Arctic Vision: Using Neural Networks for Ice Object Classification, and Controlling How They Fail


Abstract
:
1. Introduction
1.1. Related Work
1.1.1. Training CNNs With Imbalanced Data
1.1.2. Comparisons of Humans and CNNs
1.1.3. CNNs for Close-Range Ice Object Detection
2. Materials and Methods
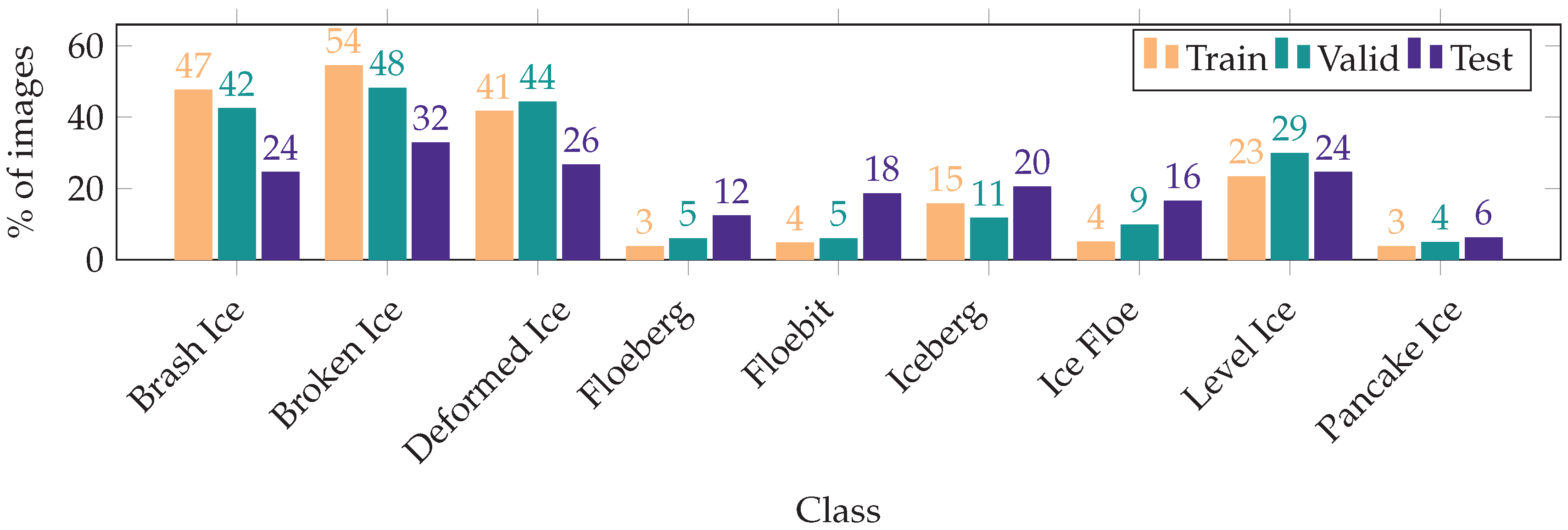
2.1. Dataset
2.2. Image Distortions
- Image blur, which can happen due to snow, rain, or water on the camera lens.
- Brightness decrease, which imitates the visual conditions at night.
- Synthetic fog.
- Gaussian noise, which is similar to the effect of using a high ISO on the camera.
