1. Introduction
In the healthcare industry, a well-known adage is “Quality care is the right care, at the right time, every time” [
1]. Modern healthcare is more often personalized, evidence-driven, and model-assisted. Large amounts of existing data allow for the creation of the data-driven approaches that have emerged to enhance decision-making processes. In the era of big data, the healthcare domain is an active area of research where various problems are addressed using machine learning (ML) approaches. For instance, experts are supported in disease diagnosis by ML algorithms, often employing classification techniques to determine the presence or absence of of a particular disease based on medical examination results and symptoms. Traditional medical diagnosis relies on a doctor’s judgment and years of experience to make a diagnosis based on the patient’s symptoms. However, ML approaches can replicate decision-making capabilities for disease diagnosis, as reported in a recent review paper on ML techniques for classifying and detecting breast cancer from medical images [
2].
Support Vector Machines (SVMs) are commonly used for classification and regression problems. The performance of SVM algorithms has been found to be comparable or superior to other ML algorithms, making them a valuable tool for healthcare practitioners.
SVMs find applications in several fields within healthcare, including:
Diagnosis and prognosis to predict the progression of diseases such as cancer, cardiovascular disease, and neurological disorders. One significant limitation is the inability to address class imbalance effectively in real-life datasets. Most algorithms are designed with the assumption of a balanced class, including classical SVM; however, this can result in poor performance when predicting the minority target class, which is often the focus in prediction processes.
Predictive modelling can be used in healthcare services to predict patient outcomes, such as complications and survival rates. In the clinical environment, decisions based on predicting risks and positive outcomes should ideally be supported by statistical learning models. ML techniques are commonly used in the diagnosis of diseases to enhance domain expert decision-making procedures. The diagnosis process relies heavily on objective data from patients and expert decisions. Classification systems can reduce errors caused by lack of expertise and provide medical data for examination in a shorter time. The effectiveness of a predictive model depends on the selection of appropriate predictors.
Personalized medicine, where SVMs can help to develop personalized treatment plans based on a patient’s genomic, demographic, and clinical data.
Risk stratification allows patients to be stratified based on their risk of developing a particular disease or condition. Interesting recent papers addressing the stratification of patient populations based on prognostic or predictive biomarkers include [
3,
4], while issues related to cancer genomics such as the discovery of new biomarkers, new drug targets, and a better understanding of genes that act as drivers of cancer have been addressed in [
5].
In gene expression analysis, SVMs can be applied to identify key genes that are associated with particular diseases, such as leukemia, colon cancer, and lymphoma [
6,
7]. Microarray data are used to record the expression values of thousands of genes. These datasets are characterized by a small sample size and numerous features.
In image analysis, SVMs can be applied to detect and diagnose various diseases and conditions in medical imaging, such as PET-CT images for patients with lung cancer [
8], breast magnetic resonance imaging [
9,
10], X-rays for infectious diseases such as pneumonia [
11,
12], and neuroimaging for Alzheimer’s Disease, as reported in a structured review [
13] (
adni.loni.usc.edu, accessed on 15 February 2024).
Recently, there has been growing interest among researchers in using electronic health records to improve various aspects of healthcare. These include improving the outcomes of medical procedures, reducing healthcare costs, evaluating the effectiveness of newly developed drugs, and predicting health trends or adverse events. Survival analysis plays a key role in predicting health trends or adverse events. It is used to investigate how a given set of factors, known as covariates, affect the time to a particular event of interest, such as death or reaching a particular stage of disease progression. The primary objective of survival analysis is to establish a relationship between these covariates and the time from baseline to the occurrence of an event. What distinguishes survival analysis from traditional ML methods is its handling of partially observed data, commonly referred to as censoring. For example, in clinical trials patients are typically followed for a period of time during which events are recorded. If a patient experiences an event such as disease progression or death, the exact timing of the event is known and the patient’s record is considered uncensored. However, for patients who do not experience the event by the end of the study period, their records are considered censored, either because the event has not yet occurred or because they were lost to follow-up. This aspect of survival analysis presents unique challenges and requires specialised techniques for analysis and interpretation. The use of SVMs for regression problems is known as Support Vector Regression (SVR). A regression model can predict the exact time of an event.
