1. Introduction
The total area of the ocean is about 360 million square kilometers, accounting for 71% of the total area of the earth, and the ocean is rich in fish resources, which are of great value. Fish species and abundance can reflect the climate, and some researchers have found that changes in species in certain areas can be used as indicators of climate change. In addition, it can also reflect the ecological environment of the region to a certain extent [
1]. In order to achieve sustainable economic development and maintain the entire marine ecological environment, it is necessary to conduct a certain assessment of the marine ecological environment.
The real-time detection of fish is the key to realizing the protection of marine fish resources. Obtaining information such as the species and number of fish in an image or video can help assess the population and growth of fish, which is of great significance for maintaining the stability of the fish population [
2]. However, it is unrealistic to rely on humans to manually analyze these images and video data, which is time-consuming, labor-intensive, and prone to errors. We urgently need to rely on computer vision to help us analyze these data automatically.
In this paper, we conduct fish object detection based on marine fish images. During this process, we first locate the position of the fish targets in the images and then further categorize the species of the fish targets. Fish detection can be categorized into two main categories, based on traditional computer vision and based on deep learning. Most of the traditional computer vision methods use hand-designed operators to extract fish features, and different operators need to be designed for different categories of fish, which generally has the disadvantages of complex detection and poor generalization. In addition to this, in the recognition process, it is also susceptible to the interference of environmental factors, such as light, background, etc., and there are problems such as difficulty in feature extraction and poor robustness.
Hsiao et al. [
3] proposed a fish recognition and localization method relying on local ranking and maximum probability based on sparse representation classification, which was trained on a dataset covering 25 fish species with a total of 1000 images, and achieved a recognition accuracy of 81.8% and a localization accuracy of up to 96%. However, the pixels of each image were only
, which could not guarantee accuracy on high-pixel images. Cutter et al. [
4] constructed an automatic fish detection method based on a cascade classifier of Haar-like features to recognize rockfish and their related species in a complex seabed rocky background, and the accuracy could reach 89%, but it was susceptible to the orientation of the fish, the distance, and the intensity of the light. Mehdi et al. [
5] proposed a shape-based fish detection, which first obtained the shape features of the related fish by Principal Component Analysis (PCA) method and then located the feature points by Hal’s classifier, which could overcome some of the background disturbances in the underwater environment test. Aiadi et al. [
6] proposed a lightweight network, namely MDFNet, for ear description. This method mentioned the concept of a lightweight model, but the network used was still based on traditional computer vision methods with limited feature extraction capability of the model.
Thanks to the continuous development of graphics processors, deep learning is widely used in many fields such as autonomous driving, medical imaging, smart agriculture, and security monitoring. For example, Khasawneh et al. [
7] used faster R-CNN and deep transfer learning to realize the detection of K-complexes in EEG waveform images. Convolutional neural networks can perform feature learning and hierarchical feature extraction with efficient algorithms. which can provide better representations of images and learn these representations from large-scale data, with better generalization performance compared to traditional approaches.
In 2015, Li et al. [
8] utilized Faster R-CNN to detect fish and tested it on the ImageCLEF dataset, which contained a total of 24,277 images of fish in 12 classes, and the mAP reached 0.814, which was an improvement of 11.2% compared to the previous approach, and the detection speed was close to 80 times faster. However, compared to the later proposed one-stage detection model, the two-stage detection model still has shortcomings in detection speed, and there is much room for improvement in detection accuracy. In 2017, Sung et al. [
9] used YOLOv1 to detect seaweed, rocks, and fish on the seabed with a dataset that included a total of 1912 images, with an accuracy of 93% and a frame rate of 16.7 frames per second. However, due to the small sample dataset, early YOLOv1 generated only two prediction frames per grid and only one class, which resulted in poor performance for dense object detection. In 2018, Miyazono et al. [
10] proposed a feature-point representation method, called annotated image, by adding four feature points (mouth, dorsal fin, caudal fin, and anal fin) to each fish image and performed it on AlexNet training, and its accuracy could reach 71.1% but there were fewer than 20 images in each category, which affected the training performance of the model. In addition, the annotation of the images was relatively complex and cumbersome, which also added workload to the target detection task. In 2018, Xu et al. [
11] applied deep learning to hydroelectricity for the first time and used stochastic gradient descent and Adam’s optimizer to train the improved YOLOv3 to recognize fish near hydroelectricity, and the average mAP on three datasets reached 0.539. This work applied fish detection to the field of hydroelectricity, which is of great significance, but further improvement is still needed in the detection accuracy of the improved model. In 2020, Cai et al. [
12] constructed a total of 2000 fish images and utilized MobileNetv1 as a feature extraction network in combination with YOLOv3 training to detect fish in a real fishing environment, with a mAP as high as 0.796. The result showed that the model had missed detections and lacked competitiveness in detection accuracy. In 2021, Zhao et al. [
13] addressed the complex underwater environments for fish recognition and localization in complex underwater environments; they improved the Residual Network (ResNet) to enhance the feature extraction ability of the network and also designed the Enhanced Path Aggregation Network (EPANet) to solve the problem of low utilization of semantic information due to linear up-sampling, with an mAP as high as 0.928. This study showed good performance in detection accuracy, and further research could be conducted on the lightweight model in the future. In 2022, Connolly et al. [
14] constructed the acoustic image dataset and compared it from three aspects, which were direct acoustic images, acoustic images with shadows, and the combination of the previous two. The experimental results showed that the F1 score was up to 0.9. The introduction of acoustic images provided a new idea for fish detection but this method could not achieve detection for specific fish species.
Deep learning has been widely used in various fields since it was proposed. In recent years, various deep-sea observing systems have been widely used in ocean monitoring, providing a large number of information-rich underwater videos and images, which makes the application of deep learning on marine fish detection possible; however, at the same time, it still faces the problems of poor quality datasets and insufficiently advanced detection algorithms; this paper will address the above problems.
In this paper, we focused on fish near coral reefs as the research object, constructed a high-quality marine fish dataset, and optimized the detection performance of the model based on the existing deep learning of previous researchers to realize the detection of marine fish. The main contributions of this paper are as follows: (1) We constructed the Fish9 marine fish dataset by crawling high-definition coral reef fish images on the web, which can satisfy the research of this paper and provide data support for other related studies at the same time. (2) We introduced migration learning, attention mechanism, gated convolution, and GhostNet to the original YOLOv5s model to improve its detection performance while lightweighting the model. The experimental results showed that the improved model reduces the model size by 19% while improving the detection accuracy by 3%.
The rest of this paper is organized as follows. The second part introduces the improvement methods and ideas used in this article, and the third part presents a series of ablation experiments and their results and analyzes and discusses the improved algorithm proposed in this article based on the experimental results. The fourth part summarizes the work performed in this article.
3. Results and Discussion
3.1. Experimental Environment
The experimental parts in this chapter are all based on the same software/hardware environment, as shown in
Table 3.
3.2. Evaluation Metrics
In object detection, the performance evaluation metrics are accuracy, precision, recall, F1-score, average precision AP, mean average precision across all categories (mAP), and frames per second (FPS).
When we perform hypothesis testing, we generally make two kinds of mistakes. The first is when the original hypothesis is correct and you judge it to be wrong; the second is when the original hypothesis is wrong and you judge it to be correct. These two types of errors are known as Type I and Type II errors, respectively. And, in the field of deep learning, the confusion matrix is usually used to describe the above errors, as shown in
Table 4.
The resulting formulas for accuracy, precision (P), recall (R), F1-score, and AP are given below:
AP is the area enclosed by the PR curve and the two axes, which represents the average value in each case of the detection rate. AP is used to measure the average detection accuracy of the model for a certain category, while mAP represents the average detection accuracy of the model for all categories, whose value ranges from 0 to 1. Obviously, the larger the mAP is, the better the performance of the model is.
In many scenarios, the object detection task often has time requirements; FPS is an important indicator of the speed of the object detection model, i.e., how many pictures can be detected in 1 s. Currently, most of the videos are roughly 30 FPS, which means that our model must be able to detect 30 pictures in 1 s to meet the real-time video detection, and the detection time of a single picture must be less than 33 ms.
