
Information Matrix-Based Adaptive Sampling in Hull Form Optimisation

Abstract
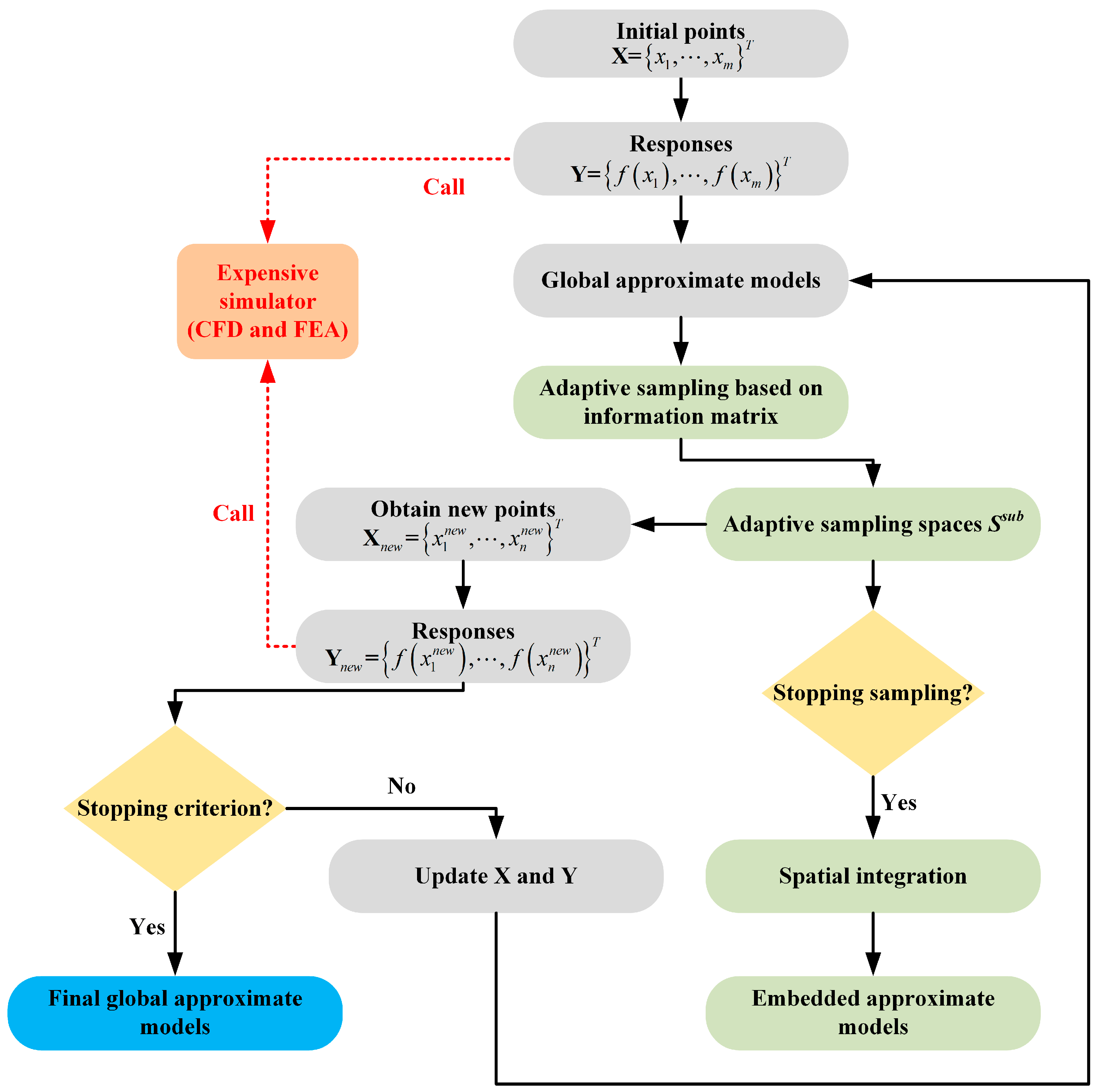
:1. Introduction
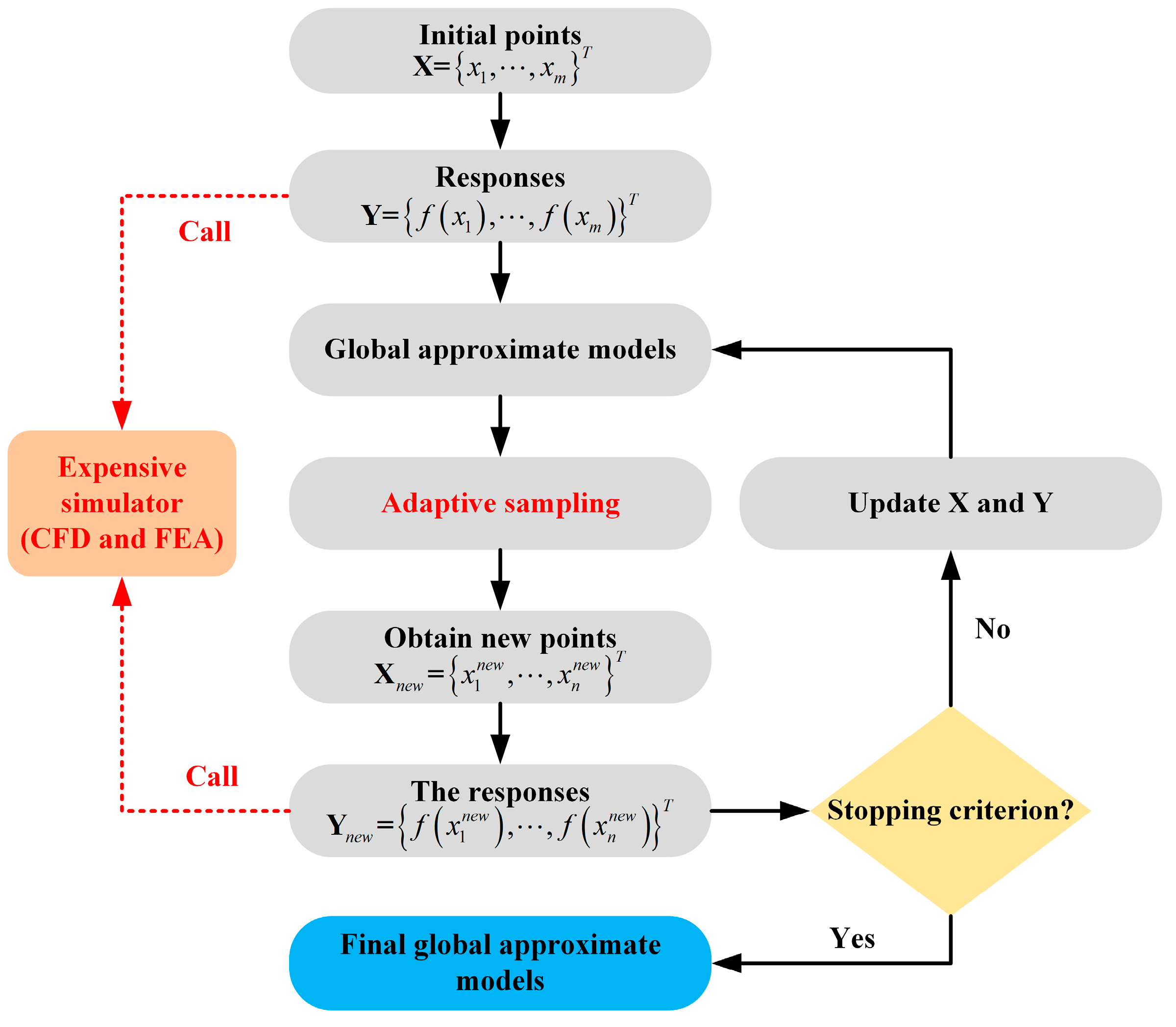
Dynamical Construction for Global Approximate Model
2. Materials and Methods
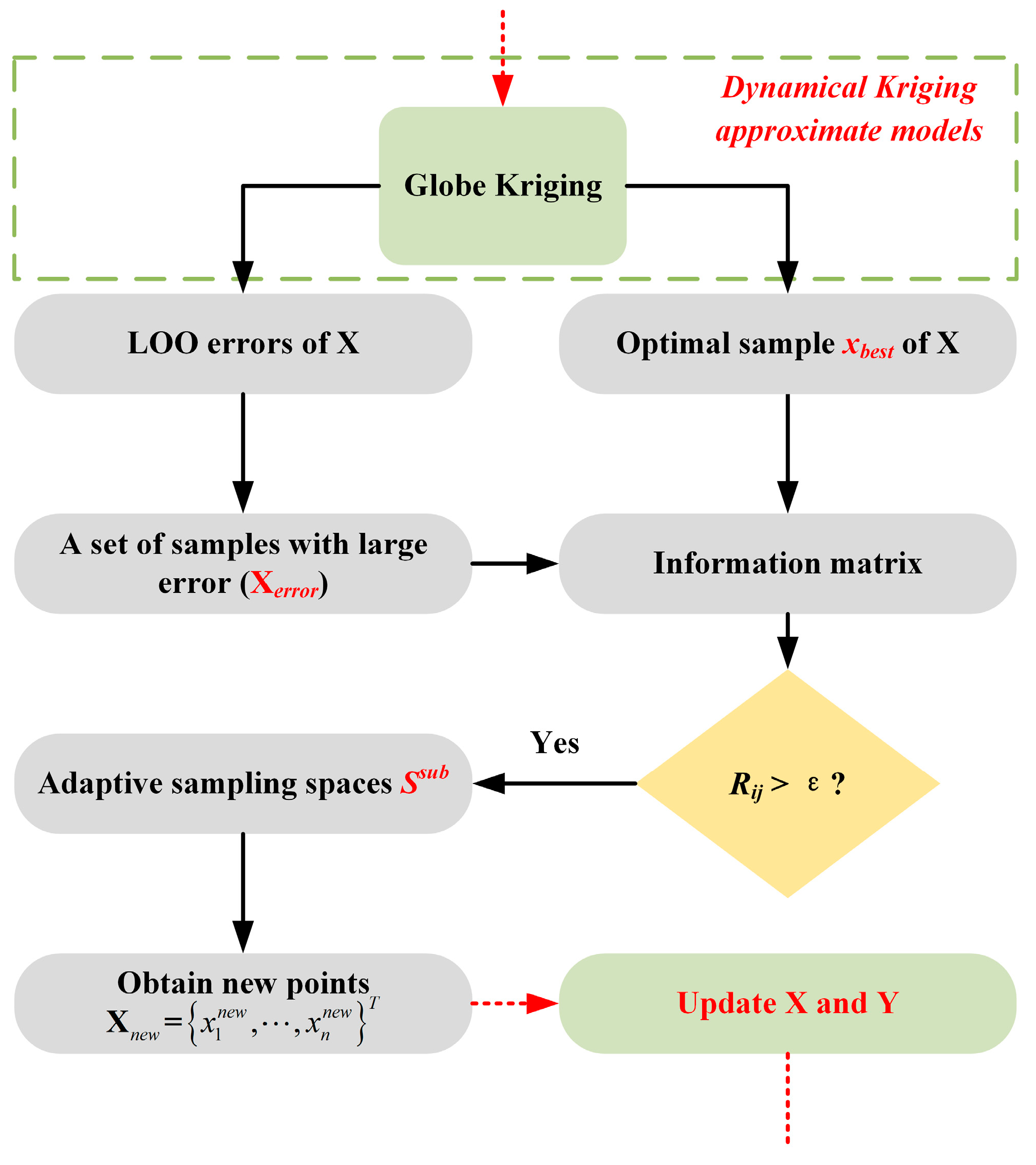
2.1. Adaptive Sampling with the Information Matrix
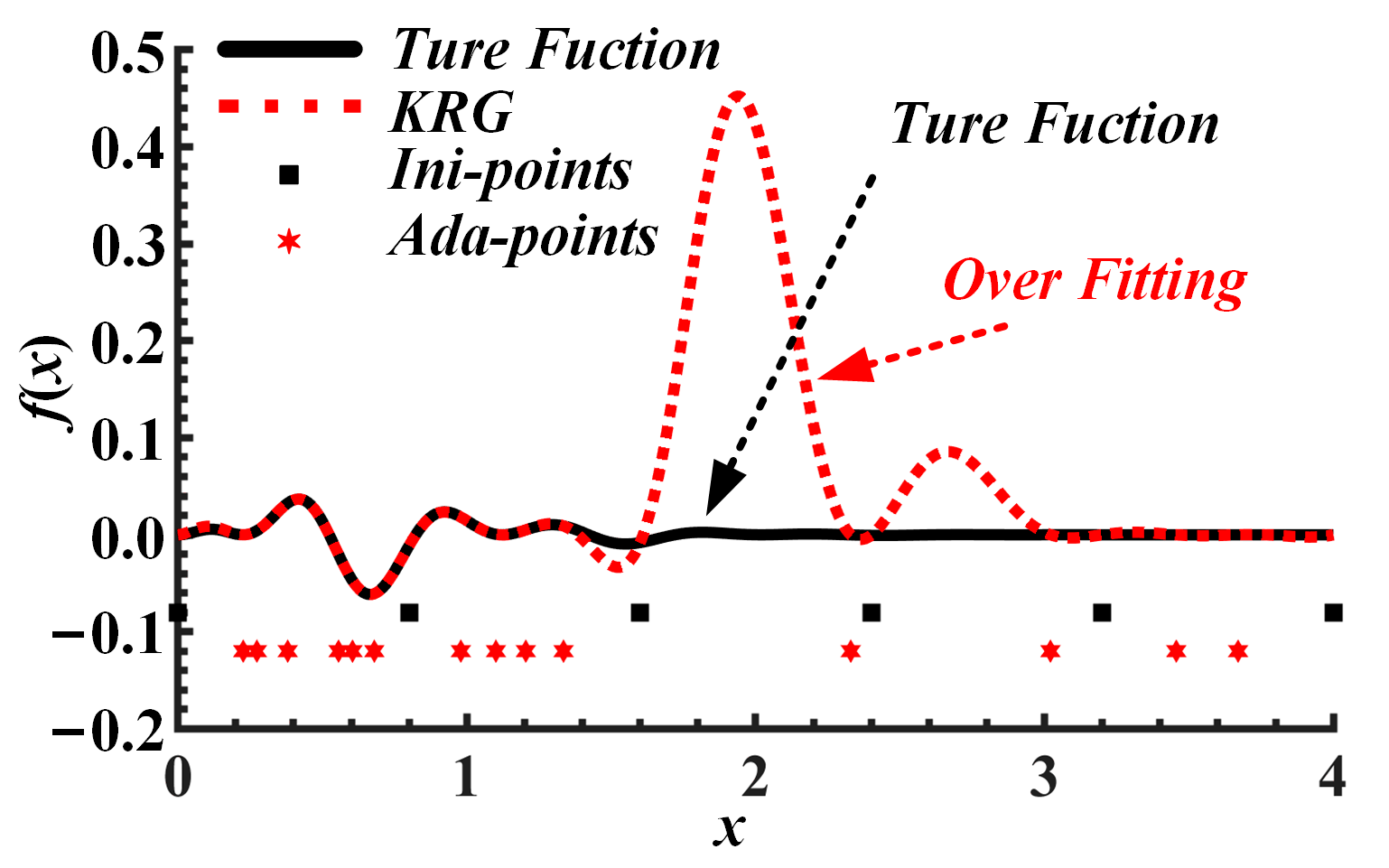
