
Vessel Type Recognition Using a Multi-Graph Fusion Method Integrating Vessel Trajectory Sequence and Dependency Relations


Abstract
1. Introduction
2. Related Work
3. Methods
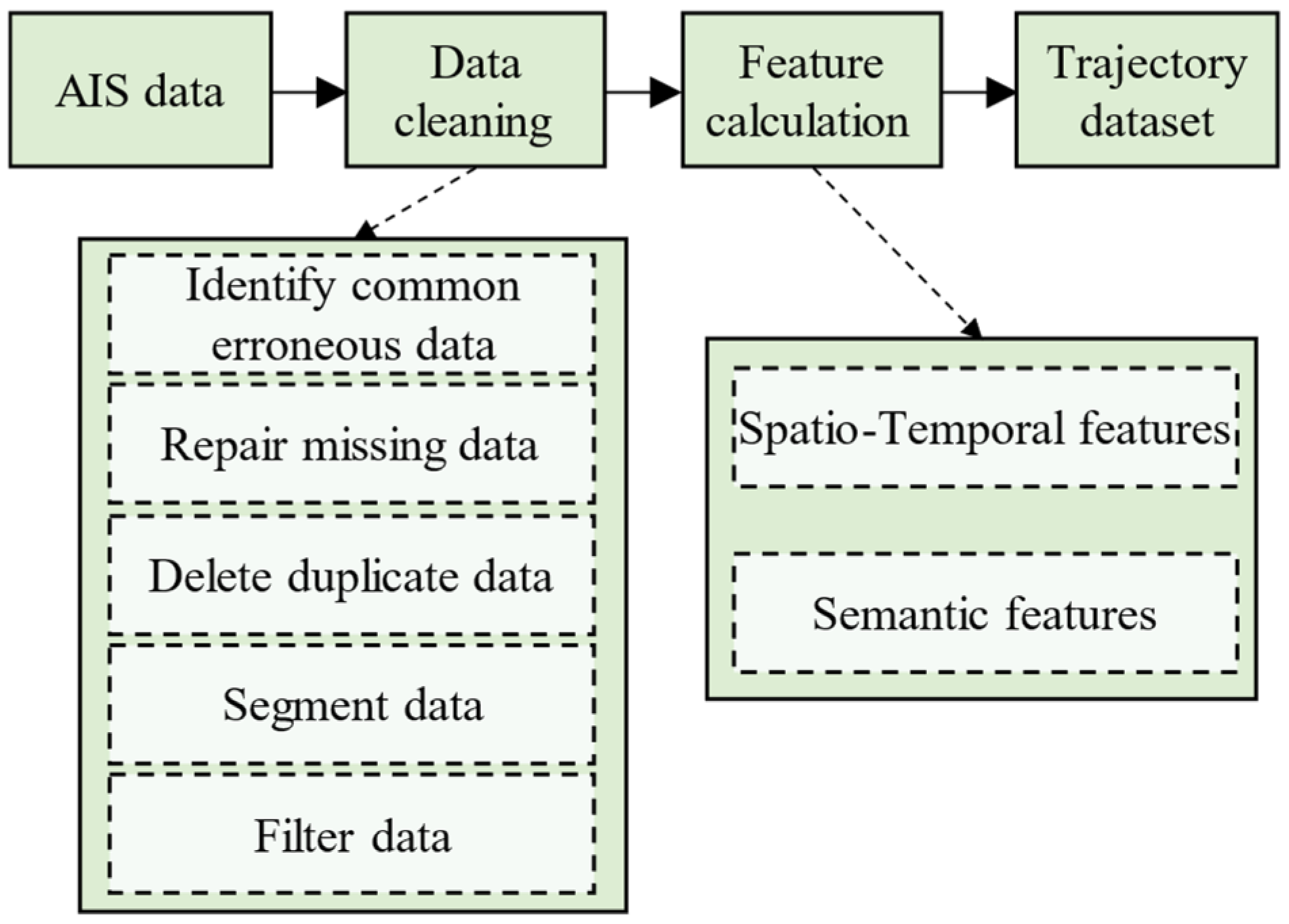
3.1. Data Preprocessing
3.1.1. Data Cleaning
- Identifying common erroneous data. We check and correct data attribute values that do not conform to common sense rules. For instance, MMSI numbers that are not nine digits, , , and , are all corrected.
