1. Introduction
SSS is commonly used for underwater detection and image acquisition, with extensive applications in underwater sediment classification [
1], underwater objects detection [
2], underwater image segmentation [
3], and other fields. The detection of small underwater objects has become a prominent research focus both domestically and internationally due to technical challenges such as limited availability of acoustic image data, difficulties in feature extraction, variable scales, and challenging detection scenarios. Traditional sonar image detection methods are mainly based on pixel [
4], feature [
5], and echo [
6] methods, which manually design filters for object detection according to pixel value features, the gray threshold, or prior information about the object. However, because the underwater environment is very complicated, sonar echoes are affected by self-noise, reverberation noise, and ambient noise, resulting in low resolution, blurred edge details, and serious speckle noise. Therefore, it is difficult to find good pixel characteristics and gray thresholds.
In recent years, with the rapid development of deep learning and convolutional neural networks, researchers have designed many detectors; these are mainly divided into single-stage detectors and two-stage detectors. A two-stage detector tries to find any number of objects in the image in the first stage, then classifies and locates them in the second stage. Two-stage detectors mainly rely on R-CNN [
7], SPP-Net [
8], Fast R-CNN [
9], Faster R-CNN [
10], FPN [
11], R-FCN [
12], MaskR-CNN [
13], DetectoRS [
14], etc. Single-stage detectors use intensive sampling to classify and locate semantic objects in a single scan. They use predefined boxes/key points of varying proportions and aspect ratios to locate objects. Single-stage object detection algorithms treat this task as a regression problem, using a single end-to-end network from the input raw image to the object location and category output. Compared with two stage-detection, single-stage detection algorithms typically have better real-time performance. The single-stage detectors mainly include YOLO [
15], SSD [
16], RetinaNet [
17], EfficientDet [
18], YOLOv7 [
19], etc.
There are several difficulties in sonar image small object detection based on deep learning. First, it is difficult to learn the correct representation from the limited and distorted information of small objects. Second, there is a scarcity of large-scale datasets for small object detection. Third, there is very low tolerance for positioning error; because the annotation box of small objects is generally relatively small, even a small positioning error can cause a large visual deviation. Yang et al. [
20] proposed a high quality sonar image generation method based on a diffusion model, which is used to generate a large number of high quality sonar images with obvious features and can be used for training to ensure that the objects in the image are more obvious. This approach can be further applied to engineering applications such as target detection and image classification. Fu et al. [
21] proposed an improved YOLOv5 method based on an attention mechanism and an improved anchor frame for real-time detection of underwater small objects in SSS images, aiming to address the shortcomings of high miss rate and high false detection rate in the detection of underwater small objects based on YOLOv5. Wang et al. [
22] proposed a new sonar image object detection algorithm called AGFE-Net, which uses multi-scale sensing domain feature extraction blocks and a self-attention mechanism to expand the convolution kernel sensing domain in order to obtain multi-scale feature information of sonar images and enhance the correlation between different features. Based on the YOLOv5 framework, Zhang et al. [
23] used the IOU values of the initial anchor frame and the object frame instead of the Euclidean distance typically used in YOLOv5 as the basis for clustering. This approach provides an initial anchor frame that is closer to the real value, increasing the convergence speed of the network. In addition, the pixel coordinates of the image were added to the feature graph as the information of the two channels. The accuracy of detection module positioning regression is improved. Li et al. [
24] proposed a real-time SSS image object detection algorithm based on YOLOv7. First, a method based on threshold segmentation and pixel importance value was used to quickly identify any suspicious objects in the SSS images, then scale information fusion and an attention mechanism were introduced to the network. The proposed algorithm achieved advanced performance and can be applied to real underwater tasks.
In the current mainstream object detection models, single-stage objects detection networks are more suitable for object detection in SSS images because of their high accuracy and good real-time performance. Among them, YOLOv7 is a leading algorithm known for its exceptional detection accuracy, fast speed, and scalability. Therefore, in this paper we propose an improved YOLOv7 method on the basis of YOLOv7 model, including an increased detection scale, re-fusion of features, and introduction of an attention mechanism.
In summary, the main contributions of this paper are as follows:
The dataset used in this paper was collected by the laboratory using SSS in a sea test, and contains four kinds of objects. To assess the effectiveness of the method proposed in this study, an ablation study was conducted. The experimental results demonstrate that the incorporation of each key innovation described in this paper significantly improves the detection accuracy of the original network. The proposed enhanced YOLOv7-based approach presents a viable solution for improving the detection of small underwater objects in SSS images. This approach offers a new option for addressing the challenges of small object detection in SSS applications.
The rest of this paper is organized as follows:
Section 2 introduces related work, including the YOLOv7 model, two attention mechanisms, and BiFPN structure;
Section 3 introduces the enhanced YOLOv7-based approach;
Section 4 describes the datasets, experiments, and resulting analysis; finally,
Section 5 summarizes the work.
2. Methods
In this section, an overview of the YOLOv7 network is provided, along with an introduction to the two attention mechanisms and the BiFPN structure.
2.1. YOLOv7 Network
There are three types of YOLOv7 [
19] network models applicable to different GPUs: YOLOV7-tiny for edge GPUs, YOLOv7 for ordinary GPUs, and YOLOv7-W6 for cloud GPUs. The three models gradually increase in depth, complexity, and detection accuracy. This section briefly introduces the network structure of YOLOv7.
