A Reliable Weighting Scheme for the Aggregation of Crowd Intelligence to Detect Fake News


Abstract
1. Introduction
- To understand concepts around crowdsourcing, aggregation models and fake news;
- To design the crowd and the third-party elements;
- To propose a model of aggregation of a crowd and third-party intelligence;
- To experiment with the proposal on a system developed online.
2. Related Works
2.1. Detection of Fake News
2.2. Limitations
2.3. Contribution
3. Background
3.1. Crowdsourcing
3.2. Fake News
- Categorization based on intent: False information based on the author’s intention, can be misinformation and disinformation. Misinformation is the act of disseminating information without the intention of misleading users. These actors may then unintentionally distribute incorrect information to others via blogs, articles, comments, tweets, and so on. Readers may sometimes have different interpretations and perceptions of the same true information, resulting in differences on how they communicate their understanding and, in turn, inform others’ perception of the facts. Contrary to misinformation, disinformation is the act of disseminating information with the intention of misleading users. It is very similar to understanding the reasons for the deception. Depending on the intention of the information or the origin of the information, false information may be grouped into several different groups. Fake news can be divided into three categories: hoaxes, satire, and malicious content. A hoax consists of falsity information to resemble the truth information. These may include events such as rumors, urban legends, pseudo-sciences. They can also be practical jokes, April Fool’s joke, etc. According to Marsick et al. [46], the hoax is a type of deliberate construction or falsification in the mainstream or social media. Attempts to deceive audiences masquerade as news and may be picked up and mistakenly validated by traditional news outlets. Hoaxes range from good faith, such as jokes, to malicious and dangerous stories, such as pseudoscience and rumors. A satire is