1. Introduction
With the rapid development of inland waterways and its important role in cargo transportation, water management, and other fields, ship target recognition technology has gradually become a key means to ensure the safety of inland waterways and improve shipping efficiency. In the complex inland environment, ship targets often present diverse appearance features and variable size distribution, and are affected by factors such as water reflection, occlusion, and illumination changes, which makes the task of ship target recognition face great challenges.
Ship detection is a typical object detection task. Object detection methods can usually be divided into two categories: traditional machine 0vision methods [
1] and deep learning methods [
2]. However, traditional mechanical vision methods are not only sensitive to illumination changes and viewpoint changes but also show great limitations when dealing with small-size targets in complex backgrounds. In addition, the previous ship target detection methods usually rely on manual feature extraction, which has the problems of slow detection speed and unable to accurately locate the position of the ship. Especially in the inland river environment with complex traffic and nearshore background, the traditional methods make it difficult to separate the ship from the complex background and detect it. These shortcomings make it difficult for traditional methods to meet the high precision requirements of ship target detection in practical applications. At present, deep learning technology has achieved a considerable degree of development. Among these advancements, the multi-feature layer extraction strategy of convolutional neural networks can better adapt to the recognition and location of ship targets. This strategy has become an effective way to improve the performance of ship target detection.
The object detection method based on deep learning has been widely used in today’s industrial field because of its excellent feature learning ability and multi-task processing ability. Such methods are mainly divided into two types: the first is a two-stage detection algorithm represented by Fast R-CNN (Fast Region-Based Convolutional Neural Network) [
3] and Faster R-CNN [
4]. These algorithms perform well in detection accuracy, but their detection speed is relatively slow because they need to complete candidate region generation and object classification in two steps. The second is a single-stage detection algorithm, including typical representatives such as YOLO (You Only Look Once) [
5], SSD (Single Shot MultiBox Detector) [
6], and RetinaNet [
7]. The single-stage detection method outputs the coordinates and class probabilities of the target simultaneously through a single network, which significantly improves the detection speed compared with the two-stage detection algorithm. In the field of ship target detection, a single-stage algorithm shows greater application potential by virtue of its efficiency and practicability. Gao et al. [
8] introduced the dynamic denoising module into YOLOv4 to construct a new feature pyramid network and enhance the representation ability. Based on the RPDet algorithm, Xu et al. [
9] introduced the path aggregation feature pyramid structure and used CIoU as the bounding box loss function to realize the ship target detection. Woo et al. [
10] proposed ConNextV2, which can be applied to Yolo to significantly improve the performance of the network on various recognition benchmarks. Kim et al. [
11] proposed an effective channel attention pyramid (ECAP-YOLO) to avoid greater information loss.
In order to further improve the performance of the model, Liu et al. [
12] inserted CA attention into the backbone network of YOLOv7-tiny, and the SE module generated weights for each channel through the global average pooling operation and enhanced the important features between channels through weighting. This method can effectively suppress the influence of irrelevant features and improve the target segmentation ability of the model in complex backgrounds. At the same time, the SPP structure is modified and the original loss function is replaced by SIoU, which improves the model detection performance. Li et al. [
13] inserted a CA module into YOLOv3, which enhanced the correlation between channel and spatial features by combining coordinate information. Compared with the traditional attention mechanism, the CA module can capture spatial location information and channel dependence at the same time and performs well, especially in small target detection. Zhao et al. [
14] inserted the CBAM module into the feature extraction stage of YOLOv5n. CBAM combines channel attention and spatial attention at the same time. It can effectively highlight important features and ignore background noise.
The above methods are optimized in different degrees on the basis of the general target detection algorithm to improve the performance of ship target detection. However, these methods still struggle to effectively separate the ship from the complex onshore background when facing nearshore scenes. At the same time, its feature extraction and expression ability is relatively weak for occluded ship targets and small-size ship targets, which leads to unsatisfactory detection results and limits its application performance in actual complex environments. While YOLOv10n is lightweight and efficient, it struggles with detecting small objects in complex backgrounds and handling occlusions due to its limited feature extraction capabilities. On the other hand, YOLOv11, despite its improved accuracy and speed, is computationally expensive and less suitable for real-time applications on resource-constrained devices.
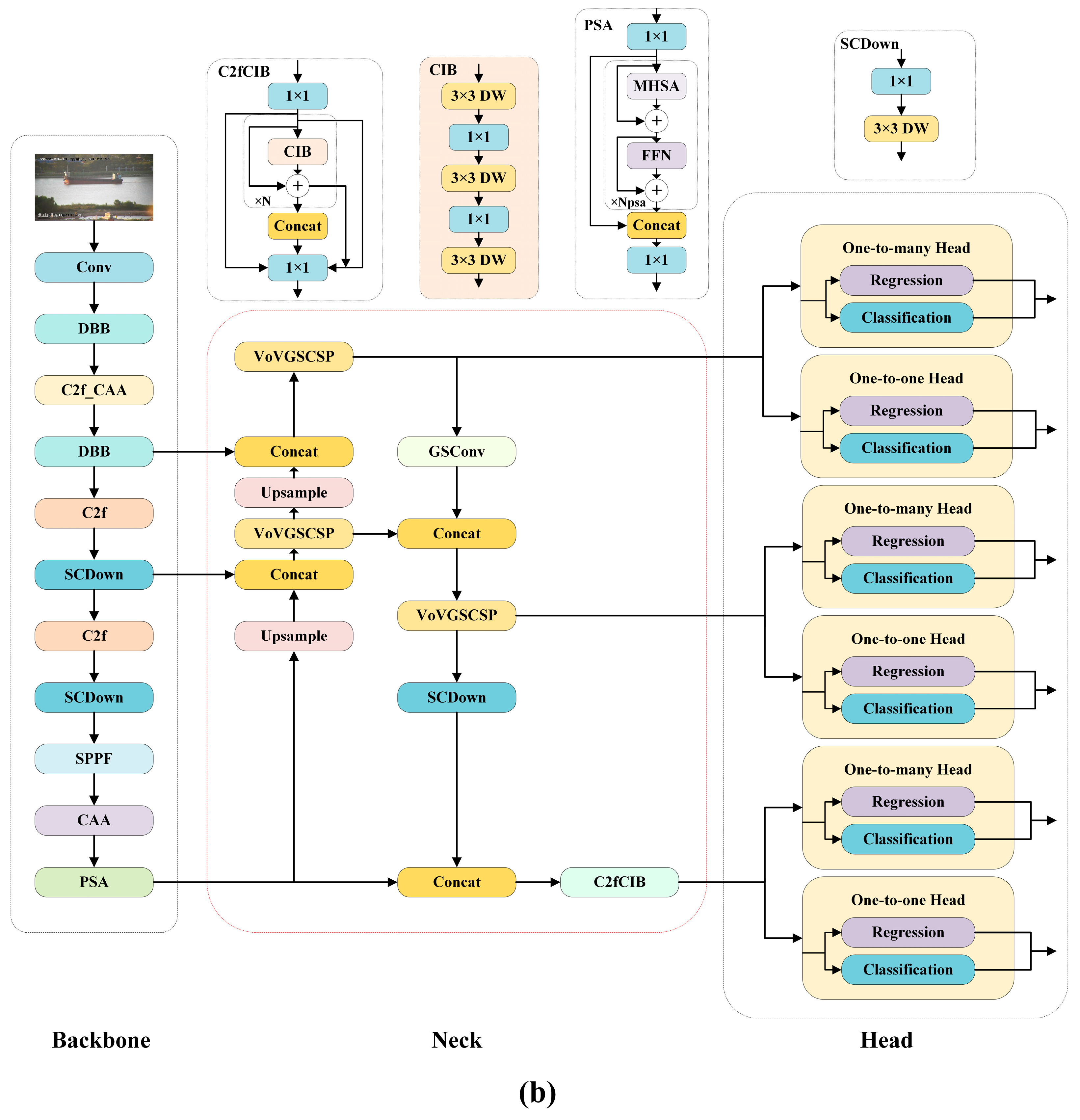
In response to the above problems, this paper proposes an inland river ship detection and identification method based on improved YOLOv10 [
15]: CDS-YOLO. Firstly, the context anchor attention mechanism [
16] (CAA) was introduced, and the C2f_CAA module was constructed to enhance the features of the central region and improve the understanding ability of complex scenes. Then, the dynamic bottleneck block [
17] (DBB convolution) was used to replace the traditional convolution module in the Backbone network, which enhanced the expression ability of a single convolution and enriched the feature space. Finally, in the Neck part, the traditional C2f module is replaced by the VoVGSCSP structure of Slim-Neck [
18] and the ordinary convolution is replaced by GSConv, which optimizes the network structure, reduces the complexity of the model, and realizes more efficient multi-scale feature fusion. Experimental results show that the CDS-YOLO proposed in this paper has better detection ability than YOLOv10 under the interference of complex background information, and has better detection effect for ship occlusion and small targets.
