Fully-Unsupervised Embeddings-Based Hypernym Discovery



Abstract
1. Introduction
| Mango IS A fruit |
| Africa IS A continent |
| Barack Obama IS A politician |
- taxonomy expansion, where an initial seed taxonomy (set of pairs such as <mango,fruit> and <fruit,food>) is given and this must be made incremented with new pairs;
- hypernym detection, that aims at determining whether a given pair of words has a hypernymy relation. This can be seen as a binary classification problem, where given a pair such as <mango,fruit> or <potato,fruit>, it answers positive or negative—that can be used as a building block for taxonomy expansion;
- hypernym discovery, a more recent and challenging task w.r.t. hypernym detection, where a list of valid hypernyms must be retrieved starting from a given hyponym.
- Unsupervised: does not require user intervention; has no supervised training steps; does not use any tool that require or is obtained through the use of supervision such as pre-trained artificial neural networks, POS taggers, knowledge bases, etc.
- Language independent: no specific language characteristics or structure is exploited. This includes Hearst patterns, stopwords lists etc.
- Unstructured-data driven: the algorithm exploits plain text as the only input, without structured information like tags, links, hierarchies etc.
2. Related Works
3. Our Proposal: Re-Ranking Semantic Similarity Based on Word Frequencies
- Embedding component: employs a dense word embedding model to compare the corpora words at a distributional level.
- Extraction component: extracts potential hypernyms
- Ranking component: assigns a score to the candidates and returns a ranked list whose target is to get the actual hypernyms to the lowest possible position. It also provides an extra filtering function to remove false positives.
3.1. Embedding Component
- Barack Obama
- New York Times
- New Zealand
| {jobs, steve, high-paying, low-paying, well-paying, bryant, high-wage, gwen, alex, kidsinpear} |
3.2. Extraction Component
- Singleton labeling: if the seed-set is a singleton, the neighbourhood size is a simple parameter which can be specified by the user. During implementation, the idea of introducing a data-augmentation phase was considered, similarly to the one adopted by CRIM system [32], using the first N neighbours of the input to generate a larger seed-set but its introduction did not produce significantly better results.
- Set Labeling: in this case we make a strong assumption: given that the starting set must necessarily contain hyponyms that share the same hypernym, then each hyponym’s neighbourhood should intersects at some point. For example it is expected that the neighbours of the continents should all contain the word “continent” at some point. Consequently in this case the algorithm executes an NNS for each seed and verifies if they overlap. When running the algorithm the user can specify how many candidates must be returned—if the neighbourhood intersection does not return enough elements, then a wider neighbourhood is explored. This goes on until the requested number of candidates is fetched or a stop criterion is met.
3.3. Ranking Component
| {Italian, Sicily, Italians, ITALY, Spain, Bologna, France, Milan, Romania} |
3.3.1. Heuristics and Re-Ranking Measure
3.3.2. Filtering
4. Pseudo-Code
| Algorithm 1: HyperRank: Computing Ranked List of Hypernyms. |
 |
5. Evaluation
5.1. Provided Corpus
- 2A: a medical domain english text, which is parsed from MEDLINE (available at https://www.nlm.nih.gov/databases/download/pubmed_medline.html) and contains scientific articles and abstracts. It contains 180 million words.
- 2B: an english text containing music-themed articles and biographies, from various sources including Last.fm and the music section of Wikipedia, for a total of 100 million words [43].
5.2. Results
6. Considerations Regarding SemEval Evaluation
Limits of the SemEval Benchmark
- Buckler (1A corpus): defined as “a small shield […] gripped in the fist” has only one label in ground truth, that is “body armor”. Not only it is wrong to define a buckler as an “armor” (a shield is normally defined as a defense weapon) but it is the American connotation of the word: if an approach finds “armour” (which is to be expected in an English corpus and found by our algorithm) it is considered wrong. Most importantly “shield” (HyperRank finds as well) is considered wrong too.
- Pragmatism (1A): commonly defined as “a philosophical tradition” or “a field of linguistics” and so forth, but the gold standard does not contain any related label at all. Instead we find labels like “social function”, “usefulness” or “ceremonial”. The proposed algorithm labels it as “philosophy” and it is considered wrong.
