
Threshold-Based Combination of Ideal Binary Mask and Ideal Ratio Mask for Single-Channel Speech Separation


Abstract
1. Introduction
2. Ideal Binary Mask (IBM) and Ideal Ratio Mask (IRM)
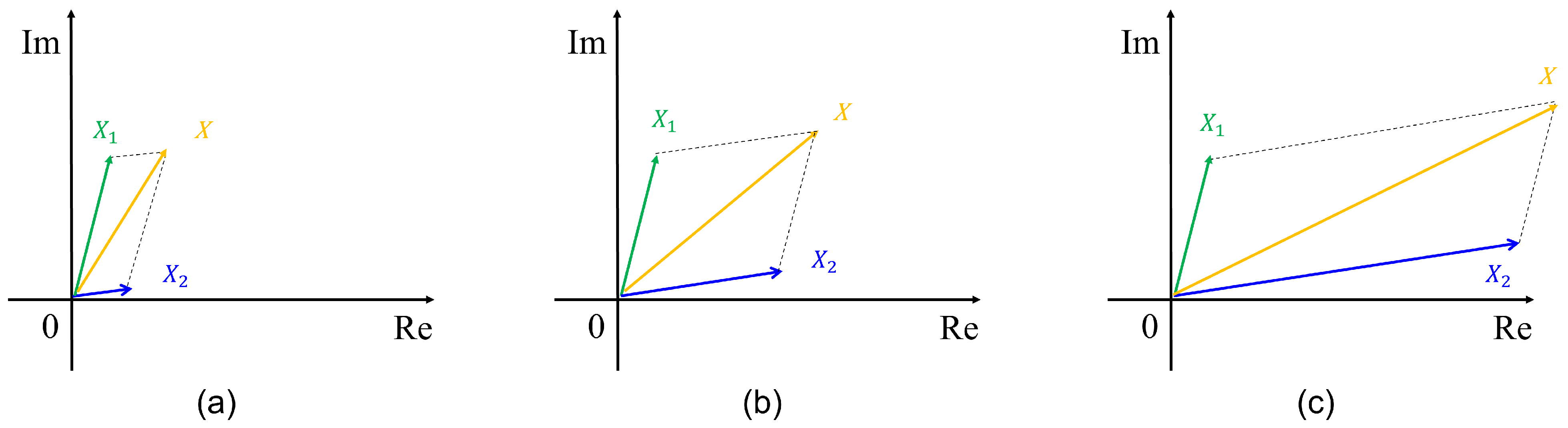
2.1. Notation and Formulation
2.2. Advantages and Disadvantages of IBM and IRM
3. Proposed T-F Mask for Speech Separation
3.1. Threshold-Based Combination Mask
3.2. Using Masks as Training Targets
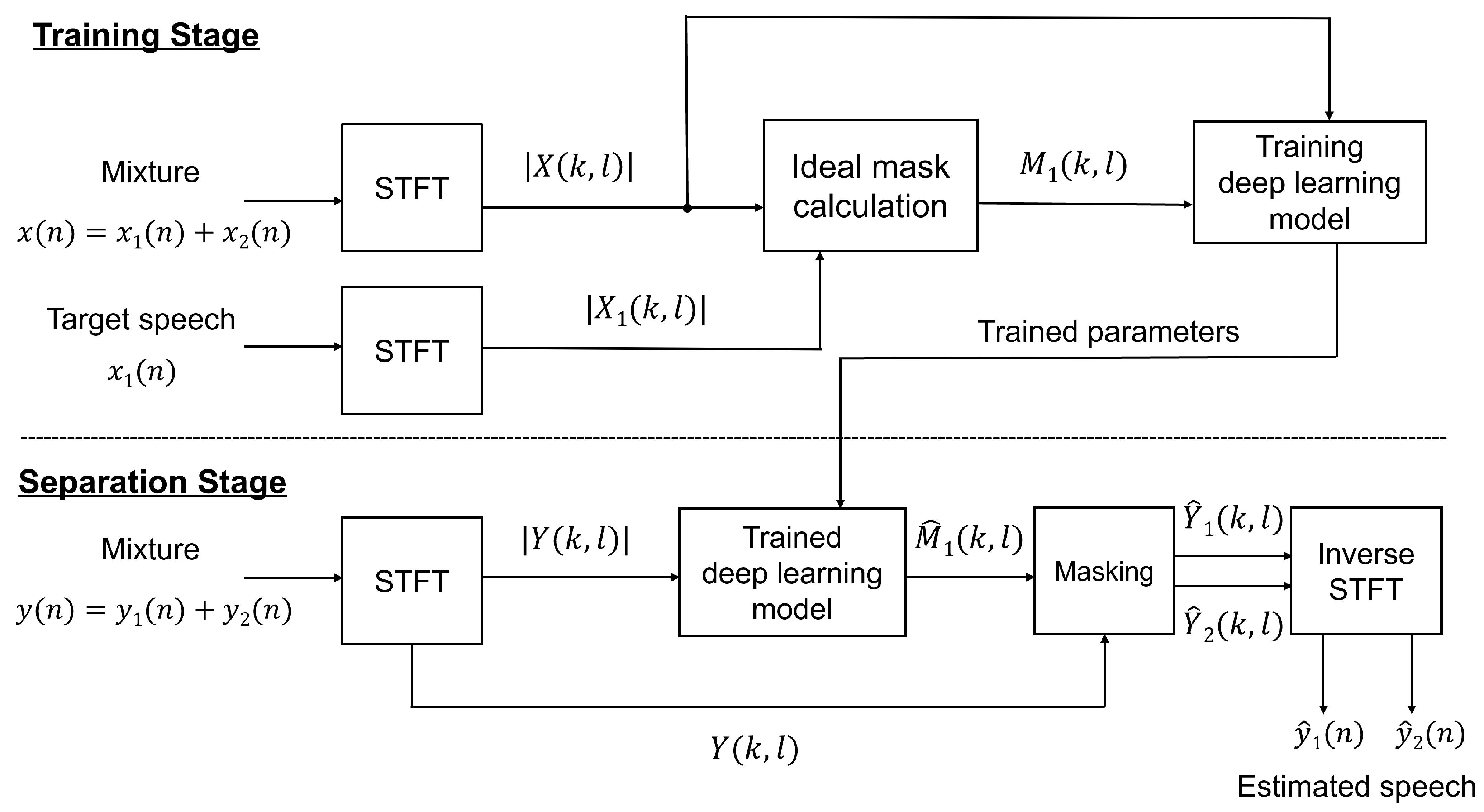
4. Experiments and Results
4.1. Experimental Setup
4.1.1. Dataset
4.1.2. Experimental Configurations
4.1.3. Evaluation Metrics
4.2. Experimental Results and Discussions
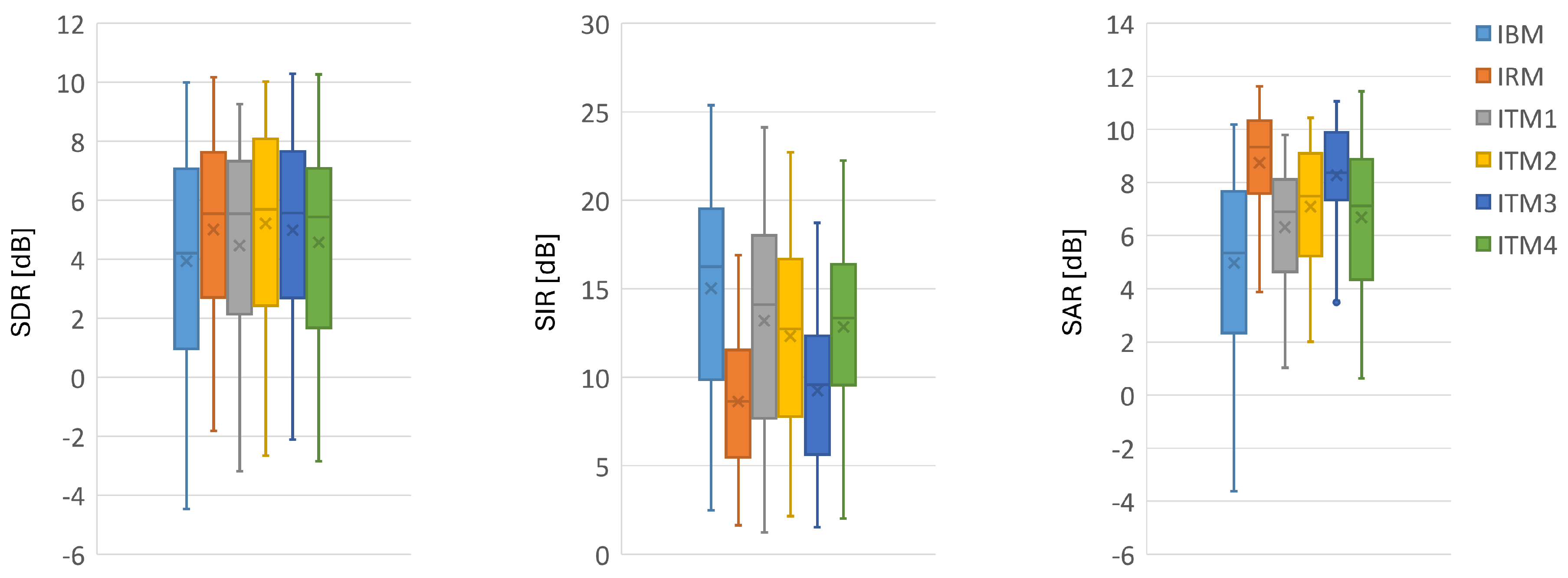
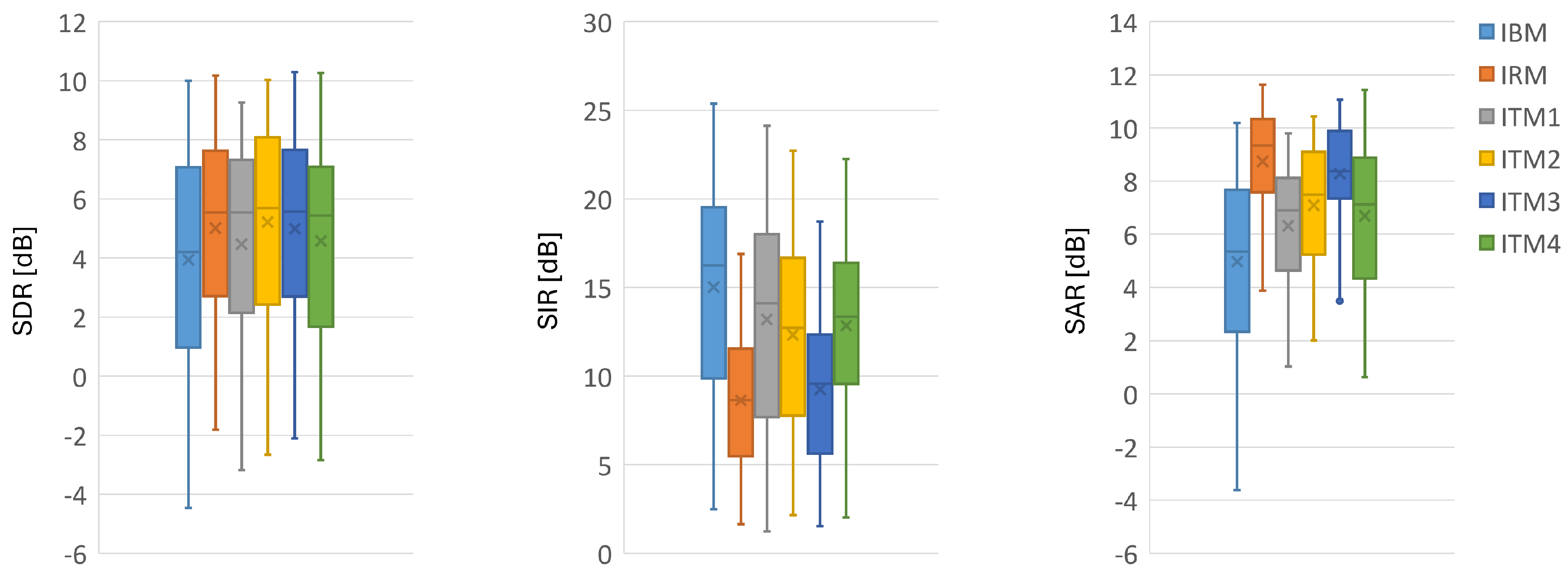
4.2.1. Comparison of Proposed and Conventional Masks in Ideal Conditions
4.2.2. Comparison of Proposed and Conventional Masks Based on Deep Learning Model for Speech Separation
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Makino, S.; Lee, T.; Sawada, H. Blind Speech Separation; Springer: Berlin/Heidelberg, Germany, 2007; Volume 615. [Google Scholar]
- Qian, Y.; Weng, C.; Chang, X.; Wang, S.; Yu, D. Past review, current progress, and challenges ahead on the cocktail party problem. Front. Inf. Technol. Electron. Eng. 2018, 19, 40–63. [Google Scholar] [CrossRef]
- Wang, D.; Chen, J. Supervised speech separation based on deep learning: An overview. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1702–1726. [Google Scholar] [CrossRef] [PubMed]
- Agrawal, J.; Gupta, M.; Garg, H. A review on speech separation in cocktail party environment: Challenges and approaches. Multimed. Tools Appl. 2023, 82, 31035–31067. [Google Scholar] [CrossRef]
- Yu, D.; Deng, L. Automatic Speech Recognition; Springer: Berlin/Heidelberg, Germany, 2016; Volume 1. [Google Scholar]
