Forecasting Net Income Estimate and Stock Price Using Text Mining from Economic Reports

 , , and
, , and
Abstract
1. Introduction
2. Related Works
3. Data
3.1. Analyst Reports
3.2. Dataset for Net Income Forecast
3.3. Dataset for Stock Price Forecast
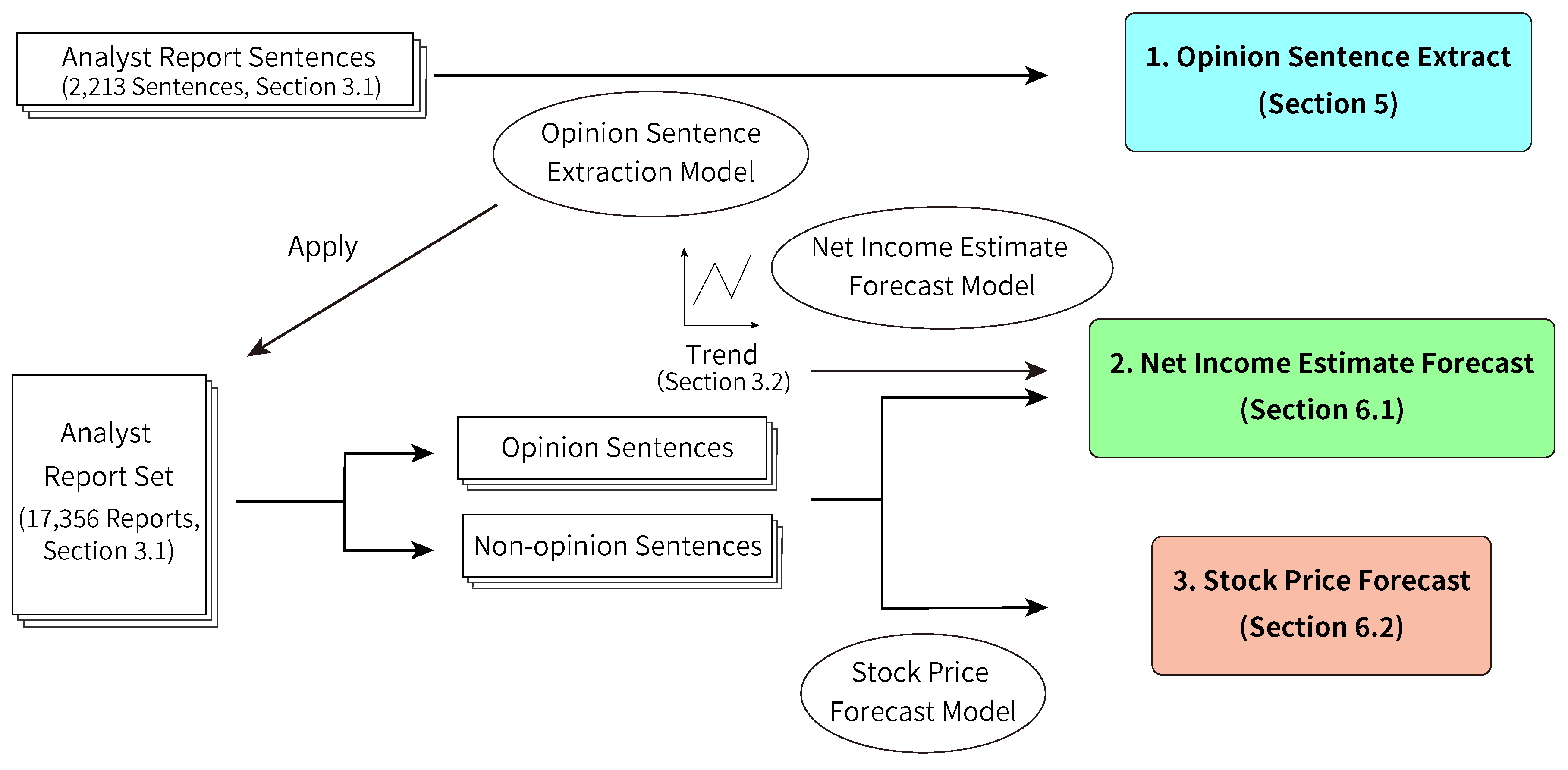
4. Methodology
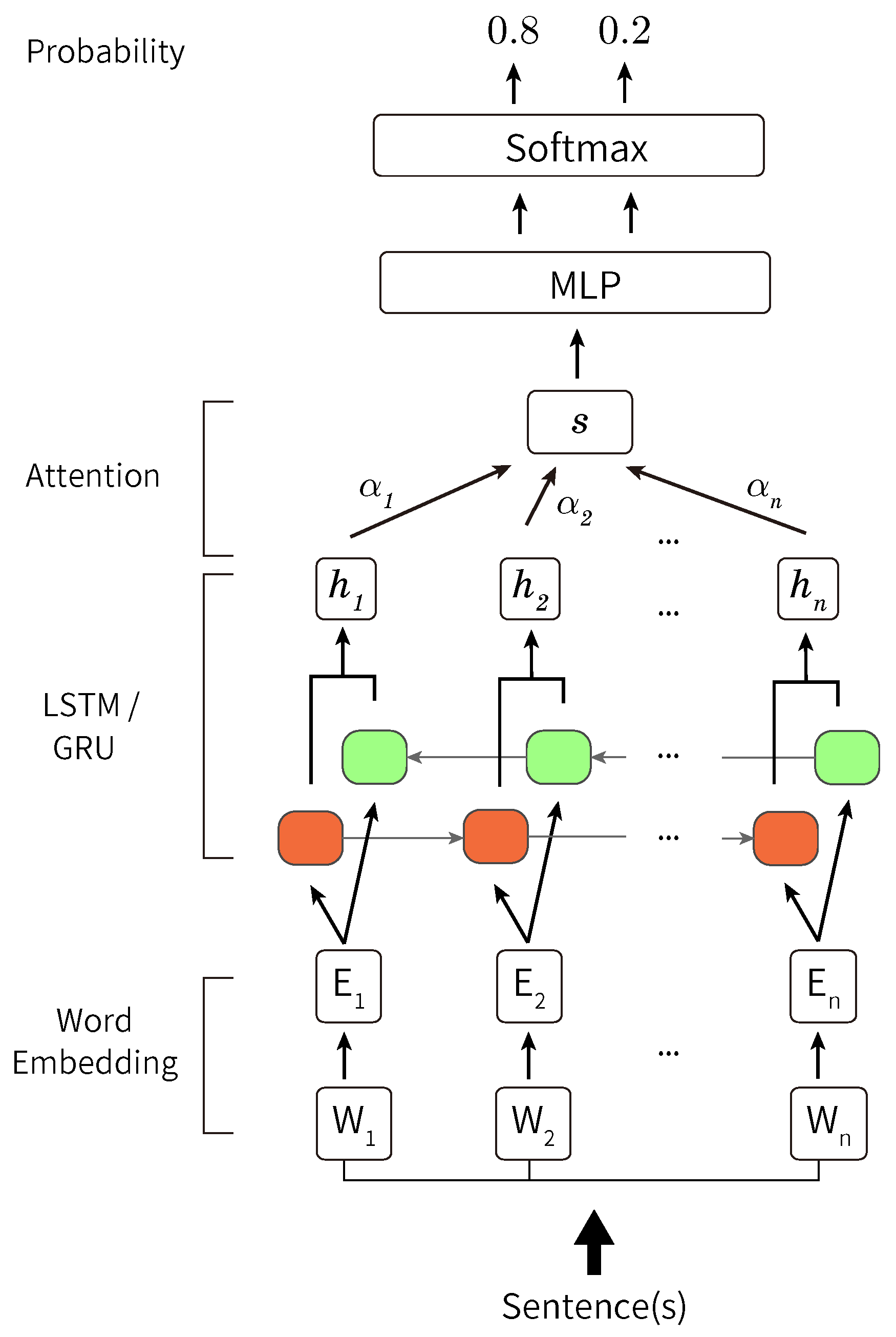
5. Opinion Sentence Extraction (Pre-Experiment)
5.1. Data
- Analyst report sentences
- Analyst reports set
- Reuters
- -
- Japanese articles of Reuters
- -
- 22,137,907 sentences
- -
- 2,890,515 articles
- -
- Period: From 1996 to 2018
- -
- Available for a fee
- Wikipedia
- -
- Japanese articles of Wikipedia
- -
- 19,364,683 sentences
- -
- 1,156,012 articles
- -
- Version on June 20, 2019
- -
- Available for free
- -
- Downloaded from https://dumps.wikimedia.org/jawiki/20190620/
- Nikkei
- -
- Articles from Nikkei news
- -
- 18,413,835 sentences
- -
- 4,959,256 articles
- -
- Period: From 1990 to 2017
- -
- Written in Japanese
- -
- Available for a fee
5.2. Experiments
5.3. Results
6. Experiments of Forecasting Net Incomes and Stock Prices