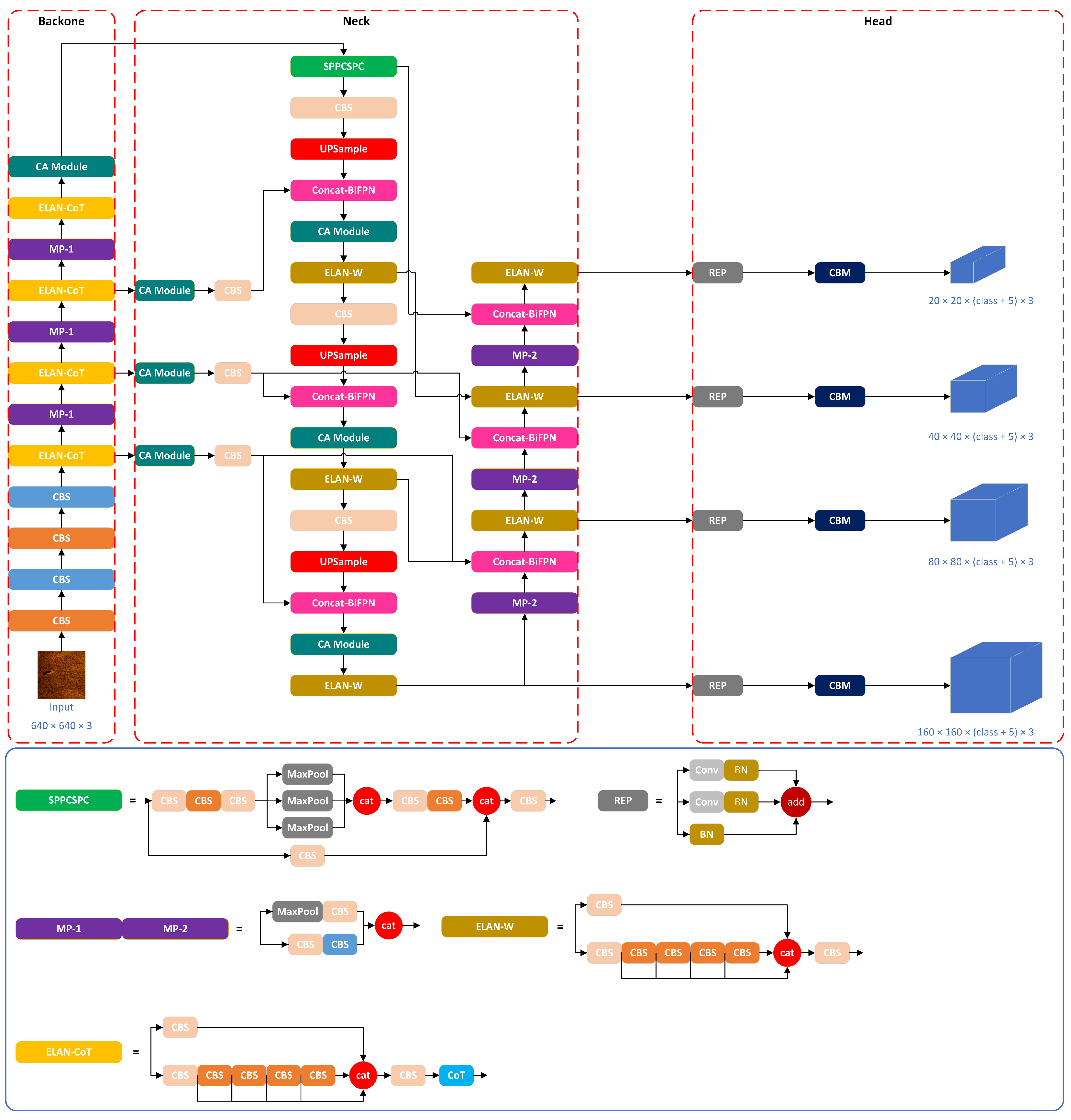
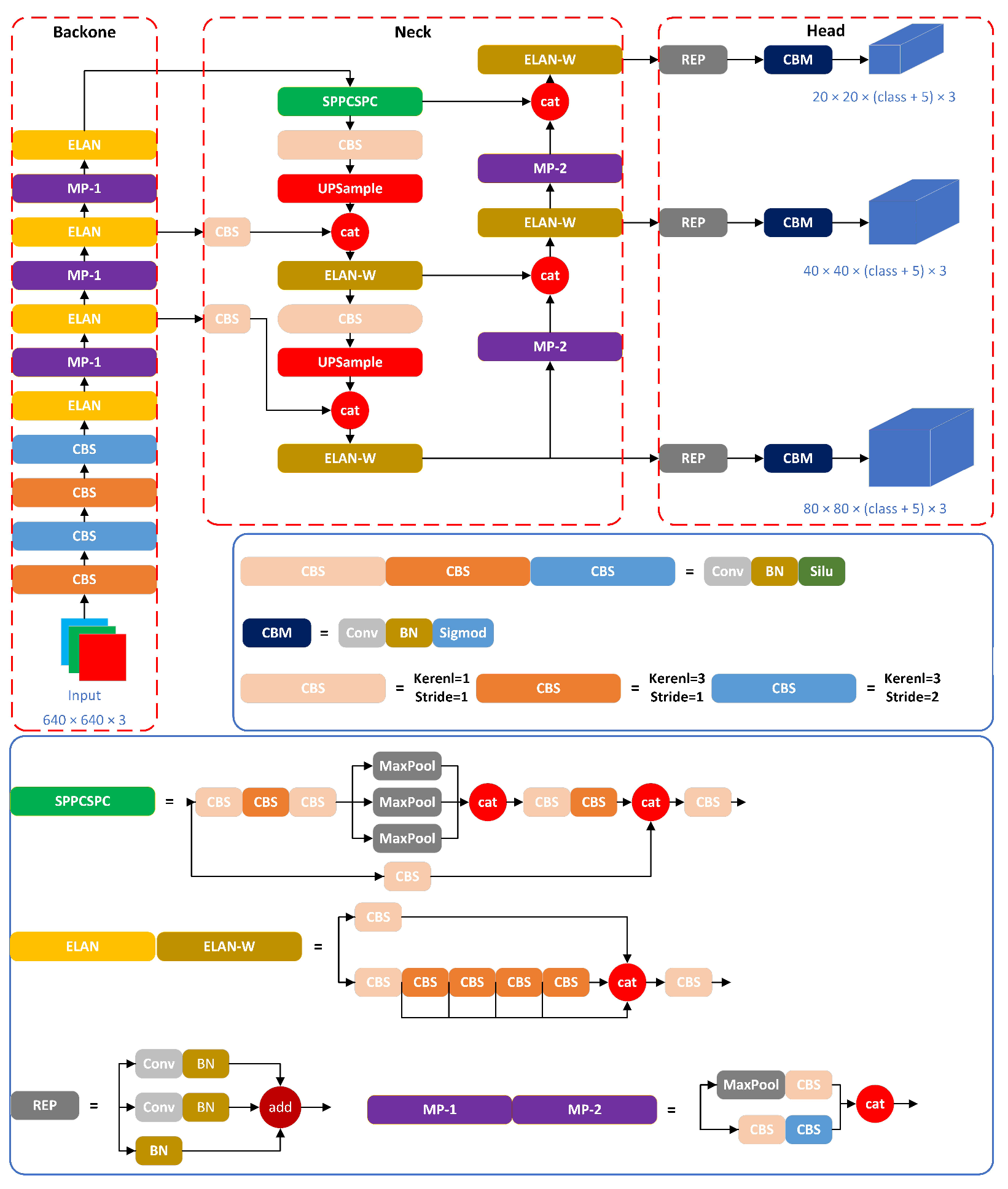
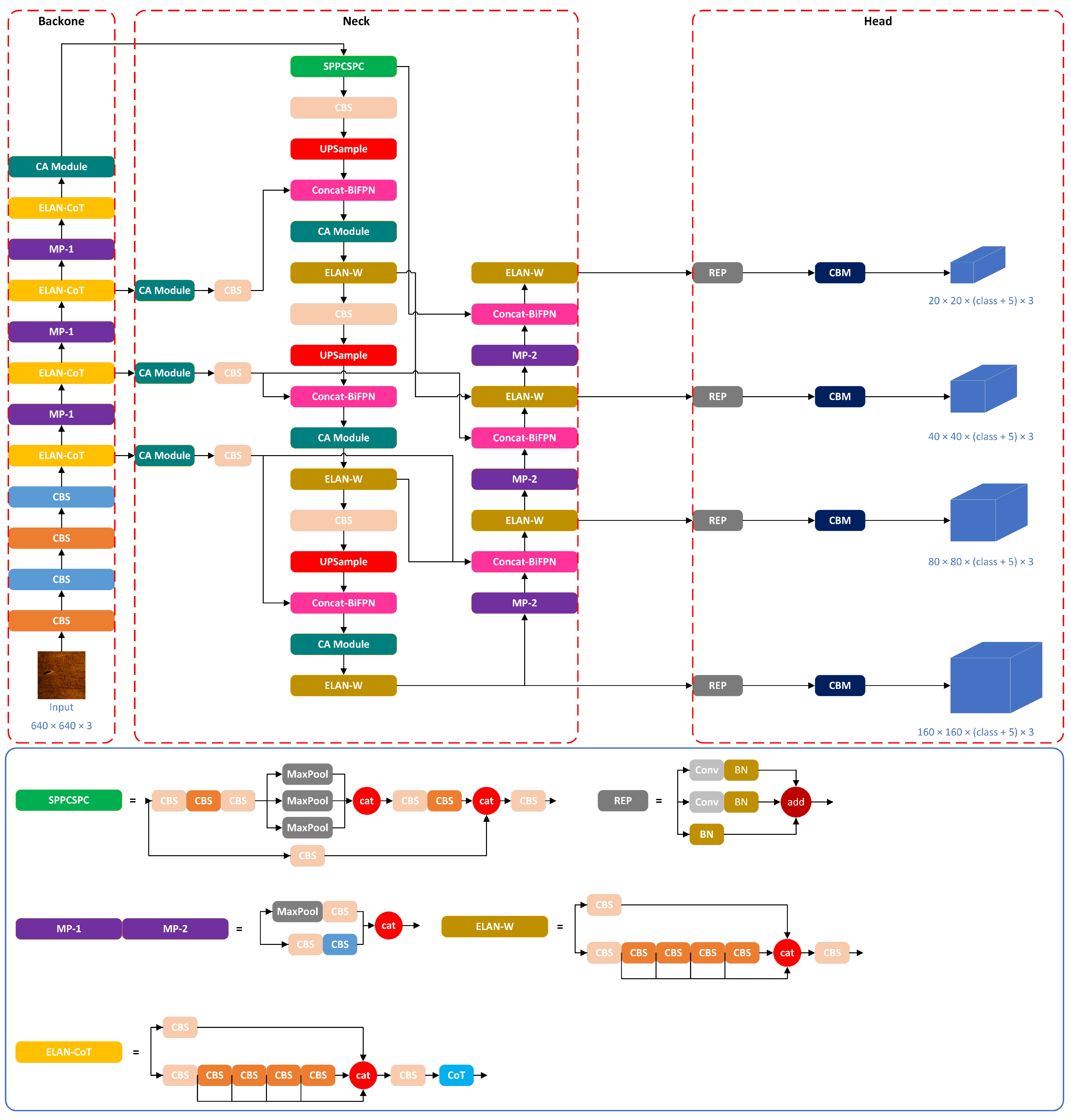
YOLOv7 is the most advanced algorithm in the YOLO series at present, and is the most typical representative of one-stage object detection algorithms, surpassing the previous YOLO series in both accuracy and speed. The YOLOv7 network is mainly composed of three parts: a backbone part, neck part, and head part, as shown in
Figure 1.
The backbone part plays a crucial role in capturing low-level features such as edges, textures, and shapes in the image, then progressively transforming them into higher-level semantic features. The neck part serves as an intermediary layer between the backbone network and the head network; its main role is to further integrate and fuse features from different levels. The head part is responsible for performing object classification and position regression on the feature map generated by the neck component. Typically, it is composed of a sequence of convolutional layers and fully connected layers that extract features and predict the object’s category label and bounding box.
In this paper, the YOLOv7 network is utilized as a benchmark network for comparison with the proposed enhanced YOLOv7-based method. The size of the input side scan sonar image is 640 × 640 × 3, and detection is carried out on three scales: 80 × 80, 40 × 40, and 20 × 20.
2.2. CA Module
