
Towards a Predictive Bio-Inspired Navigation Model



{kind=link}
{kind=link}
{kind=link}
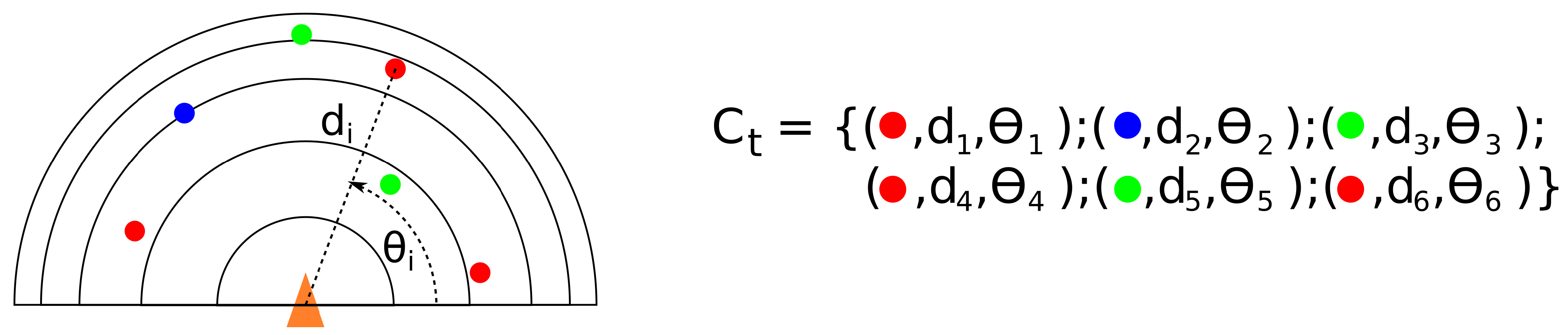{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- How can the graph model an infinite space with limited capacity?
- When should a new node be added to the graph? Conditions must be identified in order to define a distance (fixed or not) between nodes;
- How to control the navigation in a physical environment using the navigation graph? In other words, how to match the physical location to a graph node to obtain the direction and distance values necessary to reach the next node in the path?
- Knowing that the visual system of the majority of mammals do not have a field of view covering the , how to integrate newly discovered visual cues when moving through a previously visited node, with a different orientation?
