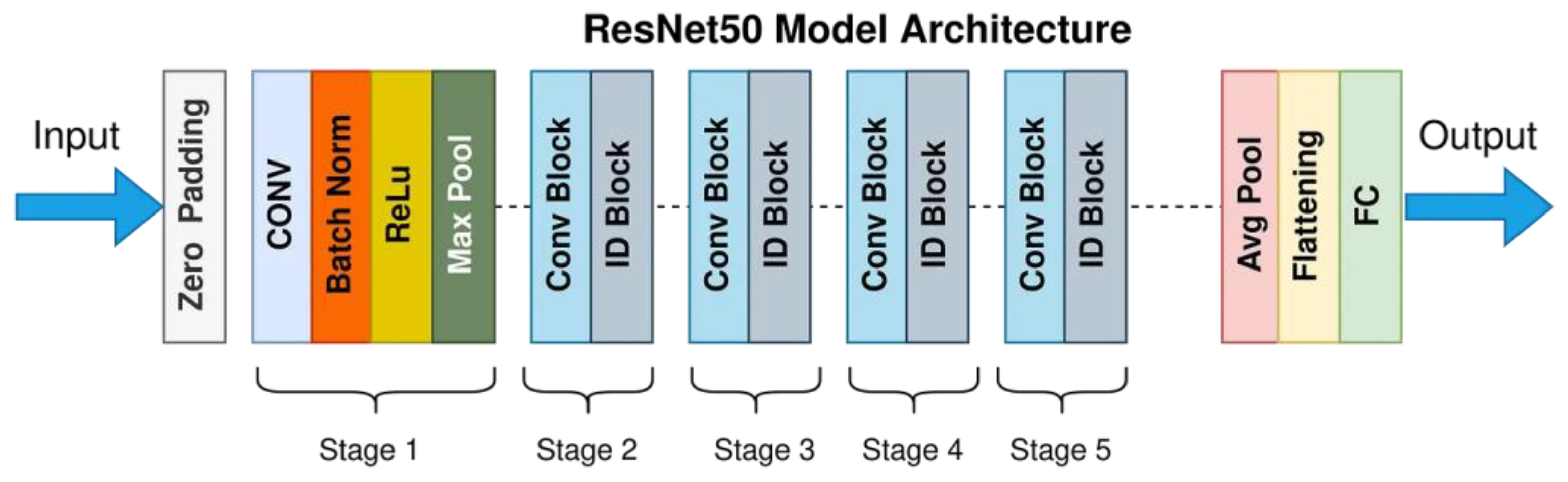
3.3. Action Recognition of Student and Teacher 3D Network Architecture
4. Experimental Framework
4.1. Datasets
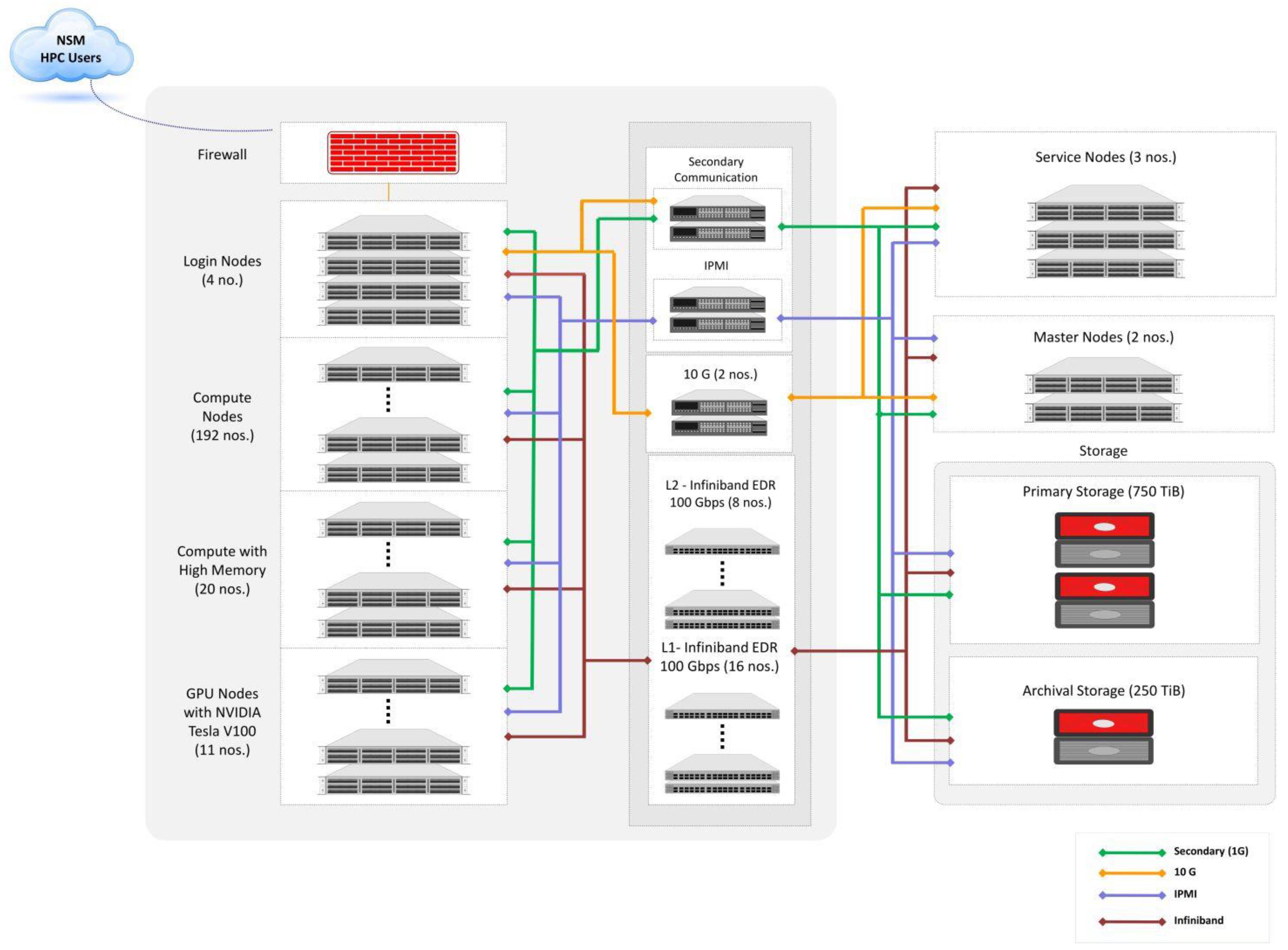
4.2. Experimental Setup on the PARAM Shivay Supercomputer
4.3. Architecture of PARAM Shivay Supercomputer
- Peak Performance
- Job Scheduler
