1. Introduction
While most children learn how to speak in their native language and learn how to correctly produce the native language phonemes by the expected ages, for some children, the language acquisition process may be challenging [
1]. As reported by Guimarães et al. for data on European Portuguese (EP),
of preschool-aged children suffer from some type of speech sound disorders (SSD) [
2]. Many children can surpass their language acquisition difficulties as they grow older and their speech organs develop, but for some children, the speech distortions are not surpassed naturally. These children may need professional help to correct their SSD. Besides, it is important to address these difficulties as early as possible since SSD can affect the child’s quality of life and literacy aquisition [
3,
4].
Sigmatism is a SSD that consists of pronouncing the sibilant consonants incorrectly. The sibilants, which include sounds like
[s] in serpent and
[z] in zipper, are consonants that are generated by letting the air flow through a very narrow channel towards the teeth [
5]. Sigmatism is a very common SSD among children with different native languages [
6,
7], including EP [
8,
9].
Speech and language pathologists (SLPs) help children with sigmatism correct the production of sibilants with speech exercises that start with the isolated sibilants and then progress to the production of the sounds within syllables and words. While the repetition of speech exercises is important to practice and master the correct production of speech sounds, it may lead to the child’s weariness and lack of interest on proceeding with the speech exercises. In order to keep children motivated and collaborative during the therapy sessions, SLPs need to adapt the speech and language exercises into fun and appealing activities.
This work is part of the BioVisualSpeech research project, in which we explore multimodal human computer interaction mechanisms for providing bio-feedback in speech and language therapy through the use of serious digital games. As a contribution to help SLPs motivating children to repeat the tasks that may lead to the correction of their speech disorder, we have been developing serious games for training the production of EP sibilants, which are controlled by the child’s voice (more details in
Section 5.1,
Section 5.2 and
Section 5.3). To make this possible, we have been developing machine learning approaches that are integrated into the games to detect the incorrect production of sibilant sounds [
10] or to validate the correctness of produced words to help SLPs on assessing if the child has sigmatism (
Section 5.4).
In order to develop the automatic speech processing modules for our serious games for sigmatism, we built a corpus of children’s speech that was previously proposed in Reference [
11]. This corpus contains isolated sibilants productions and productions of words with sibilants. Here, we focus on the data set of words with sibilants. The data set contains children’s productions of 70 different EP words with sibilant consonants. The sibilant phoneme in these words occurs either at the start, middle or final position. The word productions were recorded in three schools, and 365 children from 5 to 9 years of age participated in the data collection task. One of the novelties of this work is that the data annotations include information on the quality of the sound productions according to SLPs criteria. Another novelty is that the set of chosen words focuses on the EP sibilant consonants.
In addition to proposing this EP corpus of words with sibilants, we illustrate how to use the corpus in the development of speech and language therapy games that address sigmatism. The first game can be used with the isolated sibilants therapy exercise, in which the child must produce isolated sibilants. In addition, the second game can be used to train the production of words that start with a sibilant consonant and to identify words that start with the same sibilant, while the third game allows for training the production of words containing one or more sibilant in a varying number of configurable positions and difficulties. The games are controlled by the child’s speech and give visual feedback on the child’s production. In this way, the games motivate the child on performing these speech exercises and also help the child understand when his/her sibilant productions are not correct. As an option, one of the games gives visual feedback on the point of articulation used for the speech production and on the use of the vocal folds. This visual feedback helps the child understand what he/she must do to correct the sibilant production.
The games use an EP sibilant classifier and word recognition module for children speech. The sibilant classifier is a convolutional neural network (CNN) classifier that uses two models: one that is able to distinguish sounds made with different points of articulation, and another that distinguishes between voiced and voiceless sounds. By combining the output of both models, the classifier can distinguish the EP sibilant consonants. The word recognition module is an automatic speech recognition system adapted to children speech and configured to operate in keyword spotting mode [
12].