2. State of the Art on Bio-Inspired Navigation Models
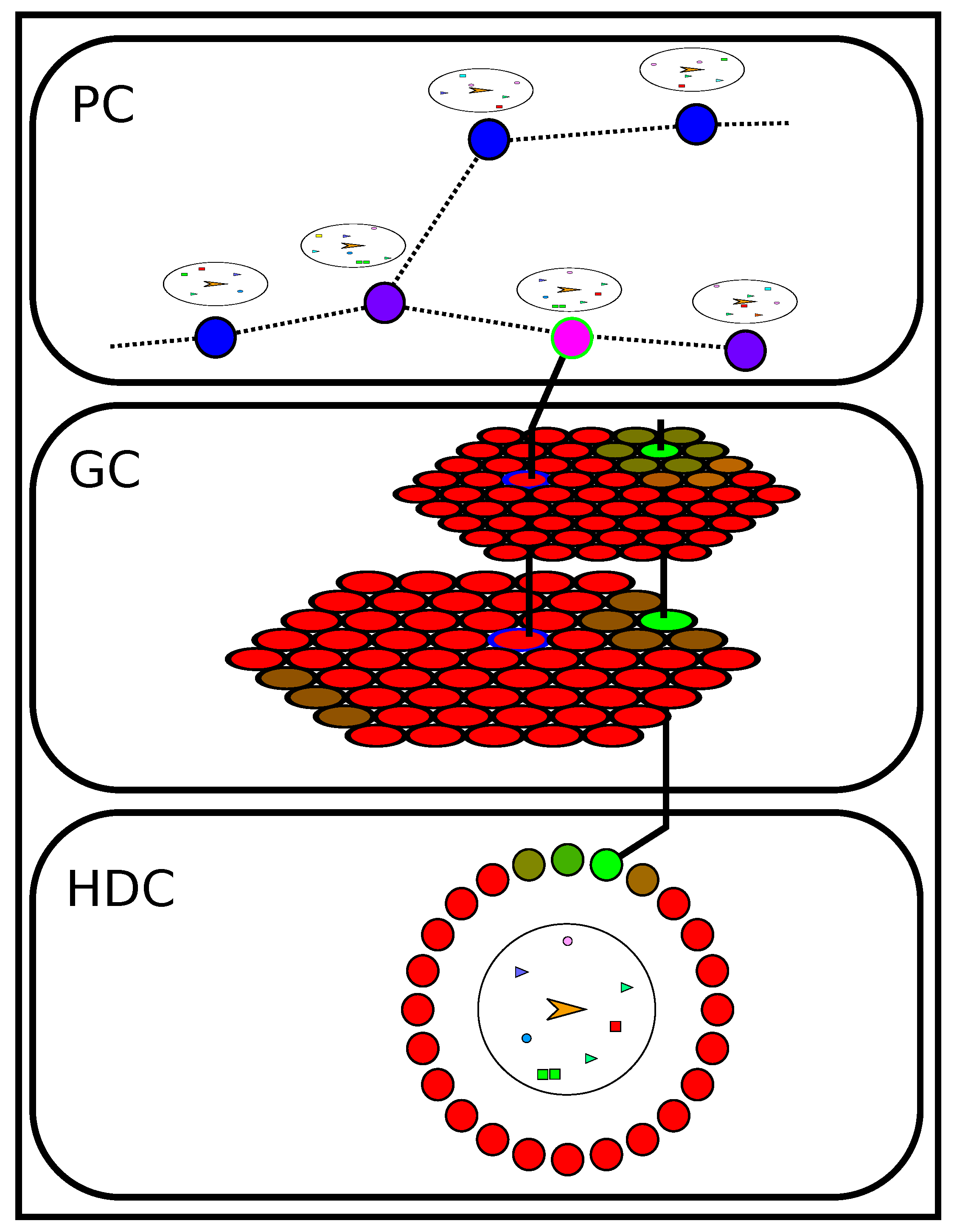
3. Predictive Bio-Inspired Model of Mobility: Overview
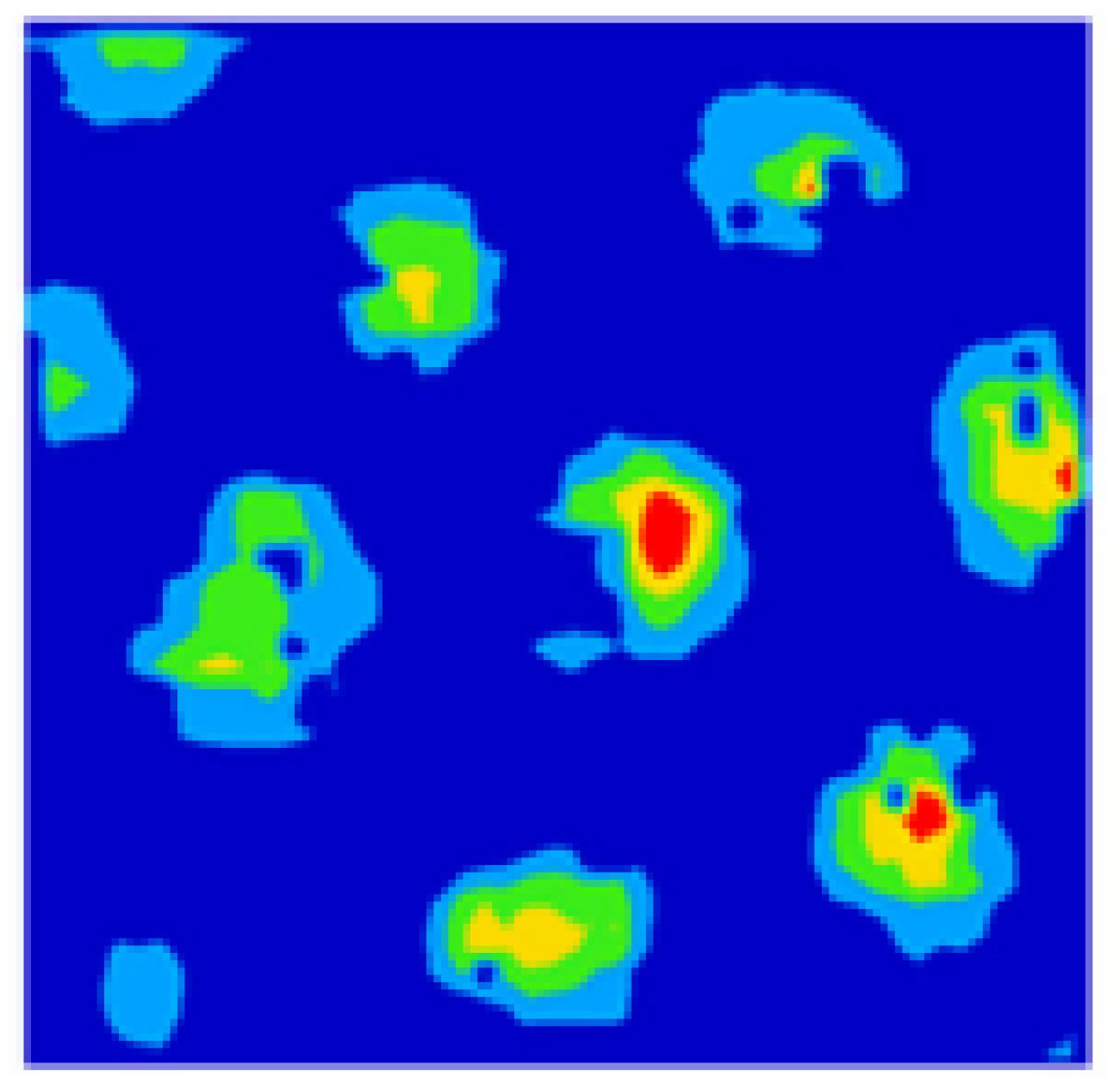
3.1. Grid Cells
3.2. Grid Cells Firing during the Navigation
3.3. Localization and Movement Prediction: A Cooperation between Place Cells, Grid Cells and Head Direction Cells
4. Predictive Model of Navigation: A Computational Approach
4.1. Environmental Context
- a movement m in space is strictly equivalent to the position p that it is allowed to reach;
- any position p in the surrounding space can be updated to through a movement m; this is expressed with .
