4.1. Environment Describe
In this paper, we firstly use the OpenAI Gym [
22] as the experimental environment to pre-validate the effectiveness of the IPD3QN algorithm. The experiment was carried out with TensorFlow 2.4 and Python 3.6 under Ubuntu 18.04 operating system. Moreover, we use two classical control problems in OpenAI Gym as the experiment scenarios, namely the CartPole-v0 and MountainCar-v0 experimental environments [
23].
CartPole-v0 problem aims to keep the inverted pendulum in a vertical state by moving the bottom plate of the inverted pendulum from left to right. The state of the environment is composed of the horizontal position
x of the inverted pendulum and the offset angle
. The action of the system has +1 and −1 horizontal thrust, the inverted pendulum starts in the vertical state. The system gives a +1 bonus for maintaining the vertical state for each round, the end of the round is marked by |
x| > 2.4 or |
| > 0.2. |
x| > 2.4 indicates that the horizontal movement of the bottom plate of the inverted pendulum has exceeded the maximum horizontal boundary of the system. According to the equation of motion of the system, the transfer function of the angle of the pendulum rod and the external force applied to the system can be deduced. Through the analysis of the transfer function, it is found that when the angle of the inverted pendulum deflection in the vertical direction is greater than 0.2, even if the system applies a force of size 1 in the horizontal direction at the next moment, the inverted pendulum cannot return to the original vertical position [
24,
25].
The experiment allows the balance bar to interact with the environment 5 times every 20 iterations, and calculates the average reward for the 5 times, iterate a total of 2000 episodes;meanwhile, a threshold value
is set for the number of rounds, and the task will automatically end if the inverted pendulum is kept for 300 rounds continuously without falling. In order to make the reward function more reasonable and effective, the reward function is set as:
To compare the convergence performance of the proposed IPD3QN algorithm with other typical algorithms such as DQN, D3QN, PD2QN, PDQN, and PD3QN, we use the convergence condition, convergence rate, and convergence stability in Definition 1. In the CartPole environment, we use
and
as the convergence condition. All the models have three-layer neural network architecture. Also, the number of neurons in the input layer is the environmental state dimension. The number of neurons in the hidden layer is set to 20. The number of neurons in the output layer is set to the environmental action dimension for all the models. ReLU (Rectified Linear Unit) is used as the activation function, and the RMSProp algorithm is selected for gradient descent optimization. In order for the experiment to be comparative, the comparison algorithm and the algorithm in this paper use the same hyperparameters, the hyperparameter settings of the reinforcement learning algorithm are shown in
Table 1. The dynamic
-greedy Equation is as Equation (
17).
The Mountain Car problem is described as a one-dimensional track of a car between two “mountains”, i.e., the bottom of a valley with a slope, and the goal is to drive the car up the mountain to the right. However, the car cannot pass the mountain in one go due to insufficient power, so the car has to pass the top of the mountain with the inertia of back and forth acceleration. The state of the Mountain Car experiment is two-dimensional, with one dimension representing position and the other dimension representing velocity. Among them, the position range of the trolley is [−1.2, 0.6], and the range of speed is [−0.07, 0.07]. There are three discrete actions in the action space representing leftward, rightward, and no action. At the beginning of the episode, the car is given a random position and speed, and then it is learned in a simulated environment.
The experiment iterated a total of 400 episodes.A threshold value of
was set for the number of rounds. If the car did not reach the target position within 2000 rounds, the task was automatically ended, and a new episode was started. In order to make the reward function more reasonable and practical, the reward function was set as follows:
Similar to the Cartpole environment, we use
and
as the convergence condition in the Mountain Car environment. Also, we use the same settings as the Cartpole environment for the six models, except that we set the number of neurons in the hidden layer as 50, because the mountaincar scene is relatively complicated. In order for the experiment to be comparative, the comparison algorithm and the algorithm in this paper use the same hyperparameters, the hyperparameter settings of the reinforcement learning algorithm are shown in
Table 2. The dynamic
-greedy Equation is as Equation (
18).