After discussing related work on the collection of children’s speech productions of the EP sibilants in
Section 2, and giving a short introduction to the EP sibilants in
Section 3, this paper discusses the proposed corpus of words with sibilants and the protocol used to record it in
Section 4.
Section 5 presents the three game examples and the automatic speech processing modules developed for these games.
3. Sibilant Consonants and Speech Sound Disorders
Fricative sounds are produced by letting a small amount of air pass through a narrow channel in the vocal tract. Different fricative sounds are made by using specific parts of the vocal tract and specific tongue shapes to configure the narrow channel. The vocal folds may be used, resulting in a voiced consonant. When the vocal folds are not used, the result is a voiceless consonant.
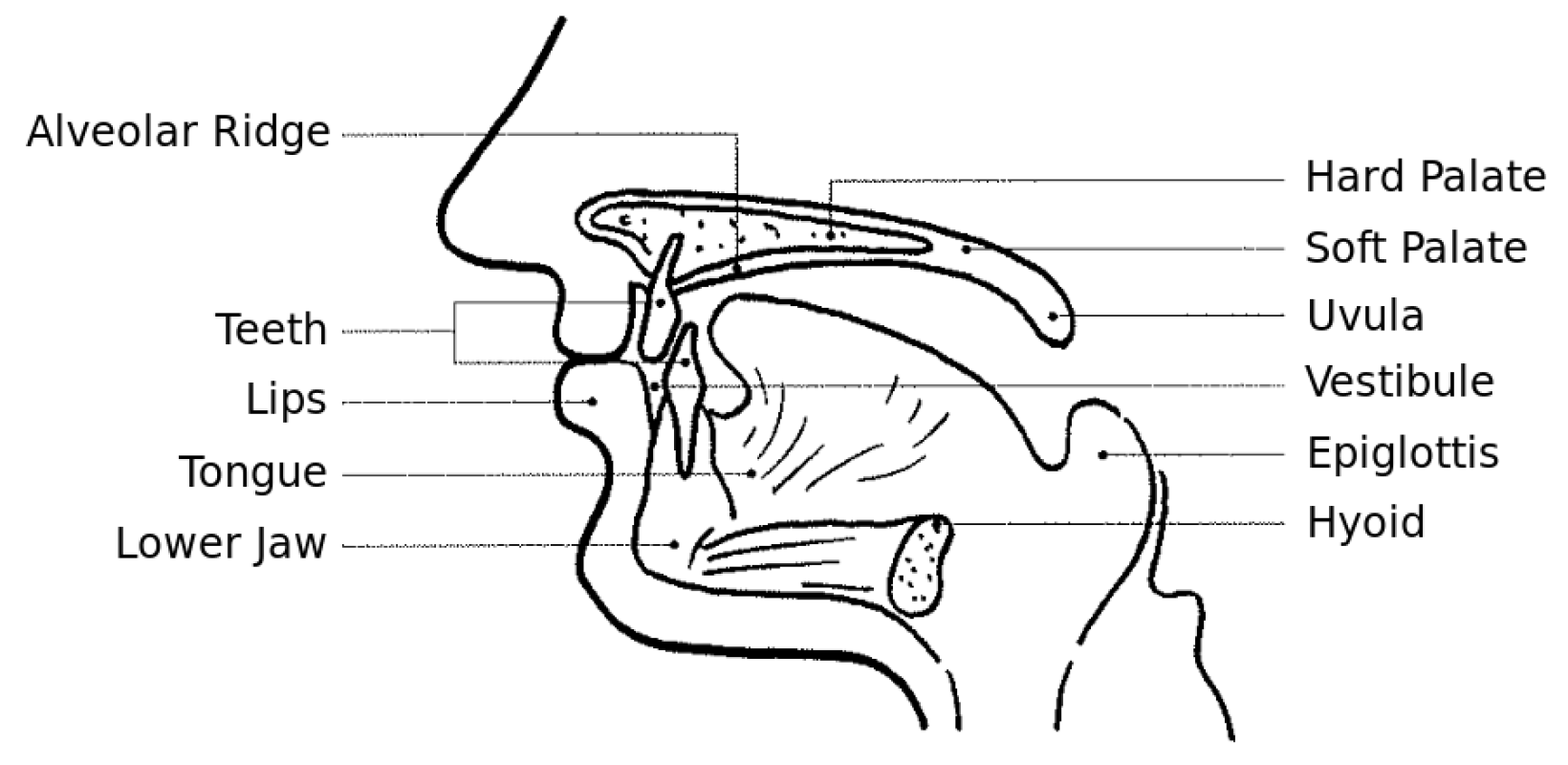
Sibilant sounds are a subset of the fricatives. There are two types of EP sibilant consonants: the alveolar sibilants, which are produced with the tongue nearly touching the alveolar region of the mouth, and the palato-alveolar sibilants, which are produced by positioning the tongue towards the palatal region of the mouth (
Figure 1). The EP sibilant consonants are:
[z] as in zebra,
[s] as in snake,
[] as the
sh sound in sheep, and
[] as the
s sound in Asia [
15] (international phonetic alphabet, IPA, symbols [
16]).
[z] and
[s] are both alveolar sibilants, while
[] and
[] are palato-alveolar sibilants. Both
[z] and
[] are voiced sibilants, and
[s] and
[] are voiceless sibilants.
Other (non-sibilant) fricative sounds include the labiodental fricatives
[f] and
[v], which are produced with the lower lip nearly touching the upper front teeth [
5].
[f] is voiceless, and
[v] is voiced (
Table 1).
There are a few variations of the rhotic consonant
r in EP, some of which are fricative sounds [
17,
18]. The rhotic consonant is the sound of
r at the word initial position, like in
rato (mouse), or double
r in a medial position, such as in
carro (car). This consonant is commonly pronounced as a voiced uvular fricative
[] [
15]. Other less common variations include the voiceless uvular fricative
