1. Introduction
Maritime transportation faces escalating demands for autonomous navigation and intelligent decision making in complex marine environments. Ship maneuvering systems, which are critical for collision avoidance, route optimization, and energy efficiency, heavily rely on precise state estimation amidst severe nonlinearity (e.g., hydrodynamic forces), environmental disturbances (e.g., wind/wave-induced motion), and sensor noise [
1]. Traditional filtering approaches, such as the RTS smoother [
2], often fail under heavy-tailed noise conditions prevalent in marine sensing (e.g., GPS jamming or sensor saturation), leading to biased trajectory reconstructions and compromised control performance [
3]. For instance, inaccurate state estimation in dynamic positioning systems (DPSs) can increase fuel consumption by up to 15% and elevate accident risks in confined waterways [
4]. Recent studies highlight that Student-t noise models outperform Gaussian frameworks in handling such outliers, yet real-time adaptive calibration of noise parameters remains challenging due to computational burdens and sensitivity to initialization.
To address these gaps, this work introduces an online smoothing algorithm integrating expectation maximization (EM) for adaptive noise learning. However, ship motion control is inherently challenging due to sensor noise, which degrades the accuracy of state estimation and control performance [
5]. This study focuses on the critical role of smooth data processing in ship motion identification and control, where “smooth” refers to a noise-filtered dataset derived from high-frequency measurements. By applying advanced filtering techniques (e.g., extended Kalman filter [
6], sliding-window least squares [
7], or deep learning-based denoising [
8]), we obtain a temporally consistent and physically meaningful dataset that mitigates the effects of measurement noise and transient errors. Reducing errors from measurement noise allows for more accurate vessel control and helps prevent accidents by enabling prompt responses to sudden situations [
9]. Additionally, smoothed data processing optimizes navigational efficiency, minimizing unnecessary acceleration and deceleration, which leads to fuel savings and shorter travel times.
Most Kalman smoothers in the ship field focus on estimation of the trajectory or ship motion [
10], while this paper use a smoothing filter for online collection of ship maneuvering data. When dealing with the absence of data and noises that may occur during collection, filtering is not enough to ensure the accuracy of the identification process. The variational Bayesian method proposed in [
11] addresses real-time, low-frequency motion-state estimation for DP ships under time-varying environmental disturbances by integrating variational Bayesian inference with multiple fading factors. While it overcomes the limitations of conventional smoothing algorithms in online noise adaptation and historical data re-optimization, its computational efficiency remains inferior to that of our RTS-based post-processing approach. Ma et al. [
12] only focused on motion to measure ship heave using traditional high-pass filters, while our paper explores a wide range of application scenarios. Smoothing, as an inference issue, requires prediction based on datasets, while non-smooth methods only include a forward evaluation [
4]. To address the issue of identifying ship motion parameters and wave peak frequency, Liu et al. [
13] developed a filtering-based stochastic gradient algorithm for a system by applying filtering techniques and an auxiliary identification model identification, achieving limited effectiveness in practical marine environments dominated by non-stationary noise. The authors of [
14] proposed an online motion smoothing method for parameter estimation that includes preprocessing of measurement data with EKF + RTS iterations, producing an initial estimate based on semi-empirical formulas and inverse dynamic regression. Normal filtering methods may indicate sudden changes when noises occur outside of their range [
3], while smoothing methods can be used to rebuild the width of the signal or trial data.
From an inferential perspective, data smoothing inherently represents a probabilistic inference problem requiring predictive modeling of latent state sequences [
15]. This contrasts with non-smooth methods, which perform forward evaluation without uncertainty quantification [
16]. Notably, smoothed estimates obtained via the Extended Kalman Filter (EKF) exhibit statistically significant accuracy improvements over conventionally filtered outputs (
p < 0.05). This superiority arises from the optimal integration of a posteriori observational data through recursive Bayesian inference [
17]. Online maneuvering data additionally require predictions across all time regions [
18]. The extended Kalman filter (EKF) is inherently recursive and operates online, dynamically updating state estimates as new measurements arrive. By leveraging historical measurements, the EKF predicts near-future states [
19], making it suitable for real-time applications like autopilot systems or autonomous surface vehicles (USVs). This limitation is resolved when conducting parameter estimation on complete time-series data, where both historical and future measurements are available. Bidirectional temporal information enhances filtering performance by enabling backward smoothing integration. Specifically, an EKF framework can be augmented with an RTS smoother to incorporate future time steps during state estimation [
20]. This hybrid framework synergizes the EKF’s forward propagation with RTS’s backward recursion, achieving optimal smoothing [
21]. Experiments on synthetic datasets with Student-t distributed noise confirm that the method significantly enhances state identifiability, particularly for marine vessel motion parameters, where traditional filters underperform.
