4.2.1. Haze Removal of Marine Images
To verify the performance of the framework on haze removal, Retinex [
40], Dark Channel Prior [
12], Contrast Limited Adaptive Histogram Equalization (CLAHE) [
41], AOD-Net [
9], and e-AOD-Net adopted in the framework are used to conduct a comparative experiment on haze removal. The experimental results are shown in
Figure 8.
The images generated by the above methods after haze removal are shown in
Figure 8. Retinex and Dark Channel Prior usually lead to image distortion, and the color of the images after haze removal is seriously abnormal. CLAHE usually makes the color of images after haze removal too dark, and maritime ship features are not prominent. After haze removal by the AOD-Net network, there is still noise remaining in the images. These phenomena may occur because none of the above competing methods can fully extract the target structural features from ocean images. By contrast, e-AOD-Net can learn more structural features of images in marine scenes after generalization training and adaptive enhancement of marine images. The evaluation results of the dehazed images in multiple scenes using the PSNR and SSIM are presented in
Table 1.
As shown in
Table 1, the e-AOD-Net adopted in this study has stable and good performance in multiple marine scenes, indicating that e-AOD-Net achieves better image enhancement performance. Images after haze removal can highlight more ship information, which is the basis of ship detection and tracking.
4.2.2. Multi-Ship Detection and Tracking Experiment after Images Enhancement
In this part, in order to verify the detection performance of the algorithm, SSD [
44], Faster RCNN [
45], and YOLO v4 [
46] are compared with the YOLOv5 algorithm [
47] adopted. The training comparison chart (
Figure 9a), the verification comparison chart (
Figure 9b), the frames per second (FPS) comparison chart (
Figure 9c), the training index table (
Table 2), the verification index table (
Table 3), the test index table (
Table 4) are drawn respectively.
As can be seen from the comparison curve, under the same training conditions, the convergence speeds of the YOLOv4 and YOLOv5 algorithms are fast, and the YOLOv5 algorithm has a faster image-processing speed (in
Figure 9c). The test and evaluation parameters show that the trained YOLOv5 algorithm also performs well in detecting accuracy in ocean scenes. To verify the performance of images after haze removal by e-AOD-Net in ship detection tasks, we adopted the stable YOLOv5 algorithm to detect ships in the synthesized hazy images and images after haze removal and compared the detection results. The detection results are presented in
Figure 10.
Figure 10 shows that YOLOv5 has high-precision detection performance in multiple ocean scenarios. However, the degree of recovery of the images after haze removal is high, and the structural features of the ships are prominent, making it easy for the ship target in the image to be detected by the YOLOv5 algorithm, such as the small ships in the red boxes in scene 4. Haze noise in images reduces the accuracy of the target detection. In the case of high haze concentrations, some ships were not detected, such as those in the red boxes in scenes 5 and 6.
Considering the accuracy, detection speed, and detection stability of the algorithm in synthetic haze scenes, the YOLOv5 algorithm is ideal for ship detection in maritime scenarios. In the evaluation of the tracking algorithms, the YOLOv5 algorithm was used as the detector in scenarios 4, 5, and 6. In the three scenarios, multi-objective tracking evaluation parameters were introduced to evaluate the tracking performance of the SORT and Deep SORT algorithms for ships in ocean scenarios. The evaluation results are presented in
Table 5,
Table 6 and
Table 7. In the tables, parameters with upward arrows indicate that the evaluated method performs better when the evaluated value is larger; those with downward arrows indicate that the evaluated method performs better when the evaluated value is smaller. And the optimal evaluation values when the hazy concentration is T = 0.3, T = 0.5, and T = 0.7 have been highlighted in red, yellow, and green, respectively in
Table 5,
Table 6 and
Table 7.
As shown in
Table 5,
Table 6 and
Table 7, the Deep SORT algorithm using YOLOv5 as a detector has higher MOTA and MOTP values as well as lower IDS and ML values in the above scenes. This indicates that Deep SORT can track ships stably while avoiding the number of ID transitions. It should be noted that in the same scenario, the evaluation results of tracking algorithms that use images after haze removal are usually the optimal values, indicating that images after haze removal can effectively improve the robustness of target tracking algorithms in maritime scenarios. It is worth noting that the YOLOv5 algorithm combined with the Deep SORT target tracking algorithm adopted in the framework can maintain high detection accuracy and stable tracking performance in multi-ship tracking, which is the basis for accurate ship speed extraction in this study.
