
Research on LSTM-PPO Obstacle Avoidance Algorithm and Training Environment for Unmanned Surface Vehicles

 ,
,
Abstract
1. Introduction
- 1.
- The obstacle avoidance strategy of the unmanned boat is optimized. This can be accomplished by autonomously training the unmanned boat through reinforcement learning so that it can efficiently avoid obstacles in non-ideal complex environments and navigate to the target point. This will avoid the problem of strategy failure that may be caused by the training of traditional plasmonic models.
- 2.
- Virtual LIDAR-based environment sensing is introduced. The local water environment information can be sensed by virtual LIDAR, so that the unmanned boat can accurately recognize obstacles and make reasonable obstacle avoidance decisions.
- 3.
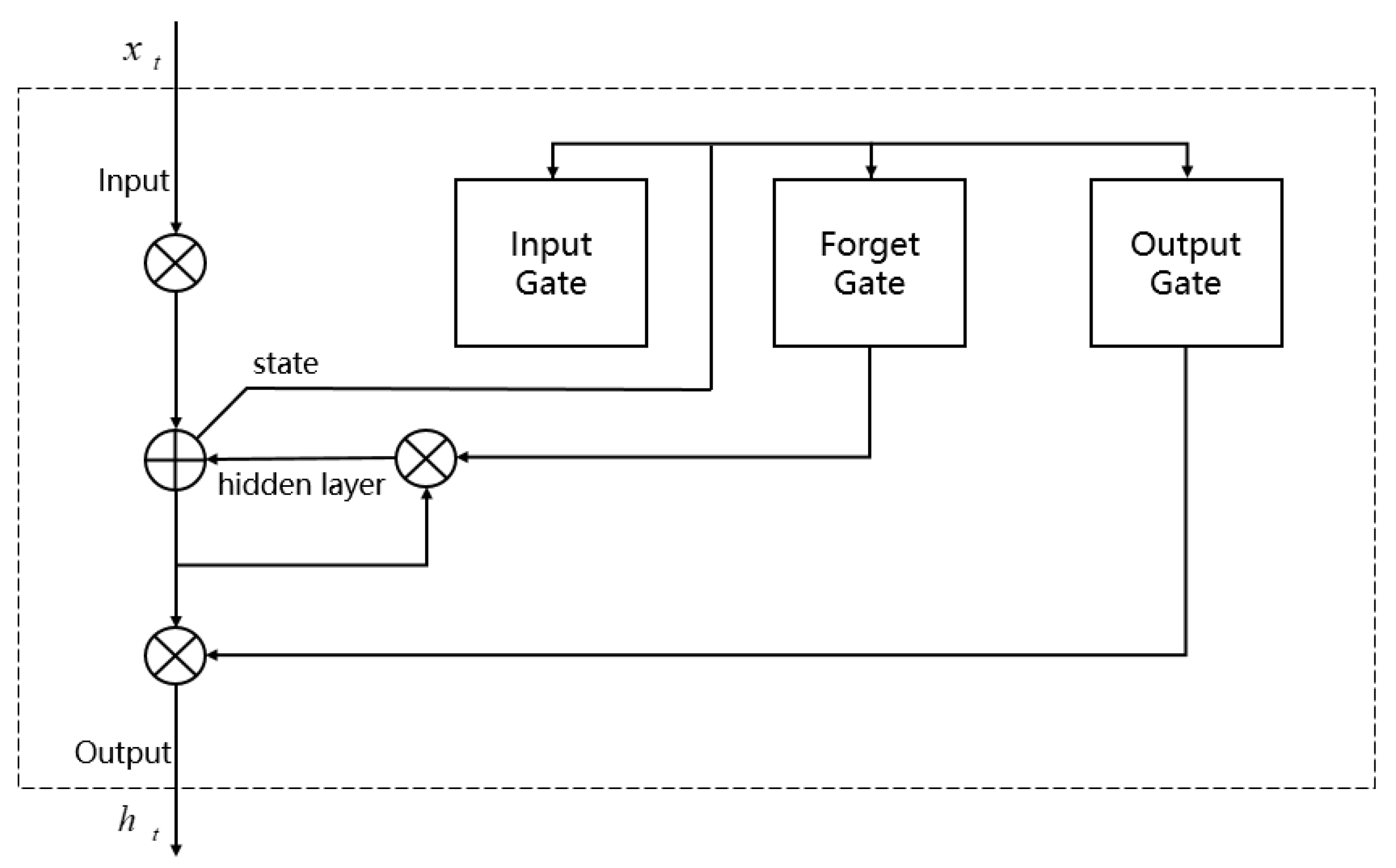
- Using LSTM to process historical information, avoiding the limitations brought by single-step observation and enabling the unmanned boat to memorize the historical state and improve the coherence of obstacle avoidance decision.
- 4.