4.2. Tracking Orientation: Head Direction Cells
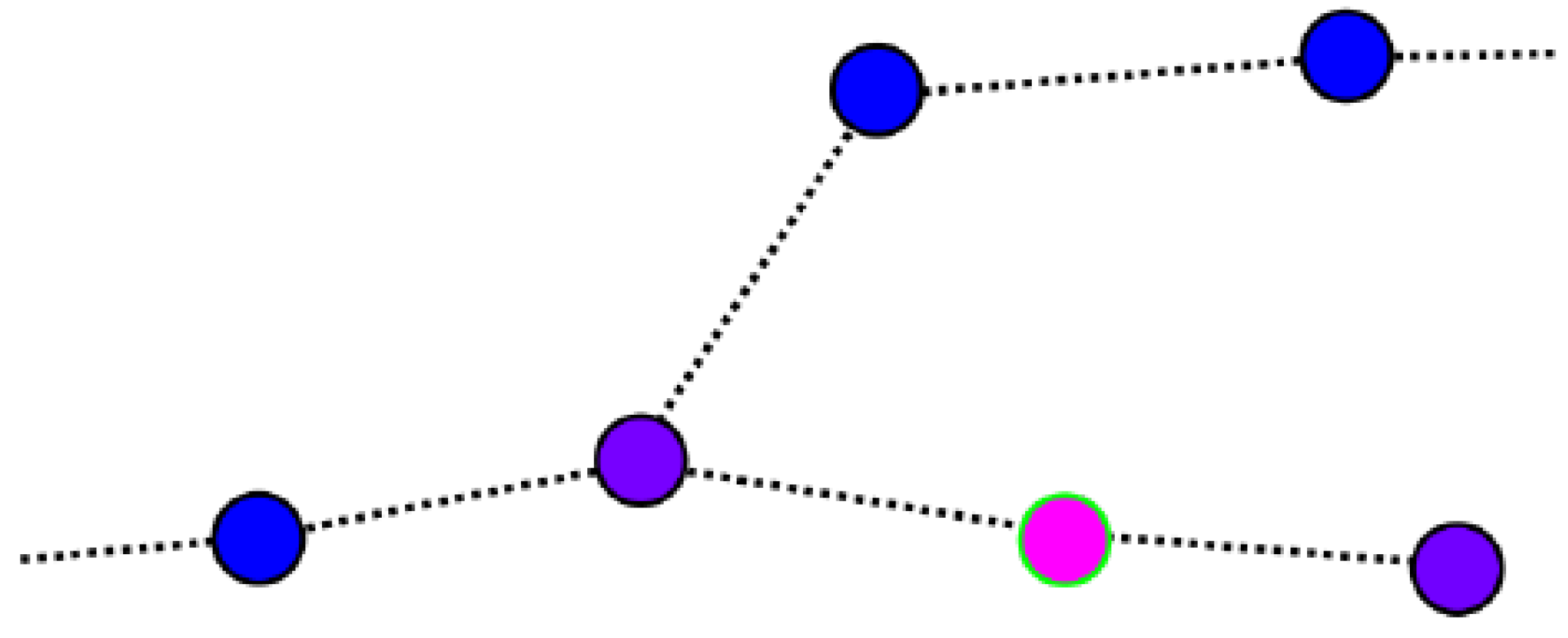
4.3. Recording and Recognizing Contexts: Place Cells
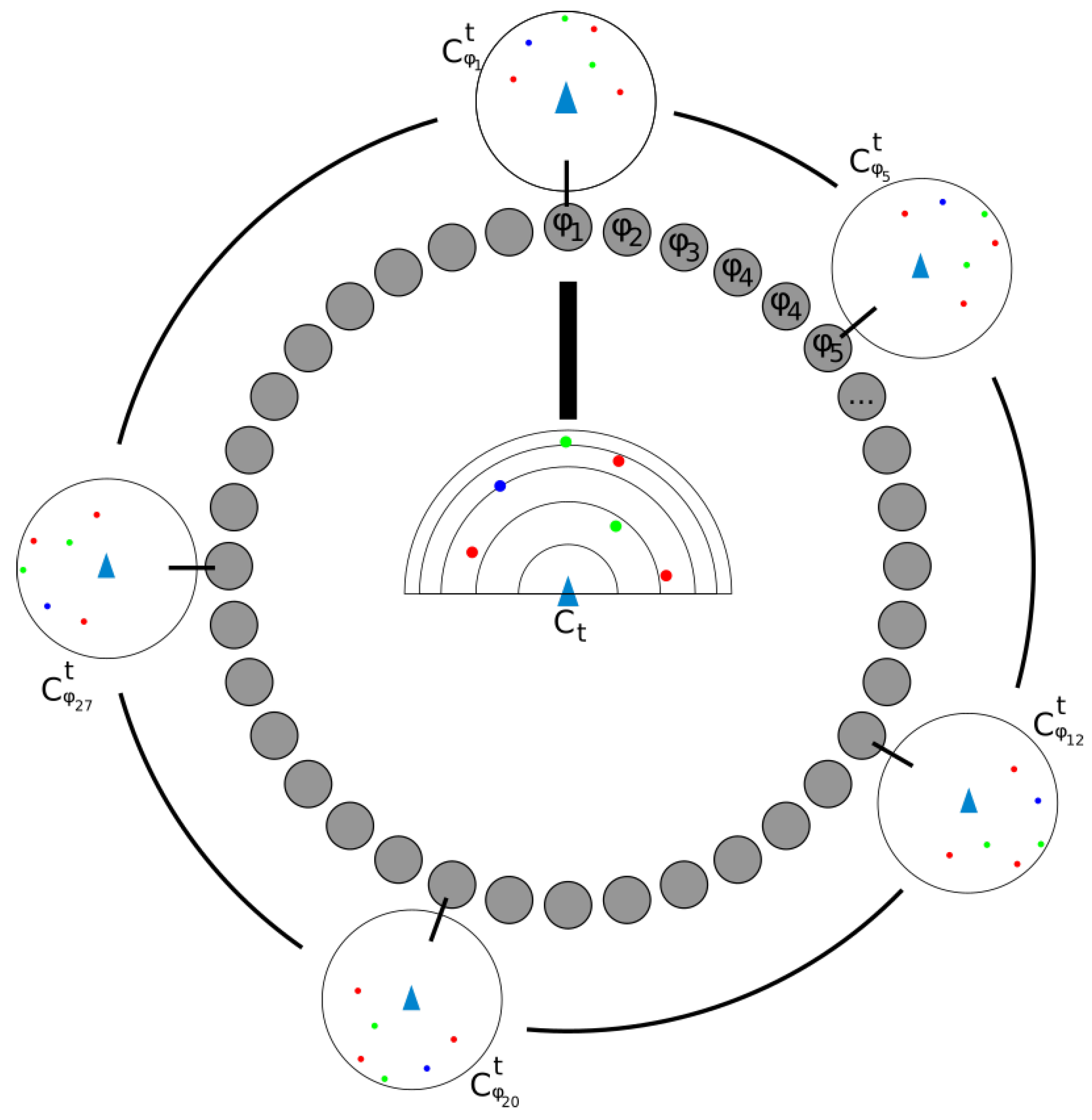
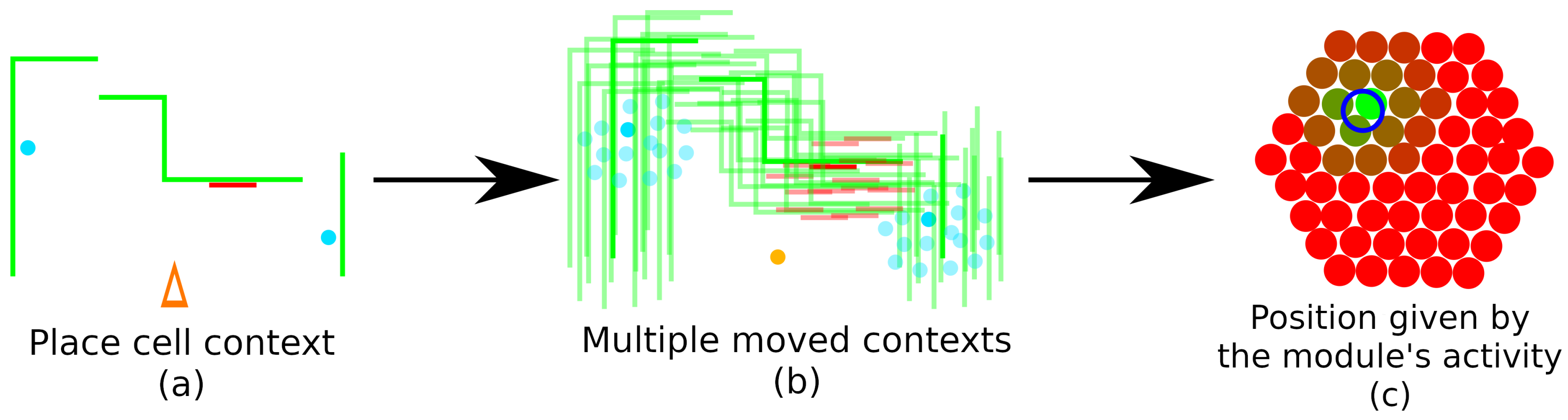
4.4. Localizing Around a Place Cell: Grid Cells
4.5. Adding New Place Cells to the Navigation Graph
4.6. Connecting Place Cells
4.7. Position Tracking in the Place Cell Graph
4.8. Using the Navigation Graph
- the next place cell and its associated grid cell to define the relative position between and ;
- the current most active grid cell to define the relative position of the agent.
- is the estimated orientation,
- the estimated position in the current place cell ,
- the shortest sequence of place cells between and .
