




A Super-Efficient TinyML Processor for the Edge Metaverse




Abstract
1. Introduction
- i
- Designing, implementing, and evaluating a super-efficient neuromorphic processor, including a Winner-Take-All (WTA) circuit and a simplified Leaky Integrate and Fire (LIF) neuron on FPGAs.
- ii
- Addressing the applicability and useability of the proposed processor as a practicable and powerful TinyML chip.
- iii
- Specifying the design process of the proposed TinyML chip for the edge-enabled Metaverse.
2. Backgrounds
2.1. TinyML
2.2. Edge-Based Metaverse
2.3. Leaky Integrated and Fire Model
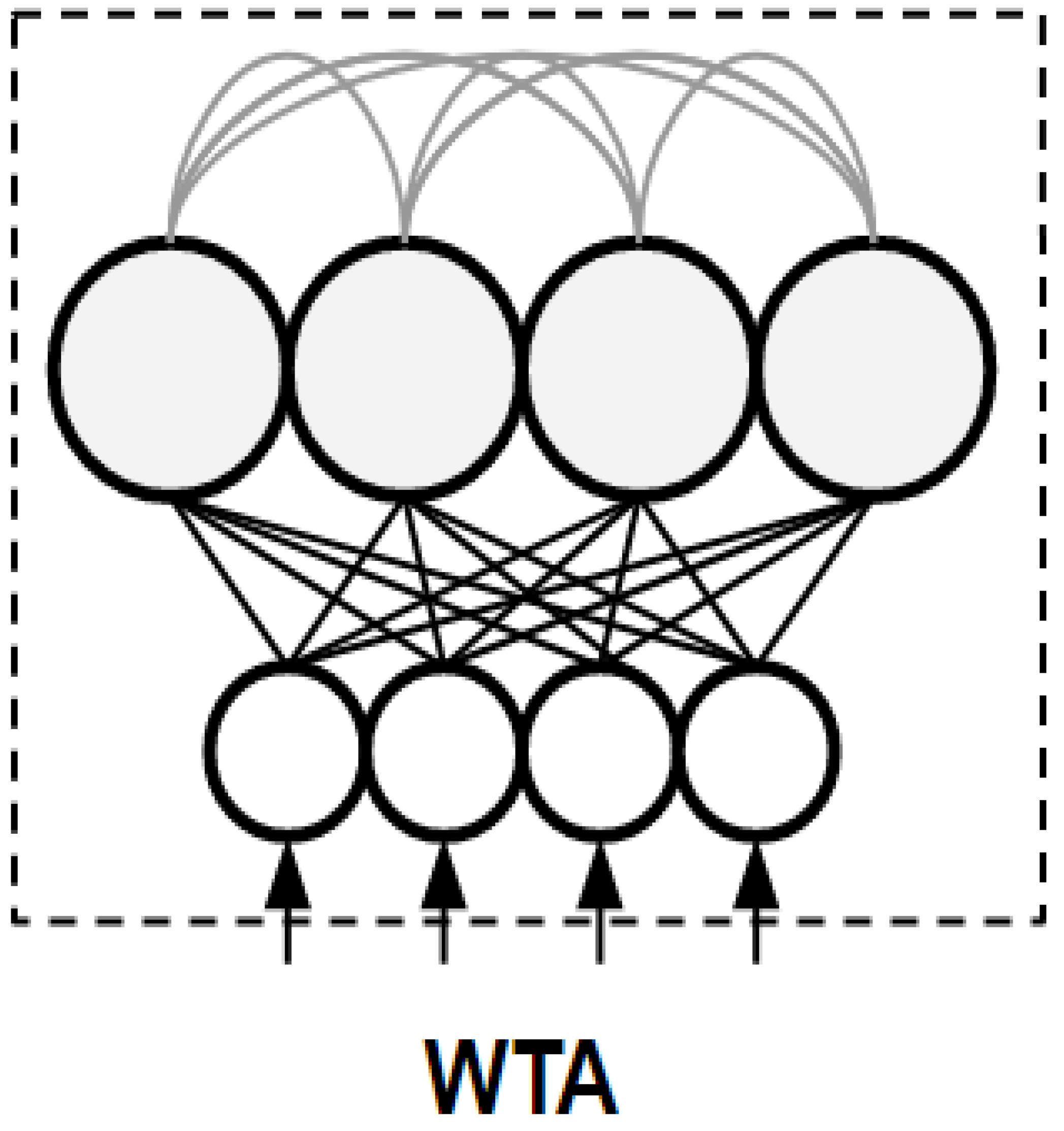
2.4. Winner-Take-All Neural Network
2.5. STDP Rule
3. Implementation Method
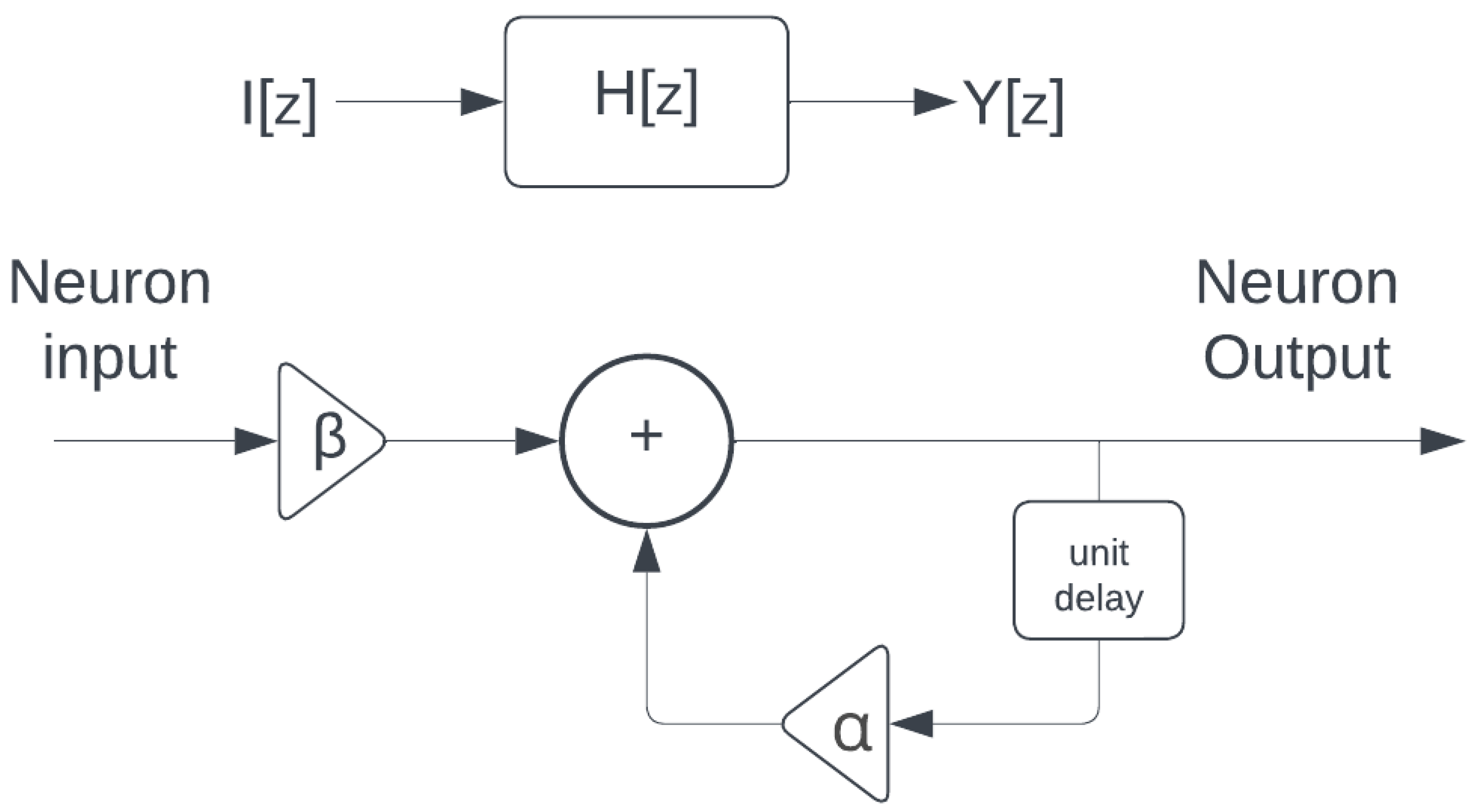
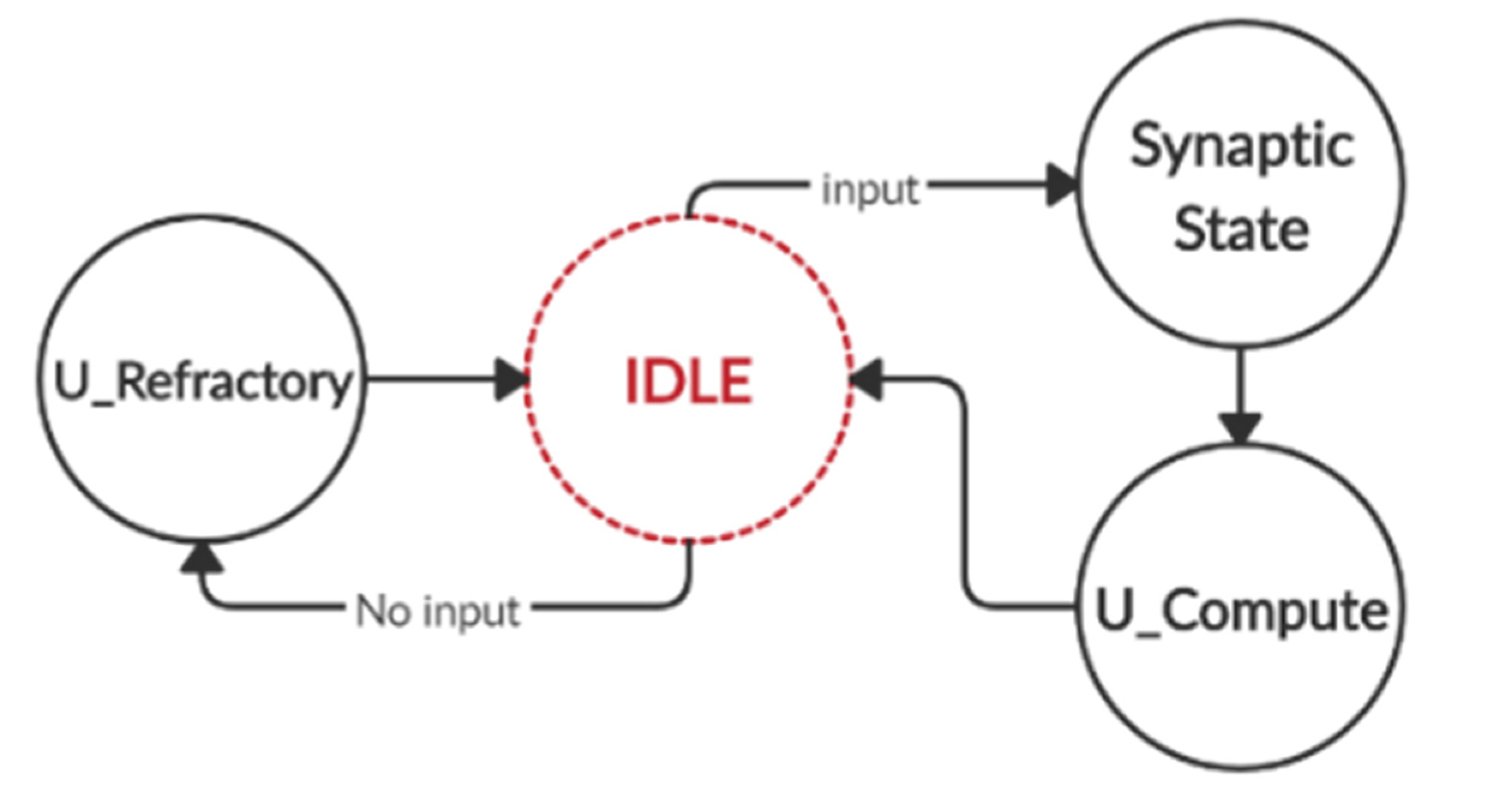