- Malik, M.; Malik, M.K.; Mehmood, K.; Makhdoom, I. Automatic speech recognition: A survey. Multimed. Tools Appl. 2021, 80, 9411–9457. [Google Scholar] [CrossRef]
- Stüber, G.L.; Steuber, G.L. Principles of Mobile Communication; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2. [Google Scholar]
- Onnela, J.P.; Saramäki, J.; Hyvönen, J.; Szabó, G.; Lazer, D.; Kaski, K.; Kertész, J.; Barabási, A.L. Structure and tie strengths in mobile communication networks. Proc. Natl. Acad. Sci. USA 2007, 104, 7332–7336. [Google Scholar] [CrossRef]
- Campbell, J.P. Speaker recognition: A tutorial. Proc. IEEE 1997, 85, 1437–1462. [Google Scholar] [CrossRef]
- Hansen, J.H.; Hasan, T. Speaker recognition by machines and humans: A tutorial review. IEEE Signal Process. Mag. 2015, 32, 74–99. [Google Scholar] [CrossRef]
- Davies, M.E.; James, C.J. Source separation using single channel ICA. Signal Process. 2007, 87, 1819–1832. [Google Scholar] [CrossRef]
- Cooke, M.; Hershey, J.R.; Rennie, S.J. Monaural speech separation and recognition challenge. Comput. Speech Lang. 2010, 24, 1–15. [Google Scholar] [CrossRef]
- Weinstein, E.; Feder, M.; Oppenheim, A.V. Multi-channel signal separation by decorrelation. IEEE Trans. Speech Audio Process. 1993, 1, 405–413. [Google Scholar] [CrossRef]
- Nugraha, A.A.; Liutkus, A.; Vincent, E. Multichannel audio source separation with deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 1652–1664. [Google Scholar] [CrossRef]
- Loizou, P.C. Speech Enhancement: Theory and Practice; CRC Press: Boca Raton, FL, USA, 2007. [Google Scholar]
- Jensen, J.; Hansen, J.H.L. Speech enhancement using a constrained iterative sinusoidal model. IEEE Trans. Speech Audio Process. 2001, 9, 731–740. [Google Scholar] [CrossRef]