- Liberty (1A): accepted labels looks more like synonyms than hypernyms (freedom, independence). Even in this case HyperRank labels it as “right” and it is considered as an error.
- Zinc (1A): does not contain any label related to the chemical element while HyperRank correctly label it as “mineral” and “metal”.
7. Custom Testset Evaluation
8. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Atzori, M. The Need of Structured Data: Introducing the OKgraph Project. In Proceedings of the 10th Italian Information Retrieval Workshop, Padova, Italy, 16–18 September 2019. [Google Scholar]
- Atzori, M.; Balloccu, B.; Bellanti, A. Unsupervised Singleton Expansion from Free Text. In Proceedings of the 12th IEEE International Conference on Semantic Computing, ICSC 2018, Laguna Hills, CA, USA, 31 January–2 February 2018. [Google Scholar]
- Yu, Z.; Wang, H.; Lin, X.; Wang, M. Learning term embeddings for hypernymy identification. In Proceedings of the 24th International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Seitner, J.; Bizer, C.; Eckert, K.; Faralli, S.; Meusel, R.; Paulheim, H.; Ponzetto, S.P. A Large DataBase of Hypernymy Relations Extracted from the Web. In Proceedings of the 10th International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 360–367. [Google Scholar]
- Kliegr, T. Linked hypernyms: Enriching dbpedia with targeted hypernym discovery. J. Web Sem. 2015, 31, 59–69. [Google Scholar] [CrossRef]
- Wang, C.; He, X.; Zhou, A. A short survey on taxonomy learning from text corpora: Issues, resources and recent advances. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 1190–1203. [Google Scholar]
- Hearst, M.A. Automatic Acquisition of Hyponyms from Large Text Corpora. In Proceedings of the 14th Conference on Computational Linguistics (COLING ’92), Gothenburg, Sweden, 23–28 August 1992; Association for Computational Linguistics: Stroudsburg, PA, USA, 1992; pp. 539–545. [Google Scholar]
- Snow, R.; Jurafsky, D.; Ng, A.Y. Learning syntactic patterns for automatic hypernym discovery. In Proceedings of the Neural Information Processing Systems Conference (NIPS 2004), Vancouver, BC, Canada, 13–18 December 2004; pp. 1297–1304. [Google Scholar]
- Nguyen, K.A.; Köper, M.; Walde, S.S.i.; Vu, N.T. Hierarchical embeddings for hypernymy detection and directionality. arXiv 2017, arXiv:1707.07273. [Google Scholar]
- Chang, H.S.; Wang, Z.; Vilnis, L.; McCallum, A. Distributional inclusion vector embedding for unsupervised hypernymy detection. arXiv 2017, arXiv:1710.00880. [Google Scholar]
- Le, M.; Roller, S.; Papaxanthos, L.; Kiela, D.; Nickel, M. Inferring concept hierarchies from text corpora via hyperbolic embeddings. arXiv 2019, arXiv:1902.00913. [Google Scholar]
- Xu, C.; Zhou, Y.; Wang, Q.; Ma, Z.; Zhu, Y. Detecting Hypernymy Relations Between Medical Compound Entities Using a Hybrid-Attention Based Bi-GRU-CapsNet Model. IEEE Access 2019, 7, 175693–175702. [Google Scholar] [CrossRef]
- Shwartz, V.; Goldberg, Y.; Dagan, I. Improving hypernymy detection with an integrated path-based and distributional method. arXiv 2016, arXiv:1603.06076. [Google Scholar]
- Ritter, A.; Soderland, S.; Etzioni, O. What Is This, Anyway: Automatic Hypernym Discovery. In Proceedings of the 2009 AAAI Spring Symposium: Learning by Reading and Learning to Read, Stanford, CA, USA, 23–25 March 2009; pp. 88–93. [Google Scholar]
- Yates, A.; Cafarella, M.; Banko, M.; Etzioni, O.; Broadhead, M.; Soderland, S. Textrunner: Open information extraction on the web. In Proceedings of the Human Language Technologies: The Annual Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations, Rochester, NY, USA; Association for Computational Linguistics: Strudsburg, PA, USA, 2007; pp. 25–26. [Google Scholar]
- Fu, R.; Qin, B.; Liu, T. Exploiting multiple sources for open-domain hypernym discovery. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1224–1234. [Google Scholar]
- Yamada, I.; Torisawa, K.; Kazama, J.; Kuroda, K.; Murata, M.; De Saeger, S.; Bond, F.; Sumida, A. Hypernym discovery based on distributional similarity and hierarchical structures. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–7 August 2009; Association for Computational Linguistics: Strudsburg, PA, USA, 2009; pp. 929–937. [Google Scholar]
- Espinosa-Anke, L.; Camacho-Collados, J.; Delli Bovi, C.; Saggion, H. Supervised distributional hypernym discovery via domain adaptation. In Proceedings of the ACL Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 424–435. [Google Scholar]
- Doval, Y.; Camacho-Collados, J.; Espinosa-Anke, L.; Schockaert, S. Meemi: A Simple Method for Post-processing Cross-lingual Word Embeddings. arXiv 2019, arXiv:1910.07221. [Google Scholar]
- Palm Myllylä, J. Domain Adaptation for Hypernym Discovery via Automatic Collection of Domain-Specific Training Data. 2019. Available online: http://www.diva-portal.org/smash/record.jsf?pid=diva2%3A1327273&dswid=1297 (accessed on 14 May 2020).