a type of information in which the information is ridiculed. For example, a public person ridiculed in good faith while some of its most prominent parts are the following ones taken out of context and made even more visible. Satire can, like hoaxes, be both good faith and humorous, but it can also be used in a malicious way to lower someone’s or something’s level. Finally, a malicious content is made with the intention of being destructive. This content is designed to destabilize situations, change public opinions, and use false information to spread a message with the aim of damaging institutions, persons, political opinions, or something similar. All the different types can be malicious if incorrect data is entered in the data element. The intention will be completely different.
- Categorization based on knowledge: According to Kumar et al. [45], knowledge-based misinformation is based on opinions or facts. The opinion-based false information describes cases where there is no absolute fundamental truth and expresses individual opinions. The author, who consciously or unconsciously creates false opinions, aims to influence the opinion or decision of readers. The fact-based false information involves information that contradicts, manufactures, or confuses unique value field truth information. The reason for this type of information is to make it more difficult for the reader to distinguish truth from false information and to make him believe in the false version of the information. This type of misinformation includes fake news, rumors, and fabricated hoaxes.
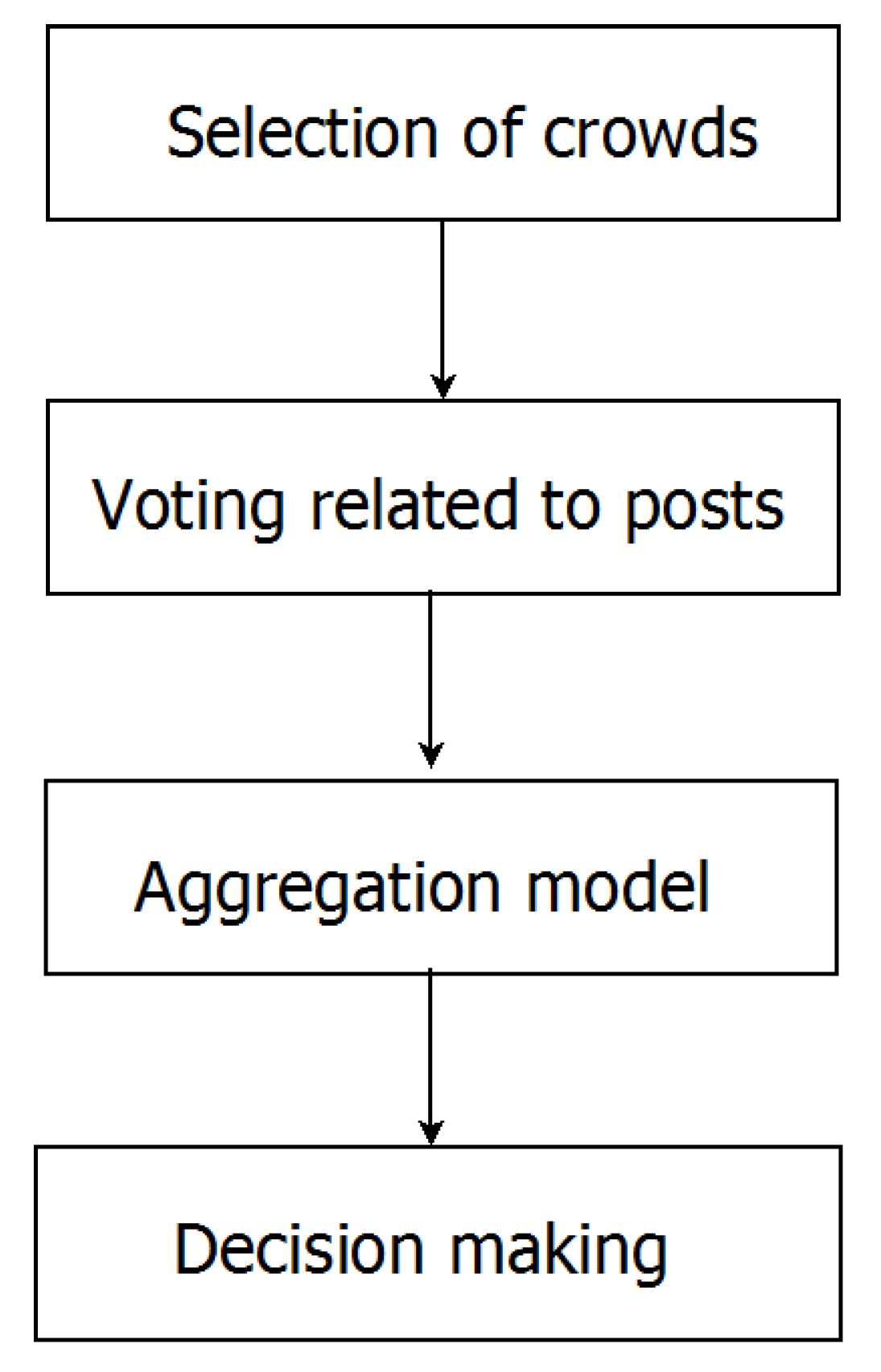
4. Aggregation Model
4.1. Research Methodology
4.2. Selection of Crowd
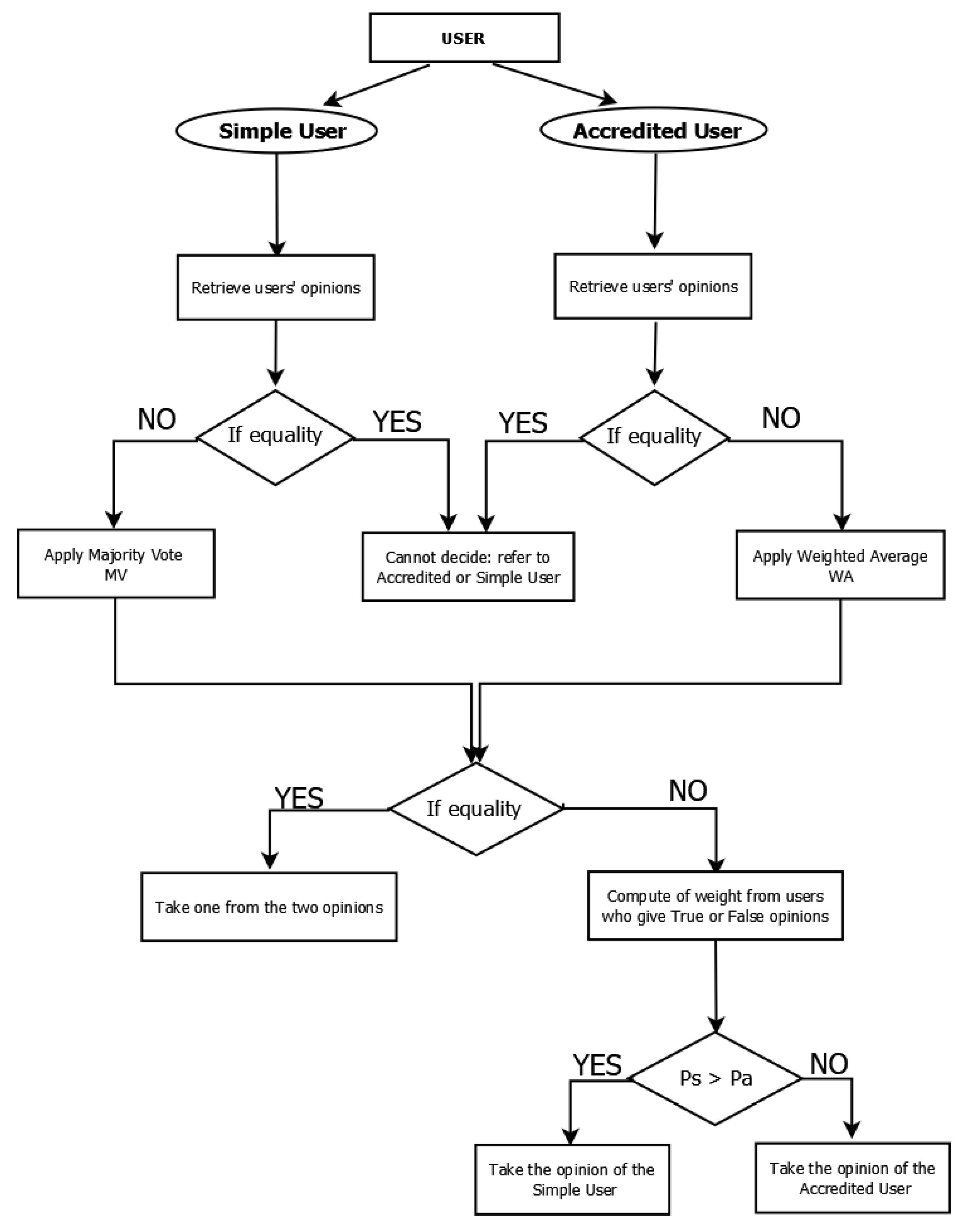
4.2.1. Simple User
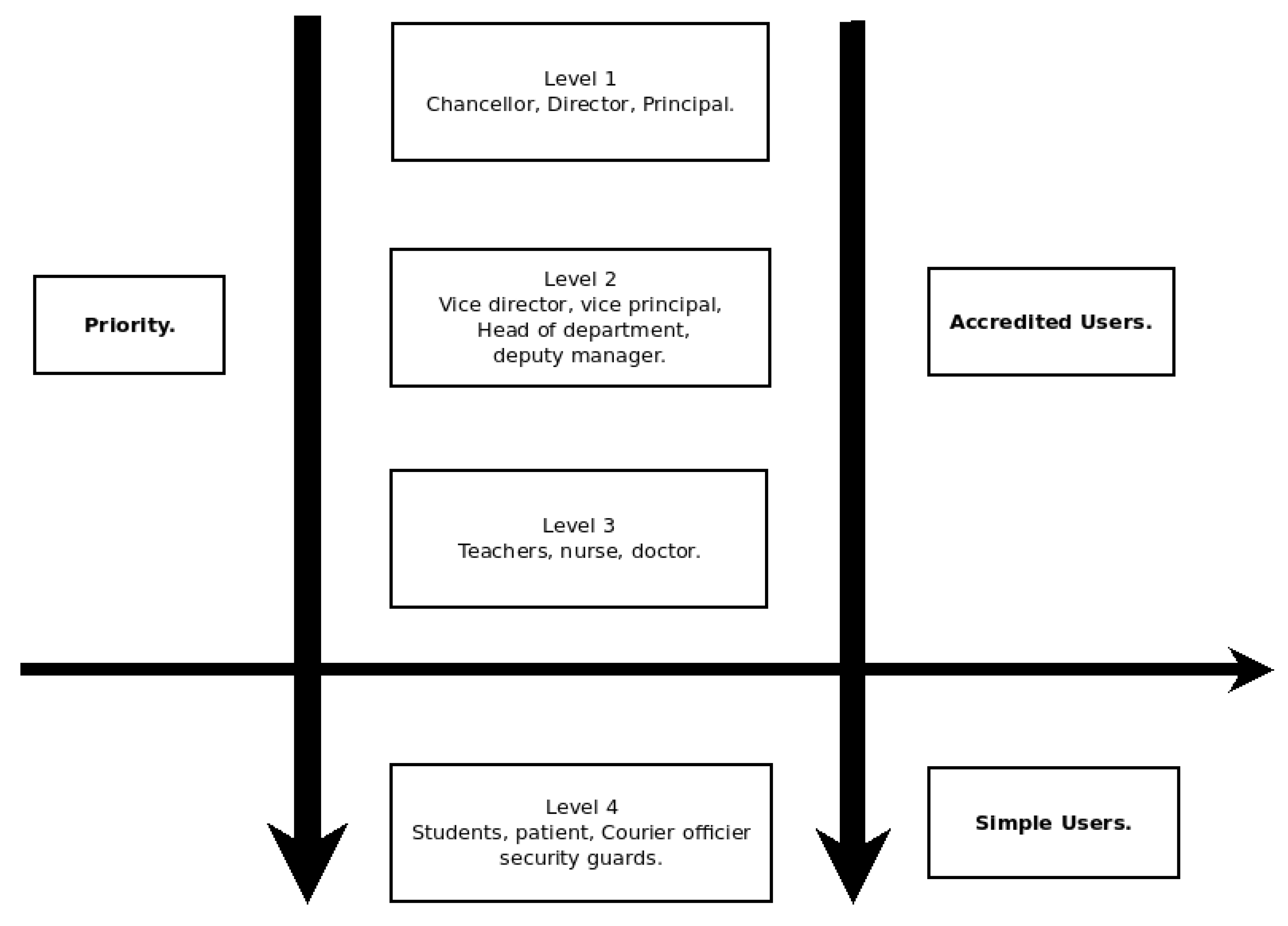
4.2.2. Accredited User
- Level 1: this level concerns users who occupy the highest positions of responsibility in the structure. These users can be Chancellor, Directors, Principals, etc. In this level, we consider that the opinions of these users have a degree of truthfulness above 90% for a weight of 1.