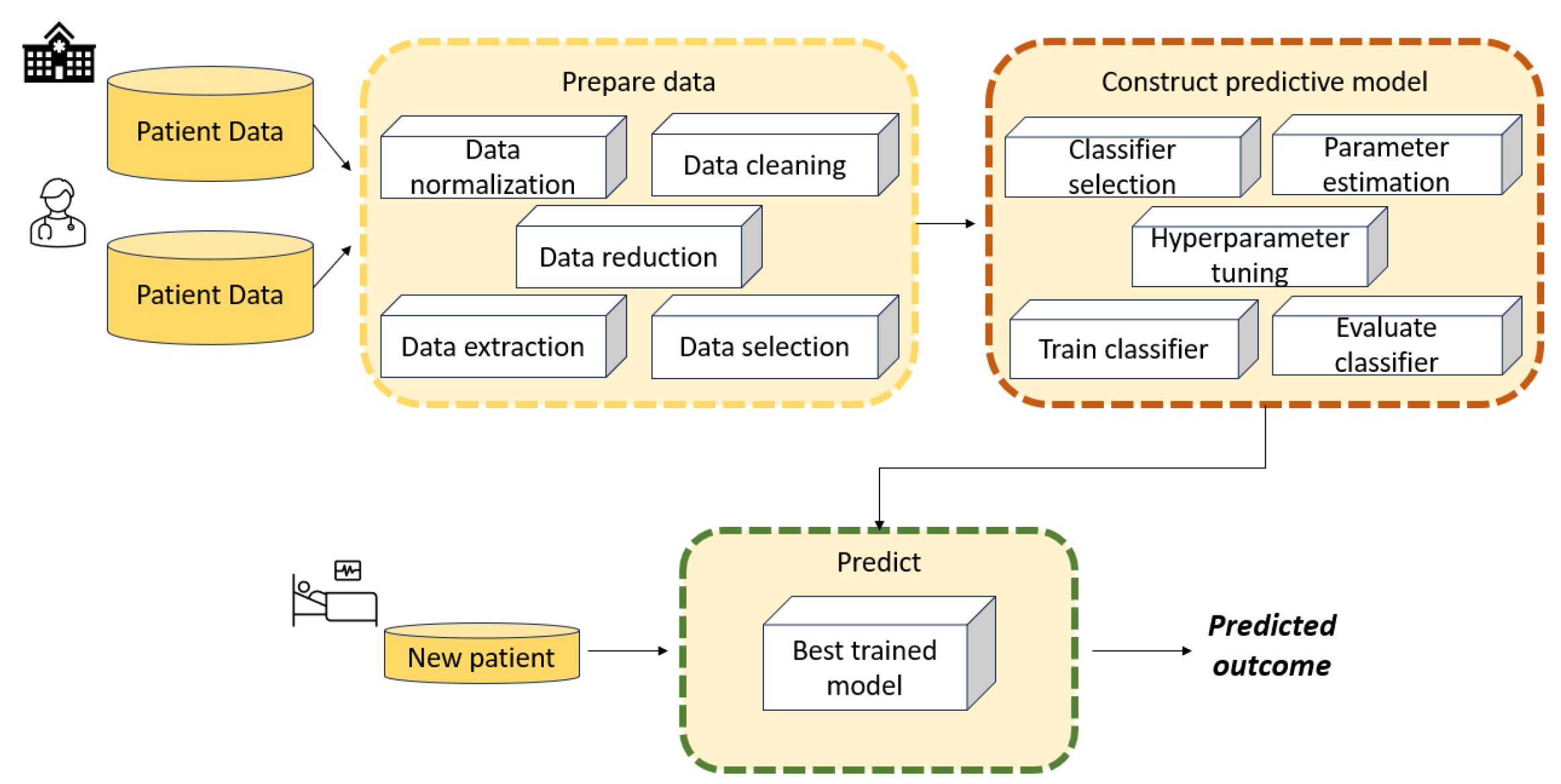
Figure 1 illustrates the main stages involved in developing an ML model such as an SVM to solve a diagnostic or regression problem. Data collection is not an issue when benchmark datasets are used to train and test SVM models; however, it becomes a fundamental phase when addressing real-world case studies.
Data collection is the first stage, and involves collecting relevant data from various sources such as databases or sensors. These data consist of case scenarios organized and grouped according to specific criteria that are relevant to decision-making.
The data processing phase aims to handle missing values, outliers, noise, and inconsistencies. Data preprocessing techniques may include data cleaning, normalisation, feature scaling, encoding categorical variables, and dimensionality reduction.
Feature engineering involves selecting, transforming, and creating new features from raw data to enhance the performance of SVM models. This may include extracting meaningful features from raw data, combining multiple features, or generating new features using domain knowledge.
Data modelling is a crucial component of the architecture, as it aims to build a model capable of learning patterns and relationships between input features and output labels. Effective data modelling requires careful consideration of data preprocessing, feature engineering, model selection, and evaluation techniques to build accurate and robust machine learning systems.
Model evaluation is the final stage. After a model has been trained, it is evaluated using a validation set in order to assess its performance on unseen data. The best model is then chosen from among those that have been evaluated.
Retrieving accurately labelled datasets can be a costly and challenging process. It often requires repeated experiments or time-consuming annotation procedures, especially in fields such as medical imaging. Therefore, learning from weakly labelled data has become crucial. Weak-label problems are categorised based on label characteristics, including partially-known labels (where most training vectors are unlabeled), implicitly-known labels (where training vectors are grouped into labelled bags), and unknown labels. Data quality issues such as label and feature noise can complicate matters, especially in medical applications, where diagnostic tests may lack perfect accuracy. Label noise can severely impact classifier performance, leading to deteriorated performance and increased learning requirements. Additionally, label noise can skew the observed frequencies of medical test results, potentially resulting in incorrect conclusions about population characteristics.