- Maldonado, A.; Klubička, F. Adapt at semeval-2018 task 9: Skip-gram word embeddings for unsupervised hypernym discovery in specialised corpora. In Proceedings of the 12th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2018; pp. 924–927. [Google Scholar]
- Aldine, A.I.A.; Harzallah, M.; Berio, G.; Béchet, N.; Faour, A. EXPR at SemEval-2018 Task 9: A Combined Approach for Hypernym Discovery. In Proceedings of the 12th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2018; pp. 919–923. [Google Scholar]
- Hassan, A.Z.; Vallabhajosyula, M.S.; Pedersen, T. UMDuluth-CS8761 at SemEval-2018 Task 9: Hypernym Discovery using Hearst Patterns, Co-occurrence frequencies and Word Embeddings. arXiv 2018, arXiv:1805.10271. [Google Scholar]
- Hashimoto, H.; Mori, S. LSTM Language Model for Hypernym Discovery. In Proceedings of the 20th International Conference on Computational Linguistics and Intelligent Text Processing 2019, La Rochelle, France, 7–13 April 2019. [Google Scholar]
- Plamada-Onofrei, M.; Hulub, I.; Trandabat, D.; Gîfu, D. Apollo at SemEval-2018 Task 9: Detecting Hypernymy Relations Using Syntactic Dependencies. In Proceedings of the 12th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2018; pp. 898–902. [Google Scholar]
- Zhang, Z.; Li, J.; Zhao, H.; Tang, B. Sjtu-nlp at semeval-2018 task 9: Neural hypernym discovery with term embeddings. arXiv 2018, arXiv:1805.10465. [Google Scholar]
- Dash, S.; Chowdhury, M.F.M.; Gliozzo, A.; Mihindukulasooriya, N.; Fauceglia, N.R. Hypernym Detection Using Strict Partial Order Networks. arXiv 2020, arXiv:1909.10572. [Google Scholar]
- Qiu, W.; Chen, M.; Li, L.; Si, L. NLP_HZ at SemEval-2018 Task 9: A Nearest Neighbor Approach. In Proceedings of the 12th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2018; pp. 909–913. [Google Scholar]
- Berend, G.; Makrai, M.; Földiák, P. 300-sparsans at SemEval-2018 Task 9: Hypernymy as interaction of sparse attributes. In Proceedings of the 12th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2018; pp. 928–934. [Google Scholar]