- Boll, S. Suppression of acoustic noise in speech using spectral subtraction. IEEE Trans. Acoust. Speech, Signal Process. 1979, 27, 113–120. [Google Scholar] [CrossRef]
- Sameti, H.; Sheikhzadeh, H.; Deng, L.; Brennan, R.L. HMM-based strategies for enhancement of speech signals embedded in nonstationary noise. IEEE Trans. Speech Audio Process. 1998, 6, 445–455. [Google Scholar] [CrossRef]
- Reynolds, D.A.; Quatieri, T.F.; Dunn, R.B. Speaker verification using adapted Gaussian mixture models. Digit. Signal Process. 2000, 10, 19–41. [Google Scholar] [CrossRef]
- Brown, G.J.; Cooke, M. Computational auditory scene analysis. Comput. Speech Lang. 1994, 8, 297–336. [Google Scholar] [CrossRef]
- Wang, D.; Brown, G.J. Computational Auditory Scene Analysis: Principles, Algorithms, and Applications; Wiley-IEEE Press: Hoboken, NJ, USA, 2006. [Google Scholar]
- Liu, Y.; Wang, D. A CASA approach to deep learning based speaker-independent co-channel speech separation. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5399–5403. [Google Scholar]
- Wang, D. On ideal binary mask as the computational goal of auditory scene analysis. In Speech Separation by Humans and Machines; Springer: Berlin/Heidelberg, Germany, 2005; pp. 181–197. [Google Scholar]
- Kjems, U.; Boldt, J.B.; Pedersen, M.S.; Lunner, T.; Wang, D. Role of mask pattern in intelligibility of ideal binary-masked noisy speech. J. Acoust. Soc. Am. 2009, 126, 1415–1426. [Google Scholar] [CrossRef]
- Narayanan, A.; Wang, D. Ideal ratio mask estimation using deep neural networks for robust speech recognition. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 7092–7096. [Google Scholar]
- Hummersone, C.; Stokes, T.; Brookes, T. On the ideal ratio mask as the goal of computational auditory scene analysis. In Blind Source Separation: Advances in Theory, Algorithms and Applications; Springer: Berlin/Heidelberg, Germany, 2014; pp. 349–368. [Google Scholar]
