1. Introduction
The oceans occupy a significant portion of the Earth’s surface and are a valuable source of oil, gas, minerals, chemicals, and other aquatic resources, attracting the attention of professionals, adventurers, and researchers, leading to an increase in marine exploration activities [
1]. To support these exploration efforts, various underwater tasks such as target location, biometric identification, archaeology, object search, environmental monitoring, and equipment maintenance must be performed [
2]. In this context, underwater target detection technology plays a crucial role. Underwater target detection can be categorized into acoustic system detection and optical system detection [
3], and image analysis, including classification, identification, and detection, can be performed based on the obtained image information. Optical images, compared to acoustic images, offer higher resolution and a greater volume of information and are more cost-effective in terms of acquisition methods [
4,
5]. As a result, underwater target detection based on optical systems is receiving increased attention. Target detection, being a core branch of computer vision, encompasses fundamental tasks such as target classification and localization. The existing approaches to target detection can be broadly classified into two categories: traditional target detection methods and deep-learning-based target detection methods [
6].
Traditional algorithms for target detection are typically structured into three phases: region selection, feature extraction, and feature classification [
7]. The goal of region selection is to localize the target, as the position and aspect ratio of the target may vary in the image. This phase is typically performed by traversing the entire image using a sliding window strategy [
8], wherein different scales and aspect ratios are considered. Subsequently, feature extraction algorithms such as Histogram of Oriented Gradients (HOG) [
9] and Scale Invariant Feature Transform (SIFT) [
10] are employed to extract relevant features. Finally, the extracted features are classified using classifiers such as Support Vector Machines (SVM) [
11] and Adaptive Boosting (Ada-Boost) [
12]. However, the traditional target detection method has two major limitations: (1) the region selection using sliding windows lacks specificity and leads to high time complexity and redundant windows, and (2) the hand-designed features are not robust to variations in pose.
The advent of deep learning has revolutionized the field of target detection and has been extensively applied in computer vision. Convolutional neural networks (CNNs) have demonstrated their superior ability to extract and model features for target detection tasks, and numerous studies have demonstrated that deep-learning-based methods outperform traditional methods relying on hand-designed features [
13,
14]. Currently, there are two main categories of deep-learning-based target detection algorithms: region proposal-based algorithms and regression-based algorithms. The former category, also referred to as Two-Stage target detection methods, are based on the principle of coarse localization and fine classification, where candidate regions containing targets are first identified and then classified. Representative algorithms in this category include R-FCN (Region-based Fully Convolutional Networks) [
15] and the R-CNN (Region-CNN) family of algorithms (R-CNN [
16], Fast-RCNN [
17], Faster-RCNN [
18], Mask-RCNN [