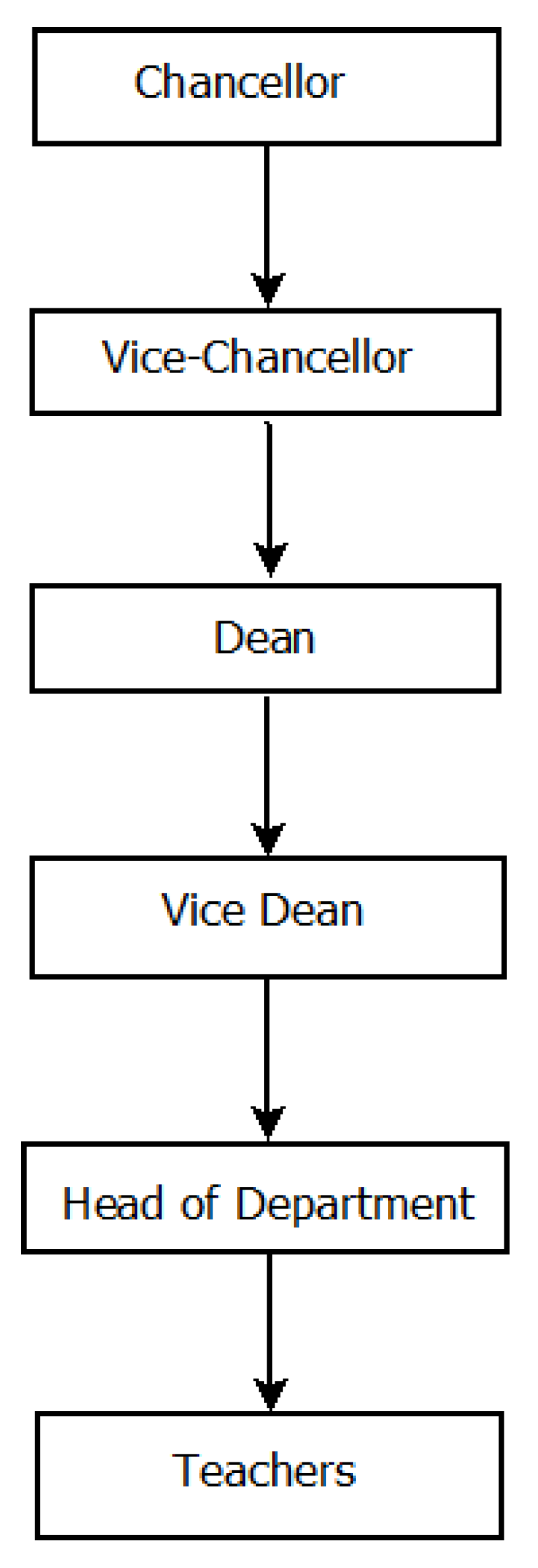
- Level 2: this level concerns users who occupy the average positions of responsibility in the structure. These users may be sub directors, vice-principal, deans, head of departments, etc. In this level, we consider that the opinions of these users have a degree of truthfulness of at least 75% for a weight of 0.75.
- Level 3: this level concerns users who occupy the weakest positions of responsibility in the structure. These users may be teaching staff, support staff, mail handlers, etc. In this level, we consider that the opinions of these users have a degree of truthfulness of at least 50% for a weight of 0.5. The level of competence of these users is shown in the Figure 2.
- Justification of degree of truthfulness We assign degree of truthfulness different from one because we consider external influences in giving opinions. All the three degrees (0.90 in level 1, 0.75 in level 2 and 0.5 in level 3) respect this consideration. Additionally, people in a level from highest to lowest is assigned a degree of truthfulness to reveal difference in terms of credibility related to information. This fact is because people in the highest level is likely to be quickly informed about a situation in the institution, i.e., the director is the one to be contacted in prior, about a situation in his institution.
4.3. Voting Related to Post
4.4. Aggregation Model
4.4.1. Formalization
4.4.2. Simple Users Side
4.4.3. Accredited Users Side
4.4.4. Computing Weight Model
- When the opinion of simple users gives 1 (true) after aggregation, we sum the weights of all users who gave their opinion 1 (true). Similarly, when the opinion gives −1 (false), we sum the weights of users who gave their opinion −1 (false).
- For accredited users, when the weighted average gives a positive result, the opinion will be 1 (true) and we sum the weights of the users who gave their opinion 1. On the other hand, when the weighted average gives a negative result, the opinion will be −1 (false) and we sum the weights of users who gave their opinion −1 (false).
4.5. Decision-Making
- If , then the final opinion is the opinion of accredited users with a weight of
- Else, then the final opinion is the opinion of simple users with a weight of
5. Experiments, Results and Discussion
5.1. Collection of Posts
5.2. Submission
5.3. Aggregation
5.4. Reporting
5.5. Detection Performance
- True Positive (TP): Number of posts correctly identified as fake news;
- False Positive (FP): Number of posts wrongly identified as fake news;
- True Negative (TN): Number of posts correctly identified as not fake news;
- False Negative (FN): Number of posts wrongly identified as not fake news;
Comparison with Related Works
6. Discussion
- Type of crowd: All the authors use only one type of crowd, i.e. they consider that all the people involved in the crowdsourcing process have the same level of competence or skill, these authors ignore that some people may have higher knowledge, experience or skills than others. The proposed model takes into account two categories of users with different knowledge. Accredited users are people with certain administrative responsibilities in an institution. Their social status confers some legitimacy to give opinions about news happened in this institution. The second category includes crowd users who are anonymous. However, they can provide judgment about the news because they also belong to the mention institutions. They belong to the lowest level of the hierarchy.
- Decision-making on a post: All these authors do not involve the crowd in the decision-making, they just use the crowd either to collect data or to check whether a post should be checked or not. Most of these authors use a third-party (expert) for decision-making. The proposed model does not involve a third party but remains focused on the knowledge and skills of the crowd to decide on a post.
- Associated techniques: most authors use hybrid techniques combining crowdsourcing and machine learning. Only the author (Kim et al. 2018) uses only crowdsourcing just to determine when the news should be checked. The proposed model uses crowdsourcing to verify and involves the crowd in the decision-making process of a post.
- Methodology: each author has a specific method to detect false information. The proposed model also has its own method to detect fake news, a method combining the intelligence of the simple crowd and third party to detect fake news.
- Role of the crowd in the crowdsourcing process: most authors do not fully use the skills of the crowd, they limit the role of the crowd just to verification and rely on an expert for decision-making. However, the crowd has a huge skill that these authors neglect, that of participation in decision-making. The proposed model takes the initiative to involve the crowd in decision-making.
7. Conclusion and Future Works
- Consider various users and posts of various domains;
- Formulate an optimization problem around the assignment of weights;
- Couple our method with other mechanisms to contribute to the detection of fake news.
