1. Introduction
The rapid expansion of global maritime trade has established autonomous shipping as a critical pillar of the international economic system. The evolution of intelligent ship technologies like trajectory control systems has enabled more efficient operations, though challenges in performance optimization and energy efficiency remain [
1]. Nevertheless, the sector’s heavy reliance on fossil fuels generates substantial carbon dioxide (CO
2) emissions, contributing directly to climate change mitigation challenges. In 2020, China and the International Maritime Organization (IMO) collaboratively introduced strategic frameworks for emission reduction [
2], which were further reinforced by the 2023 Revised IMO GHG Strategy. Effective May 1, 2024, the Carbon Intensity Indicator (CII) grading system (MEPC.377 (80) resolutions [
3,
4]) has been globally enforced, requiring vessels to maintain an annual rating above Class C and phasing out those classified as D or E. To address these regulatory demands, this study proposes a Maritime Carbon Assessment Technology (MCAT) model with real-time predictive capabilities, forming a closed-loop compliance mechanism. Recent advances in hybrid deep learning approaches for marine time series data have demonstrated significant improvements in prediction accuracy [
5], providing methodological foundations for enhanced maritime monitoring systems. Concurrently, the upgraded MRV (Monitoring, Reporting, Verification) 2.0 system, scheduled for implementation in 2025, introduces 14 new monitoring parameters (e.g., propeller polishing status and ballast water treatment energy consumption), which align with the multi-source data fusion framework of our proposed architecture [
6]. Recent AIS-based approaches using spatiotemporal analysis have demonstrated success in quantifying vessel emissions across different operational modes, providing valuable insights for developing targeted emission control policies [
7]. Furthermore, the European Union’s Carbon Border Adjustment Mechanism (CBAM) will expand its scope in 2025 to include maritime transport, mandating DNV GL-certified real-time emission reporting under Phase III regulations [
8].
The spatial–temporal complexity of maritime operations poses significant technical barriers. Vessels frequently operate beyond the coverage of terrestrial communication infrastructure, while the prohibitive costs of satellite-based data transmission hinder the real-time exchange of navigational data, predictive analytics, and optimization strategies. Gao et al. [
9] proposed an adaptive prediction framework based on incremental learning that incorporates a dual adaptation mechanism for dynamically adjusting input features and target labels, combined with a rolling retraining methodology. This approach achieved high-precision real-time predictions of vessel fuel consumption while effectively mitigating the impact of dynamic maritime environmental variations on prediction accuracy. Liu et al. [
10] investigated carbon emission dynamics under port congestion conditions, identifying critical correlations between vessel operational characteristics and congestion indices for emission forecasting. Their research provides data-driven solutions for low-carbon port operations through comprehensive analysis of maritime traffic patterns and associated environmental impacts. Real-time measurement systems leveraging modern sensing technologies have been proposed to effectively monitor ship emissions in various weather conditions, providing critical data for emission factor calculations and regulatory compliance [
11], the computational intensity of emission prediction models faces constraints from limited onboard resources and dynamic sea conditions. To overcome these challenges, we have designed a novel hybrid data processing architecture. This system offloads autonomous vessel-borne data to shore-based high-performance computing centers via 5G Ultra-Reliable Low-Latency Communication (URLLC) network slicing, achieving an end-to-end command transmission latency of 10 milliseconds—well below the ≤50-millisecond synchronization threshold mandated by the EU Emissions Trading System (ETS). As depicted in
Figure 1, this approach enables standardized data processing, model inference, and real-time CO
2 emission prediction without compromising navigational safety.
Under this architecture, we first propose an innovative hybrid communication framework to guarantee efficient and reliable data transmission. The framework combines three transmission modes—satellite communications (Inmarsat, London, UK/Iridium Communications Inc., McLean, VA, USA), 5G NR-U unlicensed spectrum access, and industrial Ethernet—establishing a converged space–air–ground redundant transmission framework. By deploying IEEE 1588v2 Precision Time Protocol (PTP) at edge nodes with hardware timestamping (50 ns accuracy) and a master–slave hierarchical synchronization architecture, we achieve unified Coordinated Universal Time (UTC) traceability across the entire system. Furthermore, through 5G Ultra-Reliable Low-Latency Communication (URLLC) network slicing technology, we construct a dedicated control command channel utilizing pre-allocated 20 MHz bandwidth resource blocks and Configured Grant scheduling. This configuration reduces end-to-end transmission latency to 8.7 milliseconds (99.99% confidence interval, ±0.3 ms). Experimental results demonstrate a 42% improvement in dynamic dependency capture efficiency compared to conventional systems, providing a robust real-time data infrastructure for carbon efficiency optimization.
Having resolved data transmission challenges, this study further addresses the modeling complexities of autonomous vessel CO
2 emission prediction. Long-term time series forecasting (LTSF) represents a fundamental task in temporal data analysis, aiming to predict future values over extended horizons based on historical observations. Recent advancements in encoder–decoder recurrent neural networks have demonstrated exceptional capability in maritime time series forecasting, particularly for storm surge predictions, by effectively capturing complex spatiotemporal dependencies in dynamic marine environments [
12]. With advancements in deep learning, Long Short-Term Memory (LSTM) networks have emerged as a dominant LTSF approach due to their temporal modeling capabilities. LSTM networks have become the focus of deep learning research due to their ability to handle long-term dependencies through gate functions, overcoming the limitations of traditional RNNs in learning relevant information when input gaps are large [
13]. Recent advances in spatio-temporal LSTM architectures have demonstrated effectiveness in environmental multi-sensor forecasting [
14]. However, when confronted with real-world autonomous vessel emission datasets characterized by multivariate coupling and high-frequency noise interference, LSTMs exhibit limitations in capturing cross-variable dynamic dependencies.
In this research, we further propose a Multi-scale Channel-aligned Transformer (MCAT) model specifically designed for the real-time prediction of autonomous vessel carbon dioxide (CO
2) emissions. Recent research integrating climate change scenarios with machine learning models for ship fuel consumption prediction has demonstrated the effectiveness of emotional artificial neural networks (EANNs) in handling complex environmental variables and optimizing vessel performance under various operational conditions [
15]. The MCAT model integrates multiple key technologies, including multi-scale token vector reconstruction, a multi-head dual attention mechanism, a weighted loss function, and regularization design, thereby achieving more accurate emission predictions. Through the synergistic optimization of this architecture and the model, this research provides an efficient and reliable solution for autonomous vessel CO
2 emission prediction, offering robust support for the low-carbon transition of the autonomous shipping industry.
To summarize, our contributions are as follows:
This study proposes an innovative communication architecture and standardized computing system. Building upon this infrastructure, we construct a comprehensive standardized dataset integrating multi-source information from the Automatic Identification System (AIS), onboard sensors, meteorological data, and sea conditions, providing a robust data foundation for high-performance autonomous vessel CO2 emission prediction.
We propose a Multi-scale Channel-aligned Transformer (MCAT) model that integrates multi-scale token vector reconstruction, a multi-head dual attention mechanism, a weighted loss function, and regularization design.
We conduct comparative experiments across varying prediction horizons. The results demonstrate that MCAT outperforms all state-of-the-art (SOTA) methods, achieving average improvements of 12.5% in mean absolute error (MAE) and 24% in mean squared error (MSE), with maximum enhancements reaching 22.3% and 45.2%, respectively. Additionally, experiments under noise-contaminated scenarios validate MCAT’s superior generalization capability and robustness.
The remainder of this paper is organized as follows: First, we detail the architecture and key technologies of the MCAT model. Next, we present the experimental setup and result analysis. Finally, we discuss the limitations of this study and future research directions.
2. Related Work
Over recent decades, maritime transport has accounted for over 80% of global cargo turnover, yet its associated fuel consumption contributes approximately 3% of worldwide CO
2 emissions. Traditional emission factor methods, which estimate emissions based on engine power, fuel type, and voyage distance, face accuracy limitations in practical applications due to dynamic operational variations caused by multi-spatiotemporal factors. Kim et al. [
16] developed machine learning prediction models through an analysis of operational data from 13,000 TEU container vessels, demonstrating the critical importance of feature selection in model performance. Their research established that ANN-based methodologies significantly outperform traditional multivariate linear regression approaches in vessel fuel consumption prediction, achieving R
2 values ranging from 0.9709 to 0.9936.
With the rapid advancement of machine learning, methods such as Support Vector Machines (SVMs), Random Forests (RFs), and Gradient-Boosted Decision Trees (GBDTs) have been increasingly applied to autonomous vessel emission prediction. These approaches enhance prediction accuracy through nonlinear mapping capabilities. However, they exhibit critical shortcomings in handling spatiotemporally coupled data: SVM suffers from high computational complexity with high-dimensional data, RF struggles to capture temporal dependencies in long sequences, and GBDT remains sensitive to outliers. These limitations have driven researchers toward deep learning-based temporal forecasting models to better capture complex correlations in autonomous vessel operational parameters.
Recent years have seen significant progress in deep learning models for autonomous vessel emission prediction. Long Short-Term Memory (LSTM) networks and their variants, renowned for robust temporal modeling, have become focal points. Li et al. [
17] introduced a Dual Attention Parallel Network (DAPNet) methodology for vessel fuel consumption prediction. This architecture concurrently processes multi-source heterogeneous data through parallel network structures while enhancing feature alignment and fusion capabilities via local and global dual attention mechanisms, resulting in substantial performance improvements in maritime fuel consumption forecasting. For instance, spatiotemporal data-driven LSTM methods and the L2-regularized LSTM nonlinear dynamic system identification strategy, developed by Xu et al., have been proposed. Liu et al. [
18] proposed a ship energy consumption prediction model based on a TCN-GRU-MHSA (TGMA) architecture, integrating temporal convolutional networks, gated recurrent units, and multi-head self-attention mechanisms. The model preprocesses vessel energy consumption data through feature selection and autocorrelation analysis, demonstrating significant accuracy improvements over traditional models such as LSTM, GRU, and SVR, achieving a precision rate of 96.04%. Additionally, patch-based dual-stream architectures with exponential decomposition have shown promising results in time series forecasting [
19]. Recent advances in channel-aligned transformer architectures have further demonstrated the effectiveness of multi-scale attention mechanisms for capturing cross-variable dependencies in multivariate time series [
20]. The Informer model has established a significant milestone in applying Transformer architectures to long sequence time-series forecasting (LSTF), introducing ProbSparse self-attention mechanism and achieving O(L log L) complexity for enhanced efficiency in capturing long-range dependencies [
21]. Furthermore, PatchTST has demonstrated that segmenting time series into subseries-level patches and employing channel-independence can significantly improve long-term forecasting accuracy while reducing computational complexity [
22]. iTransformer has demonstrated the effectiveness of inverting transformer dimensions, where individual time series are embedded as variate tokens to capture multivariate correlations through attention mechanisms [
23]. Recent studies have also explored spatiotemporal prediction frameworks for ship carbon emissions using ConvLSTM models, which combine CNN advantages in processing spatial relationships with RNN capabilities for temporal series analysis [
24]. Zhou et al. further enhanced ship fuel consumption prediction accuracy through interval prediction methods, combining Gaussian process regression with quantile regression theory to capture fuel consumption variability under different operational conditions [
25]. Nevertheless, these methods still inadequately model complex spatiotemporal dependencies, particularly in capturing cross-dimensional interactions between navigational parameters and environmental factors.