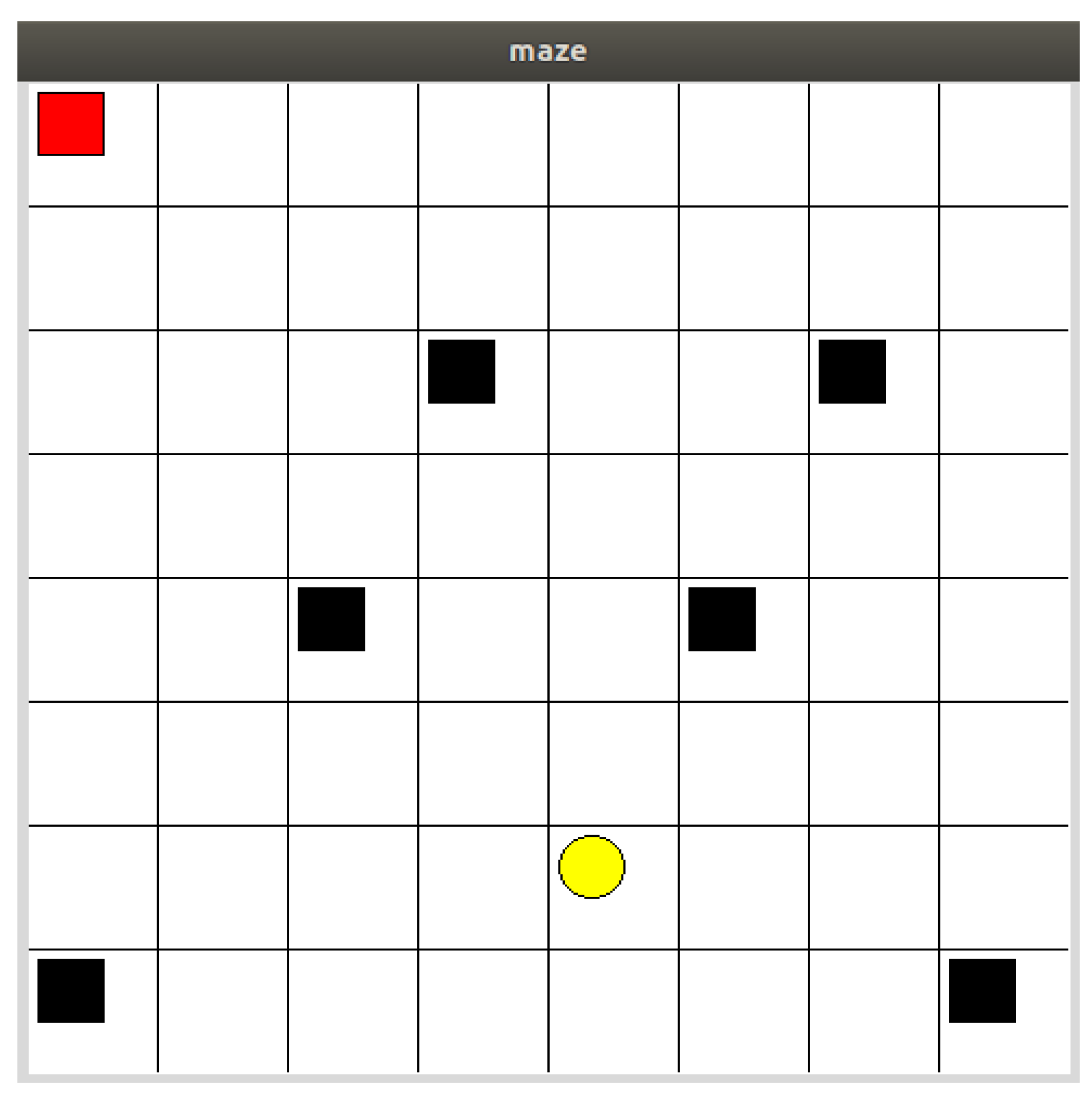
In this work, we use the Maze model to verify the effectiveness of the IPD3QN algorithm for USV path planning. The experimental environment is Python 3.6, Tensorflow 2.4, Ubuntu 18.0, Tkinter, and Maze model (as shown in
Figure 1). The environment feature model is represented using the raster method, which divides the environment map into a number of equally sized rasters, with black rasters for obstacles, white rasters for free space, and yellow rasters for target space, each representing a state, so that the complex map environment is divided into feasible and infeasible spaces. The sea environment in which the USV is located is assumed to be a two-dimensional environment [
26]. The two-dimensional space is discretized into a grid of 8 × 8 raster lengths. Then the specific element information of the environment is arranged according to the actual sea environment records. The area of the obstacle edge less than one grid area is set according to one grid, and finally, the grid serial number is recorded for the simulated set grid.
The experiment sets up four movements, namely up, down, left, and right, for the USV to explore according to the environmental state space. The environmental model and the moving process should be reasonably specified as follows. (1) To reduce the complexity of the experiment, the USV is regarded as a mass point. The movement of the USV can be treated as the process of pointing into a line, which ensures the implementation ability of the algorithm. (2) The effect on the ocean information factor is neglected. (3) Based on the physical point of view, the obstacles and the USV are mutual references during the navigation, so all obstacles such as reefs in the sea are processed in parallel.
