Comparison of Methods to Evaluate the Influence of an Automated Vehicle’s Driving Behavior on Pedestrians: Wizard of Oz, Virtual Reality, and Video


Abstract
1. Introduction
1.1. Images
1.2. Videos
1.3. Virtual Reality
1.4. Wizard of Oz
1.5. Driving Simulator
1.6. Objectives
2. Materials and Methods
2.1. Procedure
2.2. Apparatus
2.2.1. Wizard of Oz Setup
2.2.2. Virtual Reality Setup
2.2.3. Video Setups
2.3. Study Design and Variables
- For the WoZ setup, participants saw each driving profile twice.
- For the VR setup, we added the condition “walking” instead of a second trial, since we did not let participants cross the road in the WoZ setup for safety reasons. One group of participants started walking when they thought it was safe to cross, and afterward, they were asked to press the button at the moment they realized the AV’s intention. The other group started with the IRT condition and walked in the second part of the study. The allocation of participants was randomized.
- In the video setups, each participant saw the two video types, WoZ and VR, in a randomized order.
2.3.1. Independent Variables
2.3.2. Dependent Variables
2.4. Sample
2.5. Analysis
3. Results
3.1. Misinterpretations of Intentions
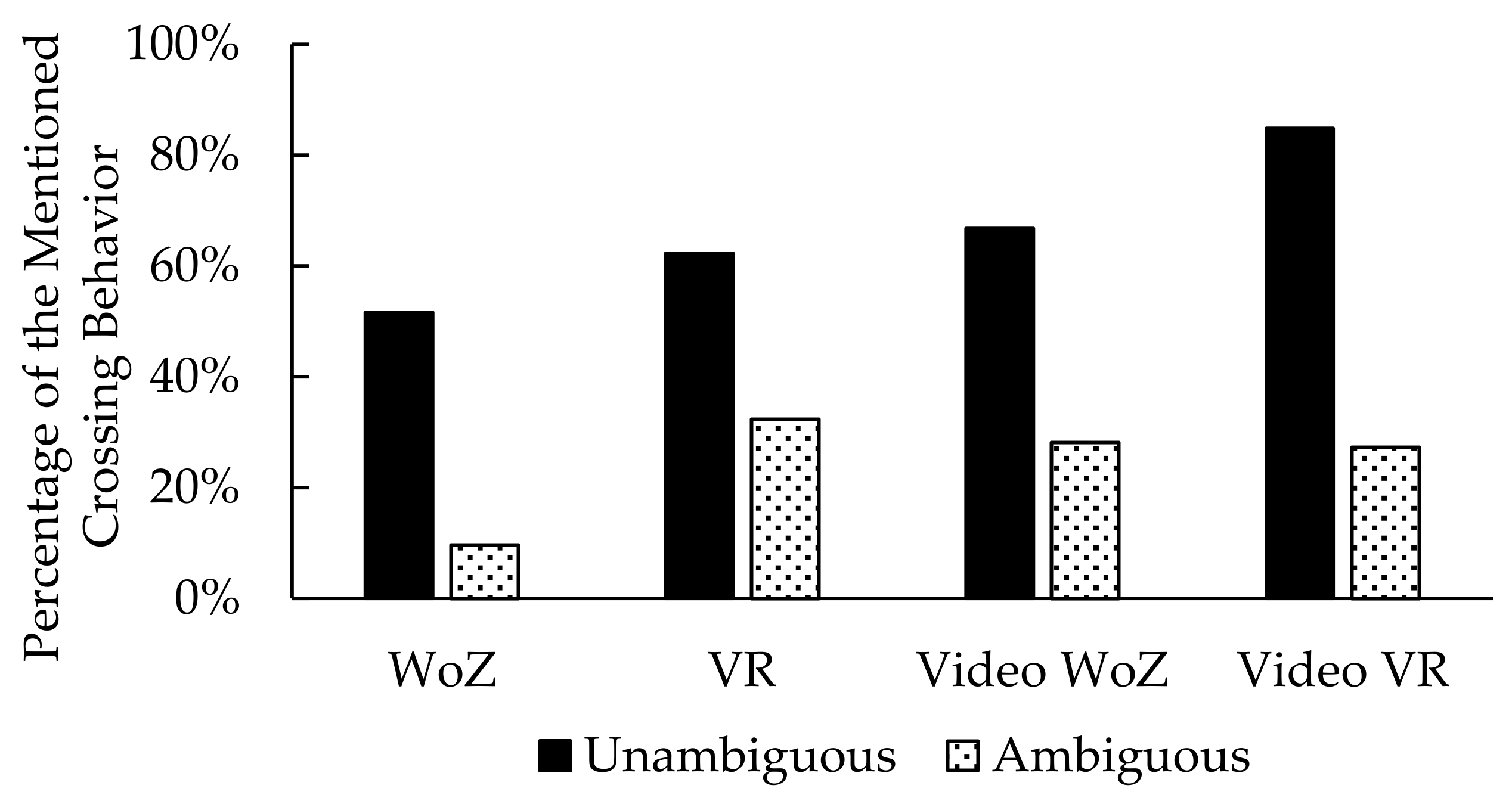
3.2. Mentioned Crossing Behavior
3.3. Time of Decision
3.4. Unambiguity of Driving Profiles: Subjective Data and Intention Recognition Time
3.4.1. Intention Recognition Time
3.4.2. Subjective Decision-Making Reliability
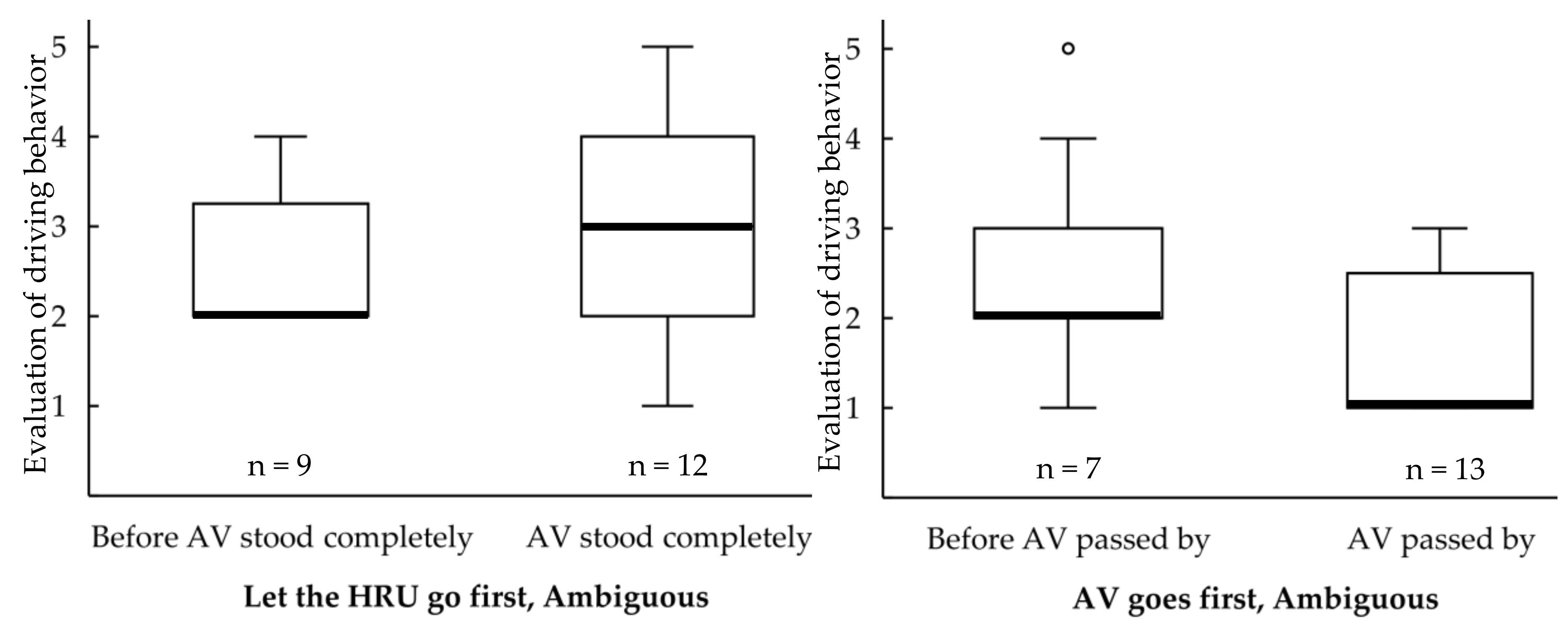
3.4.3. Evaluation of Driving Behavior
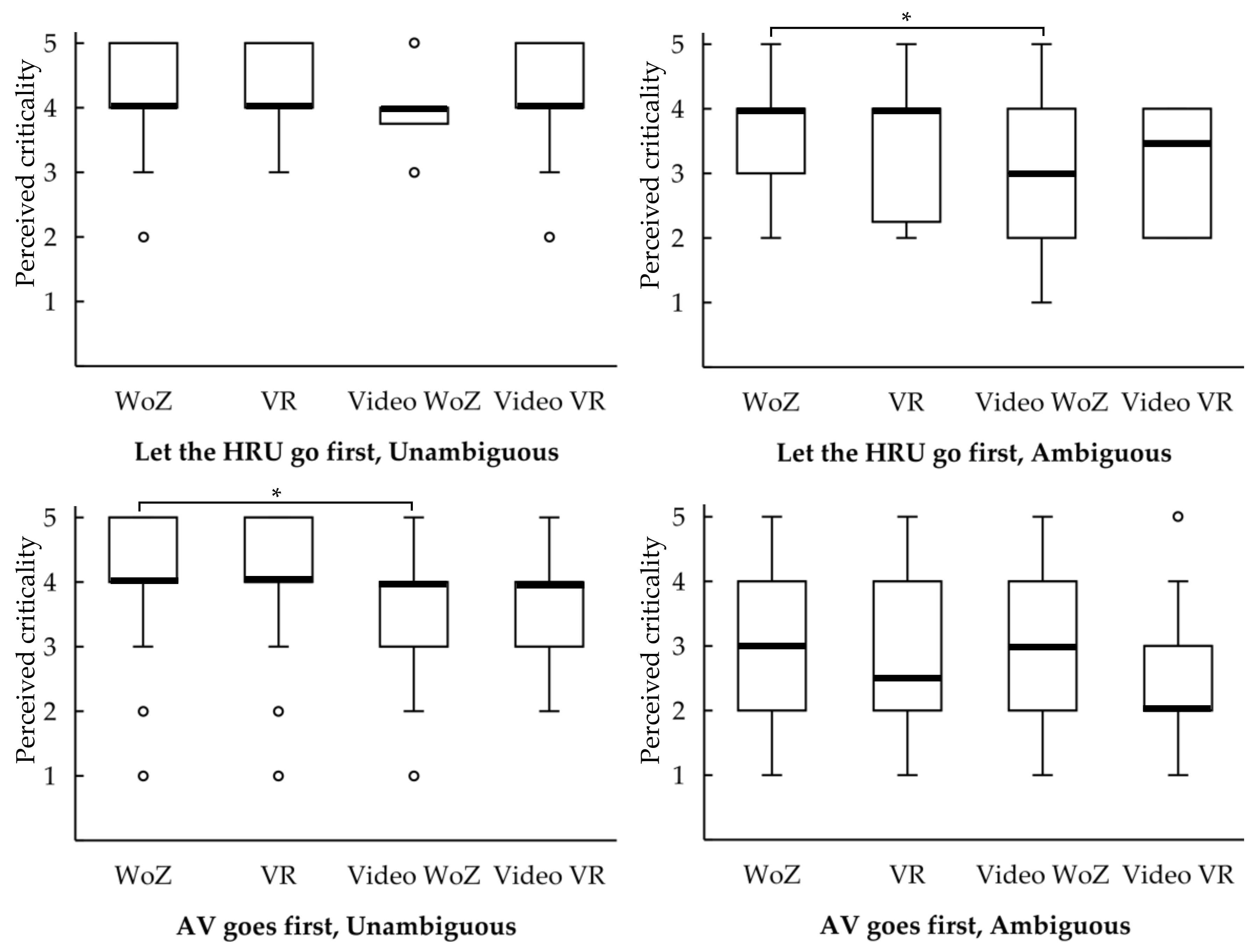
3.4.4. Perceived Criticality
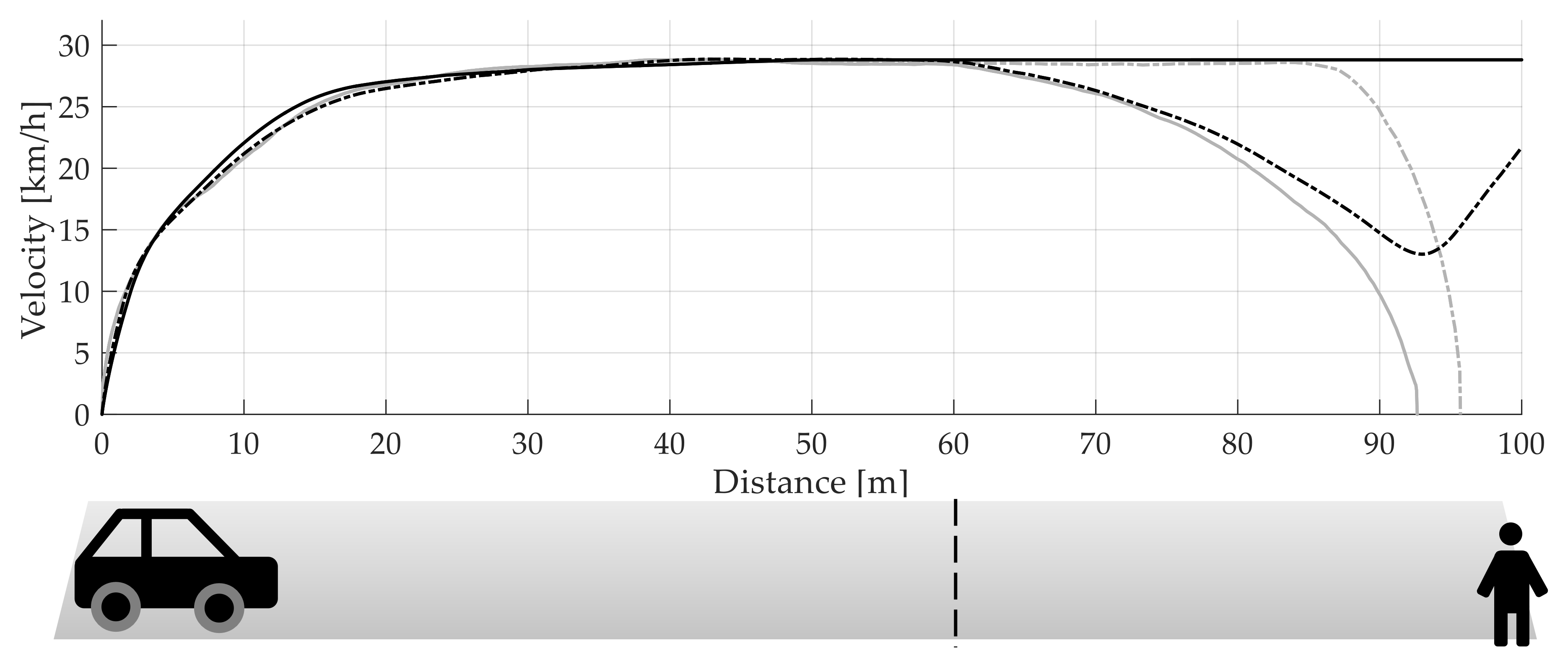
3.5. VR Study: IRT vs. Start of Road Crossing
4. Discussion
5. Limitations
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- SAE International. Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles (J3016); SAE International: Warrendale, PA, USA, 2018. [Google Scholar]
- Schneemann, F.; Gohl, I. Analyzing driver-pedestrian interaction at crosswalks: A contribution to autonomous driving in urban environments. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; pp. 38–43, ISBN 978-1-5090-1821-5. [Google Scholar]
