A Diverse Data Augmentation Strategy for Low-Resource Neural Machine Translation


Abstract
:1. Introduction
2. Related Work
3. Approach
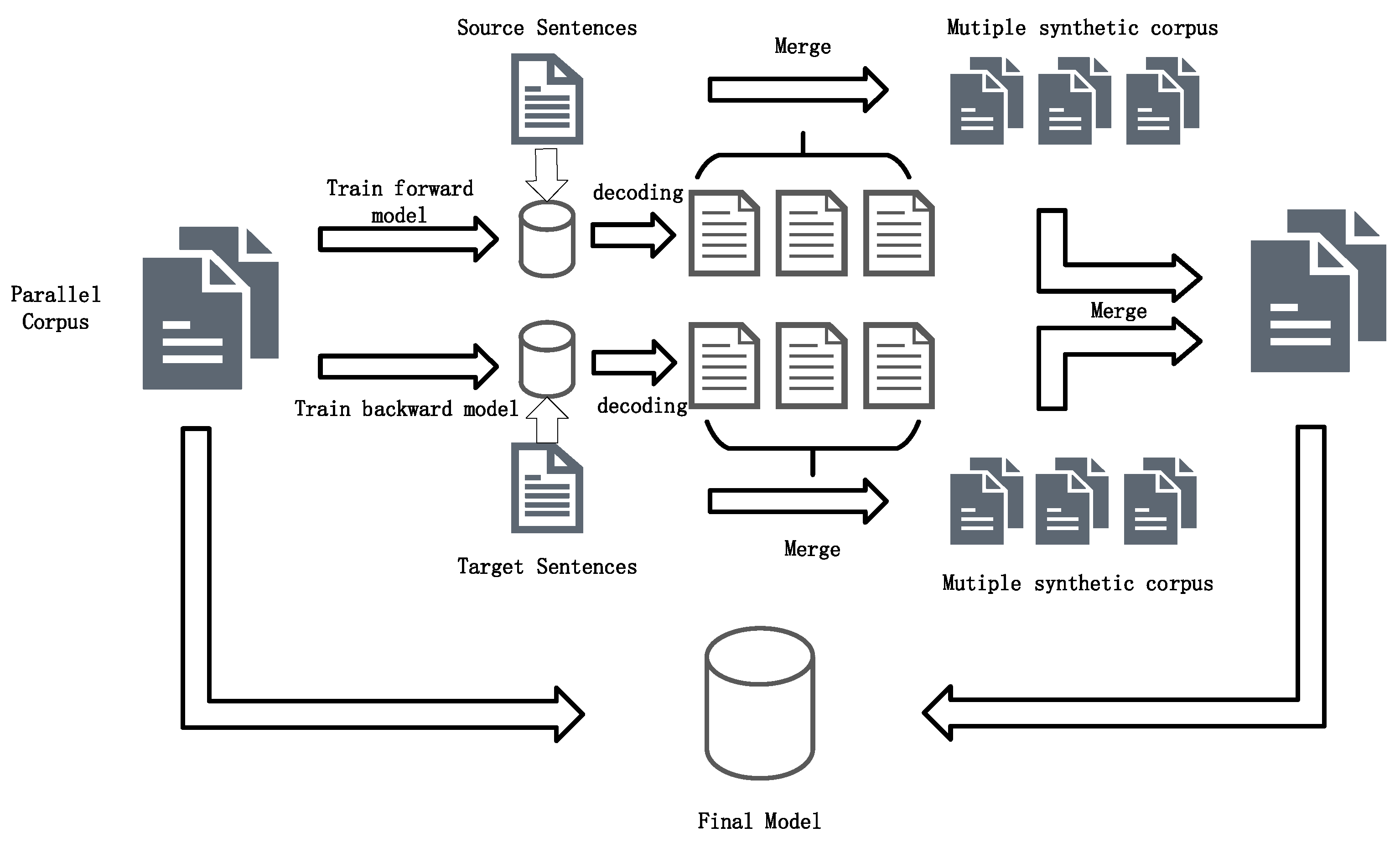
3.1. Back-Translation and Self-Learning
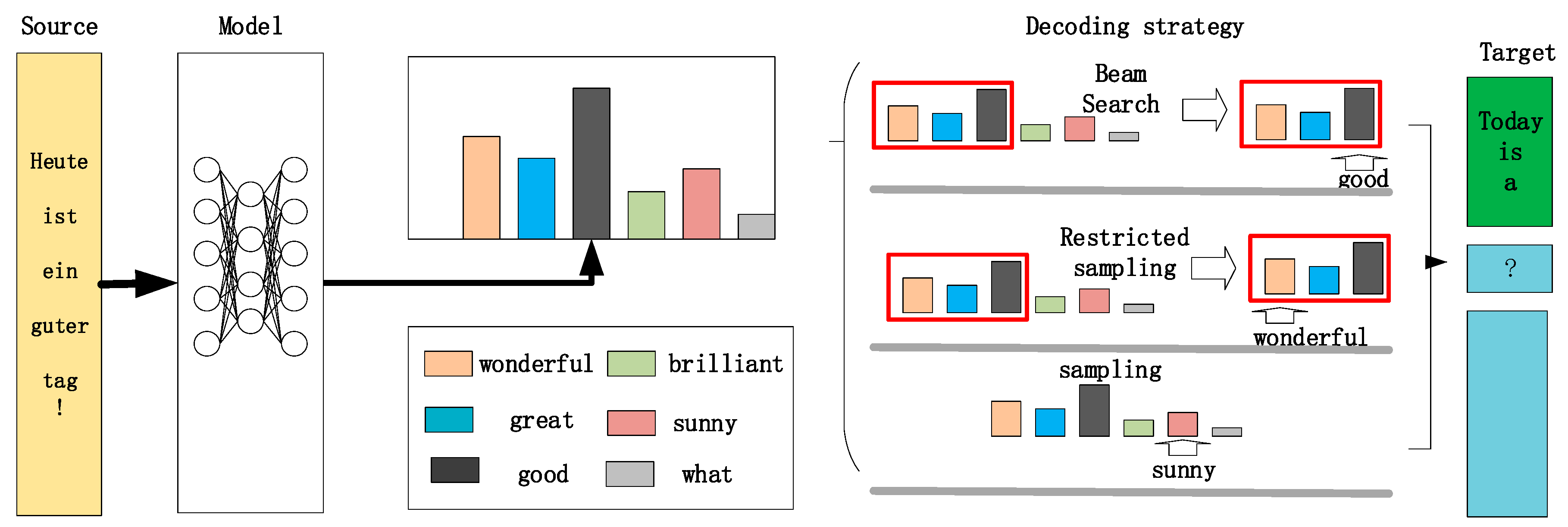
3.2. Decoder Strategy
3.3. Training Strategy
| Algorithm 1. Our data augmentation strategy. |
|
4. Experiments
4.1. IWSLT2014 EN–DE Translation Experiment
- We denote Gao’s work as SoftW. They randomly replace word embedding with a weight combination of multiple semantically similar words [26].
4.2. Low-Resource Translation Tasks
5. Discussion
5.1. Copying the Original Data
5.2. Backward Data or Forward Data
5.3. The Number of Samplings
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Neural Information Processing Systems 27 (NIPS 2014), Montreal, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Koehn, P.; Knowles, R. Six challenges for neural machine translation. arXiv 2017, arXiv:1706.03872. [Google Scholar]
- Zoph, B.; Yuret, D.; May, J.; Knight, K. Transfer learning for low-resource neural machine translation. arXiv 2016, arXiv:1604.02201. [Google Scholar]
- Gu, J.; Wang, Y.; Chen, Y.; Cho, K.; Li, V.O.K. Meta-learning for low-resource neural machine translation. arXiv 2018, arXiv:1808.08437. [Google Scholar]
- Ren, S.; Chen, W.; Liu, S.; Li, M.; Zhou, M.; Ma, S. Triangular architecture for rare language translation. arXiv 2018, arXiv:1805.04813. [Google Scholar]
- Firat, O.; Cho, K.; Sankaran, B.; Vural, F.T.Y.; Bengio, Y. Multi-way, multilingual neural machine translation. Comput. Speech Lang. 2017, 45, 236–252. [Google Scholar] [CrossRef]
- Xie, Z.; Wang, S.I.; Li, J.; Lévy, D.; Nie, A.; Jurafsky, D.; Ng, A.Y. Data noising as smoothing in neural network language models. arXiv 2017, arXiv:1703.02573. [Google Scholar]
- Gal, Y.; Ghahramani, Z. A theoretically grounded application of dropout in recurrent neural networks. In Proceedings of the Advances in Neural Information Processing Systems 29 (NIPS 2016), Barcelona, Spain, 5–10 December 2016; pp. 1019–1027. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Improving neural machine translation models with monolingual data. arXiv 2015, arXiv:1511.06709. [Google Scholar]
- Zhang, J.; Zong, C. Exploiting Source-side Monolingual Data in Neural Machine Translation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016. [Google Scholar]
- Ueffing, N.; Haffari, G.; Sarkar, A. Transductive learning for statistical machine translation. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech Republic, 23–30 June 2007; pp. 25–32. [Google Scholar]
