2. Related Work
Both NLI and STS have been studied from some time now. A benchmark for systems aimed at performing RTE was initially developed in the PASCAL challenge series [
6], where RTE was defined as the task of labelling two sentences as entailed or not entailed. To target a broader range of semantic relations, more recent challenges and corpora introduced the task of NLI, where sentences may also be labeled as contradictions or neutral (no semantic relation), other than entailment. The most popular of such challenges are the ones from the International Workshop on Semantic Evaluation (Semeval) (
https://semeval.github.io).
STS is a regression task, where the aim is to find a continuous value, usually, between 0 and 5 for the similarity among two sentences. To compare the performances of systems measuring semantic similarity, various shared tasks on STS were defined in Semeval [
7], including cross-lingual and multilingual tracks [
8], which did not cover Portuguese.
To the best of our knowledge, the first corpus to include entailment labels and similarity values for Portuguese sentences was ASSIN (Avaliação de Similaridade Semântica e Inferência Textual) [
9], containing pairs of sentences from news sources, split into subsets for Brazilian and European Portuguese, and provided in a shared task with the same name (
http://propor2016.di.fc.ul.pt/?page_id=381). The same types of annotations can be found in SICK [
10], a corpus of image and video captions, in English, annotated by crowd-sourcing. Recently, a translation of SICK sentences to Portuguese, the SICK-BR corpus [
11], was made available. The ASSIN2 shared task followed ASSIN, and produced a corpus based on SICK-BR entailment and neutral examples, expanded by lexical transformations [
12]. In this paper we evaluate our models on all of the mentioned Portuguese corpora.
Several methods were tested in these corpora, including feature-based approaches from similarity metrics on various text representations [
13], word embeddings built with word2vec [
14] from the Portuguese Wikipedia [
15,
16] and feature-based models relying on syntactic properties and lexical semantics [
17]. Compositional methods that derive sentence similarity from word similarities [
18] were also tested. With ASSIN, the corpus continued to be employed after the shared task, and in particular, Pinheiro et al. [
19] built a new Portuguese word2vec model from Brazilian news data and Wikipedia; Rocha and Cardoso [
20] employed a Portuguese WordNet; and Alves et al. [
21] explored word embedding models other than word2vec. In this paper we test several embedding models; in addition, and as previously said, we test two different approaches, one based on tuning pre-trained models; in the second by using pre-trained models as feature suppliers. For the latter approach, we also test a combination of embeddings and lexical features.
Recently, the BERT model [
2] was made available, and achieved state-of-the-art results on various NLP tasks for English, like those in the GLUE benchmark [
22], which is aimed at solving multiple NLP tasks. BERT produces contextual and dynamic embeddings from a deep learning architecture based on bidirectional transformers [
23], such that the embedding of a word is specific to the context in which it is employed, and the same word employed in different contexts results in different embeddings. Training a BERT model is expensive in terms of time and resources, but pre-trained models (in base or larger versions), based on Wikipedia, were made available on various languages including Portuguese [
5].
In ASSIN2 various systems already relied on the BERT model, where the best results were obtained by Rodrigues et al. [
24] by employing an enhanced BERT model, only available for English, with a machine translated version of the ASSIN2 corpus. Competitive results were also achieved by Rodrigues et al. [
3], through augmenting the mBERT-Base model with data not in the ASSIN2 corpus, and by Cabezudo et al. [
4], who identified and explored relations between NLI and STS annotations, such that the mBERT-Base model was fine tuned on the NLI task, and the resulting model was employed to compute embeddings to address the STS task.
The system of Cabezudo et al. [
4] employs lexical features, such as BLEU [
25], and features based on the Brazilian WordNet of OpenWordNet-PT [
26], to analyze examples relative to their NLI and STS annotations, and to combine them with BERT embeddings for addressing the ASSIN2 tasks. Such features did not improve the performance of BERT, but the mentioned corpus analysis supported an alternative split of training and development examples with which their best result was obtained.