- Repairing missing data. Since this study primarily relies on dynamic attribute information within vessel trajectories to infer vessel types, no processing was conducted on static attribute data. To address the issue of missing dynamic attributes, such as LAN, LON, SOG, and COG, we have employed cubic spline interpolation for data imputation to ensure data completeness [31,32].
- Deleting duplicate data. By comparing timestamps and coordinate information, the repeated trajectory points are identified and deleted to reduce data redundancy.
- Segmenting data. The original data is grouped by MMSI number, and then the trajectory data for the same vessel is sorted in chronological order. To address the discontinuity of AIS data, a time threshold of 1800 s is set based on expert experience. Trajectories are segmented using the time threshold method to reduce the impact of data discontinuity in subsequent analyses.
- Filtering data. To optimize the execution efficiency of the model, trajectory segments that contain at least 20 data points are selected. These segments can adequately reflect the characteristics of the vessel’s voyage, while others are discarded due to insufficient information.
3.1.2. Feature Calculation
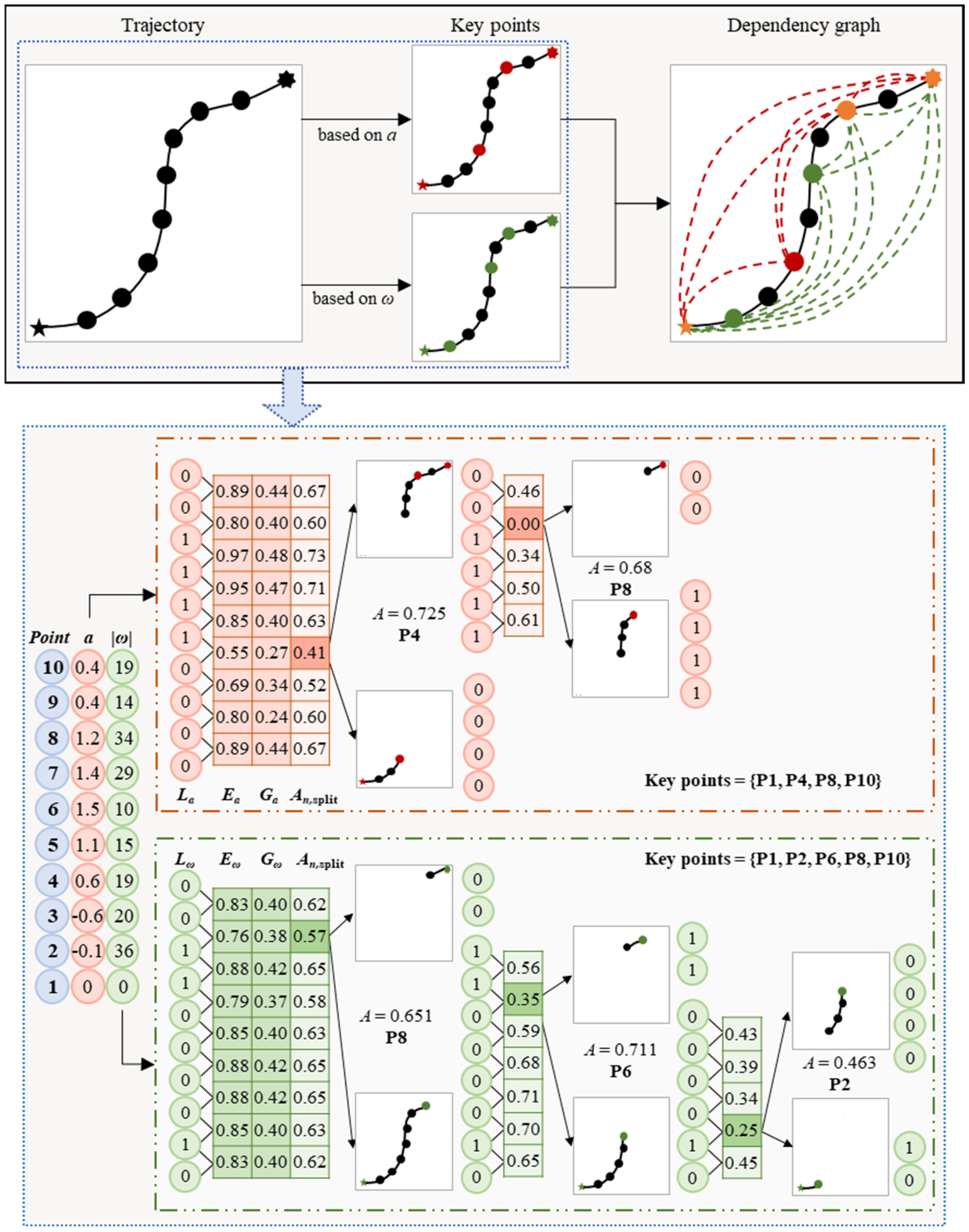
3.2. Graph Construction for Vessel Trajectories
3.2.1. Construction Sequence Graph