- Imamura, K.; Fujita, A.; Sumita, E. Enhancement of encoder and attention using target monolingual corpora in neural machine translation. In Proceedings of the 2nd Workshop on Neural Machine Translation and Generation, Melbourne, Australia, 15–20 July 2018; pp. 55–63. [Google Scholar]
- Nguyen, X.P.; Joty, S.; Kui, W.; Aw, A.T. Data Diversification: An Elegant Strategy For Neural Machine Translation. arXiv 2019, arXiv:1911.01986. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural machine translation of rare words with subword units. arXiv 2015, arXiv:1508.07909. [Google Scholar]
- Pan, Y.; Li, X.; Yang, Y.; Dong, R. Morphological Word Segmentation on Agglutinative Languages for Neural Machine Translation. arXiv 2020, arXiv:2001.01589. [Google Scholar]
- Sennrich, R.; Haddow, B. Linguistic input features improve neural machine translation. arXiv 2016, arXiv:1606.02892. [Google Scholar]
- Tamchyna, A.; Marco, M.W.D.; Fraser, A. Modeling target-side inflection in neural machine translation. arXiv 2017, arXiv:1707.06012. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. arXiv 2017, arXiv:1608.06993. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Fadaee, M.; Bisazza, A.; Monz, C. Data augmentation for low-resource neural machine translation. arXiv 2017, arXiv:1705.00440. [Google Scholar]
- Kobayashi, S. Contextual augmentation: Data augmentation by words with paradigmatic relations. arXiv 2018, arXiv:1805.06201. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Wu, X.; Lv, S.; Zang, L.; Han, J.; Hu, S. Conditional BERT contextual augmentation. In Proceedings of the International Conference on Computational Science, Faro, Portugal, 12–14 June 2019; pp. 84–95. [Google Scholar]
- Gao, F.; Zhu, J.; Wu, L.; Xia, Y.; Qin, T.; Cheng, X.; Zhou, W.; Liu, T. Soft Contextual Data Augmentation for Neural Machine Translation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5539–5544. [Google Scholar]
- Poncelas, A.; Shterionov, D.; Way, A.; de Buy Wenniger, G.M.; Passban, P. Investigating backtranslation in neural machine translation. arXiv 2018, arXiv:1804.06189. [Google Scholar]
- Burlot, F.; Yvon, F. Using monolingual data in neural machine translation: A systematic study. arXiv 2019, arXiv:1903.11437. [Google Scholar]
- Cotterell, R.; Kreutzer, J. Explaining and generalizing back-translation through wake-sleep. arXiv 2018, arXiv:1806.04402. [Google Scholar]