3.3. Transfer Learning
Transfer learning [
26] is a machine learning technique that allows knowledge to be transferred from one domain to another. In the field of computer vision, transfer learning is usually realized by using pre-trained models. Pre-trained models are models obtained by training on large datasets, which can directly reuse existing knowledge domain data and no longer need to re-label huge datasets at great cost.
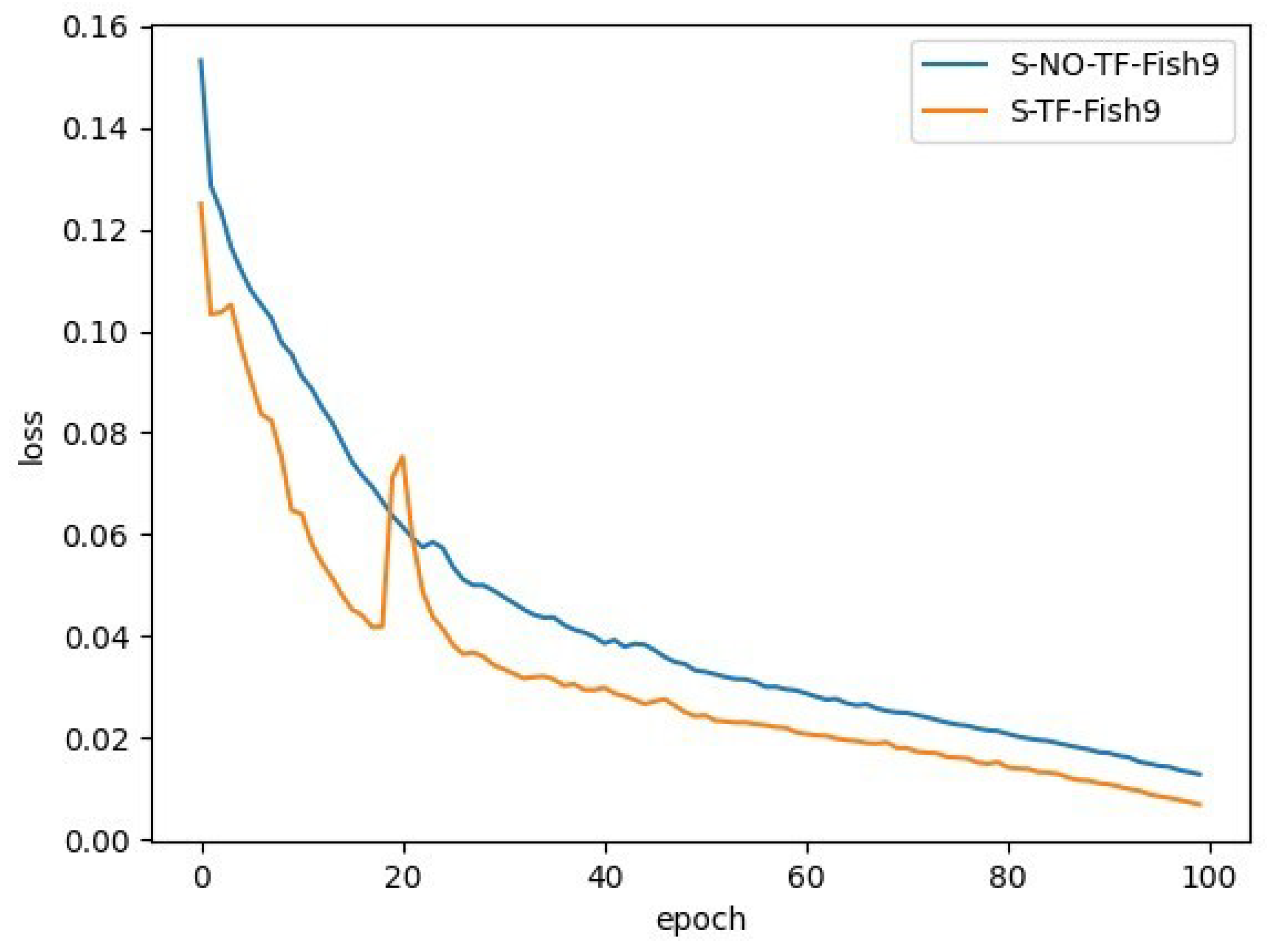
In this section, model S-TF-Fish9 is built on the basis of YOLOv5s using ImageNet pre-trained model initialization, and model S-NO-TF-Fish9 is built using random initialization. Other than that, their model structures, hyperparameters, etc., are unified. The model hyperparameters are set as follows: the training rounds epoch is 100, the batch size is 64, the SGD optimization algorithm is used, the momentum parameter momentum is 0.939, the weight decay is 0.0005. the learning rate is linear decay, the initial value is 0.01, the final value is 0.0001, the preheat warmup epochs are set to 3, the IoU threshold in training is set to 0.2, etc. The parameters in the subsequent subsections are the same.
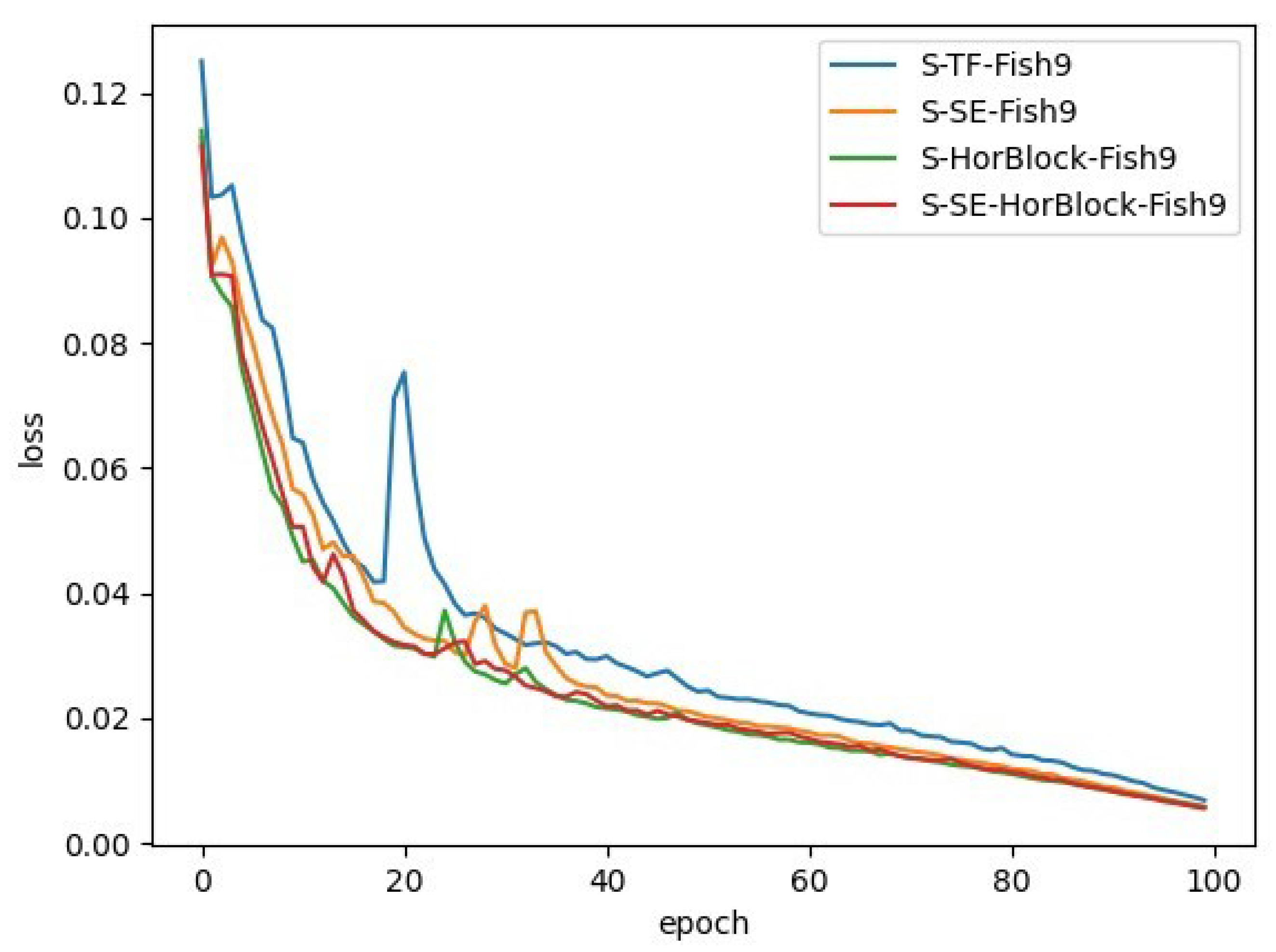
The training process loss variation is shown in
Figure 9.