Author Contributions
Acknowledgments
Conflicts of Interest
Abbreviations
| MV | Majority Vote |
| WA | Weighted Average |
| L1 | Level 1 |
| L2 | Level 2 |
| L3 | Level 3 |
Appendix A. Original Version of List of Posts
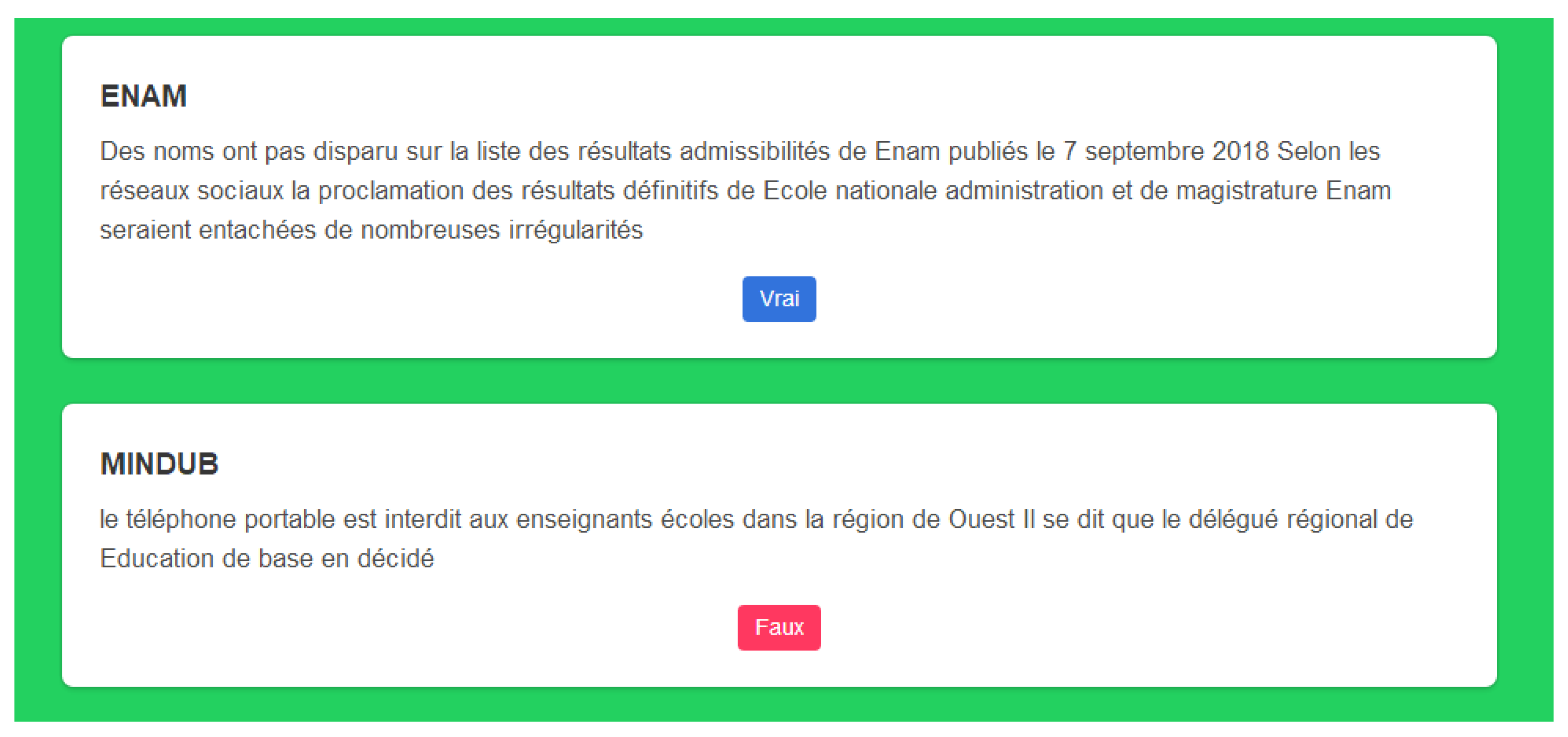
- ENAM: Des noms n’ont pas disparu sur la liste des résultats d’admissibilités de l’ENAM publiés le 7 septembre 2018, selon les réseaux sociaux la proclamation des résultats définitifs de l’Ecole Nationale d’Administration et de Magistrature (ENAM) seraient entachées de nombreuses irrégularités.
- GCE: le gouvernement camerounais n’a pas autorisé la collecte de 3500 FCFA pour le «GCE» blanc.
- MINDUB: le téléphone portable est interdit aux enseignants d’écoles dans la région de l’Ouest, Il se dit que le délégué régional de Education de base en a décidé.
- MINSEC: le Ngondo plaide pour 13 anciens proviseurs Sawa démis de leurs fonctions, un compte rendu non officiel relaie les griefs formulés par cette assemblée traditionnelle lors une rencontre tenue le 14 septembre dernier.
- Concour: les concours des ENS et ENSET ne sont pas encore lancés au Cameroun, des arrêtés lançant ces deux concours auraient été signés par le Premier ministre chef du gouvernement.
- Commission Bilinguisme: 15 véhicules une valeur de 700 millions ont été commandés par la Commission nationale du Bilinguisme, le document qui circule actuellement attribuant une grosse dépense à ce jeune organe étatique est il authentique.
- Philosophie: Dès septembre la philosophie sera enseignée en classe de la seconde, il se dit que cette matière n’est plus seulement réservée à la classe de Terminale.
- StopBlaBla: Stopblablacam s’est trompé au sujet d’une vidéo sur armée camerounaise dans l’Extrême Nord, Stopblablacam a commis une erreur en assurant il y’a quelques jours que la vidéo impliquant l’armée camerounaise était un fake.
- Week end: Des fonctionnaires camerounais prennent leur weekend dès jeudi soir le 19 décembre 2019. Certains agents de l’Etat sont absents de leur lieu de service sans permission pendant des semaines.
- FMIP kaele: il y’a eu un mouvement humeur à la faculté des mines et des industries pétrolières de l’Université de Maroua à Kaelé dans la soirée du 23 juillet 2018 des images et des messages informant une grève des étudiants à la faculté des mines et des industries pétrolières de Kaelé FMIP ont été diffusés sur les réseaux sociaux.
- Concour ENAM: la Fonction publique camerounaise a mandaté aucun groupe pour préparer les candidats au concours de l’Enam, des groupes de préparation aux concours administratifs prétendent qu’ils connaissent le réseau sûr permettant être reçu avec succès.
- UBa: cinq étudiants de l’université de Bamenda dans le Nord ouest du Cameroun n’ont pas été tués le 11 juillet 2018, ces tueries selon certains médias seraient la conséquence des brutalités policières qui opèrent des arrestations arbitraires dans les mini cités de l’université de Bamenda.
- Examen: à l’examen, écrire avec deux stylos à bille encre bleue de teintes différentes n’est pas une fraude, il existe pourtant une idée reçue assez répandue sur le sujet.
- Avocat: huit avocats stagiaires ont été radiés du barreau pour faux diplômes, cette décision a été prise lors de la session du Conseil de ordre des avocats qui s’est tenue le 30 juin dernier.
