

Advancing Patient Care with an Intelligent and Personalized Medication Engagement System




Abstract
1. Introduction
- Modeling the patient medication engagement problem into a Markov Decision Process (MDP).
- Use of RL algorithms to solve formulated MDP problem. The RL agent of PMES observes the patient’s patterns of responsiveness, learns a patient’s response to signs, and then optimizes for each individual.
- The role of the RL agent is then to engage the patient during the medication period and improve medication adherence.
- The second component of PMES is the DL Verification Agent (DLVA), which is built using the CNN model. The salient feature of DLVA is its dynamic nature, as it can be used anywhere and, more importantly, can be trained for a given number of medicines.
- The function of personalized DLVA is to assist in monitoring a patient’s drug-taking activity and minimize the chance of taking the wrong drugs.
2. Related Work
3. Technical Background
3.1. Neural Networks
3.2. Convolutional Neural Networks (CNNs)
3.3. Transfer Learning
3.4. Reinforcement Learning
3.5. Contextual Bandit
3.5.1. Epsilon-Greedy
Action Selection
- With probability , select the action with the highest estimated reward.
- With probability , randomly select an action.
Classifier Training
3.5.2. Thomson Sampling
Beta Distribution Parameters Update
Action Selection
3.5.3. Upper Confidence Bounds-UCB
Upper Confidence Bounds (UCB)
Action Selection
Empirical Mean and Number of Selections Update
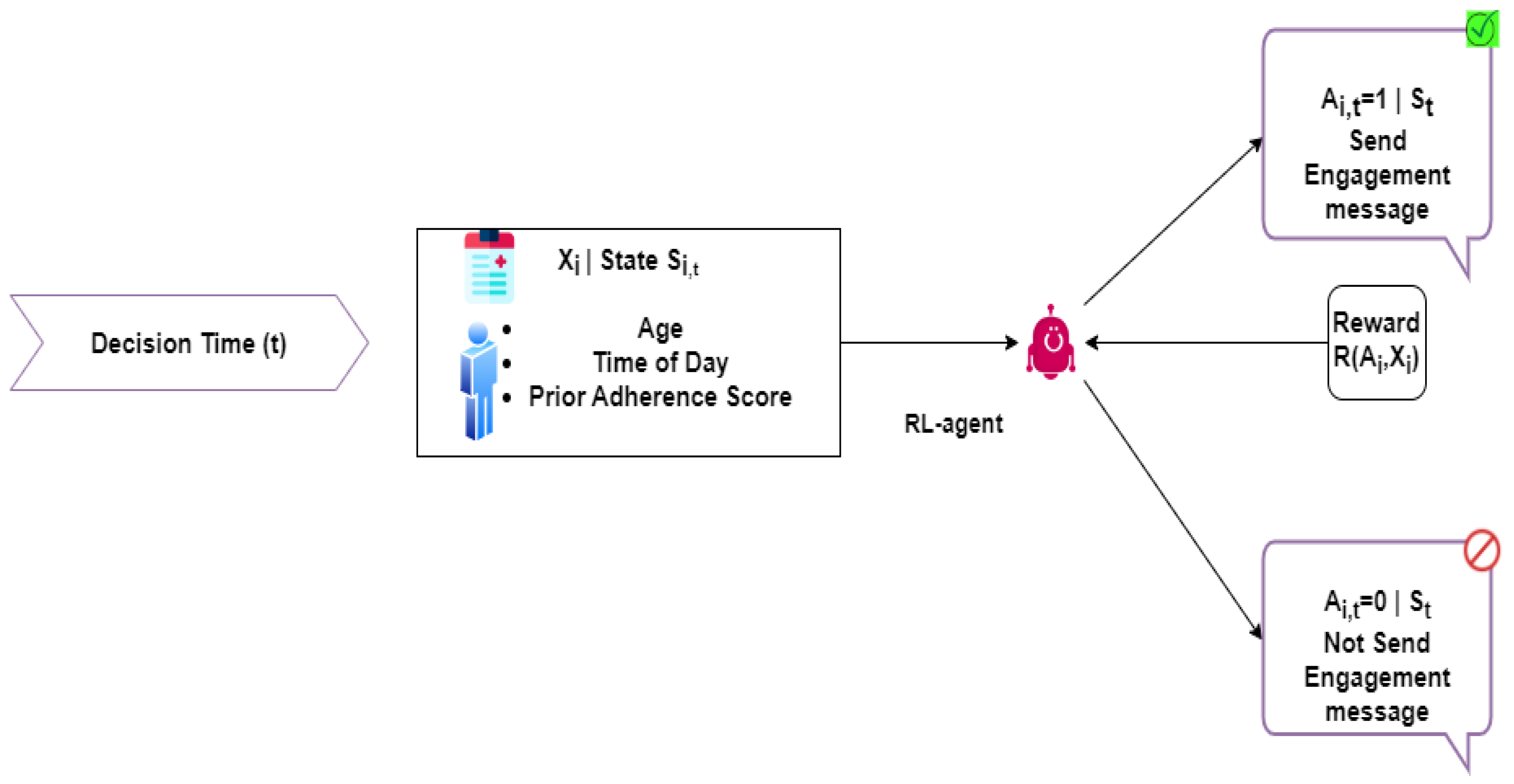
4. Patient Medication Engagement System
4.1. RL and DL for Adaptive Patient Engagement
4.2. RL Engagement Agent
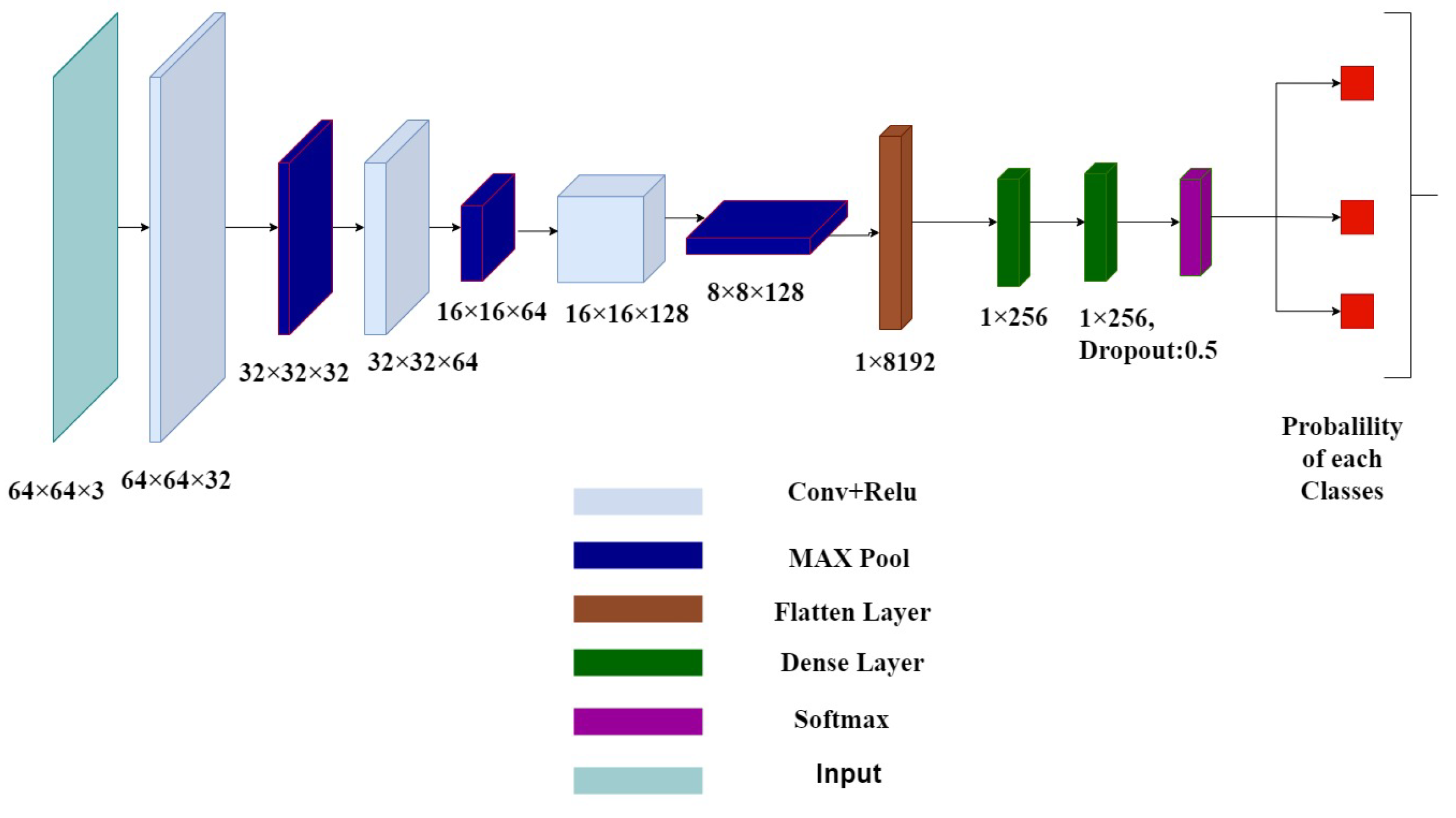
4.3. DL Verification Agent
- The user first needs to upload 20 or more images of every drug that the user must consume during a treatment process.