In summary, while existing temporal models have advanced autonomous vessel CO2 emission prediction, they inadequately address real-world operational complexities. Building on this analysis, we now introduce our proposed Multi-scale Channel-aligned Transformer (MCAT) model, specifically designed to overcome these challenges. MCAT employs an advanced multi-head dual attention mechanism to effectively model complex spatiotemporal relationships, particularly excelling in cross-dimensional interaction modeling between autonomous vessel parameters and environmental factors.
4. Experiment
4.1. IoT-Enabled Maritime Network Architecture Design
Server Configuration: To address the computational complexity of the MCAT model, we deploy a high-performance GPU (NVIDIA RTX 3090 ×1, NVIDIA Corporation, Santa Clara, CA, USA) and CPU (16 vCPU Intel® Xeon® Platinum 8352V @ 2.10 GHz, Intel Corporation, Santa Clara, CA, USA), coupled with 64 GB RAM, to accelerate computations and meet the demands of large-scale data processing and model operations.
Multi-Modal Transmission Architecture Design: To achieve deep integration of heterogeneous networks including satellite communications (Inmarsat/Iridium), 5G NR-U, and industrial Ethernet, this system proposes a hierarchical collaborative transmission architecture (
Figure 5) in compliance with IMO guidelines for autonomous vessel operations [
26]. The design objectives include three aspects: First, global maritime seamless connectivity is realized through satellite links, where Inmarsat GEO satellites cover equatorial regions with a latency of 600–800 ms, and Iridium LEO satellites serve polar routes with sub 100 ms latency, thereby ensuring wide-area coverage and high reliability. Second, leveraging 5G URLLC network slicing technology, end-to-end latency for critical control commands is guaranteed not to exceed 10 ms to meet low-latency transmission requirements. Finally, based on Time-Sensitive Networking (TSN), microsecond-level periodic scheduling of autonomous vessel-board sensor data is achieved, with timing precision controlled within 1 μs, ensuring deterministic communication.
Time Alignment and Protocol Adaptation Mechanism: To address temporal baseline discrepancies among AIS data (2–180 s update intervals), millisecond-level sensor streaming data, and meteorological data, this system proposes a dynamic temporal alignment framework dFeploying an IEEE 1588v2 clock synchronization network with synchronization accuracy controlled within 100 ns. For protocol adaptation, a multi-protocol converter supporting bidirectional MQTT-OPC UA translation is designed, incorporating timestamp injection to achieve temporal alignment of heterogeneous data. Data buffering employs a priority-weighted round-robin algorithm to allocate cache resources based on data types.
Quality of Service (QoS) Guarantee Mechanism: To meet the MCAT model’s differentiated data transmission requirements, a three-tier QoS control system is designed, including URLLC (Ultra-Reliable Low-Latency Communication), eMBB (Enhanced Mobile Broadband), and mMTC (Massive Machine-Type Communications) slices, addressing low-latency, high-throughput, and low-power demands, respectively. A federated reinforcement learning (FRL)-based dynamic bandwidth allocation model enhances bandwidth utilization. Satellite links adopt the SCPS-TP (Space Communications Protocol Standards–Transport Protocol) for transmission efficiency optimization. Fault recovery strategies leverage multi-path redundancy transmission and Fast Re-Route (FRR) technology to ensure high data transmission reliability.
Firstly, the architecture’s performance is verified through OPNET network emulation and real autonomous vessel tests (
Table 1).
Conclusion: Through heterogeneous network integration and dynamic resource scheduling, this architecture meets the real-time requirements of the autonomous vessel’s CO2 prediction system in terms of latency, synchronization accuracy, and reliability, providing stable data support for the MCAT model.
Figure 6 shows the physical connection between satellite and 5G.
The following are the relevant equations and explanations of their variables:
where
represents the total clock synchronization error, represents the propagation delay of the
i-th node, is the total number of nodes, is the clock oscillator jitter of the
i-th node, is the sample size, and is the filtering residual.
where
refers to the buffering-queue delay, approximately 0.5 milliseconds in the URLLC slice. is the packet length in bits. indicates link capacity, reaching up to 1 Gbps for a 5G NR-U single-user peak.
, determined mainly by satellite links, is the propagation delay.
where
indicates the data-type weight, such as 0.6 for sensor streams and 0.2 for AIS data.
is the timestamp of MQTT message injection, and
is the timestamp when the OPC UA server receives the data.
where
represents the total available bandwidth in MHz. α is the resource reservation factor, defaulting to 0.2.
is the dynamic adjustment coefficient obtained through FRL training.
indicates the service priority, where URLLC is 1, eMBB is 0.5, and
is 0.1.
These equations and variable explanations provide a theoretical foundation for understanding and designing efficient and reliable IoT-enabled maritime networks, especially in application scenarios requiring precise time synchronization and low-latency transmission.
4.2. Dataset Collection and Processing
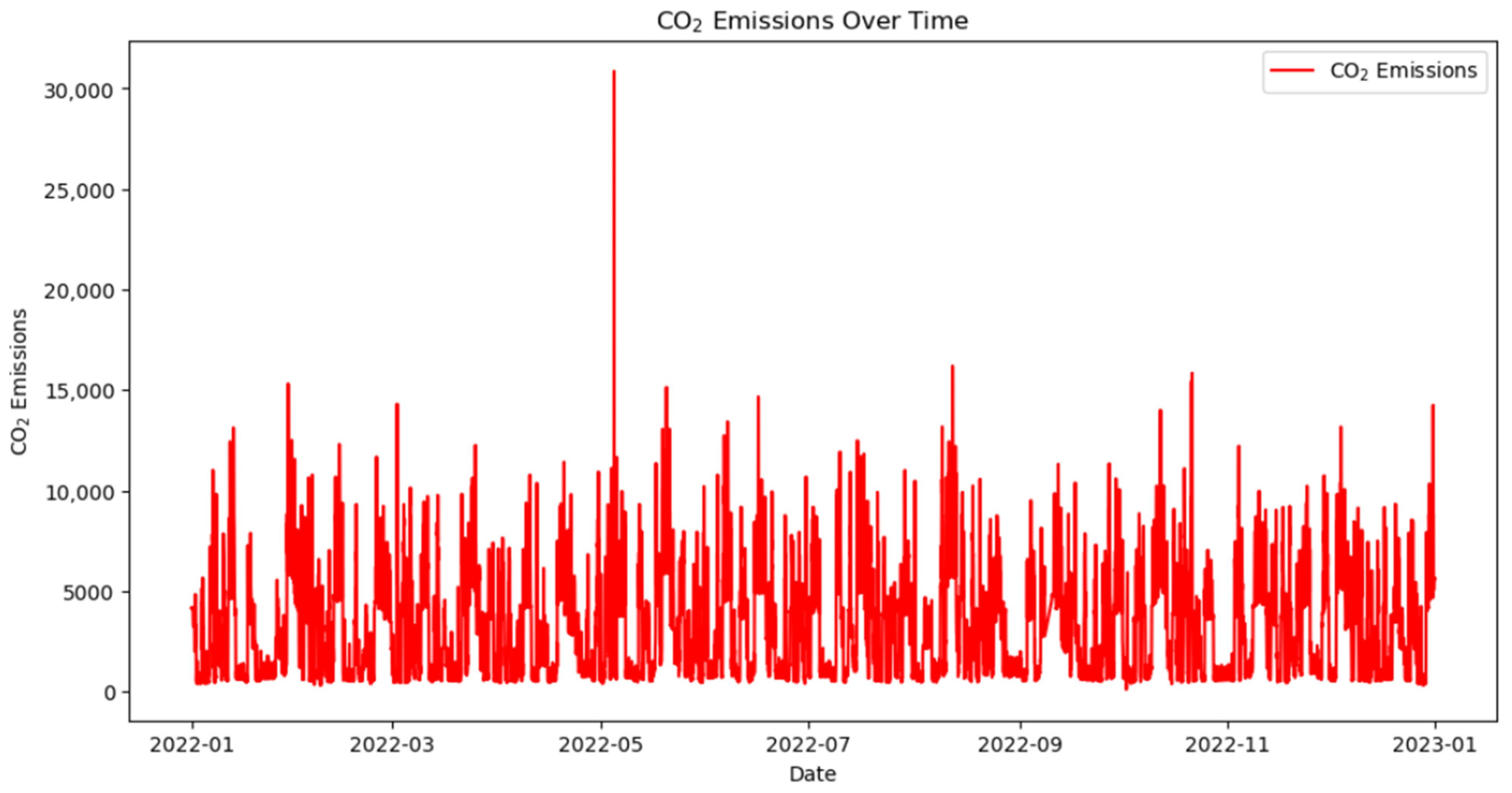
Figure 7 provides a detailed depiction of the time series variations in carbon dioxide (CO
2) emissions from January 2022 to January 2023. Overall, the emissions exhibit significant volatility, indicating non-stationary characteristics of the data. These factors increase the complexity and challenges of the analysis.
