Online At-Risk Student Identification using RNN-GRU Joint Neural Networks




Abstract
1. Introduction
- Firstly, this study proposes a novel joint neural network model framework to identify at-risk students accurately based on their demographics information and interaction stream data.
- Secondly, the data completion method was adopted for completing missing stream data, which enabled the model to be trained and validated on varying-length courses.
- Thirdly, the experiments prove that gated recurrent unit (GRU) and simple RNN perform better in analyzing academic stream information than the LSTM model.
2. Related Work
2.1. Educational Data Mining
2.2. Student Performance Prediction
3. Method
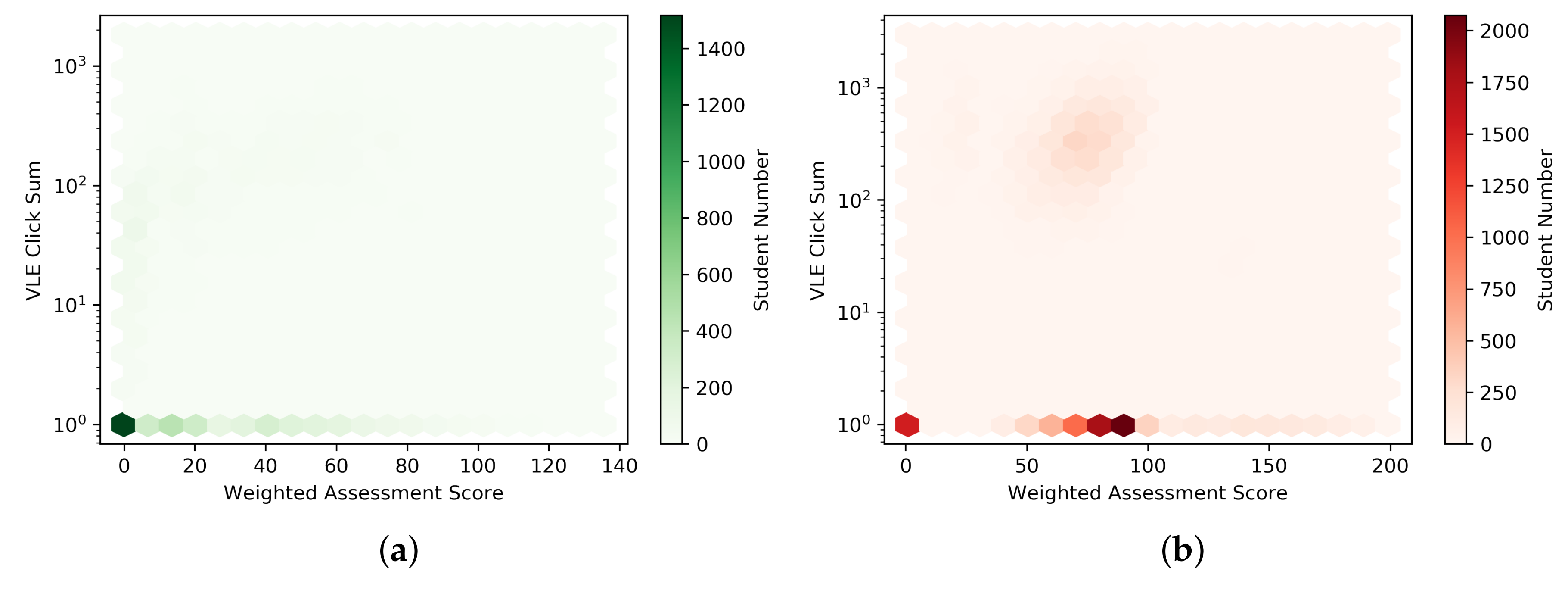
3.1. Data Pre-Processing
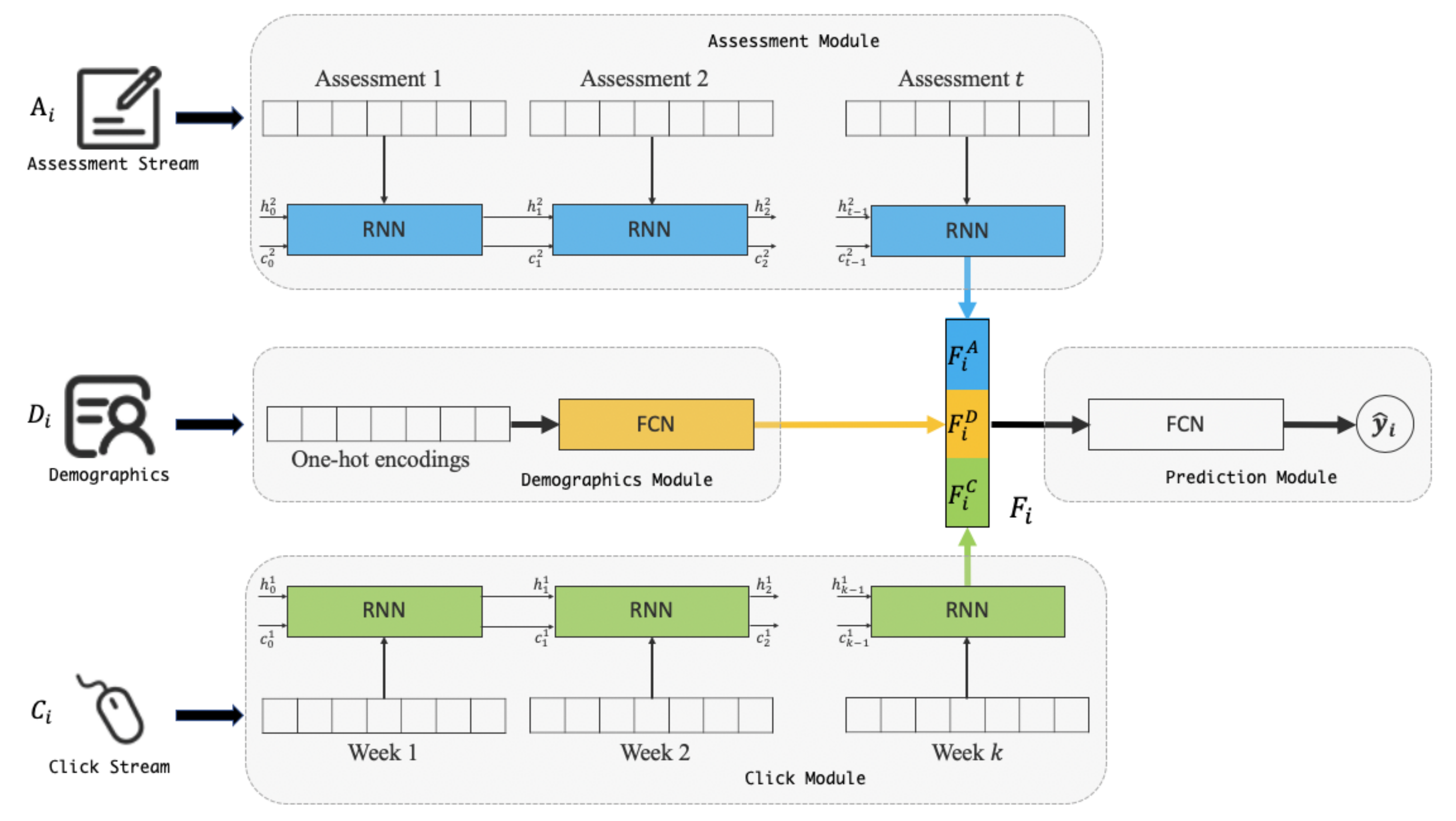
3.2. Approach
4. Experiments and Discussions
4.1. Experimental Settings
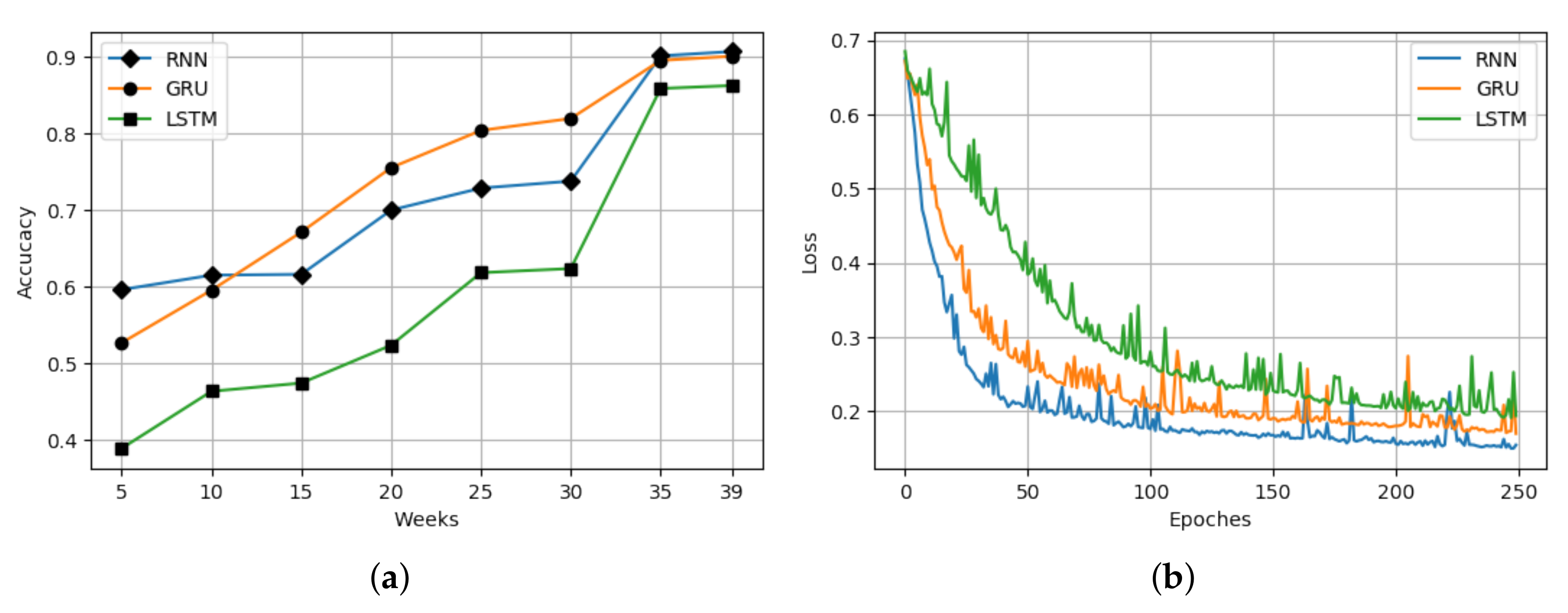
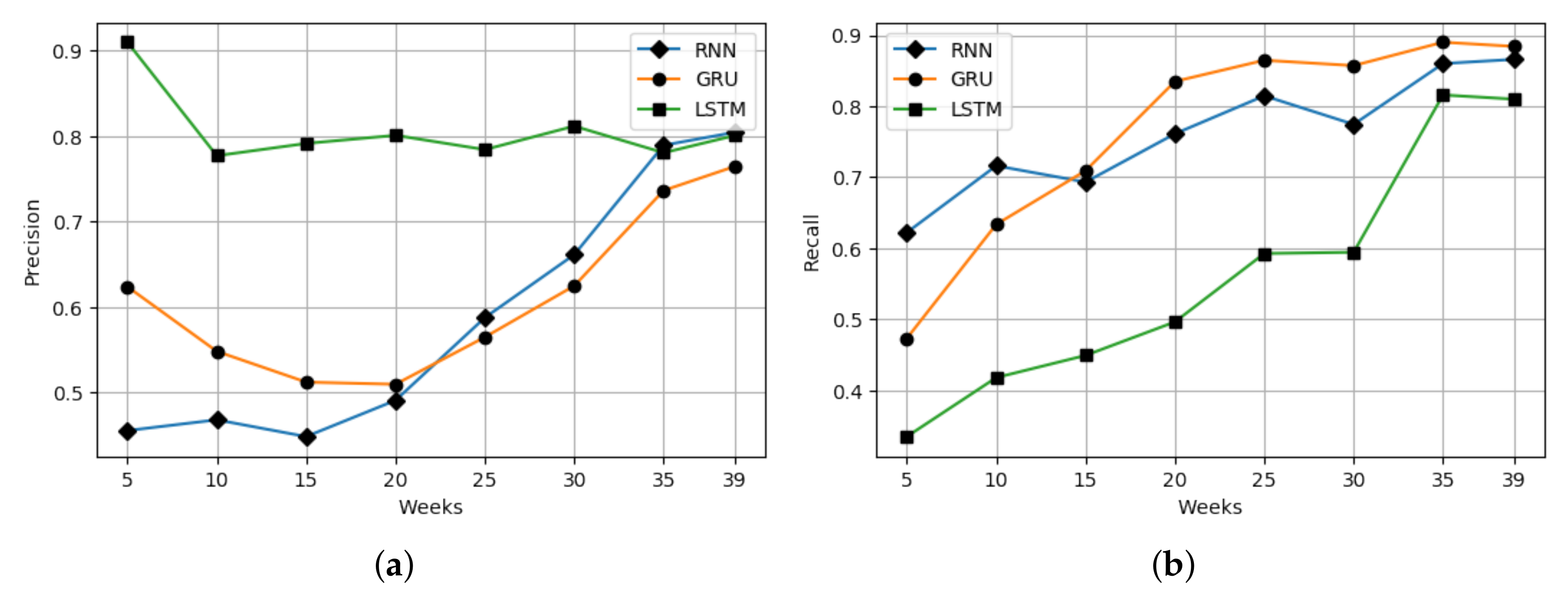
4.2. Evaluation with Baseline
4.3. Implication of Results
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Karimi, H.; Huang, J.; Derr, T. A Deep Model for Predicting Online Course Performance. Cse. Msu. Educ. 2014, 192, 302. [Google Scholar]
- Silveira, P.D.N.; Cury, D.; Menezes, C.; dos Santos, O.L. Analysis of classifiers in a predictive model of academic success or failure for institutional