- Once images are uploaded by the user, then the personalized model for the given data is trained as DLVA of PMES.
- Once the personalized model is trained, the DLVA can be used as the verification component of the PMES along with the engagement component.
4.4. Model Summary
4.5. Integration of RL and DL Components
5. Results and Analysis
5.1. Hyperparameters for Training
- Learning Rate: 0.001The learning rate controls how much to adjust the weights of the model with respect to the loss gradient. A learning rate of 0.001 is commonly used as it strikes a balance between fast convergence and stability. A rate too high might lead to overshooting the optimal weights, while a rate too low can result in slow convergence.
- Momentum: 0.9Momentum helps accelerate the optimizer in the relevant direction and dampens oscillations. A momentum of 0.9 is used to smooth the optimization process by accumulating past gradients, which helps in navigating through local minima and speeds up convergence.
- Batch Size: 16Batch size refers to the number of training examples utilized in one iteration of model training. A batch size of 16 provides a balance between the computational efficiency and the stability of the gradient estimates. Smaller batch sizes can offer a more accurate estimate of the gradient but may lead to noisier updates.
- Epochs: 40The number of epochs represents the number of times the entire training dataset is passed through the model. Training for 40 epochs allows the model sufficient iterations to learn from the data, but this should be monitored to avoid overfitting. The chosen number is based on empirical testing to achieve a good balance between underfitting and overfitting.
- Loss Function: Categorical Cross-EntropyCategorical cross-entropy is used for multi-class classification problems. It measures the performance of a classification model whose output is a probability value between 0 and 1. This loss function helps in quantifying how well the model’s predicted probabilities match the true class labels, and its optimization helps in improving the accuracy of the model.
RL Hyperparameters
- Beta Distribution Parameters : Initialized to (1, 1) for each action arm. Updated based on observed rewards, reflecting empirical success rates.
- Epsilon (): Set to 0.2. Balances exploration (20%) and exploitation (80%) of the best-known action.
- Confidence Parameter (c): Set to 0.8. Adjusts exploration bonus added to empirical mean rewards to balance exploration and exploitation.
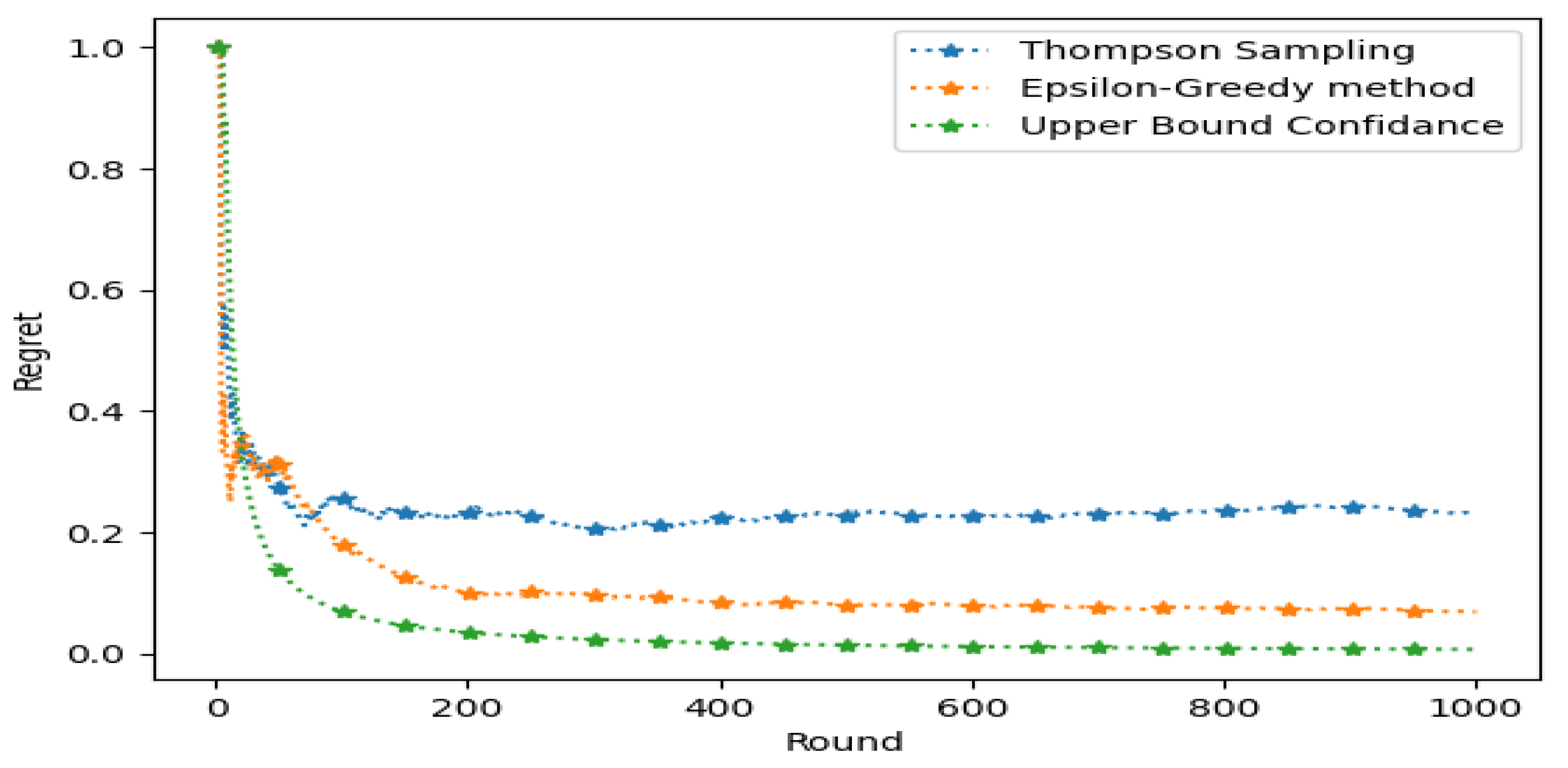
5.2. Metrics for RL Engagement Agent
5.3. Results of DLVA
- (1)
