Encrypting and Preserving Sensitive Attributes in Customer Churn Data Using Novel Dragonfly Based Pseudonymizer Approach


Abstract
:1. Introduction
2. Literature Survey
2.1. Churn Detection via Mathematical Modeling
2.2. PPDM Approaches towards Information Security
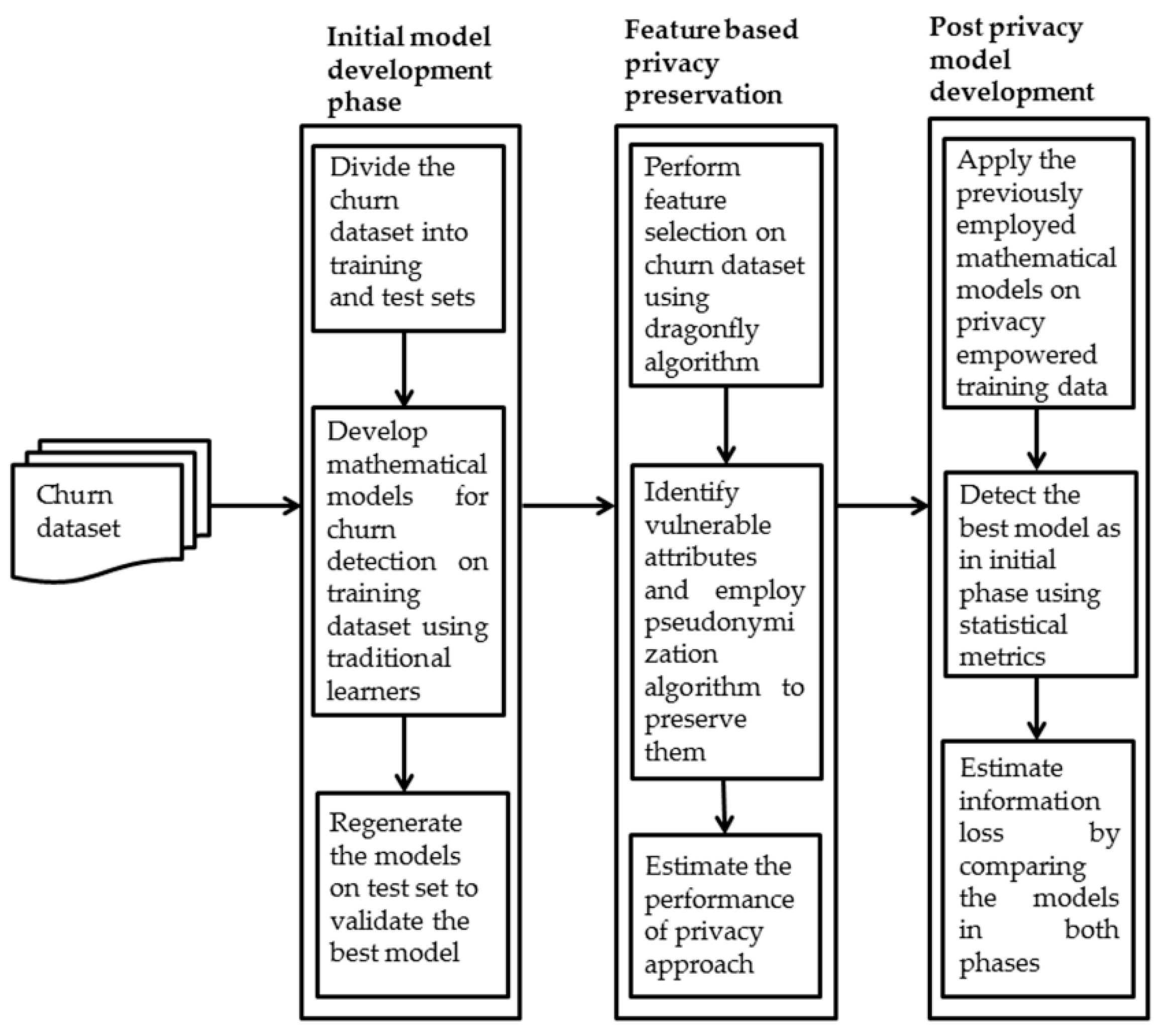
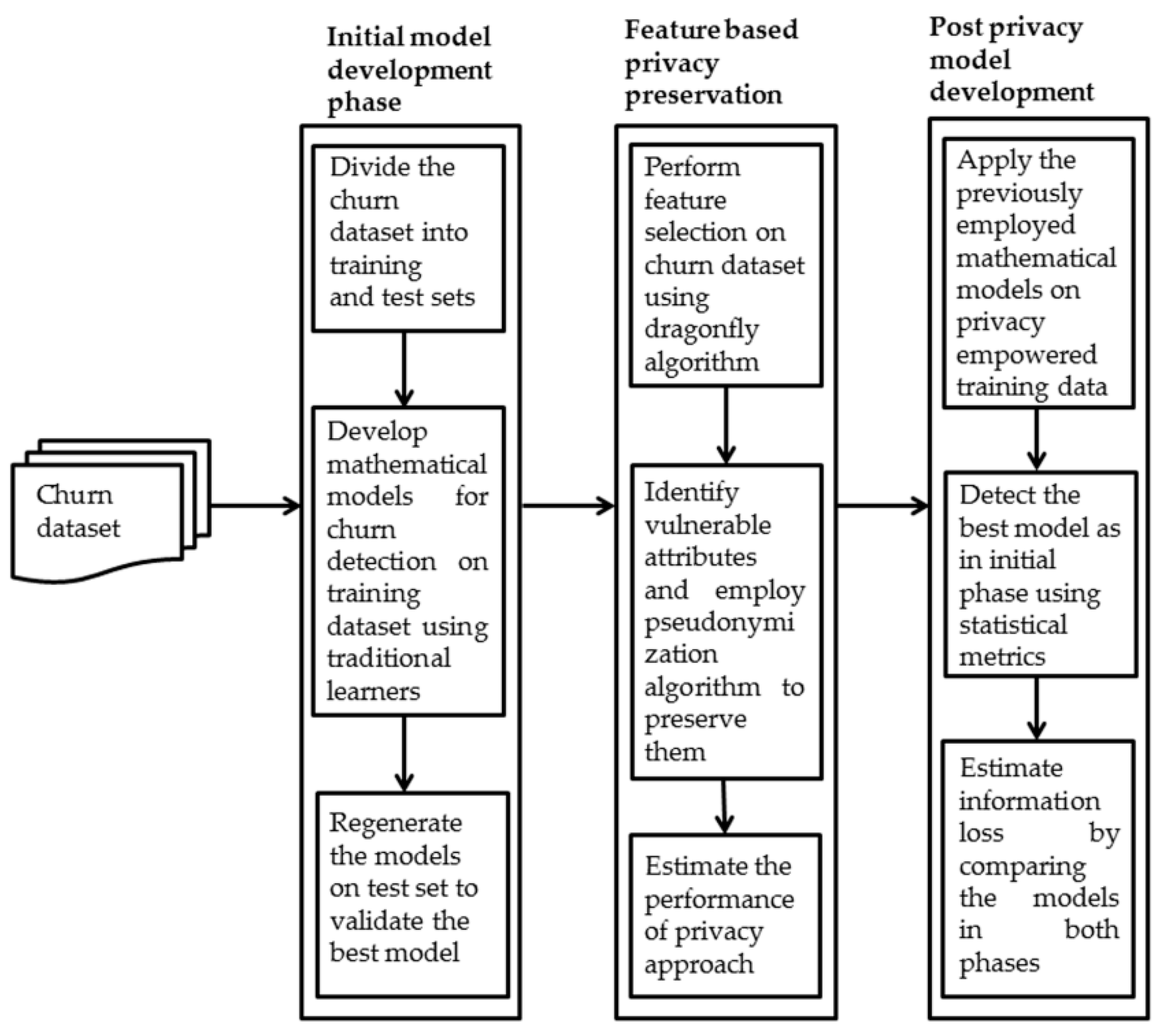
3. Materials and Methods
3.1. Churn Data Collection
3.2. Initial Model Development
3.3. Assessment of Performance of Models
3.4. Preserving Sensitive Churn Attributes Using Dragonfly Based Pseudonymization
- Separation (Si): It is defined as the difference between current position of an individual dragonfly (Z) and ith position of the neighboring individual (Zi) summated across total number of neighbors (K) of a dragonfly;
- Alignment (Ai): It is defined as the sum total of neighbor’s velocities (Vk) with reference to all the neighbors (K);
- Cohesion (Ci): It is demarcated as the ratio of sum total of neighbor’s ith position (Zi) of a dragonfly to all the neighbors (K), which is subtracted from the current position of an individual (Z) fly;
- Attraction towards prey/food source (Pi): It is the distance calculated as the difference between current position of individual (Z) and position of prey (Z+);
- Avoidance against enemy (Ei): It is the distance calculated as the difference between current position of individual (Z) and position of enemy (Z-).
