Reinforcement Learning for Efficient Network Penetration Testing


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Network hardware, software, segments or applications were added, changed or removed
- Significant systems’ upgrades or modifications are applied to infrastructure or applications
- Infrastructure changes including moving locations
- Security solutions or patches were installed or modified
- Security or users’ policies were modified
1.1. Research Context and Method
1.2. Paper Outline
2. Literature Review
2.1. Previous Works on PT Automation
2.2. Drawbacks and Limits of the Current PT Practice
2.3. Motivation and Contribution
- Reducing the cost of systematic testing and regular re-testing due to human labor cost;
- Reduce the impact on the assessed network notably the security exposure, performances, and downtime during the testing;
- Relieve human experts from boring repetitive tasks and assign them to more challenging tasks;
- Dealing more effectively with changing cyber threats by allowing flexibility and adaptability;
- Perform more broad tests by covering a wide variety of attack vectors and also consider complex and evasive attacking paths that are hard to identify and investigate by human testers.
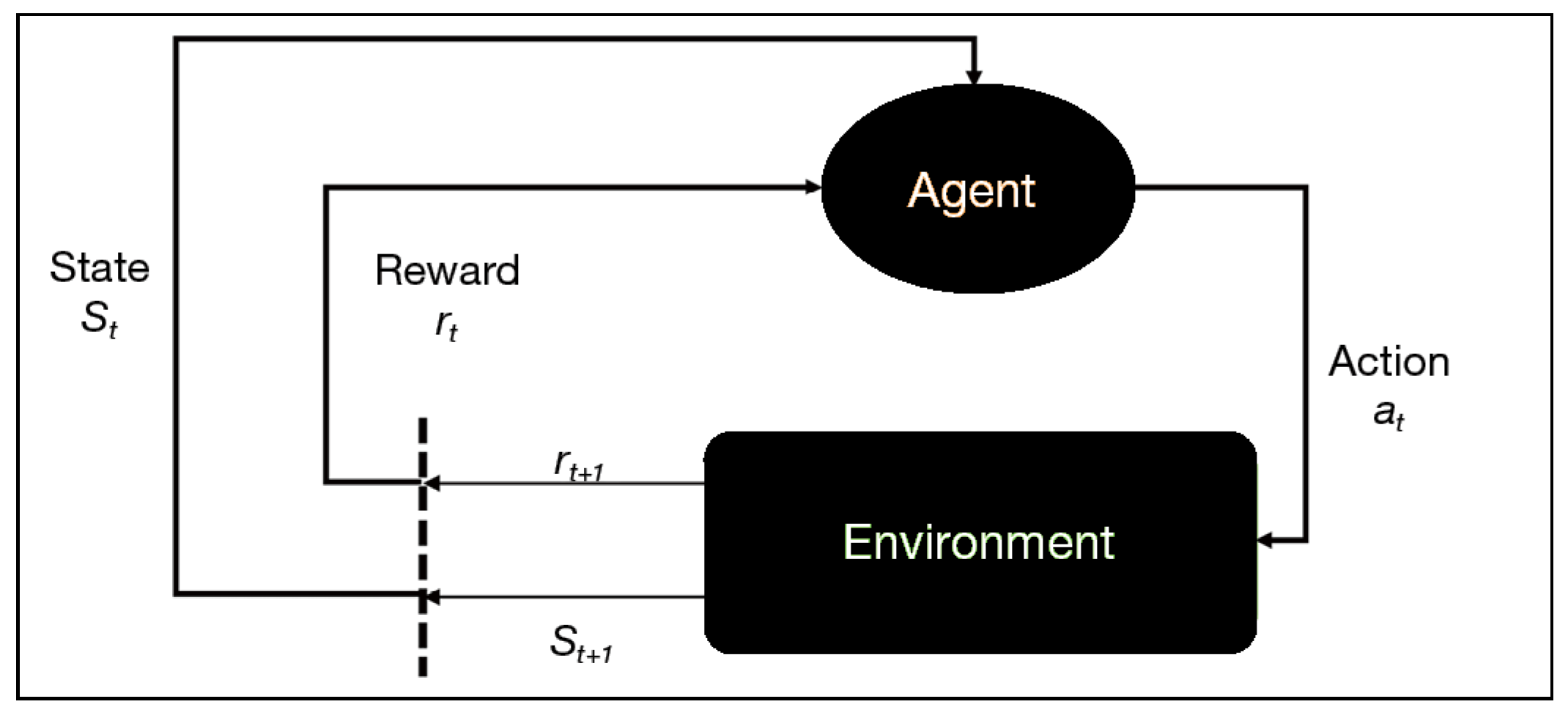
3. Reinforcement Learning Approach
- Effective autonomous learning and improving through constant interaction with the environment;
- Reward-based learning and existing flexible rewarding schemes which might be delayed to enable RL agent to maximize a long-term goal;
