
Ranking Algorithms for Word Ordering in Surface Realization




Abstract
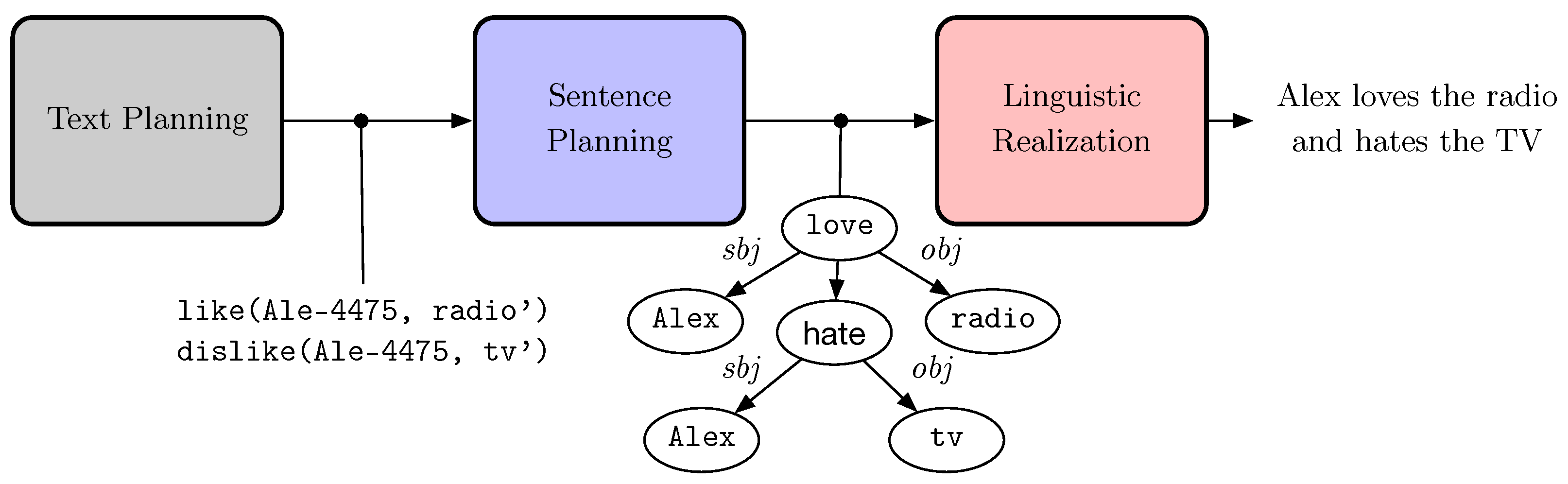
:1. Introduction
Contributions and Outline
- We formalize three deep neural models implementing pointwise, pairwise, and listwise learning-to-rank approaches to word ordering, with varying network architectures. These methods represent the neural evolution of existing methods from the literature.
- We compare the performances between the three neural learning-to-rank algorithms in the context of surface realization. In particular, we present the results of an experimentation carried out on five languages from different typological families.
2. Related Work
2.1. Algorithms for Ranking
2.2. The Word-Ordering Task in NLG
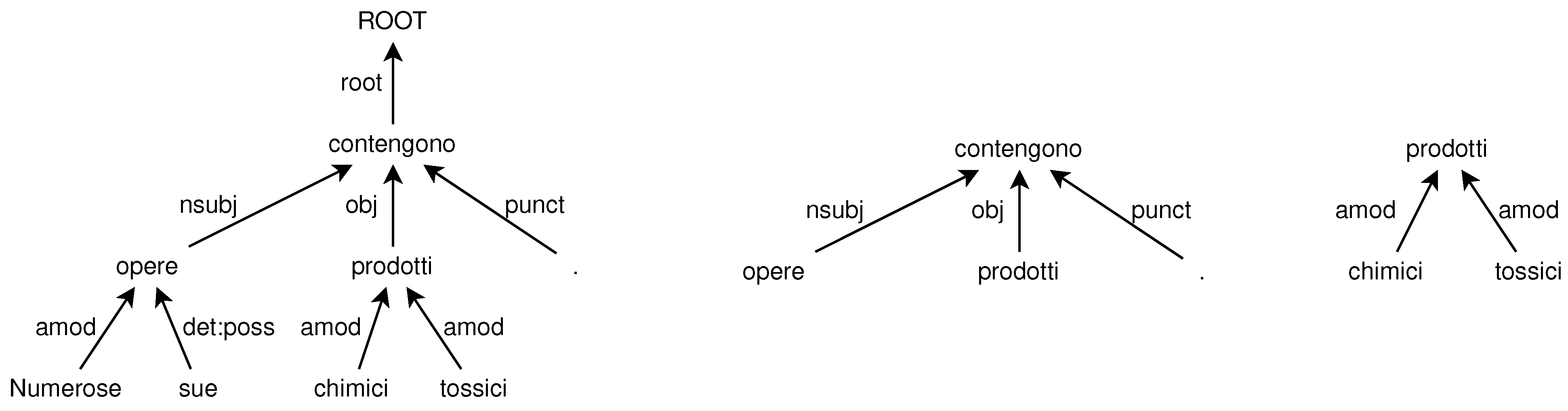
3. Predicting Word Ordering with General Ranking Algorithms
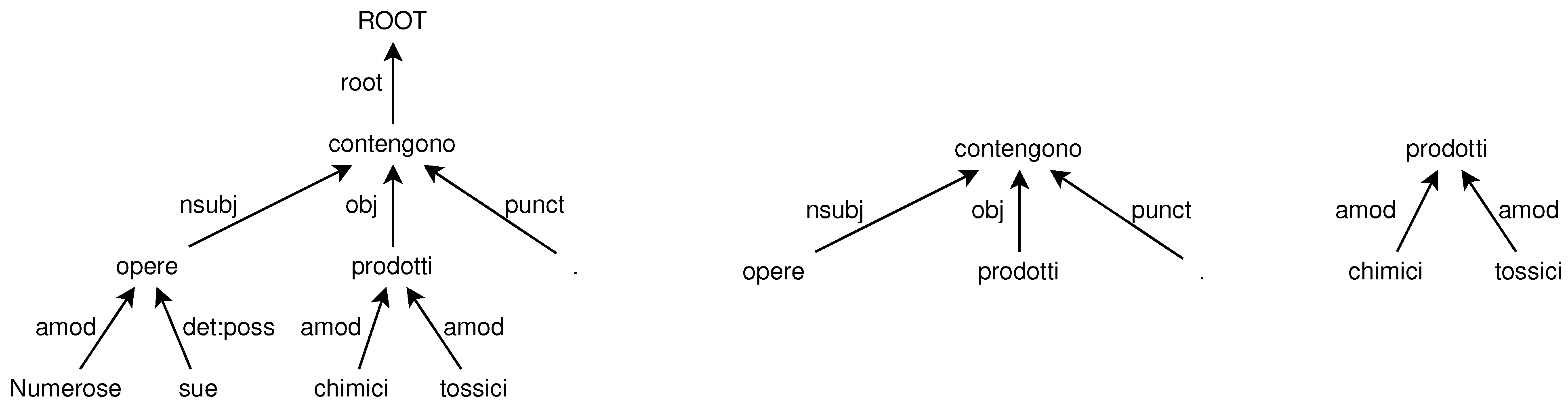
- Splitting the unordered tree into single-level unordered subtrees.
- Predicting the local word order for each subtree by using a ranking algorithm.
- Recomposing the single-level ordered subtrees into a single multi-level ordered tree to obtain the global word order.
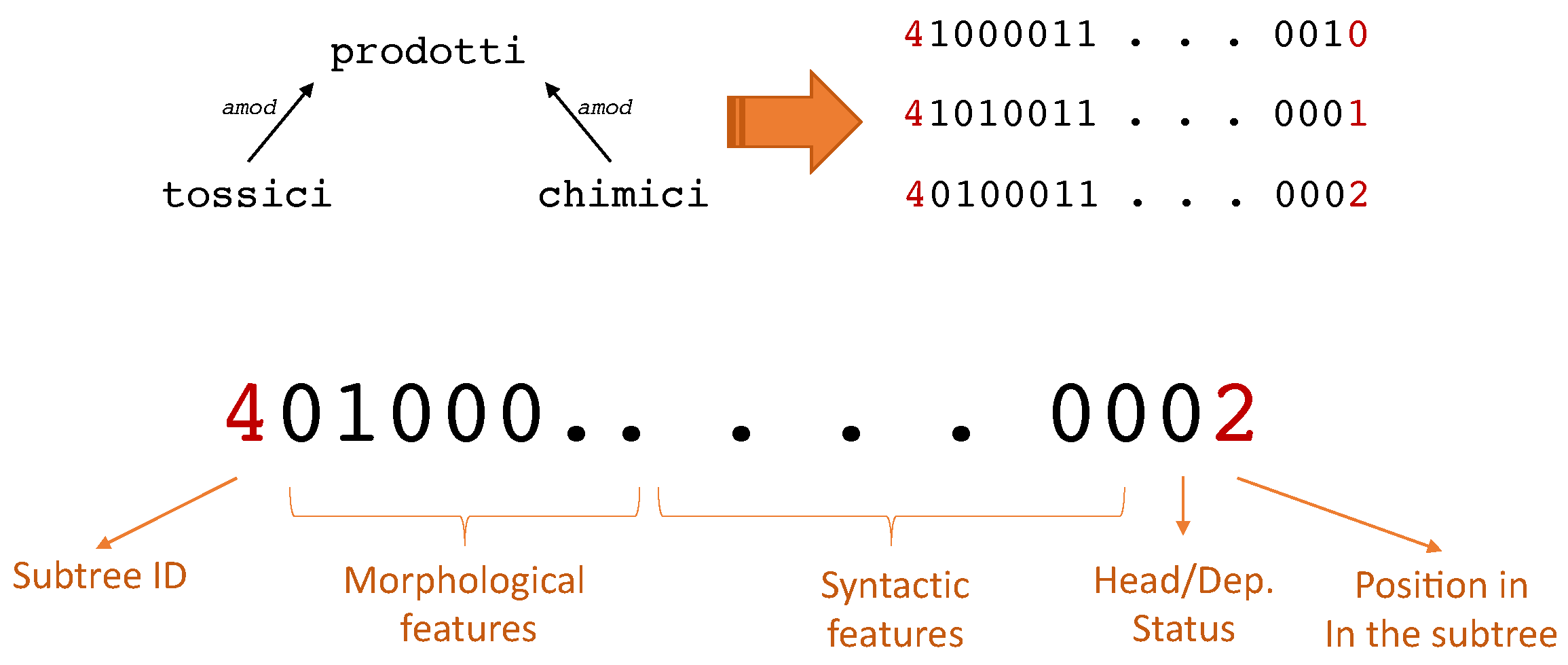
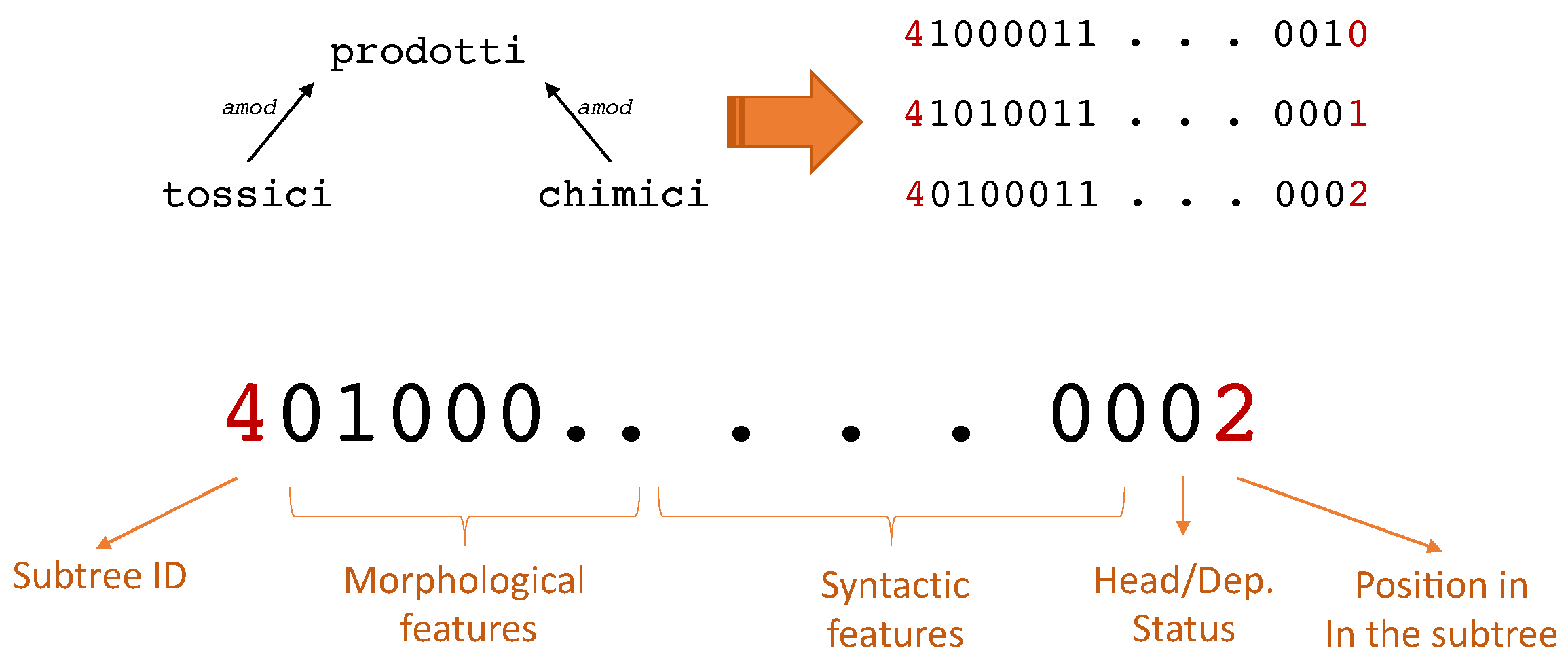
3.1. Feature Encoding
3.2. Neural Implementation of Ranking Algorithms
3.2.1. Neural Listwise
3.2.2. Neural Pairwise
3.2.3. Neural Pointwise
4. Experiments
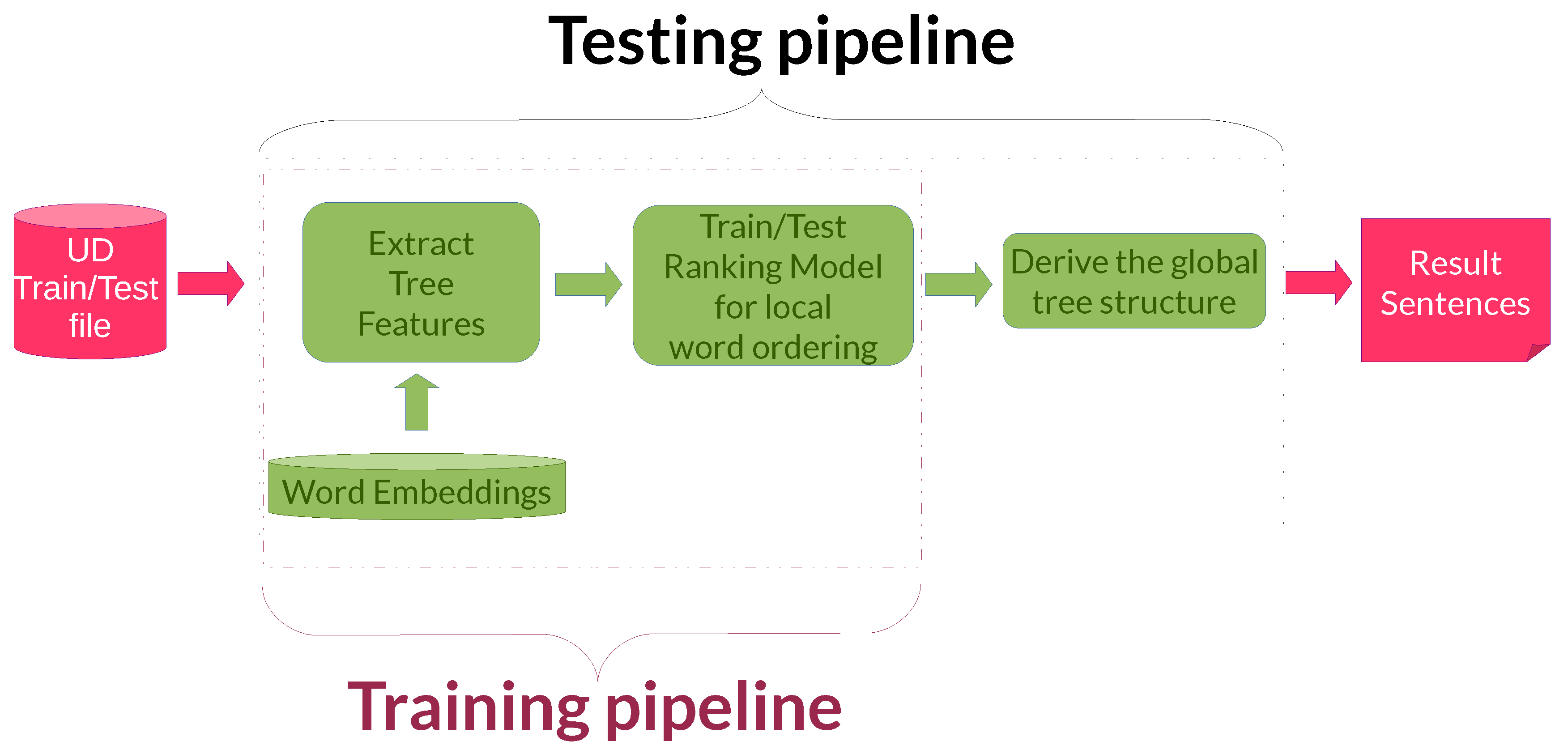