In response to the degradation of state estimation accuracy in marine vessel motion control caused by non-Gaussian sensor noise, environmental disturbances, and hydrodynamic uncertainties, our paper introduces a robust Bayesian smoothing framework integrating the expectation-maximization algorithm for adaptive parameter learning and multi-source sensor data fusion, achieving enhanced motion reconstruction fidelity through iterative temporal–spatial noise suppression and dynamic model calibration. The contributions of this paper are outlined as follows:
We propose an online data smoothing algorithm tailored for ship maneuvering test data, overcoming the limitations of traditional offline batch processing methods.
We pioneer an adaptive noise-statistic inference framework through an alternating optimization of distribution hyperparameters Q and R, enabling dynamic Bayesian updating of noise characteristics while preserving the fidelity of system dynamics in modeling maneuvering data.
We propose a novel framework integrating ship maneuvering system priors with adaptive noise modeling, effectively addressing Student-t noise challenges while outperforming traditional Gaussian smoothing methods in terms of dynamic fidelity.
2. Problem Formulation
In general, a linear motion equation may be constructed to describe the motion of a ship. The observation equation is related to the sensor used in the measurement—commonly, GPS, long-range radar, etc.
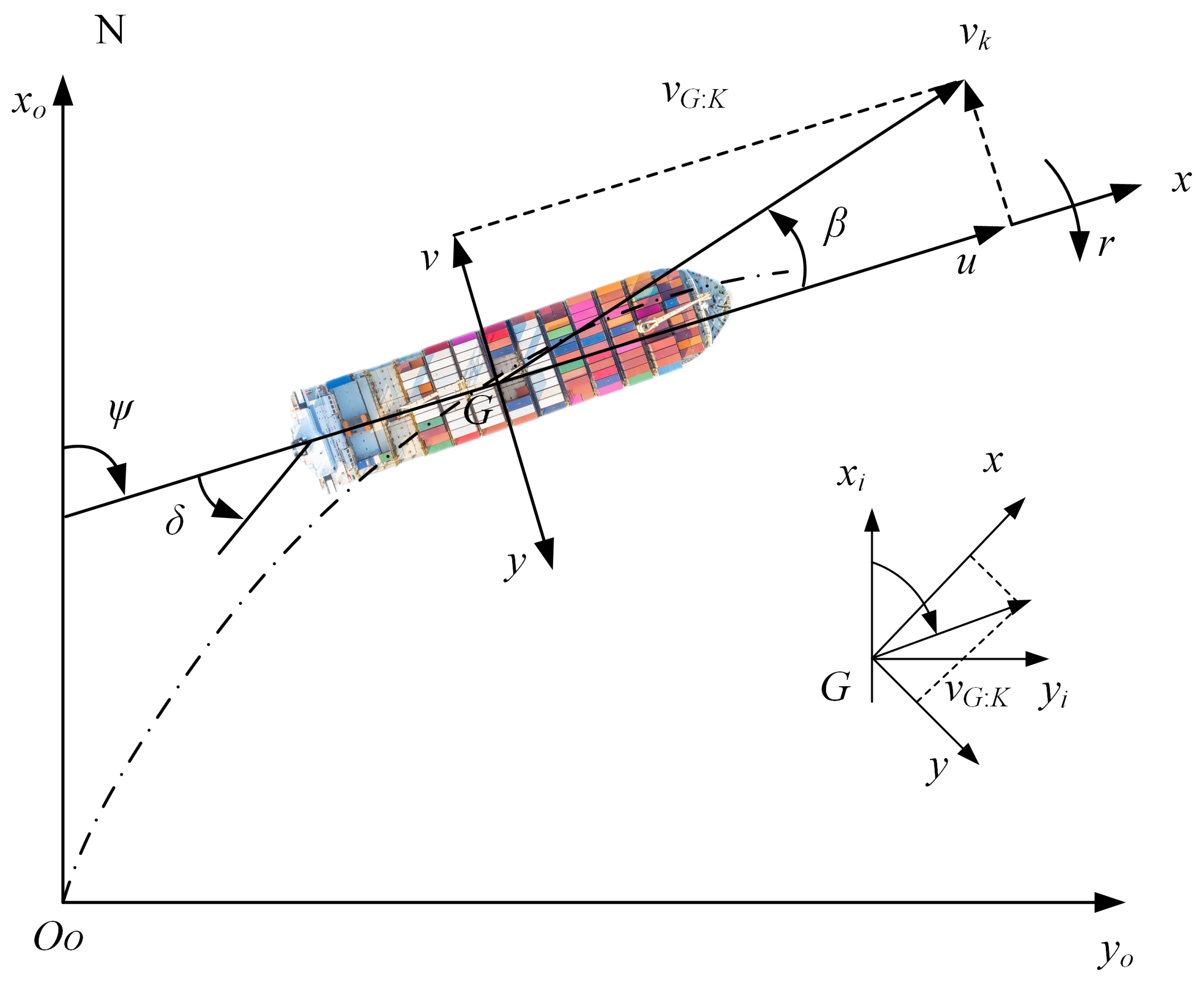
The transformation relationship between the velocity vectors in the space-fixed
coordinate system and the body-fixed coordinate system (
) is presented in
Figure 1. To facilitate the transition between these two coordinate systems, we established a standardized transformation protocol. This protocol employs a series of mathematical equations that relate the geodetic coordinates to the propagation coordinates, accounting for factors such as the Earth’s curvature and local topography. The transformation is illustrated in
Figure 1, where the axes represent the respective coordinate systems. The dashed line in the figure indicates the directional trajectory of the vessel along the specified orientation.
The ship’s kinematics are typically represented by a discrete-time, nonlinear state–space model to enable real-time processing:
where, vector
can be used to indicate the real-time status of the ship at moment
k. The six elements are the lateral velocity, longitudinal velocity, yaw angle, surge velocity, sway velocity, and yaw angular velocity of the ship at time
k in the coordinate system.
Sensor noise is often influenced by various factors, including environmental interference, equipment aging, and physical vibrations. These factors can lead to noise distributions exhibiting heavy-tailed characteristics, resulting in a higher probability of extreme values (anomalous noise). The changes in the state of the ship caused by the acceleration of the ship and the effects of the ocean current can be represented by noise (