Attention mechanisms are commonly employed in object detection to enable neural networks to learn the content and location that demand increased attention. The majority of existing methods primarily emphasize the development of more sophisticated attention modules to improve performance. However, in the context of SSS image object detection, it is equally important to prioritize detection efficiency alongside performance. Therefore, in this paper we make the decision to introduce a lightweight attention module to the neck component in a plug-and-play manner, aiming to strike a balance between model performance and complexity. Among the lightweight attention modules, the most popular methods are SE Attention [
27] and CBAM [
28]. However, the SE module primarily focuses on inter-channel information encoding, overlooking the importance of location information, while CBAM only captures local correlations and lacks the ability to capture the essential long-range dependencies required for visual tasks.
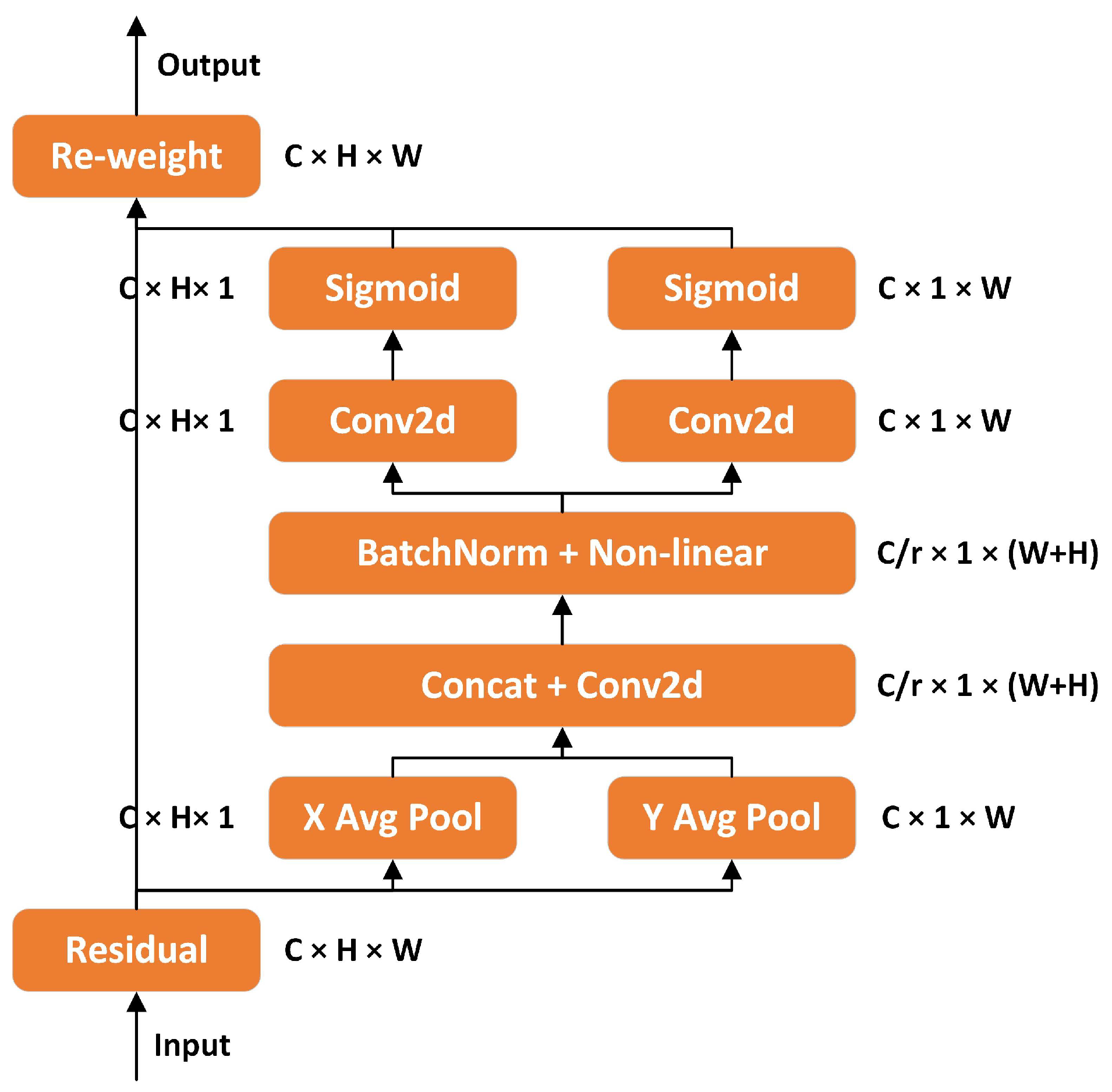
The Coordinate Attention (CA) module [
26] splits channel attention into two 1D feature coding processes that aggregate features along different directions, capturing long-range dependencies along one spatial direction and retaining precise location information along the other spatial direction, thereby effectively integrating spatial coordinate information into the generated attention map, as shown in
Figure 2.