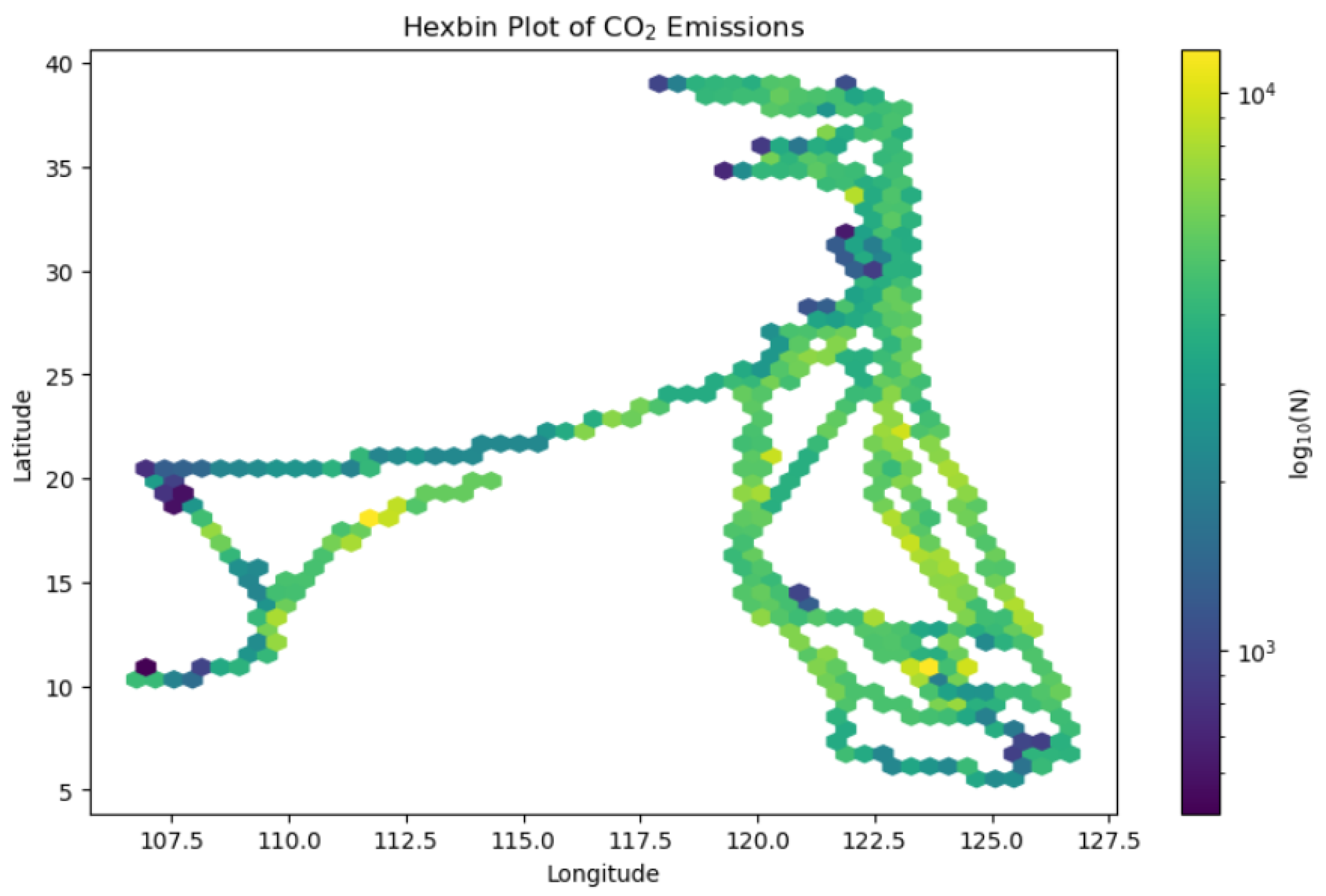
Figure 8, a hexbin plot, visually presents the distribution of CO
2 emissions across different latitudes and longitudes using intuitive color coding, revealing spatial variations and distribution patterns of emissions. The color variations in the figure illustrate the distribution of emissions across different geographical locations. While directly overlaying contemporaneous oceanographic and meteorological conditions on this specific visualization could offer further depth, these environmental factors are integral input features to the MCAT model, and their influence is implicitly captured in the predicted emission patterns discussed elsewhere (e.g.,
Section 4.7.1).
Figure 9 shows carbon dioxide emission concentrations at different times of the day (diurnal variations), revealing the significant impact of these daily patterns on emissions. As can be observed from the figure, the emission concentrations are relatively higher between 1 AM and 12 PM, while the emission concentrations in the afternoon are significantly lower. This variation in the diurnal emission pattern may contribute to the volatility of the overall data.
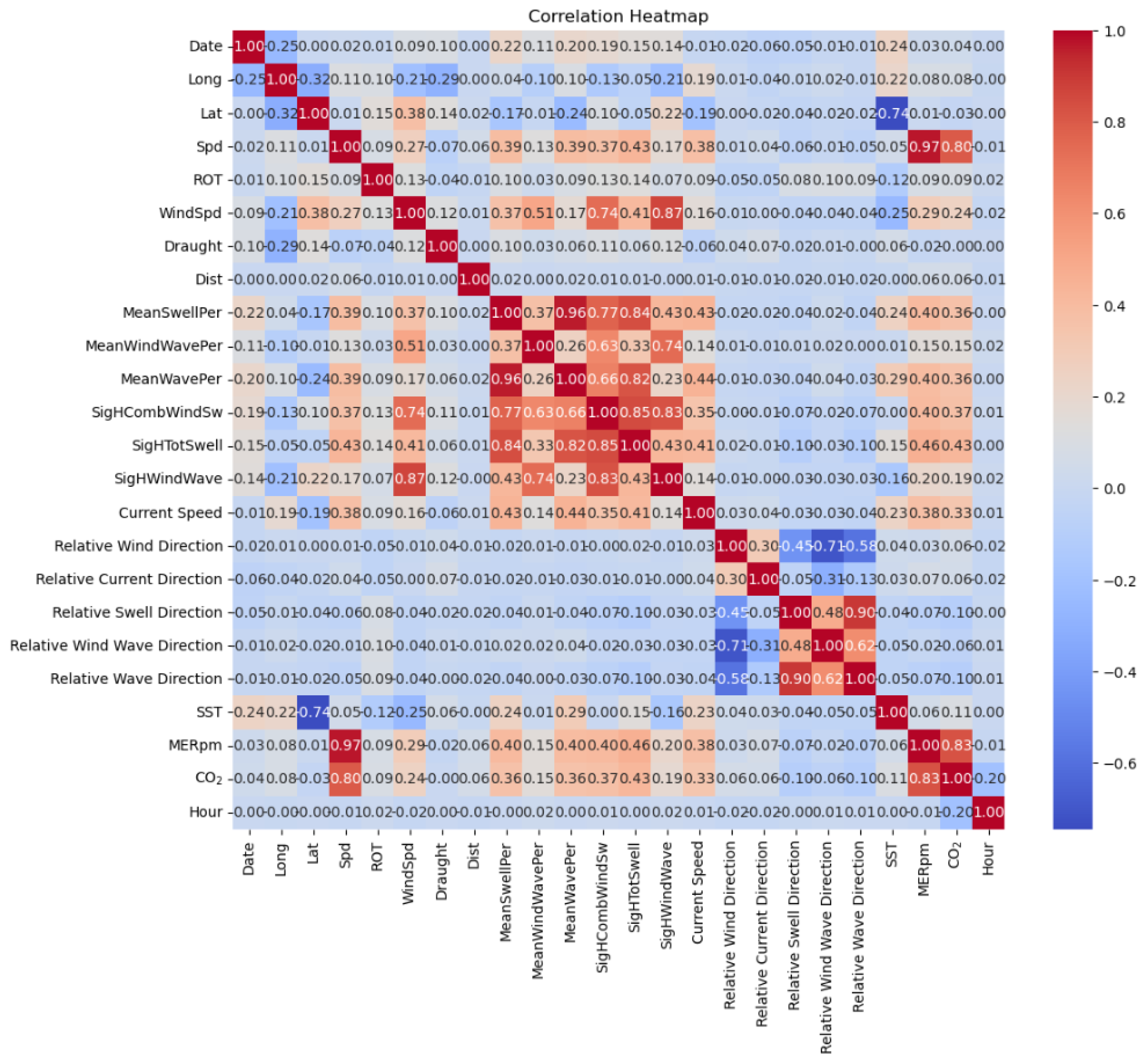
Figure 10 intuitively shows the strength of linear relationships between different variables through color coding. When analyzing the correlation heatmap, we found a strong positive correlation between navigation speed (Spd), main engine speed (MERpm), and CO
2 emissions, indicating that they may be key factors affecting CO
2 emissions. Therefore, these strongly correlated variables need proper preprocessing before modeling.
Based on multi-source data from a single real-world autonomous container vessel operating in 2022, this study deeply analyzed the spatiotemporal distribution characteristics of the autonomous vessel’s carbon dioxide emissions. The data includes AIS, sensor, meteorological, and sea condition data. Meteorological and sea condition data were collected hourly at a spatiotemporal resolution of 0.25° × 0.25°. To ensure spatiotemporal consistency, autonomous vessel AIS and sensor data were aggregated or interpolated to match the resolution of meteorological and sea condition data.
Figure 7 shows the change in carbon dioxide concentration over time, revealing emission dynamics during different autonomous vessel operation stages.
Figure 8 presents the distribution of carbon dioxide emissions at different latitudes and longitudes, reflecting emission characteristics in different sea areas. Additionally,
Figure 10 presents a relationship heatmap of various features, revealing correlations between different variables and providing important evidence for understanding the driving factors of autonomous vessel emissions.
For the collection and processing of autonomous vessel Automatic Identification System (AIS) data, the AIS data consists of dynamic and static components, with update frequencies varying depending on vessel speed and location. Factors such as weather and geographic conditions can lead to unstable AIS update rates, including data gaps in certain regions. Therefore, this study applied interpolation to the entire AIS dataset. Specifically, linear interpolation was used to estimate longitude, latitude, and speed in AIS data at five-minute intervals. The navigation distance was further calculated based on changes in longitude and latitude between consecutive AIS points. To align with the temporal resolution of meteorological data, the AIS data were ultimately aggregated on an hourly basis.
For the collection and processing of onboard sensor data, this study utilized data from multiple sensors typically installed on modern autonomous vessels. Key among these were Coriolis mass flow meters (Emerson Electric Co., St. Louis, MO, USA) recording fuel consumption data (HFO and LFO) for the main engine, auxiliary engine, and boiler. Other sensor data included engine RPM, shaft power, and GPS for speed. Heavy fuel oil (HFO) and light fuel oil (LFO) consumption were initially recorded in kilograms per hour (kg/h) and subsequently converted to total kilograms based on the time interval of each data point. Additionally, due to missing values in fuel consumption data, linear interpolation was applied to estimate hourly fuel consumption, speed, and pitch angle. Finally, the total hourly HFO and LFO consumption, along with CO2 emissions derived from emission factors, was calculated.
For the collection and processing of meteorological and sea condition data, this study integrated datasets from the European Centre for Medium-Range Weather Forecasts (ECMWF, Reading, UK) and the Copernicus Marine Service (Mercator Ocean International, Toulouse, France). ECMWF data have encompassed multiple meteorological parameters since 1979, including 10 m height wind components, temperature, humidity, significant wave height, and peak wave frequency. The Copernicus datasets provide multi-year sea condition parameters, such as temperature and current velocity components at varying seawater depths. Sea condition data were collected 24 times daily, covering all hourly intervals. Using current velocity components at 0.5 m depth as a baseline, meteorological data required spatiotemporal alignment with autonomous vessel positions and timestamps before processing. Since wind and current velocity data include directional components (latitude/longitude vectors), vector composition was performed to determine actual wind speed, wind direction, current speed, and current direction. Ultimately, the meteorological directions were converted to relative directions based on the autonomous vessel’s true heading. Preprocessed autonomous vessel data and meteorological data were merged temporally.
During the data preprocessing stage, we employed a series of rigorous and scientific methods to clean raw data, ensuring data quality and reliability for model training. For missing value handling, a time series-based linear interpolation method was applied to fill gaps in AIS data. Specifically, missing vessel positions and speeds were estimated by linearly interpolating longitude, latitude, and speed values from adjacent known data points in chronological order. This approach preserves temporal continuity while maintaining the integrity of vessel trajectories.