In the experiments, we calculate the average reward every ten episodes for a total of 1000 episodes. The threshold of the termination episode is set to
. In this case, the task automatically terminates if the USV cannot reach the target point after 250 episodes or encountering obstacles within 250 episodes. Moreover, the reward function is set as:
Similar to the Cartpole environment, we use
and
as the convergence condition in the Maze environment. Also, we use the same settings as the Cartpole environment for the six models, except that we set the number of neurons in the hidden layer as 20. The hyperparameter settings of the reinforcement learning algorithm are shown in
Table 3. The dynamic
-greedy Equation is as Equation (
19).
4.2. Result Analysis
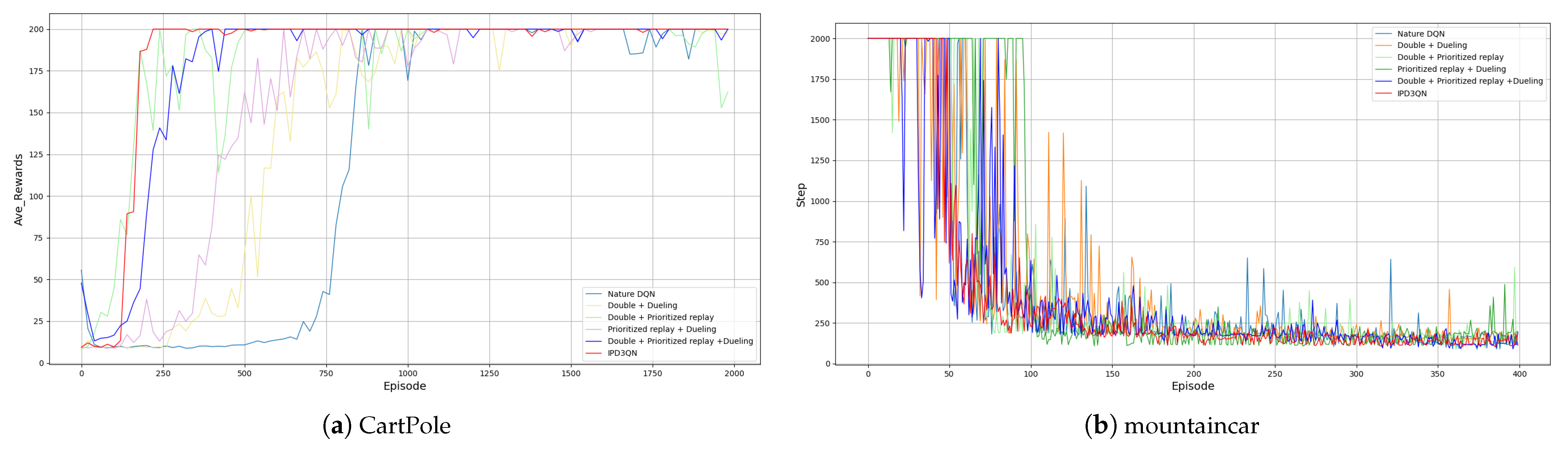
The six algorithms DQN, D3QN, PD2QN, PDQN, PD3QN, and IPD3QN, are compared in the Cartpole and MountainCar scenarios. The experimental results are shown in
Figure 2,
Table 4 and
Table 5. It can be concluded from the data in
Table 4 that IPD3QN converges faster than the rest. It can be concluded from the data in
Table 5 that the average reward of IPD3QN is greater than the other algorithms in the Cartpole environment. The standard deviation is reduced by 87.3%, 80.1%, 92.5%, 67.8%, 54.8% compared with DQN, D3QN, PD2QN, PDQN, PD3QN, respectively. In the Mountain Car environment, the convergence rate of IPD3QN is lower than the other algorithms, and the standard deviation is reduced by 53.9%, 10.4%, 37.9%, 34.2%, 15.8% compared with DQN, D3QN, PD2QN, PDQN, PD3QN, respectively. To conclude, the proposed IPD3QN algorithm has significantly improved the convergence speed and stability compared with other algorithms.