and trace data. In Proceedings of the 2019 IEEE Frontiers in Education Conference (FIE), Covington, KY, USA, 16–19 October 2019; pp. 1–8. [Google Scholar]
- Jiang, S.; Kotzias, D. Assessing the use of social media in massive open online courses. arXiv 2016, arXiv:1608.05668. [Google Scholar]
- Li, W.; Gao, M.; Li, H.; Xiong, Q.; Wen, J.; Wu, Z. Dropout prediction in MOOCs using behavior features and multi-view semi-supervised learning. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 3130–3137. [Google Scholar]
- Tan, M.; Shao, P. Prediction of student dropout in e-Learning program through the use of machine learning method. Int. J. Emerg. Technol. Learn. 2015, 10, 11–17. [Google Scholar] [CrossRef]
- Kaur, G.; Singh, W. Prediction of student performance using weka tool. Int. J. Eng. Sci. 2016, 17, 8–16. [Google Scholar]
- May, M.; Iksal, S.; Usener, C.A. The side effect of learning analytics: An empirical study on e-learning technologies and user privacy. In Communications in Computer and Information Science, Proceedings of the International Conference on Computer Supported Education, Rome, Italy, 21–23 April 2016; Springer: Cham, Switzerland, 2016; pp. 279–295. [Google Scholar]
- Cup, K. KDD Cup 2015: Predicting Dropouts in MOOC; Beijing, China. 2015. Available online: http://www.onlinejournal.in (accessed on 5 October 2020).