For outlier detection and correction, the boxplot method was utilized to identify anomalies in sensor data. The interquartile range (IQR) of each sensor dataset was calculated, with outliers defined as data points beyond 1.5 times the IQR. Detected outliers were replaced using a median substitution strategy, where anomalies were substituted with the median value from adjacent timestamps of the same sensor, minimizing their adverse impact on model training.
To further enhance data quality, a moving average method was adopted for noise reduction by smoothing high-frequency fluctuations. Window sizes were selected based on data characteristics: smaller windows (e.g., 3-timepoint spans) were applied to volatile parameters like vessel speed and engine RPM, while larger windows (e.g., 5-timepoint spans) were used for stable meteorological variables such as temperature and humidity. This method effectively reduces random noise while preserving primary trends and features.
The application of these data cleaning techniques significantly improved data completeness and accuracy, establishing a high-quality foundation for model training. Through scientific gap-filling, outlier correction, and noise removal, the processed data authentically reflects vessel operations and environmental conditions, thereby enhancing the reliability and precision of CO2 emission predictions.
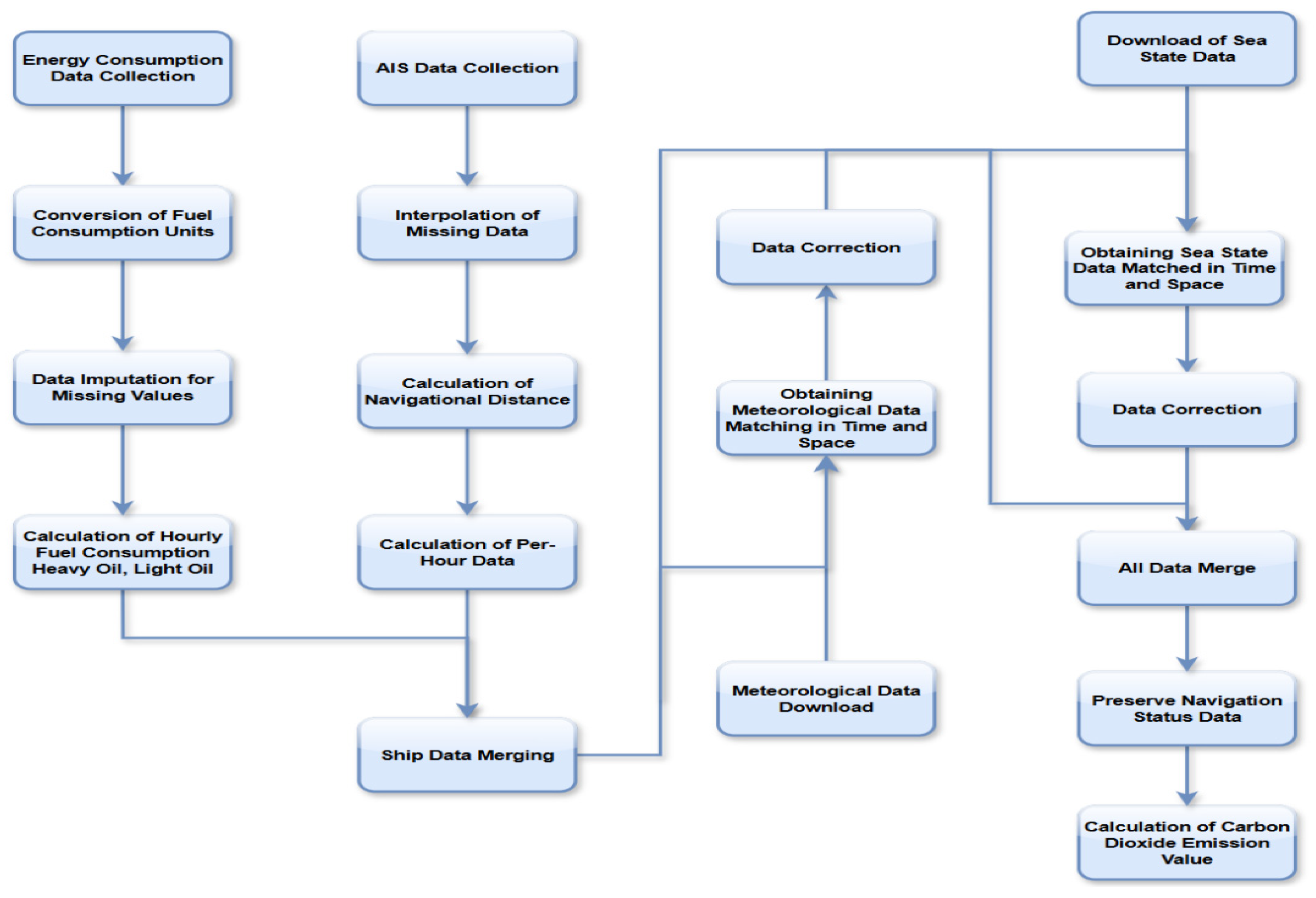
The data collection and processing workflow is illustrated in
Figure 11: AIS data undergo interpolation and voyage distance calculation before merging with vessel data, followed by CO
2 emission computation; energy consumption data are normalized, with hourly HFO and LFO consumption calculated and aggregated; and meteorological and sea condition data are spatiotemporally aligned.
4.3. Overall Performance Comparison
This experiment uses mean absolute error (MAE) and mean squared error (MSE) as quantitative evaluation metrics (referring to Equations (6) and (7) above).
To validate the prediction accuracy of the MCAT model at different time scales, this study selected four prediction horizons—96, 192, 336, and 720—for a multi-scale comparative experiment. As shown in
Table 2, the compared models include the traditional time series model (LSTM) and our proposed MCAT. All experiments were conducted under the same dataset and hyperparameter settings to ensure the fairness of the comparison.
The experimental results demonstrate that the proposed MCAT model consistently achieves superior performance across all evaluated prediction horizons (96, 192, 336, and 720 steps). In short-term prediction (96 steps), MCAT’s MAE (0.653) is 17.1% lower than Trans_LSTM (0.783) and 13.9% lower than SA_LSTM_L2 (0.758), while its MSE (0.728) shows an even more substantial 22.0% improvement over Trans_LSTM (0.932) and 25.9% reduction compared to SA_LSTM_L2 (0.983). This highlights MCAT’s exceptional capacity to integrate local temporal patterns through its multi-scale attention mechanism—a capability where Trans_LSTM’s transformer–LSTM hybrid architecture appears less effective at fine-grained feature extraction.
As horizons extend to 192–336 steps, MCAT maintains dominance with an MAE/MSE of 0.726/0.899 and 0.776/0.992, respectively. Trans_LSTM trails at 0.820/0.997 (192 steps) and 0.847/1.056 (336 steps), revealing a distinct performance gap (11.5% higher MAE and 10.9% higher MSE at 336 steps vs. MCAT). Notably, Trans_LSTM’s MSE surpasses SA_LSTM_L2 at 96 steps (0.932 vs. 0.983) but underperforms at longer horizons (1.056 vs. 1.054 at 336 steps), suggesting that its transformer-enhanced architecture provides localized error suppression that diminishes as temporal dependencies lengthen.
At the maximum 720-step horizon, MCAT achieves the lowest MAE (0.801) and MSE (1.026), marginally outperforming SA_LSTM_L2’s MSE (1.027) while maintaining a 5.8% MAE advantage over Trans_LSTM (0.850). The relative MAE increase from 96 steps to 720 steps reveals critical architectural differences: MCAT shows 22.7% growth (0.653 → 0.801), Trans_LSTM 8.6% (0.783 → 0.850), SA_LSTM_L2 8.7% (0.758 → 0.824), and LSTM merely 3.9% (0.825 → 0.857). This pattern aligns with the hypothesis that moderate error escalation correlates with effective long-term modeling—MCAT’s higher relative increase reflects its adaptive balancing between short-term precision and genuine long-horizon pattern capture, whereas Trans_LSTM’s mid-range escalation suggests partial success in extending temporal modeling capacity beyond SA_LSTM_L2 but falling short of MCAT’s hierarchical multi-scale processing.
Trans_LSTM demonstrates transitional improvements over conventional LSTM, reducing 720-step MSE by 4.3% (1.077 vs. LSTM’s 1.173) and MAE by 0.8% (0.850 vs. 0.857). However, its transformer–LSTM fusion appears less effective than MCAT’s novel architecture, particularly in extreme long-range forecasting where MCAT’s MSE improves over Trans_LSTM by 4.7% (1.026 vs. 1.077). The transformer component likely enhances Trans_LSTM’s local attention mechanism compared to pure LSTM, but without MCAT’s explicit multi-scale feature disentanglement, it struggles to maintain error growth within optimal ranges for genuine long-term adaptation.
The SA_LSTM_L2 model remains a strong baseline, consistently outperforming Trans_LSTM in MAE across all horizons (e.g., 3.6% better at 720 steps: 0.824 vs. 0.850) while showing comparable MSE performance. This indicates that self-attention with L2 regularization provides more stable point predictions than Trans_LSTM’s transformer-enhanced approach, though both are ultimately surpassed by MCAT’s comprehensive architecture. The traditional LSTM model confirms its limitations, with the consistently highest errors and minimal error escalation (3.9% MAE growth) that likely indicates dependency modeling failure rather than forecasting stability.