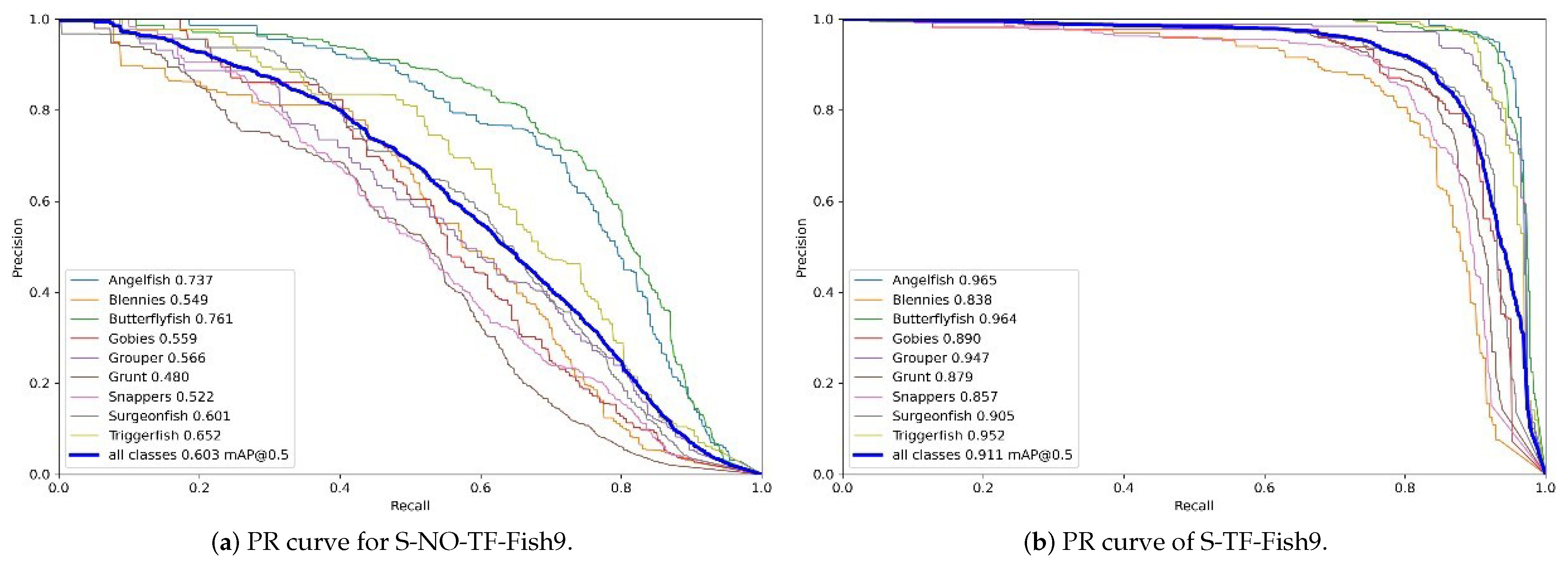
The curve of PR for model S-NO-TF-Fish9 is shown in
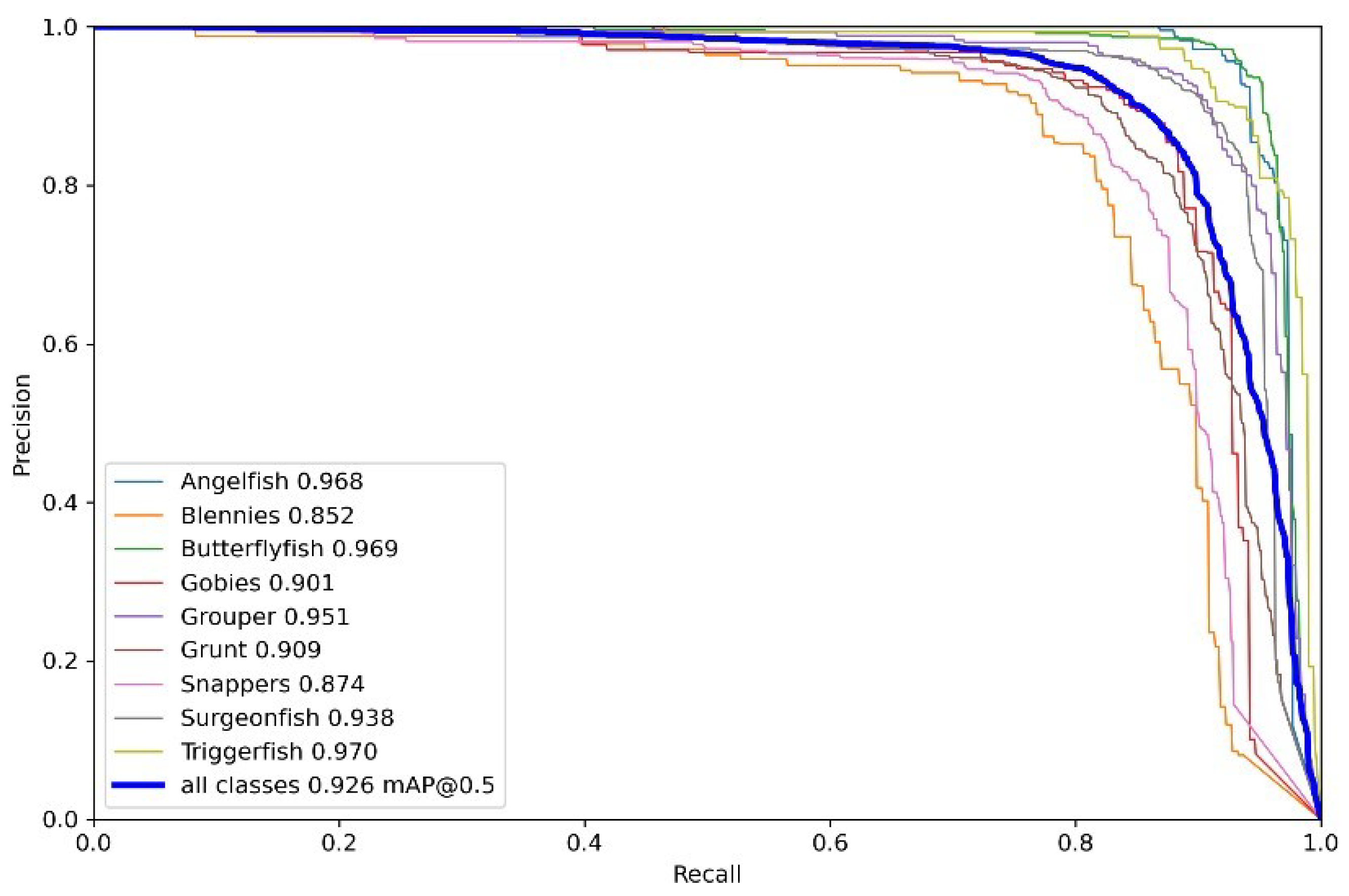
Figure 10a The curve of PR for model S-TF-Fish9 is shown in
Figure 10b. The performance comparison after the introduction of transfer learning is shown in
Table 5.