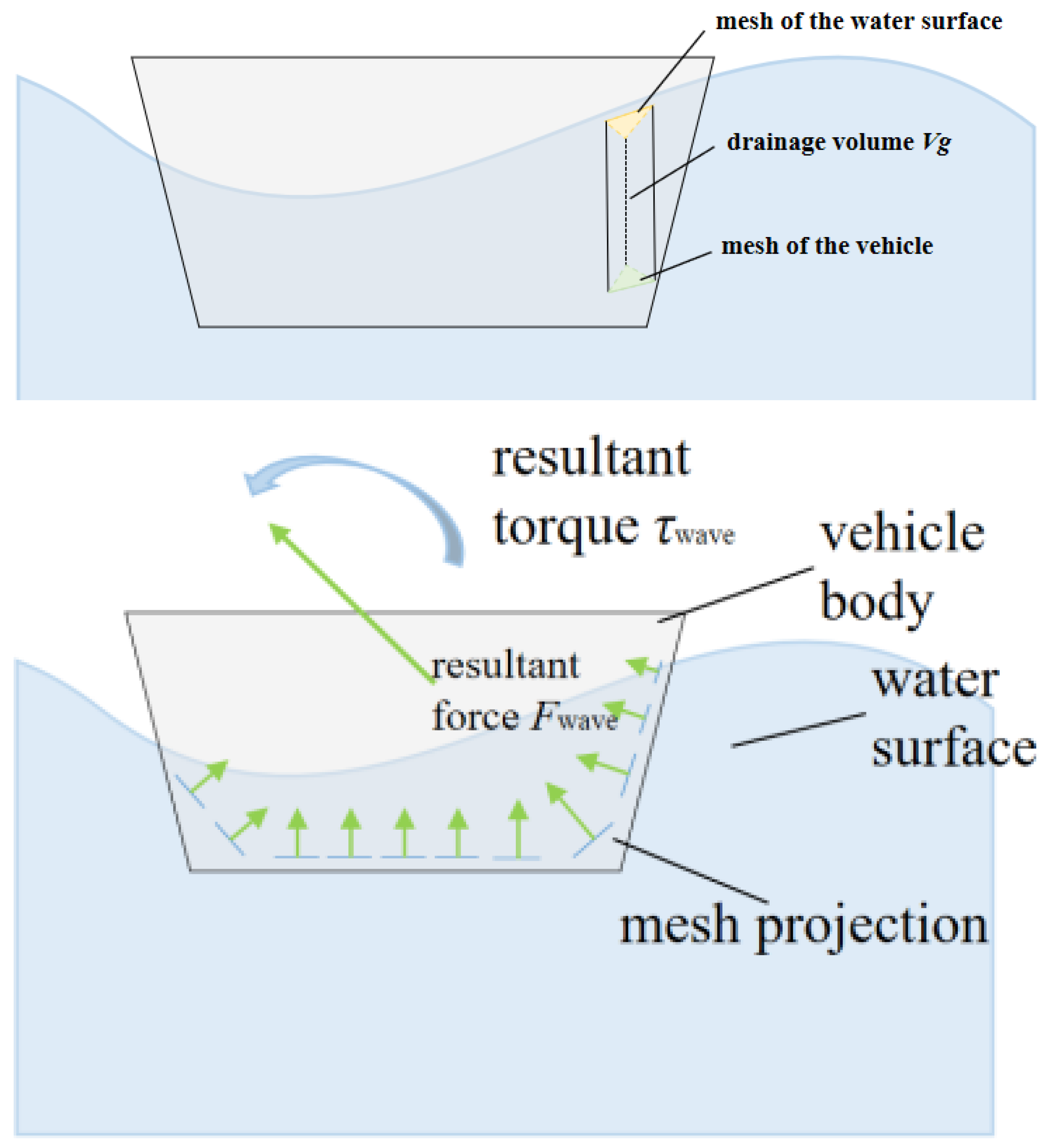
- Considering the influence of hydrodynamic forces and dynamics by introducing water surface resistance and drift penalties in the training process to enhance the adaptability of the algorithm to the actual marine environment.
- 5.
- Optimizing the design of reward function, considering the risk level of different obstacles in the design process and using the curiosity-driven mechanism to optimize the reward function to make it more reasonable and scientific.
- 6.
- Verifying the performance of the algorithm, where a comparison with the algorithms A2C, SAC, and PPO is necessary to evaluate the advantages of LSTM-PPO in terms of training efficiency, obstacle avoidance path optimization, and success rate of obstacle avoidance.
- 1.
- The development of an unmanned boat obstacle avoidance algorithm based on LSTM-PPO, which integrates the LSTM memory capability to enhance the adaptability of PPO in non-ideal complex environments.
- 2.
- The construction of a refined water simulation environment, training based on the physical model of the unmanned boat, and the introduction of hydrodynamic effects. Dynamic influence to train the unmanned boat in a way closer to the actual environment.
- 3.
- Adopting the perception model based on virtual LiDAR to optimize the local environment cognition ability of the unmanned boat, so as to make its obstacle avoidance strategy more stable and reliable.
- 4.
- Designing a multi-level reward mechanism to balance the factors of target point navigation, obstacle avoidance, sailing direction optimization, and hydrodynamic influence, so as to improve the rationality of obstacle avoidance decision making.
- 5.
- Verifying the effectiveness of the algorithm through comparative experiments, and conducting experimental comparisons with A2C, SAC, and PPO to quantify the performance improvement of LSTM in reinforcement learning.