- Edunov, S.; Ott, M.; Auli, M.; Grangier, D. Understanding back-translation at scale. arXiv 2018, arXiv:1808.09381. [Google Scholar]
- Currey, A.; Miceli-Barone, A.V.; Heafield, K. Copied monolingual data improves low-resource neural machine translation. In Proceedings of the Second Conference on Machine Translation, Copenhagen, Denmark, 7–8 September 2017; pp. 148–156. [Google Scholar]
- Cheng, Y. Semi-Supervised Learning for Neural Machine Translation. Joint Training for Neural Machine Translation; Springer: Cham, Switzerland, 2019; pp. 25–40. [Google Scholar]
- He, D.; Xia, Y.; Qin, T.; Wang, L.; Yu, N.; Liu, T.Y.; Ma, W.Y. Dual learning for machine translation. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 9 December 2016; pp. 820–828. [Google Scholar]
- Lample, G.; Conneau, A.; Denoyer, L.; Ranzato, M. Unsupervised machine translation using monolingual corpora only. arXiv 2017, arXiv:1711.00043. [Google Scholar]
- Lample, G.; Ott, M.; Conneau, A.; Denoyer, L.; Ranzato, M. Phrase-based & neural unsupervised machine translation. arXiv 2018, arXiv:1804.07755. [Google Scholar]
- Hoang, V.C.D.; Koehn, P.; Haffari, G.; Cohn, T. Iterative back-translation for neural machine translation. In Proceedings of the 2nd Workshop on Neural Machine Translation and Generation, Melbourne, Australia, 15–20 July 2018; pp. 18–24. [Google Scholar]
- Niu, X.; Denkowski, M.; Carpuat, M. Bi-directional neural machine translation with synthetic parallel data. arXiv 2018, arXiv:1805.11213. [Google Scholar]
- Zhang, J.; Matsumoto, T. Corpus Augmentation by Sentence Segmentation for Low-Resource Neural Machine Translation. arXiv 2019, arXiv:1905.08945. [Google Scholar]
- Ott, M.; Auli, M.; Grangier, D.; Ranzato, M. Analyzing uncertainty in neural machine translation. arXiv 2018, arXiv:1803.00047. [Google Scholar]
- Koehn, P.; Och, F.J.; Marcu, D. Statistical phrase-based translation. In Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology-Volume 1, Edmonton, AB, Canada, 27 May–1 June 2003; pp. 48–54. [Google Scholar]
- Artetxe, M.; Labaka, G.; Agirre, E.; Cho, K. Unsupervised neural machine translation. arXiv 2017, arXiv:1710.11041. [Google Scholar]
- Iyyer, M.; Manjunatha, V.; Boyd-Graber, J.; Daumé III, H. Deep unordered composition rivals syntactic methods for text classification. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 1681–1691. [Google Scholar]
- Guzmán, F.; Chen, P.J.; Ott, M.; Pino, J.; Lample, G.; Koehn, P.; Chaudhary, V.; Ranzato, M. Two new evaluation datasets for low-resource machine translation: Nepali-english and sinhala-english. arXiv 2019, arXiv:1902.01382. [Google Scholar]