- Bacc 2018: la délibération des jurys au bac 2018 au Cameroun s’est faite autour de la note 8 sur 20. Qui dit délibérations aux examens officiels au Cameroun dit ajouts de points et repêchage des candidats.
- Corruption: La corruption existe au ministère de la Fonction publique du Cameroun, des expressions comme Bière, Carburant, Gombo constituent tout un champ lexical utilisé par les corrompus et les corrupteurs.
- Salaire: le gouvernement n’exige pas 50 000 Fcfa à chaque fonctionnaire pour financer le plan humanitaire dans les régions anglophones, selon la rumeur la somme de 50 000 FCFA sera prélevée à la source des salaires des agents publics.
- Fonction publique: le ministère de la Fonction publique camerounaise ne recrute pas via les réseaux sociaux, des recruteurs tentent de convaincre les chercheurs emploi que l’insertion dans administration publique passe par internet.
- PBHev: il n’existe pas d’entreprise PBHev sur la toile, il se dit pourtant qu’il s’agit d’une entreprise qui emploie un nombre important de Camerounais.
- Jeux Universitaire ndere: Les jeux universitaire ngaoundere 2020 initialement prévu a ngaoundere va connaitre un glissement de date pour juin 2020 car le recteur dit que l’Université de ngaoundere ne sera pas prêt pour avril 2020, les travaux ne sont pas encore achevé.
- Examen FS: Le doyen de la faculté des sciences informe a tous les étudiants de la faculté que les examens de la faculté des sciences sont prévu pour le 11fevrier 2020.
- IUT: le Directeur de l’IUT de ndere a invalider la soutence d’une étudiante de Génie Biologique pour avoir refuser de sortir avec lui.
- CDTIC: Le Centre de developpement de Technologies de l’information et de la communication n’est plus a la responsabilité de l’université de ngaoundéré, mais plutot au chinois.
- Doctoriales: Les doctoriales de la faculté des sciences s’est tenu en janvier sous la supervision de madame le recteur, pour ce faire plusieurs doctorants sont appelés a reprendre leur travaux a zero.
- Soutenance de la FS: Il est prevu des soutenance le 15 decembre 2019.
- Greve des enseignants: les enseignants des universités d’Etat sont en grève depuis le 26 novembre 2018 Il se rapporte que les enseignants du supérieur sont en grève
- Recrutement Docteur PhD: des docteurs PhD ont manifesté ce mercredi au ministère de l’Enseignement supérieur, il se dit qu’ils ont une fois de plus réclamé leur recrutement au sein de la Fonction publique.
- Descente des élèves dans la rue: des élèves du Lycée bilingue de Mbouda sont descendus dans la rue ce mardi 24 avril, il se dit qu’ils ont bruyamment manifesté pour revendiquer le remboursement de frais supplémentaires exigés par administration de leur établissement.
- Faux diplôme: le phénomène des faux diplômes est en baisse au Cameroun, le ministère de Enseigne supérieur renseigne qu’on atteint une moyenne de 40 faux diplômes sur un ensemble de 600.
- Trucage des ages: Des Camerounais procèdent souvent au trucage de leur âge, le ministre de la Jeunesse Mounouna Foutsou présenté des cas de falsifications de date de naissance lors du dernier renouvellement du bureau du Conseil national de la Jeunesse.
- Interpellation d’ensignants: 300 enseignants camerounais n’ont pas été interpellés les 27 et 28 février 2018 à Yaoundé selon le Nouveau collectif des enseignants indignés du Cameroun le chiffre 300 ne peut être qu’erroné puisque le mouvement compte juste 56 membres soit un grossissement du nombre interpellés par cinq.
- Report d’examen: les examens officiels ont pas été reportés à cause des élections, il se murmure qu’en vue de la présidentielle des municipales législatives et sénatoriales les dates des épreuves sanctionnant enseignement secondaire ont été chamboulées.
- Assansinat d’enseignant: Boris Kevin Tchakounte, l’enseignant poignardé à mort à Nkolbisson n’y était pas officiellement en service.
- Lycée d obala: Un lycéen n’a pas eu la main coupée à Obala.
- MINJUSTICE: les résultats du concours pour le recrutement de 200 secrétaires au ministère de la Justice ont été publiés.
- Doctorat professionnel: le doctorat professionnel n’est pas reconnu dans l’enseignement supérieur au Cameroun.
- MINAD: le ministre de l’Agriculture a proscrit, pour l’année 2019, des transferts de candidats admis dans les écoles agricoles.
- MINFOPRA: le ministère camerounais de la Fonction publique dispose désormais d’une page Facebook certifiée.
- Ecole de Nyangono: Nyangono du Sud n’est pas retourné sur les bancs de l’école.
- CAMRAIL: Camrail a lancer un concours pour le recrutement de 40 jeunes camerounais et l’inscription coute 13000 fcfa
- Report date concours: la date du concours pour le recrutement de 200 secrétaires au ministère de la Justice a été reportée.
- MINFI: Le ministre camerounais des finances ne recrute pas 300 employes.
Appendix B. English Version of List of Posts
- NSAM: Names have not disappeared from the list of NSAM admissibility results published on 7 September 2018, according to social networks the proclamation of the final results of the National School of Administration and Magistracy (NSAM) would be marred by numerous irregularities.
- GCE: the Cameroonian government has not authorized the collection of 3500 FCFA for the white “GCE”.
- MINDUB: Mobile phones are forbidden to teachers in schools in the Western Region, it is said that the Regional Delegate for Basic Education has decided on this.
- MINSEC: Ngondo pleads for 13 former Sawa headmasters dismissed, an unofficial report relays the grievances formulated by this traditional assembly during a meeting held last September 14.
- Competition: The ENS and ENSET competitions have not yet been launched in Cameroon, decrees launching these two competitions would have been signed by the Prime Minister, Head of Government.
- Bilingualism Commission: 15 vehicles worth 700 million have been ordered by the National Bilingualism Commission. The document currently in circulation attributing a large expenditure to this young state body is authentic.
- Philosophy: As of September, philosophy will be taught in the second year of secondary school. It is thought that this subject is no longer reserved only for the Terminale class.
- StopBlaBla: Stopblablacam was wrong about a video about the Cameroonian army in the Far North, StopBlaBlaCam made a mistake a few days ago by assuring that the video involving the Cameroonian army was a fake.
- Weekend: Cameroonian officials are taking their weekend starting Thursday night, December 19, 2019. Some government officials are absent from their place of duty without permission for weeks.
- FMIP Kaelé: there was a mood movement at the Faculty of Mines and Petroleum Industries of the University of Maroua in Kaelé in the evening of July 23, 2018 images and messages informing of a strike by students at the Faculty of Mines and Petroleum Industries of Kaelé FMIP were broadcast on social networks.
- ENAM competition: the Cameroonian civil service has not mandated any group to prepare candidates for the ENAM competition, some groups preparing for administrative competitions claim that they know the secure network to be received successfully.
- UBa: Five students of the University of Bamenda in north-west Cameroon were not killed on 11 July 2018. According to some media reports, these killings are the consequence of police brutality which carry out arbitrary arrests in the mini cities of the University of Bamenda.
- Examination: on the exam, writing with two blue ink ballpoint pens of different shades is not a fraud, yet there is a common misconception on the subject.