Motivations and Goals
Disease diagnosis and prognosis is crucial when determining treatment strategies and is closely linked to patient safety. In recent years, new modelling approaches based on SVMs have shown good performance, either as hybrid approaches combining various ML techniques or by utilising optimization approaches. The aim of this paper is to provide an overview of the main SVM models that have been developed over the years for use in the healthcare domain to improve medical knowledge and support experts. Due to the large number of such papers, this paper represents a non-exhaustive literature review. Indeed, the following simple query of the Scopus database yielded 1764 documents from 1996 to 2023:
TITLE-ABS-KEY (“support vector machines” AND medical) AND PUBYEAR < 2024 AND (LIMIT-TO (SUBJAREA, “MATH”)) AND (LIMIT-TO (LANGUAGE, “English”)) AND (LIMIT-TO (EXACTKEYWORD, “Support Vector Machines”) OR LIMIT-TO (EXACTKEYWORD, “Support Vector Machine”) OR LIMIT-TO (EXACTKEYWORD, “Support Vectors Machine”) OR LIMIT-TO (EXACTKEYWORD, “SVM”) OR LIMIT-TO (EXACTKEYWORD, “Support Vector Machine (SVMs)”)).
Figure 2 shows the publication years of the resulting 1764 papers. A significant increase can be observed over the past five years.
The literature in this field is extensive. Thus, the purpose of this review is threefold:
First, to provide an examination of the literature in order to investigate the evolution of SVM models used in medical data and the incorporation of new techniques, for example, the novel fuzzy least squares projection twin support vector machines for class imbalance learning in [
14]. Our focus is on research introducing innovative SVM-based models and methods aimed at enhancing existing approaches or reporting novel improvements in results. Our analysis firstly focused on selecting papers that proposed innovative SVM models or reported interesting medical results in the areas of disease diagnosis, disease prognosis, or healthcare management. The primary focus was on three areas: disease diagnosis, including gene expression and image analysis; disease prognosis; and healthcare management. In addition, we discuss the underlying ideas, strengths, and weaknesses, allowing for better understanding of how to address real-life case studies and how to develop appropriate methods for specific problems. We excluded papers in which the main focus was not on SVM models.
Second, to consider real case studies selected based on the contribution of ML models including SVM for assisting clinicians in diagnosing chronic diseases (for instance, glaucoma). These papers can provide insights into a specific medical applications, such as the diagnosis and prognosis of certain cancers and chronic diseases such as glaucoma and sleep apnea, as well as the estimation of brain age from neuroimaging data. It emerged that when several ML methods were tested, SVM was not always the most effective.
Third, we believe that this review can help in developing new approaches based on SVM models. The presented taxonomy should be useful for identifying potential pitfalls and in determining which approaches could be combined into hybrid algorithms to further improve results.
The rest of this paper is organised as follows.
Section 2 provides a brief theoretical background on basic SVM models and contemporary SVM-based approaches. This section describes several challenging issues, such as methods for enhancing SVM performance with large-scale datasets and tackling imbalanced data classification problems.
Section 3 reviews relevant papers that have proposed new ML models based on SVMs and evaluated their effectiveness on medical/biomedical benchmark datasets. Typically, these studies include comparisons with state-of-the-art methods to validate the novel approaches. Here, we report only some of the compared ML models.
Section 4 surveys papers that utilized real-life data to measure the impact of their findings on patient outcomes, for example, to develop clinical decision support systems in order to facilitate self-disease management and aid healthcare professionals in decision-making.
Section 5 surveys papers that employed SVM models to predict various healthcare aspects, such as hospital readmissions, patient length of stay, mortality rates, and negative outcomes in home health care. These predictions encompass a range of diseases, including the notable case of COVID-19. Finally,
Section 6 presents several interesting future directions.