3.2.2. Construction Dependency Graph
3.2.3. Selection Key Nodes
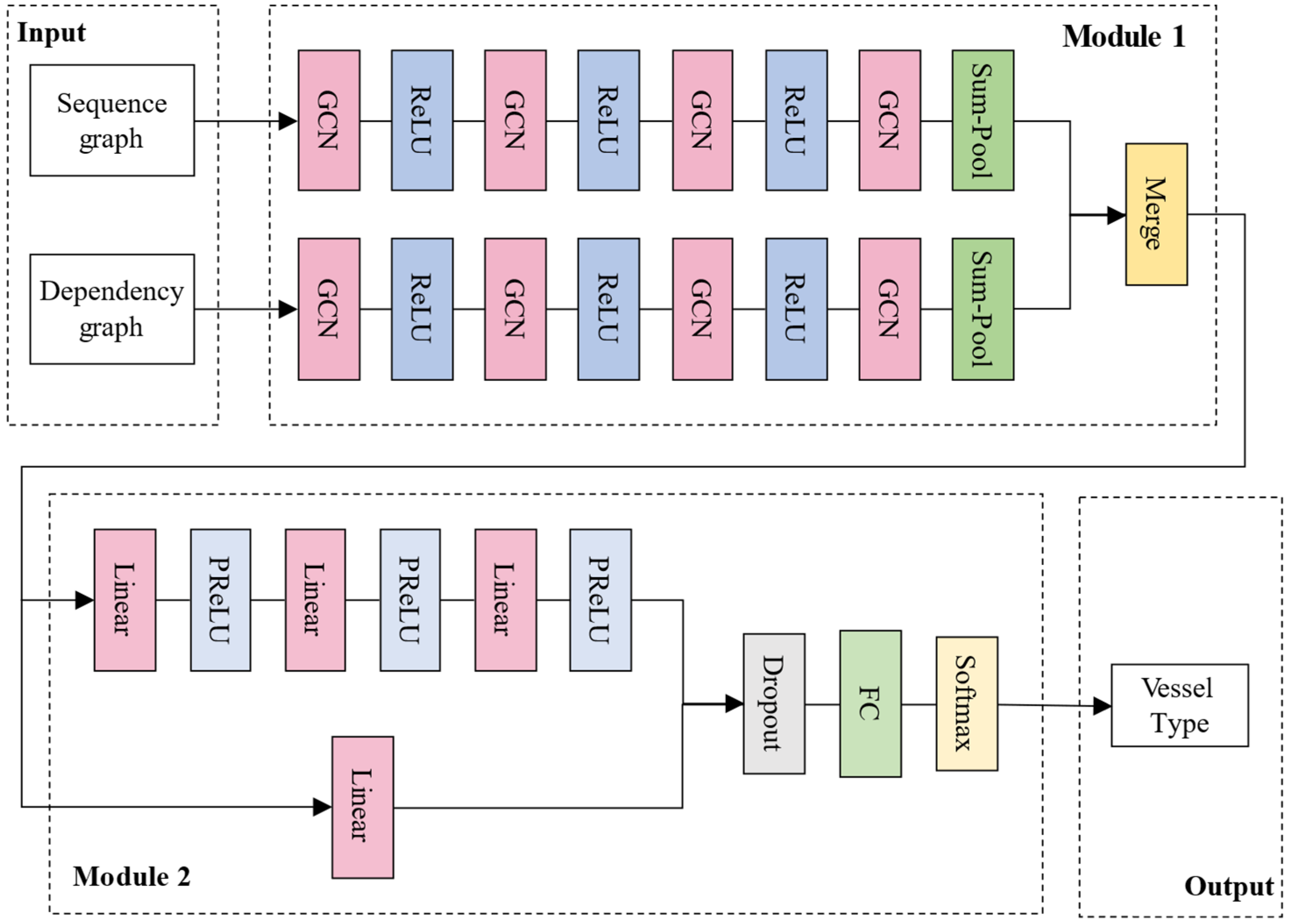
3.3. Model Building
3.3.1. Representative Fusion from Multiple Graphs
3.3.2. Classifier Construction
3.4. Evaluation Indicators
4. Experiments and Evaluation
4.1. Research Area and Datasets
4.2. Parameter Settings and Experimental Results
4.2.1. Parameter Settings
4.2.2. Result Analysis
4.3. Comparison with Other Methods
4.3.1. Comparative Methods
- DT. DT models data classification through a tree structure that simulates conditional branching [34]. Each intermediate node represents a judgment regarding a certain attribute, each branch represents the output of the result, and, ultimately, each leaf node represents a categorization result. To facilitate computation, we extracted the maximum and minimum values, as well as the average values, of all point features for each trajectory segment. These values were used as the primary features, and the data were then flattened into one-dimensional features to serve as the input features for the model.
- KNN. KNN is a simple classification algorithm based on proximity, which identifies the category of a point by looking at the categories of its nearest K neighboring samples [36].
- MLP. MLP, as the simplest form of a feedforward neural network model, includes multiple hidden layers in addition to the input and output layers.
- The 1D convolutional neural network (1D-CNN). The 1D-CNN can automatically extract important features from the data for type recognition [28]. We used only the extracted feature matrix as the model input features.
- LSTM. LSTM is a type of RNN model that is capable of learning and remembering long-term dependencies, and it is widely used for sequential data [27]. In classification tasks, the network parameters can be optimized using the cross-entropy loss function.
- GCN. The GCN model learns node representations by aggregating the neighbors of nodes in a graph while taking into account the node’s features and the structural information of the graph. We only utilized the basic GCN model for comparison, using sequence graph data as the input. To maintain consistency when comparing models, all other parameter configurations were kept uniform.
- The 1DCNN-LSTM (C-L). The C-L is a hybrid deep learning model that can capture both local features and long-term dependencies in data. This makes the C-L model very effective in handling complex sequence classification problems [29].
- LSTM-GCN (L-G). We adopted an LSTM module instead of a single GCN module to extract the sequence features, which were combined with the dependent features extracted by another GCN module.
