
SCRO: A Domain Ontology for Describing Steel Cold Rolling Processes towards Industry 4.0

Abstract
:1. Introduction
2. Literature Review
2.1. Ontologies for Industry 4.0
2.2. Ontologies for the Steel Industry
2.3. Ontology Development Methodology
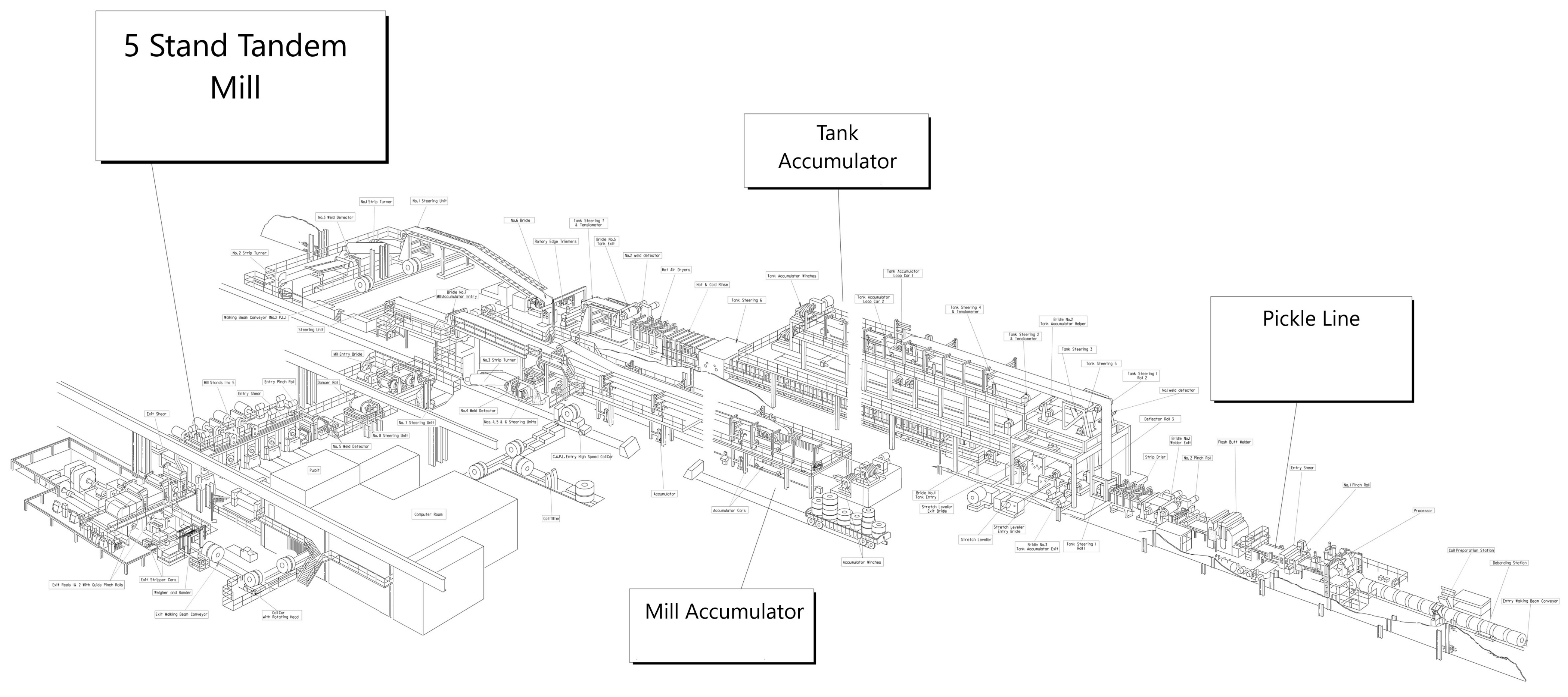
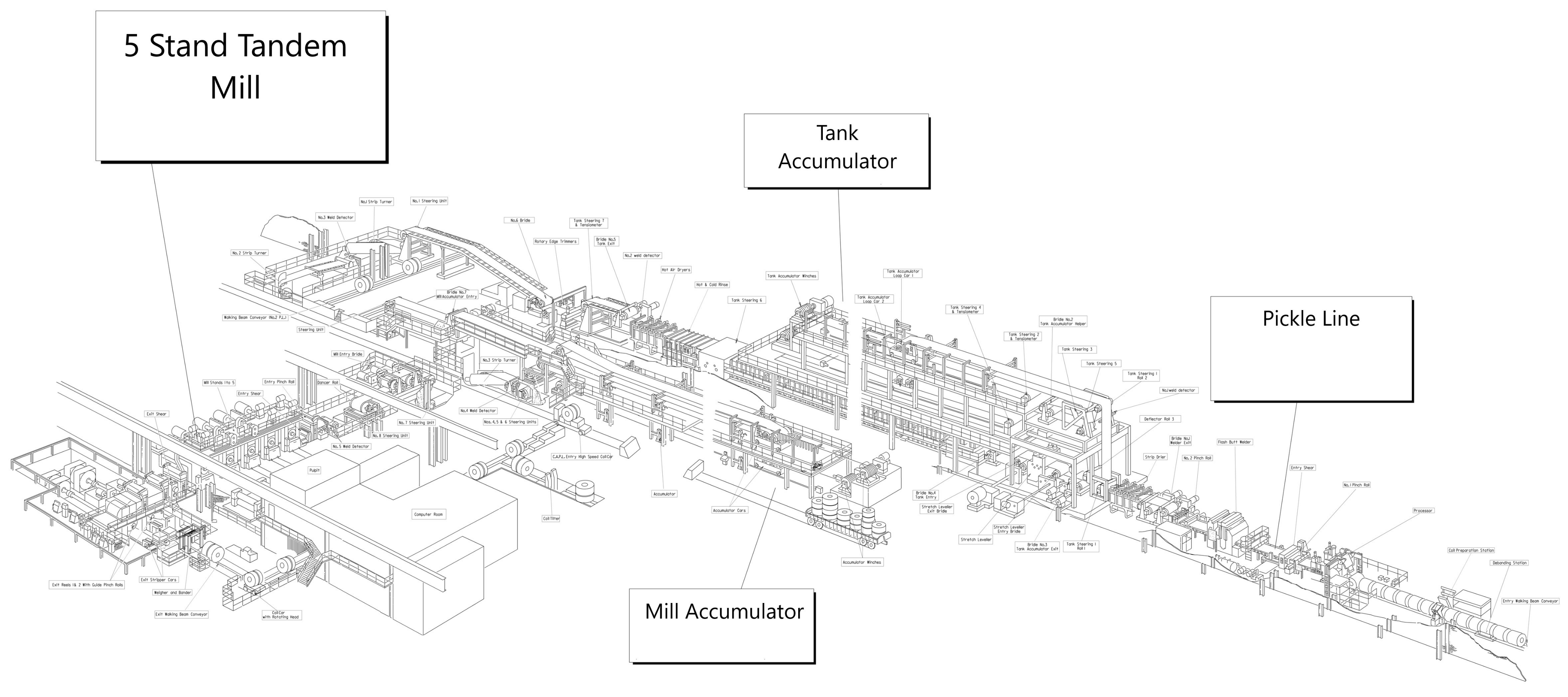
3. SCRO: Steel Cold Rolling Ontology
3.1. Coding
3.2. Reusing Existing Ontologies
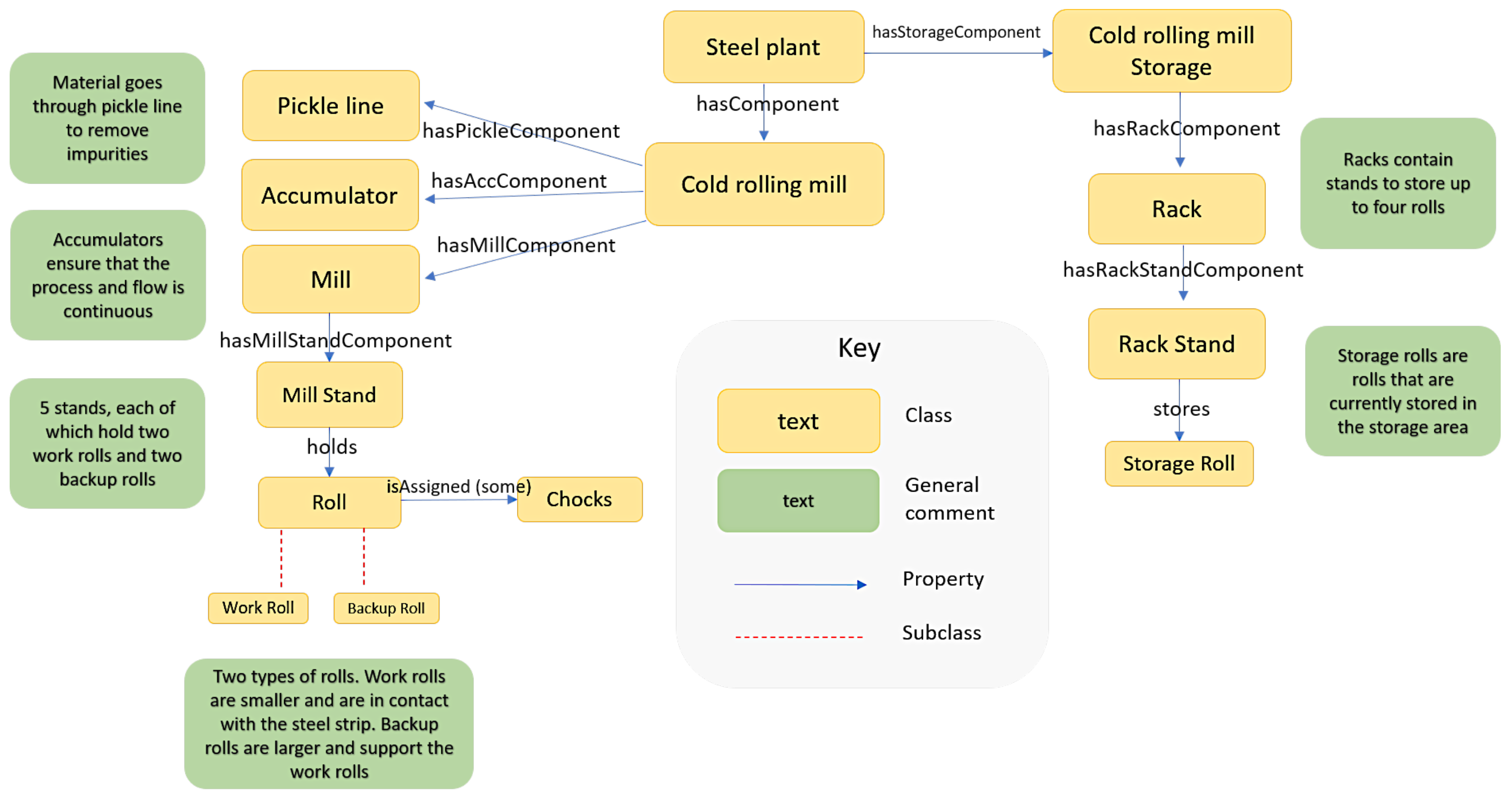
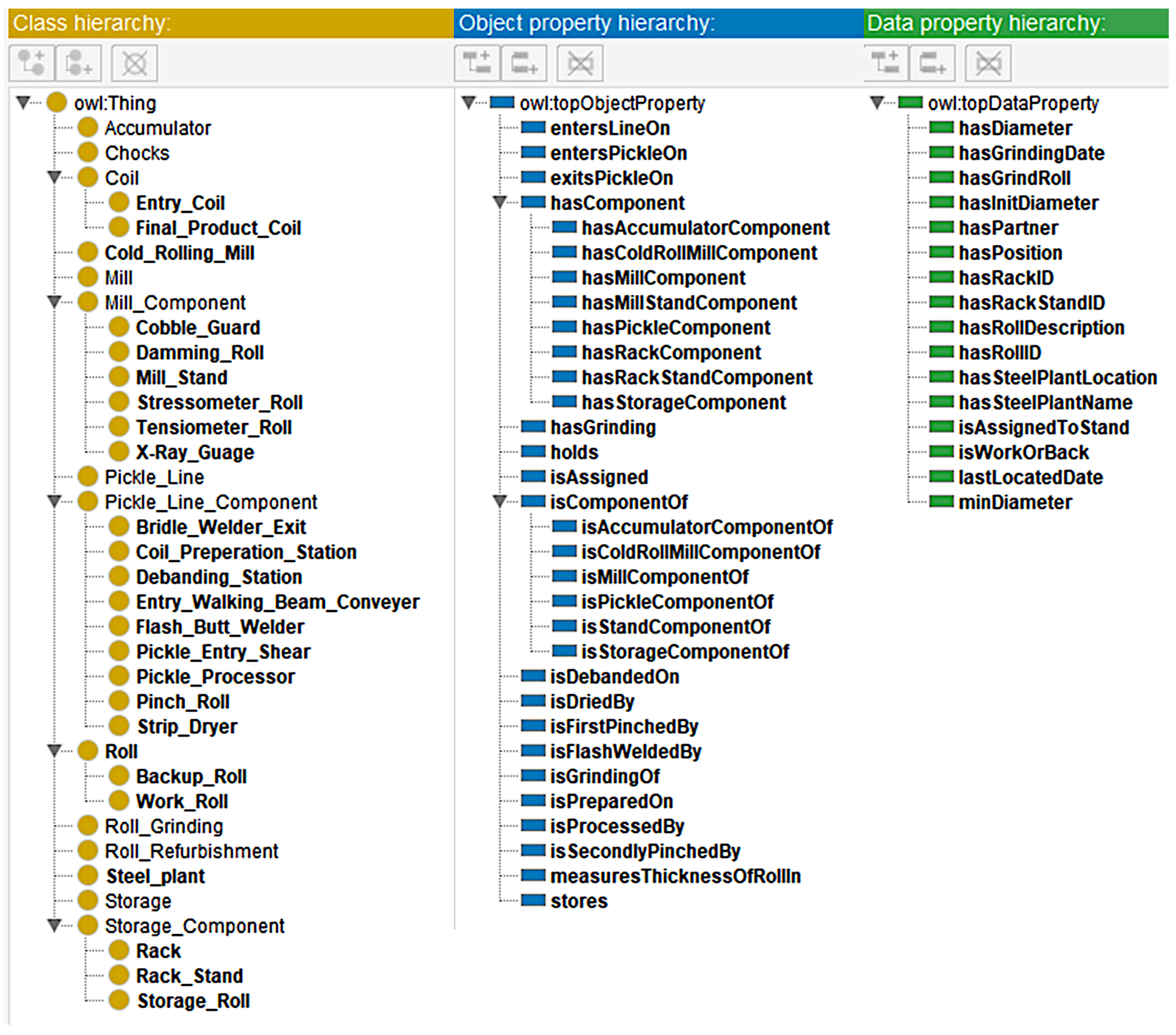
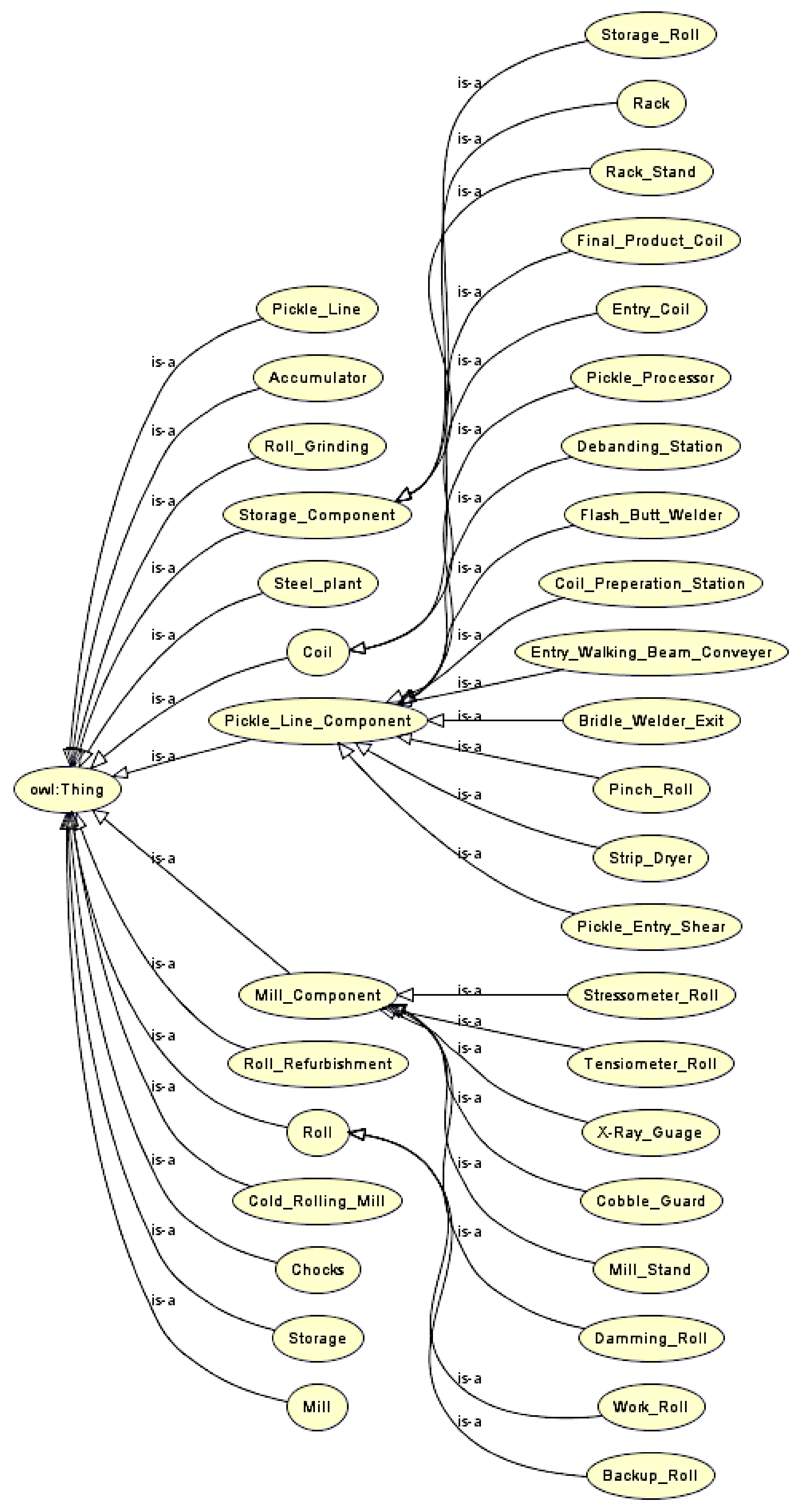
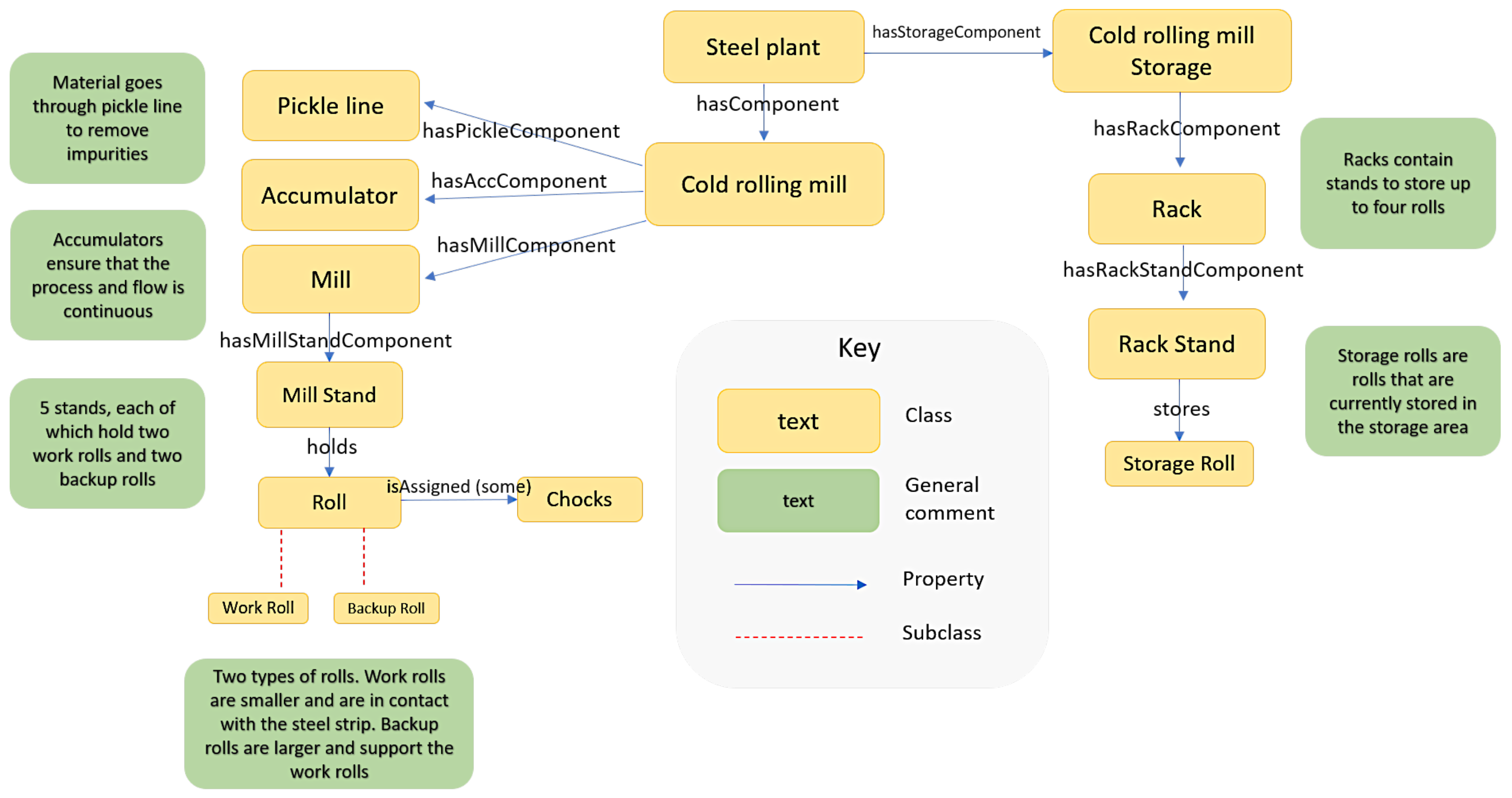
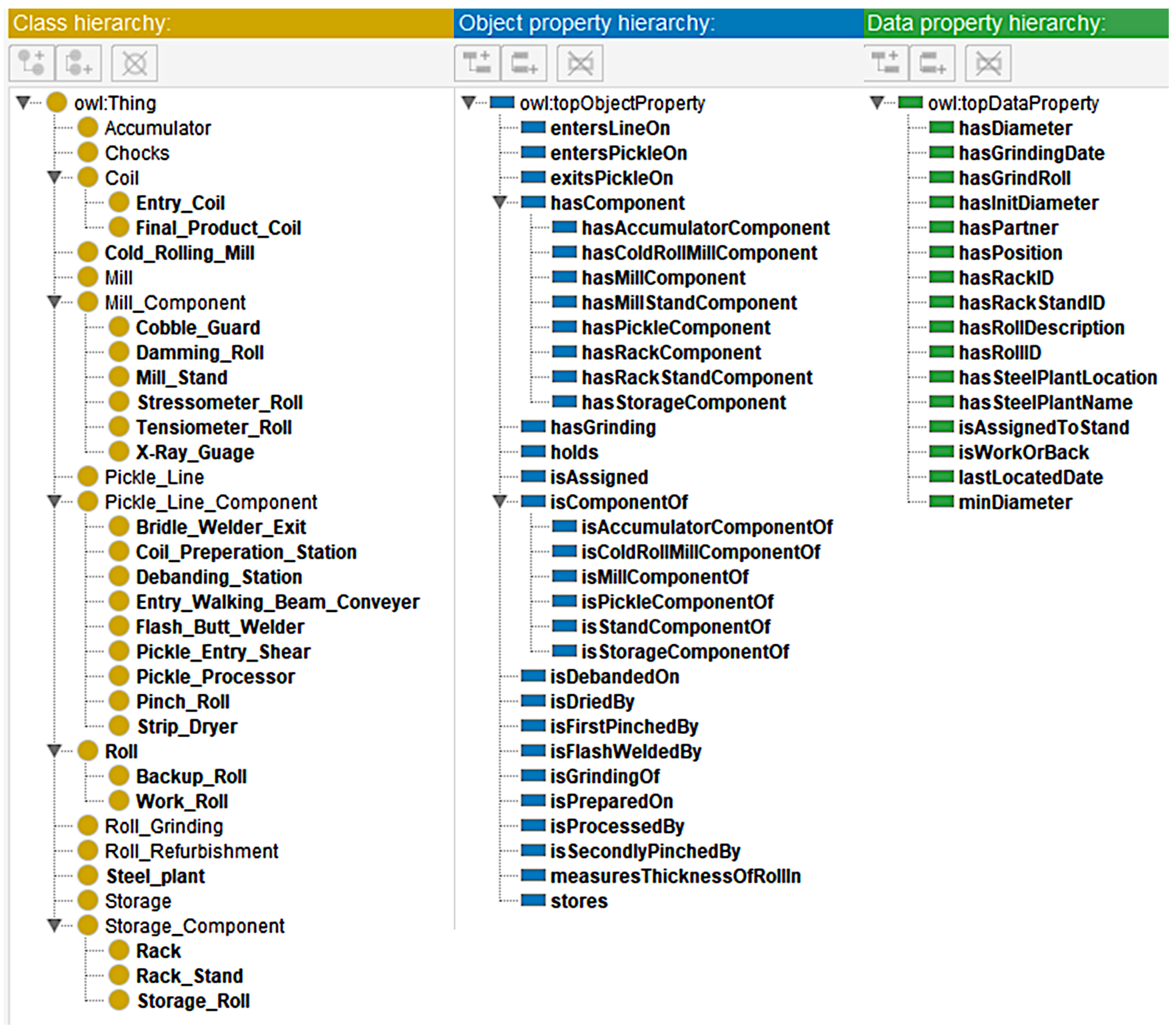
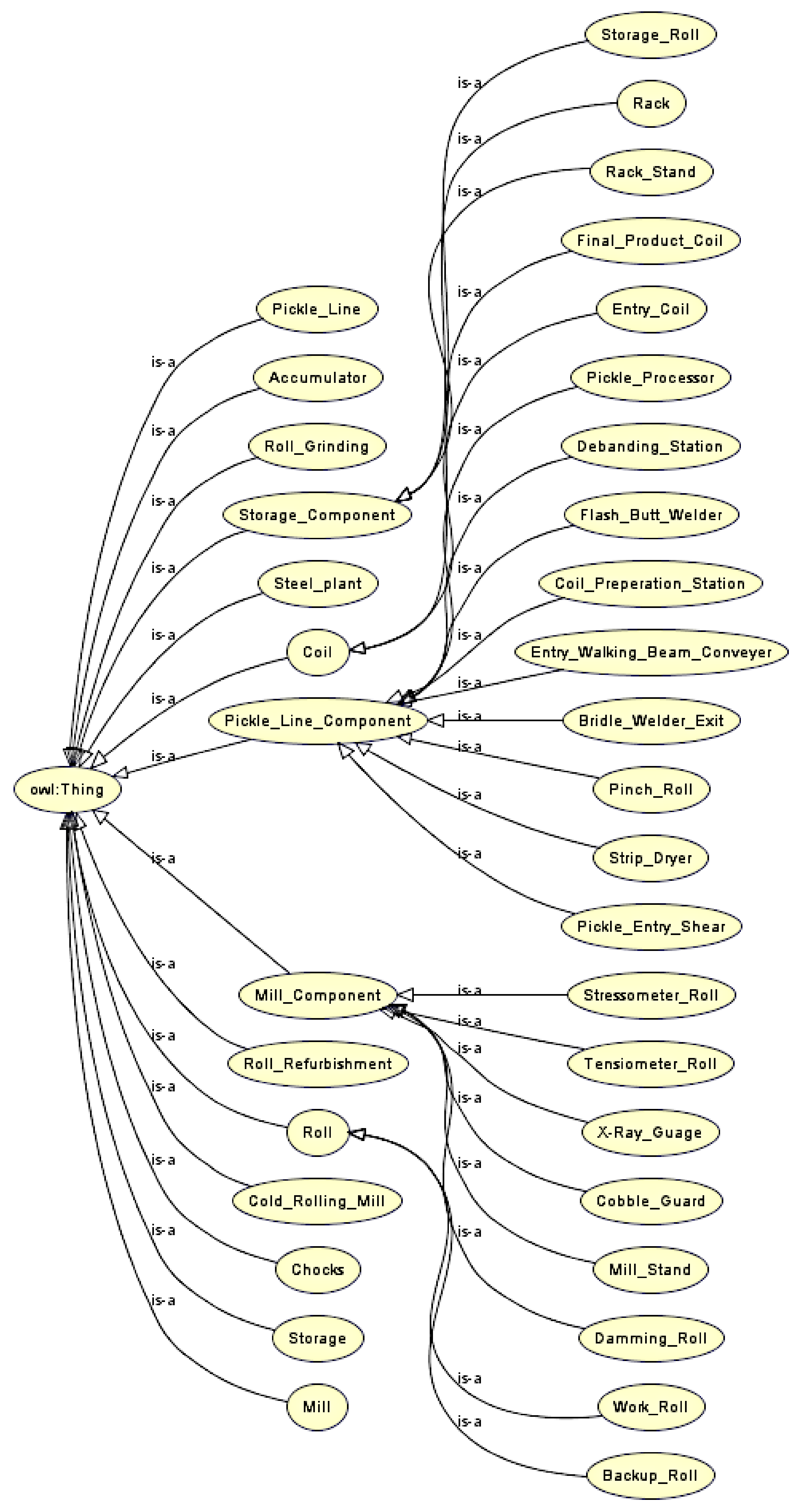
3.3. Classes
3.4. Object and Data Properties
- entersLineOn(object1, object2) where object1 is an Entry_Coil and object2 is an Entry_Walking_Beam.