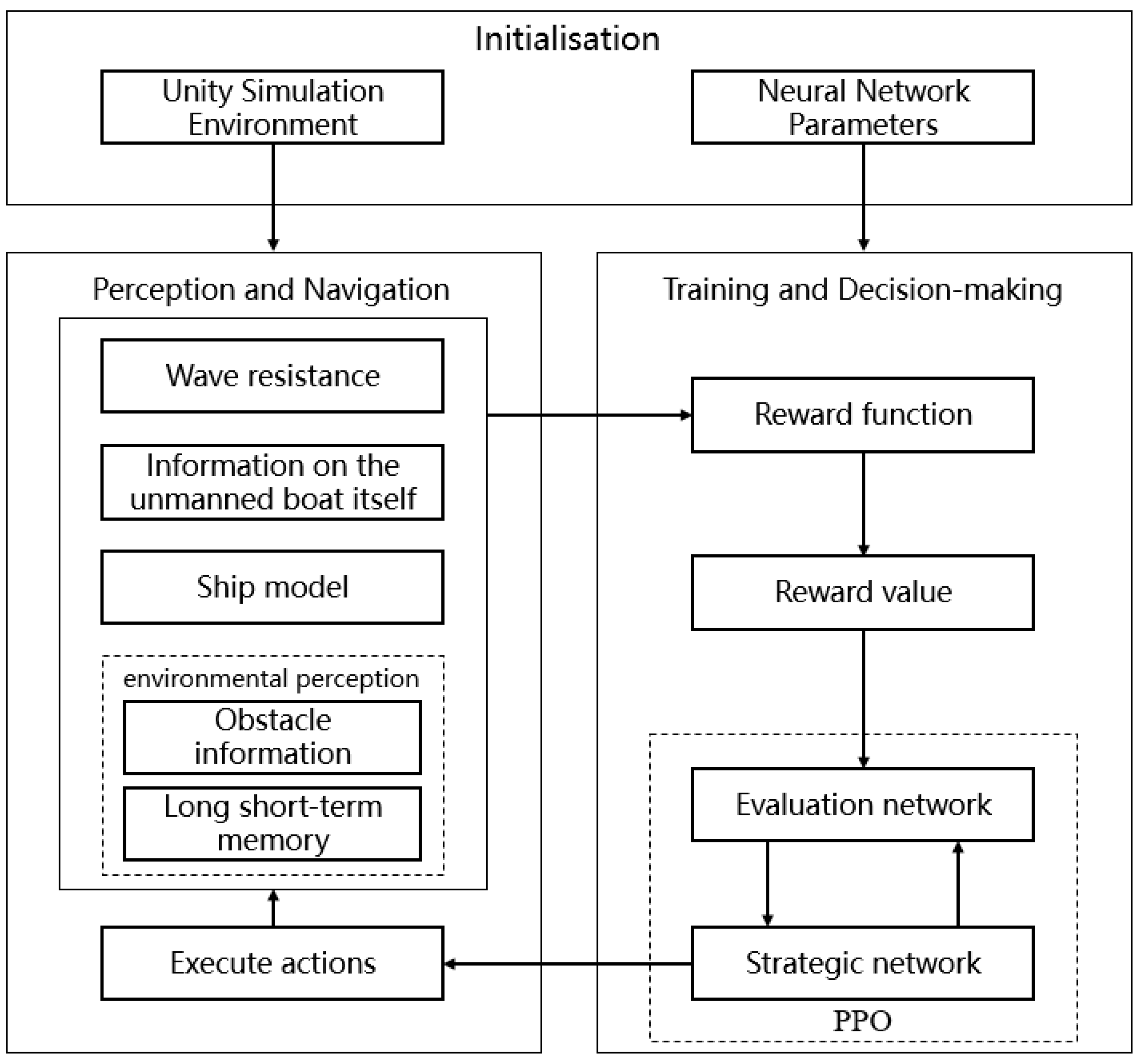
2. Methodology
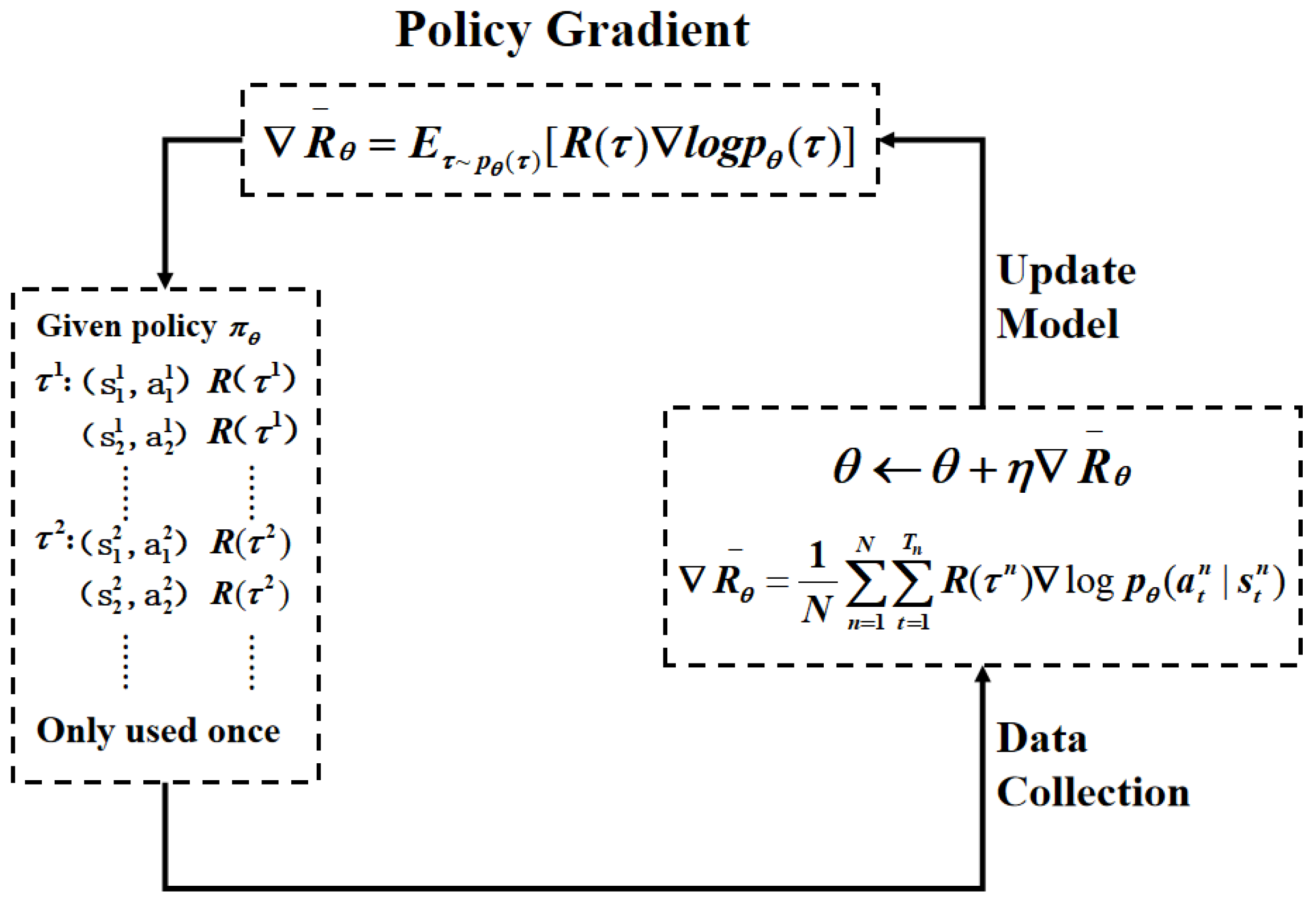
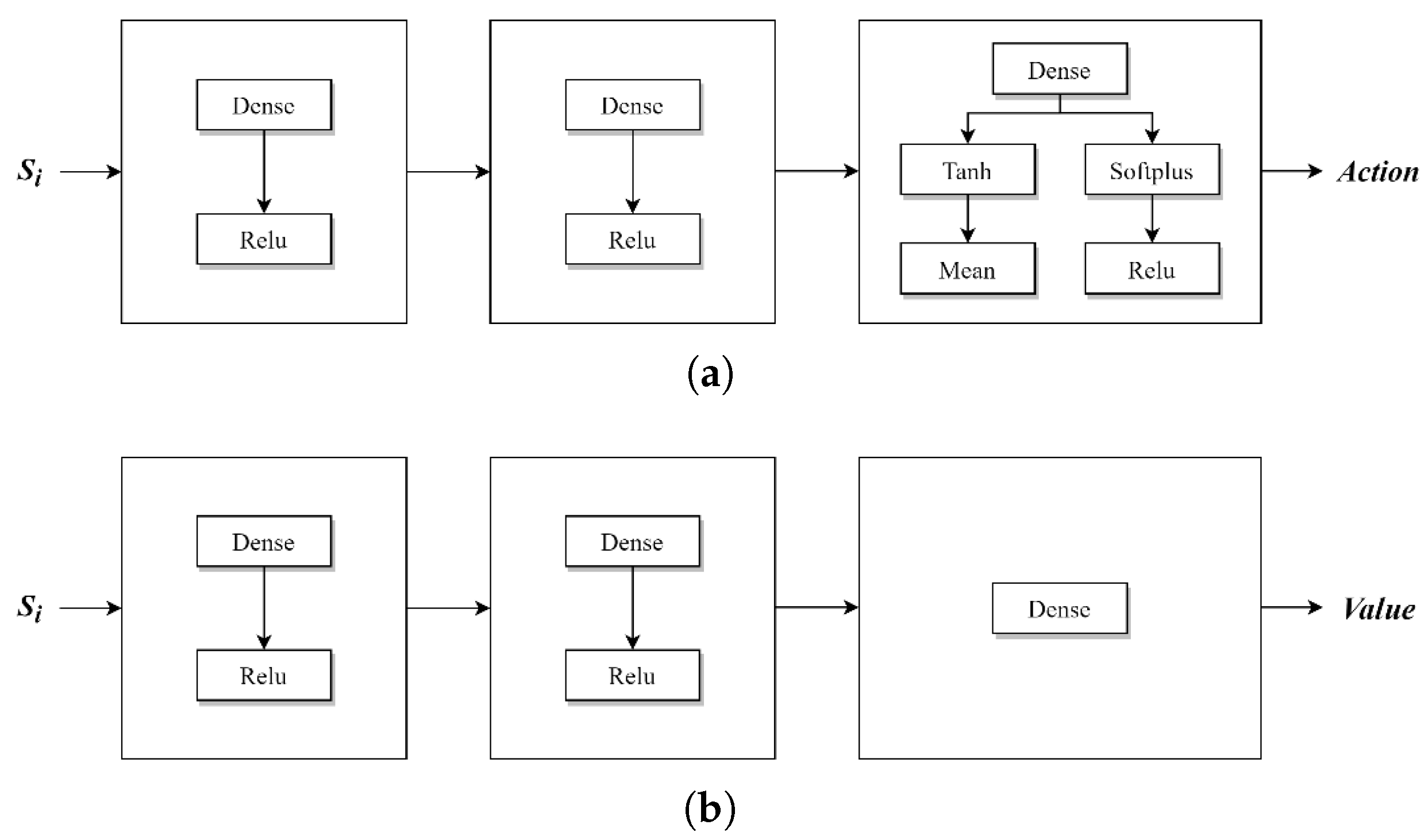
2.1. Obstacle Avoidance Strategy
- Convergence speed: Statistics on the reward convergence of LSTM-PPO, PPO, and SAC during the training process are used to verify the data utilization efficiency of the LSTM structure in complex environments.
- Obstacle avoidance success rate: The obstacle avoidance success rate of the three algorithms under different environment settings (e.g., obstacle density, etc.) is compared.