4.9. Homing without Visual Context: Visual Odometry
4.10. Finding Shortcuts
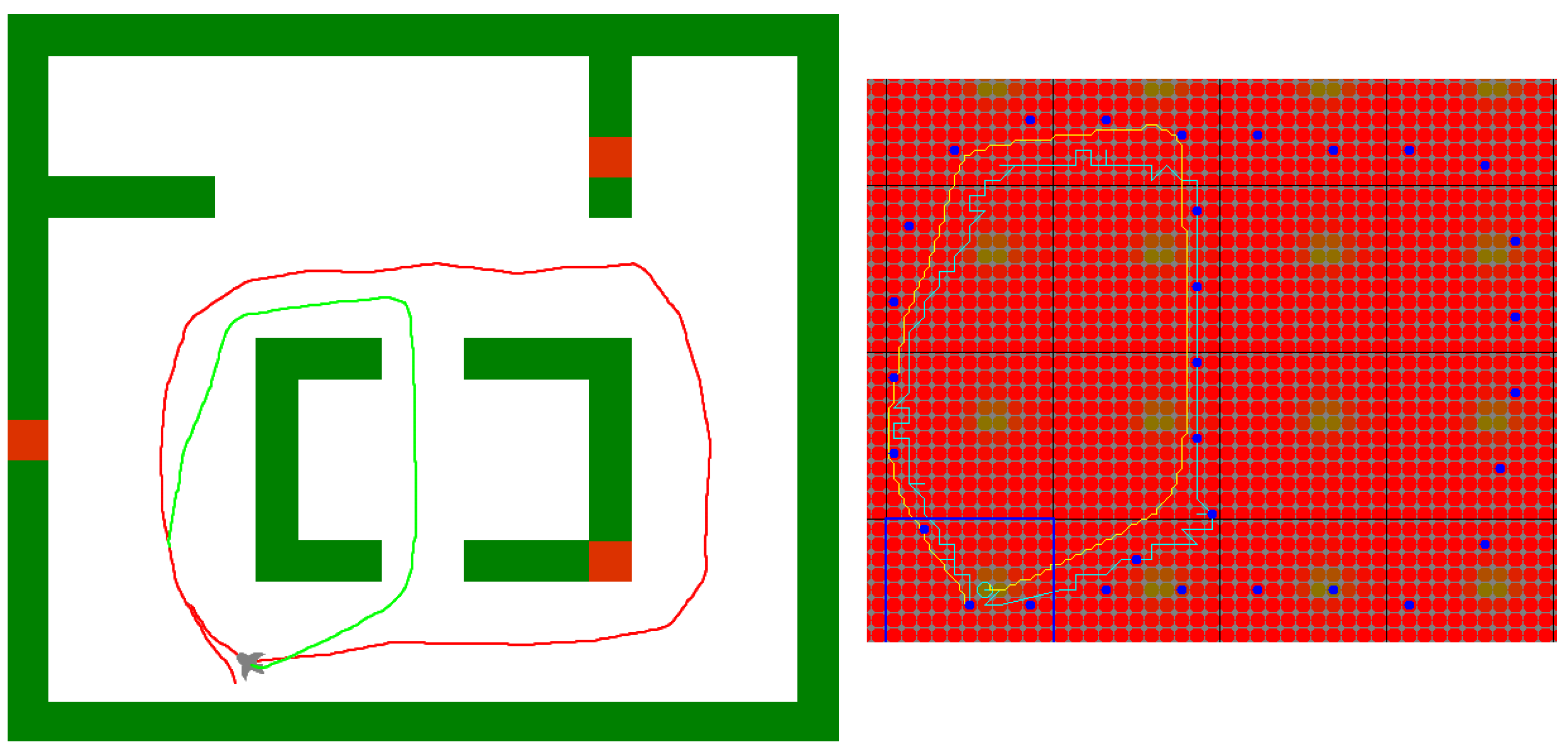
5. Experimental Evaluation
5.1. Experimental Setup
- d is the distance between elements.
- when , and otherwise.
- a decreasing positive function.
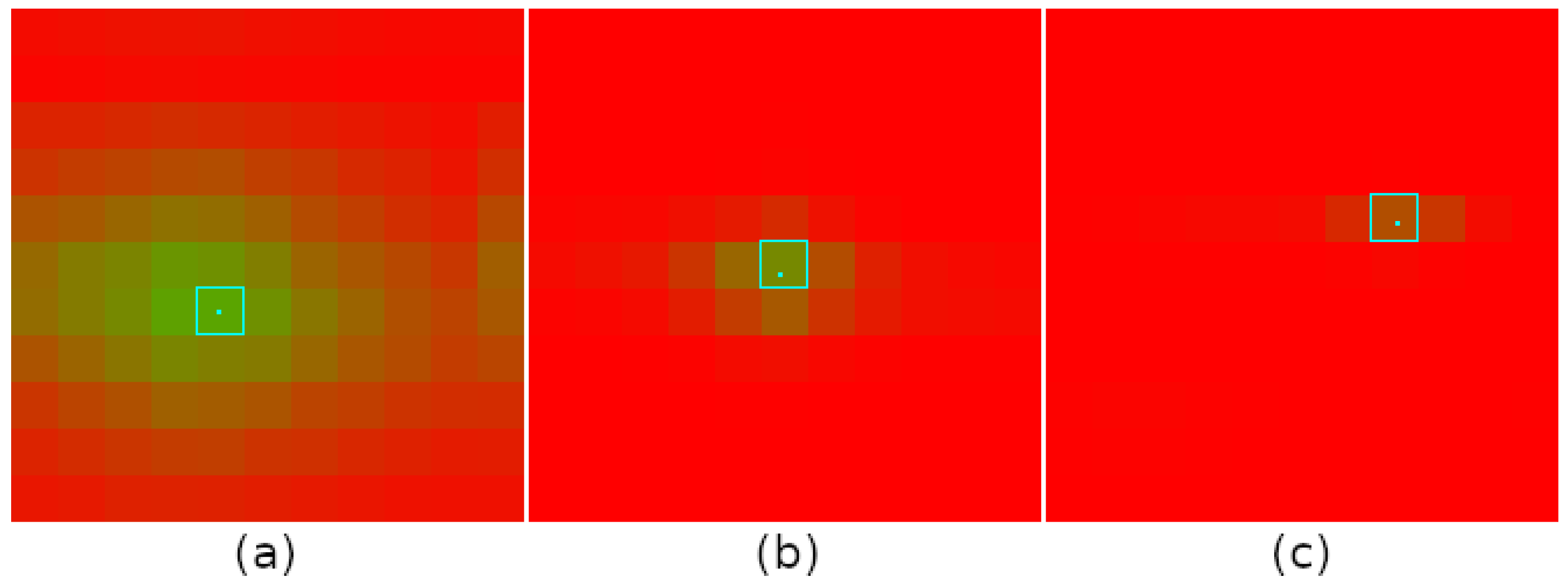
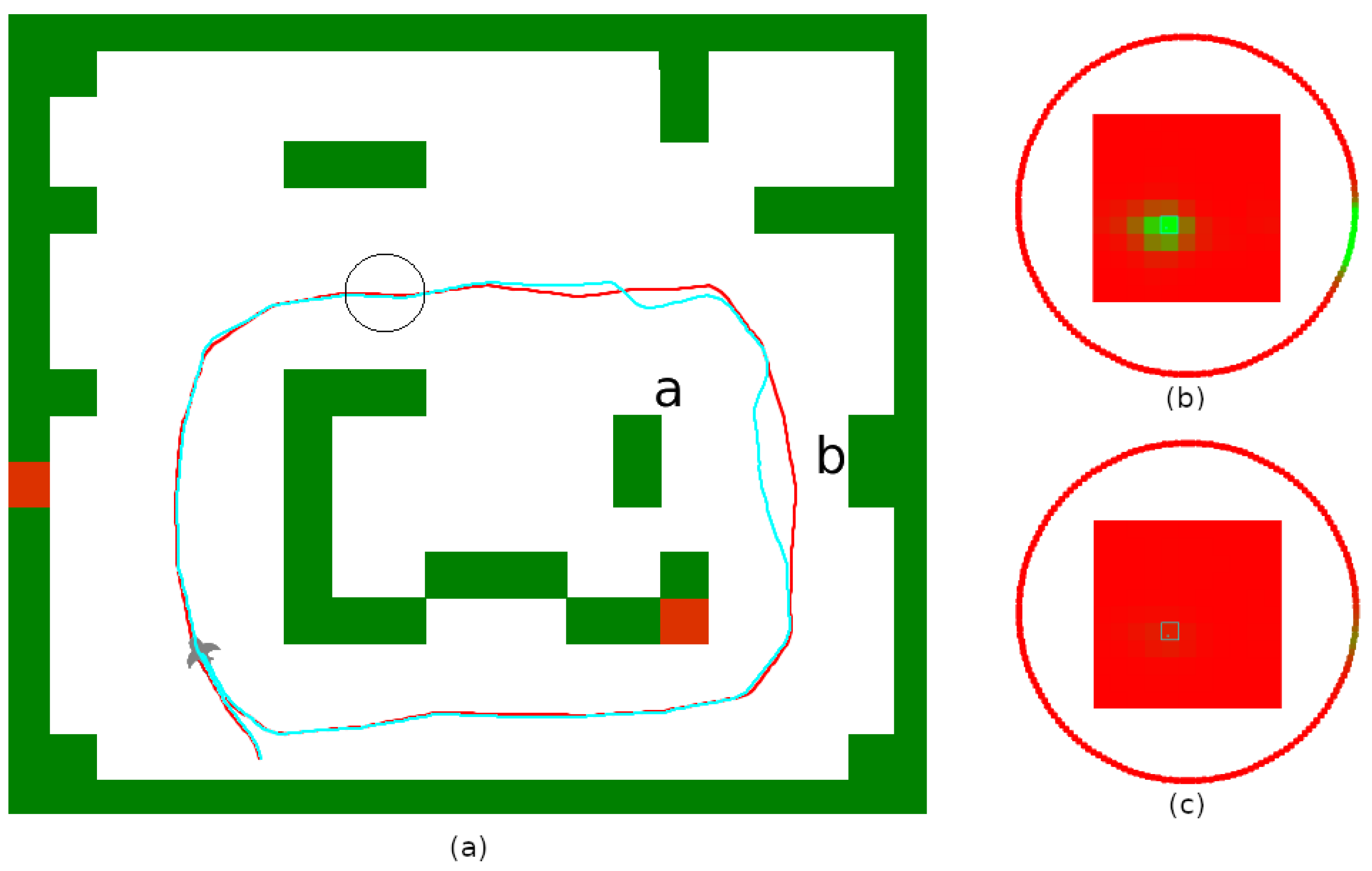
5.2. Effects of Grid Spacing
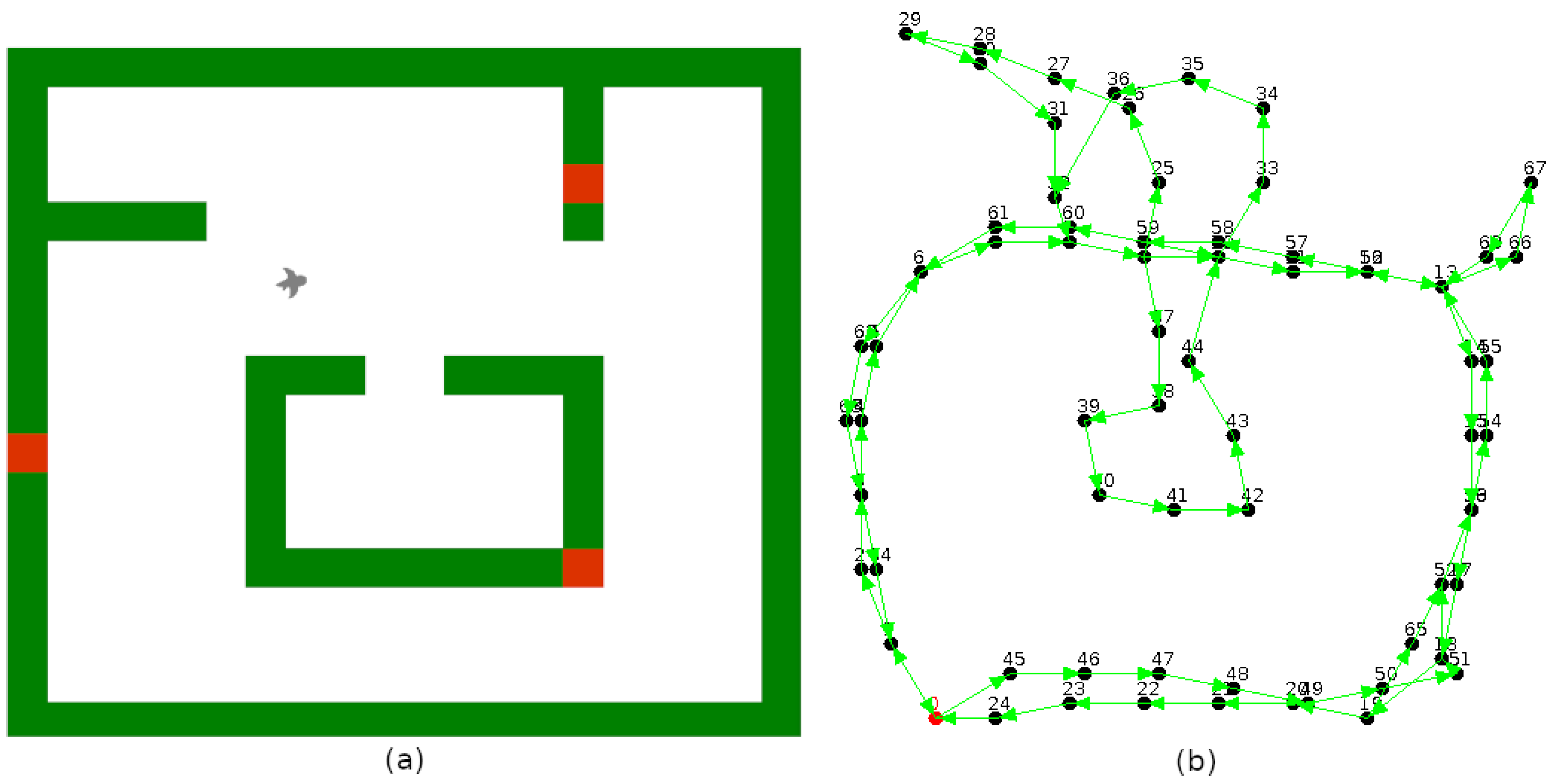
5.3. Navigation Graph Construction: Place Recognition
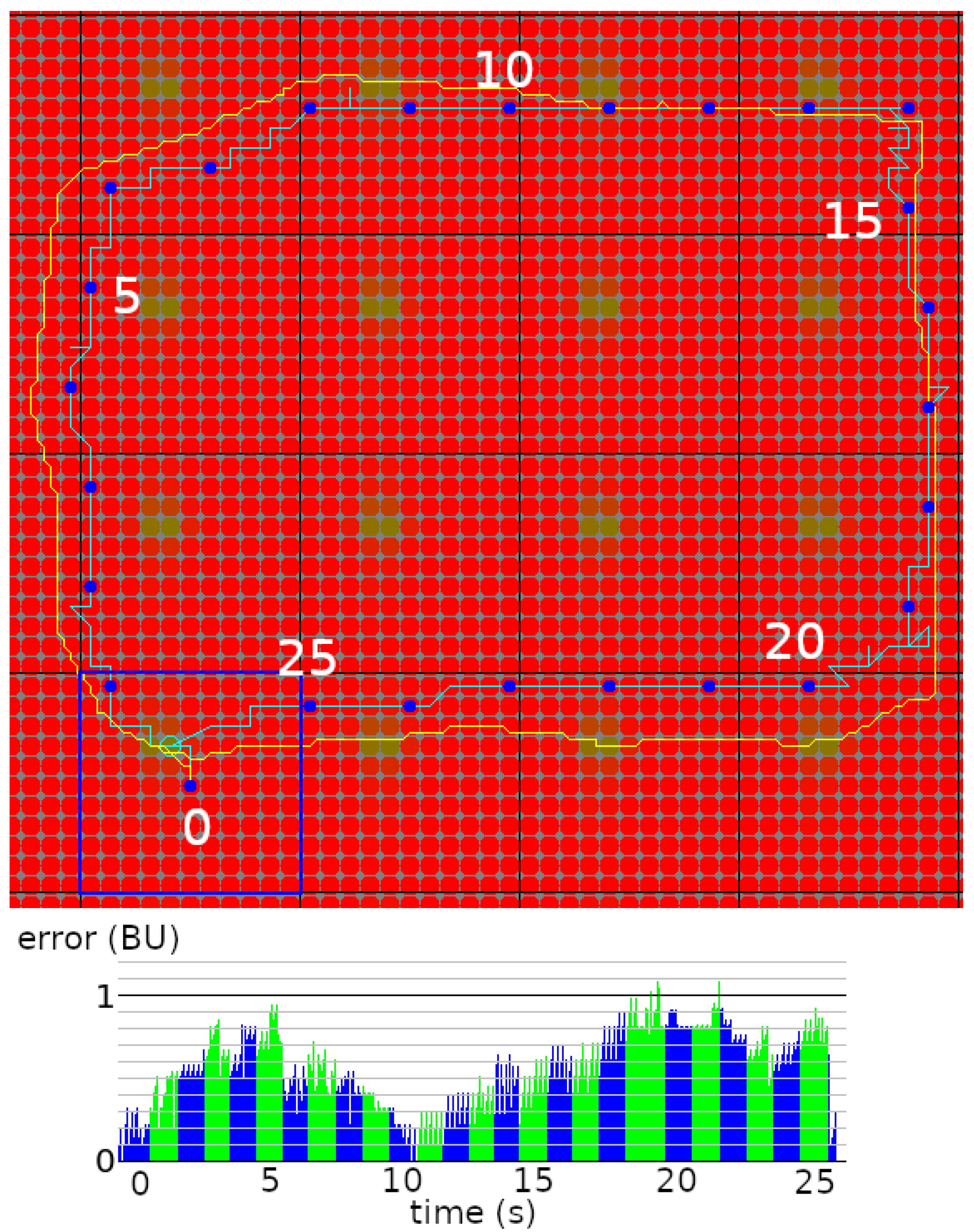
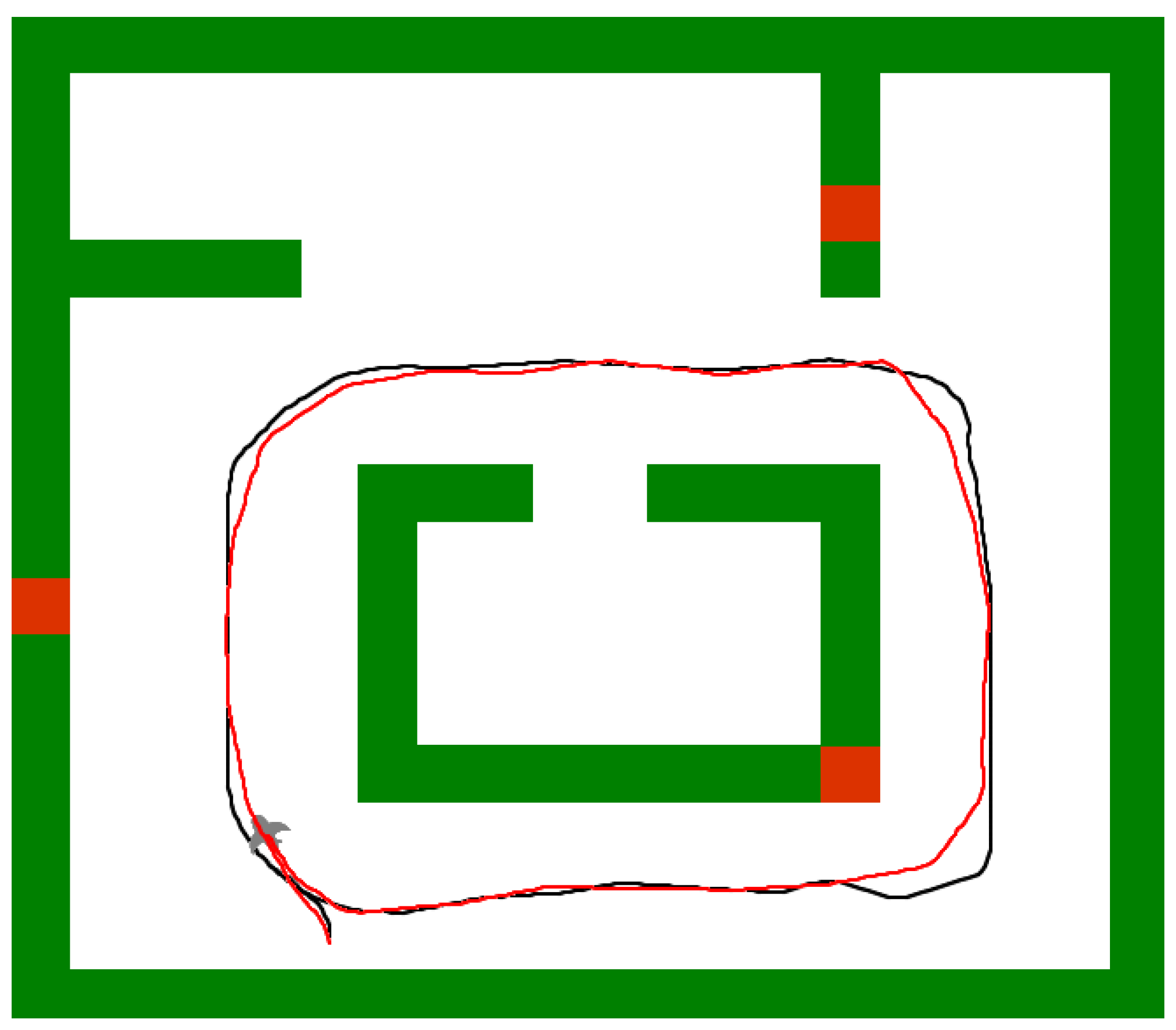