- (i)
- Initialization of parameters: Initially, all the five basic parameters are defined randomly to update the positions of dragonflies in search space. Each position corresponds to one feature in the churn dataset which needs to be optimized iteratively.
- (ii)
- Deriving the fitness function: After parameters are initialized, the positions of the dragonflies are updated based on a pre-defined fitness function F. The fitness function is defined in this study based on objective criteria. The objective ensures the features are minimized iteratively without compromising on the predictive capabilities of selected features towards churn detection. This objective is considered in the defined fitness function adopted from [68], using weight factor, wj to ensure that maximum predictive capability is maintained after feature selection. The fitness function F is defined below. Here, Pred represents the predictive capabilities of the data features, wj is the weight factor which ranges between [0, 1], La is the length of attributes selected in the feature space while Ls is the sum of all the churn data attributes;
- (iii)
- Conditions for termination: Once the fitness function F fails to update neighbor’s parameters for an individual dragonfly, the algorithm terminates on reaching the best feature space. Suppose the best feature space is not found, the algorithm terminates on reaching the maximum limit for iterations.
3.5. Development of Models Post Privacy Analysis
3.6. Detection of Information Loss Prior and Post Privacy Preservation
4. Results
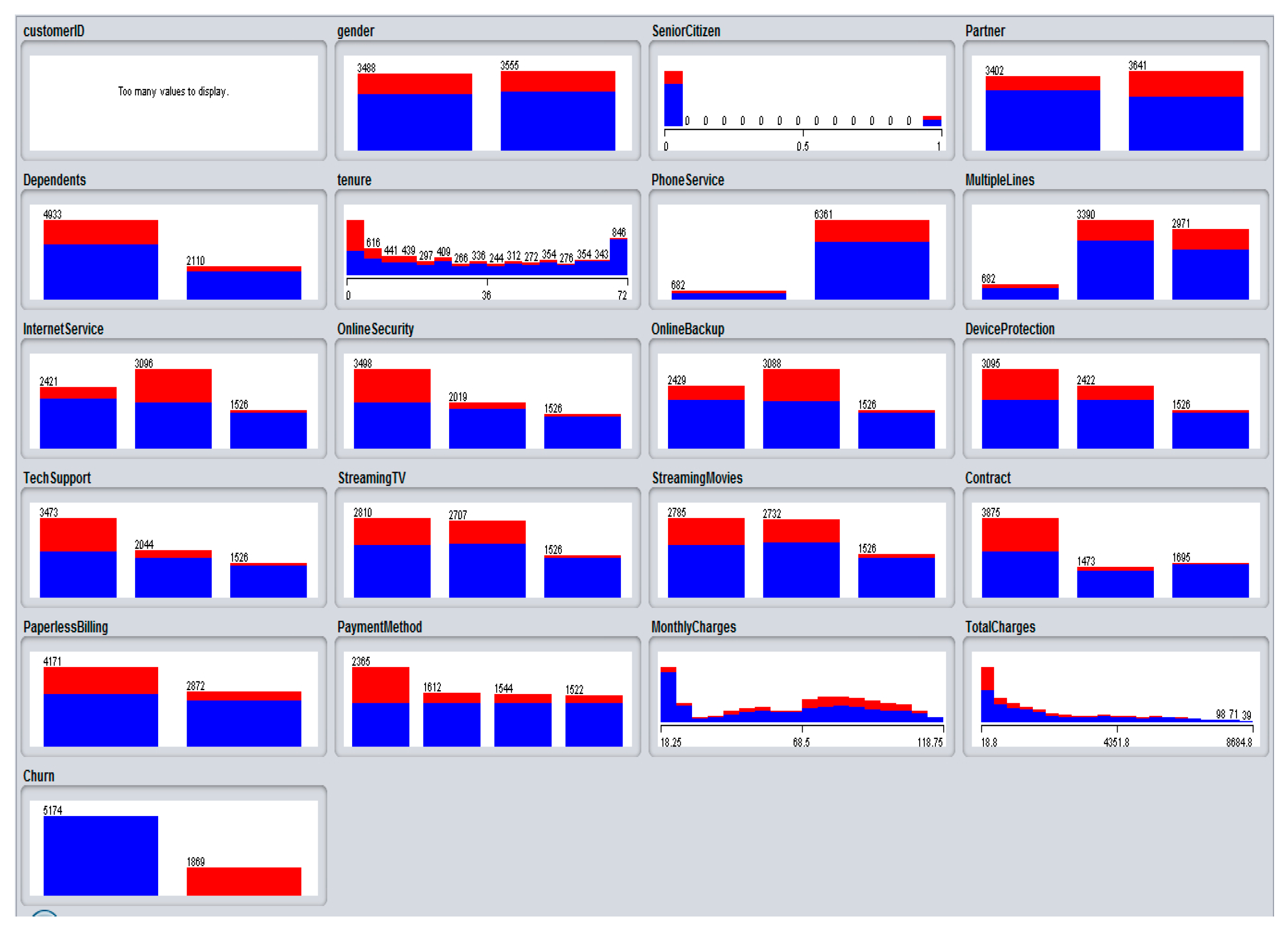
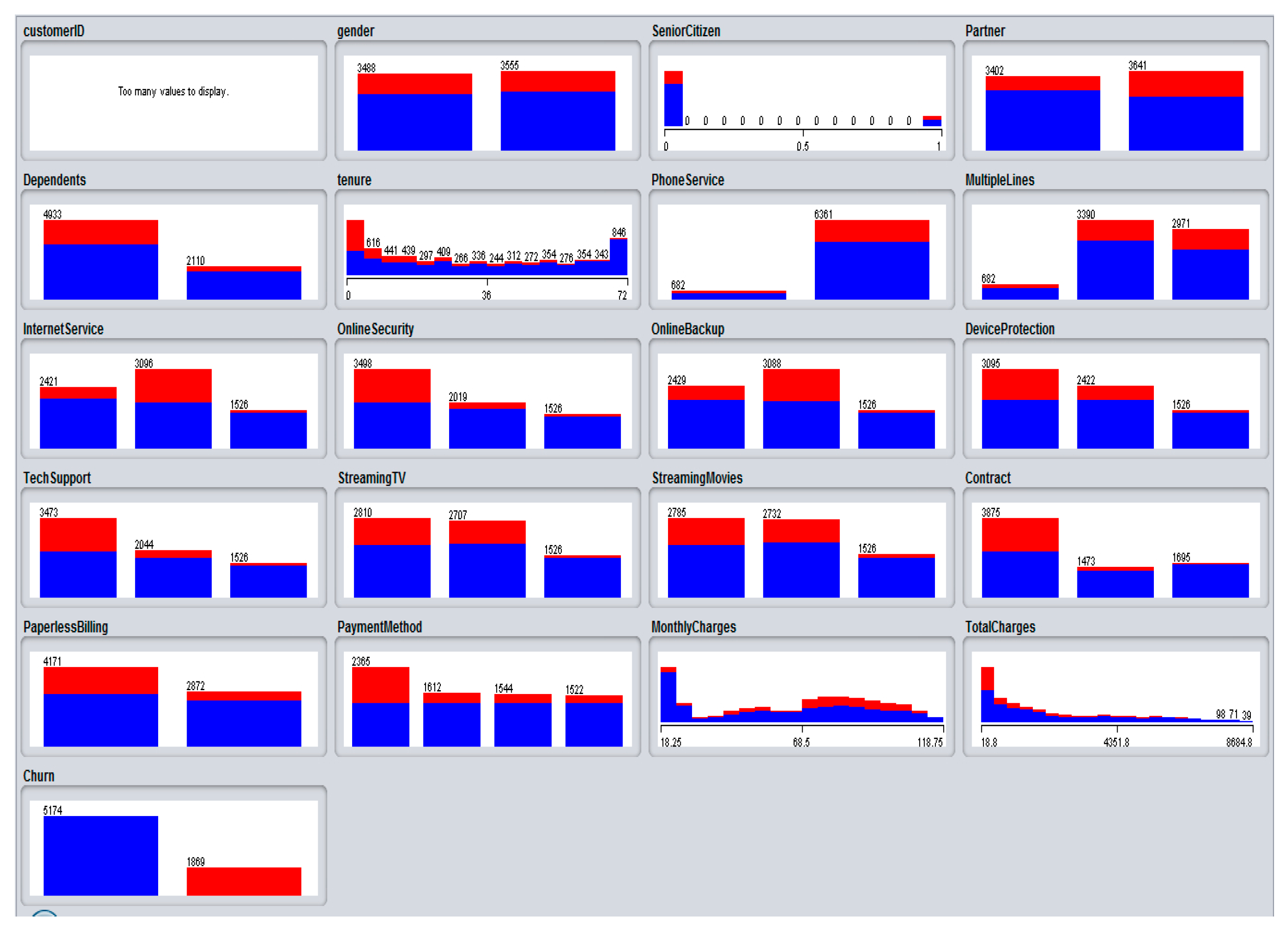
4.1. Processing of Churn Dataset
4.2. Initial Model Development Phase
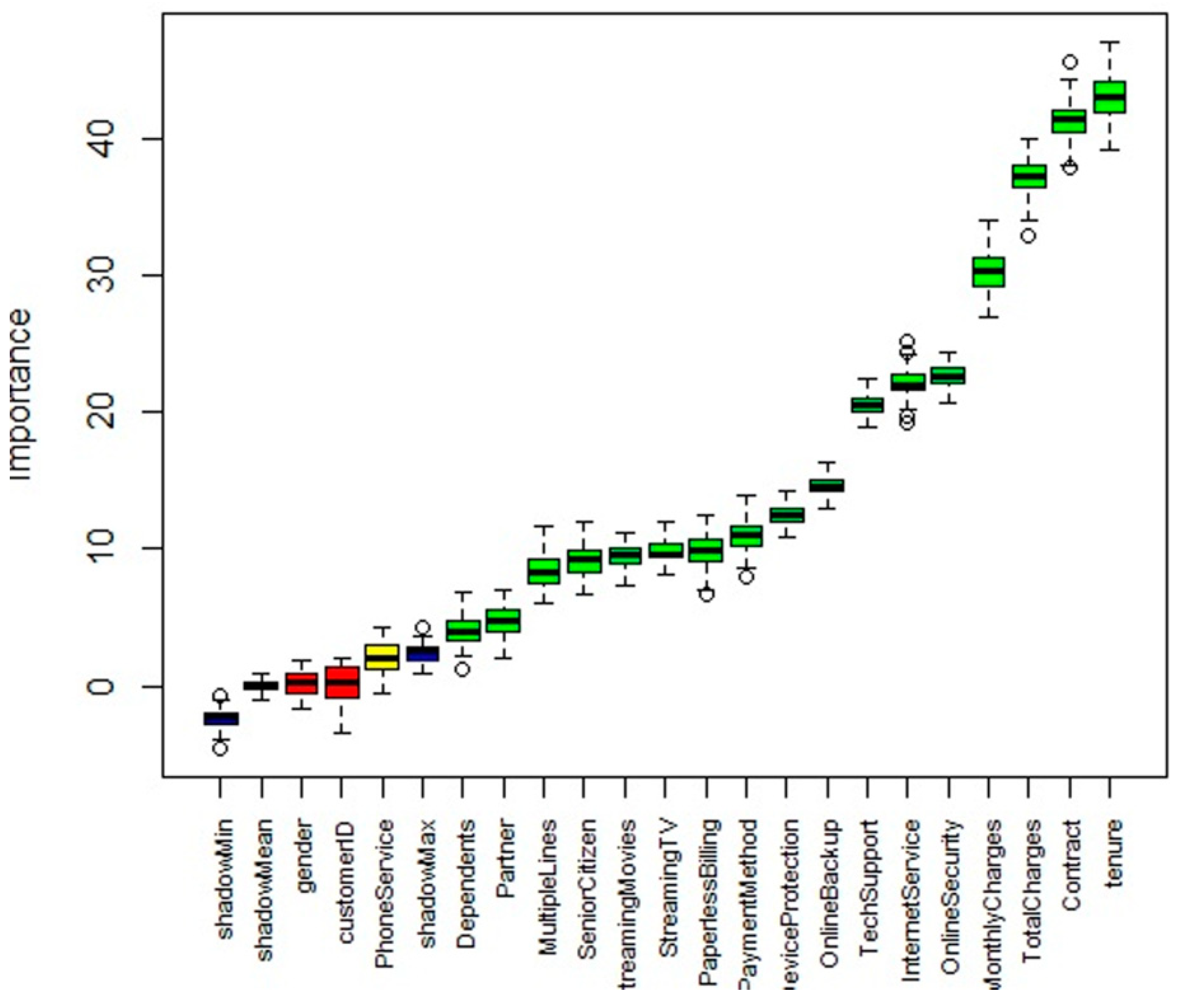
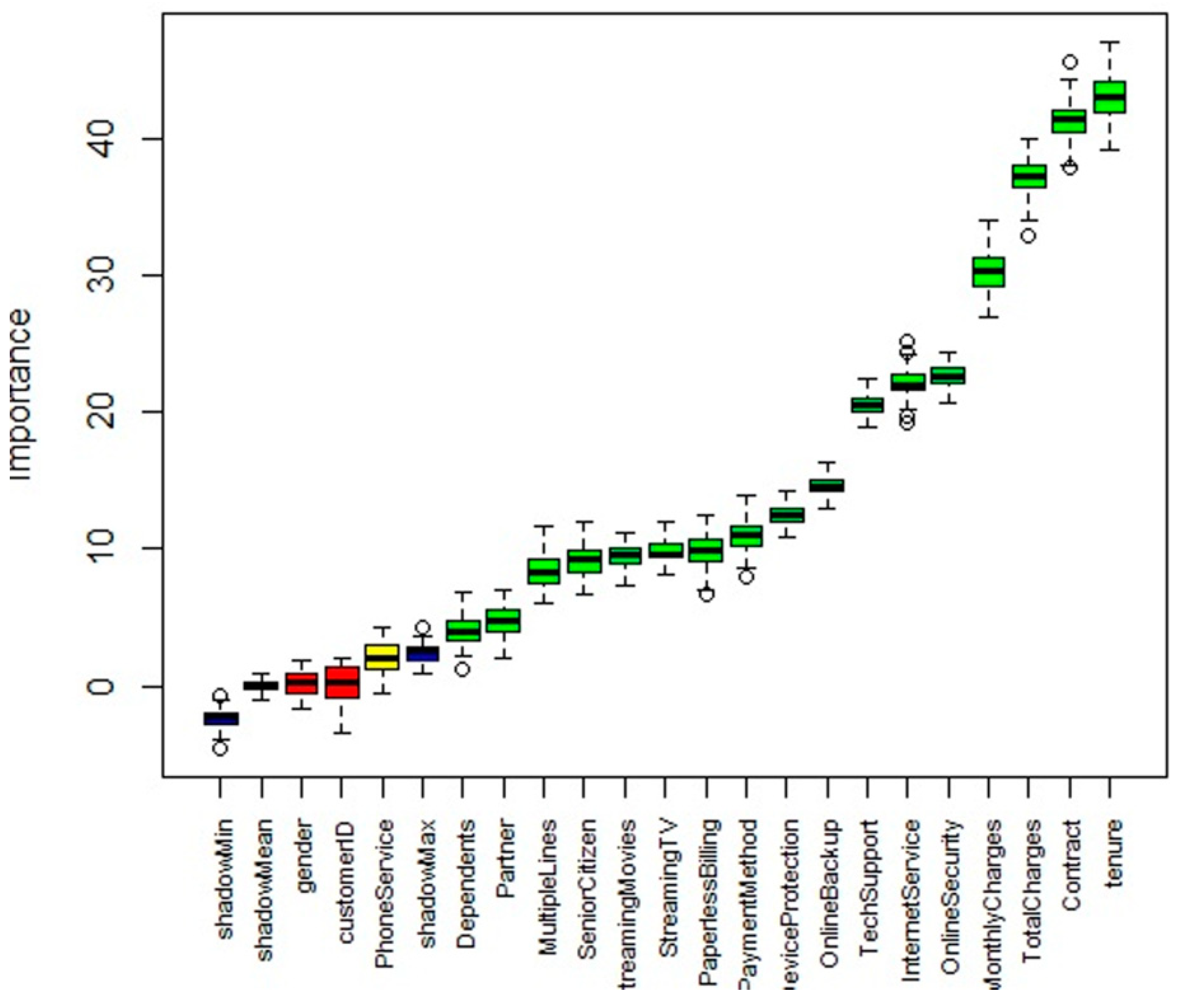
4.3. Feature Selection and Attribute Preservation Using Dragonfly Based Pseudonymizer
| Algorithm 1 Dragonfly based pseudonymizer |
| 1. Define the initial values of dragonfly population (P) for churn data denoting the boundary limits for maximum number of iterations (n) |
| 2. Define the position of dragonflies (Yi such that i = 1, 2, …., n) |
| 3. Define the step vector ∆Yi such that i = 1, 2, …., n |
| 4. while termination condition is not reached do |
| 5. Calculate the fitness function F, for every position of dragonfly |
| 6. Identify the food source and enemy |
| 7. Update the values of w, s, a, c, p and e |
| 8. Calculate Si, Ai, Ci, Pi and Ei using Equations (5)–(9) |
| 9. Update the status of neighboring dragonflies |
| 10. if atleast one neighboring dragonfly exists |
| 11. Update the step vector using (10) |
| 12. Update the velocity vector using (11) |
| 13. else |
| 14. Update the position vector using (12) |
| 15. Discover if new positions computed satisfy boundary conditions to bring back dragonflies |
| 16. Generate best optimized solution O |
| 17. Input the solution O to pseudonymizer function |
