
Performance Evaluation of Distributed Database Strategies Using Docker as a Service for Industrial IoT Data: Application to Industry 4.0




Abstract
:1. Introduction
2. Related Work
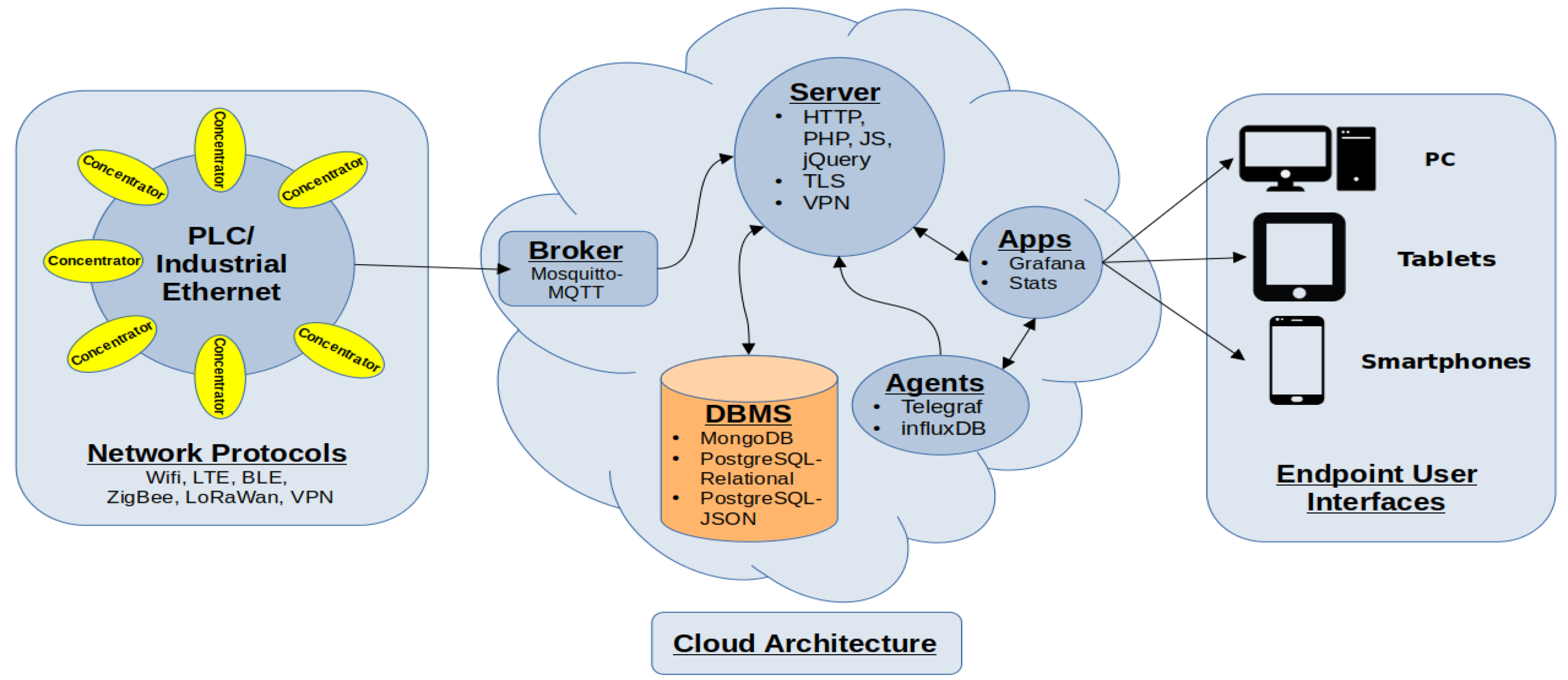
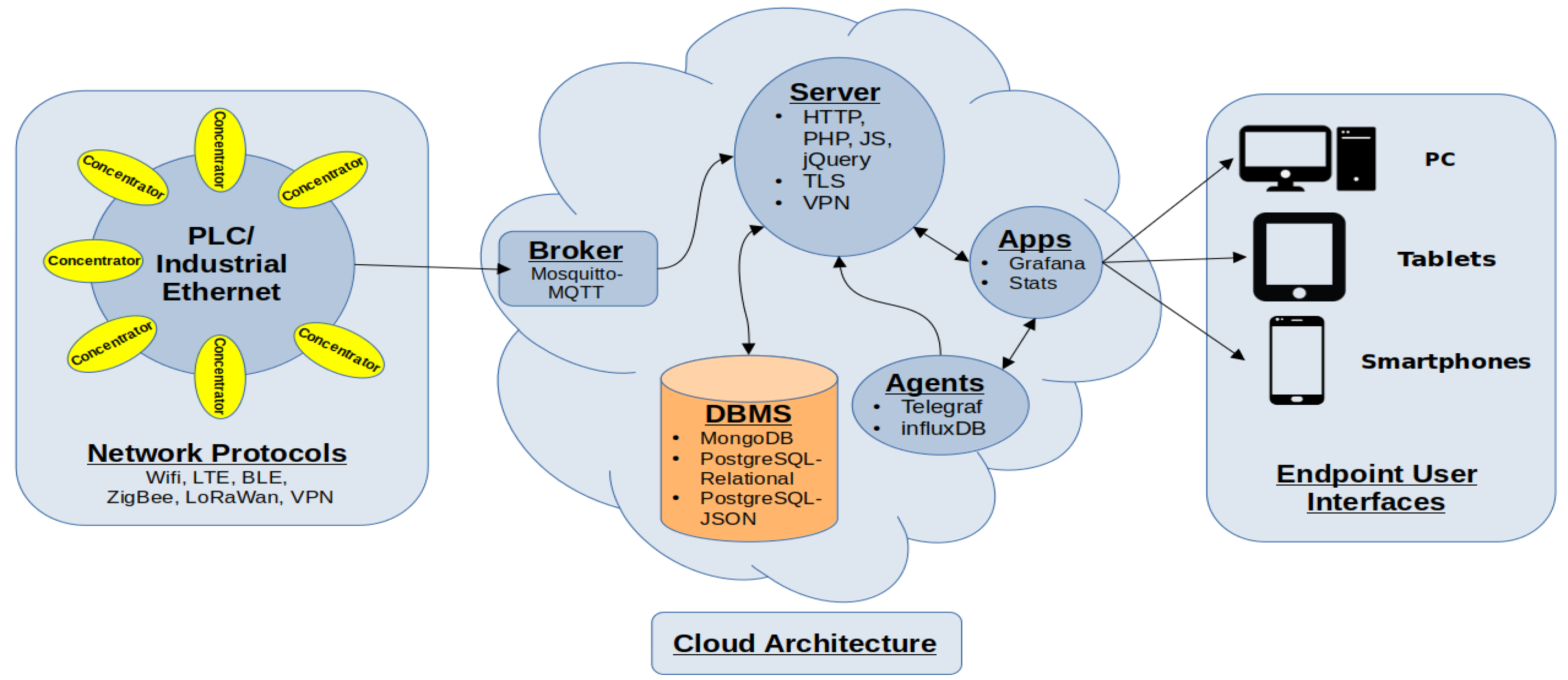
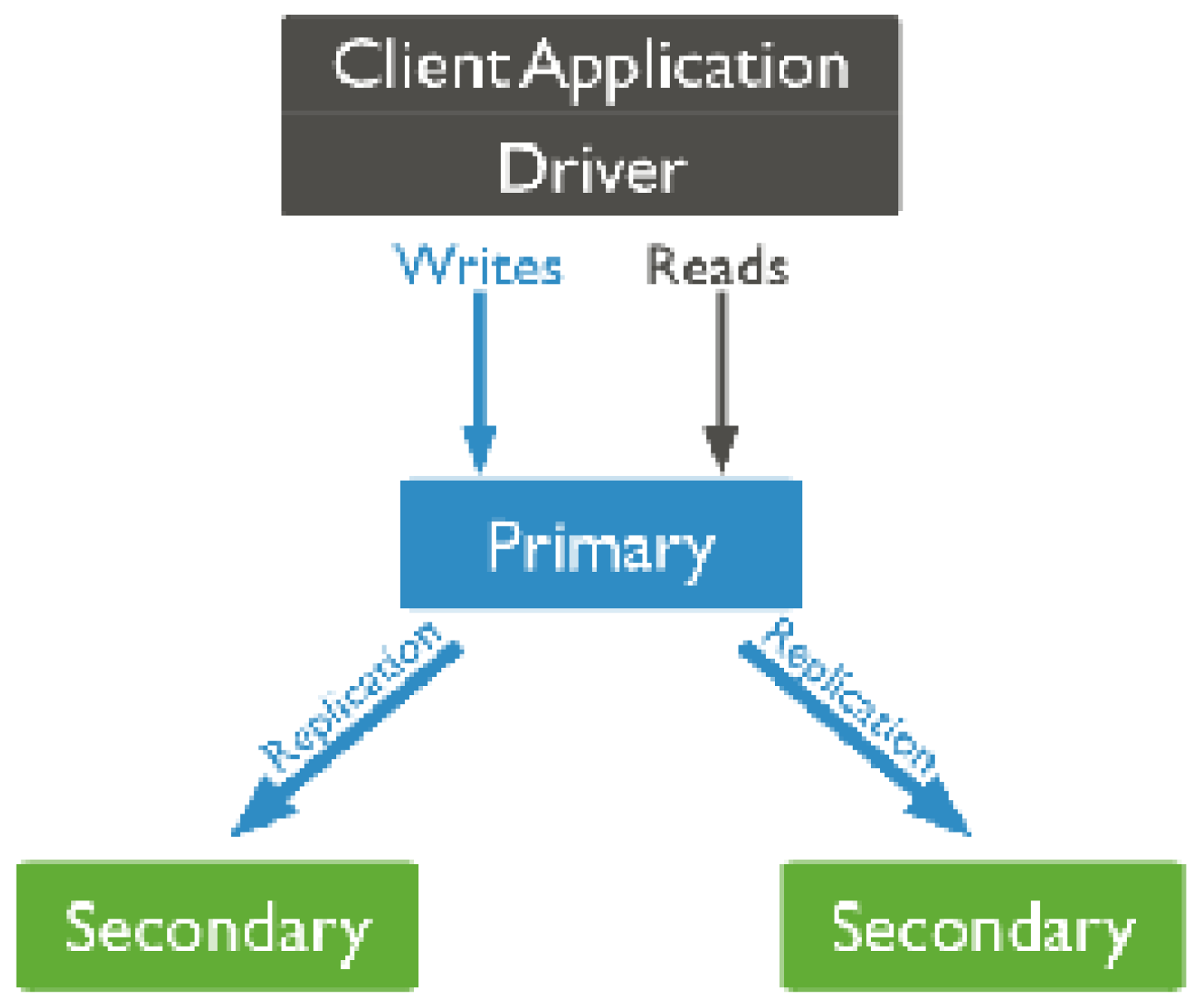
3. DBMS System Architecture for Industry 4.0 Standards
4. Database Performance Evaluation
4.1. Dataset Overview
4.2. Evaluation Metrics
4.3. Performance Evaluation Set Up
- Nonrelational MongoDB document styled records.
- Nonrelational JSON Postgres document styled records.
- Relational PostgreSQL table row styled records.
4.4. Experimental Results
4.4.1. Scenario (Q1)—IIoT Data Insertion
4.4.2. Scenario (Q2)—IIoT Data Selection
4.4.3. Scenario (Q3)—IIoT Correlation Functions
5. Discussion
Suggestions to Developers
6. Application to Industry 4.0
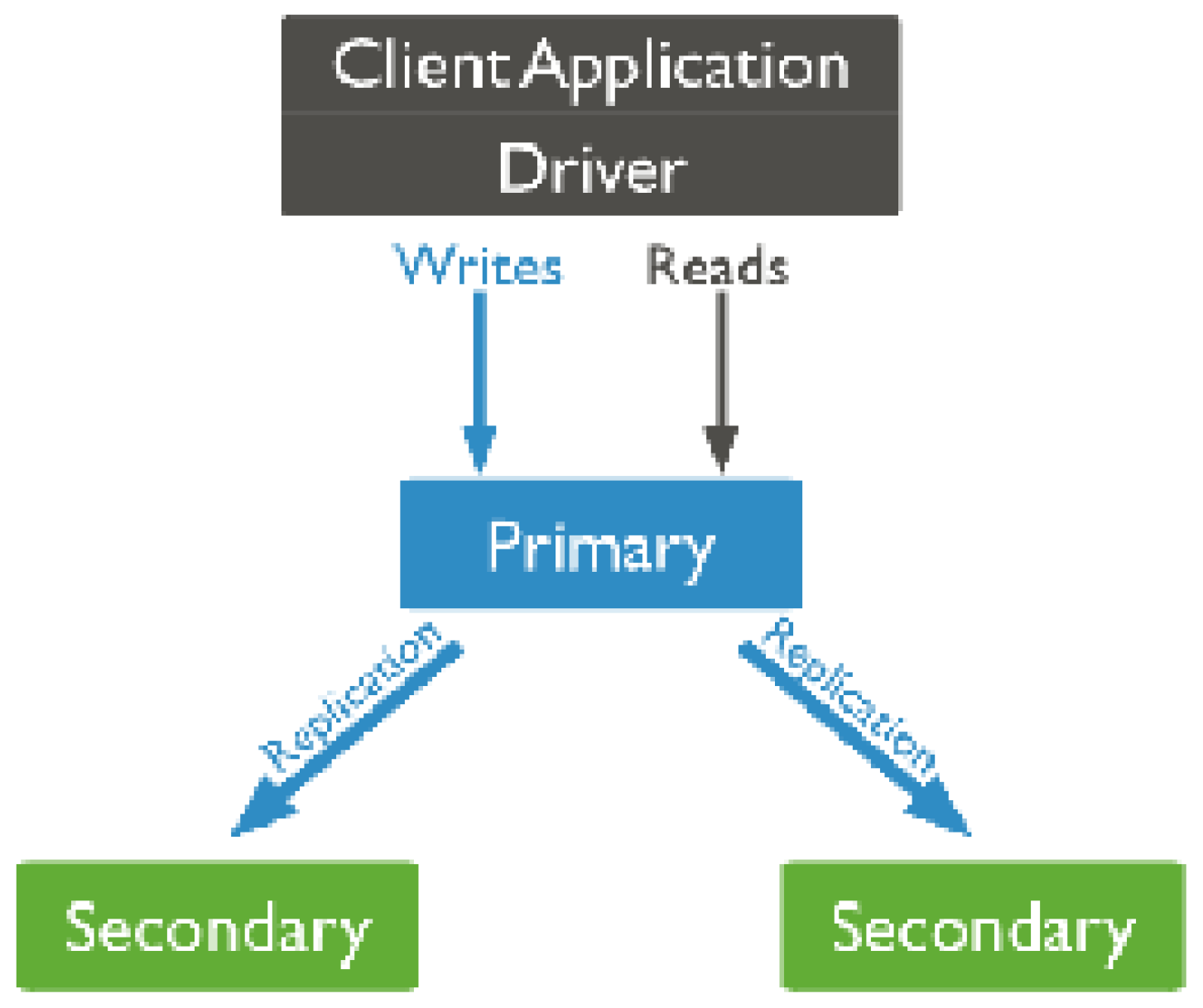
6.1. Database Architecture
6.2. Broker
6.3. Database System Portability Extension
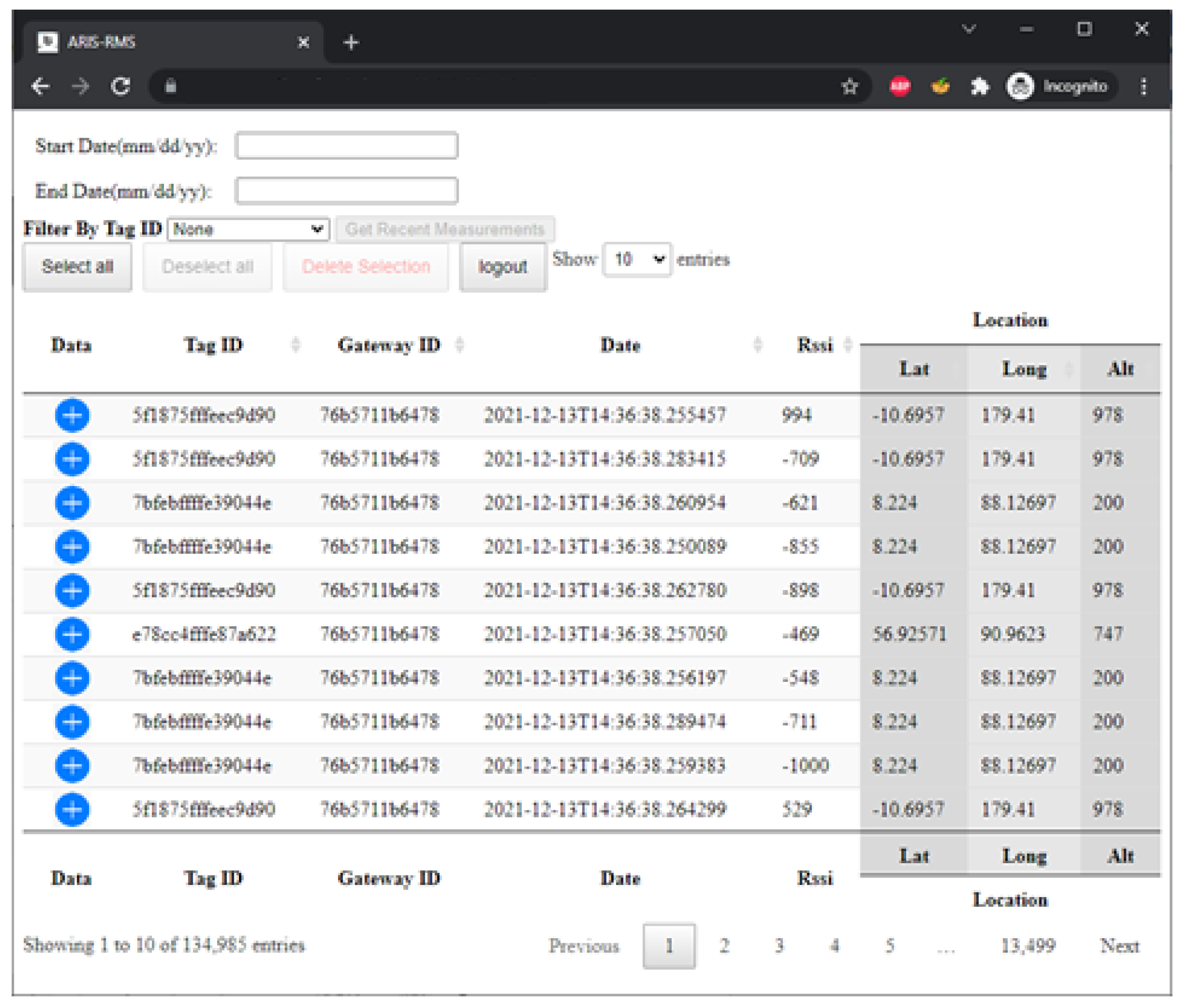