- Fuest, T.; Sorokin, L.; Bellem, H.; Bengler, K. Taxonomy of Traffic Situations for the Interaction between Automated Vehicles and Human Road Users. In Advances in Human Aspects of Transportation. AHFE 2017. Advances in Intelligent Systems and Computing; Stanton, N.A., Ed.; Springer International Publishing: Cham, Switzerland, 2018; Volume 597, pp. 708–719. [Google Scholar] [CrossRef]
- De Clercq, K.; Dietrich, A.; Núñez Velasco, J.P.; de Winter, J.; Happee, R. External Human-Machine Interfaces on Automated Vehicles: Effects on Pedestrian Crossing Decisions. Hum. Factors 2019, 61, 8. [Google Scholar] [CrossRef]
- Burns, C.G.; Oliveira, L.; Thomas, P.; Iyer, S.; Birrell, S. Pedestrian Decision-Making Responses to External Human-Machine Interface Designs for Autonomous Vehicles. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 70–75. [Google Scholar]
- Weber, F.; Chadowitz, R.; Schmidt, K.; Messerschmidt, J.; Fuest, T. Crossing the Street Across the Globe: A Study on the Effects of eHMI on Pedestrians in the US, Germany and China. In HCI in Mobility, Transport, and Automotive Systems; Krömker, H., Ed.; Springer International Publishing: Cham, Switzerland, 2019; pp. 515–530. ISBN 978-3-030-22665-7. [Google Scholar]
- Rettenmaier, M.; Pietsch, M.; Schmidtler, J.; Bengler, K. Passing through the Bottleneck—The Potential of External Human-Machine Interfaces. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1687–1692. [Google Scholar] [CrossRef]
- Clamann, M.; Aubert, M.; Cummings, M.L. Evaluation of Vehicle-to-Pedestrian Communication Displays for Autonomous Vehicles. In Proceedings of the Transportation Research Board 96th Annual Meeting, Washington, DC, USA, 8–12 January 2017. [Google Scholar]
- Kühn, M.; Stange, V.; Vollrath, M. Menschliche Reaktion auf hochautomatisierte Fahrzeuge im Mischverkehr auf der Autobahn. In VDI Tagung Mensch-Maschine-Mobilität 2019—Der (Mit-)Fahrer im 21.Jahrhundert!? VDI Verlag: Düsseldorf, Germany, 2019; pp. 169–184. [Google Scholar]
- Bengler, K.; Rettenmaier, M.; Fritz, N.; Feierle, A. From HMI to HMIs: Towards an HMI Framework for Automated Driving. Information 2020, 11, 61. [Google Scholar] [CrossRef]