3.1. Discrete Model of an LIF Neuron
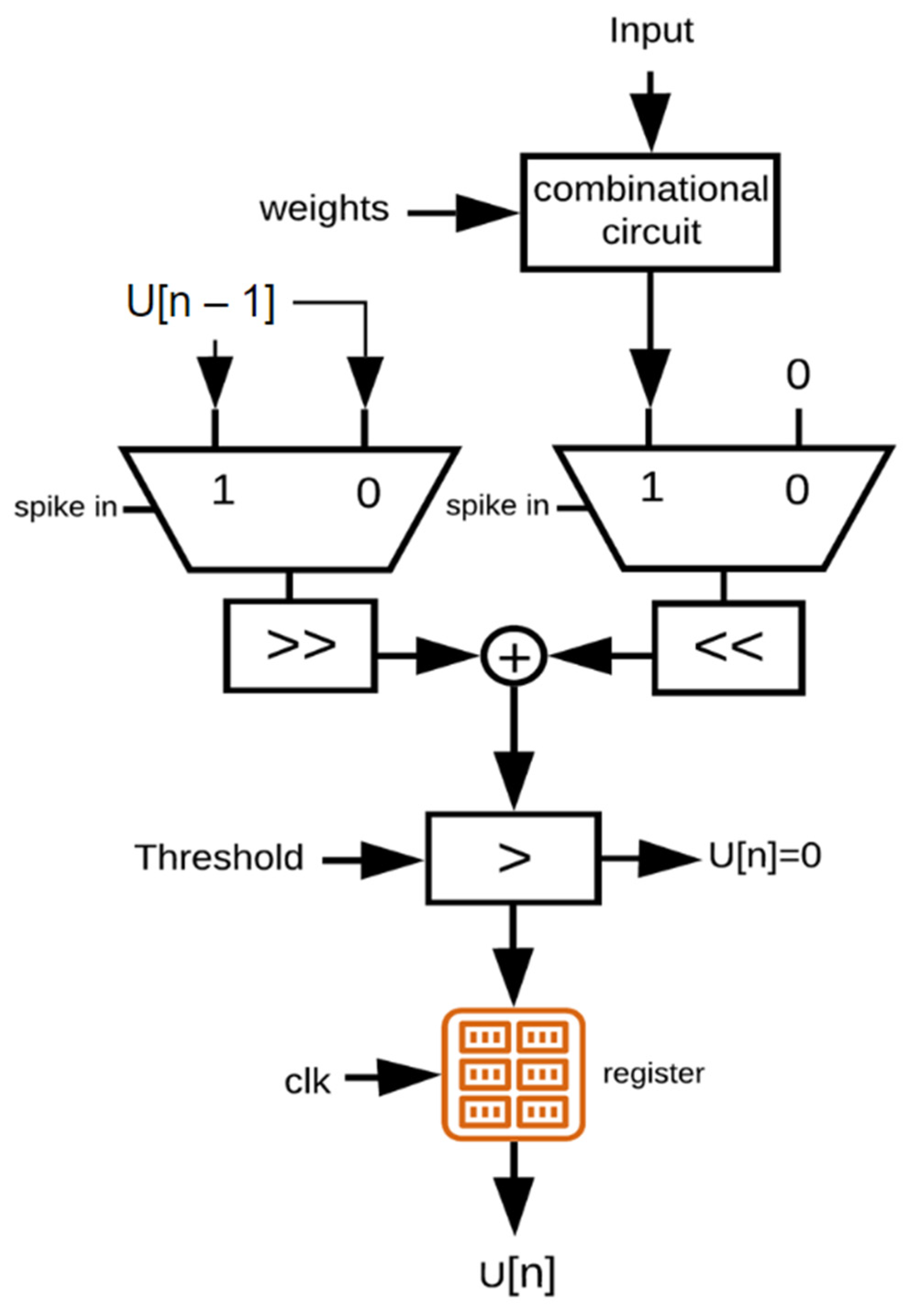
3.2. Simplified LIF Neuron
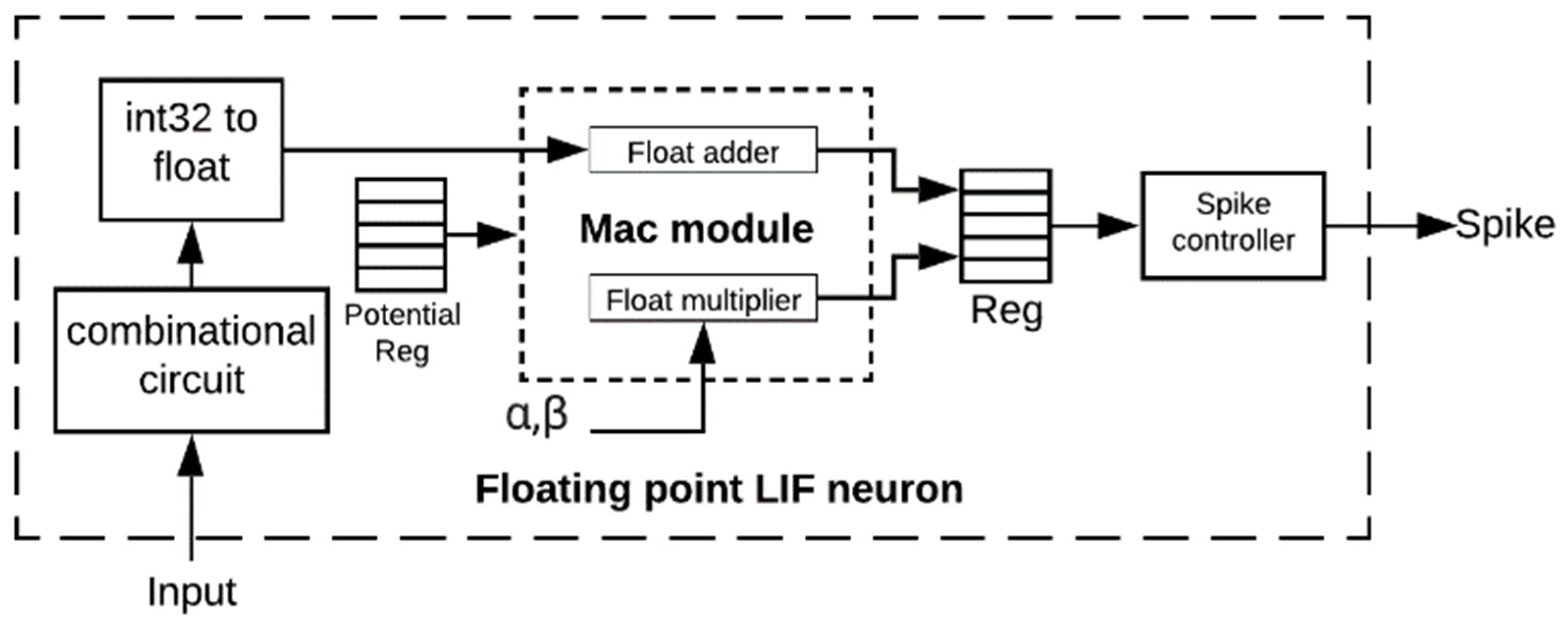
3.3. Floating-Point LIF Neuron
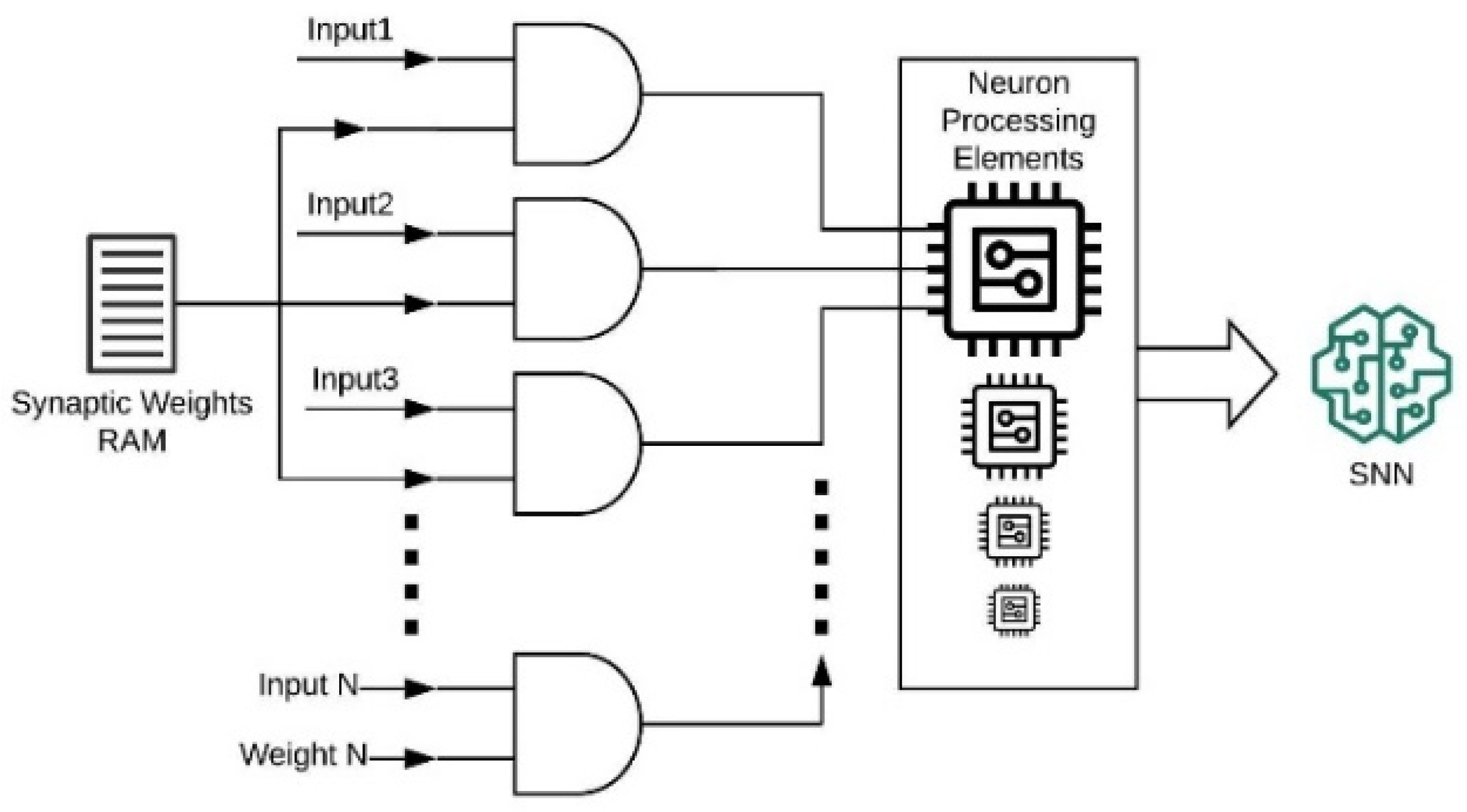
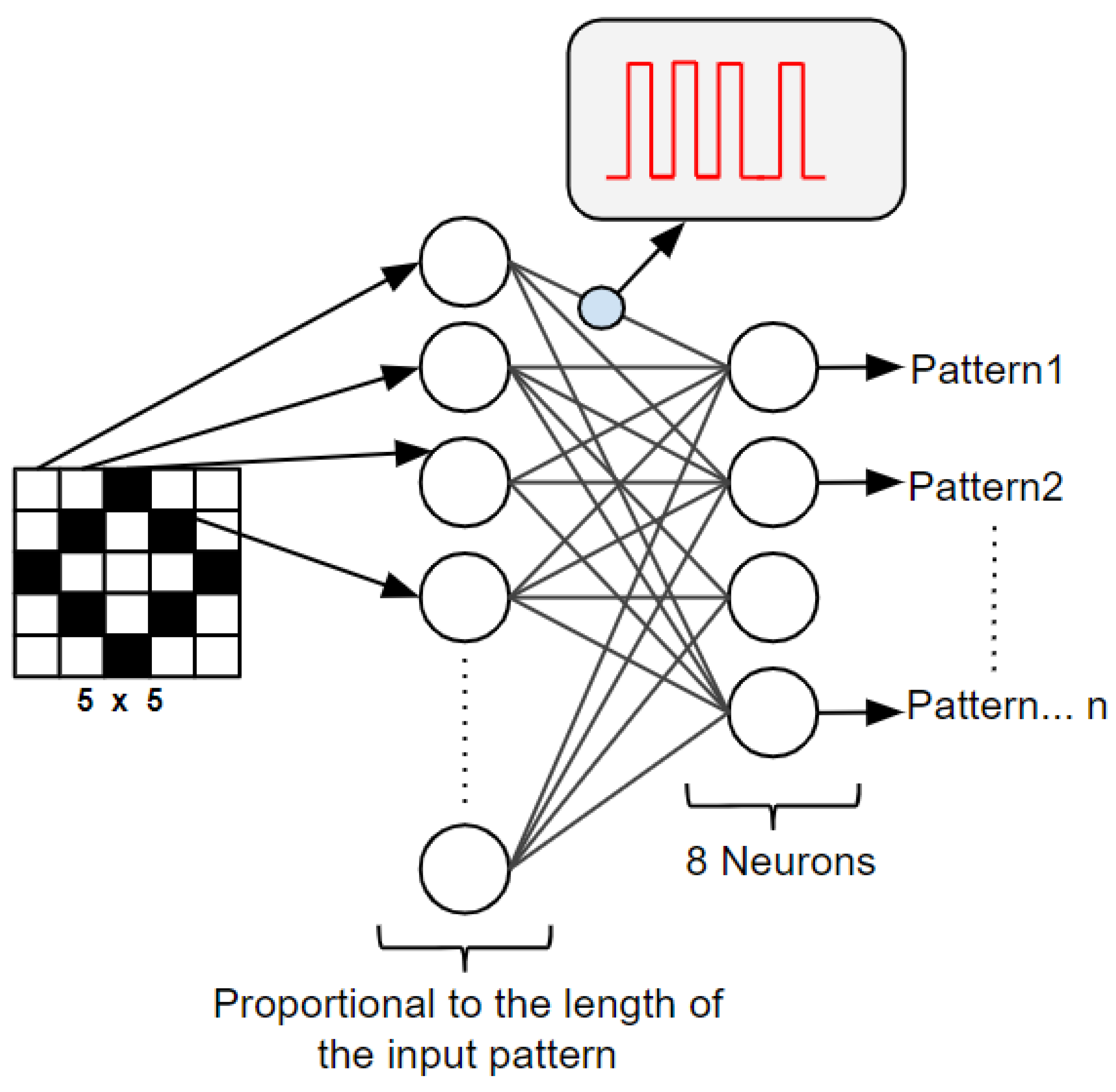