- Held, W.; Habash, N. The Effectiveness of Simple Hybrid Systems for Hypernym Discovery. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3362–3367. [Google Scholar]
- Aldine, A.I.A.; Harzallah, M.; Berio, G.; Bechet, N.; Faour, A. Mining Sequential Patterns for Hypernym Relation Extraction. In Proceedings of the TextMine’19, Metz, France, 22 January 2019. [Google Scholar]
- Bernier-Colborne, G.; Barriere, C. CRIM at SemEval-2018 task 9: A hybrid approach to hypernym discovery. In Proceedings of the 12th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2018; pp. 725–731. [Google Scholar]
- Shi, Y.; Shen, J.; Li, Y.; Zhang, N.; He, X.; Lou, Z.; Zhu, Q.; Walker, M.; Kim, M.; Han, J. Discovering Hypernymy in Text-Rich Heterogeneous Information Network by Exploiting Context Granularity. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing China, 3–7 November 2019; pp. 599–608. [Google Scholar]
- Shen, J.; Shen, Z.; Xiong, C.; Wang, C.; Wang, K.; Han, J. TaxoExpan: Self-supervised Taxonomy Expansion with Position-Enhanced Graph Neural Network. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 486–497. [Google Scholar]
- Luo, X.; Liu, L.; Yang, Y.; Bo, L.; Cao, Y.; Wu, J.; Li, Q.; Yang, K.; Zhu, K.Q. AliCoCo: Alibaba E-commerce Cognitive Concept Net. arXiv 2020, arXiv:2003.13230. [Google Scholar]
- Camacho-Collados, J.; Delli Bovi, C.; Espinosa-Anke, L.; Oramas, S.; Pasini, T.; Santus, E.; Shwartz, V.; Navigli, R.; Saggion, H. SemEval-2018 task 9: Hypernym discovery. In Proceedings of the 12th International Workshop on Semantic Evaluation (SemEval-2018), New Orleans, LA, USA, 5–6 June 2018. [Google Scholar]
- Santus, E.; Chiu, T.S.; Lu, Q.; Lenci, A.; Huang, C.R. Unsupervised measure of word similarity: How to outperform co-occurrence and vector cosine in vsms. arXiv 2016, arXiv:1603.09054. [Google Scholar]
- Kotlerman, L.; Dagan, I.; Szpektor, I.; Zhitomirsky-Geffet, M. Directional distributional similarity for lexical inference. Nat. Lang. Eng. 2010, 16, 359–389. [Google Scholar] [CrossRef]