- Li, N.; Loizou, P.C. Factors influencing intelligibility of ideal binary-masked speech: Implications for noise reduction. J. Acoust. Soc. Am. 2008, 123, 1673–1682. [Google Scholar] [CrossRef]
- Wang, D.; Kjems, U.; Pedersen, M.S.; Boldt, J.B.; Lunner, T. Speech intelligibility in background noise with ideal binary time-frequency masking. J. Acoust. Soc. Am. 2009, 125, 2336–2347. [Google Scholar] [CrossRef]
- Wang, Y.; Narayanan, A.; Wang, D. On training targets for supervised speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1849–1858. [Google Scholar] [CrossRef]
- Minipriya, T.; Rajavel, R. Review of ideal binary and ratio mask estimation techniques for monaural speech separation. In Proceedings of the 2018 Fourth International Conference on Advances in Electrical, Electronics, Information, Communication and Bio-Informatics (AEEICB), Chennai, India, 27–28 February 2018; pp. 1–5. [Google Scholar]
- Chen, J.; Wang, D. DNN Based Mask Estimation for Supervised Speech Separation. In Audio Source Separation; Springer: Cham, Switzerland, 2018; pp. 207–235. [Google Scholar]
- Xu, Y.; Du, J.; Dai, L.R.; Lee, C.H. An experimental study on speech enhancement based on deep neural networks. IEEE Signal Process. Lett. 2013, 21, 65–68. [Google Scholar] [CrossRef]
- Du, J.; Tu, Y.; Dai, L.R.; Lee, C.H.; Fellow. A Regression Approach to Single-Channel Speech Separation Via High-Resolution Deep Neural Networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 1424–1437. [Google Scholar] [CrossRef]
- Delfarah, M.; Wang, D. Features for masking-based monaural speech separation in reverberant conditions. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1085–1094. [Google Scholar] [CrossRef]