The CA mechanism addresses the encoding of channel relationships and long-range dependencies by incorporating precise position information, which involves two distinct steps: coordinate information embedding, and the generation of coordinate attention. In the first step, coordinate information embedding uses the two spatial ranges
or
of the pooled kernel to encode each channel along the horizontal and vertical coordinates, respectively. Thus, the output of the
c-th channel at height
h and width
w can be formulated as Equation (
1):
where
H and
W are the height and width of the input feature, while
is the input directly from a convolution layer with a fixed kernel size. In the second step, the aggregate feature graphs obtained from Equation (
1) are first concatenated as inputs; then, through a shared 1 × 1 convolution transform function
, the output is as follows:
where
is the concatenation operation along the spatial dimension and
is the nonlinear activation function. Then,
f is divided into two separate tensors
and
along the spatial dimension. Two other 1 × 1 convolution transformations
and
are respectively used to transform
and
into tensors with the same number of channels as the input, yielding
where
is the sigmoid function. Finally, the input
and
are used as the attention weights. The output of CA module
y can be formulated as Equation (
4):
2.3. CoT Module
The transformer self-attention mechanism has gained significant traction in the field of natural language processing, demonstrating competitive results. Motivated by this success, researchers have started to investigate the applicability of self-attention mechanisms in computer vision tasks. However, most current studies primarily focus on utilizing self-attention on 2D feature graphs, which generates an attention matrix based on isolated query and key pairs at each spatial location without fully leveraging the contextual information available among adjacent keys.
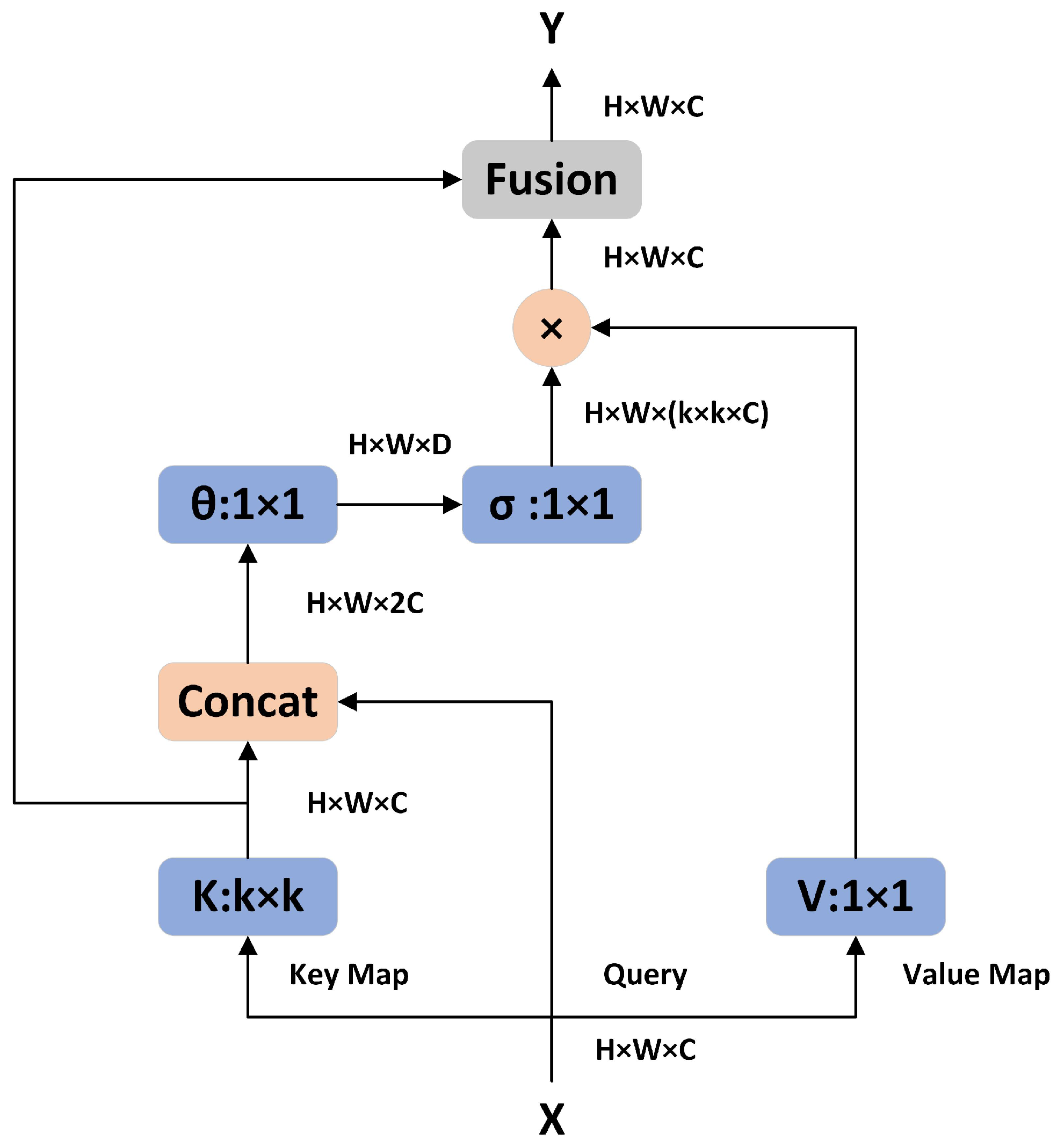
The Contextual Transformer (CoT) module [
25] leverages the inherent static contextual relationship among input keys to facilitate the learning of a dynamic attention matrix, and finally fuses the static and dynamic context information to enhance the representation of visual features. In computer vision tasks, CoT can serve as an alternative to standard convolution, thereby enhancing self-attention for contextual information that is lacking in backbone networks. More specifically, we can assume that the input 2D feature map is
and that the keys, queries, and values are defined as
,
, and
, respectively. First,
group convolution is performed for all adjacent keys in the
grid; the obtained keys
contain the context information of their adjacent keys. Then, the contextualized keys
and queries
Q are taken as inputs; after two
convolution, the attention matrix can be formulated as Equation (
5):
where
represents
convolution with the ReLU activation function and
represents the same without the activation function. Next, according to the obtained attention matrix, as in typical self-attention, the aggregate values
V are used to calculate the dynamic context representation
of the inputs; this can be formulated as Equation (
6):
where ∗ denotes the local matrix multiplication. The final output of the CoT module
is a fusion of the static context
and dynamic context
, as shown in
Figure 3.