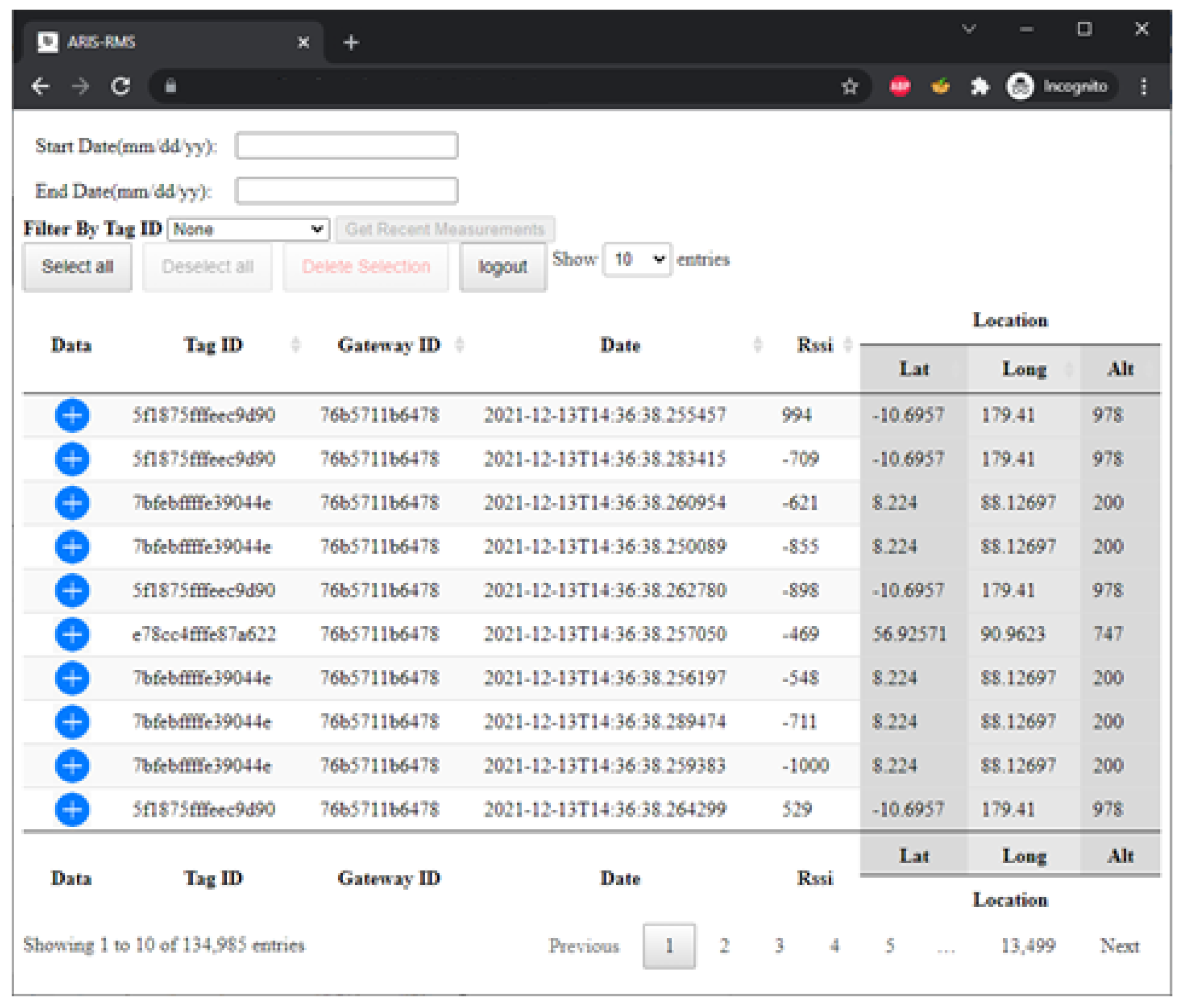
6.4. CRUD Manager HMI
- Sorting based on any field by clicking on the arrow of the desired column.
- Filtering data based on “tag ID” via the drop down menu or by date by clicking on the text boxes and selecting the corresponding date via the date/time picker submenu.
- Selectively deleting single or multiple records using the Ctrl or Shift keys and selecting the desired records to delete and pressing the red “Delete Selection” button on the HMI. Deleting is carried out after user confirmation, and the page returns a success or failure message.
- Showing measurements by pressing the blue button with a cross (+) or hiding measurements by pressing the red button with a hyphen (-) on the left side of each record.
- Dynamically displaying panel size by selecting the desired display size in the drop down menu “show 10/25/50/100 entries” in the center at the top of the HMI.
- Displaying recent measurements per “tag ID”, by selecting the desired “tag ID” through the filtering function based on “tag ID” and then selecting the “Get Recent Measurements” button.