- entersPickleOn(object1, object2) where object1 is an Entry_Coil and object2 is a Pickle_Entry_Shear.
- exitsPickleOn(object1, object2) where object1 is an Entry_Coil and object2 is a Bridle_Welder_Exit.
- hasComponent(object1, object2) where object1 and object2 are left undefined as this is the superclass for all hasComponents mentioned below.
- hasAccumaltorComponent(object1, object2) where object1 is a Cold_Rolling_Mill and object2 is an Accumulator.
- hasColdRollMillComponent(object1, object2) where object1 is a Steel_plant and object2 is a Cold_Rolling_Mill.
- hasMillComponent(object1, object2) where object1 is a Cold_Rolling_Mill and object2 is a Mill.
- hasMillStandComponent(object1, object2) where object1 is a Mill and object2 is a Mill_Stand.
- hasPickleComponent(object1, object2) where object1 is a Cold_Rolling_Mill and object2 is a Pickle_Line.
- hasRackComponent(object1, object2) where object1 is a Storage and object2 is a Rack.
- hasRackStandComponent(object1, object2) where object1 is a Rack and object2 is a Rack_Stand.
- hasStorageComponent(object1, object2) where object1 is a Steel_Plant and object2 is a Storage.
- hasGrinding(object1, object2) where object1 is a Roll and object2 is a Roll_Grinding.
- holds(object1, object2) where object1 is a Mill_Stand and object2 is a Storage_Roll.
- isAssigned(object1, object2) where object1 is a Roll and object2 are Chocks.
- The superclass isComponentOf which is the inverse of hasComponent , as well as all of its subclasses.
- isDebandedOn(object1, object2) where object1 is an Entry_Coil and object2 is a Debanding_station.
- isDriedBy(object1, object2) where object1 is a Entry_Coil and object2 is a Strip_Dryer.
- isFrstPinchedBy(object1, object2) where object1 is a Entry_Coil and object2 is a Pinch_Roll.
- isFlashWeldedBy(object1, object2) where object1 is an Entry_Coil and object2 is a Flash_Butt_Welder.
- isPreparedOn(object1, object2) where object1 is an Entry_Coil and object2 is aCoil_Preparation_Station.
- isProcessedBy(object1, object2) where object1 is an Entry_Coil and object2 is aPickle_Processor.
- MeasuresThicknessOfRollIn (object1, object2) where object1 is an X-Ray_Gauge and object2 is a Mill_Stand.
- stores(object1, object2) where object1 is a Rack_Stand and object2 is a Storage_Roll.
- hasDiameter(object, datatype) where object is Roll and datatype is xsd:double.
- hasGrindingDate(object, datatype) where object is Time instant and datatype is xsd:date.
