The proposed control technique is a compound strategy that uses the features of a disturbance observer and an optimal control approach to finding a control sequence for a receding horizon that predicts the best control actions in every sampled time step. To develop the proposed technique, this section presents first a discrete extended state observer that estimates the system’s states and a total disturbance that lumps the external disturbances and model uncertainties into a single signal. Then, a model predictive control (MPC) strategy based on the active disturbance rejection control (ADRC) approach is developed for a general system with a single input and a single output. Then, an autonomous underwater vehicle is modeled to describe the dynamics of an underactuated underwater robot, which is based on the four DoF Seabotix LBV150 ROV. This model is transformed to separate the controllable dynamics from the uncontrollable internal dynamics of the system. This results in a simplified canonical model that is used to test the proposed MPC based on ADRC.
2.1. Discrete Extended State Observer
Let us consider a general nonlinear system, defined as
where
n is the order of the system,
is the control output,
is the
n-th time derivative of
,
is the control input,
is the known dynamic model of the system,
represents the model uncertainties and unmodeled dynamics, and
represents the external disturbances.
Assuming bounded uncertainties, bounded disturbances, and bounded dynamic behavior, the signals
,
, and
can be lumped into a total disturbance
, such as that (
1) is transformed into
Then, a local approximation around a defined operation condition allows to express
as a constant
, which is valid in an open neighborhood around the operation point. Then, (
2) is expressed as,
This simplified model is used to design the extended state observer and feedback controller under the following assumptions:
Assumption 1. The internal model of can be approximated by a constant, at least during an infinitesimal period of time.
Assumption 2. and its first time derivative are bounded.
Assumption 3. The first time derivative of the total disturbance is expressed aswhere ϵ is a small constant, such as that . Then, based on such assumptions, the variable
can be used as an extended state of the dynamic system. This allows to define an extended state vector
which produces an extended state space representation of the system as
In a compact form, the extended model is represented by a linear state space model given by:
where
,
,
,
,
Now, let us define a sampling period
T and use the Euler’s method to find a discrete approximation of the extended linear model (
7). This is,
where
k represents the discrete time variable.
Based on the discrete approximation of the simplified dynamic model (
8), a discrete extended state observer (ESO) is proposed using the Luenberger’s observer form. In this case, the observer estimates the system states, but also the total disturbance represented by the extended state
. Since the pair
is observable, the discrete ESO is proposed as follows:
where
denotes the estimated variable and
is the vector of the observer’s gains.
By subtracting (
9) from (
8), the estimation error dynamics is given by
where
.
Under the assumption of a bounded and small
, the stability of (
10) depends of the eigenvalues of
. Then, the observer gains are selected in such a way that the eigenvalues of
are inside a unitary circle of a complex z-plane, which results in eigenvalues with modulus less than one. This ensures the convergence of the estimated states to the real ones and an accurate estimation of the total disturbance. This estimation will be used in the feedback control law proposed during the next section.
2.2. Robust MPC and ADRC
A model predictive control based on active disturbance rejection control is performed by using the disturbance estimation provided by the discrete ESO. The states and disturbance estimation are used into an optimal control problem (OCP) that computes an optimal control sequence for a receding horizon. The model used to predict the system behavior during the optimization process is a canonical structure that dismisses the model uncertainties, external disturbances, and model nonlinearities. This solves the optimization problem with less computation effort than the typical nonlinear MPC approaches. Since the total disturbance is rejected through feedback control, the result is a robust model predictive control strategy.
A general description of the control loop is shown into the
Figure 1, where the continuous mathematical model represents the system dynamics, whose output
y is sampled with a sampling period
T. The sampled output
and control signal
are used by the discrete ESO to estimate the system states and the total disturbance, which are a source input to solve the OCP that produces the robust MPC-ADRC control law.
The OCP is defined to find an optimal control sequence that minimizes an objective function, which is projected in a time horizon into the future and computed based on a simplified model of the system. Based on the assumption that the total disturbance estimation converges to the real disturbance, the simplified model takes a canonical form that is used as a prediction model, which is almost free of uncertainties and disturbances. This canonical model is given by
where
,
,
,
,
In order to formulate the OCP, let us define, first, the control sequence along the prediction horizon, which will be considered as a vector of search variables in the optimization process. This is
where
N is the length, in samples, of the prediction horizon,
is the time discrete variable used inside the prediction horizon, which is set to zero in every sampling step and runs until
, this is
. The prediction horizon and control sequence are depicted into the
Figure 2.