[] and the voiceless velar fricative
[x]. This consonant can also be pronounced as a (non-fricative) trill sound [
5]: it can be an alveolar trill,
[r], which is made with vibrations of the tip of the tong against the upper alveolar ridge for longer than two or three periods, and an uvular trill,
[ʀ], which is done by a vibration of the palatine uvula (Due to its different nature, this consonant is not included in
Table 1).
SSD in sibilant consonants can occur due to oral structural problems, poor phonological awareness, or developmental disorders and may occur in different types of errors and phonological representations [
3,
4]. Difficulty in learning to produce and/or use sibilant sounds correctly can be manifested in a variety of types, and these can be classified as distortions, typical syllable structure errors (e.g., final consonant deletion), typical segmental errors (e.g., /s/ Y [t]), and atypical syllable structure errors (e.g., initial consonant deletion) (2). As distortion errors typically reflect an alteration in the production of a sound (e.g., a slight problem with tongue shape or placement, such as dentalized or lateralized
[s]) are prevalent in SSD [
3,
19,
20], this study aimed to develop clinical tools for SLP.
4. The Corpus of Words with Sibilants
The BioVisualSpeech EP sibilants corpus was built as part of a speech and language screening activity that took place in three schools. The screening activity had two purposes: (1) to assess children’s speech in order to detect cases of SSD and (2) to collect data to build corpora of children’s EP speech, which can be used for speech and language therapy and computer science research purposes, and to develop computer tools to assist speech and language therapy. In fact, while the data described here focuses on the sibilants, the screening activity assessed all EP consonant sounds and included several speech and orofacial exercises that helped the SLPs to detect not only sigmatism but also other SSD cases. In addition, as seen in
Section 5.4.2, our sibilants classifier is trained with samples from the EP sibilants but also samples from the fricatives
[f] and
[v].
Section 4.1 discusses details about the screening activity.