- hasGrindRoll(object, datatype) where object is Roll_Grinding and datatype is xsd:integer.
- hasInitDiameter(object, datatype) where object is Roll and datatype is xsd:double.
- hasPartner(object, datatype) where object is Roll and datatype is xsd:integer.
- hasPosition(object, datatype) where object is Roll and datatype is xsd:string.
- hasRackID(object, datatype) where object is Rack and datatype is xsd:integer.
- hasStackStandID(object, datatype) where object is Rack_Stand and datatype is xsd:integer.
- hasRollDescription(object, datatype) where object is Storage_Roll and datatype is xsd:String.
- hasRollID(object, datatype) where object is Roll and datatype is xsd:integer.
- hasSteelPlantLocation(object, datatype) where object is Steel_Plant and datatype is xsd:String.
- hasSteelPlantName(object, datatype) where object is Steel_Plant and datatype is xsd:String.
- isAssignedToStand(object, datatype) where object is Roll and datatype is xsd:integer.
- isWorkOrBack(object, datatype) where object is Roll and datatype is xsd:string.
- lastLocatedDate(object, datatype) where object is Time instant and datatype is xsd:dateTime.
- minDiameter(object, datatype) where object is Roll and datatype is xsd:double.
4. Application
4.1. Data Set
4.2. Ontop Framework
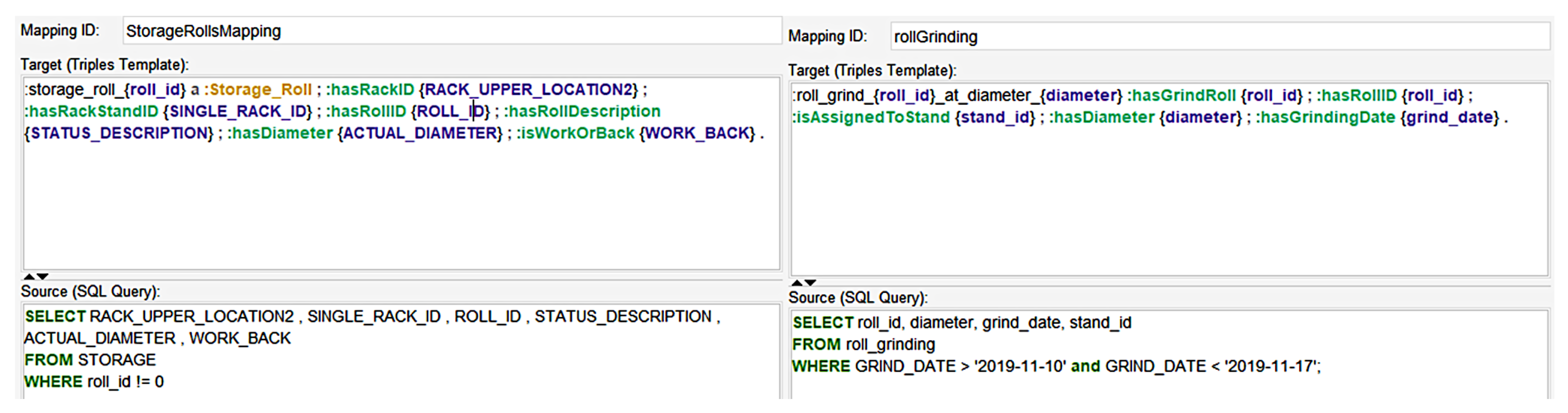
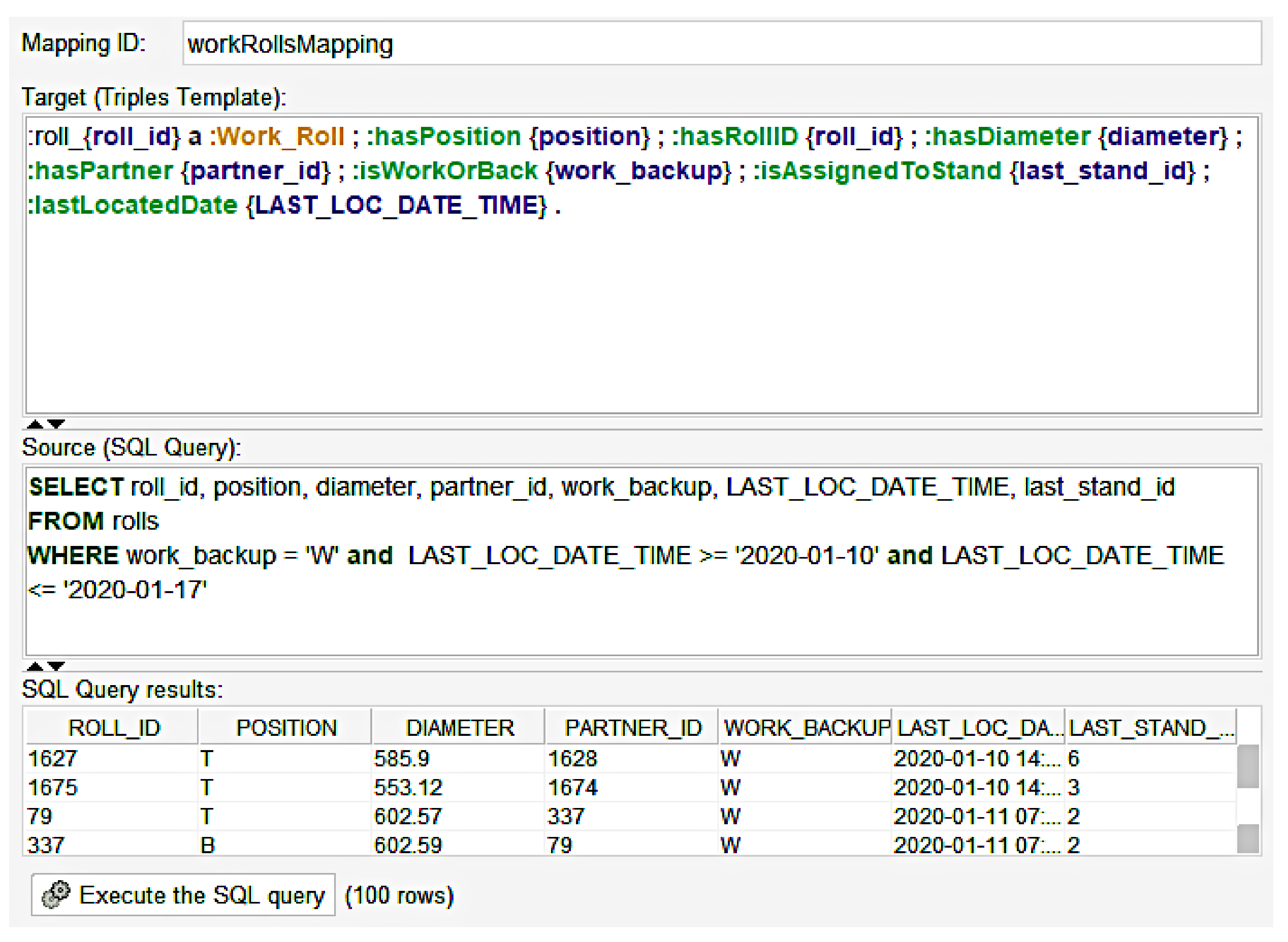
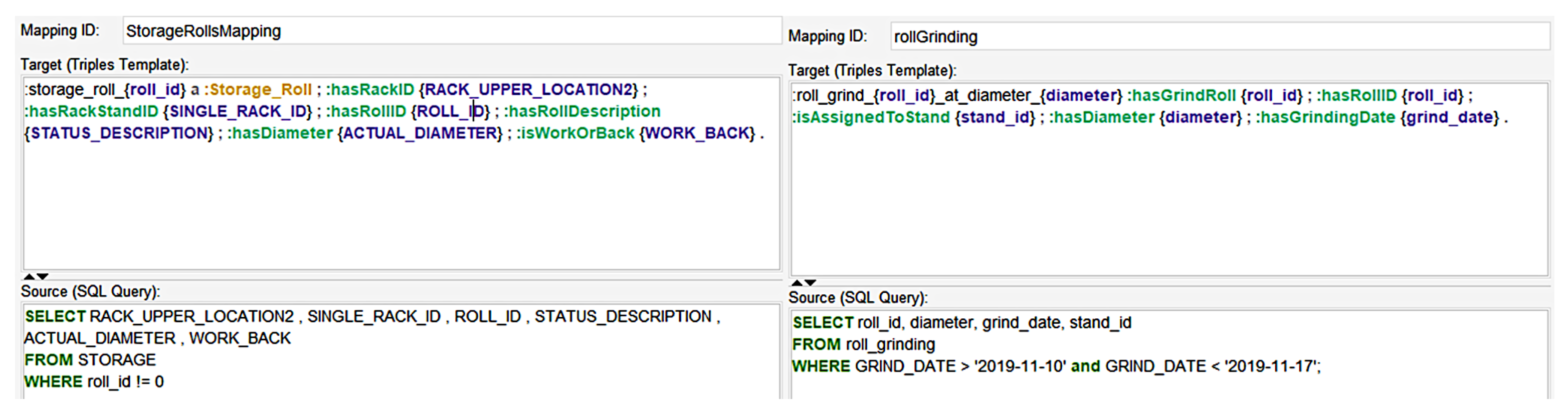
4.3. Mappings
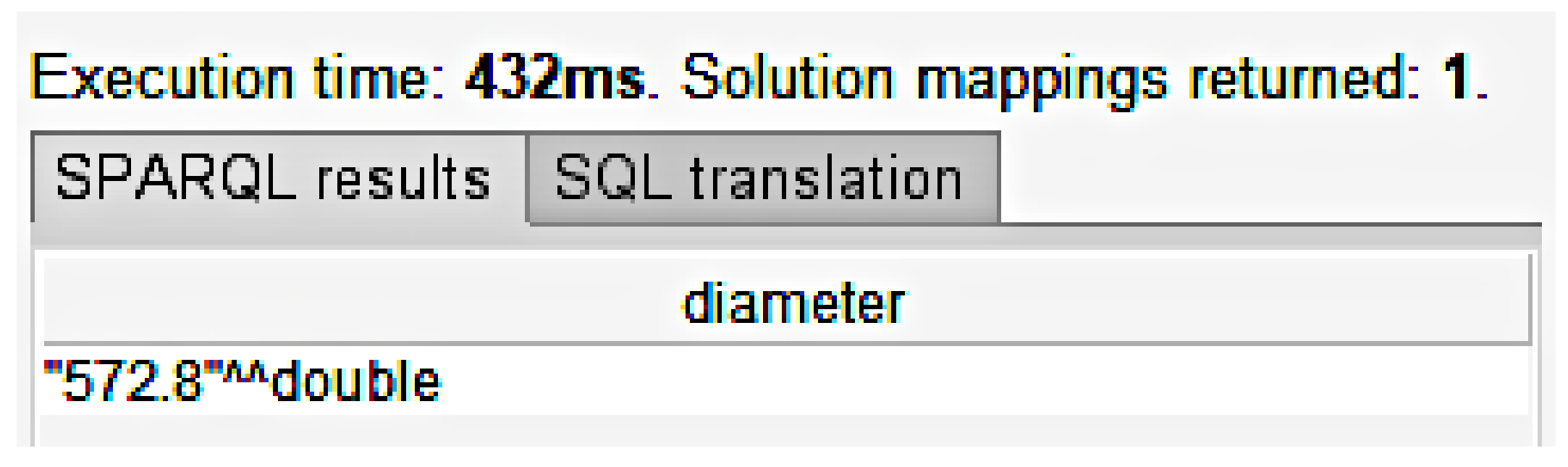
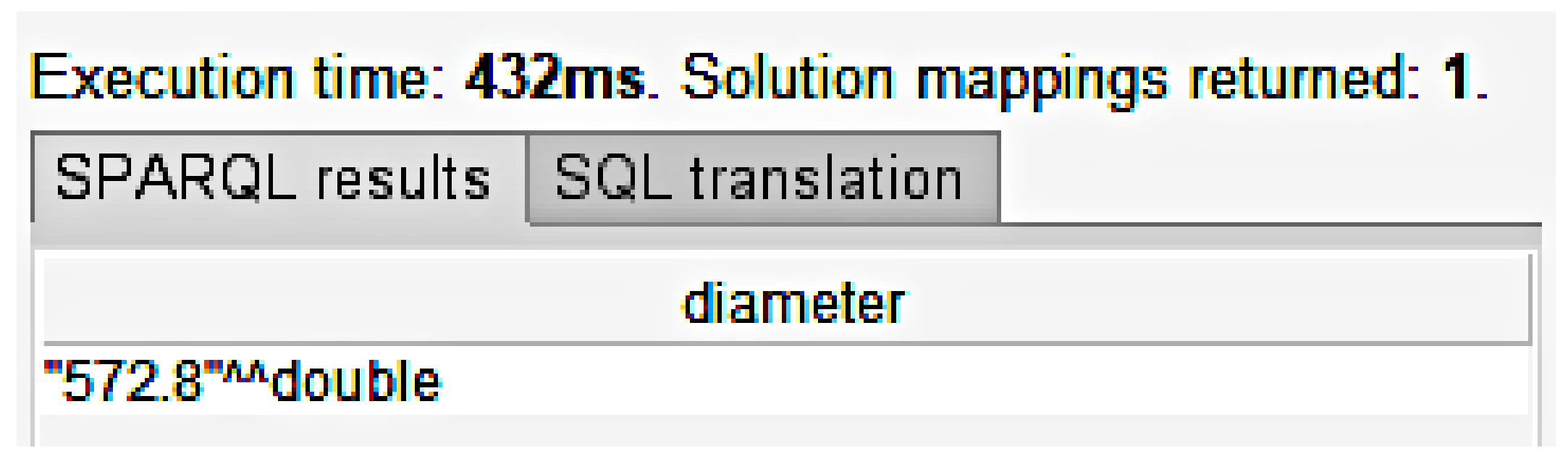
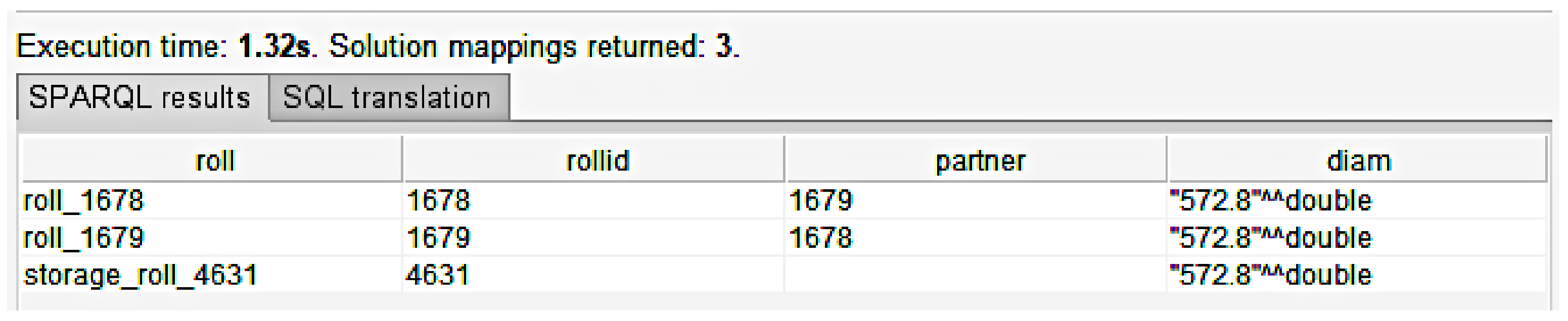
4.4. SPARQL
| Listing 1. Diameter values which appear for more than two rolls. |
 |
| Listing 2. All rolls that have a diameter of 572.8. |
 |