- Running deep-learning applications on PARAM Shivay
| ################################################### #!/bin/bash #SBATCH -N 1 #SBATCH --ntasks-per-node=64 #SBATCH --gres=gpu:2 #SBATCH --error=job.%J.err #SBATCH --output=job.%J.out #SBATCH --time=01:00:00 #SBATCH --partition=gpu // To load the module // source conda/bin/activate module load tensorflow 2.4 cd<Path of the executable>. Python3 /home/myenv/run.py ################################################### |
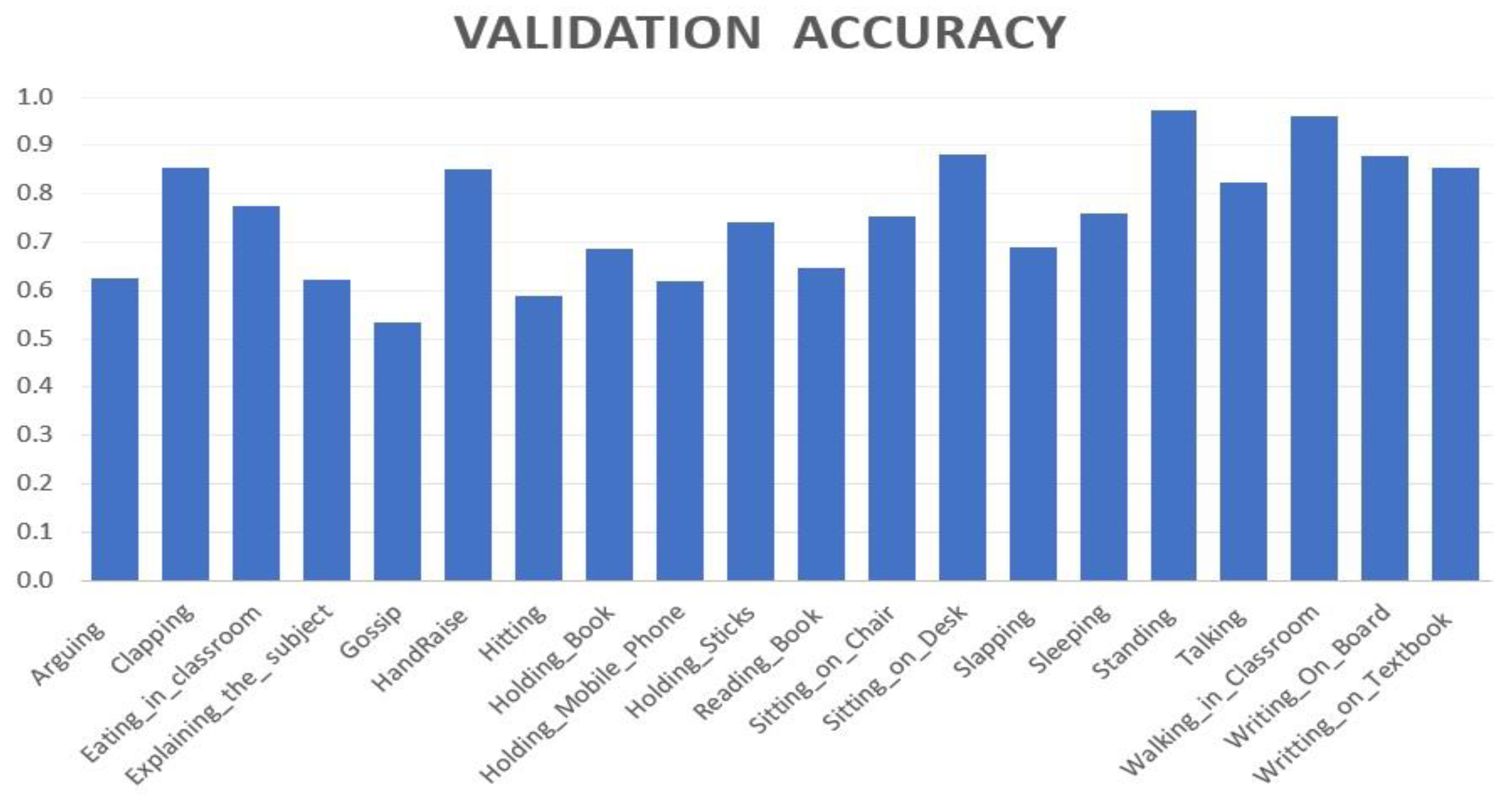
4.4. Training and Validation on the EduNet Dataset
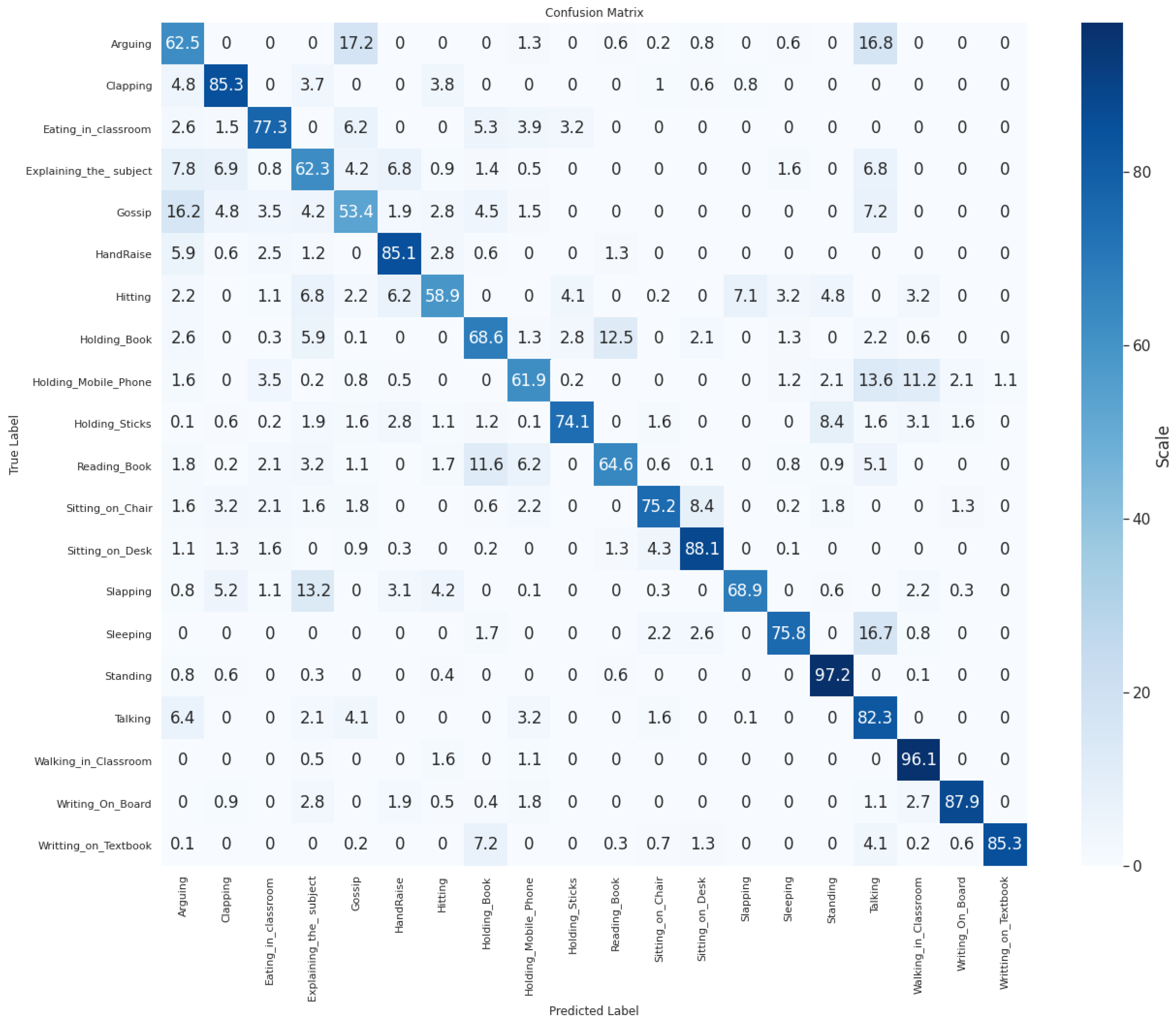
5. Result and Discussion
- Hand_Raise: Detection of students raising their hands to ask questions or to participate in discussions indicates their active participation.
- Sleeping: Identifying students sleeping in the classroom indicates boredom and lack of participation.
- Arguing: Recognising students arguing helps to understand their behaviour during interactions.