2. Method of This Article
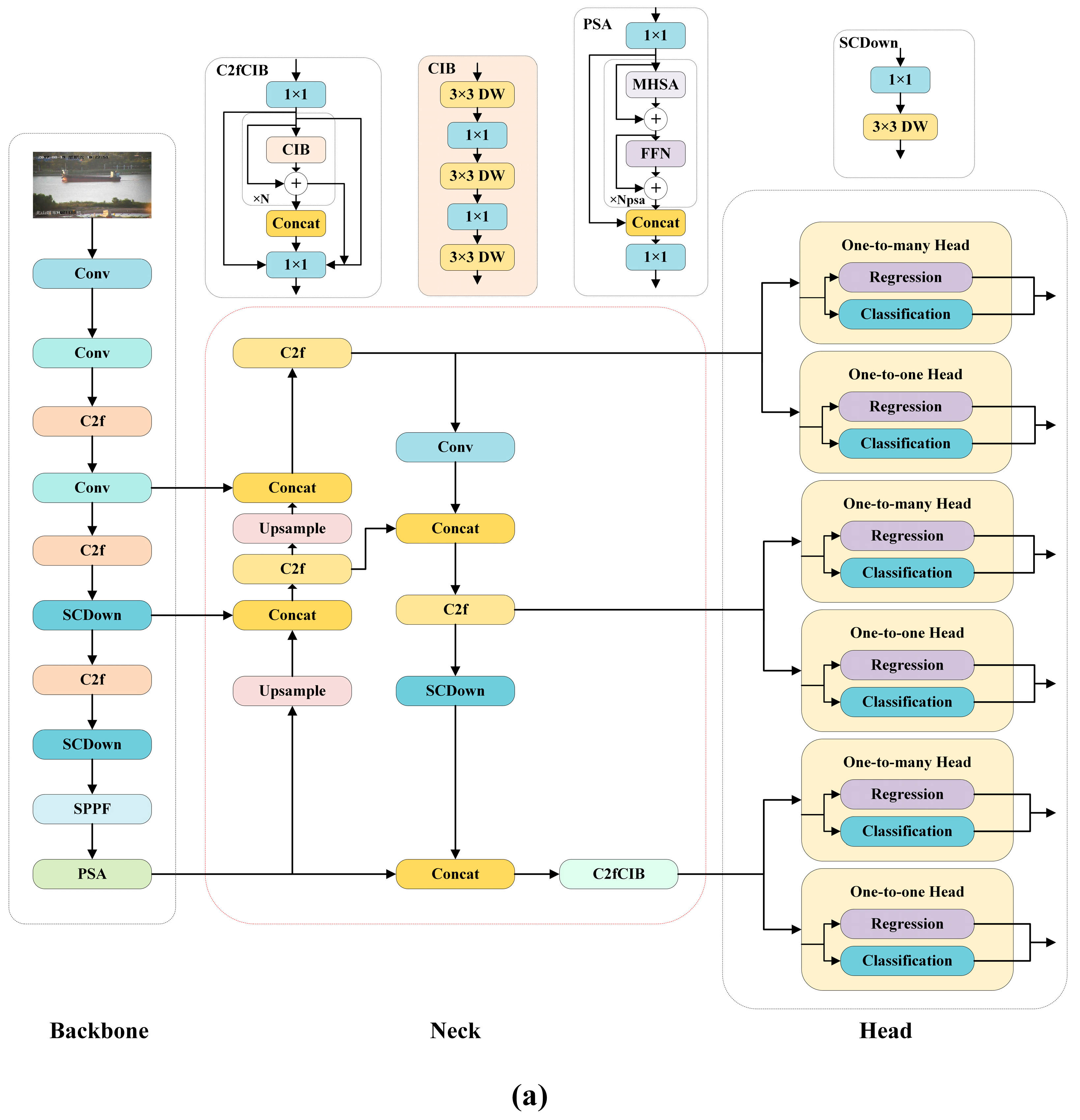
This section first introduces the overall framework of the proposed method, as illustrated in
Figure 1. The first part provides an overview of the YOLOv10 baseline network. The second part focuses on the design of the feature extraction network, where the Context Anchor Attention (CAA) mechanism is introduced into the Backbone network. The CAA mechanism combines global semantics and local features through context anchors, effectively enhancing the network’s ability to focus on key regions. Additionally, CAA optimizes feature distribution through feature division and remodeling, further improving the network’s perception of multi-scale features. Based on this, we propose an improved module, C2f_CAA, which integrates CAA into the C2f module. This integration enables the Backbone network to more accurately extract salient target features in complex backgrounds while suppressing interference and noise.
To further enhance the diversity of feature representation and improve the model’s detection performance for small and occluded objects, we replace the traditional convolution module with a Diverse Branch Block (DBB). DBB expands the feature expression space through a multi-branch design and employs structural reparameterization techniques to enrich feature diversity and enhance the network’s representation capability, all while maintaining inference efficiency.
The third part describes the lightweight optimization applied to the Neck network by introducing the GSConv (Grouped and Shuffled Convolution) and VoVGSCSP (VoVNet Grouped and CSP) modules from the Slim-Neck architecture. GSConv combines the advantages of standard convolution and depthwise separable convolution, achieving efficient cross-channel feature fusion through a feature shuffling mechanism. This significantly reduces computational costs while enhancing the expression of multi-scale features. VoVGSCSP integrates the strengths of multi-branch feature extraction and cross-stage feature fusion from VoVNet, further improving feature fusion efficiency through branch extraction and cross-channel compression.