- Fuest, T.; Feierle, A.; Schmidt, E.; Bengler, K. Effects of Marking Automated Vehicles on Human Drivers on Highways. Information 2020, 11, 286. [Google Scholar] [CrossRef]
- Hensch, A.-C.; Neumann, I.; Beggiato, M.; Halama, J.; Krems, J.F. Effects of a light-based communication approach as an external HMI for Automated Vehicles—A Wizard-of-Oz Study. ToTS 2020, 10, 18–32. [Google Scholar] [CrossRef]
- Song, Y.E.; Lehsing, C.; Fuest, T.; Bengler, K. External HMIs and Their Effect on the Interaction between Pedestrians and Automated Vehicles. In Intelligent Human Systems Integration; Karwowski, W., Ahram, T., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 13–18. ISBN 978-3-319-73887-1. [Google Scholar]
- Fridman, L.; Mehler, B.; Xia, L.; Yang, Y.; Facusse, L.Y.; Reimer, B. To Walk or Not to Walk: Crowdsourced Assessment of External Vehicle-to-Pedestrian Displays. In Proceedings of the 98th Annual Transportation Research Board Meeting, Washington, DC, USA, 12–17 January 2019. [Google Scholar]
- Fuest, T.; Maier, A.S.; Bellem, H.; Bengler, K. How Should an Automated Vehicle Communicate Its Intention to a Pedestrian?—A Virtual Reality Study. In Human Systems Engineering and Design II; Ahram, T., Karwowski, W., Pickl, S., Taiar, R., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 195–201. [Google Scholar] [CrossRef]
- Dey, D.; Martens, M.; Eggen, B.; Terken, J. Pedestrian road-crossing willingness as a function of vehicle automation, external appearance, and driving behaviour. Transp. Res. Part F Traffic Psychol. Behav. 2019, 65, 191–205. [Google Scholar] [CrossRef]
- Eisma, Y.B.; van Bergen, S.; ter Brake, S.M.; Hensen, M.T.T.; Tempelaar, W.J.; de Winter, J.C.F. External Human-Machine Interfaces: The Effect of Display Location on Crossing Intentions and Eye Movements. Information 2020, 11, 13. [Google Scholar] [CrossRef]
- Schmidt, H.; Terwilliger, J.; AlAdawy, D.; Fridman, L. Hacking Nonverbal Communication between Pedestrians and Vehicles in Virtual Reality. arXiv 2019, arXiv:1904.01931. [Google Scholar]