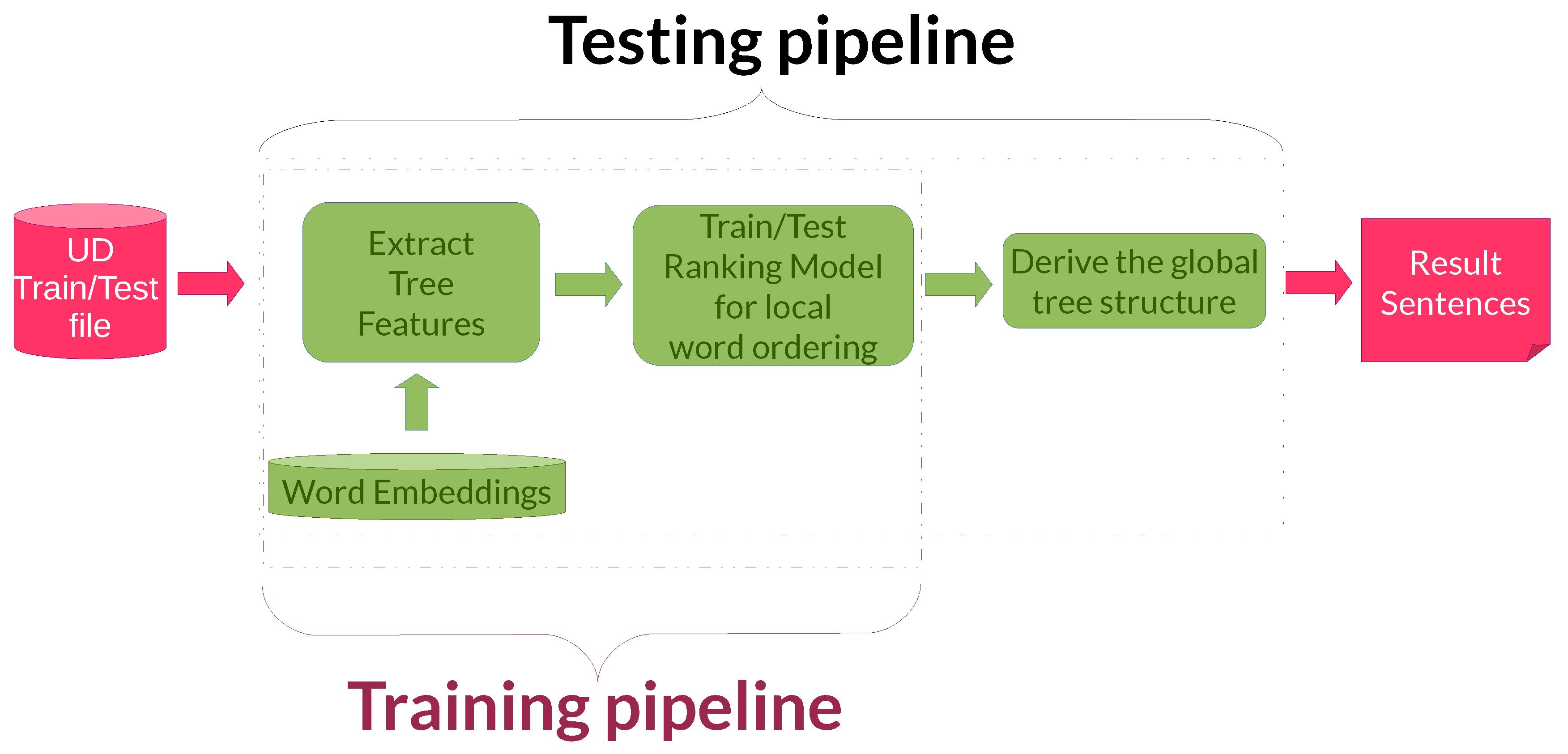
4.1. Pipelines
4.2. Datasets
4.3. Hyperparameter Search
4.4. Results
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Montague, R. Universal Grammar; Wiley: Hoboken, NJ, USA, 1970; Volume 1974, pp. 222–246. [Google Scholar]
- Banarescu, L.; Bonial, C.; Cai, S.; Georgescu, M.; Griffitt, K.; Hermjakob, U.; Knight, K.; Koehn, P.; Palmer, M.; Schneider, N. Abstract meaning representation for sembanking. In Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse, Sofia, Bulgaria, 8–9 August 2013; pp. 178–186. [Google Scholar]
- Gardent, C.; Shimorina, A.; Narayan, S.; Perez-Beltrachini, L. The WebNLG Challenge: Generating Text from RDF Data. In Proceedings of the 10th International Conference on Natural Language Generation, Santiago de Compostela, Spain, 4–7 September 2017; pp. 124–133. [Google Scholar] [CrossRef]
- Damonte, M.; Cohen, S.B. Structural Neural Encoders for AMR-to-text Generation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 3649–3658. [Google Scholar] [CrossRef]
- Basile, V.; Bos, J. Aligning Formal Meaning Representations with Surface Strings for Wide-coverage Text Generation. In Proceedings of the 14th European Workshop on Natural Language Generation, Sofia, Bulgaria, 8–9 August 2013; p. 1. [Google Scholar]
- Chen, W.; Chen, J.; Su, Y.; Chen, Z.; Wang, W.Y. Logical Natural Language Generation from Open-Domain Tables. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7929–7942. [Google Scholar] [CrossRef]