Through these designs, the Neck network not only significantly reduces the number of model parameters and computational complexity but also maintains high detection performance. Moreover, it effectively improves the detection capability for small and medium-sized targets in complex backgrounds, providing a reliable solution for real-time detection tasks on resource-constrained devices.
2.1. YOLOv10 Algorithm
As the latest version of the YOLO series, YOLOv10 further optimizes the network structure on the basis of maintaining high efficiency and accuracy. It has the advantages of fewer parameters, fast calculation speed, and strong compatibility, which is very suitable for scenarios with limited hardware resources. YOLOv10 is mainly composed of a Backbone feature extraction network (Backbone), a Neck network (Neck), and detection Head (Head). The input image is first passed through the Backbone network, and features are extracted by a design including a large convolution kernel, a Partial Self-Attention module (PSA), and a space-channel separation down-sampling module. The feature maps output by Backbone includes multiscale feature maps with 8×, 16×, and 32× downsampling. These feature maps are then fed into the Neck network. The Neck part of YOLOv10 uses enhanced feature fusion modules, such as BiC and RepGFPN modules, to achieve efficient fusion of multi-scale features and significantly improve the detection ability of small objects. Finally, the fused feature map is passed to the detection Head, which outputs the classification result and the precise location of the object. The Head part of YOLOv10 is lightweight and designed to further reduce the computational cost and inference delay while maintaining the detection accuracy. The YOLOv10n and the CDS-YOLO network structure are shown in
Figure 1.
2.2. Improvements Based on CAA Module
The attention mechanism has become an essential component in deep learning models due to its capability to enhance feature representation through flexible structural designs and powerful feature enhancement capabilities. Classical attention mechanisms such as the Squeeze-and-Excitation [
19] (SE) and Convolutional Block Attention Module [
20] (CBAM) have demonstrated remarkable performance in allocating attention weights across dimensions and integrating features effectively. These methods significantly enhance the model’s ability to capture critical features, which is crucial for tasks involving complex data. However, the computational efficiency and feature representation capabilities of these traditional attention mechanisms can still be optimized, particularly in scenarios requiring the processing of intricate and diverse feature patterns.
To address these limitations and further improve the expressive capacity of features, this paper introduces the Context Anchor Attention (CAA) mechanism. CAA integrates global semantic information with localized feature details by leveraging the context anchor mechanism, which directs the model’s focus toward critical areas of the feature map. Unlike traditional attention modules, CAA adopts a unique approach by partitioning the channel dimension into multiple sub-feature groups. This division, followed by feature reshaping, optimizes the feature distribution and enhances the model’s perception of multi-scale features. Furthermore, CAA employs a cross-dimensional interaction mechanism to fuse feature outputs from various branches, effectively enriching feature representation and improving the multi-scale perception capability of the network.
A distinctive strength of CAA lies in its ability to balance computational efficiency with feature learning capacity. By focusing computational resources on key areas and integrating critical information across dimensions, CAA significantly enhances the model’s ability to learn complex feature patterns without introducing substantial computational overhead. The implementation of the CAA module consists of the following steps:
where
is the input feature map,
is the global average pooling operation,
represents the
convolution operation.
Equations (2) and (3) represent the use of two 1D strip convolutions to extract long-distance features in the horizontal and vertical directions, respectively, where
is the convolution kernel size.
Equation (4) represents the fusion of the output of the direction-aware convolution into the original features to generate attention weights, where
is the Sigmoid activation function.
Equation (5) represents the enhancement of the original features by the weighting operation, where is the element-wise multiplication.
In this paper, the CAA attention mechanism is introduced into the Backbone network of YOLOv10, and the CAA attention module is used to improve the C2f module. The CAA is inserted into the output stage of the C2f module to construct the C2f_CAA module and replace the C2f module in the Backbone network. To enhance Backbone’s ability to express the key regions of the input feature map. Through the context anchor mechanism, CAA can more accurately capture the global semantics and key regional features, so as to effectively focus on the salient features of the ship target in the complex background, while suppressing the interference of background noise. This improvement significantly improves the feature extraction ability of Backbone for small objects and occluded objects, and provides more efficient and accurate feature representations for the subsequent Neck and Head parts, thereby improving the overall detection performance of the model. The CAA attention module structure is shown in
Figure 2.
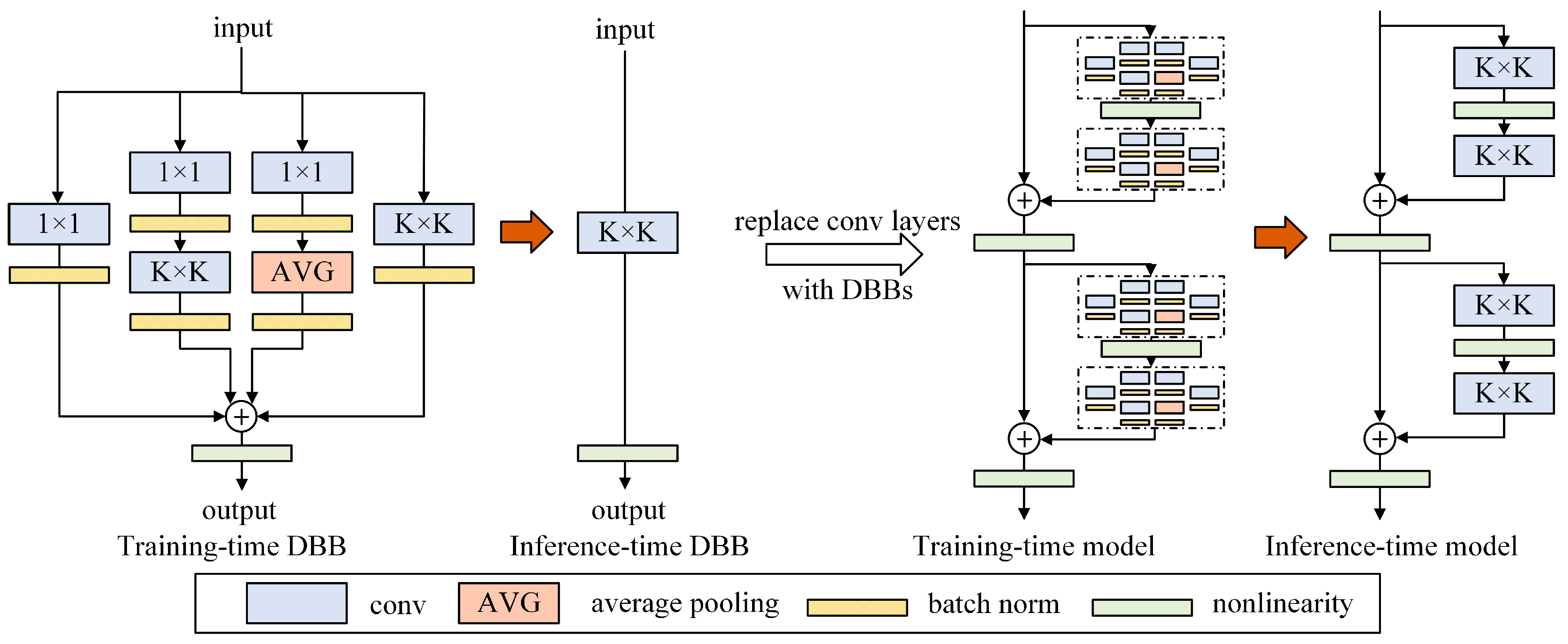
2.3. Improvement of Convolution Module
In YOLOv10, the output of the Backbone network is a three-dimensional tensor-horizontal, spatial, and channel dimensions. In order to enhance the multi-scale perception ability, spatial semantic feature expression ability and feature learning adaptability of the model, this paper replaces the standard convolution (Conv) in the original structure of YOLOv10 with Diverse Branch Block (DBB). As a general convolution module, DBB enriches the feature expression space by multi-branch design and introduces a nonlinear enhancement mechanism in the training phase, which effectively improves the diversity of features and the representation ability of the network. In addition, DBB adopts the structure reparameterization technique to simplify the complex multi-branch structure into a single convolution in the inference stage, thus taking into account the balance between model performance and inference efficiency. This design makes DBB not only suitable for single-stage object detection model but also show superior feature learning ability in a variety of tasks.