4.2.3. Ship Speed Extraction
In this section, AIS data are considered as the ground truth of the ship speed values. The AIS data of Baosteel Wharf on 5 April 2021 is downloaded from the website
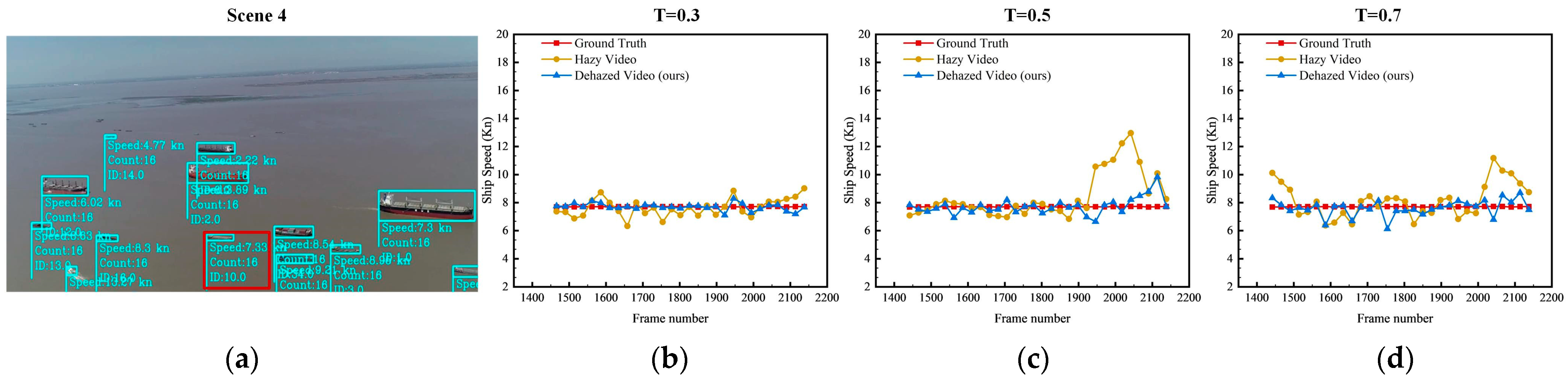
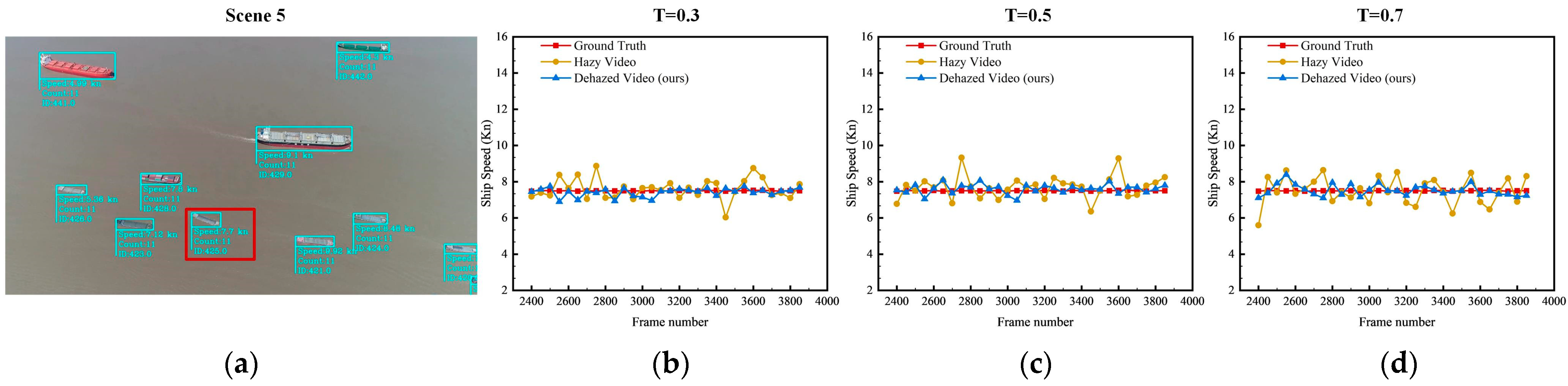
http://www.shipxy.com. To make it easier to compare the ground truth of the ship speed values with the shipping speed extracted from marine images, the AIS data were linearly interpolated to match the video image frame by frame after extracting the speed data. To highlight the effect of this framework on hazy images and the performance of ship speed extraction, this section selects a ship in scenes 4, 5, and 6 for the speed extraction simulation experiment and compares the ground truth with the extracted speed of each ship in the scene with different haze concentrations. The extraction and comparison results for the ship speed are shown in
Figure 11,
Figure 12 and
Figure 13. The mean speed of each ship and the MSE and MAE values compared to the ground truth of the speed are listed in
Table 8,
Table 9 and
Table 10. In the
Table 8,
Table 9 and
Table 10, the highlighted in yellow indicates the speed results and speed evaluation results extracted from the haze videos, the highlighted in green indicates the speed results and speed evaluation results extracted from the videos after haze removed, and the highlighted in red indicates the true value of speed extracted from the AIS data.