- Anselma, L.; Di Lascio, M.; Mana, D.; Mazzei, A.; Sanguinetti, M. Content Selection for Explanation Requests in Customer-Care Domain. In Proceedings of the 2nd Workshop on Interactive Natural Language Technology for Explainable Artificial Intelligence, Dublin, Ireland, 15–18 December 2020; pp. 5–10. [Google Scholar]
- Reiter, E.; Dale, R. Building Natural Language Generation Systems; Cambridge University Press: New York, NY, USA, 2000. [Google Scholar]
- Gatt, A.; Krahmer, E. Survey of the State of the Art in Natural Language Generation: Core tasks, applications and evaluation. J. Artif. Intell. Res. 2018, 61, 65–170. [Google Scholar] [CrossRef]
- Mille, S.; Belz, A.; Bohnet, B.; Graham, Y.; Pitler, E.; Wanner, L. The First Multilingual Surface Realisation Shared Task (SR’18): Overview and Evaluation Results. In Proceedings of the First Workshop on Multilingual Surface Realisation, Melbourne, Australia, 19 July 2018; pp. 1–12. [Google Scholar] [CrossRef]
- Mille, S.; Belz, A.; Bohnet, B.; Graham, Y.; Wanner, L. The Second Multilingual Surface Realisation Shared Task (SR’19): Overview and Evaluation Results. In Proceedings of the 2nd Workshop on Multilingual Surface Realisation (MSR 2019), Hong Kong, China, 3 November 2019; pp. 1–17. [Google Scholar] [CrossRef]