In the training phase, the multi-branch structure of the DBB module includes three typical paths: the original convolution branch, which is used to capture local features; The sequential convolution branch, convolution followed by convolution, was used for feature compression and context modeling. Average pooling branch, feature smoothing via a combination of or convolutions and average pooling.
The multi-branch structure formula of DBB module is expressed as follows:
where
represents the input feature map;
and
denote the kernel and bias of the ith branch;
denotes convolution operation;
denotes the output feature map of the module.
Each branch is independently equipped with a Batch Normalization (BN) layer, which provides a nonlinear enhancement in the training phase to further improve the feature representation ability. The convolution operation with BN can be expressed as follows:
where
and
are the mean and standard deviation of the JTH channel, respectively;
and
are learnable scaling and bias parameters.
In the inference stage, the DBB module merges the parameters of multiple branches into an equivalent single convolutional layer through the structure reparameterization technique. For the convolution kernel
and bias
, the merging formula is as follows:
In this way the complex multi-branch training structure is simplified into a standard convolutional layer, which greatly reduces the computational cost of the inference stage without affecting the performance of the model.
The introduction of DBB into YOLOv10 enhances the adaptation ability of the backbone network to complex spatial and semantic features. By adopting the multi-branch design of DBB, the network can flexibly capture diverse and complex feature patterns, which is crucial for detecting objects at different scales and contexts. The structure reparameterization technique ensures that this enhanced learning ability will not harm the efficiency of the model in the inference process, and the YOLOv10 model after replacing the original convolution with DBB convolution greatly improves the expression ability of a single convolution.
Figure 3 shows the DBB convolutional structure.
2.4. Improvement of Neck Network Based on Slim-Neck
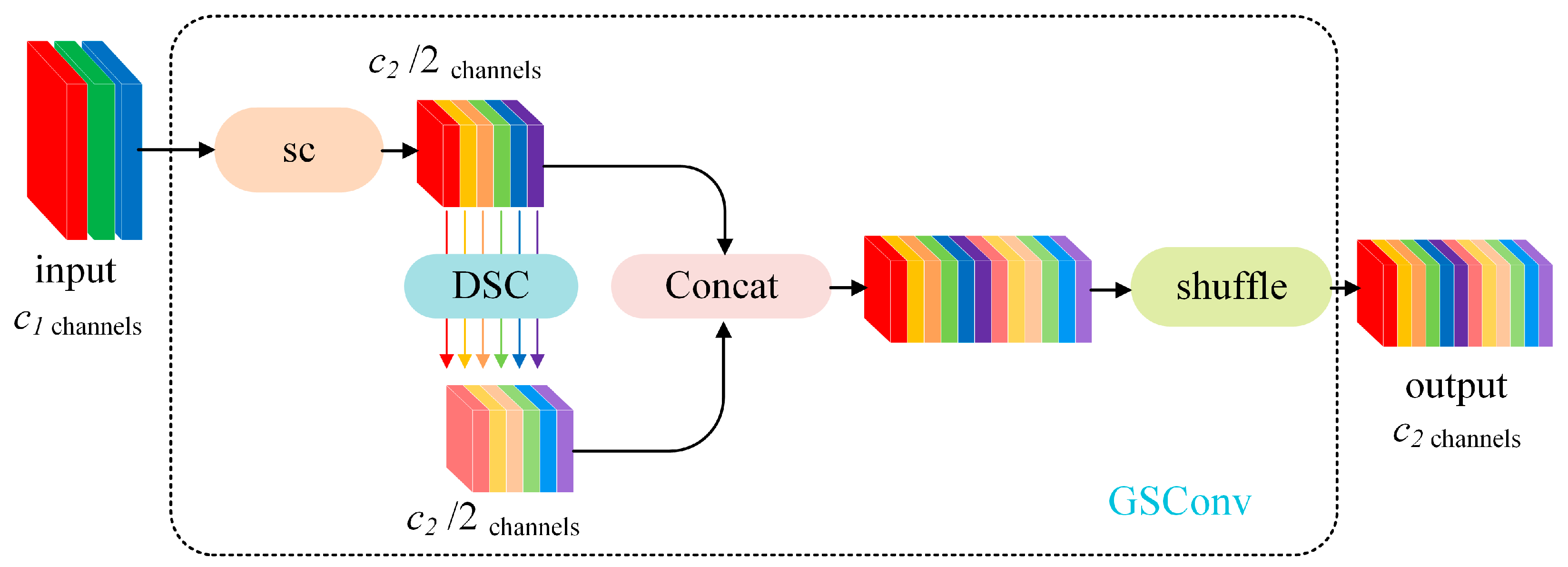
Slim-Neck is an efficient neck architecture designed for a lightweight object detection network. The core of Slim-Neck is to greatly reduce the computational cost while ensuring the detection performance of the model by introducing an efficient GSConv module and an optimized feature fusion strategy. Compared with the traditional neck network, Slim-Neck significantly reduces the number of parameters and computational complexity while maintaining the detection accuracy, which makes it perform particularly well in real-time detection tasks and resource-constrained scenarios.
The efficiency of Slim-Neck is mainly due to the application of the Grouped and Shuffled Convolution (GSConv) module. GSConv combines the characteristics of Standard Convolution (SC) and Depthwise Separable Convolution (DSC), and achieves efficient fusion of cross-channel features through the feature Shuffle mechanism. Specifically, the computation of GSConv is divided into two branches.
Standard convolution is used in the main branch, which is expressed as follows:
where
outputs features for the main branch,
is the input feature map, and
is the size of the convolution kernel.
The auxiliary branch uses depthwise separable convolution, which is expressed as follows:
where PointwiseConv is a
convolution for channel mapping, and DepthwiseConv is used to reduce computational cost and focus spatial features.
After concatenating the output features of the two branches in the channel dimension, information exchange is realized through feature shuffling. The final output features are expressed as follows:
where Concat represents the channel concatenation operation and Shuffle is used to mix the channel features to enhance the expressive power. The GSConv structure is shown in
Figure 4.