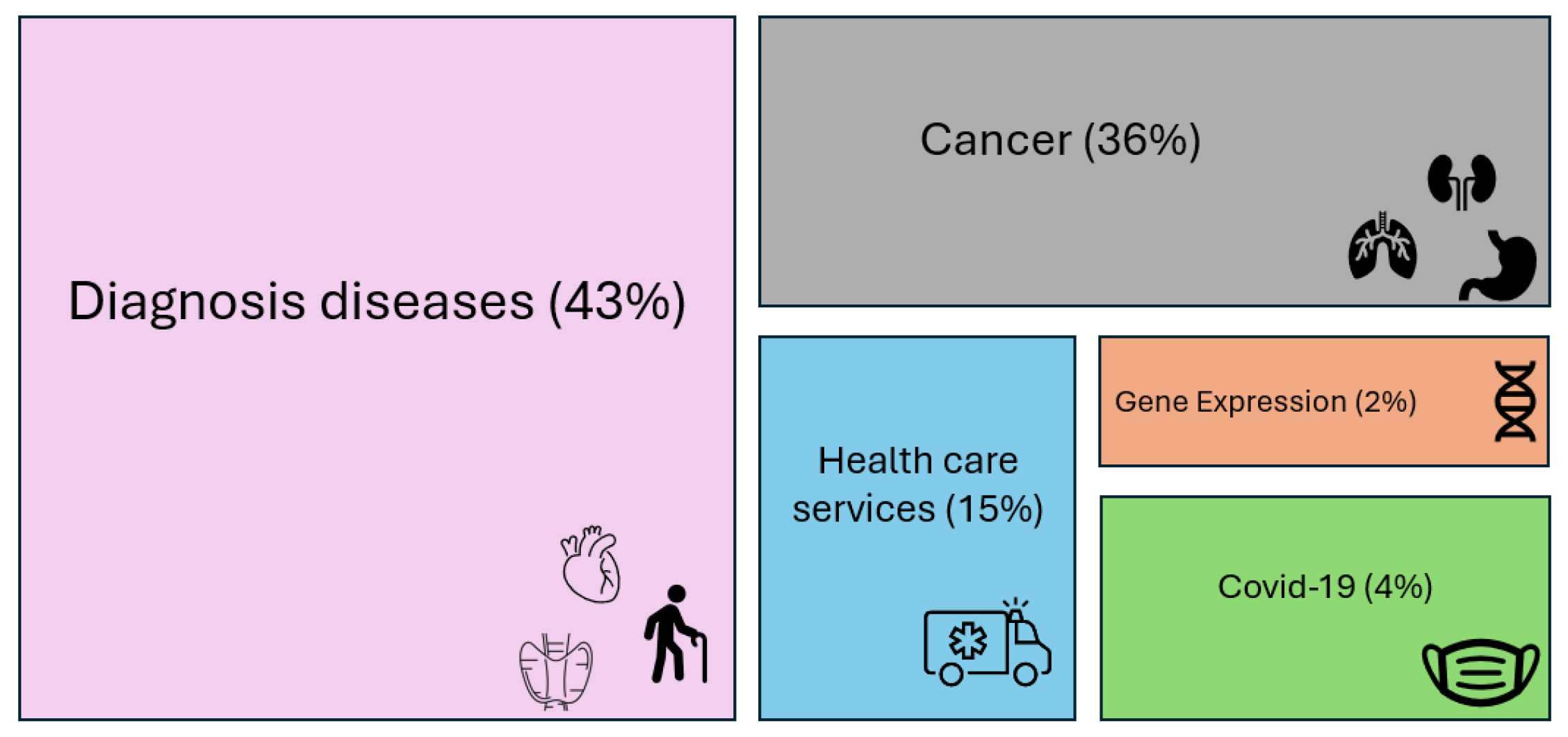
The 92 papers reviewed in the following sections are distributed as reported in
Figure 3.
2. Background on Classical SVM and Overview of SVM Model Developments
SVM is one of the most widely used ML algorithms, and is based on statistical learning theory [
15,
16,
17,
18]. It was originally designed for binary classification problems, then extended for multi-class problems.
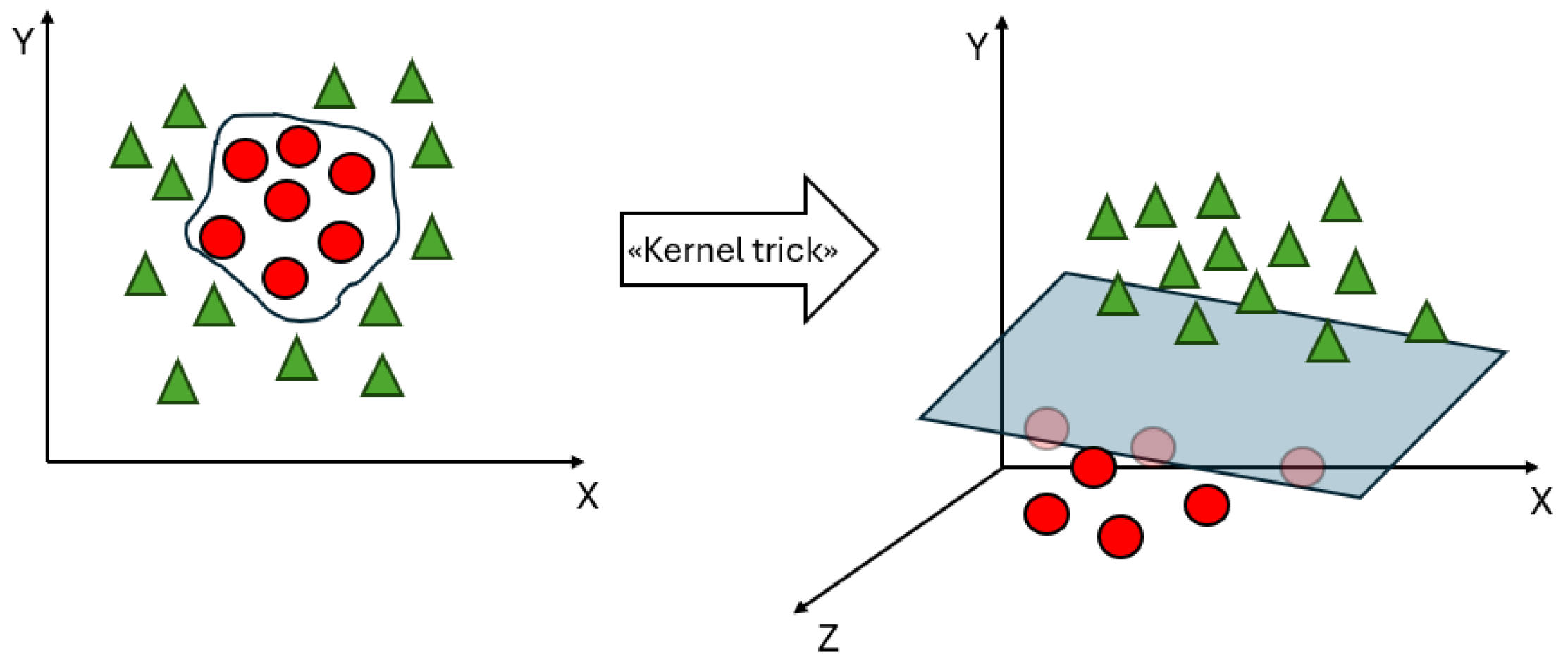
Figure 4 shows a simplified graphical representation of a binary classification problem solved by SVM.