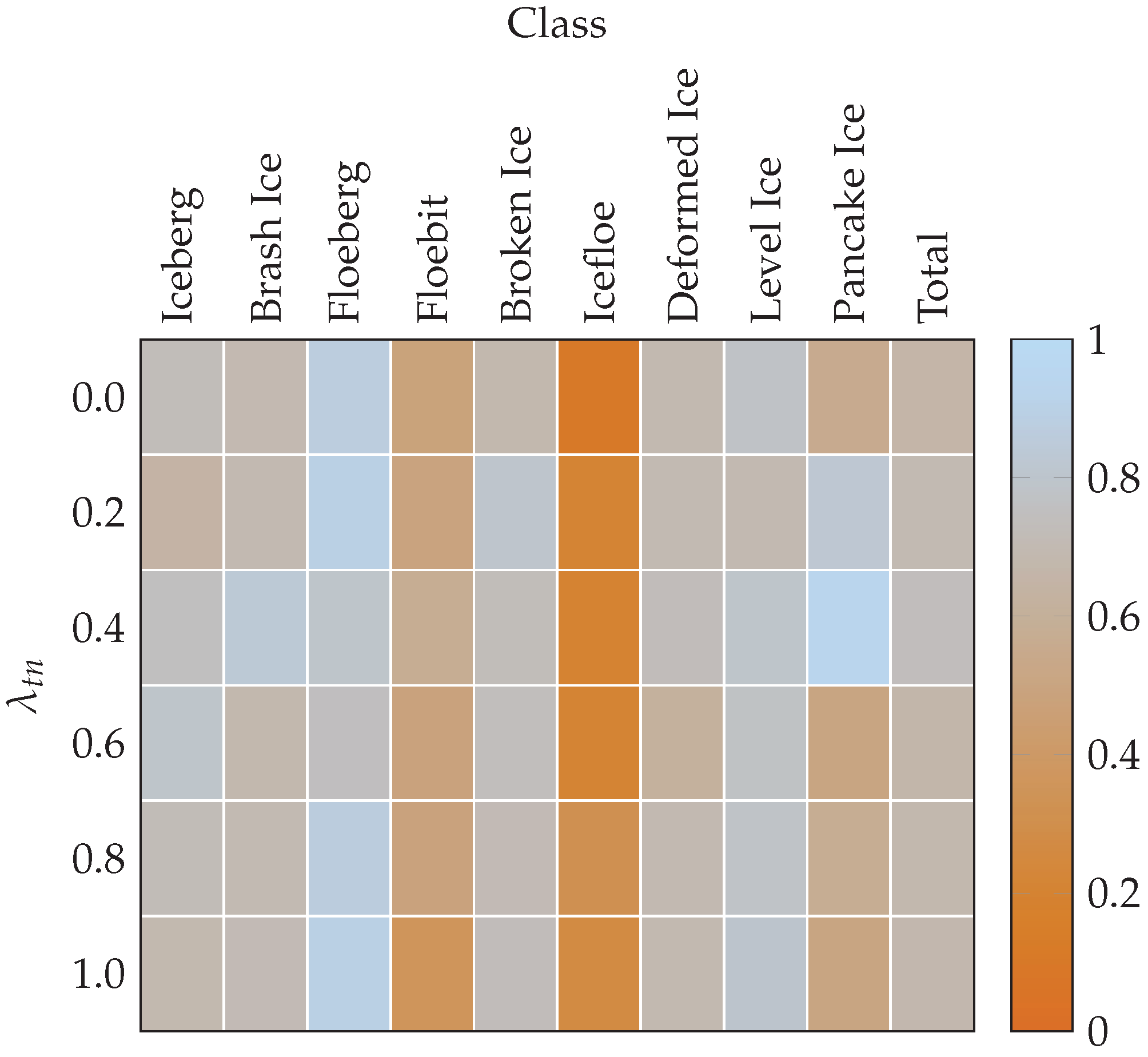
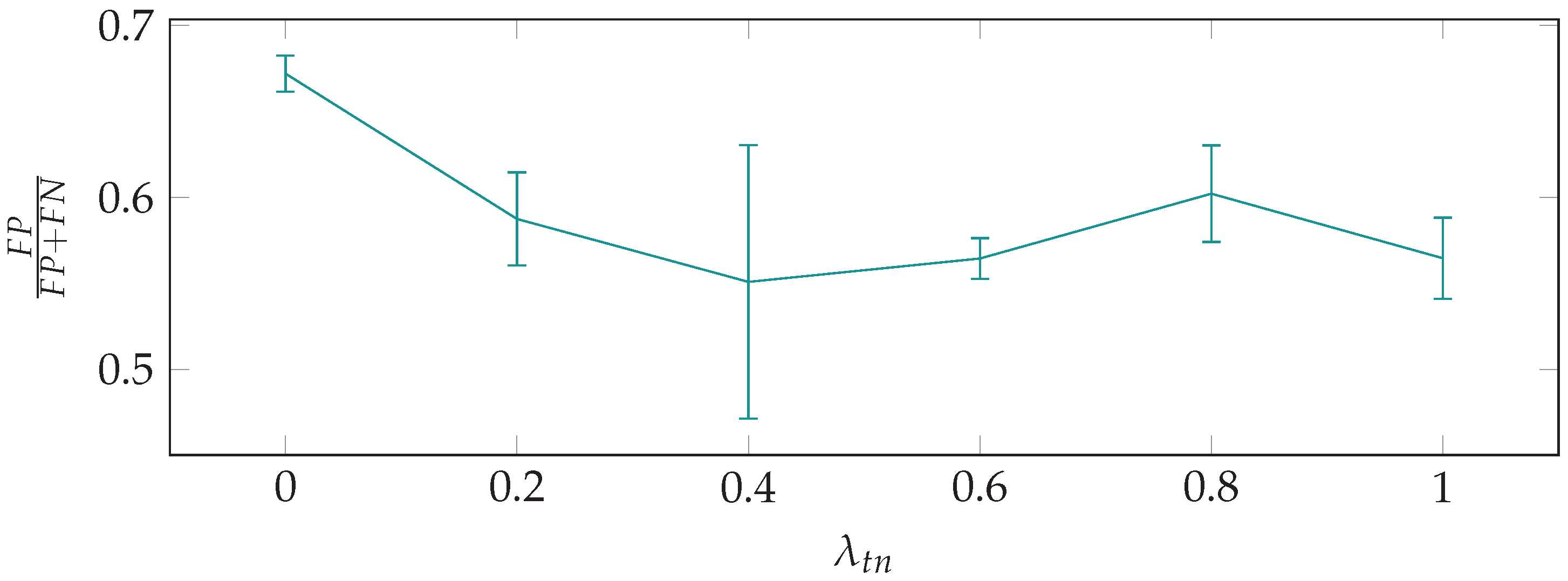
2.3. True Negative Weighted Loss
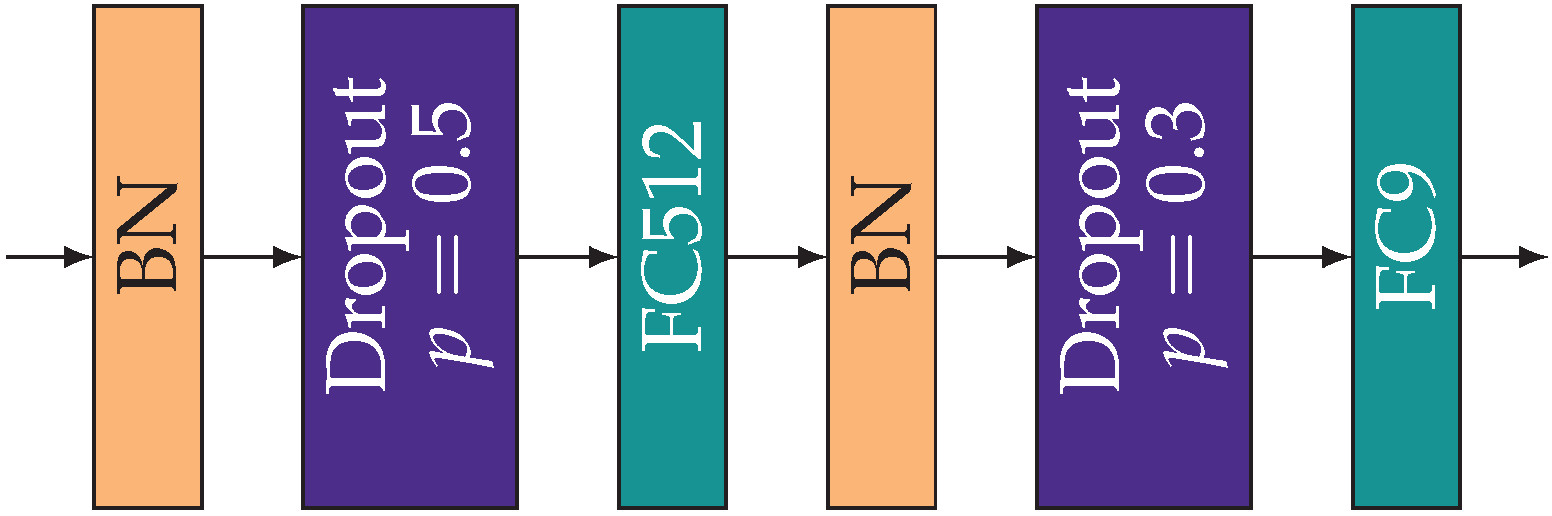
2.4. Training Procedure
2.5. Human Experiments
3. Results
4. Discussion
4.1. Effect of the True Negative Weighted Loss
4.2. What the Network Sees