- Lawyer: eight trainee lawyers were disbarred for false diplomas. This decision was taken at the session of the Bar Council held on 30 June last.
- Bacc 2018: the deliberations of the juries for the 2018 Bacc in Cameroon were based on a score of 8 out of 20. Deliberations at the official exams in Cameroon meant adding points and repechage of candidates.
- Corruption: Corruption exists in Cameroon’s Ministry of Civil Service, expressions such as Beer, Fuel, Gombo constitute a whole lexical field used by the corrupt and corrupters.
- Salary: The government does not require 50,000 FCFA from each civil servant to finance the humanitarian plan in the English-speaking regions, rumor has it that the sum of 50,000 FCFA will be deducted at source from the salaries of civil servants.
- Civil service: the Cameroonian Ministry of Civil Service does not recruit via social networks; recruiters try to convince job seekers that integration into the public administration is via the Internet.
- PBHev: There is no PBHev company on the web, yet it is said to be a company that employs a significant number of Cameroonians.
- University Games: The University Games Ngaoundéré 2020 initially planned in Ngaoundéré will experience a date shift to June 2020 because the rector says that the University of Ngaoundéré will not be ready for April 2020, the work is not yet completed.
- FS Exam: The Dean of the Faculty of Science informs all students of the Faculty of Science that the Faculty of Science exams are scheduled for February 11, 2020.
- IUT: the Director of the IUT of Ngaoundéré has invalidated the support of a student of Biological Engineering for refusing to go out with him.
- CDTIC: The Centre for the Development of Information and Communication Technologies is no longer the responsibility of the University of Ngaoundéré, but rather Chinese.
- Doctoral: The Faculty of Sciences’ doctoral session was held in January under the supervision of Madam Rector, for this purpose several doctoral students are called to resume their work from scratch.
- FS defense: The defense is scheduled for December 15, 2019.
- Teachers’ strike: State University teachers are on strike since 26 November 2018 It is reported that higher education teachers are on strike.
- Recruitment PhDs: PhDs demonstrated on Wednesday at the Ministry of Higher Education, it is said that they have once again demanded their recruitment within the civil service.
- Pupils taking to the streets: Pupils from the Bilingual High School of Mbouda took to the streets on Tuesday 24 April. It is said that they noisily demonstrated to demand the reimbursement of additional fees demanded by the administration of their school.
- False diplomas: the phenomenon of false diplomas is decreasing in Cameroon, the Ministry of Higher Education informs that an average of 40 false diplomas out of a total of 600 is reached.
- Trickery of ages: Cameroonians often trick their age, the Minister of Youth Mounouna Foutsou presented cases of falsification of date of birth during the last renewal of the office of the National Youth Council.
- Interpellation of teachers: 300 Cameroonian teachers were not questioned on 27 and 28 February 2018 in Yaounde according to the New Collective of Indignant Teachers of Cameroon, the figure 300 can only be erroneous since the movement has just 56 members, i.e., an increase in the number of teachers questioned by five.
- Postponement of exams: the official exams have not been postponed because of the elections, it is whispered that in view of the presidential, legislative and senatorial municipal elections, the dates of the exams sanctioning secondary education have been disrupted.
- Teacher’s assassination: Boris Kevin Tchakounté, the teacher stabbed to death at Nkolbisson was not officially on duty there.
- Obala High School: A high school student did not have his hand cut off in Obala.
- MINJUSTICE: The results of the competition for the recruitment of 200 secretaries in the Ministry of Justice have been published.
- Professional doctorate: The professional doctorate is not recognized in higher education in Cameroon.
- MINAD: the Minister of Agriculture has banned, for 2019, transfers of candidates admitted to agricultural schools.
- Cameroon’s Ministry of Public Service now has a certified Facebook page.
- Nyangono School: South Nyangono has not gone back to school.
- CAMRAIL: Camrail has launched a competition for the recruitment of 40 young Cameroonians and registration costs 13000 fcfa.
- Postponement of competition date: the competition date for the recruitment of 200 secretaries in the Department of Justice has been postponed.
- MINFI: Cameroon’s finance minister is not recruiting 300 employees.
References
- Fake News—Statistics & Facts. Available online: https://www.statista.com/topics/3251/fake-news/ (accessed on 31 May 2020).
- Wasserman, H.; Madrid-Morales, D. An Exploratory Study of “Fake News” and Media Trust in Kenya, Nigeria and South Africa. Afr. J. Stud. 2019, 40, 107–123. [Google Scholar] [CrossRef]
- Harsin, J.; Richet, I. Un guide critique des Fake News: de la comédie à la tragédie. Pouvoirs 2018, 1, 99–119. [Google Scholar] [CrossRef]
- Tschiatschek, S.; Singla, A.; Gomez Rodriguez, M.; Merchant, A.; Krause, A. Fake news detection in social networks via crowd signals. In Proceedings of the Web Conference 2018, Lyon, France, 23–27 April 2018; pp. 517–524. [Google Scholar]
- Della Vedova, M.L.; Tacchini, E.; Moret, S.; Ballarin, G.; DiPierro, M.; de Alfaro, L. Automatic online fake news detection combining content and social signals. In Proceedings of the 2018 22nd Conference of Open Innovations Association (FRUCT), Petrozavodsk, Russia, 11–13 April 2018; pp. 272–279. [Google Scholar]
- De Alfaro, L.; Di Pierro, M.; Agrawal, R.; Tacchini, E.; Ballarin, G.; Della Vedova, M.L.; Moret, S. Reputation systems for news on twitter: A large-scale study. arXiv 2018, arXiv:1802.08066. [Google Scholar]
- Shabani, S.; Sokhn, M. Hybrid machine-crowd approach for fake news detection. In Proceedings of the 2018 IEEE 4th International Conference on Collaboration and Internet Computing (CIC), Philadelphia, PA, USA, 18–20 October 2018; pp. 299–306. [Google Scholar]
- Kim, J.; Tabibian, B.; Oh, A.; Schölkopf, B.; Gomez-Rodriguez, M. Leveraging the crowd to detect and reduce the spread of fake news and misinformation. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; pp. 324–332. [Google Scholar]
- Zhou, X.; Zafarani, R. Fake news: A survey of research, detection methods, and opportunities. arXiv 2018, arXiv:1812.00315. [Google Scholar]
- Sharma, K.; Qian, F.; Jiang, H.; Ruchansky, N.; Zhang, M.; Liu, Y. Combating fake news: A survey on identification and mitigation techniques. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–42. [Google Scholar] [CrossRef]
- Hassan, N.; Arslan, F.; Li, C.; Tremayne, M. Toward automated fact-checking: Detecting check-worthy factual claims by ClaimBuster. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1803–1812. [Google Scholar]
- Hassan, N.; Li, C.; Tremayne, M. Detecting check-worthy factual claims in presidential debates. In Proceedings of the 24th ACM International Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015; pp. 1835–1838. [Google Scholar]
- Sethi, R.J. Crowdsourcing the verification of fake news and alternative facts. In Proceedings of the 28th ACM Conference on Hypertext and Social Media, Prague, Czech Republic, 4–7 July 2017; pp. 315–316. [Google Scholar]
- Tacchini, E.; Ballarin, G.; Della Vedova, M.L.; Moret, S.; de Alfaro, L. Some like it hoax: Automated fake news detection in social networks. arXiv 2017, arXiv:1704.07506. [Google Scholar]
- Latest Email and Social Media Hoaxes—Current Internet Scams—Hoax-Slayer. Available online: https://hoax-slayer.com/ (accessed on 31 May 2020).