- Dietrich, A.; Maruhn, P.; Schwarze, L.; Bengler, K. Implicit Communication of Automated Vehicles in Urban Scenarios: Effects of Pitch and Deceleration on Pedestrian Crossing Behavior. In Human Systems Engineering and Design II; Ahram, T., Karwowski, W., Pickl, S., Taiar, R., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 176–181. ISBN 978-3-030-27927-1. [Google Scholar]
- Böckle, M.-P.; Brenden, A.P.; Klingegård, M.; Habibovic, A.; Bout, M. SAV2P—Exploring the Impact of an Interface for Shared Automated Vehicles on Pedestrians’ Experience. In Proceedings of the 9th International Conference on Automotive User Interfaces and Interactive Vehicular Applications Adjunct(Automotive UI ’17), Oldenburg, Germany, 24–27 September 2017; Löcken, A., Boll, S., Politis, I., Osswald, S., Schroeter, R., Large, D., Baumann, M., Alvarez, I., Chuang, L., Feuerstack, S., et al., Eds.; ACM Press: New York, NY, USA, 2017; pp. 136–140. [Google Scholar]
- Chang, C.-M.; Toda, K.; Sakamoto, D.; Igarashi, T. Eyes on a Car: an Interface Design for Communication between an Autonomous Car and a Pedestrian. In Proceedings of the 9th International Conference on Automotive User Interfaces and Interactive Vehicular Applications (Automotive UI ’17), Oldenburg, Germany, 24–27 September2017; Boll, S., Pfleging, B., Politis, I., Large, D., Domnez, B., Eds.; ACM Press: New York, NY, USA, 2017; pp. 65–73. [Google Scholar]
- Bernhard, M.; Grosse, K.; Wimmer, M. Bimodal Task-Facilitation in a Virtual Traffic Scenario through Spatialized Sound Rendering. ACM Trans. Appl. Percept. 2011, 8, 1–22. [Google Scholar] [CrossRef]
- Fraser, N.M.; Gilbert, G.N. Simulating speech systems. Comput. Speech Lang. 1991, 5, 81–99. [Google Scholar] [CrossRef]
- Fuest, T.; Michalowski, L.; Schmidt, E.; Bengler, K. Reproducibility of Driving Profiles—Application of the Wizard of Oz Method for Vehicle Pedestrian Interaction. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3954–3959. [Google Scholar] [CrossRef]
- Fuest, T.; Michalowski, L.; Träris, L.; Bellem, H.; Bengler, K. Using the Driving Behavior of an Automated Vehicle to Communicate Intentions—A Wizard of Oz Study. In Proceedings of the 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3596–3601. [Google Scholar] [CrossRef]
