Addressing Misinformation in Online Social Networks: Diverse Platforms and the Potential of Multiagent Trust Modeling



 , , ,
, , ,
Abstract
:Highlights
- broad exploration of current misinformation in diverse social networks
- novel proposals for extending multiagent trust modeling to detect fake news
- support of personalization with critical case of older adults
- attuned to future requirements of graph-based techniques and healthcare
1. Introduction
2. Methods: Assembling Social Network Misinformation
3. Results: A Study of Existing Social Networks: Primary Observations
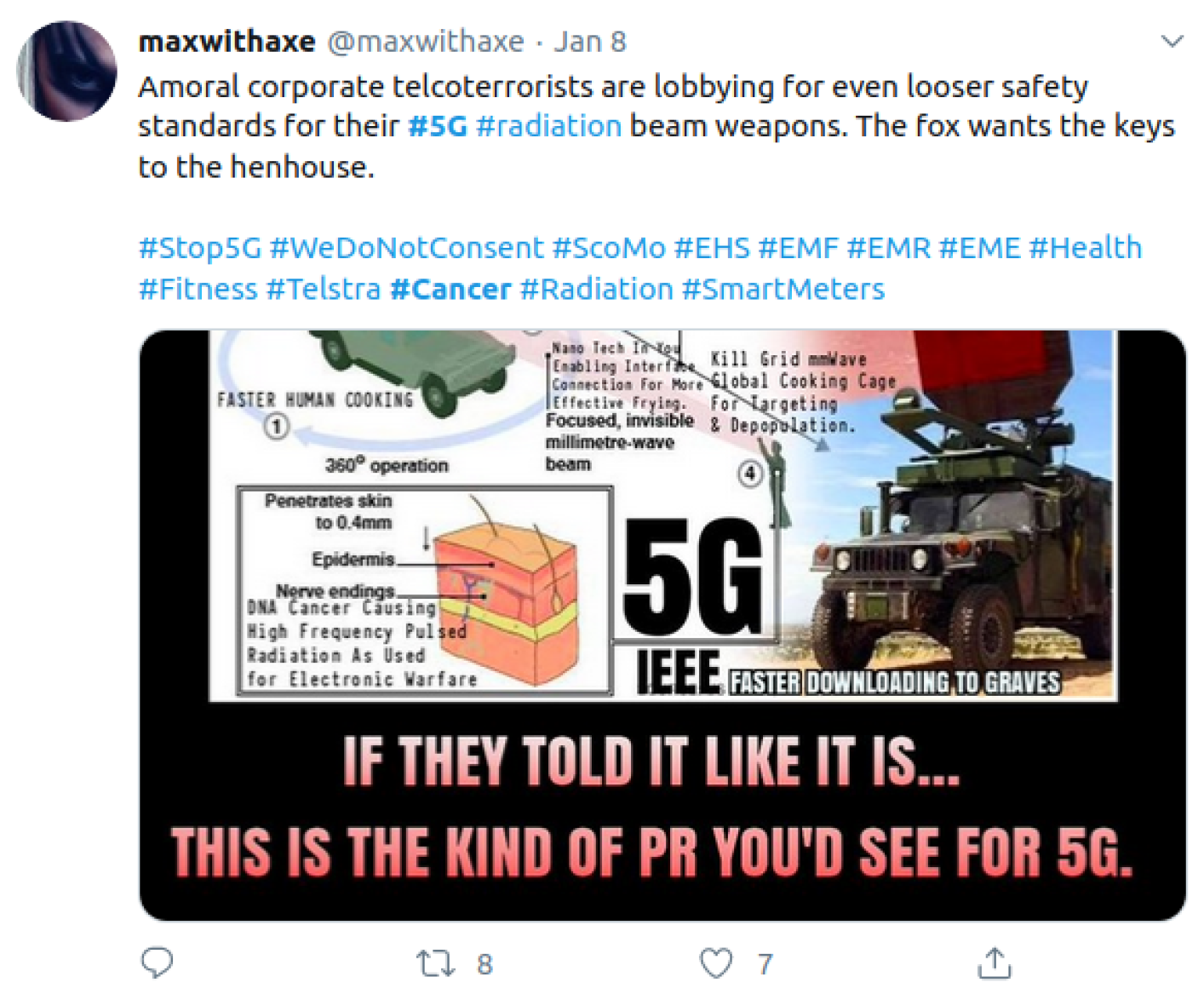
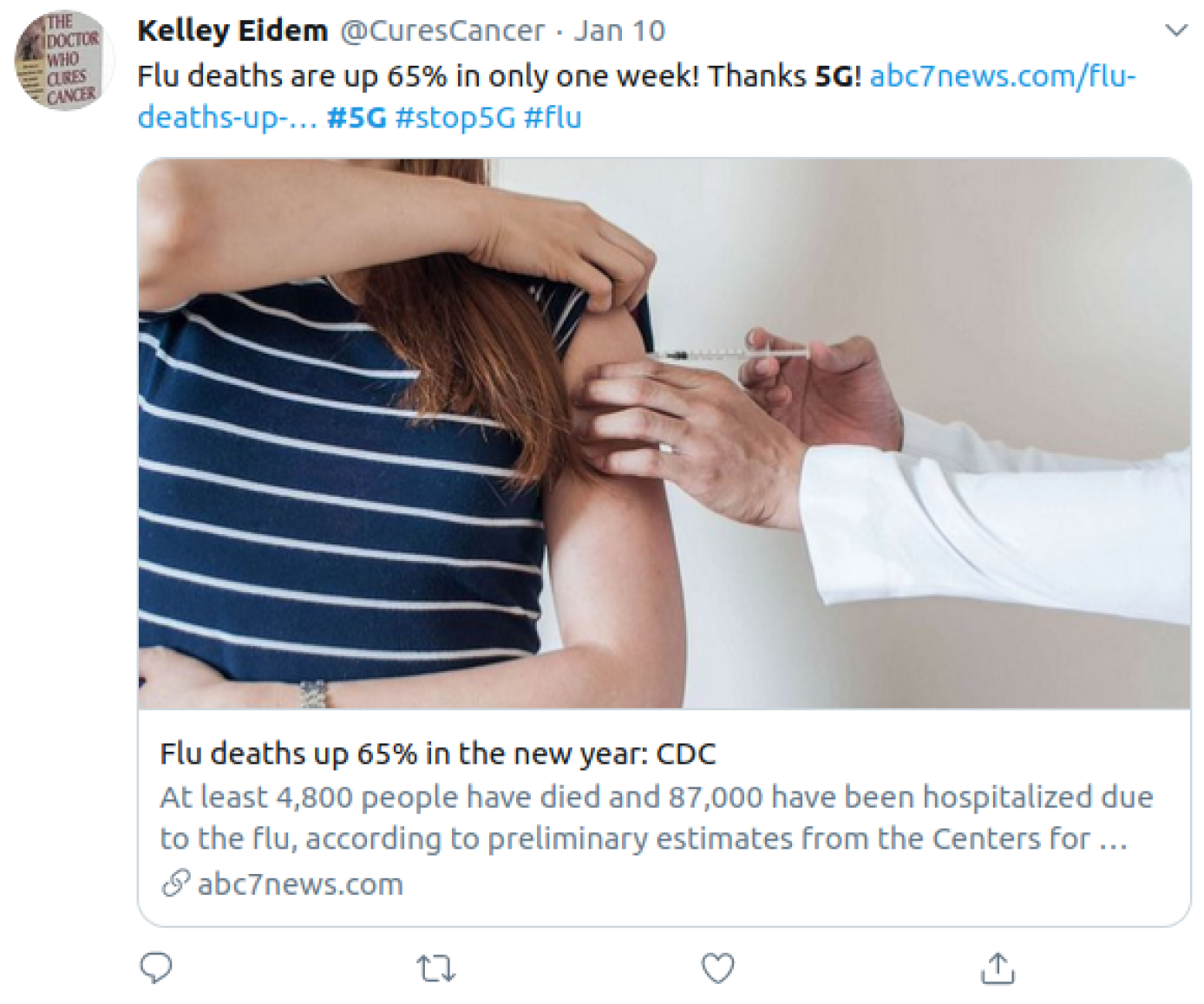
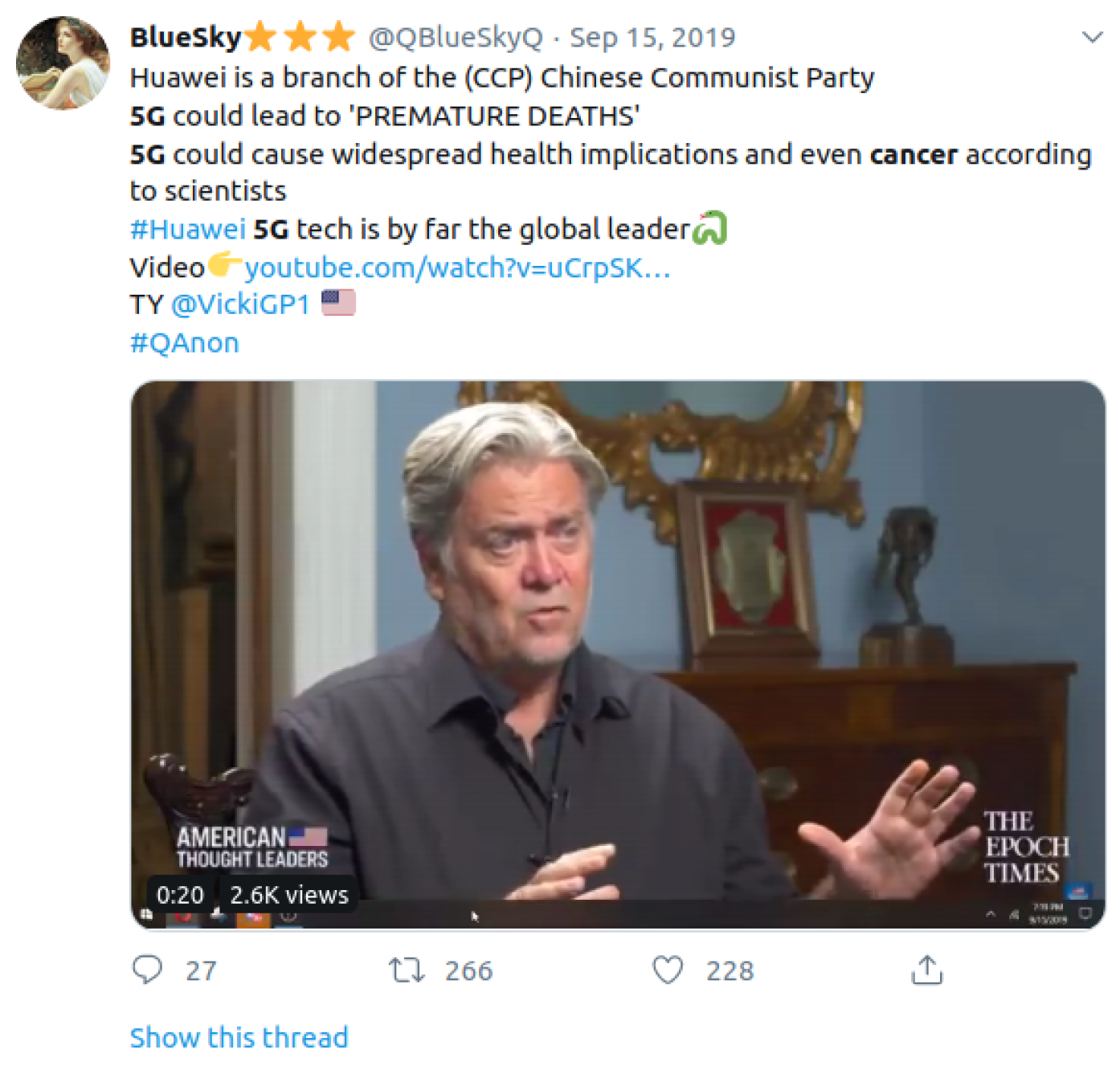
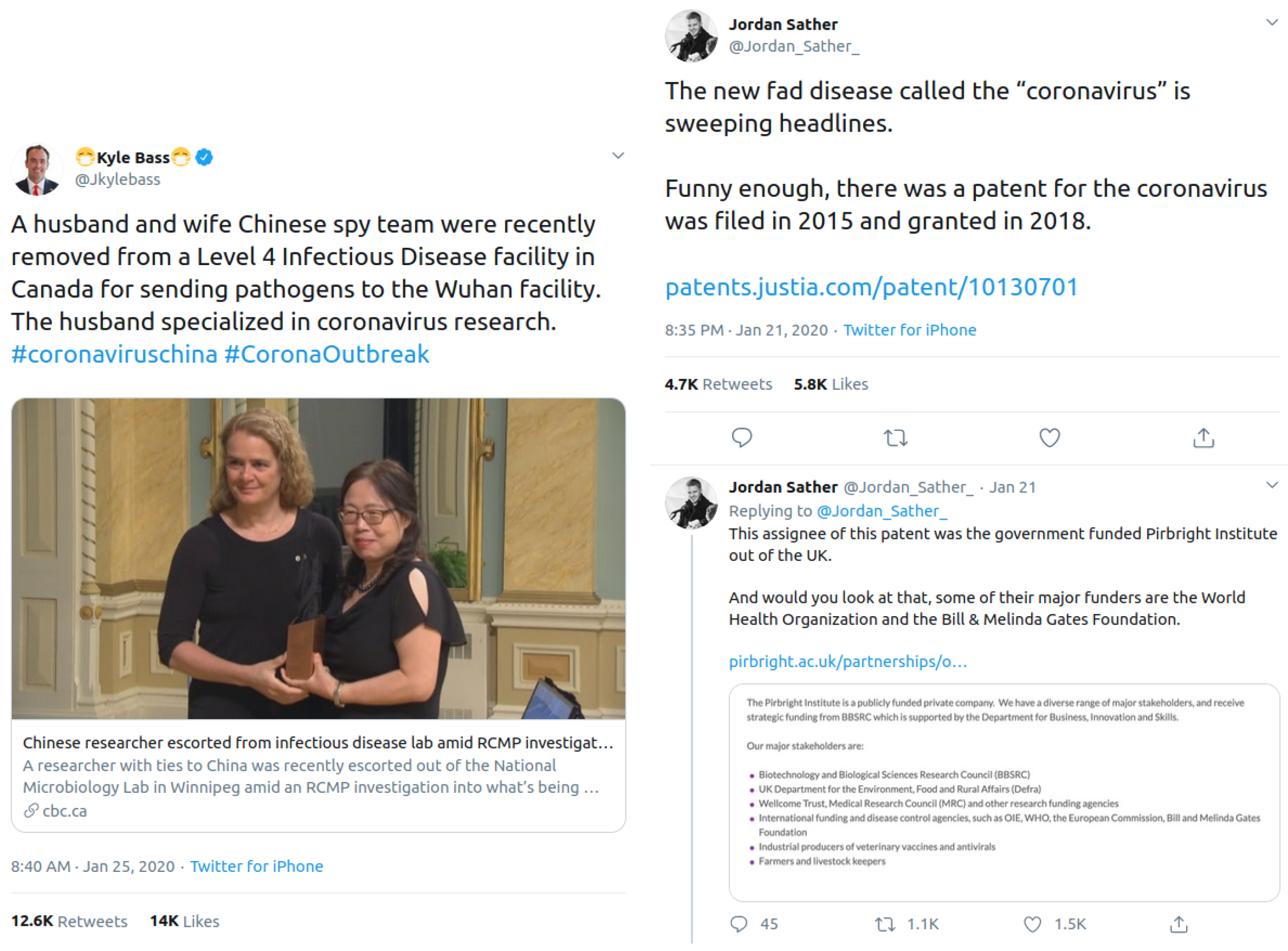
3.1. Twitter
3.1.1. Interface
3.1.2. Misinformation
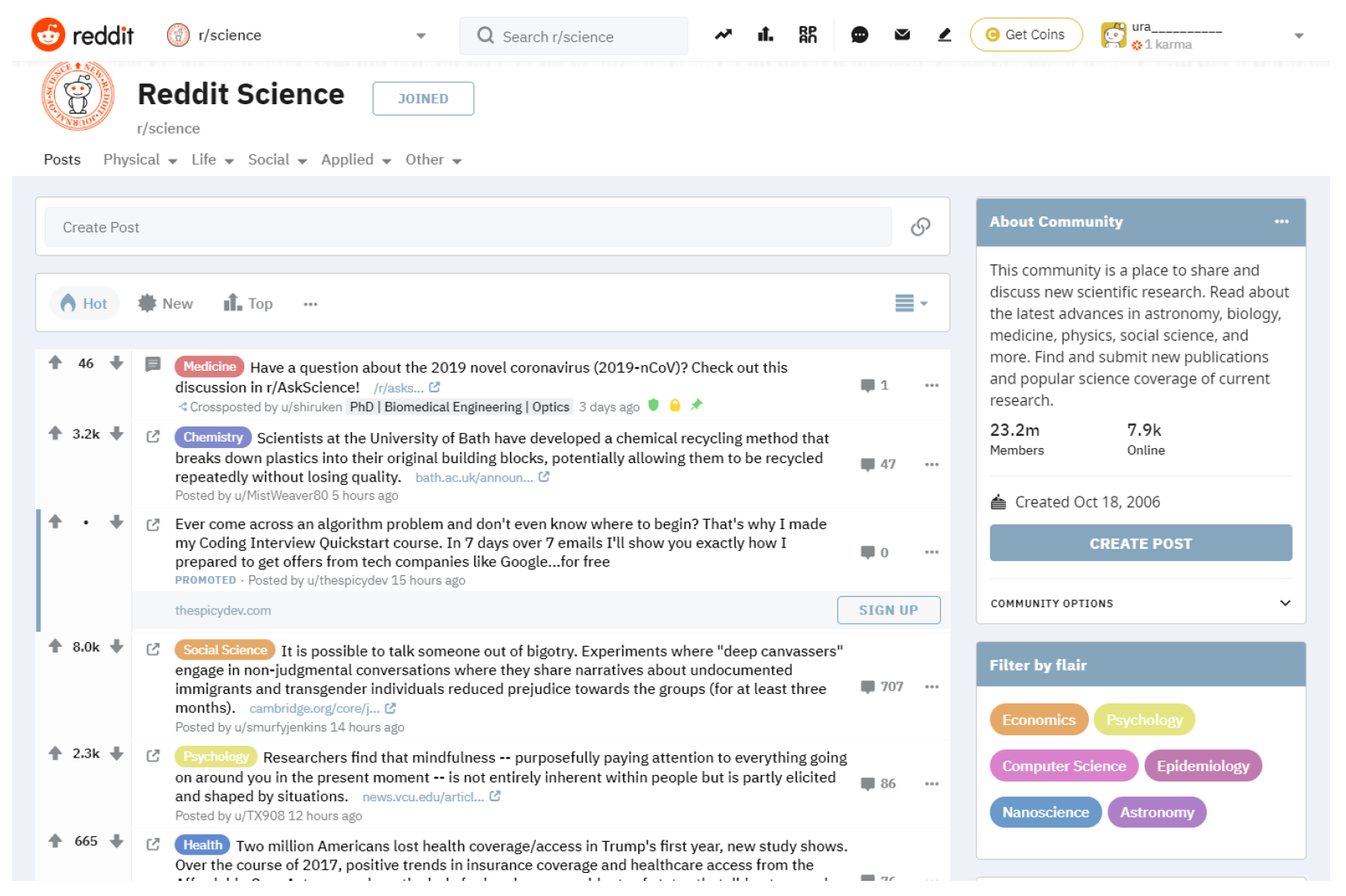
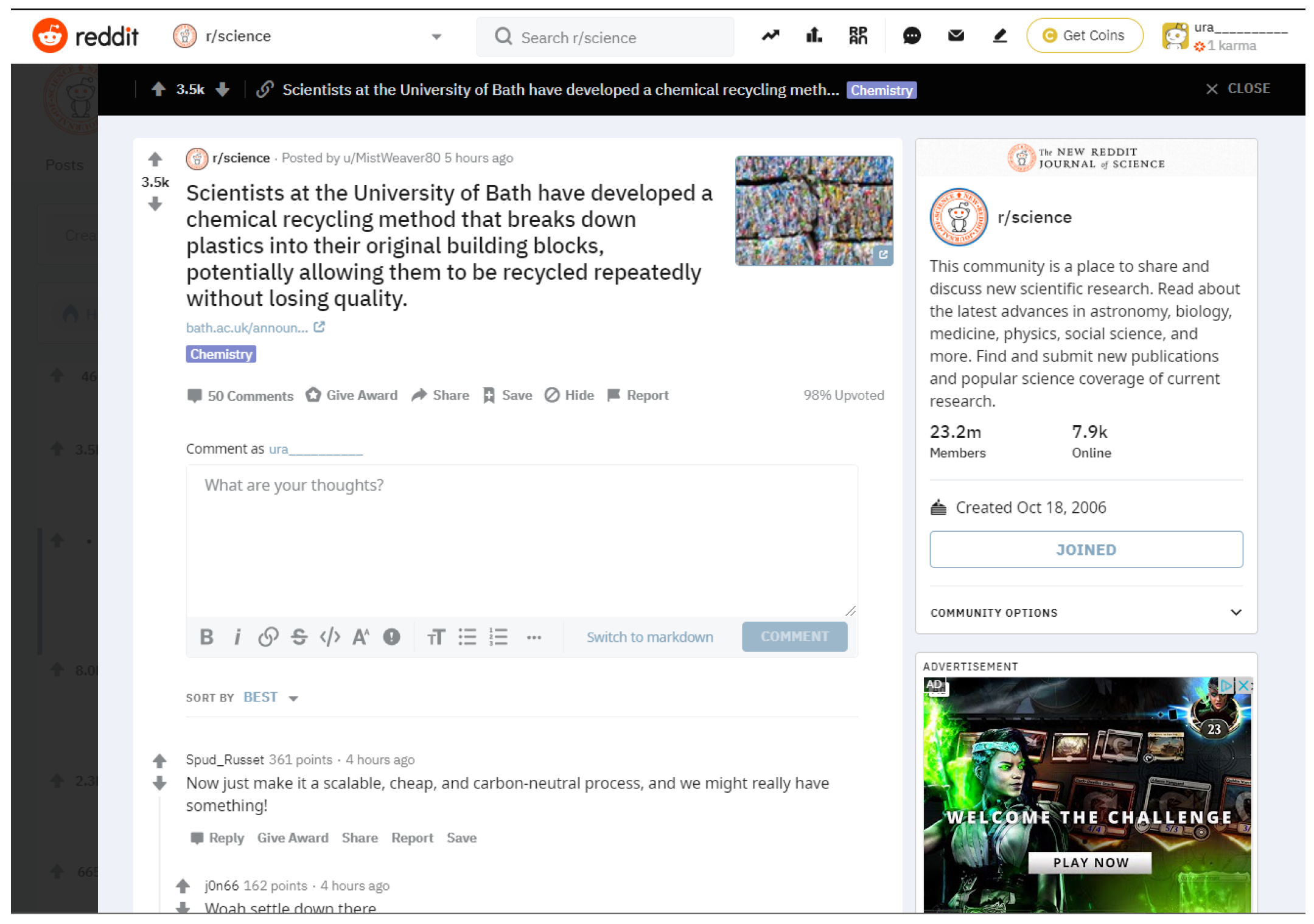
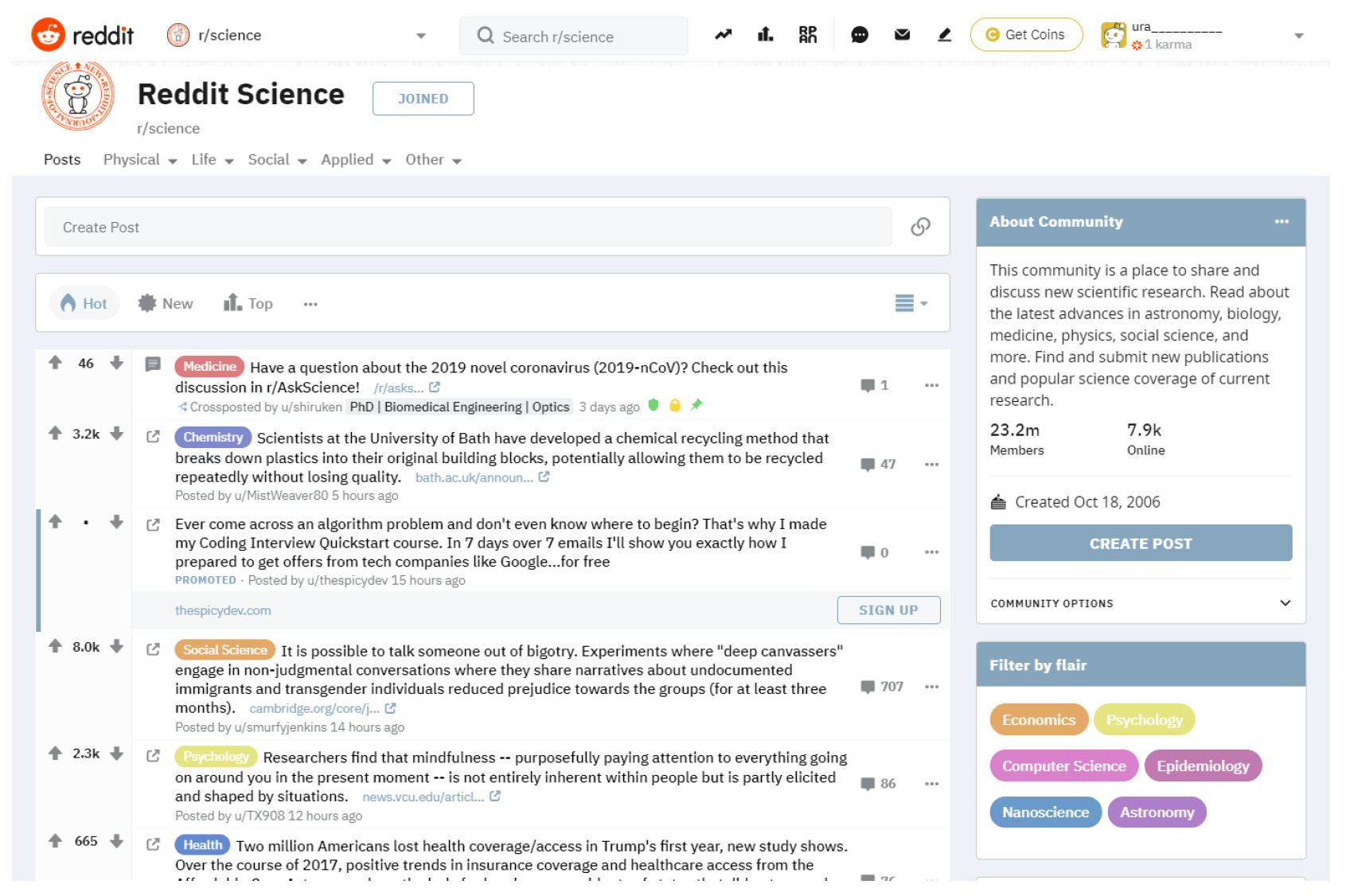
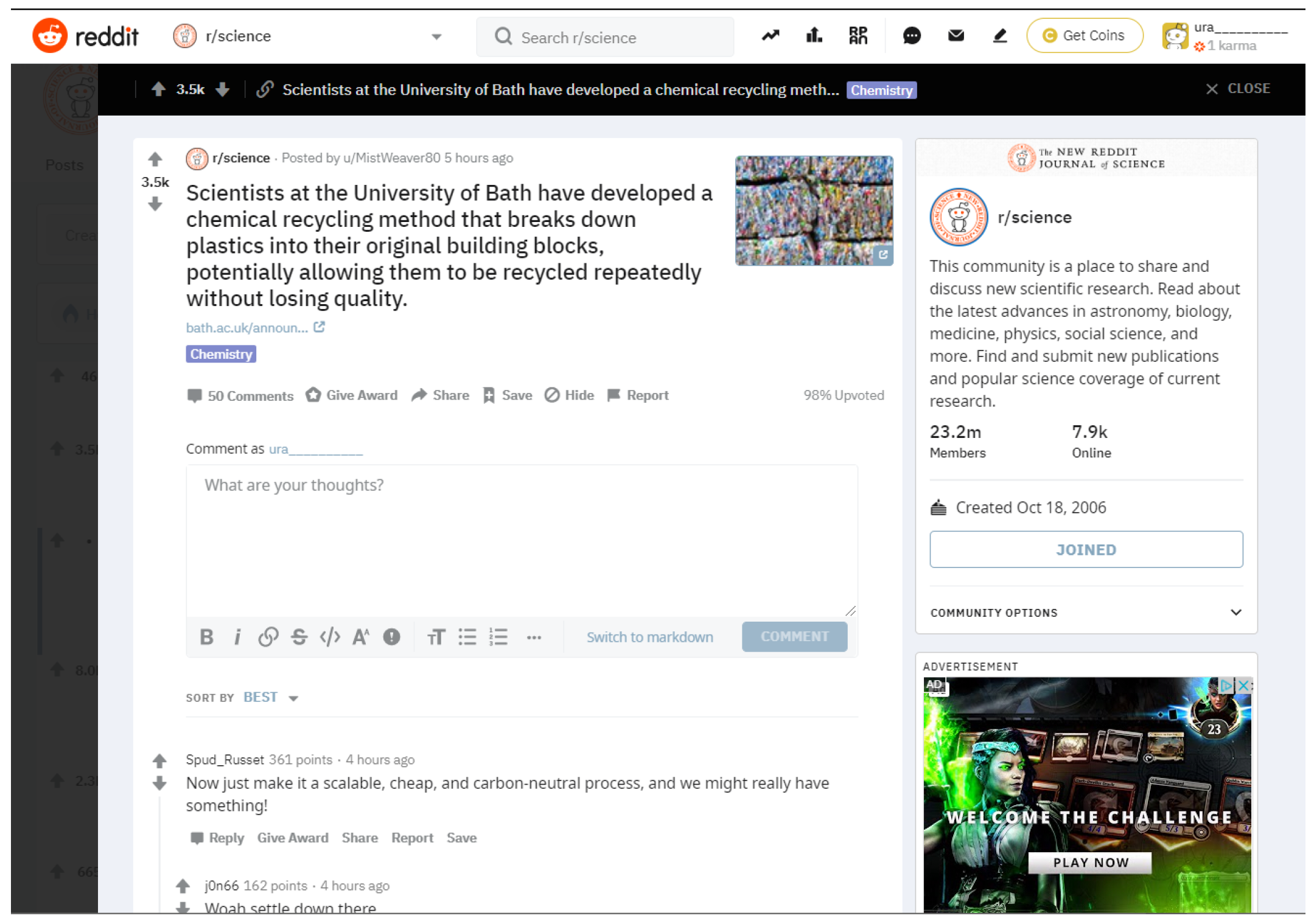
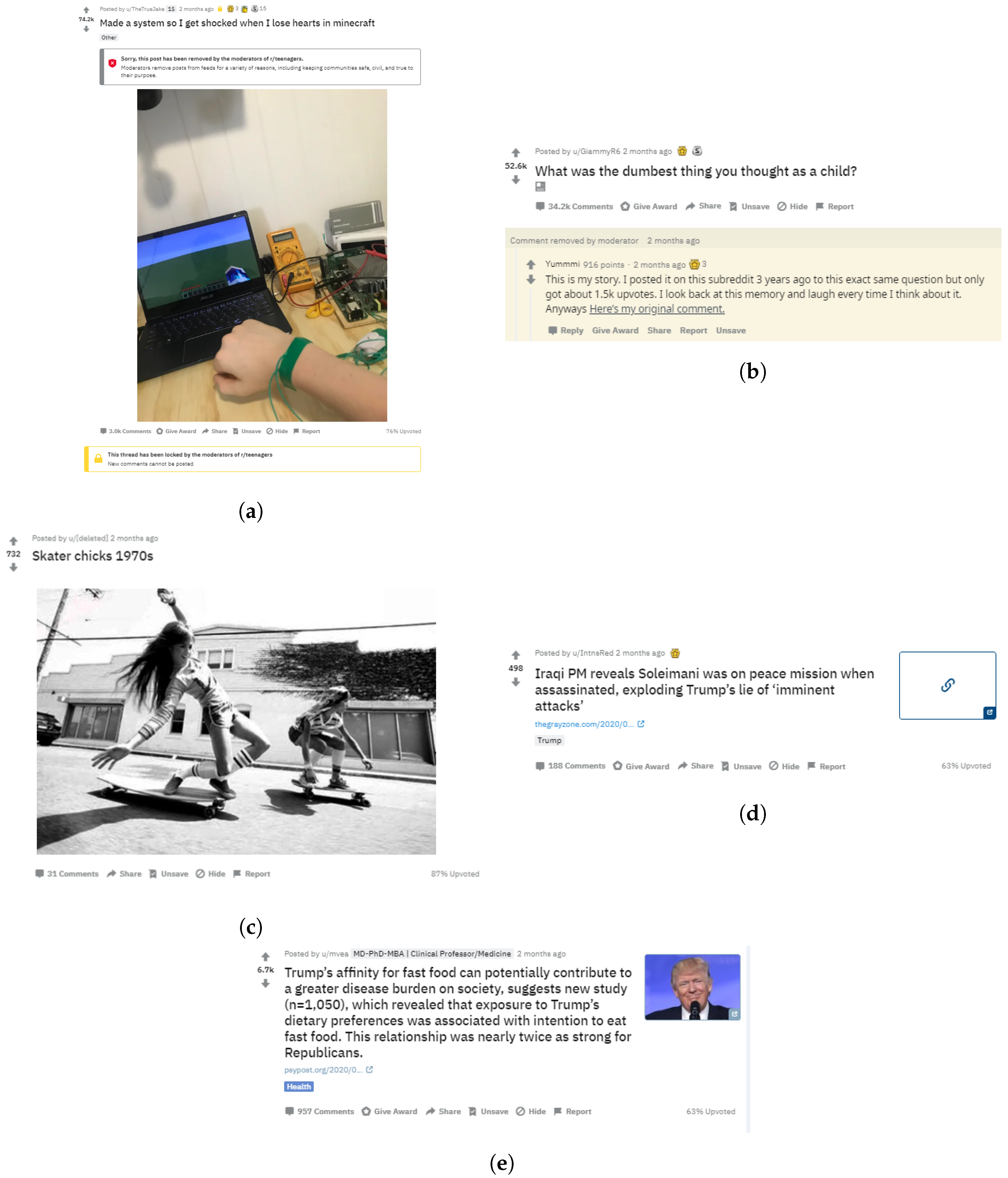
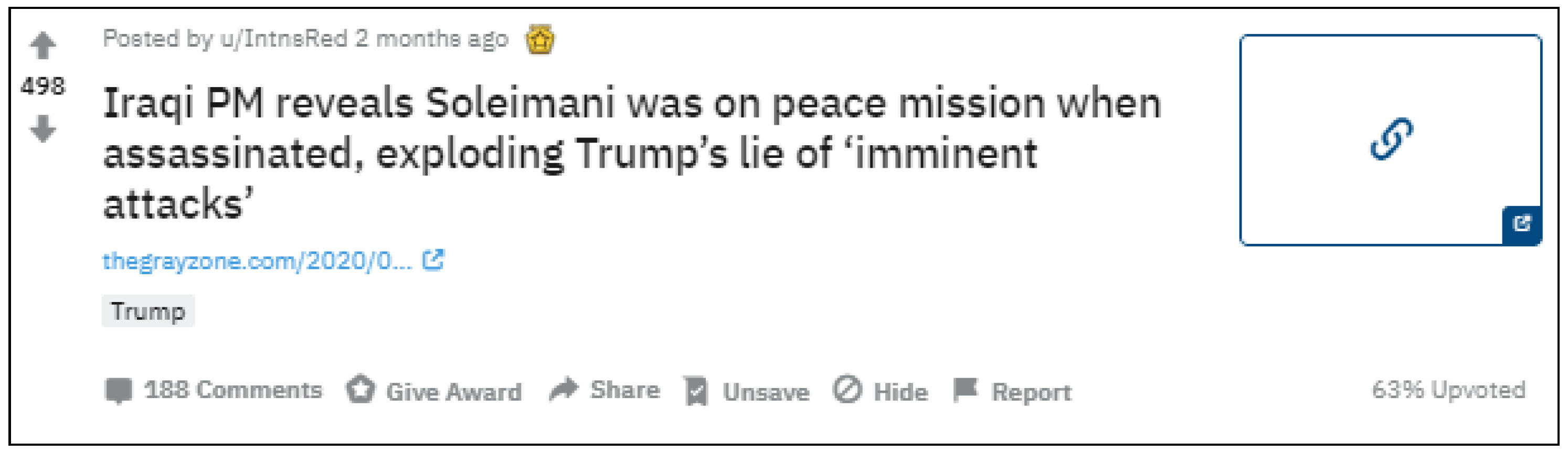
3.2. Reddit
3.2.1. Interface
3.2.2. Misinformation
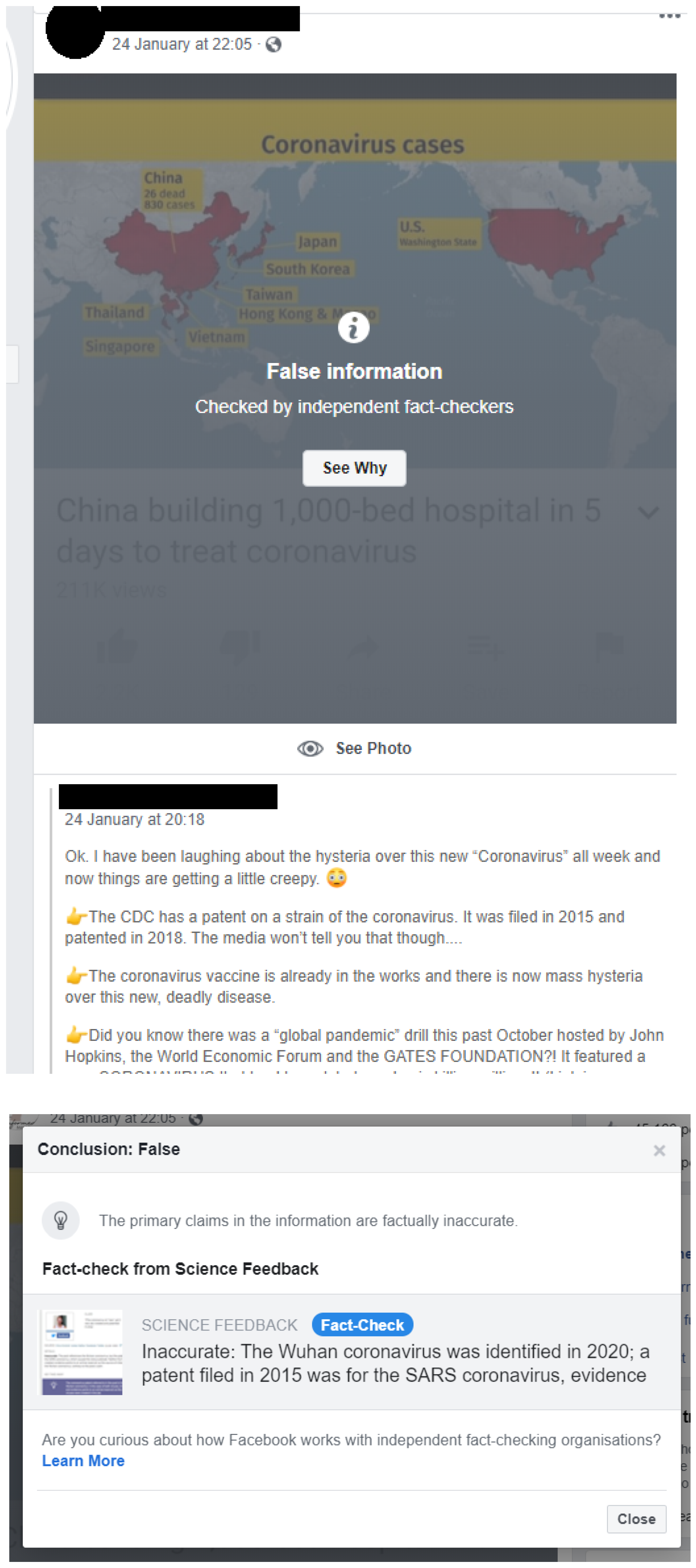