- Richness of the RL environment which helps in capturing all major characteristics of PT including uncertainty and complexity.
3.1. Towards POMDP Modeling of PT
3.2. POMDP Solving Algorithm
3.3. PERSEUS Algorithm
3.4. GIP Algorithm
3.5. PEGASUS Algorithm
3.6. Other Candidates
3.7. POMDP Solving Choices
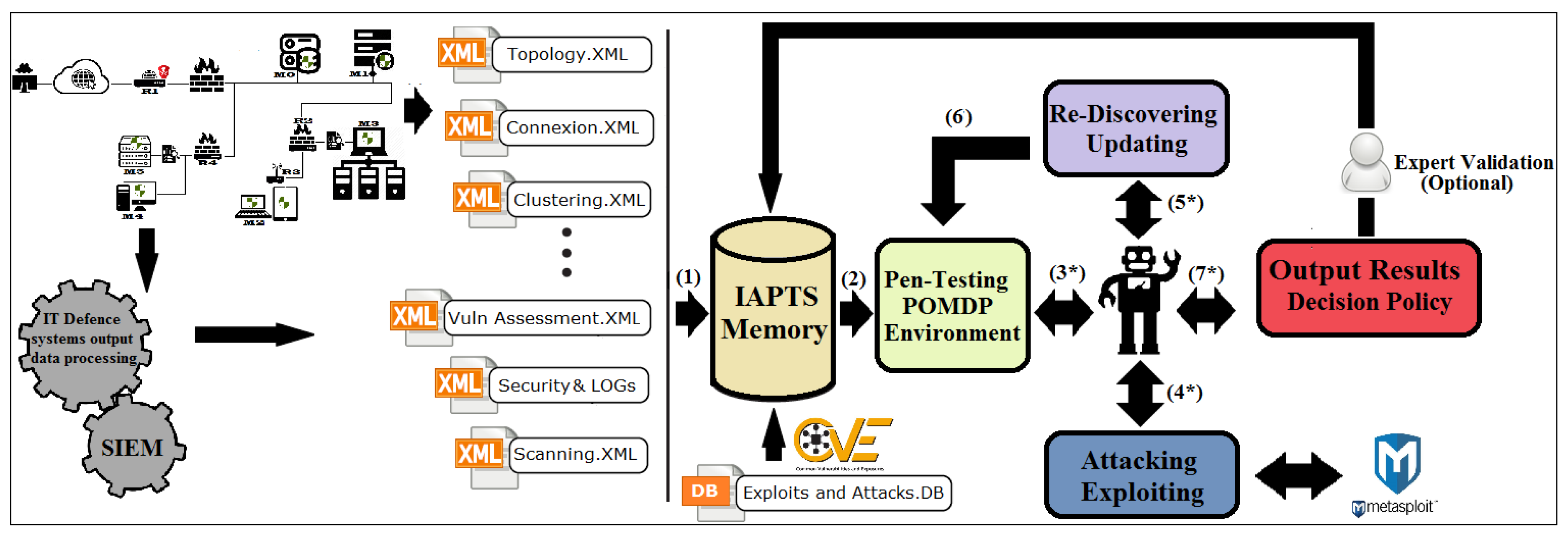
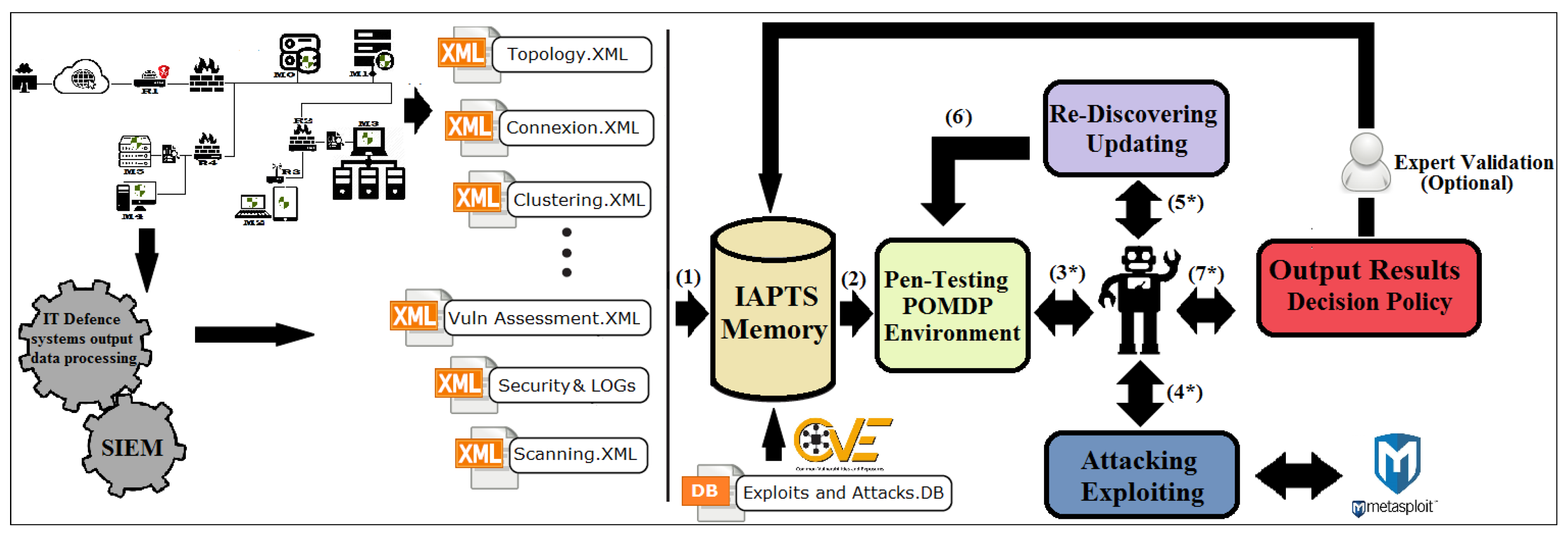
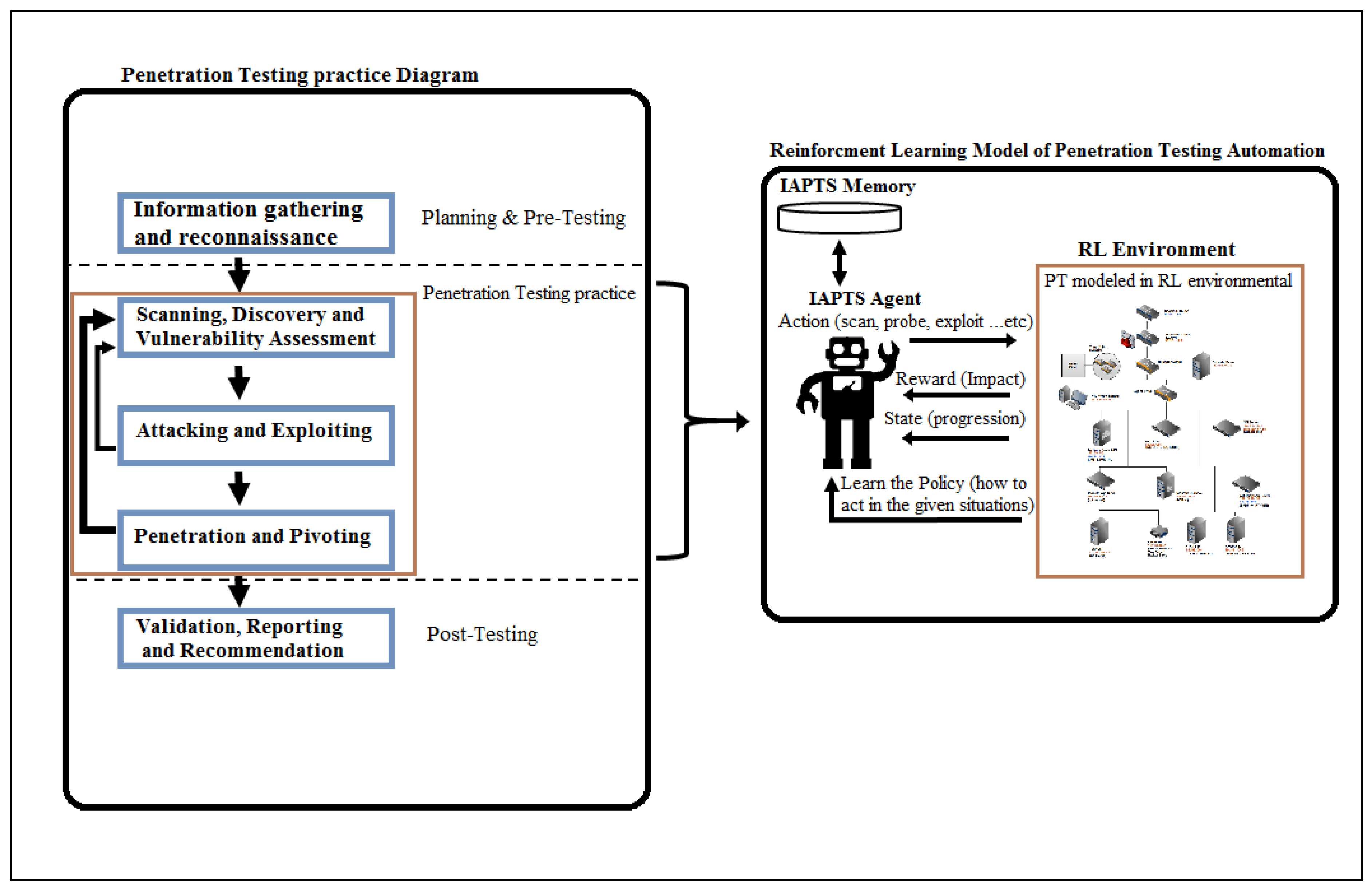
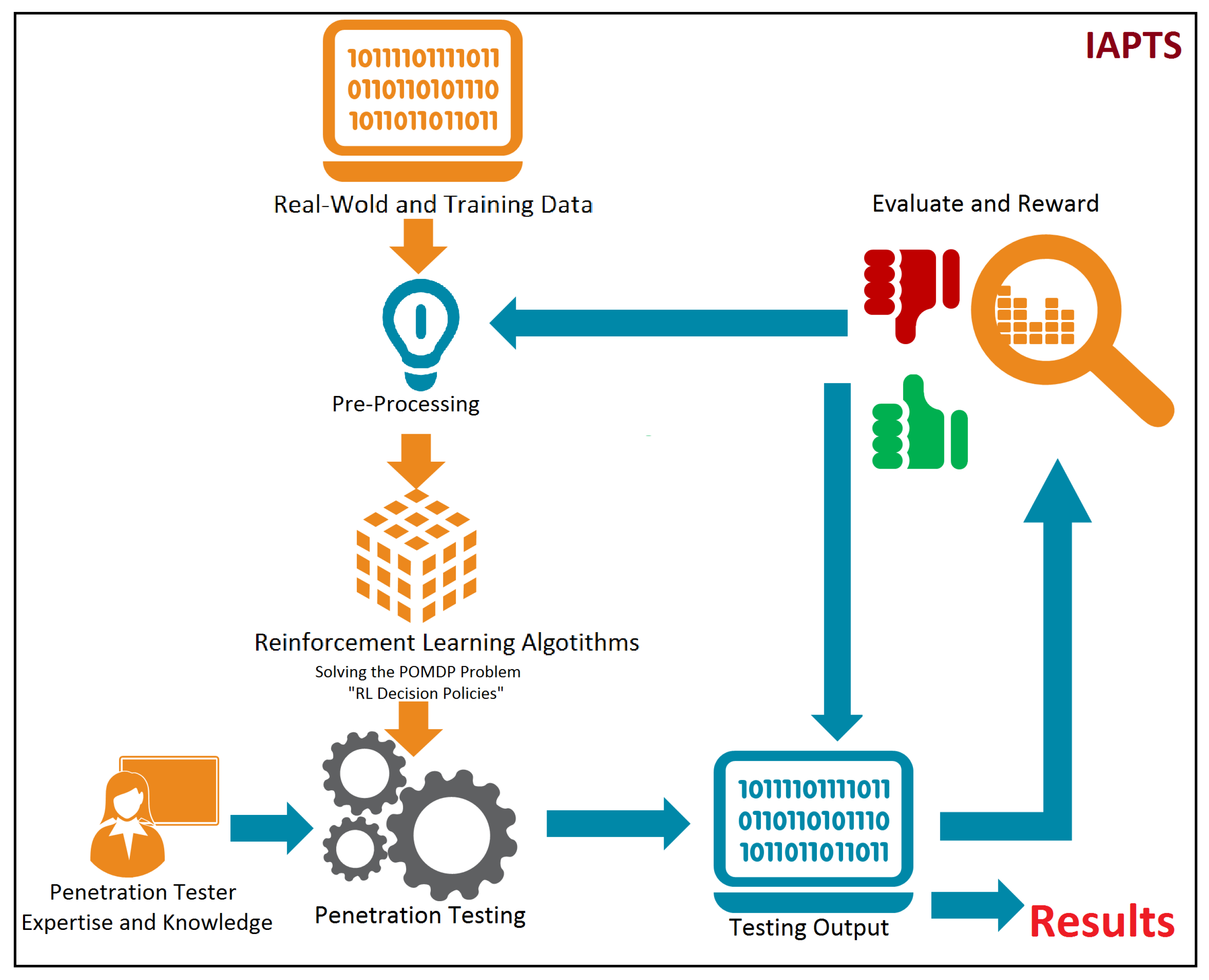
4. IAPTS Design and Functioning
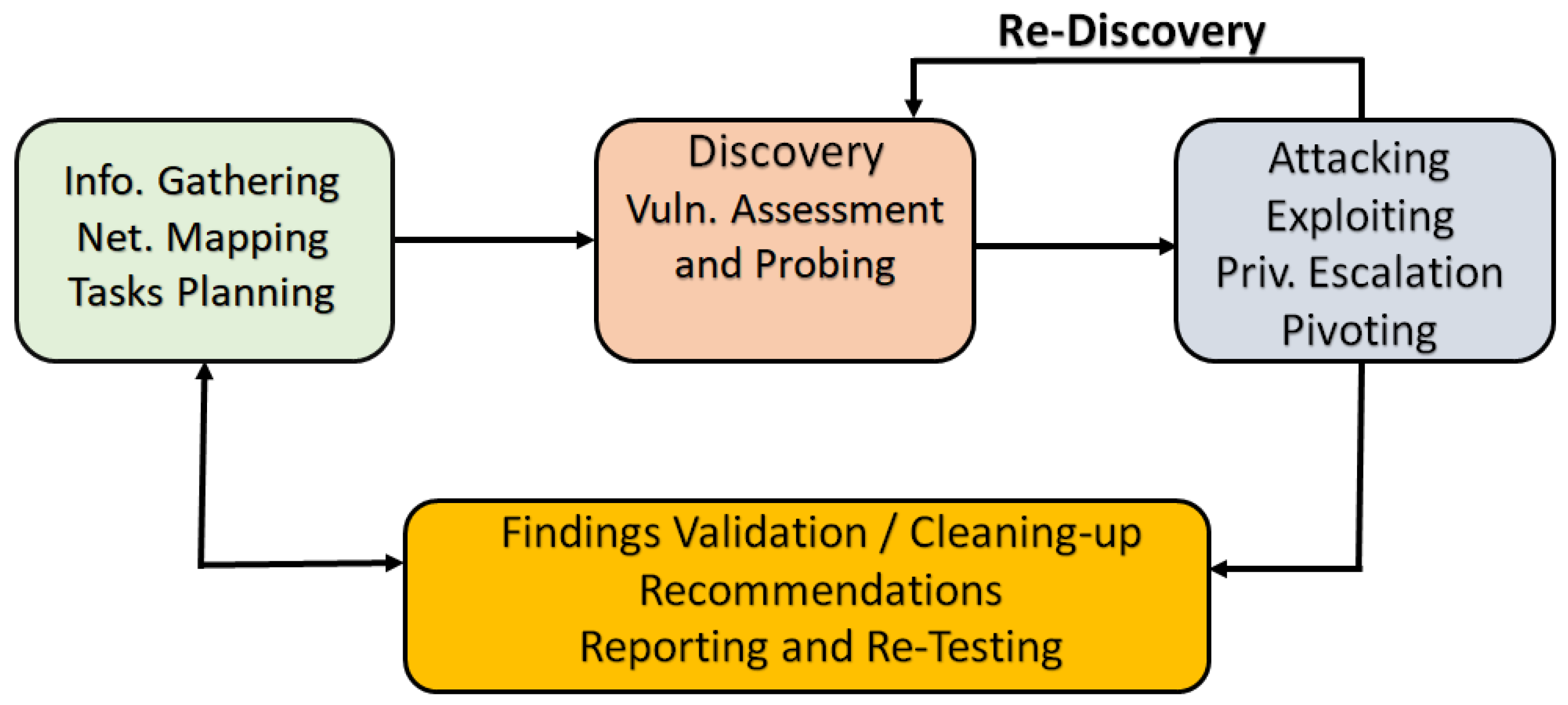
4.1. IAPTS Operative Modes
- Fully autonomous; IAPTS entirely in control of testing after achieving maturity so it can perform PT tasks in the same way that human experts will do with some minor issues that will be reported for expert review.