- StopBlaBlaCam. Available online: https://www.stopblablacam.com/ (accessed on 31 May 2020).
- Brown-Liburd, H.; Cohen, J.; Zamora, V.L. The Effect of Corporate Social Responsibility Investment, Assurance, and Perceived Fairness on Investors’ Judgments. In Proceedings of the 2011 Academic Conference on CSR, Tacoma, WA, USA, 14–15 July 2011. [Google Scholar]
- Hoffart, J.; Suchanek, F.M.; Berberich, K.; Weikum, G. YAGO2: A spatially and temporally enhanced knowledge base from Wikipedia. Artif. Intell. 2013, 194, 28–61. [Google Scholar] [CrossRef]
- Pisarevskaya, D. Deception detection in news reports in the russian language: Lexics and discourse. In Proceedings of the 2017 EMNLP Workshop: Natural Language Processing Meets Journalism, Copenhagen, Denmark, 7 September 2017; pp. 74–79. [Google Scholar]
- Potthast, M.; Kiesel, J.; Reinartz, K.; Bevendorff, J.; Stein, B. A stylometric inquiry into hyperpartisan and fake news. arXiv 2017, arXiv:1702.05638. [Google Scholar]
- Volkova, S.; Shaffer, K.; Jang, J.Y.; Hodas, N. Separating facts from fiction: Linguistic models to classify suspicious and trusted news posts on twitter. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vancouver, Canada, 30 July–4 August 2017; pp. 647–653. [Google Scholar]
- Ren, Y.; Ji, D. Neural networks for deceptive opinion spam detection: An empirical study. Inf. Sci. 2017, 385, 213–224. [Google Scholar] [CrossRef]
- Wang, Y.; Ma, F.; Jin, Z.; Yuan, Y.; Xun, G.; Jha, K.; Su, L.; Gao, J. Eann: Event adversarial neural networks for multi-modal fake news detection. In Proceedings of the 24th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), London, UK, 19–23 August 2018; pp. 849–857. [Google Scholar]
- Du, N.; Liang, Y.; Balcan, M.; Song, L. Influence function learning in information diffusion networks. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 2016–2024. [Google Scholar]
- Najar, A.; Denoyer, L.; Gallinari, P. Predicting information diffusion on social networks with partial knowledge. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 1197–1204. [Google Scholar]
- Draper, N.R.; Smith, H. Applied Regression Analysis; John Wiley & Sons: New York, NY, USA, 1998; Volume 326. [Google Scholar]
- Kucharski, A. Study epidemiology of fake news. Nature 2016, 540, 525. [Google Scholar] [CrossRef]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake news detection on social media: A data mining perspective. ACM SIGKDD Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Ma, J.; Gao, W.; Wong, K.F. Rumor detection on twitter with tree-structured recursive neural networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Vishwanathan, S.V.N.; Schraudolph, N.N.; Kondor, R.; Borgwardt, K.M. Graph kernels. J. Mach. Learn. Res. 2010, 11, 1201–1242. [Google Scholar]
- Wu, K.; Yang, S.; Zhu, K.Q. False rumors detection on sina weibo by propagation structures. In Proceedings of the2015 IEEE 31st International Conference on Data Engineering, Seoul, Korea, 13–16 April 2015; pp. 651–662. [Google Scholar]
- Petersen, E.E.; Staples, J.E.; Meaney-Delman, D.; Fischer, M.; Ellington, S.R.; Callaghan, W.M.; Jamieson, D.J. Interim guidelines for pregnant women during a Zika virus outbreak—United States, 2016. Morb. Mortal. Wkly Rep. 2016, 65, 30–33. [Google Scholar] [CrossRef] [PubMed]
- Esteves, D.; Reddy, A.J.; Chawla, P.; Lehmann, J. Belittling the source: Trustworthiness indicators to obfuscate fake news on the web. arXiv 2018, arXiv:1809.00494. [Google Scholar]
- Dungs, S.; Aker, A.; Fuhr, N.; Bontcheva, K. Can rumour stance alone predict veracity? In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 3360–3370. [Google Scholar]
- Kleemann, F.; Voß, G.; Rieder, K. Un (der) paid Innovators. The Commercial Utilization of Consumer Work through Crowdsourcing. Sci. Technol. Innov. Stud. 2008, 4, 5–26. [Google Scholar]
- Schenk, E.; Guittard, C. Towards a characterization of crowdsourcing practices. J. Innov. Econ. Manag. 2011, 93–107. [Google Scholar] [CrossRef]
- Guittard, C.; Schenk, E. Le crowdsourcing: typologie et enjeux d’une externalisation vers la foule. Document de Travail du Bureau d’économie Théorique et Appliquée 2011, 2, 7522. [Google Scholar]
- Thomas, K.; Grier, C.; Song, D.; Paxson, V. Suspended accounts in retrospect: An analysis of twitter spam. In Proceedings of the 2011 ACM SIGCOMM Conference on Internet Measurement Conference, Berlin, Germany, 2–4 November 2011; pp. 243–258. [Google Scholar]
- Bouncken, R.B.; Komorek, M.; Kraus, S. Crowdfunding: The current state of research. Int. Bus. Econ. Res. J. 2015, 14, 407–416. [Google Scholar] [CrossRef]
- Świeszczak, M.; Świeszczak, K. Crowdsourcing–what it is, works and why it involves so many people? World Sci. News 2016, 48, 32–40. [Google Scholar]
- Ghezzi, A.; Gabelloni, D.; Martini, A.; Natalicchio, A. Crowdsourcing: A review and suggestions for future research. Int. J. Manag. Rev. 2018, 20, 343–363. [Google Scholar] [CrossRef]
- Howe, J. The rise of crowdsourcing. Wired Mag. 2006, 14, 1–4. [Google Scholar]
- Lin, Z.; Murray, S.O. Automaticity of unconscious response inhibition: Comment on Chiu and Aron (2014). J. Exp. Psychol. Gen. 2015, 144, 244–254. [Google Scholar] [CrossRef] [PubMed]
- Granskogen, T. Automatic Detection of Fake News in Social Media using Contextual Information. Master’s Thesis, NTNU, Trondheim, Norway, 2018. [Google Scholar]
- Kumar, S.; Shah, N. False information on web and social media: A survey. arXiv 2018, arXiv:1804.08559. [Google Scholar]
- Marsick, V.J.; Watkins, K. Informal and Incidental Learning in the Workplace (Routledge Revivals); Routledge: Abingdon, UK, 2015. [Google Scholar]
- Ahmadou, F. Welcome to Our Crowdsourcing Platform. Available online: hoax.smartedubizness.com (accessed on 1 June 2020).