2.4. BiFPN Structure
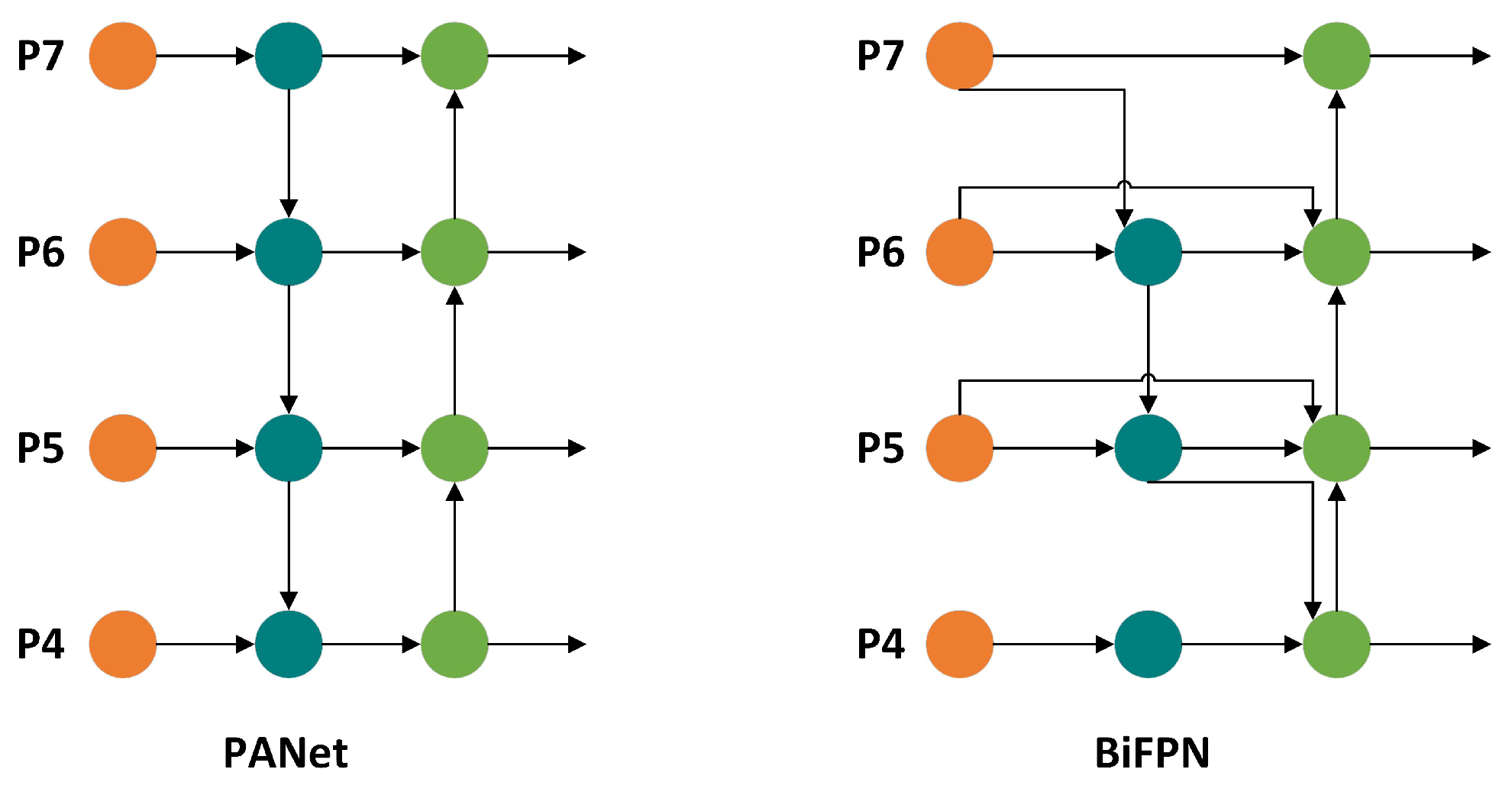
Effectively representing and processing multi-scale features in a network poses a challenging problem in object detection. Initially, object detection networks directly utilized features extracted from the backbone network for direct prediction. Subsequently, the Feature Pyramid Network (FPN) [
11] introduced a top-down approach to fuse multi-scale features, establishing the groundwork for multi-scale feature fusion. Building upon this, PANet [
29] augmented the basic FPN architecture with an additional bottom-up feature fusion network. PANet has gained significant prominence in recent years, and has been employed as the neck component in YOLOv5 and YOLOv7. However, improved performance inevitably leads to an increase in parameters and computational complexity.
Different from the above two approaches, BiFPN [
18] proposes a simple and efficient weighted bidirectional feature pyramid network that can easily and quickly carry out multi-scale feature fusion, allowing the accuracy and efficiency of the detection network to be improved at the same time. First, BiFPN removes nodes that contribute less to the network in order to achieve greater simplification. Second, an additional feature connection is added between the input node and the output node on the same scale to fuse more features without adding much cost, as shown in
Figure 4.
Moreover, due to the variation in the scales of the fused features, achieving balanced fusion becomes challenging. To address this issue, BiFPN introduces learnable weights for each feature requiring fusion. This enables the model to intelligently utilize features from different scales, which can be mathematically represented as Equation (
7):
where
,
is a small value chosen to avoid numerical instability. As a concrete example, the fusion features of the
scale shown in
Figure 4 can be formulated as Equation (
8):
where
is the intermediate feature of scale 6 in the top-down path,
is the output feature of scale 6 in the bottom-up path,
is the upsampling or downsampling operation used to unify the feature scale, and
denotes the convolution operation. Other scale features are fused in the same way.
4. Experiments and Analysis
In this section, the proposed method is utilized for conducting experiments and analysis, including the selection of datasets, training procedures, and performance evaluation.
4.1. Datasets
The dataset used in this section was obtained from repeated voyages by our laboratory using a small ship fitted with SSS along a pre-placed object during sea trials. The SSS we used had a frequency of 450 kHz and was able to effectively detect up to 150 m; the installation angle was
horizontal downward tilt. The equipment used in the experiment is shown in
Figure 6.
The sonar image obtained directly from the SSS is a waterfall stream image, and the resolution of a single image is as high as 1386 × 63,000. To streamline the process of image training and detection, the object portion is extracted from the high-resolution sonar image and used as the input image, then each image is resized to a resolution of .
In this experiment, we placed two kinds of objects in advance, one a cylinder with a base circle diameter of 60 cm and height of 60 cm, and the other a cone with a base circle diameter of 40 cm and height of 30 cm. If the pixel area of an object is less than 1% of the image area, the object can be defined as a small object. Specifically, the SSS image we used had an area of 160,000 pixel
2; thus, when the object pixel area is less than 1600 pixel
2, it is considered a small object in the context of this article. Among the three types of objects in the SSS dataset, the length of three-quarters of the objects is no more than 40 pixels, the width is no more than 20 pixels, and the area of target pixels is no more than 800 pixel
2, allowing the detection performance of small objects in the model to be measured to a certain extent. The graphical representation of this process is depicted in
Figure 7.
After analysis and comparison, the final dataset consisted of 800 SSS images with three types of objects, including 355 cones, 314 cylinders, and 312 non-preset targets for interference. Subsequently, the dataset was divided into training, testing, and validation sets in a ratio of 6:2:2. The dataset created according to this distribution was then used for training the network.
4.2. Training
The experiments are conducted under the PyTorch 1.12.1 framework. The CPU is an Intel(R) Xeon(R) Silver 4210R CPU@2.40 GHz, and four NVIDIA GeForce RTX 3090 (24 GB) are used for the experiment.
During the training phase, the training data were initially augmented using the built-in data augmentation method provided by YOLOv7. Subsequently, both the original YOLOv7 model and the improved YOLOv7 model proposed in this work were trained separately. The input image size was resized to
, the batch-size was set to 64, the initial learning rate was set to 0.01 and the the number of training epochs was set to 1000. The SGD optimizer [
33] was used, and the warm-up and cosine annealing learning strategies were adopted.