- After accessing the PMES, a user must upload a certain number of images of each drug that he/she must take during a medication period, as also illustrated in Figure 7a. For example, if a patient has a prescription for 4 medicines from a doctor, then that patient must upload images of 4 medicines on DLVA.
- (2)
- The next step is to indicate a medicine schedule, which includes the name of the uploaded medicine, scheduled time of consumption, and the number of pills at one consumption. The phase is highlighted in Figure 7b.
- (3)
- Then, the training of the CNN model on the user’s uploaded data is started on the administrative part of the PMES. Once the model completes training, the personalized CNN model is ready and available for patient medication verification. Figure 7c demonstrates that the DLVA is ready for use and starts sending reminder alerts at the scheduled time.
- (4)
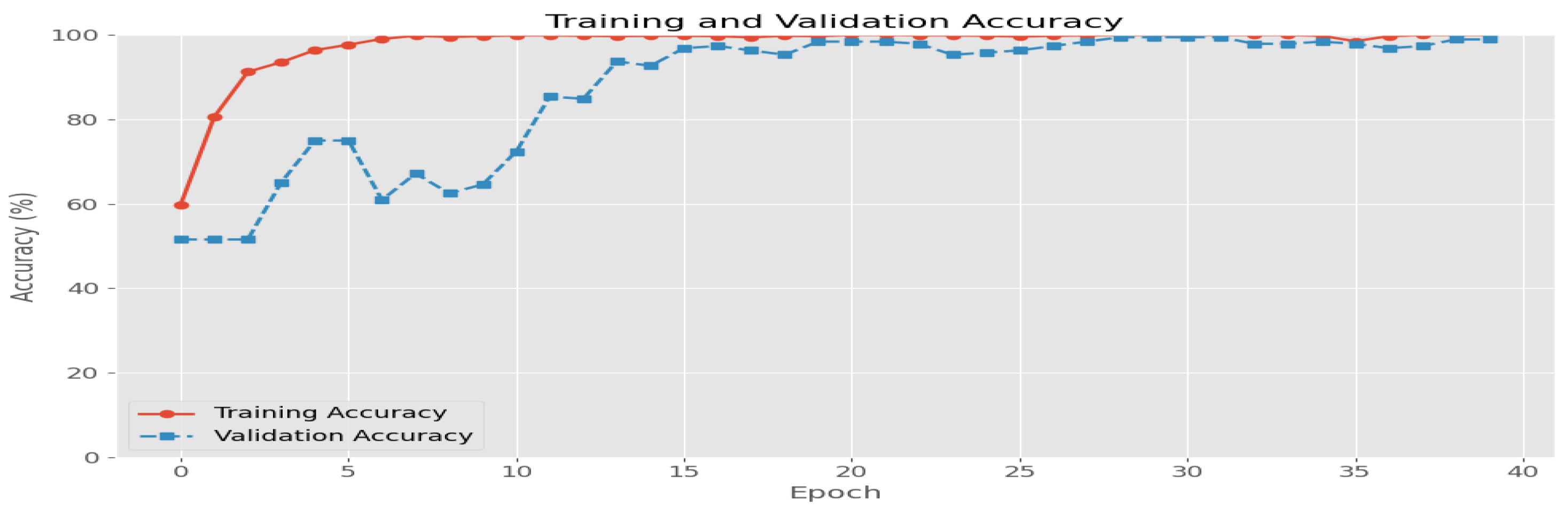
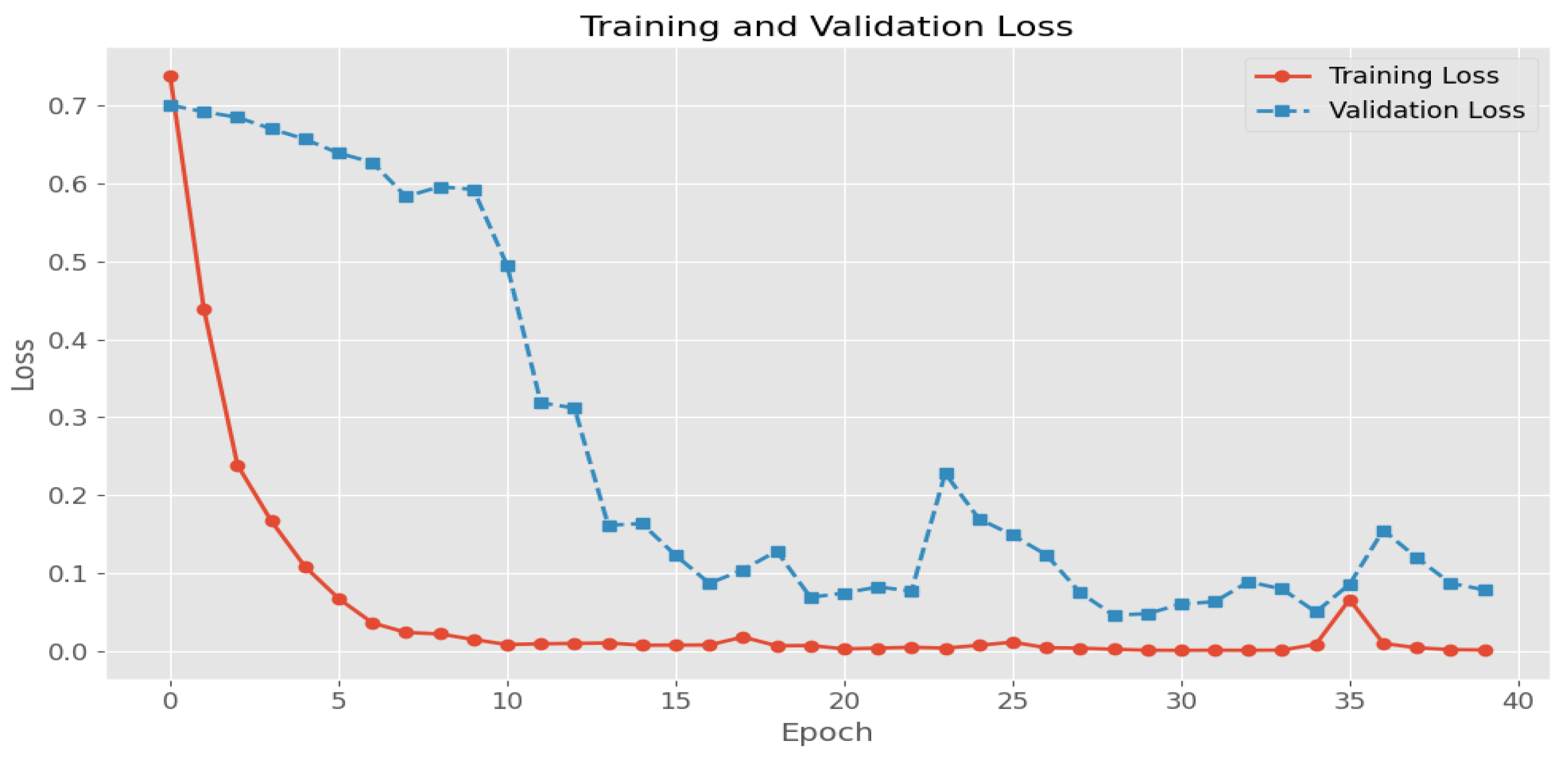
- The last Figure 7d shows the verification step of the DLVA to assist the patient in taking the correct drug. The performance of the DLVA can be evaluated using the parameters of accuracy and loss function. For instance, the accuracy and loss function graphs for the model, which is trained for seven medicines, are shown in Figure 8 and Figure 9, respectively. We can see that the CNN model gives an accuracy of 98% and a loss function of 0.08 on validation data.