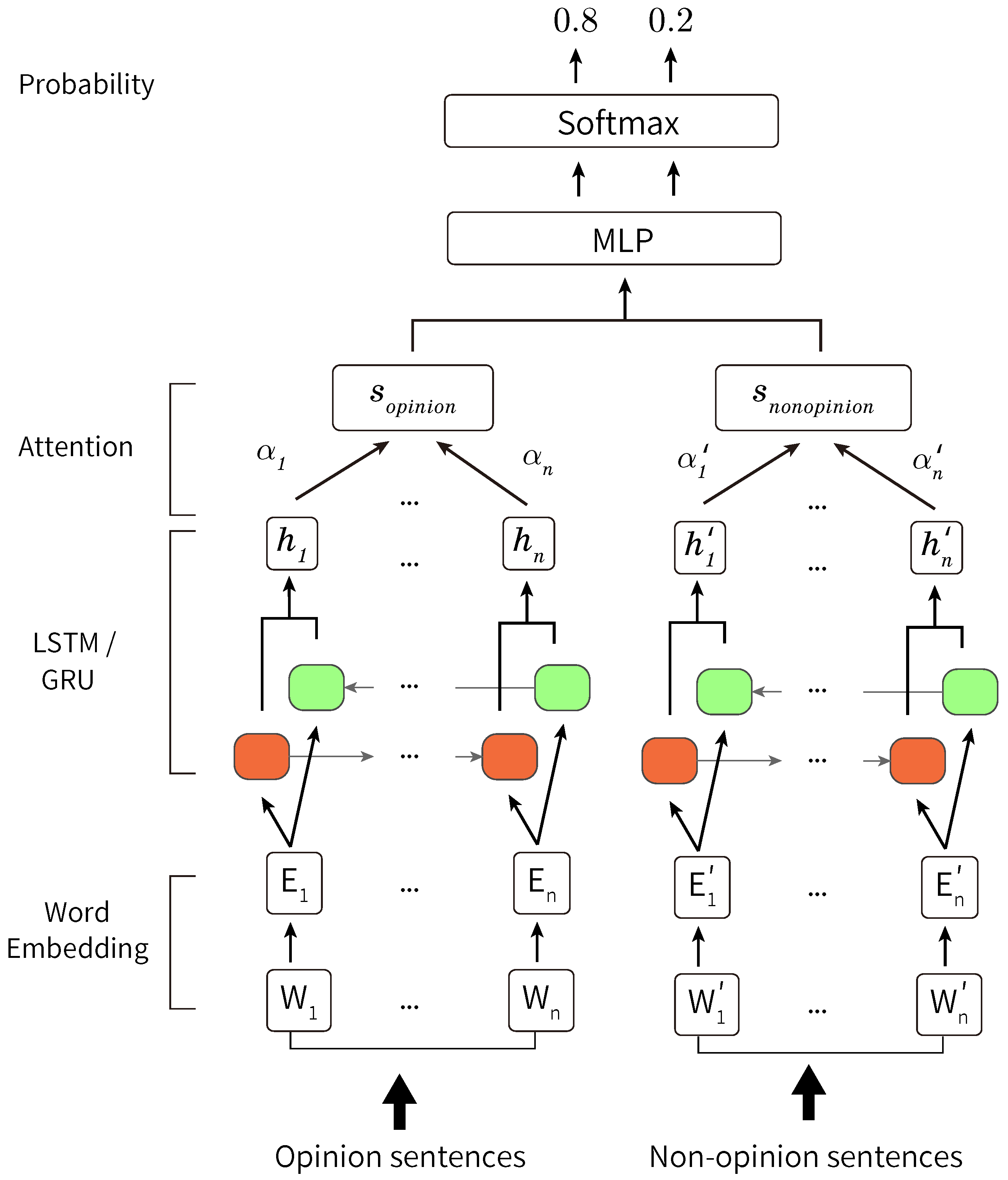
6.1. Forecasting Movements of Analyst Net Income Estimates
- All sentences
- Only opinion sentences
- Only non-opinion sentences
- Opinion and non-opinion sentences separately
6.2. Forecasting Movements of Stock Prices
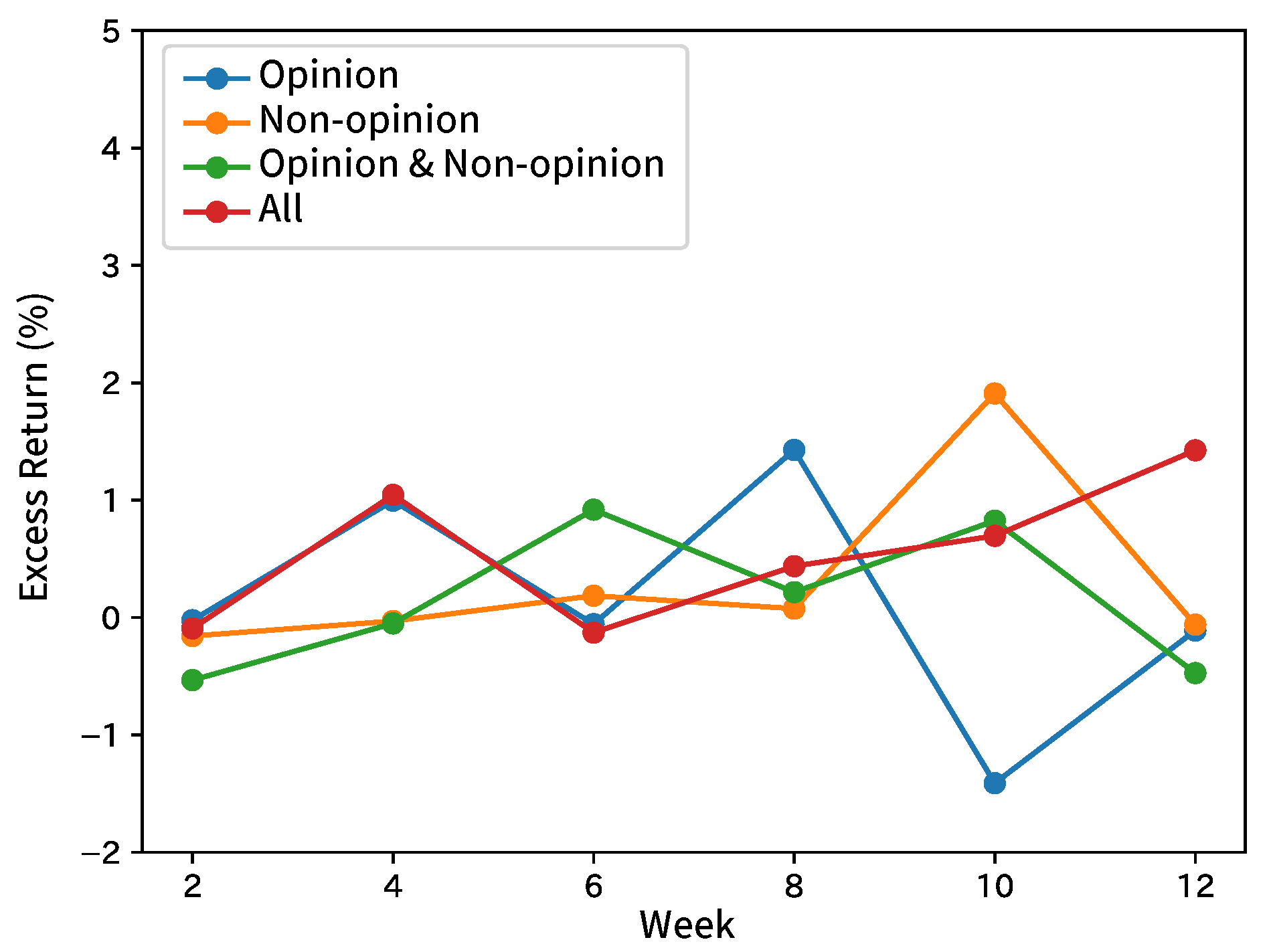
7. Experiment Results
7.1. Forecasting Movements of Analyst Net Income Estimates
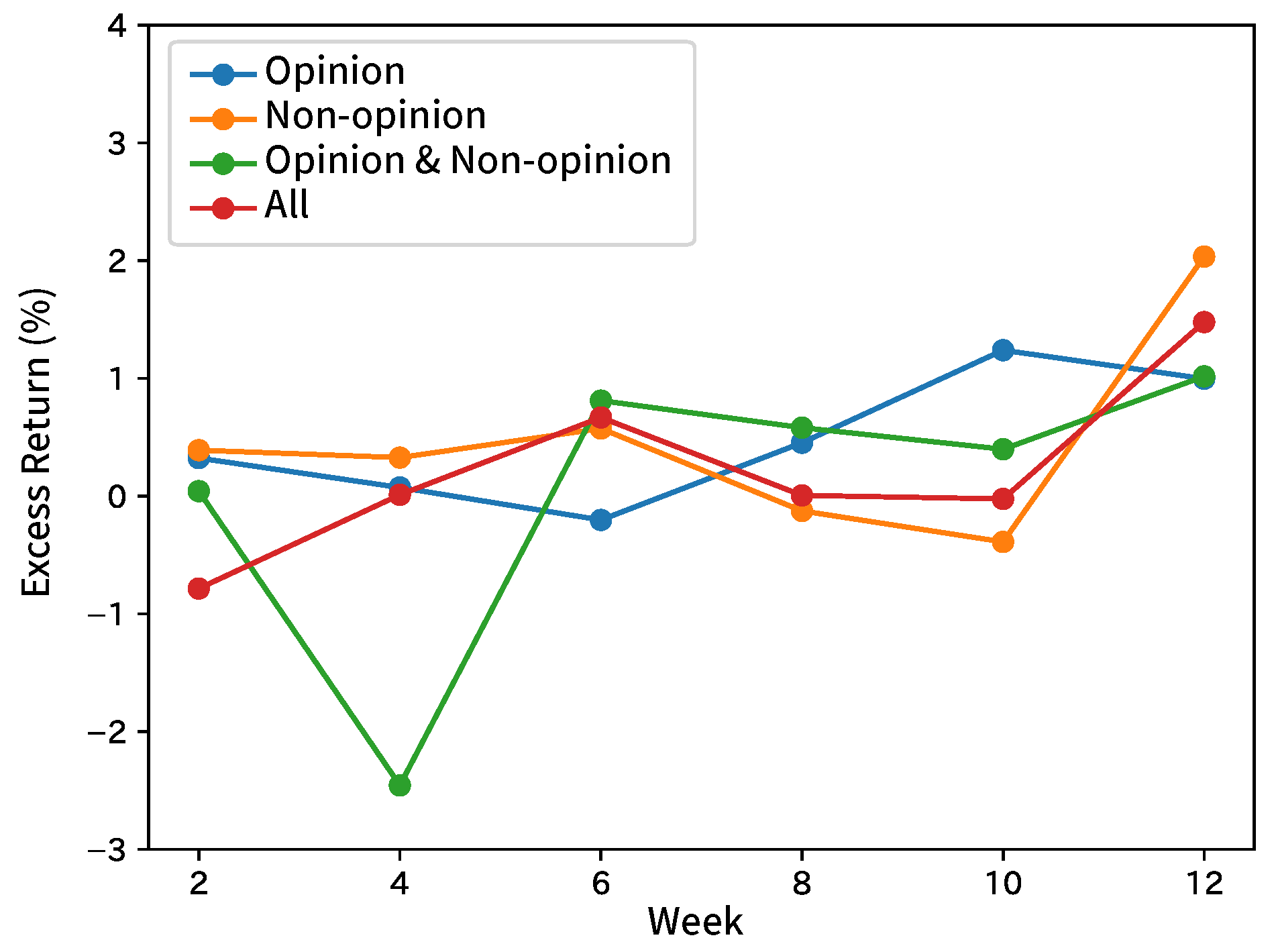
7.2. Forecasting Movements of Stock Prices
8. Discussion
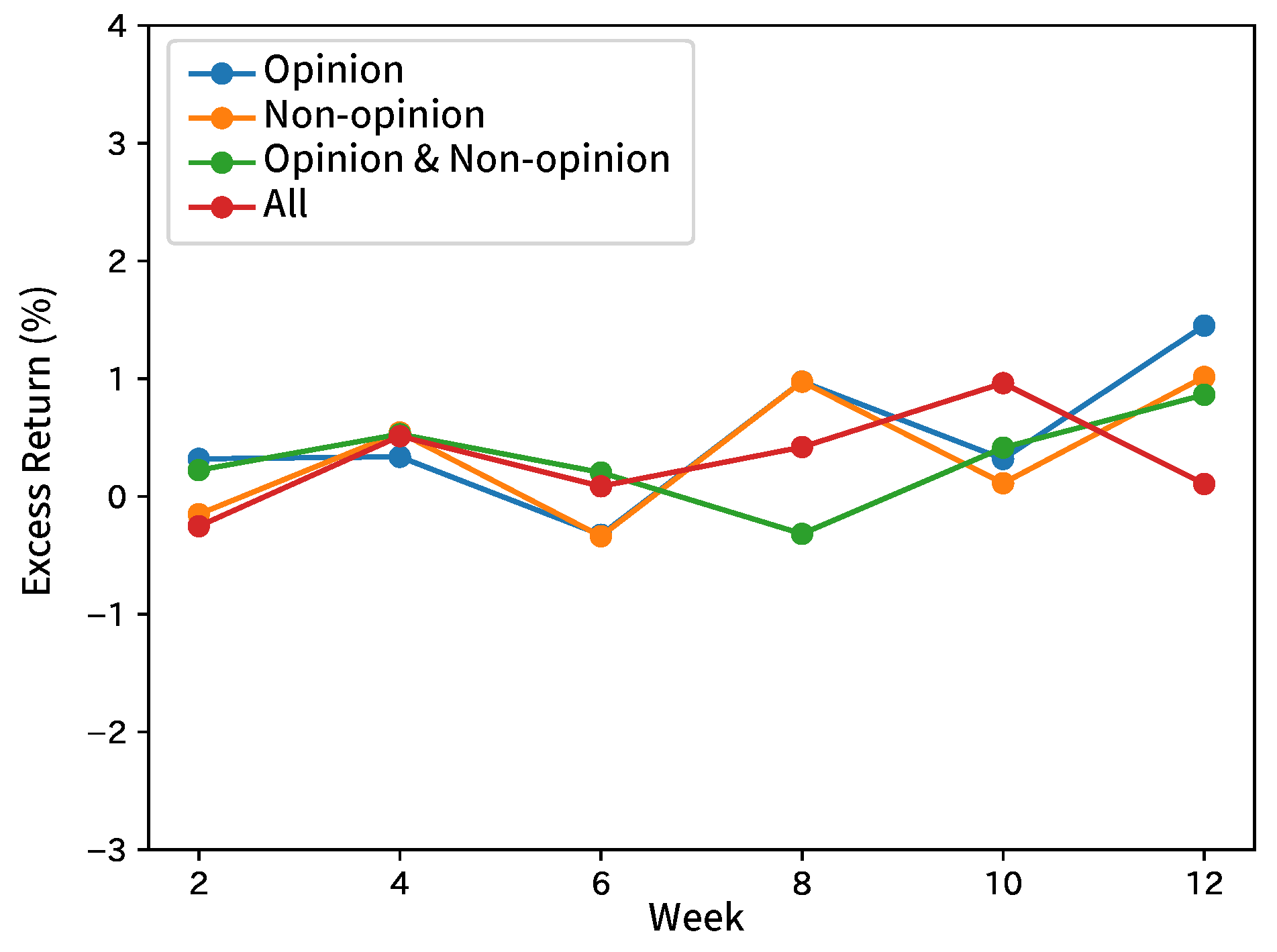
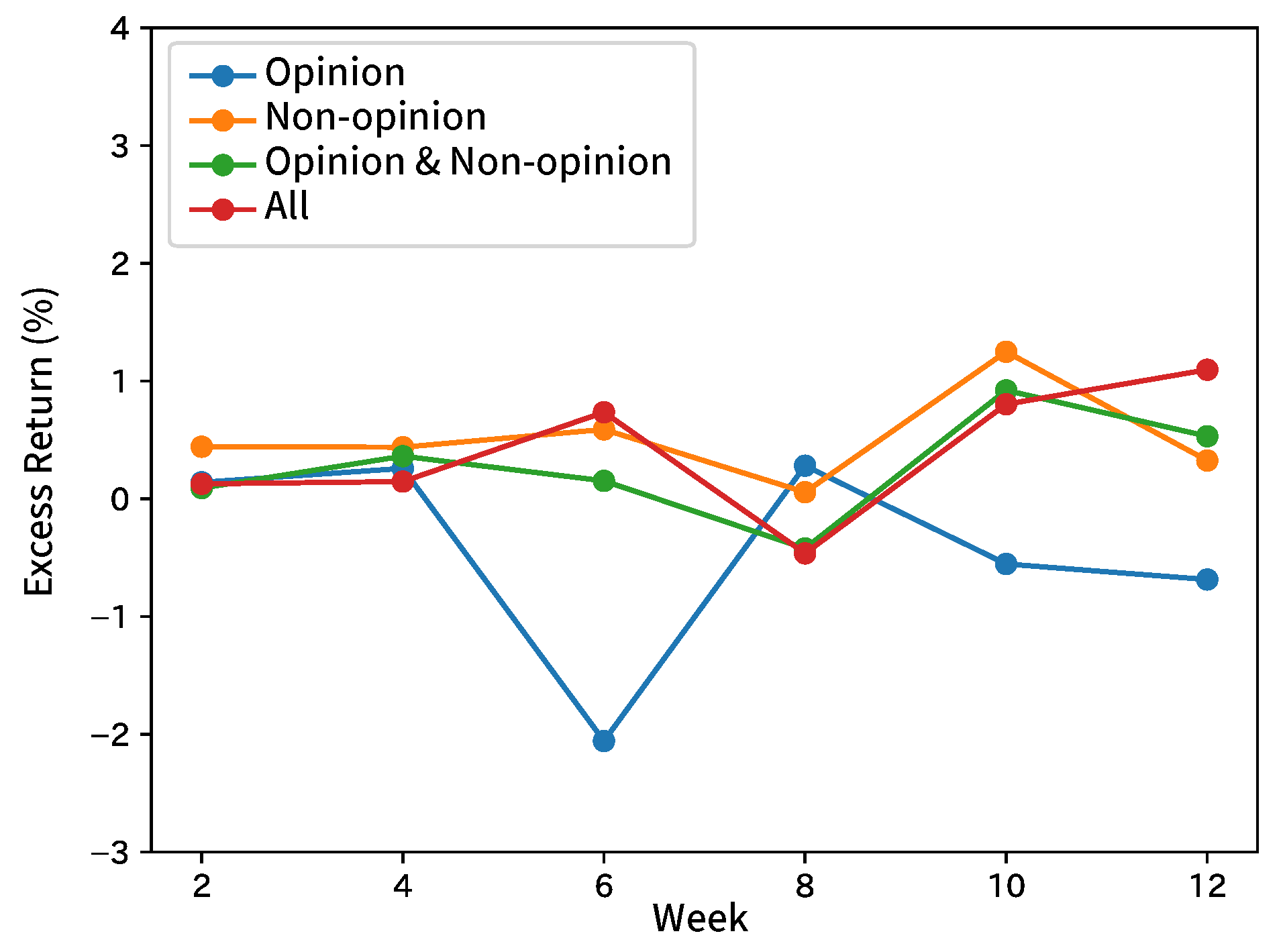
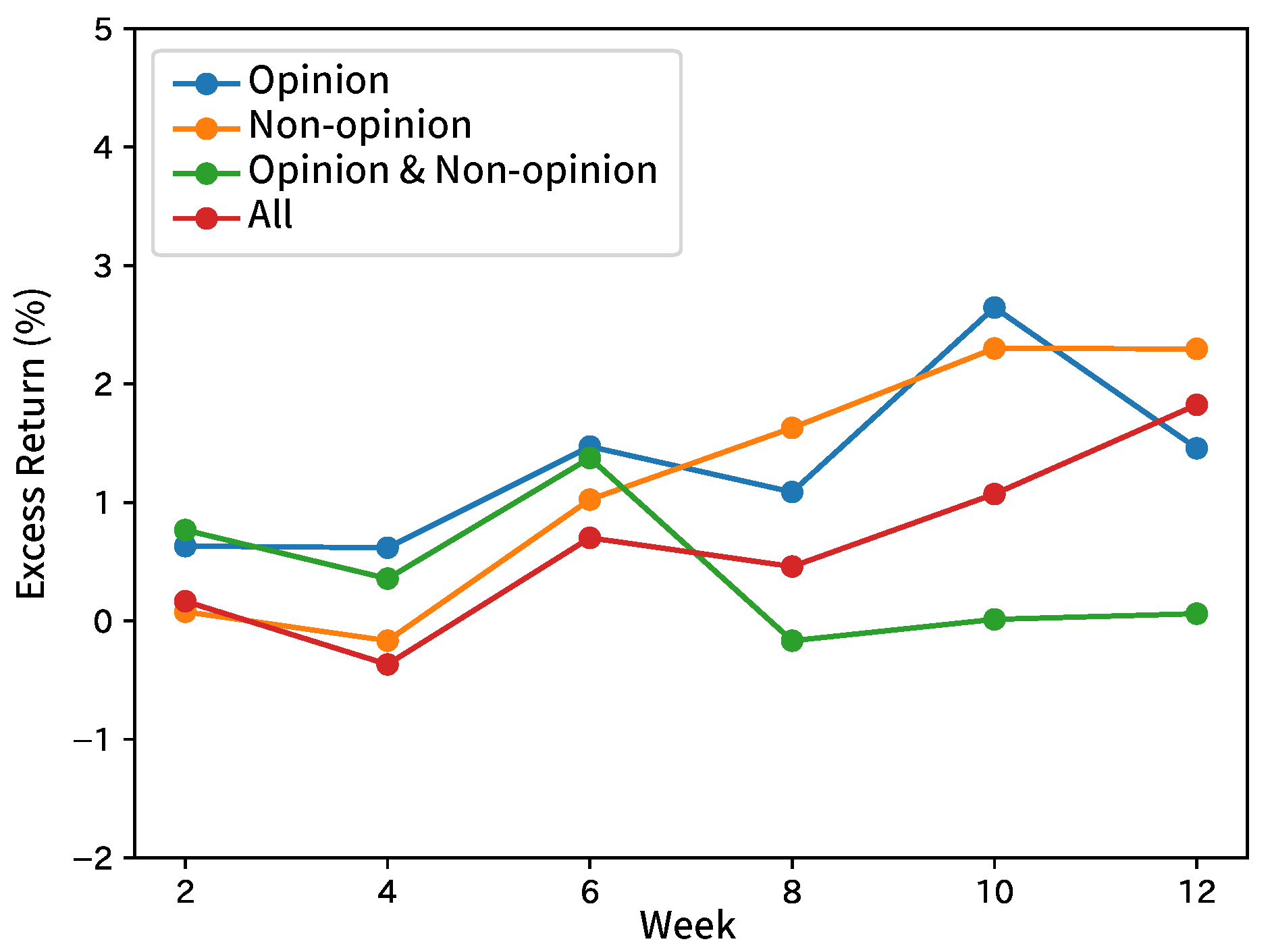
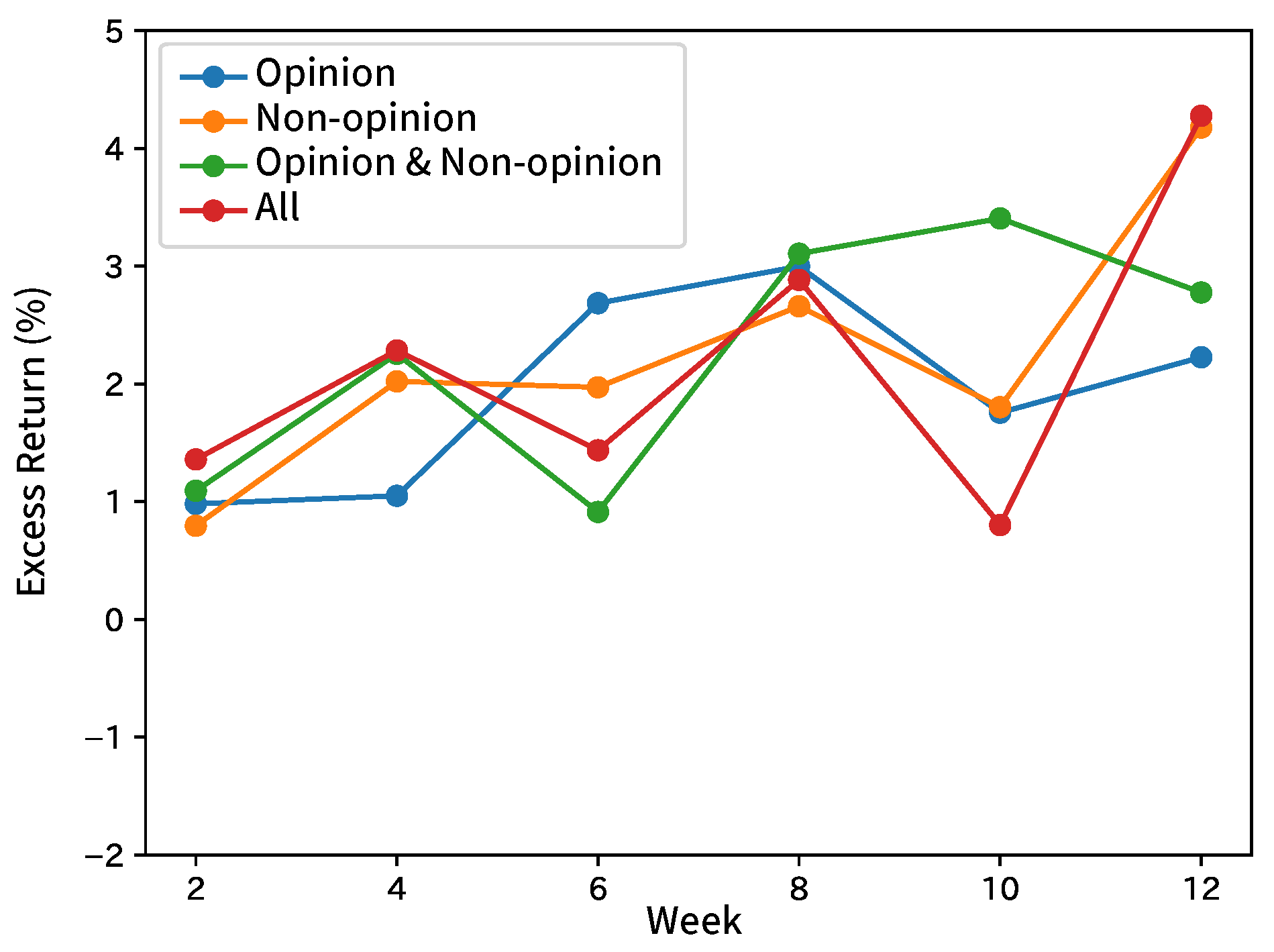
8.1. Forecasting Movements of Analyst Net Income Estimates
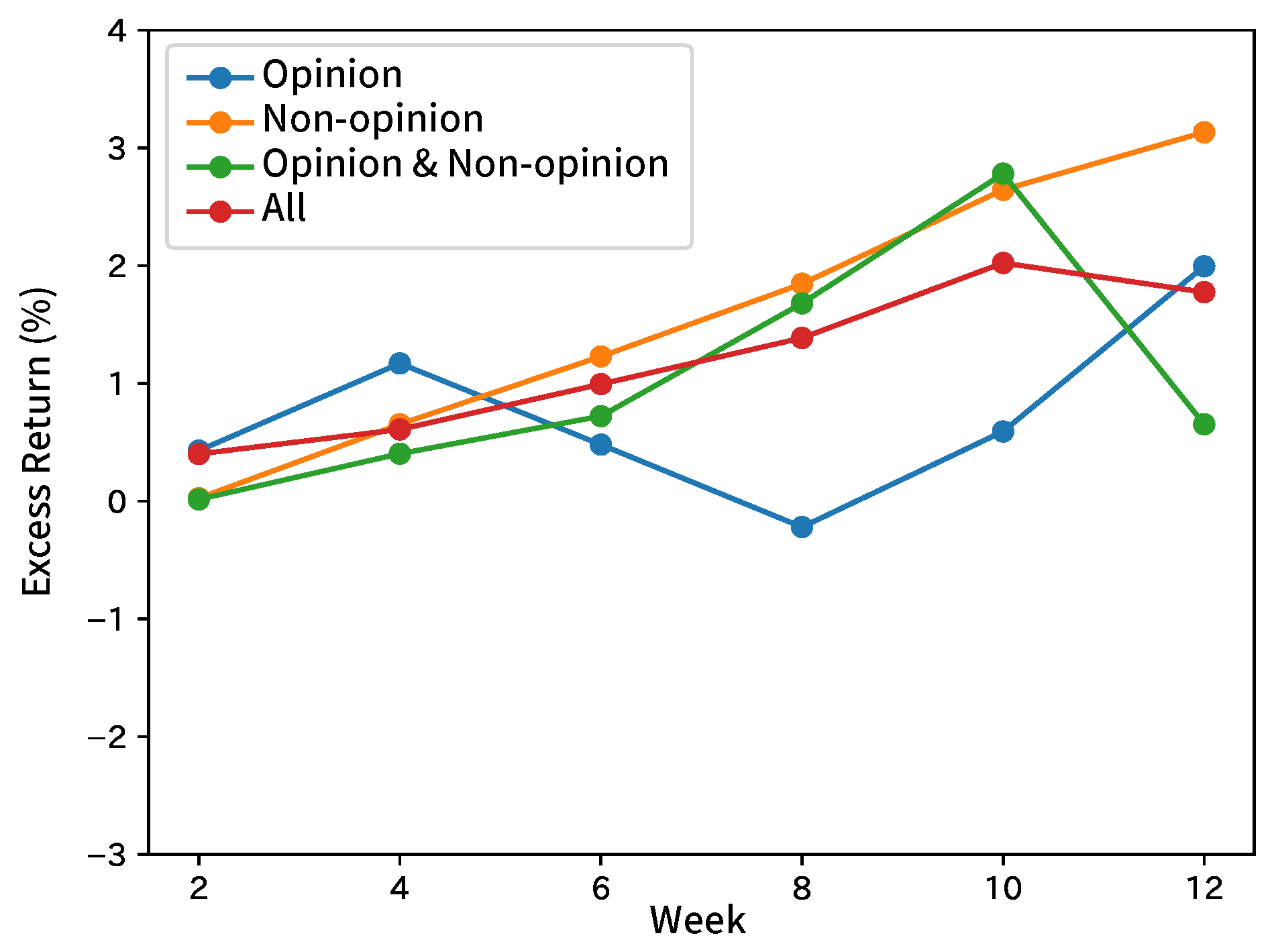
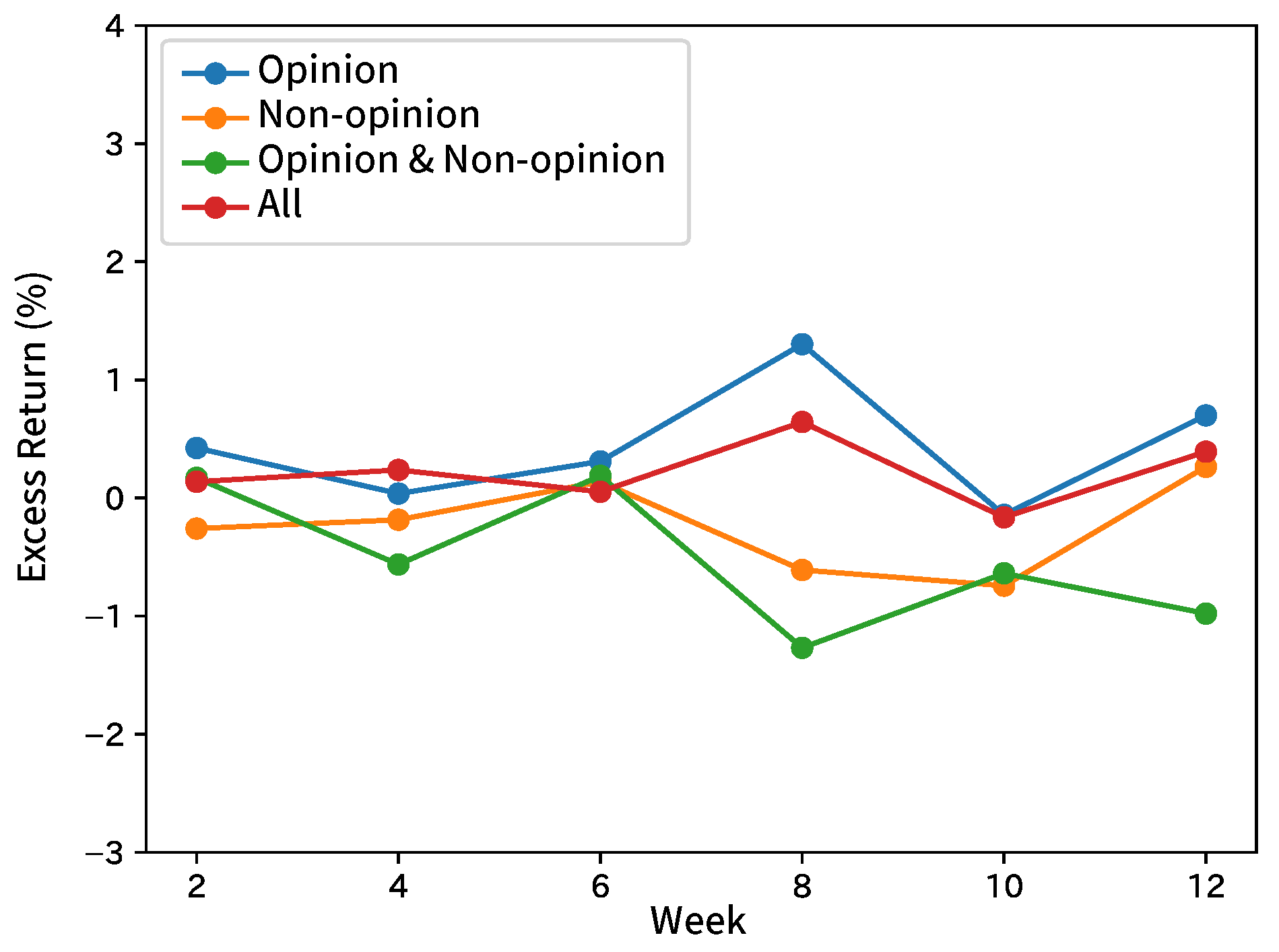
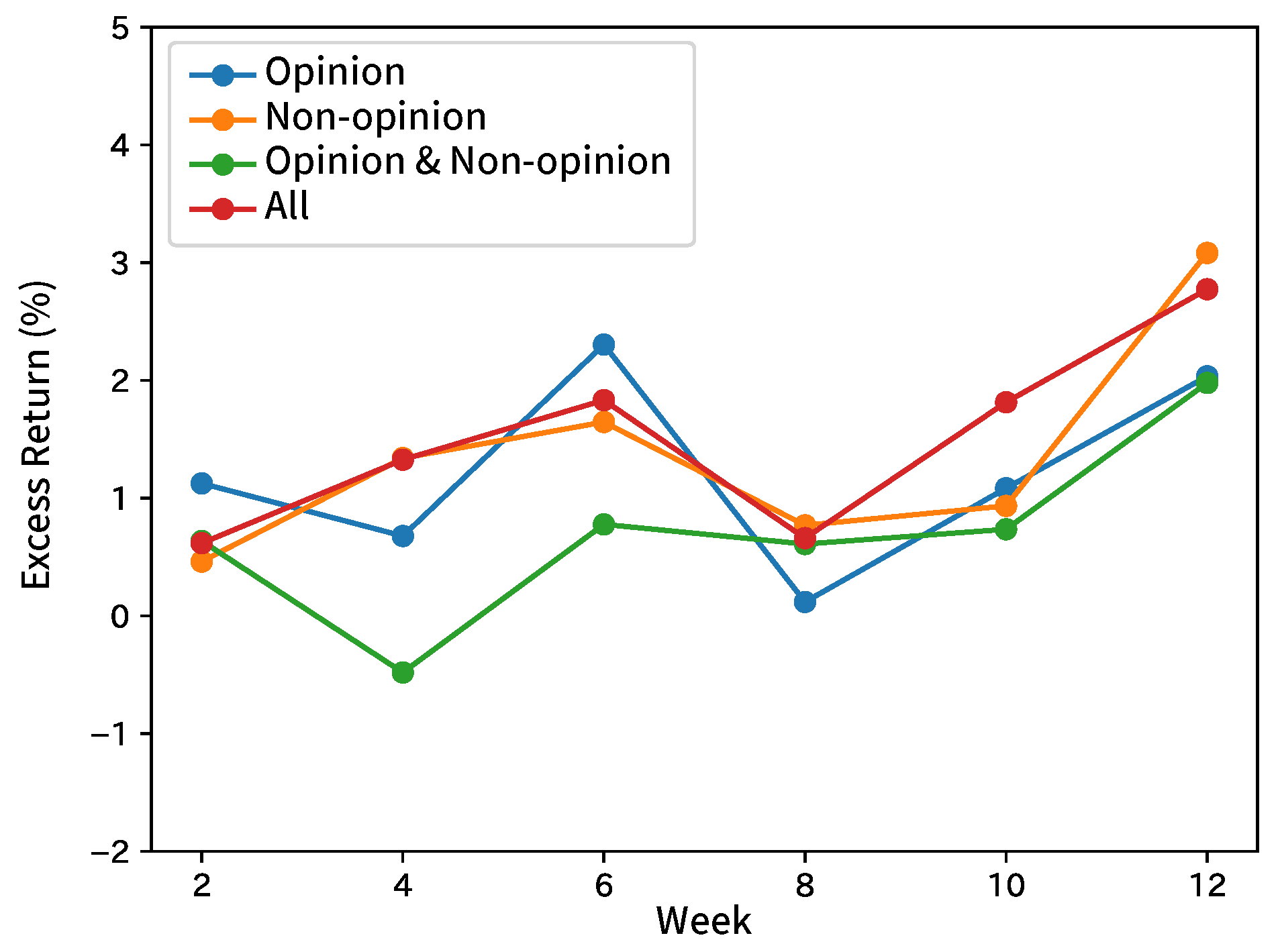
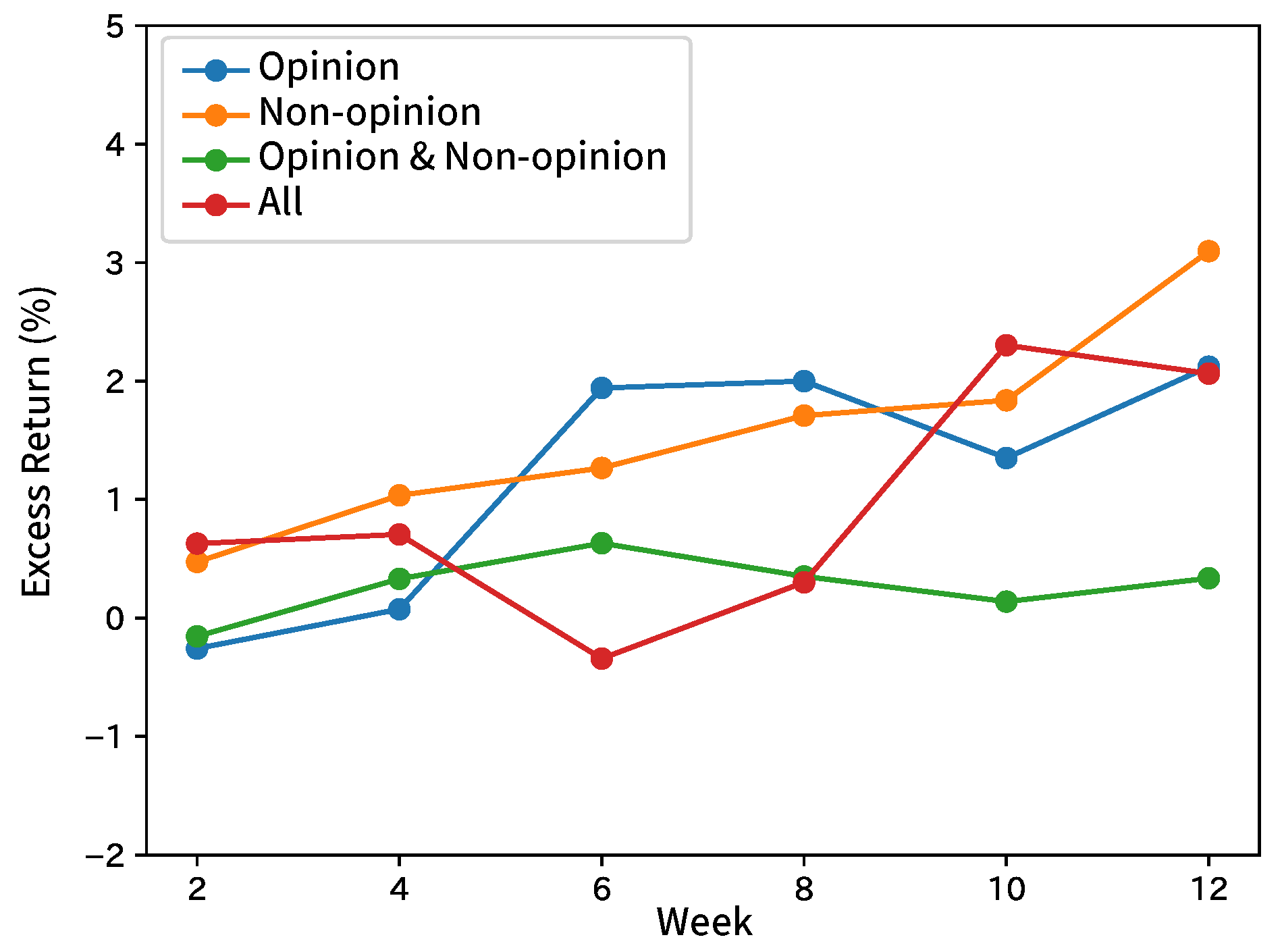
8.2. Forecasting Movements of Stock Prices
9. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bollen, J.; Mao, H.; Zeng, X. Twitter mood predicts the stock market. J. Comput. Sci. 2011, 2, 1–8. [Google Scholar] [CrossRef]