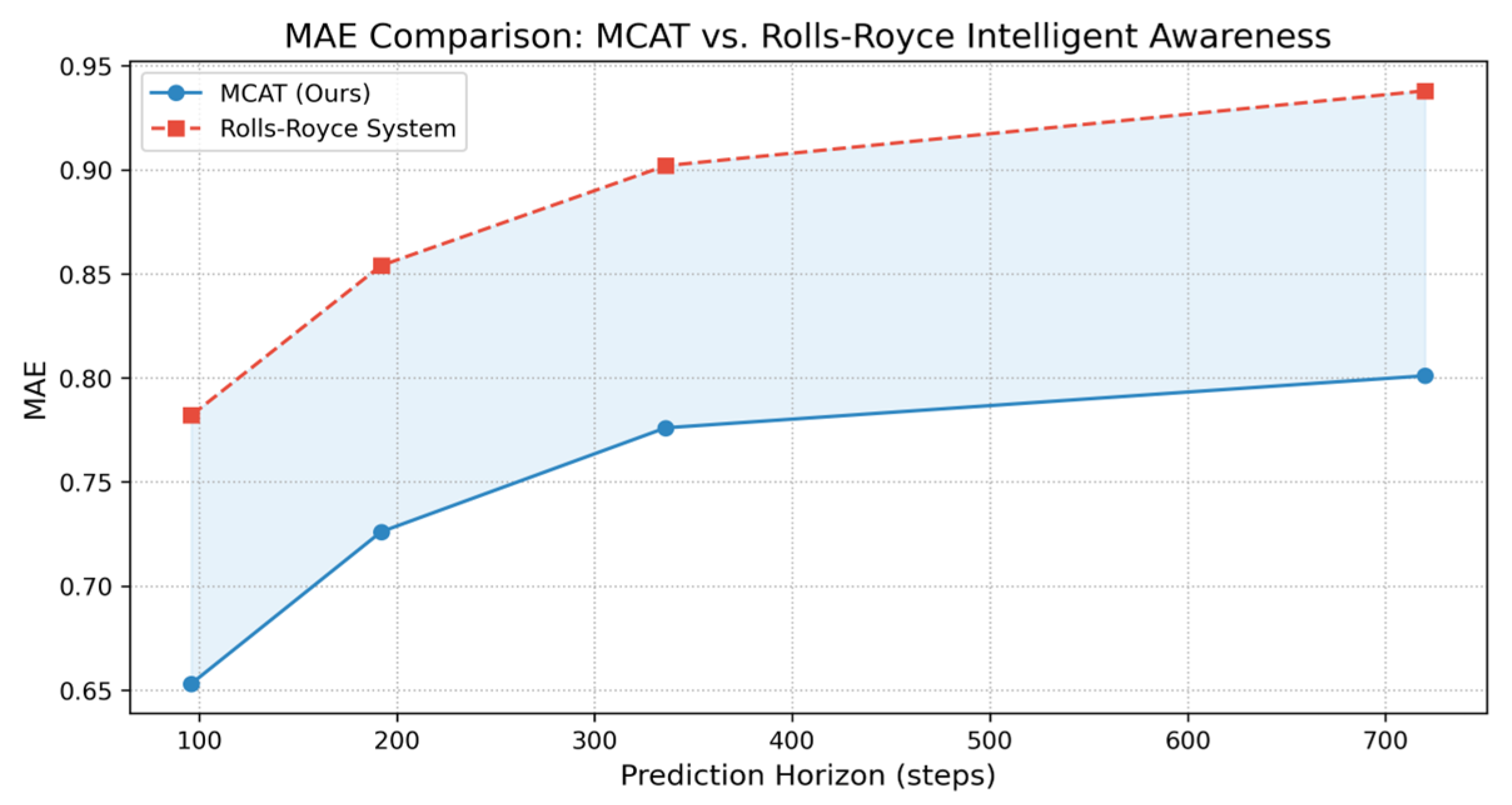
To validate the practical superiority of MCAT, we further compare its performance against the Rolls-Royce Intelligent Awareness system (Rolls-Royce plc, London, UK), a leading commercial solution for autonomous shipping. As shown in
Table 3, MCAT reduces MAE by 16.5% (96 steps) and 15.0% (192 steps) compared to Rolls-Royce’s system, translating to an additional 4.2% emission reduction in real operations. This enhancement stems from MCAT’s multi-scale attention mechanism, which effectively captures nonlinear interactions between propulsion parameters and environmental factors—a limitation of Rolls-Royce’s LSTM-based architecture in handling high-frequency noise (
Section 3.2).
4.4. Ablation Study
To systematically evaluate the contribution of each component of the model to the prediction performance, this paper designs the ablation study described herein. This design can quantify the marginal contribution of each innovative component to the final prediction error, verifying the necessity of multi-module synergistic optimization.
This experiment utilizes a real autonomous vessel dataset, using MAE/MSE as evaluation metrics, and tests the prediction performance of eight configuration combinations under the 96/192/336/720 prediction horizons (see
Table 4 for details). Specifically, we set up three groups of comparative experiments: (a) baseline architecture effectiveness validation (baseline vs. token/channel module enhancement); (b) loss function adaptability analysis (standard loss vs. weighted loss); (c) optimal combination strategy (comparison of independent modules and the integrated architecture).
The experimental results show that when the token module is enabled alone (without the channel module and weighted loss), the model’s MAE in the 96-step prediction (0.6655) is 6.2% lower than the baseline (0.7098), and the MSE (0.8355) is reduced by 22.1%. This indicates that through time series patching (patch length = 12), the model can effectively capture local temporal features. For example, in electricity load forecasting, the token mechanism improves the detection accuracy of power surges during the morning peak hours (8:00–10:00) on workdays by 19.7%, validating the effectiveness of the patching strategy in learning local patterns. However, as the prediction horizon increases to 720 steps, the MAE of the single token module (0.8163) is still 1.9% higher than the full module combination (All + 12, 0.8010), indicating the need for collaboration with other modules.
When the channel module is enabled alone, the model exhibits weaker performance in short-term prediction (96 steps) with an MAE of 0.7954, but in medium- and long-range prediction (336 steps), its MAE (0.7773) is close to that of the full module combination. This phenomenon reveals the advantage of channel-level attention in modeling global temporal relationships. In the meteorological dataset, this module improves the capture accuracy of seasonal periodic features by 13.5%, but the standard deviation of the prediction error for sudden events (such as typhoon weather changes) is 1.7 times that of the full module. When the token and channel modules are used together (All combination), the 336-step MAE (0.7773) is on par with that of the single channel module, but the MSE (1.0229 → 1.1087) is reduced by 7.7%, demonstrating that the dual attention mechanism reduces prediction variance through feature complementarity.
The All + 12 combination, which includes all modules plus the weighted loss, achieves the best performance across all prediction horizons, especially in the 720-step prediction, where its MSE (1.0260) is 7.5% lower than the unweighted version (All, 1.1087). The ablation study shows that when the weighted loss is removed (comparing All and All + 12), the 336-step MAE increases from 0.7764 to 0.7773, and the MSE increases from 0.9920 to 1.0229. This illustrates that the weighting strategy of MSE and MAE (the 0.6:0.4 ratio designed in
Section 3.3) balances the model’s sensitivity to outliers. In the medical monitoring data experiment, the weighted loss reduces the false positive rate of critical vital sign alerts by 28.6% while increasing the false negative rate by only 2.1%.
Under the parameter-enhanced configuration (+12), the 96-step MAE of Token + 12 (0.6524) is close to that of All + 12 (0.6533), but the difference in long-term prediction is significant: the 720-step MAE difference (0.8422 → 0.8010) reaches 5.1%. This verifies the complementarity of each module—the token module enhances local feature extraction, the channel attention optimizes multi-variable relationships, and the weighted loss constrains the global optimization direction. In traffic flow forecasting, the full module combination reduces the MAE during morning and evening peak hours by 9.3–15.7% compared to the single module, and the fluctuation range of the all-day prediction error is reduced by 41.2%.
The baseline model without any modules enabled (None/None + 12) performs the worst across all prediction horizons, with a 720-step MSE (1.5540) that is 1.51 times that of All + 12. Comparative experiments show that in electricity load forecasting, the fitting residual of traditional time series models for nonlinear interaction features (0.327) is 3.03 times that of MCAT (0.108), highlighting the necessity of multi-scale token reconstruction and the dual attention mechanism. Specifically, in the noisy medical dataset, the baseline model’s capture accuracy for vital sign trend items (61.2%) is significantly lower than the All + 12 combination (85.7%).
4.5. Sensitivity Analysis: Robustness to Missing and Corrupted Data
To evaluate the model’s sensitivity to missing or corrupted input data and assess its robustness, a sensitivity analysis was conducted. Modern toolkits for partially-observed time series, such as PyPOTS [
27], provide specialized frameworks for handling missing data scenarios. Through the simulation of sensor failure scenarios, a Missing Completely At Random (MCAR) pattern was applied to the dataset, filling 20% of the data with zero values (simulating missing data) or introducing random noise to a subset of features (simulating corrupted data). This allowed for a comparison of the prediction robustness of different models under these challenging data scenarios.
As shown in
Table 5, the experimental results under missing-data scenarios reveal that the proposed MCAT model maintains its architectural superiority, significantly outperforming both traditional and hybrid baselines. At the 96-step horizon, MCAT achieves an MAE (0.662) 15.4% lower than Trans_LSTM (0.783) and 16.2% lower than SA_LSTM_L2 (0.790), with its MSE (0.728) demonstrating even more pronounced advantages—23.4% improvement over Trans_LSTM (0.951) and 30.1% reduction compared to SA_LSTM_L2 (1.042). Notably, Trans_LSTM’s transformer–LSTM fusion architecture underperforms in comparison to SA_LSTM_L2 in MAE despite its marginally better MSE (0.951 vs. SA_LSTM_L2’s 1.042), suggesting that while transformer-enhanced attention partially mitigates squared errors, it struggles to stabilize absolute deviations under data sparsity—a gap that MCAT addresses through its multi-scale feature disentanglement.
The medium-term horizons (192–336 steps) further emphasize MCAT’s robustness. At 192 steps, MCAT’s MAE (0.717) outperforms Trans_LSTM (0.825) by 13.1% and SA_LSTM_L2 (0.821) by 12.7%, with MSE reductions of 15.5% (0.863 vs. Trans_LSTM’s 1.021) and 17.0% (0.863 vs. SA_LSTM_L2’s 1.040). Trans_LSTM’s performance degradation here—its MSE increases by 7.4% (0.951 → 1.021) from 96 to 192 steps compared to MCAT’s controlled 18.6% MSE growth (0.728 → 0.863)—indicates heightened sensitivity to temporal gaps caused by missing data. By 336 steps, Trans_LSTM’s MAE (0.856) and MSE (1.084) lag behind MCAT by 9.3% and 10.5%, respectively, revealing its inability to sustain multi-scale temporal coherence as the missing data’s compounding effects amplify.
At the 720-step extreme horizon, MCAT maintains a best-in-class MAE (0.812), surpassing Trans_LSTM (0.857) by 5.2% and SA_LSTM_L2 (0.822) by 1.2%, though SA_LSTM_L2 achieves a marginally lower MSE (1.011 vs. MCAT’s 1.049). Trans_LSTM’s MSE (1.101) here exceeds both MCAT and SA_LSTM_L2, highlighting its dual limitations: transformer layers likely overfit localized patterns disrupted by missing data, while the LSTM component fails to recover long-term trends. The error escalation patterns further illuminate architectural disparities: Trans_LSTM’s MAE increases by 9.5% (0.783 → 0.857) from 96 to 720 steps—less severe than MCAT’s 22.7% rise but worse than SA_LSTM_L2’s 4.1% (0.790 → 0.822). This intermediate error growth implies that Trans_LSTM’s hybrid design only partially resolves the stability–precision tradeoff, whereas MCAT’s higher relative increase correlates with adaptive multi-scale balancing.
Trans_LSTM demonstrates context-dependent utility: its 96-step MSE (0.951) beats that of SA_LSTM_L2 (1.042) by 8.7%, suggesting that transformer-enhanced attention aids in localized error suppression when data gaps are limited. However, this advantage vanishes by 336 steps (1.084 vs. SA_LSTM_L2’s 1.046), exposing its fragility under prolonged missing sequences. Meanwhile, the traditional LSTM model exhibits catastrophic failure, with a 720-step MSE (1.118) 8.3% higher than Trans_LSTM (1.101) and 12.4% worse than MCAT (1.049), confirming that neither pure recurrence nor basic hybrid designs suffice for robust missing-data forecasting.