4.3. Performance Evaluation
In this section, the performance of the proposed enhanced YOLOv7-based approach is evaluated. This evaluation encompasses criteria for performance assessment, presentation of experimental results, and an ablation study.
4.3.1. Evaluation Criteria
To assess the performance enhancement achieved by the proposed method, Precision (
P), Recall (
R), and mean average precision (mAP) metrics were utilized as evaluation criteria, as introduced in PASCAL VOC 2010. The calculation formulas for these metrics are as follows:
where
is the number of positive samples that are correctly predicted,
is the number of samples that are incorrectly predicted as positive,
is the number of samples that are incorrectly predicted as negative, and
N is the number of detected categories.
4.3.2. Experimental Results
To demonstrate the superior performance of the proposed enhanced YOLOv7-based approach, a comparative analysis was conducted with several prevailing methods in the field. The compared methods include SSD [
16], Faster R-CNN [
10], EfficientDet [
18], YOLOv5, and YOLOv7 [
19]. The above algorithms were tested on an NVIDIA GeForce RTX 3090 GPU (24 GB).
Table 1 shows the performance of different mainstream object detection algorithms on the acquired SSS images dataset.
According to
Table 1, the SSD algorithm exhibits the lowest performance among the five mainstream object detection algorithms, with an mAP value of 46.1%. In contrast, YOLOv7 demonstrates the best performance among these algorithms, with an mAP value of 50.3%. These findings further validate the rationale behind our improvements based on YOLOv7. In comparison to YOLOv7, the proposed method showcases notable advancements. Notably, the precision (P) increases by 4.8%, reaching 95.5%. The recall (R) demonstrates an improvement of 5.1%, reaching 87.0%. Additionally, the mean Average Precision (mAP) sees a substantial 4.8% rise, reaching 55.1%.