- Mille, S.; Belz, A.; Bohnet, B.; Castro Ferreira, T.; Graham, Y.; Wanner, L. The Third Multilingual Surface Realisation Shared Task (SR’20): Overview and Evaluation Results. In Proceedings of the Third Workshop on Multilingual Surface Realisation, Barcelona, Spain (Online), 12 December 2020; pp. 1–20. [Google Scholar]
- Nivre, J.; de Marneffe, M.; Ginter, F.; Goldberg, Y.; Hajic, J.; Manning, C.D.; McDonald, R.T.; Petrov, S.; Pyysalo, S.; Silveira, N.; et al. Universal Dependencies v1: A Multilingual Treebank Collection. In Proceedings of the Tenth International Conference on Language Resources and Evaluation LREC 2016, Portorož, Slovenia, 23–28 May 2016. [Google Scholar]
- Basile, V. From Logic to Language: Natural Language Generation from Logical Forms. Ph.D. Thesis, University of Groningen, Groningen, The Netherlands, 2015. [Google Scholar]
- Kamp, H. A Theory of Truth and Semantic Representation. In Truth, Interpretation and Information; Groenendijk, J., Janssen, T.M., Stokhof, M., Eds.; FORIS: Dordrecht, The Netherlands; Cinnaminson, NJ, USA, 1984; pp. 1–41. [Google Scholar]
- Basile, V.; Mazzei, A. The DipInfo-UniTo system for SRST 2018. In Proceedings of the First Workshop on Multilingual Surface Realisation, Melbourne, Australia, July 2018; pp. 65–71. Available online: https://aclanthology.org/W18-3609/ (accessed on 17 August 2021).