- Currano, R.; Park, S.Y.; Domingo, L.; Garcia-Mancilla, J.; Santana-Mancilla, P.C.; Gonzalez, V.M.; Ju, W. ¡Vamos! Observations of Pedestrian Interactions with Driverless Cars in Mexico. In Proceedings of the 10th International Conference on Automotive User Interfaces and Interactive Vehicular Applications—AutomotiveUI’18, Toronto, ON, Canada, 23–25 September 2018; ACM Press: New York, NY, USA, 2018; pp. 210–220. [Google Scholar]
- Rothenbücher, D.; Li, J.; Sirkin, D.; Mok, B.; Ju, W. Ghost Driver: A Field Study Investigating the Interaction Between Pedestrians and Driverless Vehicles. In Proceedings of the 7th International Conference on Automotive User Interfaces and Interactive Vehicular Applications—AutomotiveUI’15, Nottingham, UK, 1–3 September 2015; Burnett, G., Gabbard, J., Green, P., Osswald, S., Eds.; ACM Press: New York, NY, USA, 2015; pp. 44–49. [Google Scholar]
- Joisten, P.; Alexandi, E.; Drews, R.; Klassen, L.; Petersohn, P.; Pick, A.; Schwindt, S.; Abendroth, B. Displaying Vehicle Driving Mode—Effects on Pedestrian Behavior and Perceived Safety. In Human Systems Engineering and Design II; Ahram, T., Karwowski, W., Pickl, S., Taiar, R., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 250–256. ISBN 978-3-030-27927-1. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| WoZ | VR | Video | |
|---|---|---|---|
| Sample | N = 34 | N = 37 | N = 46 |
| ø-age (years) | M = 40.94, SD = 21.39 Min. = 17, Max. = 81 | M = 27.32, SD = 9.93 Min. = 20, Max. = 79 | M = 30.50, SD = 11.55 Min. = 17, Max. = 67 |
| Sex | ♂ = 24 ♀ = 10 | ♂ = 23 ♀ = 14 | ♂ = 20 ♀ = 26 |
| Travel as pedestrians in traffic (h per week) | M = 7.06, SD = 6.33 Min. = 1, Max. = 25 | M = 8.03, SD = 6.01 Min. = 1, Max. = 30 | M = 6.57, SD = 5.76 Min. = 1, Max. = 30 |
| WoZ | VR | Video WoZ | Video VR | |
|---|---|---|---|---|
| Unambiguous | 0.0% (0) n = 62 | 2.7% (1) n = 37 | 11.1% (4) n = 36 | 4.3% (2) n = 46 |
| Ambiguous | 77.4% (48) n = 62 | 29.7% (11) n = 37 | 61.5% (24) n = 39 | 63.6% (28) n = 44 |
| WoZ | VR | Video WoZ | Video VR | |
|---|---|---|---|---|
| Unambiguous | 3.2% (2) n = 62 | 2.7% (1) n = 37 | 7.3% (3) n = 41 | 2.4% (1) n = 42 |
| Ambiguous | 71.0% (44) n = 62 | 40.5% (15) n = 37 | 31.7% (13) n = 41 | 27.9% (12) n = 43 |