In the formulation of the optimal control problem, the cost function is defined as
where
is the tracking error,
is the reference at time
k,
and
are positive constant weights for the error and control signals, respectively.
The optimal control problem is subject to a set of equality and inequality constraints. The equality constraints ensure the satisfaction of initial conditions and the dynamic behavior of the system during the projected horizon. At the same time, the inequality constraints ensure that the control actions are inside of the actuators’ range of the action.
Then, the OCP is formulated as:
where (
14) is the cost function, (
15) sets the initial conditions of the model to the state values computed by the discrete ESO at time
k, (
16) is a dynamic constraint that ensures the satisfaction of the system dynamics based on the canonical model (
11), (
17) imposes boundaries for the control signal at the first time step of the prediction horizon, these bounds are modified every sampled time step according to the total disturbance estimation, in such a way that the optimal control sequence allows to inject the rejection of the estimated disturbance. Likewise, (
18) establishes the boundaries for the control actions over the prediction horizon between
and
.
The implementation of the dynamic constraints implies the propagation of the initial conditions through all the prediction horizon, which results in a complex nonlinear structure that increases the computation time. In order to reduce the complexity of the dynamic constraints, a multiple shooting approach is used to transform the dynamic propagation into a set of equality constraints [
21].
In order to implement the multiple shooting algorithm, let us define an extended set of search variables in a vector as
where
includes the control and state vectors sequences at
. This search vector increases the number of search variables but simplifies the nonlinearity propagation of the system dynamics along the prediction horizon. Based on this approach, the system’s dynamic constraints are included as a set of equality constraints as
and a set of inequality constraints defined as
Then, the OCP is transformed into a nonlinear programming problem (NLP) as
The solution of the NLP results in an optimal sequence of control actions and a set of state vectors that minimize the cost function for the prediction horizon. Based on that solution, the control action for the current sampled time