From the above experiments, it can be found that the performance of the model has been substantially improved after adding transfer learning, and the model also converges faster with smaller loss values. The AP values of each category are greatly improved, and the mAP is improved from 0.603 to 0.911, which is an improvement of about 51%, which shows that the pre-trained model we obtained on ImageNet is able to express the features better, and, even though there is no picture of the fish we detected on ImageNet, the general features of the object can be learned due to the massive data on ImageNet, which help to improve the feature representation of the model. Therefore, subsequent research will all be based on transfer learning.
3.4. Attention Mechanisms
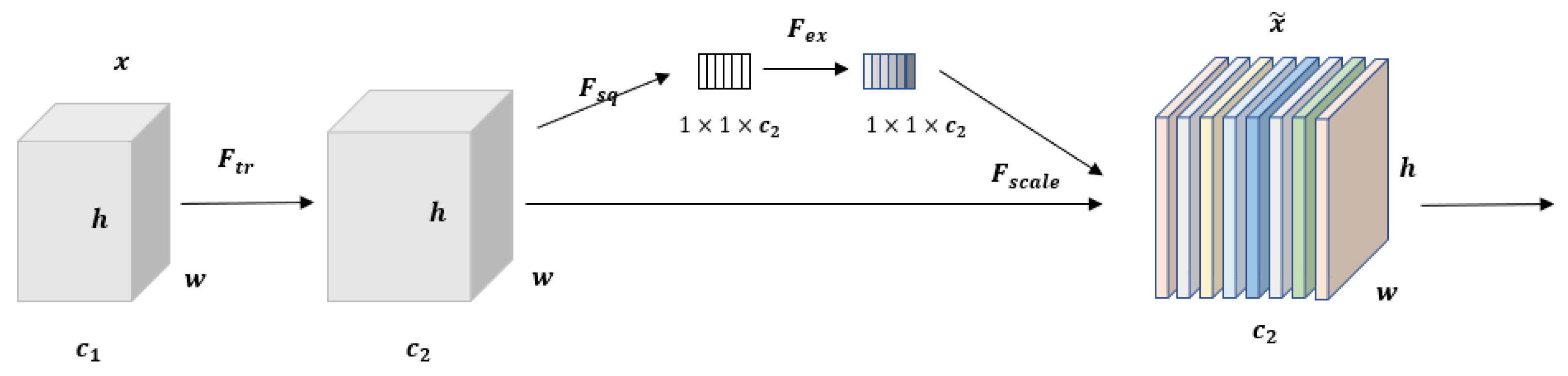
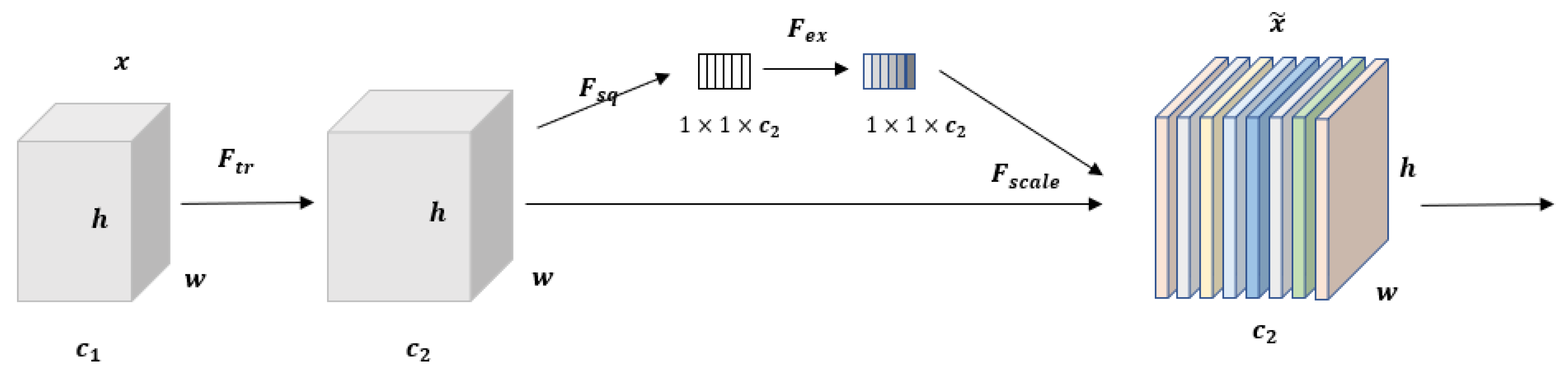
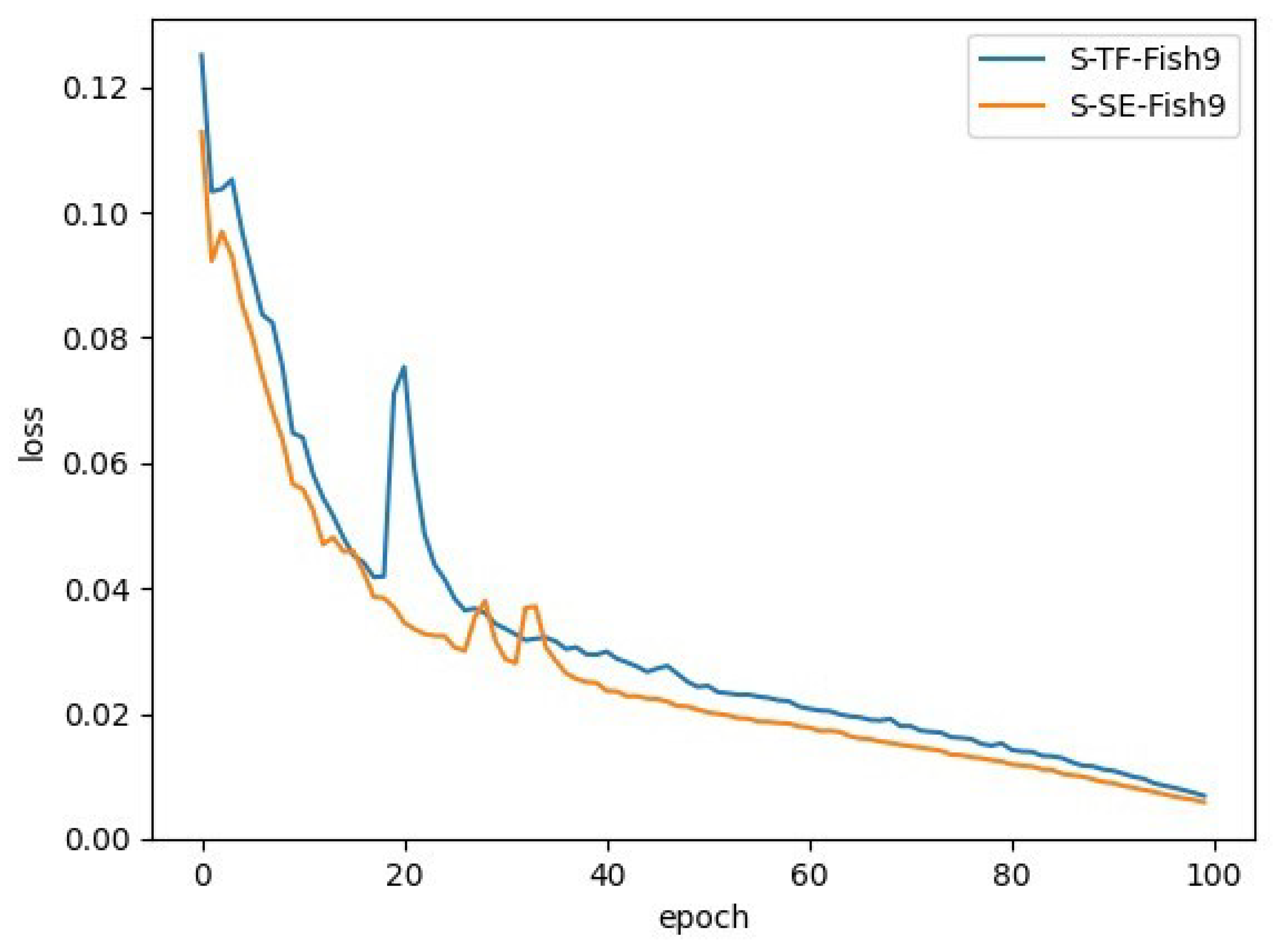
In order to strengthen the channel feature expression ability of the model, this paper introduces SENet into the C3 module, and the attention mechanism is introduced into the Backbone end and Head end of YOLOv5s, respectively, to carry out the research. As mentioned in the previous section, YOLOv5s has a total of eight C3 modules, and the Backbone end and Head end each account for four. In order to explore which part of SENet is added to improve the model performance the most, the results of a series of comparison experiments are described in
Table 6.