19], Cascade-RCNN [
20], etc.). Although region-based algorithms have high accuracy, they tend to be slower and may not be suitable for real-time applications. In contrast, regression-based target detection algorithms, also known as One-Stage target detection algorithms, directly extract features through CNNs for the prediction of target classification and localization. Representative algorithms in this category include the SSD (Single Shot MultiBox Detector) [
21] and the YOLO [
22] (You Only Look Once) family of algorithms (YOLO [
23], YOLO9000 [
24], YOLOv3 [
25], YOLOv4 [
26], YOLOv5 [
27], YOLOv6 [
28], YOLOv7 [
29]). Due to the direct prediction of classification and localization, these algorithms offer a faster detection speed, making them a popular research area in the field of target detection, with ongoing efforts aimed at improving their accuracy and performance.
The commercial viability of underwater robots equipped with highly efficient and accurate target detection algorithms is being actively pursued in the field of underwater environments [
30]. In this regard, researchers have made significant contributions to the development of target detection algorithms [
31,
32,
33,
34,
35]. For instance, in 2017, Zhou et al. [
36] integrated image enhancement techniques into an expanded VGG16 feature extraction network and employed a Faster R-CNN network with feature mapping for the detection and identification of underwater biological targets using the URPC dataset. In 2020, Chen et al. [
37] introduced a new sample distribution-based weighted loss function called IMA (Invert Multi-Class AdaBoost) to mitigate the adverse effect of noise on detection performance. In 2021, Qiao et al. [
38] proposed a real-time and accurate underwater target classifier, leveraging the combination of LWAP (Local Wavelet Acoustic Pattern) and MLP (Multilayer Perceptron) neural networks, to tackle the challenging problem of underwater target classification. Nevertheless, the joint requirement of localization and classification, in addition to classification, makes the target detection task especially challenging in underwater environments where images are often plagued by severe color distortion and low visibility caused by mobile acquisition. With the aim of enhancing the accuracy, achieving real-time performance, and promoting the portability of the underwater target detection capability, the most advanced YOLOv7 model of the YOLO series has been selected for improvement, resulting in the proposed YOLOv7-AC model, designed to address the difficulties encountered in this field. The effectiveness of the proposed model has been demonstrated through experiments conducted on underwater images. The innovations of this paper are as follows:
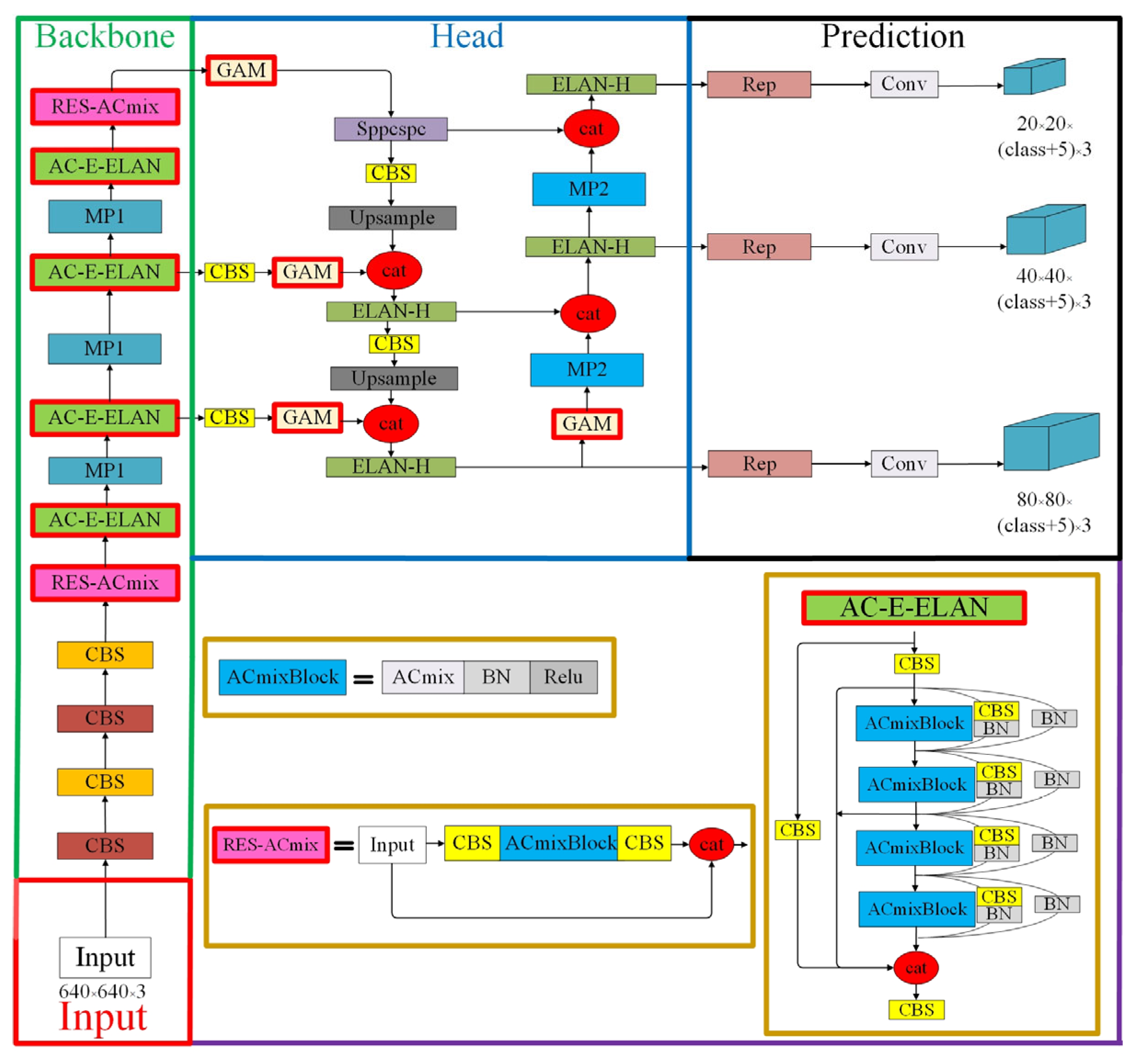
(1) In order to extract more informative features, the integration of the Global Attention Mechanism (GAM) [
39] is proposed. This mechanism effectively captures both the channel and spatial aspects of the features and increases the significance of cross-dimensional interactions.
(2) To further enhance the performance of the network, the ACmix (A mixed model incorporating the benefits of self-Attention and Convolution) [
40] is introduced.
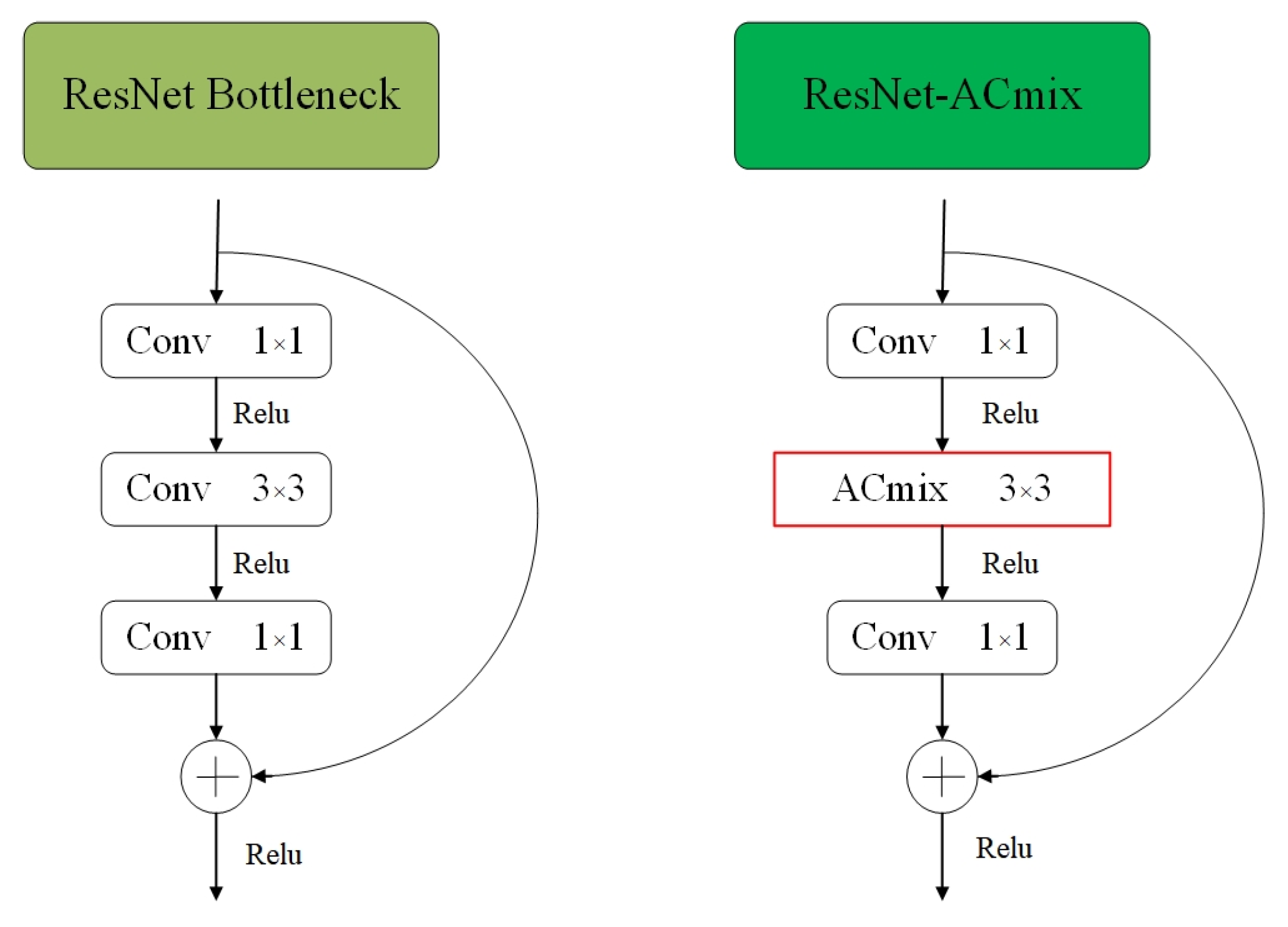
(3) The design of the ResNet-ACmix module in YOLOv7-AC aims to enhance the feature extraction capability of the backbone network and to accelerate the convergence of the network by capturing more informative features.
