
Novel Task-Based Unification and Adaptation (TUA) Transfer Learning Approach for Bilingual Emotional Speech Data


Abstract
1. Introduction
- Our work explicitly exhibits how a weight-sharing scheme and transfer learning can be integrated into a frame powerful pre-trained prototype over a diverse set of architectures at once.
- According to the information we have, this is the first work utilizing a task-specific adaptation-based transfer learning approach for emotion recognition from speech.
- A huge data pool is compiled with a unified label for emotion classes available in the Arabic and English languages.
2. Literature Review
3. System Description
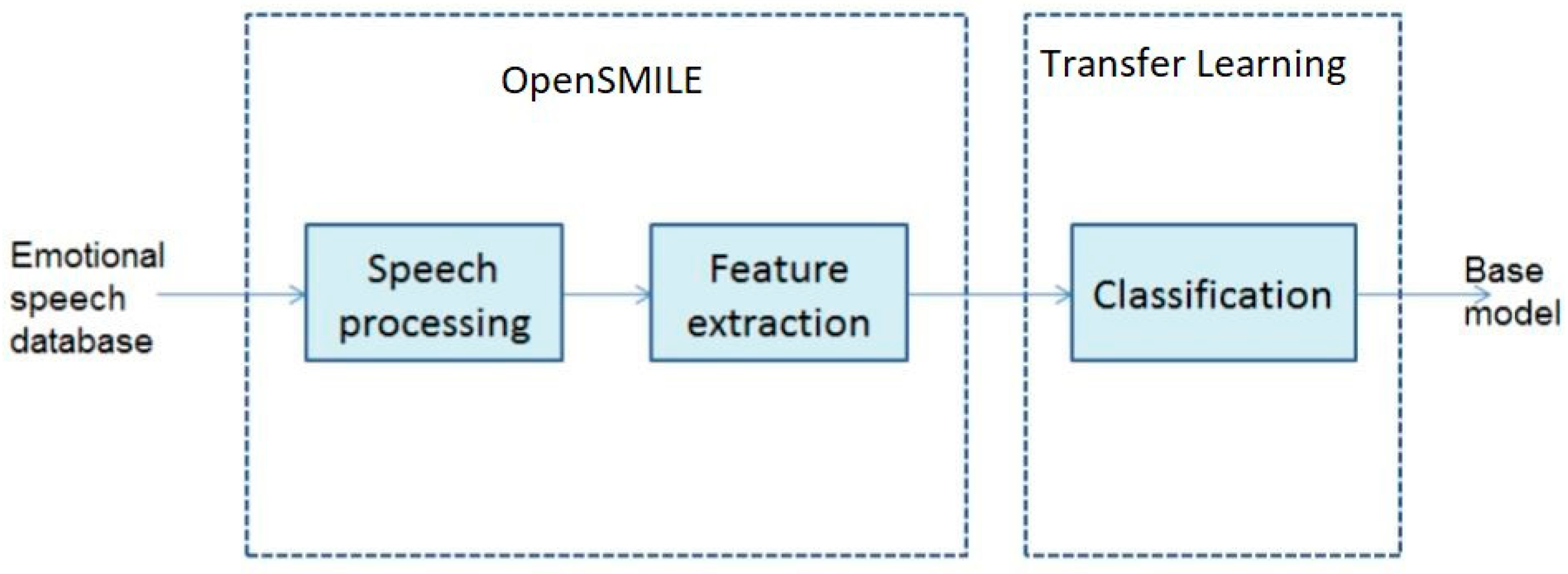
3.1. Feature Extraction and Selection
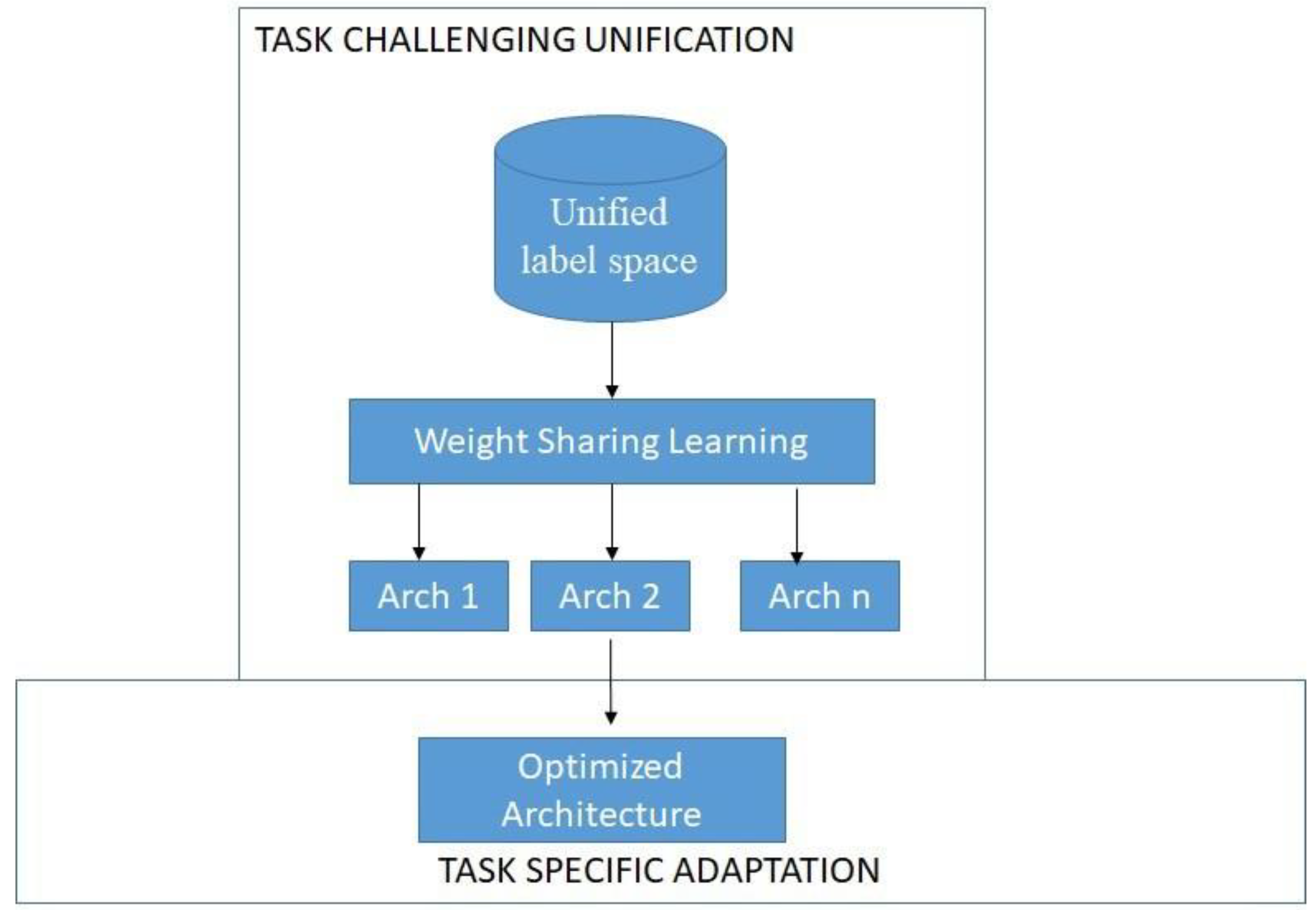
3.2. Proposed TUA Model
3.2.1. Unified Data and Label Space
3.2.2. Anchor Based Gradual Down-Sizing
3.2.3. Model Adaptation
3.3. Transfer Learning Classification for Emotion Recognition
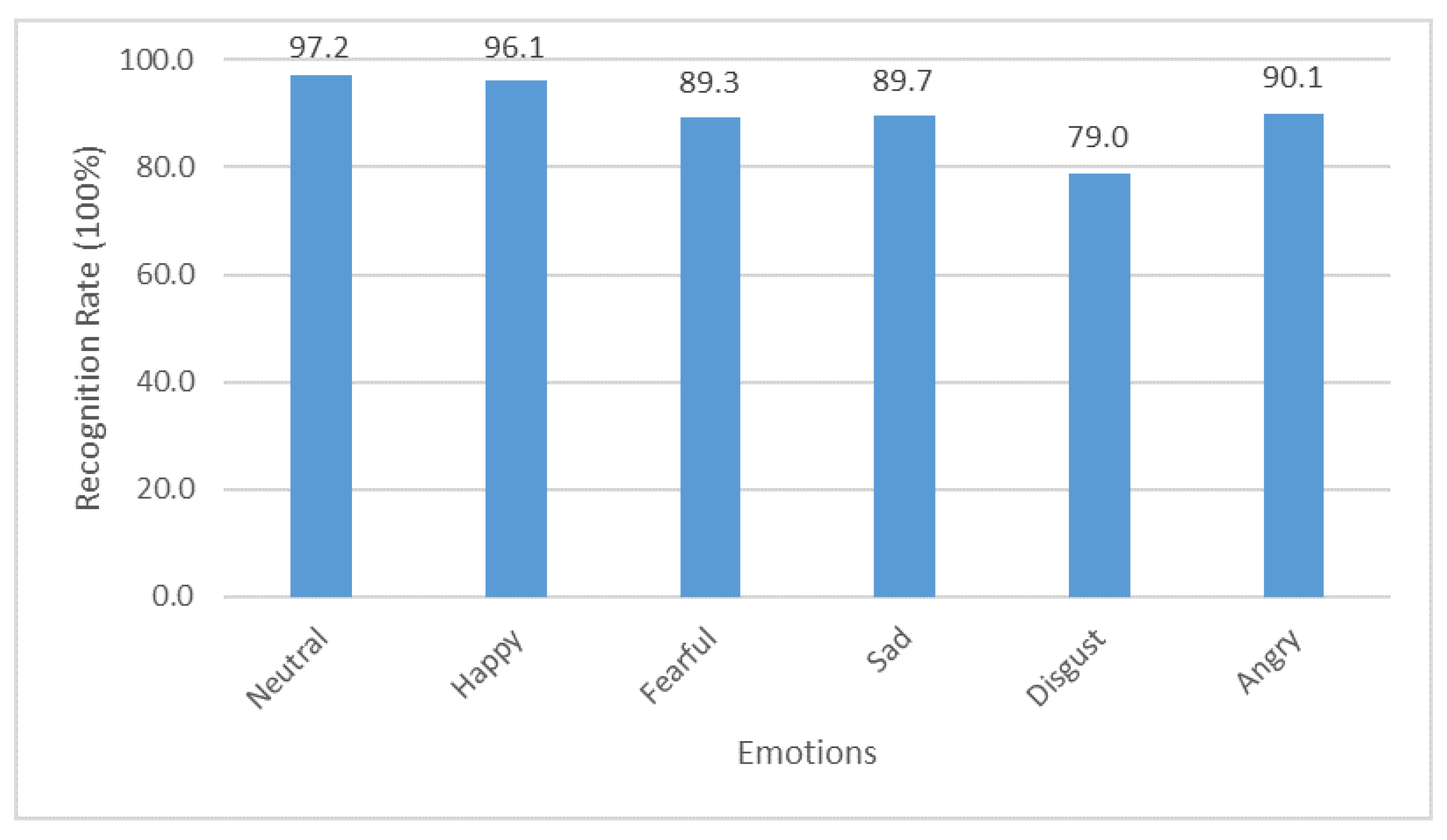
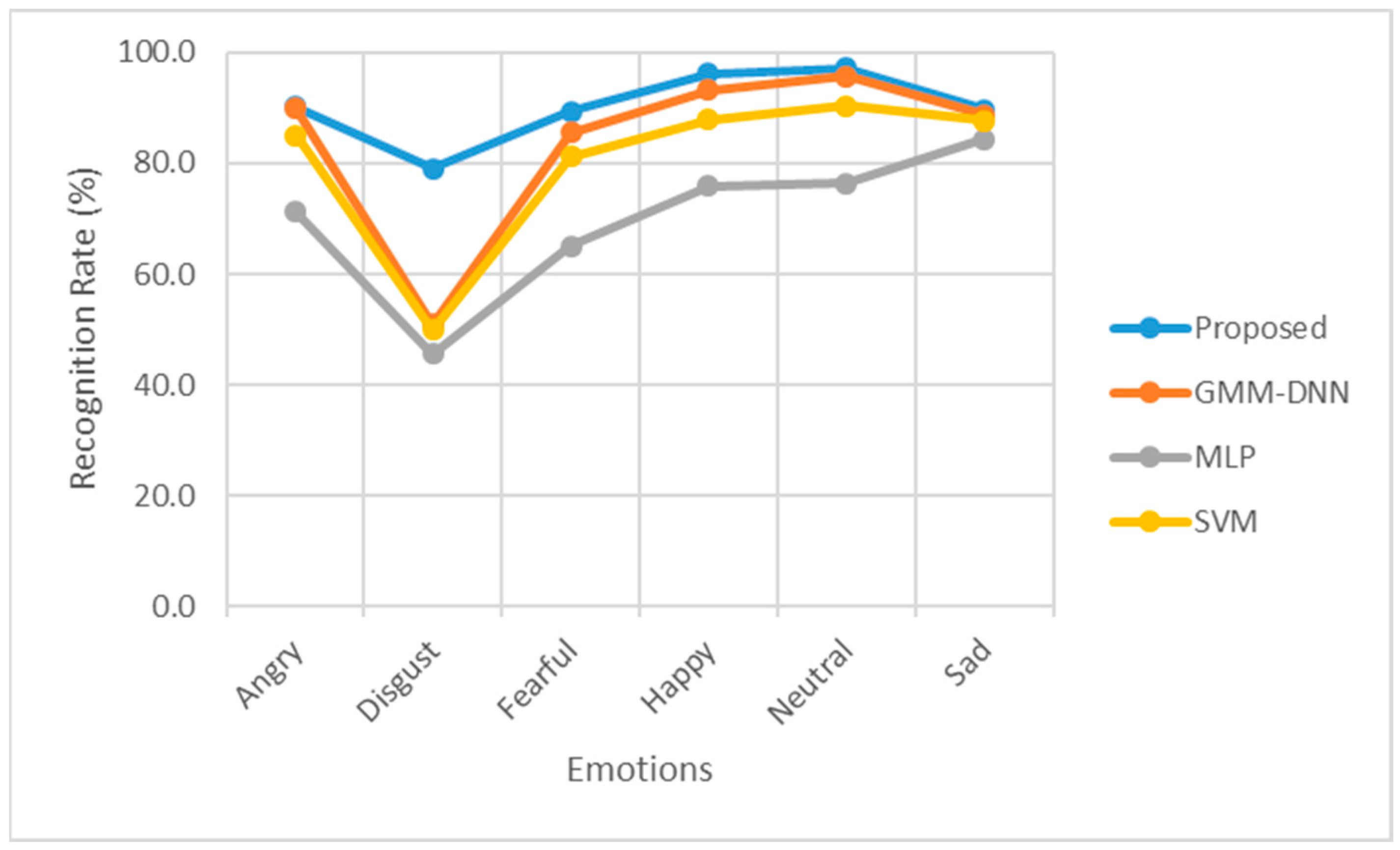
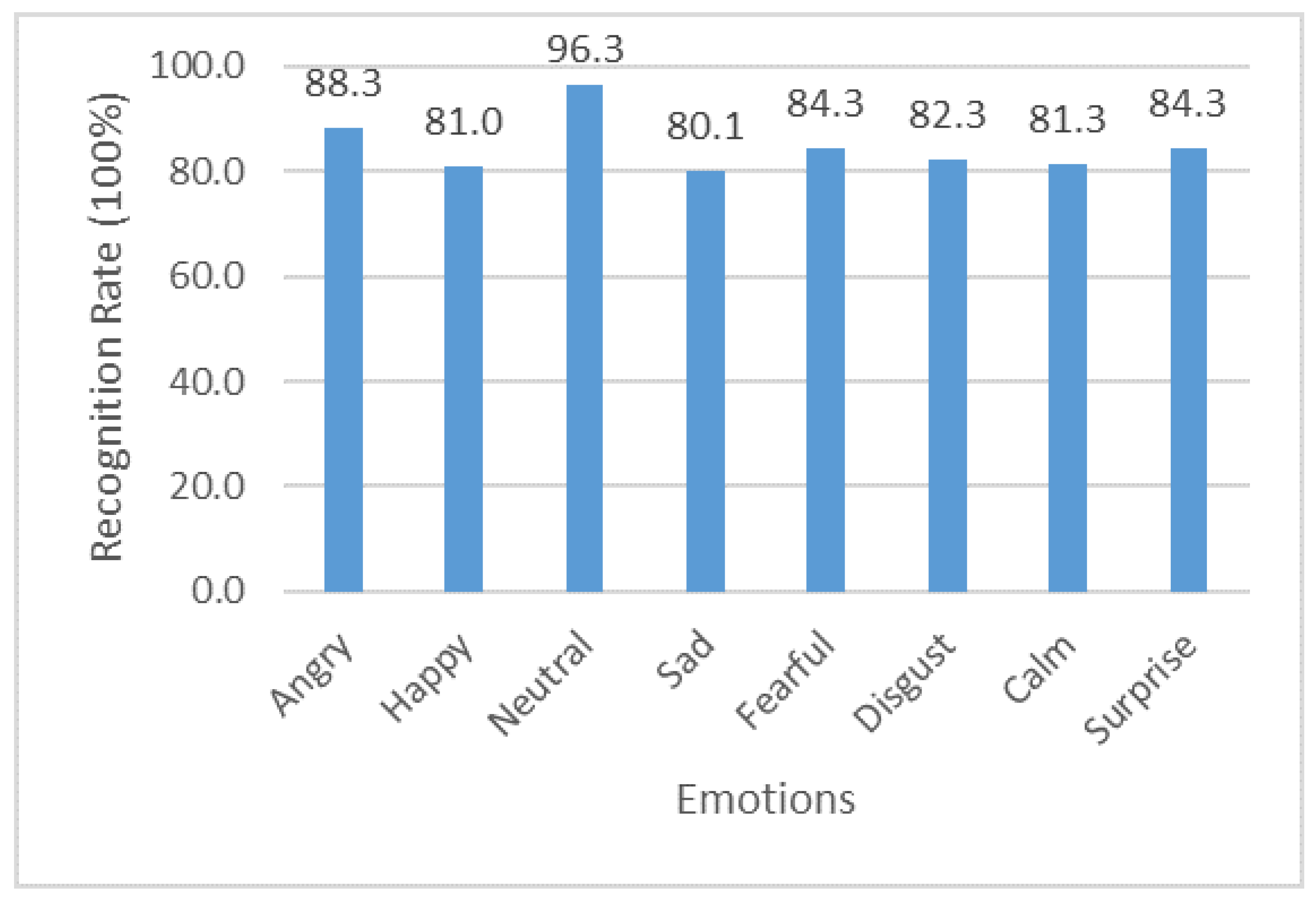
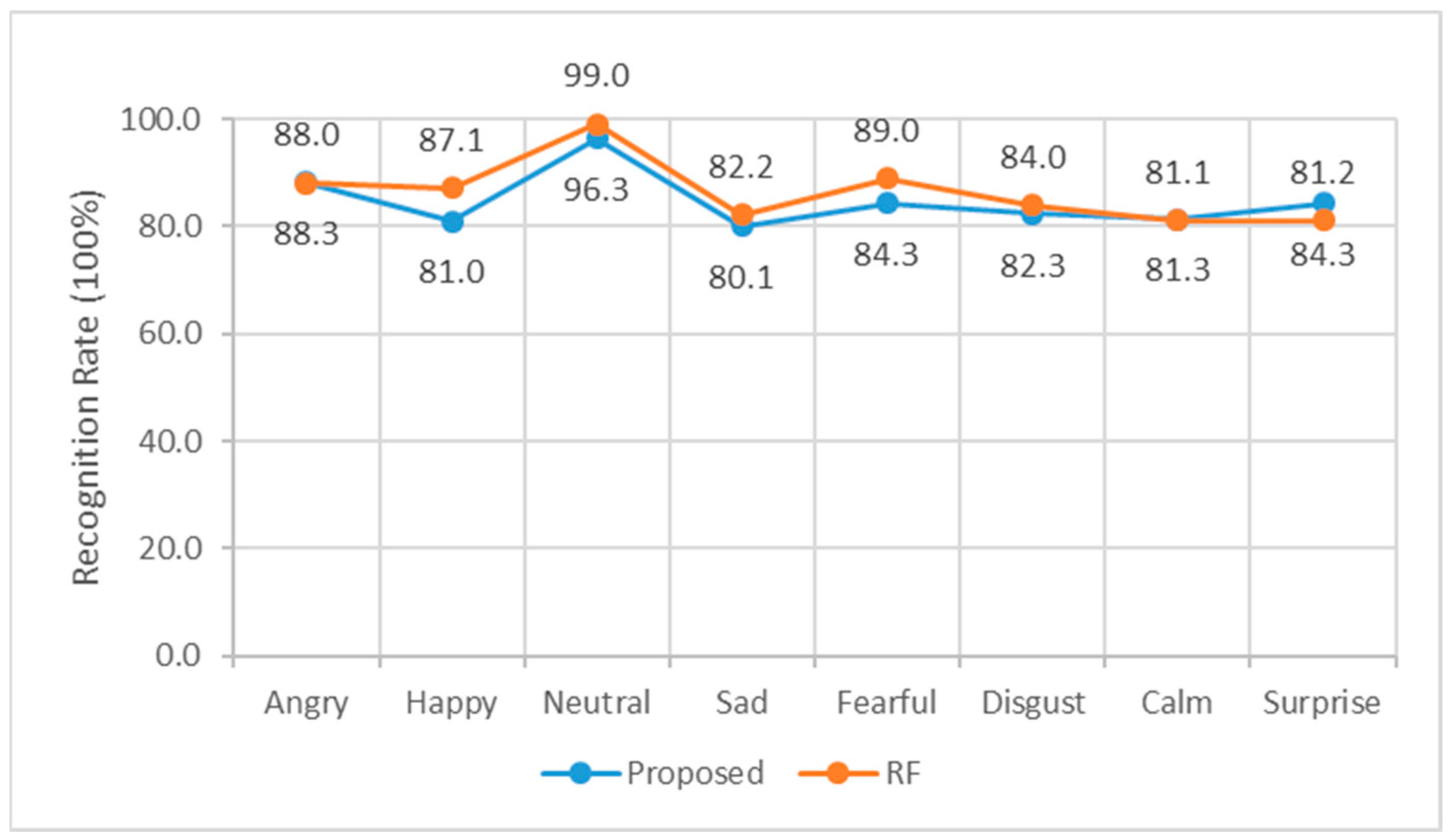
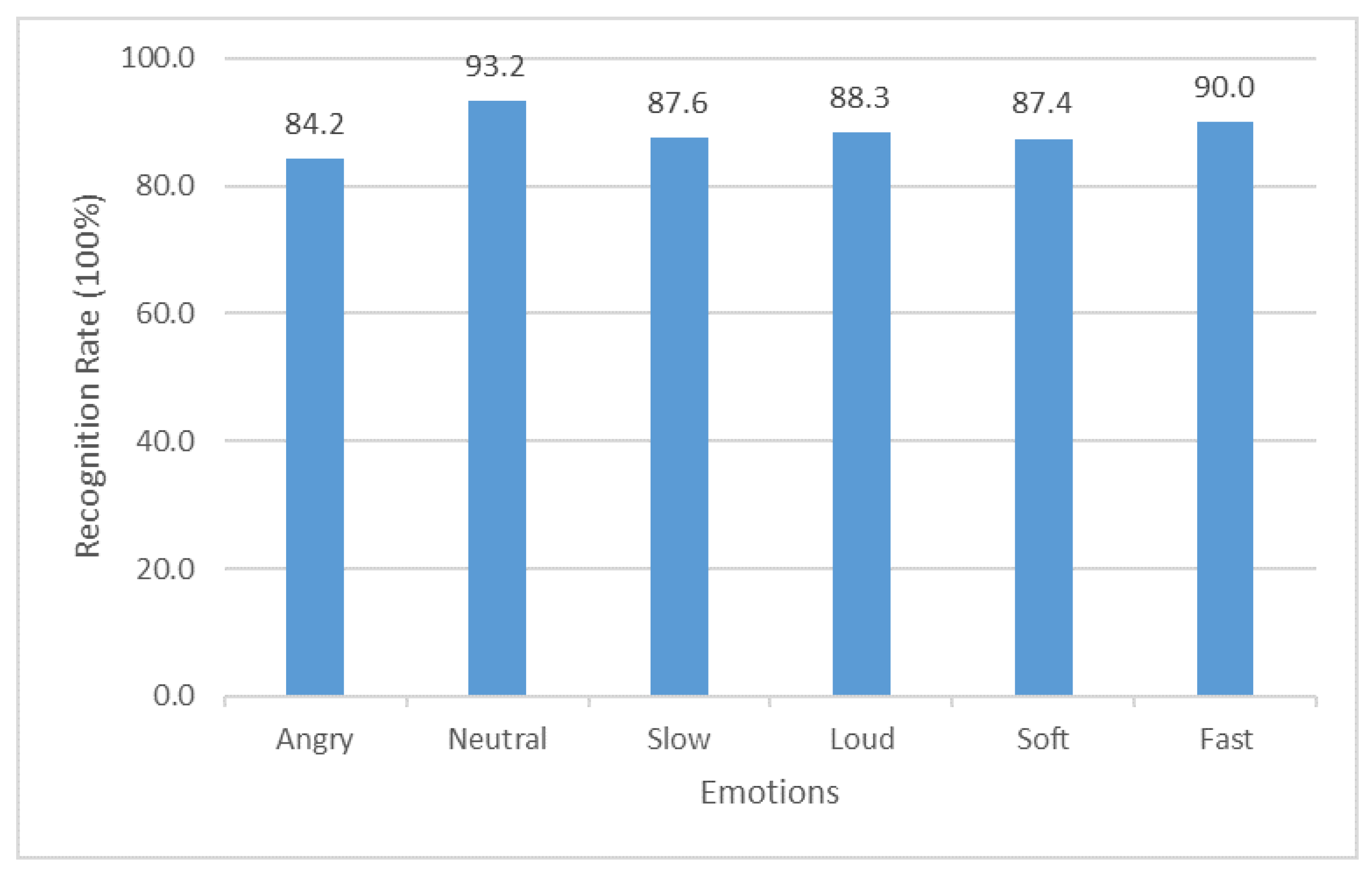
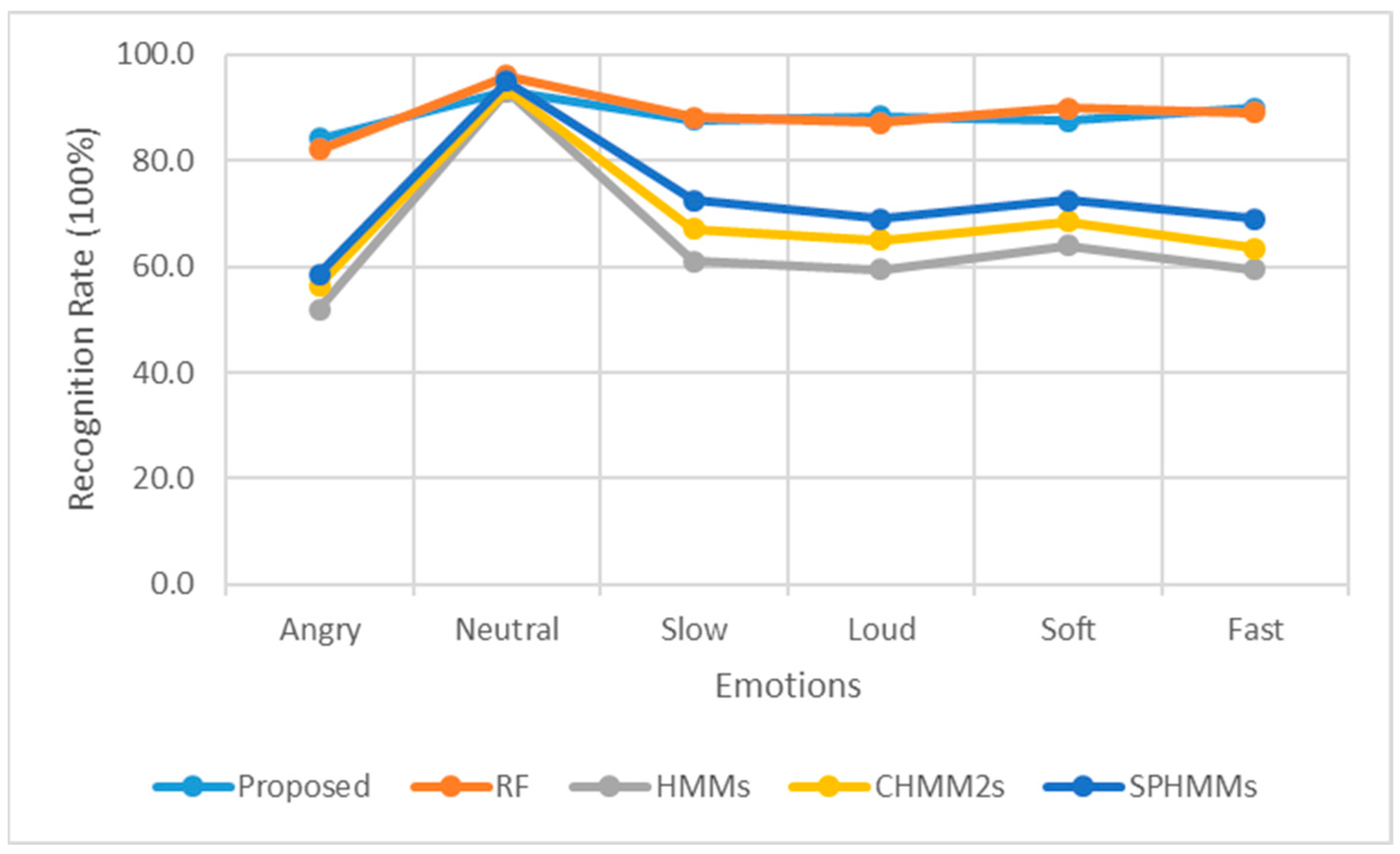
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shahin, I. Emotion Recognition Using Speaker Cues. In Proceedings of the 2020 Advances in Science and Engineering Technology International Conferences (ASET), Dubai, United Arab Emirates, 4–6 February 2020; pp. 1–5. [Google Scholar]
- Shahin, I. Speaker verification in emotional talking environments based on three-stage frame-work. In Proceedings of the 2017 International Conference on Electrical and Computing Technologies and Applications (ICECTA), Ras Al Khaimah, United Arab Emirates, 21–23 November 2017; pp. 1–5. [Google Scholar]
- Wu, C.H.; Liang, W.B. Emotion recognition of affective speech based on multiple classifiers using acoustic-prosodic information and semantic labels. IEEE Trans. Affect. Comput. 2010, 2, 10–21. [Google Scholar]