3.4. Implemented WTA Architecture
4. Results and Discussion
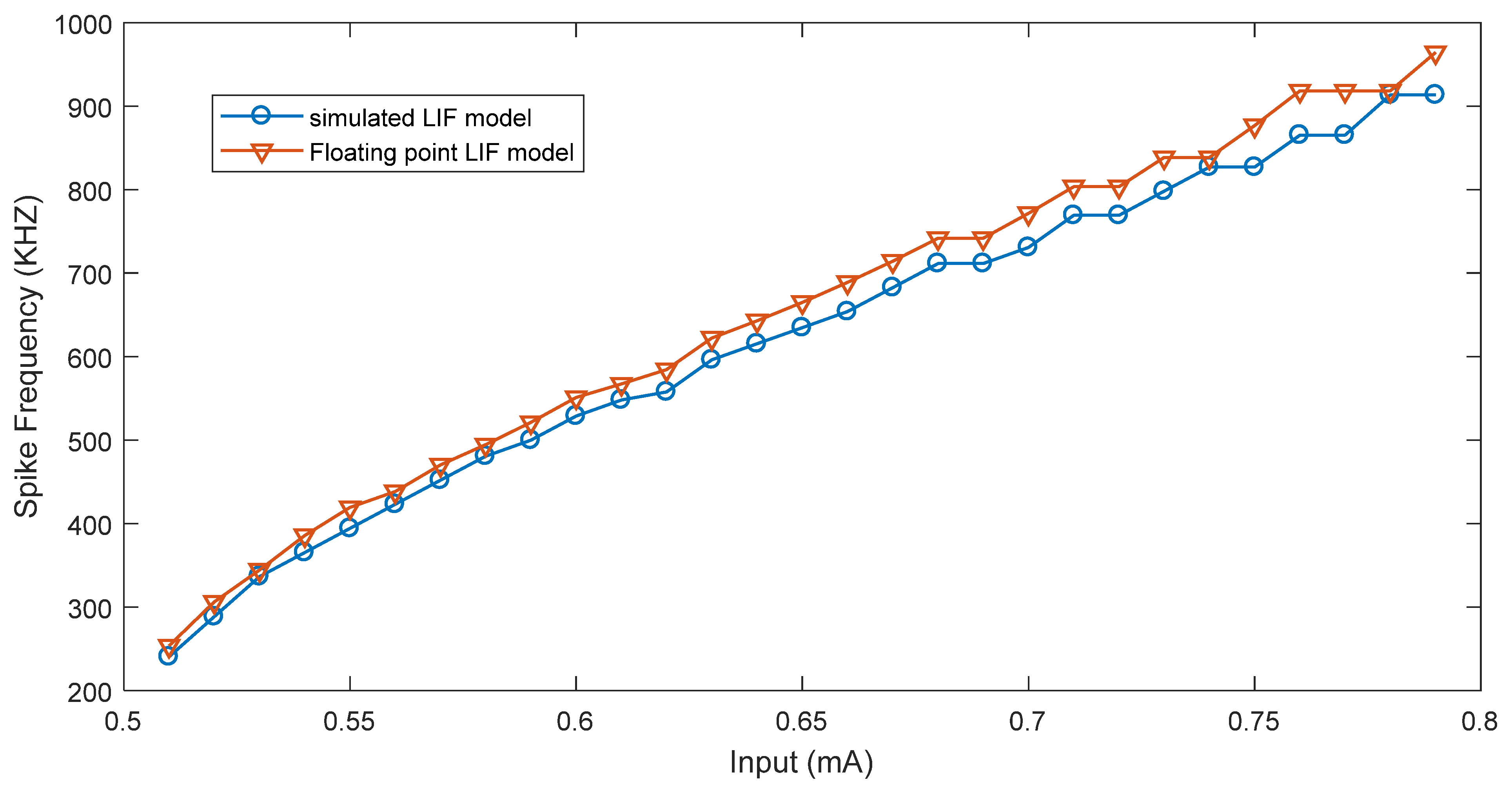
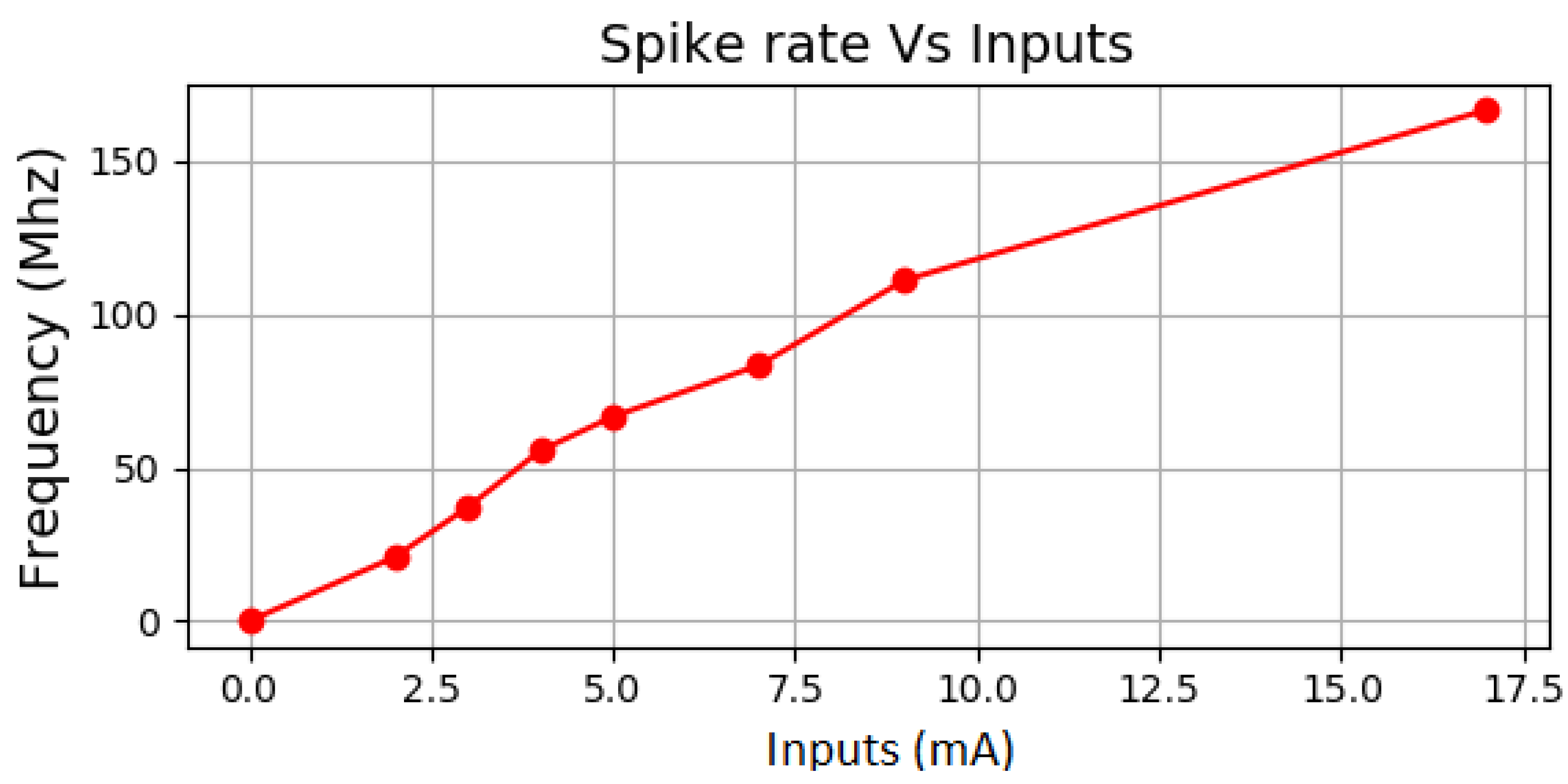
4.1. Spike Rate of the Simplified and Floating-Point Neurons
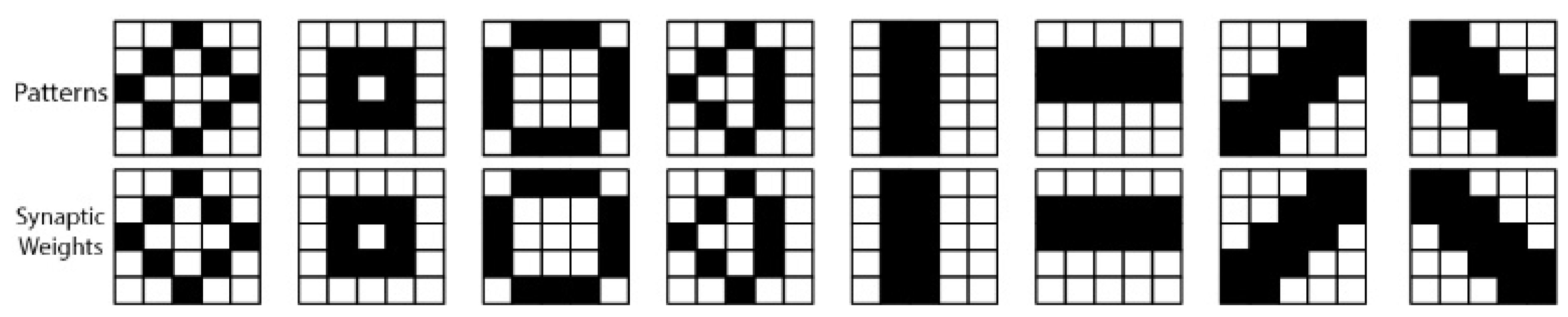
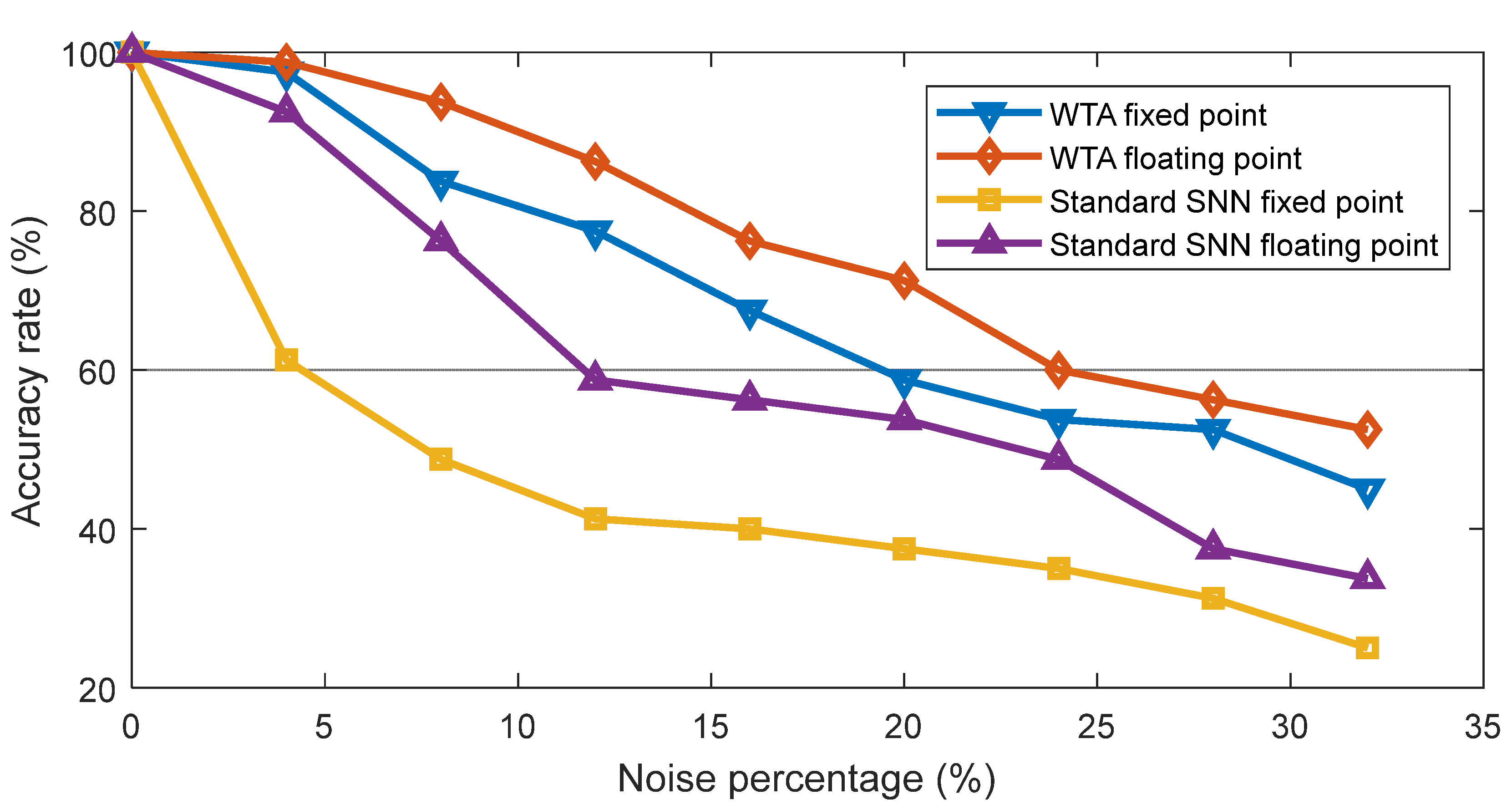