The experimental results show that the introduction of SENet leads to a small increase in the model size. Whether replacing all the C3 modules at the Head end or replacing them at both the Head and Backbone ends, the introduction of SENet at the Head end is optimal. Based on this, and replacing a C3 module individually at the Head end sequentially, the experimental results show that the introduction of SENet at the first C3 module at the Head end is optimal. The model is denoted as S-SE-Fish9, and there is no obvious difference in the size of the different models, and their detection times are almost the same. The variation of the loss curve is shown in
Figure 11. The PR curve is shown in
Figure 12.
A comparison of the performance of model S-SE-Fish9 and model S-TF-Fish9 is shown in
Table 7.
It can be seen that during training, model S-SE-Fish9 converges faster, has smaller loss values, and has a smoother process of changing losses during training. The mAP of model S-SE-Fish9 is improved by about 1.6%. The time consumed for detecting a single image (size 448 × 640) is the same as the original model; both are 16 ms.
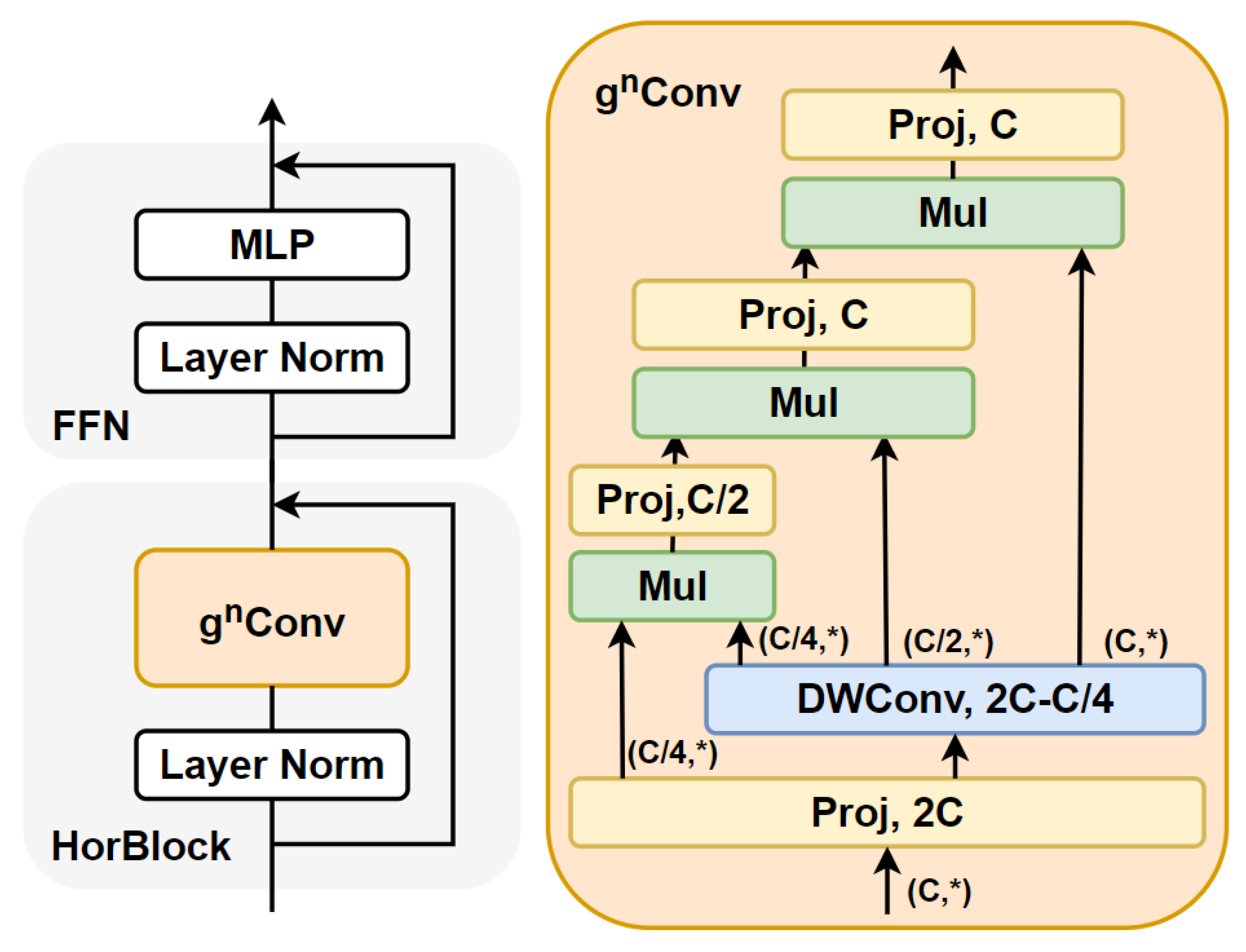
3.5. Gated Convolution
Similarly, in order to verify which place to add HorBlock at the Backbone side is more effective, this paper performs a series of comparative experiments in turn, and the results of the experiments are shown in
Table 8.
The experimental results show that the performance of the model is somewhat improved after the introduction of HorBlock, with the best performance being achieved when added to the last two C3s at the Backbone end, which is notated as S-HorBlock- Fish9. At the same time, it is worth noting that, unlike the attention mechanism module, which brings only a small amount of model size improvement, the gated convolution leads to a large amount of parameter enhancement due to the fact that it will be interacting with the feature layer domain space; it leads to a large number of parameter enhancements, which is visualized as a model size enhancement. In this study, both the gated convolution and the attention mechanism are introduced, where the attention mechanism is introduced in the first C3 part of the Head side as described in
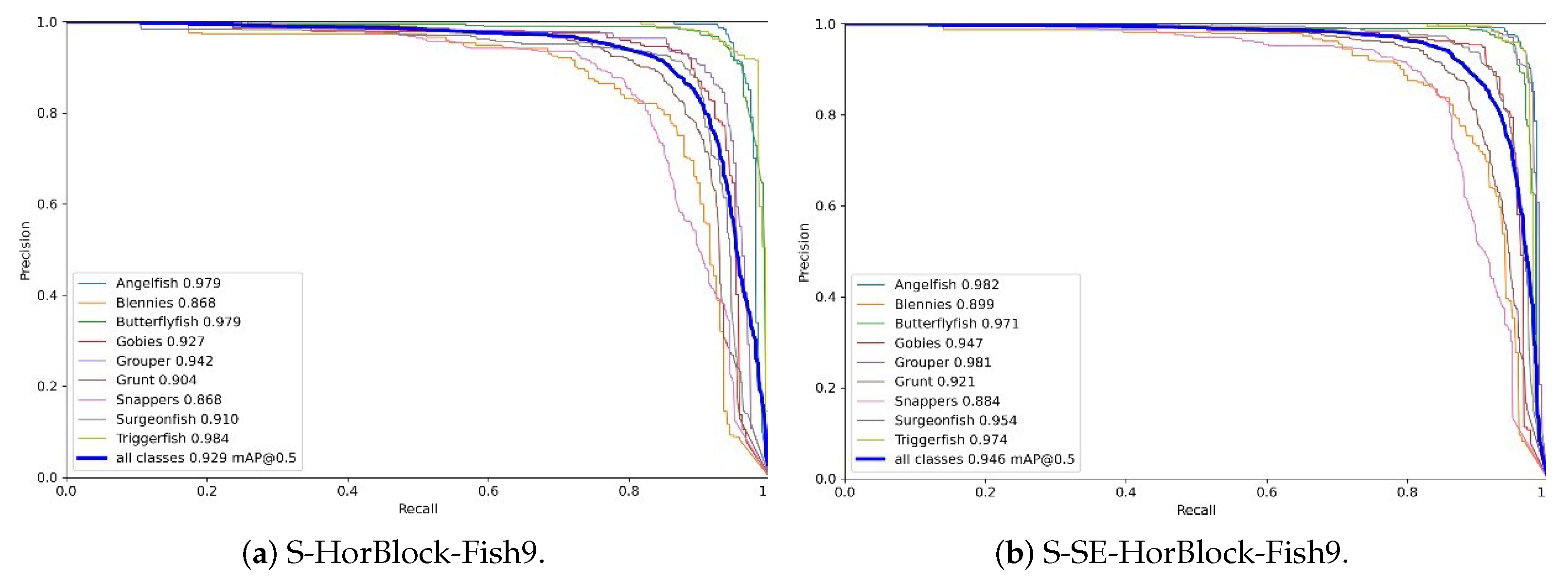
Section 3.4. Considering that the gated convolution will lead to a significant increase in the number of parameters (model size) as described earlier, the number of HorBlocks is reduced to one in this study, which is added in the last C3 part of the Backbone side. The model is denoted as S-SE-HorBlock-Fish9. The loss curves and PR curves for model S-HorBlock-Fish9 and model S-SE-HorBlock-Fish9 are shown in
Figure 13 and
Figure 14.