5. Ontology Validation
5.1. Ontology Pitfall Scanner
5.2. Expert Knowledge Validation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Horvath, D.; Szabo, R. Driving forces and barriers of Industry 4.0: Do multinational and small and medium-sized companies have equal opportunities? Technol. Forecast. Soc. Chang. 2019, 146, 119–132. [Google Scholar] [CrossRef]
- Xiao, G.; Ding, L.; Cogrel, B.; Calvanese, D. Virtual Knowledge Graphs: An Overview of Systems and Use Cases. Data Intell. 2019, 1, 201–223. [Google Scholar] [CrossRef]
- Peters, H. How Could Industry 4.0 Transform the Steel Industry; Future Steel Forum: Prague, Czech Republic, 2017. [Google Scholar]
- Miśkiewicz, R.; Wolniak, R. Practical Application of the Industry 4.0 Concept in a Steel Company. Sustainability 2020, 12, 5776. [Google Scholar]
- Naujok, N.; Stamm, H. Industry 4.0 in Steel: Status, Strategy, Roadmap and Capabilities; Future Steel Forum: Prague, Czech Republic, 2017. [Google Scholar]
- Noy, N.F.; McGuinness, D.L. Ontology Development 101: A Guide to Creating Your First Ontology; Technical Report; Knowledge Systems Laboratory Stanford University: Stanford, CA, USA, 2001. [Google Scholar]
- Cao, Q.; Zanni-Merk, C.; Reich, C. Ontologies for manufacturing process modeling: A survey. In International Conference on Sustainable Design and Manufacturing; Springer: Berlin/Heidelberg, Germany, 2018; pp. 61–70. [Google Scholar]
- Roberts, W.L. Cold Rolling of Steel; Routledge: London, UK, 1978. [Google Scholar]
- Schroeder, D.K.H. A Basic Understanding of the Mechanics of Rolling Mill Rolls. 2003. Available online: http://docshare04.docshare.tips/files/15568/155680328.pdf (accessed on 26 July 2021).