- Liu, H.; Simonyan, K.; Yang, Y. Darts: Differentiable architecture search. arXiv 2018, arXiv:1806.09055. [Google Scholar]
- Pham, H.; Guan, M.; Zoph, B.; Le, Q.; Dean, J. Efficient neural architecture search via parameters sharing. In Proceedings of the International Conference on Machine Learning, Macau, China, 26–28 February 2018; pp. 4095–4104. [Google Scholar]
- Cai, H.; Gan, C.; Wang, T.; Zhang, Z.; Han, S. Once-for-all: Train one network and specialize it for efficient deployment. arXiv 2019, arXiv:1908.09791. [Google Scholar]
- Yu, J.; Jin, P.; Liu, H.; Bender, G.; Kindermans, P.J.; Tan, M.; Huang, T.; Song, X.; Pang, R.; Le, Q. Bignas: Scaling up neural architecture search with big single-stage models. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2020; pp. 702–717. [Google Scholar]
- Shahin, I. Using emotions to identify speakers. In Proceedings of the The 5th International Workshop on Signal Processing and its Applications (WoSPA 2008), Sharjah, United Arab Emirates, 18–20 March 2008. [Google Scholar]
- Rong, J.; Li, G.; Chen, Y.P.P. Acoustic feature selection for automatic emotion recognition from speech. Inf. Process. Manag. 2009, 45, 315–328. [Google Scholar] [CrossRef]
- Shahin, I. Identifying speakers using their emotion cues. Int. J. Speech Technol. 2011, 14, 89–98. [Google Scholar] [CrossRef]
- Shahin, I. Studying and enhancing talking condition recognition in stressful and emotional talking environments based on HMMs, CHMM2s and SPHMMs. J. Multimodal User Interfaces 2012, 6, 59–71. [Google Scholar] [CrossRef]
- Shahin, I. Employing both gender and emotion cues to enhance speaker identification performance in emotional talking environments. Int. J. Speech Technol. 2013, 16, 341–351. [Google Scholar] [CrossRef]