In the healthcare domain, binary classification problems involve diagnosing a disease, while multi-class classification deals with predicting disease progression. SVMs have proven particularly adept at handling complex medical data due to their ability to address nonlinear relationships between features and classes.
The key strength of an SVM classifier lies in its ability to identify an optimized decision boundary representing the largest separation (maximum margin) between classes. The creation of the optimal hyperplane is influenced by only a small subset of training samples, known as support vectors (SVs), which are the pivotal data structure in an SVM. This means that the training samples that are not relevant to the SVs can be removed without affecting the construction of the SVM’s decision function, that is, the optimal hyperplane. SVMs were initially used to tackle linearly separable problems, with their capabilities later extended to handle nonlinear ones. For nonlinear problems, samples are mapped from a finite-dimensional space to a higher-dimension space.
In a classification problem, let
D be a dataset, represented as pairs of patterns
, where
is an instance with
n features and
is the related class label. A pattern (also called a data point or vector) is an example, which in a binary classification problem can be either positive (denoted by a label
) or negative (denoted by
); the goal of a binary classifier is to map the feature vectors
to the class labels
. In terms of functions, a binary classifier can be written as
, where the function
is denoted as the classifier predictor. It searches for an
optimal hyperplane that separates the patterns of two classes by maximizing the margin. In a dataset that is not linearly separable, the SVM essentially maps the inputs into higher-dimensional feature spaces using so-called kernel functions. A possible separating hyperplane in the transformed higher-dimensional feature space can be represented as
where
is the weight vector normal to the hyperplane and
.
Often, datasets may not be completely linearly separable even when mapped into a higher dimensional feature space; therefore, a set of slack variables
is introduced. Each slack variable
corresponds to a misclassified example
i, i.e., it measures the violation of a constraint corresponding to the training point
. The classical SVM classifiers are known as “maximum margin” classifiers, as they attempt to reduce the generalisation error by maximizing the margin between two disjoint half-planes. Finding the optimal hyperplane means solving the quadratic programming model (1)–(3), called a
soft margin optimization problem:
where the penalty parameter
C is a user-specified parameter and represents a trade-off between the two objectives, that is, maximum size of the margin and minimum sum of the slack variables. This is called the regularization term.
To deal with datasets that are not linearly separable, kernel functions are introduced in the SVM.
Figure 5 shows an example of the introduction of a kernel function, denoted as the “kernel trick”, which can make a dataset linearly separable in a feature space of a higher dimension than the input space. A kernel function denotes an inner product in a feature space; it measures the similarity between any pair of inputs
and
, and is usually denoted as
[
19]. Classical kernel functions include polynomial kernel
, radial basis function (RBF) kernel
, and sigmoid function
. Linear kernels are a special case of polynomial kernels; the degree
d is set to 1, and they compute the similarity in the input space, whereas other kernel functions compute the similarity in the feature space. The choice of a suitable kernel function depends on both the specific problem and the characteristics of the data. The choice of an appropriate kernel function can significantly impact the performance of SVMs.
As mentioned earlier, a conventional SVM solves a complex Quadratic Programming Problem (QPP) with inequality constraints in order to construct an optimal separating hyperplane that maximizes the margin between two classes; however, obtaining the solution to such a QPP poses a significant challenge. The dual formulation of SVM relies on the size of the training dataset, with all data points contributing constraints to the QPP. One major drawback of SVMs is their rapid growth in training time as the number of data points increases. The computational complexity of an SVM is for a training dataset of size l, making it computationally expensive. Another important issue is that SVMs are based on the minimization of a symmetric loss function (the hinge loss), which is cost-insensitive. This means that it is assumed that all misclassifications have the same cost. In addition, the performance of an SVM is greatly influenced by the choice of the kernel functions and the associated parameters.
