
A Novel Reactive Power Sharing Control Strategy for Shipboard Microgrids Based on Deep Reinforcement Learning


Abstract
1. Introduction
- 1.
- Integration of Deep Learning and Reinforcement Learning: Combining these techniques facilitates adaptive control within intricate microgrid settings.
- 2.
- Development of an Adaptive Virtual Impedance Droop Control Strategy: This strategy dynamically modifies the virtual impedance according to reactive power deviations, leading to enhanced reactive power distribution.
- 3.
- Comprehensive Simulation Validation: The simulations demonstrate the proposed strategy’s superior performance in improving reactive power sharing among DGs.
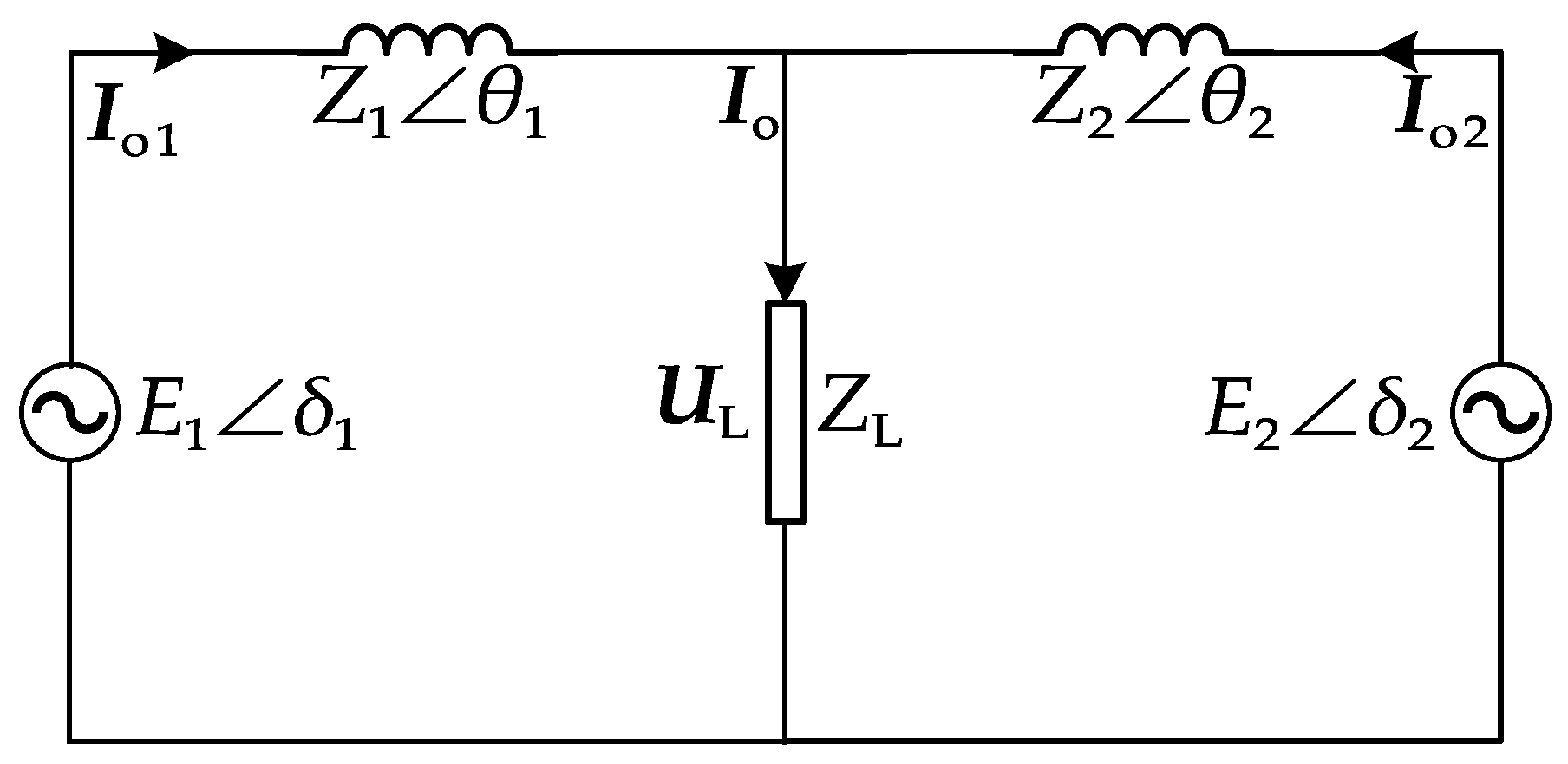
2. Conventional Droop Control Strategy for Ship AC Microgrids
2.1. Conventional Droop Control Principle
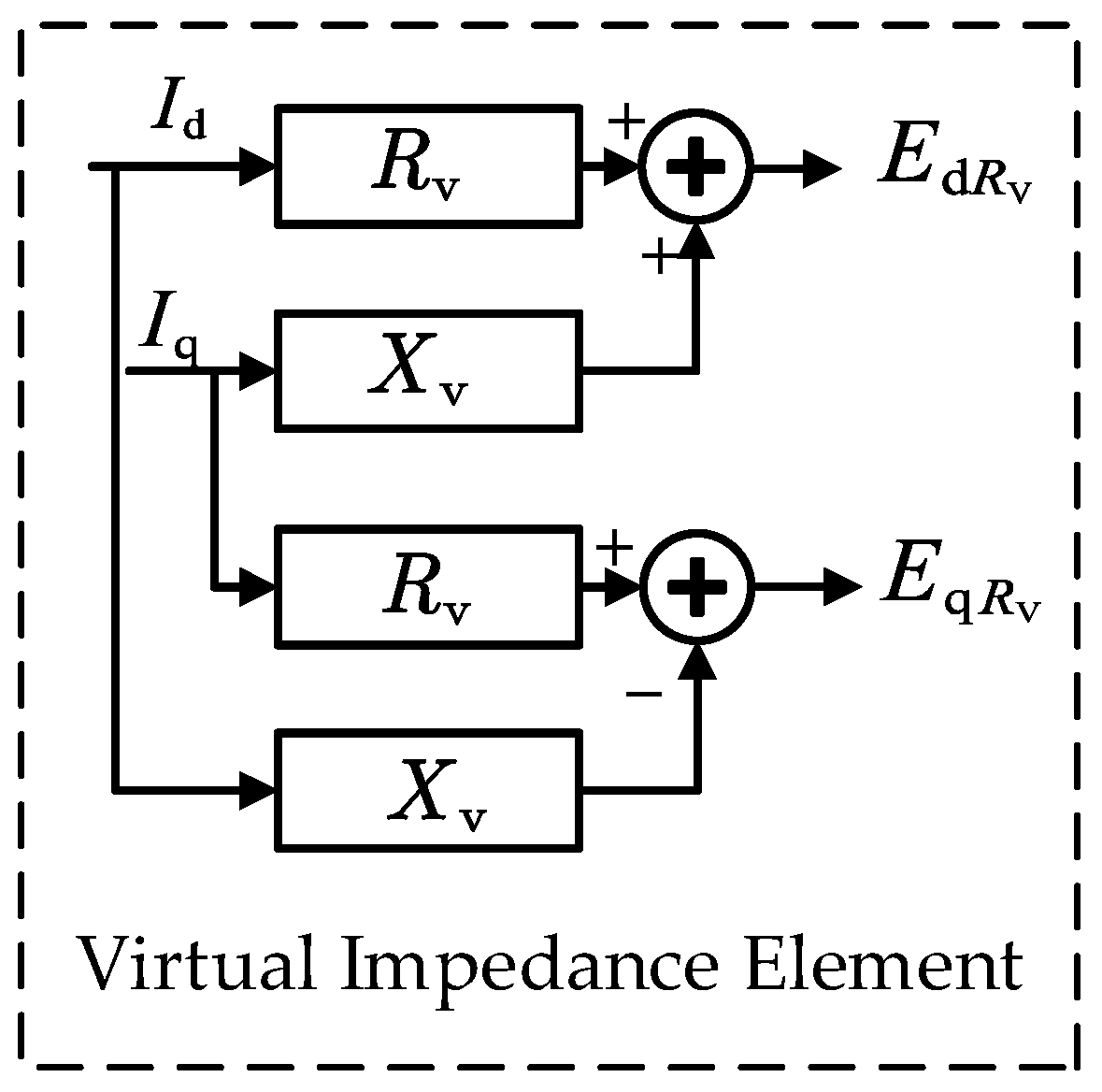
2.2. Adaptive Droop Control Strategy Based on Virtual Impedance (VI)
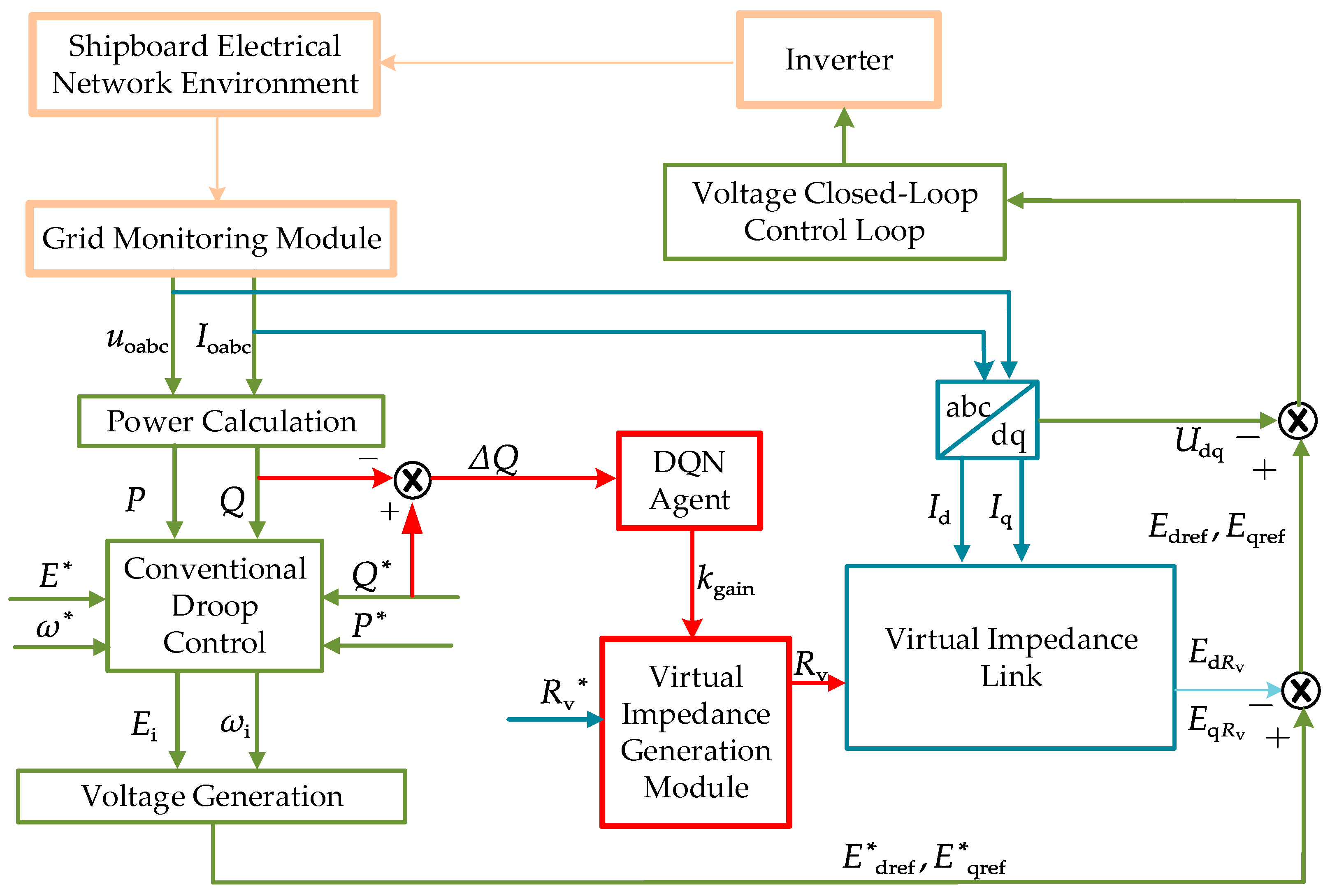
3. Intelligent Control Strategy for Ship Microgrids Based on DQN
3.1. General Framework of Intelligent DQN-Based Control of Ship Microgrids
3.2. Design of Droop Control Strategy Based on DQN-VI
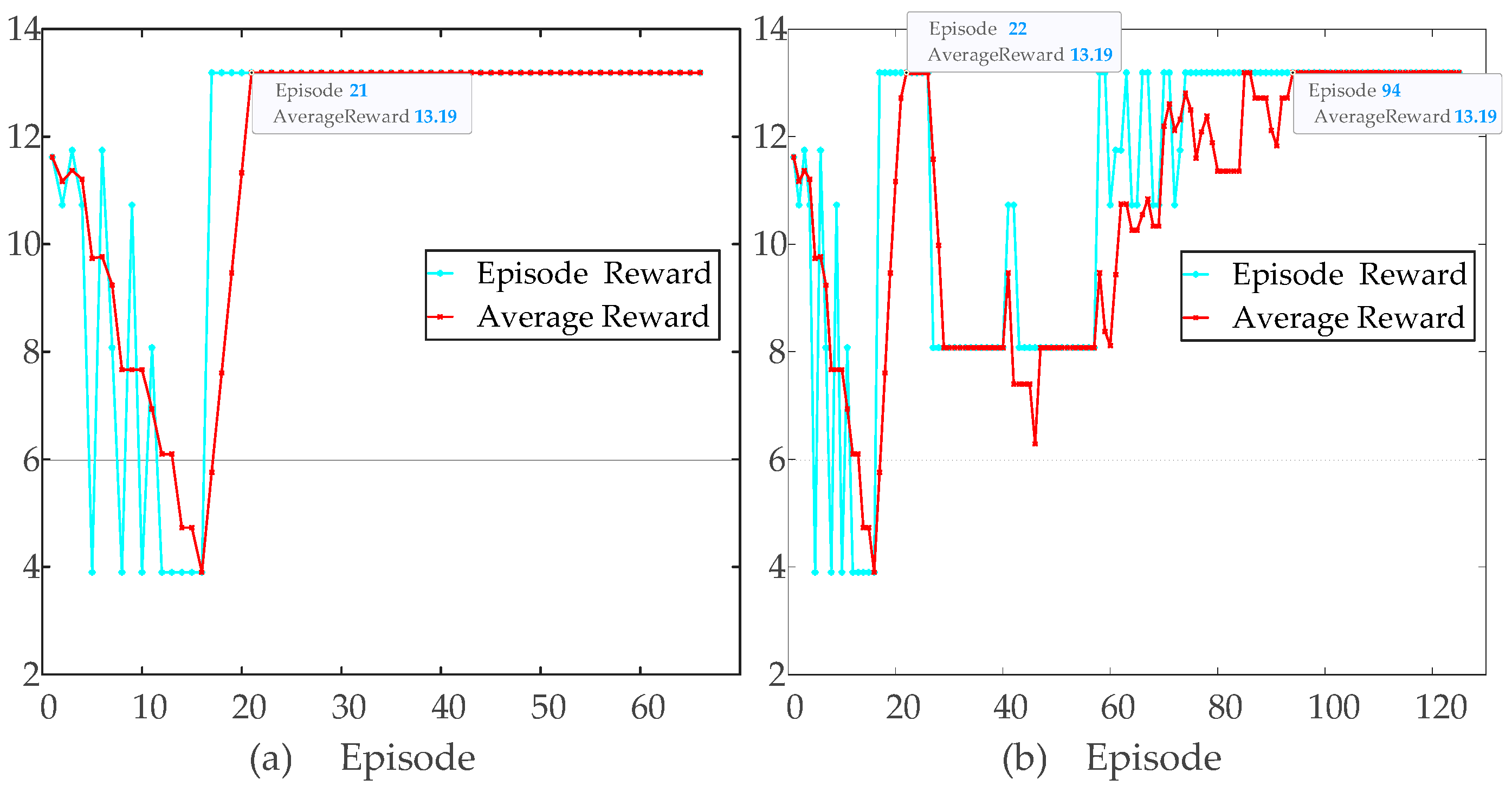
3.3. Training and Optimization Process of the DQN Agent
| Algorithm 1: DQN-based VI droop control strategy |
 |
4. Simulation Analysis
4.1. DQN Agent Training Simulation Parameter Settings