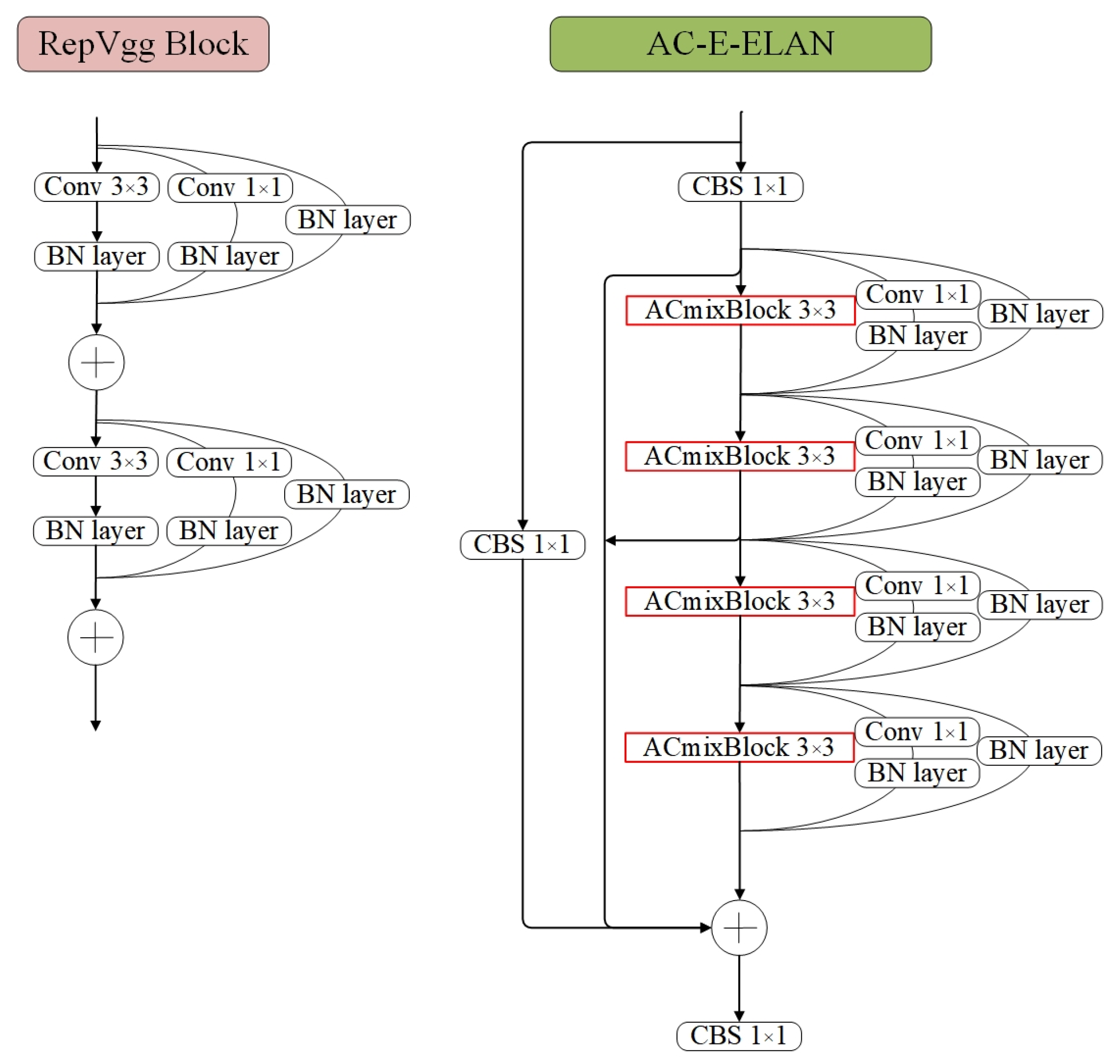
(4) The E-ELAN module in the YOLOv7 network is optimized by incorporating Skip Connections and a 1 × 1 convolutional structure between modules and replacing the 3 × 3 Convolutional layer with the ACmixBlock. This results in an enhanced feature extraction ability and improved speed during inference.
The rest of this paper is organized as follows.
Section 2 describes the architecture of YOLOv7 model and related methods.
Section 3 presents the proposed YOLOv7-AC model and its theoretical foundations. The performance of the YOLOv7-AC model is evaluated and analyzed through experiments conducted on underwater image datasets in
Section 4. The limitations and drawbacks of the proposed method are discussed in
Section 5. Finally, we provide a conclusion of this work in
Section 6.
2. Related Works
2.1. YOLOv7
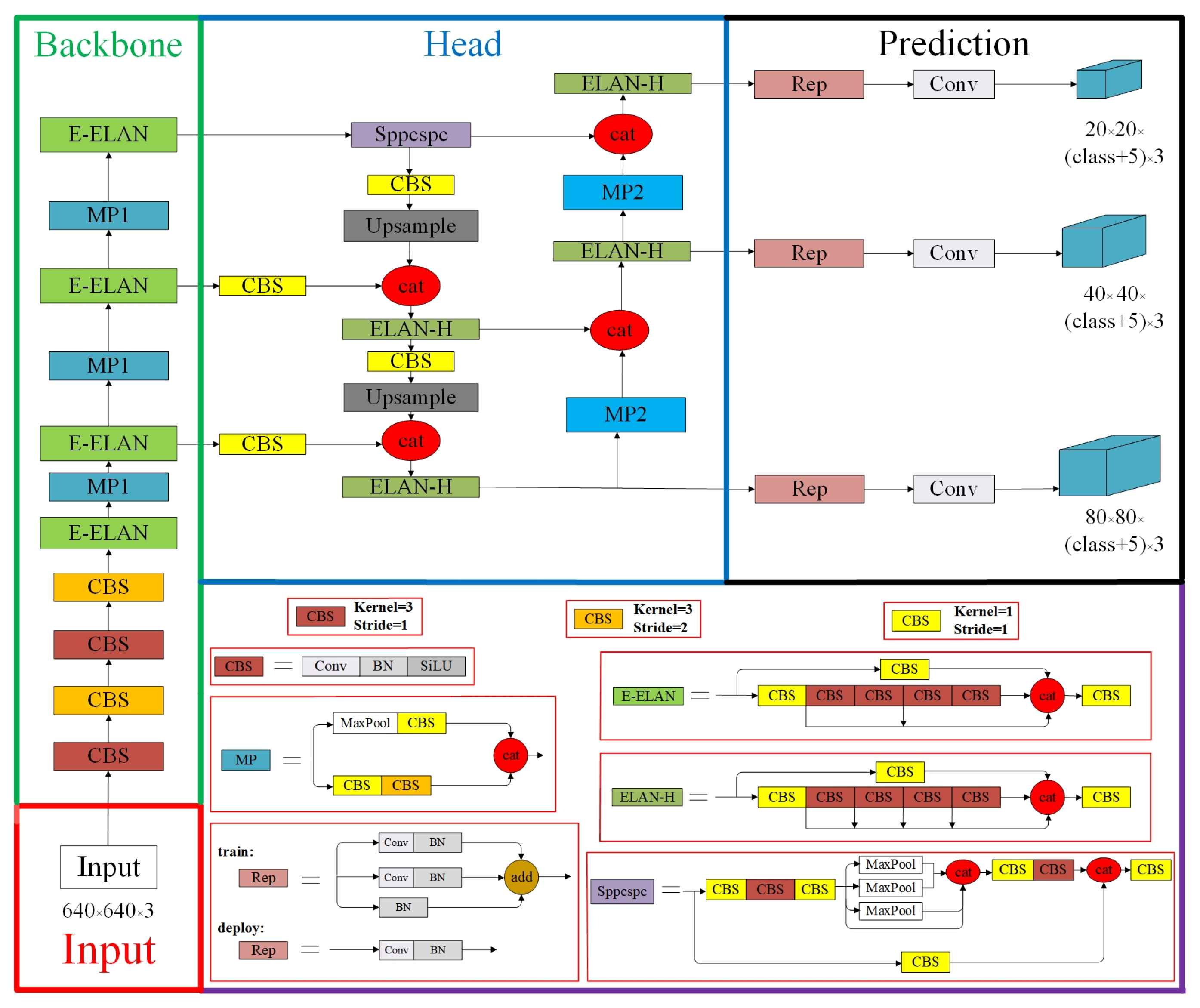
The YOLOv7 model [
29], developed by Chien-Yao Wang and Alexey Bochkovskiy et al. in 2022, integrates strategies such as E-ELAN (Extended efficient layer aggregation networks) [
41], model scaling for concatenation-based models [
42], and model re-parameterization [
43] to achieve a favorable balance between detection efficiency and precision. As shown in
Figure 1, the YOLOv7 network consists of four distinct modules: the Input module, the Backbone network, the Head network and the Prediction network.