In the following sections, we review different developments involving SVMs that have aimed to improve performance metrics by addressing the aforementioned drawbacks. Specifically, we underline how SVMs can address multi-class classification problems and identify SVM-based models that have been developed to solve important issues around training time, identification of redundant data points, and classifying imbalanced datasets.
2.2. Imbalanced Datasets and Cost-Sensitive SVMs
In the healthcare field, there are a very large number of imbalanced datasets. A simple example is the large number of patients with no rare disease. Most real-life datasets have classes that are not evenly distributed, that is, they are imbalanced. This topic is known in the literature as class imbalance learning [
33]. The larger class is named the majority class, while the smaller class is the minority. How to obtain an accurate prediction from such a dataset is a subject of ongoing research, as most current classifiers tend to predict the majority class and ignore the minority class. This occurs because a classifier attempts to reduce the overall error, and the classification error does not take into account the underlying data distribution. As a consequence, there is usually a lack of accuracy for minor class. The misclassification of the minority target class has serious consequences in healthcare, such as when positive cases are erroneously predicted as not positive when attempting to detect chronic diseases. As an example, consider a dataset of 1000 patients in which 900 out of 1000 patients have no disease and the remaining 100 have disease. If a model has an accuracy of 90%, it is necessary to evaluate its sensitivity. If the sensitivity is 0, then all 100 patients with disease will be misclassified. The aim of the different approaches developed in the literature is to reduce the effects of the imbalance ratio in order to improve the sensitivity of ML approaches to the minority class. Useful in this regard is the recent review paper by Haixiang et al. [
34], where 527 papers related to imbalanced learning and rare event detection typical of medical and biomedical datasets were analysed from both a technical and a practical perspective. Typically, higher costs are used to misclassify instances of a minority class than instances of a majority class. The commonly used approaches for handling imbalanced data can be divided in
data-level approaches, which rely on preprocessing and are sometimes called external methods, and
algorithmic-level approaches, also called internal methods. Data-level approaches modify the data distribution to produce a balanced dataset, whereas algorithmic-level approaches involve modifying the classical classification algorithms. An example of a sampling-based technique is the Synthetic Minority Over-sampling Technique (SMOTE) [
35], an oversampling algorithm that employs the
k-nearest neighbour (kNN) technique to over-sample the minority class by creating synthetic samples. Other data-level approaches for rebalancing class distributions include random over-sampling and random under-sampling. Random over-sampling replicates instances of the minority class, while random under-sampling eliminates instances of the majority class. However, it is important to note that both methods have disadvantages. Random over-sampling can lead to problems with overfitting due to the replication of instances, while random under-sampling may discard potentially useful information by removing instances. Algorithmic-level approaches involve modifications to algorithms and cost-sensitive approaches.
Standard methods such as SVM and TWSVM are sensitive to imbalanced datasets, potentially leading to suboptimal results. Regular SVMs do not perform well on imbalanced data, as the resulting models tend to be trained with respect to the majority class and technically ignore the minority class. Different methods have been developed in the literature to handle the class imbalance problem for SVMs, such as the multilevel weighted SVM (MLW-SVM) and Fuzzy SVM for Class Imbalance Learning (FSVM-CIL) settings. Results have shown that FSVM-CIL outperforms other standard SVM methods such as random oversampling, random undersampling, and SMOTE in terms of classification accuracy.
The biased penalties (B-SVM) method, also known as cost-sensitive SVM, was introduced in [
36]. Two penalty weights
and
are introduced for the positive and negative SVM slack variables during training. The basic SVM is
Iranmehr et al. [
37] proposed an alternative strategy for the design of SVMs, seeking to optimize the classifier with respect to class imbalance or class costs. In this approach, Bayesian consistency is guaranteed by drawing connections between risk minimization and probability elicitation. Moreover, by performing experimental analysis of class imbalance and cost-sensitive learning with given class and example costs, the results showed that the algorithm provides superior generalisation performance compared to conventional methods.
Universum has become a new research topic in ML [
38]. It consists of a collection of non-examples that do not belong to any class of interest. To improve the abilities of TWSVMs on imbalanced datasets, universum learning has been incorporated with SVM to solve the problem of class imbalance. The resulting model is called reduced universum TWSVM for class imbalance learning (RUTWSVM-CIL) [
39]. The universum data points are used to provide prior information about the data, while both oversampling and undersampling techniques are applied to remove the imbalance between the classes.
One of the drawbacks of all TWSVM-based models is that they need to invert a matrix; this operation is computationally expensive, and the matrix may not be invertible. RU-TWSVM was improved in [
40] (IRU-TWSVM) by reducing the size of the kernel matrix, thereby avoiding the computation of inverse matrices and reducing the computation time. IRU-TWSVM outperformed the TWSVM, U-TWSVM, and RU-TWSVM algorithms in terms of generalisation performance on benchmark datasets.