). In order to solve the model,
is assumed to conform to the Gaussian distribution.
is Gaussian process noise with a zero mean value. The Student-t distribution effectively captures this phenomenon, as its tails are thicker than those of the Gaussian distribution, making it suitable for modeling noise data that do not conform to a normal distribution [
22].
Here,
is the amount observed by sensors (DGPS) at moment
k, including coordinates and velocities, all of which are expressed in terms of the international system of units. Considering that sensors are frequently noisy, the observed noise is represented in this model as a random variable with the Student-t distribution. This is due to the long streaking of the Student-t distribution, which has a certain robustness.
is the observed noise that is distributed independently from the Student-t distribution for each element, which can be expressed as
. Here,
is the accuracy of the distribution, while
is the degree of freedom.
where
and
denote the state and observation vector of
, respectively, and
and
are nonlinear and observation functions, respectively.
is the Gaussian process noise with zero means, which satisfies the condition of
.
is the observation noise of the Student-t distribution, in which each element is independently and identically distributed, that is,
. Here,
is the distribution accuracy, and
is the degree of freedom (DOF). For the sake of brevity, the declaration is expressed as follows:
;
. The state matrix is
, and the observation matrix is
. The observation distribution of a given state should be taken into consideration:
The elements of
are functions of the system’s dynamic parameters, not instantaneous measurements:
Based on the kinematic relationships in the above formula, its Jacobian matrix (
) can be derived as follows:
The items are expressed as follows:
By establishing and introducing a weight vector (
) that is independent of the state (
) into the model, the prior distribution can be expressed as follows:
In the equation above, the weight vector matrix () and the weight matrix () are further obtained, whose diagonal element is a hidden variable that follows the Gamma distribution. When the weight matrix () and the diagonal matrix () collectively form the given state and the observation vector, the Gaussian distribution can be used to observe the covariance matrix of . The hyper-parameter of the Gamma distribution can be calculated by , and both parameters have a value of , whereas . Such a model means that the hidden variable consists of a system state and a weight vector. When the hidden variable () is given, the observation conforms to the Gaussian distribution, and the covariance varies with the moment. Hence, it can suppress the noise of the observation.