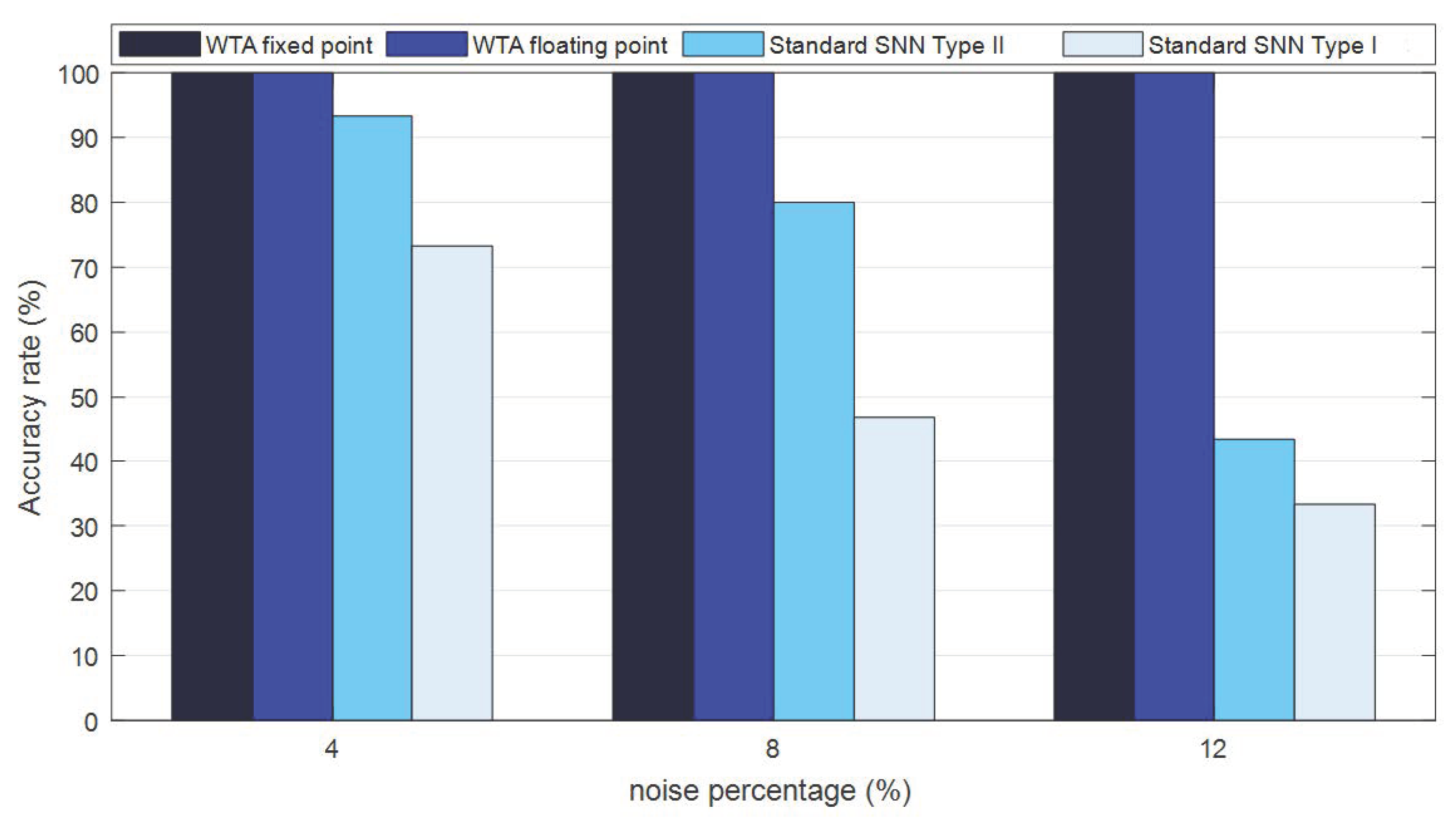
4.2. Recognition Accuracy of the Spiking WTA
4.3. Resource Consumption
5. Conclusions
- i
- Presenting a super-efficient TinyML chip for a wide range of IoTs and smart gadgets to be used in the edge-enabled Metaverse.