- Santus, E.; Lenci, A.; Lu, Q.; Im Walde, S.S. Chasing hypernyms in vector spaces with entropy. In Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, Gothenburg, Sweden, 26–30 April 2014; pp. 38–42. [Google Scholar]
- Han, L.; Finin, T. UMBC Webbase Corpus. 2013. Available online: http://ebiq.org/r/351 (accessed on 14 May 2020).
- Baroni, M.; Bernardini, S.; Ferraresi, A.; Zanchetta, E. The WaCky wide web: A collection of very large linguistically processed web-crawled corpora. Lang. Resour. Evaluat. 2009, 43, 209–226. [Google Scholar] [CrossRef]
- Cardellino, C. Spanish Billion Words Corpus And Embeddings. 2016. Available online: https://crscardellino.github.io/SBWCE/ (accessed on 14 May 2020).
- Oramas, S.; Espinosa-Anke, L.; Sordo, M.; Saggion, H.; Serra, X. ELMD: An automatically generated entity linking gold standard dataset in the music domain. In Proceedings of the 10th International Conference on Language Resources and Evaluation LREC 2016, Portoroz, Slovenia, 23–28 May 2016; Calzolari, N., Choukri, K., Declerck, T., Goggi, S., Grobelnik, M., Maegaard, B., Mariani, J., Mazo, H., Moreno, A., Odijk, J., et al., Eds.; European Language Resources Association: Paris, France, 2016; pp. 3312–3317. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Corpus | N. of Words | Language | Topic | TS Elements | GS Elements |
|---|---|---|---|---|---|
| 1A | 3B | English | General | 1500 | 8548 |
| 1B | 1.3B | Italian | General | 1000 | 5770 |
| 1C | 1.8B | Spanish | General | 1000 | 7070 |
| 2A | 180M | English | Medical | 500 | 4616 |
| 2B | 100M | English | Music | 500 | 5733 |
| Corpus | Model Size (GB) |
|---|---|
| 1A | 7.6 |
| 1B | 5.5 |
| 1C | 7.0 |
| 2A | 1.8 |
| 2B | 1.2 |
| Corpus | ST Concepts | MT Concepts | ST Hypernyms | MT Hypernyms |
|---|---|---|---|---|
| 1A | 70% | 30% | 73% | 27% |
| 1B | 79% | 21% | 84% | 26% |
| 1C | 71% | 29% | 77% | 23% |
| 2A | 47% | 53% | 64% | 36% |