5. Predictive Modelling for Health Care Services
Measuring the quality of patient care and other health outcomes is a challenging task that is necessary in order to identify appropriate improvement actions around purchasing and healthcare management. Various health outcomes, such as Length of Stay (LOS) and re-admissions to hospital within 30 days after previous discharge or mortality, can be assessed to measure quality. These factors allow quality to be assessed, and have a significant impact on healthcare costs. ML techniques have proved to be efficient tools for predicting quality indicators of health care services.
Tremblay et al. [
128] conducted research to develop predictive models for LOS using NN and SVM. Their study focused on data preparation within a restricted surgical domain, namely, the digestive system. This phase involved selecting and transforming relevant features from the dataset, as often not all attributes are useful for prediction in large datasets. In this research, DT and LR techniques were used for feature selection, resulting in very similar outcomes. Among the various models applied, SVM demonstrated better performance in predicting LOS. Alturki et al. [
129] built a predictive model for LOS of the diabetic patients, addressing the problem as a classification problem. The continuous variable “time in hospital” was discretized as follows: short (<5 days), medium (5 to 8 days), and long (>8 days) stays. Among several ML techniques, an SVM with the RBF kernel function and intermediate values for C and
parameters turned out to be the best for the problem under investigation.
Zheng et al. [
130] built a high-performance risk prediction model. They solved a binary problem, in which the two class labels were low-risk and high-risk. The best model, with better generalisation ability and higher sensitivity in classifying readmitted patients, turned out to be an SVM with the Radial Basic Function (RBF) kernel on which the Particle Swarm Optimization (PSO) swarm intelligence technique was applied for the parameter search. Higher prediction performance was obtained by combining GA and SVM for the re-admission prediction problem considering diabetic patients [
131,
132]. Turgeman and May [
133] developed an ensemble hospital readmission predictive model able to control the trade off between transparency and prediction accuracy. The boosted C5.0 tree and the SVM were used as the base and second classifier, respectively. When tested on a real-world dataset, good prediction performance was achieved.
Liu et al. [
134] proposed an ICU mortality prediction model that addresses the challenges of high dimensionality and imbalanced distribution in digital health data, which can result in reduced classifier performance. Their model used modified cost-sensitive principal component analysis (MCSPCA) to improve the imbalanced distribution of the data and obtain low-dimensional features. An SVM with the RBF kernel was chosen as the classifier, with a chaos particle swarm optimization (CPSO) algorithm used to optimize the parameters. The proposed MCSPCA + CPSO + SVM achieved results in a shorter elapsed time (814 s) and showed good performance on the problem. Ghorbani et al. [
135] introduced a new hybrid predictive model for ICU mortality that addresses the data imbalance problem using the SVM-SMOTE technique. A Genetic Algorithm (GA) based on Wrapper Feature Selection (GAWFS) was used to determine the optimal subset of features, and a new ensemble model based on the combination of Stacking and Boosting ensemble methods was proposed. After testing different combinations of ML models to build a stacking ensemble model, the authors selected the Multilayer Perceptron Neural Network (MLP), kNN, and Extra Tree Classifier as the base classifiers and a Boosted SVM with adaptive boosting using 57 SVMs with the RBF kernel as the meta-classifier. The testing phase of the proposed model on a real-world MIMIIC-III health care dataset showed that it outperformed all the state-of-art models in terms of both accuracy and AUC measures. Barsasella et al. [
136] predicted the mortality risk for T2D and HTN patients in a tertiary hospital in Indonesia, testing several ML techniques. Their results showed that the SVM was able to achieve an accuracy performance close to the efficient MLP with backpropagation. For the prediction of mortality in adult patients with sepsis, the SVM obtained an accuracy prediction equal to the ANN method, demonstrating its ability to elaborate big medical data [
137]. To predict in-hospital mortality in patients with acute ST-segment elevation myocardial infarction, Gong et al. [
138] proposed a combination of a variant algorithm based on the original sine–cosine optimization algorithm and an SVM, resulting in a predictive framework that they called AGCOSCA-SVM. Superior accuracy, sensitivity, and specificity were achieved by the proposed framework compared to traditional ML methods, demonstrating its promise as a model framework for supporting the diagnostic process of MI. SVM showed great potential in the prediction of neonatal mortality considering four groups of categories: demographics, pregnancy, neonatal, and delivery factors. The method was tested on a real-world dataset and outperformed five other ML models (DT, Gaussian process, MLP, ensemble RF, and bagging) [
139].
Another application of ML techniques concerns the prediction of negative outcomes such as hospitalizations and emergency department visits in Home Health Care (HHC). Identifying at-risk patients allows for timely risk mitigation interventions and optimal allocation of hospital resources. Utilizing clinical notes is crucial for improving risk prediction in HHC contexts. Song et al. [
140] demonstrated that clinical notes play a crucial role in determining the optimal risk predictive model by combining standardized data with information extracted from clinical notes. They achieved high risk prediction ability considering a predictor set with an SVM. Previously, Ghassemi et al. [
141] demonstrated that clinical notes have an impact on ICU mortality prediction by applying an SVM model to predict ICU mortality in-hospital, 30 days post-discharge, and 1 year post-discharge.