- Basile, V.; Mazzei, A. Neural Surface Realization for Italian. In Proceedings of the Fifth Italian Conference on Computational Linguistics (CLiC-it 2018), Berlin, Germany, 8 July 2018; pp. 1–6. [Google Scholar]
- Mazzei, A.; Basile, V. The DipInfoUniTo Realizer at SRST’19: Learning to Rank and Deep Morphology Prediction for Multilingual Surface Realization. In Proceedings of the 2nd Workshop on Multilingual Surface Realisation (MSR 2019), Hong Kong, China, 3 November 2019; pp. 81–87. [Google Scholar] [CrossRef]
- Cao, Y.; Xu, J.; Liu, T.Y.; Li, H.; Huang, Y.; Hon, H.W. Adapting Ranking SVM to Document Retrieval. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, WA, USA, 6–11 August 2006; pp. 186–193. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 1189–1232. [Google Scholar]
- Cooper, W.S.; Gey, F.C.; Dabney, D.P. Probabilistic Retrieval Based on Staged Logistic Regression. In Proceedings of the 15th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Copenhagen, Denmark, 21–24 June 1992; pp. 198–210. [Google Scholar]
- Li, P.; Burges, C.J.C.; Wu, Q. McRank: Learning to Rank Using Multiple Classification and Gradient Boosting. In Advances in Neural Information Processing Systems; NIPC: Vancouver, BC, Canada, 2007; pp. 897–904. [Google Scholar]
- Burges, C.; Shaked, T.; Renshaw, E.; Lazier, A.; Deeds, M.; Hamilton, N.; Hullender, G. Learning to Rank Using Gradient Descent. In Proceedings of the 22nd International Conference on Machine Learning, New York, NY, USA, 16–20 June 2005; pp. 89–96. [Google Scholar] [CrossRef]