As shown in
Figure 11,
Figure 12 and
Figure 13, the fold line representing the speed value of the ship extracted from the AIS data is set to red in the figure; the fold line graph representing the speed value of the ship extracted directly from the haze video is set to yellow, and the fold line representing the speed value of the ship extracted by our framework after removing the haze from the maritime haze image is set to blue. According to the extraction results and the mean ground truth of the ship speed, the speeds of the three ships were at 7.71 Kn, 7.50 Kn, and 7.70 Kn, respectively. For ship No. 1 in
Figure 11, the accuracy of the speed extracted is easily affected by noise in the images owing to the small sizes of the ships. When T = 0.3, the MSE and MAE values of the speed are 0.37 Kn and 0.49 Kn due to the slight noise in the images. After haze removal, the fluctuation of the velocity image improved. At this time, the values of MSE are 0.12 Kn, the values of MAE are 0.21 Kn, and the ship’s average speed is improved from 7.54 Kn to 7.73 Kn, which is closer to the average speed of the ground truth of the ship speed.
When T = 0.5, due to the influence of haze noise in the images, the curve chart of ship velocity fluctuates wildly, especially in the late video period, and the MSE of ship velocity is 1.71 Kn, and MAE is 1.03 Kn. Although the extraction value of the velocity after haze removal still fluctuated, it was significantly improved compared with that before haze removal. After removing the haze, the MSE and MAE of the ship speed extracted from the image are 0.33 Kn and 0.41 Kn, and the average ship speed was 7.75 Kn.
When T = 0.7, the velocity fluctuation was more prominent. Currently, the MSE and MAE of ship velocity are 3.57 Kn and 1.14 Kn. After haze removal, the fluctuation of the velocity curve chart decreased. Both the MSE and MAE of the ship velocity decreased, and the mean value of the ship velocity was closer to the ground truth.
The same situation appeared in ship No. 2 in
Figure 12. It can be seen from the truth line chart is approximately 7.5 Kn. According to the MSE and MAE of ship No. 2, the accuracy of the ship speed extracted can be improved by removing haze.
For ship No. 3 in scenario 6, the curve chart of ship speed fluctuates greatly because the image brightness is low, and the accuracy of the ship speed extracted is reduced after the haze noise is superimposed. The MSE of ship speed under different haze concentration environments was 0.47 Kn, 0.58 Kn, and 0.65 Kn, respectively. The MAE of speed is 0.60 Kn, 0.60 Kn, and 0.66 Kn. The MSE of speed extracted after removing haze is 0.14 Kn, 0.16 Kn, and 0.22 Kn. The MAE is 0.27 Kn, 0.31 Kn, and 0.38 Kn, respectively. After haze removal, the average ship speed extracted from the images was closer to the average value of the ground truth. It shows that the framework adopted in this paper can effectively enhance the quality of haze images in ocean scenes with low brightness and improve the accuracy of ship speed extracted from the images.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}