4.2. Evaluation Index of System Performance
4.3. Simulation Analysis
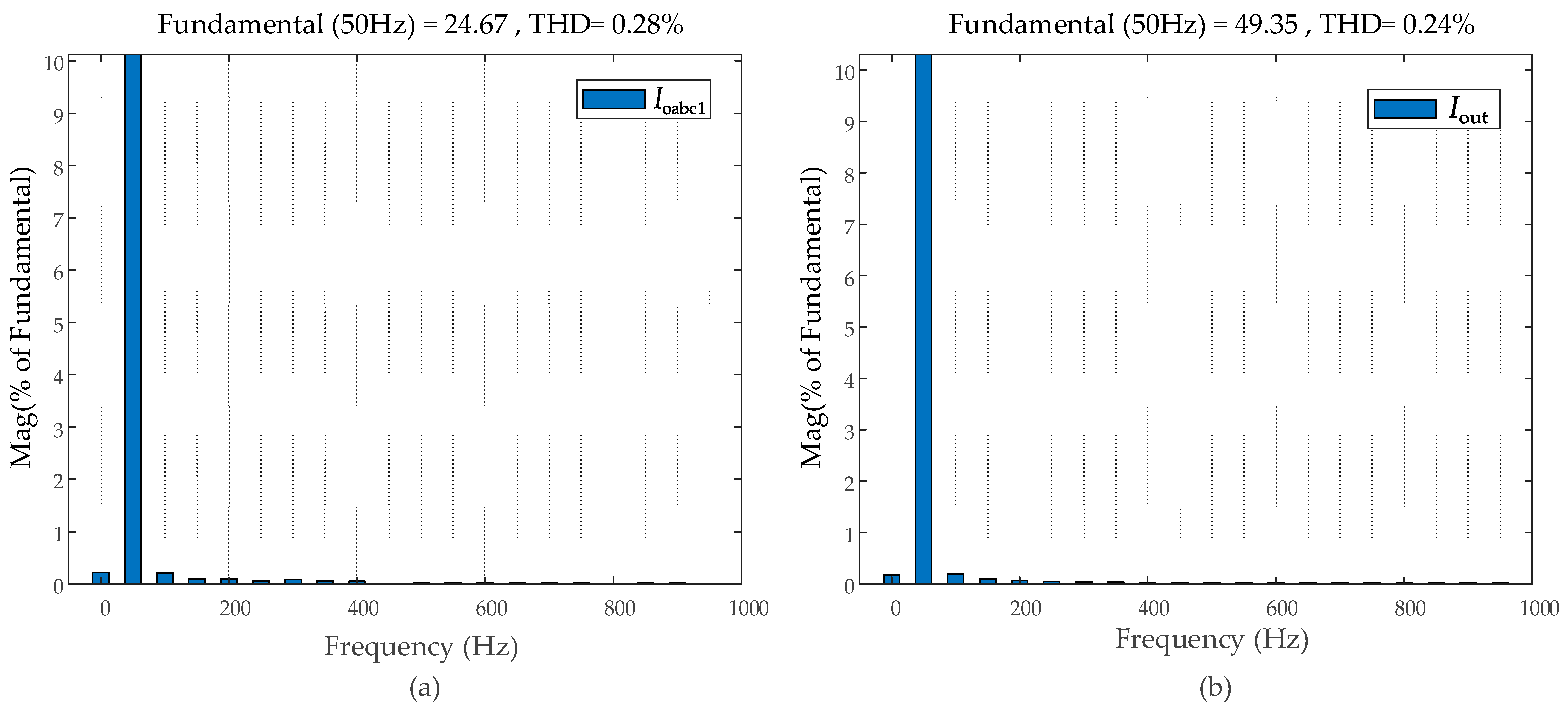
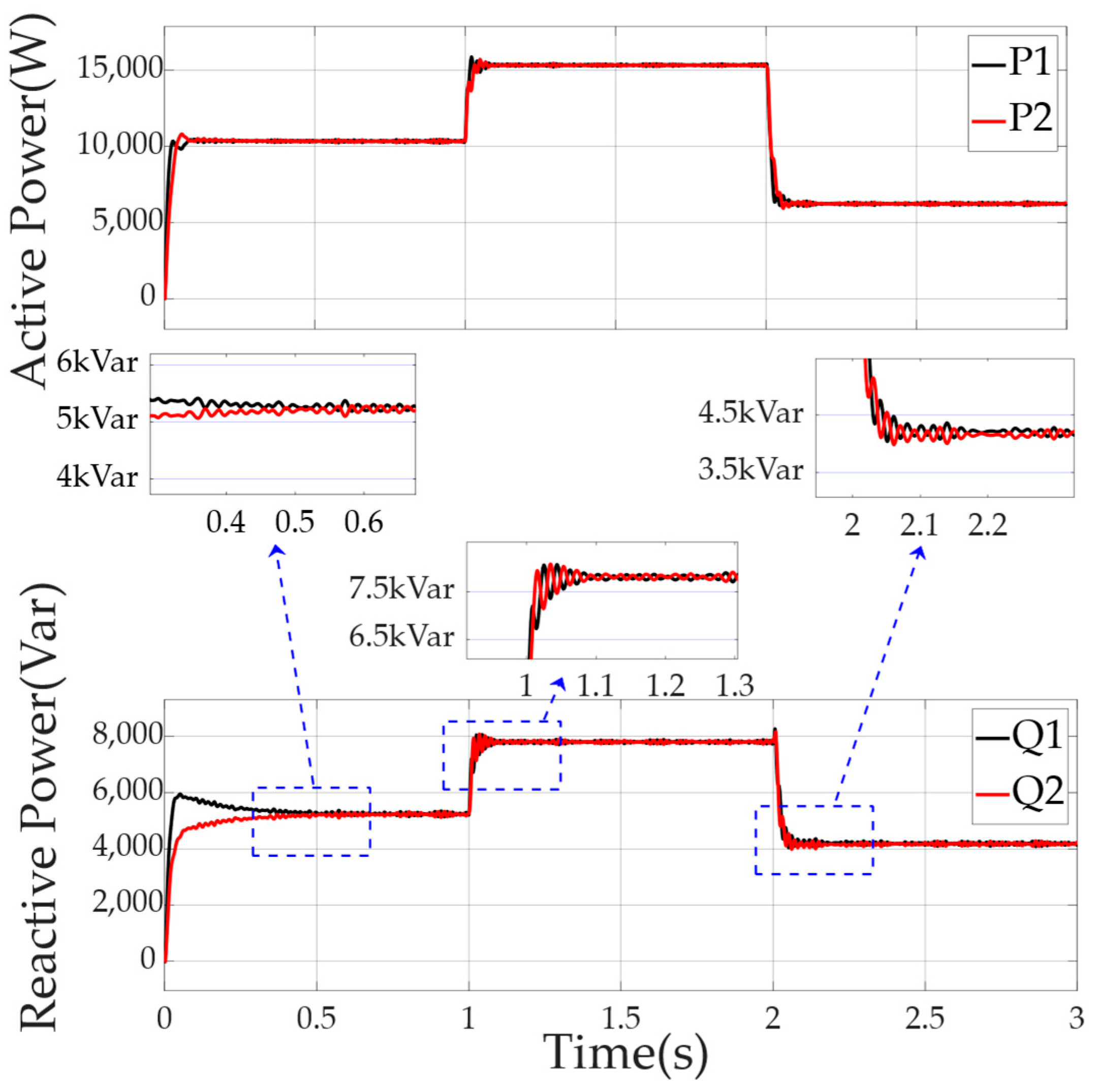
4.3.1. Simulation Case 1
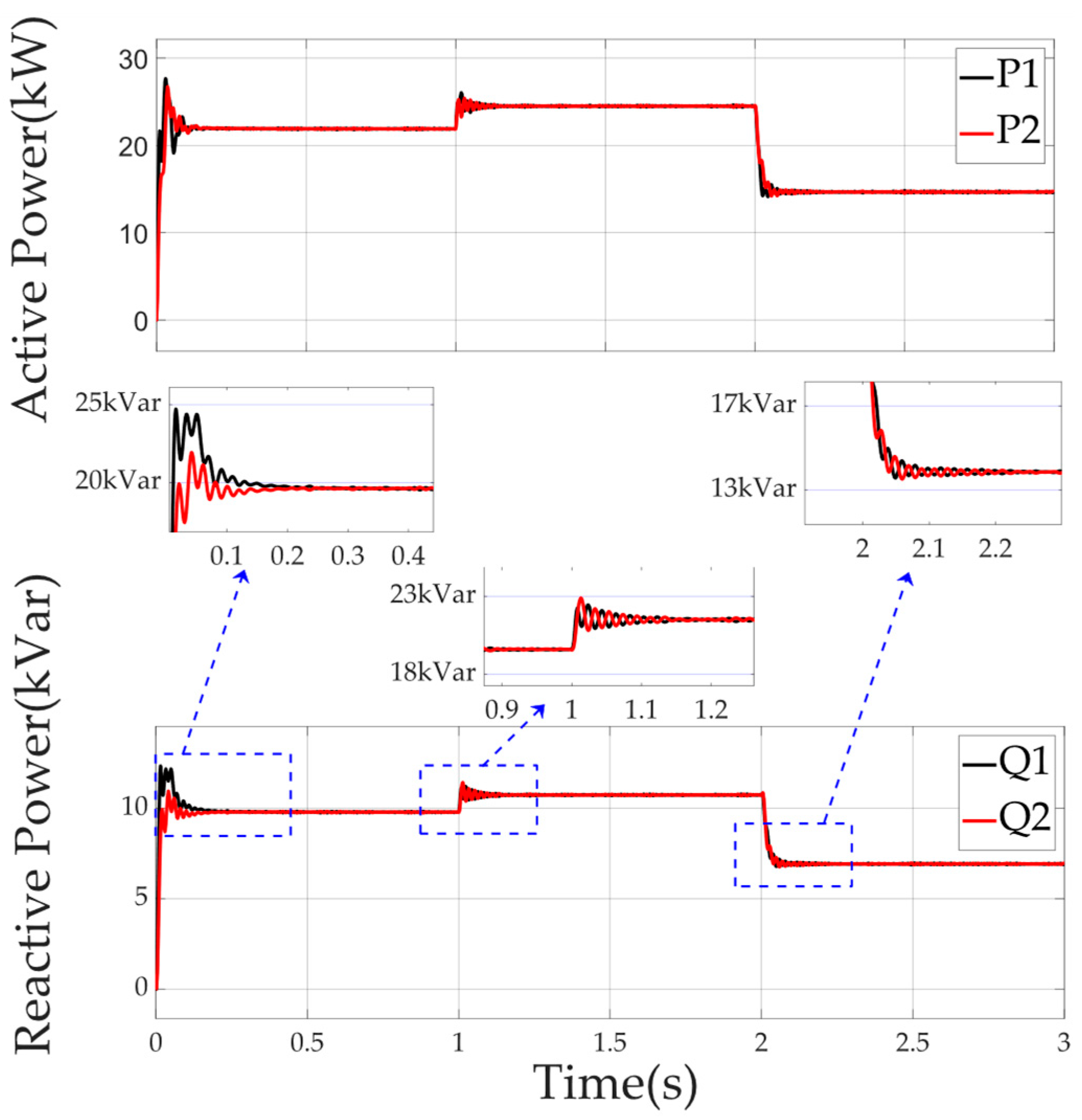
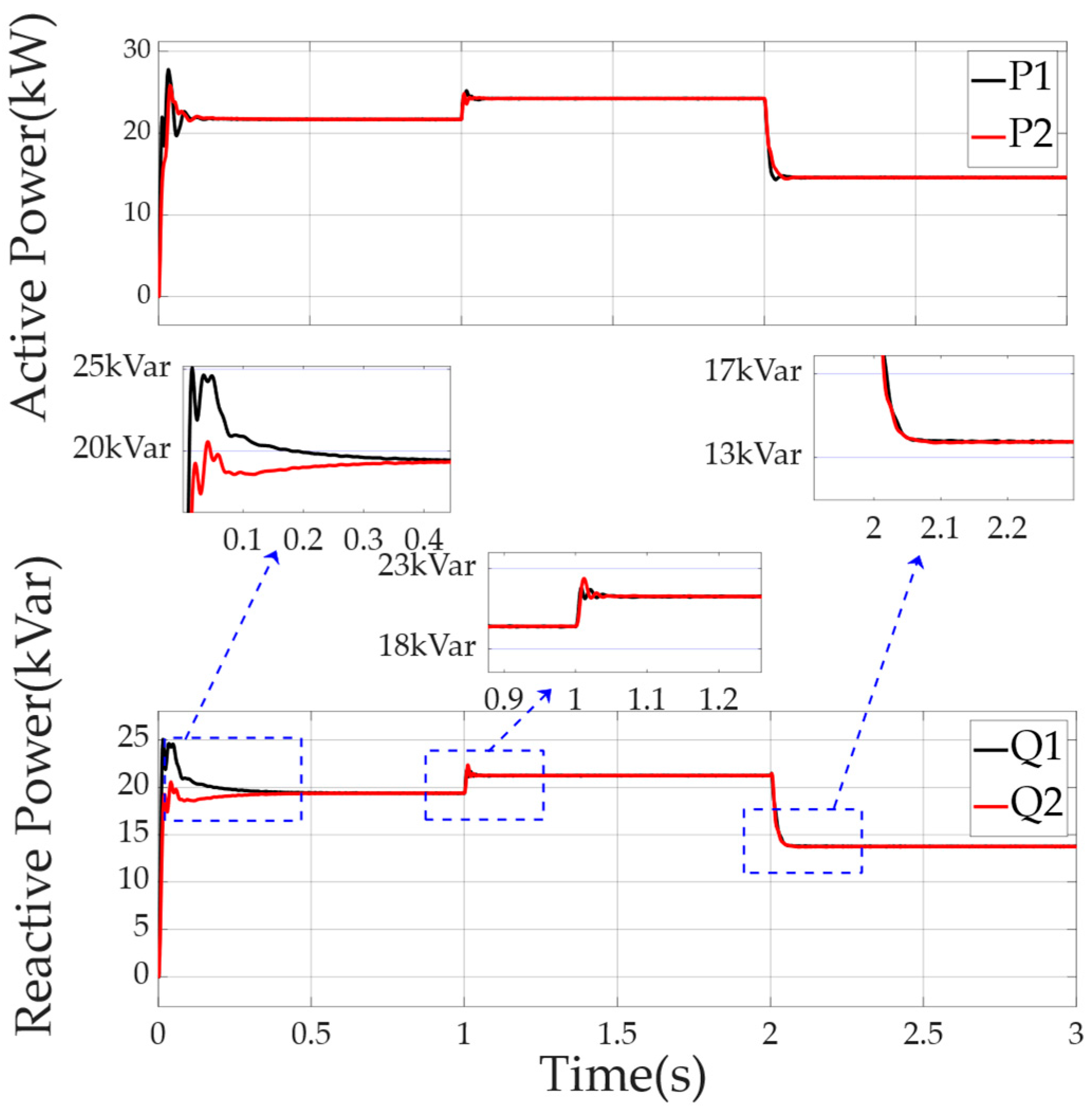
4.3.2. Simulation Case 2
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Badakhshan, S.; Senemmar, S.; Zhang, J. Dynamic Modeling and Reliable Operation of All-Electric Ships with Small Modular Reactors and Battery Energy Systems. In Proceedings of the 2023 IEEE Electric Ship Technologies Symposium (ESTS), Alexandria, VA, USA, 1–4 August 2023; pp. 327–332. [Google Scholar]
- Jin, Z.; Meng, L.; Guerrero, J.M.; Han, R. Hierarchical control design for a shipboard power system with DC distribution and energy storage aboard future more-electric ships. IEEE Trans. Ind. Inform. 2017, 14, 703–714. [Google Scholar]
- Han, Y.; Ning, X.; Yang, P.; Xu, L. Review of power sharing, voltage restoration and stabilization techniques in hierarchical controlled DC microgrids. IEEE Access 2019, 7, 149202–149223. [Google Scholar]
- Zhaoxia, X.; Tianli, Z.; Huaimin, L.; Guerrero, J.M.; Su, C.L.; Vásquez, J.C. Coordinated control of a hybrid-electric-ferry shipboard microgrid. IEEE Trans. Transp. Electrif. 2019, 5, 828–839. [Google Scholar]
- Li, Y.W.; Kao, C.N. An accurate power control strategy for power-electronics-interfaced distributed generation units operating in a low-voltage multibus microgrid. IEEE Trans. Power Electron. 2009, 24, 2977–2988. [Google Scholar]