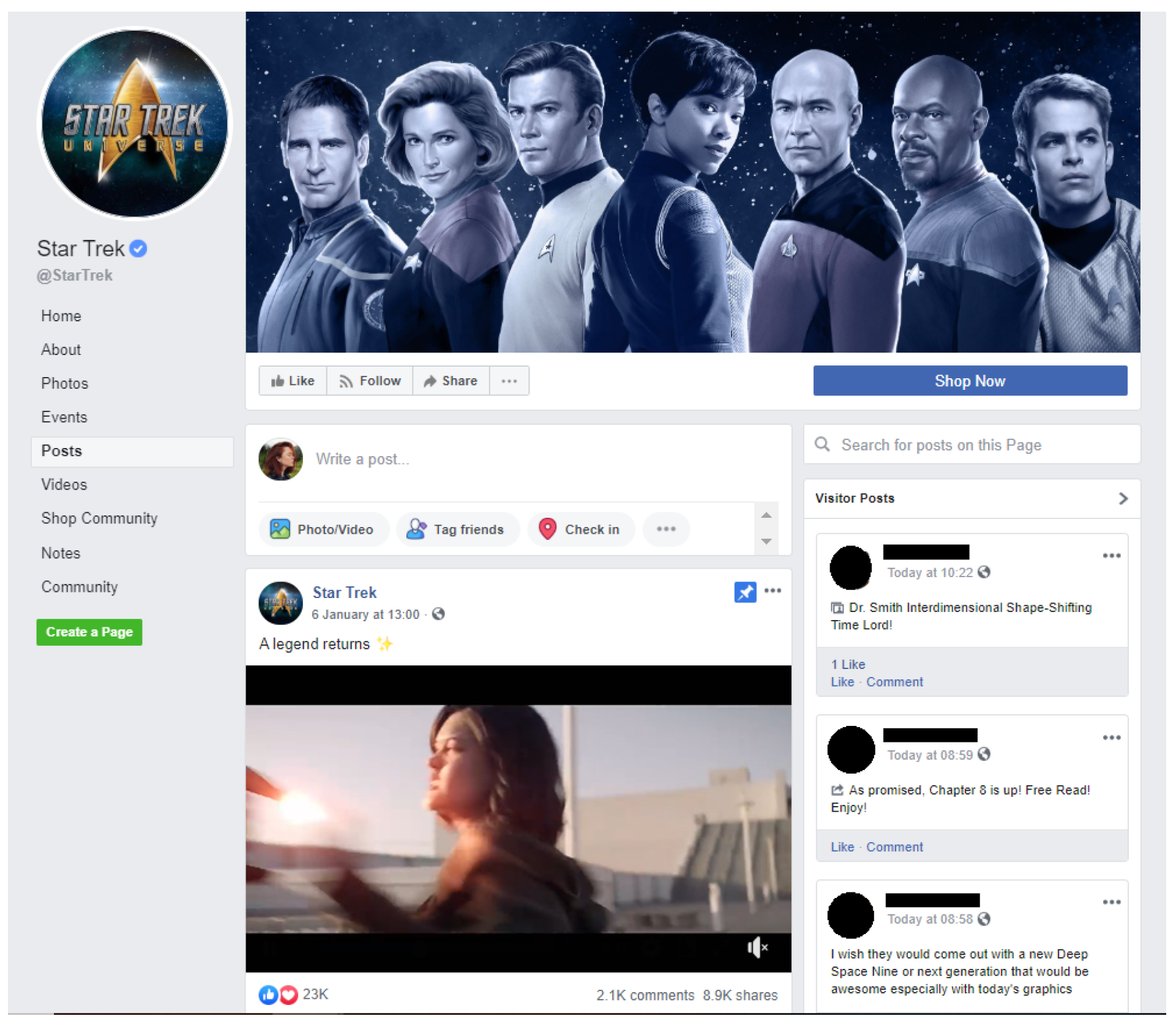
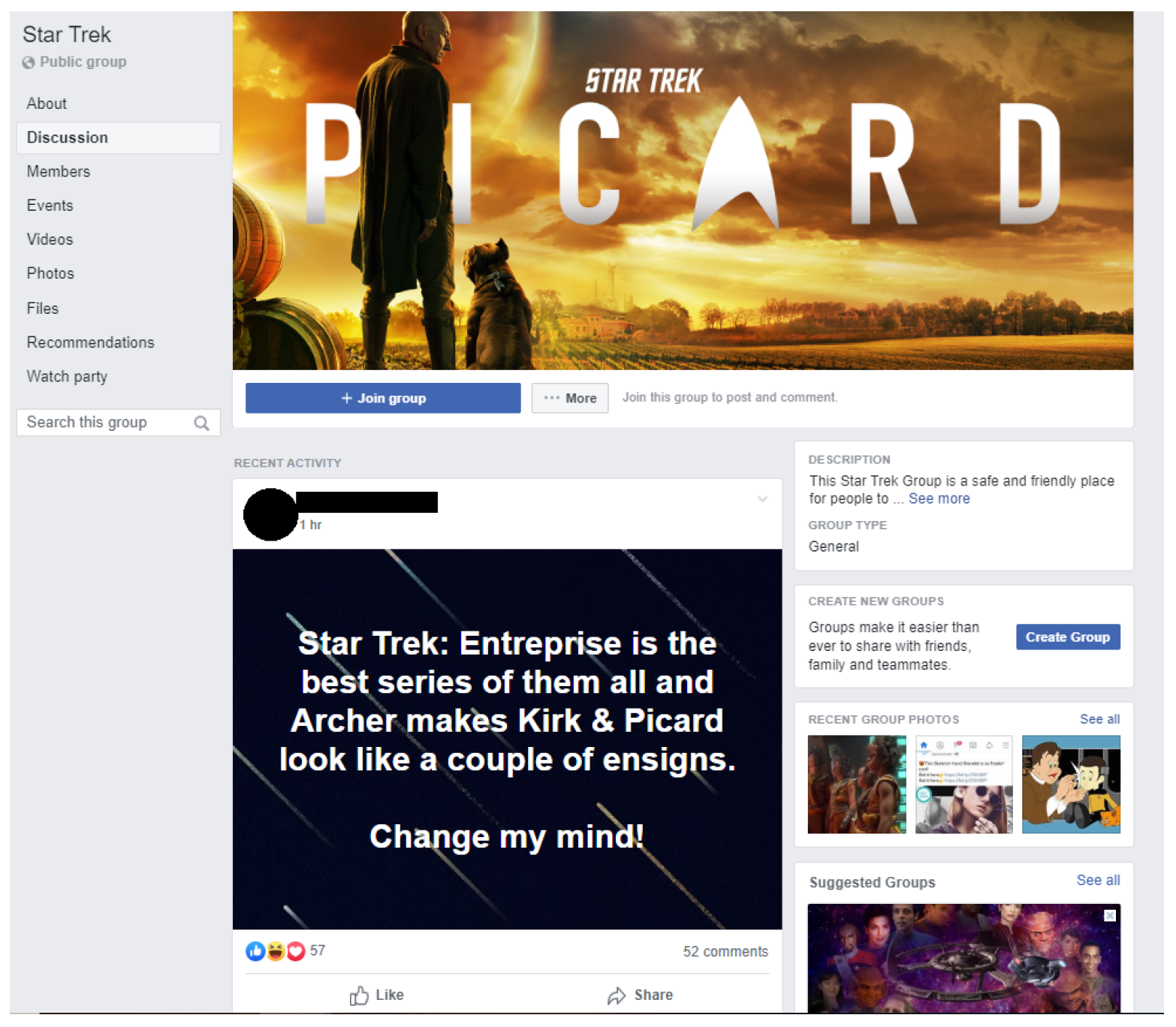
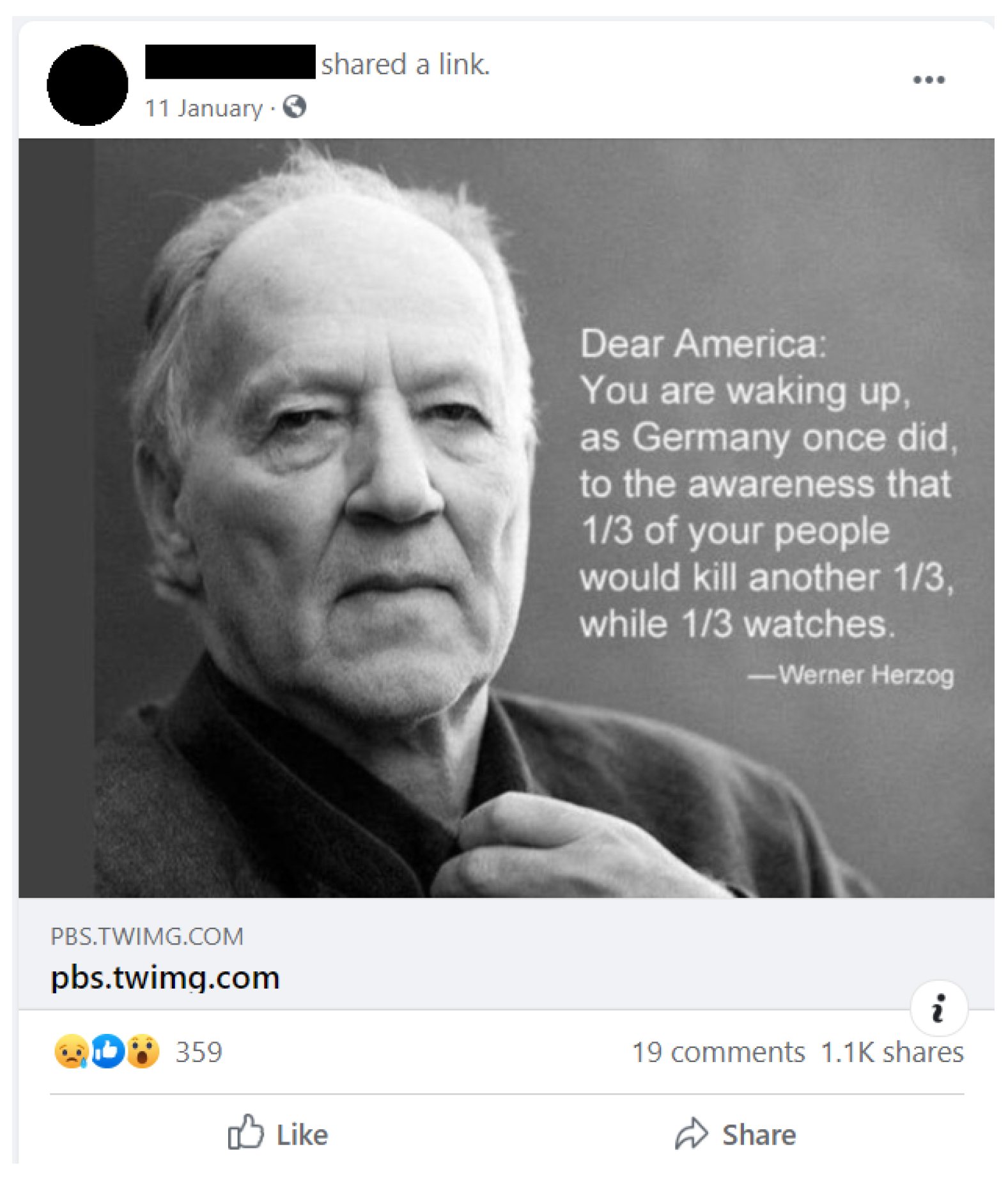
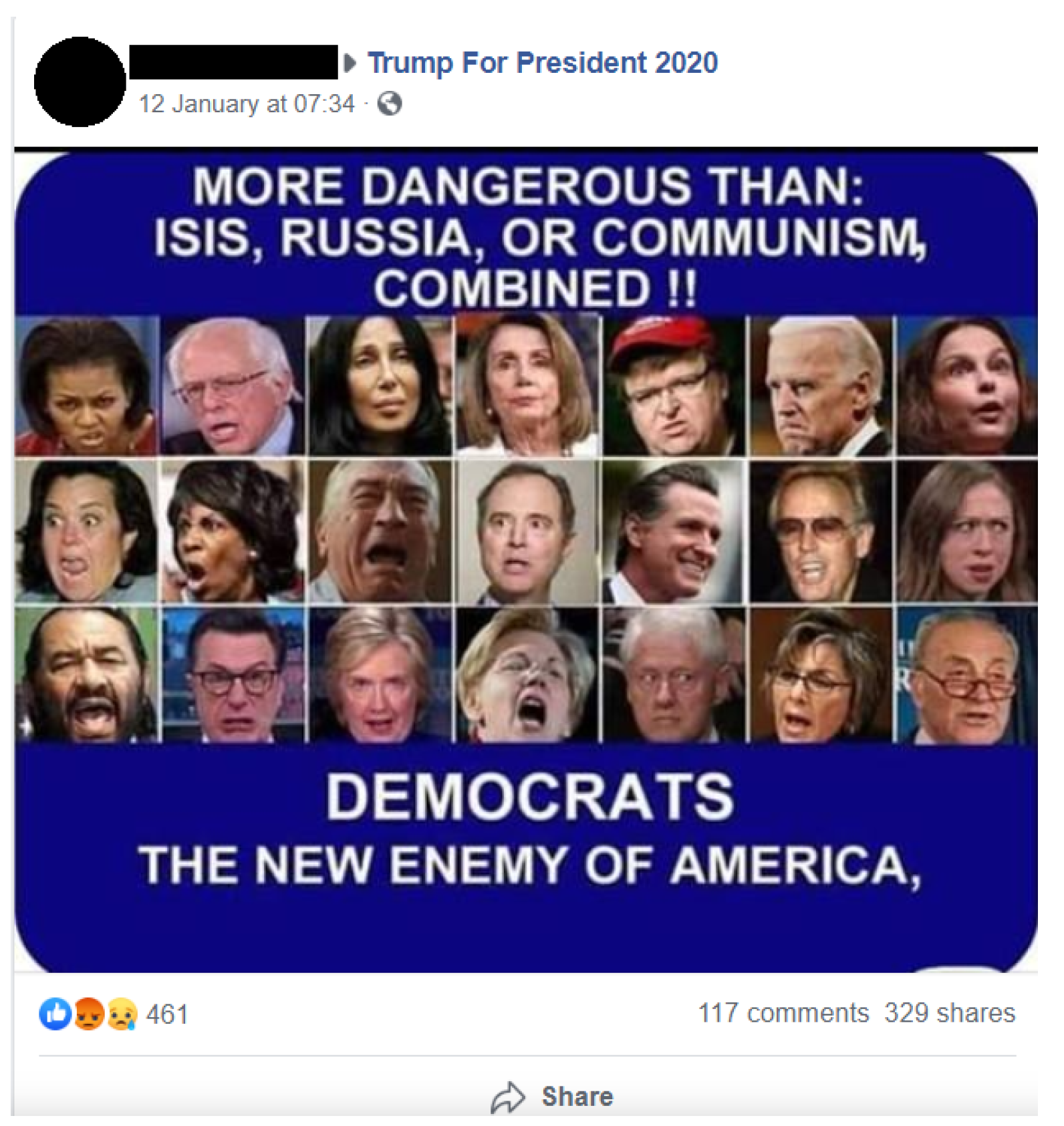
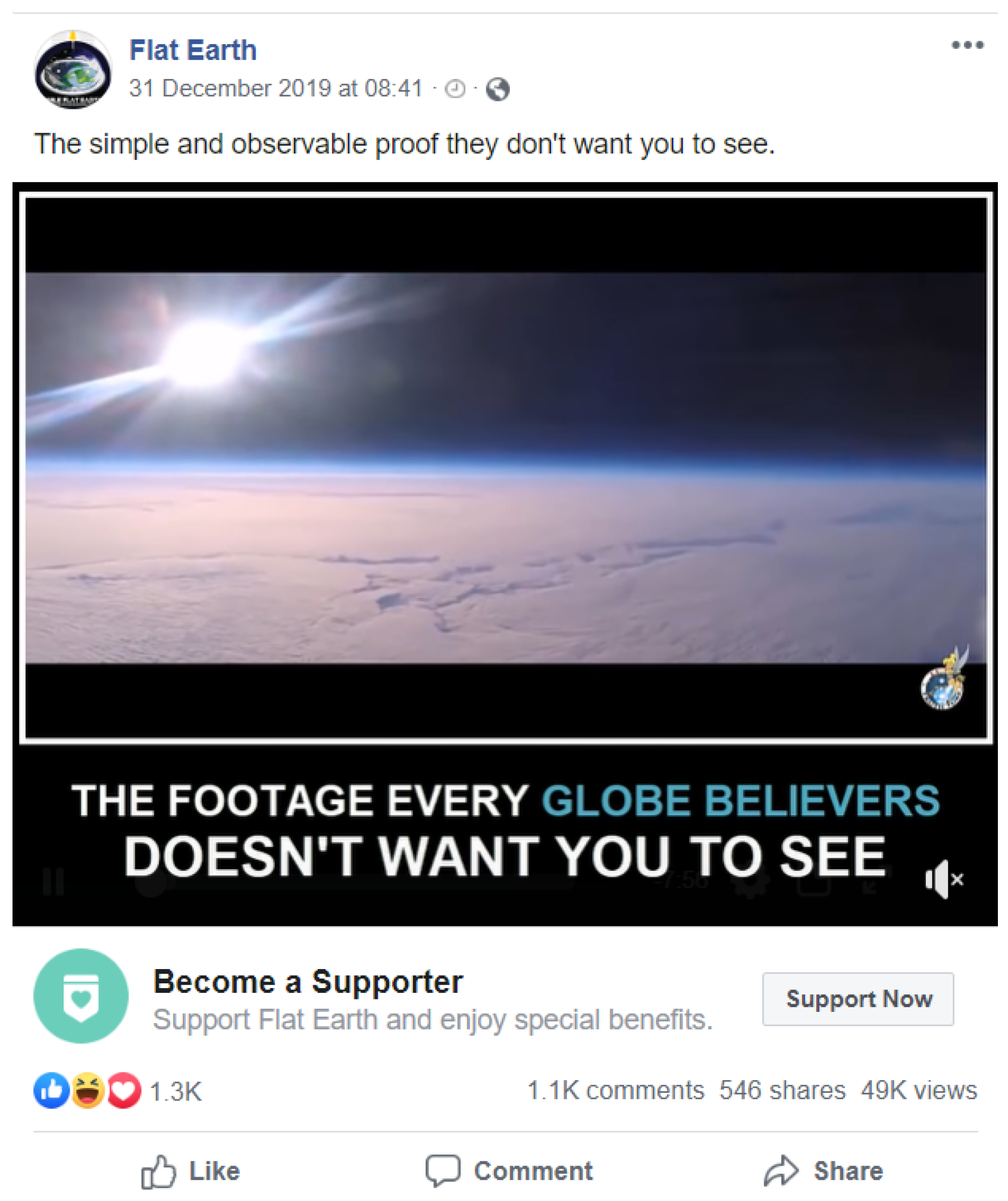
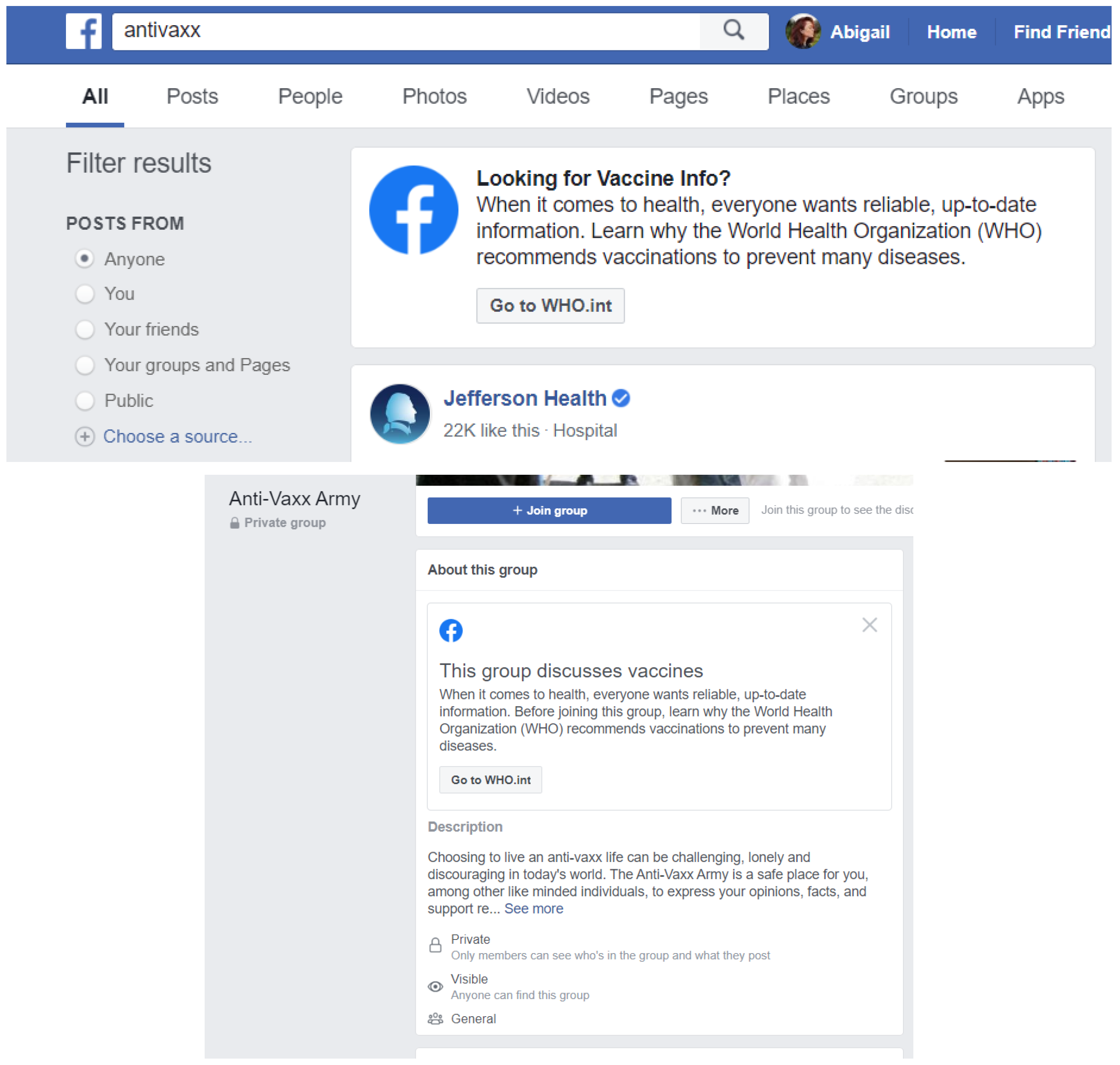
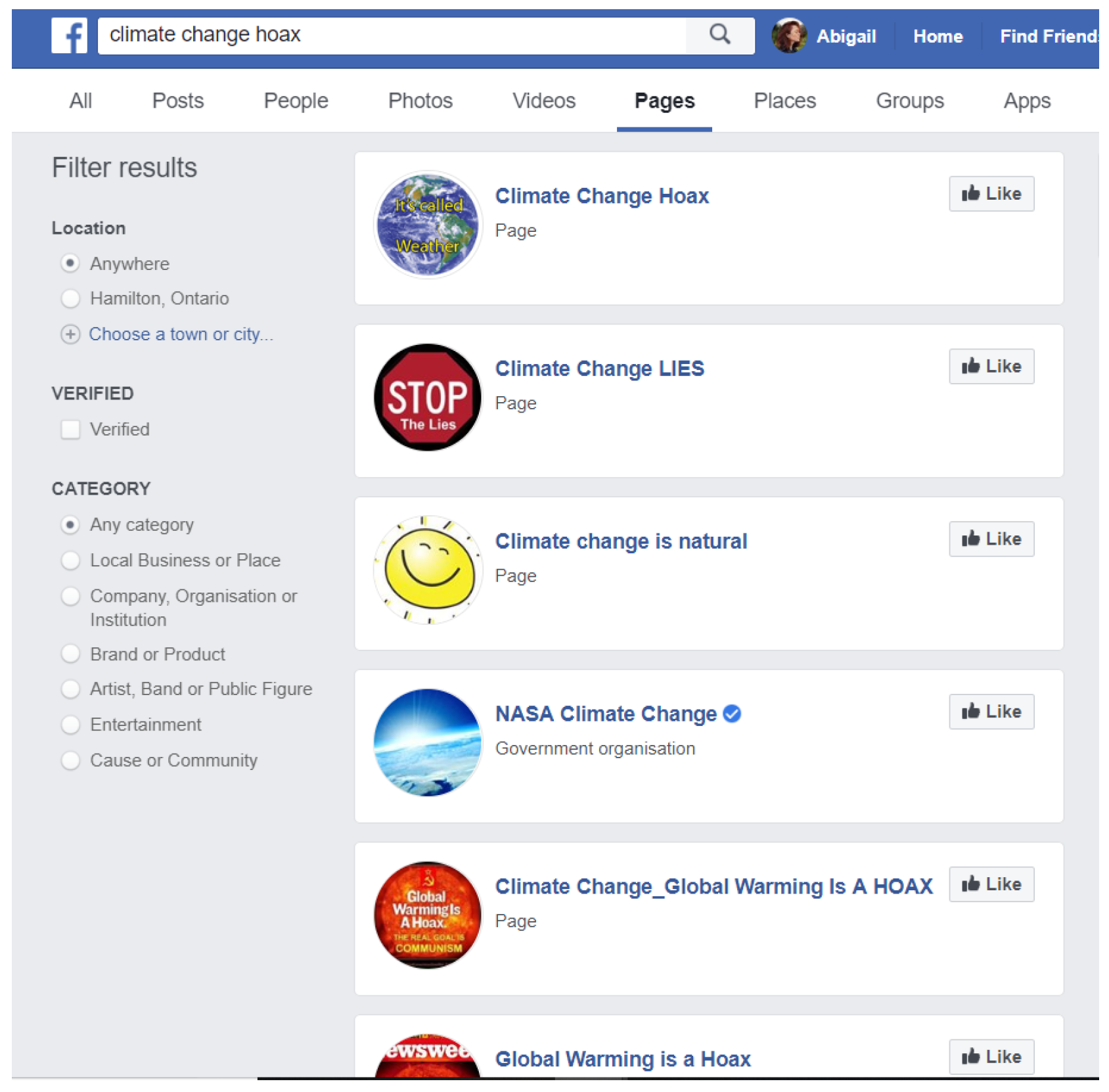
3.3. Facebook
3.3.1. Interface
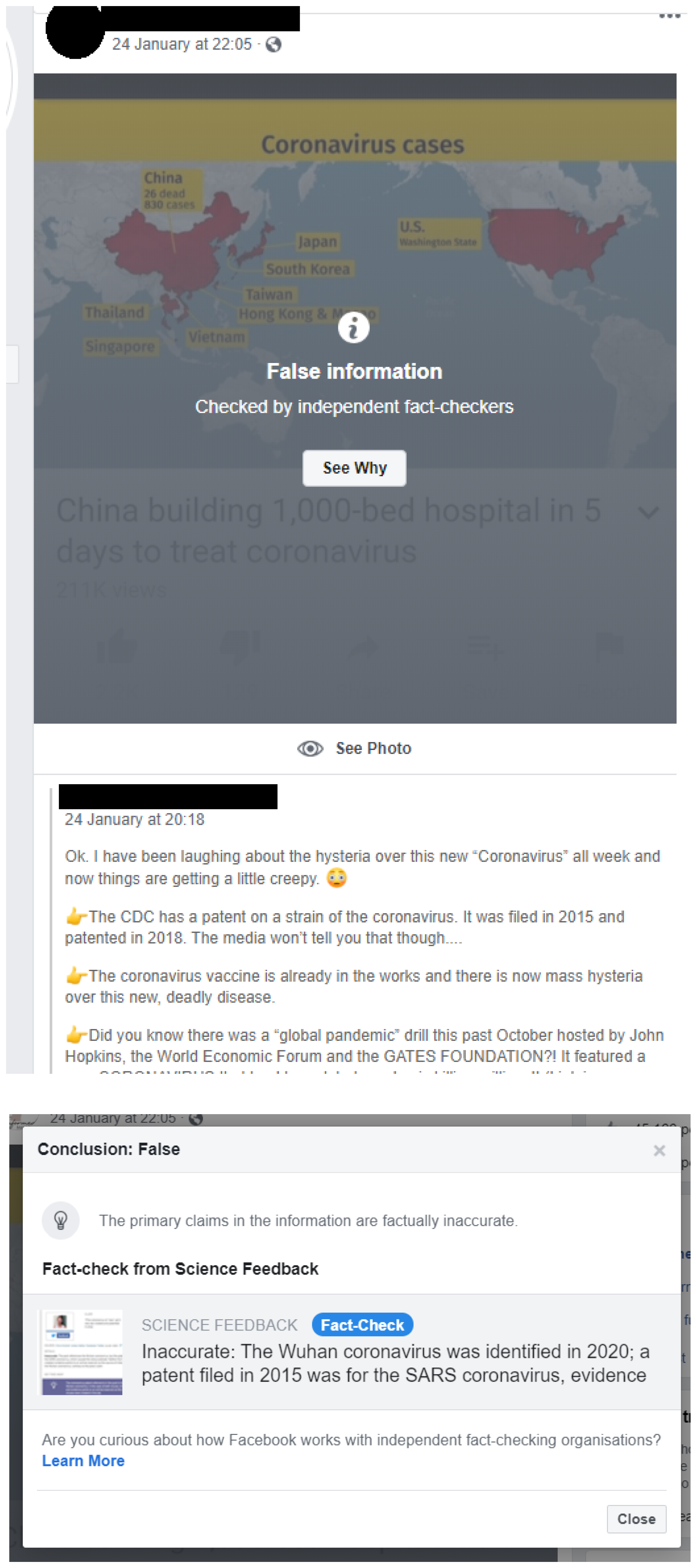
3.3.2. Misinformation
Healthcare Examples
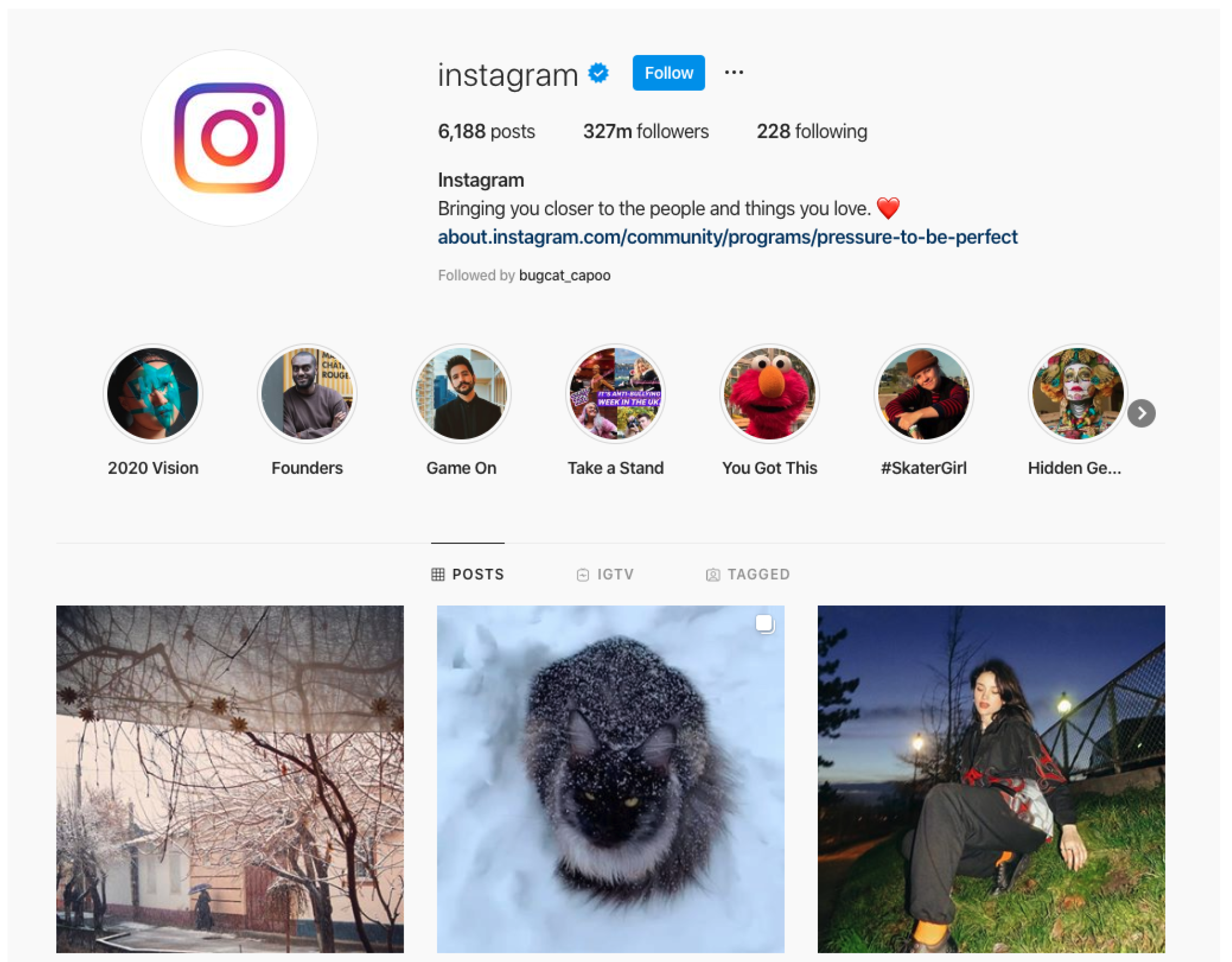
3.4. Snapchat and Instagram
3.4.1. Interfaces
3.4.2. Misinformation
- intent (1–5) where 1 is unintended and 5 is deliberate