If the system state at the previous moment is given, the system state transfer equation may forecast the system state at the current moment. Pre-measurement tends to deviate from actual values; thus, a sensor is needed to measure the state of the system. Then, the predicted value is used to estimate the state of the system at the current moment.
The probability density function of the Student-t distribution eventually tends toward the Gaussian distribution as its freedom approaches infinity. Therefore, it is possible to select the appropriate
based on the probability of occurrence of the field value in the sensor measurement or to estimate it with the parameter learning method described in
Section 3.2. Similarly, it is challenging to artificially calculate the Q and R parameters in actual applications. Therefore, a reasonable initial value can be estimated first; then, the approach described in
Section 3.2 can be used to learn while smoothing. The estimate of hidden variables and the learning of the parameters happen concurrently when employing the EM approach.
3. Improved Online Kalman Smoothing Method Using Expectation-Maximization Algorithm
The proposed model is optimized through the expectation-maximization (EM) algorithm. In the E step, the posterior distribution of the hidden variables ( and ) is derived, while the M step focuses on maximizing the likelihood function to estimate the system parameters. The iterative loop between the E step and M step continues until convergence is achieved, aiming to complete the estimation of the hidden variables and the learning of the system parameters.
Given that the hidden variables (
and
) are unrelated to one another,
represents the step taken by the algorithm, and the complete data have the following posterior distribution:
Applying the Markov property of the system equation [
23], the prior distribution of states can be expanded as follows:
By leveraging the independence of the weight matrices across different time points, as well as the internal components and observations at various moments, the joint distribution can be expressed in the following manner:
The rate of marginal likelihood (
) is the result of observation. Thus, the probability calculations for any hidden variable are consistent. Taking the normalization into consideration, the effects can be ignored, and the results are expressed as follows:
Taking the distribution features of the hidden variables ( and ) into consideration, it is quite difficult to directly calculate the joint posterior distribution () of hidden variables and . Instead, an interactive approach is applied to calculate and , which simplifies the estimation process without compromising the accuracy of the estimation.
In Bayesian parameter estimation, the posterior density characterizing the weight vector demonstrates a Gaussian analytical form governed by hyperparameters that inherently satisfy the conjugate relationship with the Gamma distribution, thereby reinforcing the statistical synergy between the Gaussian likelihood framework and its Gamma-distributed conjugate prior [
24], that is,
follows the Gamma distribution, on which the derivation in
Section 3.2 is based. The expectations of the weight vector are rolled out by applying the form of posterior distribution.
Assume
; then, the posterior distribution is the form of the Gaussian distribution multiplied by the Gaussian distribution for the system state (
) of a given moment. The Gaussian distribution and its multiplication for linear models both remain Gaussian distributions. Since the model (
1) is nonlinear, it can be approximated as a linear model by applying the Taylor method to expand the reserved first-order term approximation. Consequently, the posterior distribution of state
still complies with the Gaussian distribution, that is,
can be considered to be subject to the Gaussian distribution, which serves as the foundation for the derivation in
Section 3.1.
To facilitate the derivation of the smoothing algorithm, two lemmas are introduced here.
Lemma 1 ([
25]).
If random variable and variable follow the following Gaussian distribution:then, the joint distribution of variables
x and
y and the marginal distribution of
y are expressed as follows:
Lemma 2. If random variable and variable follow the following Gaussian distribution:then the marginal distribution and conditional distribution of variables
x and
y are expressed as follows:
By utilizing these two lemmas, posterior estimation of the hidden variables can be achieved as follows.