Some of the exercises performed during the screening activity were recorded. In particular, we recorded an exercise in which the children produced isolated sibilants and another in which the children were prompted to say words with sibilant occurrences. These words were used to build the BioVisualSpeech EP corpus of words with sibilants.
Section 4.2 describes in more detail the set of words and the protocol used to record the sibilant word productions. While here we focus on the words with sibilants data set, for more details on the isolated sibilants see Reference [
11].
The recorded word productions were annotated according to SLPs criteria. The annotation task is discussed in
Section 4.3.
4.2. Data Collection of Words with Sibilant Consonants
The equipment used to collect the sibilants data consisted of a dedicated unidirectional condenser microphone, a portable battery powered digital audio tape (DAT) recorder (Sony TCD-D8) and acoustic foam to attenuate background noise (
Figure 2). Due to the children’s age group, we did not use head mounted microphones. The recordings were made in a reasonably quiet room at the schools, but, in many cases, it was still possible to hear the noise coming from the playground and corridors. While the recording conditions were not perfect, having background noise in the data samples is appropriate for our goal since we aim to develop automatic recognition models that are robust enough to be used in SLP’s offices or at schools. The data was recorded with a 44,100 Hz sampling rate.
The data was recorded continuously, that is, the recorded speech signals include the SLP and the child’s speech. Thus, after the data collection task was finished, we had to segment all the recorded speech signals, not only to extract the children relevant speech portions but also to discard all the speech data from the SLPs.
We used a total of 70 words with sibilant consonants. The chosen words start with one of the four sibilant consonants (e.g.,
sino), have the sibilant in a middle position (e.g.,
pijama), or finish with the sibilant
[] (e.g.,
livros or
peixe). Ten of these words contain more than one sibilant phoneme (like
cereja, in which the initial phoneme is
[s] and there is a middle phoneme with
[]). The 70 chosen words have 81 sibilant-phoneme occurrences (
Table 2). The number of occurrences is not equal for all sibilants because these words were chosen taking into consideration their frequency of appearance in EP, and their semantic predictability [
23,
24]. In addition,
[] is the only sibilant that can occur in word final positions in EP.
In order to have the children produce these words, the stimuli consisted of age-appropriate color images representing the words. We used plain images in a white background and printed in A5 paper (one image per paper sheet) to direct the attention to the aimed word as much as possible. As an example,
Figure 3 shows the image used for one of the words (
mochila, which is the EP word for backpack and which contains the
[] phoneme in a middle position). In order to have the child pronouncing the word in his/her usual way and not having the child mimicking the SLP pronunciation, the SLP did not say the aimed word. Each picture was shown to the child, who was asked to name it. If the child did not answer, the examiner could give standardized semantic clues.
In total, we collected 22,830 word samples from these 70 words from the productions of 356 children (
Table 3 and
Table 4). There are 20,198 correct word productions and 2632 word samples incorrectly produced. From these incorrectly word productions, there are 1138 word samples with incorrectly produced sibilants (fourth column of
Table 3). In each word with sibilant phoneme
x (where
x is
[],
[],
[s], or
[z]), we considered that the sibilant is incorrectly produced when the word contains the sibilant phoneme
x, but the child speech production does not contain
x, substitutes or has a distortion of
x. While this is a good approximation of the real number of word samples with incorrect sibilant productions, it may fail in some cases in which the word production contains the
x phoneme but in a different word position/syllable. In addition, note that the total number of words for all sibilants presented in the table (22,830) does not result from adding the numbers in the fifth column since some words can contain more than one sibilant sound.
The second column of
Table 3 shows the number of incorrect sibilant productions. The third column of this table shows the total number of occurrences (correct and incorrect) of each sibilant phoneme. Note that one word can have more than one sibilant production; thus, the total presented in this column (22,969) is higher than the total number of word samples (22,830).