- Sun, X.; Hao, Y.; Wu, Q.; Guo, X.; Wang, B. A multifunctional and wireless droop control for distributed energy storage units in islanded AC microgrid applications. IEEE Trans. Power Electron. 2016, 32, 736–751. [Google Scholar]
- Vu, T.V.; Paran, S.; El Mezyani, T.; Edrington, C.S. Real-time distributed power optimization in the DC microgrids of shipboard power systems. In Proceedings of the 2015 IEEE Electric Ship Technologies Symposium (ESTS), Old Town Alexandria, VA, USA, 21–24 June 2015; pp. 118–122. [Google Scholar]
- Mohammed, N.; Lashab, A.; Ciobotaru, M.; Guerrero, J.M. Accurate reactive power sharing strategy for droop-based islanded AC microgrids. IEEE Trans. Ind. Electron. 2022, 70, 2696–2707. [Google Scholar]
- Zhang, X.; Gong, L.; Zhang, Y.; Ma, X.; Han, L.; Jiang, S.; Zhou, W. A novel virtual inductor optimization methodology of virtual synchronous generators for enhanced power decoupling. Int. J. Electr. Power Energy Syst. 2025, 165, 110473. [Google Scholar]
- Liu, W.; Pei, J.; Ye, Y.; Liu, Y.; Bucknall, R.; Xu, D. Prescribed-performance-based adaptive fractional-order sliding mode control for ship DC microgrid. Ocean Eng. 2024, 311, 118885. [Google Scholar]
- Peng, Z.; Wang, J.; Bi, D.; Wen, Y.; Dai, Y.; Yin, X.; Shen, Z.J. Droop control strategy incorporating coupling compensation and virtual impedance for microgrid application. IEEE Trans. Energy Convers. 2019, 34, 277–291. [Google Scholar]