| WoZ | VR | Video WoZ | Video VR | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Intention Recognition | Intention Recognition | Intention Recognition | Intention Recognition | ||||||||||||
| Correct | False | Correct | False | Correct | False | Correct | False | ||||||||
| Crossing | Yes | 51.6% (32) | 0.0% (0) | Crossing | Yes | 62.2% (23) | 0.0% (0) | Crossing | Yes | 66.7% (24) | 0.0% (0) | Crossing | Yes | 84.8% (39) | 0.0% (0) |
| No | 48.4% (30) | 0.0% (0) | No | 35.1% (13) | 2.7% (1) | No | 22.2% (8) | 11.1% (4) | No | 10.9% (5) | 4.3% (2) | ||||
| WoZ | VR | Video WoZ | Video VR | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Intention Recognition | Intention Recognition | Intention Recognition | Intention Recognition | ||||||||||||
| Correct | False | Correct | False | Correct | False | Correct | False | ||||||||
| Crossing | Yes | 9.7% (6) | 0.0% (0) | Crossing | Yes | 32.4% (12) | 0.0% (0) | Crossing | Yes | 28.2% (11) | 0.0% (0) | Crossing | Yes | 27.3% (12) | 2.3% (1) |
| No | 12.9% (8) | 77.4% (48) | No | 37.8% (14) | 29.7% (11) | No | 10.3% (4) | 61.5% (24) | No | 9.1% (4) | 61.4% (27) | ||||
| WoZ | VR | Video WoZ | Video VR | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Intention Recognition | Intention Recognition | Intention Recognition | Intention Recognition | ||||||||||||
| Correct | False | Correct | False | Correct | False | Correct | False | ||||||||
| Crossing | Yes | 0.0% (0) | 3.2% (2) | Crossing | Yes | 0.0% (0) | 2.7% (1) | Crossing | Yes | 0.0% (0) | 7.3% (3) | Crossing | Yes | 0.0% (0) | 0.0% (0) |
| No | 96.8% (60) | 0.0% (0) | No | 97.3% (36) | 0.0% (0) | No | 92.7% (38) | 0.0% (0) | No | 97.6% (41) | 2.4% (1) | ||||
| WoZ | VR | Video WoZ | Video VR | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Intention Recognition | Intention Recognition | Intention Recognition | Intention Recognition | ||||||||||||
| Correct | False | Correct | False | Correct | False | Correct | False | ||||||||
| Crossing | Yes | 0.0% (0) | 22.6% (14) | Crossing | Yes | 0.0% (0) | 16.2% (6) | Crossing | Yes | 2.4% (1) | 22.0% (9) | Crossing | Yes | 2.3% (1) | 16.3% (7) |
| No | 29.0% (18) | 48.4% (30) | No | 59.5% (22) | 24.3% (9) | No | 65.8% (27) | 9.8% (4) | No | 69.8% (30) | 11.6% (5) | ||||