6.5. JSON ReST API
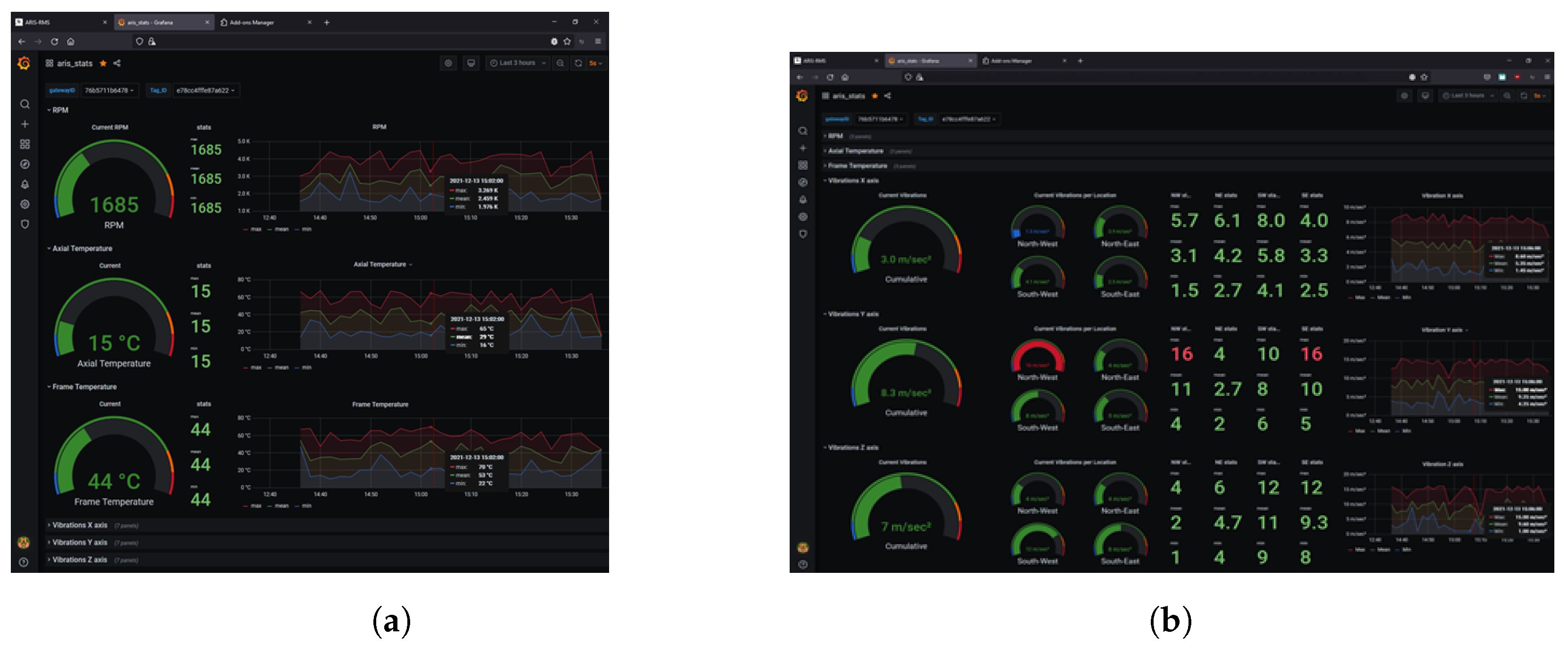
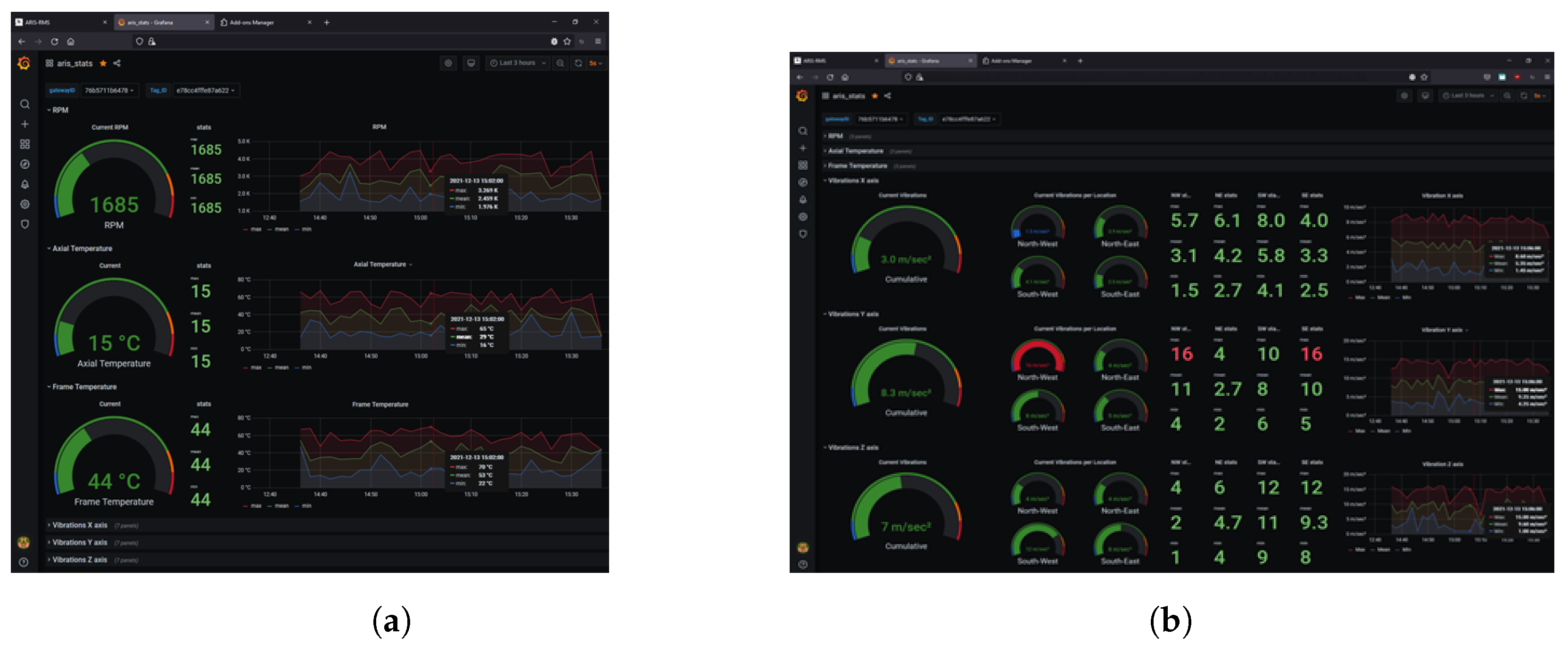
6.6. Stats Manager HMI
- Telegraf is an open source server agent for collecting and sending metrics and events from IoT databases, systems and sensors.
- InfluxDB is an open source timeline database that provides data storage for real time metrics, events, and analytics.
- The most recent measurement displayed on the left side of the panel,
- Statistical values of the selected time period for the maximum value (max), the mean value (mean), and the minimum value (min), displayed on the center left side of the panel (Figure 4a),
- Detailed graph of the previous values (max, mean, min) concerning their change in the selected time period, displayed on the right side of the panel. The red line corresponds to the maximum value, the green line to the arithmetic mean, and the blue line to the minimum value.