In terms of detection speed, YOLOv7 achieves the highest detection speed, detecting an image in 7.3 ms, while Faster R-CNN has the slowest detection speed of 142.8 ms. The method proposed in this paper achieves a detection speed of 63.1 ms, which represents a trade-off between efficiency and accuracy. However, it is important to note that in terms of real-time performance, the generation time for each data ping from the side-scan sonar ranged from 0.6 s to 0.8 s. Consequently, it takes at least 240 s to generate the image size required for detection according to the methodology proposed in this paper. This time requirement significantly surpasses the 63.1 ms achieved by the proposed method. Nevertheless, the method outlined in this paper adequately fulfills the real-time demands of the project.
Figure 8 shows ground truth labels from part of the SSS dataset. These images were employed to assess and verify the performance improvement of the YOLOv7 network.
Figure 9 shows partial detection results before and after the improvements made to the YOLOv7 network. It can be observed that when using the same SSS images to test the network before and after the improvement, our method can detect more objects, especially small objects, which indicates that our improvements enhance the ability of the model to detect such small objects.
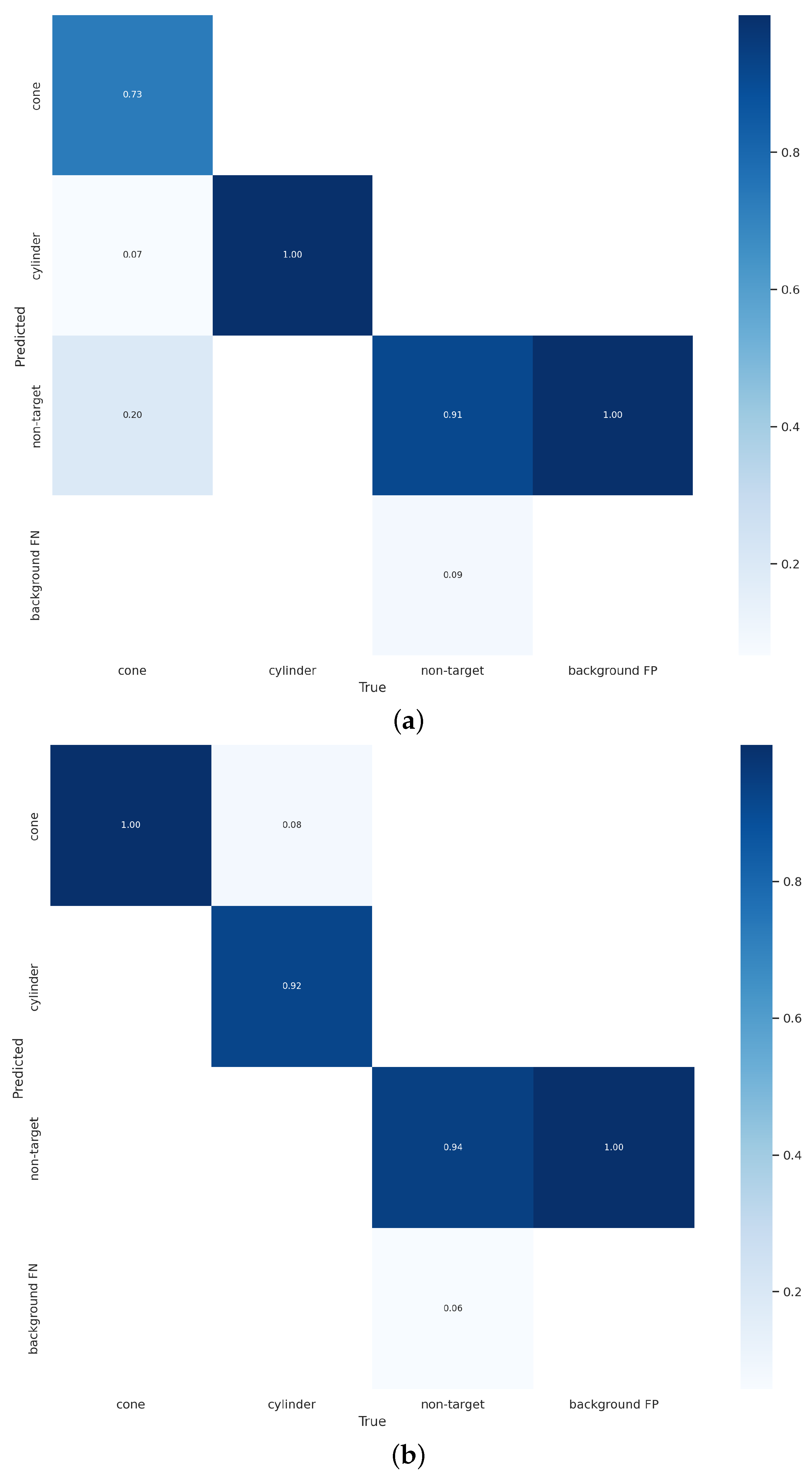
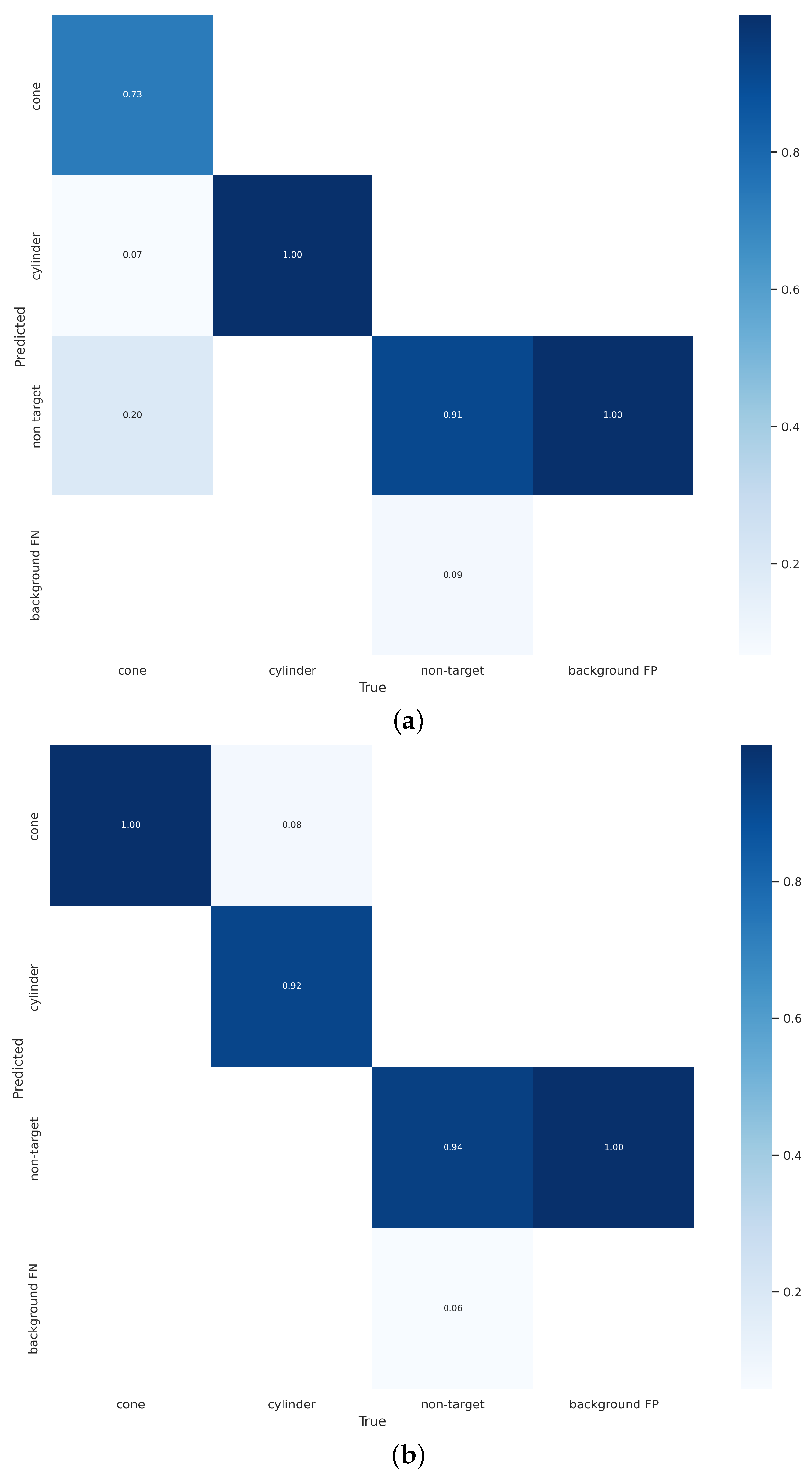
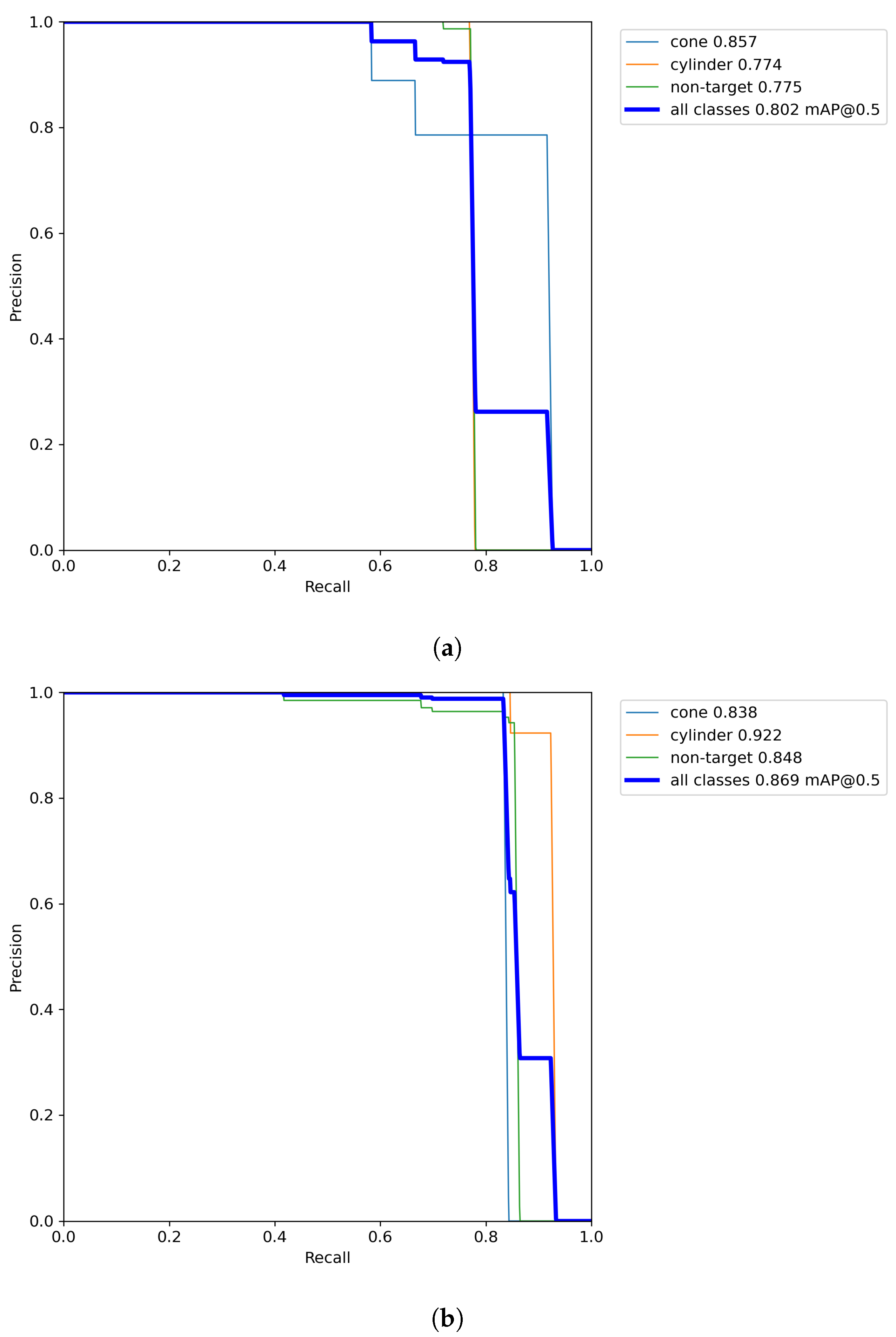
Furthermore, to conduct a comprehensive comparison between YOLOv7 and our method, the confusion matrices and PR curves of both models were compared. As shown in
Figure 10, our method exhibits higher accuracy and better balance in detecting both the object class and the background class.