In Rodrigues et al. [
3], a new instance of the BERT model was introduced, specific to Portuguese, as trained with the Portuguese Wikipedia and various news sources, from European and Brazilian Portuguese variants. The motivation for such model is to avoid language interpretation issues proper to the encoding of multiple languages in the official mBERT-Base model, as exemplified by the authors. However, said model did not succeed in providing the best results, which were instead obtained with mBERT-Base. Experiments included fine tuning on each task, fine tuning in the mentioned Portuguese texts and using the corpus from the previous ASSIN edition to increase training data.
4. Experimental Setup
4.1. Models
The fine tuning architecture was defined with the Keras framework (
https://keras.io/). Loading the BERT model and preparing its inputs from a sentence pair was performed with the Transformers toolkit (
https://huggingface.co/transformers/). We followed the fine tuning parameter recommendations from Devlin et al. [
2], such as for the range of values for epochs, batch size and learning rate, but did not perform automatic search for optimal parameters. Instead, we selected the maximum number of recommended epochs and batch size, respectively 4 and 32, and the intermediate value for learning rate (3 × 10
−5). For the optimizer, we employed Adam [
31], since in early experiments this was the best setting, unlike the original BERT model which employs a version of Adam featuring weight decay [
2]. ptBERT-Large, ptBERT-Base and mBERT were all tuned in our experiments.
Regarding the most traditional classification/regression setting, all machine learning was performed in scikit-learn [
32]. Classification models were chosen in various combinations, mainly by considering learning algorithms with simple and complex versions available, and the processing times to build them. The final set was composed of two types of SVM and random forests of decision trees. In addition, we considered an ensemble of all models based on a voting algorithm. The simple version of SVM has a linear kernel (LIBLINEAR implementation), while the more complex versions correspond to the non linear polynomial and RBF kernels. A random forest is a combination of decision trees and random feature selection, hence a complex version of decision trees. The voting model also considers decision trees, as the simpler version of random forests, although its algorithm is not competitive with the latter. Regression models implement the same types of algorithms selected for classification models.
With respect to the voting model, we considered that all models have the same weight, and for classification models we employed a strategy (named “soft voting” in
scikit-learn) in which the output class was chosen by averaging the prediction probabilities that each classifier reported for a certain class, and choosing the highest class average using argmax. To ensure reliable prediction probabilities, all classifiers were calibrated [
33], using the Platt method [
34] in
scikit-learn.
For all models, optimal parameters were identified from a combination of various parameters, including various degrees for the polynomial kernel, the number of decision trees in random forests and the existence of class imbalance on all classification models. Said parameter search was applied for each corpus. For instance, to obtain the final model, for a certain corpus and feature sets, when using SVM with a linear kernel, seven different models were trained, corresponding to different values for the C parameter, sampled from a logarithmic scale between 0.001 and 1000. When using SVM with the remaining kernels, the search included at least the C and gamma parameters, such that each of the mentioned seven models implies training another set of models, corresponding to combinations of a certain C values and various values for gamma, which were sampled from a logarithmic scale between 0.0001 and 10. For random forests, various types of parameters were also included in the search, such as the number of trees (we experiment with 100 or 200 trees) and the maximum depth of each tree.
4.3. Evaluation Metrics
For NLI, we report accuracy, precision, recall and F score (F1, as we consider precision and recall to have the same weight/importance).
Precision measures the performance of a system in predicting the correct class of all its predictions for a certain class. It is implemented as the number of examples where the predicted class matches the true class, divided by the total number of examples predicted as being of said class.
Recall measures the fraction of examples of a certain class that were correctly predicted, and is implemented as the number of examples wherein the predicted class matches the true class, divided by the total number of examples of said class.
The F1 score represents the harmonic mean of precision and recall, where 1 indicates the importance factor of precision in respect to recall. Generally, the F score is defined as in Equation (
1), which we employ with
.
Accuracy measures the fraction of correct predictions with respect to all predictions.