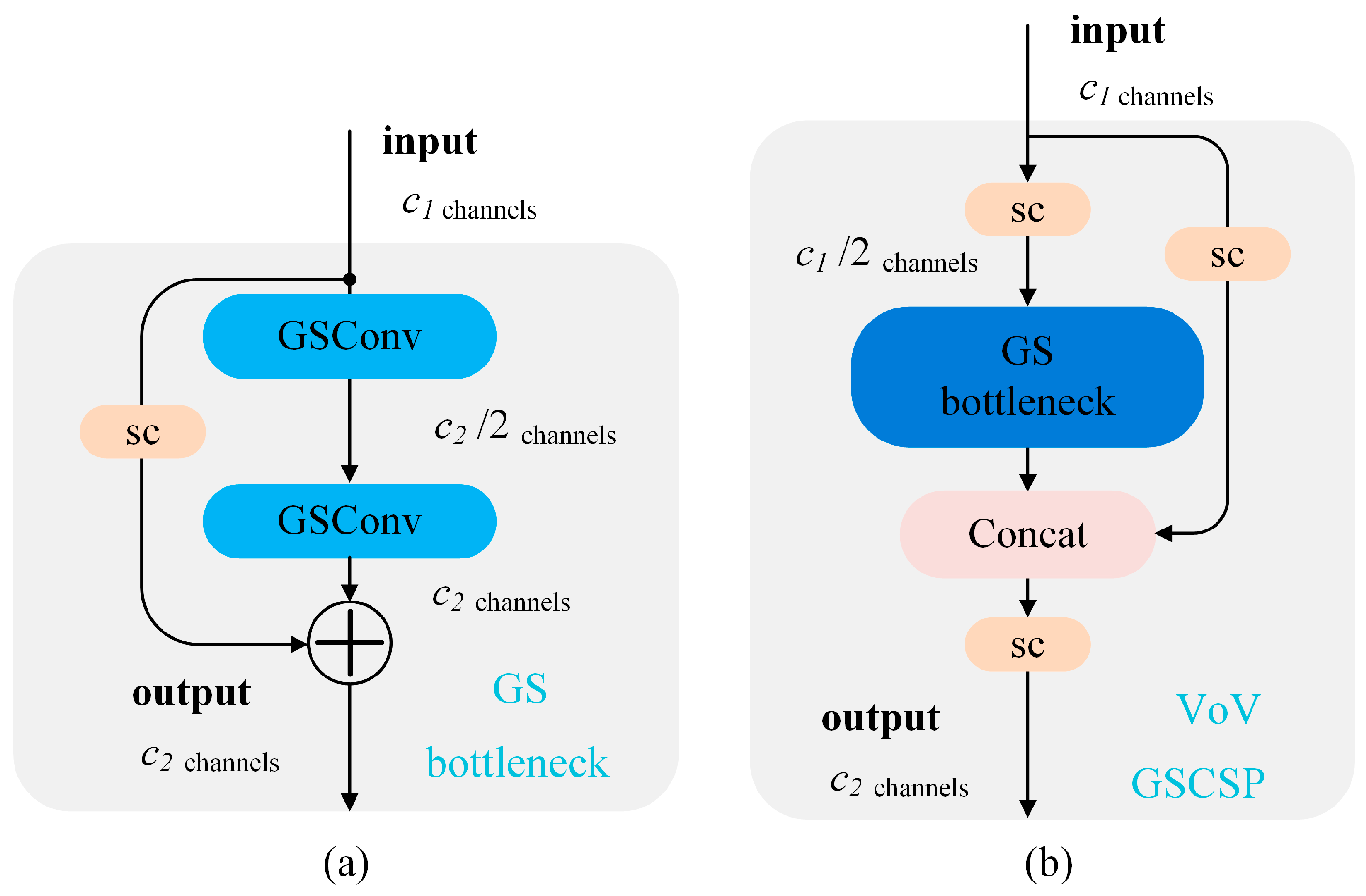
On this basis, Slim-Neck further introduces an optimized VoVGSCSP (VoVNet Grouped and CSP) module to enhance the multi-scale feature fusion ability. VoVGSCSP combines the multi-branch feature extraction of VoVNet and the cross-stage feature fusion mechanism of CSP (Cross Stage Partial).
The input features are first divided into two parts, denoted as:
where,
is the main branch feature and
is the bypass reserved feature. Equation (13) indicates that the master branch extracts multi-scale features through multiple GSConv branches, and
is the number of branches.
After concatenating the two features in the channel dimension, the two features are compressed and enhanced by a GSConv layer, and the fused feature map is finally output:
The GS bottleneck and VoVGSCSP structures are shown in
Figure 5.
In this work, the Slim-Neck architecture is incorporated into CDS-YOLO, a model designed for ship detection tasks. Slim-Neck not only reduces the model’s computational overhead but also enhances its adaptability to diverse detection scenarios, such as ships in cluttered or dynamic backgrounds.
To further boost detection performance, the model employs a dual-attention mechanism within Slim-Neck, augmenting the representation of ship target features. This dual-attention mechanism ensures that the model focuses on salient features while mitigating background interference. The architecture achieves a fine balance between performance and computational efficiency, making it particularly effective for detecting small or occluded targets.
3. Experiment and Analysis
3.1. Experiment Configuration and Parameters
The experiment configuration of this paper is Windows 11 (64-bit) home Chinese version, the CPU is Intel Core-14600KF @ 3.5GHz, the GPU is NVIDIA GeForece RTX 4070Ti Super, and the running memory is 32GB. CUDA version 12.4 and Pytorch version 2.4.0 were used, and the pre-trained weights were used for transfer learning. The training parameters configuration is shown in
Table 1.
3.2. Experimental Data Set
The dataset used in this paper is Sesships [
21] inland ship dataset, which contains 7000 images of inland ships under different backgrounds, weather conditions, viewpoints, and different times. The Seaships dataset contains images of six classes of ships, namely mining ships, general cargo ships, bulk cargo ships, container ships, passenger ships, and fishing boats. Partial samples are shown in
Figure 6. Firstly, the dataset was divided into a training and validation set with 6300 images and a test set with 700 images according to the ratio of 9:1. The training and validation set was then divided into a training set with 5670 images and a validation set with 630 images according to the ratio of 9:1.
3.3. Evaluation Metrics
In order to evaluate the recognition accuracy of the model, Precision, mean Average Precision (mAP) and Recall are used as evaluation indicators. Among them, the precision is the precision rate, which indicates the proportion of correctly predicted positive samples in the predicted positive samples. AP represents the average accuracy of a single class. mAP is the average value of Average Precision (AP), and the higher the value, the better the detection effect. Recall is the proportion of correctly predicted positive samples among the positive samples. The expressions for precision, recall, average precision, and mean average precision are as follows:
where: TP stands for true positives; FP stands for False Positives. TN stands for True Negatives. FN stands for False Negatives. n is the number of ship classes, n = 6 in the dataset in this paper.