- Indic NLP Library. Available online: https://github.com/anoopkunchukuttan/indic_nlp_library (accessed on 5 May 2020).
- SentencePiece. Available online: https://github.com/google/sentencepiece (accessed on 5 May 2020).
- Post, M. A call for clarity in reporting BLEU scores. arXiv 2018, arXiv:1804.08771. [Google Scholar]

{kind=link}
{kind=link}
| Model | DE–EN |
|---|---|
| Base | 34.72 |
| SW | 34.70 * |
| DW | 35.13 * |
| BW | 35.37 * |
| SmoothW | 35.45 * |
| LMW | 35.40 * |
| SoftW | 35.78 * |
| Our method | 36.68 |
| Model | Train | Dev | Test |
|---|---|---|---|
| TR–EN | 0.35M | 2.3k | 4k |
| SI–EN | 0.4M | 2.9k | 2.7k |
| NE–EN | 0.56M | 2.5k | 2.8k |
| Test | Test2011 | Test2012 | Test2013 | Test2014 | AVG |
|---|---|---|---|---|---|
| Baseline | 24.08 | 24.79 | 26.38 | 25.03 | |
| Our model | 25.55 | 26.11 | 28.26 | 26.41 | 1.51 |
| Model | NE–EN | SI–EN |
|---|---|---|
| Baseline | 7.64 | 6.68 |
| Our model | 8.92 | 8.21 |
| Method | DE–EN | TR–EN (Test2013) |
|---|---|---|
| Baseline | 34.72 | 26.38 |
| 7Baseline | 34.51 | 26.23 |
| Our method | 36.68 | 28.26 |
| Method | DE–EN | TR–EN (Test2013) |
|---|---|---|
| Baseline | 34.72 | 26.38 |
| Random | 36.73 | 28.27 |
| Our method | 36.68 | 28.26 |
| Method | Test2011 | Test2014 |
|---|---|---|
| TR–EN | TR–EN | |
| Baseline | 24.08 | 25.03 |
| Forward | 24.42 | 25.07 |
| Backward | 25.08 | 25.94 |
| Bidirectional | 25.55 | 26.41 |
| Method | DE–EN | TR–EN(Test2013) |
|---|---|---|
| Baseline | 34.72 | 26.38 |
| Sample_5 | 36.68 | 28.27 |
| Sample_10 | 36.48 | 28.23 |
| Sample | 36.59 | 27.86 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Li, X.; Yang, Y.; Dong, R. A Diverse Data Augmentation Strategy for Low-Resource Neural Machine Translation. Information 2020, 11, 255. https://doi.org/10.3390/info11050255
Li Y, Li X, Yang Y, Dong R. A Diverse Data Augmentation Strategy for Low-Resource Neural Machine Translation. Information. 2020; 11(5):255. https://doi.org/10.3390/info11050255
Chicago/Turabian StyleLi, Yu, Xiao Li, Yating Yang, and Rui Dong. 2020. "A Diverse Data Augmentation Strategy for Low-Resource Neural Machine Translation" Information 11, no. 5: 255. https://doi.org/10.3390/info11050255
APA StyleLi, Y., Li, X., Yang, Y., & Dong, R. (2020). A Diverse Data Augmentation Strategy for Low-Resource Neural Machine Translation. Information, 11(5), 255. https://doi.org/10.3390/info11050255