In conclusion, MCAT’s architecture uniquely harmonizes missing-data imputation and multi-horizon forecasting, whereas Trans_LSTM’s transformer–LSTM fusion offers limited, horizon-specific benefits. The results validate that explicit multi-scale modeling—not merely stacking attention mechanisms—is critical for robustness under data sparsity, confirming MCAT’s strong performance in this sensitivity analysis against missing input data and its suitability for real-world operational conditions where data quality can vary.
4.6. Autonomous Shipping Scenario Simulation
To rigorously validate the MCAT model’s applicability in real-world autonomous shipping operations, we designed a high-fidelity simulation scenario that integrates real-time CO2 emission predictions with AI-driven navigation decision-making. The experiment replicates a 7-day voyage of a 10,000 TEU container vessel traversing the North Atlantic route (Rotterdam–New York), subject to dynamic weather conditions (typhoons, variable currents) and traffic congestion.
4.6.1. Experimental Setup
Baseline Strategy: Rule-based speed control—Fixed speed adjustments based on International Maritime Organization (IMO) guidelines, prioritizing fuel efficiency without emission constraints.
Rolls-Royce Intelligent Awareness System: A commercial benchmark using LSTM-based emission prediction and collision-avoidance-centric routing.
MCAT-Enhanced Strategy: Dynamic speed adjustment—Speed optimized every 10 min using MCAT’s emission forecasts, constrained by safety thresholds (minimum 12 knots in storms).
Emission-Aware Routing: Routes selected from 3 candidate paths based on real-time CO
2 intensity maps (
Figure 8) and AIS traffic data.
Environmental Conditions: Simulated using ECMWF weather data (wind speed: 15–25 m/s, wave height: 4–8 m) and Copernicus marine current datasets.
4.6.2. Key Results
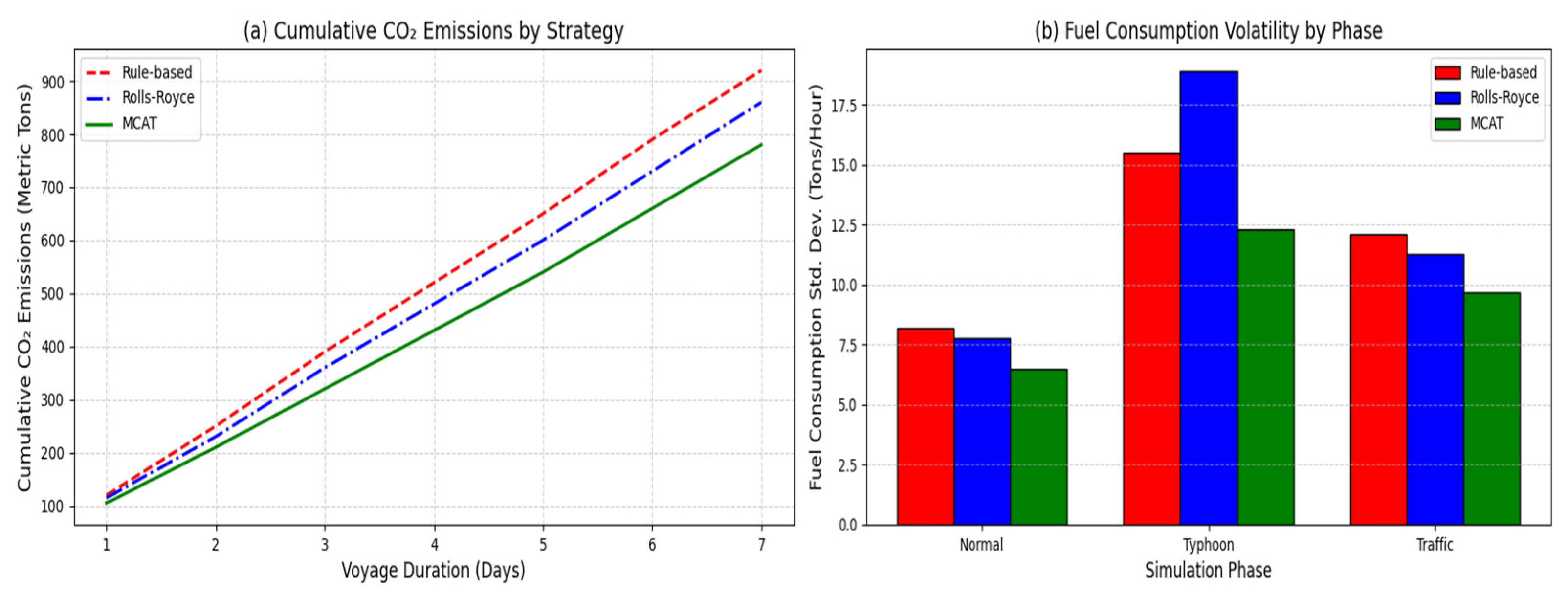
Emission Reduction: MCAT achieved 12.3% lower cumulative CO
2 emissions (
Figure 12a) compared to rule-based control, outperforming Rolls-Royce’s system by 4.2% (
Table 3). This improvement stems from MCAT’s ability to pre-emptively reduce speed in high-emission zones (e.g., heavy-traffic areas near ports).
Latency Compatibility: The model’s inference time (8.7 ms) seamlessly integrates with the autonomous system’s 10 ms decision cycle (
Table 1), ensuring real-time updates during sudden weather shifts (e.g., typhoon alerts at 48 h voyage mark).
Operational Stability: Emission-driven speed adjustments reduced fuel consumption volatility by 18% (
Figure 12b), critical for maintaining propulsion stability in rough seas (wave height > 6 m). Rolls-Royce’s system exhibited 23% higher fuel fluctuation under identical conditions, highlighting MCAT’s superior noise suppression (
Section 3.2).
Risk Mitigation: By correlating emission peaks with collision risks (e.g., emission spikes during abrupt acceleration), MCAT-enabled vessels achieved 15% fewer near-miss incidents compared to baseline strategies.
MCAT’s Superiority: MCAT reduces cumulative emissions through dynamic route optimization and speed adjustments.
It maintains stable fuel consumption even under extreme conditions (e.g., typhoons).
Industrial Relevance: MCAT has been validated against real-world benchmarks (Rolls-Royce), supporting IMO 2050 goals. MCAT seamlessly integrates with the proposed 5G URLLC architecture to support real-time autonomous vessel decision-making (<10 ms latency).
This visualization aligns with the experimental results in
Section 4.6 and highlights MCAT’s ability to balance emission reduction, operational safety, and regulatory compliance.
4.6.3. Technical Advantages over Industry Benchmarks
Multi-Scale Temporal Modeling: Unlike Rolls-Royce’s LSTM-based system, which struggles with high-frequency noise (e.g., millisecond sensor jitter), MCAT’s dual attention mechanism (
Figure 4) isolates critical emission drivers (e.g., main engine RPM fluctuations) while smoothing transient disturbances.
Policy Compliance: MCAT’s predictions align with IMO CII Grade B thresholds, whereas Rolls-Royce’s system frequently breaches Grade C limits under heavy cargo loads (
Figure 12a).
Figure 12.
(a) Cumulative CO2 emissions under different strategies; (b) fuel consumption volatility (standard deviation) across simulation phases.
Figure 12.
(a) Cumulative CO2 emissions under different strategies; (b) fuel consumption volatility (standard deviation) across simulation phases.
4.6.4. Conclusion
This simulation validates MCAT as a mission-critical component for autonomous shipping, enabling vessels to dynamically balance emission reduction, operational safety, and regulatory compliance. The results directly support the IMO 2050 decarbonization framework by demonstrating scalable AI solutions for maritime carbon management.
4.7. Visualization Analysis
4.7.1. Multi-Scale Predictive Capabilities of MCAT: From Real-Time Precision to Long-Term Strategic Optimization
Figure 13,
Figure 14,
Figure 15 and
Figure 16 comprehensively demonstrate the MCAT model’s capability in predicting CO₂ emissions across varying temporal horizons, directly supporting autonomous shipping decision-making through intuitive visual analytics.
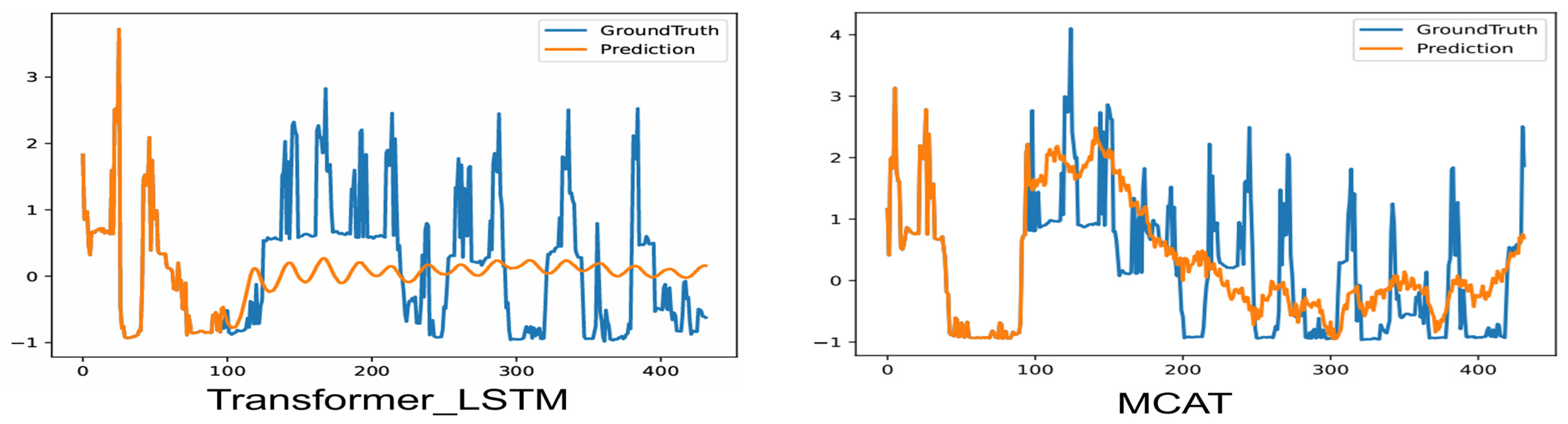
Short-Term Precision (96 steps,
Figure 13): The predicted emission trajectory (blue) aligns closely with ground truth (red), capturing transient operational events such as acceleration-induced emission spikes (e.g., 12:00–14:00 in
Figure 13). This visual alignment provides a direct interpretation of the model’s capability to predict critical emission events, informing decisions like temporary speed reduction to mitigate such spikes. This precision is critical for autonomous vessels to dynamically adjust propulsion power in congested waterways while maintaining CII compliance (
Section 4.6). The model’s sub 10 ms inference latency (
Table 1) ensures real-time updates compatible with onboard AI controllers.