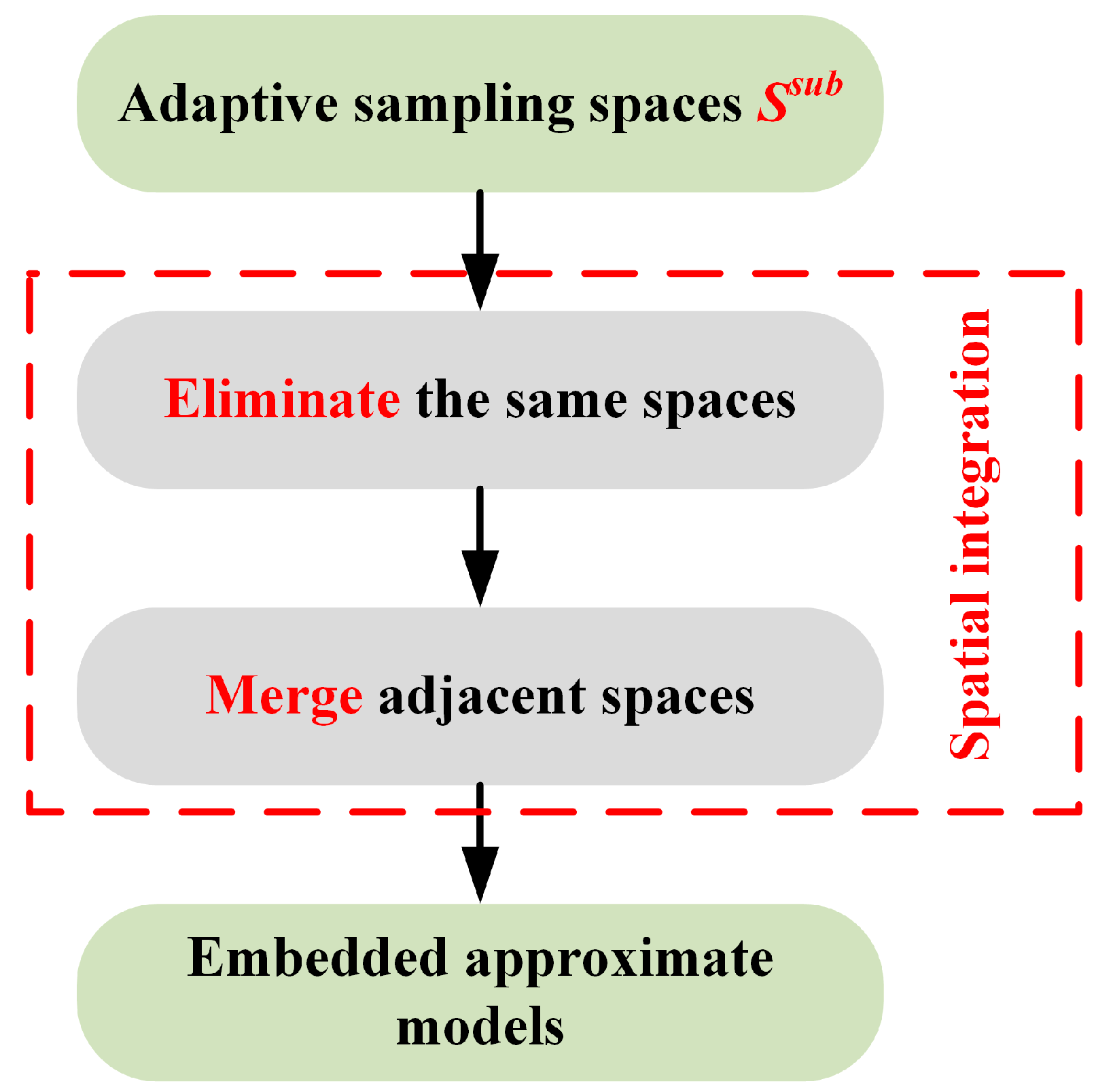
2.2. Embedded Approximate Models
- (1)
- Obtain the centre sample points of all the sub spaces Ssub;
- (2)
- Eliminate spaces that have the same center point;
- (3)
- Calculate the correlation coefficients between and ; Merge adjacent spaces that the correlation coefficients ≥ σ (σ = 0.8 in this paper), and;
- (4)
- Construct local embedded approximation models in the spatial integration regions.
3. Examples
3.1. Two Dimensional Benchmark
- Ackley function with two-dimensional (D = 2)
- 2.
- Alpine function with two-dimensional (D = 2)
- 3.
- Branin-Hoo function (BH) with two-dimensional (D = 2)
- 4.
- Griewank function with two-dimensional (D = 2)
- 5.
- Six-hump Camel-Back (SC) function with two-dimensional (D = 2)
3.2. High Dimensionally Scalable Benchmark
- Alpine function with five-dimensional (D = 5)
- 2.
- Griewank function with eight-dimensional (D = 8)
- 3.
- Trid function (TR) with ten-dimensional (D = 10)
- 4.
- Sum squares function (SF) with twelve-dimensional (D = 12)
4. Application to Hull Form Optimisation
4.1. Definition
4.2. IM-DEAM
4.3. Results
5. Conclusions
- (1)
- Adaptive sampling is performed by fully utilising the Gaussian-function information matrix and adaptively extracting subspaces with significant LOO-CV errors and potential optimum subspaces. In other words, subspaces with two different natures are considered simultaneously to improve the efficiency of additional sampling and explore optimum information.