- Sun, Y.; Wen, G.; Wang, J. Weighted spectral features based on local Hu moments for speech emotion recognition. Biomed. Signal Process. Control 2015, 18, 80–90. [Google Scholar] [CrossRef]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the Ninth European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005. [Google Scholar]
- Haq, S.; Jackson, P.J.; Edge, J. Speaker-dependent audio-visual emotion recognition. In Proceedings of the AVSP, Norwich, UK, 10–13 September 2009; pp. 53–58. [Google Scholar]
- Li, Y.; Tao, J.; Chao, L.; Bao, W.; Liu, Y. CHEAVD: A Chinese natural emotional audio–visual database. J. Ambient. Intell. Humaniz. Comput. 2017, 8, 913–924. [Google Scholar] [CrossRef]
- Wang, K.; An, N.; Li, B.N.; Zhang, Y.; Li, L. Speech emotion recognition using Fourier parameters. IEEE Trans. Affect. Comput. 2015, 6, 69–75. [Google Scholar] [CrossRef]
- Schuller, B.; Rigoll, G.; Lang, M. Speech emotion recognition combining acoustic features and linguistic information in a hybrid support vector machine-belief network architecture. In Proceedings of the 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing, Montreal, QC, Canada, 17–21 May 2004; Volume 1, pp. 1–577. [Google Scholar]
- Shahin, I.; Ba-Hutair, M.N. Talking condition recognition in stressful and emotional talking environments based on CSPHMM2s. Int. J. Speech Technol. 2015, 18, 77–90. [Google Scholar] [CrossRef]
- Hansen, J.H.; Bou-Ghazale, S.E. Getting started with SUSAS: A speech under simulated and actual stress database. In Proceedings of the Fifth European Conference on Speech Communication and Technology, Rhodes, Greece, 22–25 September 1997. [Google Scholar]
- Deng, J.; Xu, X.; Zhang, Z.; Frühholz, S.; Schuller, B. Semisupervised autoencoders for speech emotion recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 26, 31–43. [Google Scholar] [CrossRef]
- Huang, A.; Bao, P. Human vocal sentiment analysis. arXiv 2019, arXiv:1905.08632. [Google Scholar]