4.3.2. Comparative Analysis of Recognition Results
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kim, H.; Lee, E.; Lee, E.; Hyun, J.; Gong, I.; Kim, K.; Lee, Y. A Study on Grid-Cell-Type Maritime Traffic Distribution Analysis Based on AIS Data for Establishing a Coastal Maritime Transportation Network. J. Mar. Sci. Eng. 2023, 11, 354. [Google Scholar] [CrossRef]
- Ferreira, M.D.; Campbell JN, A.; Matwin, S. A novel machine learning approach to analyzing geospatial vessel patterns using AIS data. GISci. Remote Sens. 2022, 59, 1473–1490. [Google Scholar] [CrossRef]
- Zou, Y.; Zhang, Y.; Wang, S.; Jiang, Z.; Wang, X. Ship regulatory method for maritime mixed traffic scenarios based on key risk ship identification. Ocean Eng. 2024, 298, 117105. [Google Scholar] [CrossRef]
- Rapalis, P.; Šilas, G.; Žaglinskis, J. Ship Air Pollution Estimation by AIS Data: Case Port of Klaipeda. J. Mar. Sci. Eng. 2022, 10, 1950. [Google Scholar] [CrossRef]
- Meyers, S.D.; Yilmaz, Y.; Luther, M.E. Some methods for addressing errors in static AIS data records. Ocean Eng. 2022, 264, 112367. [Google Scholar] [CrossRef]
- Gupta, P.; Rasheed, A.; Steen, S. Correlation-based outlier detection for ships’ in-service datasets. J. Big Data 2024, 11, 85. [Google Scholar] [CrossRef]
- Gaglione, D.; Soldi, G.; Meyer, F.; Hlawatsch, F.; Braca, P.; Farina, A.; Win, M.Z. Bayesian information fusion and multitarget tracking for maritime situational awareness. IET Radar Sonar Navig. 2020, 14, 1845–1857. [Google Scholar] [CrossRef]
- Petković, M.; Vujović, I.; Kaštelan, N.; Šoda, J. Every Vessel Counts: Neural Network Based Maritime Traffic Counting System. Sensors 2022, 23, 6777. [Google Scholar] [CrossRef]
- Wolsing, K.; Roepert, L.; Bauer, J.; Wehrle, K. Anomaly Detection in Maritime AIS Tracks: A Review of Recent Approaches. J. Mar. Sci. Eng. 2021, 10, 112. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, J.; Liu, R.W.; Liu, Y.; Yuan, Z. Data-driven methods for detection of abnormal ship behavior: Progress and trends. Ocean Eng. 2023, 271, 113673. [Google Scholar] [CrossRef]
- Mazzarella, F.; Vespe, M.; Alessandrini, A.; Tarchi, D.; Aulicino, G.; Vollero, A. A novel anomaly detection approach to identify intentional AIS on-off switching. Expert Syst. Appl. 2017, 78, 110–123. [Google Scholar] [CrossRef]
- Kurekin, A.A.; Loveday, B.R.; Clements, O.; Quartly, G.D.; Miller, P.I.; Wiafe, G.; Adu Agyekum, K. Operational Monitoring of Illegal Fishing in Ghana through Exploitation of Satellite Earth Observation and AIS Data. Remote Sens. 2018, 11, 293. [Google Scholar] [CrossRef]
- Ribeiro, C.V.; Paes, A.; Oliveira, D.D. AIS-based maritime anomaly traffic detection: A review. Expert Syst. Appl. 2023, 231, 120561. [Google Scholar] [CrossRef]
- Weerakody, P.B.; Wong, K.W.; Wang, G.; Ela, W. A review of irregular time series data handling with gated recurrent neural networks. Neurocomputing 2021, 441, 161–178. [Google Scholar] [CrossRef]