Precision, recall and F1 metrics are based on the assumption that a positive class exists (as in binary classification). For classification tasks with multiple classes, such as NLI in most of our evaluated corpora, these metrics are computed for each class, by considering predictions of other classes as negative instances. As such, a multi class problem is solved as a series of binary problems. An average of all such outputs produces the multi-class version of these metrics, where certain forms of averaging may consider data aspects such as class imbalance. Following the ASSIN task definition, we compute a macro average for all evaluated corpora, which corresponds to an unweighted average where all classes are considered equally important. However, most evaluated corpora describe an unbalanced distribution of examples per class.
We report multi-class precision, recall and F1 metrics with macro averaging for all evaluated systems, and also per class evaluation metrics for the system with best overall performance. Accuracy is also computed per class, considering examples of other classes as the negative class, which disregards the differences between other classes.
For STS, as in the Semeval edition that employs the English SICK corpus [
35], we report Pearson and Spearman correlations, and the mean squared error (MSE), all of which are suitable to measure the performance of a system that outputs a single unbounded and real valued prediction.
To compute the MSE, the difference between each prediction and its true value is squared, so that all differences are positive numbers, and the average of all such values is the MSE. Hence, the lowest possible MSE value is 0 and there is no upper bound.
The Pearson correlation coefficient measures the strength and direction of the linear relation between predictions and true values, and corresponds to a continuous value from −1 to 1, where 0 indicates no linear relationship. Visually, a prediction and its true value is represented as a point in a bi-dimensional space, and there is a linear relationship between predictions and true values if all points are near a single line/path. The sign of the Pearson coefficient is the same as the slope for such line, and its value indicates the proximity of points to the line. For instance, a Pearson value near −1 indicates that predictions and true values have distant magnitudes, but vary proportionally on most examples.
The Spearman correlation coefficient is defined as s Pearson that instead considers predictions and true values as ranks, and not their actual values. Namely, the Spearman coefficient corresponds to the Pearson applied to such ranks.
A lower MSE is better, while for the remaining metrics, both for NLI and STS, a higher value is better. All metrics for NLI produce values in the 0 to 1 range; hence we report such results in percentages.
5. Results
In the following, we report the results of our systems in the NLI and STS tasks on Portuguese corpora, where for each corpus we provide a table with results from various systems, ours and others, followed by a table with per class results for an ensemble of the five instances of the fine tuned ptBERT-Large model, obtained by averaging their predictions, since this is the most complex system and achieves the best results on most evaluation metrics. In the former table, the best results for each metric, considering all systems, are highlighted with boldface. For fine tuned models, we report the mean and standard deviation of the evaluation metrics on the five instances of each model. Supporting each table of systems, we also frame or describe results from systems that we computed which did not achieved competitive results; hence these are not shown in the tables.
Results for other systems were obtained from the original publications, according to the therein addressed tasks, corpora and evaluation metrics. For each corpus, we report results for all other systems, to the best of our knowledge, that achieve competitive performances. Some systems report results on multiple corpora, and not all of the evaluation metrics we report for our systems are reported in the original publications of other systems. Moreover, some of the other systems were trained with additional data or combine multiple corpora, while our systems are trained per corpus and only with the data in such s corpus.
Our systems are grouped by type of feature; systems based on BERT are identified by the name of the BERT model followed by the learning algorithm employed to build the model of such system. Learning algorithms are abbreviated as lsvc for linear SVM, rf for random forests, poly and rbf for SVM with such kernels and voting for the ensemble of all non-deep-learning models. Systems based only on lexical features are identified only by the name of the involved learning algorithm. Results for decision trees are not shown, since the performance of said model was not competitive.
6. Discussion
In models based on neural networks, we measured statistical significance between the values returned by each pair of models, using a t-test (five runs for each model) for all metrics. Considering p = 0.05, there are statistically significant differences between models ptBERT-Base and mBERT-Base, and also between models ptBERT-Large and mBERT-Base, for most evaluation metrics and corpora. Exceptions include, for instance, the accuracy metric in the ASSIN-PTPT corpus, for the former pair of models, and most evaluation metrics in the SICK-BR corpus, for the latter pair of models. Regarding the differences between models ptBERT-Base and ptBERT-Large, results varied, since we found statistically significant differences for some metrics, but not for others, on all corpora.