- Göthner, F.; Roldán-Pérez, J.; Torres-Olguin, R.E.; Midtgård, O.M. Harmonic virtual impedance design for optimal management of power quality in microgrids. IEEE Trans. Power Electron. 2021, 36, 10114–10126. [Google Scholar]
- Zaid, S.A.; Albalawi, H.; AbdelMeguid, H.; Alhmiedat, T.A.; Bakeer, A. Performance Improvement of H8 Transformerless Grid-Tied Inverter Using Model Predictive Control Considering a Weak Grid. Processes 2022, 10, 1243. [Google Scholar] [CrossRef]
- Zaid, S.A.; Bakeer, A.; Magdy, G.; Albalawi, H.; Kassem, A.M.; El-Shimy, M.E.; AbdelMeguid, H.; Manqarah, B. A New Intelligent Fractional-Order Load Frequency Control for Interconnected Modern Power Systems with Virtual Inertia Control. Fractal Fract. 2023, 7, 62. [Google Scholar] [CrossRef]
- Zaid, S.A.; Bakeer, A.; Albalawi, H.; Alatwi, A.M.; AbdelMeguid, H.; Kassem, A.M. Optimal Fractional-Order Controller for the Voltage Stability of a DC Microgrid Feeding an Electric Vehicle Charging Station. Fractal Fract. 2023, 7, 677. [Google Scholar] [CrossRef]
- Shi, J.; Zhang, C.; Wu, H.; Xuan, S.; Gao, L.; Shen, J. Q-learning method in reactive power sharing control of high-penetration photovoltaic micro-grids. J. Electr. Power Syst. Autom. 2021, 33, 88–93. [Google Scholar]