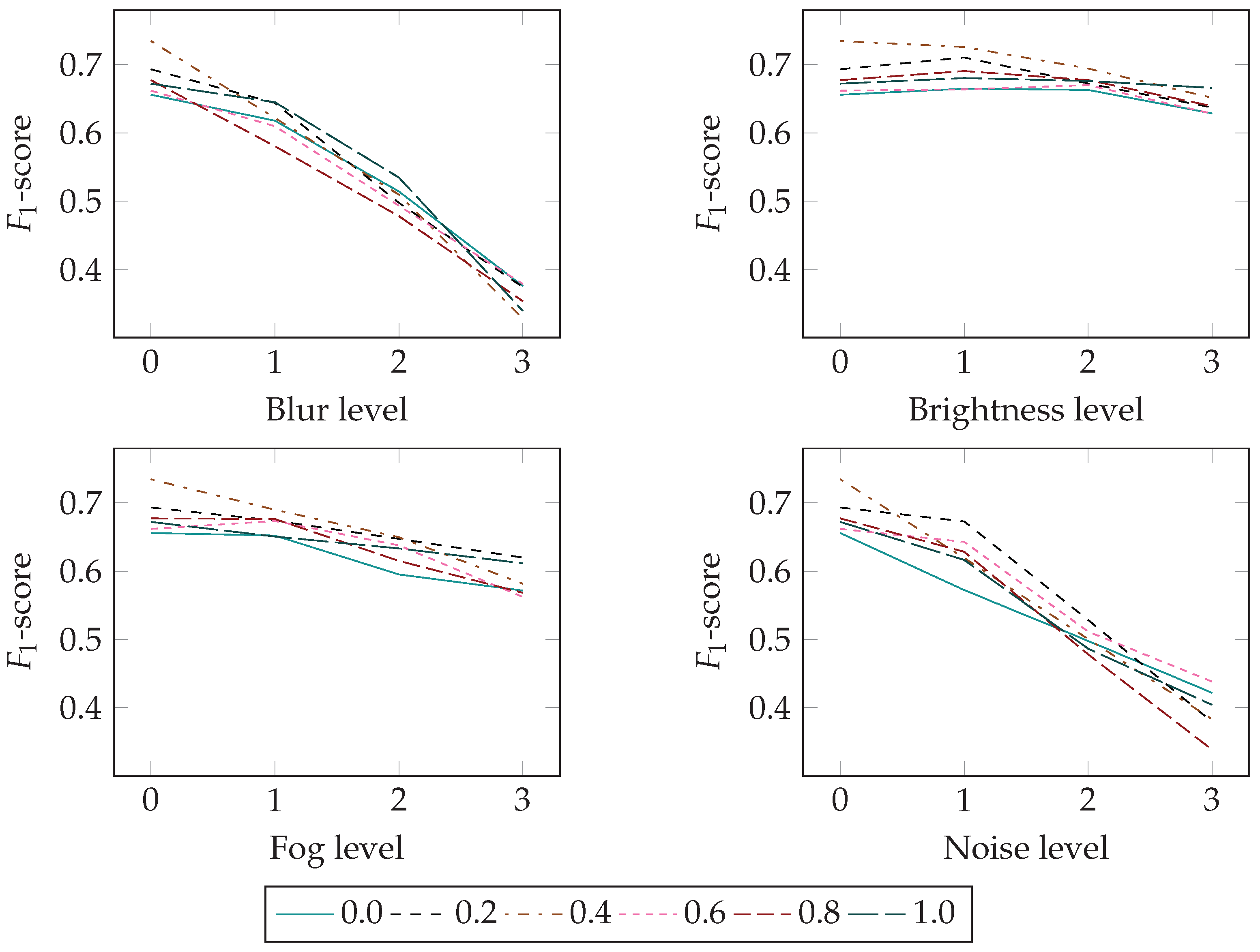
4.3. The Effects of Distortions
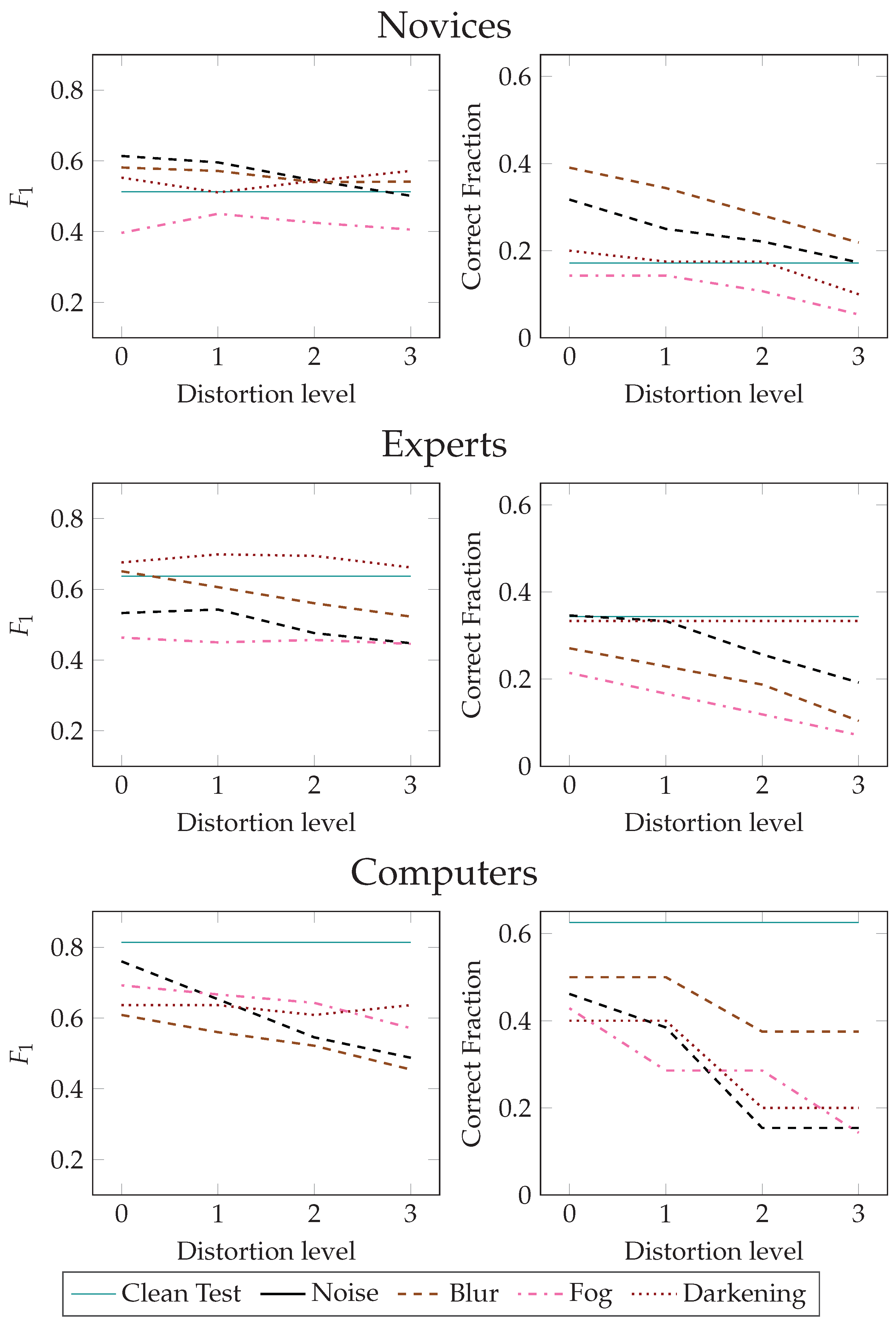
4.4. Difference between Novices, Experts, and Computers
5. Summary and Conclusions
- A loss-weighting scheme for making the trained model more likely to predict that classes are present in an image was introduced. Results show that the scheme works as intended, by avoiding an excess of false negative classifications and the possibility of missing important ice objects in images.
- A demonstration of how CNNs can successfully recognize some ice objects in images using meaningful filters was provided, along with a discussion of why they struggle with some classes.
- A thorough analysis of the effect of semi-realistic image distortions on the classification task was provided. It was shown that even though the network fails to classify an image, it still recognizes the area of importance in the image for the given class.