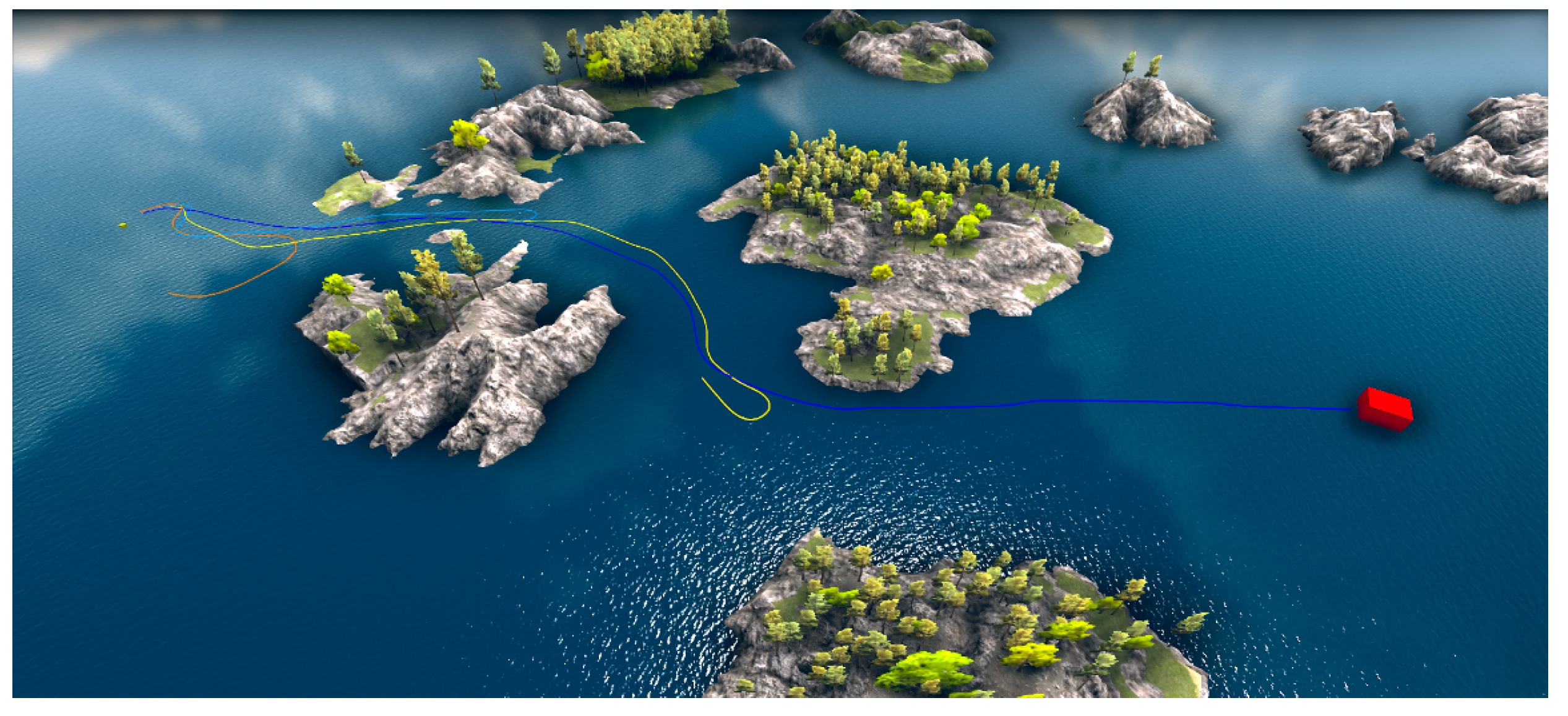
- Trajectory smoothness is analyzed by examining the motion trajectories of USVs under different algorithms. This analysis verifies whether LSTM-PPO reduces unnecessary trajectory oscillations and improves navigation smoothness.
2.2. Reward and Penalty Functions
- 1.
- Staged adjustment: At varying stages of training, the weights undergo staged adjustments. Initially, the weight assigned to obstacle avoidance is augmented to ensure that the unmanned boat can prioritize obstacle avoidance; as the training progresses, the weight allocated to path optimization is incrementally increased to facilitate more efficient navigation by the unmanned boat.
- 2.
- Heuristic adjustment: according to the actual difficulties encountered by the USV during training (e.g., frequent collisions or large path deviation), we adjust the corresponding weights in real time. When encountering more collisions, we enhance the obstacle avoidance reward; if the trajectory deviates too far from the target, we increase the weight of path optimization.
- 3.