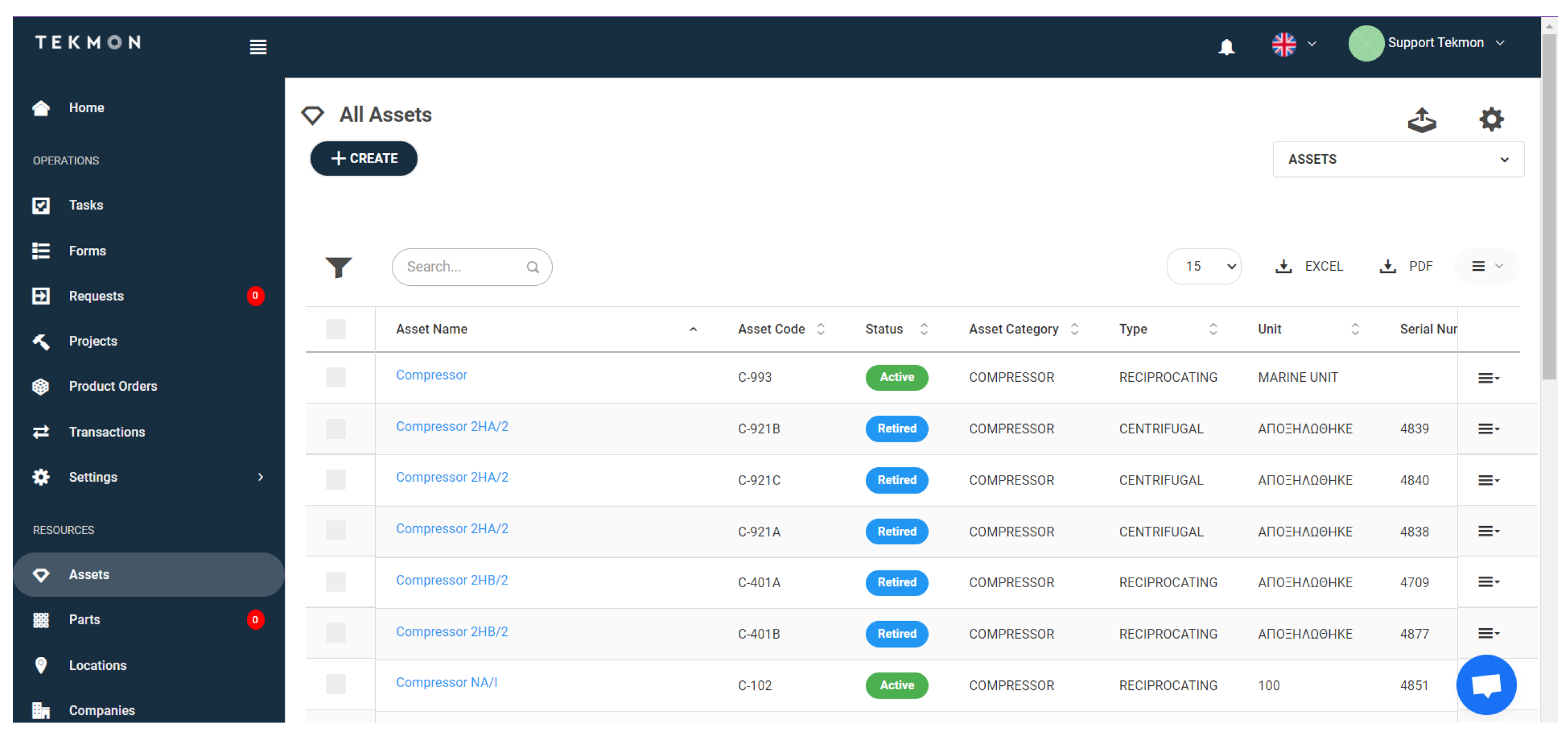
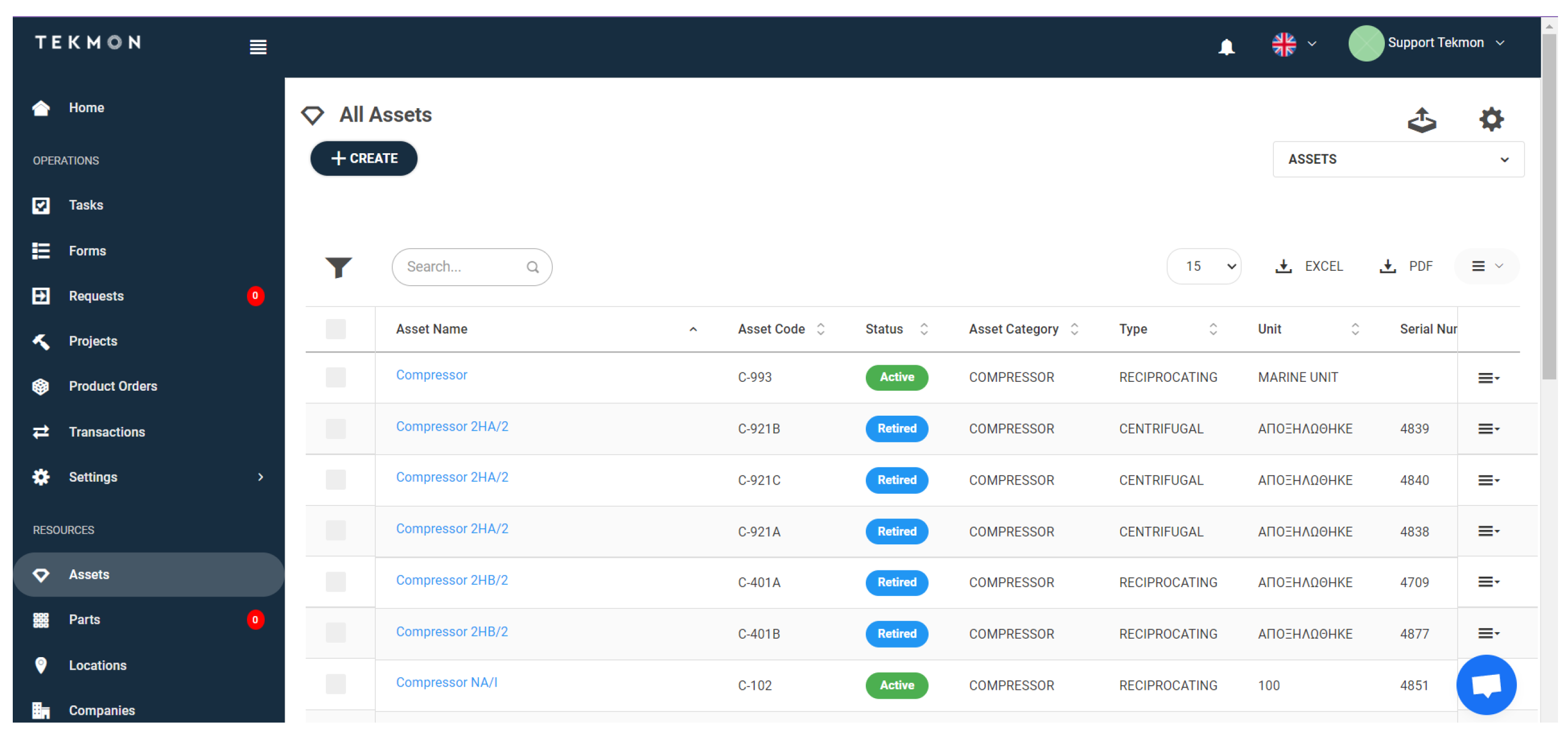
6.7. Daily Operations System via Assets Manager HMI
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| API | Application programming interface |
| AR | Augmented reality |
| A.R.I.S. | Augmented reality information system |
| AWS | Amazon Web Services |
| CPPS | Cyber–physical production system |
| CPU | Central processing unit |
| CRUD Manager | Create, read, update and delete manager |
| DB | Database |
| DBMS | Database management system |
| DCS | Decentralized control system |
| GCE | Google Compute Engine |
| GPS | Global positioning system |
| HMI | Human–machine interface |
| IaaS | Infrastructure as a service |
| IIoT | Industrial internet of things |
| IoE | Internet of everything |
| IoT | Internet of things |
| JSON | JavaScript object notation |
| M2M | Machine to machine |
| MQTT | MQ telemetry transport |
| NB-IoT | NarrowBand IoT |
| NE | North-east |
| NW | North-west |
| OR-DBMS | Object relational database management system |