- (2)
- Local approximate models are embedded in subspaces, thereby preventing the overfitting and spurious optima of global approximate models caused by an excessively concentrated sample distributions. In addition, the embedded local approximate models assist in global optimisation, thereby improving the reliability of optima.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Andrić, J.; Kitarović, S.; Bičak, M. IACS incremental-iterative method in progressive collapse analysis of various hull girder structures. Brodogradnja Teorija i Praksa Brodogradnje i Pomorske Tehnike 2014, 65, 65–77. [Google Scholar]
- Andrić, J.; Prebeg, P.; Andrisic, J.; Žanić, V. Structural optimisation of a bulk carrier according to IACS CSR-BC. Ships Offshore Struct. 2020, 15, 123–137. [Google Scholar] [CrossRef]
- Andrić, J.; Prebeg, P.; Pala:ersa, M.; Žanić, V. Influence of different topological variants on optimized structural scantlings of passenger ship. Mar. Struct. 2021, 78, 102981. [Google Scholar] [CrossRef]
- Prebeg, P.; Zanic, V.; Vazic, B. Application of a surrogate modeling to the ship structural design. Ocean Eng. 2014, 84, 259–272. [Google Scholar] [CrossRef]
- Nouri, N.M.; Mohammadi, S.; Zarezadeh, M. Optimization of a marine contra-rotating propellers set. Ocean Eng. 2018, 167, 397–404. [Google Scholar] [CrossRef]
- Koch, P.N.; Simpson, T.W.; Allen, J.K.; Mistree, F. Statistical approximations for multidisciplinary design optimization: The problem of size. J. Aircr. 1999, 36, 275. [Google Scholar] [CrossRef]
- Prebeg, P.; Žanić, V.; Važić, B. An application of a complex system optimization techniques to the ship structural design. In Proceedings of the 11th International Marine Design Conference 2012, Glasgow, UK, 11–14 June 2012. [Google Scholar]
- Žanić, V.; Andrić, J.; Prebeg, P. Design synthesis of complex ship structures. Ships Offshore Struct. 2013, 8, 383–403. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Ong, Y.-S.; Cai, J. A survey of adaptive sampling for global metamodeling in support of simulation-based complex engineering design. Struct. Multidiscip. Optim. 2017, 57, 393–416. [Google Scholar] [CrossRef]
- Chang, H.; Cheng, X.; Liu, Z.; Feng, B.; Zhan, C. Sample selection method for ship resistance performance optimization based on approximated model. J. Ship Res. 2016, 60, 1–13. [Google Scholar] [CrossRef]
- Grosso, A.; Jamali, A.; Locatelli, M. Finding maximin latin hypercube designs by Iterated Local Search heuristics. Eur. J. Oper. Res. 2009, 197, 541–547. [Google Scholar] [CrossRef]
- Gorissen, D.; Crombecq, K.; Hendrickx, W.; Dhaene, T. Adaptive distributed metamodeling. In Proceedings of the International Conference on High Performance Computing for Computational Science; Rio de Janeiro, Brazil, 10–13 June 2006, Springer: Berlin/Heidelberg, Germany, 2006; pp. 579–588. [Google Scholar]
- Settles, B. Active Learning Literature Survey; University of Wisconsin: Madison, WI, USA, 2010. [Google Scholar]
- Peri, D. Insean Self-Learning Metamodels for Optimization. Ship Technol. Res. 2009, 56, 95–109. [Google Scholar] [CrossRef]
- Jiang, P.; Shu, L.; Zhou, Q.; Zhou, H.; Shao, X.; Xu, J. A novel sequential exploration-exploitation sampling strategy for global metamodeling. IFAC-PapersOnLine 2015, 48, 532–537. [Google Scholar] [CrossRef]
- Beck, J.; Guillas, S. Sequential design with mutual information for computer experiments (MICE): Emulation of a tsunami model. SIAM/ASA J. Uncertain. Quantif. 2016, 4, 739–766. [Google Scholar] [CrossRef] [Green Version]