Fine tuned models achieved better results than traditional models in most of the evaluated corpora and tasks. Particularly, the ptBERT-Large fine tuned model achieved the best results in most corpora and tasks, compared to our other setups and to other systems. However, for instance, in ASSIN-PTBR it did not achieve the best precision, recall and F1, and in ASSIN (PTPT + PTBR) it failed to achieve the best F1 and MSE. In the following we further investigate this model.
Regarding the STS task, the results of the ptBERT-Large fine tuned model for Pearson and Spearman correlation coefficients are near 0.9 in most evaluated corpora, which reveals a strong correlation between predictions and true values, indicating that the predictions for most examples are distant from their true values in approximately the same magnitude.
However, with the ASSIN2 corpus this model achieved an MSE worse than one of the state-of-the-art systems, and also worse than some of our traditional models.
To further study the performance of the ptBERT-Large fine tuned model, we employed the ensemble for the five instances of this model, wherein the predictions from each instance were averaged, and the MSE was computed on said average. The ptBERT-Large fine tuned model mentioned in the following corresponds to said ensemble.
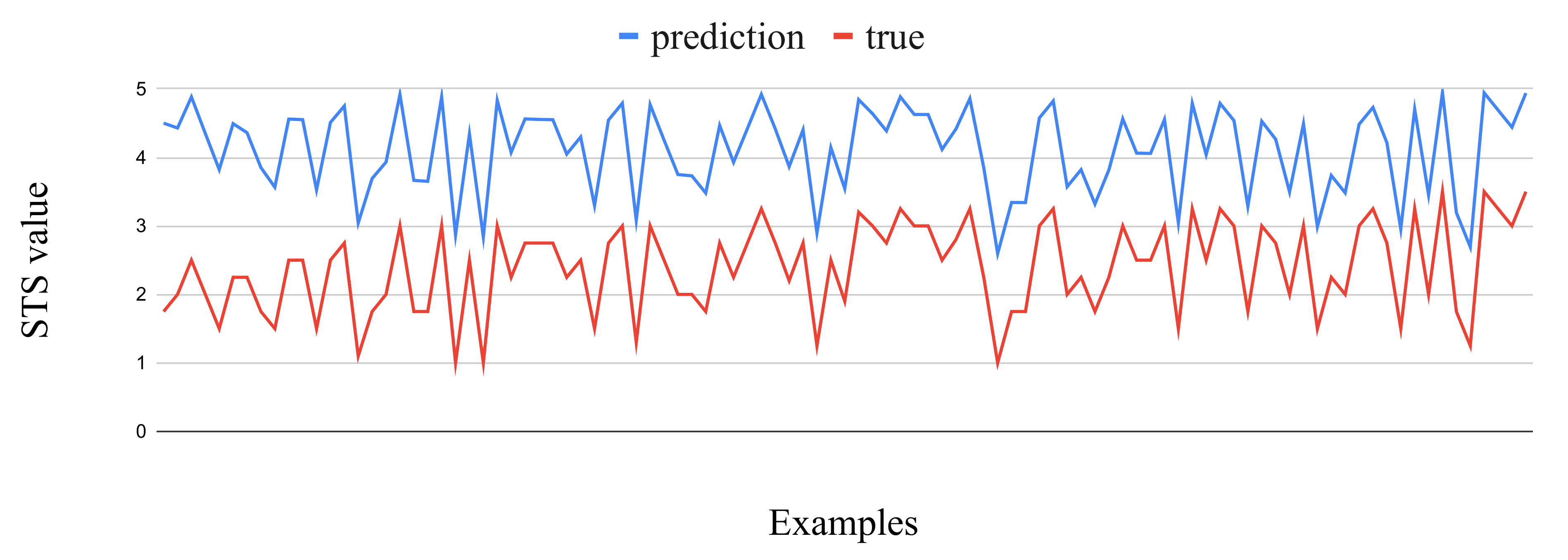
Interestingly, in examples with greater distance between predictions and true values, this difference is almost constant, as shown in
Figure 1, and the predictions are greater than the true values, suggesting that the STS predictions of ptBERT-Large fine tuned model are overly confident. As such, we did an experiment subtracting a constant value whenever the difference between prediction and true was greater than a certain value. The best results were obtained by subtracting 0.9 from the prediction, when the difference between the prediction and the true value was greater than 0.5. The resulting MSE was 0.11, as opposed to the 0.47 originally obtained, and the prediction was subtracted in 1014 of the 2448 test examples. As this condition implies knowing the true value, we also experimented with subtracting 0.9 on all predictions, which resulted in a MSE of 0.43.