- persistence (1–5) where 1 is an isolated incident and 5 is frequently
- acceptance (1–5) where 1 is universally rejected and 5 is widely accepted
- popularity (1–5) where 1 is very few likes and 5 is a large number of likes (using a log scale where 1 means zero or more likes, 2 means 100 or more likes, 3 means 10,000 or more likes, 4 means 1,000,000 or more likes, and 5 means 100,000,000 or more likes)
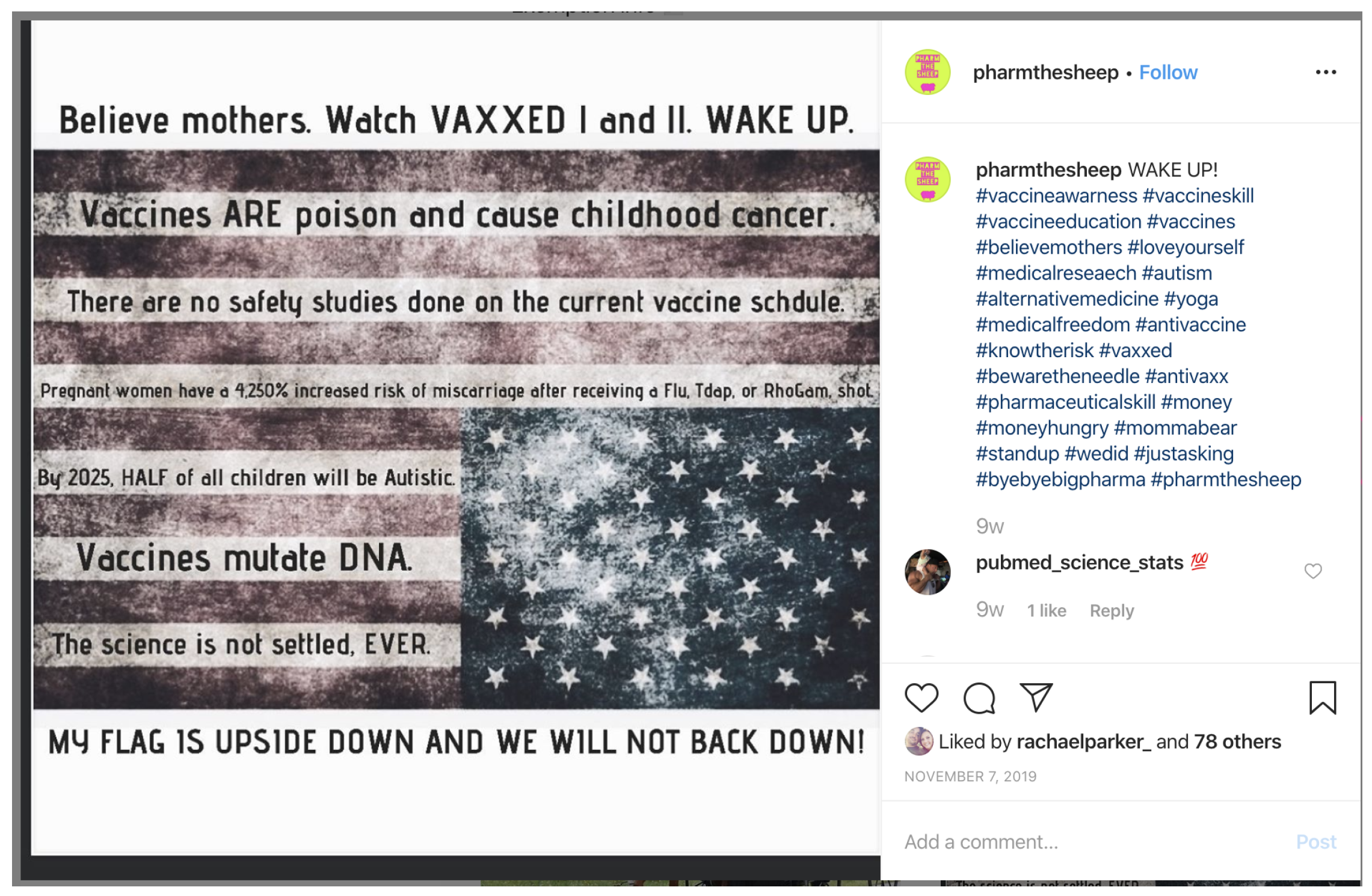
3.5. WeChat
3.5.1. Interface
3.5.2. Misinformation
3.6. Weibo
Misinformation
4. Older Adult Users
5. Results: Artificial Intelligence Trust Modeling to Detect Misinformation
5.1. Twitter
5.2. Reddit
5.3. Facebook
5.4. Returning to Sample Cases of Misinformation
5.5. Towards a Comprehensive Approach for Detecting Social Network Misinformation
6. Materials and Methods: Addressing Detected Misinformation
6.1. Holding Anti-Social Posts to Further Inspection
6.2. Options to Provide to Users
6.3. Applying the Lens of Older Adults to Active Approaches
7. Discussion
7.1. Healthcare Misinformation
7.2. Rumour Spread in Social Networks
8. Conclusions
8.1. Impact and the Future
8.2. Summary of Research Questions in This Work: Lessons Learned
- RQ1:
- Does misinformation exist in different popular social networking sites?
- RQ2:
- Can existing multiagent trust modeling algorithms be effectively applied towards the detection of misinformation in social media?
- RQ3:
- Do the algorithms developed in RQ2 support personalized solutions for key user communities such as older adults?
- RQ4:
- Do the algorithms developed in RQ2 provide insights into how to address key concerns such as health misinformation?