| 2B | 56% | 44% | 52% | 48% |
| Method | Superv. | P@1 | P@5 | P@15 | Improvement (Over “Team 13”) |
|---|---|---|---|---|---|
| CRIM r1 | ✔ | 29.67 | 19.03 | 18.27 | +636% |
| Hybrid of SVD & NN | ✔ | - | 15.00 | - | - |
| MSCG-SANITY r1 | ✔ | 19.6 | 11.60 | 10.28 | +314% |
| vanillaTaxoEmbed | ✔ | 19.73 | 9.91 | 9.26 | +273% |
| HyperRank | 6.8 | 5.99 | 9.11 | +267% | |
| NLP HZ | ✔ | 12 | 9.19 | 8.78 | +254% |
| 300-sparsians r1 | ✔ | 14.93 | 8.63 | 8.13 | +227% |
| MFH | ✔ | 19.8 | 7.81 | 7.53 | +203% |
| SJTU BCMI | ✔ | 4.07 | 5.96 | 5.78 | +133% |
| Team 13 | 4.33 | 2.72 | 2.48 | - | |
| Apollo r2 | 4.07 | 2.69 | 2.42 | −3% | |
| apsyn r1 | 1.4 | 1.39 | 1.34 | −46% | |
| balapinc r1 | 1.8 | 1.30 | 1.30 | −48% | |
| slqs | 0.67 | 0.61 | 0.61 | −75% |
| Method | Superv. | P@1 | P@5 | P@15 | Improvement (over “Balapinc“) |
|---|---|---|---|---|---|
| 300-sparsians r1 | ✔ | 17.6 | 11.73 | 11.20 | +212% |
| NLP_HZ | ✔ | 13.1 | 11.23 | 10.90 | +204% |
| HyperRank | 7.8 | 6.29 | 10.10 | +182% | |
| MFH | ✔ | 17.1 | 6.82 | 6.51 | +81% |
| vanillaTaxoEmbed | ✔ | 12.2 | 6.47 | 6.00 | +67% |
| Meemi (VecMap) | ✔ | - | 5.95 | - | - |
| balapinc | 5.2 | 3.9 | 3.58 | - | |
| apsyn | 3.9 | 3.56 | 3.42 | −4% | |
| slqs | 1.1 | 1.63 | 1.67 | −54% | |
| Team 13 | 1 | 0.48 | 0.43 | −88% |
| Method | Superv. | P@1 | P@5 | P@15 | Improvement (over “apsyn”) |
|---|---|---|---|---|---|
| NLP_HZ | ✔ | 21.4 | 20.39 | 19.38 | +746% |
| 300-sparsians r1 | ✔ | 27.8 | 17.06 | 16.28 | +610% |
| MFH | ✔ | 24.6 | 11.26 | 11.04 | +382% |
| Meemi (VecMap) | ✔ | - | 7.48 | - | - |
| HyperRank | 6.7 | 4.48 | 6.39 | +179% | |
| vanillaTaxoEmbed | ✔ | 12.2 | 7.16 | 5.99 | +161% |
| apsyn | 2.3 | 2.35 | 2.29 | - | |
| balapinc | 3.1 | 2.48 | 2.23 | −3% | |
| Team 13 | 2.7 | 1.65 | 1.30 | −44% | |
| slqs | 0.3 | 0.83 | 1.05 | −55% |
| Method | Superv. | P@1 | P@5 | P@15 | Improvement (over ADAPT) |
|---|---|---|---|---|---|
| Hybrid of SVD & NN | ✔ | - | 40.19 | - | - |
| CRIM r1 | ✔ | 49.2 | 36.77 | 27.10 | +328% |