| OS | Operating system |
| PaaS | Platform as a service |
| PC | Personal computer |
| PID | Proportional, integral, derivative |
| PLC | Programmable logic controller |
| QPS | Queries per second |
| ReST API | Representational state transfer application programming interface |
| RPM | Rotations per minute |
| RSSI | Received signal strength indicator |
| SaaS | Software as a service |
| SE | South-east |
| SDK | Software development kit |
| SW | South-west |
| TP | Throughput |
| YCSB | Yahoo Cloud Serving Benchmarking Tool |
References
- Lasi, H.; Fettke, P.; Kemper, H.-G.; Feld, T.; Hoffmann, M. Industry 4.0. Bus. Inf. Syst. Eng. (BISE) 2014, 6, 239–242. [Google Scholar] [CrossRef]
- Padovano, A.; Longo, F.; Nicoletti, L.; Mirabelli, G. A Digital Twin based Service Oriented Application for a 4.0 Knowledge Navigation in the Smart Factory. IFAC-PapersOnLine 2018, 51, 631–636. [Google Scholar] [CrossRef]
- Chen, B.; Wan, J.; Shu, L.; Li, P.; Mukherjee, M.; Yin, B. Smart Factory of Industry 4.0: Key Technologies, Application Case, and Challenges. IEEE Access 2018, 6, 6505–6519. [Google Scholar] [CrossRef]
- Hu, P. A System Architecture for Software-Defined Industrial Internet of Things. In Proceedings of the IEEE International Conference on Ubiquitous Wireless Broadband (ICUWB), Montreal, QC, Canada, 4–7 October 2015; pp. 1–5. [Google Scholar]
- Yue, X.; Cai, H.; Yan, H.; Zou, C.; Zhou, K. Cloud-Assisted Industrial Cyber-Physical Systems: An Insight. Microprocess. Microsyst. 2015, 39, 1262–1270. [Google Scholar] [CrossRef]
- Lee, J.; Bagheri, B.; Kao, H.A. A Cyber-Physical Systems architecture for Industry 4.0-based manufacturing systems. Manuf. Lett. 2015, 3, 18–23. [Google Scholar] [CrossRef]
- Alam, K.M.; El Saddik, A. C2PS: A Digital Twin Architecture Reference Model for the Cloud-Based Cyber-Physical Systems. IEEE Access 2017, 5, 2050–2062. [Google Scholar] [CrossRef]
- IIoT and Automation. Available online: https://www.punetechtrol.com/blogs/iiot-and-automation (accessed on 9 November 2021).