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Compendium of Sample Misinformation





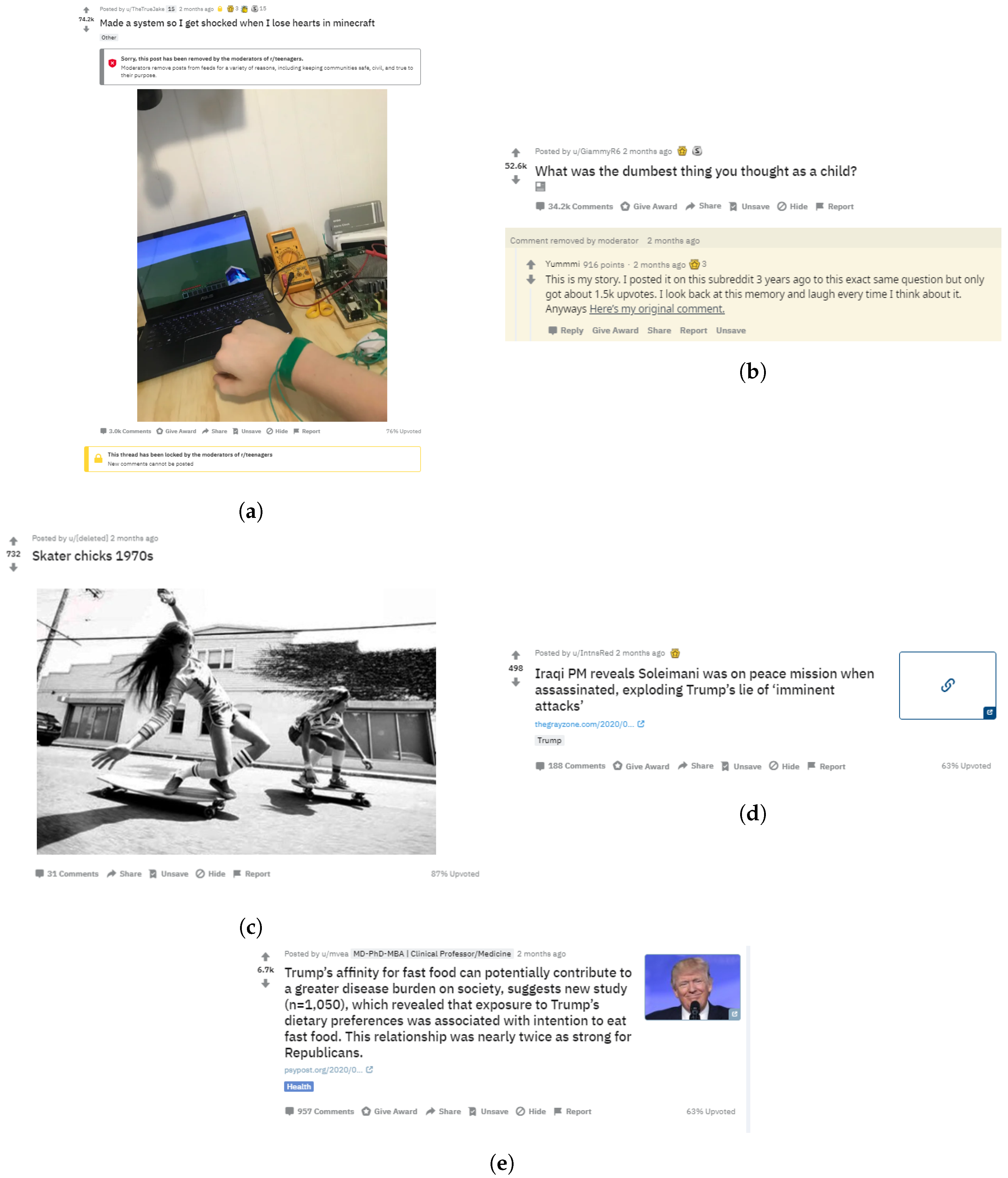














Appendix B. Key Processes for Reasoning about Misinformation



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Possible Values |
|---|---|
| Message type | {post, comment} |
| Net score | integer |
| Number of comments | integer |
| Highest score on follow-up comment with sentiment of distrust | integer |
| Intentional? | {yes, no} |
| Author karma | integer |
| Author is repeat offender? | {yes, no} |
| Easily verifiable? | {yes, no} |
| Supporting evidence provided? | {yes, no} |
| Informal use of language? | {yes, no} |
| Feature | Description |
|---|---|
| Message type | Whether the message in question is a post or a comment. |
| Net score | The net score of a post/comment. This is an indication of the positivity/negativity in the reactions of the community to the message. As this is approximately number of upvotes minus number of downvotes (i.e., a difference), it should be compared with the number of comments to estimate a proportion. |
| Number of comments | This is an indication of the amount of attention the message received. Since the size of a subreddit influences visibility of its content, to get a more relative estimate, one could compare the number of comments with the number of followers of the subreddit, or the number of comments in the highest rated posts on that subreddit. |
| Highest score on follow-up comment with sentiment of distrust | This is an indication of how distrustful the community is to the message. This should be compared with the number of comments or net score for a more relative estimate. |
| Intentional? | Whether the author accidentally or intentionally tried to spread misinformation. For the most part, this can only come as an impression. An author that apologizes in follow-up comments could indicate an accident, whereas an author that denies untruthfulness with additional poor arguments could indicate they acted intentionally. |
| Author karma | The author’s total karma (i.e., score) for past posts/comments. This is an indication of how credible an author is. |
| Author is repeat offender? | This is another indication of how credible an author is. |
| Easily verifiable? | Whether it is easy to verify the truthfulness of the message. This may influence the highest score on a follow-up comment with a sentiment of distrust as fewer members of the community would be able to verify the message. Things such as general facts or public events would be easier to verify, whereas things such as personal stories would be more difficult. |
| Supporting evidence provided? | This is an indication for the credibility of a post. |
| Informal use of language? | This is an indication for the credibility of a post. |
Appendix C. Sardana’s Model
- S: The state space for a message, defined as {good, bad}
- A: The action space for the agent, defined as {accept, reject, elicit_advice}
- O: The set of observations associated with actions. In this work, the accept and reject actions always result in a nil observation, while requesting advice results in a tuple , where r is the rating a peer has given to the message, m is the similarity that peer has to the recomendee, and c is the credibility of the peer.
- : The transition function for message state given the current state and the chosen action.
- : The probability of seeing observation o given action a is taken at and the state at is .
- : The reward function representing the utility of each state-action pair for a particular agent.
- : Reward discount factor.
- h: Horizon (finite or infinite).
Appendix D. Illustration on Sample Misinformation
| Algorithm A1: Belief Updating |
 |
Example
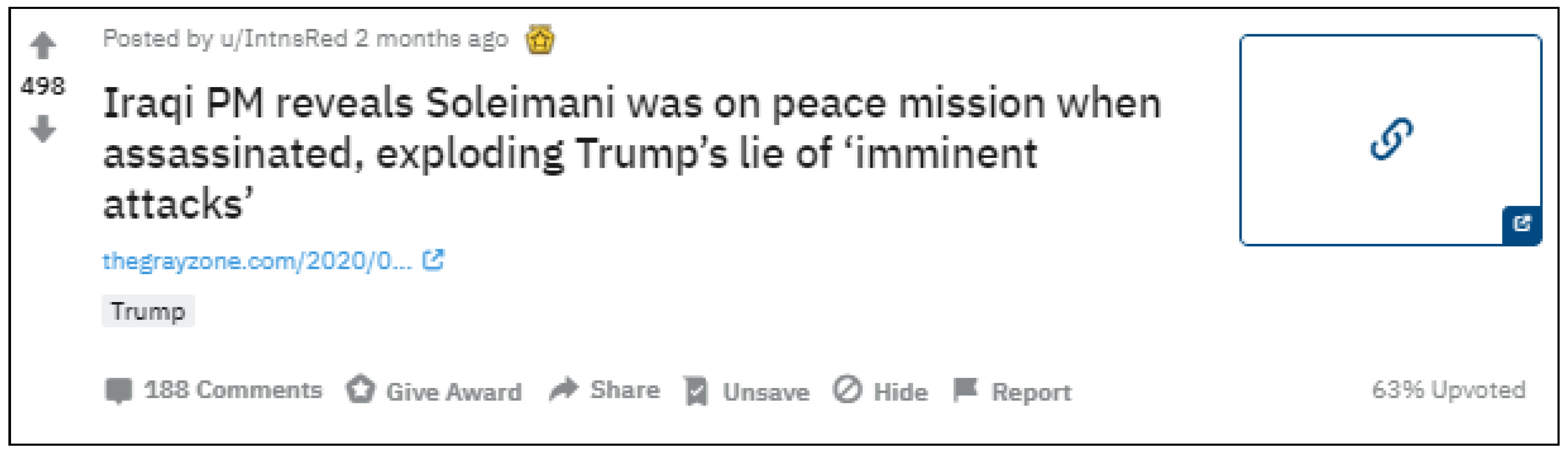
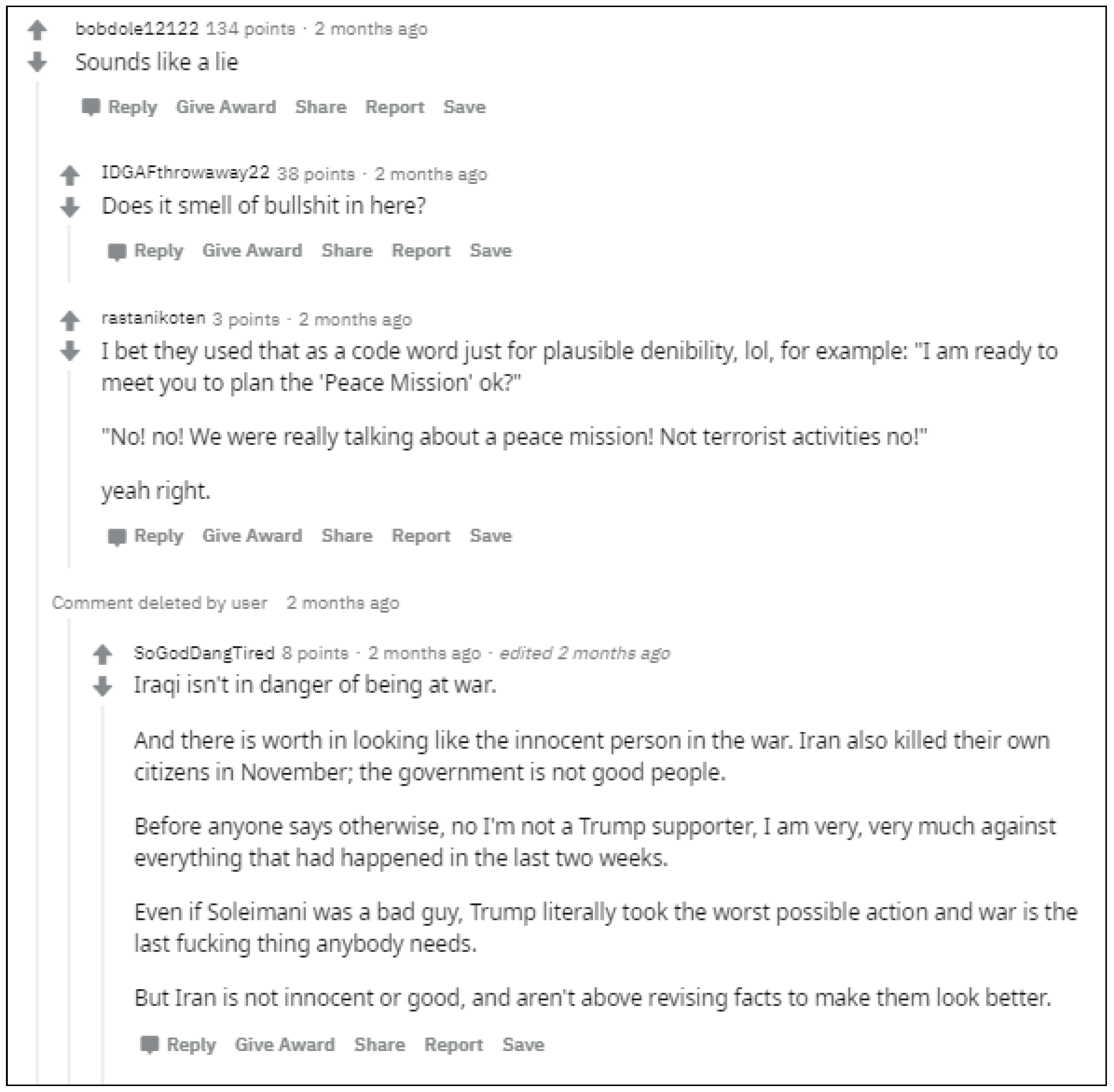
- the rating information—which users voted, what did they vote
- comments on the post
- past ratings of users
- likelihood that the post contains misinformation—the belief that this message is bad, the output from detecting misinformation
- severity—some value based on how severe the consequences may be if this post is misinterpreted. As the subreddit is about world news and this post covers a serious political event, this value would be somewhat high here.