- Cao, Z.; Qin, T.; Liu, T.Y.; Tsai, M.F.; Li, H. Learning to Rank: From Pairwise Approach to Listwise Approach. In Proceedings of the 24th International Conference on Machine Learning, New York, NY, USA, 19–24 June 2007; pp. 129–136. [Google Scholar] [CrossRef]
- Xu, J.; Li, H. AdaRank: A boosting algorithm for information retrieval. In Proceedings of the SIGIR 2007: Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007; pp. 391–398. [Google Scholar]
- Köppel, M.; Segner, A.; Wagener, M.; Pensel, L.; Karwath, A.; Kramer, S. Pairwise Learning to Rank by Neural Networks Revisited: Reconstruction, Theoretical Analysis and Practical Performance. In Proceedings of the Machine Learning and Knowledge Discovery in Databases-European Conference, ECML PKDD 2019, Würzburg, Germany, 16–20 September 2019. [Google Scholar]
- Chomsky, N. Syntactic Structures; Mouton and Co.: The Hague, The Netherlands, 1957. [Google Scholar]
- Robin, J. An overview of surge: A reusable comprehensive syntactic realization component. In INLG’96 Demonstrations and Posters; Association for Computational Linguistics: Herstmonceux Castle, Sussex, UK, 1996; pp. 1–4. [Google Scholar]
- White, M.; Steedman, M.; Baldridge, J.; Kruijff, G. OpenCCG: The OpenNLP CCG Library. 2008. Available online: https://sourceforge.net/projects/openccg/ (accessed on 17 August 2021).