3.1. Posterior Distribution of State
3.1.1. Forward Recursion
First, the forward recursion is derived. Considering that observation
and hidden variable
are given, the joint distribution of hidden variables
and
is as expressed as follows:
According to the model mentioned in
Section 2, one-step prediction
is subject to the Gaussian distribution, which can be expressed as
. Since posterior
follows the Gaussian distribution, the mean value of the distribution is represented by
, and the covariance matrix of the distribution can be represented by
.
The Taylor expansion of function
at point
can be obtained, where Jacobian matrix
can be expressed as follows:
Following these steps, the above joint distribution can be further expressed as follows:
Again, applying Lemma 1, the following can be obtained [
26]:
where the mean value (
) and the covariance matrix (
) can be respectively expressed as follows:
Subsequently, the one-step prediction distribution [
20] can be obtained by Lemma 2:
For further illustration, the means and covariance matrices of one-step predictions are expressed in terms of
and
, respectively.
Next, considering that observation
and hidden variable
are given, the joint distribution of
and
is expressed as follows:
According to the model described in
Section 2, observation
obeys the Gaussian distribution and can be represented by
. While
represents a one-step predicted distribution, the Gaussian distribution hasan obedience mean of
and a covariance matrix of
, as described above.
The Taylor expansion of function
at point
, and
can be obtained, where Jacobian matrix
can be expressed as follows:
Therefore, combined with Lemma 1, the joint distribution of variables
and
can be further expressed as follows:
Then, using Lemma 2, it can be determined that
obeys the Gaussian distribution (
), whose mean and covariance matrices can be expressed as follows:
This completes the forward recursion of RTS smoothing, which includes one-step prediction and observation correction. One-step prediction completes the distribution estimation of , and observation correction completes the distribution estimation of .
3.1.2. Backward Recursion
Following the derivation of the backward recursion, first consider that when observation
and hidden variable
are given, the joint distribution of hidden variables
and
can be expressed as follows:
According to the model and
, which conforms to the mean value of
and the covariance matrix (
) of the Gaussian distribution described in
Section 3.1.1, the above joint distribution can be further represented as follows:
where
is the Jacobian matrix of function
at
. Then, applying Lemma 2, the result is expressed as follows:
where the mean value (
) and the covariance matrix (
) can be expressed respectively as follows:
Ultimately, when looking at a given observation (
) and a hidden variable (
), the joint distribution of the hidden variables
and
is expressed as follows:
The first formula on the right of the equals sign is the backward recursion derived from the previous step. The second formula represents the posterior distribution of the system state (
) for a given observation (
) and hidden variable (
), that is, the solution of the smooth distribution is required by the RRTS algorithm. As mentioned in
Section 3.1.1, this distribution still belongs to the Gaussian distribution. Suppose the mean value of the distribution is
and the covariance matrix is
; then, the above joint distribution can be further expressed as follows:
Let
Then, is settled.
Next, the following can be inferred by Lemma 2:
This completes the backward recursion of the system state, which includes backward prediction and correction. The calculation process is dependent on weight vector , followed by a posterior estimation.
3.2. Posterior Distribution of Weight Vector
For the derivation of the posterior distribution of weight vector
, all items related to
in the posterior distribution need to be taken into consideration:
Utilizing
to express
, the above function can be expressed as follows:
Obviously, the posterior distribution of
still conforms to the Gamma distribution. Thus, it can be found that the posterior distribution of
has the following form:
where
is the expected value of
for the posterior distribution.
represents the
value of vector
. Here, the value of
can be divided into two cases; when the algorithm is forward recursion, a value of
can be taken, while when the algorithm is backward recursion, a value of
can be taken. Additionally, the expected value of
under a posterior distribution can be calculated to learn the
parameter, expressed as follows:
where
is the digamma function.
Section 3.1 and
Section 3.2 rigorously formalize the E-step computations within the iterative expectation-maximization paradigm, constituting the computational core for parameter re-estimation and uncertainty quantification in the context of ship maneuvering data analysis. The E step deduces the posterior distribution of hidden variables
and
using existing observation data (
). The expected values of
and
in the given old parameter set (
) are obtained to be further applied to learn the new parameter set in the M step.
3.3. Bayesian Hyperparameter Optimization
The parameters in the EM algorithm are learned by maximizing function
, that is,
where
is the value before the learning of the parameter set, that is, the parameter value used in the E step.