- Khadjeh Nassirtoussi, A.; Aghabozorgi, S.; Ying Wah, T.; Ngo, D.C.L. Text mining for market prediction: A systematic review. Expert Syst. Appl. 2014, 41, 7653–7670. [Google Scholar] [CrossRef]
- Schumaker, R.P.; Chen, H. Textual Analysis of Stock Market Prediction Using Breaking Financial News: The AZFin Text System. ACM Trans. Inf. Syst. 2009, 27, 1–19. [Google Scholar] [CrossRef]
- Schumaker, R.P.; Zhang, Y.; Huang, C.N.; Chen, H. Evaluating sentiment in financial news articles. Decis. Support Syst. 2012, 53, 458–464. [Google Scholar] [CrossRef]
- Koppel, M.; Shtrimberg, I. Good News or Bad News? Let the Market Decide. In Computing Attitude and Affect in Text: Theory and Applications; Shanahan, J.G., Qu, Y., Wiebe, J., Eds.; Springer: Dordrecht, The Netherland, 2006; pp. 297–301. [Google Scholar]
- Low, B.T.; Chan, K.; Choi, L.L.; Chin, M.Y.; Lay, S.L. Semantic expectation-based causation knowledge extraction: A study on Hong Kong stock movement analysis. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), Hong Kong, China, 16–18 April 2001; pp. 114–123. [Google Scholar]