| MFH | ✔ | 32.6 | 34.2 | 21.39 | +237% |
| 300-sparsians r1 | ✔ | 31.6 | 21.43 | 17.05 | +169% |
| vanillaTaxoEmbed | ✔ | 35.4 | 20.71 | 12.4 | +96% |
| SJTU BCMI | ✔ | 15.2 | 11.69 | 10.24 | +61% |
| HyperRank | 10.2 | 7.23 | 7.37 | +16% | |
| ADAPT | 13.2 | 8.32 | 6.33 | - | |
| Anu | ✔ | 12.6 | 7.29 | 5.57 | −13% |
| Team 13 | 5.6 | 2.52 | 1.83 | −71% | |
| balapinc | 0.6 | 1.08 | 0.9 | −76% | |
| apsyn | 0.2 | 0.72 | 0.68 | −79% | |
| slqs | 0 | 0.33 | 0.4 | −94% |
| Method | Superv. | P@1 | P@5 | P@15 | Improvement (over Team 13) |
|---|---|---|---|---|---|
| Hybrid of SVD & NN | ✔ | - | 55.08 | - | - |
| CRIM r2 | ✔ | 47.6 | 41.58 | 38.54 | +1040% |
| MFH | ✔ | 36.2 | 35.76 | 28.44 | +741% |
| 300-sparsians r1 | ✔ | 33 | 28.86 | 27.69 | +719% |
| vanillaTaxoEmbed | ✔ | 33.2 | 12.41 | 8.70 | +157% |
| Anu | ✔ | 14.4 | 8.87 | 6.8 | +101% |
| HyperRank | 10.6 | 5.40 | 5.89 | +74 | |
| SJTU BCMI | ✔ | 2.6 | 5.41 | 5.09 | +50% |
| Team 13 | 12.2 | 4.51 | 3.38 | - | |
| ADAPT | 4 | 1.89 | 1.35 | −60% | |
| balapinc | 1.6 | 1.58 | 1.24 | −63% | |
| apsyn | 0.8 | 1.3 | 1.13 | −67% | |
| slqs | 0 | 0.65 | 0.84 | −76% |
| Field | Hyponyms Example | Hypernyms Example |
|---|---|---|
| Colours | Red, Purple, White… | Colour, Coloration, Hue… |
| Continents | Asia, Africa, Antarctica… | Continent, Mainlands, landmass… |
| Foods/Ingred. | Bread, Onion, Salt… | Food, Ingredient, foods… |
| Vehicles | Car, Bycicle, Tank… | Vehicle, Transpor, Vehicles… |
| Deities | Thor, Allah, Horus… | God, Divinities, Deity… |
| Ideologies | Marxism, Nazism, Fascism | Ideology, Movement, Policies… |
| Parties | Radical, Pirate, Civic… | Party, Parties, Faction… |
| Animals | Lion, Dog, Chameleon… | Animal, Creatures, Exemplary… |
| Electr. companies | Google, Amazon, DELL… | Companies, Company, Firm… |
| Fashion Brands | Gucci, Armani, Guess… | Fashion, Brand, Label… |
| Languages/origins | Greek, Italian, English | Languages, Citizenship, Origin… |
| Countries | Italy, Germany, Belgium | Country, State, Nation… |