- Ray, A.; Mishra, K.; Das, G.; Chaudhary, P. Life of rolls in a cold rolling mill in a steel plant-operation versus manufacture. Eng. Fail. Anal. 2000, 7, 55–67. [Google Scholar] [CrossRef]
- Zezulka, F.; Marcon, P.; Vesely, I.; Sajdl, O. Industry 4.0—An Introduction in the phenomenon. IFAC-PapersOnLine 2016, 49, 8–12. [Google Scholar] [CrossRef]
- Beden, S.; Cao, Q.; Beckmann, A. Semantic Asset Administration Shells in Industry 4.0: A Survey. In Proceedings of the 2021 4th IEEE International Conference on Industrial Cyber-Physical Systems (ICPS), Victoria, BC, Canada, 10–13 May 2021; pp. 31–38. [Google Scholar] [CrossRef]
- Vegetti, M.; Henning, G.P.; Leone, H.P. Product ontology: Definition of an ontology for the complex product modelling domain. In Proceedings of the Mercosur Congress on Process Systems Engineering, Rio de Janeiro, Brazil, 14–18 August 2005. [Google Scholar]
- Panetto, H.; Dassisti, M.; Tursi, A. ONTO-PDM: Product-driven ONTOlogy for Product Data Management interoperability within manufacturing process environment. Adv. Eng. Inform. 2012, 26, 334–348. [Google Scholar]
- Lemaignan, S.; Siadat, A.; Dantan, J.Y.; Semenenko, A. MASON: A proposal for an ontology of manufacturing domain. In Proceedings of the IEEE Workshop on Distributed Intelligent Systems: Collective Intelligence and Its Applications (DIS’06), Prague, Czech Republic, 15–16 June 2006; IEEE: Piscataway, NY, USA, 2006; pp. 195–200. [Google Scholar]
- Borgo, S.; Leitão, P. Foundations for a core ontology of manufacturing. In Ontologies; Springer: Berlin/Heidelberg, Germany, 2007; pp. 751–775. [Google Scholar]
- Grüninger, M. Using the PSL ontology. In Handbook on Ontologies; Springer: Berlin/Heidelberg, Germany, 2009; pp. 423–443. [Google Scholar]
- Cao, Q.; Giustozzi, F.; Zanni-Merk, C.; de Bertrand de Beuvron, F.; Reich, C. Smart condition monitoring for industry 4.0 manufacturing processes: An ontology-based approach. Cybern. Syst. 2019, 50, 82–96. [Google Scholar] [CrossRef]
- Cao, Q.; Samet, A.; Zanni-Merk, C.; de Bertrand de Beuvron, F.; Reich, C. Combining chronicle mining and semantics for predictive maintenance in manufacturing processes. Semant. Web 2020, 11, 927–948. [Google Scholar]
- Bao, Q.; Wang, J.; Cheng, J. Research on ontology modeling of steel manufacturing process based on big data analysis. In Proceedings of the MATEC Web of Conferences, Amsterdam, The Netherlands, 23–25 March 2016; EDP Sciences: Ulis, France, 2016; Volume 45, p. 04005. [Google Scholar]
- Horrocks, I.; Patel-Schneider, P.F.; Boley, H.; Tabet, S.; Grosof, B.; Dean, M. SWRL: A semantic web rule language combining OWL and RuleML. W3C Memb. Submiss. 2004, 21, 1–31. [Google Scholar]
- Wang, X.; Wong, T.; Fan, Z.P. Ontology-based supply chain decision support for steel manufacturers in China. Expert Syst. Appl. 2013, 40, 7519–7533. [Google Scholar]
- Dobrev, M.; Gocheva, D.; Batchkova, I. An ontological approach for planning and scheduling in primary steel production. In Proceedings of the 2008 4th International IEEE Conference Intelligent Systems, Varna, Bulgaria, 6–8 September 2008; IEEE: Piscataway, NY, USA, 2008; Volume 1, pp. 6–14. [Google Scholar]
- Ugwu, O.; Anumba, C.J.; Thorpe, A.; Arciszewski, T. Building knowledge level ontology for the collaborative design of steel frame structures. In Advances in Intelligent Computing in Engineering—Proceedings of the 9th International Workshop of the European Group of Intelligent Computing in Engineering (EG-ICE), Darmstadt, Germany, 1–3 August 2002; Technische Universitat Darmstadt: Darmstadt, Germany, 2002; pp. 1–3. [Google Scholar]
- Jones, D.M.; Bench-Capon, T.J.M.; Visser, P.R.S. Methodologies for Ontology Development. 2007. Available online: https://cgi.csc.liv.ac.uk/~tbc/publications/itknows.pdf (accessed on 26 July 2021).
- Gangemi, A.; Presutti, V. Ontology Design Patterns; Springer: Berlin/Heidelberg, Germany, 2009; pp. 221–243. [Google Scholar] [CrossRef]
- Presutti, V.; Daga, E.; Gangemi, A.; Blomqvist, E. eXtreme design with content ontology design patterns. In Proceedings of the Workshop on Ontology Patterns, Washington, DC, USA, 25–29 October 2009; pp. 83–97. [Google Scholar]
- Beck, K.; Gamma, E. Extreme Programming Explained: Embrace Change; Apt Book Series; An Alan, R., Ed.; Addison-Wesley: Boston, MA, USA, 2000. [Google Scholar]
- Blomqvist, E.; Presutti, V.; Daga, E.; Gangemi, A. Experimenting with eXtreme Design. In Knowledge Engineering and Management by the Masses; Cimiano, P., Pinto, H.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 120–134. [Google Scholar]
- Musen, M.A. The protégé project: A look back and a look forward. AI Matters 2015, 1, 4–12. [Google Scholar] [CrossRef]
- Antoniou, G.; van Harmelen, F. Web Ontology Language: OWL; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar] [CrossRef] [Green Version]
- Hobbs, J.R.; Pan, F. Time ontology in OWL. W3C Work. Draft 2006, 27, 133. [Google Scholar]
- Xiao, G.; Lanti, D.; Kontchakov, R.; Komla-Ebri, S.; Güzel-Kalaycı, E.; Ding, L.; Corman, J.; Cogrel, B.; Calvanese, D.; Botoeva, E. The Virtual Knowledge Graph System Ontop. In The Semantic Web—ISWC 2020; Pan, J.Z., Tamma, V., d’Amato, C., Janowicz, K., Fu, B., Polleres, A., Seneviratne, O., Kagal, L., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 259–277. [Google Scholar]
- Calvanese, D.; Giacomo, G.D.; Lembo, D.; Lenzerini, M.; Poggi, A.; Rodriguez-Muro, M.; Rosati, R.; Ruzzi, M.; Savo, D.F. The MASTRO system for ontology-based data access. Semant. Web 2011, 2, 43–53. [Google Scholar]
- Priyatna, F.; Corcho, O.; Sequeda, J. Formalisation and Experiences of R2RML-Based SPARQL to SQL Query Translation Using Morph. In WWW’14, Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 479–490. [Google Scholar] [CrossRef]
- Calvanese, D.; Cogrel, B.; Komla-Ebri, S.; Kontchakov, R.; Lanti, D.; Rezk, M.; Rodriguez-Muro, M.; Xiao, G. Ontop: Answering SPARQL queries over relational databases. Semant. Web 2016, 8, 471–487. [Google Scholar] [CrossRef] [Green Version]
- Bagosi, T.; Calvanese, D.; Hardi, J.; Komla-Ebri, S.; Lanti, D.; Rezk, M.; Rodríguez-Muro, M.; Slusnys, M.; Xiao, G. The Ontop Framework for Ontology Based Data Access. In The Semantic Web and Web Science; Zhao, D., Du, J., Wang, H., Wang, P., Ji, D., Pan, J.Z., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 67–77. [Google Scholar]
- Rodríguez-Muro, M.; Rezk, M. Efficient SPARQL-to-SQL with R2RML mappings. J. Web Semant. 2015, 33, 141–169. [Google Scholar] [CrossRef]
- Sequeda, J.F.; Tirmizi, S.H.; Corcho, O.; Miranker, D.P. Review: Survey of Directly Mapping Sql Databases to the Semantic Web. Knowl. Eng. Rev. 2011, 26, 445–486. [Google Scholar] [CrossRef]