- Eating_in_Classroom: Recognising students eating in the classroom indicates a lack of participation.
- Explaining_the_Subject: Analysing how teachers respond to student questions or participation.
- Walking_in_Classroom: Monitoring how teachers manage the classroom environment, including attention to students.
- Holding_Mobile_Phone: Indicates that the teacher is distracted and not engaged with students during the class session.
6. Conclusions, Limitation and Future Research
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Brandisauskiene, A.; Cesnaviciene, J.; Bruzgeleviciene, R.; Nedzinskaite-Maciuniene, R. Connections between teachers’ motivational behaviour and school student engagement. Electron. J. Res. Educ. Psychol. 2021, 19, 165–184. [Google Scholar] [CrossRef]
- Obenza-Tanudtanud, D.M.; Obenza, B. Evaluating Teacher-Student Interaction and Student Learning Engagement in the New Normal: A Convergent-Parallel Design. Psychol. Educ. A Multidiscip. J. 2023, 15, 1–13. [Google Scholar]
- Kundu, A.; Bej, T.; Dey, K.N. Time to grow efficacious: Effect of teacher efficacy on students’ classroom engagement. SN Soc. Sci. 2021, 1, 266. [Google Scholar] [CrossRef]
- Pabba, C.; Kumar, P. An intelligent system for monitoring students’ engagement in large classroom teaching through facial expression recognition. Expert Syst. 2022, 39, e12839. [Google Scholar] [CrossRef]
- Fannakhosrow, M.; Nourabadi, S.; Ngoc Huy, D.T.; Dinh Trung, N.; Tashtoush, M.A. A Comparative Study of Information and Communication Technology (ICT)-Based and Conventional Methods of Instruction on Learners’ Academic Enthusiasm for L2 Learning. Educ. Res. Int. 2022, 2022, 5478088. [Google Scholar] [CrossRef]
- Zhai, X.; Chu, X.; Chai, C.S.; Jong, M.S.Y.; Istenic, A.; Spector, M.; Liu, J.-B.; Yuan, J.; Li, Y. A Review of Artificial Intelligence (AI) in Education from 2010 to 2020. Complexity 2021, 2021, 8812542. [Google Scholar] [CrossRef]
- Miao, F.; Holmes, W.; Huang, R.; Zhang, H. AI and Education: Guidance for Policy-Makers; United Nations Educational, Scientific and Cultural Organization: Paris, France, 2021. [Google Scholar]
- Whitehill, J.; Serpell, Z.; Lin, Y.-C.; Foster, A.; Movellan, J.R. The faces of engagement: Automatic recognition of student engagementfrom facial expressions. IEEE Trans. Affect. Comput. 2014, 5, 86–98. [Google Scholar] [CrossRef]
- Vanneste, P.; Oramas, J.; Verelst, T.; Tuytelaars, T.; Raes, A.; Depaepe, F.; Van den Noortgate, W. Computer vision and human behaviour, emotion and cognition detection: A use case on student engagement. Mathematics 2021, 9, 287. [Google Scholar] [CrossRef]
- Dimitriadou, E.; Lanitis, A. Student Action Recognition for Improving Teacher Feedback during Tele-Education. IEEE Trans. Learn. Technol. 2023, 17, 569–584. [Google Scholar] [CrossRef]
- Bourguet, M.-L.; Jin, Y.; Shi, Y.; Chen, Y.; Rincon-Ardila, L.; Venture, G. Social robots that can sense and improve student engagement. In Proceedings of the 2020 IEEE International Conference on Teaching, Assessment, and Learning for Engineering (TALE), Takamatsu, Japan, 8–11 December 2020; pp. 127–134. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Jisi, A.; Yin, S. A new feature fusion network for student behavior recognition in education. J. Appl. Sci. Eng. 2021, 24, 133–140. [Google Scholar]