- Cross-validation method: In different experimental setups, we utilize cross-validation to ascertain the optimal combination of weights, and gradually adjust the weights through multiple experiments, and finally select the weight setting that can balance obstacle avoidance and path optimization in most cases. Through these adjustments, the reward function is able to balance the effects of obstacle avoidance and path optimization in different training phases and different experimental conditions, thus improving the overall navigation performance of the unmanned boat.
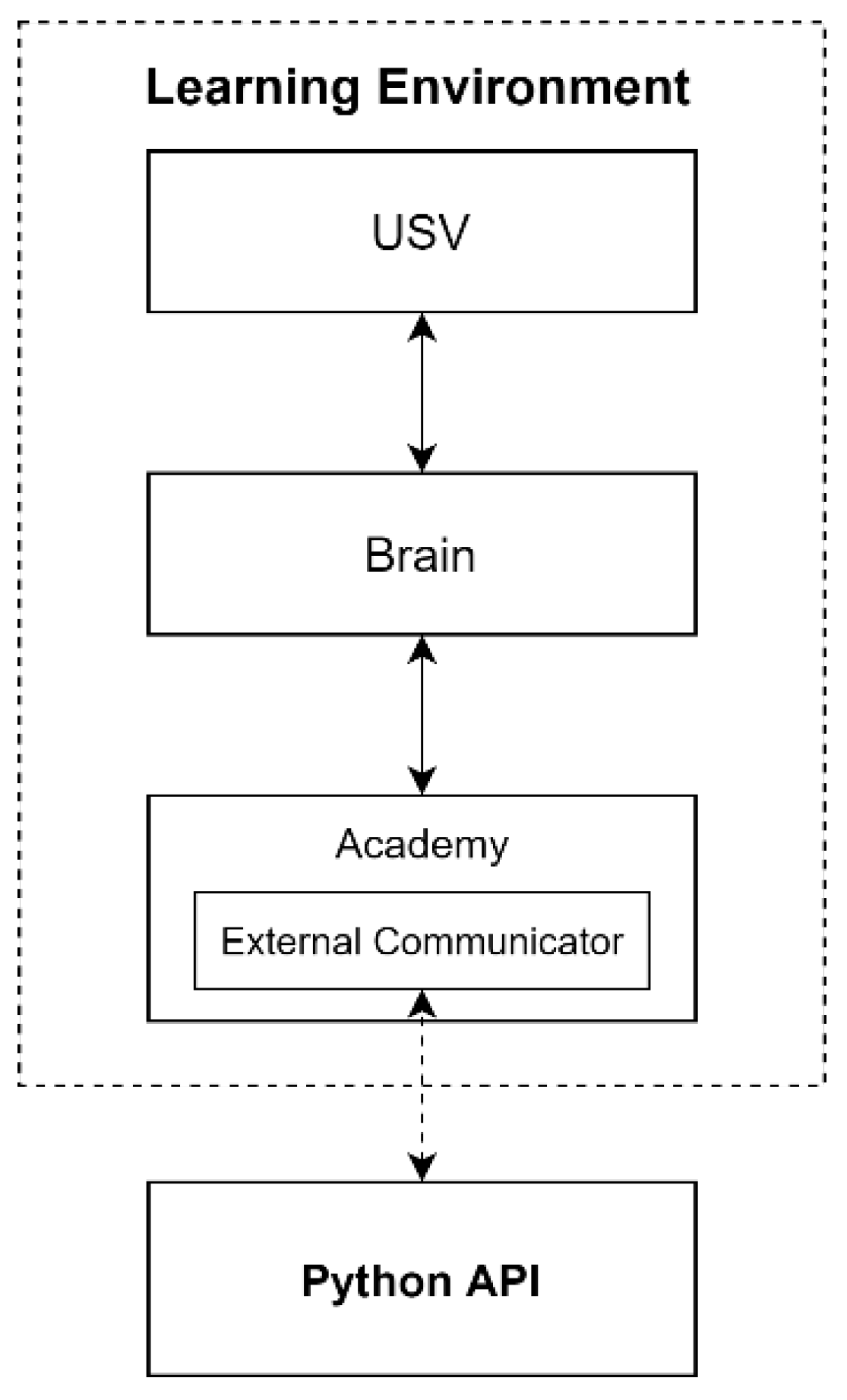
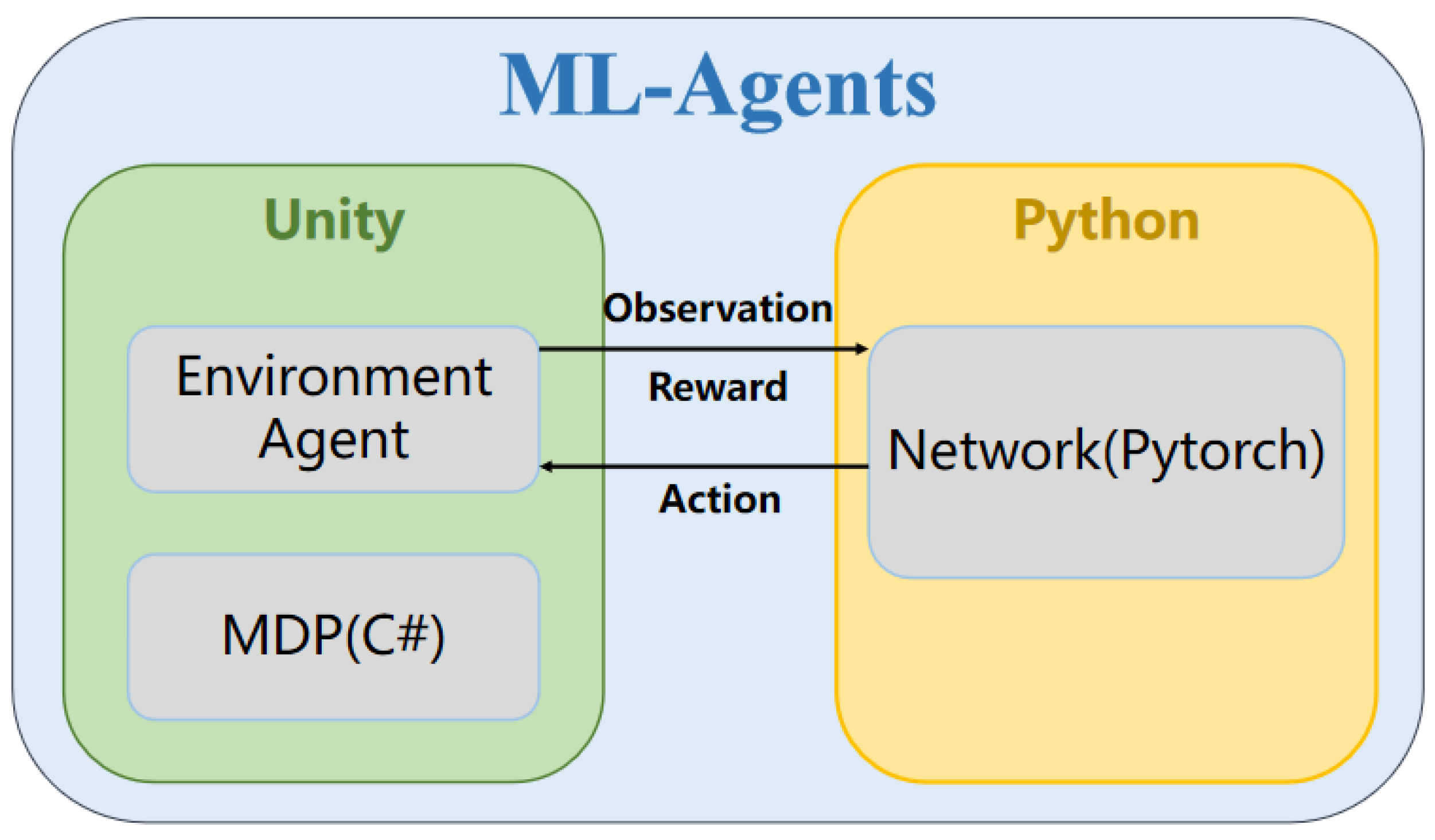
3. Training Environment
3.1. Navigation Water Construction
3.2. USV Physical Model
3.3. Obstacle Sensing
4. Simulation Verification
- Variety of obstacle distribution: The algorithm was tested for its ability to adapt to complex distributions of static obstacles, with fixed obstacles (i.e., floats) and randomly generated obstacles (i.e., floats) utilized for this purpose.
- Path complexity control: The density and distribution of obstacles were adapted in different experimental environments to ensure that there was a progressive increase in difficulty from simple environments (no obstacles) to complex environments (high density of obstacles). This was performed to test the algorithm’s ability to generalize across different environments.