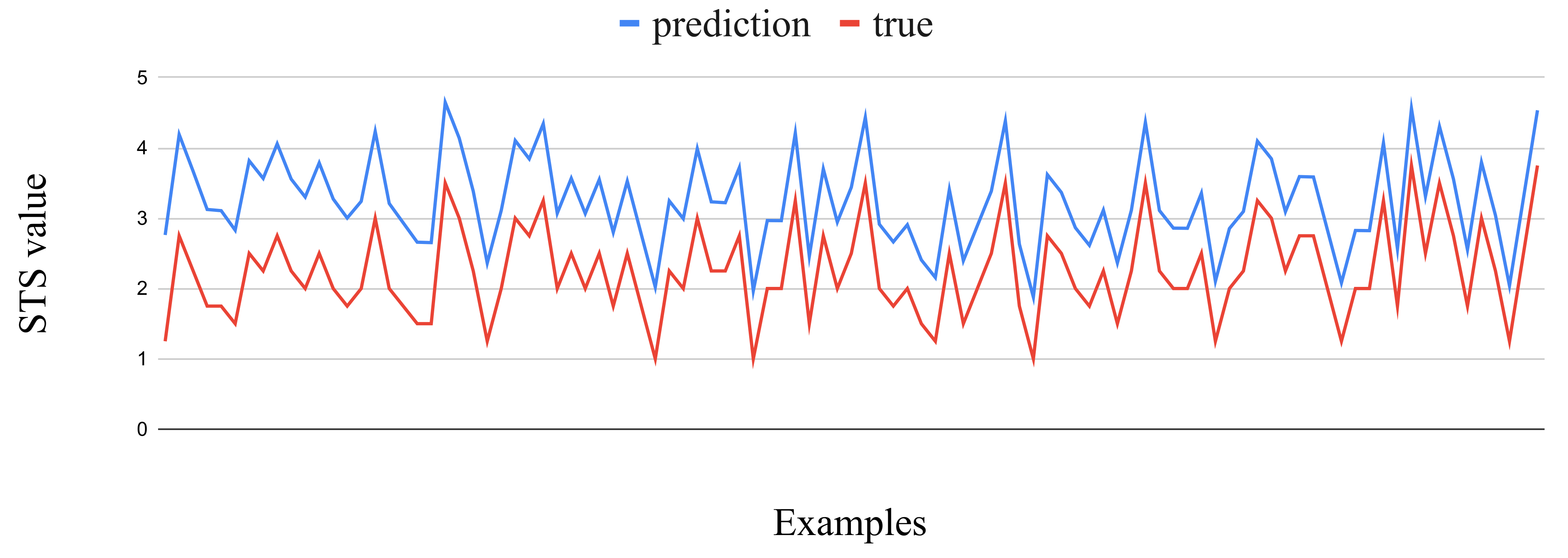
We also performed the same analysis for the ASSIN-PTBR corpus, wherein the ptBERT-Large fine tuned model achieved the best MSE value of all corpora. Here, the distance between predictions and true values is also approximately constant, as shown in
Figure 2. Again, we experimented with the previously mentioned conditional subtraction, but here the best MSE was obtained by subtracting 0.8 from the predicted value whenever the distance between original prediction and true value was greater than 0.5. The resulting MSE was 0.12, instead of the original 0.21, and the condition complied with 285 of the 2000 test examples. Subtracting 0.8 from all predictions resulted in a MSE of 0.8, which is worse than the original result, since only approximately 10% of the test examples complied with the condition for subtraction.