| 18. Define the length of the pseudonym Ji for each vulnerable attribute Va such that a = 1, 2, …., n |
| 19. Eliminate duplicate pseudonyms |
| 20. Encrypt with relevant pseudonyms for all data instances of vulnerable attributes |
| 21. Repeat until pseudonyms are generated for all vulnerable attributes |
| 22. Replace the vulnerable attribute Va with pseudonyms Ji |
| 23. Reiterate until all sensitive information in Va is preserved |
| 24. Produce the final preserved data instances for churn prediction |
| 25. Decrypt the pseudonyms by removing the aliases to view original churn dataset |
4.4. Performance Analysis of Dual Approach
4.5. Model Re-Development Phase
4.6. Estimating Differences in Models Based on Hypothesis
4.7. Estimating Information Loss Between Initial and Re-Development Models
5. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Diaz, F.; Gamon, M.; Hofman, J.M.; Kıcıman, E.; Rothschild, D. Online and Social Media Data as an Imperfect Continuous Panel Survey. PLoS ONE 2016, 11, e014506. [Google Scholar] [CrossRef] [PubMed]
- Tomlinson, M.; Solomon, W.; Singh, Y.; Doherty, T.; Chopra, M.; Ijumba, P.; Tsai, A.C.; Jackson, D. The use of mobile phones as a data collection tool: A report from a household survey in South Africa. BMC Med. Inf. Decis. Mak. 2009, 9, 1–8. [Google Scholar] [CrossRef] [PubMed]
- McDonald, C. Big Data Opportunities for Telecommunications. Available online: https://mapr.com/blog/big-data-opportunities-telecommunications/ (accessed on 11 January 2019).