- Yan, Z.; Song, X.; Zhong, H.; Yang, L.; Wang, Y. Ship Classification and Anomaly Detection Based on Spaceborne AIS Data Considering Behavior Characteristics. Sensors 2022, 22, 7713. [Google Scholar] [CrossRef]
- Huang, I.; Lee, M.; Nieh, C.; Huang, J. Ship Classification Based on AIS Data and Machine Learning Methods. Electronics 2024, 13, 98. [Google Scholar] [CrossRef]
- Yang, T.; Wang, X.; Liu, Z. Ship Type Recognition Based on Ship Navigating Trajectory and Convolutional Neural Network. J. Mar. Sci. Eng. 2021, 10, 84. [Google Scholar] [CrossRef]
- Seong, N.; Kim, J.; Lim, S. Graph-Based Anomaly Detection of Ship Movements Using CCTV Videos. J. Mar. Sci. Eng. 2023, 11, 1956. [Google Scholar] [CrossRef]
- Li, T.; Xu, H.; Zeng, W. Ship Classification Method for Massive AIS Trajectories Based on GNN. J. Phys. Conf. Ser. 2021, 2025, 012024. [Google Scholar] [CrossRef]
- Kong, Z.; Cui, Y.; Xiong, W.; Xiong, Z.; Xu, P. Ship Target Recognition Based on Context-Enhanced Trajectory. ISPRS Int. J. Geo-Inf. 2022, 11, 584. [Google Scholar] [CrossRef]
- Ristic, B.; La Scala, B.; Morelande, M.; Gordon, N. Statistical analysis of motion patterns in AIS data: Anomaly detection and motion prediction. In Proceedings of the 11th International Conference on Information Fusion, Cologne, Germany, 30 June–3 July 2008; pp. 1–7. [Google Scholar]
- Kraus, P.; Mohrdieck, C.; Schwenker, F. Ship classification based on trajectory data with machine-learning methods. In Proceedings of the 19th International Radar Symposium (IRS), Bonn, Germany, 20–22 June 2018; pp. 1–10. [Google Scholar]
- Lang, H.; Wu, S.; Xu, Y. Ship classification in SAR images improved by AIS knowledge transfer. IEEE Geosci. Remote Sens. Lett. 2018, 15, 439–443. [Google Scholar] [CrossRef]
- Ginouhac, R.; Barbaresco, F.; Scheider, J.; Pannier, J.M.; Savary, S. Coastal radar target recognition based on kinematic data (AIS) with machine learning. In Proceedings of the 2019 International Radar Conference (RADAR), Toulon, France, 23–27 September 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Wang, B.; Wand, Y.; Qin, K.; Xia, Q. Detecting Transportation Modes Based on LightGBM Classifier from GPS Trajectory Data. In Proceedings of the 2018 26th International Conference on Geoinformatics, Kunming, China, 28–30 June 2018; pp. 32–41. [Google Scholar]
- Guo, T.; Xie, L. Research on Ship Trajectory Classification Based on a Deep Convolutional Neural Network. J. Mar. Sci. Eng. 2022, 10, 568. [Google Scholar] [CrossRef]
- Llerena, J.P.; García, J.; Molina, J.M. LSTM vs. CNN in real ship trajectory classification. Log. J. IGPL 2024. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, L.; Song, X. A Multi-Feature Ensemble Learning Classification Method for Ship Classification with Space-Based AIS Data. Appl. Sci. 2020, 11, 10336. [Google Scholar] [CrossRef]
- Syed, M.A.; Ahmed, I. A CNN-LSTM Architecture for Marine Vessel Track Association Using Automatic Identification System (AIS) Data. Sensors 2022, 23, 6400. [Google Scholar] [CrossRef]