- Path feasibility: The feasibility of the path was evaluated to ensure that after obstacles were placed, a reasonable and feasible path still existed, allowing the USV to arrive at the target point through reasonable decision making without falling into an unsolvable state.
4.1. Comparison of LSTM-PPO, PPO, SAC, and A2C Algorithm Sailing Experiments
- -
- Obstacle avoidance success rate: the proportion of unmanned boats that successfully avoid all the obstacles and reaches the target point in multiple experiments.
- -
- Path length: reflects the path planning efficiency of the unmanned boats in the obstacle avoidance process.
- -
- Convergence time: refers to the time required for the algorithm to reach stable performance during training.
4.2. Algorithm Convergence Verification
5. Results and Discussion
5.1. Analysis of the Failure Reasons of SAC, PPO, and A2C Algorithms
5.2. Analysis of LSTM-PPO Success Reasons
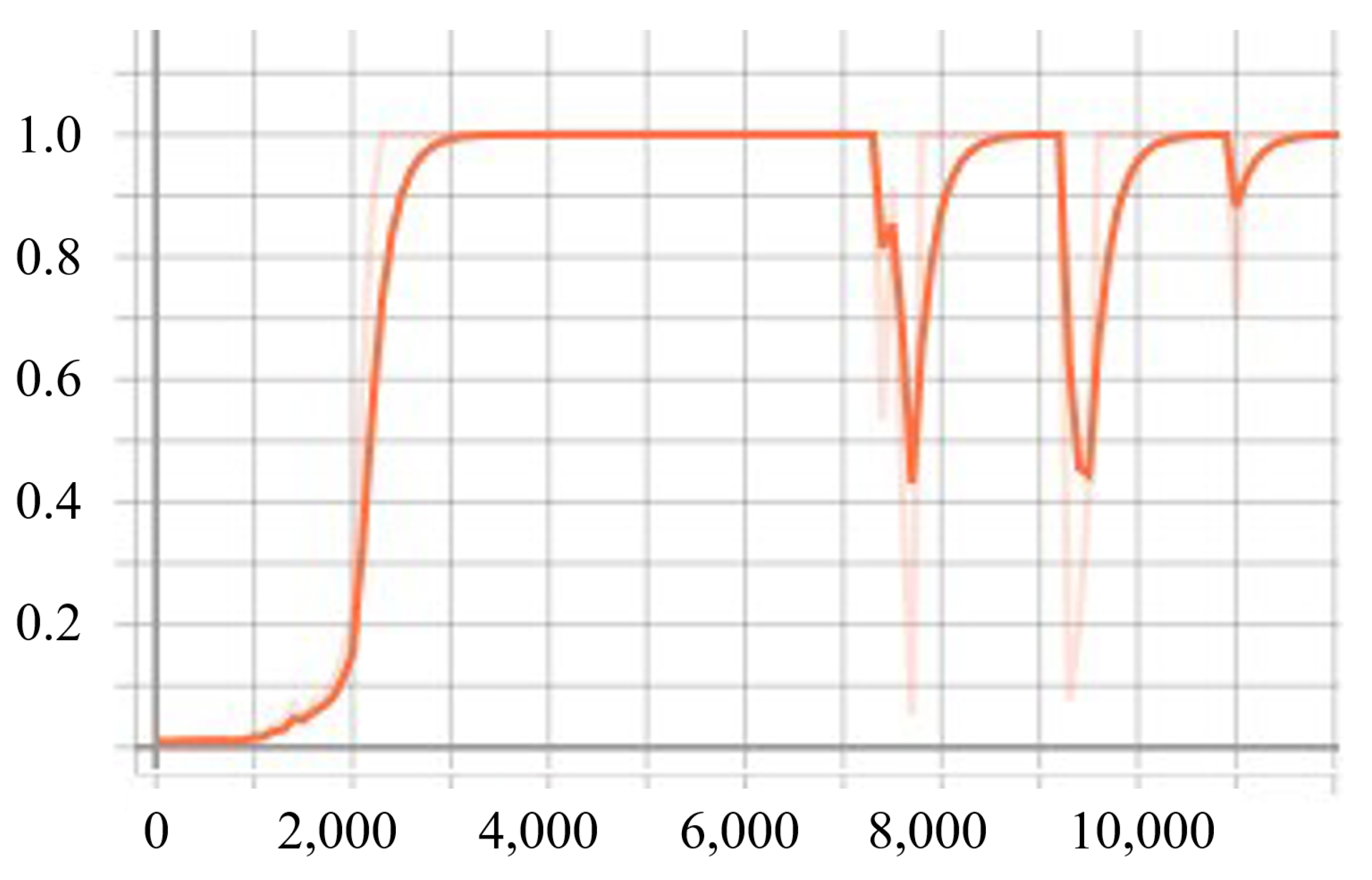
5.3. Convergence Speed and Stability Analysis
5.4. Research Limitations
5.5. Directions for Future Improvement
- Real-Water Testing: Test LSTM-PPO in different waters (lakes, offshore, etc.) and analyze the obstacle avoidance effect under the interference of wind, waves, and water currents.