5. Games for Sigmatism
In order to correct the sibilant distortion errors, SLPs use different speech exercises during the speech and language therapy sessions. They usually start assessing the child’s capacity of distinguishing and producing the isolated sibilant consonants, and then proceed to have the child practice the production of the sibilants as isolated sounds. This consists of the isolated sibilants exercise, in which the child produces each sibilant with short and/or long duration. The main goal of this exercise is to teach the child to distinguish and correctly produce the different sibilant consonants.
At the next stage, SLPs use the isolated sibilants exercise for multiple alternate productions of the different sibilants, in which the SLP asks for sounds that alternate the point of articulation and the use of the vocal folds. Once the child can say the isolated sibilants correctly, the therapy activities can proceed to more complex exercises that use the sibilant consonants within words.
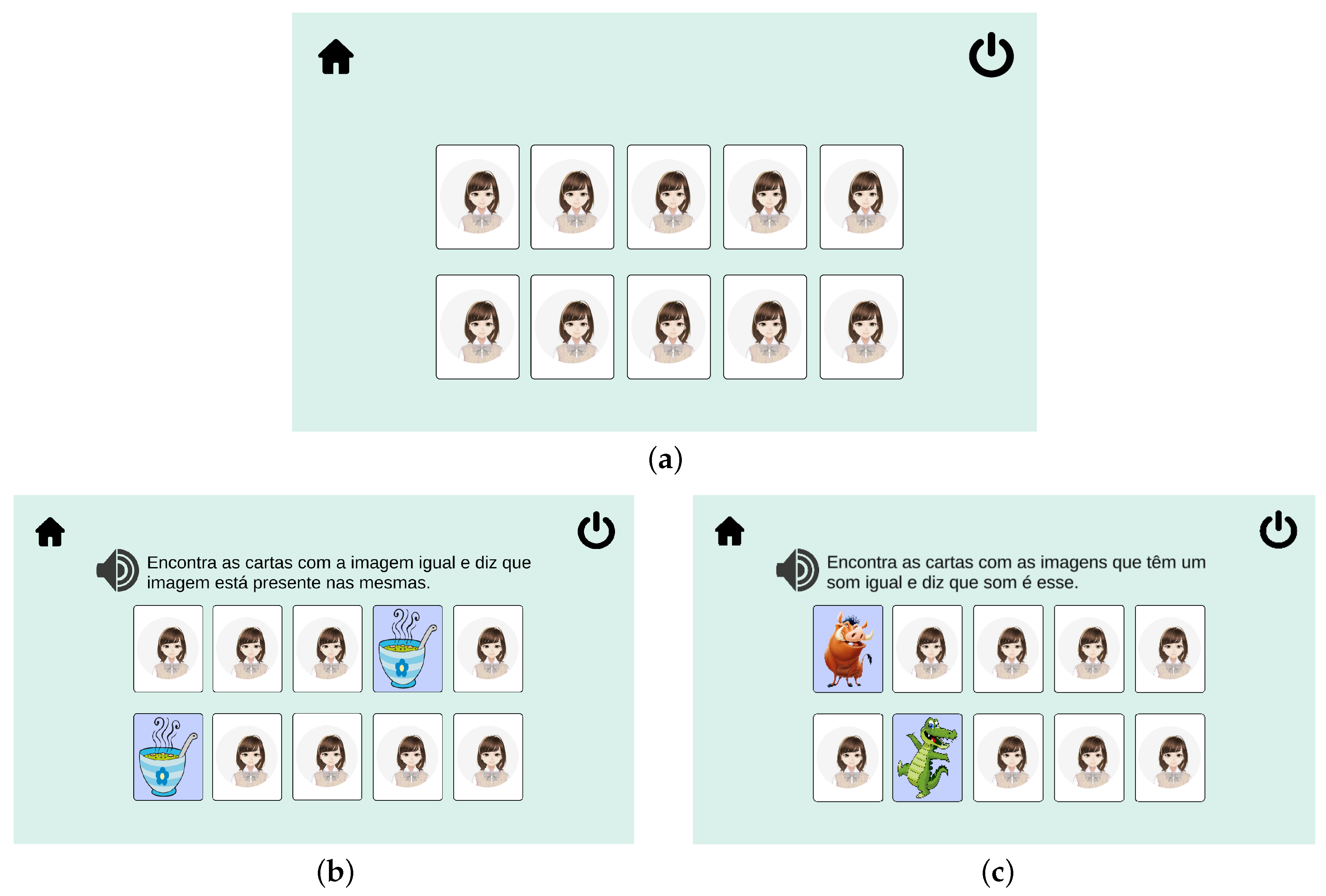
In the BioVisualSpeech project, we have developed different speech therapy games, some of which focus on helping children master the production of the EP sibilants (
Figure 4). In particular the
VisualSpeech isolated sibilants game, the
VisualSpeech pairs game and the
BioVisualSpeech word naming game give visual feedback on the child’s sibilant production performance. The BioVisualSpeech isolated sibilants game uses the isolated sibilants exercise and can be used in the initial speech and language therapy stages (
Section 5.1). On the other hand, the BioVisualSpeech pairs game is a cards game that can be used to practice the production of words with sibilants, and therefore, is aimed at subsequent stages of speech and language therapy (
Section 5.2). The BioVisualSpeech word naming game—also designed for the subsequent stages of therapy—consists of a series of word naming exercises of varying difficulty containing sibilant sounds (
Section 5.3).