- Yuan, J.; Zhang, Q.; Zhang, J.; Li, Y.; Liu, Z.; Xue, M.; Zeng, Y. Fishing Vessel Type Recognition Based on Semantic Feature Vector. Int J. Data Warehous. Min. 2024, 20, 1–18. [Google Scholar] [CrossRef]
- Ye, L.; Chen, X.; Liu, H.; Zhang, R.; Li, J.; Lu, C.; Zhao, Y. A Study of Multi-Step Sparse Vessel Trajectory Restoration Based on Feature Correlation. Appl. Sci. 2024, 14, 4057. [Google Scholar] [CrossRef]
- Shin, G.; Yang, H. Vessel trajectory prediction in harbors: A deep learning approach with maritime-based data preprocessing and Berthing Side Integration. Ocean Eng. 2024, 316, 119908. [Google Scholar] [CrossRef]
- Ye, L.; Chen, X.; Zhang, R.; Zhang, B.; Liu, H. An adaptive trajectory segmentation and simplification algorithm based on vessel behavioral features. Ocean Eng. 2024, 312, 119329. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Peterson, L.E. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vessel Type | Vessel Type Code |
|---|---|
| Cargo | 70–79, 1003, 1004 |
| Fishing | 30, 1001, 1002 |
| Passenger | 60–69, 1012–1015 |
| Tug/Tow | 21, 22, 31, 32, 52, 1023 |
| Pleasure Craft | 36, 37, 1019 |
| Vessel Type | Dataset-1 | Dataset-2 | ||
|---|---|---|---|---|
| Number of Trajectory Points | Number of Trajectories | Number of Trajectory Points | Number of Trajectories | |
| Cargo | 1,295,153 | 1804 | 1,211,478 | 1503 |
| Fishing | 328,378 | 592 | 658,165 | 446 |
| Passenger | 1,657,198 | 3579 | 994,217 | 2223 |
| Tug/Tow | 1,750,639 | 2572 | 1,680,430 | 1650 |
| Pleasure Craft | 393,193 | 1212 | 630,024 | 806 |
| Dataset | Points | A | P | R | F |
|---|---|---|---|---|---|
| Dataset-1 | 20 | 84.07% | 81.09% | 75.82% | 77.99% |
| 30 | 85.39% | 82.46% | 78.01% | 79.83% | |
| Dataset-2 | 20 | 82.13% | 82.40% | 80.90% | 81.53% |
| 30 | 83.22% | 83.47% | 82.01% | 82.65% |
| Methods | Point = 30 | Point = 20 | ||||||
|---|---|---|---|---|---|---|---|---|
| A | P | R | F | A | P | R | F | |
| DT | 70.91% | 71.46% | 54.21% | 55.80% | 70.79% | 70.21% | 54.00% | 55.43% |
| RF | 72.02% | 71.62% | 55.64% | 57.63% | 72.75% | 71.43% | 57.69% | 59.82% |
| KNN | 71.42% | 64.01% | 61.23% | 62.44% | 71.84% | 65.01% | 62.45% | 63.49% |
| SVM | 58.93% | 58.48% | 41.21% | 40.05% | 59.66% | 55.23% | 41.49% | 40.46% |
| MLP | 71.20% | 65.24% | 59.01% | 60.42% | 70.81% | 68.00% | 56.51% | 59.23% |
| 1D-CNN | 76.36% | 73.77% | 63.68% | 66.27% | 72.98% | 70.41% | 57.87% | 60.58% |
| LSTM | 78.77% | 75.25% | 65.97% | 68.72% | 79.82% | 75.54% | 68.66% | 70.96% |
| GCN | 79.06% | 76.61% | 66.68% | 69.37% | 80.25% | 76.06% | 70.20% | 71.97% |
| C-L | 79.51% | 73.47% | 71.45% | 72.22% | 81.15% | 83.83% | 69.18% | 73.40% |
| L-G | 80.51% | 75.26% | 72.93% | 73.46% | 80.92% | 79.75% | 70.84% | 73.96% |
| OUR | 85.39% | 82.46% | 78.01% | 79.83% | 84.07% | 81.09% | 75.82% | 77.99% |
| Methods | Point = 30 | Point = 20 | ||||||
|---|---|---|---|---|---|---|---|---|
| A | P | R | F | A | P | R | F | |