- Xu, S.; Liu, H.; Wang, X.; Jiang, X. A robust error-pursuing sequential sampling approach for global metamodeling based on voronoi diagram and cross validation. J. Mech. Des. 2014, 136, 071009. [Google Scholar] [CrossRef]
- Zhu, Z.; Du, X. Reliability analysis with monte carlo simulation and dependent kriging predictions. J. Mech. Des. 2016, 138, 121403. [Google Scholar] [CrossRef]
- Ye, P.; Pan, G. Global optimization method using ensemble of metamodels based on fuzzy clustering for design space reduction. Eng. Comput. 2017, 33, 573–585. [Google Scholar] [CrossRef]
- Yu, H.; Tan, Y.; Sun, C.; Zeng, J. A generation-based optimal restart strategy for surrogate-assisted social learning particle swarm optimization. Knowl. Based Syst. 2019, 163, 14–25. [Google Scholar] [CrossRef]
- Li, C.; Fang, H.; Gong, C. Development of an efficient global optimization method based on adaptive infilling for structure optimization. Struct. Multidiscip. Optim. 2020, 62, 3383–3412. [Google Scholar]
- Yu, M.; Li, X.; Liang, J. A dynamic surrogate-assisted evolutionary algorithm framework for expensive structural optimization. Struct. Multidiscip. Optim. 2020, 61, 711–729. [Google Scholar] [CrossRef]
- Cai, X.; Qiu, H.; Gao, L.; Jiang, C.; Shao, X. An efficient surrogate-assisted particle swarm optimization algorithm for high-dimensional expensive problems. Knowl. -Based Syst. 2019, 184. [Google Scholar] [CrossRef]
- Chang, H.; Zhan, C.; Liu, Z.; Cheng, X.; Feng, B. Dynamic sampling method for ship resistance performance optimisation based on approximated model. Ships Offshore Struct. 2021, 16, 386–396. [Google Scholar] [CrossRef]
- Žanić, V.; Čudina, P. Multiattribute decision making methodology in the concept design of tankers and bulk carriers. Brodogradnja Teorija i Praksa Brodogradnje i Pomorske Tehnike 2009, 60, 19–43. [Google Scholar]
- Lophaven, S.N.; Nielsen, H.B.; Søndergaard, J. DACE: A Matlab Kriging Toolbox; IMM, Informatics and Mathematical Modelling; The Technical University of Denmark: Copenhagen, Denmark, 2002; Volume 2. [Google Scholar]
- Farhang-Mehr, A.; Azarm, S. Bayesian meta-modelling of engineering design simulations: A sequential approach with adaptation to irregularities in the response behaviour. Int. J. Numer. Methods Eng. 2005, 62, 2104–2126. [Google Scholar] [CrossRef]
- Viana, F.; Haftka, R.T.; Steffen, V. Multiple surrogates: How cross-validation errors can help us to obtain the best predictor. Struct. Multidiscip. Optim. 2009, 39, 439–457. [Google Scholar] [CrossRef]
- Aute, V.; Saleh, K.; Abdelaziz, O.; Azarm, S.; Radermacher, R. Cross-validation based single response adaptive design of experiments for Kriging metamodeling of deterministic computer simulations. Struct. Multidiscip. Optim. 2013, 48, 581–605. [Google Scholar] [CrossRef]
- Wang, G.G. Adaptive response surface method using inherited latin hypercube design points. J. Mech. Des. 2003, 125, 210–220. [Google Scholar] [CrossRef]
- Wu, J.; Liu, X.; Zhao, M.; Wan, D. Neumann-Michell theory-based multi-objective optimization of hull form for a naval surface combatant. Appl. Ocean Res. 2017, 63, 129–141. [Google Scholar] [CrossRef]
- Feng, B.; Feng, M.; Chang, H.; Zhang, L. Application of surface deformation method based on radial basis interpolation in multi-objective optimization of ship hull. JSCUT Nat. Sci. Ed. 2019, 47, 128–136. [Google Scholar]