- Telecom Regulatory Authority of India Highlights of Telecom Subscription Data as on 31 January 2019. Available online: https://main.trai.gov.in/sites/default/files/PR_No.22of2019.pdf (accessed on 21 February 2019).
- Albreem, M.A.M. 5G wireless communication systems: Vision and challenges. In Proceedings of the 2015 International Conference on Computer, Communications, and Control Technology (I4CT), Kuching, SWK, Malaysia, 21–23 April 2015; pp. 493–497. [Google Scholar]
- Weiss, G.M. Data Mining in Telecommunications. In Data Mining and Knowledge Discovery Handbook; Springer: Boston, MA, USA, 2005; pp. 1189–1201. [Google Scholar]
- Berson, A.; Smith, S.; Thearling, K. Building Data Mining Applications for CRM; McGraw-Hill Professional: New York, NY, USA, 1999. [Google Scholar]
- Lu, H.; Lin, J.C.-C. Predicting customer behavior in the market-space: A study of Rayport and Sviokla’s framework. Inf. Manag. 2002, 40, 1–10. [Google Scholar] [CrossRef]
- Mendoza, L.E.; Marius, A.; Pérez, M.; Grimán, A.C. Critical success factors for a customer relationship management strategy. Inf. Softw. Technol. 2007, 49, 913–945. [Google Scholar] [CrossRef]
- Hung, S.-Y.; Yen, D.C.; Wang, H.-Y. Applying data mining to telecom churn management. Expert Syst. Appl. 2006, 31, 515–524. [Google Scholar] [CrossRef] [Green Version]
- Penders, J. Privacy in (mobile) Telecommunications Services. Ethics Inf. Technol. 2004, 6, 247–260. [Google Scholar] [CrossRef] [Green Version]
- Agarwal, S.; Aulakh, G. TRAI Recommendations on Data Privacy Raises Eyebrows. Available online: https://economictimes.indiatimes.com/industry/telecom/telecom-policy/trai-recommendations-on-data-privacy-raises-eyebrows/articleshow/65033263.cms (accessed on 21 March 2019).
- Hauer, B. Data and Information Leakage Prevention Within the Scope of Information Security. IEEE Access 2015, 3, 2554–2565. [Google Scholar] [CrossRef]
- Blum, A.L.; Langley, P. Selection of relevant features and examples in machine learning. Artif. Intell. 1997, 97, 245–271. [Google Scholar] [CrossRef] [Green Version]
- Lindell, Y.; Pinkas, B. Privacy Preserving Data Mining. In Proceedings of the 20th Annual International Cryptology Conference on Advances in Cryptology, Santa Barbara, CA, USA, 20–24 August 2000; pp. 36–54. [Google Scholar]
- Clifton, C.; Kantarcioǧlu, M.; Doan, A.; Schadow, G.; Vaidya, J.; Elmagarmid, A.; Suciu, D. Privacy-preserving data integration and sharing. In Proceedings of the 9th ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery DMKD’04, Paris, France, 13 June 2004; pp. 19–26. [Google Scholar]
- Machanavajjhala, A.; Gehrke, J.; Kifer, D.; Venkitasubramaniam, M. L-diversity: Privacy beyond k-anonymity. In Proceedings of the 22nd International Conference on Data Engineering (ICDE’06), Atlanta, Georgia, 3–7 April 2006; p. 24. [Google Scholar]
- Mendes, R.; Vilela, J.P. Privacy-Preserving Data Mining: Methods, Metrics, and Applications. IEEE Access 2017, 5, 10562–10582. [Google Scholar] [CrossRef]
- Karp, A.H. Using Logistic Regression to Predict Customer Retention. 1998. Available online: https://www.lexjansen.com/nesug/nesug98/solu/p095.pdf (accessed on 16 August 2019).
- Mozer, M.C.; Wolniewicz, R.; Grimes, D.B.; Johnson, E.; Kaushansky, H. Predicting Subscriber Dissatisfaction and Improving Retention in the Wireless Telecommunications Industry. IEEE Trans. Neural Netw. 2000, 11, 690–696. [Google Scholar] [CrossRef]
- Hur, Y.; Lim, S. Customer Churning Prediction Using Support Vector Machines in Online Auto Insurance Service; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2005; pp. 928–933. [Google Scholar]
- Larivière, B.; Van den Poel, D. Predicting customer retention and profitability by using random forests and regression forests techniques. Expert Syst. Appl. 2005, 29, 472–484. [Google Scholar] [CrossRef]
- Shao, J.; Li, X.; Liu, W. The Application of AdaBoost in Customer Churn Prediction. In Proceedings of the 2007 International Conference on Service Systems and Service Management, Chengdu, China, 9–11 June 2007; pp. 1–6. [Google Scholar]
- Zhao, J.; Dang, X.-H. Bank Customer Churn Prediction Based on Support Vector Machine: Taking a Commercial Bank’s VIP Customer Churn as the Example. In Proceedings of the 2008 4th International Conference on Wireless Communications, Networking and Mobile Computing, Dalian, China, 12–17 October 2008; pp. 1–4. [Google Scholar]
- Xie, Y.; Li, X.; Ngai, E.W.T.; Ying, W. Customer churn prediction using improved balanced random forests. Expert Syst. Appl. 2009, 36, 5445–5449. [Google Scholar] [CrossRef]
- Lee, H.; Lee, Y.; Cho, H.; Im, K.; Kim, Y.S. Mining churning behaviors and developing retention strategies based on a partial least squares (PLS) mode. Decis. Support Syst. 2011, 52, 207–216. [Google Scholar] [CrossRef]
- Idris, A.; Khan, A.; Lee, Y.S. Genetic Programming and Adaboosting based churn prediction for Telecom. In Proceedings of the 2012 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Seoul, Korea, 14–17 October 2012; pp. 1328–1332. [Google Scholar]
- Idris, A.; Rizwan, M.; Khan, A. Churn prediction in telecom using Random Forest and PSO based data balancing in combination with various feature selection strategies. Comput. Electr. Eng. 2012, 38, 1808–1819. [Google Scholar] [CrossRef]
- Kirui, C.; Hong, L.; Cheruiyot, W.; Kirui, H. Predicting Customer Churn in Mobile Telephony Industry Using Probabilistic Classifiers in Data Mining. Int. J. Comput. Sci. Issues 2013, 10, 165–172. [Google Scholar]
- Keramati, A.; Jafari-Marandi, R.; Aliannejadi, M.; Ahmadian, I.; Mozaffari, M.; Abbasi, U. Improved churn prediction in telecommunication industry using data mining techniques. Appl. Soft Comput. 2014, 24, 994–1012. [Google Scholar] [CrossRef]
- Amin, A.; Shehzad, S.; Khan, C.; Ali, I.; Anwar, S. Churn Prediction in Telecommunication Industry Using Rough Set Approach. New Trends Comput. Collect. Intell. 2015, 572, 83–95. [Google Scholar]
- Khodabandehlou, S.; Rahman, M.Z. Comparison of supervised machine learning techniques for customer churn prediction based on analysis of customer behavior. J. Syst. Inf. Technol. 2017, 19, 65–93. [Google Scholar] [CrossRef]