Compared to the original model, whether introducing the attention mechanism or gated convolution, the model can converge faster, and the training process has less jitter, smoother loss changes, and smaller loss values. When only HorBlock was introduced, the mAP value of the model also increased from the original 0.911 to 0.929; after introducing both SENet and HorBlock, the mAP value of the model increased from the original 0.911 to 0.946. The experimental results for each model are shown in
Table 9.
From the above table, it can be seen that compared to model S-TF-Fish9, the model size of model S-SE-Fish9 is almost unchanged, and the model detection accuracy is improved by about 1.6%. In addition, the detection accuracy of model S-HorBlock-Fish9 is improved by about 2% but, at the same time, the model size is improved by about 51%. The detection accuracy of model S-SE-HorBlock-Fish9 has been improved the most, by about 3.8%, and the model size has been improved by about 27%. In addition, the detection time of the three models is basically the same.
3.6. GhostNet
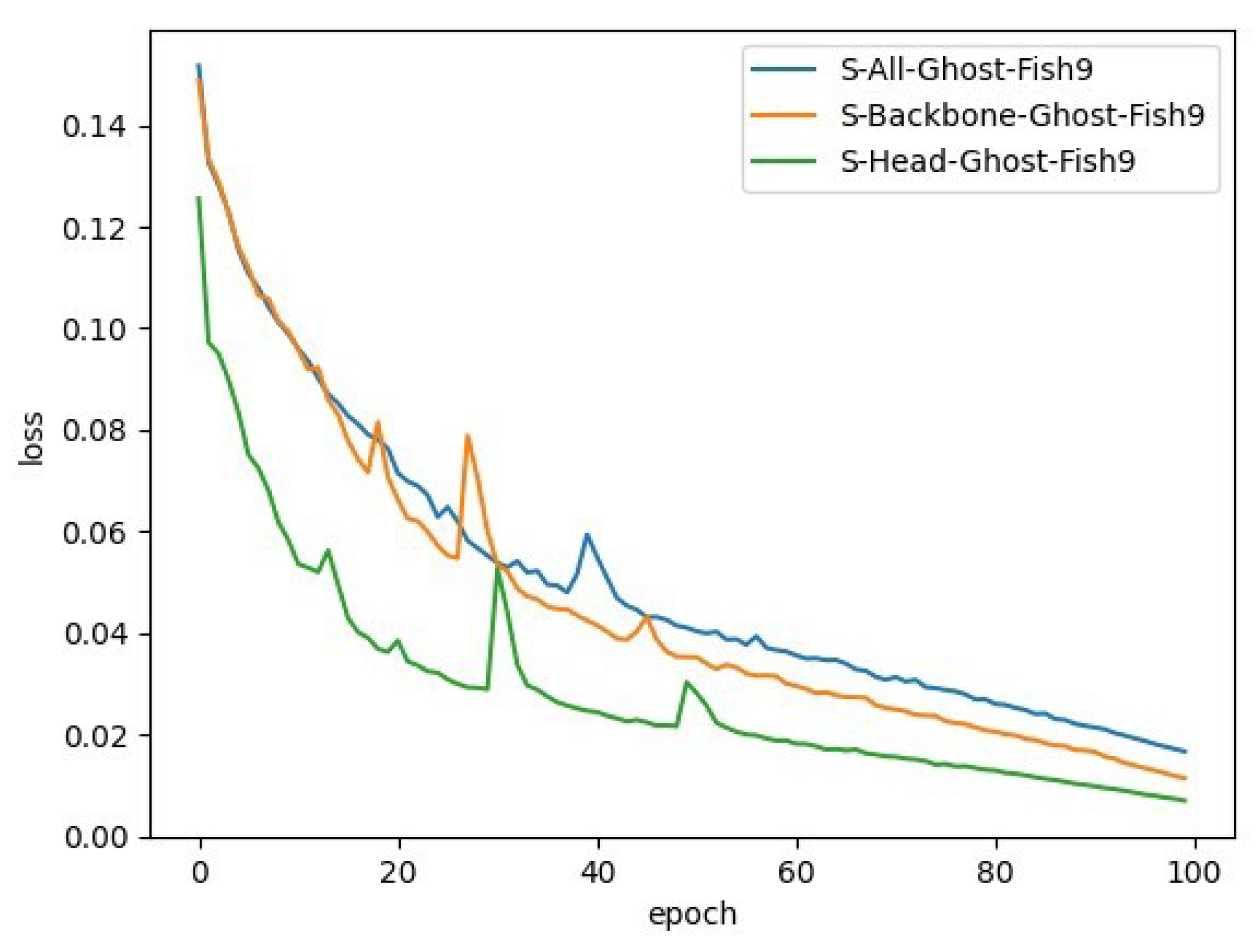
In this study, GhostNet was added to the Head end, Backbone end, and both Head and Backbone ends of YOLOv5s, respectively, to obtain three sets of control models named S-Head-Ghost-Fish9, S-Backbone-Ghost-Fish9, and S-All-Ghost-Fish9. Their loss variations are shown in
Figure 15.
The experimental results are shown in
Table 10.
The outputs of the different models are also shown through feature map visualization. Specifically, this study inputs the same image to the models, respectively, and since the last convolutional layers at the Head end and Backbone end are the 8th and 23rd layers, respectively, this study visualizes the outputs of the four models and selects the first 32 of them (four rows and eight columns), as shown in
Figure 16.
Comparing
Table 10, there is no significant difference in the detection time of the three models, and, according to the mAP values of the different models, it can be found that S-Head-Ghost-Fish9 is more effective, and the mAP is improved by about 24.9% and 29% compared to S-All-Ghost-Fish9 and S-Backbone-Ghost-Fish9, respectively. To summarize, the GhostNet module added to the Head side of YOLOv5 can improve the accuracy of the model, and, at the same time, can have some model pruning effect.