5.4. Usage of the Navigation Graph
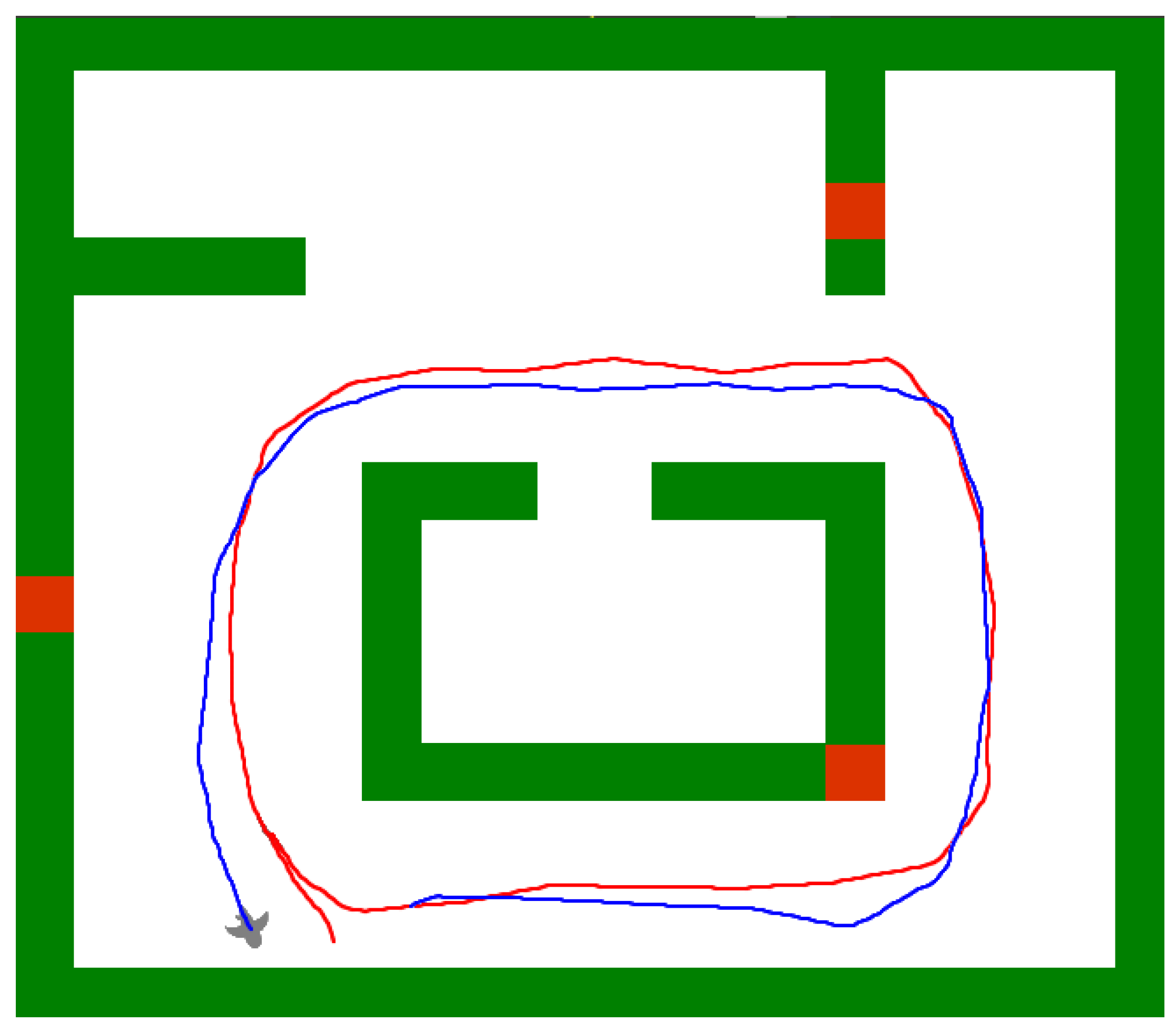
5.5. Robustness to Environmental Changes
5.6. Finding Shortcuts
6. Conclusions and Discussion
- using multiple sensory inputs. The use of inertial data (e.g., IMU) will increase the tracking reliability and enable navigation with few or no visual cues. Other sensory modalities, such as touch and audio, could help to complete a context.
- improving the place cell graph management, with mechanisms to split or merge place cells to avoid redundancies and correct observed errors (drift).
- using multiple grid cell modules with different orientations and spacings to increase the accuracy and reliability of localization. Following the approach proposed by Banino et al. [26] and Sparse Distributed Representations [27], associating a place cell with grid cells from different modules will help define a more unique position in space, as their combined activation will be sparser, which will increase the reliability of a place cell’s recognition.
- testing our model on physical devices. In a preliminary work, we successfully tested a grid cell module with a stereo camera. We intend to make our model applicable to robotic platforms, developmental agents, but also to assistive devices for people with visual impairments or spatial neglect. This last use case implies that our model can work with embedded cameras of limited field of view (we intend to use a stereo camera worn on the chest of the user), which can move in any direction, and cannot rely on absolute odometry (e.g., wheel encoders).