- Erdem, K.; Dong, X.; Suhara, Y.; Balcisoy, S.; Bozkaya, B.; Pentland, A.S. Behavioral attributes and financial churn prediction. EPJ Data Sci. 2018, 7, 1–18. [Google Scholar]
- Amin, A.; Al-Obeidat, F.; Shah, B.; Adnan, A.; Loo, J.; Anwar, S. Customer churn prediction in telecommunication industry using data certainty. J. Bus. Res. 2019, 94, 290–301. [Google Scholar] [CrossRef]
- Ahmad, A.K.; Jafar, A.; Aljoumaa, K. Customer churn prediction in telecom using machine learning in big data platform. J. Big Data 2019, 6, 1–24. [Google Scholar] [CrossRef]
- Samarati, P.; Sweeney, L. Generalizing Data to Provide Anonymity when Disclosing Information. In Proceedings of the 17th ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, Seattle, WA, USA, 1–4 June 1998; p. 188. [Google Scholar]
- Sweeney, L. Achieving k-anonymity privacy protection using generalization and suppression. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2002, 10, 571–588. [Google Scholar] [CrossRef]
- Xu, J.; Wang, W.; Pie, J.; Wang, X.; Shi, B.; Fu, A.W.-C. Utility-based anonymization using local recoding. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 785–790. [Google Scholar]
- Cormode, G.; Srivastava, D.; Yu, T.; Zhang, Q. Anonymizing bipartite graph data using safe groupings. Proc. VLDB Endow. 2008, 1, 833–844. [Google Scholar] [CrossRef]
- Muntés-Mulero, V.; Nin, J. Privacy and anonymization for very large datasets. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; pp. 2117–2118. [Google Scholar]
- Masoumzadeh, A.; Joshi, J. Preserving Structural Properties in Edge-Perturbing Anonymization Techniques for Social Networks. IEEE Trans. Dependable Secur. Comput. 2012, 9, 877–889. [Google Scholar] [CrossRef]
- Emam, K.E.I.; Rodgers, S.; Malin, B. Anonymising and sharing individual patient data. BMJ 2015, 350, h1139. [Google Scholar] [CrossRef] [PubMed]
- Goswami, P.; Madan, S. Privacy preserving data publishing and data anonymization approaches: A review. In Proceedings of the 2017 International Conference on Computing, Communication and Automation (ICCCA), Greater Noida, India, 5–6 May 2017; pp. 139–142. [Google Scholar]
- Bild, R.; Kuhn, K.A.; Prasser, F. SafePub: A Truthful Data Anonymization Algorithm With Strong Privacy Guarantees. Proc. Priv. Enhancing Technol. 2018, 1, 67–87. [Google Scholar] [CrossRef]
- Liu, F.; Hua, K.A.; Cai, Y. Query l-diversity in Location-Based Services. In Proceedings of the 2009 Tenth International Conference on Mobile Data Management: Systems, Services and Middleware, Taipei, Taiwan, 18–20 May 2009; pp. 436–442. [Google Scholar]
- Das, D.; Bhattacharyya, D.K. Decomposition+: Improving ℓ-Diversity for Multiple Sensitive Attributes. Adv. Comput. Sci. Inf. Technol. Comput. Sci. Eng. 2012, 85, 403–412. [Google Scholar]
- Kern, M. Anonymity: A Formalization of Privacy-l-Diversity. Netw. Archit. Serv. 2013, 49–56. [Google Scholar] [CrossRef]
- Mehta, B.B.; Rao, U.P. Improved l-Diversity: Scalable Anonymization Approach for Privacy Preserving Big Data Publishing. J. King Saud Univ. Comput. Inf. Sci. 2019, in press. [Google Scholar] [CrossRef]
- Li, N.; Li, T.; Venkatasubramanian, S. t-Closeness: Privacy Beyond k-Anonymity and l-Diversity. In Proceedings of the 2007 IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 16–20 April 2007; pp. 106–115. [Google Scholar]
- Liang, H.; Yuan, H. On the Complexity of t-Closeness Anonymization and Related Problems. Database Syst. Adv. Appl. 2013, 7825, 331–345. [Google Scholar]
- Domingo-Ferrer, J.; Soria-Comas, J. From t-Closeness to Differential Privacy and Vice Versa in Data Anonymization. Knowl. Based Syst. 2015, 74, 151–158. [Google Scholar] [CrossRef]
- Soria-Comas, J.; Domingo-Ferrer, J.; Sánchez, D.; Martínez, S. t-closeness through microaggregation: Strict privacy with enhanced utility preservation. In Proceedings of the 2016 IEEE 32nd International Conference on Data Engineering (ICDE), Helsinki, Finland, 16–20 May 2016; pp. 1464–1465. [Google Scholar]
- Kumar, P.M.V. T-Closeness Integrated L-Diversity Slicing for Privacy Preserving Data Publishing. J. Comput. Theor. Nanosci. 2018, 15, 106–110. [Google Scholar] [CrossRef]
- Evfimievski, A. Randomization in privacy preserving data mining. ACM SIGKDD Explor. Newsl. 2002, 4, 43–48. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Yu, P.S. A Survey of Randomization Methods for Privacy-Preserving Data Mining. Adv. Database Syst. 2008, 34, 137–156. [Google Scholar]
- Szűcs, G. Random Response Forest for Privacy-Preserving Classification. J. Comput. Eng. 2013, 2013, 397096. [Google Scholar] [CrossRef]
- Batmaz, Z.; Polat, H. Randomization-based Privacy-preserving Frameworks for Collaborative Filtering. Procedia Comput. Sci. 2016, 96, 33–42. [Google Scholar] [CrossRef]
- Kargupta, H.; Datta, S.; Wang, Q.; Sivakumar, K. Random-data perturbation techniques and privacy-preserving data mining. Knowl. Inf. Syst. 2005, 7, 387–414. [Google Scholar] [CrossRef]
- Liu, L.; Kantarcioglu, M.; Thuraisingham, B. The Applicability of the Perturbation Model-based Privacy Preserving Data Mining for Real-world Data. In Proceedings of the 6th IEEE International Conference on Data Mining, Hing Kong, China, 18–22 December 2006; pp. 507–512. [Google Scholar]
- Shah, A.; Gulati, R. Evaluating applicability of perturbation techniques for privacy preserving data mining by descriptive statistics. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016; pp. 607–613. [Google Scholar]
- Upadhyay, S.; Sharma, C.; Sharma, P.; Bharadwaj, P.; Seeja, K.R. Privacy preserving data mining with 3-D rotation transformation. J. King Saud Univ. Comput. Inf. Sci. 2018, 30, 524–530. [Google Scholar] [CrossRef] [Green Version]
- Kotschy, W. The New General Data Protection Regulation—Is There Sufficient Pay-Off for Taking the Trouble to Anonymize or Pseudonymize data? Available online: https://fpf.org/wp-content/uploads/2016/11/Kotschy-paper-on-pseudonymisation.pdf (accessed on 18 August 2019).