- Weninger, F.; Erdogan, H.; Watanabe, S.; Vincent, E.; Le Roux, J.; Hershey, J.R.; Schuller, B. Speech enhancement with LSTM recurrent neural networks and its application to noise-robust ASR. In Proceedings of the Latent Variable Analysis and Signal Separation: 12th International Conference, LVA/ICA 2015, Liberec, Czech Republic, 25–28 August 2015; Proceedings 12. pp. 91–99. [Google Scholar]
- Chen, J.; Wang, D. Long short-term memory for speaker generalization in supervised speech separation. J. Acoust. Soc. Am. 2017, 141, 4705–4714. [Google Scholar] [CrossRef] [PubMed]
- Strake, M.; Defraene, B.; Fluyt, K.; Tirry, W.; Fingscheidt, T. Separated noise suppression and speech restoration: LSTM-based speech enhancement in two stages. In Proceedings of the 2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 20–23 October 2019; pp. 239–243. [Google Scholar]
- Garofolo, J.S. Timit Acoustic Phonetic Continuous Speech Corpus; Linguistic Data Consortium: Philadelphia, PA, USA, 1993. [Google Scholar]
- Huang, P.S.; Kim, M.; Hasegawa-Johnson, M.; Smaragdis, P. Deep learning for monaural speech separation. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014. [Google Scholar]
- Grais, E.M.; Sen, M.U.; Erdogan, H. Deep neural networks for single channel source separation. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Vincent, E.; Gribonval, R.; Fevotte, C. Performance measurement in blind audio source separation. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1462–1469. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | TIMIT Acoustic Phonetic Continuous Speech Corpus |
| Sampling frequency | 16 kHz |
| Frame length | 32 ms |
| Frame overlap | 75% |
| Window | Hann |
| SDR | SIR | SAR | |
|---|---|---|---|
| IBM | 11.53 | 28.36 | 11.73 |
| IRM | 19.58 |
| 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | |
| 0.5 | 11.60 | 11.87 | 11.88 | 11.86 | 11.53 |
| 0.6 | 11.92 | 12.18 | 12.24 | 12.05 | 11.87 |
| 0.7 | 12.10 | 12.35 | 12.40 | 12.16 | 11.99 |
| 0.8 | 12.05 | 12.27 | 12.35 | 12.13 | 11.95 |
| 0.9 | 11.89 | 12.13 | 12.20 | 11.97 | 11.87 |
| 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | |
| 0.5 | 26.11 | 26.92 | 27.63 | 28.13 | 28.36 |
| 0.6 | 24.63 | 25.53 | 26.42 | 27.30 | 28.17 |
| 0.7 | 23.35 | 24.30 | 25.29 | 26.38 | 27.66 |
| 0.8 | 22.31 | 23.28 | 24.32 | 25.53 | 27.02 |
| 0.9 | 21.41 | 22.40 | 23.46 | 24.73 | 26.32 |
| 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | |
| 0.5 | 12.06 | 12.24 | 12.16 | 12.10 | 11.73 |
| 0.6 | 12.39 | 12.55 | 12.54 | 12.30 | 12.11 |
| 0.7 | 12.61 | 12.77 | 12.74 | 12.46 | 12.28 |
| 0.8 | 12.63 | 12.75 | 12.76 | 12.50 | 12.33 |
| 0.9 | 12.56 | 12.70 | 12.71 | 12.45 | 12.36 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, P.; Nguyen, B.T.; Iwai, K.; Nishiura, T. Threshold-Based Combination of Ideal Binary Mask and Ideal Ratio Mask for Single-Channel Speech Separation. Information 2024, 15, 608. https://doi.org/10.3390/info15100608
Chen P, Nguyen BT, Iwai K, Nishiura T. Threshold-Based Combination of Ideal Binary Mask and Ideal Ratio Mask for Single-Channel Speech Separation. Information. 2024; 15(10):608. https://doi.org/10.3390/info15100608
Chicago/Turabian StyleChen, Peng, Binh Thien Nguyen, Kenta Iwai, and Takanobu Nishiura. 2024. "Threshold-Based Combination of Ideal Binary Mask and Ideal Ratio Mask for Single-Channel Speech Separation" Information 15, no. 10: 608. https://doi.org/10.3390/info15100608
APA StyleChen, P., Nguyen, B. T., Iwai, K., & Nishiura, T. (2024). Threshold-Based Combination of Ideal Binary Mask and Ideal Ratio Mask for Single-Channel Speech Separation. Information, 15(10), 608. https://doi.org/10.3390/info15100608