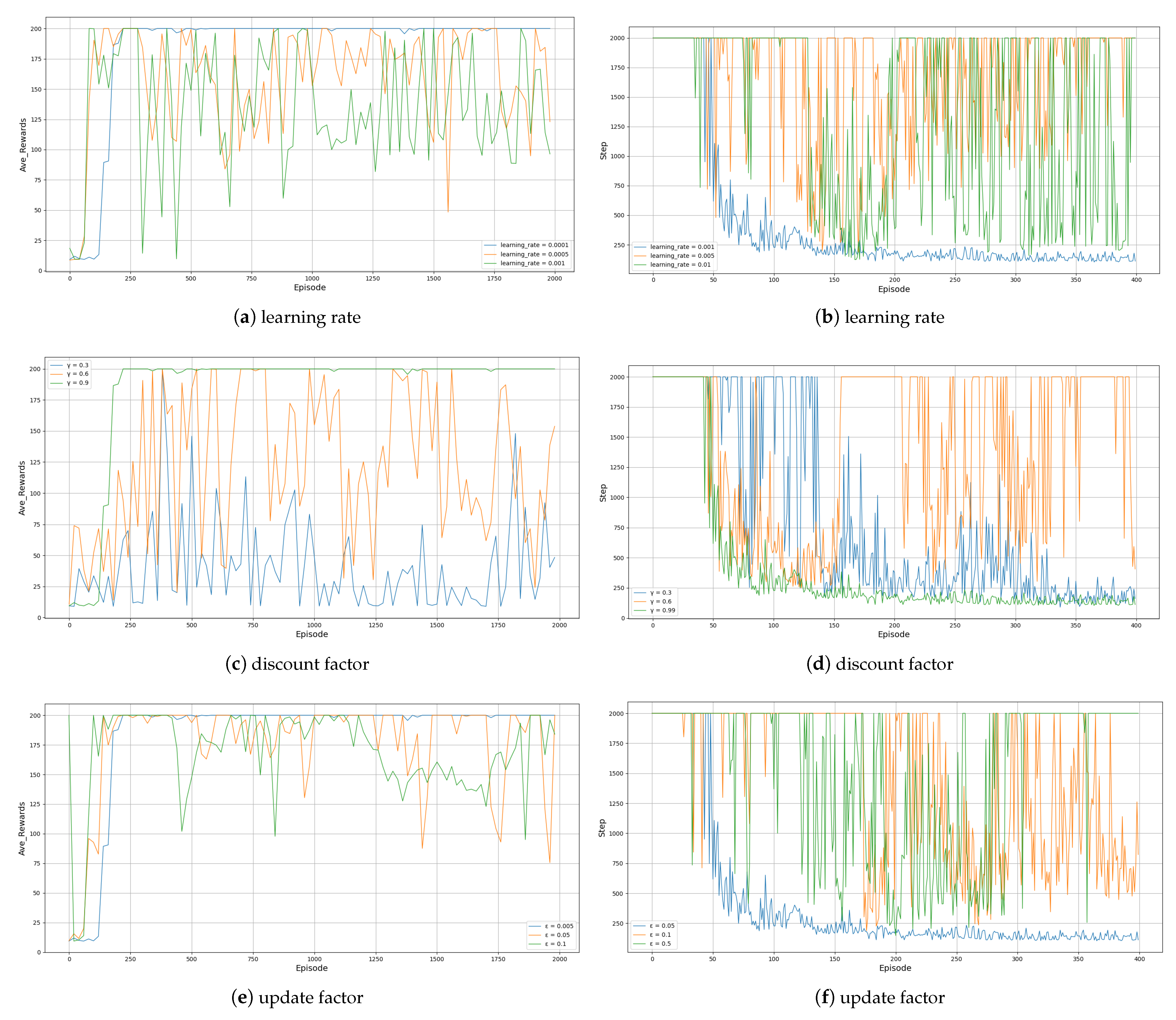
The effects of different learning rates on the convergence rate and convergence stability are given in
Figure 3a,b. It can be seen that in the Cartpole and Mountain Car environments, the learning process is more stable when the learning rate is low. When the learning rate is large, although the learning can be accelerated in the early stage, it is persistently oscillating and challenging to converge in the later stage.
Figure 3c,d reflect the effect of the discount factor
on the convergence speed and convergence stability. It can be seen that when
is larger, the greater the influence of future returns on the current expected return value, the higher the proportion of future returns predicted in it when the intelligence calculates the expected return, which is beneficial to the learning environment and uses less training time. So
needs to be set large when the environment has a strong temporal correlation.
The effects of different interval update coefficients on the convergence speed and convergence stability are given in
Figure 3e,f. It can be seen that in the Cartpole and Mountain Car environments, the learning process is more stable when the interval coefficient is small. When the interval coefficient is large, although it can be explored faster in the early stage, it is persistently oscillating and challenging to converge in the later stage.