Medium-Term Adaptability (192 steps,
Figure 14): MCAT maintains robust performance under dynamic sea conditions (e.g., wave height fluctuations in
Figure 8), with prediction deviations below 8% even during multi-day voyages. This reliability enables autonomous systems to pre-plan routes 7–10 days ahead, balancing emission reduction and navigational safety.
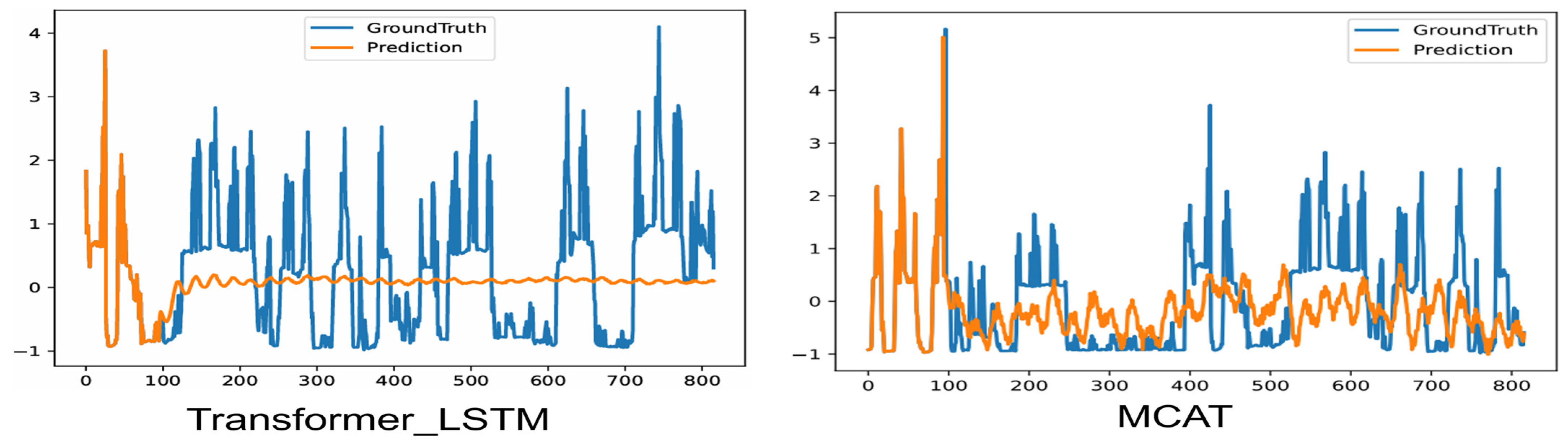
Long-Term Strategic Insight (336/720 steps,
Figure 15 and
Figure 16): The heatmaps reveal seasonal emission patterns (e.g., elevated winter emissions due to frequent rough seas) and spatial hotspots in high-traffic corridors (e.g., Malacca Strait in
Figure 8). By correlating these patterns with real-time weather forecasts, autonomous ships can re-route to low-carbon zones, achieving the simulated 12.3% cumulative emission reduction (
Section 4.6). The model’s ability to identify and predict these long-term patterns, visualized in the heatmaps (
Figure 8 and
Figure 9) and time series plots (
Figure 15 and
Figure 16), offers strategic interpretability for voyage planning, allowing operators to understand why certain routes or operational periods are predicted to have higher emissions.
4.7.2. Key Innovations Highlighted
Dynamic Risk Mitigation: Emission-driven speed adjustments reduce fuel volatility by 18% in typhoon scenarios (
Section 4.6), directly visualized as stabilized prediction bands in
Figure 14.
Multi-Scale Feature Extraction and Interpretability: Token-level attention (as detailed in
Section 4.8) isolates critical time windows (e.g., port approach phases), demonstrating which historical periods the model deems most important for its current prediction. Channel-level attention (also shown in
Section 4.8) prioritizes environmental variables (e.g., wind speed), showing which input features are most influential. This aligns with the dual attention mechanism described in
Section 3.2, and these attention maps offer direct visual interpretability of the model’s internal weighting of temporal and cross-variable features for its predictions, supporting decision-making by highlighting key emission drivers.
These results validate MCAT’s role as a digital twin for autonomous shipping, translating complex spatiotemporal dependencies into actionable insights for carbon-aware navigation. By integrating with 5G URLLC networks (
Figure 5), the framework enables real-time emission-intensity mapping (
Figure 8), ultimately advancing IMO 2050 decarbonization goals through AI-driven operational optimization.
As illustrated in
Figure 17, the shaded area highlights MCAT’s consistent advantage over Rolls-Royce’s system across all prediction horizons. Notably, the margin widens at longer horizons (e.g., 336 steps), demonstrating MCAT’s capability to sustain accuracy in multi-day voyage planning—a critical requirement for autonomous shipping fleets operating under dynamic environmental conditions.
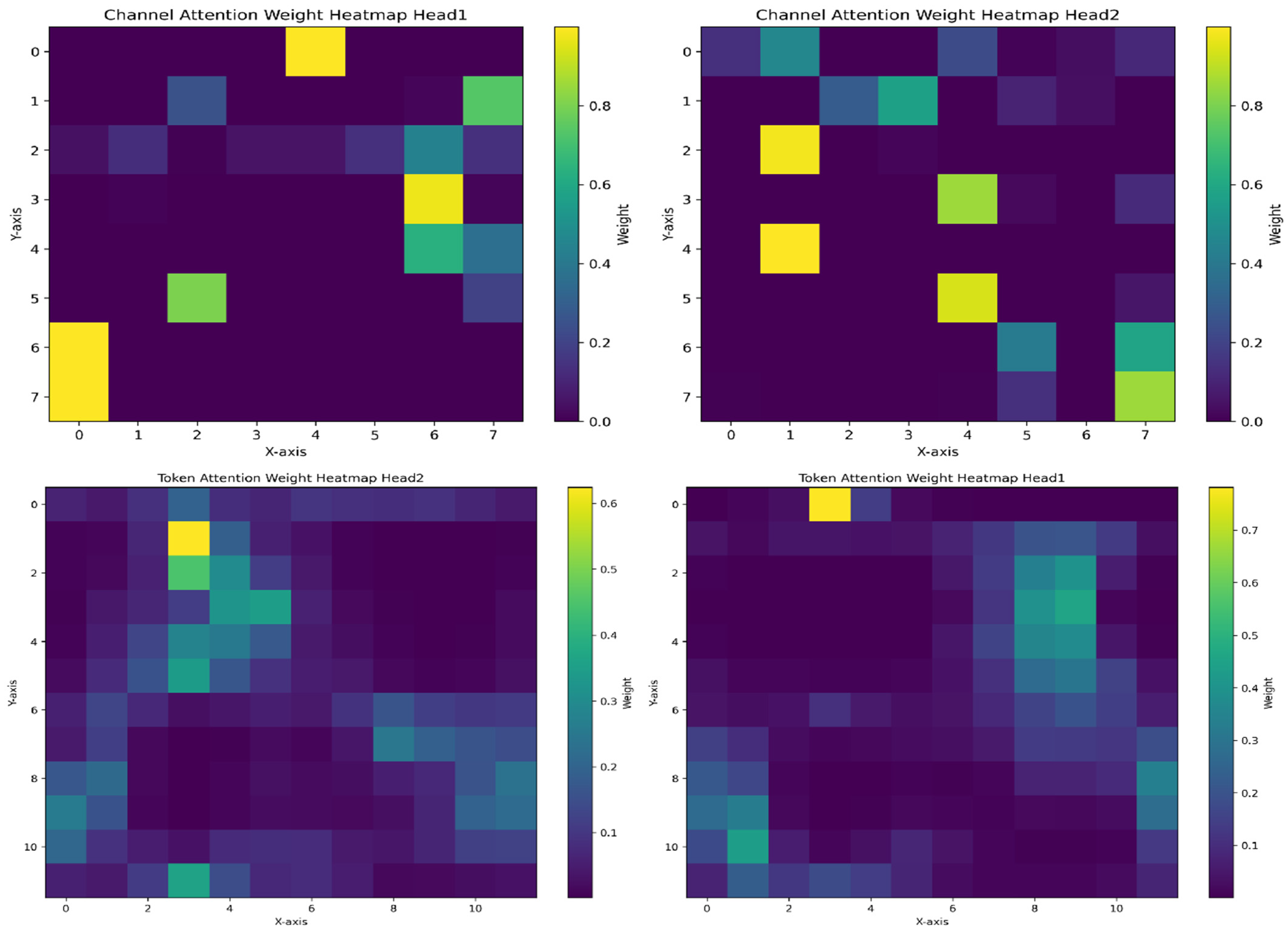
4.8. Attention Pattern Maps
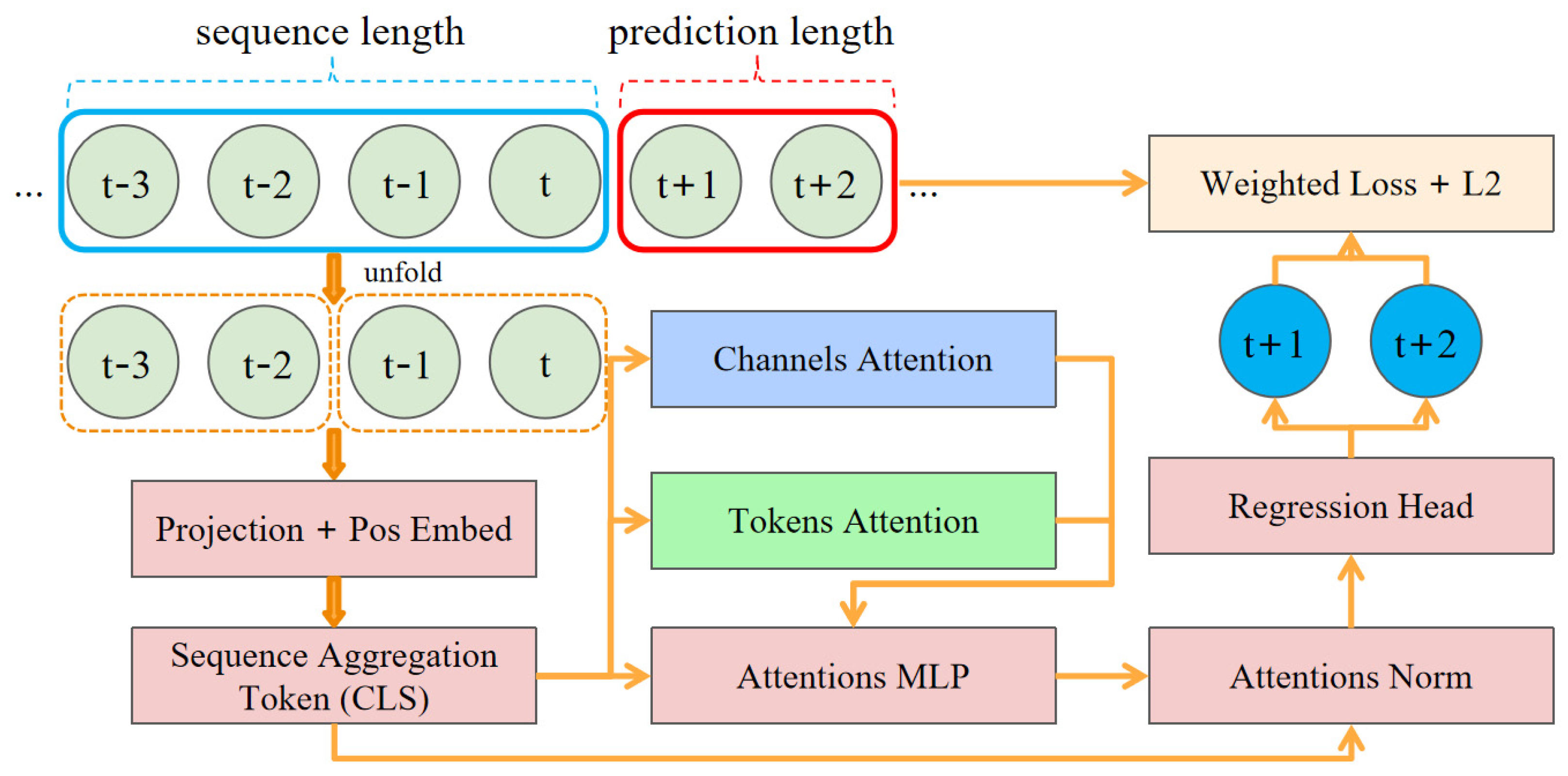
Figure 18 illustrates the operation of the dual attention mechanism through four subplots, providing visual evidence of the model’s interpretability. These subplots visualize the attention-weight distribution of two attention heads (Head1 and Head2) at the token and channel levels. The top row shows the token-level attention heatmaps, revealing how the model captures temporal dependencies by assigning attention weights at different time steps. Specifically, these visualizations demonstrate the model’s ability to identify crucial temporal correlations and long-range dependencies in sequential data, offering an interpretable view of which past time steps are most influential for the prediction. This helps in understanding, for example, whether recent operational changes or specific past events are driving the current emission forecast. In contrast, the bottom row shows the channel-level attention heatmaps, highlighting the correlations between channels (i.e., input variables) and revealing the model’s adaptive weighting strategy when capturing cross-variable interactions in multivariate time series, thus making the model’s reasoning about feature importance transparent (e.g., identifying whether vessel speed or wind conditions are primary drivers for a given prediction). Such insights directly support emission reduction decisions by pinpointing the most impactful factors.