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- López, E.; García, S.; Barea, R.; Bergasa, L.; Molinos, E.; Arroyo, R.; Romera, E.; Pardo, S. A Multi-Sensorial Simultaneous Localization and Mapping (SLAM) System for Low-Cost Micro Aerial Vehicles in GPS-Denied Environments. Sensors 2017, 17, 802. [Google Scholar] [CrossRef] [PubMed]
- Stasse, O. SLAM and Vision-based Humanoid Navigation. In Humanoid Robotics: A Reference; HAL: Lyon, France, 2018; pp. 1739–1761. [Google Scholar] [CrossRef]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization And Mapping: Towards the Robust-Perception Age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- O’Keefe, J.; Nadel, L. The Hippocampus as a Cognitive Map; Clarendon Press: Oxford, UK, 1978. [Google Scholar]
- Taube, J.; Muller, R.; Ranck, J. Head-Direction Cells Recorded from the Postsubiculum in Freely Moving Rats. I. Description and Quantitative Analysis. J. Neurosci. 1990, 10, 420. [Google Scholar] [CrossRef] [PubMed]
- Rivière, M.A.; Gay, S.; Pissaloux, E. TactiBelt: Integrating Spatial Cognition and Mobility Theories into the Design of a Novel Orientation and Mobility Assistive Device for the Blind. In Computers Helping People with Special Needs; Lecture Notes in Computer Science; Miesenberger, K., Kouroupetroglou, G., Eds.; Springer: Berlin, Germany, 2018; Volume 10897, pp. 110–113. [Google Scholar] [CrossRef]
- Li, K.; Malhotra, P.A. Spatial neglect. Pract. Neurol. 2015, 15, 333–339. [Google Scholar] [CrossRef] [PubMed]
- Bainbridge, W.A.; Pounder, Z.; Eardley, A.F.; Baker, C.I. Quantifying Aphantasia through drawing: Those without visual imagery show deficits in object but not spatial memory. bioRxiv 2020. [Google Scholar] [CrossRef]
- Hafting, T.; Fyhn, M.; Molden, S.; Moser, M.B.; Moser, E.I. Microstructure of a spatial map in the entorhinal cortex. Nature 2005, 436, 801–806. [Google Scholar] [CrossRef] [PubMed]
- Gaussier, P.; Banquet, J.P.; Cuperlier, N.; Quoy, M.; Aubin, L.; Jacob, P.Y.; Sargolini, F.; Save, E.; Krichmar, J.L.; Poucet, B. Merging information in the entorhinal cortex: What can we learn from robotics experiments and modeling? J. Exp. Biol. 2019, 222, jeb186932. [Google Scholar] [CrossRef] [PubMed]
- Jauffret, A.; Cuperlier, N.; Gaussier, P. From grid cells and visual place cells to multimodal place cell: A new robotic architecture. Front. Neurorobotics 2015, 9. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Weber, C.; Wermter, S. A Self-organizing Method for Robot Navigation based on Learned Place and Head-Direction Cells. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Zhou, X.; Bai, T.; Gao, Y.; Han, Y. Vision-Based Robot Navigation through Combining Unsupervised Learning and Hierarchical Reinforcement Learning. Sensors 2019, 19, 1576. [Google Scholar] [CrossRef] [PubMed]
- Chen, Q.; Mo, H. A Brain-Inspired Goal-Oriented Robot Navigation System. Appl. Sci. 2019, 9, 4869. [Google Scholar] [CrossRef]
- Karaouzene, A.; Delarboulas, P.; Vidal, D.; Gaussier, P.; Quoy, M.; Ramesh, C. Social interaction for object recognition and tracking. In Proceedings of the IEEE ROMAN Workshop on Developmental and Bio-Inspired Approaches for Social Cognitive Robotics, Coimbra, Portugal, 18–22 March 2013. [Google Scholar]
- Milford, M.; Wyeth, G. Persistent Navigation and Mapping using a Biologically Inspired SLAM System. Int. J. Robot. Res. 2010, 29, 1131–1153. [Google Scholar] [CrossRef]
- Milford, M.J.; Wyeth, G.F. SeqSLAM: Visual route-based navigation for sunny summer days and stormy winter nights. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 1643–1649. [Google Scholar] [CrossRef]
- Tang, H.; Yan, R.; Tan, K.C. Cognitive Navigation by Neuro-Inspired Localization, Mapping, and Episodic Memory. IEEE Trans. Cogn. Dev. Syst. 2018, 10, 751–761. [Google Scholar] [CrossRef]
- O’Regan, J.K.; Noë, A. What it is like to see: A sensorimotor theory of perceptual experience. Synthese 2001, 129, 79–103. [Google Scholar] [CrossRef]
- Georgeon, O.L.; Aha, D. The Radical Interactionism Conceptual Commitment. J. Artif. Gen. Intell. 2013, 4, 31–36. [Google Scholar]
- Gay, S.L.; Mille, A.; Georgeon, O.L.; Dutech, A. Autonomous construction and exploitation of a spatial memory by a self-motivated agent. Cogn. Syst. Res. 2017, 41, 1–35. [Google Scholar] [CrossRef]
- Grieves, R.M.; Jeffery, K.J. The representation of space in the brain. Behav. Process. 2017, 135, 113–131. [Google Scholar] [CrossRef] [PubMed]
- Gay, S.L.; Mille, A.; Cordier, A. Autonomous affordance construction without planning for environment-agnostic agents. In Proceedings of the 2016 Joint IEEE International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob), Cergy-Pontoise, France, 19–22 September 2016; pp. 111–116. [Google Scholar] [CrossRef]
- Stensola, H.; Stensola, T.; Solstad, T.; Frøland, K.; Moser, M.B.; Moser, E.I. The entorhinal grid map is discretized. Nature 2012, 492, 72–78. [Google Scholar] [CrossRef]
- Wood, E.R.; Dudchenko, P.A.; Robitsek, R.; Eichenbaum, H. Hippocampal Neurons Encode Information about Different Types of Memory Episodes Occurring in the Same Location. Neuron 2000, 27, 623–633. [Google Scholar] [CrossRef]
- Banino, A.; Barry, C.; Uria, B.; Blundell, C.; Lillicrap, T.; Mirowski, P.; Pritzel, A.; Chadwick, M.J.; Degris, T.; Modayil, J.; et al. Vector-based navigation using grid-like representations in artificial agents. Nature 2018, 557, 429–433. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, S.; Hawkins, J. Properties of Sparse Distributed Representations and their Application to Hierarchical Temporal Memory. arXiv 2015, arXiv:1503.07469. [Google Scholar]















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gay, S.; Le Run, K.; Pissaloux, E.; Romeo, K.; Lecomte, C. Towards a Predictive Bio-Inspired Navigation Model. Information 2021, 12, 100. https://doi.org/10.3390/info12030100
Gay S, Le Run K, Pissaloux E, Romeo K, Lecomte C. Towards a Predictive Bio-Inspired Navigation Model. Information. 2021; 12(3):100. https://doi.org/10.3390/info12030100
Chicago/Turabian StyleGay, Simon, Kévin Le Run, Edwige Pissaloux, Katerine Romeo, and Christèle Lecomte. 2021. "Towards a Predictive Bio-Inspired Navigation Model" Information 12, no. 3: 100. https://doi.org/10.3390/info12030100
APA StyleGay, S., Le Run, K., Pissaloux, E., Romeo, K., & Lecomte, C. (2021). Towards a Predictive Bio-Inspired Navigation Model. Information, 12(3), 100. https://doi.org/10.3390/info12030100