k is computed by subtracting the total disturbance effect, which was estimated by the discrete ESO, from the first element of the optimal control sequence found in the NLP. This allows to define a control law as
where
denotes the optimal control sequence and
is the first element of the sequence.
In order to compute the closed-loop behavior under the effect of the control signal proposed in (
22), it is applied to the discrete model shown in (
8), which results in a closed-loop dynamics describe by
The stability analysis of the closed-loop dynamics is divided into two parts. The first part considers the stability guaranteed by the selection of the ESO’s gains. The appropriate selection of ESO’s gains allows for defining an ultimate bound to the total disturbance estimation as
where
is a positive constant that can be arbitrarily reduced as much as the physical limitation in the hardware allows. The second part of the stability analysis considers the effect of the optimal control sequence
. Since this control sequence is computed from a subset of control signals that guarantee the closed-loop stability through the convergence of the optimization problem system, then it is possible to affirm that the closed-loop is stable and the controlled variables converge to the vicinity of the target trajectory with an ultimate bound.
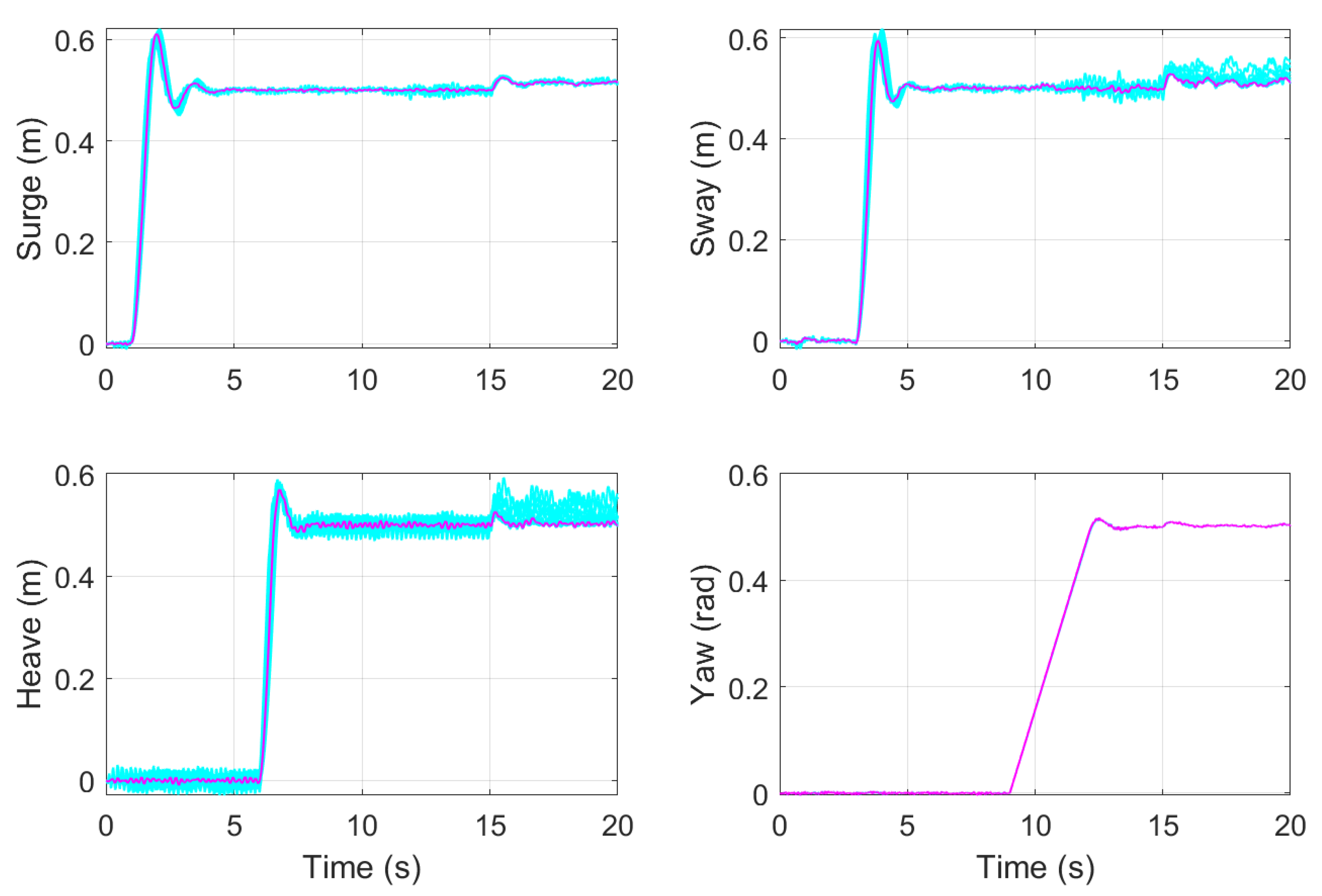
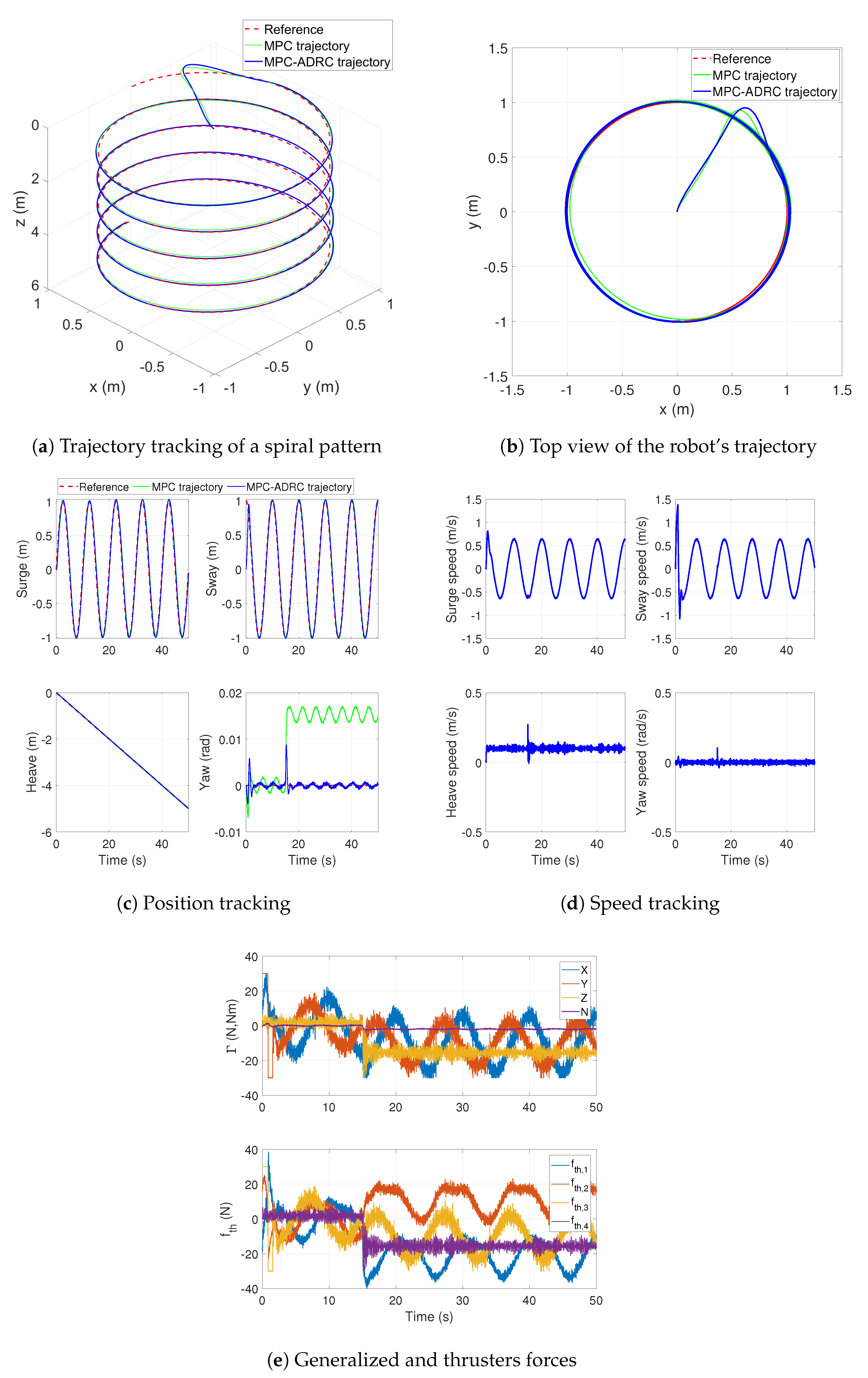
Finally, The a summary of the implementation procedure of the MPC based on ADRC is shown in the Algorithm 1. The following section shows the implementation of the algorithm on an autonomous underwater robot.
| Algorithm 1: MPC-ADRC implementation |
Step 0: Find a simulation model. Step 1: Design ESO. Step 1.1: Define the order of the design dynamic model n and find an approximation of the control input gain . Step 1.2: Build the extended state model with the canonical form described in ( 7). Step 1.3: Define a sampling period T according the Nyquist–Shannon sampling theorem and find a discrete model approximation of the system dynamics as ( 8). Step 1.4: Assign the observer gains L such as the eigenvalues of are inside the unite circle in the complex z-plane and build the extended state observer ESO as shown in ( 9). Step 2: MPC implementation. Step 2.1: Define the weights and and build the cost function ( 13). Step 2.2: Define the equality constraints ( 20) and inequalities constraints ( 21). Step 2.3: Define