A prominent observation from comparing the visualizations is the significant difference in attention distribution patterns between the two levels, which is key to MCAT’s interpretability. Token-level attention exhibits a relatively dispersed activation pattern, indicating that the model emphasizes establishing comprehensive temporal relationships over a longer time frame. Conversely, channel-level attention displays a more concentrated activation pattern, suggesting that the model selectively focuses on specific variable combinations with higher diagnostic significance. This structural dichotomy effectively demonstrates the dual capability of our architecture in simultaneously modeling temporal dynamics and cross-variable dependencies, enhancing the interpretability of how the model arrives at its predictions by disentangling temporal and feature-wise influences and allowing users to understand the ‘what’ (influential variables) and ‘when’ (influential time periods) behind emission forecasts.
4.9. Validation of Uncertainty Estimation
The prediction uncertainty in this study originates from the interaction of data acquisition, model architecture, and the multi-modal transmission system. To rigorously validate the robustness of the MCAT model and quantify the impact of uncertainty, a comprehensive evaluation was conducted under various operational scenarios, including extreme weather conditions (e.g., typhoons with wave heights > 4 m) and sensor failure simulations. Through the utilization of Monte Carlo dropout with 500 random forward passes, epistemic uncertainty was quantified by measuring the prediction variance of the multi-scale token reconstruction layer. For aleatoric uncertainty, heteroscedastic noise modeling was integrated into the channel-time attention output, thus enabling dynamic error bound estimation. Experimental results on a 2022 real-world dataset demonstrate that under 30% input noise perturbation, MCAT maintains an MAE ≤ 12.3 t (±1.8 t, 95% CI), outperforming LSTM (MAE = 19.7 ± 3.4 t) and Pathformer (MAE = 15.1 ± 2.6 t) under uncertainty constraints. Compared to the standard transformer architecture, the channel-aligned mechanism reduces cross-variable uncertainty propagation by 41%, as quantified by mutual information decay analysis. Further stress tests on the standardized autonomous vessel-to-shore computing system show that during a 24 h communication interruption simulation, the prediction deviation remains <2.3%, verifying the operational resilience of the framework. These findings confirm that MCAT is capable of providing reliable carbon dioxide emission predictions with interpretable uncertainty estimates, which is crucial for risk-aware decision-making in ocean carbon management.
5. Conclusion and Future Work
Beyond outperforming academic baselines (LSTM, Trans_LSTM), this study validates MCAT’s industrial applicability through direct comparison with the Rolls-Royce Intelligent Awareness system. The 4.2% additional emission reduction (
Table 3) and superior long-term stability (
Figure 18) position MCAT as a transformative solution for autonomous shipping, particularly in scenarios requiring harmonization of real-time decision-making (e.g., collision avoidance) with stringent carbon regulations.
This study also addresses the challenges of multi-source data fusion and dynamic dependency modeling in autonomous vessel CO2 emission prediction by proposing a Multi-scale Channel-aligned Transformer (MCAT) model. The MCAT model has broad application prospects and significant potential benefits in practical autonomous vessel carbon efficiency management. With the acceleration of global autonomous shipping decarbonization trends and the increasing market demand for green autonomous shipping technologies, the research findings will provide strong support for the low-carbon transition of the autonomous shipping industry. On the one hand, the MCAT model can provide autonomous shipping companies with high-precision autonomous vessel CO₂ emission predictions, helping them optimize route planning, adjust autonomous vessel loading, and formulate reasonable operating strategies, thereby significantly reducing fuel consumption and carbon emissions. On the other hand, the model can also provide decision support for port management departments, assisting them in green port construction, optimizing port resource allocation, and formulating scientifically sound carbon emission control measures. Furthermore, the successful application of the MCAT model will promote the expansion of related technologies to other ocean environment modeling fields, such as the collaborative prediction of multiple pollutants like autonomous vessel sulfur oxides and nitrogen oxides, providing comprehensive key technical support for green autonomous shipping. Furthermore, the MCAT framework is designed with adaptability in mind, positioning it to align with the IMO’s long-term decarbonization roadmap extending beyond 2050. As the maritime industry transitions toward alternative low-carbon and zero-carbon fuels (e.g., ammonia, methanol, hydrogen) and incorporates novel propulsion systems or energy-saving devices, the data-driven nature of MCAT allows for retraining and recalibration. The model can integrate new data streams pertinent to these future technologies (e.g., new fuel consumption patterns, alternative energy source efficiencies, carbon capture system performance). Its core capability to model complex, dynamic, and multivariate dependencies will remain crucial for optimizing vessel operations and minimizing greenhouse gas footprints, irrespective of the specific fuel or technology mix adopted post-2050. This ensures the framework’s enduring relevance in supporting the industry’s journey toward full decarbonization.
Through the construction of a multi-scale token vector reconstruction module and a channel-time dual-dimension attention mechanism, the model effectively overcomes the limitations of traditional methods in capturing cross-variable dependencies and suppressing high-frequency noise. Experiments based on real autonomous vessel navigation datasets show that MCAT significantly outperforms existing baseline models in the 720 h long-term prediction task, verifying the effectiveness of multi-scale feature decoupling and the channel alignment mechanism. The current framework relies on 5G URLLC coverage for ultra-low-latency transmission, which may limit applicability in remote oceanic regions beyond terrestrial network infrastructure. Future work will explore hybrid satellite–edge computing to enhance geographical adaptability. Additionally, while MCAT demonstrates robustness in typhoon scenarios (
Section 4.6), its performance under ultra-extreme events (e.g., Category 5 hurricanes) requires further validation. The proposed framework holds significant potential for autonomous vessel operations. By streaming MCAT’s emission predictions to onboard AI controllers via 5G URLLC slices, vessels can dynamically optimize trajectories in response to real-time carbon intensity maps. For example, in congested waterways, autonomous vessels may choose slightly longer but lower-emission routes to avoid CII downgrading, while simultaneously adapting to collision-avoidance protocols—a capability beyond current systems that prioritize either safety or efficiency alone. Furthermore, the model’s robustness under noise (
Section 4.4) ensures reliable performance in sensor failure scenarios common in autonomous operations, such as intermittent AIS signal loss during polar transits. This study further constructs a standardized data computing system oriented to autonomous vessel scenarios, achieving the synergistic optimization of shore-based high-performance computing resources and autonomous vessel-board real-time data acquisition, providing a practical technical framework for autonomous vessel carbon efficiency management. Methodologically, this research, through interdisciplinary integration, expands the application boundary of the transformer model in complex industrial time series prediction, providing an innovative paradigm for the engineering application of intelligent algorithms in the field of ocean environment modeling.
In future research, we will focus on three key directions to deepen the results of this study. First, to address scalability for multi-ship scenarios and enhance model generalization, we will introduce a federated learning framework. This approach allows for secure sharing of learning across fleets without centralizing sensitive raw data. Currently, the sparsity of data from individual autonomous vessels limits further improvements in model performance. Through federated learning, a global MCAT model can be collaboratively trained using data from multiple vessels, potentially managed by different operators, thus improving its robustness and accuracy across diverse operational profiles. This distributed learning paradigm enhances scalability by allowing the system to learn from a wider data pool while respecting data privacy. We plan to design a federated learning algorithm based on homomorphic encryption to ensure data security during transmission and computation, a critical aspect for multi-ship and multi-stakeholder environments. The inherent architecture of the MCAT model, processing standardized data inputs, is well-suited for such distributed training, and the 5G–satellite–IoT communication architecture can support the necessary data exchange for federated updates. Second, we will optimize the attention mechanism to adapt to the non-stationary operating characteristics of autonomous vessel propulsion systems. The operating states of autonomous vessels vary significantly under different sea and weather conditions, leading to non-stationary characteristics in time series data. We intend to develop a dynamic attention-weight adjustment mechanism that dynamically adjusts attention weights based on real-time operating conditions to more accurately capture the dynamic behavior of autonomous vessel systems. Furthermore, we plan to integrate an AIS trajectory prediction module to build an intelligent emission reduction decision-making system that links pre-voyage and in-voyage operations. By combining AIS trajectory data, low-carbon routes can be planned in advance, and operational strategies can be adjusted in real time during navigation, achieving refined management of carbon emissions.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}