- Andrić, J.; Prebeg, P.; Žanić, V. Multi-level Pareto supported design methodology- application to RO-PAX structural design. Mar. Struct. 2019, 67, 102638. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fun | Opt(f) | Mean(f∗) | Min(f∗min) | NFE | NEAM |
|---|---|---|---|---|---|
| Ackley | 0 | 1.02073 | 0.05208 | 40 | 35 |
| Alpine | 0 | 0.39469 | 0.00148 | 40 | 40 |
| BH | 0.39790 | 0.39798 | 0.39790 | 40 | 1 |
| Griewank | 0 | 0.02073 | 0.01155 | 40 | 33 |
| SC | −1.03163 | −1.02454 | −1.03163 | 40 | 9 |
| Fun | Opt(f) | Mean(f∗) | Min(f∗min) | NFE | NEAM |
|---|---|---|---|---|---|
| Alpine | 0 | 2.97921 | 0.50602 | 85 | 48 |
| Griewank | 0 | 0.68073 | 0.38176 | 130 | 45 |
| TR | −210 | 517.559 | −209.903 | 160 | 15 |
| SF | 0 | 0.02764 | 0.00117 | 190 | 44 |
| Main Principal | Symbol | Value |
|---|---|---|
| Length between perpendiculars | Lpp/m | 5.719 |
| Designed waterline length | Lw/m | 5.726 |
| Moulded breadth | B/m | 0.758 |
| Designed draft | T/m | 0.248 |
| Wetted surface area | SW/m2 | 4.865 |
| Displacement volume | ∇/m3 | 0.550 |
| Block coefficient | CB | 0.505 |
| Wave-making resistance | CW/10−3 | 0.918 |
| Y1 | Y2 | X3 | Y4 | Y5 | Y6 | Y7 | Y8 | Y9 | Y10 | Y11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Upper limit | 0.240 | 0.150 | 0.400 | 0.037 | 0.030 | 0.160 | 0.060 | 0.095 | 0.065 | 0.160 | 0.115 |
| Lower limit | 0.200 | 0.120 | 0.200 | 0.012 | 0.020 | 0.100 | 0.040 | 0.050 | 0.038 | 0.150 | 0.090 |
| Initial value | 0.227 | 0.134 | 0.395 | 0.014 | 0.026 | 0.120 | 0.055 | 0.086 | 0.049 | 0.154 | 0.105 |
| CW | Y1 | Y2 | X3 | Y4 | Y5 | Y6 | Y7 | Y8 | Y9 | Y10 | Y11 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GAM | 0.364 × 10−3 | 0.621 × 10−3 | 0.216 | 0.150 | 0.200 | 0.028 | 0.026 | 0.152 | 0.040 | 0.082 | 0.038 | 0.160 | 0.115 |
| EAM | 0.382 × 10−3 | 0.419 × 10−3 | 0.221 | 0.137 | 0.291 | 0.031 | 0.023 | 0.129 | 0.048 | 0.059 | 0.057 | 0.156 | 0.093 |
| Upper limit | 0.239 | 0.149 | 0.348 | 0.035 | 0.029 | 0.154 | 0.059 | 0.094 | 0.063 | 0.160 | 0.112 | ||
| Lower limit | 0.201 | 0.121 | 0.200 | 0.012 | 0.020 | 0.101 | 0.040 | 0.054 | 0.038 | 0.151 | 0.090 | ||
| Ini | Opt | Variation | |
|---|---|---|---|
| Displacement volume/m3 | 0.550 | 0.554 | +0.73% |
| Wetted surface area/m2 | 4.865 | 4.929 | +1.32% |
| CW/10−3 | 0.918 | 0.419 | −54.36% |
| Total resistance RT/N | 22.091 | 19.410 | −12.14% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ouyang, X.; Chang, H.; Feng, B.; Liu, Z.; Zhan, C.; Cheng, X. Information Matrix-Based Adaptive Sampling in Hull Form Optimisation. J. Mar. Sci. Eng. 2021, 9, 973. https://doi.org/10.3390/jmse9090973
Ouyang X, Chang H, Feng B, Liu Z, Zhan C, Cheng X. Information Matrix-Based Adaptive Sampling in Hull Form Optimisation. Journal of Marine Science and Engineering. 2021; 9(9):973. https://doi.org/10.3390/jmse9090973
Chicago/Turabian StyleOuyang, Xuyu, Haichao Chang, Baiwei Feng, Zuyuan Liu, Chengsheng Zhan, and Xide Cheng. 2021. "Information Matrix-Based Adaptive Sampling in Hull Form Optimisation" Journal of Marine Science and Engineering 9, no. 9: 973. https://doi.org/10.3390/jmse9090973
APA StyleOuyang, X., Chang, H., Feng, B., Liu, Z., Zhan, C., & Cheng, X. (2021). Information Matrix-Based Adaptive Sampling in Hull Form Optimisation. Journal of Marine Science and Engineering, 9(9), 973. https://doi.org/10.3390/jmse9090973