the prediction horizon length N. Step 2.4: Implement a nonlinear programming algorithm that solves the optimization problem at each sampling step. Step 3: Evaluation. Step 3.1: Build the control law as ( 22) and evaluate the closed-loop control using the simulation model. Step 3.2: Evaluate the performance and robustness of the closed-loop, if it is necessary change observer gains L, weights and , or prediction horizon length N and repeat evaluation.
|
2.3. Autonomous Underwater Robot Model
In order to test the proposed robust MPC based on ADRC, an autonomous underwater robot is used as a test platform of the control strategy. This system has dynamic features that make it a suitable application of the robust MPC based on ADRC. First, the system dynamics is highly nonlinear with hydrostatic and hydrodynamic effects that difficult an accurate model identification. Second, the environment where the robot works has a high degree of uncertainty with unpredictable ocean currents, especially in the vicinity of reefs where the water flow is distorted by the rocks. These produce external disturbances on the robot dynamics, which must be rejected by the control system. A third reason to apply the proposed control strategy to the robotic AUV is the need to guarantee the satisfaction of safety constraints to avoid the collision of the robot with obstacles in the environment and to optimize the performance of the robot to increase its energy autonomy.
Let us consider the robotic autonomous underwater vehicle (AUV) shown in the
Figure 3, which has four thrusters: two in the rear, one in the top, and one in the port (left side) [
22]. The frames
and
shown in the figure represent the fixed inertial frame and the body frame, respectively.
In order to find a mathematical model that describes the dynamic behavior of the robotic AUV, the motion variables are defined according with the SNAME notation for a submerged body through a fluid [
23]. In this sense, the position of the robot is defined as
, where
represents the position with respect to the inertial frame
and
represents the robot’s attitude, as well known as pose. To describe the position of the robot, the three Cartesian coordinates are used such as that
, where
x,
y, and
z represent the motion in the directions of
surge,
sway, and
heave, respectively. Likewise, the attitude is represented with the Euler angles as
, where
,
, and
represent
roll,
pitch, and
yaw, respectively.