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Mao, X.; Chen, L. Speech emotion recognition using deep 1D & 2D CNN LSTM networks. Biomed. Signal Process. Control 2019, 47, 312–323. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Bhavan, A.; Chauhan, P.; Shah, R.R. Bagged support vector machines for emotion recognition from speech. Knowl.-Based Syst. 2019, 184, 104886. [Google Scholar] [CrossRef]
- Meng, H.; Yan, T.; Yuan, F.; Wei, H. Speech emotion recognition from 3D log-mel spectrograms with deep learning network. IEEE Access 2019, 7, 125868–125881. [Google Scholar] [CrossRef]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Jiang, P.; Fu, H.; Tao, H.; Lei, P.; Zhao, L. Parallelized convolutional recurrent neural network with spectral features for speech emotion recognition. IEEE Access 2019, 7, 90368–90377. [Google Scholar] [CrossRef]
- Schuller, B.; Arsic, D.; Rigoll, G.; Wimmer, M.; Radig, B. Audiovisual behavior modeling by combined feature spaces. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07, Honolulu, HI, USA, 15–20 April 2007; Volume 2, pp. 2–733. [Google Scholar]
- Hamsa, S.; Shahin, I.; Iraqi, Y.; Werghi, N. Emotion recognition from speech using wavelet packet transform cochlear filter bank and random forest classifier. IEEE Access 2020, 8, 96994–97006. [Google Scholar] [CrossRef]
- Shahin, I.; Nassif, A.B.; Hamsa, S. Novel cascaded Gaussian mixture model-deep neural network classifier for speaker identification in emotional talking environments. Neural Comput. Appl. 2020, 32, 2575–2587. [Google Scholar] [CrossRef]
- Shahin, I.; Nassif, A.B.; Hamsa, S. Emotion recognition using hybrid Gaussian mixture model and deep neural network. IEEE Access 2019, 7, 26777–26787. [Google Scholar] [CrossRef]
- Hamsa, S.; Shahin, I.; Iraqi, Y.; Damiani, E.; Nassif, A.B.; Werghi, N. Speaker identification from emotional and noisy speech using learned voice segregation and speech VGG. Expert Syst. Appl. 2023, 224, 119871. [Google Scholar] [CrossRef]