Moreover, we inspected individual examples where the ptBERT-Large fine tuned model failed to identify the NLI class. We did not find particular differences between the language employed in such cases and that of successful classification cases. As embeddings are not interpretable, and hence do not provide an explanation from their features, we were not able to reason about the language in misclassifications. However, it was possible to observe that some examples from the corpora are difficult to understand. For instance, in ASSIN2, sentences
Um peixe está sendo cortado por um cara and
Um cara está fatiando um peixe are not considered as entailment, but
A comida nas bandejas está sendo comida pelos filhotes de gato and
Poucos filhotes de gato estão comendo are considered as entailment. However, it is out of the scope of this paper to discuss the quality of the corpora, although issues with NLI corpora can be found in [
40], particularly regarding the development guidelines of the SICK corpus [
10], on which our evaluated ASSIN2 and SICK-BR corpora were based.
Author Contributions
Conceptualization, P.F., L.C. and P.Q.; methodology, P.F., L.C. and P.Q.; software, P.F.; validation, P.F., L.C. and P.Q.; formal analysis, P.F., L.C. and P.Q.; investigation, P.F., L.C. and P.Q.; resources, P.F.; data curation, P.F., L.C. and P.Q.; writing—original draft preparation, P.F., L.C. and P.Q.; writing—review and editing, P.F., L.C. and P.Q.; visualization, P.F., L.C. and P.Q.; supervision, L.C. and P.Q.; project administration, L.C.; funding acquisition, L.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by national funds through FCT, Fundação para a Ciência e Tecnologia, under project UIDB/50021/2020 and by FCT’s INCoDe 2030 initiative, in the scope of the demonstration project AIA, “Apoio Inteligente a empreendedores (chatbots)”, which also supports the scholarship of Pedro Fialho.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Dagan, I.; Dolan, B.; Magnini, B.; Roth, D. Recognizing textual entailment: Rational, evaluation and approaches. Nat. Lang. Eng. 2009, 15, i–xvii. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), New Orleans, LA, USA, 1–6 June 2018; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Rodrigues, R.; Couto, P.; Rodrigues, I. IPR: The Semantic Textual Similarity and Recognizing Textual Entailment Systems. 2019. Available online: http://ceur-ws.org/Vol-2583/4_IPR.pdf (accessed on 1 October 2020).
- Cabezudo, M.A.S.; Inácio, M.; Rodrigues, A.C.; Casanova, E.; de Sousa, R.F. NILC at ASSIN 2: Exploring Multilingual Approaches. 2019. Available online: http://ceur-ws.org/Vol-2583/5_NILC.pdf (accessed on 1 October 2020).
- Pires, T.; Schlinger, E.; Garrette, D. How Multilingual is Multilingual BERT? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4996–5001. [Google Scholar] [CrossRef]
- Bar-Haim, R.; Dagan, I.; Szpektor, I. Benchmarking Applied Semantic Inference: The PASCAL Recognising Textual Entailment Challenges. In Language, Culture, Computation. Computing—Theory and Technology—Essays Dedicated to Yaacov Choueka on the Occasion of His 75th Birthday, Part I; Dershowitz, N., Nissan, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8001, pp. 409–424. [Google Scholar] [CrossRef]
- Agirre, E.; Diab, M.; Cer, D.; Gonzalez-Agirre, A. SemEval-2012 Task 6: A Pilot on Semantic Textual Similarity. In Proceedings of the First Joint Conference on Lexical and Computational Semantics—Volume 1: Proceedings of the Main Conference and the Shared Task, and Volume 2: Proceedings of the Sixth International Workshop on Semantic Evaluation, Montréal, QC, Canada, 7–8 June 2012; pp. 385–393. [Google Scholar]
- Cer, D.; Diab, M.; Agirre, E.; Lopez-Gazpio, I.; Specia, L. SemEval-2017 Task 1: Semantic Textual Similarity Multilingual and Crosslingual Focused Evaluation. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 1–14. [Google Scholar] [CrossRef]