- Gatt, A.; Reiter, E. SimpleNLG: A realisation engine for practical applications. In Proceedings of the 12th European Workshop on Natural Language Generation, Athens, Greece, 30–31 March 2009. [Google Scholar]
- Joshi, A.; Rambow, O. A formalism for dependency grammar based on tree adjoining grammar. In Proceedings of the Conference on Meaning-Text Theory; MTT: Paris, France, 2003; pp. 207–216. [Google Scholar]
- Callaway, C.B. Evaluating Coverage for Large Symbolic NLG Grammars. In Proceedings of the Eighteenth International Joint Conference on Artificial Intelligence, Acapulco, Mexico, 9–15 August 2003; pp. 811–817. [Google Scholar]
- White, M.; Rajkumar, R.; Martin, S. Towards broad coverage surface realization with CCG. In Proceedings of the Workshop on Using Corpora for NLG: Language Generation and Machine Translation, Copenhagen, Denmark, 11 September 2007; pp. 22–30. [Google Scholar]
- Langkilde-Geary, I. A Foundation for General-Purpose Natural Language Generation: Sentence Realization Using Probabilistic Models of Language; University of Southern California: Los Angeles, CA, USA, 2003. [Google Scholar]
- Zhang, Y.; Clark, S. Discriminative Syntax-Based Word Ordering for Text Generation. Comput. Linguist. 2015, 41, 503–538. [Google Scholar] [CrossRef]
- Manning, C.D. Last Words: Computational Linguistics and Deep Learning. Comput. Linguist. 2015, 41, 701–707. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Hasler, E.; Stahlberg, F.; Tomalin, M.; de Gispert, A.; Byrne, B. A Comparison of Neural Models for Word Ordering. In Proceedings of the 10th International Conference on Natural Language Generation, Santiago de Compostela, Spain, 4–7 September 2017; pp. 208–212. [Google Scholar] [CrossRef]
- Belz, A.; White, M.; Espinosa, D.; Kow, E.; Hogan, D.; Stent, A. The First Surface Realisation Shared Task: Overview and Evaluation Results. In Proceedings of the 13th European Workshop on Natural Language Generation, Nancy, France, 28–31 September 2011; pp. 217–226. [Google Scholar]
- Yu, X.; Tannert, S.; Vu, N.T.; Kuhn, J. Fast and Accurate Non-Projective Dependency Tree Linearization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 1451–1462. [Google Scholar] [CrossRef]
- Bohnet, B.; Björkelund, A.; Kuhn, J.; Seeker, W.; Zarrieß, S. Generating non-projective word order in statistical linearization. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, 12–14 July 2012; pp. 928–939. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Available online: http://alpha.di.unito.it/storage/papers/2018_hpc4ai_ACM_CF.pdf (accessed on 17 August 2021).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: http://tensorflow.org (accessed on 17 August 2021).