An important characteristic of these games is that they are controlled by the child’s voice. The games process the child’s speech productions in real time and the sequence of game actions are determined by the quality of these productions. Thus, unlike with other speech and language therapy computer games that are manually controlled by the SLP, in these games the main character movement or the sequence of actions are controlled by the child’s voice. In this way, the games give real time visual feedback about the sound production, which is an intuitive way of pointing out to the child whether his/her sound productions are correct.
In order to react to child’s speech productions, the games use an isolated EP sibilants classifier trained with data extracted from the BioVisualSpeech EP sibilants corpus and a word recognition module for EP children trained with additional data. These modules are described in more detail in
Section 5.4.
Author Contributions
Conceptualization, S.C., I.G., M.G., N.M., A.A.; Methodology, S.C., I.G., A.A., N.M., M.E., J.M., M.G.; Software, I.A., F.O., S.M., N.M.; Validation, N.M., I.A., S.C., A.A., F.O.; Investigation, S.C., I.G., M.A., A.A., I.A., F.O., S.M., N.M., M.E., J.M., M.G.; Resources, I.G., M.G.; Data Curation, M.G., I.G., I.A., A.A., M.A.; Writing Original Draft Preparation, S.C, A.A., N.M.; Writing Review and Editing, S.C., A.A., F.O., N.M.; Visualization, N.M., I.A., S.C.; Supervision, S.C., I.G., A.A., N.M., M.E., M.G.; Project Administration, S.C., A.A., M.E., M.G.; Funding Acquisition, S.C., M.E., A.A, J.M., I.G., M.G. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Portuguese Foundation for Science and Technology under projects BioVisualSpeech (CMUP-ERI/TIC/0033/2014), NOVA-LINCS (UIDB/04516/2020) and INESC-ID (UIDB/50021/2020).
Acknowledgments
We thank Cátia Pedrosa, Diogo Carrasco and Catarina Botelho for the segmentation and annotation of our corpus, Mário Sansana for training the initial children speech acoustic model, and all postgraduate SLP students from Escola Superior de Saúde do Alcoitão who collaborated in the data collection task. We also thank the schools from Agrupamento de Escolas de Almeida Garrett, and the children who participated in the study.
Conflicts of Interest
The authors declare no conflict of interest.