- Wunderlich, A.; Wong, A.; Cronin, J.; Santi, E. Novel Rate-Limited Droop Control for DC Distribution with Impulsive Loads. In Proceedings of the 2023 IEEE Electric Ship Technologies Symposium (ESTS), Alexandria, VA, USA, 1–4 August 2023; pp. 303–310. [Google Scholar]
- Han, Y. Modeling and Control of Power Electronic Converters for Microgrid Applications; Springer Nature: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Li, Z.; Li, H.; Zheng, X.; Gao, M. Virtual model predictive control for virtual synchronous generators to achieve coordinated voltage unbalance compensation in islanded micro grids. Int. J. Electr. Power Energy Syst. 2023, 146, 108756. [Google Scholar]
- Mahmood, H.; Michaelson, D.; Jiang, J. Accurate reactive power sharing in an islanded microgrid using adaptive virtual impedances. IEEE Trans. Power Electron. 2014, 30, 1605–1617. [Google Scholar]
- Jiang, E.; Zhao, J.; Shi, Z.; Mi, Y.; Lin, S.; Muyeen, S.M. Intelligent Virtual Impedance Based Control to Enhance the Stability of Islanded Microgrid. J. Electr. Eng. Technol. 2023, 18, 3971–3984. [Google Scholar]
- Vijay, A.S.; Parth, N.; Doolla, S.; Chandorkar, M.C. An adaptive virtual impedance control for improving power sharing among inverters in islanded AC microgrids. IEEE Trans. Smart Grid 2021, 12, 2991–3003. [Google Scholar]
- Saimadhuri, K.Y.; Janaki, M. Advanced control strategies for microgrids: A review of droop control and virtual impedance techniques. Results Eng. 2024, 25, 103799. [Google Scholar]