5.4. Comparison with the State of the Art
6. Discussion
6.1. Challenges for Real-World Deployment
- Personalized Model Training for Each PatientComplexity of Data Collection: A significant challenge is the difficulty of gathering sufficient and relevant data for each individual patient. This process is often time-consuming and complex, complicating the training of accurate, personalized models.High Computational Requirements: Another major challenge is the substantial computational resources needed to train separate models for each patient. This demand can strain available resources in healthcare settings.
- Medication VerificationHandling Data Variability: Ensuring the system can accurately verify medications despite variations in packaging, lighting, and image quality presents a considerable challenge. Managing these inconsistencies is crucial for reliable medication verification.Real-Time Processing Demands: Implementing a system that performs medication verification in real time poses a challenge due to the need for efficient processing and integration with existing healthcare systems.
- Adherence Score CollectionPrivacy Management: One of the major challenges is safeguarding sensitive patient data while collecting adherence scores. Ensuring privacy and data protection throughout the adherence monitoring process is a critical concern.Maintaining Accuracy: Collecting precise adherence scores is challenging due to potential issues such as inconsistent data collection times and patient non-compliance. Addressing these factors to ensure accuracy in adherence measurements is a complex task.
- ScalabilityHandling Large-Scale Deployment: Scaling the cloud-based system to support deployment across multiple healthcare facilities presents challenges. The system must be capable of managing increased data volume and user load while maintaining performance and reliability. Efficiently scaling resources and ensuring consistent service quality across various facilities requires robust infrastructure planning and dynamic resource allocation strategies.
- Security and PrivacyEnsuring Data Security: Protecting patient data in a cloud-based system involves addressing security concerns such as unauthorized access and data breaches. Implementing strong encryption protocols, secure authentication methods, and regular security audits are essential measures to safeguard patient information.Compliance with Regulations: The system must adhere to regulatory requirements such as HIPAA (Health Insurance Portability and Accountability Act) or GDPR (General Data Protection Regulation) for data privacy and security. Ensuring compliance with these regulations adds a layer of complexity to the system’s design and operation.
6.2. Addressing Scalability and Security
- Scalable InfrastructureCloud Solutions: Leveraging scalable cloud infrastructure such as AWS, Azure, or Google Cloud to handle varying loads and facilitate seamless expansion. Utilizing cloud services that offer auto-scaling capabilities ensures the system can adapt to increasing demands across multiple healthcare facilities.Load Balancing: Implementing load balancing techniques to distribute traffic evenly across servers, therefore improving system performance and reliability.
- Robust Security MeasuresData Encryption: Employing advanced encryption techniques both at rest and in transit to ensure the confidentiality and integrity of patient data.Access Controls: Implementing stringent access controls and authentication mechanisms to prevent unauthorized access to sensitive information.Regulatory Compliance: Ensuring the system complies with relevant data protection regulations, including conducting regular security audits and updates to meet evolving compliance requirements.
- Continuous Monitoring and ImprovementPerformance Monitoring: Implementing continuous monitoring tools to track system performance, detect potential issues, and optimize resource usage.Feedback Mechanisms: Establishing feedback channels with healthcare facilities to gather insights and make iterative improvements to the system based on real-world usage and needs.