- Ito, T.; Sakaji, H.; Tsubouchi, K.; Izumi, K.; Yamashita, T. Text-visualizing Neural Network Model: Understanding Online Financial Textual Data. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), Melbourne, Australia, 3–6 June 2018; pp. 247–259. [Google Scholar]
- Ito, T.; Sakaji, H.; Izumi, K.; Tsubouchi, K.; Yamashita, T. GINN: Gradient interpretable neural networks for visualizing financial texts. Int. J. Data Sci. Anal. 2020, 9, 431–445. [Google Scholar] [CrossRef]
- Milea, V.; Sharef, N.M.; Almeida, R.J.; Kaymak, U.; Frasincar, F. Prediction of the MSCI EURO index based on fuzzy grammar fragments extracted from European Central Bank statements. In Proceedings of the 2010 International Conference of Soft Computing and Pattern Recognition, Paris, France, 7–10 December 2010; pp. 231–236. [Google Scholar] [CrossRef]
- Wuthrich, B.; Cho, V.; Leung, S.; Permunetilleke, D.; Sankaran, K.; Zhang, J. Daily stock market forecast from textual web data. In Proceedings of the SMC’98 Conference Proceedings, 1998 IEEE International Conference on Systems, Man, and Cybernetics (Cat. No.98CH36218), San Diego, CA, USA, 14 October 1998; Volume 3, pp. 2720–2725. [Google Scholar]