- Fonseca, E.; Borges dos Santos, L.; Criscuolo, M.; Aluísio, S. Visão Geral da Avaliação de Similaridade Semântica e Inferência Textual. Linguamática 2016, 8, 3–13. [Google Scholar]
- Marelli, M.; Menini, S.; Baroni, M.; Bentivogli, L.; Bernardi, R.; Zamparelli, R. A SICK cure for the evaluation of compositional distributional semantic models. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC-2014), Reykjavik, Iceland, 26–31 May 2014; European Languages Resources Association (ELRA): Reykjavik, Iceland, 2014; pp. 216–223. [Google Scholar]
- Real, L.; Rodrigues, A.; Vieira e Silva, A.; Albiero, B.; Thalenberg, B.; Guide, B.; Silva, C.; de Oliveira Lima, G.; Câmara, I.C.S.; Stanojević, M.; et al. SICK-BR: A Portuguese Corpus for Inference. In Computational Processing of the Portuguese Language; Villavicencio, A., Moreira, V., Abad, A., Caseli, H., Gamallo, P., Ramisch, C., Gonçalo Oliveira, H., Paetzold, G.H., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 303–312. [Google Scholar]
- Real, L.; Fonseca, E.; Gonçalo Oliveira, H. The ASSIN 2 Shared Task: A Quick Overview. In Computational Processing of the Portuguese Language; Quaresma, P., Vieira, R., Aluísio, S., Moniz, H., Batista, F., Gonçalves, T., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 406–412. [Google Scholar]
- Fialho, P.; Marques, R.; Martins, B.; Coheur, L.; Quaresma, P. INESC-ID@ASSIN: Medição de Similaridade Semântica e Reconhecimento de Inferência Textual. Linguamática 2016, 8, 33–42. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Advances in Neural Information Processing Systems 26; Burges, C.J.C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K.Q., Eds.; Curran Associates: Red Hook, NY, USA, 2013; pp. 3111–3119. [Google Scholar]
- Barbosa, L.; Cavalin, P.; Guimarães, V.; Kormaksson, M. Blue Man Group no ASSIN: Usando Representações Distribuídas para Similaridade Semântica e Inferência Textual. Linguamática 2016, 8, 15–22. [Google Scholar]
- Hartmann, N. Solo Queue at ASSIN: Combinando Abordagens Tradicionais e Emergentes. Linguamática 2016, 8, 59–64. [Google Scholar]
- Oliveira Alves, A.; Rodrigues, R.; Gonçalo Oliveira, H. ASAPP: Alinhamento Semântico Automático de Palavras aplicado ao Português. Linguamática 2016, 8, 43–58. [Google Scholar]
- Freire, J.; Pinheiro, V.; Feitosa, D. FlexSTS: Um Framework para Similaridade Semântica Textual. Linguamática 2016, 8, 23–31. [Google Scholar]
- Pinheiro, A.; Ferreira, R.; Ferreira, M.A.D.; Rolim, V.B.; Tenório, J.V.S. Statistical and Semantic Features to Measure Sentence Similarity in Portuguese. In Proceedings of the 2017 Brazilian Conference on Intelligent Systems (BRACIS), Uberlândia, Brazil, 2–5 October 2017; pp. 342–347. [Google Scholar]
- Rocha, G.; Cardoso, H.L. Recognizing Textual Entailment: Challenges in the Portuguese Language. Information 2018, 9, 76. [Google Scholar] [CrossRef]
- Alves, A.; Oliveira, H.G.; Rodrigues, R.; Encarnação, R. ASAPP 2.0: Advancing the state-of-the-art of semantic textual similarity for Portuguese. In Proceedings of the 7th Symposium on Languages, Applications and Technologies (SLATE 2018), Guimaraes, Portugal, 21–22 June 2018; Henriques, P.R., Leal, J.P., Leitão, A.M., Guinovart, X.G., Eds.; Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik: Dagstuhl, Germany, 2018; Volume 62, pp. 12:1–12:17. [Google Scholar] [CrossRef]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Brussels, Belgium, 1 November 2018; pp. 353–355. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates: Red Hook, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Rodrigues, R.C.; da Silva, J.R.; de Castro, P.V.Q.; da Silva, N.F.F.; da Silva Soares, A. Multilingual Transformer Ensembles for Portuguese Natural Language Tasks. Available online: http://ceur-ws.org/Vol-2583/3_DLB.pdf (accessed on 10 October 2020).