- Bharara, S.; Sabitha, S.; Bansal, A. Application of learning analytics using clustering data Mining for Students’ disposition analysis. Educ. Inf. Technol. 2018, 23, 957–984. [Google Scholar] [CrossRef]
- Wang, X.; Yang, D.; Wen, M.; Koedinger, K.; Rosé, C.P. Investigating How Student’s Cognitive Behavior in MOOC Discussion Forums Affect Learning Gains. Presented at the International Educational Data Mining Society, Madrid, Spain, 26–29 June 2015. [Google Scholar]
- Shridharan, M.; Willingham, A.; Spencer, J.; Yang, T.Y.; Brinton, C. Predictive learning analytics for video-watching behavior in MOOCs. In Proceedings of the 2018 52nd Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 21–23 March 2018; pp. 1–6. [Google Scholar]
- Kuzilek, J.; Hlosta, M.; Zdrahal, Z. Open university learning analytics dataset. Sci. Data 2017, 4, 170171. [Google Scholar] [CrossRef] [PubMed]
- Hlioui, F.; Aloui, N.; Gargouri, F. Withdrawal Prediction Framework in Virtual Learning Environment. Int. J. Serv. Sci. Manag. Eng. Technol. 2020, 11, 47–64. [Google Scholar]
- Fayyad, U.; Piatetsky-Shapiro, G.; Smyth, P. From data mining to knowledge discovery in databases. AI Mag. 1996, 17, 37. [Google Scholar]
- Injadat, M.; Salo, F.; Nassif, A.B.; Essex, A.; Shami, A. Bayesian optimization with machine learning algorithms towards anomaly detection. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, UAE, 9–13 December 2018; pp. 1–6. [Google Scholar]
- Yang, L.; Moubayed, A.; Hamieh, I.; Shami, A. Tree-based intelligent intrusion detection system in internet of vehicles. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Moubayed, A.; Injadat, M.; Shami, A.; Lutfiyya, H. Dns typo-squatting domain detection: A data analytics & machine learning based approach. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, UAE, 9–13 December 2018; pp. 1–7. [Google Scholar]
- Peña-Ayala, A. Educational data mining: A survey and a data mining-based analysis of recent works. Expert Syst. Appl. 2014, 41, 1432–1462. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S. Educational data mining: A survey from 1995 to 2005. Expert Syst. Appl. 2007, 33, 135–146. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S. Educational data mining: A review of the state of the art. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2010, 40, 601–618. [Google Scholar] [CrossRef]
- Perera, D.; Kay, J.; Koprinska, I.; Yacef, K.; Zaïane, O.R. Clustering and sequential pattern mining of online collaborative learning data. IEEE Trans. Knowl. Data Eng. 2008, 21, 759–772. [Google Scholar] [CrossRef]
- Gaudioso, E.; Montero, M.; Talavera, L.; Hernandez-del Olmo, F. Supporting teachers in collaborative student modeling: A framework and an implementation. Expert Syst. Appl. 2009, 36, 2260–2265. [Google Scholar] [CrossRef][Green Version]
- Cambruzzi, W.L.; Rigo, S.J.; Barbosa, J.L. Dropout prediction and reduction in distance education courses with the learning analytics multitrail approach. J. UCS 2015, 21, 23–47. [Google Scholar]
- Lykourentzou, I.; Giannoukos, I.; Nikolopoulos, V.; Mpardis, G.; Loumos, V. Dropout prediction in e-learning courses through the combination of machine learning techniques. Comput. Educ. 2009, 53, 950–965. [Google Scholar] [CrossRef]
- Márquez-Vera, C.; Cano, A.; Romero, C.; Noaman, A.Y.M.; Mousa Fardoun, H.; Ventura, S. Early dropout prediction using data mining: A case study with high school students. Expert Syst. 2016, 33, 107–124. [Google Scholar] [CrossRef]
- Helal, S.; Li, J.; Liu, L.; Ebrahimie, E.; Dawson, S.; Murray, D.J.; Long, Q. Predicting academic performance by considering student heterogeneity. Knowl. Based Syst. 2018, 161, 134–146. [Google Scholar] [CrossRef]