- user tolerance for misinformation—depends on the user

Appendix E. Ghenai’s Rumour Spread Model


References
- Shao, C.; Ciampaglia, G.; Varol, O.; Flammini, A.; Menczer, F.; Yang, K.C. The spread of low-credibility content by social bots. Nat. Commun. 2018, 9, 4787. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sardana, N.; Cohen, R.; Zhang, J.; Chen, S. A Bayesian Multiagent Trust Model for Social Networks. IEEE Trans. Comput. Soc. Syst. 2018, 5, 995–1008. [Google Scholar]
- Parmentier, A.; Cohen, R. Learning User Reputation on Reddit. In Proceedings of the 2019 IEEE/WIC/ACM International Conference on Web Intelligence (WI 2019), Thessaloniki, Greece, 14–17 October 2019; Barnaghi, P.M., Gottlob, G., Manolopoulos, Y., Tzouramanis, T., Vakali, A., Eds.; ACM: New York, NY, USA, 2019; pp. 242–247. [Google Scholar] [CrossRef]
- Parmentier, A.; Cohen, R. Personalized Multi-Faceted Trust Modeling in Social Networks. In Proceedings of the Advances in Artificial Intelligence—33rd Canadian Conference on Artificial Intelligence (Canadian AI 2020), Ottawa, ON, Canada, 13–15 May 2020; pp. 445–450. [Google Scholar] [CrossRef]
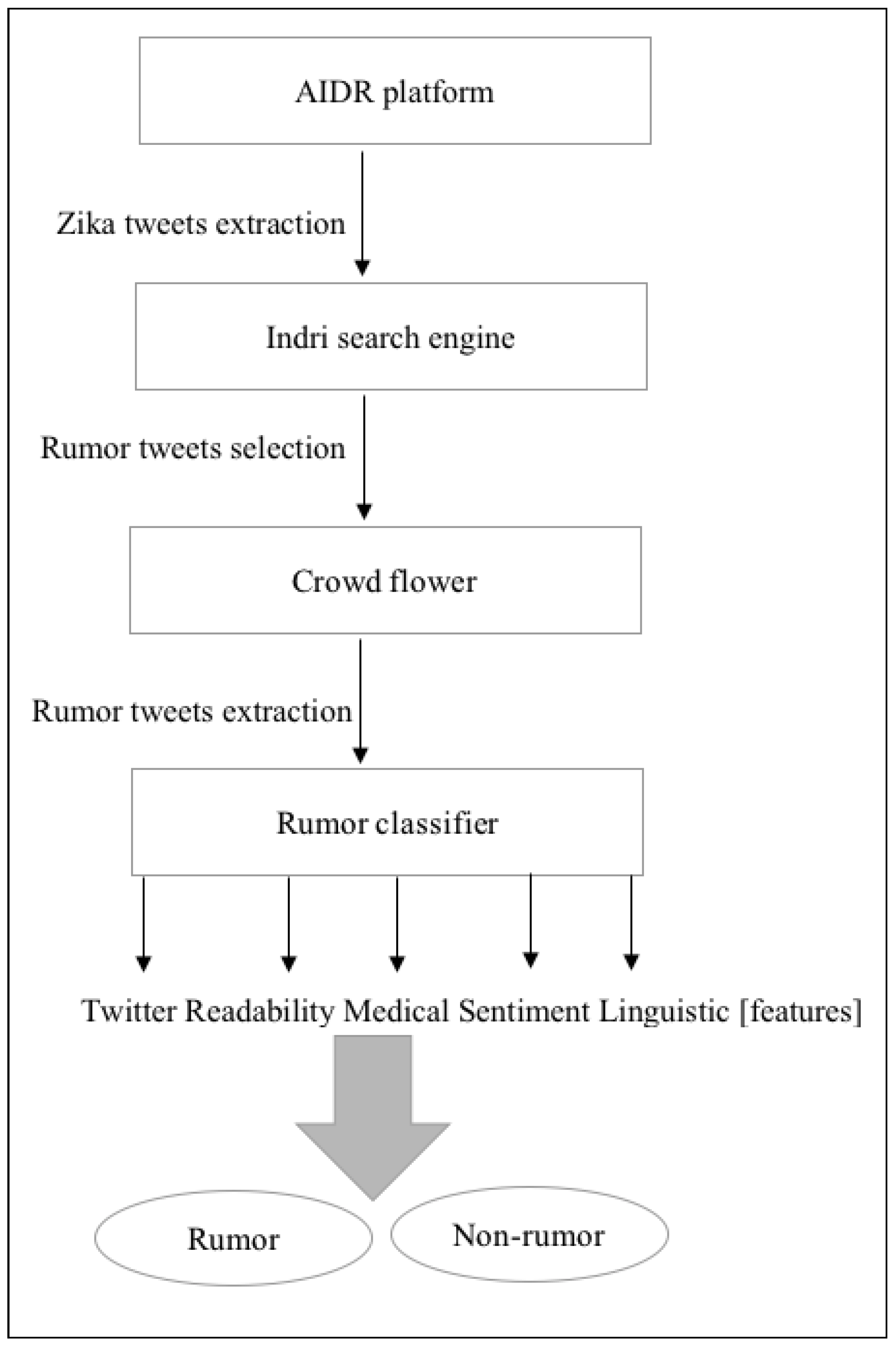
- Ghenai, A.; Mejova, Y. Catching Zika Fever: Application of Crowdsourcing and Machine Learning for Tracking Health Misinformation on Twitter. In Proceedings of the 2017 IEEE International Conference on Healthcare Informatics (ICHI 2017), Park City, UT, USA, 23–26 August 2017; p. 518. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Singh, M.P. Evidence-Based Trust: A Mathematical Model Geared for Multiagent Systems. ACM Trans. Auton. Adapt. Syst. 2010, 5, 1–28. [Google Scholar] [CrossRef]
- Teacy, W.; Patel, J.; Jennings, N.; Luck, M. TRAVOS: Trust and Reputation in the Context of Inaccurate Information Sources. Auton. Agents Multi Agent Syst. 2006, 12, 183–198. [Google Scholar] [CrossRef] [Green Version]
- Burnett, C.; Norman, T.J.; Sycara, K.P. Trust Decision-Making in Multi-Agent Systems. In Proceedings of the IJCAI 2011 the 22nd International Joint Conference on Artificial Intelligence, Catalonia, Spain, 16–22 July 2011; pp. 115–120. [Google Scholar] [CrossRef]
- Sabater-Mir, J.; Sierra, C. Review on Computational Trust and Reputation Models. Artif. Intell. Rev. 2005, 24, 33–60. [Google Scholar] [CrossRef]
- Granatyr, J.; Botelho, V.; Lessing, O.R.; Scalabrin, E.E.; Barthès, J.P.; Enembreck, F. Trust and Reputation Models for Multiagent Systems. ACM Comput. Surv. 2015, 48, 1–42. [Google Scholar] [CrossRef]
- Sen, S.; Rahaman, Z.; Crawford, C.; Yücel, O. Agents for Social (Media) Change; International Foundation for Autonomous Agents and Multiagent Systems: Richland, DC, USA, 2018; pp. 1198–1202. [Google Scholar]
- Sapienza, A.; Falcone, R. How to Manage the Information Sources’ Trustworthiness in a Scenario of Hydrogeological Risks. In Proceedings of the 18th International Workshop on Trust in Agent Societies co-located with the 15th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2016), Singapore, 10 May 2016; pp. 71–82. [Google Scholar]
- Cormier, M.; Moffatt, K.; Cohen, R.; Mann, R. Purely Vision-Based Segmentation of Web Pages for Assistive Technology. Comput. Vis. Image Underst. 2016, 148, 46–66. [Google Scholar]
- Ohashi, D.; Cohen, R.; Fu, X. The Current State of Online Social Networking for the Health Community: Where Trust Modeling Research May Be of Value. In Proceedings of the 2017 International Conference on Digital Health, Association for Computing Machinery, New York, NY, USA, 2–5 July 2017; pp. 23–32. [Google Scholar] [CrossRef]
- Manjoo, F. How Twitter Is Being Gamed to Feed Misinformation; The New York Times: New York, NY, USA, 2017. [Google Scholar]
- Press Association. Twitter Directs Users to Government Information on Coronavirus with a Link to the Department of Health and Social Care That also Provides Official Updates about the Deadly Virus; Press Association: London, UK, 2020. [Google Scholar]
- Zadrozny, B.; Rosenblatt, K.; Collins, B. Coronavirus Misinformation Surges, Fueled by Clout Chasers; NBC News: New York, NY, USA, 2020. [Google Scholar]
- Schultz, A. How Does Facebook Measure Fake Accounts? 2019. Available online: https://about.fb.com/news/2019/05/fake-accounts/ (accessed on 20 August 2020).
- Facebook. What Types of ID Does Facebook Accept? Available online: https://www.facebook.com/help/159096464162185 (accessed on 20 August 2020).
- Thomala, L.L. Number of Sina Weibo Users in China 2017–2021. 2019. Available online: https://www.statista.com/statistics/941456/china-number-of-sina-weibo-users/ (accessed on 19 February 2020).
- Chokshid, N. Older People Shared Fake News on Facebook More Than Others in 2016 Race, Study Says; The New York Times: New York, NY, USA, 2019. [Google Scholar]
- Guess, A.; Nagler, J.; Tucker, J. Less than you think: Prevalence and predictors of fake news dissemination on Facebook. Sci. Adv. 2019, 5, eaau4586. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wylie, L.E.; Patihis, L.; McCuller, L.; Davis, D.; Brank, E.; Loftus, E.F.; Bornstein, B. Misinformation Effect in Older versus Younger Adults: A Meta-Analysis and Review. In The Elderly Eyewitness in Court; Psychology Press: New York, NY, USA, 2014. [Google Scholar]
- Bosak, K.; Park, S.H. Characteristics of Adults’ Use of Facebook and the Potential Impact on Health Behavior: Secondary Data Analysis. Interact. J. Med. Res. 2018, 7, e11. [Google Scholar] [CrossRef] [PubMed]
- Wood, S.; Lichtenberg, P.A. Financial Capacity and Financial Exploitation of Older Adults: Research Findings, Policy Recommendations and Clinical Implications. Clin. Gerontol. 2017, 40, 3–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jung, E.H.; Sundar, S.S. Senior citizens on Facebook: How do they interact and why? Comput. Hum. Behav. 2016, 61, 27–35. [Google Scholar] [CrossRef]
- Moffatt, K.; David, J.; Baecker, R.M. Connecting Grandparents and Grandchildren. In Connecting Families: The Impact of New Communication Technologies on Domestic Life; Neustaedter, C., Harrison, S., Sellen, A., Eds.; Springer: London, UK, 2013; pp. 173–193. [Google Scholar] [CrossRef]
- Yu, J.; Moffatt, K. Improving the Accessibility of Social Media for Older Adults. In Proceedings of the CSCW’19 Workshop on Addressing the Accessibility of Social Media, Austin, TX, USA, 9–13 November 2019; pp. 1–6. [Google Scholar]
- John, O.P.; Donahue, E.M.; Kentle, R.L. The Big Five Inventory: Versions 4a and 54; Institute of Personality and Social Research, University of California: Berkeley, CA, USA, 1991. [Google Scholar]
- Ghenai, A.; Mejova, Y. Fake Cures: User-Centric Modeling of Health Misinformation in Social Media. Proc. ACM Hum. Comput. Interact. 2018, 2, 1–20. [Google Scholar] [CrossRef]
- Ghenai, A. Health Misinformation in Search and Social Media. Ph.D. Thesis, University of Waterloo, Waterloo, ON, Canada, 2019. [Google Scholar]
- Zhang, J.; Cohen, R. Evaluating the trustworthiness of advice about seller agents in e-marketplaces: A personalized approach. Electron. Commer. Res. Appl. 2008, 7, 330–340. [Google Scholar] [CrossRef]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Parmentier, A.; PNg, J.; Tan, W.; Cohen, R. Learning Reddit user reputation using graphical attention networks. In Proceedings of the Accepted to Future Technologies Conference 2020, Vancouver, BC, Canada, 5–6 November 2020; pp. 1–13. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Chu, J.; McDonald, J. Helping the World Find Credible Information about Novel #Coronavirus. 2020. Available online: https://blog.twitter.com/en_us/topics/company/2020/authoritative-information-about-novel-coronavirus.html (accessed on 31 March 2020).
- TwitterSafety. Content that Increases the Chance that Someone Contracts or Transmits the Virus, Including: Denial of Expert Guidance—Encouragement to Use Fake or Ineffective Treatments, Preventions, and Diagnostic Techniques—Misleading Content Purporting to be from Experts or Authorities. 2020. Available online: https://twitter.com/TwitterSafety/status/1240418440982040579 (accessed on 31 March 2020).
- Davanipour, Z.; Sobel, E.; Ziogas, A.; Smoak, C.G.; Bohr, T.; Doram, K.; Liwnicz, B. Ocular Tonometry and Sporadic Creutzfeldt-Jakob Disease (sCJD): A Confirmatory Case-Control Study. Br. J. Med. Med. Res. 2014, 4, 2322–2333. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abelson, M.B.; Lilyestrom, L. Mad Eye Disease: Should You Worry? Rev. Ophthalmol. 2008, 15. Available online: https://www.reviewofophthalmology.com/article/mad-eye-disease-should-you-worry (accessed on 6 September 2020).
- Fernandez, M.; Alani, H. Online misinformation: Challenges and future directions. In Proceedings of the Companion Proceedings of the Web Conference 2018, Lyon, France, 23–27 April 2018; pp. 595–602. [Google Scholar]
- Gupta, A.; Kumaraguru, P.; Castillo, C.; Meier, P. Tweetcred: Real-time credibility assessment of content on Twitter. In International Conference on Social Informatics; Springer: Berlin/Heidelberg, Germany, 2014; pp. 228–243. [Google Scholar]
- Ratkiewicz, J.; Conover, M.; Meiss, M.; Gonça lves, B.; Patil, S.; Flammini, A.; Menczer, F. Truthy: Mapping the spread of astroturf in microblog streams. In Proceedings of the 20th International Conference Companion on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 249–252. [Google Scholar]
- Resnick, P.; Carton, S.; Park, S.; Shen, Y.; Zeffer, N. Rumorlens: A system for analyzing the impact of rumors and corrections in social media. In Proceedings of the Computational Journalism Conference, New York, NY, USA, 24 October 2014; Volume 5, p. 7. [Google Scholar]
- Metaxas, P.T.; Finn, S.; Mustafaraj, E. Using twittertrails.com to investigate rumor propagation. In Proceedings of the 18th ACM Conference Companion on Computer Supported Cooperative Work & Social Computing, Vancouver, BC, Canada, 14–18 March 2015; pp. 69–72. [Google Scholar]
- Agarwal, R.R.; Cohen, R.; Golab, L.; Tsang, A. Locating Influential Agents in Social Networks: Budget-Constrained Seed Set Selection. In Proceedings of the Advances in Artificial Intelligence—33rd Canadian Conference on Artificial Intelligence (Canadian AI 2020), Ottawa, ON, Canada, 13–15 May 2020. [Google Scholar] [CrossRef]
- Johnson, N. Simply Complexity: A Clear Guide to Complexity Theory; Oneworld Publications: London, UK, 2009. [Google Scholar]
- Watts, D.J. Six Degrees: The Science of a Connected Age; Norton: New York, NY, USA, 2007. [Google Scholar]
- Menczer, F.; Fortunato, S.; Davis, C.A. A First Course in Network Science; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar] [CrossRef]
- Ciampaglia, G.L.; Mantzarlis, A.; Maus, G.; Menczer, F. Research Challenges of Digital Misinformation: Toward a Trustworthy Web. AI Mag. 2018, 39, 65–74. [Google Scholar] [CrossRef] [Green Version]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cohen, R.; Moffatt, K.; Ghenai, A.; Yang, A.; Corwin, M.; Lin, G.; Zhao, R.; Ji, Y.; Parmentier, A.; P’ng, J.; et al. Addressing Misinformation in Online Social Networks: Diverse Platforms and the Potential of Multiagent Trust Modeling. Information 2020, 11, 539. https://doi.org/10.3390/info11110539
Cohen R, Moffatt K, Ghenai A, Yang A, Corwin M, Lin G, Zhao R, Ji Y, Parmentier A, P’ng J, et al. Addressing Misinformation in Online Social Networks: Diverse Platforms and the Potential of Multiagent Trust Modeling. Information. 2020; 11(11):539. https://doi.org/10.3390/info11110539
Chicago/Turabian StyleCohen, Robin, Karyn Moffatt, Amira Ghenai, Andy Yang, Margaret Corwin, Gary Lin, Raymond Zhao, Yipeng Ji, Alexandre Parmentier, Jason P’ng, and et al. 2020. "Addressing Misinformation in Online Social Networks: Diverse Platforms and the Potential of Multiagent Trust Modeling" Information 11, no. 11: 539. https://doi.org/10.3390/info11110539
APA StyleCohen, R., Moffatt, K., Ghenai, A., Yang, A., Corwin, M., Lin, G., Zhao, R., Ji, Y., Parmentier, A., P’ng, J., Tan, W., & Gray, L. (2020). Addressing Misinformation in Online Social Networks: Diverse Platforms and the Potential of Multiagent Trust Modeling. Information, 11(11), 539. https://doi.org/10.3390/info11110539