- Bar-Haim, R.; Dinur, E.; Feldman, R.; Fresko, M.; Goldstein, G. Identifying and Following Expert Investors in Stock Microblogs. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Scotland, UK, 27–31 July 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 1310–1319. [Google Scholar]
- Guijarro, F.; Moya-Clemente, I.; Saleemi, J. Liquidity Risk and Investors’ Mood: Linking the Financial Market Liquidity to Sentiment Analysis through Twitter in the S&P500 Index. Sustainability 2019, 11, 7048. [Google Scholar] [CrossRef]
- Vu, T.T.; Chang, S.; Ha, Q.T.; Collier, N. An Experiment in Integrating Sentiment Features for Tech Stock Prediction in Twitter. In Proceedings of the Workshop on Information Extraction and Entity Analytics on Social Media Data, Mumbai, India, 9 December 2012; The COLING 2012 Organizing Committee: Mumbai, India, 2012; pp. 23–38. [Google Scholar]
- Oliveira, N.; Cortez, P.; Areal, N. The impact of microblogging data for stock market prediction: Using Twitter to predict returns, volatility, trading volume and survey sentiment indices. Expert Syst. Appl. 2017, 73, 125–144. [Google Scholar] [CrossRef]
- Zhang, L.; Xiao, K.; Zhu, H.; Liu, C.; Yang, J.; Jin, B. CADEN: A Context-Aware Deep Embedding Network for Financial Opinions Mining. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 757–766. [Google Scholar]
- Ranco, G.; Aleksovski, D.; Caldarelli, G.; Grčar, M.; Mozetič, I. The Effects of Twitter Sentiment on Stock Price Returns. PLoS ONE 2015, 10, e0138441. [Google Scholar] [CrossRef] [PubMed]
- Smailović, J.; Grčar, M.; Lavrač, N.; Žnidaršič, M. Predictive Sentiment Analysis of Tweets: A Stock Market Application. In Human-Computer Interaction and Knowledge Discovery in Complex, Unstructured, Big Data; Holzinger, A., Pasi, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 77–88. [Google Scholar]
- Sakaji, H.; Sakai, H.; Masuyama, S. Automatic Extraction of Basis Expressions That Indicate Economic Trends. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), Osaka, Japan, 20–23 May 2008; pp. 977–984. [Google Scholar]
- Sakaji, H.; Murono, R.; Sakai, H.; Bennett, J.; Izumi, K. Discovery of Rare Causal Knowledge from Financial Statement Summaries. In Proceedings of the 2017 IEEE Symposium on Computational Intelligence for Financial Engineering and Economics (CIFEr), Kolkata, India, 24–25 March 2017; pp. 602–608. [Google Scholar]
- Kitamori, S.; Sakai, H.; Sakaji, H. Extraction of sentences concerning business performance forecast and economic forecast from summaries of financial statements by deep learning. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–7. [Google Scholar]
- Hirano, M.; Sakaji, H.; Kimura, S.; Izumi, K.; Matsushima, H.; Nagao, S.; Kato, A. Selection of Related Stocks using Financial Text Mining. In Proceedings of the 2018 IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; pp. 191–198. [Google Scholar]
- Hirano, M.; Sakaji, H.; Kimura, S.; Izumi, K.; Matsushima, H.; Nagao, S.; Kato, A. Related Stocks Selection with Data Collaboration Using Text Mining. Information 2019, 10, 102. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Sato, T. Neologism Dictionary Based on the Language Resources on the WEB for Mecab. 2015. Available online: https://github.com/neologd/mecab-ipadic-neologd (accessed on 28 April 2020).