- Partially autonomous; the most common mode of IAPTS and reflect the first weeks or months of professional use when IAPTS will be performing tests under the constant and continuous supervision of a high-caliber PT expert.
- Decision-making assistant; IAPTS will shadow human experts and assist him/her by providing a pinpoint decision on scenarios identical to those saved into the expertise base and thus alight tester from repetitive tasks.
- Expertise building; IAPTS running in the background while human tester performs tests and capture the decisions made in form of expertise and proceed to the generalization and of the extracted experience and build the expertise base for future use.
4.2. From PT to A Reinforcement Learning Problem
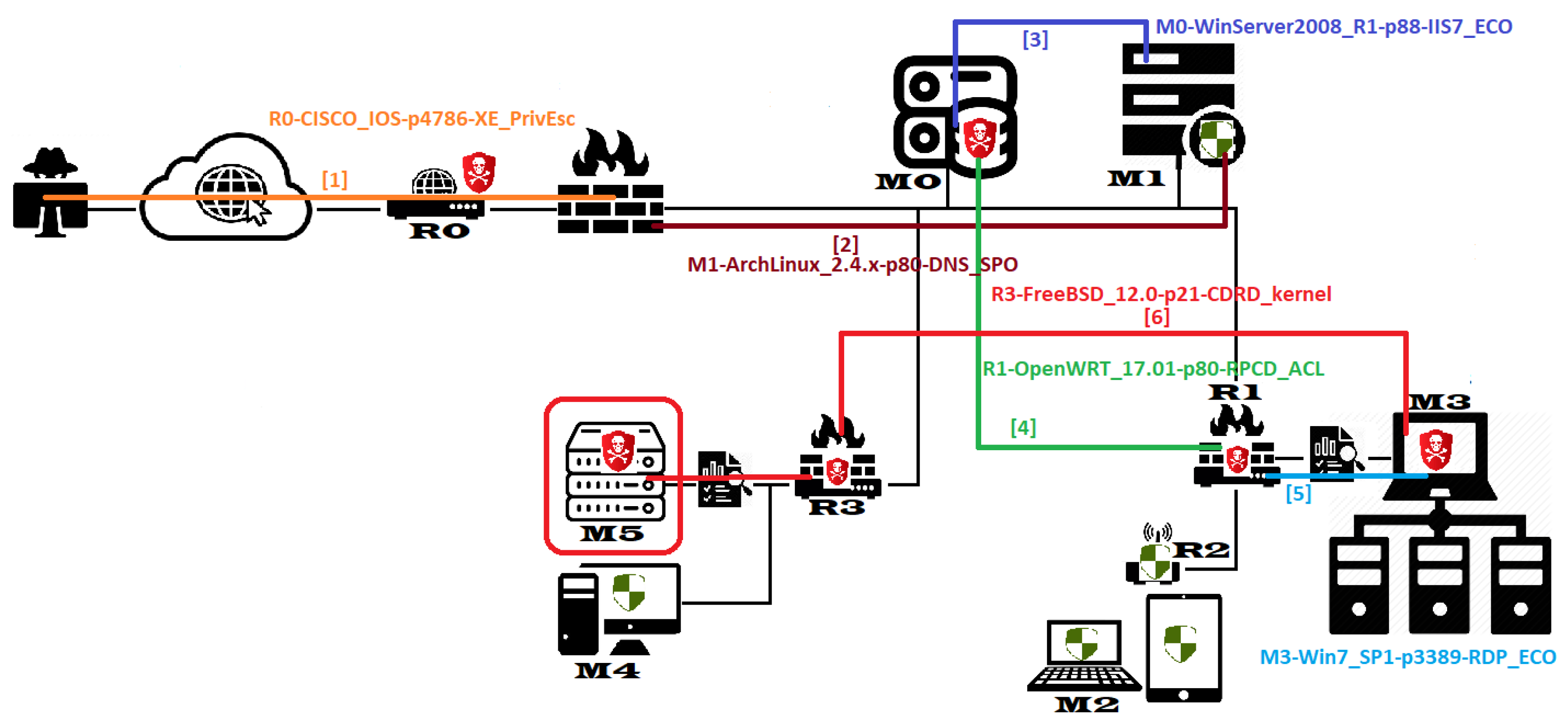
4.3. Representing Network PT As RL Environment
- A failed action to fully (root) control a machine that leads to further action attempting user session or escalates privileges or switching to other attack paths;
- Dealing with action relying on uncertain information and fail because of the assumption made and require further actions when additional information becomes available and might be successful;
- Actions prevented or stopped by security defense (FWs or IDPSs) which may be re-attempted under different circumstances.