References
- McLeod, S. The International Guide to Speech Acquisition; Thomson Delmar Learning: Florence, KY, USA, 2007. [Google Scholar]
- Guimarães, I.; Birrento, C.; Figueiredo, C.; Flores, C. Teste de Articulaçã Overbal; Oficina Didáctica: Lisboa, Portugal, 2014. [Google Scholar]
- Preston, J.; Edwards, M.L. Phonological awareness and types of sound errors in preschoolers with speech sound disorders. J. Speech Lang. Hear. Res. 2010, 53, 44–60. [Google Scholar] [CrossRef]
- Nathan, L.; Stackhouse, J.; Goulandris, N.; Snowling, M.J. The development of early literacy skills among children with speech difficulties: A test of the critical age hypothesis. J. Speech Lang. Hear. Res. 2004, 47, 377–391. [Google Scholar] [CrossRef]
- Guimarães, I. Ciência e Arte da Voz Humana; Escola Superior de Saúde de Alcoitão: Alcabideche, Portugal, 2007. [Google Scholar]
- Honová, J.; Jindra, P.; Pešák, J. Analysis of articulation of fricative praealveolar sibilant “s” in control population. Biomed. Pap. 2003, 147, 239–242. [Google Scholar] [CrossRef]
- Weinrich, M.; Zehner, H. Phonetiche und Phonologische Störungen bein Kindern; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Figueiredo, A.C. Análise Acústica dos Fonemas /s, z/ Produzidos por Crianças com Desempenho Articulatório Alterado. Master’s Thesis, Escola Superior de Saúde do Alcoitão, Santa Casa da Misericórdia de Lisboa, Lisboa, Portugal, 2017. [Google Scholar]
- Rua, M. Caraterização do Desempenho Articulatório e Oromotor de Crianças Com Alterações da Fala. Master’s Thesis, Escola Superior de Saúde do Alcoitão, Santa Casa da Misericórdia de Lisboa, Lisboa, Portugal, 2015. [Google Scholar]
- Anjos, I.; Grilo, M.; Ascensão, M.; Guimarães, I.; Magalhães, J.; Cavaco, S. A Model for Sibilant Distortion Detection in Children. In Proceedings of the 2018 International Conference on Digital Medicine and Image Processing (DMIP), Okinawa, Japan, 12–14 November 2018. [Google Scholar]
- Grilo, M.; Guimarães, I.; Ascensão, M.; Abad, A.; Anjos, I.; Magalhães, J.; Cavaco, S. The BioVisualSpeech European Portuguese Sibilants Corpus. In International Conference on Computational Processing of the Portuguese Language (PROPOR); Springer: Berlin/Heidelberg, Germany, 2020; pp. 23–33. [Google Scholar]
- Abad, A.; Pompili, A.; Costa, A.; Trancoso, I.; Fonseca, J.; Leal, G.; Farrajota, L.; Martins, I. Automatic word naming recognition for an on-line aphasia treatment system. Comput. Speech Lang. 2013, 27, 1235–1248. [Google Scholar] [CrossRef]
- Proença, J.; Celorico, D.; Candeias, S.; Lopes, C.; Perdigão, F. The LetsRead Corpus of Portuguese Children Reading Aloud for Performance Evaluation. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 781–785. [Google Scholar]
- Hämäläinen, A.; Rodrigues, S.; Júdice, A.; Silva, S.; Calado, A.; Pinto, F.; Dias, M. The CNG Corpus of European Portuguese Children’s Speech. In Proceedings of the International Conference on Text, Speech and Dialogue, Pilsen, Czech Republic, 1–5 September 2013; Volume 8082. [Google Scholar] [CrossRef]
- Cruz-Ferreira, M. Portuguese (European). In Handbook of the International Phonetic Association, A Guide to the Use of the International Phonetic Alphabet; Cambridge University Press: Cambridge, UK, 1999. [Google Scholar]
- Handbook of the International Phonetic Association, A Guide to the Use of the International Phonetic Alphabet; Cambridge University Press: Cambridge, UK, 1999.