- Sato, T.; Hashimoto, T.; Okumura, M. Operation of a word segmentation dictionary generation system called NEologd. In Proceedings of the Information Processing Society of Japan, Special Interest Group on Natural Language Processing (IPSJ-SIGNL), Tokyo, Japan, 20–22 December 2016; p. NL-229-15. [Google Scholar]
- Sato, T.; Hashimoto, T.; Okumura, M. Implementation of a word segmentation dictionary called mecab-ipadic-NEologd and study on how to use it effectively for information retrieval. In Proceedings of the Twenty-three Annual Meeting of the Association for Natural Language Processing, Tsukuba, Japan, 14–16 March 2017. [Google Scholar]
- Jeffrey, P.; Richard, S.; Christopher, M. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), Association for Computational Linguistics, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics, Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Association for Computational Linguistics, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Period | Positive Excess Returns | Negative Excess Returns |
|---|---|---|
| 2 weeks | 8516 | 8840 |
| 4 weeks | 8620 | 8736 |
| 6 weeks | 8804 | 8552 |
| 8 weeks | 8774 | 8582 |
| 10 weeks | 8814 | 8542 |
| 12 weeks | 8686 | 8670 |
| Opinion/Non-Opinion | Sentence |
|---|---|
| Opinion |  (We will revise our earnings forecast downwards based on 2Q results.) |
| Opinion |  (The factors that could reduce profitability are the launch of new production bases and R&D investment.) |
| Non-opinion |  (This term sales reached a record high of 10 billion yen.) |
| Non-opinion |  (The dividend is planned to be 270 yen for the interim period of September 2007, 120 yen and 150 yen at the end of the year.) |
| Model | Corpus | F1 |
|---|---|---|
| Our Method | Analyst Report Sentences | 0.835 |
| Our Method | Analyst Report Set | 0.836 |
| Our Method | Reuters | 0.820 |
| Our Method | Wikipedia | 0.809 |
| Our Method | Nikkei News | 0.822 |
| SVM | - | 0.780 |
| RF | - | 0.664 |
| Broker | Opinion Sentences | Non-Opinion Sentences | Opinion and Non-Opinion Sentences | All Sentences |
|---|---|---|---|---|
| A | 0.643 | 0.653 | 0.612 | 0.543 |
| B | 0.701 | 0.680 | 0.777 | 0.703 |
| C | 0.776 | 0.687 | 0.666 | 0.725 |
| D | 0.587 | 0.907 | 0.548 | 0.904 |
| E | 0.631 | 0.695 | 0.664 | 0.594 |
| Index | Our Method | RNN without the Trend | SVM | RF |
|---|---|---|---|---|
| Input: opinion sentences | 0.668 | 0.610 | 0.657 | 0.596 |
| Input: non-opinion sentences | 0.724 | 0.605 | 0.654 | 0.594 |
| Input: opinion and non-opinion sentences | 0.653 | 0.611 | - | - |
| Input: all sentences | 0.694 | 0.627 | 0.691 | 0.624 |
| Broker: A | 0.613 | 0.615 | 0.642 | 0.596 |
| Broker: B | 0.715 | 0.658 | 0.746 | 0.574 |
| Broker: C | 0.713 | 0.617 | 0.678 | 0.649 |
| Broker: D | 0.736 | 0.604 | 0.653 | 0.637 |
| Broker: E | 0.646 | 0.573 | 0.620 | 0.568 |
| Period: 2 weeks | 0.710 | 0.614 | 0.668 | 0.602 |
| Period: 4 weeks | 0.674 | 0.614 | 0.666 | 0.601 |
| Period: 6 weeks | 0.679 | 0.606 | 0.668 | 0.608 |
| Period: 8 weeks | 0.683 | 0.611 | 0.671 | 0.610 |
| Period: 10 weeks | 0.686 | 0.616 | 0.666 | 0.603 |
| Period: 12 weeks | 0.678 | 0.618 | 0.667 | 0.604 |
| Broker | Opinion Sentences | Non-Opinion Sentences | Opinion and Non-Opinion Sentences | All Sentences |
|---|---|---|---|---|
| A | 0.529 | 0.526 | 0.520 | 0.506 |
| B | 0.558 | 0.563 | 0.569 | 0.573 |
| C | 0.530 | 0.535 | 0.503 | 0.533 |
| D | 0.518 | 0.525 | 0.509 | 0.523 |
| E | 0.500 | 0.503 | 0.492 | 0.499 |
| Broker | Opinion Sentences | Non-Opinion Sentences | Opinion and Non-Opinion Sentences | All Sentences |
|---|---|---|---|---|
| A | 0.618 | 0.587 | 0.630 | 0.596 |
| B | 0.634 | 0.633 | 0.657 | 0.657 |
| C | 0.585 | 0.626 | 0.593 | 0.638 |
| D | 0.575 | 0.581 | 0.575 | 0.588 |
| E | 0.568 | 0.584 | 0.590 | 0.601 |
| Index | Our Method | SVM | RF |
|---|---|---|---|
| Input: opinion sentences | 0.527 | 0.549 | 0.499 |
| Input: non-opinion sentences | 0.530 | 0.546 | 0.484 |
| Input: opinion and non-opinion sentences | 0.519 | - | - |
| Input: all sentences | 0.527 | 0.556 | 0.509 |
| Broker: A | 0.520 | 0.527 | 0.484 |
| Broker: B | 0.566 | 0.619 | 0.508 |
| Broker: C | 0.525 | 0.542 | 0.520 |
| Broker: D | 0.519 | 0.546 | 0.516 |
| Broker: E | 0.499 | 0.518 | 0.489 |
| Period: 2 weeks | 0.519 | 0.537 | 0.473 |
| Period: 4 weeks | 0.519 | 0.542 | 0.494 |
| Period: 6 weeks | 0.523 | 0.546 | 0.494 |
| Period: 8 weeks | 0.525 | 0.546 | 0.505 |
| Period: 10 weeks | 0.525 | 0.564 | 0.522 |
| Period: 12 weeks | 0.532 | 0.569 | 0.532 |
| Index | Our Method | SVM | RF |
|---|---|---|---|
| Input: opinion sentences | 0.596 | 0.648 | 0.628 |
| Input: non-oppinion sentences | 0.602 | 0.666 | 0.633 |
| Input: opinion and non-opinion sentences | 0.609 | - | - |
| Input: all sentences | 0.616 | 0.698 | 0.659 |
| Broker: A | 0.608 | 0.669 | 0.654 |
| Broker: B | 0.646 | 0.726 | 0.662 |
| Broker: C | 0.611 | 0.665 | 0.641 |
| Broker: D | 0.580 | 0.637 | 0.608 |
| Broker: E | 0.586 | 0.657 | 0.636 |
| Period: 2 weeks | 0.562 | 0.629 | 0.607 |
| Period: 4 weeks | 0.593 | 0.655 | 0.629 |
| Period: 6 weeks | 0.618 | 0.674 | 0.646 |
| Period: 8 weeks | 0.613 | 0.680 | 0.653 |
| Period: 10 weeks | 0.616 | 0.693 | 0.657 |
| Period: 12 weeks | 0.633 | 0.693 | 0.649 |
| Period | Opinion Sentences | Non-Opinion Sentences | Opinion and Non-Opinion Sentences | All Sentences |
|---|---|---|---|---|
| 2 weeks | 0.502 | 0.510 | 0.509 | 0.497 |
| 4 weeks | 0.521 | 0.515 | 0.516 | 0.517 |
| 6 weeks | 0.502 | 0.516 | 0.539 | 0.540 |
| 8 weeks | 0.527 | 0.523 | 0.529 | 0.539 |
| 10 weeks | 0.549 | 0.510 | 0.540 | 0.552 |
| 12 weeks | 0.547 | 0.547 | 0.525 | 0.544 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suzuki, M.; Sakaji, H.; Izumi, K.; Matsushima, H.; Ishikawa, Y. Forecasting Net Income Estimate and Stock Price Using Text Mining from Economic Reports. Information 2020, 11, 292. https://doi.org/10.3390/info11060292
Suzuki M, Sakaji H, Izumi K, Matsushima H, Ishikawa Y. Forecasting Net Income Estimate and Stock Price Using Text Mining from Economic Reports. Information. 2020; 11(6):292. https://doi.org/10.3390/info11060292
Chicago/Turabian StyleSuzuki, Masahiro, Hiroki Sakaji, Kiyoshi Izumi, Hiroyasu Matsushima, and Yasushi Ishikawa. 2020. "Forecasting Net Income Estimate and Stock Price Using Text Mining from Economic Reports" Information 11, no. 6: 292. https://doi.org/10.3390/info11060292
APA StyleSuzuki, M., Sakaji, H., Izumi, K., Matsushima, H., & Ishikawa, Y. (2020). Forecasting Net Income Estimate and Stock Price Using Text Mining from Economic Reports. Information, 11(6), 292. https://doi.org/10.3390/info11060292