- Jiménez-Ruiz, E.; Kharlamov, E.; Zheleznyakov, D.; Horrocks, I.; Pinkel, C.; Skjæveland, M.G.; Thorstensen, E.; Mora, J. BootOX: Practical Mapping of RDBs to OWL 2. In The Semantic Web-ISWC 2015; Arenas, M., Corcho, O., Simperl, E., Strohmaier, M., d’Aquin, M., Srinivas, K., Groth, P., Dumontier, M., Heflin, J., Thirunarayan, K., Staab, S., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 113–132. [Google Scholar]
- Pinkel, C.; Binnig, C.; Jiménez-Ruiz, E.; May, W.; Ritze, D.; Skjæveland, M.; Solimando, A.; Kharlamov, E. RODI: A Benchmark for Automatic Mapping Generation in Relational-to-Ontology Data Integration. In European Semantic Web Conference; Springer: Cham, Switzerland, 2015; pp. 21–37. [Google Scholar] [CrossRef]
- Soylu, A.; Kharlamov, E.; Zheleznyakov, D.; Jimenez-Ruiz, E.; Giese, M.; Skjaeveland, M.G.; Hovland, D.; Schlatte, R.; Brandt, S.; Lie, H.; et al. OptiqueVQS: A visual query system over ontologies for industry. Semant. Web 2018, 9, 627–660. [Google Scholar] [CrossRef] [Green Version]
- Brank, J.; Mladenic, D.; Grobelnik, M. Gold standard based ontology evaluation using instance assignment. In Proceedings of the EON 2006 Workshop, Edinburgh, UK, 22 May 2006. [Google Scholar]
- Poveda-Villalón, M.; Gómez-Pérez, A.; Suárez-Figueroa, M.C. OOPS! (OntOlogy Pitfall Scanner!): An On-line Tool for Ontology Evaluation. Int. J. Semant. Web Inf. Syst. IJSWIS 2014, 10, 7–34. [Google Scholar]
- Gómez-Pérez, A. Ontology evaluation. In Handbook on Ontologies; Springer: Berlin/Heidelberg, Germany, 2004; pp. 251–273. [Google Scholar]
- Horridge, M.; Knublauch, H.; Rector, A.; Stevens, R.; Wroe, C. A Practical Guide to Building OWL Ontologies Using the Prot’eg’e-OWL Plugin and CO-ODE Tools; University of Manchester: Manchester, UK, 2004. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SCRO Classes | Description |
|---|---|
| Accumulator | Manage the speed of the rolling processes to ensure flow is continuous |
| Chocks | Attached to rolls. Chocks contain bearings that allow rolls to rotate |
| Coil | Superclass of the material and final product |
| Entry_Coil | Denotes the steel strip that enters the cold rolling mill |
| Final_Product_Coil | The final product sold to customers |
| Cold_Rolling_Mill | Denotes the shop floor of the cold rolling mill |
| Mill | Process of the cold rolling mill where thickness of the steel strip is reduced |
| Mill_Component | Superclass of all Mill components |
| Cobble_Guard | Component that reduces chance of producing cobbles |
| Damming_Roll | Component that restrains the outward flow of coolants |
| Mill_Stand | Stand that fits two work rolls and two backup rolls |
| Stressometer_Roll | Measures the flatness of the steel strip |
| Tensiometer_Roll | Measures the tension of the steel strip |
| X-Ray_Gauge | Measures the thickness of the steel strip |
| Pickle_Line | Process where the entry coil undergoes surface pickling |
| Pickle_Line_Component | Superclass of all Pickle components |
| Bridle_Welder_Exit | Mill exit equipment that the strip uses to exit the pickling process |
| Coil_Preparation_Station | Station where the entry coils are entered |
| Debanding_Station | Station where the entry coils are debanded |
| Entry_Walking_Beam_Conveyor | Conveyor where entry coils are first placed |
| Flash_Butt_Welder | Machine that presses together and welds the ends of the workpiece |
| Pickle_Entry_Shear | Machine that cuts rolls to desired size |
| Pickle_Processor | Processes the coil and minimizes the tendency for coils to break |
| Pinch_Roll | Machine that holds and moves the strip |
| Strip_Dryer | Removes excess water from the strip to prevent rusting |
| Roll | Superclass of the two types of rolls at a cold rolling mill |
| Backup_Roll | Larger roll that support a work roll during milling |
| Work_Roll | Smaller roll that rotates to reduce thickness of steel during milling |
| Roll_Grinding | Contains previous grinding data of rolls |
| Roll_Refurbishment | Process where rolls are sent to be refurbished |
| Steel_Plant | Denotes the whole steel plant |
| Storage | Section of the cold rolling mill where assets (e.g., unused rolls) are stored |
| Storage_Component | Superclass of the Storage components |
| Rack | Contains stands for rolls to be stored |
| Rack_Stand | Stores one storage roll |
| Storage_Roll | A roll that is not currently being used and is stored away |
| Table and Fields | Data Type | Description |
|---|---|---|
| Rolls | Table | Contains static data relevant to the rolls |
| Roll_ID | Integer | Unique identifier of the roll. Primary key |
| Diameter | Double | Stores the value of the diameter of the roll |
| Position | String | Top or Bottom to denote the position in mill |
| Partner_ID | Integer | Unique identifier of the roll’s partner |
| Work_Backup | String | Identifier to specify whether a roll is a work or backup roll |
| Last_Loc_Date_Time | Date | Timestamp of the date when the roll was last located |
| Last_Stand_ID | Integer | The last stand this roll was placed in |
| Roll_Grinding | Table | Table that stores the previous grindings of each roll |
| Roll_ID | Integer | Non-unique identifier to specify which roll |
| Diameter | Double | Stores the value of the diameter of the roll |
| Grind_date | Date | Timestamp of the date when that roll was ground |
| Stand_ID | Integer | The last stand this roll was placed in |
| Roll_Storage | Table | Table that stores the data of rolls that are currently not in use |
| Rack_Location | Integer | Non-unique identifier of the location of the racks |
| Single_Rack_ID | Integer | Unique identifier of the rack |
| Roll_ID | Integer | Unique identifier of the roll that is stored on a rack |
| Status_description | String | The status of the roll, i.e., if it is a new roll or damaged roll |
| Actual_Diameter | Double | Stores the value of the diameter of the roll |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Beden, S.; Cao, Q.; Beckmann, A. SCRO: A Domain Ontology for Describing Steel Cold Rolling Processes towards Industry 4.0. Information 2021, 12, 304. https://doi.org/10.3390/info12080304
Beden S, Cao Q, Beckmann A. SCRO: A Domain Ontology for Describing Steel Cold Rolling Processes towards Industry 4.0. Information. 2021; 12(8):304. https://doi.org/10.3390/info12080304
Chicago/Turabian StyleBeden, Sadeer, Qiushi Cao, and Arnold Beckmann. 2021. "SCRO: A Domain Ontology for Describing Steel Cold Rolling Processes towards Industry 4.0" Information 12, no. 8: 304. https://doi.org/10.3390/info12080304
APA StyleBeden, S., Cao, Q., & Beckmann, A. (2021). SCRO: A Domain Ontology for Describing Steel Cold Rolling Processes towards Industry 4.0. Information, 12(8), 304. https://doi.org/10.3390/info12080304