- Stalla-Bourdillon, S.; Knight, A. Anonymous Data v. Personal Data—A False Debate: An EU Perspective on Anonymization, Pseudonymization and Personal Data. Wis. Int. Law J. 2017, 34, 284–322. [Google Scholar]
- Neumann, G.K.; Grace, P.; Burns, D.; Surridge, M. Pseudonymization risk analysis in distributed systems. J. Internet Serv. Appl. 2019, 10, 1–16. [Google Scholar] [CrossRef]
- Telco Customer Churn Dataset. Available online: https://www.kaggle.com/blastchar/telco-customer-churn (accessed on 23 January 2019).
- Tuv, E.; Borisov, A.; Runger, G.; Torkkola, K. Feature Selection with Ensembles, Artificial Variables, and Redundancy Elimination. J. Mach. Learn. Res. 2009, 10, 1341–1366. [Google Scholar]
- Mafarja, M.; Heidari, A.A.; Faris, H.; Mirjalili, S.; Aljarah, I. Dragonfly Algorithm: Theory, Literature Review, and Application in Feature Selection. Nat. Inspired Optim. 2019, 811, 47–67. [Google Scholar]
- Mirjalili, S. Dragonfly algorithm: A new meta-heuristic optimization technique for solving single-objective, discrete, and multi-objective problems. Neural Comput. Appl. 2016, 27, 1053–1073. [Google Scholar] [CrossRef]
- Kursa, M.B.; Rudnicki, W.R. Feature Selection with the Boruta Package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef]
- Biskup, J.; Flegel, U. Transaction-Based Pseudonyms in Audit Data for Privacy Respecting Intrusion Detection. In Proceedings of the Third International Workshop on Recent Advances in Intrusion Detection, London, UK, 2–4 October 2000; pp. 28–48. [Google Scholar]
- Privacy-Preserving Storage and Access of Medical Data through Pseudonymization and Encryption. Available online: https://www.xylem-technologies.com/2011/09/privacy-preserving-storage-and-access-of-medical-data-through-pseudonymization-and-encryption/ (accessed on 19 August 2019).
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA Data Mining Software: An Update. SIGKDD Explor. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Riza, L.S.; Nugroho, E.P. Metaheuristicopt: Metaheuristic for Optimization. Available online: https://cran.r-project.org/web/packages/metaheuristicOpt/metaheuristicOpt.pdf (accessed on 21 April 2019).
- An R Package to Generate Synthetic Data with Realistic Empirical Probability Distributions. Available online: https://github.com/avirkki/synergetr (accessed on 23 May 2019).

{kind=link}
{kind=link}
{kind=link}
| Studies Performed | Mathematical Model/s Adopted | Substantial Outcomes | Limitations/Future Scope |
|---|---|---|---|
| [19] | Linear Regression | The study achieved 95% confidence interval in detecting customer retention | - |
| [20] | Legit regression, Boosting, Decision trees, neural network | The non-linear neural network estimated better customer dissatisfaction compared to other classifiers | - |
| [21] | Support Vector Machine (SVM), neural network, legit regression | SVM outperformed other classifiers in detecting customer churn in online insurance domain | Optimization of kernel parameters of SVM could further uplift the predictive performance |
| [22] | Random forest, Regression forest, logistic & linear regression | Results indicated that random and regression forest models outperformed with better fit compared to linear techniques | - |
| [23] | AdaBoost, SVM | Three variants of AdaBoost classifier (Real, Gentle, Meta) predicted better churn customers from credit debt database compared to SVM | - |
| [24] | SVM, artificial neural network, naïve bayes, logistic regression, decision tree | SVM performed enhanced customer churn detection compared to other classifiers | - |
| [25] | Improved balanced random forest (IBRF), decision trees, neural networks, class-weighted core SVM (CWC-SVM) | IBRF performed better churn prediction on real bank dataset compared to other classifiers | - |
| [26] | Partial least square (PLS) classifier | The model outperforms traditional classifiers in determining key attributes and churn customers | - |
| [27] | Genetic programming, Adaboost | Genetic program based Adaboosting evaluates churn customers with better area under curve metric of 0.89 | - |
| [28] | Random forest, Particle Swarm Optimization (PSO) | PSO is used to remove data imbalance while random forest is implemented to detect churn on reduced dataset. The model results in enhanced churn prediction | - |
| [29] | Naïve Bayes, Bayesian network & C4.5 | Feature selection implemented by naïve Bayes and Bayesian network resulted in improved customer churn prediction | Overfitting of minor class instances may result in false predictions. Hence balancing the data is to be performed extensively. |
| [30] | Decision tree, K-nearest neighbor, artificial neural network, SVM | Hybrid model generated from the classifiers resulted in 95% accuracy for detecting churn from Iran mobile company data | - |
| [31] | Rough set theory | Rules are extracted for churn detection. Rough set based genetic algorithm predicted churn with higher efficacy | - |
| [32] | Bagging, boosting | Among multiple classifiers compared for churn detection, bagging and boosting ensembles performed better prediction | - |
| [33] | Dynamic behavior models | Spatio-temporal financial behavioral patterns are known to influence churn behavior | Possibility of bias in the data may affect the predictive performances |
| [34] | Naïve Bayes | Customer churn prediction is detected from publically available datasets using naïve Bayes classifier | The current approach can be implemented for detecting bias and outliers effectively |
| [35] | Decision tree, Gradient boosted machine tree, Extreme gradient boost and random forest | The extreme gradient boosting model resulted in area under curve (AUC) value of 89% indicating an enhanced churn classification rate compared to other classifiers | - |
| PPDM Techniques | Features of the Technique | Studies Adopted Based on the Technique |
|---|---|---|
| k-anonymity | The technique masks the data by suppressing the vulnerable instances and generalizing them similar to other (k-1) records. | [36,37,38,39,40,41,42,43,44] |
| l-diversity | Extension of k-anonymity technique which reduces granularity of sensitive information to uphold privacy | [17,45,46,47,48] |
| t-closeness | Extension of l-diversity that reduces granularity by considering distribution of sensitive data | [49,50,51,52,53] |
| Randomization | Randomizes the data instances based on its properties to result in distorted data aggregates | [54,55,56,57] |