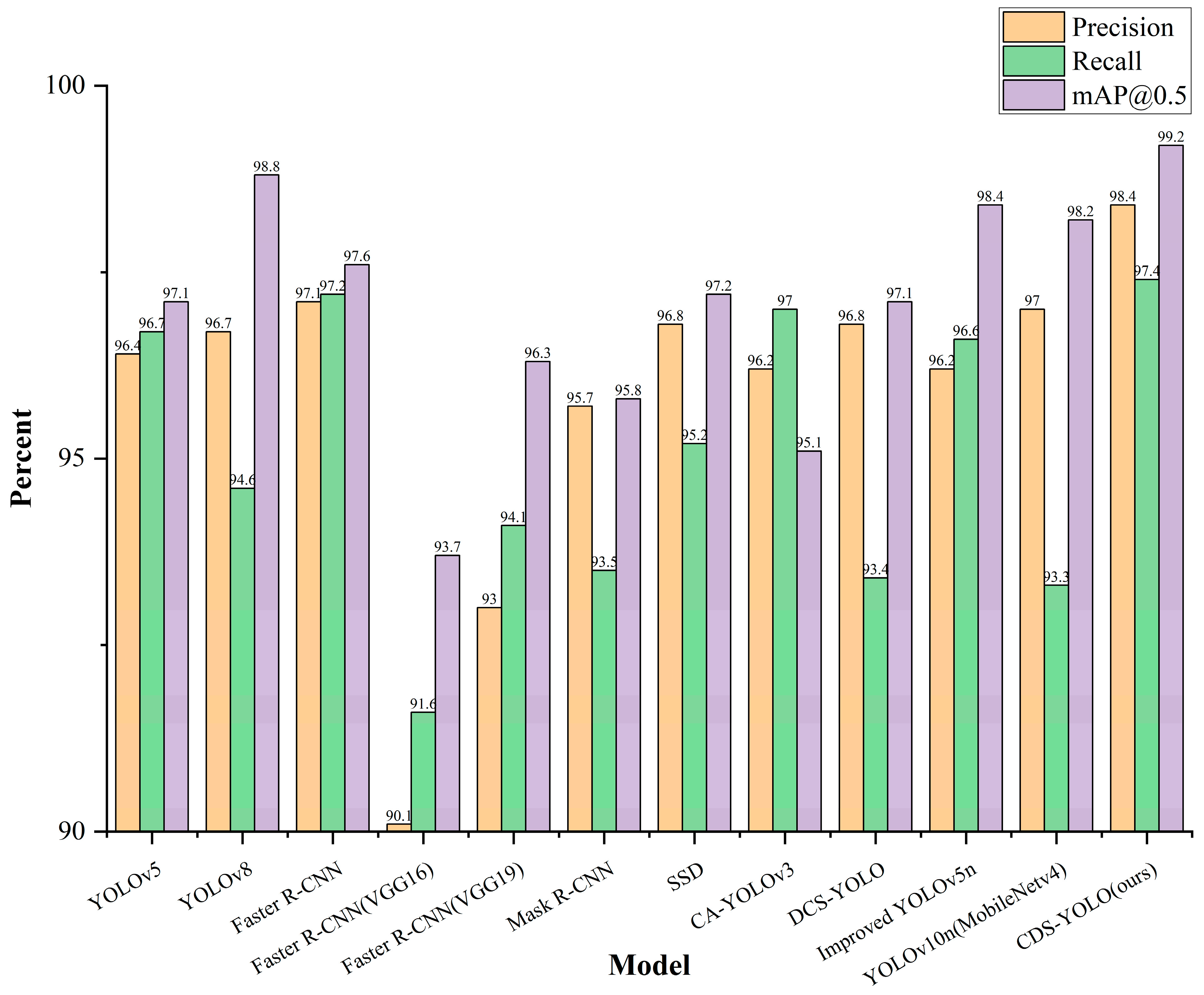
3.4. Comparative Experiments
In order to further verify the superiority of the improved algorithm in this paper, CDS-YOLO is compared with mainstream object detection algorithms such as YOLOv5, YOLOv8 [
22], Fast R-CNN, Faster R-CNN, Mask R-CNN, and SSD under the same experimental conditions, and the results are shown in
Table 2 and
Figure 7.
As illustrated in
Table 3, the CDS-YOLO model introduced in this study demonstrates varying degrees of enhancement in detection accuracy, recall rate, and mAP@0.5 relative to other leading object detection algorithms. Experimental evidence corroborates the superior performance of CDS-YOLO for inshore vessel detection. The processing speed in YOLOv10n original network and CDS-YOLO is 0.1 ms preprocess, 1.0 ms inference, 0.0 ms loss, respectively, 0.1 ms postprocess per image and 0.1ms preprocess, 1.1ms inference, 0.0 ms loss, 0.1 ms postprocess per image.
Figure 8 shows a visual example of the ship target detection results of YOLOv10n and CDS-YOLO. In the first set of examples, when there are two types of ships in the detection range and the ships are occluded, the detection confidence of CDS-YOLO for bulk carriers is increased from 0.63 to 0.87 compared with YOLOv10n, which is more significant. In the second set of examples, when YOLOv10n misses detection, CDS-YOLO can correctly detect all ships in the image and its accuracy is better than that of the former. Therefore, CDS-YOLO is better than YOLOv10n in detecting ship targets under complex backgrounds. In the third set of instances, CDS-YOLO significantly improves the detection confidence of small target ships.
In summary, the CDS-YOLO algorithm model proposed in this paper maintains the lightweight nature of the original algorithm. Additionally, it demonstrates enhanced feature perception and extraction capabilities. These improvements lead to higher detection accuracy for ship targets in complex inland river backgrounds. Furthermore, the model performs better in scenarios involving mutual occlusion of ships and the detection of small target ships. As a result, CDS-YOLO offers significant advantages for inland river ship target detection.
3.5. Ablation Experiment
In order to verify the effectiveness of the improvement of YOLOv10n algorithm model in this paper, under the premise of the same experimental parameters, an ablation experiment is designed based on YOLOv10n, and the influence of each improved method on the performance of the model is analyzed. The results of the ablation experiment are shown in
Table 2, where “√” means that this method is used to improve the model in the experiment, and “×” means that it is not used.
As shown in
Table 3, the experimental results are analyzed as follows:
In Group A, the CAA attention mechanism was integrated into the Backbone network of YOLOv10n, and the C2f_CAA module was constructed simultaneously. After this improvement, the precision increased by 2.9%, the recall rate increased by 1.9%, and the mAP@0.5 increased by 0.5%. These results demonstrate the superiority of the CAA attention mechanism in feature extraction, enabling better capture of image features in inland ship images.
Group B and Group C experiments represent further improvements to YOLOv10n. In Group B, the traditional Conv in the Backbone network was replaced by DBB convolution. In Group C, the GSConv and VoVGSCSP modules from the Slim-Neck architecture were introduced. Both improvements enhanced the model’s performance to varying degrees. Notably, when the Slim-Neck structure was introduced, the number of parameters and floating-point operations decreased from 2.7 M parameters and 8.4 GFLOPS to 2.66 M parameters and 8.0 GFLOPS, respectively. These results verify the effectiveness of DBB convolution in enhancing feature representation and the lightweight nature of the Slim-Neck structure.
Group D and Group E experiments present the results of pairwise combinations of two improved methods applied to YOLOv10n after integrating the CAA attention mechanism into the Backbone network. The experimental results of these pairwise combinations show slight improvements compared to the first three groups of experiments.