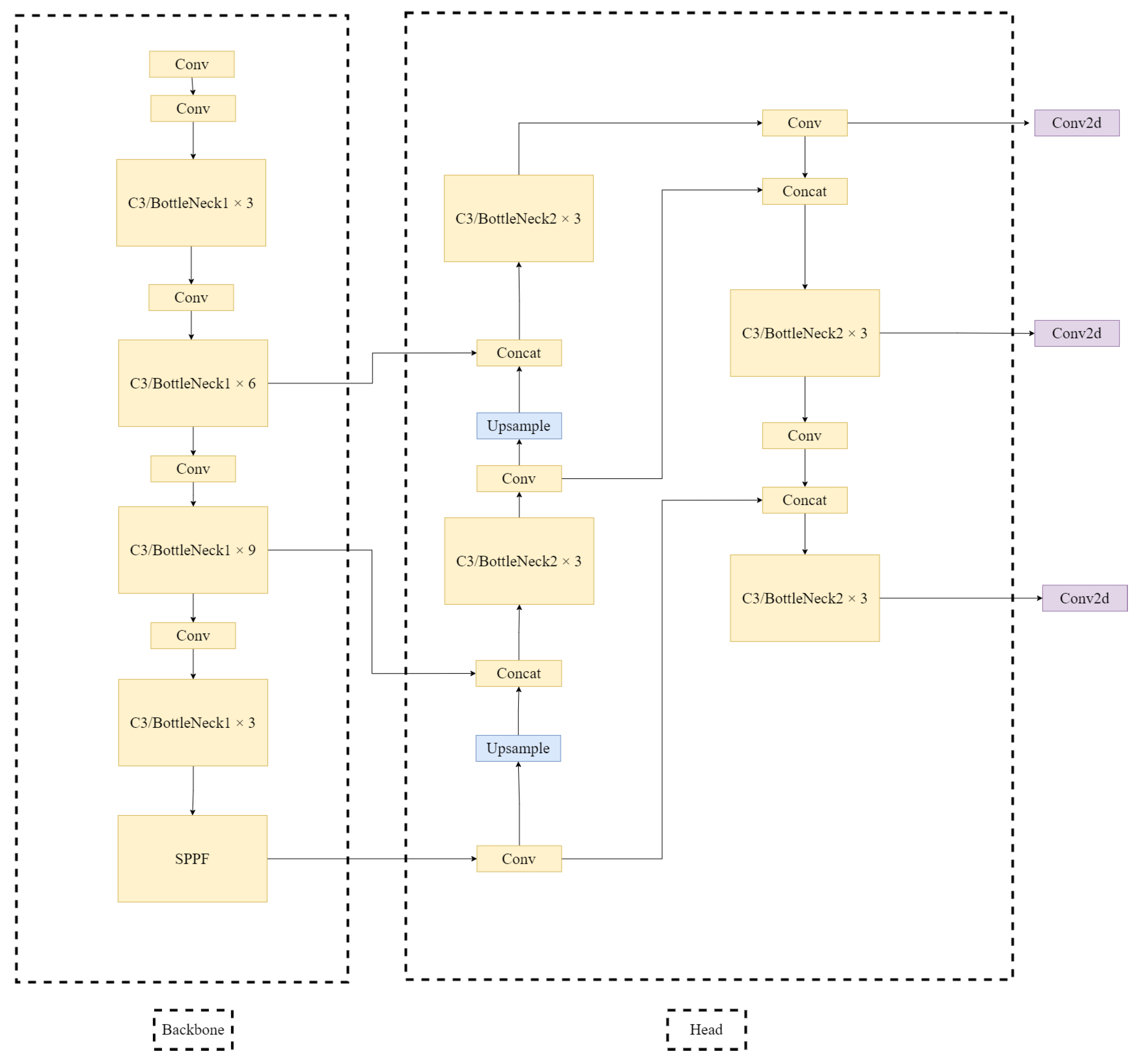
3.7. Improved YOLOv5 Algorithm
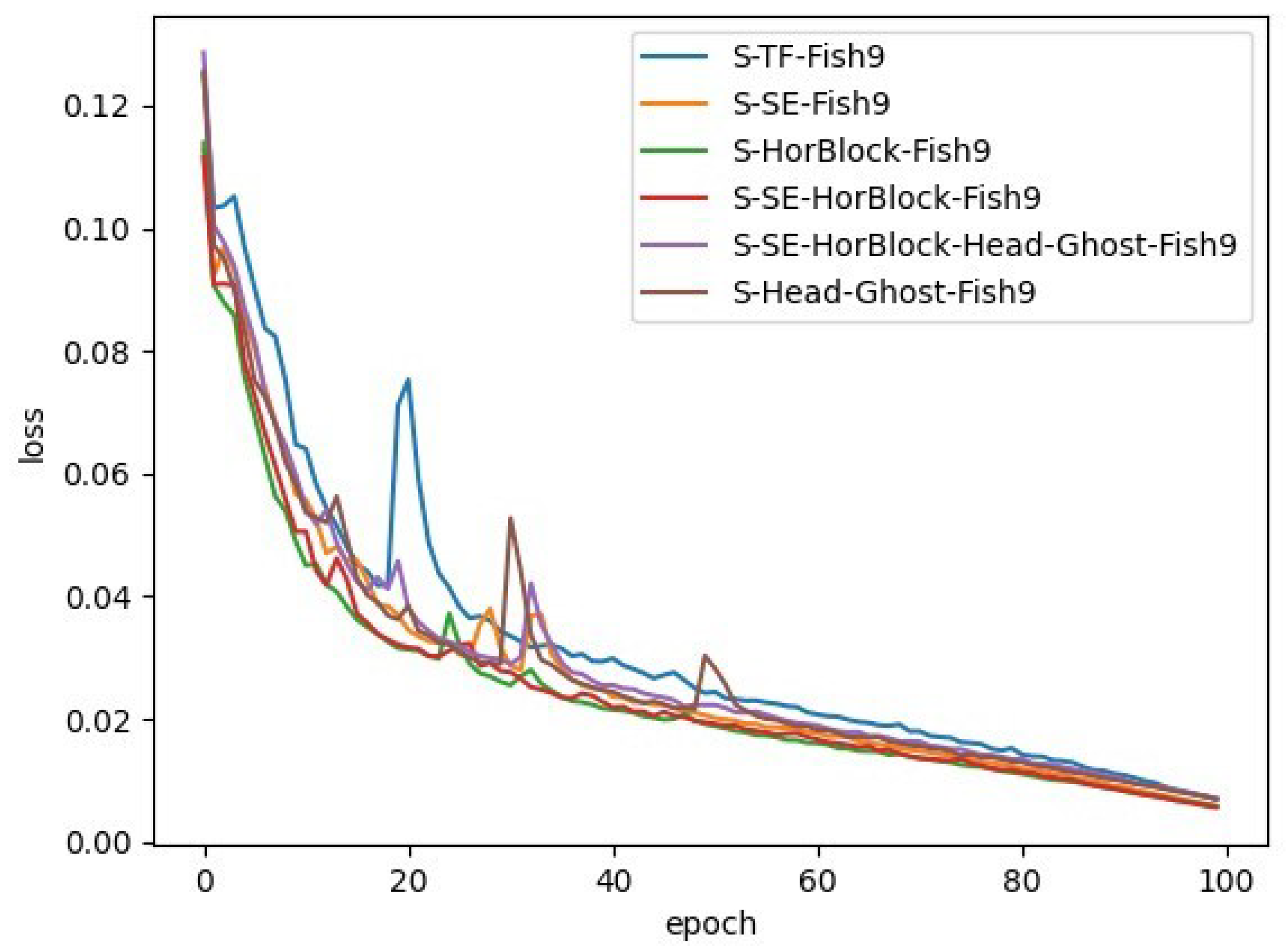
Based on the original YOLOv5s algorithm, through transfer learning research, attention mechanism research, gated convolution research, and GhostNet research, the experiments found that the transfer learning can significantly improve the detection accuracy of the model, and the mAP was improved by about 51% after the introduction of transfer learning. Meanwhile, the attention mechanism can enhance the channel expression ability of the model, and the gated convolution can strengthen the spatial modeling ability of the model; this paper finally determines two improvement schemes: one is to introduce GhostNet in the Head end, which is notated as S-Head-Ghost-Fish9, and the other is to build on the model S-SE-HorBlock-Fish9, and the Head part introduces GhostNet, which is notated as S-SE-HorBlock-Head-Ghost-Fish9. The training loss diagram of each model is shown in
Figure 17, and the model performance comparison is shown in
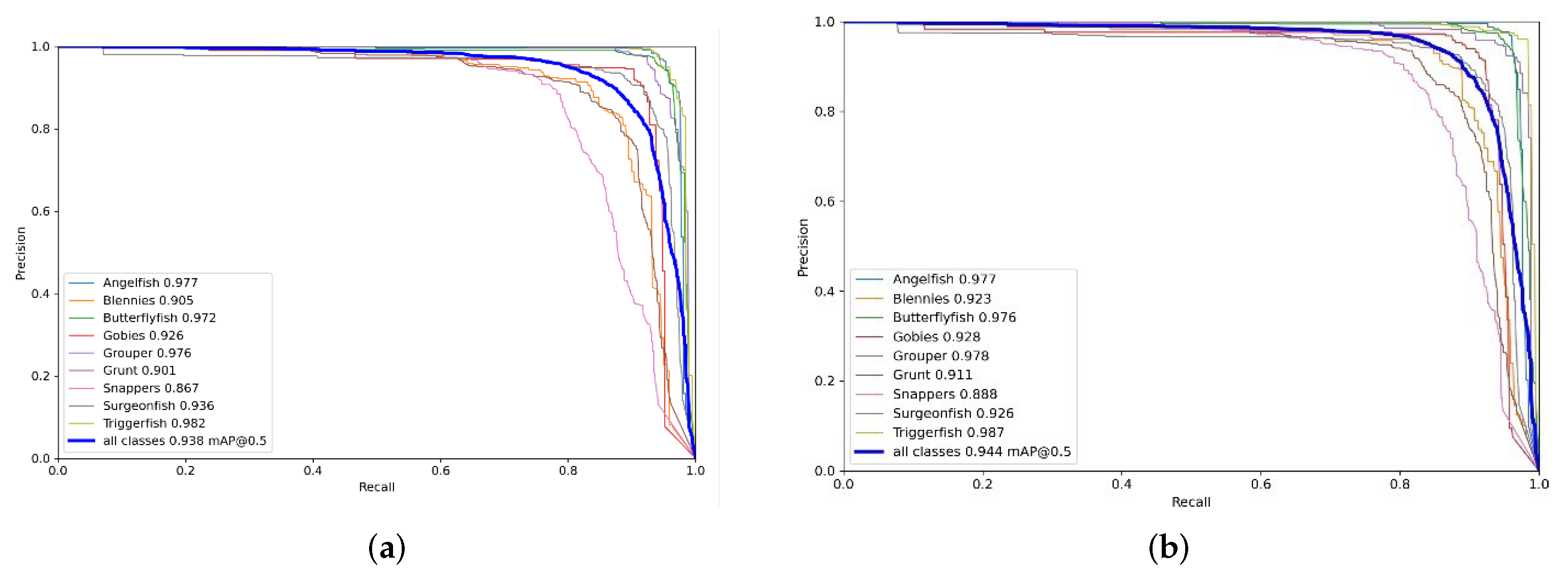
Table 11. The PR curves of the improved models are shown in
Figure 18.
The two improved models were compared to the original model and some of the detection results are shown in
Figure 19 and
Figure 20.
Figure 18 corresponds to the original model S-TF-Fish9,
Figure 19 corresponds to model S-Head-Ghost-Fish9 and model S-SE-HorBlock-Head-Ghost-Fish9. We have compared the performance of the original model and improved models under five different scenarios. Here, since most of the fish in the dataset live together in the same population, it is difficult to include different types of fish in the same image. We concentrated several images together to simulate the situation of different types of fish in the same image. In the simple situation, the improved model localizes the box more accurately and, in the intensive situation, there are fewer missed detections when using improved models. In addition, when the fish body is closer to the background color, the improved models still have better performance. In the multi-species situation, the original model has missed detections while our improved models reduce missed detections. As for the blurry situation, all the models have good detection results. The performance comparisons of the different models are shown in
Table 11, in which YOLOv6 is the detection model released by Meituan for industrial applications, which adopts a large number of heavily parameterized modules and is characterized by fast speed, high accuracy, friendly deployment, etc. YOLOv8 is the model released by the YOLOv5 team in early 2023. In this study, the s-size models are used uniformly, and the above two models correspond to YOLOv6-Fish9 and YOLOv8-Fish9, respectively.
In this paper, from the comprehensive consideration of the mAP value, model size, computation amount, and detection time, we found that there was no significant difference in the detection time of each of the improved models, among which three models performed the best; model S-SE-HorBlock-Fish9 had the highest mAP value of 0.946; model S-Head-Ghost-Fish9 had the smallest size and computation amount of 11.1 Mb and 13.4 GFLOPs, respectively. However, model S-SE-HorBlock-Fish9 had a small increase in both size and computation compared to the original model, considering that the current model deployment tends to be lighter, while model S-SE-HorBlock-Head-Ghost-Fish9 had a difference of only 0.02 in mAP. And, the model size and computation are both reduced, so the best models in this study were selected as S-Head-Ghost-Fish9 and model S-SE-HorBlock-Head-Ghost-Fish9.
Relative to the original model, the former improves the mAP by about 3%, reduces the model size by about 19%, and reduces the computation by about 15.7%; the latter improves the mAP by about 3.6%, increases the model size by about 9.5%, and reduces the computation by about 3.1%. Compared to the latest detection models, in which YOLOv6 uses a large number of reparametrized modules, mainly to reduce the hardware latency, which tend to be deployed, the detection time is only 8 ms. YOLOv8, on the other hand, is structurally re-designed with a Decoupled-Head structure, which separates the classification and localization, alleviating the inherent conflicts therein, and the detection accuracy is slightly higher than that of the improved model. The model proposed in this study still has a comparable detection accuracy compared to the latest model, with a slight reduction of about 1%, but has a lower model size, lower model computation, and is more friendly for model deployment.