- ii
- Demanding low resource consumption.
- iii
- High operating frequency and speed.
- iv
- Increasing the accuracy significantly, making it an ideal option for medical applications in Metaverse applications.
Author Contributions
Funding
Conflicts of Interest
References
- Liu, H.; Wei, Z.; Zhang, H.; Li, B.; Zhao, C. Tiny Machine Learning (Tiny-ML) for Efficient Channel Estimation and Signal Detection. IEEE Trans. Veh. Technol. 2022, 71, 6795–6800. [Google Scholar] [CrossRef]
- Ray, P.P. A review on TinyML: State-of-the-art and prospects. J. King Saud Univ.-Comput. Inf. Sci. 2021, 34, 1595–1623. [Google Scholar] [CrossRef]
- Dutta, L.; Bharali, S. Tinyml meets iot: A comprehensive survey. Internet Things 2021, 16, 100461. [Google Scholar] [CrossRef]
- Asutkar, S.; Chalke, C.; Shivgan, K.; Tallur, S. TinyML-enabled edge implementation of transfer learning framework for domain generalization in machine fault diagnosis. Expert Syst. Appl. 2023, 213, 119016. [Google Scholar] [CrossRef]
- Dwivedi, Y.K.; Hughes, L.; Baabdullah, A.M.; Ribeiro-Navarrete, S.; Giannakis, M.; Al-Debei, M.M.; Dennehy, D.; Metri, B.; Buhalis, D.; Cheung, C.M. Metaverse beyond the hype: Multidisciplinary perspectives on emerging challenges, opportunities, and agenda for research, practice and policy. Int. J. Inf. Manag. 2022, 66, 102542. [Google Scholar] [CrossRef]
- Shafiei, A.; Jamshidi, M.B.; Khani, F.; Talla, J.; Peroutka, Z.; Gantassi, R.; Baz, M.; Cheikhrouhou, O.; Hamam, H. A Hybrid Technique Based on a Genetic Algorithm for Fuzzy Multiobjective Problems in 5G, Internet of Things, and Mobile Edge Computing. Math. Probl. Eng. 2021, 2021, 9194578. [Google Scholar] [CrossRef]
- Shen, S. Metaverse-driven new energy of Chinese traditional culture education: Edge computing method. Evol. Intell. 2022, 1–9. [Google Scholar] [CrossRef]
- Zhang, M.; Cao, J.; Sahni, Y.; Chen, Q.; Jiang, S.; Wu, T. Eaas: A service-oriented edge computing framework towards distributed intelligence. In Proceedings of the 2022 IEEE International Conference on Service-Oriented System Engineering (SOSE), Newark, CA, USA, 15–18 August 2022; pp. 165–175. [Google Scholar]
- Shamim, M.Z.M. TinyML Model for Classifying Hazardous Volatile Organic Compounds Using Low-Power Embedded Edge Sensors: Perfecting Factory 5.0 Using Edge AI. IEEE Sens. Lett. 2022, 6, 1–4. [Google Scholar] [CrossRef]
- Jamshidi, M.B.; Roshani, S.; Talla, J.; Peroutka, Z.; Roshani, S. A novel filter-based power divider for wireless communication in intelligent transportation systems. In Proceedings of the 2020 19th International Conference on Mechatronics-Mechatronika (ME), Prague, Czech Republic, 2–4 December 2020; pp. 1–5. [Google Scholar]
- Cassidy, A.S.; Georgiou, J.; Andreou, A.G. Design of silicon brains in the nano-CMOS era: Spiking neurons, learning synapses and neural architecture optimization. Neural Netw. 2013, 45, 4–26. [Google Scholar] [CrossRef]
- Karimi, G.; Gholami, M.; Farsa, E.Z. Digital implementation of biologically inspired Wilson model, population behavior, and learning. Int. J. Circuit Theory Appl. 2018, 46, 965–977. [Google Scholar] [CrossRef]
- Nouri, M.; Karimi, G.; Ahmadi, A.; Abbott, D. Digital multiplierless implementation of the biological FitzHugh–Nagumo model. Neurocomputing 2015, 165, 468–476. [Google Scholar] [CrossRef]
- Hayati, M.; Nouri, M.; Abbott, D.; Haghiri, S. Digital Multiplierless Realization of Two-Coupled Biological Hindmarsh–Rose Neuron Model. IEEE Trans. Circuits Syst. II Express Briefs 2016, 63, 463–467. [Google Scholar] [CrossRef]
- Hayati, M.; Nouri, M.; Haghiri, S.; Abbott, D. Digital Multiplierless Realization of Two Coupled Biological Morris-Lecar Neuron Model. IEEE Trans. Circuits Syst. I Regul. Pap. 2015, 62, 1805–1814. [Google Scholar] [CrossRef]
- Farsa, E.Z.; Ahmadi, A.; Maleki, M.A.; Gholami, M.; Rad, H.N. A Low-Cost High-Speed Neuromorphic Hardware Based on Spiking Neural Network. IEEE Trans. Circuits Syst. II Express Briefs 2019, 66, 1582–1586. [Google Scholar] [CrossRef]
- Zenke, F.; Bohté, S.M.; Clopath, C.; Comşa, I.M.; Göltz, J.; Maass, W.; Masquelier, T.; Naud, R.; Neftci, E.O.; Petrovici, M.A.; et al. Visualizing a joint future of neuroscience and neuromorphic engineering. Neuron 2021, 109, 571–575. [Google Scholar] [CrossRef] [PubMed]
- Shafique, M.; Theocharides, T.; Reddy, V.J.; Murmann, B. TinyML: Current Progress, Research Challenges, and Future Roadmap. Proc. Des. Autom. Conf. 2021, 2021, 1303–1306. [Google Scholar] [CrossRef]
- Bethi, Y.; Xu, Y.; Cohen, G.; Van Schaik, A.; Afshar, S. An Optimized Deep Spiking Neural Network Architecture without Gradients. IEEE Access 2021, 10, 97912–97929. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, S.; Geng, G. Initialization-Based k-Winners-Take-All Neural Network Model Using Modified Gradient Descent. IEEE Trans. Neural Netw. Learn. Syst. 2021, 2021, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Rinkus, G.J. A cortical sparse distributed coding model linking mini- and macrocolumn-scale functionality. Front. Neuroanat. 2010, 4, 17. [Google Scholar] [CrossRef]
- Abbott, L.F.; Kepler, T.B. Model neurons: From Hodgkin-Huxley to hopfield. In Statistical Mechanics of Neural Networks; Springer: Berlin/Heidelberg, Germany, 1990; pp. 5–18. [Google Scholar] [CrossRef]
- Wilson, H.R. Simplified Dynamics of Human and Mammalian Neocortical Neurons. J. Theor. Biol. 1999, 200, 375–388. [Google Scholar] [CrossRef] [PubMed]
- Burkitt, A.N. A review of the integrate-and-fire neuron model: I. Homogeneous synaptic input. Biol. Cybern. 2006, 95, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Izhikevich, E.M. Simple model of spiking neurons. IEEE Trans. Neural Netw. 2003, 14, 1569–1572. [Google Scholar] [CrossRef] [PubMed]
- Guo, T.; Pan, K.; Sun, B.; Wei, L.; Yan, Y.; Zhou, Y.; Wu, Y. Adjustable Leaky-Integrate-and-fire neurons based on memristor-coupled capacitors. Mater. Today Adv. 2021, 12, 100192. [Google Scholar] [CrossRef]
- Soro, S. TinyML for Ubiquitous Edge AI, February 2021. [Online]. Available online: https://arxiv.org/abs/2102.01255v1 (accessed on 8 April 2023).