Input module: The pre-processing stage of the YOLOv7 model employs both mosaic and hybrid data enhancement techniques and leverages the adaptive anchor frame calculation method established by YOLOv5 to ensure that the input color images are uniformly scaled to a 640 × 640 size, thereby meeting the requirements for the input size of the backbone network.
Backbone network: The YOLOv7 network comprises three main components: CBS, E-ELAN, and MP1. The CBS module is composed of convolution, batch normalization, and SiLU activation functions. The E-ELAN module maintains the original ELAN design architecture and enhances the network’s learning ability by guiding different feature group computational blocks to learn more diverse features, preserving the original gradient path. MP1 is composed of CBS and MaxPool and is divided into upper and lower branches. The upper branch uses MaxPool to halve the image’s length and width and CBS with 128 output channels to halve the image channels. The lower branch halves the image channels through a CBS with a 1 × 1 kernel and stride, halves the image length and width with a CBS of 3 × 3 kernel and 2 × 2 stride, and finally fuses the features extracted from both branches through the concatenation (Cat) operation. MaxPool extracts the maximum value information of small local areas while CBS extracts all value information of small local areas, thereby improving the network’s feature extraction ability.
Head network: The Head network of YOLOv7 is structured using the Feature Pyramid Network (FPN) architecture, which employs the PANet design. This network comprises several Convolutional, Batch Normalization, and SiLU activation (CBS) blocks, along with the introduction of a Spatial Pyramid Pooling and Convolutional Spatial Pyramid Pooling (Sppcspc) structure, the extended efficient layer aggregation network (E-ELAN), and MaxPool-2 (MP2). The Sppcspc structure improves the network’s perceptual field through the incorporation of a Convolutional Spatial Pyramid (CSP) structure within the Spatial Pyramid Pooling (SPP) structure, along with a large residual edge to aid optimization and feature extraction. The ELAN-H layer, which is a fusion of several feature layers based on E-ELAN, further enhances feature extraction. The MP2 block has a similar structure to the MP1 block, with a slight modification to the number of output channels.
Prediction network: The Prediction network of YOLOv7 employs a Rep structure to adjust the number of image channels for the features output from the head network, followed by the application of 1 × 1 convolution for the prediction of confidence, category, and anchor frame. The Rep structure, inspired by RepVGG [
44], introduces a special residual design to aid in the training process. This unique residual structure can be reduced to a simple convolution in practical predictions, resulting in a decrease in network complexity without sacrificing its predictive performance.
2.2. GAM
The attention mechanism is a method used to improve the feature extraction in complex contexts by assigning different weights to the various parts of the input in the neural network. This approach enables the model to focus on the relevant information and ignore the irrelevant information, resulting in improved performance. Examples of attention mechanisms include pixel attention, channel attention, and multi-order attention [
45].
GAM [
39] could improve the performance of deep neural networks by reducing information dispersion and amplifying the global interaction representation.
The GAM encompasses a channel attention submodule and a spatial attention submodule. The channel attention submodule is designed as a three-dimensional transformation, allowing it to preserve the three-dimensional information of the input. This is followed by a multi-layer perception (MLP) with two layers, which serves to amplify the inter-dimensional dependence in the channel space, thus enabling the network to focus on the more meaningful and foreground regions of the image.
The spatial attention submodule incorporates two convolutional layers to effectively integrate spatial information, enabling the network to concentrate on contextually significant regions across the image.
2.3. ACmix
The authors of [
40] discovered that self-attention and convolution both heavily rely on the 1 × 1 convolution operation. To address this, they developed a hybrid model known as ACmix, which elegantly combines self-attention and convolution with minimal computational overhead.
The first core is convolution [
46]: Given a standard convolution of the kernel
, tensor
,
as input and output feature maps, respectively,
is the kernel size,
and
are input and output channels.
,
denote height and width.
,
denote the feature tensor of the pixels
corresponding to
and
. The standard convolution can be expressed as Equation (1):
where
subjecting to
denotes the weight of the nucleus at position
. Equation (1) can be simplified into Equations (2) and (3).
To further simplify the formula, define the Shift operation by
≜
where
correspond to horizontal and vertical displacements. Thus, equation (3) can be abbreviated to
Standard convolution can be summarized in two steps:
(Convolution:)
The next is Self-Attention [
47]: Assuming that there is a standard self-attentive module with
heads, the output of the attention module is calculated as:
where
is the concatenation of the output of
attention headers,
,
,
are the projection matrices of query, key and value.
denotes a local region of pixels of spatial width
centered on
.
is the corresponding attention weight with regard to the features within
. For the widely adopted self-attentive modules, the
weights are calculated as:
where
is the characteristic dimension of
. Similarly, multi-head self-attention can be decomposed into two stages:
The ACmix module performs the 1 × 1 convolution projection operation on the input feature mapping once and reuses the intermediate feature maps for subsequent aggregation operations in both convolution and self-attention paths. The strengths of these outputs are controlled by two learnable scalars:
The ACmix module reveals the robust correlation between self-attention and convolution, leveraging the advantages of both techniques, and mitigating the need for repeated, high-complexity projection operations. As a result, it offers minimal computational overhead compared to either self-attention or pure convolution alone.