- Makris, A.; Tserpes, K.; Spiliopoulos, G.; Anagnostopoulos, D. Performance Evaluation of MongoDB and PostgreSQL for spatio-temporal data. In Proceedings of the EDBT/ICDT Workshops, Lisbon, Portugal, 26–29 March 2019. [Google Scholar]
- Daskevics, A.; Nikiforova, A. IoTSE-based open database vulnerability inspection in three Baltic countries: ShoBEVODSDT sees you. In Proceedings of the 8th International Conference on Internet of Things: Systems, Management and Security (IOTSMS), Gandia, Spain, 6–9 December 2021; pp. 1–8. [Google Scholar]
- Bad Actors Target MongoDB Databases, Threatening to Contact GDPR Legislators Unless Ransom Is Paid. Available online: https://www.bitdefender.com/blog/hotforsecurity/bad-actors-target-mongodb-databases-threatening-to-contact-gdpr-legislators-unless-ransom-is-paid/ (accessed on 15 March 2022).
- Mongodb. Available online: http://www.mongodb.com/ (accessed on 21 November 2021).
- Makris, A.; Tserpes, K.; Andronikou, V.; Anagnostopoulos, D. A Classification of NoSQL Data Stores Based on Key Design Characteristics. Procedia Comput. Sci. 2016, 97, 94–103. [Google Scholar] [CrossRef] [Green Version]
- Sharding. Available online: https://docs.mongodb.com/manual/sharding/ (accessed on 22 February 2022).
- Performance Benchmark POSTGRESQL/MONGODB. Available online: https://info.enterprisedb.com/rs/069-ALB-339/images/PostgreSQL_MongoDB_Benchmark-WhitepaperFinal.pdf (accessed on 22 November 2021).
- TimescaleDB. Available online: https://www.timescale.com/ (accessed on 26 November 2021).
- What Is Citus? Available online: https://docs.citusdata.com/en/v7.3/get_started/what_is_citus.html (accessed on 22 February 2022).
- Postgres, Pg-Stat-Statement. Available online: https://www.postgresql.org/docs/9.4/pgstatstatements.html (accessed on 26 November 2021).
- PostGIS. Available online: https://postgis.net/ (accessed on 26 November 2021).
- Docker. Available online: https://www.ibm.com/ae-en/cloud/learn/docker (accessed on 22 February 2022).
- Plugge, E.; Membrey, P.; Hawkins, T. The Definitive Guide to MongoDB: The NoSQL Database for Cloud and Desktop Computing, 1st ed.; Apress: New York, NY, USA, 2010. [Google Scholar]
- Matthew, N.; Stones, R. Beginning Databases with Postgresql: From Novice to Professional, 2nd ed.; Apress: Berkeley, CA, USA, 2005. [Google Scholar]
- Gkamas, T.; Karaiskos, V.; Kontogiannis, S. Evaluation of cloud databases as a service for Industrial IoT data. In Proceedings of the 7th International Congress on Information and Communication Technology (ICICT), London, UK, 21–24 February 2022. [Google Scholar]
- Rossman, G. New Benchmarks Show Postgres Dominating MongoDB in Varied Workloads. Available online: https://www.enterprisedb.com/news/new-benchmarks-show-postgres-dominating-mongodb-varied-workloads (accessed on 11 November 2021).
- OnGres. Available online: https://ongres.com/ (accessed on 26 November 2021).
- Comparing MongoDB vs. PostgreSQL. Available online: https://www.mongodb.com/compare/mongodb-postgresql (accessed on 11 November 2021).
- Martins, P.; Abbasi, M.; Sá, F. A study over NoSQL performance. In Proceedings of the 7th World Conference on Information Systems and Technologies, La Toja Island, Galicia, Spain, 16–19 April 2019; pp. 603–611. [Google Scholar]
- Martins, P.; Tomé, P.; Wanzeller, C.; Sá, F.; Abbasi, M. NoSQL Comparative Performance Study. In Proceedings of the 9th World Conference on Information Systems and Technologies, Terceira Island, Azores, Portugal, 30 March–2 April 2021; pp. 428–438. [Google Scholar]
- Seghier, N.B.; Kazar, O. Performance Benchmarking and Comparison of NoSQL Databases: Redis vs. MongoDB vs. Cassandra Using YCSB Tool. In Proceedings of the International Conference on Recent Advances in Mathematics and Informatics (ICRAMI), Tebessa, Algeria, 21–22 September 2021; pp. 1–6. [Google Scholar]
- SaaS vs. PaaS vs. IaaS: What’s The Difference & How to Choose. Available online: https://www.bmc.com/blogs/saas-vs-paas-vs-iaas-whats-the-difference-and-how-to-choose/ (accessed on 28 November 2021).
- Asiminidis, C.; Kokkonis, G.; Kontogiannis, S. Database Systems Performance Evaluation for IoT Applications. Int. J. Database Manag. Syst. 2018, 10, 1–14. [Google Scholar] [CrossRef]
- Mosquitto™ an Open Source MQTT Broker. Available online: https://mosquitto.org/ (accessed on 15 March 2022).
- Telegraf Open Source Server Agent. Available online: https://www.influxdata.com/time-series-platform/telegraf/ (accessed on 15 March 2022).