However, function
is the cost function, which can be calculated as follows:
To learn the
parameter, the related item,
in
, needs to be considered, which can be expressed as follows:
It is the computation of posterior distribution
, which represents all of the formula independent of the pending estimation. The above formulation finds the partial derivative of
, letting the partial derivative equal zero. The result is expressed as follows:
Similarly, in order to learn the
parameter, all the related items in
need to be considered, expressed as follows:
The above formulation finds the partial derivative of
, letting the partial derivative equal zero. The result is expressed as follows:
In order to learn parameter
Q, all the related items in
need to be considered, expressed as follows:
The above formulation finds the partial derivative of
, letting the partial derivative equal zero. The result is expressed as follows:
where the calculation of the expected values is complemented by the calculation of the expected values reported in
Section 3.4, computed in conjunction with the Taylor expansion. The first-order Taylor expansion of
can be expressed as follows:
To learn the parameter matrix (
R), all elements (
) on the diagonal of the matrix are required. All the related items in
can be expressed as follows:
where
is the
value of
. The above formulation finds the partial derivative of
, letting the partial derivative equal zero. The result is expressed as follows:
Then, parameter matrix
can be expressed as follows:
In order to learn the parameter vector (
), the calculation of each element (
) is required. All the related elements in
can be represented as follows:
where
is the gamma function, that is,
. The above formulation finds the partial derivative of
, letting the partial derivative equal zero. The result is expressed as follows:
where
is the digamma function. An estimate of
can be obtained by solving the above equation to obtain the parameter vector (
).
3.4. Algorithmic Processes
The three sections above describe the process by which the EM algorithm solves the model, and the complete EM framework is described as follows. The joint distribution () of hidden variable x and observation variable z is given, and is the parameter set. The purpose of EM is to maximize likelihood function by selecting the appropriate posterior distribution and parameter set. For the model in this paper, the steps of the algorithm are as described as follows:
Select the initial parameter set ().
E step: The posterior estimation (
) of the hidden variables is calculated by forward recursion of Equations (
34) and (
35). Then, the posterior estimation (
) of the hidden variables is calculated by recursion of Equations (
44) and (
45). Ultimately, the expected values of the hidden variables
and
are obtained, and the outcomes are
and
, respectively.
M step: Learn the parameter set using Equations (
54), (
56), (
58), (
62) and (
64) as follows:
The convergence criteria are given, and the difference between two adjacent parameters is determined to check whether they meet the requirements. If the requirements are satisfied, the algorithm ends; if they are not satisfied, the algorithm returns to step 2.
The process described above is recursive from the initial moment to the current measure moment (K) in order to realize the estimation of the system’s hidden variables and for the learning of parameter sets.
3.5. Supplementary Instructions for Calculations of Expected Values
Additionally, two calculations on the expected values are supplemented.
The expected value and covariance of the posterior estimation expectations at moment
k of the system state meet the following requirements:
Thus, the calculation formula of the expected value is expressed as follows:
Then,
is calculated:
Considering that the expected value of the state noise is zero,
The expected value and covariance of the posterior estimation of the system state moment (k − 1) meet the following requirement:
The above formulas ((
68) and (
72)) are applied to learn parameter
Q as described in
Section 3.2.
Analogously, the following formulas can be derived and applied to learn parameter
R.