- Finally, a comparison of the performances of human novices, experts, and computers on the classification task was given. The results indicate that for clean images, the model outperforms human novices, although it is less clear how it compares to experts. Both human participant groups handled distortions better than the network.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| i.i.d. | Independent, Identically Distributed |
| ReLU | Rectified Linear Unit |
| SAR | Synthetic Aperture Radar |
| SVM | Support Vector Machine |
| UAV | Unmanned Aerial Vehicle |
References
- Gao, H.; Cheng, B.; Wang, J.; Li, K.; Zhao, J.; Li, D. Object Classification Using CNN-Based Fusion of Vision and LIDAR in Autonomous Vehicle Environment. IEEE Trans. Ind. Inform. 2018, 14, 4224–4231. [Google Scholar] [CrossRef]
- Kim, H.; Hong, S.; Son, H.; Roska, T.; Werblin, F. High speed road boundary detection on the images for autonomous vehicle with the multi-layer CNN. In Proceedings of the 2003 International Symposium on Circuits and Systems, Bangkok, Thailand, 25–28 May 2003. [Google Scholar]
- Ouyang, Z.; Niu, J.; Liu, Y.; Guizani, M. Deep CNN-Based Real-Time Traffic Light Detector for Self-Driving Vehicles. IEEE Trans. Mob. Comput. 2020, 19, 300–313. [Google Scholar] [CrossRef]
- Gao, F.; Wu, T.; Li, J.; Zheng, B.; Ruan, L.; Shang, D.; Patel, B. SD-CNN: A shallow-deep CNN for improved breast cancer diagnosis. Comput. Med. Imaging Graph. 2018, 70, 53–62. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reda, I.; Ayinde, B.O.; Elmogy, M.; Shalaby, A.; El-Melegy, M.; El-Ghar, M.A.; El-fetouh, A.A.; Ghazal, M.; El-Baz, A. A new CNN-based system for early diagnosis of prostate cancer. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 207–210. [Google Scholar]
- WMO. Sea-Ice Nomenclature; WMO: Geneva, Switzerland, 2014. [Google Scholar]
- Geirhos, R.; Schütt, H.H.; Medina Temme, C.R.; Bethge, M.; Rauber, J.; Wichmann, F.A. Generalisation in Humans and Deep Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 7538–7550. [Google Scholar]
- Dodge, S.; Karam, L. Human and DNN Classification Performance on Images with Quality Distortions: A Comparative Study. ACM Trans. Appl. Percept. 2019, 16, 1–17. [Google Scholar] [CrossRef]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef] [Green Version]
- Guo, H.; Li, Y.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Janowczyk, A.; Madabhushi, A. Deep learning for digital pathology image analysis: A comprehensive tutorial with selected use cases. J. Pathol. Inform. 2016, 7, 29. [Google Scholar] [CrossRef]
- Kim, E.; Dahiya, G.S.; Løset, S.; Skjetne, R. Can a Computer See What an Ice Expert Sees? Multilabel Ice Objects Classification with Convolutional Neural Networks. Results Eng. 2019, 4. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Cui, Y.; Jia, M.; Lin, T.Y.; Song, Y.; Belongie, S. Class-Balanced Loss Based on Effective Number of Samples. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–19 June 2019. [Google Scholar]
- Byrd, J.; Lipton, Z.C. What is the Effect of Importance Weighting in Deep Learning? In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 872–881. [Google Scholar]