| CEOs | Zuckerbeg, Bezos, Musk… | CEO, principal, businessman… |
| Progr. languages | PERL, Ocaml, LISP… | Programming, Language, Languages… |
| Bin. Sex Genres | Male, Female | Sex, Human, Gender… |
| USA Candidates | Kaine, Biden, Moore… | Candidate, Politician, Nominee… |
| USA Presidents | Obama, Nixon, Bush… | Politician, Candidate, Presidents… |
| Chemicals | Calcium, Chlorine, Silver… | Chemical, Chemicals, Element… |
| Study Fields | History, Maths, Art… | Subjects, Studies, Field… |
| Jobs | Plumber, Actor, Teacher… | Job, Occupations, Labor… |
| Cities | Turin, London, Berlin… | City, Places, Localities… |
| Capitals | Tokyo, Paris, London… | City, Capital, Places… |
| Islands | Sardinia, Java, Rhodes… | Island, Islands, Places… |
| Clothes | Shirt, Trouser, Sock… | Clothes, Clothing, Dresses… |
| Tech lineups | Surface, Macbook, Galaxy… | Electronics, Lineup, Model… |
| Fruits | Apple, Pear, Kiwi… | Food, Fruit, Fruits… |
| Currencies | Dollar, Euro, Franc… | Money, Cash, Currency… |
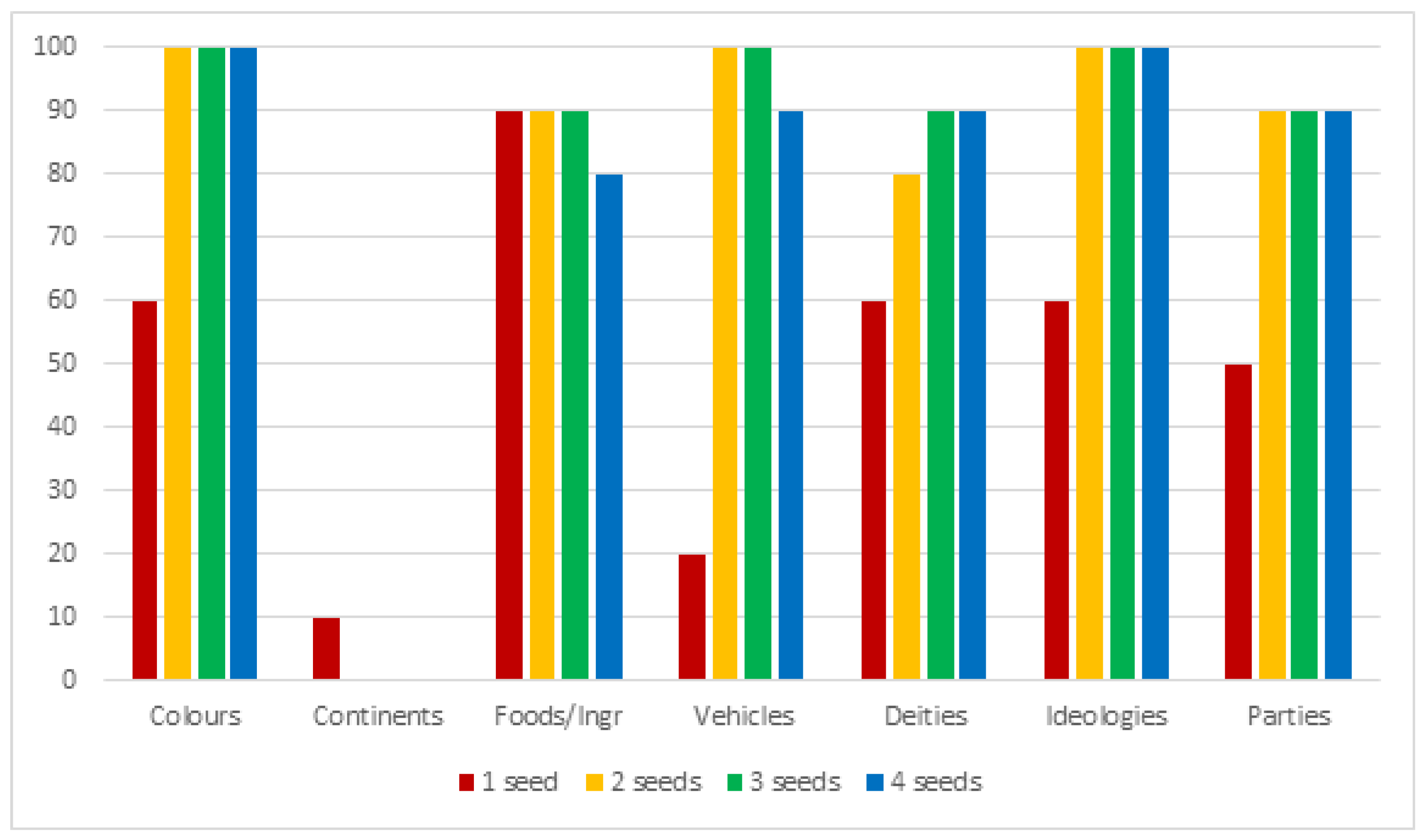
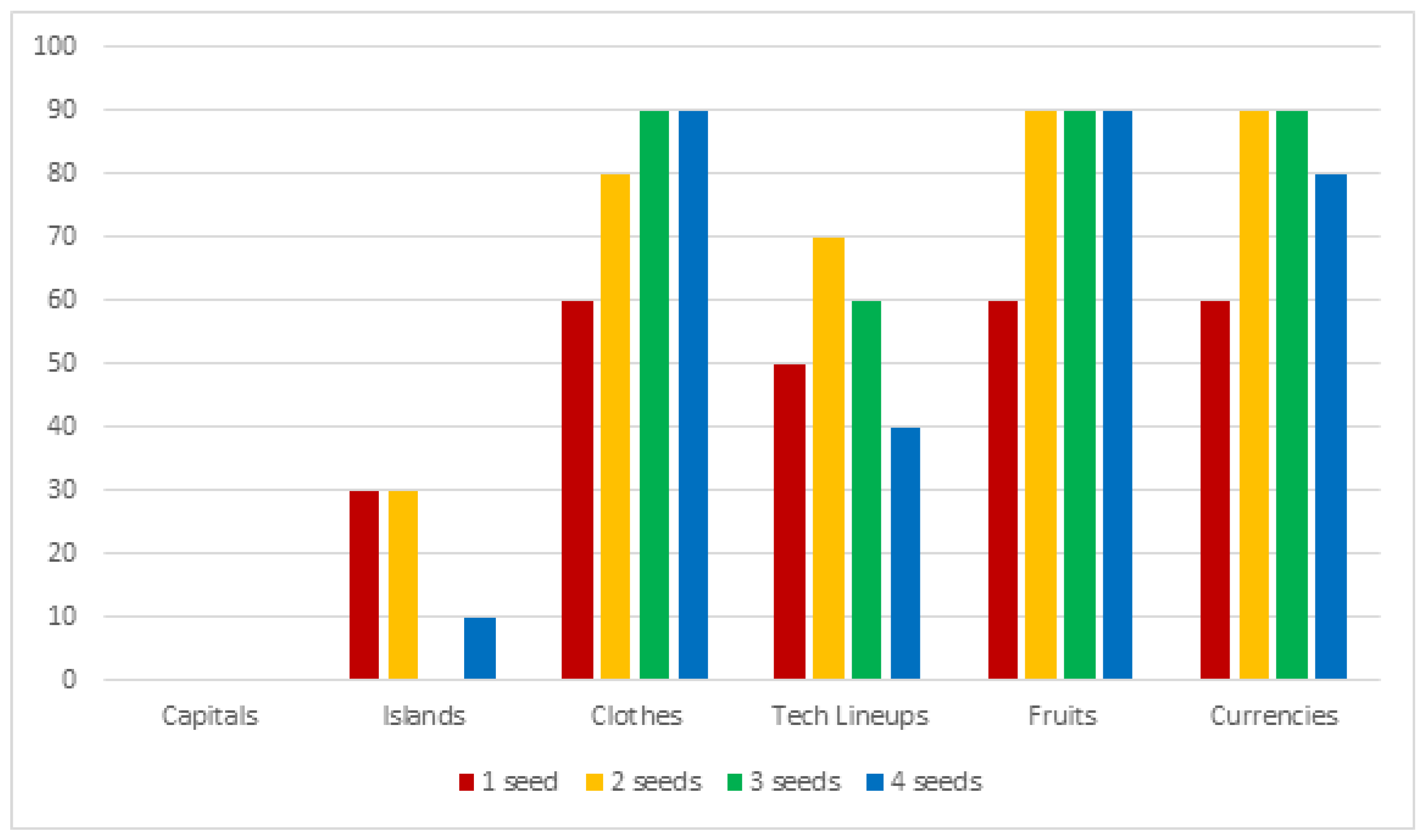
| Seed-Set Size | Sufficient Coverage (≥60%) | Good Coverage (≥80%) | Full Coverage (≥100%) |
|---|---|---|---|
| 1 | 48% | 7% | 0% |
| 2 | 60% | 48% | 7% |
| 3 | 55% | 51% | 7% |
| 4 | 51% | 44% | 11% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Atzori, M.; Balloccu, S. Fully-Unsupervised Embeddings-Based Hypernym Discovery. Information 2020, 11, 268. https://doi.org/10.3390/info11050268
Atzori M, Balloccu S. Fully-Unsupervised Embeddings-Based Hypernym Discovery. Information. 2020; 11(5):268. https://doi.org/10.3390/info11050268
Chicago/Turabian StyleAtzori, Maurizio, and Simone Balloccu. 2020. "Fully-Unsupervised Embeddings-Based Hypernym Discovery" Information 11, no. 5: 268. https://doi.org/10.3390/info11050268
APA StyleAtzori, M., & Balloccu, S. (2020). Fully-Unsupervised Embeddings-Based Hypernym Discovery. Information, 11(5), 268. https://doi.org/10.3390/info11050268