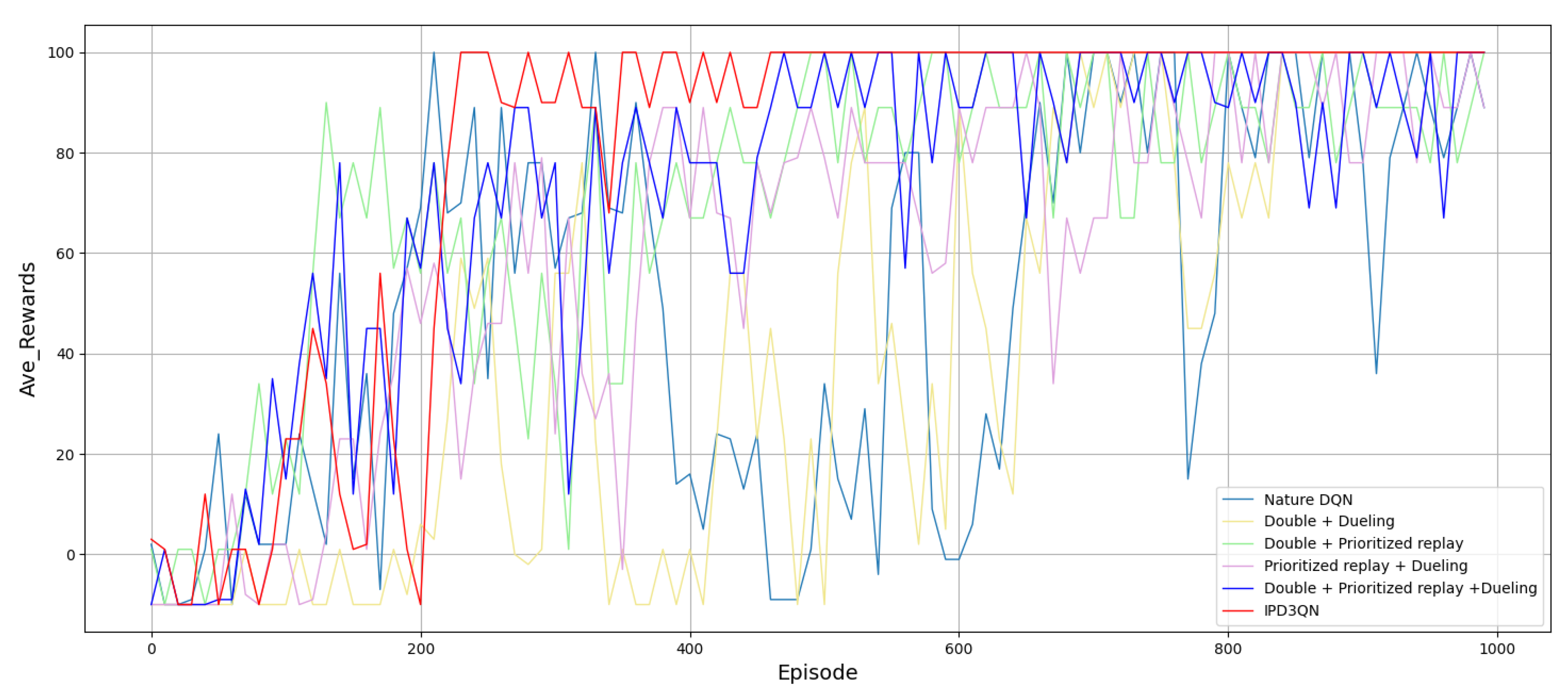
Through pre-verification in CartPole and mountaincar environments, experiments prove that IPD3QN can improve stability and convergence. Compare the six algorithms of DQN, D3QN, PD2QN, PDQN, PD3QN, and IPD3QN in the Maze scenario. The experimental results are shown in
Figure 4,
Table 6 and
Table 7. The data in
Table 6 shows that IPD3QN converges faster than the rest; the data in
Table 7 shows that in the maze environment, the average reward of IPD3QN is greater than Other algorithms, and the standard deviation compared with DQN, D3QN, PD2QN, PDQN, PD3QN reduced by 59.6%, 53.1%, 54.3%, 61.1%, 46.2%, performance is more stable.
To sum up, compared with other algorithms, the IPD3QN algorithm in this article has significantly improved convergence speed and convergence stability.




{kind=link}
{kind=link}
{kind=link}
{kind=link}