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Piercefield, E.W.; Howard, M.E.; Robinson, M.H.; Kirk, C.E.; Ragan, A.P.; Reese, S.D. Antihypertensive medication adherence and blood pressure control among central Alabama veterans. J. Clin. Hypertens. 2017, 19, 543–549. [Google Scholar] [CrossRef] [PubMed]
- Barello, S.; Graffigna, G.; Vegni, E. Patient engagement as an emerging challenge for healthcare services: Mapping the literature. Nurs. Res. Pract. 2012, 2012, 905934. [Google Scholar] [CrossRef] [PubMed]
- Bizimana, P.C.; Zhang, Z.; Asim, M.; El-Latif, A.A.A.; Hammad, M. Learning-based techniques for heart disease prediction: A survey of models and performance metrics. Multimed. Tools Appl. 2024, 83, 39867–39921. [Google Scholar] [CrossRef]
- Ho, P.M.; Magid, D.J.; Shetterly, S.M.; Olson, K.L.; Maddox, T.M.; Peterson, P.N.; Masoudi, F.A.; Rumsfeld, J.S. Medication nonadherence is associated with a broad range of adverse outcomes in patients with coronary artery disease. Am. Heart J. 2008, 155, 772–779. [Google Scholar] [CrossRef] [PubMed]
- Liquori, G.; De Leo, A.; Di Simone, E.; Dionisi, S.; Giannetta, N.; Ganci, E.; Trainito, S.P.; Orsi, G.B.; Di Muzio, M.; Napoli, C. Medication adherence in chronic older patients: An Italian observational study using Medication Adherence Report Scale (MARS-5I). Int. J. Environ. Res. Public Health 2022, 19, 5190. [Google Scholar] [CrossRef]
- Davis, R.E.; Jacklin, R.; Sevdalis, N.; Vincent, C.A. Patient involvement in patient safety: What factors influence patient participation and engagement? Health Expect. 2007, 10, 259–267. [Google Scholar] [CrossRef]
- Doherty, C.; Stavropoulou, C. Patients’ willingness and ability to participate actively in the reduction of clinical errors: A systematic literature review. Soc. Sci. Med. 2012, 75, 257–263. [Google Scholar] [CrossRef]
- Izonin, I.; Ribino, P.; Ebrahimnejad, A.; Quinde, M. Smart technologies and its application for medical/healthcare services. J. Reliab. Intell. Environ. 2023, 9, 1–3. [Google Scholar] [CrossRef]
- Paragliola, G.; Naeem, M. Risk management for nuclear medical department using reinforcement learning algorithms. J. Reliab. Intell. Environ. 2019, 5, 105–113. [Google Scholar] [CrossRef]
- Krist, A.H.; Tong, S.T.; Aycock, R.A.; Longo, D.R. Engaging patients in decision-making and behavior change to promote prevention. Inf. Serv. Use 2017, 37, 105–122. [Google Scholar] [CrossRef]
- Germanese, D.; Colantonio, S.; Del Coco, M.; Carcagnì, P.; Leo, M. Computer Vision Tasks for Ambient Intelligence in Children’s Health. Information 2023, 14, 548. [Google Scholar] [CrossRef]
- Shah, S.I.H.; Coronato, A.; Naeem, M.; De Pietro, G. Learning and assessing optimal dynamic treatment regimes through cooperative imitation learning. IEEE Access 2022, 10, 78148–78158. [Google Scholar] [CrossRef]
- Bottrighi, A.; Pennisi, M. Exploring the State of Machine Learning and Deep Learning in Medicine: A Survey of the Italian Research Community. Information 2023, 14, 513. [Google Scholar] [CrossRef]
- Fiorino, M.; Naeem, M.; Ciampi, M.; Coronato, A. Defining a Metric-Driven Approach for Learning Hazardous Situations. Technologies 2024, 12, 103. [Google Scholar] [CrossRef]
- Subasi, A.; Kevric, J.; Abdullah Canbaz, M. Epileptic seizure detection using hybrid machine learning methods. Neural Comput. Appl. 2019, 31, 317–325. [Google Scholar] [CrossRef]
- Yedurkar, D.P.; Metkar, S.; Al-Turjman, F.; Yardi, N.; Stephan, T. An IoT Based Novel Hybrid Seizure Detection Approach for Epileptic Monitoring. IEEE Trans. Ind. Inform. 2024, 20, 1420–1431. [Google Scholar] [CrossRef]
- Naeem, M.; Coronato, A.; Paragliola, G. Adaptive treatment assisting system for patients using machine learning. In Proceedings of the 2019 Sixth International Conference on Social Networks Analysis, Management and Security (SNAMS), Granada, Spain, 22–25 October 2019; pp. 460–465. [Google Scholar]
- Coronato, A.; Naeem, M. Ambient Intelligence for Home Medical Treatment Error Prevention. In Proceedings of the 2021 17th International Conference on Intelligent Environments (IE), Dubai, United Arab Emirates, 21–24 June 2021; pp. 1–8. [Google Scholar]
- Lupión, M.; Sanjuan, J.F.; Medina-Quero, J.; Ortigosa, P.M. Epilepsy Seizure Detection Using Low-Cost IoT Devices and a Federated Machine Learning Algorithm. In Ambient Intelligence—Software and Applications—13th International Symposium on Ambient Intelligence; Springer: Cham, Switzerland, 2022; pp. 229–238. [Google Scholar]