- Rennicke, I.; Martins, P. As realizações Fonéticas de /R/ em Português Europeu: Análise de um Corpus Dialetal e Implicações no Sistema Fonológico; Encontro Nacional da Associação Portuguesa de Linguística, Universidade do Algarve: Faro, Portugal, 2013; pp. 509–523. [Google Scholar]
- Grossinho, A.; Guimarães, I.; Magalhães, J.; Cavaco, S. Robust phoneme recognition for a speech therapy environment. In Proceedings of the IEEE International Conference on Serious Games and Applications for Health (SeGAH), Orlando, FL, USA, 11–13 May 2016. [Google Scholar]
- Smit, A.B.; Hand, L.; Freilinger, J.J.; Bernthal, J.E.; Bird, A. The Iowa Articulation Norms Project and its Nebraska replication. J. Speech Hear. Disord. 1990, 55, 779–797. [Google Scholar] [CrossRef] [PubMed]
- Shriberg, L.D.; Kwiatkowski, J. Developmental phonological disorders: I. A clinical profile. J. Speech Lang. Hear. Res. 1994, 37, 1100–1126. [Google Scholar] [CrossRef] [PubMed]
- Lousada, M.; Mendes, A.; Valente, R.; Hall, A. Standardization of a Phonetic-Phonological Test for European-Portuguese Children. Folia Phoniatr. Logop. Off. Organ Int. Assoc. Logop. Phoniatr. (IALP) 2012, 64, 151–156. [Google Scholar] [CrossRef] [PubMed]
- Wren, I.; McLeod, S.; White, P.; Miller, L.; Roulstone, S. Speech characteristics of 8-year-old children: Findings from a prospective population study. J. Commun. Disord. 2013, 46, 53–69. [Google Scholar] [CrossRef] [PubMed]
- Charles-Luce, J.; Dressler, K.M.; Ragonese, E. Effects of semantic predictability on children’s preservation of a phonemic voice contrast. J. Child Lang. 1999, 26, 505–530. [Google Scholar] [CrossRef] [PubMed]
- Mestre, I. Sibilantes e Motricidade orofacial em CriançAs Portuguesas dos 5;00 aos 9;11 Anos de Idade: Estudo Preliminar. Master’s Thesis, Escola Superior de Saúde do Alcoitão, Santa Casa da Misericórdia de Lisboa, Lisboa, Portugal, 2017. [Google Scholar]
- Anjos, I.; Grilo, M.; Ascensão, M.; Guimarães, I.; Magalhães, J.; Cavaco, S. A Serious Mobile Game with Visual Feedback for Training Sibilant Consonants. In Advances in Computer Entertainment Technology; Cheok, A.D., Inami, M., Romão, T., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 430–450. [Google Scholar]
- Anjos, I.; Marques, N.; Grilo, M.; Guimarães, I.; Magalhães, J.; Cavaco, S. Sibilant consonants classification comparison with multi and single-class neural networks. Expert Syst. 2020. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Anjos, I.; Eskenazi, M.; Marques, N.; Grilo, M.; Guimarães, I.; Magalhães, J.; Cavaco, S. Detection of voicing and place of articulation of fricatives with deep learning in a virtual speech and language therapy tutor. In Proceedings of the Interspeech, Shanghai, China, 28 October 2020. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi Speech Recognition Toolkit. In Proceedings of the IEEE 2011 Workshop on Automatic Speech Recognition and Understanding, Waikoloa, HI, USA, 11–15 December 2011. [Google Scholar]
- Abad, A.; Pompili, A.; Costa, A.; Trancoso, I. Automatic word naming recognition for treatment and assessment of aphasia. In Proceedings of the 13th Annual Conference of the International Speech Communication Association, Portland, OH, USA, 9–13 September 2012. [Google Scholar]
- Meinedo, H.; Abad, A.; Pellegrini, T.; Neto, J.; Trancoso, I. The L2F Broadcast News Speech Recognition System. Available online: http://lorien.die.upm.es/~lapiz/rtth/JORNADAS/VI/pdfs/0018.pdf (accessed on 24 September 2020).
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}