where
represents the Jacobian matrix of observation function
at
, which can be represented as follows:
The described computational sequence corresponds to the expectation (E) phase within the expectation-maximization (EM) framework, while the subsequent parameter optimization phase embodies the maximization (M) operator. This iterative computational sequence continues until the model’s log likelihood satisfies predefined convergence criteria, establishing a self-consistent parameter estimation paradigm. Finally, robust extended Kalman smoothing is achieved. A schematic representation of the smoothing procedure is illustrated in
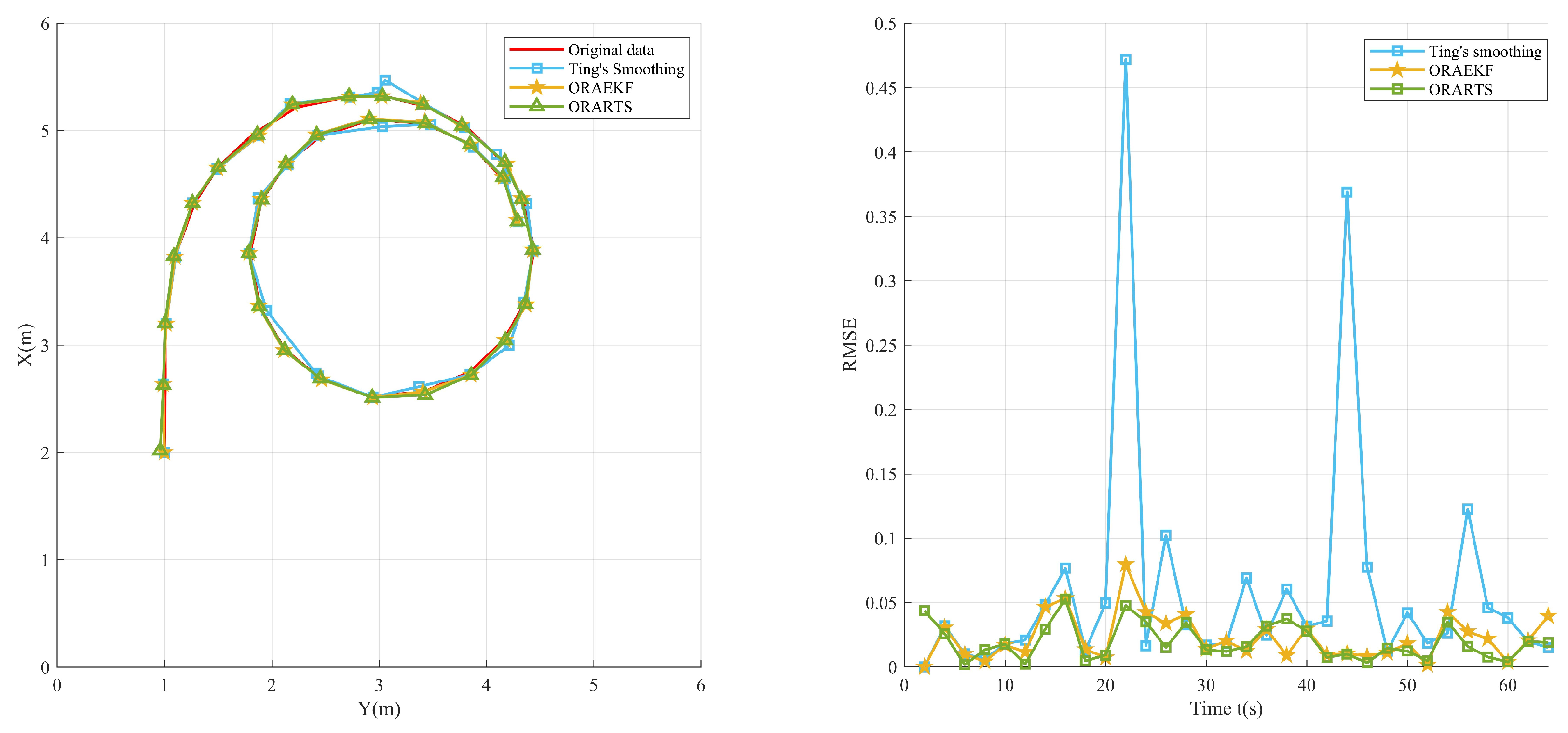
Figure 2, and the pseudocode of the procedure is presented in Algorithm 1, demonstrating the iterative application.
| Algorithm 1 Extended Kalman Filter with RTS Smoothing Algorithm |
| | Initialization |
| 1: | , |
| 2: | for to |
| | Prediction Step |
| 3: | |
| | State prediction |
| 4: | |
| | Covariance prediction |
| | Measurement Update |
| 5: | |
| | Kalman gain |
| 6: | |
| | State update |
| 7: | |
| | Covariance update |
| | end for |
| | RTS Smoothing |
| 8: | , |
| | Final time state |
| 9: | for to 0 |
| 10: | |
| | Smoothing gain |
| 11: | |
| | Smoothed state |
| 12: | |
| | Smoothed covariance |
| | end for |
| | Output Smoothed state estimates for |







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}