| DT | 72.91% | 75.63% | 71.81% | 72.41% | 72.83% | 74.00% | 72.21% | 72.69% |
| RF | 67.25% | 68.85% | 66.87% | 66.22% | 65.98% | 67.00% | 66.68% | 65.00% |
| KNN | 67.38% | 66.47% | 65.83% | 66.03% | 67.93% | 67.29% | 66.66% | 66.89% |
| SVM | 49.00% | 36.44% | 35.82% | 31.81% | 50.18% | 54.26% | 37.89% | 36.11% |
| MLP | 68.29% | 66.85% | 68.28% | 67.67% | 68.89% | 69.00% | 66.23% | 67.27% |
| 1D-CNN | 70.75% | 71.46% | 67.98% | 69.30% | 73.61% | 73.75% | 71.88% | 72.68% |
| LSTM | 76.48% | 76.36% | 74.88% | 75.51% | 75.45% | 76.21% | 73.79% | 74.80% |
| GCN | 75.90% | 76.09% | 74.13% | 74.94% | 76.47% | 77.69% | 74.25% | 75.68% |
| C-L | 68.71% | 66.26% | 60.80% | 59.70% | 80.39% | 83.03% | 77.59% | 79.75% |
| L-G | 81.43% | 81.95% | 80.02% | 80.75% | 81.55% | 82.14% | 80.18% | 80.93% |
| OUR | 83.22% | 83.47% | 82.01% | 82.65% | 82.13% | 82.40% | 80.90% | 81.53% |
| Methods | Point = 30 | Point = 20 | ||||||
|---|---|---|---|---|---|---|---|---|
| A | P | R | F | A | P | R | F | |
| WO-S | 77.38% | 71.68% | 67.80% | 68.95% | 78.34% | 73.51% | 69.07% | 70.47% |
| WO-D | 82.52% | 79.57% | 72.16% | 74.46% | 82.65% | 78.44% | 74.75% | 76.01% |
| WO-M | 74.78% | 71.34% | 61.91% | 64.03% | 74.16% | 71.80% | 61.31% | 63.48% |
| OUR | 85.39% | 82.46% | 78.01% | 79.83% | 84.07% | 81.09% | 75.82% | 77.99% |
| Methods | Point = 30 | Point = 20 | ||||||
|---|---|---|---|---|---|---|---|---|
| A | P | R | F | A | P | R | F | |
| WO-S | 68.11% | 71.43% | 63.37% | 65.85% | 72.30% | 74.91% | 69.71% | 71.55% |
| WO-D | 79.26% | 78.93% | 78.44% | 78.63% | 77.83% | 78.56% | 75.80% | 76.97% |
| WO-M | 70.89% | 71.15% | 69.11% | 69.90% | 71.38% | 72.08% | 69.43% | 70.36% |
| OUR | 83.22% | 83.47% | 82.01% | 82.65% | 82.13% | 82.40% | 80.90% | 81.53% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, L.; Chen, X.; Liu, H.; Zhang, R.; Zhang, B.; Zhao, Y.; Zhou, D. Vessel Type Recognition Using a Multi-Graph Fusion Method Integrating Vessel Trajectory Sequence and Dependency Relations. J. Mar. Sci. Eng. 2024, 12, 2315. https://doi.org/10.3390/jmse12122315
Ye L, Chen X, Liu H, Zhang R, Zhang B, Zhao Y, Zhou D. Vessel Type Recognition Using a Multi-Graph Fusion Method Integrating Vessel Trajectory Sequence and Dependency Relations. Journal of Marine Science and Engineering. 2024; 12(12):2315. https://doi.org/10.3390/jmse12122315
Chicago/Turabian StyleYe, Lin, Xiaohui Chen, Haiyan Liu, Ran Zhang, Bing Zhang, Yunpeng Zhao, and Dewei Zhou. 2024. "Vessel Type Recognition Using a Multi-Graph Fusion Method Integrating Vessel Trajectory Sequence and Dependency Relations" Journal of Marine Science and Engineering 12, no. 12: 2315. https://doi.org/10.3390/jmse12122315
APA StyleYe, L., Chen, X., Liu, H., Zhang, R., Zhang, B., Zhao, Y., & Zhou, D. (2024). Vessel Type Recognition Using a Multi-Graph Fusion Method Integrating Vessel Trajectory Sequence and Dependency Relations. Journal of Marine Science and Engineering, 12(12), 2315. https://doi.org/10.3390/jmse12122315