- Gang, Z.; Wenjuan, Z.; Biling, H.; Jie, C.; Hui, H.; Qing, X. A simple teacher behavior recognition method for massive teaching videos based on teacher set. Appl. Intell. 2021, 51, 8828–8849. [Google Scholar] [CrossRef]
- Sharma, V. Deep Learning for Human Action Recognition in the Classroom Environment. Ph.D. Thesis, Banaras Hindu University, Varanasi, India, 2021. [Google Scholar]
- Chang, M.-J.; Hsieh, J.-T.; Fang, C.-Y.; Chen, S.-W. A vision-based human action recognition system for moving cameras through deep learning. In Proceedings of the 2019 2nd International Conference on Signal Processing and Machine Learning, Hangzhou, China, 27–29 November 2019; pp. 85–91. [Google Scholar]
- Nida, N.; Yousaf, M.H.; Irtaza, A.; Velastin, S.A. Instructor activity recognition through deep spatiotemporal features and feedforward extreme learning machines. Math. Probl. Eng. 2019, 2019, 2474865. [Google Scholar] [CrossRef]
- Zhang, R.; Ni, B. Learning behavior recognition and analysis by using 3D convolutional neural networks. In Proceedings of the 2019 5th International Conference on Engineering, Applied Sciences and Technology (ICEAST), Luang Prabang, Laos, 2–5 July 2019; pp. 1–4. [Google Scholar]
- Li, X.; Wang, M.; Zeng, W.; Lu, W. A students’ action recognition database in smart classroom. In Proceedings of the 2019 14th International Conference on Computer Science & Education (ICCSE), Toronto, ON, Canada, 19–21 August 2019; pp. 523–527. [Google Scholar]
- Cheng, Y.; Dai, Z.; Ji, Y.; Li, S.; Jia, Z.; Hirota, K.; Dai, Y. Student action recognition based on deep convolutional generative adversarial network. In Proceedings of the 2020 Chinese Control And Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 128–133. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes from Videos in the Wild. Available online: https://www.crcv.ucf.edu/data/UCF101.php (accessed on 12 November 2021).
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar]
- Zuo, K.; Su, X. Three-Dimensional Action Recognition for Basketball Teaching Coupled with Deep Neural Network. Electronics 2022, 11, 3797. [Google Scholar] [CrossRef]
- Qiu, Q.; Wang, T.; Chen, F.; Wang, C. LD-Recognition: Classroom Action Recognition Based on Passive RFID. IEEE Trans. Comput. Soc. Syst. 2023, 11, 1182–1191. [Google Scholar] [CrossRef]
- Ren, H.; Xu, G. Human action recognition in smart classroom. In Proceedings of the Fifth IEEE International Conference on Automatic Face Gesture Recognition, Washington, DC, USA, 21 May 2002; pp. 417–422. [Google Scholar]
- Raza, A.; Yousaf, M.H.; Sial, H.A.; Raja, G. HMM-based scheme for smart instructor activity recognition in a lecture room environment. SmartCR 2015, 5, 578–590. [Google Scholar] [CrossRef]
- Sharma, V.; Gupta, M.; Kumar, A.; Mishra, D. EduNet: A new video dataset for understanding human activity in the classroom environment. Sensors 2021, 21, 5699. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Hua, Z.; Li, J. Attention-based adaptive feature selection for multi-stage image dehazing. Vis. Comput. 2023, 39, 663–678. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14, 2016. pp. 21–37. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 139–144. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Pei, Y.; Biswas, S.; Fussell, D.S.; Pingali, K. An elementary introduction to Kalman filtering. Commun. ACM 2019, 62, 122–133. [Google Scholar] [CrossRef]
- Ajagekar, A. Adam. Available online: https://optimization.cbe.cornell.edu/index.php?title=Adam (accessed on 15 November 2021).