- Chen, G.; Zhang, S.; Tao, X.; Zhao, X. Speech Emotion Recognition by Combining a Unified First-Order Attention Network with Data Balance. IEEE Access 2020, 8, 215851–215862. [Google Scholar] [CrossRef]
- Zhalehpour, S.; Onder, O.; Akhtar, Z.; Erdem, C.E. BAUM-1: A spontaneous audio-visual face database of affective and mental states. IEEE Trans. Affect. Comput. 2016, 8, 300–313. [Google Scholar] [CrossRef]
- Dhall, A.; Ramana Murthy, O.; Goecke, R.; Joshi, J.; Gedeon, T. Video and image based emotion recognition challenges in the wild: Emotiw 2015. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 423–426. [Google Scholar]
- Li, Y.; Tao, J.; Schuller, B.; Shan, S.; Jiang, D.; Jia, J. Mec 2017: Multimodal emotion recognition challenge. In Proceedings of the 2018 First Asian Conference on Affective Computing and Intelligent Interaction (ACII Asia), Beijing, China, 20–22 May 2018; pp. 1–5. [Google Scholar]
- Peng, Z.; Li, X.; Zhu, Z.; Unoki, M.; Dang, J.; Akagi, M. Speech emotion recognition using 3d convolutions and attention-based sliding recurrent networks with auditory front-ends. IEEE Access 2020, 8, 16560–16572. [Google Scholar] [CrossRef]
- Busso, C.; Parthasarathy, S.; Burmania, A.; AbdelWahab, M.; Sadoughi, N.; Provost, E.M. MSP-IMPROV: An acted corpus of dyadic interactions to study emotion perception. IEEE Trans. Affect. Comput. 2016, 8, 67–80. [Google Scholar] [CrossRef]
- Zhong, S.; Yu, B.; Zhang, H. Exploration of an Independent Training Framework for Speech Emotion Recognition. IEEE Access 2020, 8, 222533–222543. [Google Scholar] [CrossRef]
- Zhang, S.; Chen, A.; Guo, W.; Cui, Y.; Zhao, X.; Liu, L. Learning deep binaural representations with deep convolutional neural networks for spontaneous speech emotion recognition. IEEE Access 2020, 8, 23496–23505. [Google Scholar] [CrossRef]