- Li, S.; Tang, X.; Zheng, J.; Wang, C. Power Sharing Control Strategy of High-Frequency Chain Matrix Converter Parallel System Based on Adaptive Virtual Impedance. J. Phys. Conf. Ser. 2021, 2136, 012022. [Google Scholar]
- Chen, J.; Yue, D.; Dou, C.; Chen, L.; Weng, S.; Li, Y. A virtual complex impedance based droop method for parallel-connected inverters in low-voltage AC microgrids. IEEE Trans. Ind. Inform. 2020, 17, 1763–1773. [Google Scholar]
- Zhu, Y.; Zhuo, F.; Wang, F.; Liu, B.; Gou, R.; Zhao, Y. A virtual impedance optimization method for reactive power sharing in networked microgrid. IEEE Trans. Power Electron. 2015, 31, 2890–2904. [Google Scholar] [CrossRef]
- Wang, Y.; Kuang, Y.; Xu, Q. A current-limiting scheme for voltage-controlled inverter using instantaneous current to generate virtual impedance. IEEE J. Emerg. Sel. Top. Circuits Syst. 2023, 13, 524–535. [Google Scholar] [CrossRef]
- Wang, H.; Wang, X. Distributed reactive power control strategy based on adaptive virtual reactance. IET Renew. Power Gener. 2023, 17, 762–773. [Google Scholar] [CrossRef]
- Sharma, B.; Pankaj, P.K.; Terriche, Y.; Saim, A.; Shrestha, A.; Su, C.L.; Guerrero, J.M. Power sharing in three-level NPC inverter based three-phase four-wire islanding microgrids with unbalanced loads. IEEE Access 2023, 11, 20725–20740. [Google Scholar] [CrossRef]