- Lim, W.Y.B.; Xiong, Z.; Niyato, D.; Cao, X.; Miao, C.; Sun, S.; Yang, Q. Realizing the Metaverse with Edge Intelligence: A Match Made in Heaven. IEEE Wirel. Commun. 2022, 2022, 1–9. [Google Scholar] [CrossRef]
- Khan, L.U.; Han, Z.; Niyato, D.; Hossain, E.; Hong, C.S.; Member, S. Metaverse for Wireless Systems: Vision, Enablers, Architecture, and Future Directions, June 2022. [Online]. Available online: https://arxiv.org/abs/2207.00413v1 (accessed on 8 April 2023).
- Xu, M.; Ng, W.C.; Lim, W.Y.B.; Kang, J.; Xiong, Z.; Niyato, D.; Yang, Q.; Shen, X.S.; Miao, C. A Full Dive Into Realizing the Edge-Enabled Metaverse: Visions, Enabling Technologies, and Challenges. IEEE Commun. Surv. Tutorials 2022, 25, 656–700. [Google Scholar] [CrossRef]
- Sunyaev, A. Internet Computing: Principles of Distributed Systems and Emerging Internet-Based Technologies. In Internet Computing: Principles of Distributed Systems and Emerging Internet-Based Technologies; Springer: Berlin/Heidelberg, Germany, 2020; pp. 1–413. [Google Scholar] [CrossRef]
- Dhelim, S.; Kechadi, T.; Chen, L.; Aung, N.; Ning, H.; Atzori, L. Edge-Enabled Metaverse: The Convergence of Metaverse and Mobile Edge Computing, April 2022. [Online]. Available online: https://arxiv.org/abs/2205.02764v1 (accessed on 8 April 2023).
- Fang, Y.; Cohen, M.A.; Kincaid, T.G. Dynamics of a Winner-Take-All Neural Network. Neural Netw. 1996, 9, 1141–1154. [Google Scholar] [CrossRef] [PubMed]
- Handrich, S.; Herzog, A.; Wolf, A.; Herrmann, C.S. A biologically plausible winner-takes-all architecture. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2009; Volume 5755, pp. 315–326. [Google Scholar] [CrossRef]
- Ng, W.C.; Lim, W.Y.B.; Ng, J.S.; Xiong, Z.; Niyato, D.; Miao, C. Unified Resource Allocation Framework for the Edge Intelligence-Enabled Metaverse. In Proceedings of the IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; pp. 5214–5219. [Google Scholar] [CrossRef]
- Chen, Y. Mechanisms of Winner-Take-All and Group Selection in Neuronal Spiking Networks. Front. Comput. Neurosci. 2017, 11, 20. [Google Scholar] [CrossRef] [PubMed]
- Shamsi, J.; Mohammadi, K.; Shokouhi, S.B. Columnar-Organized Memory (COM): Brain-inspired associative memory with large capacity and robust retrieval. Biol. Inspired Cogn. Arch. 2017, 20, 39–46. [Google Scholar] [CrossRef]
- Wu, X.; Saxena, V.; Zhu, K. Homogeneous Spiking Neuromorphic System for Real-World Pattern Recognition. IEEE J. Emerg. Sel. Top. Circuits Syst. 2015, 5, 254–266. [Google Scholar] [CrossRef]
- Diehl, P.U.; Cook, M. Unsupervised learning of digit recognition using spike-timing-dependent plasticity. Front. Comput. Neurosci. 2015, 9, 99. [Google Scholar] [CrossRef] [PubMed]
- Shouval, H.Z.; Wang, S.S.-H.; Wittenberg, G.M. Spike timing dependent plasticity: A consequence of more fundamental learning rules. Front. Comput. Neurosci. 2010, 4, 19. [Google Scholar] [CrossRef]
- Soleimani, H.; Ahmadi, A.; Bavandpour, M. Biologically Inspired Spiking Neurons: Piecewise Linear Models and Digital Implementation. IEEE Trans. Circuits Syst. I Regul. Pap. 2012, 59, 2991–3004. [Google Scholar] [CrossRef]
- Gomar, S.; Ahmadi, A. Digital Multiplierless Implementation of Biological Adaptive-Exponential Neuron Model. IEEE Trans. Circuits Syst. I Regul. Pap. 2013, 61, 1206–1219. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Slice Registers | Slice LUTs | Max Frequency (MHZ) | Target Device | ||
|---|---|---|---|---|---|---|
| Number | Utilization | Number | Utilization | |||
| Izhikevich [41] | 493 | 2% | 617 | 2% | 241.9 | Virtex-II Pro XC2VP30 |
| AdEx [42] | 388 | 1% | 1279 | 4% | 190 | Virtex-II Pro XC2VP30 |
| Morris–Lecar [15] | 618 | 2% | 3616 | 13% | 135 | Virtex-II Pro XC2VP30 |
| FitzHugh–Nagumo [13] | 529 | 18% | 1085 | 38% | - | Virtex-II Pro XC2VP30 |
| Hindmarsh–Rose [14] | 431 | 1% | 659 | 2% | 81.2 | Virtex-II Pro XC2VP30 |
| Wilson [12] | 365 | 0% | 611 | 0% | 98 | Virtex-6 ML605 |
| Leaky Integrate and Fire [16] | 46 | 0% | 56 | 0% | 412.371 | Virtex-6 ML605 |
| This work (fixed-point model) | 17 | 1% | 36 | 1% | 576.319 | Virtex-6 XC6VLX240T |
| This work (floating-point model) | 266 | 1% | 417 | 1% | 314.095 | Virtex-6 XC6VLX240T |
| Logic Utilization | WTA Fixed-Point | WTA Floating-Point | Standard SNN [16] |
|---|---|---|---|
| Number of Slice Registers | 204 | 2016 | 1023 |
| Number of Slice LUTs | 350 | 1767 | 11,339 |
| Number of BUFG/BUFGCTRLs | 1 | 3 | 1 |
| Max Frequency (MHz) | 514.095 MHz | 443.941 MHz | 189.071 MHz |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khajooei, A.; Jamshidi, M.; Shokouhi, S.B. A Super-Efficient TinyML Processor for the Edge Metaverse. Information 2023, 14, 235. https://doi.org/10.3390/info14040235
Khajooei A, Jamshidi M, Shokouhi SB. A Super-Efficient TinyML Processor for the Edge Metaverse. Information. 2023; 14(4):235. https://doi.org/10.3390/info14040235
Chicago/Turabian StyleKhajooei, Arash, Mohammad (Behdad) Jamshidi, and Shahriar B. Shokouhi. 2023. "A Super-Efficient TinyML Processor for the Edge Metaverse" Information 14, no. 4: 235. https://doi.org/10.3390/info14040235
APA StyleKhajooei, A., Jamshidi, M., & Shokouhi, S. B. (2023). A Super-Efficient TinyML Processor for the Edge Metaverse. Information, 14(4), 235. https://doi.org/10.3390/info14040235