- India, C.-D. PARAM SHIVAY Architecture Diagram. 2019. Available online: https://www.iitbhu.ac.in/cf/scc/param_shivay/architecture (accessed on 13 November 2021).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | Description |
|---|---|
| Actions | 20 |
| Clips | 7851 |
| Min clip length | 3.25 s |
| Max clip length | 12.7 s |
| Total duration | 12 h |
| Minimum clip per class | 200 |
| Maximum clip per class | 593 |
| Frame rate | 30 |
| Resolution | 1280 × 720 |
| Audio | Yes |
| Coloured | Yes |
| S.No. | Class | Action Belongs to Teacher/Student | Number of Clips |
|---|---|---|---|
| 1 | Arguing | Student | 480 |
| 2 | Clapping | Student | 393 |
| 3 | Eating_in_Classroom | Student | 361 |
| 4 | Explaining_the_Subject | Teacher | 611 |
| 5 | Gossip | Student | 218 |
| 6 | Hand_Raise | Student | 389 |
| 7 | Hitting | Teacher | 387 |
| 8 | Holding_Books | Teacher | 403 |
| 9 | Holding_Mobile_Phone | Teacher | 385 |
| 10 | Holding_Stick | Teacher | 319 |
| 11 | Reading_Book | Student | 593 |
| 12 | Sitting_on_Chair | Teacher | 329 |
| 13 | Sitting_on_Desk | Student | 263 |
| 14 | Slapping | Teacher | 384 |
| 15 | Sleeping | Student | 219 |
| 16 | Standing | Student | 453 |
| 17 | Talking | Student | 294 |
| 18 | Walking_in_Classroom | Teacher | 403 |
| 19 | Writing_on_Board | Teacher | 419 |
| 20 | Writing_on_Textbook | Student | 548 |
| Characteristics | Values |
|---|---|
| Peak Performance | 837 Teraflops |
| Total number of nodes | 233 |
| Architecture | X86_64 |
| Provisioning | xCAT 2.14.6 |
| Cluster Manager | Openhpc (ohpc-xCAT 1.3.8) |
| Monitoring Tools | C-CHAKSHU, Nagios, Ganglia, XDMoD |
| Resource Manager | Slurm |
| I/O Services | Lustre Client |
| High-Speed Interconnects | Mellanox InfiniBand |
| Method | Purpose | Dataset | Pretrained On | Accuracy |
|---|---|---|---|---|
| Two-Stream I3D [12] | Human daily action recognition | UCF101, HMDB51 | Kinetics | 97.8%, 80.9% |
| 3D BP-TBR [14] | Teacher behaviour recognition | TAD08 (Self-developed) | - | 81.0% |
| UCF101, HMDB51 | Kinetics | 97.11%, 81.0% | ||
| Feature Fusion Network [13] | Student behaviour recognition | UCF101, HMDB51 | - | 92.4%, 83.9% |
| STAR-3D | Action recognition of student and teacher | EduNet | - | 83.5% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, V.; Gupta, M.; Kumar, A.; Mishra, D. STAR-3D: A Holistic Approach for Human Activity Recognition in the Classroom Environment. Information 2024, 15, 179. https://doi.org/10.3390/info15040179
Sharma V, Gupta M, Kumar A, Mishra D. STAR-3D: A Holistic Approach for Human Activity Recognition in the Classroom Environment. Information. 2024; 15(4):179. https://doi.org/10.3390/info15040179
Chicago/Turabian StyleSharma, Vijeta, Manjari Gupta, Ajai Kumar, and Deepti Mishra. 2024. "STAR-3D: A Holistic Approach for Human Activity Recognition in the Classroom Environment" Information 15, no. 4: 179. https://doi.org/10.3390/info15040179
APA StyleSharma, V., Gupta, M., Kumar, A., & Mishra, D. (2024). STAR-3D: A Holistic Approach for Human Activity Recognition in the Classroom Environment. Information, 15(4), 179. https://doi.org/10.3390/info15040179