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; Association for Computational Linguistics: Philadelphia, PA, USA, 2002; pp. 311–318. [Google Scholar] [CrossRef]
- De Paiva, V.; Rademaker, A.; de Melo, G. OpenWordNet-PT: An Open Brazilian Wordnet for Reasoning. In Proceedings of the COLING 2012: Demonstration Papers, Mumbai, India, 8–15 December 2012; The COLING 2012 Organizing Committee: Mumbai, India, 2012; pp. 353–360. [Google Scholar]
- Jawahar, G.; Sagot, B.; Seddah, D. What Does BERT Learn about the Structure of Language? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 3651–3657. [Google Scholar] [CrossRef]
- Tenney, I.; Das, D.; Pavlick, E. BERT Rediscovers the Classical NLP Pipeline. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 4593–4601. [Google Scholar] [CrossRef]
- Liu, N.F.; Gardner, M.; Belinkov, Y.; Peters, M.E.; Smith, N.A. Linguistic Knowledge and Transferability of Contextual Representations. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), New Orleans, LA, USA, 1–6 June 2018; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 1073–1094. [Google Scholar] [CrossRef]
- Jaccard, P. THE DISTRIBUTION OF THE FLORA IN THE ALPINE ZONE.1. New Phytol. 1912, 11, 37–50. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Zadrozny, B.; Elkan, C. Transforming Classifier Scores into Accurate Multiclass Probability Estimates. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; Association for Computing Machinery: New York, NY, USA, 2002; pp. 694–699. [Google Scholar] [CrossRef]
- Platt, J. Probabilistic outputs for support vector machines and comparison to regularize likelihood methods. In Advances in Large Margin Classifiers; Smola, A., Bartlett, P., Schoelkopf, B., Schuurmans, D., Eds.; MIT Press: Cambridge, MA, USA, 2000; pp. 61–74. [Google Scholar]
- Marelli, M.; Bentivogli, L.; Baroni, M.; Bernardi, R.; Menini, S.; Zamparelli, R. SemEval-2014 Task 1: Evaluation of Compositional Distributional Semantic Models on Full Sentences through Semantic Relatedness and Textual Entailment. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014; pp. 1–8. [Google Scholar] [CrossRef]
- De Souza, J.V.A.; e Oliveira, L.E.S.; Gumiel, Y.B.; Carvalho, D.R.; Moro, C.M.C. Incorporating Multiple Feature Groups to a Siamese Neural Network for Semantic Textual Similarity Task in Portuguese Texts. 2019. Available online: http://ceur-ws.org/Vol-2583/6_PUCPR.pdf (accessed on 1 October 2020).
- Santos, J.; Alves, A.; Oliveira, H.G. ASAPPpy: A Python Framework for Portuguese STS. 2019. Available online: http://ceur-ws.org/Vol-2583/2_ASAPPpy.pdf (accessed on 1 October 2020).
- Silva, A.d.B.; Rigo, S.J. Enhancing Brazilian Portuguese Textual Entailment Recognition with a Hybrid Approach. J. Comput. Sci. 2018, 14, 945–956. [Google Scholar] [CrossRef][Green Version]
- Fonseca, E.; Alvarenga, J.P.R. Multilingual Transformer Ensembles for Portuguese Natural Language Tasks. In Proceedings of the ASSIN 2 Shared Task: Evaluating Semantic Textual Similarity and Textual Entailment in Portuguese Co-Located with XII Symposium in Information and Human Language Technology (STIL 2019), Salvador, Brazil, 15 October 2019; Volume 2583, pp. 68–77. [Google Scholar]
- Kalouli, A.L.; Buis, A.; Real, L.; Palmer, M.; de Paiva, V. Explaining Simple Natural Language Inference. In Proceedings of the 13th Linguistic Annotation Workshop, Florence, Italy, 1 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 132–143. [Google Scholar] [CrossRef]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).






{kind=link}
{kind=link}