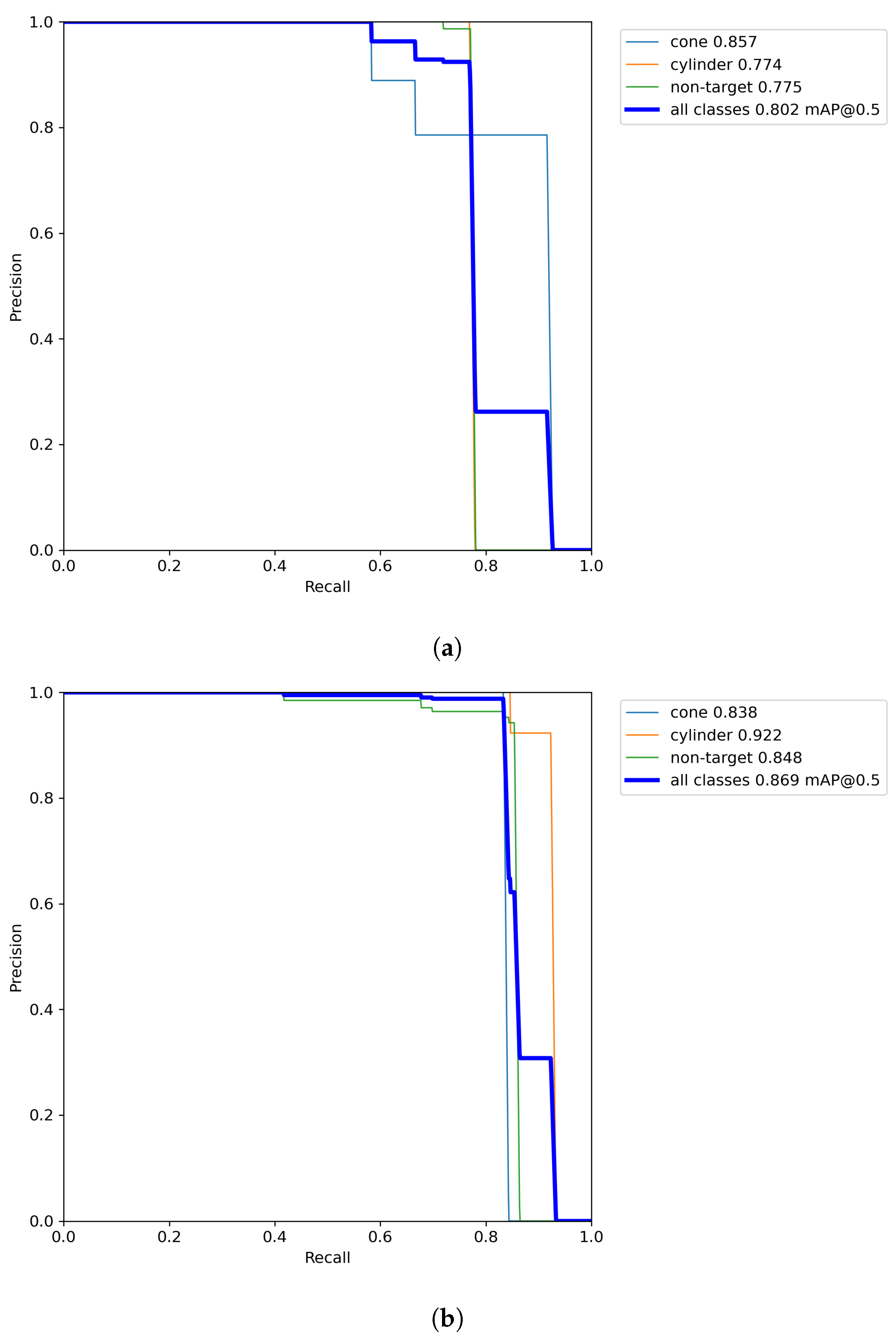
Figure 11 showcases the enhanced detection performance of diverse objects accomplished through our method; it can be seen that the mAP@0.5 value achieves a remarkable growth of 6.7%.
Based on the experimental results presented above, it can be concluded that our method greatly enhances the detection performance of SSS images, making it particularly well-suited for detecting small underwater objects. However, the inherent nature of deep learning heavily relies on extensive data, and the limited availability of large-scale SSS image datasets poses a challenge for training our method on a sufficient number of samples. This limitation inevitably impacts the scope and generalizability of our experimental results. For instance,
Figure 12 shows that our method exhibits false detections in comparison to the original YOLOv7 method. Although our method improves the detection performance of the model, it brings about new special cases of instability. This situation can be attributed to the limited size of the dataset, which results in the attention mechanism excessively prioritizing the shadow portion of the object. As a consequence, false detections may occur. The study of sonar image data expansion is a hot topic today, which can provide a way to further optimize our methods. Our future research will focus on the expansion and enhancement of sonar images to make it easier for the network to learn the features of the object.
4.3.3. Ablation Study
To assess the effectiveness and individual impact of each of the proposed innovations on network performance, an ablation study was conducted. This study mainly makes four improvements to the original YOLOv7 network, including expanding the detection scale, adding a CoT module, adding a CA module, and using BiFPN feature fusion. The four proposed improvements were incrementally incorporated into the original YOLOv7 network. The SSS image dataset was then used to conduct experiments while evaluating the impact of each improvement in a step-by-step manner. The results of each experiment are shown in
Table 2.
As depicted in
Table 2, each proposed improvement integrated into the YOLOv7 model contributes to the enhancement of the network’s detection performance to a different extent. Specifically, after expanding the detection scale, the mAP value sees a 1.5% increase, validating the introduction of a 160 × 160 scale detection layer to effectively enhance the network’s recognition capability. After adding the CoT module, the mAP value increases by 1.7%, which is the largest single improvement, while after adding the CA module the mAP value increases by 0.7%. These results show that the improvement of the attention mechanism on the network performance is closely related to the location of the addition. Lastly, the incorporation of BiFPN feature fusion contributes to a 0.9/% increase in the mAP value, affirming that the utilization of learnable weights enhances the reasonableness and reliability of feature fusion. Overall, the mAP value experiences a noteworthy 4.8% improvement, confirming the effectiveness of each proposed enhancement.
5. Conclusions
In this paper, we have introduced a novel object detection method for small objects in SSS images, which we refer to as the enhanced YOLOv7-based approach. Specifically, our approach makes the following major improvements. (1) An additional detection layer with a scale of 160 × 160 is incorporated into the existing three detection layers of YOLOv7. This enhancement aims to specifically improve the detection capability for small objects. (2) A CoT module is integrated into the ELAN module to enhance the network’s feature representation. The self-attention mechanism of the CoT module is leveraged for this purpose. (3) In the neck section, an additional CA module is introduced to guide the network’s attention towards the essential features present in the image, thereby promoting effective learning. (4) Utilizing the BiFPN structure as the foundation, a novel feature fusion approach is applied to address the challenge of balancing features across various scales. Our experiments and ablation study provide compelling evidence that the proposed method outperforms mainstream object detection algorithms. In comparison to the original YOLOv7 network, the Precision shows a remarkable improvement of 4.8%, achieving an impressive accuracy of 95.5%. Furthermore, the Recall exhibits a notable enhancement of 5.1%, reaching a commendable level of 87.0%. The mAP@.5 showcases a substantial improvement of 6.7%, resulting in an impressive mAP score of 86.9%. Moreover, the mAP@.5:.95 reaches an outstanding 55.1%, indicating a significant boost of 4.8%. Overall, our proposed method proves effective in delivering these substantial improvements. The results indicate that our method is more suitable for autonomous detection of small underwater objects, and provides a innovative approach to object detection based on SSS images.
In our future work, we intend to focus on two main areas: developing intelligent algorithms to generate high-quality sonar images in order to expand the SSS data and enrich the dataset, and exploring the influence of ocean currents on side-scan sonar images while developing advanced image processing techniques to reduce interference. These efforts have the aim of significantly improving the effectiveness and stability of detection in side-scan sonar applications.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}