COVID-19
With the outbreak of the COVID-19 pandemic, better defining the allocation of scarce healthcare resources became a major challenge for the entire world. Therefore, an urgent need arose to apply ML techniques for the construction of risk prediction models that could predict peoples’ needs in order to optimize limited clinical resources.
Afrash et al. [
142] conducted research to construct a model for predicting the LOS of patients who tested positive for COVID-19. The selected model was an SVM with a Gaussian kernel function, which proved to be the model with the highest accuracy and the lowest running time. Among the limitations of this study is the dimension of the dataset, which was based on a single center. Song et al. [
143] conducted a study on predicting hospitalizations of elderly people who tested positive for COVID-19, with the goal to identifying severe risk factors. Four hospitalization prediction models were developed, including regularized LR, SVM, RF, and NN. The final input variable list for models counted 44 characteristics based on a literature review, an online survey of clinicians treating COVID-19 patients, and an interview with a group of physicians. All four models obtained good prediction results, especially random forest and SVM (AUC = 0.83). Gao et al. [
144] proposed an ensemble method combining SVM, Gradient Boosted Decision Tree (GSBT), and Neural Network (NN) to predict the occurrence of critical illness in patients with COVID-19 based on immune–inflammatory parameters. The proposed model obtained better performance compared to five traditional models (LR, SVM, GBDT, KNN, and NN) considering a total of 450 patients from two hospitals in China.
Other studies conducted following the outbreak of the pandemic concerned the suitability of rapid antigen tests (RAT) for diagnosing COVID-19. Amer et al. [
145] used an SVM model to investigate whether the predictive accuracy of RAT for diagnosing COVID-19 could be improved by considering different measured laboratory parameters in participants’ blood. The SVM model with Monte Carlo cross-validation and the combination of the top two features, revealed to be HB and urea, obtained the highest prediction accuracy (59.3%). From this research, it emerged that combining the RAT results with laboratory measurements did not enhance the predictive accuracy of RAT.
6. Conclusions and Future Work
The main objective of this review is to provide an overview of the potential of SVMs in healthcare along with a summary of the most recent developments. SVM has proven to be a powerful machine learning tool, especially in the medical field, due to its solid theoretical foundations and advantages. Our analysis shows that there are general advantages of applying specialized SVMs to healthcare data. It is worth noting that many models based on SVMs are often more effective than other machine learning approaches. SVMs are suitable for dealing with higher-dimensional data as they are able to automatically regularise such data, helping to avoid issues around overfitting.
A number of extensions of SVM have been defined in order to face specific issues. One variant of SVM is TWSVM and its further extensions, which have shown to better prediction performance, including in the medical field. Despite countless developments, research on applications of TWSVM to big data remains limited.
It is important to point out that SVM performance is largely dependent on the selection of kernel functions and their parameters, which affects the results of the prediction to an extent, as well as the choice of the optimal input feature subset that influences the appropriate kernel parameters. There is currently not enough research on this topic to guide researchers in choosing the most appropriate kernel for different applications to achieve the desired performance. In addition, healthcare datasets are often characterised by high dimensionality and class imbalance, which can negatively impact SVM accuracy, especially in cases where the minority class is the target. Techniques such as cost-sensitive learning can help to address this issue. Another issue, especially in healthcare, is that while interpretability is paramount, SVMs produce complex decision boundaries that can make it difficult to interpret results. Furthermore, effective feature engineering is often necessary to improve the performance of SVM when dealing with heterogeneous medical data.
A critical factor for improving SVM performance in healthcare is the extraction of relevant features from heterogeneous medical data, including both structured data such as demographics and lab results and unstructured data such as medical images. Another important issue concerns missing values due to incomplete records or measurement errors. SVMs require complete datasets; thus, developing robust approaches to deal with missing values could be a future research direction. Feature selection is an important issue in the construction of prediction systems. It is advantageous to limit the number of input features in order to ensure a good predictive model that is less computationally demanding. The construction of a model that can handle this obstacle is very important, and despite the developments recorded in the literature, further research is required.
Another future direction concerns the application and development of cost-sensitive SVMs, which have been extensively tested in the laboratory but only rarely applied in real-world settings. Although the cost-sensitive SVMs have demonstrated good predictive performance in medical settings, their performance may be affected by factors characteristic of real-world scenarios, such as missing data, unbalanced datasets, and the presence of confounding variables. Future research could address the gaps in the literature on cost-sensitive SVMs in healthcare settings. This research should focus on evaluating the performance of these algorithms in real-world healthcare settings and comparing them with other learning algorithms. Such research would provide valuable insights into the practical application of these algorithms in clinical practice. Additionally, it is important to note that the number of papers reporting useful information for replicating their results is very small. Researchers should pay more attention to the information that they provide in order to facilitate the continued progress of SVMs and improve their applicability. In conclusion, results and applications on both real and benchmark data have demonstrated the superiority of SVMs over most alternative algorithms, providing motivation for their future developments.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}