The final group presents the experimental results of the CDS-YOLO algorithm proposed in this paper, trained on the dataset. Multiple sets of comparative experiments demonstrate that CDS-YOLO achieves the best overall performance, benefiting from its efficient multi-scale feature learning and cross-regional feature fusion capabilities. Compared to YOLOv10n, CDS-YOLO improves precision, recall rate, and mAP@0.5 by 3.7%, 2%, and 0.9%, respectively, reaching 98.4%, 97.4%, and 99.2%. These results indicate that CDS-YOLO can adapt to various scene changes and exhibits strong generalization performance. Additionally, while the computational cost does not increase significantly, CDS-YOLO meets the requirements for deployment on devices with limited computational resources.
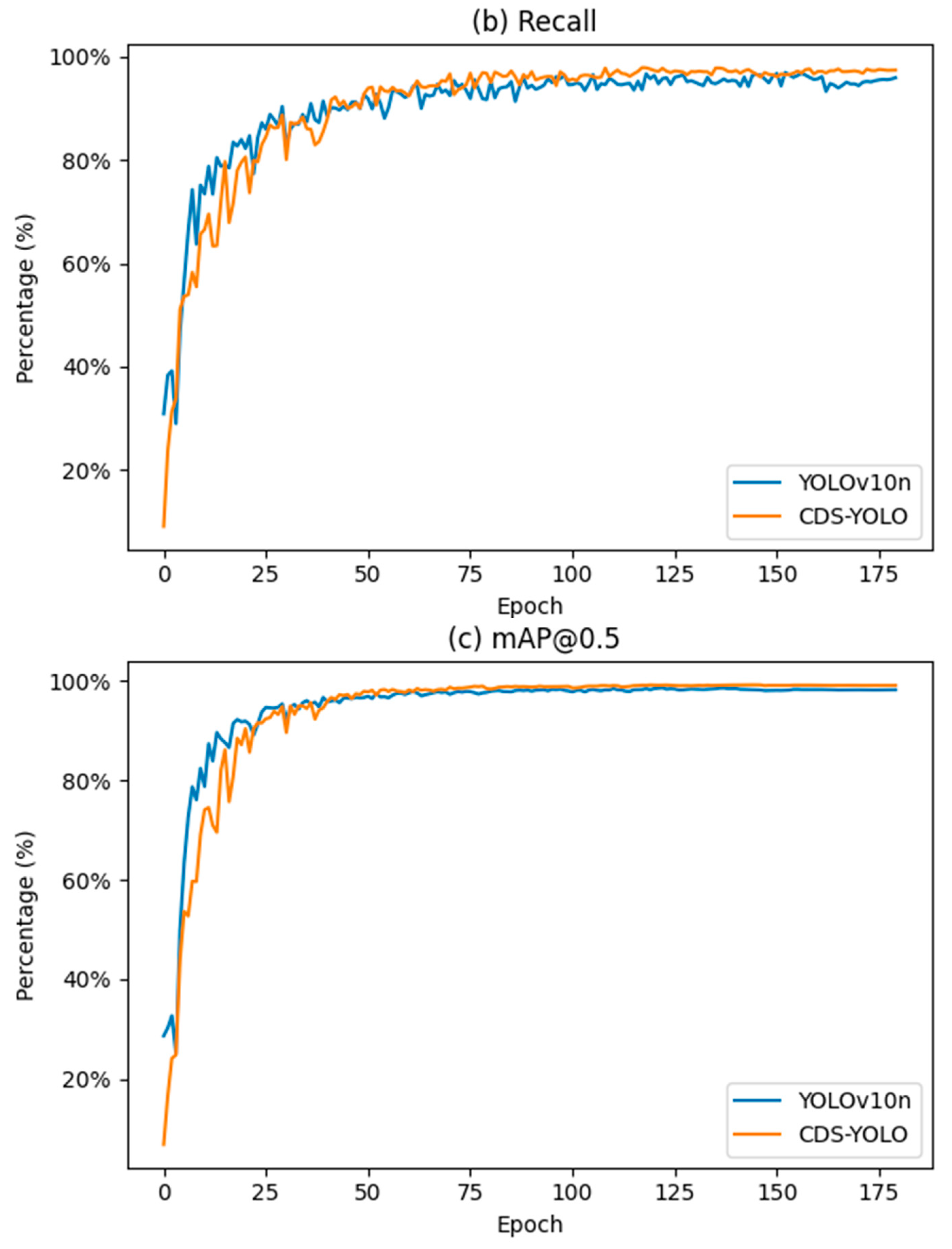
Furthermore,
Figure 9 compares the precision, recall, and mAP@0.5 change curves of CDS-YOLO and YOLOv10n during training, further illustrating the performance advantages of the proposed method.
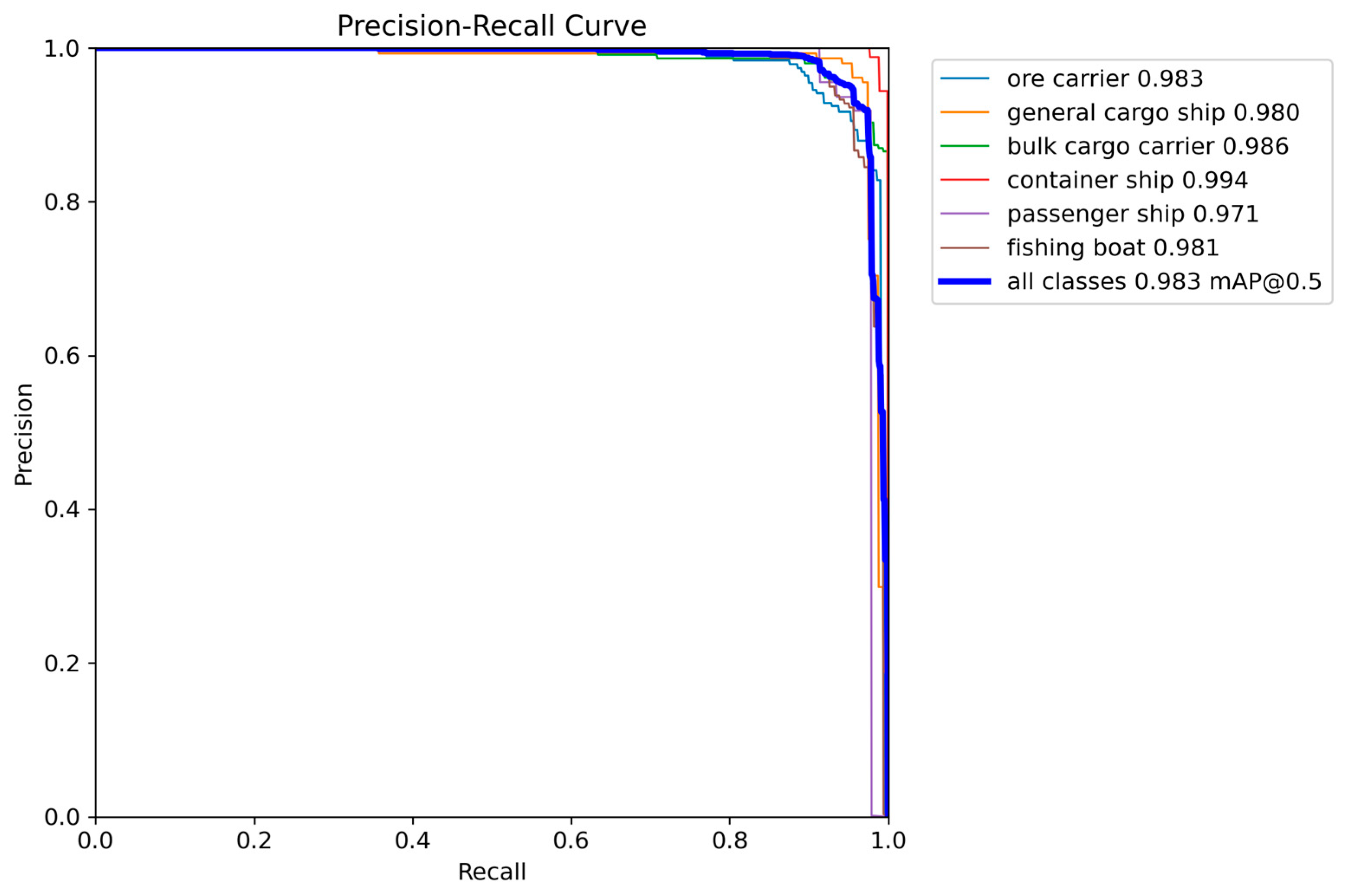
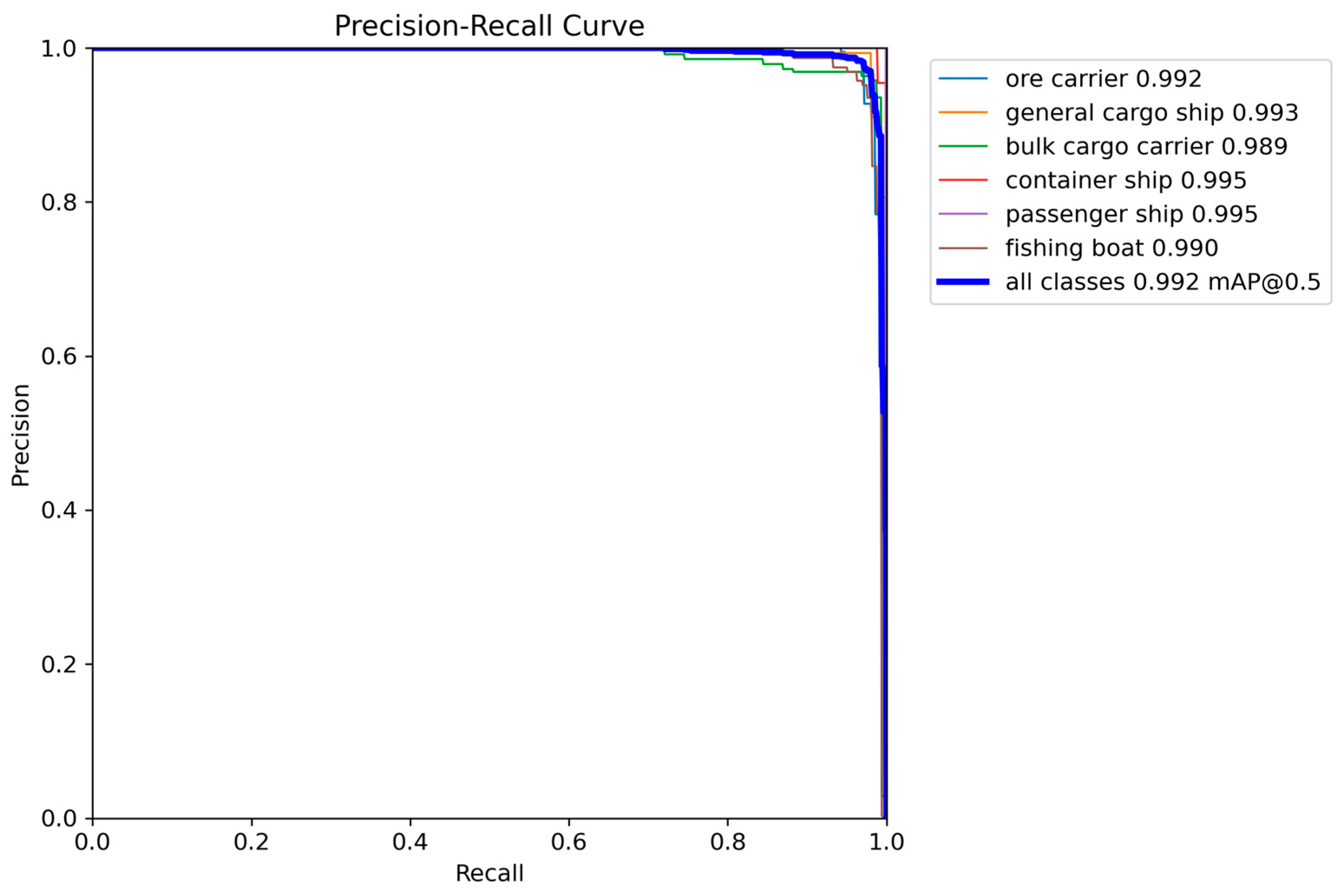
Precision is the proportion of predicted positive samples that are actually positive, and Recall is the proportion of actual positive samples that are true. The larger the area occupied in the PR graph, the better the recognition effect. The PR curve is shown in
Figure 10 and
Figure 11. By comparing the PR curve of the two, it can be intuitively seen that the improved model has significantly improved the accuracy, which proves the effectiveness of CDS-YOLO in improving the performance of inshore ship target detection.
4. Discussion
The proposed CDS-YOLO method addresses the challenges of poor recognition accuracy in small target ship detection and the interference caused by complex backgrounds, such as shoreline buildings, trees, and ship occlusion. By introducing the CAA attention module into the Backbone network and constructing the C2f_CAA module, the model enhances the features of the central region, thereby improving its ability to understand complex scenes. Additionally, replacing Conv with DBB enriches the feature space and enhances the expression ability of a single convolution. The integration of GSConv and VovGSCSP in the Neck network further optimizes the architecture, reducing model complexity while improving performance.