- Kirsch, S. Sustainable mining. Dialect. Anthropol. 2010, 34, 87–93. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| A1 | A2 | A3 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 0 | 1 |
| 0 | 1 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 0 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
| 1 | 1 | 1 |
| Simple Users | Accredited Users | Decision |
|---|---|---|
| −1 (F) | −1 (F) | −1 (F) |
| −1 (F) | 1 (T) | 1 (T) |
| 1 (T) | −1 (F) | −1 (F) |
| 1 (T) | 1 (T) | 1 (T) |
| Simple User | Accredited User | Weight | Decision |
|---|---|---|---|
| −1 (F) | −1 (F) | — | −1 (F) |
| −1 (F) | 1 (T) | 1 (T) | |
| 1 (T) | −1 (F) | −1 (F) | |
| 1 (T) | 1 (T) | — | 1 (T) |
| Simple User | Accredited User | Weight | Decision |
|---|---|---|---|
| −1 (F) | −1 (F) | — | −1 (F) |
| −1 (F) | 1 (T) | −1 (F) | |
| 1 (T) | −1 (F) | Ps > Pa | 1 (T) |
| 1 (T) | 1 (T) | — | 1 (T) |
| Simple User | Competence | Vote |
|---|---|---|
| Student 1 | 0.25 | 1 |
| Student 2 | 0.25 | 1 |
| Student 3 | 0.25 | −1 |
| Student 4 | 0.25 | 1 |
| Student 5 | 0.25 | 1 |
| Student 6 | 0.25 | 1 |
| Student 7 | 0.25 | −1 |
| Student 8 | 0.25 | 1 |
| Student 9 | 0.25 | 1 |
| Student 10 | 0.25 | 1 |
| Accredited User | Competence | Vote |
|---|---|---|
| Principal | 1 | −1 |
| Vice-principal | 0.75 | 1 |
| SG | 0.75 | −1 |
| Teacher | 0.5 | 1 |
| Title Post | Nature of Post | Number of User | ||||
|---|---|---|---|---|---|---|
| 1- ENAM | True | 50 | 26 | 24 | True | True |
| 2- GCE | True | 47 | 30 | 17 | True | True |
| 3-MINDUB | True | 45 | 20 | 25 | False | False |
| 4- MINSEC | True | 47 | 27 | 20 | True | True |
| 5- Concour | False | 48 | 18 | 30 | False | False |
| 6- Bilingusme | True | 44 | 28 | 16 | True | True |
| 7- Philosophie | True | 49 | 41 | 8 | True | True |
| 8- StopBlaBla | True | 47 | 26 | 21 | True | True |
| 9- Week end | True | 48 | 32 | 16 | True | True |
| 10- FMIP Kaelé | True | 47 | 28 | 19 | False | True |
| 11-Conc ENAM | False | 48 | 25 | 23 | False | True |
| 12- UBa | False | 46 | 22 | 24 | False | False |
| 13- Examen | False | 48 | 23 | 25 | True | False |
| 14- Avocat | True | 47 | 24 | 23 | False | True |
| 15-Bacc 2018 | True | 50 | 33 | 17 | True | True |
| 16- Corruption | True | 50 | 41 | 9 | True | True |
| 17- Salaire | False | 48 | 18 | 30 | False | False |
| 18- MINFOPRA | False | 48 | 25 | 23 | True | True |
| 19-PBHev | False | 49 | 25 | 24 | False | True |
| 20- Jeux-U | False | 49 | 25 | 24 | True | True |
| 21- Examen FS | False | 48 | 14 | 34 | False | False |
| 22-IUT | False | 50 | 10 | 40 | False | False |
| 23-CDTIC | False | 48 | 16 | 32 | False | False |
| 24-Doctoriales | False | 46 | 21 | 25 | True | False |
| 25- Soutenance FS | False | 45 | 26 | 19 | False | True |
| Samples | TP | TN | FP | FN | Acc | |||
|---|---|---|---|---|---|---|---|---|
| Majority Vote Model | 25 | 11 | 8 | 5 | 1 | 0.68 | 0.88 | 0.76% |
| Our Model | 25 | 11 | 9 | 4 | 1 | 0.73 | 0.9 | 0.80% |
| Authors | Types of Crowd | Decision | Associated Techniques | Methods | Role of Crowd | Problem | Nature of Post |
|---|---|---|---|---|---|---|---|
| (Tschiatschek et al., 2018) | One type (Simple) | Expert involvement | Hybrid (Crowdsourcing, Artificial Intelligence) | to select a small subset of k news, send them to an expert for review, and then block the news which are labeled as fake by the expert | Selection of facts to be checked | Classification post as fake and not fake | Unknown at start |
| (Vedova et al., 2018) | One type (Simple) | Use harmonic Boolean label crowdsourcing for making decision logistic regression and harmonic Boolean label crowdsourcing | Define a threshold λand classified the posts | Combining content-based and social-based approaches | Provide the BLC algorithm input data | Classification post as fake or not fake | Known at start |
| (Tacchini et al. 2017) | One type (Simple) | Use algorithms derived from crowdsourcing (BLC) for making decision | Logistic regression and crowdsourcing | The algorithms compare what people say, correct for the effect of the liars, and reconstruct a consensus truth | Provide the BLC algorithm input data | Classification post as hoax or not | Known at start |
| (Pérez-Rosas et al., 2017) | One type (Simple) | Machine Learning make decision | Crowdsourcing and Machine Learning | Explore and analyze linguistic properties to detect false content | Uses the crowd just to collect dataset | Identification of fake content in online news | Known at start |
| (Kim et al. 2018) | One type (Simple) | Expert involvement | Crowdsourcing | Users flag any story in their feed as misinformation and, if a story receives enough flags, it is sent to a third party for fact-checking. | To determine when the news needs to be verified | Detection fake news | Unknown at start |
| (Shabani et Shakhn, 2018) | One type (Simple) | Expert involvement | Hybrid (Machine Learning and crowdsourcing) | Combines the machine learning algorithms with the wisdom of crowds to detect fake news and satire | Selection of facts to be checked | Classification post | Known at start |
| Our model | Two types (Simple and Accredited) | Simple user and Accredited user involvement | Crowdsourcing | Detect fake news while combining crowd intelligence and third-party expert knowledge. | Involved in decision-making | Detection fake news | Unknown at start |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tchakounté, F.; Faissal, A.; Atemkeng, M.; Ntyam, A. A Reliable Weighting Scheme for the Aggregation of Crowd Intelligence to Detect Fake News. Information 2020, 11, 319. https://doi.org/10.3390/info11060319
Tchakounté F, Faissal A, Atemkeng M, Ntyam A. A Reliable Weighting Scheme for the Aggregation of Crowd Intelligence to Detect Fake News. Information. 2020; 11(6):319. https://doi.org/10.3390/info11060319
Chicago/Turabian StyleTchakounté, Franklin, Ahmadou Faissal, Marcellin Atemkeng, and Achille Ntyam. 2020. "A Reliable Weighting Scheme for the Aggregation of Crowd Intelligence to Detect Fake News" Information 11, no. 6: 319. https://doi.org/10.3390/info11060319
APA StyleTchakounté, F., Faissal, A., Atemkeng, M., & Ntyam, A. (2020). A Reliable Weighting Scheme for the Aggregation of Crowd Intelligence to Detect Fake News. Information, 11(6), 319. https://doi.org/10.3390/info11060319