- Optimization of dynamic model: The incorporation of wind, wave, and current modeling within the simulation environment is recommended. This will enable LSTM-PPO to adapt to diverse marine environments and enhance its practical application capabilities.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tang, P.; Zhang, R.; Liu, D.; Huang, L.; Liu, G.; Deng, T. Local reactive obstacle avoidance approach for high-speed unmanned surface vehicle. Ocean Eng. 2015, 106, 128–140. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H. Learning from Delayed Rewards. Ph.D. Thesis, University of Cambridge, Cambridge, UK, 1989. [Google Scholar]
- Kovács, B.; Szayer, G.; Tajti, F.; Burdelis, M.; Korondi, P. A novel potential field method for path planning of mobile robots by adapting animal motion attributes. Robot. Auton. Syst. 2016, 82, 24–34. [Google Scholar] [CrossRef]
- Fox, D.; Burgard, W.; Thrun, S. The dynamic window approach to collision avoidance. IEEE Robot. Autom. Mag. 1997, 4, 23–33. [Google Scholar] [CrossRef]
- Wu, B.; Xiong, Y. Automatic collision avoidance algorithm for unmanned surface vehicle based on velocity obstacle principle. J. Dalian Marit. Univ. 2014, 13–16. [Google Scholar]
- Zhang, Y.; Qu, D.; Ke, J. Dynamic obstacle avoidance for unmanned surface vehicle based on velocity obstacle method and dynamic window approach. J. Shanghai Univ. 2017, 23, 1–16. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Mnih, V. Playing Atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Wan, L.; Lan, X.; Zhang, H. A survey of deep reinforcement learning theory and applications. Pattern Recognit. Artif. Intell. 2019, 67–81. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling network architectures for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1995–2003. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef]
- Schulman, J. Trust Region Policy Optimization. arXiv 2015, arXiv:1502.05477. [Google Scholar]
- Barto, A. Neuron-like adaptive elements that can solve difficult learning control-problems. Behav. Brain Sci. 1984, 9, 331–360. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Mnih, V. Asynchronous Methods for Deep Reinforcement Learning. arXiv 2016, arXiv:1602.01783. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Duguleana, M.; Mogan, G. Neural networks based reinforcement learning for mobile robots obstacle avoidance. Expert Syst. Appl. 2016, 62, 104–115. [Google Scholar] [CrossRef]
- Fathinezhad, F.; Derhami, V.; Rezaeian, M. Supervised fuzzy reinforcement learning for robot navigation. Appl. Soft Comput. 2016, 40, 33–41. [Google Scholar] [CrossRef]
- Tai, L.; Liu, M. Towards cognitive exploration through deep reinforcement learning for mobile robots. arXiv 2016, arXiv:1610.01733. [Google Scholar]
- Wang, K.; Bu, X.; Li, R.; Zhao, J. Path planning of depth-constrained reinforcement learning robot. J. Huazhong Univ. Sci. Technol. 2018, 46, 77–82. [Google Scholar]
- Zhang, M.; McCarthy, Z.; Finn, C.; Levine, S.; Abbeel, P. Learning deep neural network policies with continuous memory states. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 520–527. [Google Scholar]
- Xu, G.; Zong, X.; Yu, G.; Su, J. Research on intelligent obstacle avoidance for unmanned vehicle based on DDPG. Automot. Eng. 2019, 41, 206–212. [Google Scholar]
- Li, D.; Zhao, D.; Zhang, Q.; Chen, Y. Reinforcement learning and deep learning based lateral control for autonomous driving. arXiv 2018, arXiv:1802.00280. [Google Scholar]
- Huang, Z.; Qu, Z.; Zhang, J.; Zhang, Y. End-to-end autonomous driving decision-making based on deep reinforcement learning. J. Electron. 2020, 48, 1711–1718. [Google Scholar]
- Xu, X.; Lu, Y.; Liu, X.; Zhang, W. Intelligent collision avoidance algorithms for USVs via deep reinforcement learning under COLREGs. Ocean Eng. 2020, 217, 107704. [Google Scholar] [CrossRef]
- Woo, J.; Kim, N. Collision avoidance for an unmanned surface vehicle using deep reinforcement learning. Ocean Eng. 2020, 199, 107001. [Google Scholar] [CrossRef]
- Qian, Z.; Lu, J. A brief analysis of deep learning applications on future unmanned surface vehicle platforms. Shipbuild. China 2020, 61, 6–13. [Google Scholar]
- Zheng, L.; Yang, J.; Cai, H.; Zhou, M.; Zhang, W.; Wang, J.; Yu, Y. Magent: A many-agent reinforcement learning platform for artificial collective intelligence. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Pieter Abbeel, O.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Gan, W.; Qu, X.; Song, D.; Sun, H.; Guo, T.; Bao, W. Research on Key Technology of Unmanned Surface Vehicle Motion Simulation Based on Unity3D. In Proceedings of the OCEANS 2022, Hampton Roads, VA, USA, 17–20 October 2022; pp. 1–5. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Convergence Time/h | Path Length/m | Avoidance Success Rate |
|---|---|---|---|
| A2C | 2.5 | 256.34 | 53.8% |
| PPO | 1.9 | 224.72 | 67.4% |
| SAC | 1.8 | 210.37 | 63.8% |
| LSTM-PPO * | 1.5 | 198.52 | 86.7% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, W.; Wang, X.; Han, F.; Zhou, Z.; Cai, J.; Zeng, L.; Chen, H.; Chen, J.; Zhou, X. Research on LSTM-PPO Obstacle Avoidance Algorithm and Training Environment for Unmanned Surface Vehicles. J. Mar. Sci. Eng. 2025, 13, 479. https://doi.org/10.3390/jmse13030479
Luo W, Wang X, Han F, Zhou Z, Cai J, Zeng L, Chen H, Chen J, Zhou X. Research on LSTM-PPO Obstacle Avoidance Algorithm and Training Environment for Unmanned Surface Vehicles. Journal of Marine Science and Engineering. 2025; 13(3):479. https://doi.org/10.3390/jmse13030479
Chicago/Turabian StyleLuo, Wangbin, Xiang Wang, Fang Han, Zhiguo Zhou, Junyu Cai, Lin Zeng, Hong Chen, Jiawei Chen, and Xuehua Zhou. 2025. "Research on LSTM-PPO Obstacle Avoidance Algorithm and Training Environment for Unmanned Surface Vehicles" Journal of Marine Science and Engineering 13, no. 3: 479. https://doi.org/10.3390/jmse13030479
APA StyleLuo, W., Wang, X., Han, F., Zhou, Z., Cai, J., Zeng, L., Chen, H., Chen, J., & Zhou, X. (2025). Research on LSTM-PPO Obstacle Avoidance Algorithm and Training Environment for Unmanned Surface Vehicles. Journal of Marine Science and Engineering, 13(3), 479. https://doi.org/10.3390/jmse13030479