- Daniel, A.; Dayalan, S. A simple network reduction technique for large autonomous microgrids incorporating an efficient reactive power sharing. Int. J. Emerg. Electr. Power Syst. 2022, 23, 161–170. [Google Scholar] [CrossRef]
- Vijay, A.S.; Doolla, S.; Chandorkar, M.C. Varying negative sequence virtual impedance adaptively for enhanced unbalanced power sharing among DGs in islanded AC microgrids. IEEE Trans. Energy Convers. 2021, 36, 3271–3281. [Google Scholar] [CrossRef]
- Pournazarian, B.; Seyedalipour, S.S.; Lehtonen, M.; Taheri, S.; Pouresmaeil, E. Virtual impedances optimization to enhance microgrid small-signal stability and reactive power sharing. IEEE Access 2020, 8, 139691–139705. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| Learning rate | |
| L2 regularization factor | |
| Replay buffer size | |
| Target smooth factor | |
| Target update frequency | 5 |
| Discount factor | 1.0 |
| Epsilon min | |
| Epsilon final | 1 |
| Epsilon decay rate | 1/30 |
| Maximum iteration episode | 2000 |
| Stop training value |
| Parameter | Value | |
|---|---|---|
| DGs | Filter inductor | 3 × 10−3 |
| Filter capacitor | 30 × 10−6 | |
| Filter inductor equivalent resistance | 0.015 | |
| line | line resistance | 1 × 10−2 |
| line reactance | 1 × 10−2 | |
| line resistance | 2 × 10−2 | |
| Line reactance . | 2 × 10−2 |
| Linear Load | Active Power | Reactive Power |
|---|---|---|