- Shahin, I.; Hindawi, N.; Nassif, A.B.; Alhudhaif, A.; Polat, K. Novel dual-channel long short-term memory compressed capsule networks for emotion recognition. Expert Syst. Appl. 2022, 188, 116080. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Eyben, F.; Wöllmer, M.; Schuller, B. Opensmile: The munich versatile and fast open-source audio feature extractor. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1459–1462. [Google Scholar]
- Latif, S.; Rana, R.; Younis, S.; Qadir, J.; Epps, J. Transfer learning for improving speech emotion classification accuracy. arXiv 2018, arXiv:1801.06353. [Google Scholar]
- Feng, K.; Chaspari, T. A review of generalizable transfer learning in automatic emotion recognition. Front. Comput. Sci. 2020, 2, 9. [Google Scholar] [CrossRef]
- Schuller, B.; Steidl, S.; Batliner, A. The interspeech 2009 emotion challenge. In Proceedings of the Tenth Annual Conference of the International Speech Communication Association, Brighton, UK, 6–10 September 2009. [Google Scholar]
- Yao, Q. Multi-Sensory Emotion Recognition with Speech and Facial Expression. Ph.D. Thesis, The University of Southern Mississippi, Hattiesburg, MS, USA, 2016. [Google Scholar]
- Ghifary, M.; Kleijn, W.B.; Zhang, M. Domain adaptive neural networks for object recognition. In Proceedings of the Pacific Rim International Conference on Artificial Intelligence, Gold Coast, QLD, Australia, 1–5 December 2014; pp. 898–904. [Google Scholar]
- Sawada, Y.; Kozuka, K. Transfer learning method using multi-prediction deep Boltzmann machines for a small scale dataset. In Proceedings of the 2015 14th IAPR International Conference on Machine Vision Applications (MVA), Tokyo, Japan, 18–22 May 2015; pp. 110–113. [Google Scholar]
- Latif, S.; Rana, R.; Younis, S.; Qadir, J.; Epps, J. Cross corpus speech emotion classification-an effective transfer learning technique. arXiv 2018, arXiv:1801.06353v2. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hogg, R.V.; McKean, J.; Craig, A.T. Introduction to Mathematical Statistics; Pearson Education: London, UK, 2005. [Google Scholar]