- Kendall, M.G. A New Measure of Rank Correlation. Biometrika 1938, 30, 81–93. [Google Scholar] [CrossRef]
- Biewald, L. Experiment Tracking with Weights and Biases. 2020. Available online: http://wandb.com (accessed on 17 August 2021).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Id | Form | Lemma | UPOS | XPOS | Features | Head | DepRel |
|---|---|---|---|---|---|---|---|
| 1 | Numerose | numeroso | ADJ | A | Gender = Fem|Number = Plur | 3 | amod |
| 2 | sue | suo | DET | AP | Gender = Fem|Number = Plur| Poss = Yes|PronType = Prs | 3 | det:poss |
| 3 | opere | opera | NOUN | S | Gender = Fem|Number = Plur | 4 | nsubj |
| 4 | contengono | contenere | VERB | V | Mood = Ind|Number = Plur| Person = 3|Tense = Pres| VerbForm = Fin | 0 | root |
| 5 | prodotti | prodotto | NOUN | S | Gender = Masc|Number = Plur | 4 | obj |
| 6 | chimici | chimico | ADJ | A | Gender = Masc|Number = Plur | 5 | amod |
| 7 | tossici | tossico | ADJ | A | Gender = Masc|Number = Plur | 5 | amod |
| 8 | . | . | PUNCT | FS | _ | 4 | punct |
| TB | Language | Morphology Features Length | Syntactic Features Length | Positioning Part Length | Total Vector Length |
|---|---|---|---|---|---|
| ud-ewt | EN | 541 | 51 | 3 | 595 |
| ud-ancora | ES | 394 | 39 | 3 | 436 |
| ud-hdtb | HI | 587 | 28 | 3 | 618 |
| ud-isdt | IT | 500 | 47 | 3 | 550 |
| ud-gsd | ZH | 1213 | 47 | 3 | 1263 |
| TB | Language | Number of Sentences | Number of Words |
|---|---|---|---|
| ud-ewt | EN | 16,622 | 254,830 |
| ud-ancora | ES | 17,680 | 547,655 |
| ud-hdtb | HI | 16,647 | 351,704 |
| ud-isdt | IT | 14,167 | 278,429 |
| ud-gsd | ZH | 4997 | 123,291 |
| Hyperparameters | ||||
|---|---|---|---|---|
| Learning Rate | Regularization | Architecture | Activation Function | |
| Values | [] | [] | {[100, 50], [100, 100], [100], [50] } | {sigmoid, relu} |
| Architecture | Activation | Learning Rate | Regularization () | ||
|---|---|---|---|---|---|
| Listwise | EN | [100] | relu | ||
| IT | [100] | relu | 4.211 × 10 | ||
| HI | [100] | relu | |||
| ZH | [150] | relu | |||
| ES | [150] | relu | |||
| Pairwise | EN | [150,100] | relu | ||
| IT | [100] | relu | |||
| HI | [100,50] | relu | |||
| ZH | [100] | relu | |||
| ES | [100,50] | relu | |||
| Pointwise | EN | [150] | relu | ||
| IT | [100] | sigmoid | |||
| HI | [150,100] | relu | |||
| ZH | [100] | relu | |||
| ES | [150,100] | relu |
| System | Language | BLEU-4 | NIST | DIST | Subposition Accuracy |
|---|---|---|---|---|---|
| Neural-Listwise | EN | 60.56 | 12.69 | 70.56 | 0.73 |
| Neural-Pairwise | EN | 68.93 | 13.13 | 74.82 | 0.80 |
| Neural-Pointwise | EN | 45.23 | 12.04 | 61.08 | 0.64 |
| ADAPT (20b) | EN | 87.50 | 13.81 | 90.35 | N.A. |
| Neural-Listwise | ES | 56.86 | 13.52 | 54.57 | 0.71 |
| Neural-Pairwise | ES | 56.86 | 13.56 | 58.16 | 0.72 |
| Neural-Pointwise | ES | 51.57 | 13.36 | 52.42 | 0.68 |
| IMS (20a) | ES | 87.42 | 14.90 | 85.66 | N.A. |
| Neural-Listwise | HI | 58.24 | 12.28 | 63.37 | 0.74 |
| Neural-Pairwise | HI | 60.05 | 12.35 | 64.79 | 0.74 |
| Neural-Pointwise | HI | 36.00 | 11.33 | 50.60 | 0.57 |
| IMS (20b) | HI | 84.77 | 13.34 | 83.14 | N.A. |
| Neural-Listwise | IT | 56.15 | 11.86 | 61.12 | 0.73 |
| Neural-Pairwise | IT | 50.88 | 11.51 | 59.25 | 0.69 |
| Neural-Pointwise | IT | 51.28 | 11.51 | 59.51 | 0.69 |
| Tilburg-MT18 | IT | 44.16 | 9.11 | 58.61 | N.A. |
| DipInfo-Unito18 | IT | 36.60 | 9.30 | 32.70 | N.A. |
| Neural-Listwise | ZH | 54.99 | 11.86 | 62.53 | 0.73 |
| Neural-Pairwise | ZH | 55.81 | 11.88 | 61.27 | 0.72 |
| Neural-Pointwise | ZH | 34.76 | 11.26 | 52.64 | 0.58 |
| IMS (20b) | ZH | 88.05 | 12.91 | 85.19 | N.A. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mazzei, A.; Cerrato, M.; Esposito, R.; Basile, V. Ranking Algorithms for Word Ordering in Surface Realization. Information 2021, 12, 337. https://doi.org/10.3390/info12080337
Mazzei A, Cerrato M, Esposito R, Basile V. Ranking Algorithms for Word Ordering in Surface Realization. Information. 2021; 12(8):337. https://doi.org/10.3390/info12080337
Chicago/Turabian StyleMazzei, Alessandro, Mattia Cerrato, Roberto Esposito, and Valerio Basile. 2021. "Ranking Algorithms for Word Ordering in Surface Realization" Information 12, no. 8: 337. https://doi.org/10.3390/info12080337
APA StyleMazzei, A., Cerrato, M., Esposito, R., & Basile, V. (2021). Ranking Algorithms for Word Ordering in Surface Realization. Information, 12(8), 337. https://doi.org/10.3390/info12080337