| Perturbation | Noise is added to data to ensure that sensitive information is not disclosed | [58,59,60,61] |
| Pseudonymization | Reversible pseudonyms replaces sensitive information in data to avoid data theft | [62,63,64] |
| Sl. No | Classifier | R Language Dependency | True Positive Rate | Accuracy | RMSE | F-Measure |
|---|---|---|---|---|---|---|
| 1. | Logistic Regression | glm | 0.887 | 0.793 | 0.398 | 0.793 |
| 2. | Naïve Bayes | naivebayes | 0.893 | 0.791 | 0.334 | 0.801 |
| 3. | SVM | e1071 | 0.910 | 0.839 | 0.298 | 0.835 |
| 4. | Bagging | adabag | 0.912 | 0.860 | 0.263 | 0.866 |
| 5. | Boosting | adabag | 0.934 | 0.889 | 0.191 | 0.905 |
| 6. | Random Forest | randomForest | 0.997 | 0.956 | 0.112 | 0.956 |
| Sl. No | Feature Name | Feature Description | Feature Category | Fitness Value |
|---|---|---|---|---|
| 1. | Contract | Denotes the contract period of the customer if it is monthly, yearly or for two years | Account information | 0.9356 |
| 2. | Tenure | Indicates the number of months a customer is patron to the service provider | Account information | 0.9174 |
| 3. | Total charges | Indicates the total charges to be paid by the customer | Account information | 0.9043 |
| 4. | Monthly charges | Indicates the monthly charges to be paid by the customer | Account information | 0.8859 |
| 5. | Tech support | Indicates if the customer has technical support or not, based on the internet service accustomed | Customer services | 0.8533 |
| 6. | Online security | Indicates if the customer has online security or not, based on the internet service accustomed | Customer services | 0.8476 |
| 7. | Internet service | Indicates the internet service provider of the customer, which can be either fiber optic, DSL or none of these | Customer services | 0.7971 |
| 8. | Online backup | Indicates if the customer has online backup or not, based on the internet service accustomed | Customer services | 0.8044 |
| 9. | Payment method | Denotes the type of payment method. It can be automatic bank transfer mode, automatic credit card mode, electronic check or mailed check | Account information | 0.7433 |
| 10. | Streaming TV | Denotes if the customer has the service for streaming television or not | Customer services | 0.7239 |
| 11. | Paperless billing | Denotes if the customer has the service for paperless billing or not | Account information | 0.7009 |
| 12. | Streaming movies | Indicates if the customer has the service for streaming movies or not | Customer services | 0.6955 |
| 13. | Multiple lines | Indicates if the customer has service for multiple lines or not | Customer services | 0.5487 |
| 14. | Senior Citizen | Indicates if the customer is a senior citizen or not | Demographic details | 0.5321 |
| 15. | Partner | Denotes whether the customer has a partner or not | Demographic details | 0.5093 |
| 16. | Phone Service | Indicates if the customer has services of the phone or not | Customer services | 0.5005 |
| 17. | Dependents | Indicates if the customer has any dependents or not | Demographic details | 0.4799 |
| 18. | Device protection | Denotes if the customer has protection or not for the device | Customer services | 0.4588 |
| 19. | Gender | Indicates if the customer is male or female | Demographic details | 0.3566 |
| 20. | Customer ID | A unique identifier given to each customer | Demographic details | 0.2967 |
| Sl. No | Features to Be Preserved | Iterations | Pseudonymization | Anonymization | Randomization | Perturbation |
|---|---|---|---|---|---|---|
| 1. | Tenure | 1000 | Preserved | Preserved | Preserved | Not preserved |
| 2. | Contract | 1000 | Preserved | Preserved | Not preserved | Preserved |
| 3. | Monthly charges | 1000 | Preserved | Not preserved | Not preserved | Preserved |
| 4. | Total charges | 1000 | Preserved | Not preserved | Preserved | Preserved |
| Sl. No | Classifier | R Language Dependency | True Positive Rate | Accuracy | RMSE | F-Measure |
|---|---|---|---|---|---|---|
| 1 | Logistic Regression | glm | 0.887 | 0.788 | 0.398 | 0.793 |
| 2 | Naïve Bayes | naivebayes | 0.893 | 0.780 | 0.334 | 0.801 |
| 3 | SVM | e1071 | 0.910 | 0.828 | 0.298 | 0.835 |
| 4 | Bagging | adabag | 0.912 | 0.858 | 0.263 | 0.866 |
| 5 | Boosting | adabag | 0.934 | 0.873 | 0.191 | 0.905 |
| 6 | Random Forest | randomForest | 0.997 | 0.943 | 0.112 | 0.956 |
| Group 1 (Initial Models) | Group 2 (Re-Development Models) | Sample Data Size | p-Value | t-Score |
|---|---|---|---|---|
| Logistic regression | Logistic regression | 500 | 0.04 | 188.86 |
| Naïve Bayes | Naïve Bayes | 500 | 0.04 | 198.67 |
| SVM | SVM | 500 | 0.03 | 165.23 |
| Bagging | Bagging | 500 | 0.03 | 154.89 |
| Boosting | Boosting | 500 | 0.02 | 99.35 |
| Random Forest | Random Forest | 500 | 0.01 | 66.95 |
| Sl. No | Classifier | Iterations | Total Churn Instances in the Dataset | Data Instances Detecting Churn in Initial Model Development | Data Instances Detecting Churn After Model Re-Development | Information Loss after Dual Approach (%) |
|---|---|---|---|---|---|---|
| 1. | Logistic Regression | 900 | 1869 | 1203 | 1109 | 5.02 |
| 2. | Naïve Bayes | 900 | 1869 | 1301 | 1245 | 2.99 |
| 3. | SVM | 900 | 1869 | 1432 | 1397 | 1.87 |
| 4. | Bagging | 900 | 1869 | 1645 | 1657 | 0.64 |
| 5. | Boosting | 900 | 1869 | 1793 | 1804 | 0.58 |
| 6 | Random Forest | 900 | 1869 | 1823 | 1829 | 0.32 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nagaraj, K.; GS, S.; Sridhar, A. Encrypting and Preserving Sensitive Attributes in Customer Churn Data Using Novel Dragonfly Based Pseudonymizer Approach. Information 2019, 10, 274. https://doi.org/10.3390/info10090274
Nagaraj K, GS S, Sridhar A. Encrypting and Preserving Sensitive Attributes in Customer Churn Data Using Novel Dragonfly Based Pseudonymizer Approach. Information. 2019; 10(9):274. https://doi.org/10.3390/info10090274
Chicago/Turabian StyleNagaraj, Kalyan, Sharvani GS, and Amulyashree Sridhar. 2019. "Encrypting and Preserving Sensitive Attributes in Customer Churn Data Using Novel Dragonfly Based Pseudonymizer Approach" Information 10, no. 9: 274. https://doi.org/10.3390/info10090274
APA StyleNagaraj, K., GS, S., & Sridhar, A. (2019). Encrypting and Preserving Sensitive Attributes in Customer Churn Data Using Novel Dragonfly Based Pseudonymizer Approach. Information, 10(9), 274. https://doi.org/10.3390/info10090274