- Gao, Y.; Li, B.; Wang, N.; Zhu, T. Speech emotion recognition using local and global features. In Proceedings of the International Conference on Brain Informatics, Beijing, China, 16–18 November 2017; pp. 3–13. [Google Scholar]
- Zhang, B.; Essl, G.; Provost, E.M. Recognizing emotion from singing and speaking using shared models. In Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction (ACII), Xi’an, China, 21–24 September 2015; pp. 139–145. [Google Scholar]
- Hong, Q.; Kwong, S. A genetic classification method for speaker recognition. Eng. Appl. Artif. Intell. 2005, 18, 13–19. [Google Scholar] [CrossRef]
- Kinnunen, T.; Karpov, E.; Franti, P. Real-time speaker identification and verification. IEEE Trans. Audio Speech Lang. Process. 2005, 14, 277–288. [Google Scholar] [CrossRef]
- Hamsa, S.; Iraqi, Y.; Shahin, I.; Werghi, N. An Enhanced Emotion Recognition Algorithm Using Pitch Correlogram, Deep Sparse Matrix Representation and Random Forest Classifier. IEEE Access 2021, 9, 87995–88010. [Google Scholar] [CrossRef]
- Campbell, W.M.; Campbell, J.P.; Reynolds, D.A.; Singer, E.; Torres-Carrasquillo, P.A. Support vector machines for speaker and language recognition. Comput. Speech Lang. 2006, 20, 210–229. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| t1,2 | Calculated t Value |
|---|---|
| tproposed, GMM-DNN | 1.70 |
| tproposed, SVM | 1.81 |
| tproposed, MLP | 1.89 |
| Method | Features | Classifier | Validation | Accuracy (%) |
|---|---|---|---|---|
| I. Shahin [33] | MFCC | GMM-DNN hybrid classification | 1:2 ratio | 83.9 |
| S. Hamsa [31] | MFCC | Gradient Boosting | K-fold | 88.2 |
| S. Hamsa [31] | MFCC | Random Forest Classifier | K-fold | 89.6 |
| S. Hamsa [34] | DSMR | Random Forest Classifier | K-fold | 90.9 |
| Proposed | Learned | Transfer Learning | K-fold | 91.2 |
| Method | Features | Classifier | Validation | Accuracy |
|---|---|---|---|---|
| Y. Gao [58] | MFCC, LSP, Pitch, ZCR | SVM | 10-fold | 79.3 |
| A. Huang [22] | MFCC, STFT | CNN | 10-fold | 72.2 |