4.4. POMDP Transitions and Observations Probabilities
4.5. Rewarding Schema
4.6. IAPTS Memory, Expertise Management and Pre-Processing
5. Testing IAPTS and Results
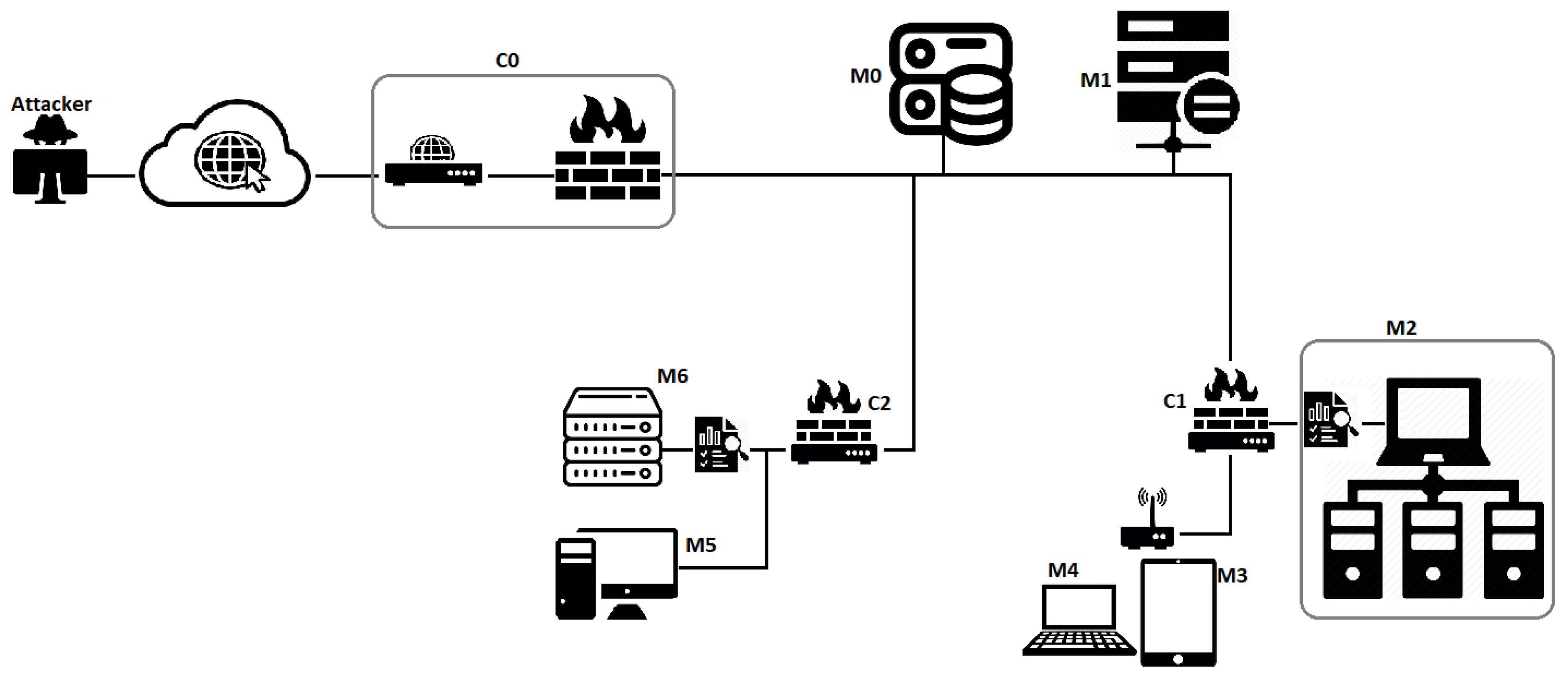
5.1. Simulation Platform