| WoZ | VR | Video WoZ | Video VR | |
|---|---|---|---|---|
| Let the HRU go first, Unambiguous | 0.0% (0) n = 62 | 11.1% (4) n = 36 | 43.8% (14) n = 32 | 13.6% (6) n = 44 |
| Let the HRU go first, Ambiguous | 0.0% (0) n = 14 | 42.9% (9) n = 21 | 73.3% (11) n = 15 | 87.5% (14) n = 16 |
| AV goes first, Unambiguous | 0.0% (0) n = 60 | 6.1% (2) n = 33 | 42.1% (16) n = 38 | 22.0% (9) n = 41 |
| AV goes first, Ambiguous | 1.6% (1) n = 18 | 35.0% (7) n = 20 | 39.3% (11) n = 28 | 41.9% (13) n = 31 |
| WoZ | VR | Video WoZ | Video VR | |
|---|---|---|---|---|
| Let the HRU go first, Unambiguous | 4.1 s | 4.5 s | 5.3 s | 5.6 s |
| Let the HRU go first, Ambiguous | 4.2 s | 4.8 s | 6.5 s | 5.5 s |
| z = −0.62 p = 0.534 (n = 11) | z = −0.45 p = 0.657 (n = 26) | z = −3.26 p = 0.001 r = 0.87 (n = 14) | z = −2.80 p = 0.005 r = 0.70 (n = 16) | |
| AV goes first, Unambiguous | 3.3 s | 3.8 s | 4.7 s | 4.4 s |
| AV goes first, Ambiguous | 4.6 s | 5.3 s | 6.7 s | 6.8 s |
| z = −2.85 p = 0.004 r = 0.86 (n = 11) | z = −2.82 p = 0.005 r = 0.81 (n = 12) | z = −3.75 p ≤ 0.001 r = 0.74 (n = 26) | z = −4.72 p ≤ 0.001 r = 0.88 (n = 29) |
| WoZ | VR | Video WoZ | Video VR | |
|---|---|---|---|---|
| Let the HRU go first, Unambiguous | 4.5 | 4.0 | 4.0 | 4.0 |
| Let the HRU go first, Ambiguous | 4.0 | 4.0 | 4.0 | 4.0 |
| z = −1.21 p = 0.226 (n = 11) | z = −0.83 p = 0.406 (n = 26) | z = −0.98, p = 0.329 (n = 14) | z = −0.50 p = 0.615 (n = 16) | |
| AV goes first, Unambiguous | 5.0 | 4.5 | 5.0 | 5.0 |
| AV goes first, Ambiguous | 3.0 | 5.0 | 4.0 | 4.0 |
| z = −2.94 p = 0.003 r = 0.89 (n = 11) | z = −0.88 p = 0.377 (n = 22) | z = −1.83 p = 0.068 (n = 26) | z = −1.84 p = 0.066 (n = 29) |
| WoZ | VR | Video WoZ | Video VR | |
|---|---|---|---|---|
| Let the HRU go first, Unambiguous | 4.5 | 4.0 | 4.0 | 4.0 |
| Let the HRU go first, Ambiguous | 3.5 | 3.0 | 2.0 | 2.0 |
| z = −2.70, p = 0.007, r = 0.81 (n = 11) | z = −3.79, p ≤ 0.001, r = 0.74 (n = 26) | z = −2.99 p = 0.003 r = 0.80 (n = 14) | z = −2.56 p = 0.011 r = 0.64 (n = 16) | |
| AV goes first, Unambiguous | 4.5 | 4.0 | 3.5 | 3.0 |
| AV goes first, Ambiguous | 2.0 | 2.0 | 2.0 | 2.0 |