- Phan, H.; Krawczyk-Becker, M.; Gerkmann, T.; Mertins, A. DNN and CNN with Weighted and Multi-task Loss Functions for Audio Event Detection. arXiv 2017, arXiv:1708.03211. [Google Scholar]
- Zhang, X.; Jin, J.; Lan, Z.; Li, C.; Fan, M.; Wang, Y.; Yu, X.; Zhang, Y. ICENET: A Semantic Segmentation Deep Network for River Ice by Fusing Positional and Channel-Wise Attentive Features. Remote Sens. 2020, 12, 221. [Google Scholar] [CrossRef] [Green Version]
- Singh, A.; Kalke, H.; Loewen, M.; Ray, N. River Ice Segmentation With Deep Learning. IEEE Trans. Geosci. Remote Sens. 2020, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Kim, E.; Panchi, N.; Dahiya, G.S. Towards Automated Identification of Ice Features for Surface Vessels Using Deep Learning. J. Phys. Conf. Ser. 2019, 1357. [Google Scholar] [CrossRef]
- Banfield, J.D.; Raftery, A.E. Ice Floe Identification in Satellite Images Using Mathematical Morphology and Clustering about Principal Curves. J. Am. Stat. Assoc. 1992, 87, 7–16. [Google Scholar] [CrossRef]
- Karvonen, J.; Simila, M. Classification of Sea Ice Types from Scansar Radarsat Images Using Pulse-coupled Neural Networks. In Proceedings of the 1998 IEEE International Symposium on Geoscience and Remote Sensing, Seattle, WA, USA, 6–10 July 1998; pp. 2505–2508. [Google Scholar]
- Karvonen, J.A. Baltic Sea Ice Sar Segmentation and Classification Using Modified Pulse-coupled Neural Networks. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1566–1574. [Google Scholar] [CrossRef]
- Zhang, Q.; Skjetne, R. Image Techniques for Identifying Sea-ice Parameters. Model. Identif. Control 2014, 35, 293–301. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Skjetne, R. Image Processing for Identification of Sea-ice Floes and the Floe Size Distributions. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2913–2924. [Google Scholar] [CrossRef]
- Zhang, Q.; Skjetne, R.; Metrikin, I.; Løset, S. Image Processing for Ice Floe Analyses in Broken-ice Model Testing. Cold Reg. Sci. Technol. 2015, 111, 27–38. [Google Scholar] [CrossRef] [Green Version]
- Weissling, B.; Ackley, S.; Wagner, P.; Xie, H. EISCAM—Digital image acquisition and processing for sea ice parameters from ships. Cold Reg. Sci. Technol. 2009, 57, 49–60. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Torchvision Model Zoo. Available online: https://pytorch.org/docs/stable/torchvision/models.html (accessed on 23 September 2020).
- Smith, L.N. A Disciplined Approach to Neural Network Hyper-parameters: Part 1—Learning Rate, Batch Size, Momentum, and Weight Decay. arXiv 2018, arXiv:cs.LG/1803.09820. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2019, arXiv:cs.LG/1711.05101. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal 515 Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A SimpleWay to 517 Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Pedersen, O.M.; Kim, E. Evaluating Human and Machine Performance on the Classification of Sea Ice Images. In Proceedings of the 25th IAHR International Symposium on Ice, Trondheim, Norway, 23–25 November 2020. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef] [Green Version]
- Geirhos, R.; Michaelis, C.; Wichmann, F.A.; Rubisch, P.; Bethge, M.; Brendel, W. Imagenet-trained CNNs Are Biased Towards Texture; Increasing Shape Bias Improves Accuracy and Robustness. arXiv 2018, arXiv:1811.12231. [Google Scholar]