| I. Shahin [33] | MFCC | GMM-DNN | 1:2 ratio | 83.6 |
| S. Hamsa [31] | MFCC | Random Forest | 5-fold | 86.4 |
| Z. Biqiao [59] | LLD (Mt Hier) | SVM | 5-fold | 81.7 |
| S. Hamsa [34] | DSMR | Random Forest | 5-fold | 93.8 |
| Z. Biqiao [59] | LLD (St Hier) | SVM | 5-fold | 79.7 |
| Proposed | Learned | Transfer Learning | Cross validation | 84.7 |
| Method | Features | Classifier | Validation | Accuracy |
|---|---|---|---|---|
| Q.Y. Hong [60] | MFCC | GA | - | 68.7 |
| I. Shahin [33] | MFCC | GMM-DNN | 10-fold | 86.6 |
| S. Hamsa [31] | MFCC | Random Forest | 10-fold | 88.6 |
| T. Kinnunen [61] | MFCC | VQ | Not mentioned | 68.4 |
| S. Hamsa [62] | DSMR | Random Forest | 10-fold | 90.9 |
| W.M. Campbell [63] | MFCC | SVM | Not mentioned | 72.8 |
| Proposed | Learned | Proposed TUA | Cross validation | 88.5 |
| Model | Training | Testing |
|---|---|---|
| Random Forest | 84,128.13 | 2.46 |
| GMM-DNN | 95,921.45 | 4.12 |
| Proposed | 69,331.1 | 2.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shahin, I.; Nassif, A.B.; Thomas, R.; Hamsa, S. Novel Task-Based Unification and Adaptation (TUA) Transfer Learning Approach for Bilingual Emotional Speech Data. Information 2023, 14, 236. https://doi.org/10.3390/info14040236
Shahin I, Nassif AB, Thomas R, Hamsa S. Novel Task-Based Unification and Adaptation (TUA) Transfer Learning Approach for Bilingual Emotional Speech Data. Information. 2023; 14(4):236. https://doi.org/10.3390/info14040236
Chicago/Turabian StyleShahin, Ismail, Ali Bou Nassif, Rameena Thomas, and Shibani Hamsa. 2023. "Novel Task-Based Unification and Adaptation (TUA) Transfer Learning Approach for Bilingual Emotional Speech Data" Information 14, no. 4: 236. https://doi.org/10.3390/info14040236
APA StyleShahin, I., Nassif, A. B., Thomas, R., & Hamsa, S. (2023). Novel Task-Based Unification and Adaptation (TUA) Transfer Learning Approach for Bilingual Emotional Speech Data. Information, 14(4), 236. https://doi.org/10.3390/info14040236