- InfluxDB: Open Source Time Series Database. Available online: https://www.influxdata.com/ (accessed on 15 March 2022).
- Grafana: The Open Observability Platform. Available online: https://grafana.com/ (accessed on 15 March 2022).
- Graphite. Available online: https://graphiteapp.org/ (accessed on 15 March 2022).
- Prometheus—Monitoring System & Time Series Database. Available online: https://prometheus.io/ (accessed on 15 March 2022).
- Elasticsearch. Available online: https://www.elastic.co/ (accessed on 15 March 2022).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenarios | Database Type | Average Response Time (s) | Jitter | Failure (%) | Average Achieved TP |
|---|---|---|---|---|---|
| Native | MongoDB | 0.149 | 0.044 | 0.00 | 390 |
| Post-JSON | 0.095 | 0.043 | 0.0002 | 250 | |
| Post-Rel. | 0.103 | 0.046 | 0.00 | 243 | |
| Two shards | MongoDB | 0.185 | 0.145 | 0.00 | 332 |
| Post-JSON | 0.177 | 0.042 | 0.00 | 177 | |
| Post-Rel. | 0.182 | 0.043 | 0.00 | 174 | |
| Four shards | MongoDB | 0.210 | 0.084 | 0.00 | 279 |
| Post-JSON | 0.196 | 0.051 | 0.00 | 165 | |
| Post-Rel. | 0.196 | 0.052 | 0.00 | 165 | |
| Six shards | MongoDB | 0.180 | 0.057 | 0.00 | 320 |
| Post-JSON | 0.216 | 0.061 | 0.00 | 155 | |
| Post-Rel. | 0.215 | 0.056 | 0.00 | 156 | |
| Eight shards | MongoDB | 0.190 | 0.069 | 0.00 | 305 |
| Post-JSON | 0.232 | 0.064 | 0.00 | 148 | |
| Post-Rel. | 0.231 | 0.073 | 0.00 | 149 |
| Scenarios | Database Type | Average Response Time (s) | Jitter | Failure (%) | Average Achieved TP |
|---|---|---|---|---|---|
| Native | MongoDB | 4.28 | 1.33 | 0.00 | 17 |
| Post-JSON | 4.55 | 3.17 | 0.00 | 12 | |
| Post-Rel. | 2.13 | 1.74 | 0.00 | 23 | |
| Two shards | MongoDB | 5.69 | 1.80 | 0.00 | 13 |
| Post-JSON | 11.41 | 2.64 | 0.00 | 6 | |
| Post-Rel. | 6.78 | 1.58 | 0.003 | 9 | |
| Four shards | MongoDB | 5.97 | 2.05 | 0.00 | 13 |
| Post-JSON | 12.49 | 3.92 | 0.003 | 5 | |
| Post-Rel. | 7.47 | 1.42 | 0.00 | 8 | |
| Six shards | MongoDB | 5.88 | 2.14 | 0.00 | 13 |
| Post-JSON | 13.12 | 4.69 | 0.00 | 5 | |
| Post-Rel. | 7.46 | 1.76 | 0.00 | 8 | |
| Eight shards | MongoDB | 6.35 | 2.58 | 0.00 | 12 |
| Post-JSON | 13.90 | 6.24 | 0.00 | 5 | |
| Post-Rel. | 8.34 | 2.55 | 0.00 | 8 |
| Scenarios | Database Type | Average Response Time (s) | Jitter | Failure (%) | Average Achieved TP |
|---|---|---|---|---|---|
| Native | MongoDB | 3.77 | 1.03 | 0.00 | 16 |
| Post-JSON | 5.05 | 1.29 | 0.00 | 11 | |
| Post-Rel. | 0.93 | 0.23 | 0.00 | 52 | |
| Two shards | MongoDB | 3.67 | 0.56 | 0.00 | 16 |
| Post-JSON | 6.72 | 1.45 | 0.00 | 8 | |
| Post-Rel. | 2.34 | 0.40 | 0.00 | 21 | |
| Four shards | MongoDB | 3.51 | 0.70 | 0.00 | 17 |
| Post-JSON | 4.36 | 0.87 | 0.00 | 12 | |
| Post-Rel. | 3.06 | 0.47 | 0.00 | 16 | |
| Six shards | MongoDB | 3.56 | 0.49 | 0.00 | 17 |
| Post-JSON | 4.77 | 1.09 | 0.00 | 12 | |
| Post-Rel. | 2.83 | 0.56 | 0.00 | 17 | |
| Eight shards | MongoDB | 3.57 | 0.47 | 0.00 | 17 |
| Post-JSON | 4.33 | 1.05 | 0.00 | 13 | |
| Post-Rel. | 3.47 | 0.51 | 0.00 | 15 |
| Scenarios | Distributed Strategy | ||
|---|---|---|---|
| Standalone | 2–4 Shards | 6–8 Shards | |
| Q1 | −45% | −2% to −7% | +20% to +22% |
| Q2 | −101% | +19% to +25% | +27% to +31% |
| Q3 | −305% | −57% to −15% | −26% to −3% |
| Scenarios | Burstness | |
|---|---|---|
| LOW | HIGH | |
| (Up to 100 Concentrators/1 K QPS) | (500–1 K Concentrators/5 K–10 K QPS) | |
| Standalone Rel. Postgres | 6-shards MongoDB | |
| Q1 | or | or |
| Standalone Postgres JSON | 6-shards Rel. Postgres | |
| Standalone Rel. Postgres | 8-shards MongoDB | |
| Q2 | or | or |
| 2-shards MongoDB | 6-shards MongoDB | |
| Standalone Rel. Postgres | 8-shards Rel. Postgres | |
| Q3 | or | or |
| 2-shards Rel. Postgres | 8-shards MongoDB | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gkamas, T.; Karaiskos, V.; Kontogiannis, S. Performance Evaluation of Distributed Database Strategies Using Docker as a Service for Industrial IoT Data: Application to Industry 4.0. Information 2022, 13, 190. https://doi.org/10.3390/info13040190
Gkamas T, Karaiskos V, Kontogiannis S. Performance Evaluation of Distributed Database Strategies Using Docker as a Service for Industrial IoT Data: Application to Industry 4.0. Information. 2022; 13(4):190. https://doi.org/10.3390/info13040190
Chicago/Turabian StyleGkamas, Theodosios, Vasileios Karaiskos, and Sotirios Kontogiannis. 2022. "Performance Evaluation of Distributed Database Strategies Using Docker as a Service for Industrial IoT Data: Application to Industry 4.0" Information 13, no. 4: 190. https://doi.org/10.3390/info13040190
APA StyleGkamas, T., Karaiskos, V., & Kontogiannis, S. (2022). Performance Evaluation of Distributed Database Strategies Using Docker as a Service for Industrial IoT Data: Application to Industry 4.0. Information, 13(4), 190. https://doi.org/10.3390/info13040190