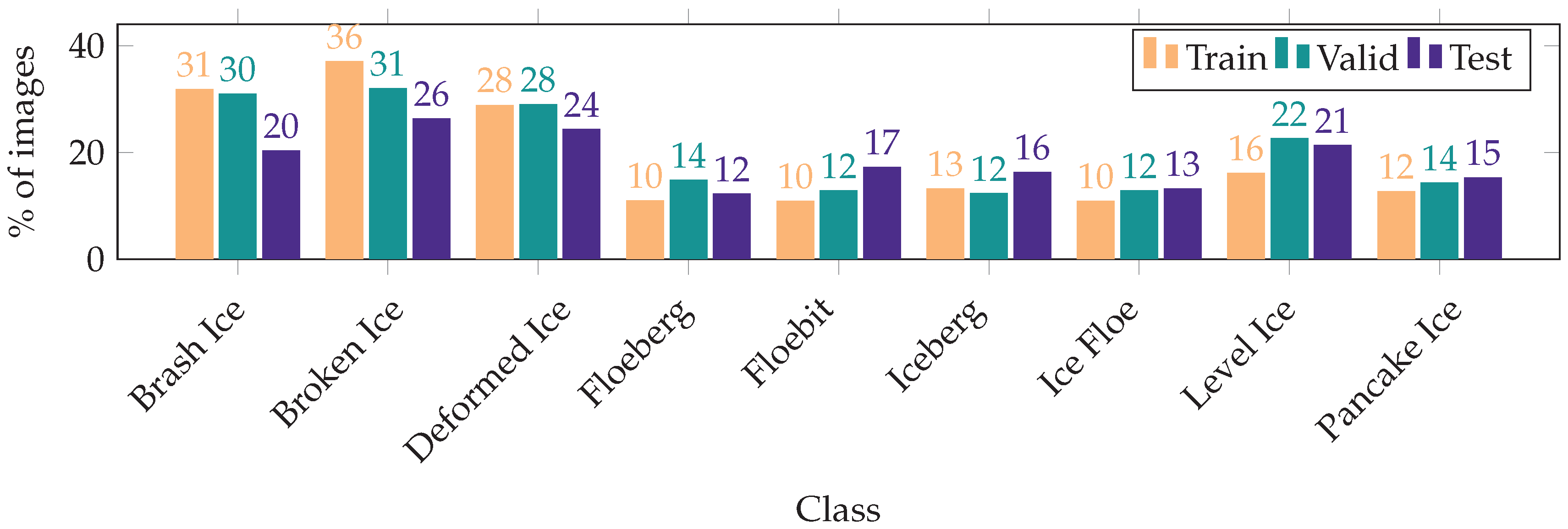






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Description |
|---|---|
| Brash Ice | Accumulations of floating ice made up of fragments not more than 2 m across, the wreckage of other forms of ice. |
| Broken Ice | Predominantly flat ice cover broken by gravity waves or due to melting decay. |
| Deformed Ice | A general term for ice that has been squeezed together and, in places, forced upwards (and downwards). Subdivisions are rafted ice, ridged ice and hummocked ice. |
| Floeberg | A large piece of sea ice composed of a hummock, or a group of hummocks frozen together, and separated from any ice surroundings. It typically protrudes up to 5 m above sea level. |
| Floebit | A relatively small piece of sea ice, normally not more than 10 m across, composed of a hummock (or more than one hummock) or part of a ridge (or more than one ridge) frozen together and separated from any surroundings. It typically protrudes up to 2 m above sea level. |
| Iceberg | A piece of glacier origin, floating at sea. |
| Ice Floe | Any contiguous piece of sea ice. |
| Level Ice | Sea ice that has not been affected by deformation. |
| Pancake Ice | Predominantly circular pieces of ice from 30 cm–3 m in diameter, and up to approximately 10 cm in thickness, with raised rims due to the pieces striking against one another. |
| Parameter | Description | Value |
|---|---|---|
| Maximum learning rate for initial training phase | 2 × 10−2 | |
| Maximum learning rate for first layer during final phase | 1 × 10−8 | |
| Maximum learning rate for last layer during final phase | 5 × 10−3 | |
| Weight decay rate | 1 × 10−3 | |
| Minimum value for use with Adam, cycled inversely to the learning rate | 0.8 | |
| Maximum value for use with Adam, cycled inversely to the learning rate | 0.95 | |
| Parameter for Adam | 0.99 | |
| Training steps of initial phase | 20,000 | |
| Training steps of final phase | 6000 |
| Metric | Definition |
|---|---|
| Precision | |
| Recall | |
| Group | Minimum Degradation | Maximum Degradation | Average Degradation |
|---|---|---|---|
| Novices | 0.089 | 0.172 | 0.126 |
| Experts | 0.000 | 0.167 | 0.116 |
| Computers | 0.125 | 0.308 | 0.230 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pedersen, O.-M.; Kim, E. Arctic Vision: Using Neural Networks for Ice Object Classification, and Controlling How They Fail. J. Mar. Sci. Eng. 2020, 8, 770. https://doi.org/10.3390/jmse8100770
Pedersen O-M, Kim E. Arctic Vision: Using Neural Networks for Ice Object Classification, and Controlling How They Fail. Journal of Marine Science and Engineering. 2020; 8(10):770. https://doi.org/10.3390/jmse8100770
Chicago/Turabian StylePedersen, Ole-Magnus, and Ekaterina Kim. 2020. "Arctic Vision: Using Neural Networks for Ice Object Classification, and Controlling How They Fail" Journal of Marine Science and Engineering 8, no. 10: 770. https://doi.org/10.3390/jmse8100770
APA StylePedersen, O.-M., & Kim, E. (2020). Arctic Vision: Using Neural Networks for Ice Object Classification, and Controlling How They Fail. Journal of Marine Science and Engineering, 8(10), 770. https://doi.org/10.3390/jmse8100770