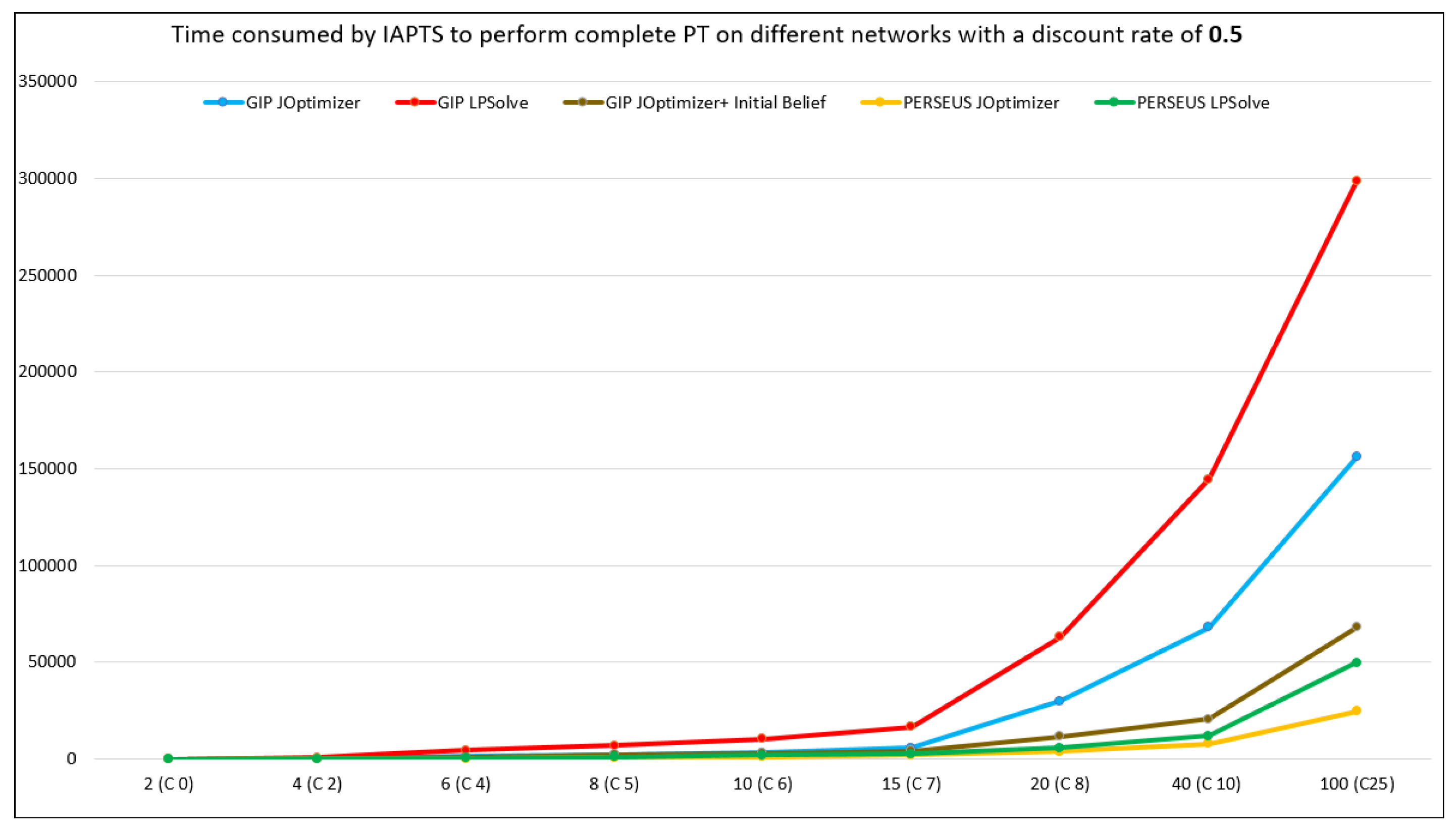
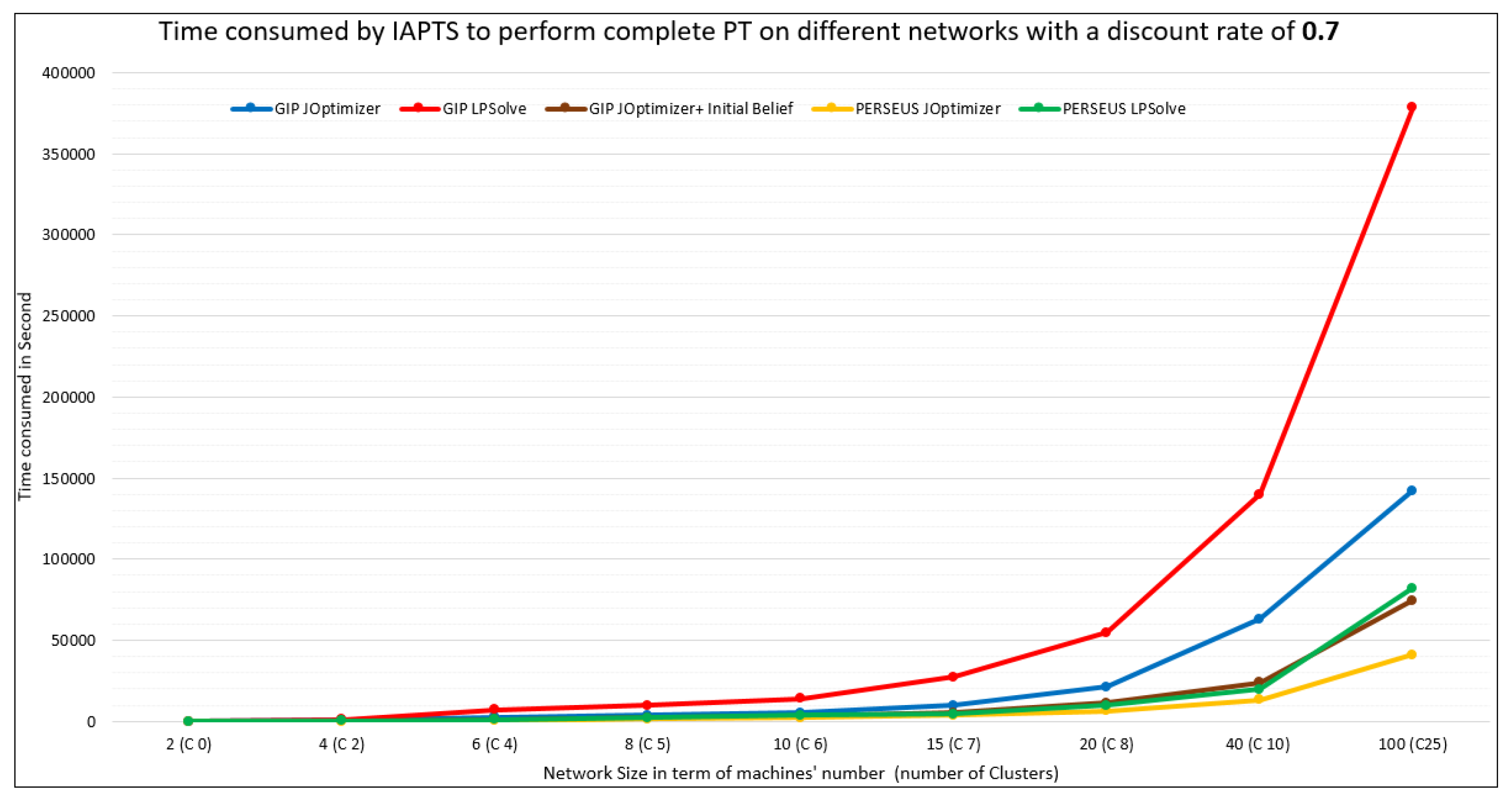
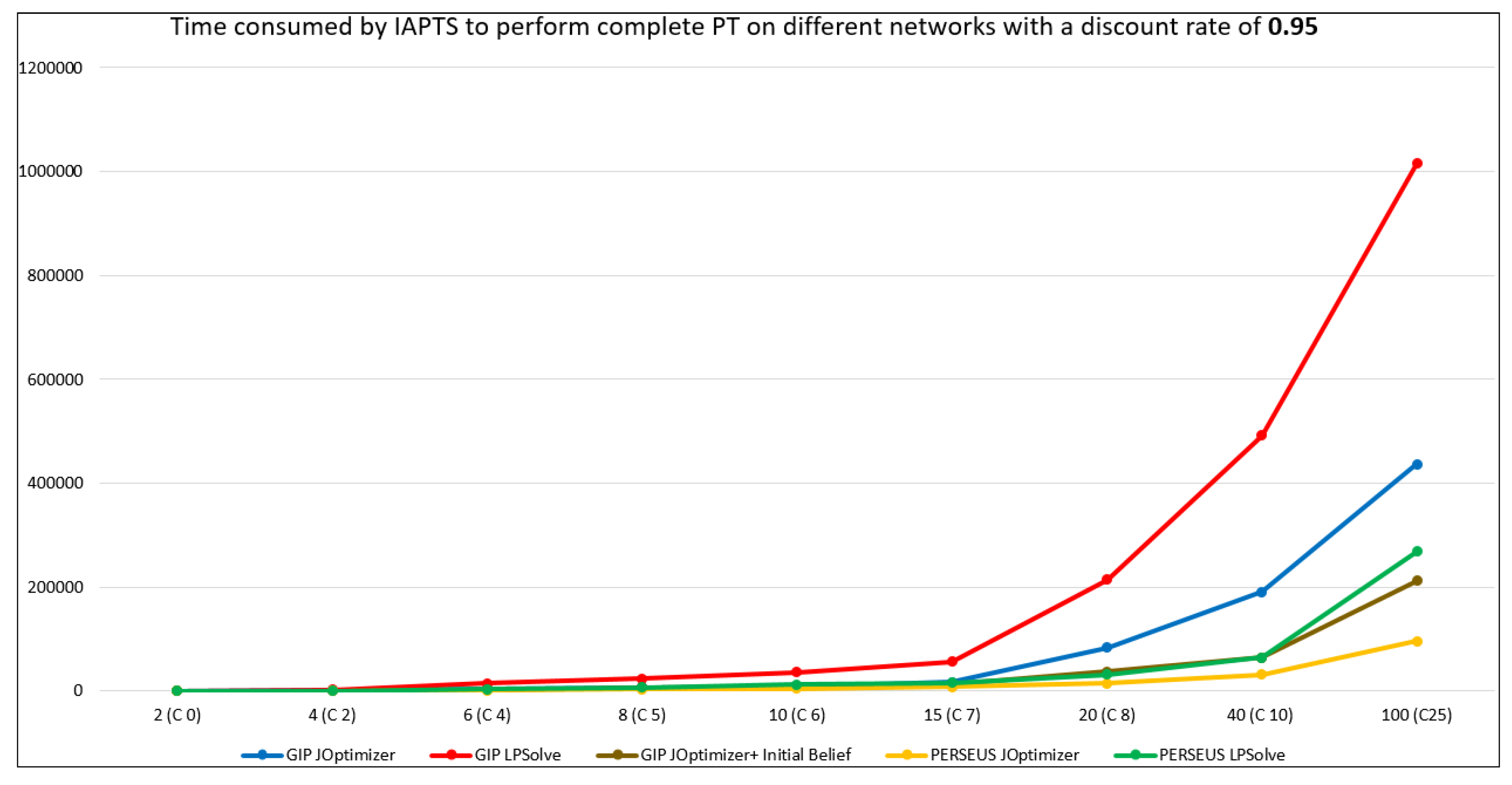
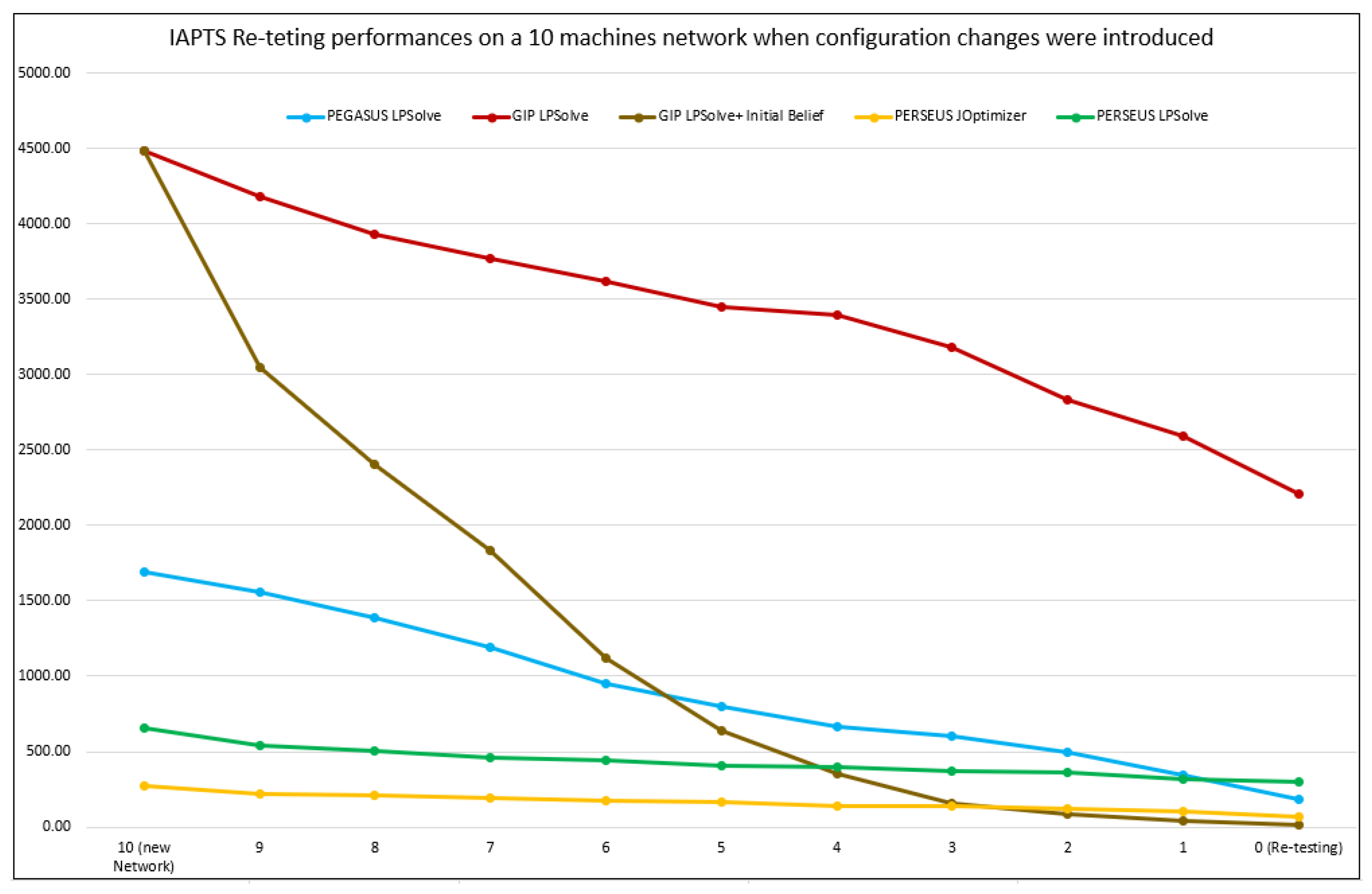
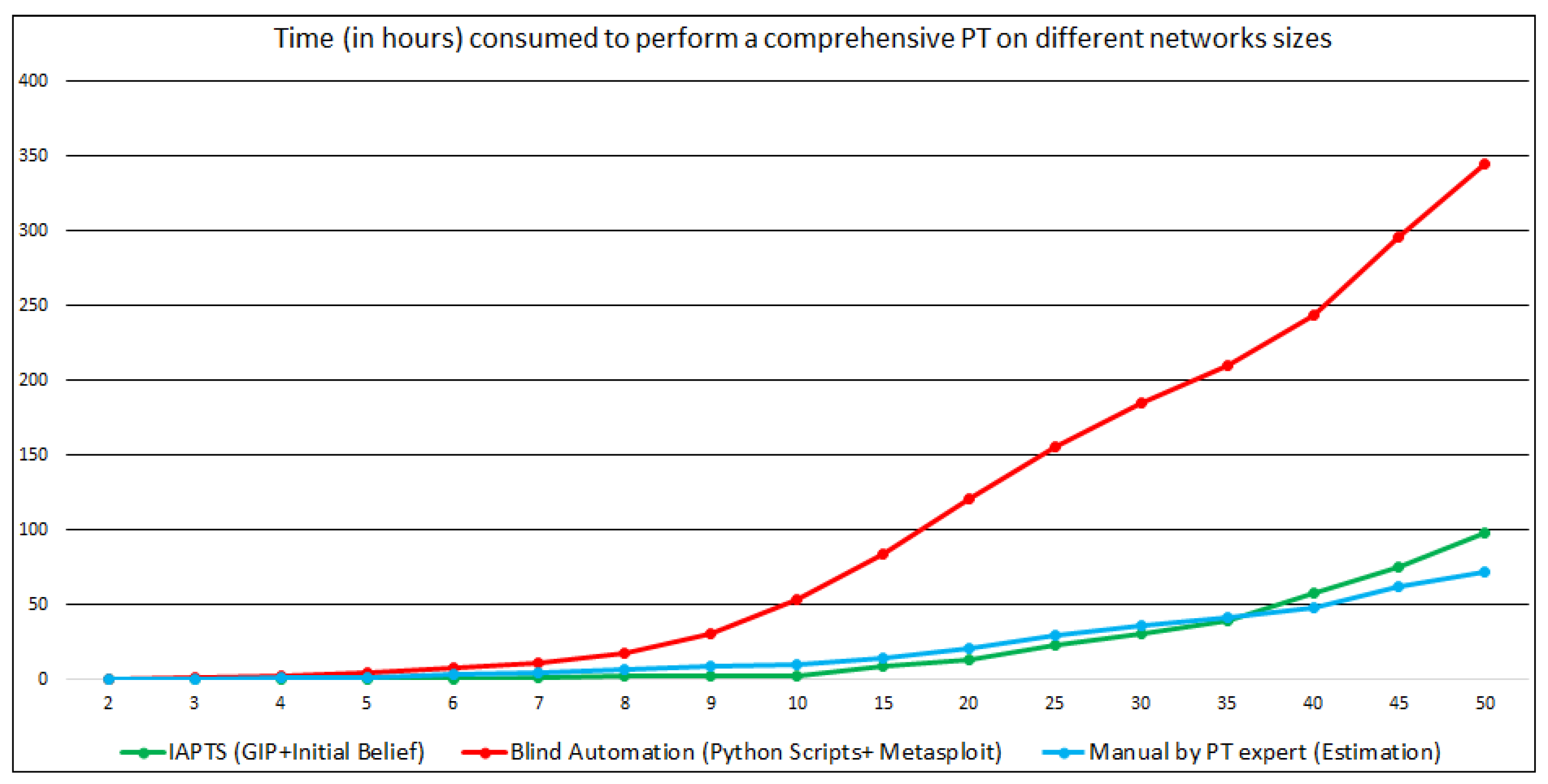
5.2. IAPTS Results
5.3. Discussion
6. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Creasey, J.; Glover, I. A Guide for Running an Effective Penetration Testing Program; CREST Publication: Slough, UK, 2017; Available online: http://www.crest-approved.org (accessed on 18 December 2019).