- Sugumar, D.; Suriya, K.; Suraj, T.A.M.; Jose, J.A.V.; Kavitha, K. Seizure Detection using Machine Learning and Monitoring through IoT Devices. In Proceedings of the 2023 10th International Conference on Wireless Networks and Mobile Communications (WINCOM), Istanbul, Turkey, 26–28 October 2023; pp. 1–6. [Google Scholar]
- Hayakawa, M.; Uchimura, Y.; Omae, K.; Waki, K.; Fujita, H.; Ohe, K. A Smartphone-based Medication Self-management System with Real-time Medication Monitoring. Appl. Clin. Inform. 2013, 4, 37–52. [Google Scholar] [CrossRef]
- He, Y.; Tan, E.H.; Wong, A.L.A.; Tan, C.C.; Wong, P.; Lee, S.C.; Tai, B.C. Improving medication adherence with adjuvant aromatase inhibitor in women with breast cancer: Study protocol of a randomised controlled trial to evaluate the effect of short message service (SMS) reminder. BMC Cancer 2018, 18, 727. [Google Scholar] [CrossRef]
- Vithanwattana, N.; Karthick, G.; Mapp, G.; George, C.; Samuels, A. Securing future healthcare environments in a post-COVID-19 world: Moving from frameworks to prototypes. J. Reliab. Intell. Environ. 2022, 8, 299–315. [Google Scholar] [CrossRef]
- Alarood, A.A.; Faheem, M.; Al-Khasawneh, M.A.; Alzahrani, A.I.; Alshdadi, A.A. Secure medical image transmission using deep neural network in e-health applications. Healthc. Technol. Lett. 2023, 10, 87–98. [Google Scholar] [CrossRef]
- Faheem, M.; Butt, R.A.; Raza, B.; Alquhayz, H.; Abbas, M.Z.; Ngadi, M.A.; Gungor, V.C. A multiobjective, lion mating optimization inspired routing protocol for wireless body area sensor network based healthcare applications. Sensors 2019, 19, 5072. [Google Scholar] [CrossRef] [PubMed]
- Yu, J.; Guo, L.; Zhang, J.; Wang, G. A survey on graph neural network-based next POI recommendation for smart cities. J. Reliab. Intell. Environ. 2024, 10, 299–318. [Google Scholar] [CrossRef]
- Chen, L.; Wang, D. Cost Estimation and Prediction for Residential Projects Based on Grey Relational Analysis–Lasso Regression–Backpropagation Neural Network. Information 2024, 15, 502. [Google Scholar] [CrossRef]
- Gąsienica-Józkowy, J.; Cyganek, B.; Knapik, M.; Głogowski, S.; Przebinda, L. Deep Learning-Based Monocular Estimation of Distance and Height for Edge Devices. Information 2024, 15, 474. [Google Scholar] [CrossRef]
- Song, J.; Dong, H.; Chen, Y.; Zhang, X.; Zhan, G.; Jain, R.K.; Chen, Y.W. Early Recurrence Prediction of Hepatocellular Carcinoma Using Deep Learning Frameworks with Multi-Task Pre-Training. Information 2024, 15, 493. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Approach | Personalization | Remote Monitoring | AI Methods | Medication Error Prevention | Patient Engagement |
|---|---|---|---|---|---|---|
| Subasi et al. [15] | EEG-based classification | x | x | PSO, GA, SVM | x | x |
| Yedurkar et al. [16] | IoT-powered EEG system | x | ✓ | CNN, IoT | x | x |
| Naeem et al. [17] | Medication reminders | ✓ | Bayesian UCB | x | x | |
| Coronato et al. [18] | Ambient sensors | ✓ | ✓ | Sensor-based, IoT | x | x |
| Lupion et al. [19] | Wearable device | x | ✓ | Federated learning | x | x |
| Sugumar et al. [20] | Seizure detection | x | ✓ | Random forest | x | x |
| Uchimura et al. [21] | Smartphone-based | ✓ | Rule-based | x | x | |
| He et al. [22] | Mobile text reminders | x | Rule-based | x | x | |
| PMES (Our Work) | RL + DL | ✓ | ✓ | RL, DL | ✓ | ✓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ismail, A.; Naeem, M.; Syed, M.H.; Abbas, M.; Coronato, A. Advancing Patient Care with an Intelligent and Personalized Medication Engagement System. Information 2024, 15, 609. https://doi.org/10.3390/info15100609
Ismail A, Naeem M, Syed MH, Abbas M, Coronato A. Advancing Patient Care with an Intelligent and Personalized Medication Engagement System. Information. 2024; 15(10):609. https://doi.org/10.3390/info15100609
Chicago/Turabian StyleIsmail, Ahsan, Muddasar Naeem, Madiha Haider Syed, Musarat Abbas, and Antonio Coronato. 2024. "Advancing Patient Care with an Intelligent and Personalized Medication Engagement System" Information 15, no. 10: 609. https://doi.org/10.3390/info15100609
APA StyleIsmail, A., Naeem, M., Syed, M. H., Abbas, M., & Coronato, A. (2024). Advancing Patient Care with an Intelligent and Personalized Medication Engagement System. Information, 15(10), 609. https://doi.org/10.3390/info15100609