By introducing the attention mechanism, the representation ability of the model is improved, which allows the network to better focus on useful information. In addition, the gated convolution greatly improved the modeling capability of the model. Through these methods, the mAP of the proposed model is hugely improved. Moreover, the introduction of GhostNet reduces redundancy in the model parameters, so we achieve a lightweight model. Here, the reduction in the model size by the GhostNet module is not obvious; on the one hand, it is due to the fact that the model of YOLOv5s itself is small and the space for model compression is limited, and, on the other hand, after the study in
Section 3.6, it is shown that it can still be compressed by 45% in the limiting case. However, from the perspective of the detection accuracy of mAP, the ability of introducing GhostNet at the Backbone side to improve model performance is still debatable. However, from the perspective of model deployment and mAP values, it still makes sense to bring limited model compression while significantly improving detection accuracy. Meanwhile, the above improvement scheme is still relevant to the large models of other versions of YOLOv5 (l and x) and the latest model.
4. Conclusions
In this paper, we first investigated the impact of transfer learning on the model and verified the benefits brought by the pre-trained model, i.e., the ability to accelerate the model convergence while significantly improving the model performance. Then, starting from the model’s channel expression ability and spatial interaction ability, the attention mechanism and gated convolution were introduced, respectively, and compared with the original model; the mAP was improved by 1.6% and 2%, respectively. However, at the same time, gated convolution brought more parameters, which meant the size of the model became larger. Therefore, the model was lightened by introducing GhostNet and added to different places (Head end and Backbone end) of the model, which was evaluated by the mAP value and feature map visualization. The experimental results showed that GhostNet was more effective when added to the Head end of the model. Finally, the decision-making basis of the model was visualized by means of the heat map, and the improved model has a more accurate decision-making range, as well as localization ability.
Through a series of model comparisons, this paper finalized two improved models, S-Head-Ghost-Fish9 and S-SE-HorBlock-Head-Ghost-Fish9, with the former being smaller in model size. In terms of detection speed, a single image took about 17 ms, both of which can meet the demand of real-time detection, and in terms of detection accuracy, compared with the original model, the former was improved by 3% and the latter by 3.6%. Compared with the latest detection algorithms, the above-proposed model has a lower size and computational effort while maintaining a comparable accuracy, which is more conducive to the deployment of the model.
In this paper, by adding improvements to the original YOLOv5s model, we finally achieved the accurate detection of marine fish through our improved lightweight object detection model. Since we used supervised learning to train the object detection model, the improved models could only detect and recognize the nine fish species annotated in our dataset. If we want to achieve the detection of more fish species, we only need to expand our dataset and train the model.
In the future, this proposed method can be applied to seabed removable equipment to obtain the population and number of marine fish and make certain assessments of the marine ecological environment, so as to better realize the protection of marine fish resources.


 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}