| Operating Condition | Active Power | Reactive Power |
|---|---|---|
| Rated | ||
| Overload | ||
| Light load |
| Load Type | Control Strategy | ||
|---|---|---|---|
| Linear load | Adaptive VI | 3.44% | 0.85 |
| Fuzzy adaptive VI | 2.48% | 0.89 | |
| DQN-VI | 1.66% | 0.67 | |
| Non-linear load | Adaptive VI | 2.83% | 0.107 |
| Fuzzy adaptive VI | 1.54% | 0.118 | |
| DQN-VI | 1.27% | 0.076 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Zhao, H.; Zhu, J.; Yang, T. A Novel Reactive Power Sharing Control Strategy for Shipboard Microgrids Based on Deep Reinforcement Learning. J. Mar. Sci. Eng. 2025, 13, 718. https://doi.org/10.3390/jmse13040718
Li W, Zhao H, Zhu J, Yang T. A Novel Reactive Power Sharing Control Strategy for Shipboard Microgrids Based on Deep Reinforcement Learning. Journal of Marine Science and Engineering. 2025; 13(4):718. https://doi.org/10.3390/jmse13040718
Chicago/Turabian StyleLi, Wangyang, Hong Zhao, Jingwei Zhu, and Tiankai Yang. 2025. "A Novel Reactive Power Sharing Control Strategy for Shipboard Microgrids Based on Deep Reinforcement Learning" Journal of Marine Science and Engineering 13, no. 4: 718. https://doi.org/10.3390/jmse13040718
APA StyleLi, W., Zhao, H., Zhu, J., & Yang, T. (2025). A Novel Reactive Power Sharing Control Strategy for Shipboard Microgrids Based on Deep Reinforcement Learning. Journal of Marine Science and Engineering, 13(4), 718. https://doi.org/10.3390/jmse13040718