6. Conclusions
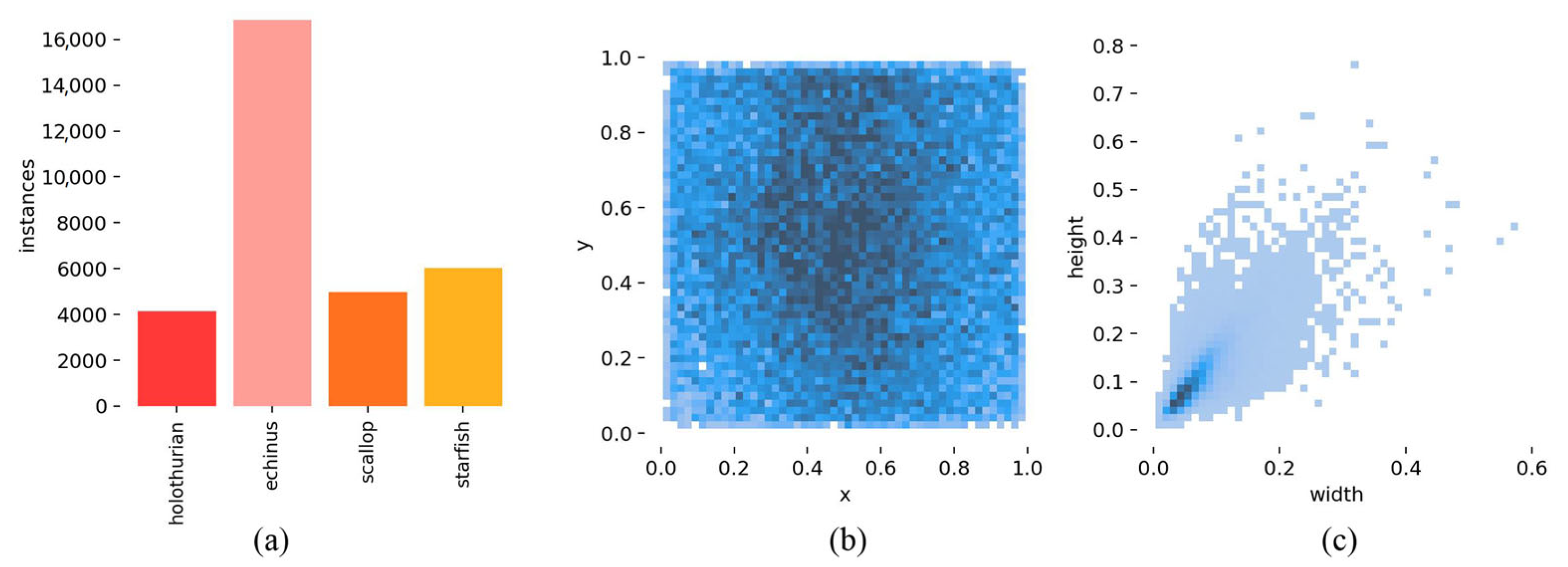
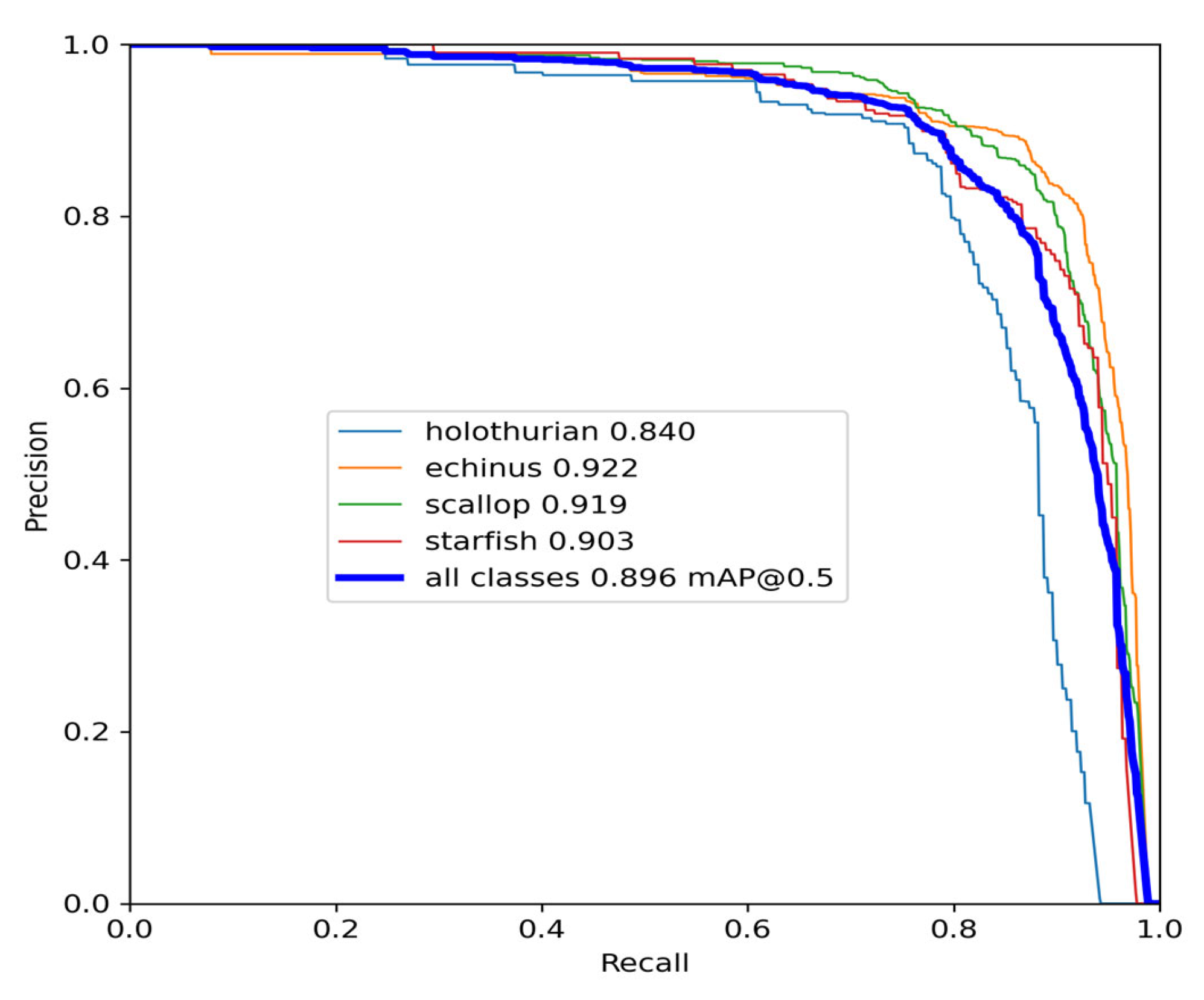
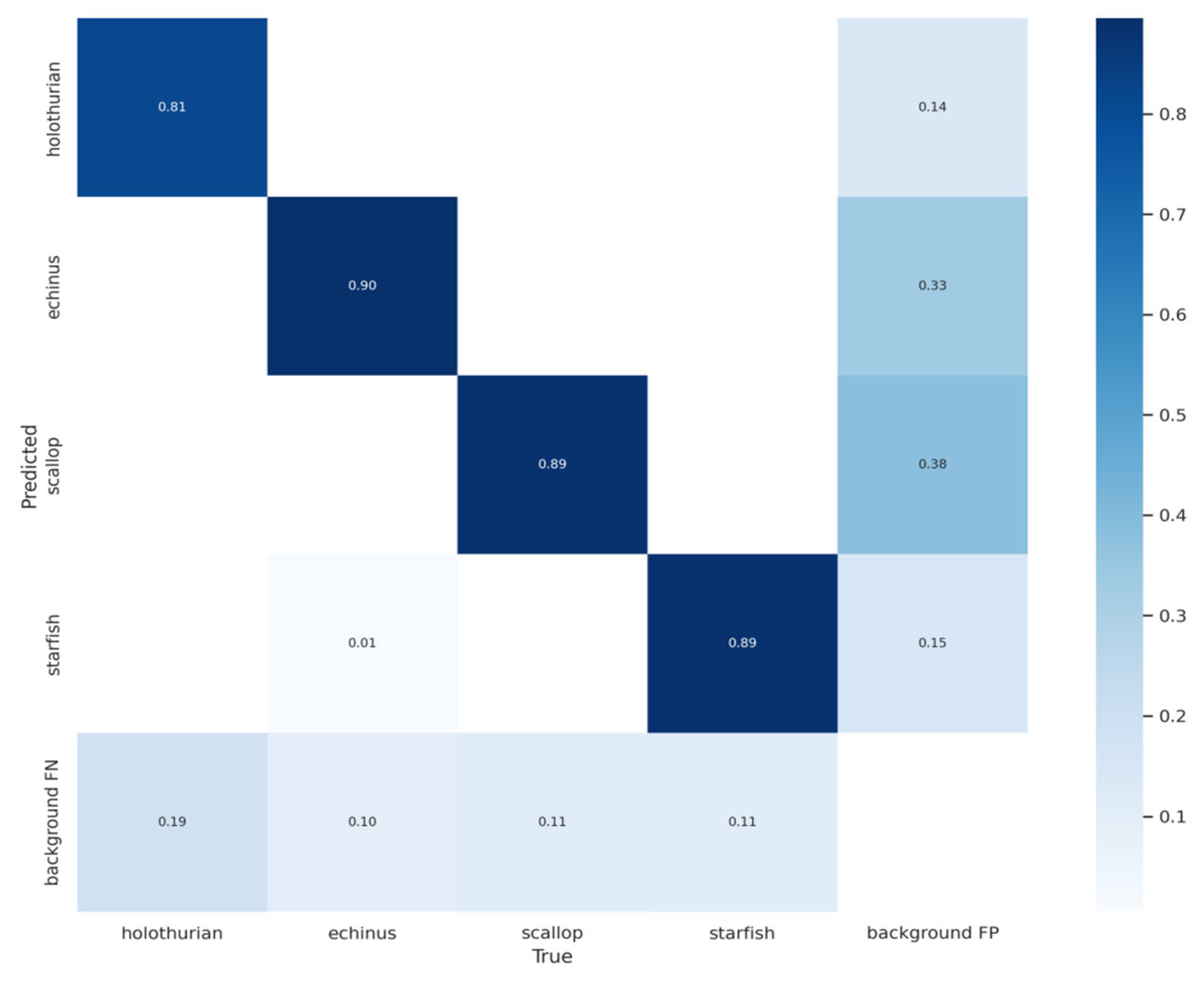
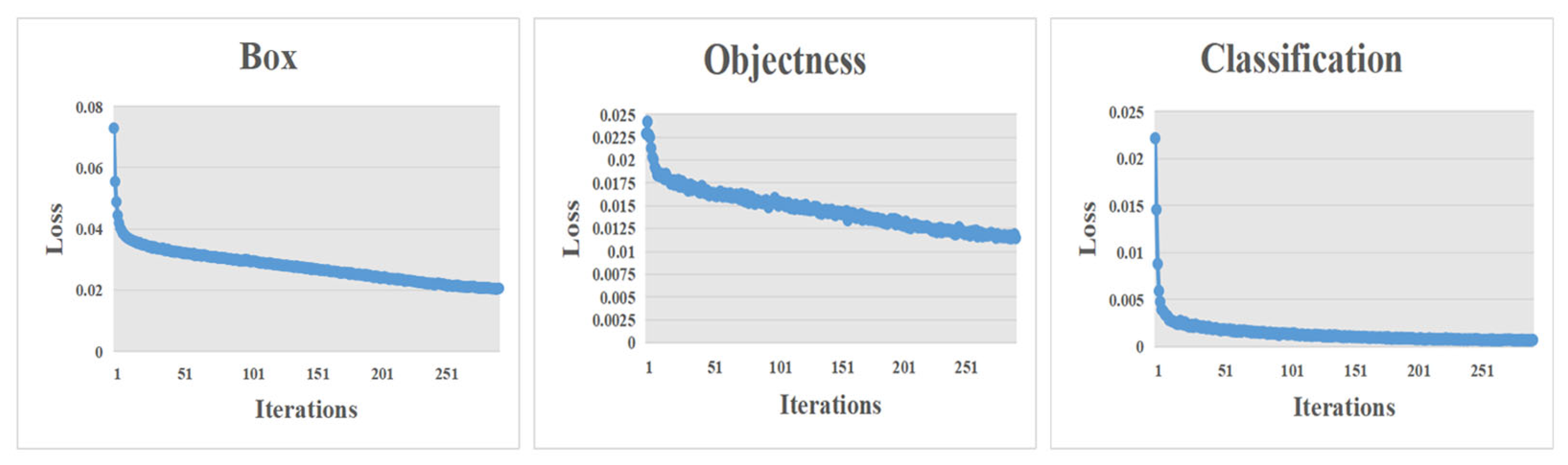
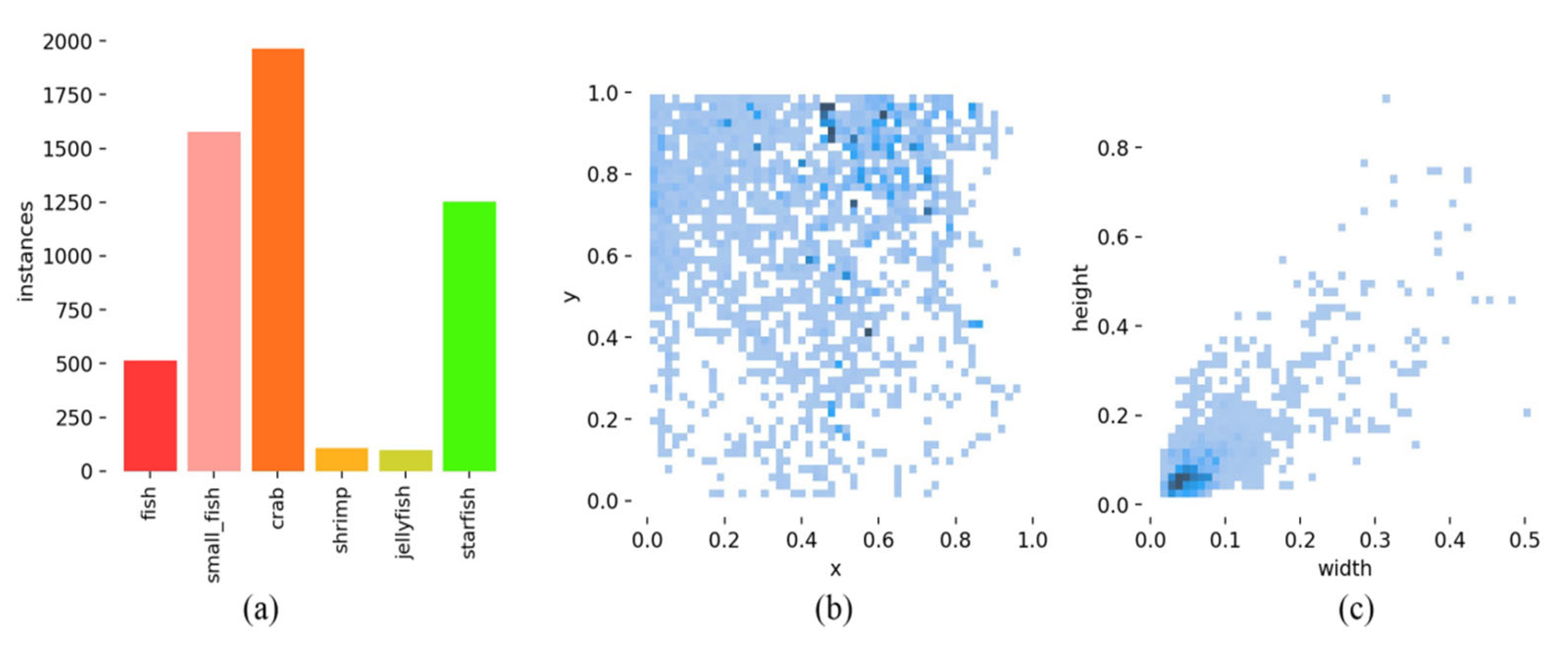
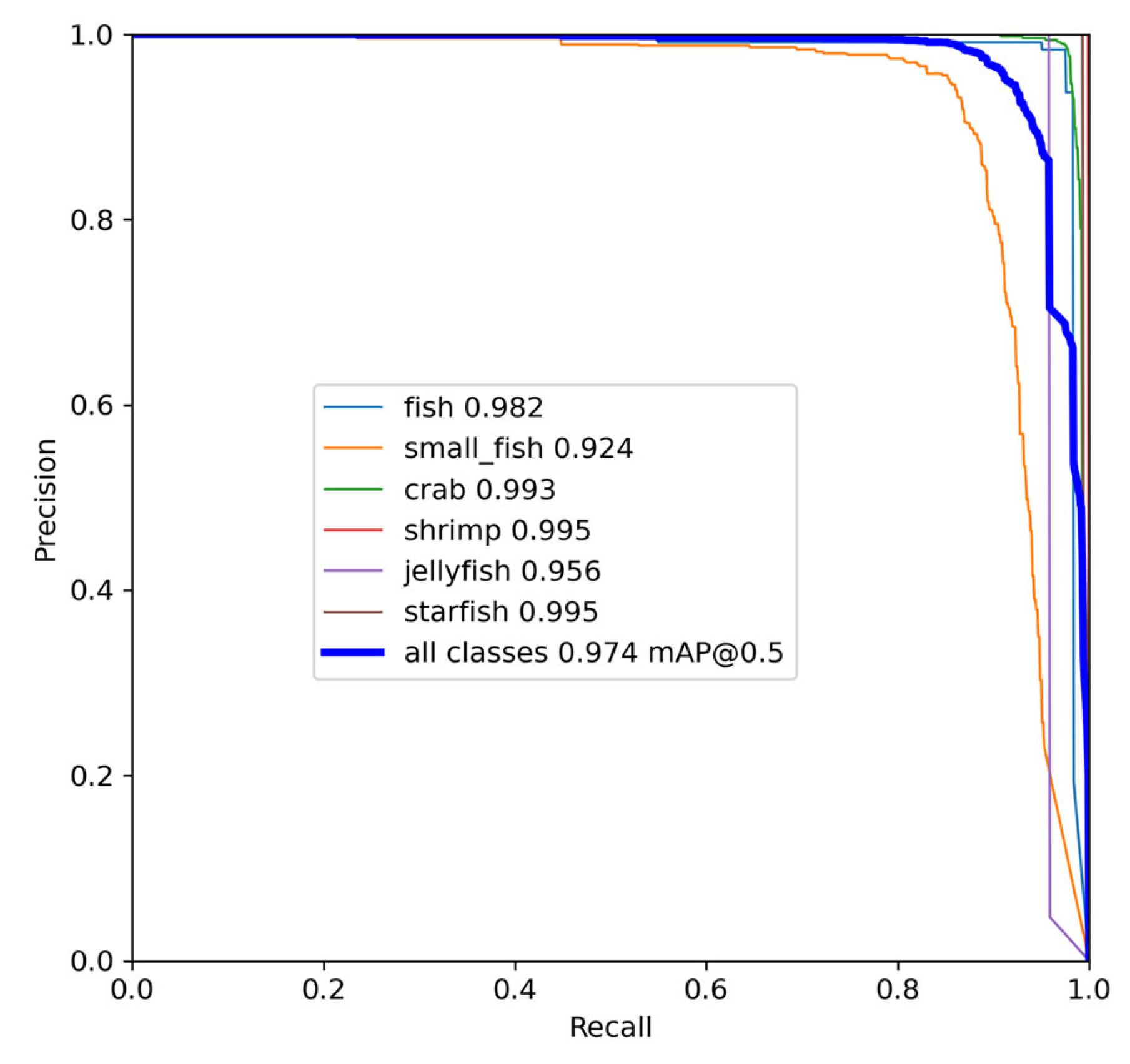
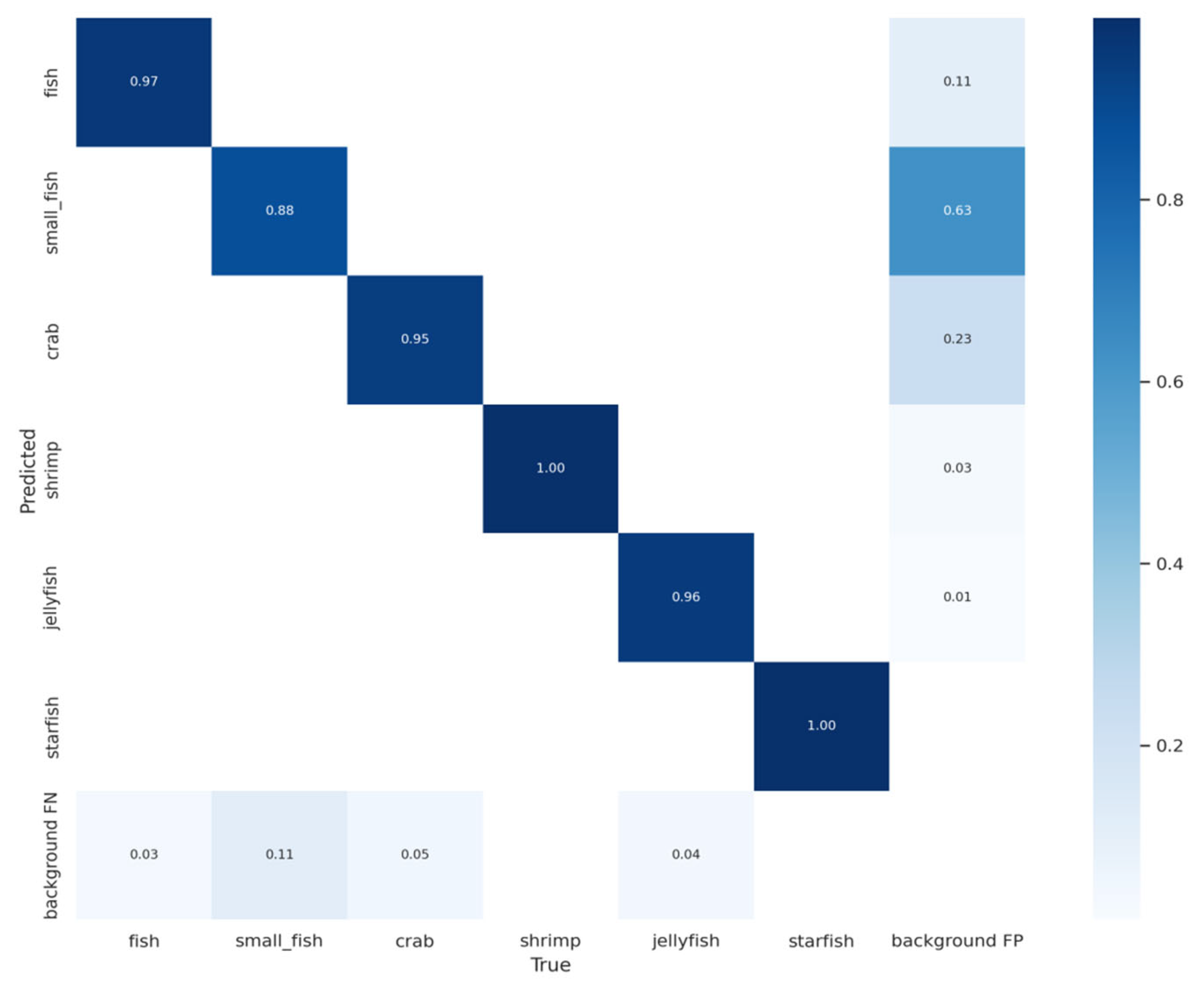
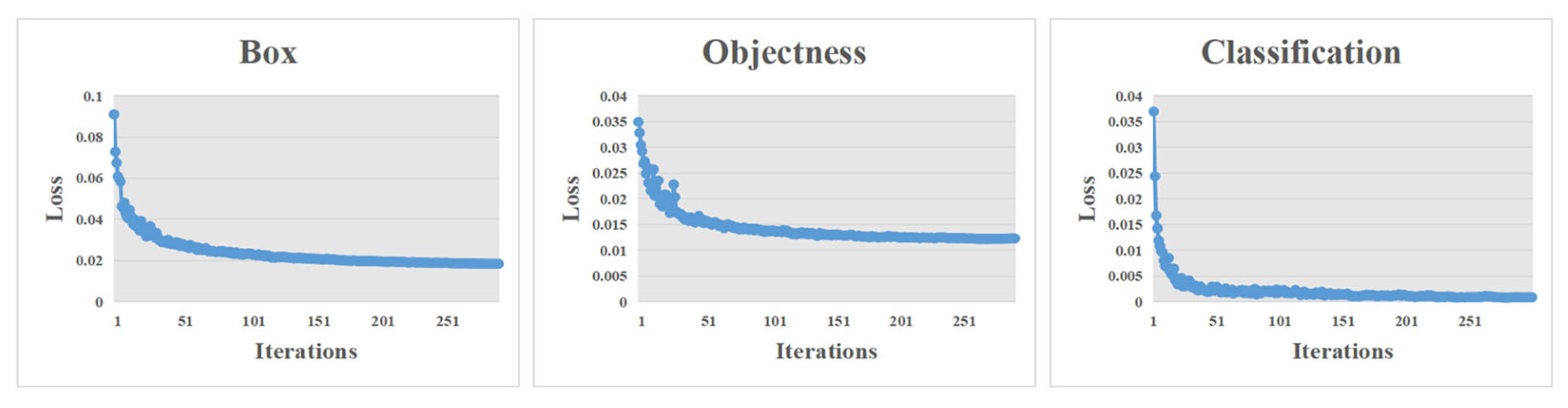
In this study, an improved YOLOv7-based network, referred to as YOLOv7-AC, is presented for the purpose of detecting targets in complex underwater environments. To achieve this, the AC-E-ELAN module is designed to emphasize target features, while the incorporation of jump connections and a 1 × 1 convolutional structure within the ACmixBlock improves computational speed and memory utilization. The ResNet-ACmix module is further developed to extract deep features that are more effectively trained by the network. Furthermore, the use of GAM and K-means++ enhances the overall performance of the detection. Experiments were conducted using the URPC and Brackish datasets, and the results were compared to those obtained using popular target detection algorithms and the proposed YOLOv7-AC model. The results indicate that the proposed YOLOv7-AC model surpasses the state-of-the-art target detection models in terms of its robustness and performance in complex underwater environments.
However, it must be noted that the availability of high-quality underwater datasets and images remains a major challenge in the development of target detection in underwater environments. Hence, the future research efforts will aim at collecting a large and diverse set of underwater datasets and employing image enhancement techniques to improve the overall quality of underwater images, which are crucial for the detection of underwater targets.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}