The experimental results on the Seaships dataset demonstrate the effectiveness of the proposed method, with detection accuracy, recall rate, and mAP@0.5 reaching 98.4%, 97.4%, and 99.2%, respectively. These results indicate that CDS-YOLO not only enhances the extraction and integration of multi-scale information but also improves the model’s detection performance in complex backgrounds. The method is particularly effective in capturing small target detection objects, showcasing its accuracy and robustness in the detection and classification of inshore ships.
However, the study has certain limitations. The proposed method has primarily been validated on the Seaships dataset, and its generalizability to other datasets or real-world scenarios remains to be investigated. Furthermore, the computational efficiency of the model in real-time applications needs thorough evaluation to ensure its practicality in operational environments.
5. Conclusions
In conclusion, the CDS-YOLO method presents a significant improvement in ship target detection, particularly in complex environments with small targets and background interference. The integration of attention mechanisms, enhanced convolution operations, and optimized network architecture contributes to the model’s high accuracy and robustness. Despite its promising performance, further research is needed to validate the method’s generalizability and computational efficiency in real-time applications.
Future research directions could explore the integration of CDS-YOLO with newer versions of the YOLO series, such as YOLOv11, to leverage the latest architectural advancements. Investigating how CDS-YOLO performs on these advanced models could provide valuable insights for further enhancing ship target detection in complex environments. Additionally, expanding the validation to diverse datasets and real-world scenarios would strengthen the method’s applicability and reliability.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}