- Ben-Zadok, G.; Hershkovitz, A.; Mintz, E.; Nachmias, R. Examining online learning processes based on log files analysis: A case study. In Proceedings of the 5th International Conference on Multimedia and ICT in Education (m-ICTE’09), Lisbon, Portugal, 22–24 April 2009. [Google Scholar]
- Sabourin, J.L.; Mott, B.W.; Lester, J.C. Early Prediction of Student Self-Regulation Strategies by Combining Multiple Models. Presented at the International Educational Data Mining Society, Chania, Greece, 19–21 June 2012. [Google Scholar]
- Wasif, M.; Waheed, H.; Aljohani, N.; Hassan, S.U. Understanding Student Learning Behavior and Predicting Their Performance. In Cognitive Computing in Technology-Enhanced Learning; IGI Global: Hershey, PN, USA, 2019; pp. 1–28. [Google Scholar] [CrossRef]
- Costa, E.B.; Fonseca, B.; Santana, M.A.; de Arajo, F.F.; Rego, J. Evaluating the Effectiveness of Educational Data Mining Techniques for Early Prediction of Students’ Academic Failure in Introductory Programming Courses. Comput. Hum. Behav. 2017, 73, 247–256. [Google Scholar] [CrossRef]
- Yi, J.C.; Kang-Yi, C.D.; Burton, F.; Chen, H.D. Predictive analytics approach to improve and sustain college students’ non-cognitive skills and their educational outcome. Sustainability 2018, 10, 4012. [Google Scholar] [CrossRef]
- Wilson, J.; Olinghouse, N.G.; McCoach, D.B.; Santangelo, T.; Andrada, G.N. Comparing the accuracy of different scoring methods for identifying sixth graders at risk of failing a state writing assessment. Assess. Writ. 2016, 27, 11–23. [Google Scholar] [CrossRef]
- Marbouti, F.; Diefes-Dux, H.A.; Madhavan, K. Models for early prediction of at-risk students in a course using standards-based grading. Comput. Educ. 2016, 103, 1–15. [Google Scholar] [CrossRef]
- Aljohani, N.R.; Fayoumi, A.; Hassan, S.U. Predicting at-risk students using clickstream data in the virtual learning environment. Sustainability 2019, 11, 7238. [Google Scholar] [CrossRef]
- Karimi, H.; Derr, T.; Huang, J.; Tang, J. Online Academic Course Performance Prediction using Relational Graph Convolutional Neural Network. In Proceedings of the 13th International Conference on Educational Data Mining (EDM 2020), Fully Virtual Conference, 10–13 July 2020. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Code Module | Train/Validation Data | Test Data |
|---|---|---|
| AAA | 2013J | 2014J |
| BBB | 2013B | 2013J |
| 2013B, 2013J | 2014B | |
| 2013B, 2013J, 2014B | 2014J | |
| CCC | 2014B | 2014J |
| DDD | 2013B | 2013J |
| 2013B, 2013J | 2014B | |
| 2013B, 2013J, 2014B | 2014J | |
| EEE | 2013J | 2014B |
| 2013J, 2014B | 2014J | |
| FFF | 2013B | 2013J |
| 2013B, 2013J | 2014B | |
| 2013B, 2013J, 2014B | 2014J | |
| GGG | 2013J | 2014B |
| 2013J, 2014B | 2014J |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Y.; Chen, R.; Li, X.; Hao, C.; Liu, S.; Zhang, G.; Jiang, B. Online At-Risk Student Identification using RNN-GRU Joint Neural Networks. Information 2020, 11, 474. https://doi.org/10.3390/info11100474
He Y, Chen R, Li X, Hao C, Liu S, Zhang G, Jiang B. Online At-Risk Student Identification using RNN-GRU Joint Neural Networks. Information. 2020; 11(10):474. https://doi.org/10.3390/info11100474
Chicago/Turabian StyleHe, Yanbai, Rui Chen, Xinya Li, Chuanyan Hao, Sijiang Liu, Gangyao Zhang, and Bo Jiang. 2020. "Online At-Risk Student Identification using RNN-GRU Joint Neural Networks" Information 11, no. 10: 474. https://doi.org/10.3390/info11100474
APA StyleHe, Y., Chen, R., Li, X., Hao, C., Liu, S., Zhang, G., & Jiang, B. (2020). Online At-Risk Student Identification using RNN-GRU Joint Neural Networks. Information, 11(10), 474. https://doi.org/10.3390/info11100474