Then, the Newton-Euler’s method is used to analyze the motion of a submerged rigid-body with six degrees of freedom (DoF) [
24]. The mathematical model that describes the AUV motion is given by
where
denotes the linear and angular velocities with
and
, respectively.
designates a vector of generalized forces and moments defined as:
, where the body-fixed forces in
x,
y, and
z are represented as
and the body-fixed moments in
,
, and
are defined as
.
Since the submerged body is exposed to hydrostatic and hydrodynamic effects, the mass matrix includes the rigid body mass and inertial in
, and an added mass term in
, which represents the mass of fluid surrounding the robot that it must move to deflect the resistance of the fluid. This is modeled as a virtual mass added to the rigid body as:
where
and
. Likewise, the Coriolis and centrifugal effects are represented as
where
designates the effects of the rigid-body and
designates the effects of the added mass. An additional factor in the description of the AUV is the viscous damping. This is a hydrodynamic effect that produces dissipative moments and forces. The main sources of damping are the skin friction and the interaction with waves and internal currents. The total effects of damping are lumped into a drag matrix
, which is approximated as
where
and
are the quadratic and linear drag matrices, respectively.
The term
describes the restoring forces acting in the robot. It includes the gravitational effects represented by a force
W passing through the center of gravity (CG) and a buoyancy force
B passing through the center of buoyancy (CB). The restoring forces and moments are expressed in the body-fixed frame as
where
,
,
m is the sum of the robot mass and the mass of water in the ballast tanks,
g is the acceleration of the gravity,
is the water density, ∇ is the volume of liquid displaced by the robot,
,
,
, and
,
,
, are the coordinates of the CG and CB with respect to the frame
. In an effort to simplify the dynamic interaction between these two forces, the CG and CB are considered coincident in the origin of
; however, in general, it is desirable to design AUV with the CB ahead of the CG to guarantee controllability and stability in pitch.
The Jacobian matrix
transforms the relative velocities expressed in
into the inertial reference frame
. This is
where
and
are a rotational and a transformation matrices, respectively.
Since the underwater thrusters installed on the robot are not strictly aligned with the body-fixed frame axis, the propulsion forces do not produce a pure vector of generalized forces and moments in
. Then, it is necessary to find a mathematical expression that relates the propulsion force vector
with the
. This is
where
is known as an allocation matrix, which depends on the robot’s architecture and the location of the thrusters. Additional details about the model can be found in [
22,
25].
Since the robot considered in this paper has four thrusters and can move in six DoF, then the system is underactuated. This implies that the robot is partially controllable and part of its dynamics is not directly affected by the propulsion of the actuators. According to the geometrical distribution of the thrusters, the robot is underactuated in the pitch and roll angles. Therefore, the following assumptions are adopted:
Assumption 4. It is assumed that the dynamics of the underactuated DoF are stabilized with complementary elements such as fairwater planes.
Assumption 5. High speed and sharp turns are avoided to evade instability effects in the vertical plane.
In order to adapt the proposed control strategy to the robotic AUV, a transformation of the model is executed such as that the nonlinearities, model uncertainties, and external disturbances are shown as input equivalent signals and the controllable dynamics is isolated from the uncontrollable one. First, let us write the model as general nonlinear system
where
represents the unmodeled dynamics and external disturbances,
,
,
and
Then, the control output is defined as:
where
denotes the control reference.
By applying successive time derivatives to the control output until the control input is explicit, the system dynamics takes the form
where
is the gradient of
,
is the Lie derivative of
along
,
is its second Lie derivative, and
is a decoupling matrix, which is locally invertible [
26].
Based on the normal form described in (
39) and (
40), a simplified model is proposed to design the control system. In this case, a canonical model is assumed as the base model for the control design. This model is dynamically decoupled, affine to the control input, and it includes a vector of lumped disturbances as described in its state space form:
where the state vector for the actuated DoF is
the nonlinearities, model uncertainties, and external disturbances are lumped in a vector of total disturbances as
and the decoupling matrix
is approximated by a diagonal matrix with control input gains as,
This model represents a multiple-input multiple-output system; however, since the dynamics of each DoF are considered decoupled, the control can be designed following the procedures described in the
Section 2.2 for each element of the following set of single-input single-output systems
which are canonical models to be implemented as dynamic constraints during the prediction horizon.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}