- Almubairik, N.; Wills, G. Automated penetration testing based on a threat model. In Proceedings of the 11th International Conference for Internet Technologies and Secured Transactions, ICITST, Barcelona, Spain, 5–7 December 2016. [Google Scholar]
- Applebaum, A.; Miller, D.; Strom, B.; Korban, C.; Wol, R. Intelligent, automated red team emulation. In Proceedings of the 32nd Annual Conference on Computer Security Applications (ACSAC ’16), Los Angeles, CA, USA, 5–8 December 2016; pp. 363–373. [Google Scholar]
- Obes, J.; Richarte, G.; Sarraute, C. Attack planning in the real world. arXiv 2013, arXiv:1306.4044. [Google Scholar]
- Spaan, M. Partially Observable Markov Decision Processes, Reinforcement Learning: State of the Art; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Hoffmann, J. Simulated penetration testing: From Dijkstra to aaTuring Test++. In Proceedings of the 25th International Conference on Automated Planning and Scheduling, Israel, 7–11 June 2015. [Google Scholar]
- Sarraute, C. Automated Attack Planning. Available online: https://arxiv.org/abs/1307.7808 (accessed on 20 December 2019).
- Qiu, X.; Jia, Q.; Wang, S.; Xia, C.; Shuang, L. Automatic generation algorithm of penetration graph in penetration testing. In Proceedings of the Ninth International Conference on P2P, Parallel, Grid, Cloud and Internet Computing, Guangdong, China, 8–10 November 2014. [Google Scholar]
- Heinl, C. Artificial (intelligent) agents and active cyber defence: Policy implications. In Proceedings of the 6th International Conference On Cyber Conflict (CyCon 2014), Tallinn, Estonia, 3–6 June 2014. [Google Scholar]
- Sarraute, C.; Buffet, O.; Hoffmann, J. POMDPs Make Better Hackers: Accounting for Uncertainty in Penetration Testing. Available online: https://arxiv.org/abs/1307.8182 (accessed on 20 December 2019).
- Backes, M.; Hoffmann, J.; Kunnemann, R.; Speicher, P.; Steinmetz, M. Simulated Penetration Testing and Mitigation Analysis. arXiv 2017, arXiv:1705.05088. [Google Scholar]
- Ghanem, M.; Chen, T. Reinforcement Learning for Intelligent Penetration Testing. In Proceedings of the WS4 the World Conference on Smart Trends in Systems, Security and Sustainability, London, UK, 30–31 October 2018. [Google Scholar]
- Durkota, K.; Lisy, V.; Bosansk, B.; Kiekintveld, C. Optimal network security hardening using attack graph games. In Proceedings of the 24th International Joint Conference on on Artificial Intelligence (IJCAI-2015), Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Veeramachaneni, K.; Arnaldo, I.; Cuesta-Infante, A.; Korrapati, V.; Bassias, C.; Li, K. AI2: Training a Big Data Machine to Defend; CSAIL, MIT Cambridge: Cambridge, MA, USA, 2016. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Jimenez, S.; De-la-rosa, T.; Fernandez, S.; Fernandez, F.; Borrajo, D. A review of machine learning for automated planning. Knowl. Eng. Rev. 2009, 27, 433–467. [Google Scholar]
- Walraven, E.; Spaan, M. Point-Based Value Iteration for Finite-Horizon POMDPs. J. Artif. Intell. Res. 2019, 65, 307–341. [Google Scholar] [CrossRef]
- Walraven, E.; Spaan, M. Planning under Uncertainty in Constrained and Partially Observable Environments. Ph.D. Thesis, Delft University of Technology, Delft, The Netherlands, 2019. [Google Scholar]
- Spaan, M.; Vlassis, N. PERSEUS: Randomized point-based value iteration for POMDPs. J. Artif. Intell. Res. 2005, 24, 195–220. [Google Scholar] [CrossRef]
- Andrew, Y.; Jordan, M. PEGASUS: A policy search method for large MDPs and POMDPs. In Proceedings of the 16th Conference on Uncertainty in Artificial Intelligence, Stanford, CA, USA, 30 June–3 July 2000. [Google Scholar]
- Meuleau, N.; Kim, K.; Kaelbling, L.; Cassandra, A. Solving POMDPs by searching the space of finite policies. In Proceedings of the 15th Conference on Uncertainty in Artificial Intelligence, Bellevue, WA, USA, 11–15 July 2013. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay, Google DeepMind. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Dimitrakakis, C.; Ortner, R. Decision Making Under Uncertainty and Reinforcement Learning. Available online: http://www.cse.chalmers.se/~chrdimi/downloads/book.pdf (accessed on 20 December 2019).
- Osband, I.; Russo, D.; van Roy, B. Efficient Reinforcement Learning via Posterior Sampling. Available online: https://papers.nips.cc/paper/5185-more-efficient-reinforcement-learning-via-posterior-sampling.pdf (accessed on 20 December 2019).
- Grande, R.; Walsh, T.; How, J. Sample efficient reinforcement learning with gaussian processes. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1332–1340. [Google Scholar]
- Agrawal, S.; Jia, R. Optimistic posterior sampling for reinforcement learning: Worst-case regret bounds. In Proceedings of the Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1184–1194. [Google Scholar]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Washington, DC, USA, 28 June–2 July 2011; pp. 689–696. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. arXiv 2018, arXiv:1801.01290. [Google Scholar]
- Zhang, Z.; Hsu, D.; Lee, W.; Lim, Z.; Bai, A. PLEASE: Palm Leaf Search for POMDPs with Large Observation Spaces. In Proceedings of the International Conference on Automated Planning and Scheduling, Israel, 7–11 June 2015; pp. 249–257. [Google Scholar]
- NIST. Computer Security Resource Center—NATIONAL VULNERABILITY DATABASE (CVSS). 2019. Available online: https://nvd.nist.gov (accessed on 18 December 2019).
- MITRE. The MITRE Corporation—Common Vulnerabilities and Exposures (CVE) Database. 2019. Available online: https://cve.mitre.org (accessed on 18 December 2019).
- Lyu, D. Knowledge-Based Sequential Decision-Making Under Uncertainty. In Proceedings of the 15th International Conference on Logic Programming and Non-monotonic Reasoning, LPNMR, Philadelphia, PA, USA, 3–7 June 2019. [Google Scholar]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghanem, M.C.; Chen, T.M. Reinforcement Learning for Efficient Network Penetration Testing. Information 2020, 11, 6. https://doi.org/10.3390/info11010006
Ghanem MC, Chen TM. Reinforcement Learning for Efficient Network Penetration Testing. Information. 2020; 11(1):6. https://doi.org/10.3390/info11010006
Chicago/Turabian StyleGhanem, Mohamed C., and Thomas M. Chen. 2020. "Reinforcement Learning for Efficient Network Penetration Testing" Information 11, no. 1: 6. https://doi.org/10.3390/info11010006
APA StyleGhanem, M. C., & Chen, T. M. (2020). Reinforcement Learning for Efficient Network Penetration Testing. Information, 11(1), 6. https://doi.org/10.3390/info11010006