| z = −2.96 p = 0.003 r = 0.89 (n = 11) | z = −3.01 p = 0.003 r = 0.64 (n = 22) | z = −3.03 p = 0.002 r = 0.59 (n = 26) | z = −3.20 p = 0.001 r = 0.59 (n = 29) |
| WoZ | VR | Video WoZ | Video VR | |
|---|---|---|---|---|
| Let the HRU go first, Unambiguous | 4.5 | 4.0 | 4.0 | 4.0 |
| Let the HRU go first, Ambiguous | 4.0 | 4.0 | 3.0 | 3.5 |
| z = −2.41 p = 0.016 r = 0.73 (n = 11) | z = −2.98 p = 0.003 r = 0.58 (n = 26) | z = −2.57 p = 0.010 r = 0.69 (n = 14) | z = −2.23 p = 0.026 r = 0.56 (n = 16) | |
| AV goes first, Unambiguous | 4.5 | 4.0 | 4.0 | 4.0 |
| AV goes first, Ambiguous | 3.0 | 2.5 | 3.0 | 2.0 |
| z = −2.82 p = 0.005 r = 0.85 (n = 11) | z = −2.42 p = 0.016 r = 0.52 (n = 22) | z = −2.02 p = 0.043 r = 0.40 (n = 26) | z = −2.98 p = 0.003 r = 0.55 (n = 29) |
| Let the HRU Go First, Unambiguous | Let the HRU Go First, Ambiguous | AV Goes First, Unambiguous | AV Goes First, Ambiguous | |
|---|---|---|---|---|
| IRT | 2.7% (1) n = 37 | 29.7% (11) n = 37 | 2.7% (1) n = 37 | 40.5% (15) n = 37 |
| Start of Road Crossing | 2.7% (1) n = 37 | 2.7% (1) n = 37 | 2.7% (1) n = 37 | 5.4% (2) n = 37 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fuest, T.; Schmidt, E.; Bengler, K. Comparison of Methods to Evaluate the Influence of an Automated Vehicle’s Driving Behavior on Pedestrians: Wizard of Oz, Virtual Reality, and Video. Information 2020, 11, 291. https://doi.org/10.3390/info11060291
Fuest T, Schmidt E, Bengler K. Comparison of Methods to Evaluate the Influence of an Automated Vehicle’s Driving Behavior on Pedestrians: Wizard of Oz, Virtual Reality, and Video. Information. 2020; 11(6):291. https://doi.org/10.3390/info11060291
Chicago/Turabian StyleFuest, Tanja, Elisabeth Schmidt, and Klaus Bengler. 2020. "Comparison of Methods to Evaluate the Influence of an Automated Vehicle’s Driving Behavior on Pedestrians: Wizard of Oz, Virtual Reality, and Video" Information 11, no. 6: 291. https://doi.org/10.3390/info11060291
APA StyleFuest, T., Schmidt, E., & Bengler, K. (2020). Comparison of Methods to Evaluate the Influence of an Automated Vehicle’s Driving Behavior on Pedestrians: Wizard of Oz, Virtual Reality, and Video. Information, 11(6), 291. https://doi.org/10.3390/info11060291